
TL;DR
This paper introduces weighted mean curvature (WMC) as a new image prior, demonstrating its favorable properties, efficient computation, and superiority over existing methods like total variation in image processing tasks.
Contribution
The paper presents a novel weighted mean curvature prior, an efficient GPU computation scheme, and a convolutional neural network implementation, advancing image regularization techniques.
Findings
WMC exhibits sampling, scale, and contrast invariance.
The computation scheme processes over 33.2 giga-pixels/second on GPU.
WMC outperforms total variation and mean curvature in experiments.
Abstract
In image processing tasks, spatial priors are essential for robust computations, regularization, algorithmic design and Bayesian inference. In this paper, we introduce weighted mean curvature (WMC) as a novel image prior and present an efficient computation scheme for its discretization in practical image processing applications. We first demonstrate the favorable properties of WMC, such as sampling invariance, scale invariance, and contrast invariance with Gaussian noise model; and we show the relation of WMC to area regularization. We further propose an efficient computation scheme for discretized WMC, which is demonstrated herein to process over 33.2 giga-pixels/second on GPU. This scheme yields itself to a convolutional neural network representation. Finally, WMC is evaluated on synthetic and real images, showing its superiority quantitatively to total-variation and mean curvature.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4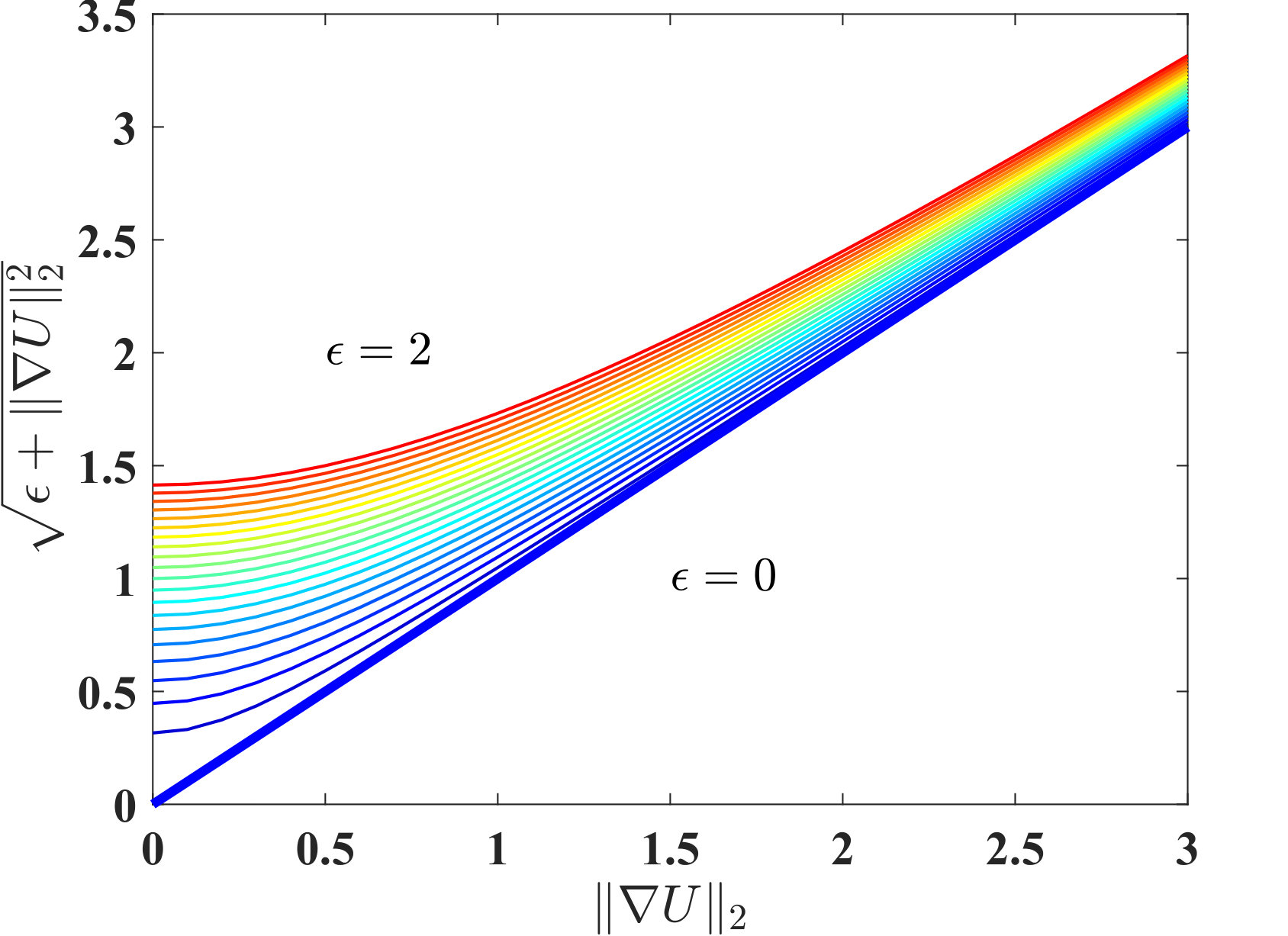 Figure 5
Figure 5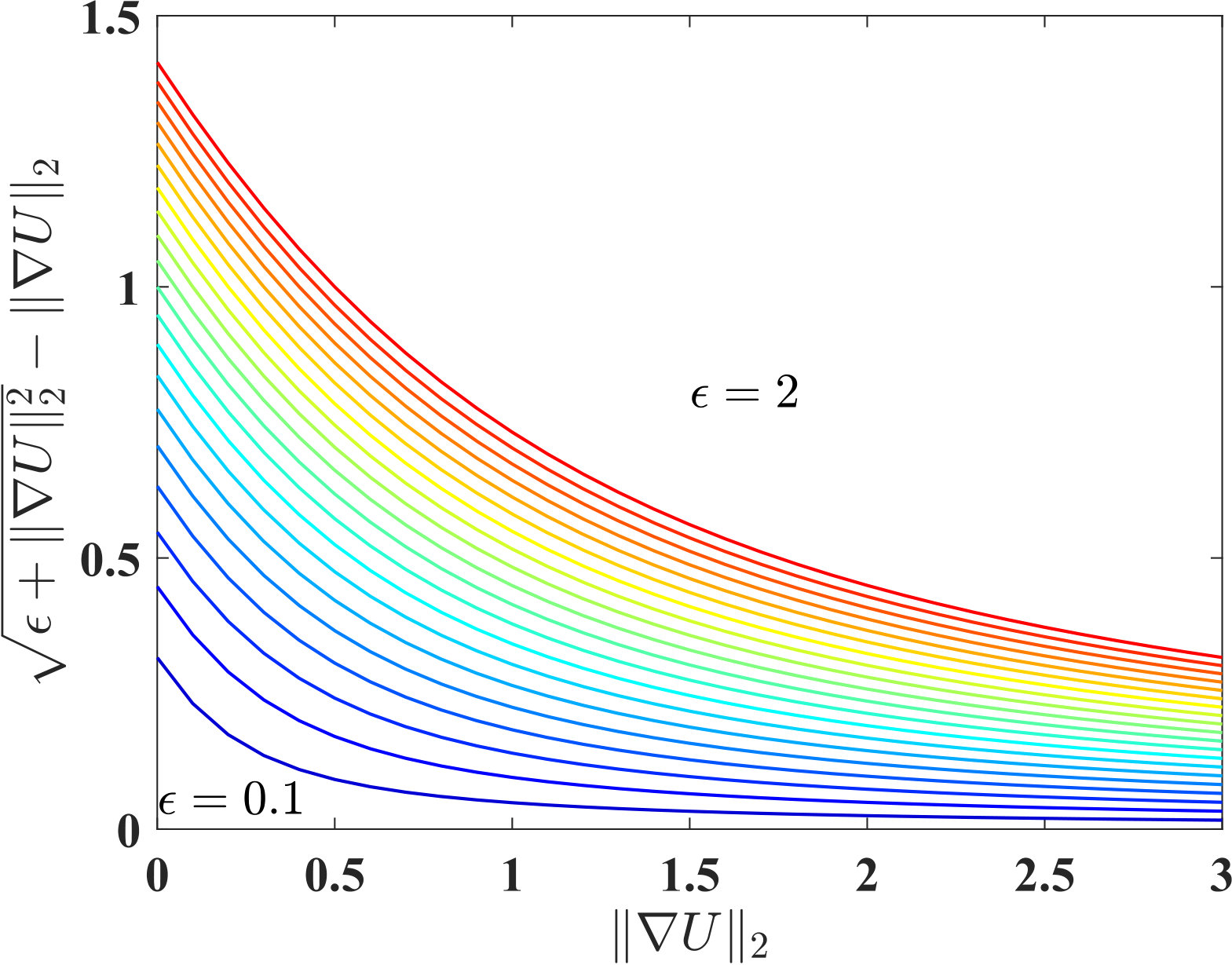 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15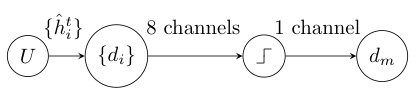 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18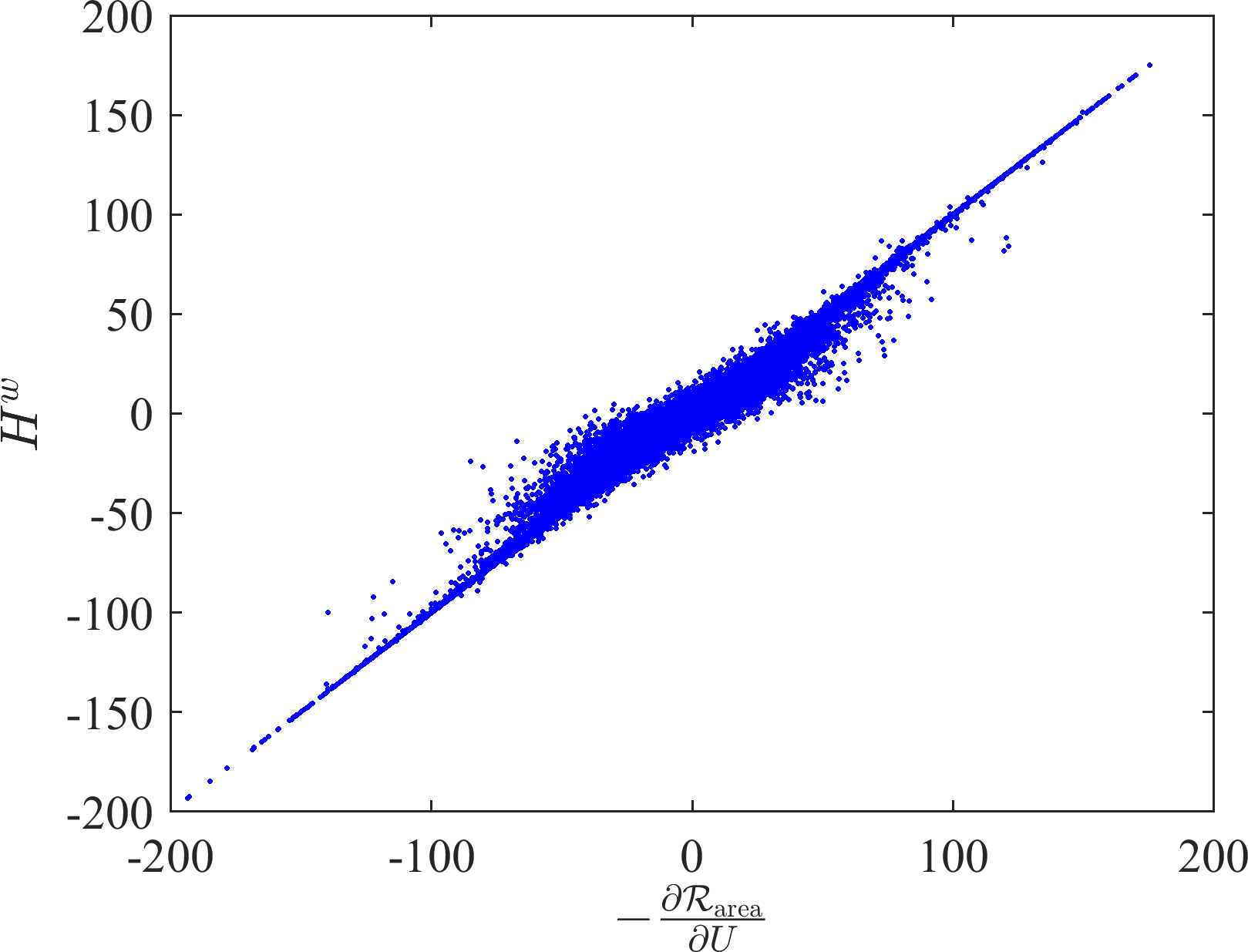 Figure 19
Figure 19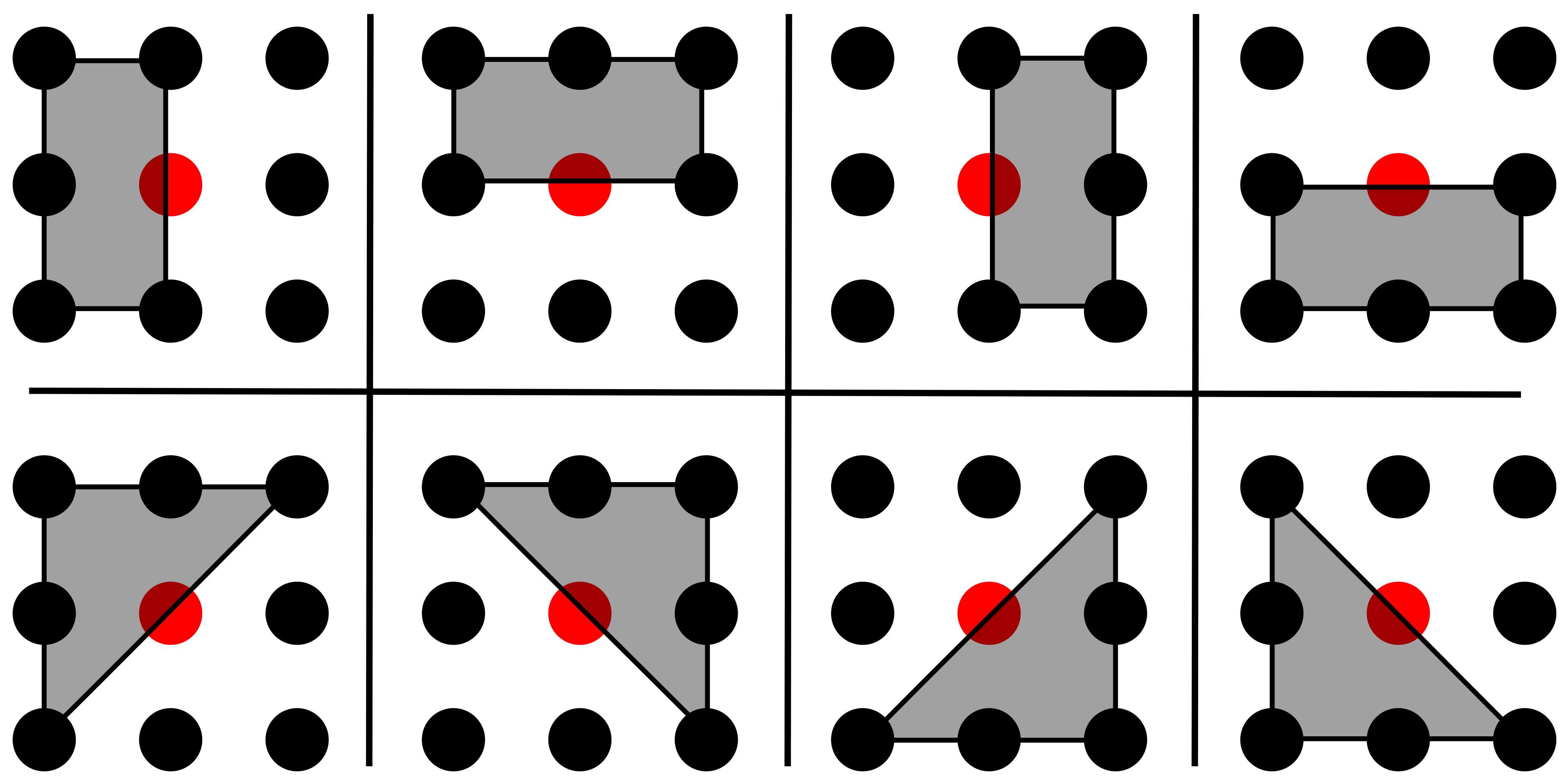 Figure 20
Figure 20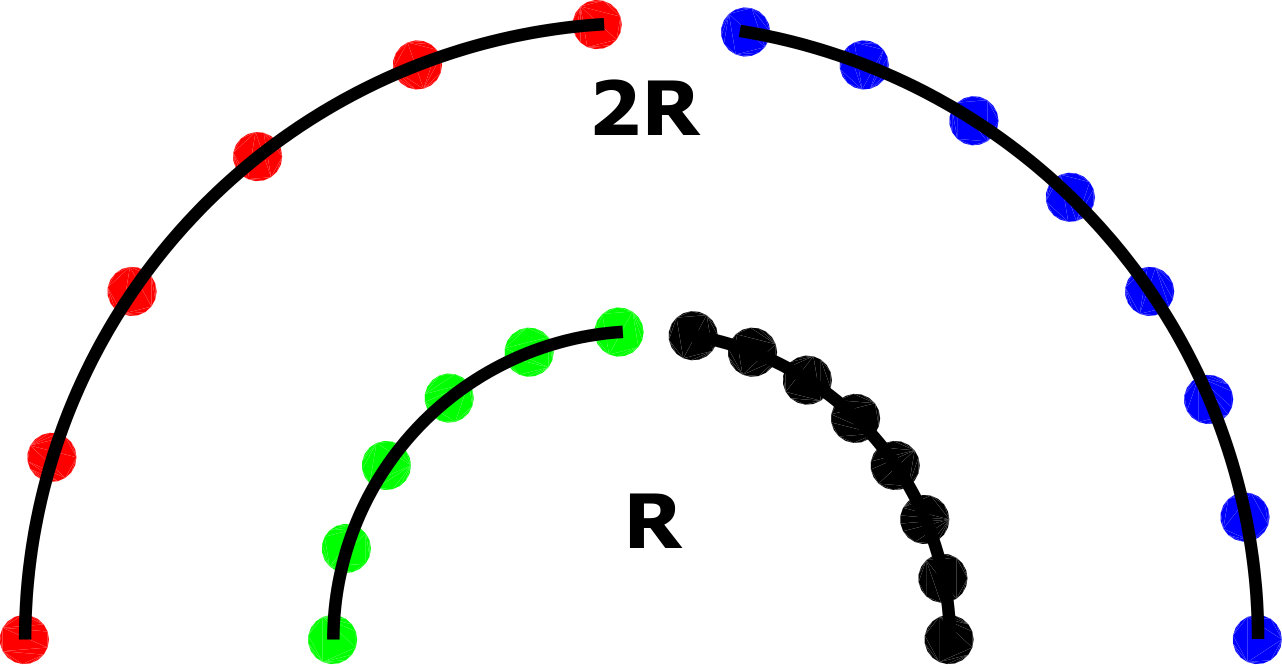 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33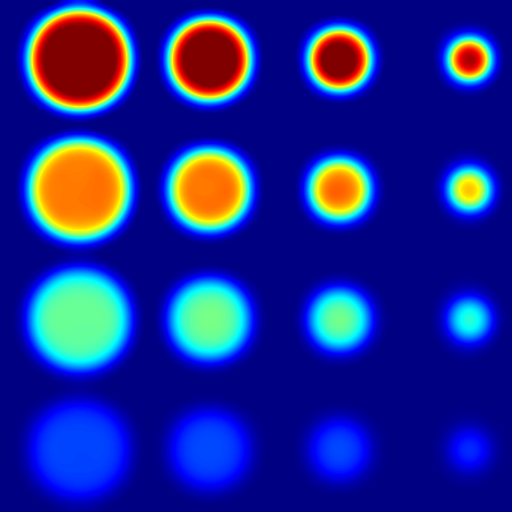 Figure 34
Figure 34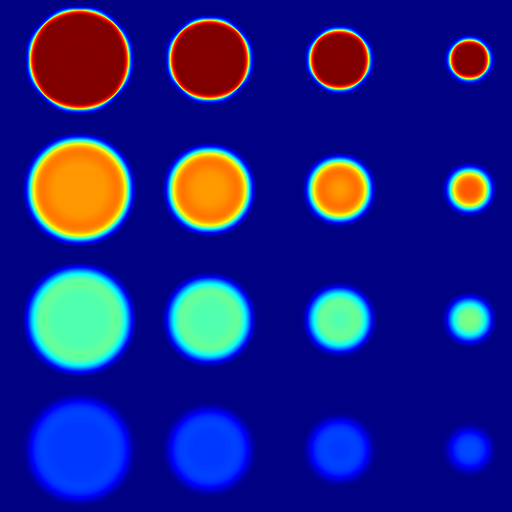 Figure 35
Figure 35 Figure 36
Figure 36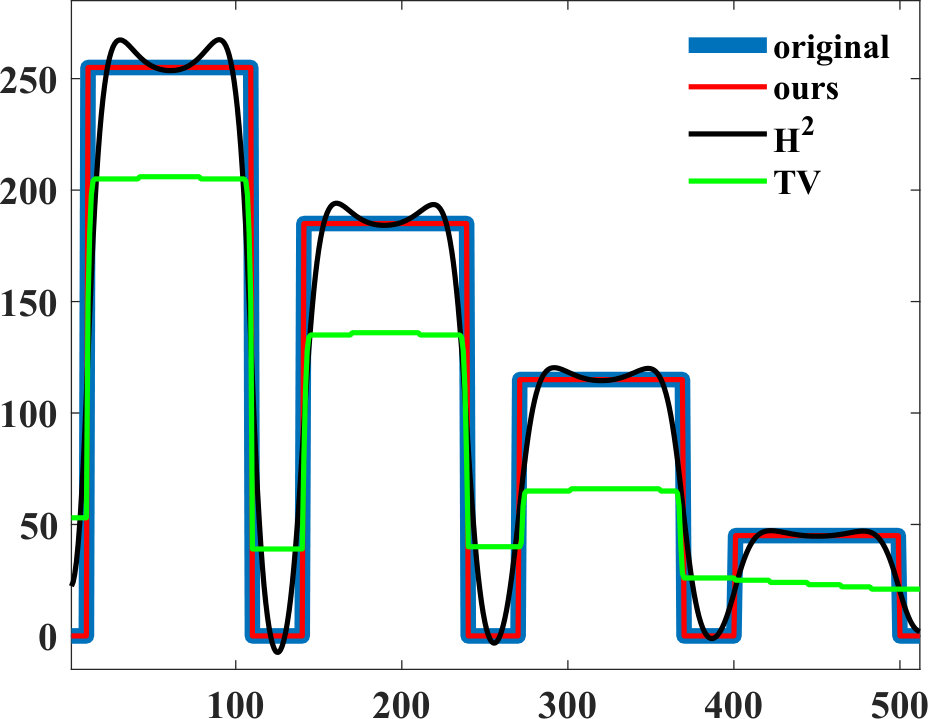 Figure 37
Figure 37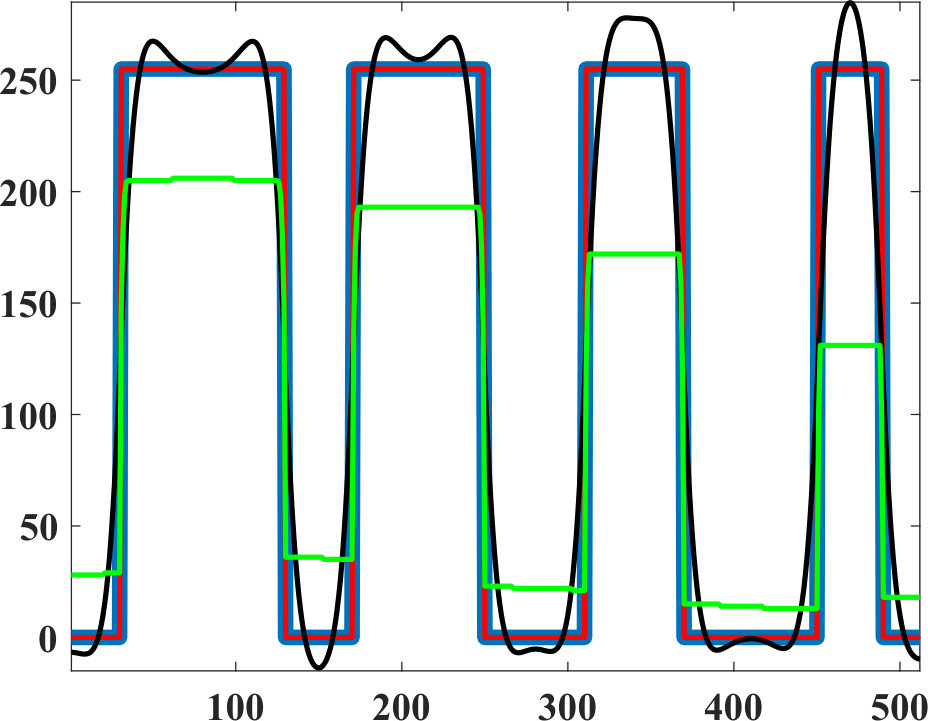 Figure 38
Figure 38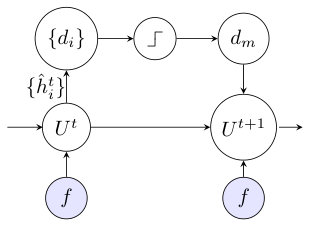 Figure 39
Figure 39 Figure 40
Figure 40| Our Neural Network Method | Iterative Method | |||
| # filters = 4 | 8 | 16 | iteration=1000 | |
| 35.0 | 33.3 | 32.7 | 39.4 | |
| 66.5 | 66.3 | 66.1 | 69.8 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Weighted Mean Curvature
Yuanhao Gong and Orcun Goksel Yuanhao Gong and Orcun Goksel are with Computer-assisted Applications in Medicine, Computer Vision Lab, ETH Zurich, Switzerland
Abstract
In image processing tasks, spatial priors are essential for robust computations, regularization, algorithmic design and Bayesian inference. In this paper, we introduce weighted mean curvature (WMC) as a novel image prior and present an efficient computation scheme for its discretization in practical image processing applications. We first demonstrate the favorable properties of WMC, such as sampling invariance, scale invariance, and contrast invariance with Gaussian noise model; and we show the relation of WMC to area regularization. We further propose an efficient computation scheme for discretized WMC, which is demonstrated herein to process over 33.2 giga-pixels/second on GPU. This scheme yields itself to a convolutional neural network representation. Finally, WMC is evaluated on synthetic and real images, showing its superiority quantitatively to total-variation and mean curvature.
I Introduction
Recovering a signal from one or more observations is a fundamental task in image processing, such as in denoising, super-resolution, deconvolution, dehazing, and enhancement. The act of generating an observation from the physical space (or an original signal) is called the imaging process, while the model governing this process is the imaging model. Prior information on this model is a fundamental piece of assumption, which can determine the success or failure of image processing methods. A typical example is image denoising, where the observed data contains measurement errors or noise, which is commonly assumed to follow an expected distribution, given some prior knowledge on the imaging (observation) process. In image smoothing, the goal is to remove undesired details while preserving “major” structures, where the structure-detail differentiation is again based on some assumed priors.
Among priors, the well-known Total Variation (TV) assumes that the signal or image to be recovered is a piecewise-constant function [25], which has been used successfully in many image processing tasks over the years. Another potential prior is the assumption that the original image has minimal area [16], which enforces both the gradient and the normal changes to be small, hence resulting in smoother images. However, this minimal-area assumption is difficult to apply using conventional optimization algorithms. Alternatively, a general gradient distribution prior can be assumed, which imposes the gradient to satisfy certain distributions, rather than being minimized [10]. Beyond first-order information, higher-order quantities such as curvature can also be used as a prior. Popular choices are Gaussian curvature [13] and mean curvature [29, 5, 14, 11]. Since these higher-order priors already assume the original signal is higher-order differentiable, the resulting images are enforced to be smooth; consequently, often losing any sharp edge detail.
For an image processing task, even when the imaging model is the same, the use of different priors may lead to different results. For example, assuming TV will lead to piecewise-constant image results; while with area regularization, the final estimation will be close to a piecewise-minimal surface. Similarly, for Gaussian curvature regularization, the result would be close to a piecewise developable surface [14]. Accordingly, the prior and applied regularization may affect the results that can be expected from an image processing task in a major way, and a suitable prior is a crucial choice.
Prior choice may also be affected by the available or affordable solution strategy, since imposing some priors require specific numerical solvers for computation. For instance, many solvers have been developed for TV for algorithmic efficiency, including the primal-dual method [3], split-Bregmann method [9], and the alternating direction method of multipliers (ADMM). These solvers nevertheless cannot be easily extended for other efficacious priors such as mean curvature or Gaussian curvature [33, 14, 26, 11]. As a result, physically-natural priors representative for many imaging models and with advantageous properties and efficient solution strategies are an ever-existing need.
Among image priors, mean curvature (MC) and its variants are especially interesting, as mean curvature is the gradient of TV term and is further related with the classical mean curvature flow [4] and the Euler elastic bending energy [26]. A special case of Euler elasticity, called Willmore energy, is used in computer graphics for triangular mesh processing [6, 20]. Willmore energy is also preferred by most cell membranes [34, 27], demonstrating its biomechanical relevance.
In mathematics, MC is the average of all principal curvatures. It is also the average of all curvatures of cross-sectional curves created on that surface when it is cut at a point by all possible planes rotated around the surface normal at that point. This relates to the diffusion of heat-type equations, and in fluid mechanics, to the equilibrium of spherical droplets.
In this paper, we present a weighted mean curvature (WMC) prior that has several advantages properties, including sampling- and scale-invariance, its sparsity on natural images and relation to the gradient of a typical regularization. These properties are presented on example images and WMC is compared with traditional priors in numerical experiments on synthetic and real images. Since WMC does not assume the image smoothness, it is shown to successfully preserve sharp details in the resulting images. We further present a novel computation scheme to efficiently calculate WMC, including a neural-network implementation for GPU computations.
II Background and Motivation
Many image processing models can be expressed with the following variational framework:
[TABLE]
where is the imaging model, is the unknown image to be estimated, is the observed data, \vec{x}$$\in$$R^{n} is the spatial coordinate, is the image dimension, \lambda$$>[math] is a parameter (usually related with noise level), and is the regularization term that imposes the assumed prior information. The prior term is often independent from the imaging model ; i.e., the same prior can be used for various imaging models.
II-A Total Variation Regularization
One of the most popular prior terms is TV regularization
[TABLE]
where is the gradient operator, and for most further notations, we drop for simplicity. This regularization has many variants. One of them adopts norm to impose anisotropy
[TABLE]
which prefers horizontal and vertical edges in . To improve numerical stability, the following variant is also used:
[TABLE]
where \epsilon$$>[math] is a small real number. Although numerically approximates , these two terms are fundamentally different. This is demonstrated in Fig. 1 as is varied between 0 and 2 in increments of 0.1. Although, for small , this approximation error may be small at any given location , its integration on the whole imaging domain may add up to a substantial value, especially if the image area is large. This highlights the effect of beyond its numerical reasons.
For , the above becomes the area regularization
[TABLE]
which imposes that has a minimum area. Thus, this requires not only the gradient to be smooth, but also the image normal to be smooth. As a result, common staircase artifacts from TV can be significantly reduced using [16].
Minimizing TV usually requires the gradient of to be computed with respect to [25], i.e.
[TABLE]
where is the divergence operator. The right hand side of Eq. (6) is indeed the mean curvature of the isocontours of . Note that this computation as such would lead to numerical issues as vanishes. Note that the above definition of mean curvature for contours is different from that for surfaces or graphs, the latter of which was studied in earlier works [14, 12]. In this paper, we focus on the mean curvature definition commonly used in image community as in Eq. 6, and extend this to address its shortcomings with our proposed definition of weighted mean curvature.
II-B Mean Curvature in Image Processing
Mean curvature (MC) has been used extensively in image processing problems [29, 18, 5, 14, 11], such as denoising [31, 33], registration [30], reconstruction [24], and decomposition [7]. For an image , the mean curvature of at is
[TABLE]
where and are gradient and divergence operators, respectively. For n$$=$$2, MC is equivalent to the right-hand side of Eq. (6) and we have
[TABLE]
This equation links MC with the Laplace operator and the diffusion along normal direction.
Mean curvature is independent of image contrast because H(\alpha U)$$=$$H(U) for any scalar \alpha$$\neq[math]. Thanks to this property, MC can provide a uniform regularization for images that contain objects of different contrast and thus is advantageous as image prior for regularization.
Mean curvature regularization is defined as
[TABLE]
where q$$>[math] is a scalar parameter; usually set to 1 or 2. If {\cal R}_{H}(U)$$=[math], the corresponding is then a piecewise minimal surface (i.e., \forall\vec{x},H(U)$$=[math]).
Compared to TV regularization, leads to better results for image denoising in practice [31, 32], which has been explained theoretically from a geometry point of view in [14, 11, 15] and a function analysis point of view in [12, 13].
II-C Challenges with Mean Curvature
Despite its attractive features, application of MC has several difficulties in practice. First, the MC depends on scale and its use as regularization, i.e. , depends on sampling rate (described further in Section III-A). Thus, MC is not only affected by the geometry itself, but also by the sampling method and scale space, posing challenges as undesired side-effects in practical applications.
Second, minimizing the mean curvature regularization is relatively challenging as it leads to a fourth-order partial differential equation [32]. Although several methods have been proposed, such as the multi grid method [2], augmented Lagrange method [32, 24], and the fixed point method [28], to substantially reduced computations, their application on larger images is still far from practical, given realistic amount of computational resources.
Third, the discretization of Eq. (8) requires the first and second order derivatives to be approximated, for instance, by finite differencing, which is susceptible to noise and can be highly unstable. Further numerical issues arise for vanishing that appears in the denominator.
Finally, needs to be assumed as smooth when numerically calculating its second order derivative. Although the mean curvature filter was proposed recently to relax this constraint via implicit minimization without computing the high-order derivatives [14, 12], the above computational challenges still persist.
II-D Our Motivation and Contribution
To overcome the above challenges, we propose herein weighted mean curvature (WMC) to be used instead of mean curvature. WMC is fundamentally different from MC, with its following advantageous properties detailed further in the next section:
- •
sampling- and scale-invariance, crucial for images that contain objects with different scales and/or of different sampling rates.
- •
sparsity on natural images: As is later shown statistically on natural images, WMC is sparser than gradient, and thus would be preferred as a regularizer.
- •
gradient of area regularization can be numerically approximated using WMC, significantly simplifying the corresponding optimization procedure.
- •
fast computation scheme: For applying our weighted mean curvature on discrete images, we further propose herein a fast discrete computation scheme that can approximate WMC numerically. This has further advantages, including: (i) it does not require the signal to be second-order differentiable, hence better preserving edges; (ii) it is a very fast discrete operation, making WMC practical for most (even computatinally-demanding) image processing tasks; and (iii) it is numerical stable when vanishes and thus avoids any numerical issues, e.g. in contrast to those encountered with TV in Eq.(6) and MC in Eq.(7).
III Weighted Mean Curvature
We define WMC as
[TABLE]
For 2D images , this equation becomes
[TABLE]
where is the isotropic Laplace operator. Although this term still has the problem when , its discrete computation can avoid such issue as shown later in Section IV. This WMC definition can be interpreted either as gradient weighted by mean curvature (weighted Total-Variation) or as mean curvature weighted by gradient. The relationship of WMC to gradient and MC is illustrated graphically in Fig. 2, in order to emphasize that the multiplication of the terms makes WMC fundamentally different from both gradient and mean curvature.
For WMC it is apparent that when either contributing term vanishes, their multiplication WMC will also go to zero. The small value of TV is a sufficient condition for the small value of WMC. Therefore, WMC is sparser i.e. is statistically more likely to be zero compared to the TV. We present a statistical comparison of these given natural images in Section III-D.
The above implies that WMC regularization is a superset of both and . WMC regularization term can be defined as
[TABLE]
where q$$>[math] is a scalar parameter defining the norm. We use q$$=$$1 unless explicitly stated. Minimizing our WMC regularization requires either gradient or mean-curvature to be small. In other words, it will allow one of them to be large while the other one is close to zero. This behavior allows to automatically choose gradient or MC or both to be minimized, leading to less artifacts compared to MC regularization and TV regularization .
In this paper, we introduce and study WMC as it can be used as both a regularization as well as the gradient of some regularization as shown in the following section. To that end, efficient numerical computation of WMC is essential, which is later addressed in Section IV. We also show below the sampling and scale invariance properties of WMC regularization. The gradient of WMC regularization, however, is not straight-forward to calculate, which is left for future work for potential application scenarios that may necessitate that. Nevertheless, we show several other practical applications in our results where WMC itself can be successfully computed and used.
III-A Sampling- and Scale-Invariance
Note that while the MC regularizer in Eq.(9) is an integration of individual curvatures, the WMC regularizer we proposed is normalized (weighted) by divergence magnitude, cf. Eq.(12). Therefore, the spatial sampling effect is taken into account inherently by WMC. Similarly, the effect of scale is also incorporated through this weighting in WMC, which makes it a physically meaningful quantity. We further demonstrate this on a toy example below.
Consider arcs with different sampling rates at two scales in Fig. 3, where gradients and curvatures of the arcs are computed at the given samples along these segments. For the inner (green and black) arcs of radii, curvature at the samples on the left and right segments are both equal, i.e. . This then yields their integration to be different as the number of integration points (samples) differ, i.e. vs. for the given examples, despite the fact that they present the same underlying geometry and continuum. In contrast, yields the same value
[TABLE]
demonstrating the sampling-invariance of WMC regularization .
Consider the scaled versions of these arcs, i.e. the outer segments with radii. would be reduced in both cases to and thus each also been halved. In contrast, does not change as increases proportionally, demonstrating the scale-invariance of both and .
The above presented shortcomings of mean-curvature is conventionally treated via heuristic-methods in image processing community, which is handled intrinsically by our WMC.
III-B Contrast Invariance
Below we first analyze the classical TV model, showing MC as not contrast invariant. Consider a generic imaging model where is observed data, is the imaging matrix, and the image. This commonly has the solution strategy
[TABLE]
The optimal solution must satisfy Euler-Lagrange equation
[TABLE]
Note that, since , a scaled solution does not satisfy the above for scaled data , for any . Therefore, the above is not contrast invariant, i.e.
[TABLE]
Nevertheless, if MC in the above equation is replaced with WMC, contrast invariance can be shown as
[TABLE]
Note that this is the Euler-Lagrange equation of some optimization form, i.e.
[TABLE]
given some regularization term . The form of such unknown regularization could be nontrivial; nevertheless for any solution strategy, its gradient is the main concern – which is defined above as WMC. In the following subsection, this unknown regularization term is shown to be a variant of area regularization and therefore WMC to be an approximation to the gradient of area regularization.
III-C Approximate the Gradient of Area Regularization
Noticing the similarity between in Eq. 11 and the gradient of area regularization in Eq. 5, i.e.
[TABLE]
we can consequently treat WMC as a numerical approximation to the gradient of the area regularization. This numerical approximation reduces computations significantly (thanks to the fast computation scheme presented in Section IV), which will enable many image processing tasks to apply area regularization in practical settings.
Although the approximation in (22) is less accurate when the gradient magnitude vanishes for constant regions of the image, in this case (20) becomes the Laplace operator, while per definition in (10) also becomes the Laplace operator due to imposed Neumann boundary conditions; making these two quantities similar. We analyze WMC approximation to the gradient of the area regularization from two aspects: First, from the function analysis point of view, the approximation error is reduced when the gradient norm gets larger, as can be seen from the equations (21 and 22). Second, the relationship between and can also be shown statistically, e.g. in Fig. 4 as computed on 500 natural images from BSDS500 dataset [1].
Based on the above approximation, the following model becomes contrast-robust (although not invariant due to the approximation)
[TABLE]
Practical numerical applications of this model are shown in Section V-B.
III-D Statistics of WMC on Natural Images
It is well-known that the gradient in natural images exhibits a heavy tail distribution. The mean curvature MC also presents a similar distribution [11]. Here, we show that WMC satisfies a similar but even sparser distribution. We used 500 natural images from BSDS500 dataset. We computed (axis-aligned) gradients and WMC in these images, and in Fig. 5(a) we show the average gradient and average WMC distributions in log scale.
It shows that WMC is sparser than gradient in this dataset. More specifically, let and denote the probability of WMC and the probability of gradient, respectively. Then, it can be seen that for any given real positive threshold , the following holds: . For example, for a threshold of , the probability of WMC is while the probability of gradient is , as shown in Fig. 5(a). The sparsity can also be seen from the cumulative distributions in Fig. 5(b), where WMC raises tighter around zero, meaning it is more sparse (i.e. considering absolute values below any given threshold as practically zeros, then WMC will have more of those values). This fact also corroborates with the theoretical discussion earlier in the paragraph below Fig. 2 on observing zeros statistically.
Furthermore, the average WMC distribution can be modeled as
[TABLE]
as shown the black line in Fig. 5(c), where represents the probability. The power of term in this model fitting suggests that the parameter in Eq. 12 should be close to when using as regularization for natural images. Although is better from a modeling point of view, q$$=$$1 is preferred from optimization point of view, since is easier than to minimize.
III-E Connection with Mean Curvature Flow
Conventional mean curvature flow minimizes the total surface area by evolving a surface according to
[TABLE]
Note that the above is indeed a normalized form of WMC, i.e.
[TABLE]
With a discrete time step size of , we then have the iterations
[TABLE]
This equation can be seen as minimizing the area regularization alone without a data fitting term. The bottleneck in performing this iteration is the evaluation of WMC, which conventionally requires an approximation of the first and second derivatives of , which further suffers from numerical issues near . Nevertheless, this is overcome by the novel computation scheme proposed herein to efficiently approximate WMC on images with a discrete Laplace operator.
IV Fast Discrete Computation Scheme for WMC
We first show the connection between WMC and Laplace operator, and next analyze discrete Laplace kernels and normal directions. We then present the combination of a regression kernel with discrete normal directions as a fast computation scheme.
IV-A Discretization of Weighted Mean Curvature
Given the WMC expression in Eq.(11), the first term can be approximated by a Laplace operator and the second term is the diffusion along the normal direction.
IV-A1 Discrete Isotropic Laplace Operator
Let us represent the Laplace operator with a convolution kernel, i.e. . We compare the following four discrete convolution kernels as promising Laplace operator options for 2D images:
[TABLE]
Kernel is a common isotropic Laplace operator. Kernel is from the mean curvature filter in [14]. Kernel originates from the numerical analysis field [23]. Kernel is common in the image processing community [21]. To analyze the isotropy of these kernels, we transformed them into Fourier domain with their spectral magnitude plotted in Fig. 6 with isolines.
Kernel is seen to be the most isotropic one and is thus used in this work as the discrete Laplace operator.
IV-A2 Discrete Normal Direction
Since gradient, MC and WMC are local properties, as their support region gets smaller, they provide better approximation, especially at sharp edges (although this may differ in smoother regions). In this paper, we choose a window and consider only 8 possible normal directions separated by 45∘ indicated with half windows shown in Fig. 7. At any location , its normal is then approximated by one of these eight cases . Note that these directions include the horizontal and vertical gradients typically used in (anisotropic) TV regularization.
The limitation of this discrete normal assumption is that the continuous normal is only approximated by the discrete , with potential approximation errors. Nevertheless, with a limited discrete directions as in Fig. 7, the normal diffusion term of in Eq.(11) becomes enumerable such that its computation is fast and straight-forward. Additionally, by replacing this normal diffusion term with regression of half windows, any numerical instability due to is avoided. Moreover, since the diffusion can only happen along edges (but not normal to edges), this discretization also helps to preserve edges. This can be envisioned as an extreme case of anisotropic diffusion.
For the half-window regressions, we use Neumann boundary conditions. This imposes the reflection symmetry property in our convolution kernels [15]. This boundary condition is imposed at every pixel, which is different from traditional boundary conditions that are only enforced at large gradient locations.
IV-B Convolution Scheme
Combining the proposed discrete Laplace kernel with the 8 half-windows with Neumann boundary conditions [15] yields the following eight convolution kernel candidates:
[TABLE]
From these kernels, we compute eight signed distances
[TABLE]
Resulting can be interpreted as the signed projection distances to the hyperplanes defined by each half-window. Therefore, the that has the minimum absolute value is the proximal projection distance that has the highest probability to a minimal surface. We use it as our estimation for WMC, i.e.
[TABLE]
We call the algorithm described by Eq. (43) and (44) as Half Laplace Operator because the support region is a half window.
IV-C Neural Network Representation
This computation scheme has a convolutional neural network representation. The convolutions in Eq. 43 can be represented as convolution layers in a neural network structure while Eq. 44 acts as a nonlinear activation function. Thus, our discrete computation scheme can be interpreted as a neural network. For instance, an architecture for computing mean curvature is shown in Fig. 8. The step symbol in Fig. 8 indicates Eq. 44 and is the activation function in neural networks.
Based on such neural-network representation, two further extensions of our discrete computation scheme can be envisioned. First, could be extended as learnable kernels ( is the layer index) for a specific dataset, such as natural images or medical images of a certain modality and given anatomy; such that these learned kernels would be more effective than the general . Since are coupled with the kernels and in the previous and next layers, their layer specific setting might be more efficient in minimizing the loss function. Second, the number of kernels can be increased, allowing for more than 8 normal directions or possible operator structures. We present numerical results from a neural network representation of our computational scheme later in Section V-E.
IV-D Support Region and Computational Complexity
The presented computation scheme has linear computational complexity and is computationally very efficient, with an implementation presented in the Appendix. The eight convolution operations can also be implemented in parallel on modern hardwares, such as Graphic Processing Unit (GPU). Our parallel implementation can process 33.2 Giga-pixels per second on a TITAN X Pascal GPU, using its native CUDA language. This indicates that our proposed methods can be used for images with very large sizes or in real-time image processing tasks. Furthermore, since the half windows in Fig. 7 have overlapping regions, it is also possible to use integral images to further improve computational performance.
Since mean curvature is a local property, smaller support region is always preferred (as well resulting in a faster computation). Although the continuous definition of can represent edges from a mathematical point of view, its finite difference approximation in Eq. 8 requires a relatively larger support region ( or larger depending on the finite difference scheme used) and thus cannot preserve edges due to such larger support region. The support region for our proposed scheme has only 6 taps (half-windows seen in Fig. 7) and thus WMC can preserve edges better than MC . This is demonstrated in the next section.
V Experiments
V-A Comparison between , and
In order to show the difference between gradient , mean-curvature , and WMC , we apply them on a sample image, where a patch is shown in Fig. 9 as a close-up. Since WMC has a smaller support region, it captures local geometries better than MC; e.g. the variance of is small in the sky, while still presents strong local variance in Fig. 9.
V-B *Comparison of , , and *
We compare three different regularization options for the same imaging problem
[TABLE]
where is one of , and . For simplicity, we set as identity matrix and checked the behaviors of these regularizations at different . We used a numerical ground-truth image seen in Fig. 10(a)(a), where each row of circles indicate scale change and each column indicate contrast difference.
For case, we solve it using [19] with an arbitrarily high 50 K iterations. We set , 700, and 1000 with the resulting seen in Fig. 10(a)(b-d). Herein relatively large values of were selected to demonstrate the effect of and artifacts from regularization at its extreme. When is increased, staircase artifacts are observed and the contrast is lost, where the smaller circles with lower contrast get smoothed out first. Note that although the TV model can capture sharp edges ideally [22], it may lose contrast, especially at high regularization weights, as seen in cross-sections in Fig. 10(a)(e and i).
For case, we solve it using [2]. We set , 150, and 1000, with the results seen in Fig. 10(a)(f-h). When is increased, resulting images get smoother. Since mean-curvature is contrast invariant, the results are robust to contrast change, but not robust to scale change.
For area regularization, we use gradient descent for the data fitting term with our approximation Eq. 20 for . More specifically, we apply the following iteration
[TABLE]
where . We set , 150, and 200, with the results seen in Fig. 10(a)(j-l). Note that with increasing , the shrinking and smoothing behavior is the same across all scale and contrast levels. This empirical observation corroborates the contrast invariance discussion of area regularization earlier in Section III-C. Since the normal directions are limited to 8 possible cases, WMC results at high regularization weights might get axis-biased; nonetheless this artifact is not distracting nor often observable in our results, as demonstrated in the next sections.
Fig. 10(a)(e) shows the contrast profiles for the three methods above along the first column of circles, and similarly Fig. 10(a)(i) along the first row of circles. Our WMC results are seen to be the closest to the ground-truth.
V-C Data Fidelity with Norm
We herein study the following -based variation model, which is known to treat Laplace noise well and is robust to outliers while imposing sparsity:
[TABLE]
We show the solution of this model based on our WMC-based area regularization, using the following primal-dual method.
For , we then have the following model
[TABLE]
This is equivalent to the dual representation
[TABLE]
where is a small constant and is a scaled dual variable.
Within an iterative solution, at each iteration, given there is a closed-form solution for as
[TABLE]
and for as
[TABLE]
For , the following problem needs to be solved
[TABLE]
for which one way is to use gradient descent as follows:
[TABLE]
As a result, is eliminated from the optimization procedure, and need to be updated alternately until convergence. As only a matrix multiplication is needed each for and updates, the iterations can be computed very fast.
For area regularization as in Eq. 20, we then have
[TABLE]
We can solve this equation using our computation scheme for . When is the identity matrix, this model leads to a smoothing problem. Results of this model for different are shown in Fig. 11 with a qualitative assessment on the preservation of most major structures even at higher . We used structural similarity index measurement (SSIM) to quantify the structural similarity between images.
V-D Mean Curvature Flow with Edge Preservation
Given the advantages of WMC, we herein show that its proposed computation scheme is ideal, yielding significantly further advantages in its applications. We study the iterative mean curvature flow application in Eq.(28), which is independent of an imaging modal and data term. We discretize WMC using the conventional method or our proposed computation scheme, and present results at different iterations in Fig. 12. As seen in Fig. 12, our discrete computation scheme can preserve local geometry and sharp edges much better compared to the traditional discretization.
This is due to two reasons: (i) our method is performed within a smaller support with limited diffusion directions; and (ii) our computation does not require the image to be second-order differentiable, whereas the traditional discretization computes second derivatives hence requiring the result to be at least second-order smooth within given supports.
A close-up is shown in Fig. 12(e) to demonstrate the smoothing-while-edge-preserving behavior of our computation scheme. With increasing iteration number, the wrinkles on the flag are correctly smoothed out, while the edges of cross are well preserved. A similar optimal behavior is also observed on the mountain and snow textures. In contrast, with traditional mean-curvature computation, the sharp corners become rounded while most structural information is also smoothed as Fig. 12(d).
Note that the above is merely a difference from the two approximations (computation schemes) of the same WMC operation. We conclude that our proposed discrete computation is potentially more suitable for most image processing tasks.
V-E Convolutional Neural Network Implementation
As mentioned, our computation scheme has a neural network representation, which can be used to find data adaptive kernels . Using our neural network structure in Fig. 13, we solve the following model
[TABLE]
for and . For simplicity, we again assume as identity. Traditional gradient decent method for this model required hundreds of iterations to converge, whereas our neural network method was able to obtain acceptable results with only two layers and eight learned filters. Neural network implementation thus required two to three orders of magnitude shorter time than the iteration method, when both are performed on the same hardware.
To obtain the learned kernels, we extracted 10,000 image patches of pixels each, randomly from natural image dataset BSDS500. We used the network structure shown in Fig. 13, with two such consecutive layers (more layers did not reduce the loss function anymore for this problem). We separately learned 4, 8, and 16 convolutional filters of size each. We set a learning rate of , batch size of 32, and regularization of 5. The eight learned kernels in the first layer from our 8 filter network are shown in Fig. 14. Some of these kernels already look like our half Laplace kernels. The average loss function for different number of learned filters is tabulated in Table I, in comparison to the iterative method with 1000 iterations. Note that merely a two-layer network yields better results (energy-level and quality) compared to the iterative approach, since these filters are now data-adaptive. Since the filters are independent from image resolution, they can be trained on low resolution images. Note that the content of testing images should be similar with the training dataset, i.e. natural scenery in this case. Nevertheless, while these learned filters would be valid only for training-like input, the generic kernels given in Section IV-B are valid for any input data.
Figure 15 shows some example results from our neural network implementation with , , and 8 kernels used. The details are seen to be removed, while the main structures being successfully preserved. With TensorFlow library and Python implementation, each prediction took 1.2 ms on a GeForce 940MX (384 CUDA cores) with Windows 10 (Thinkpad T480) and 0.25 ms on a GeForce GTX TITAN X (3072 CUDA cores) with Linux. Better performance can be obtained by using native CUDA C++ language. A two-layer network is seen to be orders of magnitude faster than the iterative structure.
V-F Compared with Other Edge Preserving Filters
One iteration of the mean curvature flow with our discrete computation scheme can be considered as a filter. Therefore, our filter is comparable with other edge preserving filters, such as Domain Transform (DT) [8] and Guided Filter (GF) [17]. We tested these three filters on four images as shown in Fig. 16. As seen with these results, DT tends to generate block artifacts while GF may lose the color contrast. Our method successfully removes the details while preserving the major structures, without any such side-effects.
VI Conclusion
We presented weighted mean curvature and showed its advantageous properties such as scale- and sampling-invariance. It can be used as an approximation of gradient for area regularization, which facilitates optimization in image processing applications. We discretized the computation with 8 kernels with directional normals, which avoids numerical issues and leads to a very efficient computation scheme. Our experiments confirm the benefits from the proposed WMC and its discrete computation scheme, including scale- and contrast-robustness, fast computation, and edge preservation. We compared mean curvature flow computed by a classical method and our new scheme, demonstrating better edge preservation with the latter. We also presented our scheme as a neural network layer with its performance on natural images and potential to learn these filters. In comparison to other edge preserving filters, our method can produce higher quality results.
As being independent from any particular imaging model, WMC and area regularization can both be applied on a large range of image processing problems, including smoothing, denoising, super resolution, deconvolution, and image reconstruction. In most of these problems, minimizing the area regularization becomes the bottleneck, where our efficient WMC approximation can significantly accelerate this procedure. Our computation scheme can be further extended for higher dimensional data such as video and 3D images. Thanks to the high performance, our method can be adopted for real time image processing tasks or used on embedded devices such as FPGA, with potential applications in mobile applications such as on smart phones, medical devices, and microscopes.
Acknowledgments
Funding was provided by the Swiss National Science Foundation (SNSF) and the Titan X GPU was sponsored by the NVIDIA Corporation. The authors wish to thank Dr. Valeriy Vishnevskiy for his feedback on the convergence of the fast-TV implementation.
Appendix A Matlab Code for computing WMC
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik, “Contour detection and hierarchical image segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 33, no. 5, pp. 898–916, May 2011.
- 2[2] C. Brito-Loeza and K. Chen, “Multigrid algorithm for high order denoising,” SIAM Journal on Imaging Sciences , vol. 3, no. 3, pp. 363–389, 2010.
- 3[3] A. Chambolle and T. Pock, “A first-order primal-dual algorithm for convex problems with applications to imaging,” Journal of Mathematical Imaging and Vision , vol. 40, pp. 120–145, 2011.
- 4[4] Y. G. Chen, Y. Giga, and S. Goto, “Uniqueness and existence of viscosity solutions of generalized mean curvature flow equations,” J. Differential Geom. , vol. 33, no. 3, pp. 749–786, 1991.
- 5[5] A. Ciomaga, P. Monasse, and J. M. Morel, “Level lines shortening yields an image curvature microscope,” in 2010 IEEE International Conference on Image Processing , Sept 2010, pp. 4129–4132.
- 6[6] K. Crane, U. Pinkall, and P. Schröder, “Robust fairing via conformal curvature flow,” ACM Trans. Graph. , vol. 32, 2013.
- 7[7] S. D. El Hadji, R. Alexandre, and A.-O. Boudraa, “2d curvature-based analysis of intrinsic mode functions,” IEEE Signal Processing Letters , vol. PP, no. 99, pp. 1–1, August 2017.
- 8[8] E. S. L. Gastal and M. M. Oliveira, “Domain transform for edge-aware image and video processing,” ACM TOG , vol. 30, no. 4, pp. 69:1–69:12, 2011, proceedings of SIGGRAPH 2011.