A linear programming approach to sparse linear regression with quantized data
Vito Cerone, Sophie M. Fosson, Diego Regruto

TL;DR
This paper introduces a linear programming method for sparse linear regression with quantized data, providing theoretical robustness guarantees and demonstrating improved performance over existing methods.
Contribution
It presents a novel linear programming approach specifically designed for sparse regression with low-precision data, addressing non-convexity issues.
Findings
Proves robustness guarantees for the proposed method.
Shows improved numerical performance compared to state-of-the-art techniques.
Effectively handles quantized and low-precision data in sparse regression.
Abstract
The sparse linear regression problem is difficult to handle with usual sparse optimization models when both predictors and measurements are either quantized or represented in low-precision, due to non-convexity. In this paper, we provide a novel linear programming approach, which is effective to tackle this problem. In particular, we prove theoretical guarantees of robustness, and we present numerical results that show improved performance with respect to the state-of-the-art methods.
Click any figure to enlarge with its caption.
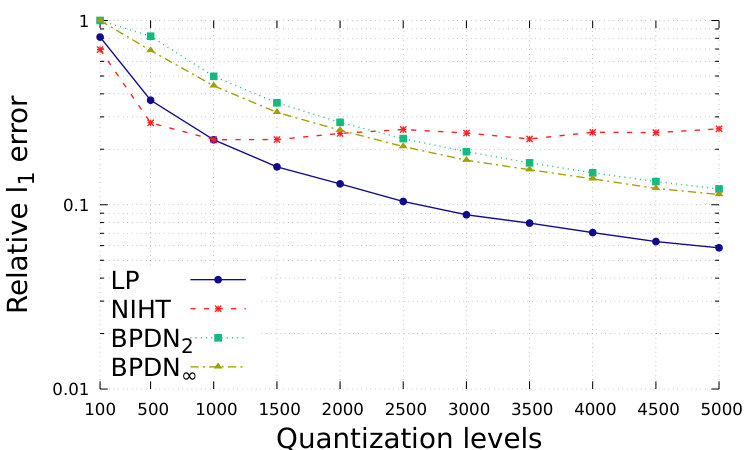 Figure 1
Figure 1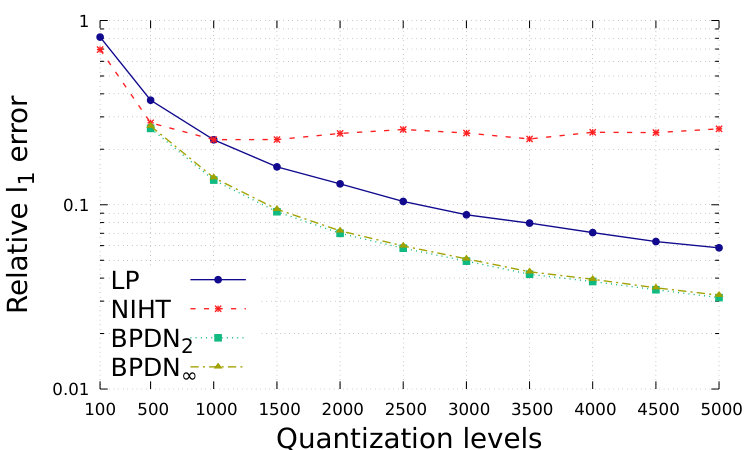 Figure 2
Figure 2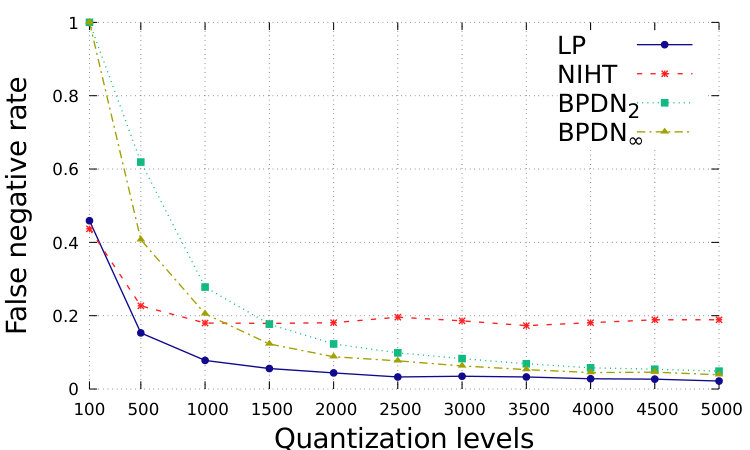 Figure 3
Figure 3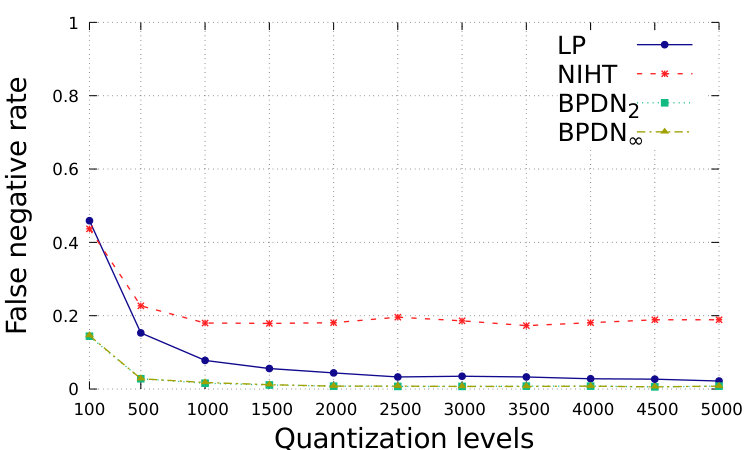 Figure 4
Figure 4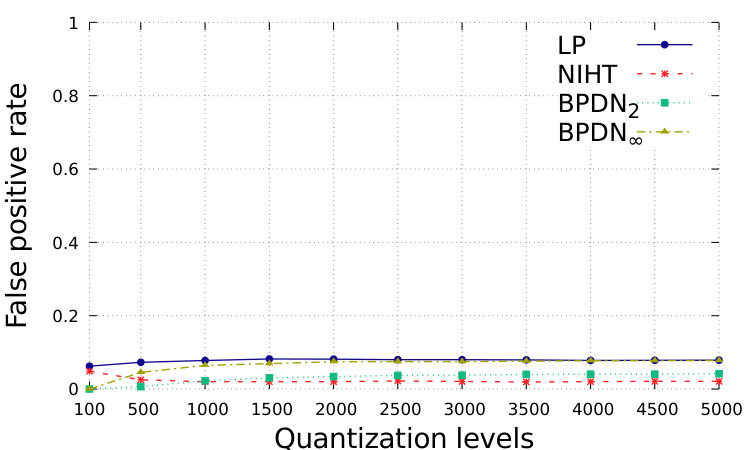 Figure 5
Figure 5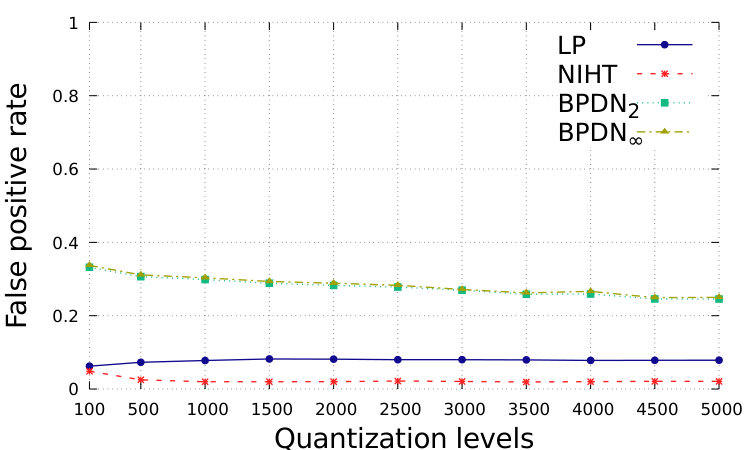 Figure 6
Figure 6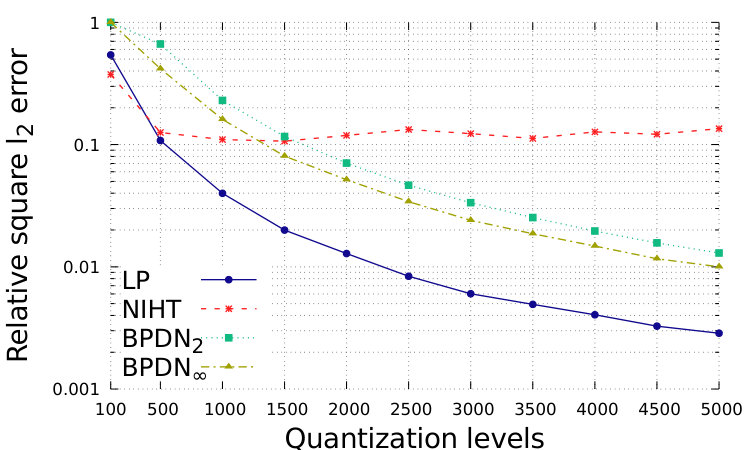 Figure 7
Figure 7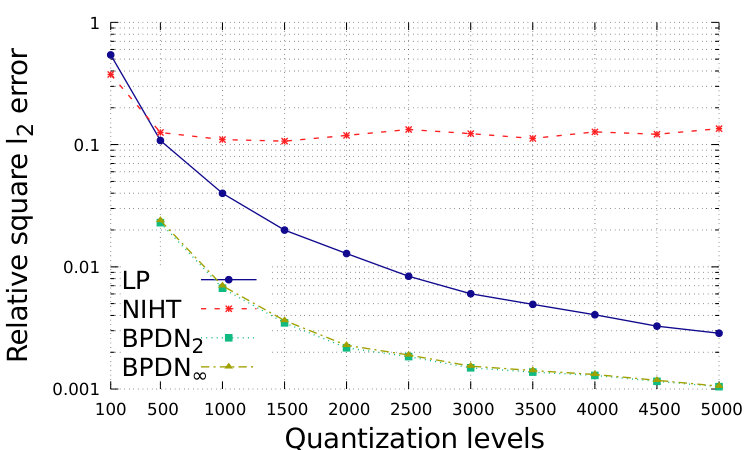 Figure 8
Figure 8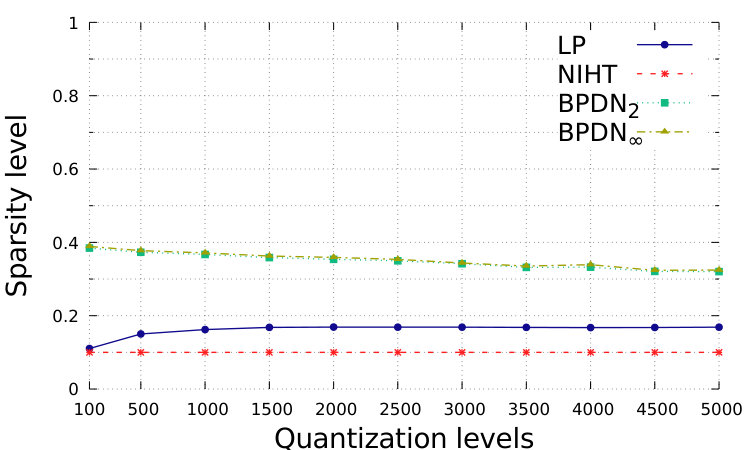 Figure 9
Figure 9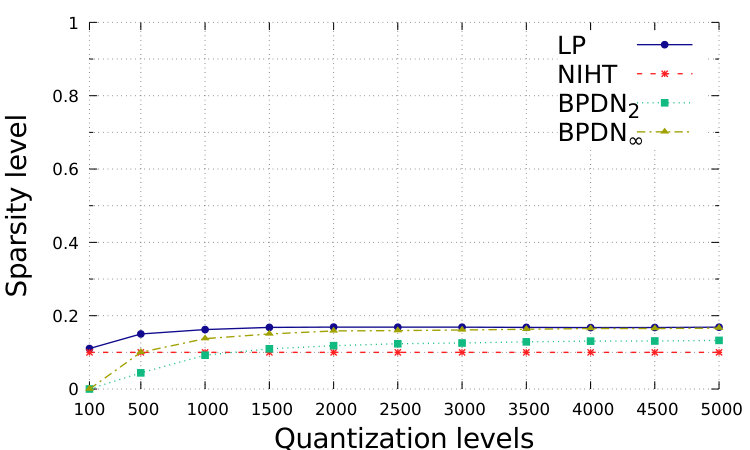 Figure 10
Figure 10Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A linear programming approach to
sparse linear regression with quantized data
V. Cerone, S. M. Fosson*∗*, D. Regruto ∗ Corresponding author. The authors are with the Dipartimento di Automatica e Informatica, Politecnico di Torino, corso Duca degli Abruzzi 24, 10129 Torino, Italy; e-mail: [email protected], [email protected], [email protected];
Abstract
The sparse linear regression problem is difficult to handle with usual sparse optimization models when both predictors and measurements are either quantized or represented in low-precision, due to non-convexity. In this paper, we provide a novel linear programming approach, which is effective to tackle this problem. In particular, we prove theoretical guarantees of robustness, and we present numerical results that show improved performance with respect to the state-of-the-art methods.
I Introduction
Sparse optimization refers to those optimization problems where the solution is encouraged to be sparse, i.e., to have few non-zero components. This research area has dramatically increased in the last decades in many different fields including signal processing, machine learning, and system identification. In signal processing, the widespread presence of signals that admit sparse representations has promoted the research on new sparse optimization problems and algorithms, see, e.g., [1, 2]. In machine learning and system identification, sparsity is desirable to reduce as much as possible the complexity of the estimated models. In the literature, sparsity is exploited for the identification of linear systems, see, e.g., [3, 4, 5]; non-linear functions in [6]; polynomial models in [7]; time-varying systems in [8, 9].
A popular paradigm in sparse optimization is given by the case where the collected measurements are linearly related, through a predictor matrix , to the sparse signal or vector of parameters to be estimated. This paradigm leads to the problem of computing the sparsest solution of the linear system of equation , , , . In the literature, this problem is generically referred to as sparse linear regression. The undetermined case, , has attracted the attention of many researchers, whose work originated the theory of compressed sensing (CS) [1, 2]. Finding the sparsest solution of an undetermined linear system is an NP-hard problem. However, it is well known that sparsity can also be achieved by minimizing the -norm of under suitable constraints accounting for the linear structure of the problem, which makes the problem convex. Specifically, the minimization of the -norm of subject to is known as Basis Pursuit [2, Chapter 4]. When a measurement noise is present, the constraint is generally formulated as , where is a suitable norm and is a known bound; this is referred to as Basis Pursuit Denoising (BPDNp).
In the literature, and are the most common choices. In particular, BPDN2 is very popular, as it is suitable to cope with Gaussian noise, which is the typical model in a number of applications, such as transmission systems. The choice provides solutions that are more tolerant to possible outliers, since it bounds the mean energy of the error.
The case was first analyzed in [10], where results on robustness to noise are proven based on the coherence properties of , and has been recently retrieved to deal with quantized or low-precision measurements in the CS setting. When is quantized, in fact, there is a bounded error on each component , , which makes the -norm description more suitable than the one, as illustrated in [11, 12]. In particular, the -norm supports the consistency principle: the measurements obtained from the recovered signal lie in the same quantization intervals of the observed measurements, as considered in [13, 14, 11, 12].
As to CS, the study of quantization is strongly motivated from the practical point of view. As a matter of fact, the CS paradigm moves the computational burden from the acquisition-compression phase (which simply consists in computing ) to the recovery phase. This feature is successfully exploited in systems where signals’ acquisition is performed by remote devices with reduced computational capability, e.g., either space probes or environmental sensors, while recovery is performed in powerful computational centers. However, for transmission purposes, measurements are often not only compressed, but also quantized. We refer the interested reader to [15, 16] for a complete overview on CS with quantized measurements.
In many applications, also is generated by the remote device and has to be transmitted. Therefore, it is more realistic to assume that also undergoes quantization. It is worth noticing that, in some cases, can be designed on purpose, then it may be quantized in its original form, which prevents the addition of a quantization error. For example, Bernoulli matrices (whose entries are binary) are suitable for CS. However, in most of the applications, is not arbitrarily chosen, instead it depends either on the hardware of the remote device or on the physical nature of the problem.
The quantization of plays the role of an undesired perturbation in the recovery phase. Inaccuracies in are a serious drawback because they lead to an uncertain sparse linear regression problem which is not convex anymore. The problem of perturbed in sparse optimization and CS is addressed in [17, 18, 19].
The goal of this paper is to tackle the problem of sparse linear regression when both and are quantized, with main focus on the CS setting. To the best of our knowledge, this joint problem has been considered only in [20], while, as already mentioned, the two single problems of quantized and perturbed have already been studied. In [20], the normalized iterative hard thresholding algorithm [21] is adapted to tackle the problem of quantized and . The algorithm is tested in the case of a specific stochastic quantization function, with possible applications in the radio astronomy framework. In this setting, a robustness result is proved, which shows that the mean recovery error is controlled by the quantization error.
In this paper, we propose a novel approach to this problem, which can be applied in the presence of any quantization function with bounded error. We extend the formulation of BPDN*∞* and the results in [10] to the case where also is quantized. First we recast the considered problem into the framework of the static error-in-variables estimation considered in [22]. Then, by exploiting results from [22], we show that the solution can be computed by solving a suitable number of linear programming (LP) problems. The paper is organized as follows. In Section II, we formally state the problem and specify the considered assumptions. In Section III, we introduce the novel LP formulation. In Section IV, we prove theoretical results on the robustness of the proposed approach. In Section V, we show some numerical simulations that support the efficiency of the proposed method with respect to the state-of-the-art. Finally, some conclusions are drawn in Section VI.
II Problem statement
Let us consider a device performing compressed data acquisition according to the equation , , where . The device is assumed to transmit quantized/low-precision versions of and to a recovery center. We denote by and the quantized versions of and , respectively. The problem considered in this work is to recover a sparse such that , given and . The quantization strategy is supposed to be unknown, though a bound on the maximum quantization error is given. Apart from the quantization, for simplicity, no other sources of uncertainty/noise are considered here, although such extension is under investigation. More precisely, we formulate the following optimization problem.
Problem 1
Given , , , and ,
[TABLE]
In the rest of the paper, we assume that the signs of the components of are known, in the sense that for each , , we know if it is either non-negative or non-positive. More specifically, without loss of generality, we assume the non-negativity of .
Assumption 1
* for all .
This assumption naturally occurs in a number of applications, such as localization problems [23], image processing [24], and power allocation [25]. However, extensions to more general classes are possible and will be studied in future work. Here, we only observe that if the signs are not known, one can split the problem in LP problems, trying all the possible combinations of signs. Therefore, there is a way to compute the global minimum of the general non-convex problem, though computationally not efficient for large . In future work, we will also analyze possible pre-processing methods to obtain prior information on the signs from available data.
III A linear programming approach
Thanks to the following result, we show that, under Assumption 1, Problem 1 is equivalent to an LP problem.
In the following, given two vectors , we write to indicate that for each . We denote by the identity matrix. Moreover, , where is for transpose.
Result 1
Under Assumption 1, Problem 1 can be equivalently formulated as the following LP problem:
[TABLE]
Proof of Result 1 is obtained by first noticing that Problem 1 can be equivalently rewritten in a more compact way as follows:
[TABLE]
Model (2) is obtained by applying the results about bounded errors-in-variables identification of static linear systems presented in [22] to the set of constraints of problem (3), under Assumption 1. Model (2) with Assumption 1 is an LP problem whose solution is straightforward. Moreover, its formulation is compliant with the quantization consistency principle.
Remark 1
*It is worth noting that, by suitably exploiting results in [22], Result 1 can be extended to cover the general case where the signs of are unknown, although in that case the solution is obtained by solving a larger number of LP’s. However, this general case is outside the scope of this conference contribution and will be the subject of a future work.
Remark 2
*We notice that a working hypothesis similar to Assumption 1 is considered in [19, Theorem 6]. In [19], the perturbation on is assumed to have a specific structure, namely, it is equal to , where is known, and , , is unknown. In other terms, the direction of each column of the perturbation is known, and the dimension of the unknown is reduced from to . The proposed model [19, Equation 11] is a BPDN2 with an additive perturbation bounded in the -norm. This model is biconvex and can be approached with alternating minimization, which only achieves a local minimum. However, in [19, Theorem 6], it is observed that if , for all , the problem admits convex formulation, which guarantees to get the global minimum.
IV Analysis of robustness
In this section, we show that Model (2) with Assumption 1 is robust, i.e., the distance between its solution and the original signal is bounded by a quantity , which is controlled by and . In particular, if , the robustness result in [10] is obtained.
The result that we now prove is based on the mutual coherence of , which is defined as:
[TABLE]
where the index denotes the -th column.
From the theory on underdetermined linear systems and CS, it is well known that a sufficiently small coherence guarantees a successful sparse linear regression, up to errors due to noise [26, 27, 10]. The following theorem shows that sparse linear regression from quantized data is successful when coherence is sufficiently small, up to quantization errors.
Theorem 1
Let , where the unknown has non-zero components. and are known. Let us assume that: for some , for any , , and
[TABLE]
Then, the solution of problem (2) is robust, that is,
[TABLE]
Proof:
Let
[TABLE]
be the feasible set of Model (2). By definition, . Let us consider the subset . We then prove that for any we have , which means that there is no solution in . This implies that all the solutions are in , which proves the thesis. Thus, we study the problem:
[TABLE]
Let As illustrated in [28], it is straightforward to prove that
[TABLE]
where is the support of . Since , we obtain
[TABLE]
from which we also get By assuming for any column , we have:
[TABLE]
where we use the triangle inequality . Now, we notice that
[TABLE]
where . From (8), we obtain a bound for . Furthermore, for the off-diagonal elements of , we have:
[TABLE]
Similarly, for the diagonal elements, we obtain:
[TABLE]
Therefore,
[TABLE]
where . Coming back to (9),
[TABLE]
By assuming , we can write
[TABLE]
Finally,
[TABLE]
Let We can now rewrite problem (5), using (6), as follows:
[TABLE]
where is the -dimensional column vector with entries equal to 1 in the positions of the support of , and 0 otherwise.
As in [10, equations (20)-(21)], we consider the dual problem:
[TABLE]
Exploiting the zero duality gap between primal and dual in LP problems [29], if (12) has solution that originates a positive penalty, the penalty is positive also for (11), which is our final aim. From this point, the thesis can be obtained following the same procedure used in [10, pages 518-519], since problem (12) is analogous to problem (21) in [10], with different constants. We omit the details for brevity. We just notice that the constraint is necessary to fulfill equations (22)-(23) in [10]. ∎
We remark that if , Theorem 1 provides the same bound of Theorem 3 in [10] (with ).
It is worth noticing that, in CS, coherence-based analyses [26, 27] have the drawback of providing less tight bounds with respect to other properties, such as the restricted isometry property (RIP) [2]. Nevertheless, RIP is difficult to assess for a specific matrix (in the literature, RIP is proved for some classes of random matrices). Coherence, instead, can be easily computed for any matrix. This work provides results in terms of coherence, while future extensions might envisage other properties.
V Numerical results
We propose the following experiment. A system acquires a sparse vector through a predictor matrix . The dimensions are , , . is generated according to a Gaussian distribution ; the support of is generated uniformly at random, while the non-zero entries uniformly distributed in with . The quantization is uniform: fixed a certain number of equidistant quantization levels, each entry of and of is approximated with the closest point in the quantization codebook. We assume a quantization range sufficiently large so that saturation problems are negligible.
We compare the proposed LP method to three state-of-the-art methods: BPDN*∞, BPDN2*, and the normalized iterative hard thresholding (NIHT), as presented in [20].
To design the measurement noise bounds for BPDN*∞* and BPDN2, we propose two different settings.
-
Setting 1: quantization of is ignored, while we know . Therefore, we impose and, as a consequence, .
-
Setting 2: quantization of is known, though the related error is moved on the measurements. Assuming to know , , and a bound such that , for any , from we obtain and, as a consequence,
We notice that NIHT requires the knowledge of .
In Fig. 1 and Fig. 2, we show the performance with respect to different quantization levels, from 100 to 5000. For simplicity, we consider that same quantization levels for and for , while distinguished approximations could be suitably designed. The total range is assumed to be with . which is generally sufficient to avoid problems of saturation for the proposed setting. We show the relative square error, defined as ; the relative square error, defined as ; the normalized sparsity level of the estimation, the false positive rate, defined as the number of events where while , over ; the false negative rate, defined as the number of events where while , over .
In Fig. 1, we show the simulations in Setting 1. In this case, the distance from the desired vector is smaller for BDPNp, , with respect to our LP: the smaller feasible set forces a closer consistency to data. However, the smaller feasible set limits the sparsity of the obtained solution, which is between and for BDPNp, while the correct one is . The false positive rate is then large. This is in contrast to the wish of producing sparse solutions.
In order to obtain sparser solutions for BDPNp, , we implement the Setting 2, which is depicted in Fig. 2. By assuming to know , we can suitably enlarge the feasible set and obtain sparse solutions. However, in this case BDPNp, , has a larger number of false negatives, and the recovery accuracy is worse than the proposed LP.
Finally, we notice that the low precision NIHT [20, Algorithm 1] does not show good performance in this experiment. NIHT is proved to be robust when a specific stochastic quantizer is used [20, Section 3.1], while this experiment shows that further adjustment should be done for other quantizers. We specify that our approach does not require a specific quantization operator and uses only information about the maximum quantization error.
In conclusion, the proposed LP method provides the best performance in this experiment, since at similar sparsity levels, it obtains the best recovery accuracy.
VI Conclusions
In this paper, we have addressed the problem of sparse linear regression, with particular attention to the compressed case, when only quantized versions of the predictors and of the measurements are available. This problem is relevant in the applications, while difficult to tackle due to its intrinsic non-convexity. In this work, we have undertaken an approach, based on results in error-in-variables system identification, which allows us to recast the problem into a linear programming model, under suitable sign assumptions. The proposed approach is theoretically proved to be robust, i.e., a finer quantization leads to a smaller recovery error. Moreover, numerical simulations show an improved recovery accuracy with respect to known methods. Generalizations of the sign assumption are possible, as well as the addition of other sources of noise. This will be the subject of future work.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] D. L. Donoho, “Compressed sensing,” IEEE Trans. Inf. Theory , vol. 52, no. 4, pp. 1289–1306, 2006.
- 2[2] S. Foucart and H. Rauhut, A Mathematical Introduction to Compressive Sensing . New York: Springer, 2013.
- 3[3] Y. Gu, J. Jin, and S. Mei, “ ℓ 0 subscript ℓ 0 \ell_{0} norm constraint LMS algorithm for sparse system identification,” IEEE Signal Process. Lett. , vol. 16, no. 9, pp. 774–777, 2009.
- 4[4] R. Tóth, B. M. Sanandaji, K. Poolla, and T. L. Vincent, “Compressive system identification in the linear time-invariant framework,” in Proc. IEEE Conf. Decision Control (CDC) , 2011, pp. 783–790.
- 5[5] R. Toth, H. Hjalmarsson, and C. Rojas, “Sparse estimation of rational dynamical models,” in Proc. IFAC SYSID , 2012, pp. 983–988.
- 6[6] C. Novara, “Sparse identification of nonlinear functions and parametric set membership optimality analysis,” in Proc. American Control Conf. (ACC) , 2011, pp. 663–668.
- 7[7] G. Calafiore, L. E. Ghaoui, and C. Novara, “Sparse identification of polynomial and posynomial models,” in Proc. IFAC World Congress , 2014, pp. 3239–3243.
- 8[8] B. M. Sanandaji, T. L. Vincent, M. B. Wakin, and R. Tóth, “Compressive system identification of lti and ltv arx models,” in Proc. IEEE Conf. Decision Control (CDC) , 2011, pp. 783–790.