Network Weight Estimation for Binary-Valued Observation Models
Yu Xing, Xingkang He, Haitao Fang, Karl Henrik Johansson

TL;DR
This paper introduces a recursive estimation algorithm for network weights in systems with binary, quantized observations, addressing challenges posed by unknown quantization and system coupling, with proven consistency and applicability to real-time tasks.
Contribution
It presents a novel recursive estimation method using stochastic approximation for systems with binary observations, ensuring strong consistency and handling unknown quantization effects.
Findings
The proposed algorithm is strongly consistent.
The objective function is strictly concave with a unique maximum.
Applicable to online real-time decision-making and surveillance.
Abstract
This paper studies the estimation of network weights for a class of systems with binary-valued observations. In these systems only quantized observations are available for the network estimation. Furthermore, system states are coupled with observations, and the quantization parts are unknown inherent components, which hinder the design of inputs and quantizers. To fulfill the estimation, we propose a recursive algorithm based on stochastic approximation techniques. More precisely, to deal with the temporal dependency of observations and achieve the recursive estimation of network weights, a deterministic objective function is constructed based on the likelihood function by extending the dimension of observations and applying ergodic properties of Markov chains. It is shown that this function is strictly concave and has unique maximum identical to the true parameter vector. Finally, the…
Click any figure to enlarge with its caption.
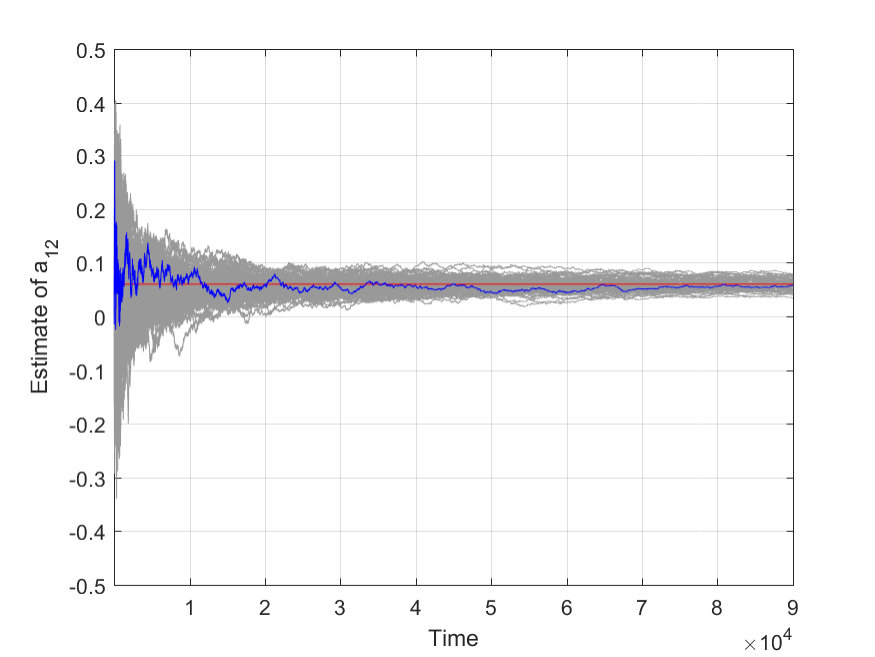 Figure 1
Figure 1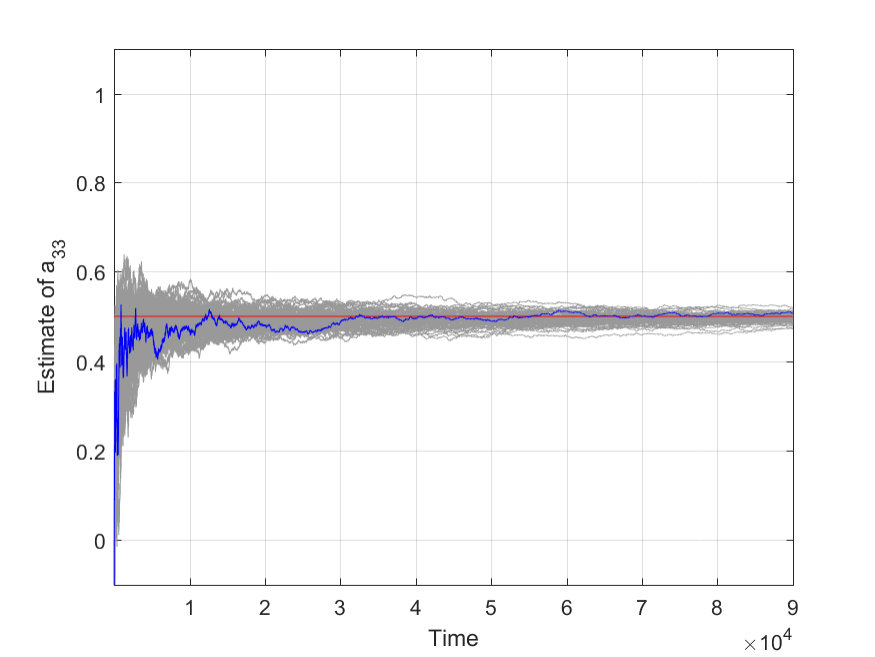 Figure 2
Figure 2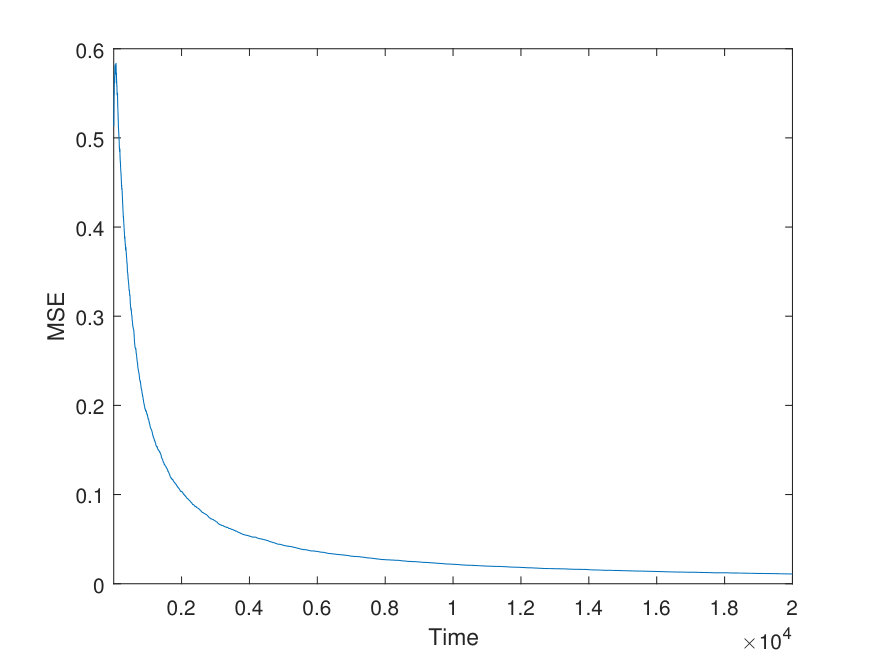 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsOpinion Dynamics and Social Influence · Complex Network Analysis Techniques · Distributed Sensor Networks and Detection Algorithms
Network Weight Estimation for Binary-Valued Observation Models
Yu Xing, Xingkang He, Haitao Fang, Karl Henrik Johansson This work is supported by National Key R&D Program of China (2016YFB0901900), the National Natural Science Foundation of China (61573345), Knut & Alice Wallenberg foundation of Sweden, and Swedish Research Council.Yu Xing and Haitao Fang are with Key Lab of Systems and Control, Academy of Mathematics and Systems Science, Chinese Academy of Sciences, Beijing 100190, and School of Mathematical Sciences, University of Chinese Academy of Sciences, Beijing 100049, P. R. China [email protected]; [email protected] He and Karl Henrik Johansson are with Division of Decision and Control Systems, School of Electrical Engineering and Computer Science, KTH Royal Institute of Technology, SE-10044 Stockholm, Sweden [email protected]; [email protected]
Abstract
This paper studies the estimation of network weights for a class of systems with binary-valued observations. In these systems only quantized observations are available for the network estimation. Furthermore, system states are coupled with observations, and the quantization parts are unknown inherent components, which hinder the design of inputs and quantizers. To fulfill the estimation, we propose a recursive algorithm based on stochastic approximation techniques. More precisely, to deal with the temporal dependency of observations and achieve the recursive estimation of network weights, a deterministic objective function is constructed based on the likelihood function by extending the dimension of observations and applying ergodic properties of Markov chains. It is shown that this function is strictly concave and has unique maximum identical to the true parameter vector. Finally, the strong consistency of the algorithm is established. Our recursive algorithm can be applied to online tasks like real-time decision-making and surveillance for networked systems. This work also provides a new scheme for the identification of systems with quantized observations.
I INTRODUCTION
The estimation problem of networks for dynamical systems is fundamental in diverse domains such as bioinformatics, communication, as well as social networks. For example, the knowledge of gene regulatory networks can deepen our understanding of diseases and development [1]. Besides, relationship networks among individuals contain information of group structures, which is crucial for the prediction of group behavior [2]. There are various formulations for the network estimation, e.g., topological inference [3], latent node identification [4], etc. This paper focuses on the first one, and we define networks as weighted graphs.
The estimation of network weights has attracted multidisciplinary attention for the last decades. [3] reviews methods of recovering complex networks from nonlinear dynamics. Also for nonlinear systems, [5] utilizes input design and passivity approach to solve the estimation problem. Network estimation for consensus dynamics is considered in [6], in which the estimation problem is converted to a convex optimization one. Plenty of network estimation methods for opinion dynamics, such as DeGroot and Friedkin-Johnsen models, have also been investigated, such as compressed sensing [2], vector autoregressive processes [7], and least square algorithms [8].
Most existing works concentrate on systems with continuous observations. In practical scenarios, however, agents often present discrete outputs rather than continuous ones [9, 10]. For instance, binary-valued signals may be the only information transmitted and observed in communication networks because of limited storage and bandwidth resources. Therefore, the study of network estimation for systems with quantized observations is necessary. To tackle this challenge, we resort to identification methods for quantized output systems.
The estimation of quantized systems has developed rapidly in recent years. Based on full-rank periodic inputs, [11] introduces the optimal quasi-convex combination estimator. [12] replaces the full-rank periodic inputs assumption by general quantized inputs. Under conditions of sufficiently rich inputs and prior knowledge of parameters, [13, 14] study a recursive projection algorithm for finite impulse response (FIR) systems. Besides, input conditions can be relaxed by designing adaptive quantizers [15, 16]. The Expectation Maximization (EM) algorithms are utilized to solve maximum likelihood estimation (MLE) problems for FIR systems in [17] and for ARX systems in [18], but they are batch algorithms. Finally, [19] investigates recursive identification of systems with binary outputs and ARMA noises by using stochastic approximation (SA) algorithms.
In this paper, we study the estimation of network weights for a class of binary-valued observation systems, which may not allow the design of inputs and quantizers. In these systems, agents present binary-valued outputs, which can be interpreted as true/false or active/inactive signals, and update their states based on these binary outputs. An example is quantized opinion dynamics [10], in which agents display discrete opinions and update based on these quantized values. Other examples can be found in quantized consensus algorithms for engineering [9] and human face-to-face interactions [20]. This update rule implies that system states are coupled with observations that cannot be modeled as selected or i.i.d. inputs as in [12, 13, 19]. Additionally, the quantization parts of the systems are unknown inherent components and cannot be designed like in [15, 16].
Our contributions are summarized as follows. We formulate a dynamical model over networks with binary-valued observations. The stability of outputs and the identifiability of the model are investigated in detail. To estimate network weights for this model, a recursive algorithm based on SA techniques [21] is proposed. More precisely, to deal with the temporal dependency of observations and achieve the recursive estimation of network weights, a deterministic objective function is constructed based on the likelihood function by extending the dimension of observations and applying ergodic properties of Markov chains. It is shown that this function is strictly concave and has unique maximum identical to the true parameter vector. Finally, the strong consistency of the proposed algorithm is established. Unlike batch algorithms solving MLE problems in [17, 18, 22], our recursive algorithm can be applied to online tasks like real-time decision-making and surveillance for networked systems. This work also provides a new scheme for the identification of systems with quantized observations.
The remainder of this paper is organized as follows. Section II introduces some notations. We formulate the estimation problem in Section III, and study the model and its identifiability in Section IV. The estimation algorithm and numerical simulations are given in Section V. Section VI concludes the paper.
II NOTATIONS
In this paper, we use boldfaced lower-case or Greek letters to represent column vectors. Their entries are represented by lower-case letters with corresponding subscripts, e.g., is the -th entry of . Matrices and random vectors are written as upper-case letters such as and , but we will not emphasize the meaning unless this causes ambiguity. The expectation of a random variable is denoted by .
For a matrix , its entries, rows, and transpose are denoted by , , and , respectively. For a sequence of random vectors, say , is used to represent the -th entry of . Denote and , where is the absolute value of real number . The -length all-zeros and all-ones vectors are written as and , or simply and . The symbol denotes a unit vector with -th entry being . Denote and . We use to represent the Descartes product of identical binary sets .
For a Markov chain in , the transition probability from to is , and the t-step transition probability from to is , . We say that is reachable from , if there exists such that .
We say that is reachable from , if there exists such that . The Markov chain is said to be irreducible, if is reachable from for all . The greatest common divisor of set is called the period of , denoted by . The Markov chain is aperiodic if for all . We call a probability distribution on as a stationary distribution, if , .
III PROBLEM FORMULATION
In the sequel, suppose that the network size . The binary observation model is as follows,
[TABLE]
where , , , are the state vector, the disturbance, and the observation vector at time respectively. is the weight matrix, and is the unknown quantized threshold vector. is the quantizer. Here is the indicator function such that for and for .
In this model, the outputs rather than states or inputs are available for individual updates. This takes place in a variety of systems such as quantized opinion dynamics [10], human face-to-face interactions [23, 20], and quantized consensus algorithms [9]. Our main aim in this paper is to estimate the network weight matrix and the quantization threshold vector . We propose a recursive algorithm based on stochastic approximation techniques, and prove the strong consistency of the algorithm.
For weight matrix , the -th entry represents the influence weight of to . To cover more situations, we do not assume that the row sums of are 1. Negative weights are permitted, which represent antagonistic relationships. Without loss of generality, we assume that has no row with zero sum, i.e., for all , which means that every agent has certain connections with others.
The observations are only binary in this paper, but this assumption is sufficient for characterizing diverse scenarios. For example, in the voter model [24], agents have only two choices, i.e., to vote () or not ([math]), and in human-human interactions, speaking or not can be defined as the individual outputs [20].
The disturbance can be interpreted as the unmodeled part of the process or the summation of observation noises. We give the following standard normal assumption for it. The normal distribution assumption is not unusual for quantized systems, since it facilitates the approximation of the MLE [17, 18, 22].
Assumption 1
* are i.i.d. standard normal random variables.*
IV THE MODEL AND THE IDENTIFIABILITY
IV-A STOCHASTIC STABILITY
This section investigates the stability of observations and the identifiability of the model in detail.
As in (1), the observation sequence is actually a Markov chain with finite states. The existence of stationary distributions is a significant aspect of stochastic stability of Markov chains [25], and Assumption 1 guarantees stability for observations of our model, as the following shows.
Theorem 1
Suppose that Assumption 1 holds. The Markov chain defined by (1) is irreducible and aperiodic, and hence converges in distribution to the unique stationary distribution positive on from any initial distribution.
Define , . This chain is critical for our estimation. Note that taking values in is also a Markov chain. For and , ,
[TABLE]
So is aperiodic. For states , since is irreducible, we have that there exists such that . Moreover from the proof of Theorem 1, holds. Hence it follows from (2) that
[TABLE]
which implies that is also irreducible, and further we have the following result:
Theorem 2
Suppose that Assumption 1 holds. The Markov chain converges in distribution to the unique stationary distribution positive on from any initial distribution.
The next lemma illustrates the relation between and the stationary distribution of .
Lemma 1
Suppose that Assumption 1 holds, and is subject to the stationary distribution of . Then
[TABLE]
for all , where and are the first and last entries of respectively, i.e., .
IV-B IDENTIFIABILITY
One of the central concerns in system identification is whether parameters of different values can determine an identical model [26]. For model (1), when we fix the distribution of disturbances in advance, the answer is negative by considering the result below.
Theorem 3
Suppose that Assumption 1 holds. Then distinct parameters correspond to distinct Markov chain defined by (1), where is the parameter matrix of dimension . That is to say, for two parameter matrices and such that or for some , the corresponding Markov chains and are not the same in the sense that their transition probability matrices are not the same.
If the noise assumption is relaxed to i.i.d. normal random variables with zero mean and variance , then the noise distribution function is , where is the cumulative density function (c.d.f.) of the standard normal random variable. It follows from the proof of Theorem 3 that , , for all . This implies that the model (1) is unique up to constant multiples of the parameters. For the situation in which the quantized threshold is known for , the model is uniquely defined. In general it is not true, but we can assume that , because the proportion of network weights that each agent gives out to different agents is the only concern, and it remains the same when the weight matrix is multiplied by a diagonal matrix with nonzero diagonal entries.
In the literature of quantized consensus and opinion dynamics [9, 10], the influence weight matrix is assumed to be row stochastic (, , and , ) or absolutely row stochastic (, ). Our model can in fact capture this assumption. It is because, denoting as the diagonal matrix with diagonal entries with , (1) can be written as
[TABLE]
where , , , and . Here , and exists since . So is absolutely row stochastic in (3), and , , become heterogeneous Gaussian noises with different variances. Under this condition, the identifiability still holds.
V THE IDENTIFICATION ALGORITHM
V-A THE OBJECTIVE FUNCTION AND ITS PROPERTY
Our goal is to estimate parameters \theta:=\text{vec}\big{\{}(A~{}\bm{c})\big{\}}, where is a matrix of dimension , and operator generates a vector from a matrix by stacking the transpose of its rows on one another. Denote . To avoid ambiguity, \theta^{*}:=\text{vec}\big{\{}(A^{*}~{}\bm{c}^{*})\big{\}}=(((\theta^{*})^{(1)})^{T},\dots,(\theta^{*})^{(n)})^{T})^{T} is used to represent the true parameters. Given observation data , the log maximum likelihood function is
[TABLE]
where with in and identical to the last entries of , and .
For fixed , and are bounded since takes values in . Thus, from Strong Law of Large Numbers for Markov chains (Theorem 17.1.7 in [25]), the following hold for the chain and fixed a.s.:
[TABLE]
[TABLE]
where is subject to the stationary distribution of .
Therefore, the function
[TABLE]
will be used to fulfill the estimation of . It has an agreeable property:
Theorem 4
Under Assumption 1, the true parameter vector is the unique maximum of the function , and the unique solution of the equation , where is subject to the stationary distribution of .
V-B THE ESTIMATION ALGORITHM
We use the SA algorithm to address the estimation problem for the binary observation model. For and , denote
[TABLE]
[TABLE]
where , and with in and identical to the last entries of .
The estimation algorithm is as follows:
[TABLE]
where is the estimation of at time step , and is the step size.
Remark 1
In this algorithm, we assume that is bounded. If this assumption does not hold, one can apply the SA algorithm with expanding truncations [21], in which estimate is also bounded because of truncation. It is also verified that the times of truncation is finite a.s.
Assumption 2
Let be the step size in (5), satisfying , , and .
Theorem 5
Suppose that Assumptions 1 and 2 hold. Then the estimates of the algorithm (5) converge to a.s. from any fixed initial value, where is the true parameter vector.
V-C NUMERICAL SIMULATIONS
We use an influence weight matrix with four individuals from an empirical study [27] to illustrate the consistency of the above algorithm. The weight matrix is given by
[TABLE]
The noises are set to be independent Gaussian with zero mean and variance , and is randomly selected as . Therefore, as previous discussion, the parameters are identical to that and in our model.
We set the step size , and run the algorithm for trials. Fig. shows the strong consistency of the algorithm, illustrated by two parameters and . The blue line represents one sample path, and the red line represents the true value. The gray ones are sample paths for all trials. Fig. shows the mean square error (MSE), which is defined as with the number of trials .
VI CONCLUSION
In this paper we study the estimation of network weights for a class of binary observation systems. These systems are distinctly different from models studied in the literature of quantized identification, because there is no room for the design of inputs and quantizers. We propose a recursive algorithm based on stochastic approximation techniques, and prove its consistency. Future work includes investigation of the convergence rate and asymptotical efficiency, generalization of the model and noise conditions, and application of the algorithm in practice.
APPENDIX
Proof of Theorem 1:
Under Assumption 1, the probability transition matrix can be obtained via the following way:
[TABLE]
for all , . Therefore, the transition matrix of is irreducible and aperiodic, and the conclusion holds by Corollary 1.17 and Theorem 4.9 in [28].
Proof of Lemma 1:
Let be the transition probability matrix of . From the definition of stationary distribution, we have that
[TABLE]
Define
[TABLE]
and it follows from the definition of that for . Hence,
[TABLE]
Similarly, we have that
[TABLE]
where
[TABLE]
[TABLE]
where the entries of are identical to the first entries of . Hence,
[TABLE]
Proof of Theorem 3:
From (APPENDIX) in the proof of Theorem 1, we have the following
[TABLE]
[TABLE]
[TABLE]
where and , and the same for . Here is the c.d.f. of standard normal distribution.
Suppose that and have the same probability transition matrices. From Assumption 1 and the above equations, it follows that
[TABLE]
where and . Hence by the strictly increasing property of ,
[TABLE]
where and . Therefore, if we set when , and when , then we have for all , . Consequently holds for all .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. Dhaeseleer, S. Liang, and R. Somogyi, “Genetic network inference: from co-expression clustering to reverse engineering,” Bioinformatics , vol. 16, no. 8, pp. 707–726, 2000.
- 2[2] C. Ravazzi, R. Tempo, and F. Dabbene, “Learning influence structure in sparse social networks,” IEEE Transactions on Control of Network Systems , 2017.
- 3[3] M. Timme and J. Casadiego, “Revealing networks from dynamics: an introduction,” Journal of Physics A: Mathematical and Theoretical , vol. 47, no. 34, p. 343001, 2014.
- 4[4] E. Nozari, Y. Zhao, and J. Cortés, “Network identification with latent nodes via autoregressive models,” IEEE Transactions on Control of Network Systems , vol. 5, no. 2, pp. 722–736, 2018.
- 5[5] M. Sharf and D. Zelazo, “Network identification: A passivity and network optimization approach,” in 2018 IEEE Conference on Decision and Control (CDC) , pp. 2107–2113, IEEE, 2018.
- 6[6] S. Segarra, M. T. Schaub, and A. Jadbabaie, “Network inference from consensus dynamics,” in 2017 IEEE 56th Annual Conference on Decision and Control (CDC) , pp. 3212–3217, IEEE, 2017.
- 7[7] C. Ravazzi, S. Hojjatinia, C. M. Lagoa, and F. Dabbene, “Randomized opinion dynamics over networks: influence estimation from partial observations,” in 2018 IEEE Conference on Decision and Control (CDC) , pp. 2452–2457, IEEE, 2018.
- 8[8] Y. Dong, W. Zhao, et al. , “The identification of social networks by the least-square algorithm,” in 2018 37th Chinese Control Conference (CCC) , pp. 1931–1936, IEEE, 2018.