Inverse Path Tracing for Joint Material and Lighting Estimation
Dejan Azinovi\'c, Tzu-Mao Li, Anton Kaplanyan, Matthias Nie{\ss}ner

TL;DR
This paper presents Inverse Path Tracing, a method that jointly estimates scene materials and lighting by using a differentiable Monte Carlo renderer, enabling accurate scene editing and re-rendering.
Contribution
It introduces a novel invertible light transport simulation and an optimization approach for simultaneous estimation of materials and lighting in indoor scenes.
Findings
Accurate joint estimation of materials and lighting achieved.
Enables scene editing and re-rendering under new conditions.
Uses a differentiable Monte Carlo renderer for optimization.
Abstract
Modern computer vision algorithms have brought significant advancement to 3D geometry reconstruction. However, illumination and material reconstruction remain less studied, with current approaches assuming very simplified models for materials and illumination. We introduce Inverse Path Tracing, a novel approach to jointly estimate the material properties of objects and light sources in indoor scenes by using an invertible light transport simulation. We assume a coarse geometry scan, along with corresponding images and camera poses. The key contribution of this work is an accurate and simultaneous retrieval of light sources and physically based material properties (e.g., diffuse reflectance, specular reflectance, roughness, etc.) for the purpose of editing and re-rendering the scene under new conditions. To this end, we introduce a novel optimization method using a differentiable Monte…
Click any figure to enlarge with its caption.
_figures_input_photos.jpg) Figure 1
Figure 1_figures_matterport.jpg) Figure 2
Figure 2_figures_matterport_fine_textures.jpg) Figure 3
Figure 3_figures_matterport_subdivision.jpg) Figure 4
Figure 4_figures_matterport_teddy.jpg) Figure 5
Figure 5_figures_pathtracing.jpg) Figure 6
Figure 6_figures_pathtracing_backprop.jpg) Figure 7
Figure 7_figures_plot_batch.jpg) Figure 8
Figure 8_figures_plot_bounces.jpg) Figure 9
Figure 9_figures_plot_mis.jpg) Figure 10
Figure 10_figures_plot_samples.jpg) Figure 11
Figure 11_figures_plot_srays.jpg) Figure 12
Figure 12_figures_room0_emission.jpg) Figure 13
Figure 13_figures_shadow.jpg) Figure 14
Figure 14_figures_specular.jpg) Figure 15
Figure 15_figures_synth_insert_object.jpg) Figure 16
Figure 16_figures_synth_results.jpg) Figure 17
Figure 17_figures_synth_textures.jpg) Figure 18
Figure 18_figures_teaser.jpg) Figure 19
Figure 19_figures_workflow_geometry_scan.jpg) Figure 20
Figure 20_figures_workflow_reconstructed.jpg) Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26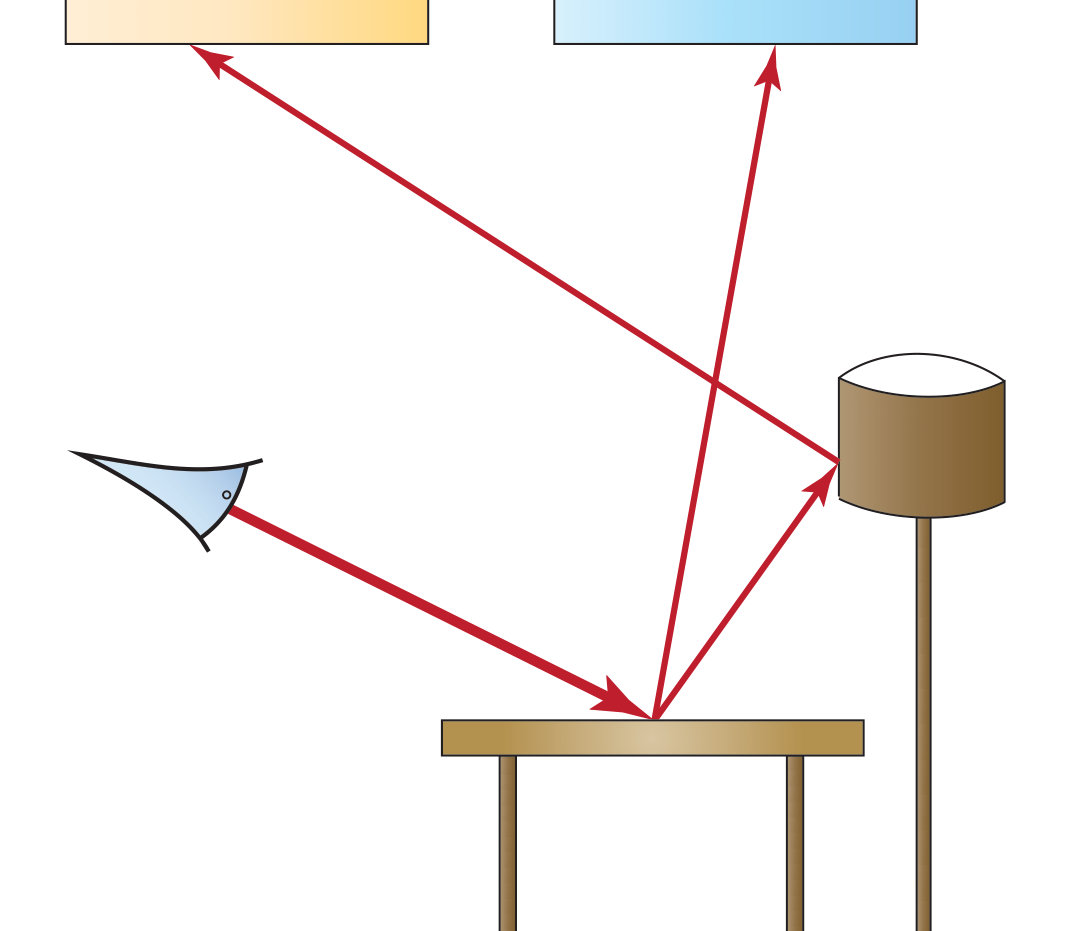 Figure 27
Figure 27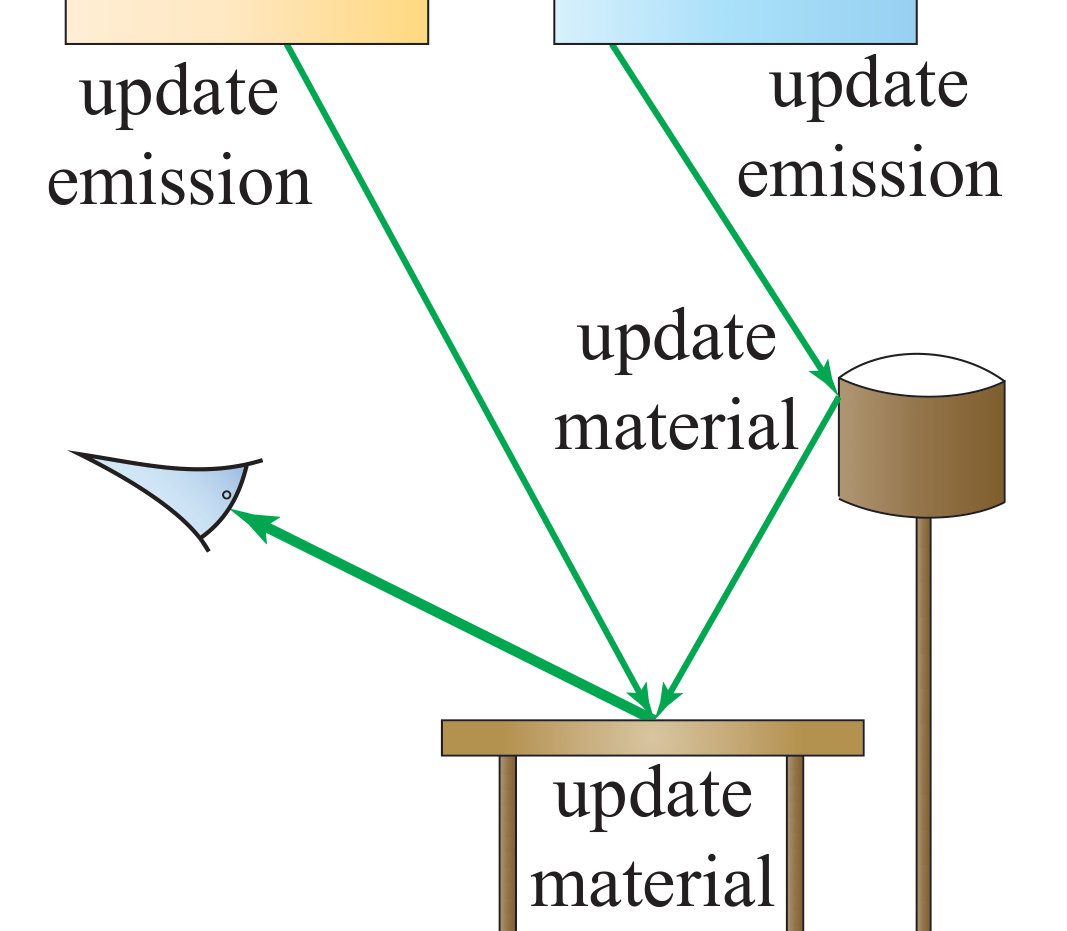 Figure 28
Figure 28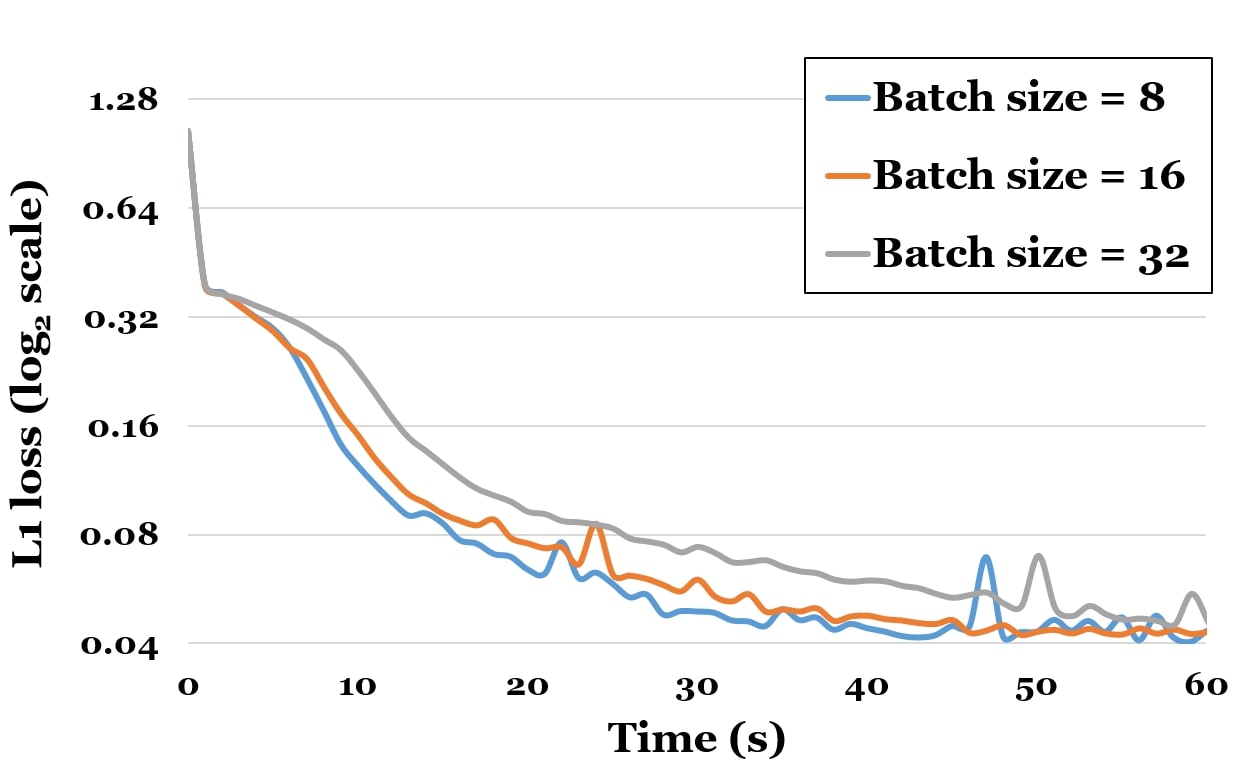 Figure 29
Figure 29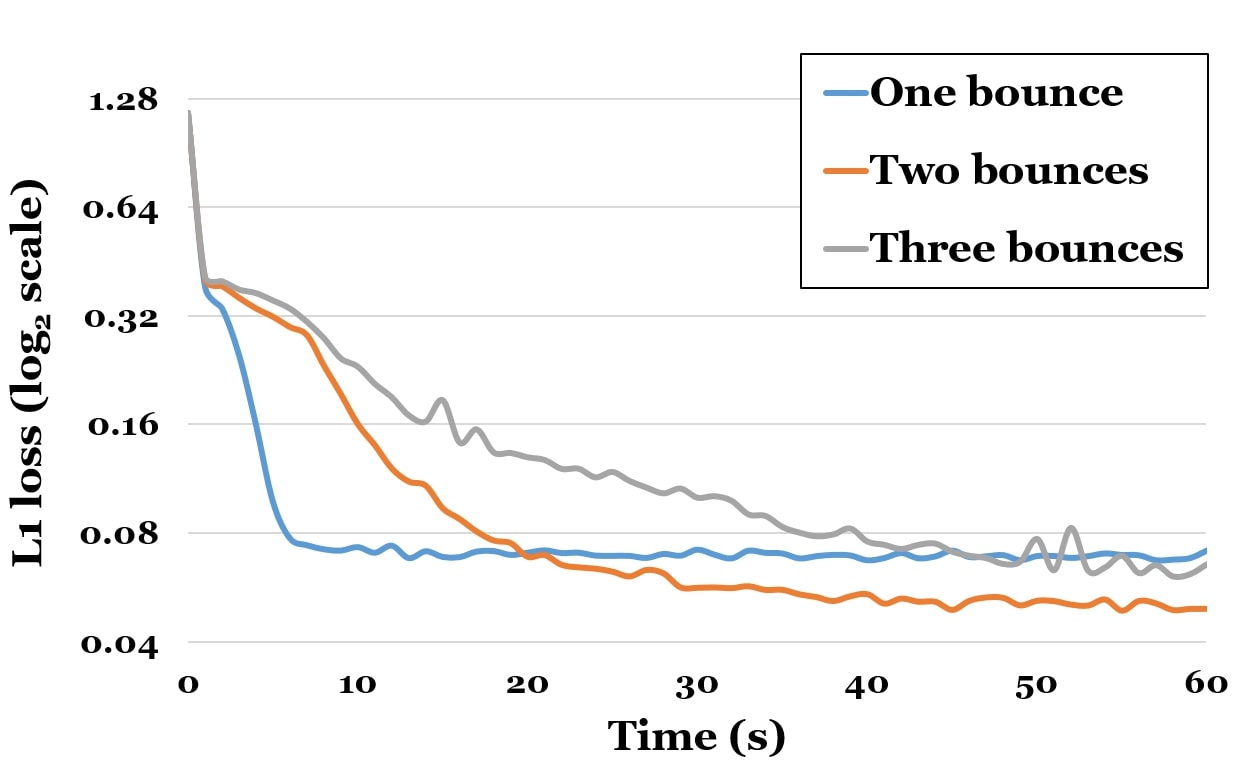 Figure 30
Figure 30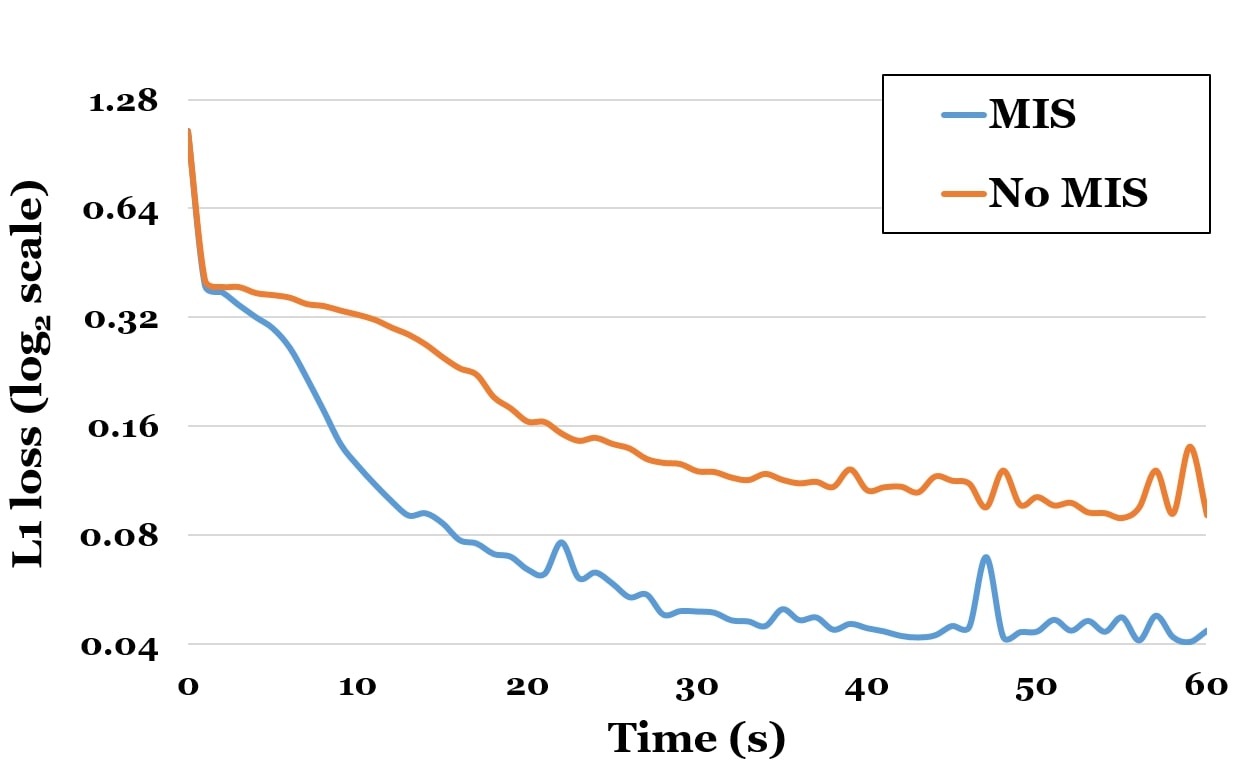 Figure 31
Figure 31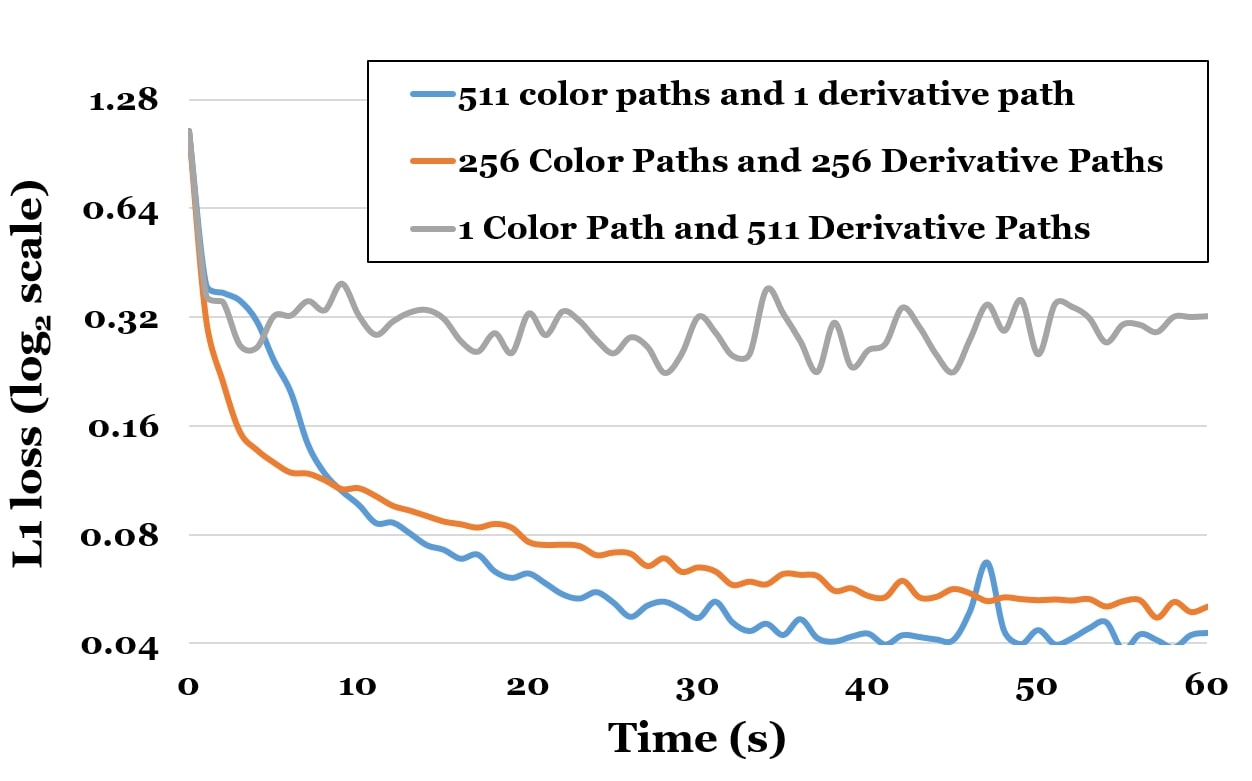 Figure 32
Figure 32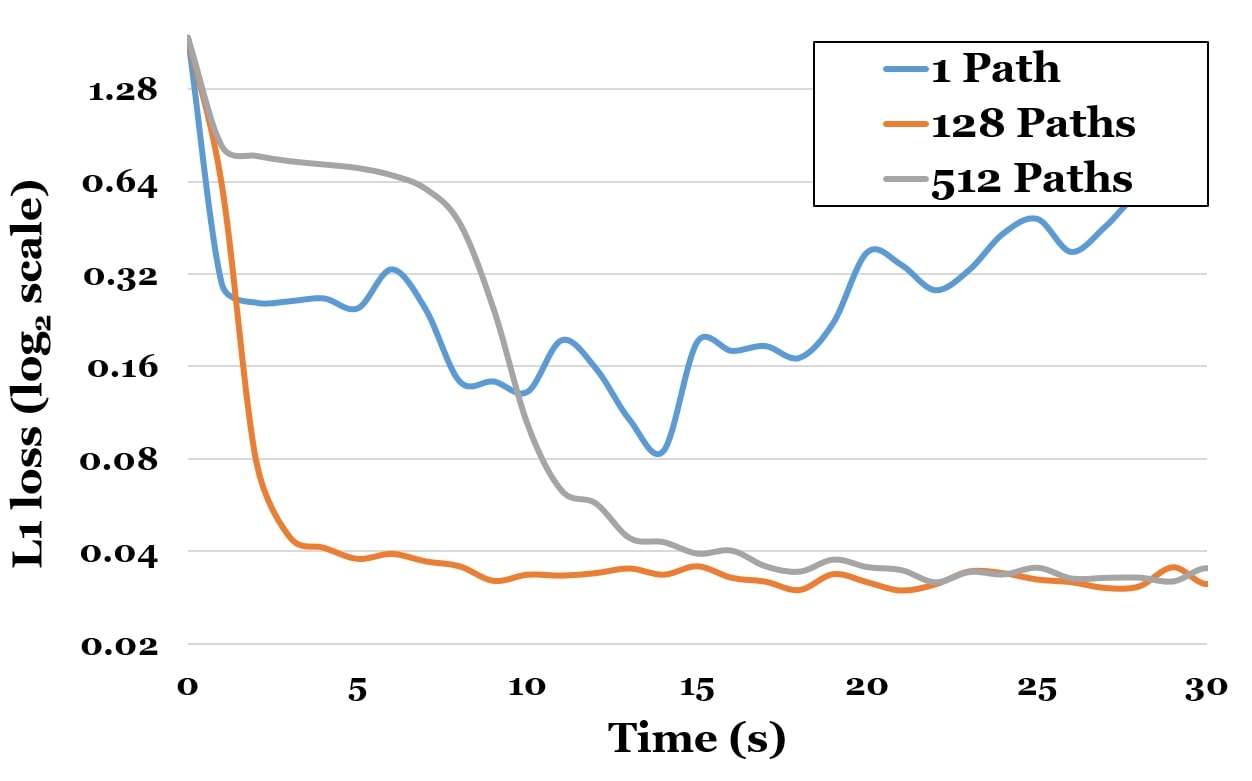 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35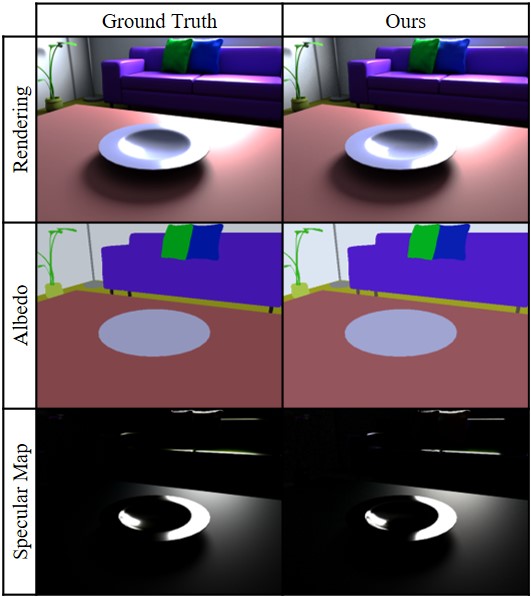 Figure 36
Figure 36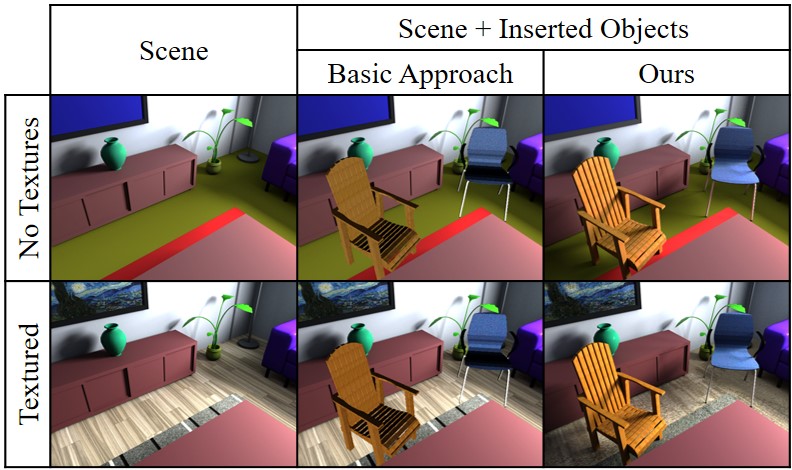 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Method | Scene 1 | Scene 2 | Scene 3 |
|---|---|---|---|
| SVSH Rendering Loss | 0.052 | 0.048 | 0.093 |
| Our Rendering Loss | 0.006 | 0.010 | 0.003 |
| SVSH Albedo Loss | 0.052 | 0.037 | 0.048 |
| Our Albedo Loss | 0.002 | 0.009 | 0.010 |
| Method | LIME [26] | Ours |
|---|---|---|
| Object 1 | 0.45% | 0.00037% |
| Object 2 | 1.37% | 0.14% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\hypersetup
pdftitle=Inverse Path Tracing for Joint Material and Lighting Estimation, pdfauthor=Dejan Azinović, Tzu-Mao Li, Anton Kaplanyan and Matthias Nießner, pdfsubject=Computer Vision; Computer Graphics; Inverse Path Tracing; , pdfkeywords=Inverse Rendering, Path Tracing, Material Estimation, Lighting Estimation
Inverse Path Tracing for Joint Material and Lighting Estimation
Dejan Azinović1
Tzu-Mao Li2,3
Anton Kaplanyan3
Matthias Nießner1
1Technical University of Munich 2MIT CSAIL 3Facebook Reality Labs
Abstract
Modern computer vision algorithms have brought significant advancement to 3D geometry reconstruction. However, illumination and material reconstruction remain less studied, with current approaches assuming very simplified models for materials and illumination. We introduce Inverse Path Tracing, a novel approach to jointly estimate the material properties of objects and light sources in indoor scenes by using an invertible light transport simulation. We assume a coarse geometry scan, along with corresponding images and camera poses. The key contribution of this work is an accurate and simultaneous retrieval of light sources and physically based material properties (e.g., diffuse reflectance, specular reflectance, roughness, etc.) for the purpose of editing and re-rendering the scene under new conditions. To this end, we introduce a novel optimization method using a differentiable Monte Carlo renderer that computes derivatives with respect to the estimated unknown illumination and material properties. This enables joint optimization for physically correct light transport and material models using a tailored stochastic gradient descent.
1 Introduction
With the availability of inexpensive, commodity RGB-D sensors, such as the Microsoft Kinect, Google Tango, or Intel RealSense, we have seen incredible advances in 3D reconstruction techniques [28, 15, 29, 35, 8]. While tracking and reconstruction quality have reached impressive levels, the estimation of lighting and materials has often been neglected. Unfortunately, this presents a serious problem for virtual- and mixed-reality applications, where we need to re-render scenes from different viewpoints, place virtual objects, edit scenes, or enable telepresence scenarios where a person is placed in a different room.
This problem has been viewed in the 2D image domain, resulting in a large body of work on intrinsic images or videos [1, 27, 26]. However, the problem is severely underconstrained on monocular RGB data due to lack of known geometry, and thus requires heavy regularization to jointly solve for lighting, material, and scene geometry. We believe that the problem is much more tractable in the context of given 3D reconstructions. However, even with depth data available, most state-of-the-art methods, e.g., shading-based refinement [36, 39] or indoor re-lighting [38], are based on simplistic lighting models, such as spherical harmonics (SH) [31] or spatially-varying SH [24], which can cause issues on occlusion and view-dependent effects (Fig. 3).
In this work, we address this shortcoming by formulating material and lighting estimation as a proper inverse rendering problem. To this end, we propose an Inverse Path Tracing algorithm that takes as input a given 3D scene along with a single or up to several captured RGB frames. The key to our approach is a differentiable Monte Carlo path tracer which can differentiate with respect to rendering parameters constrained on the difference of the rendered image and the target observation. Leveraging these derivatives, we solve for the material and lighting parameters by nesting the Monte Carlo path tracing process into a stochastic gradient descent (SGD) optimization. The main contribution of this work lies in this SGD optimization formulation, which is inspired by recent advances in deep neural networks.
We tailor this Inverse Path Tracing algorithm to 3D scenes, where scene geometry is (mostly) given but the material and lighting parameters are unknown. In a series of experiments on both synthetic ground truth and real scan data, we evaluate the design choices of our optimizer. In comparison to current state-of-the-art lighting models, we show that our inverse rendering formulation and its optimization achieves significantly more accurate results.
In summary, we contribute the following:
- •
An end-to-end differentiable inverse path tracing formulation for joint material and lighting estimation.
- •
A flexible stochastic optimization framework with extensibility and flexibility for different materials and regularization terms.
2 Related Work
Material and illumination reconstruction has a long history in computer vision (e.g., [30, 4]). Given scene geometry and observed radiance of the surfaces, the task is to infer the material properties and locate the light source. However, to our knowledge, none of the existing methods handle non-Lambertian materials with near-field illumination (area light sources), while taking interreflection between surfaces into account.
3D approaches. A common assumption in reconstructing material and illumination is that the light sources are infinitely far away. Ramamoorthi and Hanrahan [31] project both material and illumination onto spherical harmonics and solve for their coefficients using the convolution theorem. Dong et al. [11] solve for spatially-varying reflectance from a video of an object. Kim et al. [20] reconstruct the reflectance by training a convolutional neural network operating on voxels constructed from RGB-D video. Maier et al. [24] generalize spherical harmonics to handle spatial dependent effects, but do not correctly take view-dependent reflection and occlusion into account. All these approaches simplify the problem by assuming that the light sources are infinitely far away, in order to reconstruct a single environment map shared by all shading points. In contrast, we model the illumination as emission from the surfaces, and handle near-field effects such as the squared distance falloff or glossy reflection better.
Image-space approaches (e.g., [2, 1, 10, 26]). These methods usually employ sophisticated data-driven approaches, by learning the distributions of material and illumination. However, these methods do not have a notion of 3D geometry, and cannot handle occlusion, interreflection and geometry factors such as the squared distance falloff in a physically based manner. These methods also usually require a huge amount of training data, and are prone to errors when subjected to scenes with different characteristics from the training data.
Active illumination (e.g., [25, 9, 17]). These methods use highly-controlled lighting for reconstruction, by carefully placing the light sources and measuring the intensity. These methods produce high-quality results, at the cost of a more complicated setup.
Inverse radiosity (e.g., [37, 38]) achieves impressive results for solving near-field illumination and Lambertian materials for indoor illumination. It is difficult to generalize the radiosity algorithm to handle non-Lambertian materials (Yu et al. handle it by explicitly measuring the materials, whereas Zhang et al. assume Lambertian).
Differentiable rendering. Blanz and Vetter utilized differentiable rendering for face reconstruction using 3D morphable models [3], which is now leveraged by modern analysis-by-synthesis face trackers [32]. Gkioulekas et al. [13, 12] and Che et al. [7] solve for scattering parameters using a differentiable volumetric path tracer. Kasper et al. [18] developed a differentiable path tracer, but focused on distant illumination. Loper and Black [23] and Kato [19] developed fast differentiable rasterizers, but do not support global illumination. Li et al. [22] showed that it is possible to compute correct gradients of a path tracer while taking discontinuities introduced by visibility into consideration.
3 Method
Our Inverse Path Tracing method employs physically based light transport simulation [16] to estimate derivatives of all unknown parameters w.r.t. the rendered image(s). The rendering problem is generally extremely high-dimensional and is therefore usually solved using stochastic integration methods, such as Monte Carlo integration. In this work, we nest differentiable path tracing into stochastic gradient descent to solve for the unknown scene parameters. Fig. LABEL:fig:overview illustrates the workflow of our approach. We start from the captured imagery, scene geometry, object segmentation of the scene, and an arbitrary initial guess of the illumination and material parameters. Material and emission properties are then estimated by optimizing for rendered imagery to match the captured images.
The path tracer renders a noisy and undersampled version of the image using Monte Carlo integration and computes derivatives of each sampled light path w.r.t. the unknowns. These derivatives are passed as input to our optimizer to perform a single optimization step. This process is performed iteratively until we arrive at the correct solution. Path tracing is a computationally expensive operation, and this optimization problem is non-convex and ill-posed. To this end, we employ variance reduction and novel regularization techniques (Sec. 4.4) for our gradient computation to arrive at a converged solution within a reasonable amount of time, usually a few minutes on a modern 8-core CPU.
3.1 Light Transport Simulation
If all scene and image parameters are known, an expected linear pixel intensity can be computed using light transport simulation. In this work, we assume that all surfaces are opaque and there is no participating media (e.g., fog) in the scene. In this case, the rendered intensity for pixel is computed using the path integral [33]:
[TABLE]
where is a light path, i.e. a list of vertices on the surfaces of the scene starting at the light source and ending at the sensor; the integral is a path integral taken over the space of all possible light paths of all lengths, denoted as , with a product area measure ; is the measurement contribution function of a light path that computes how much energy flows through this particular path; and is the pixel filter kernel of the sensor’s pixel , which is non-zero only when the light path ends around the pixel and incorporates sensor sensitivity at this pixel. We refer interested readers to the work of Veach [33] for more details on the light transport path integration.
The most important term of the integrand to our task is the path measurement contribution function , as it contains the material parameters as well as the information about the light sources. For a path of length , the measurement contribution function has the following form:
[TABLE]
where is the radiance emitted at the scene surface point (beginning of the light path) towards the direction . At every interaction vertex of the light path, there is a bidirectional reflectance distribution function (BRDF) defined. The BRDF describes the material properties at the point , i.e., how much light is scattered from the incident direction towards the outgoing direction . The choice of the parametric BRDF model is crucial to the range of materials that can be reconstructed by our system. We discuss the challenges of selecting the BRDF model in Sec. 4.1.
Note that both the BRDF and the emitted radiance are unknown and the desired parameters to be found at every point on the scene manifold.
3.2 Optimizing for Illumination and Materials
We take as input a series of images in the form of real-world photographs or synthetic renderings, together with the reconstructed scene geometry and corresponding camera poses. We aim to solve for the unknown material parameters and lighting parameters that will produce rendered images of the scene that are identical to the input images.
Given the un-tonemapped captured pixel intensities at all pixels of all images, and the corresponding noisy estimated pixel intensities (in linear color space), we seek all material and illumination parameters by solving the following optimization problem using stochastic gradient descent:
[TABLE]
where is the number of pixels in all images. We found that using an norm as a loss function helps with robustness to outliers, such as extremely high contribution samples coming from Monte Carlo sampling.
3.3 Computing Gradients with Path Tracing
In order to efficiently solve the minimization problem in Eq. 3 using stochastic optimization, we compute the gradient of the energy function with respect to the set of unknown material and emission parameters :
[TABLE]
where is the sign function, and the gradient of the Monte Carlo estimate with respect to all unknowns .
Note that this equation for computing the gradient now has two Monte Carlo estimates for each pixel : (1) the estimate of pixel color itself ; and (2) the estimate of its gradient . Since the expectation of product only equals the product of expectation when the random variables are independent, it is important to draw independent samples for each of these estimates to avoid introducing bias.
In order to compute the gradients of a Monte Carlo estimate for a single pixel , we determine what unknowns are touched by the measurement contribution function for a sampled light path . We obtain the explicit formula of the gradients by differentiating Eq. 2 using the product rule (for brevity, we omit some arguments for emission and BRDF ):
[TABLE]
where the gradient vector is very sparse and has non-zero values only for unknowns touched by the path . The gradients of emissions (Eq. 5) and materials (Eq. 6) have similar structure to the original path contribution (Eq. 2). Therefore, it is natural to apply the same path sampling strategy; see the appendix for details.
3.4 Multiple Captured Images
The single-image problem can be directly extended to multiple images. Given multiple views of a scene, we aim to find parameters for which rendered images from these views match the input images. A set of multiple views can cover parts of the scene that are not covered by any single view from the set. This proves important for deducing the correct position of the light source in the scene. With many views, the method can better handle view-dependent effects such as specular and glossy highlights, which can be ill-posed with just a single view, as they can also be explained as variations of albedo texture.
4 Optimization Parameters and Methodology
In this section we address the remaining challenges of the optimization task: what are the material and illumination parameters we actually optimize for, and how to resolve the ill-posed nature of the problem.
4.1 Parametric Material Model
We want our material model to satisfy several properties. First, it should cover as much variability in appearance as possible, including such common effects as specular highlights, multi-layered materials, and spatially-varying textures. On the other hand, since each parameter adds another unknown to the optimization, we would like to keep the number of parameters minimal. Since we are interested in re-rendering and related tasks, the material model needs to have interpretable parameters, so the users can adjust the parameters to achieve the desired appearance. Finally, since we are optimizing the material properties using first-order gradient-based optimization, we would like the range of the material parameters to be similar.
To satisfy these properties, we represent our materials using the Disney material model [5], the state-of-the-art physically based material model used in movie and game rendering. It has a “base color” parameter which is used by both diffuse and specular reflectance, as well as other parameters describing the roughness, anisotropy, and specularity of the material. All these parameters are perceptually mapped to , which is both interpretable and suitable for optimization.
4.2 Scene Parameterization
We use triangle meshes to represent the scene geometry. Surface normals are defined per-vertex and interpolated within each triangle using barycentric coordinates. The optimization is performed on a per-object basis, i.e., every object has a single unknown emission and a set of material parameters that are assumed constant across the whole object. We show that this is enough to obtain accurate lighting and an average constant value for the albedo of an object.
4.3 Emission Parameterization
For emission reconstruction, we currently assume all light sources are scene surfaces with an existing reconstructed geometry. For each emissive surface, we currently assume that emitted radiance is distributed according to a view-independent directional emission profile , where is the unknown radiant flux at ; is the emission direction at surface point , is the surface normal at and is the dot product (cosine) clamped to only positive values. This is a common emission profile for most of the area lights, which approximates most of the real soft interior lighting well. Our method can also be extended to more complex or even unknown directional emission profiles or purely directional distant illumination (e.g., sky dome, sun) if needed.
4.4 Regularization
The observed color of an object in a scene is most easily explained by assigning emission to the triangle. This is only avoided by differences in shading of the different parts of the object. However, it can happen that there are no observable differences in the shading of an object, especially if the object covers only a few pixels in the input image. This can be a source of error during optimization. Another source of error is Monte Carlo and SGD noise. These errors lead to incorrect emission parameters for many objects after the optimization. The objects usually have a small estimated emission value when they should have none. We tackle the problem with an L1-regularizer for the emission. The vast majority of objects in the scene is not an emitter and having such a regularizer suppresses the small errors we get for the emission parameters after optimization.
4.5 Optimization Parameters
We use ADAM [21] as our optimizer with batch size estimated pixels and learning rate . To form a batch, we sample pixels uniformly from the set of all pixels of all images. Please see the appendix for an evaluation regarding the impact of different batch sizes and sampling distributions on the convergence rate. While a higher batch size reduces the variance of each iteration, having smaller batch sizes, and therefore faster iterations, proves to be more beneficial.
5 Results
Evaluation on synthetic data.
We first evaluate our method on multiple synthetic scenes, where we know the ground truth solution. Quantitative results are listed in Tab. 1, and qualitative results are shown in Fig. 4. Each scene is rendered using a path tracer with the ground truth lighting and materials to obtain the “captured images”. These captured images and scene geometry are then given to our Inverse Path Tracing algorithm, which optimizes for unknown lighting and material parameters. We compare to the closest previous work based on spatially-varying spherical harmonics (SVSH) [24]. SVSH fails to capture sharp details such as shadows or high-frequency lighting changes. A comparison of the shadow quality is presented in Fig. 3.
Our method correctly detects light sources and converges to a correct emission value, while the emission of objects that do not emit light stays at zero. Fig. 5 shows a novel view, rendered with results from an optimization that was performed on input views from Fig. 4. Even though the light source was not visible in any of the input views, its emission was correctly computed by Inverse Path Tracing.
In addition to albedo, our Inverse Path Tracer can also optimize for other material parameters such as roughness. In Fig. 7, we render a scene containing objects of varying roughness. Even when presented with the challenge of estimating both albedo and roughness, our method produces the correct result as shown in the re-rendered image.
Evaluation on real data.
We use the Matterport3D [6] dataset to evaluate our method on real captured scenes obtained through 3D reconstruction. The scene was parameterized using the segmentation provided in the dataset. Due to imperfections in the data, such as missing geometry and inaccurate surface normals, it is more challenging to perform an accurate light transport simulation. Nevertheless, our method produces impressive results for the given input. After the optimization, the optimized light direction matches the captured light direction and the rendered result closely matches the photograph. Fig. 10 shows a comparison to the SVSH method.
The albedo of real-world objects varies across its surface. Inverse Path Tracing is able to compute an object’s average albedo by employing knowledge of the scene segmentation. To reproduce fine texture, we refine the method to optimize for each individual triangle of the scene with adaptive subdivision where necessary. This is demonstrated in Fig. 6.
Optimizer Ablation.
There are several ways to reduce the variance of our optimizer. One obvious way is to use more samples to estimate the pixel color and the derivatives, but this also results in slower iterations. Fig. 8 shows that the method does not converge if only a single path is used. A general recommendation is to use between and depending on the scene complexity and number of unknowns.
Another important aspect of our optimizer is the sample distribution for pixel color and derivatives estimation. Our tests in Fig. 9 show that minimal variance can be achieved by using one sample to estimate the derivatives and the remaining samples in the available computational budget to estimate the pixel color.
Limitations.
Inverse Path Tracing assumes that high-quality geometry is available. However, imperfections in the recovered geometry can have big impact on the quality of material estimation as shown in Fig. 10. Our method also does not compensate for the distortions in the captured input images. Most cameras, however, produce artifacts such as lens flare, motion blur or radial distortion. Our method can potentially account for these imperfections by simulating the corresponding effects and optimize not only for the material parameters, but also for the camera parameters, which we leave for future work.
6 Conclusion
We present Inverse Path Tracing, a novel approach for joint lighting and material estimation in 3D scenes. We demonstrate that our differentiable Monte Carlo renderer can be efficiently integrated in a nested stochastic gradient descent optimization. In our results, we achieve significantly higher accuracy than existing approaches. High-fidelity reconstruction of materials and illumination is an important step for a wide range of applications such as virtual and augmented reality scenarios. Overall, we believe that this is a flexible optimization framework for computer vision that is extensible to various scenarios, noise factors, and other imperfections of the computer vision pipeline. We hope to inspire future work along these lines, for instance, by incorporating more complex BRDF models, joint geometric refinement and completion, and further stochastic regularizations and variance reduction techniques.
Acknowledgements
This work is funded by Facebook Reality Labs. We also thank the TUM-IAS Rudolf Mößbauer Fellowship (Focus Group Visual Computing) for their support. We would also like to thank Angela Dai for the video voice over and Abhimitra Meka for the LIME comparison.
APPENDIX
In this appendix, we provide additional quantitative evaluations of our design choices in Sec. A. To this end, we evaluate the choice of the batch size, the impact of the variance reduction, and the number of bounces for the inverse path tracing optimization. In addition, we provide additional results on scenes with textures, where we evaluate our subdivision scheme for high-resolution surface material parameter optimization; see Sec. B. Sec. C presents a quantitative comparison to another material estimation method. In Sec. D, we provide examples for mixed-reality application settings where we insert new virtual objects into existing scenes. Here, the idea is to leverage our optimization results for lighting and materials in order to obtain a consistent compositing for AR applications. Finally, we discuss additional implementation details in Sec. E.
Appendix A Qualitative Evaluation of Design Choices
A.1 Choice of Batch Size
In Fig. 12, we evaluate the choice of the batch size for the optimization. To this end, we assume the compute budget for all experiments, and plot the results with respect to time on the -axis and the loss of our problem (log scale) on the -axis. If the batch size is too low (blue curve), then the estimated gradients are noisy, which leads to a slower convergence; if batches are too large (gray curve), then we require too many rays for each gradient step, which would be used instead to perform multiple gradient update steps.
A.2 Variance Reduction
In order to speed up the convergence of our algorithm, we must aim to reduce the variance of the gradients as much as possible. There are two sources of variance: the Monte Carlo integration in path tracing and the SGD, since we path trace only a small fraction of captured pixels in every batch.
As mentioned in the main paper, the gradients of the rendering integral have similar structure to the original integral, therefore we employ the same importance sampling strategy as in usual path tracing. The path tracing variance is reduced using Multiple Importance Sampling (i.e., we combine BRDF sampling with explicit light sampling) [33]. We follow the same computation for estimating the gradients with respect to our unknowns. A comparison between implementation with and without MIS is shown in Fig. 13.
A.3 Number of Bounces
We argue that most diffuse global illumination effects can be approximated by as few as two bounces of light. To this end, we render an image with bounces and use it as ground truth for our optimization. We try to approximate the ground truth by renderings with one, two, and three bounces, respectively (see Fig. 14). One bounce corresponds to direct illumination; adding more bounces allows us to take into account indirect illumination as well. Optimization with only a single bounce is the fastest, but the error remains high even after convergence. Having more than two bounces leads to high variance and takes a lot of time to converge. Using two bounces strikes the balance between convergence speed and accuracy.
Appendix B Results on Scenes with Textures
In order to evaluate surfaces with high-frequency surface signal, we consider both real and synthetic scenes with textured objects. To this end, we optimize first for the light sources and material parameters on the coarse per-object resolution. Once converged, we keep the light sources fixed, and we subdivide all other regions based on the surface texture where the re-rendering error is high; i.e., we subdivide every triangle based on the average error of the pixels it covers, and continue until convergence. This coarse-to-fine strategy allows us to first separate out material and lighting in the more well-conditioned setting; in the second step, we then obtain high-resolution material information. Results on synthetic data [14] are shown in Fig. 15, and results on real scenes from Matterport3D [6] are shown in Fig. 16.
Appendix C Additional Comparison to Data-driven Approaches
We compare our approach to Meka et al. [26] and present quantitative results in Tab. 2. Please note that our approach is not limited to a single material of a single object at a time. The other data-driven references are mostly on planar surfaces only and/or assume specific lighting conditions, such as a single point light close to the surface.
Appendix D Object Insertion in Mixed-reality Settings
One of the primary target applications of our method is insertion of virtual objects into an existing scene while maintaining a coherent appearance. Here, the idea is to first estimate the lighting and material parameters of a given 3D scene or 3D reconstruction. We then insert a new 3D object into the environment, and re-render the scene using both the estimated lighting and material parameters for the already existing content, and the known intrinsics parameters for the newly-inserted object. A complete 3D knowledge is required to produce photorealistic results, in order to take interreflection and shadow between objects into consideration.
In Fig. 11, we show an example on a synthetic scene where we virtually inserted two new chairs. As a baseline, we consider a naive image compositing approach where the new object is first lit by spherical harmonics lighting and then inserted while not considering the rest of the scene; this is similar to most existing AR applications on mobile devices. We can see that a naive compositing approach (middle) is unable to produce a consistent result, and the two inserted chairs appear somewhat out of place. Using our approach, we can estimate the lighting and material parameters of the original scene, composite the scene in 3D, and then re-render. We are able to show that we can produce consistent results for both textured and non-textured optimization results (right column).
In Fig. 2, we show a real-world example on the Matterport3D [6] dataset, where we insert a virtual teddy into the environment. To this end, we first estimate lighting and surface materials in a 3D scan; we then insert a new virtual object, render it, and then apply the delta image to the original input. Compared to the SVSH baseline, our approach achieves significantly better compositing results.
Appendix E Implementation Details
We implement our inverse path tracer in C++, and all of our experiments run on an 8-core CPU. We use Embree [34] for the ray casting operations. For efficient implementation, instead of employing automatic differentiation libraries, the light path gradients are computed using manually-derived derivatives.
We use ADAM [21] as our optimizer of choice with an initial learning rate of . We further use an initial batch size of 8 pixels which are uniformly sampled from the set of all pixels of all images. We found marginal benefit of having larger batches, but we believe there is high potential in investigating better sampling strategies. In all our experiments, the emission and albedo parameters are initialized to zero.
For every pixel in the batch, we need to compute an estimate of the pixel color based on the current value of the unknown material and emission parameters. This estimated color is compared against the ground truth color and a gradient is computed depending on the choice of the loss function. For most commonly used loss functions, this gradient will involve a multiplication of the estimated pixel color and its derivative with respect to the unknown parameters. Since these are random variables (approximated by Monte Carlo integration), it is important that they are calculated from independent samples to avoid bias. We use path tracing with multiple importance sampling for the computation of the pixel color, but any unbiased light transport method will produce the correct result.
We extend our path tracer to analytically compute derivatives w.r.t. emission and materials parameters as defined by Eq. 5 and 6. To this end, we pass a reference to a structure holding the derivatives to our ray casting function. The product of BSDFs in Eq. 5 is incrementally calculated at each bounce. Given that is the unknown emission parameter on surface , the derivative w.r.t. this emission parameter is equal to the product of the BSDFs at each surface intersection from surface to the sensor. The derivatives w.r.t. to the materials are computed in similar manner. As per chain rule, we multiply the throughput by the derivative of the BSDF w.r.t. the unknown material parameters to obtain the derivative of the pixel color w.r.t. the unknown material parameters.
We implement multiple importance sampling, a combination of light source sampling and BRDF importance sampling. The importance for light source sampling is based on the unknown emission parameters which may change in every iteration of our optimization. An efficient data structure is needed to store the sampling probabilities for every object. We implement a binary indexed tree (also known as Fenwick tree) for this purpose. This provides logarithmic complexity for both reading and updating the probabilities.
Finally, to make the optimization more robust, we propose a coarse-to-fine approach, where we first optimize for one emission and one material parameter per object instance. Most scenes have only a few emitters, so we employ an L1-regularizer on all the emission parameters. After convergence, the result is refined by optimizing for material parameters of individual object triangles. The light sources stay fixed in this phase, but their emission value may still change. In the end, the triangles may be subdivided as explained in Sec. B to further improve the results.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Jonathan T Barron and Jitendra Malik. Shape, illumination, and reflectance from shading. Transactions on Pattern Analysis and Machine Intelligence , 37(8):1670–1687, 2015.
- 2[2] Harry Barrow, J Tenenbaum, A Hanson, and E Riseman. Recovering intrinsic scene characteristics. Comput. Vis. Syst , 2:3–26, 1978.
- 3[3] Volker Blanz and Thomas Vetter. A morphable model for the synthesis of 3d faces. In SIGGRAPH , pages 187–194, 1999.
- 4[4] Nicolas Bonneel, Balazs Kovacs, Sylvain Paris, and Kavita Bala. Intrinsic decompositions for image editing. Computer Graphics Forum (Eurographics State of the Art Reports) , 36(2), 2017.
- 5[5] Brent Burley and Walt Disney Animation Studios. Physically-based shading at disney.
- 6[6] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport 3D: Learning from RGB-D data in indoor environments. International Conference on 3D Vision (3DV) , 2017.
- 7[7] Chengqian Che, Fujun Luan, Shuang Zhao, Kavita Bala, and Ioannis Gkioulekas. Inverse transport networks. ar Xiv preprint ar Xiv:1809.10820 , 2018.
- 8[8] Angela Dai, Matthias Nießner, Michael Zollhöfer, Shahram Izadi, and Christian Theobalt. Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration. ACM Transactions on Graphics (TOG) , 36(4):76a, 2017.