Pose-Invariant Object Recognition for Event-Based Vision with Slow-ELM
Rohan Ghosh, Siyi Tang, Mahdi Rasouli, Nitish Thakor, Sunil Kukreja

TL;DR
This paper introduces a novel pose-invariant object recognition method for event-based vision using a slow-ELM architecture that combines Extreme Learning Machines and Slow Feature Analysis, achieving high speed and accuracy.
Contribution
The paper presents a new slow-ELM architecture tailored for pose-invariant object recognition in event-based vision systems, addressing a gap in transformation invariance algorithms.
Findings
Achieves 10,000 classifications per second.
Attains 1% classification error for 8 objects over 90 degrees of pose.
Demonstrates effectiveness on neuromorphic DVS data.
Abstract
Neuromorphic image sensors produce activity-driven spiking output at every pixel. These low-power consuming imagers which encode visual change information in the form of spikes help reduce computational overhead and realize complex real-time systems; object recognition and pose-estimation to name a few. However, there exists a lack of algorithms in event-based vision aimed towards capturing invariance to transformations. In this work, we propose a methodology for recognizing objects invariant to their pose with the Dynamic Vision Sensor (DVS). A novel slow-ELM architecture is proposed which combines the effectiveness of Extreme Learning Machines and Slow Feature Analysis. The system, tested on an Intel Core i5-4590 CPU, can perform 10,000 classifications per second and achieves 1% classification error for 8 objects with views accumulated over 90 degrees of 2D pose.
Click any figure to enlarge with its caption.
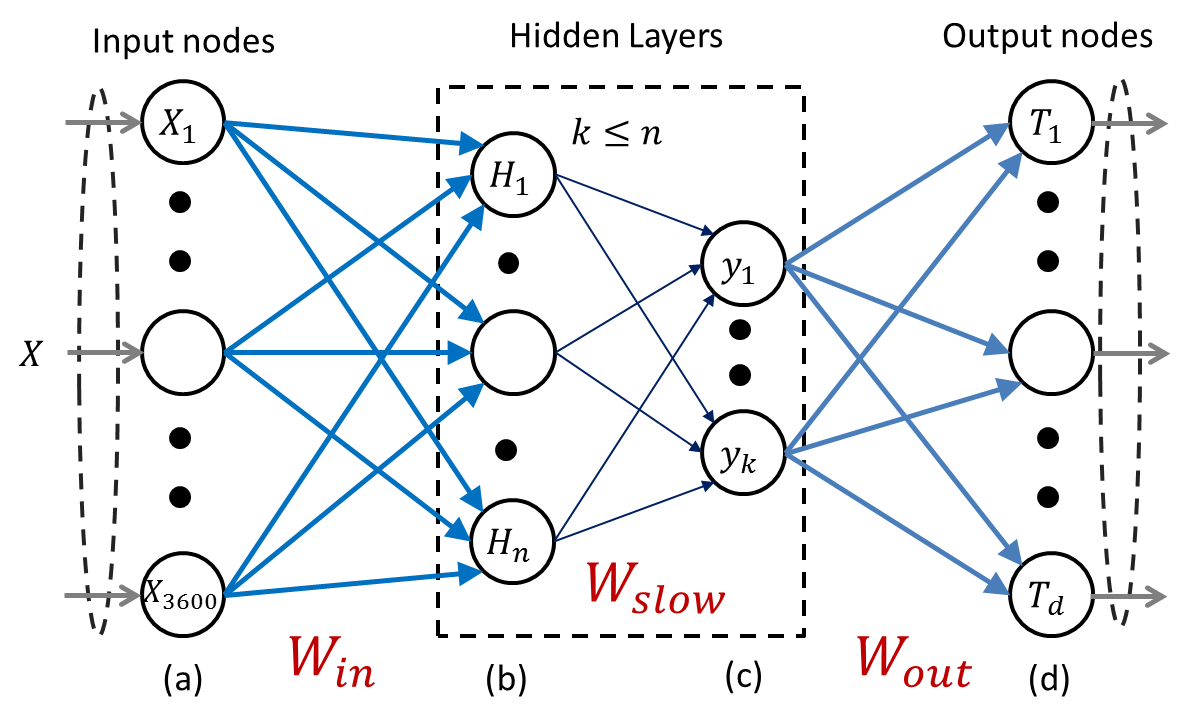 Figure 1
Figure 1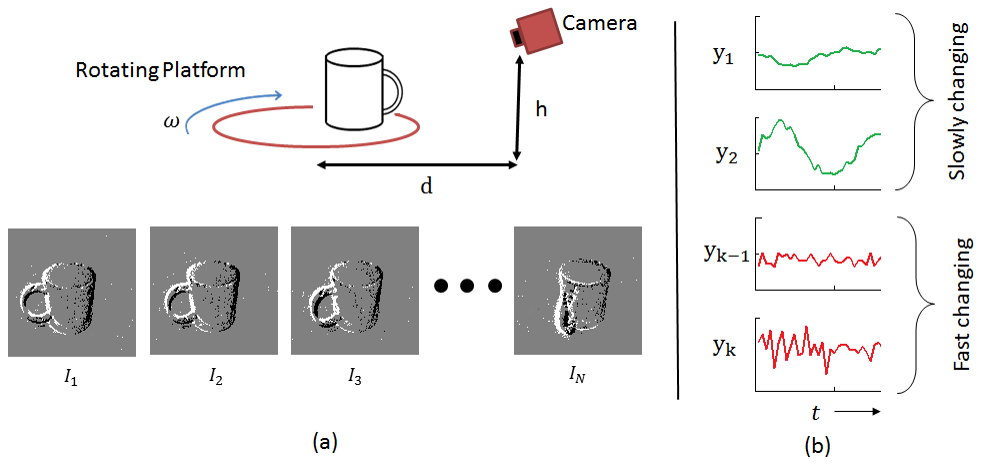 Figure 2
Figure 2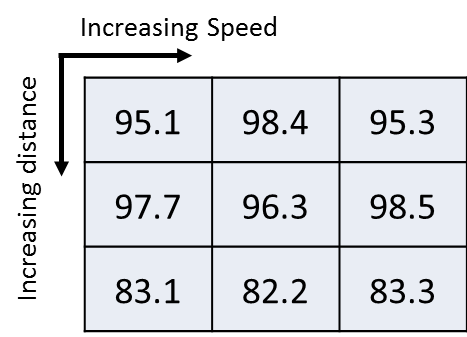 Figure 3
Figure 3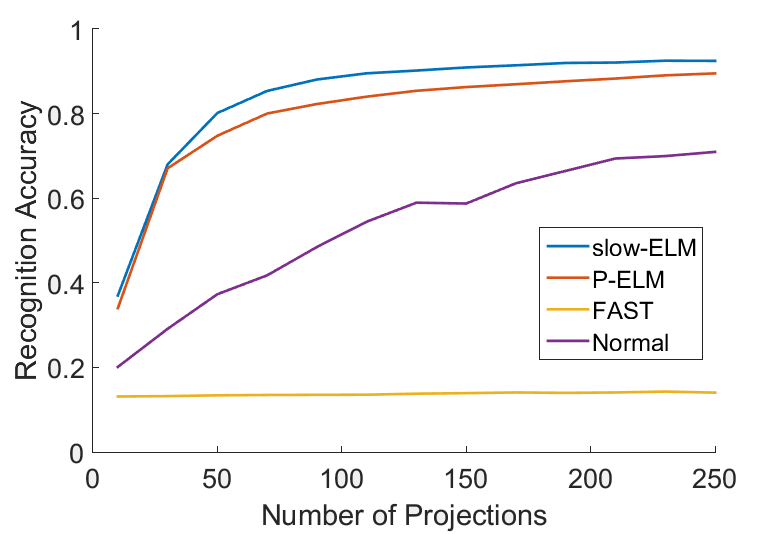 Figure 4
Figure 4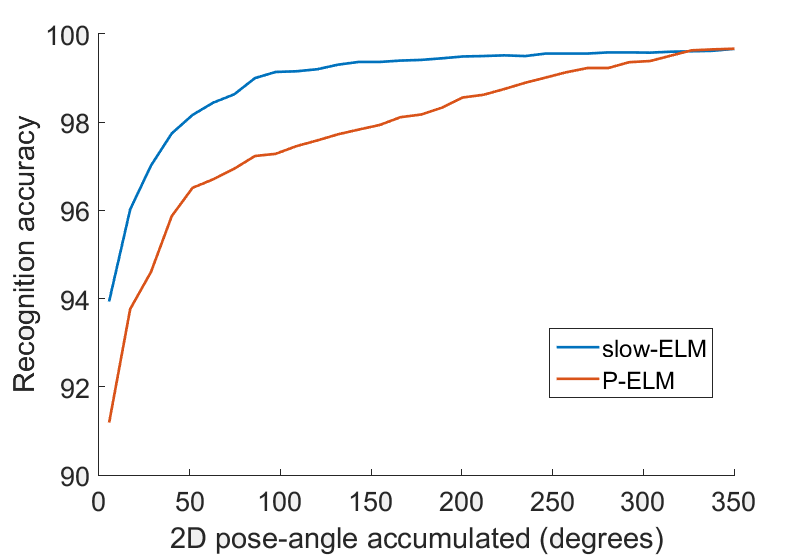 Figure 5
Figure 5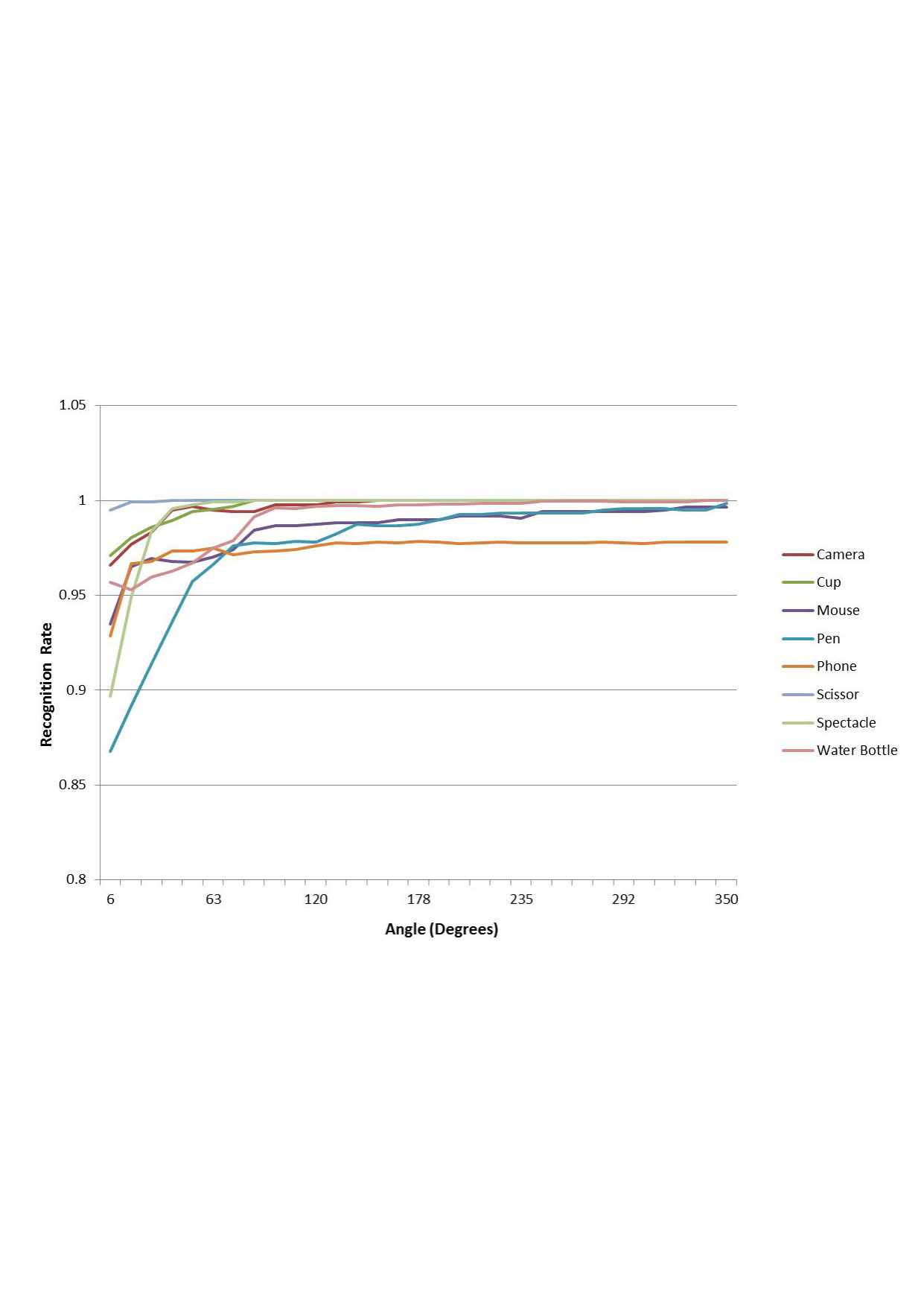 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Pose-invariant object recognition for event-based vision with slow-ELM
Rohan Ghosh Singapore Institute for Neurotechnology
National University of Singapore, Singapore
{rghosh92,tangsy935,mahdi.rasouli,|\urldef{\mailsb}\path|sinapsedirector,sunilkukreja.sinapse}@gmail.com
\mailsb
Tang Siyi Singapore Institute for Neurotechnology
National University of Singapore, Singapore
{rghosh92,tangsy935,mahdi.rasouli,|\urldef{\mailsb}\path|sinapsedirector,sunilkukreja.sinapse}@gmail.com
\mailsb
Mahdi Rasouli Singapore Institute for Neurotechnology
National University of Singapore, Singapore
{rghosh92,tangsy935,mahdi.rasouli,|\urldef{\mailsb}\path|sinapsedirector,sunilkukreja.sinapse}@gmail.com
\mailsb
Nitish V. Thakor Singapore Institute for Neurotechnology
National University of Singapore, Singapore
{rghosh92,tangsy935,mahdi.rasouli,|\urldef{\mailsb}\path|sinapsedirector,sunilkukreja.sinapse}@gmail.com
\mailsb
Sunil L. Kukreja Singapore Institute for Neurotechnology
National University of Singapore, Singapore
{rghosh92,tangsy935,mahdi.rasouli,|\urldef{\mailsb}\path|sinapsedirector,sunilkukreja.sinapse}@gmail.com
\mailsb
Abstract
Neuromorphic image sensors produce activity-driven spiking output at every pixel. These low-power consuming imagers which encode visual change information in the form of spikes help reduce computational overhead and realize complex real-time systems; object recognition and pose-estimation to name a few. However, there exists a lack of algorithms in event-based vision aimed towards capturing invariance to transformations. In this work, we propose a methodology for recognizing objects invariant to their pose with the Dynamic Vision Sensor (DVS). A novel slow-ELM architecture is proposed which combines the effectiveness of Extreme Learning Machines and Slow Feature Analysis. The system can perform classifications per second, and achieves 1% classification error for 8 objects with views accumulated over 90 degrees of 2D pose.
Keywords:
Neuromorphic Vision; Slow Feature Analysis; Extreme Learning Machines; Object Recognition
1 Introduction
Conventional frame-based sensors capture intensity values of the whole pixel array at fixed time intervals. In contrast, asynchronous imagers remove the notion of a frame by essentially being responsive to intensity changes at an almost continual time-scale. As an example, the Dynamic Vision Sensor (DVS) elicits a spike event at a pixel when the pixel records a relative change in intensity. With their sparse, non-redundant input data stream only capturing salient moving edges, computational burden is reduced by only computing with the active events at any time as in [1]. For object recognition this points to faster inference as highlighted in [2], wherein a few spikes acquired from moving objects enable the architecture to estimate object class. The high temporal resolution of also allows for accurate pose-estimation in real-time when the underlying edge-structure of the object is known as shown in [3].
This work proposes a method for pose-invariant object recognition with event-based visual data. Like in [4] where separate eigen-faces were found pertaining to each pose, each object class is subdivided into multiple pose-specific classes. Here we use a variant of Extreme Learning Machines [5] for classification. ELMs have shown a faster way of training neural networks, exhibiting universal approximation capabilities with their random projection based feedforward model. Our approach involves an ELM architecture with excess hidden random projections. Since not all random projections are useful for classification, we proceed to add a layer that separates the noisy and irrelevant subspaces of the projections, stripping the feature vector to a much smaller dimensional space. Quantifying the utility of a projection is not easy, but however slow feature analysis (SFA, [6, 7]) proposes a simple way of arriving at informative and invariant features. For frame-based vision, SFA has been successfully applied before to learn pose-invariant features in [8]. The slowness principle targets only smoothly changing features with time, and can therefore be used to derive feature spaces which are robust to transformations. By recording data linearly varying over 2D-pose, we are able to apply the slowness principle in arriving at robust, time-supervised features. Furthermore, our constant event number sampling of events introduced in [9] allows a consistent object representation which enhances recognition performance.The slow-ELM architecture proposed therefore learns to identify robust features from the recorded data exhibiting gradual 2D pose transformations of objects.
As the DVS only responds to changes, one can only expect spikes generated by the object edges when either the object or the camera is in motion. Thereby, the invariance of our classifier performance to speed is demonstrated, along with quantifying the amount of multi-pose-view information needed to make reliable class estimates. Our Slow-ELM learner shows a considerable improvement in classification performance compared to the standard ELM, achieving 1% error with 8 objects, with their 2D pose views spanning 90 degrees. Compared to the principal components based projections as used in P-ELM [10], slow projections are found to give better recognition estimates. Furthermore, the system is capable of classifying times per second, allowing real-time operation. For frame-based vision such high speeds are of not much use due to the 30 FPS input itself, unless there are other computational modules involved which benefit from fast classification. However, for event based vision the high temporal resolution essentially means a frame rate of , which emphasizes the importance of fast computational modules.
2 Methods
The algorithm consists of four steps: Spatiotemporal ROI estimation; slow-ELM; pose-specific labelling; multi-view object class estimation.
2.1 Spatiotemporal ROI Estimation
This consists of estimating both the temporal and the spatial ROI. To obtain temporal ROI we employ the constant event number approach used in our previous work in [9] which maintains event structure w.r.t change of speed. Similar to [9], a rectangular spatial ROI is obtained by considering a certain fraction of the events on each side (up, down, left, and right) of the centroid of the extracted events. Once the current spatio-temporal ROI events have been obtained, we disregard the temporal differences between those events and form a purely spatial binary image. Differently to [9], however, we add a smoothness prior to the way the ROIs change through time. This involves only including the events which are lesser than a threshold distance to the previous spatial ROI’s edges. The image formed by the pixels within the ROI was then resized to a square image of a fixed size before passing onto the Slow-ELM.
2.2 Slow-ELM
We have training samples , where are the binary images obtained from the ROIs. is the target object class vector assigned to . Every dimension of is scaled to the range [-1,1] before passing onto the ELM. The ELM is initialized with the entries of the input layer weights in being initialized randomnly according to the normal distribution . The hidden neuron values in are computed via adding a sigmoidal non-linearity onto the random projections as follows
[TABLE]
Now the SFA algorithm elaborated in [6] is applied, which finds uncorrelated linear projections of as expressed by the projection matrix :
[TABLE]
The elements of are found according to the SFA optimization method. In particular SFA looks for projections which minimize:
[TABLE]
Under the constraints:
[TABLE]
[TABLE]
[TABLE]
denotes the expectation of over time, in our case being the average value of the projection across all classes. The unit variance condition ensures projections stay informative. is the squared energy of the difference of a projection over two consecutive instances of input (difference energy). In our experiments, two consecutive instances of input only differ in the 2D-pose of the object. As noted in [6], these slow features can be obtained simply by sphering the data followed by finding the lowest eigenvalues of the difference data . As the hidden neuron vector is n-dimensional, will be an (x) matrix with each column being a projection found through SFA. Since SFA returns the projections in order of decreasing difference energies we only keep the first columns of .
2.3 Pose-specific Labelling
Every object data captured is categorized differently according to the 2D pose range it belongs in as we record from all viewpoints across 360 degrees (Fig. 2a). In particular, we take 8 uniform partitions of the 2D pose: (0*∘-45∘), (45∘-90∘), .. (315∘-360∘*). So with N objects, we have 8N classes. The algorithm up to this point remains unsupervised as the only learning happens for finding the entries of . As shown in Fig. 1 the final layer is learnt through the regularized least squares algorithm shown in [11]. For each training sample , we extract the slow projections through the aforementioned steps. Now the supervised RLS algorithm estimates the linear mapping between and , in as used in [5]:
[TABLE]
Here and . The parameter controls the tradeoff between the regularization and the error term. Higher the value of , lesser the smoothness constraint on the weights and therefore higher the chance of over-fitting the data. Given the input to the final layer we then finally end up with the output vector :
[TABLE]
The class estimate is then the object for which one of its pose-specific class has the maximum value across all 8N classes in .
2.4 Multi-view object class estimation
This describes the method used to estimate object class when multiple input data derived from many view-points of a single object is presented to the classifier. Since we record the event data with the object smoothly changing in pose, are the successive instances of the event-structure as the object rotates. The estimated object class is the one receiving the maximum number of votes across the samples, where the vote cast is to the object category inferred by the slow-ELM for .
3 Experimental Setup
As the DVS only responds to changes in the scene, the experimental setup consisted of a rotating platform on which an object was placed. Such a setup however makes the pixels near the centre of rotation generate lesser spike-events than the pixels near the edge. To avoid this motion intensity bias, the objects were placed near the edge of the platform (as shown in Fig. 2a). For each object, the event data was captured as the platform was rotated over 6 radians, thus uniformly covering the range of 2D-pose. The experiment was repeated for two elevations (10 cm and 40 cm) of the camera, similar to what was done in [12], and across 3 different distances from the platform centre (30 cm, 45 cm, 60 cm), giving a total of 18 data recordings. For each configuration, object data was recorded for 3 different angular velocities of the platform, with a total of 8 objects. The objects chosen were: camera, cup, computer mouse, pen, mobile phone, scissors, spectacle and bottle. The output weight matrix learns a 64-class classification problem.
4 Results and Discussion
Out of the 18 recordings, 9 were used for testing (40 cm elevation) and the other 9 for training (10 cm elevation). Not every object had the same number of data, as they generated spikes at different event rates. Therefore for an unbiased estimate of performance, testing data for the classes having lesser examples were duplicated randomly to ensure equal instances of each class. After duplication, each class had approximately 2700 samples. The image extracted from the ROI is resized to a 60x60 image, input as a 3600 dimensional vector to the ELM. is chosen such that has 3000 projections. We try a range of values of , i.e. the dimensionality of the final vector input to the classification layer.
4.1 Performance with varying speed and distance
Shown in Fig. 3 is the effect of changing speeds and distance of the platform on the accuracy. The accuracy remains high for distances 30 and 45 cm, but drops abruptly for 60 cm. This indicates that the classes become less separable quickly as the distance to the object is increased beyond a limit. The effect with varying speed of the motor of the platform however is not discernible which indicates the invariance to speed changes.
4.2 Comparing slow-ELM with other selection criteria
Fig. 4(a). demonstrates how Slow-ELM compares in performance with traditional ELM and other variants, as a function of the number of projections used for learning. In particular, we compare slow-ELM (our approach), P-ELM [10], normal ELM and fast varying features (with the projections maximizing Eq.3). The figure clearly demonstrates that SFA based projections give the best recognition accuracies ( ). In contrast, the FAST features perform very near to chance itself ( 14%, chance is 100/64=15%). This suggests that fast, fluctuating features do not provide abstract category information essential for classification.
4.3 Multi-pose view object recognition
Here the method described in Section 2.4 is used to arrive at class estimates with event-data accumulated across changing pose as the objects rotate. Precisely, we quantify the recognition accuracy when event data spread out in different range of 2D pose is available. This is averaged across all possible starting 2D-poses of the objects. Fig. 4(b) compares the recognition accuracy for both SFA and PCA based projections. It can be seen that SFA quickly reaches a low error rate (1%) in classification with only 90 degrees of pose information whereas PCA requires 280 degrees to achieve the same error.
5 Conclusion
This work presents a system capable of recognizing objects from a real-time feed of spike-events and capable of generating accurate class estimates by combining information from successive views varying in object pose. Apart from the low computation time which allows upto classifications per second, the training time is also considerably lesser than the state-of-the-art Convolutional Neural Networks. The speed invariance and the partial scale invariance (object distance) of the classifier has been demonstrated. A novel slow-ELM architecture has been proposed to extract features invariant to pose changes.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Z. Ni, A. Bolopion, J. Agnus, R. Benosman, and S. Regnier. Asynchronous event-based visual shape tracking for stable haptic feedback in microrobotics. IEEE Transactions on Robotics , 28(5):1081–1089, Oct 2012.
- 2[2] J.A. Perez-Carrasco, Bo Zhao, C. Serrano, B. Acha, T. Serrano-Gotarredona, Shouchun Chen, and B. Linares-Barranco. Mapping from frame-driven to frame-free event-driven vision systems by low-rate rate coding and coincidence processing–application to feedforward convnets. Pattern Analysis and Machine Intelligence, IEEE Transactions on , 35(11):2706–2719, Nov 2013.
- 3[3] David Reverter Valeiras, Garrick Orchard, Sio Hoi Ieng, and Ryad Benjamin Benosman. Neuromorphic event-based 3d pose estimation. Frontiers in Neuroscience , 9(522), 2015.
- 4[4] Fu Jie Huang, Hong-Jiang Zhang, Tsuhan Chen, and Zhihua Zhou. Pose invariant face recognition. Institute of Electrical and Electronics Engineers, Inc., March 2000.
- 5[5] Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew. Extreme learning machine: Theory and applications. Neurocomputing , 70(1–3):489 – 501, 2006. Neural Networks Selected Papers from the 7th Brazilian Symposium on Neural Networks (SBRN ’04)7th Brazilian Symposium on Neural Networks.
- 6[6] L Wiskott and T Sejnowski. Slow feature analysis: Unsupervised learning of invariances. Neural Computation , 14(4):715–770, April 2002.
- 7[7] Pietro Berkes and Laurenz Wiskott. Slow feature analysis yields a rich repertoire of complex cell properties. Journal of Vision , 5(6):9, 2005.
- 8[8] Mathias Franzius, Niko Wilbert, and Laurenz Wiskott. Artificial Neural Networks - ICANN 2008: 18th International Conference, Prague, Czech Republic, September 3-6, 2008, Proceedings, Part I , chapter Invariant Object Recognition with Slow Feature Analysis, pages 961–970. Springer Berlin Heidelberg, Berlin, Heidelberg, 2008.