Learning Latent Representations of Bank Customers With The Variational Autoencoder
Rogelio A Mancisidor, Michael Kampffmeyer, Kjersti Aas, Robert Jenssen

TL;DR
This paper demonstrates how Variational Autoencoders can learn meaningful latent representations of bank customers, capturing creditworthiness and enabling effective clustering for banking applications.
Contribution
It introduces a method to steer VAE latent spaces using Weight of Evidence, creating clusters that reflect customer creditworthiness, scalable to large, complex datasets.
Findings
Latent space clustering aligns with customer creditworthiness.
Method generalizes to new customers and high-dimensional data.
Clusters are useful for banking activities.
Abstract
Learning data representations that reflect the customers' creditworthiness can improve marketing campaigns, customer relationship management, data and process management or the credit risk assessment in retail banks. In this research, we adopt the Variational Autoencoder (VAE), which has the ability to learn latent representations that contain useful information. We show that it is possible to steer the latent representations in the latent space of the VAE using the Weight of Evidence and forming a specific grouping of the data that reflects the customers' creditworthiness. Our proposed method learns a latent representation of the data, which shows a well-defied clustering structure capturing the customers' creditworthiness. These clusters are well suited for the aforementioned banks' activities. Further, our methodology generalizes to new customers, captures high-dimensional and…
Click any figure to enlarge with its caption.
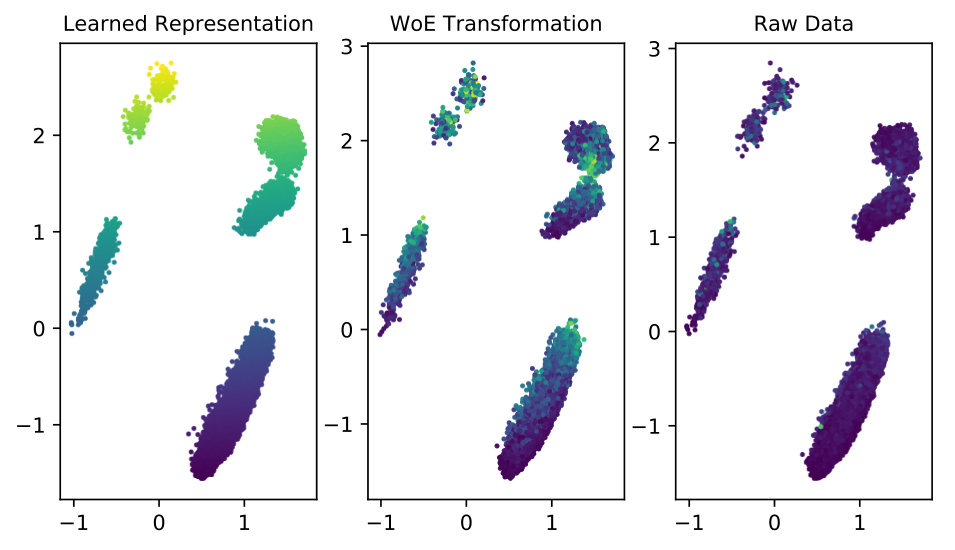 Figure 1
Figure 1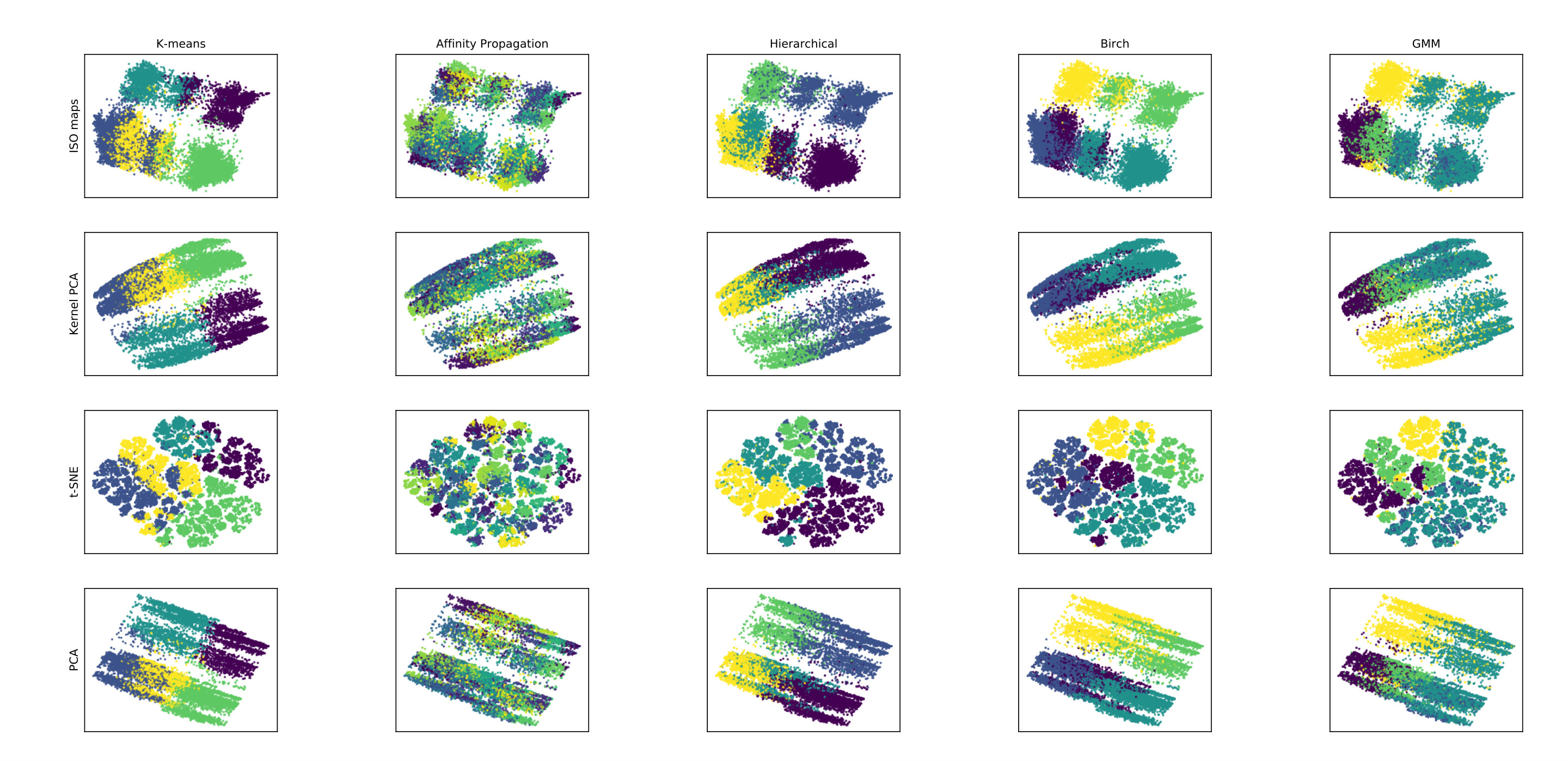 Figure 2
Figure 2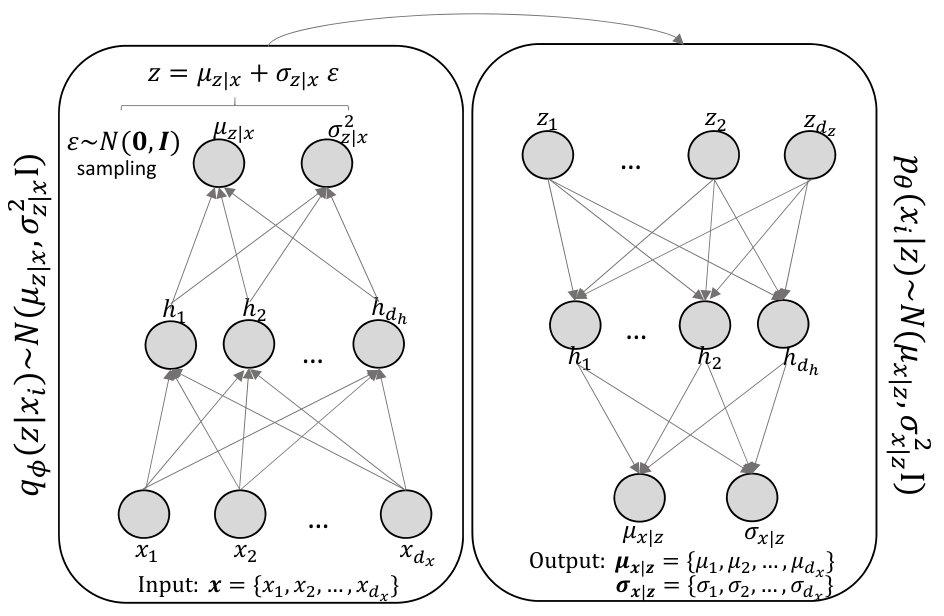 Figure 3
Figure 3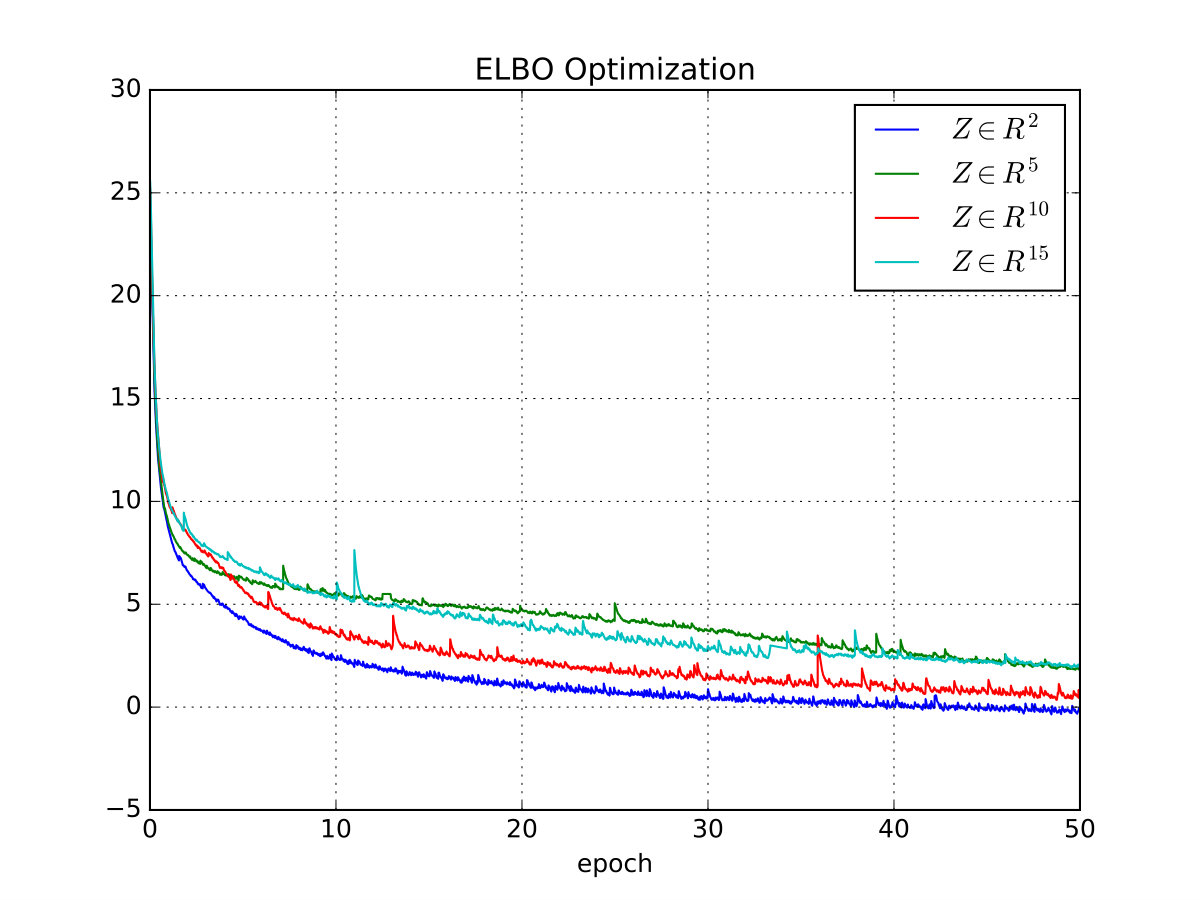 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8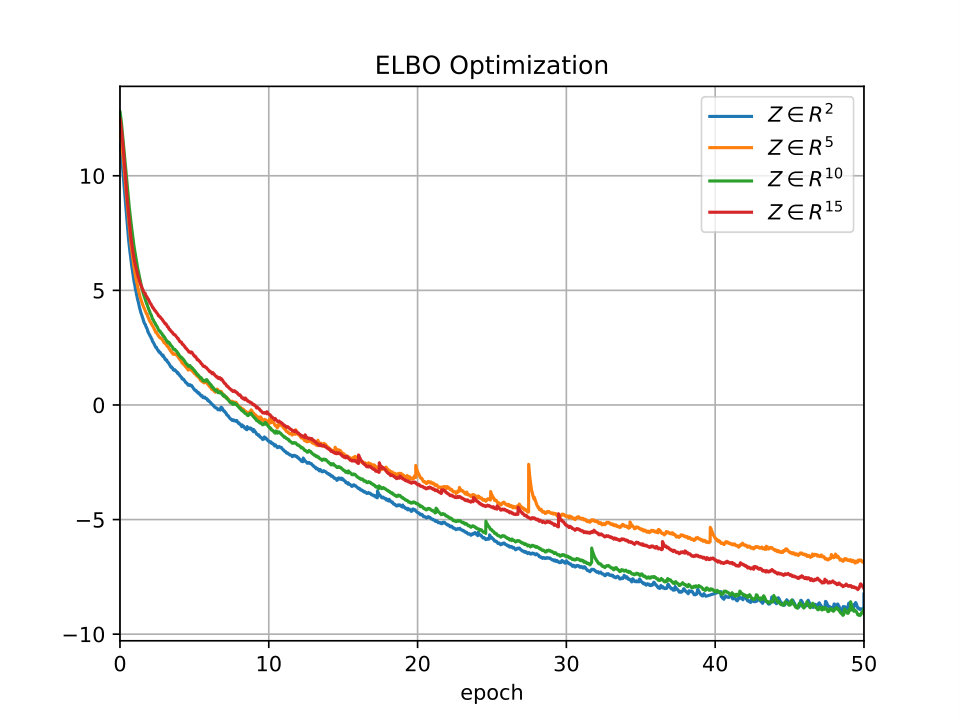 Figure 9
Figure 9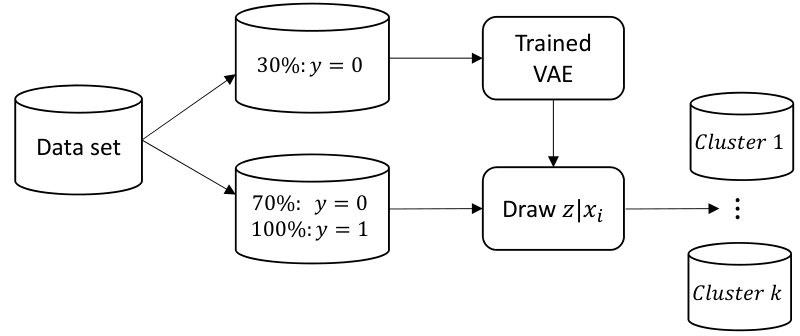 Figure 10
Figure 10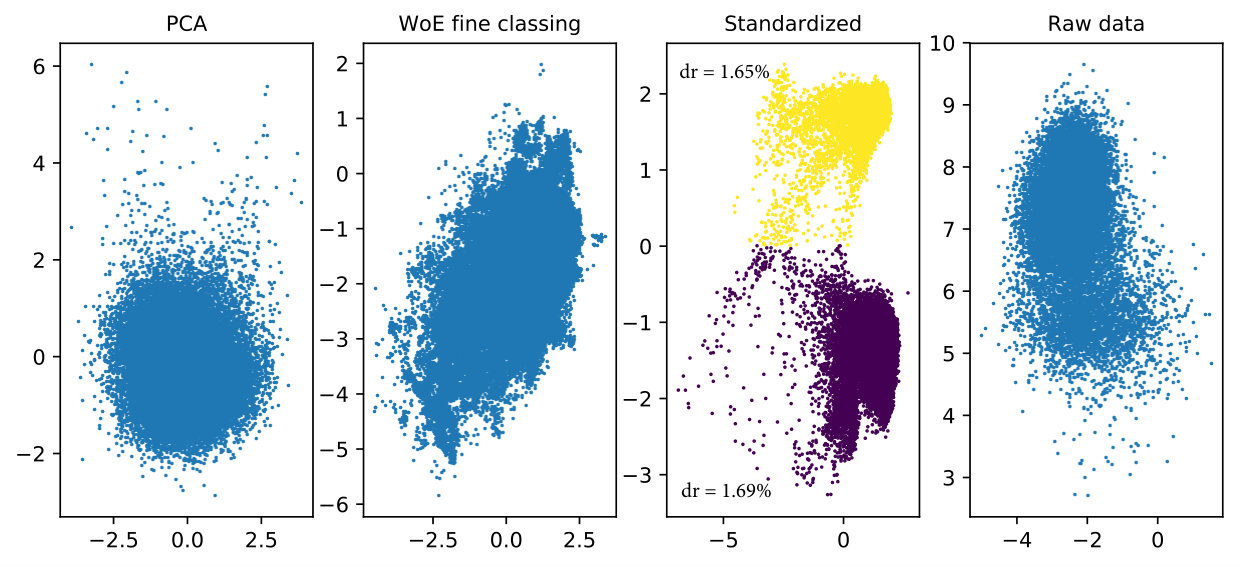 Figure 11
Figure 11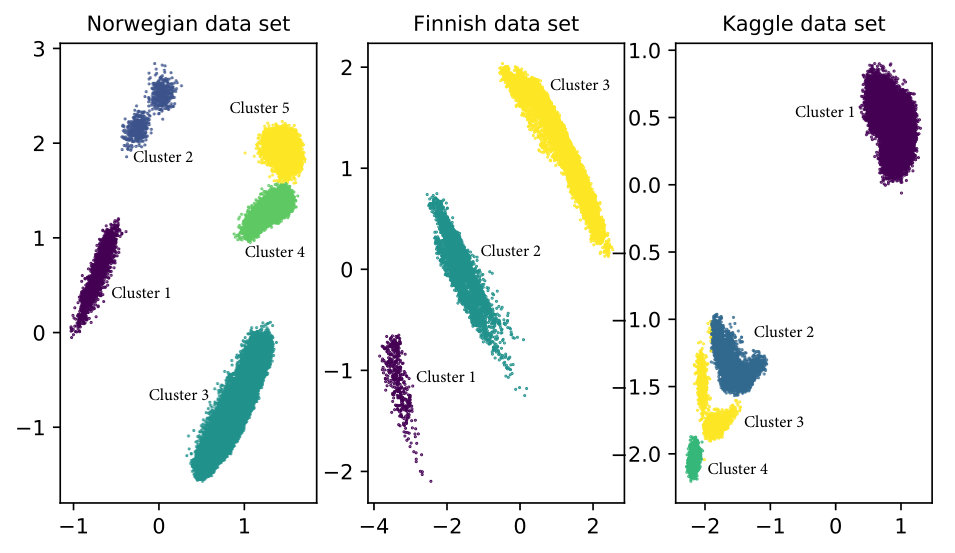 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSolana Customer Service Number +1-833-534-1729
Learning Latent Representations of
Bank Customers With
The Variational Autoencoder
Rogelio A. Mancisidora,b,∗, Michael Kampffmeyer a, Kjersti Aas c, Robert Jenssen a
aUiT Machine Learning Group, Faculty of Science and Technology,
Department of Physics and Technology, University of Tromsø, 9019 Tromsø Norway,
bCredit Risk Models, Santander Consumer Bank AS, 1325 Lysaker Norway
cStatistical Analysis, Machine Learning and Image Analysis,
Norwegian Computing Center, 0373 Oslo Norway
∗Corresponding author; E-mail: [email protected]
Abstract
Learning data representations that reflect the customers’ creditworthiness can improve marketing campaigns, customer relationship management, data and process management or the credit risk assessment in retail banks. In this research, we adopt the Variational Autoencoder (VAE), which has the ability to learn latent representations that contain useful information. We show that it is possible to steer the latent representations in the latent space of the VAE using the Weight of Evidence and forming a specific grouping of the data that reflects the customers’ creditworthiness. Our proposed method learns a latent representation of the data, which shows a well-defied clustering structure capturing the customers’ creditworthiness. These clusters are well suited for the aforementioned banks’ activities. Further, our methodology generalizes to new customers, captures high-dimensional and complex financial data, and scales to large data sets.
Keywords: Variational Autoencoder, Data Representations, Dimesionality Reduction, Clusters, Machine Learning
1 Introduction
Banks need to estimate the creditworthiness of both customers and applicants to improve marketing campaigns, customer relationship management, data and process management or the credit risk assessment [2]. Customers with high creditworthiness can obtain higher credit limits or get offered new financial products, while applicants with low creditworthiness may not be eligible for credit at all. Therefore, learning data representations that can support these activities is critical.
The Variational Autoencoder (VAE) [17, 23] has shown promising results in different research domains. The powerful information embedded in its latent space has been documented e.g., in health analytics [22, 29, 31, 32], in speech emotion recognition (SER) [18], and in natural language processing (NLP) [7, 27], among others. Additionally, research has been conducted where the VAE has been modified to improve its feature learning properties, e.g. [6, 12, 15, 27]. However, to the best of our knowledge there is no previous work on data representations of bank customers using the VAE.
Inspired by the previous results in other research fields and the lack of research on learning data representations of bank customers, we adopt the VAE and the Auto Encoding Variational Bayesian (AEVB) algorithm [17] to learn a data representation that is useful to support the banking activities. Our proposed method is able to steer the latent embeddings in the VAE by transforming the input data into a meaningful representation, and by creating a specific grouping of the data. Hence, the focus of this research is on the effective manifold learning capabilities of the VAE [11], which captures valuable information in the latent space.
The main advantage of our method is that it provides a data representation in the low-dimensional latent space of the VAE, which can be visualized and it suggests well-defined clustering structures. These clusters are well suited to the bank industry given that they encapsulate customers’ creditworthiness. In addition, customers’ creditworthiness is perfectly ranked across the dimensions of the latent space. Further, using the generative properties of the VAE, we can draw the latent space of unseen customers and map them into an existing cluster without the need of further supervision. Finally, this technique is able to analyse high-dimensional financial data with complex non-linear relationships [16], and it scales to large data sets [17].
This paper is organized as follows. Section 2 reviews the related work where the VAE has been used to learn data representations in different research fields, while Section 3 introduces variational inference and the VAE. In Section 4 we explain the data transformation used to learn latent representations of bank customers and Section 5 presents our experiments and findings. Finally, Section 6 presents the main conclusions in this paper.
2 Related Work
Methods to learn data representations from the input data can be divided into probabilistic graphical models (PGMs) and neural network-based models [4]. This data representation plays an important role in the results we can achieve in detection or classification tasks [4, 19, 34]. The ability to express general-purpose priors, such as natural clustering or spatial coherence, among others, is what make data representations to be good [4].
Further, PGMs aim to learn latent representations , which are able to describe the input data . This is done by modelling their joint distribution . Depending on how this joint distribution is constructed, PGMs can be divided in directed or undirected graphical models [4].
The Variational Autoencoder (VAE) [17, 23] is an influential (unsupervised) directed probabilistic graphical model, which has been widely used to learn meaningful latent representations of the input data. For example, latent representations of gene expression data are used in [31] for cancer prediction. The results show that the VAE latent features are useful to predict cancer and its predictive power is similar to other data transformation methods, e.g. principal component analysis (PCA) [21].
Latent representations in the VAE have also been used for predictions in a semi-supervised context. In [22], latent representations for pre-treatment and post-treatment gene expression are use to predict drug response. Their proposed model achieves higher performance relative to Ridge logistic regression [14] using the original input data. In addition, PCA transformations are used in three different classifiers to predict drug responses, but their performance, in most of the experiments, is not better relative to Ridge regression and the VAE model.
Classification of speech emotion is another example where latent representations of the input data have been successfully used for classification. Using Long Short Term Memory (LSTM) networks to classify emotion, [18] compares the predictive power of data transformations using VAE and regular Auto Encoders. Speech emotion prediction is more accurate when the latent representations in the VAE are used as predictors. The classification results are further improved by using latent representations obtained with conditional VAE [26].
In another classification study, [29] train logistic regression models, on t-SNE [13] embeddings of high-dimensional VAE latent variables, to classify tumours. Their results show that the latent embeddings in the VAE learn a biological relevant information and successfully classify disease sub-types. Both works in [18, 29] build upon the Tybalt model [32]. The Tybalt exploits the data transformation capabilities of the VAE to generate latent representations of gene expression data.
The VAE has also been used in the natural language processing field. Studying bilingual word embeddings, [27] use the VAE to generate latent representations, which explicitly induce the underlying semantics of bilingual text. Their model is able to learn a hidden representation of paired bag-of-words sentences. Furthermore, in [7] recurrent neural networks are combined with the VAE to model text data. The latent transformations are able to generate coherent sentences. In addition, the proposed model in this research is able to impute missing words in text corpus.
Research has also been conducted on modifying the original VAE aiming to improve the quality of the learned latent representations. In [12], for example, the authors add an hyperparamter to the VAE, which limits the capacity of the latent information channel and impose an emphasis on learning statistically independent latent factors. Hence, the model is able to learn disentangled factors of variation.
In [6] the concept of supervision in VAE is introduced. The authors group the input data, aiming to learn representations of the data that reflect the semantics behind a specific grouping of the data. In other words, the grouping makes it possible to learn a semantically useful data transformation. Similarly, [15, 27] use supervision but in the latent space. Both works [15, 27], manipulate the latent representations arithmetically to decompose the latent representation into different attributes.
In this research, as in [6, 15, 27], we introduce a supervision stage in the VAE. In this stage, we form groups that share a common factor of variation. The difference in our method is that the grouping is derived from the class label, see Section 4. This means that our proposed method is a semi-supervised representation learning model where we indirectly steer the data transformation using a specific grouping of the input data. Finally, we only focus on learning a data representation of bank customers’ data that is able to capture the customers’ creditworthiness in the latent space of the VAE, and not in the predictive power of such representations.
3 The Variational Autoencoder
3.1 Variational Inference
In the rest of the paper we use the following notation. We consider i.i.d. data where is the customers data, e.g. income, age, marital status etc. Further, the latent variables where are the data transformation of . The subscript is dropped whenever the context allows for it.
The latent variable in the joint density is drawn from a prior density and then it is linked to the observed data through the likelihood . Inference amounts to conditioning on data and computing the posterior [5].
The problem is that the posterior distribution is intractable in most cases. Note that
[TABLE]
involves the marginal distribution . This integral, called the evidence, in some cases requires exponential time to be evaluated since it considers all configurations of latent variables. In other instances, it is unavailable in a closed form [5].
Variational Inference (VI) copes with this kind of problem by minimizing the Kullback-Leibler (KL) divergence111The KL divergence is a measure of the proximity between two densities, e.g. , and it is commonly measured in bits. It is non-negative and it is minimized when . between the true posterior distribution and a parametric function , which is chosen among a set of densities [5]. This set of densities is parameterized by variational parameters and they should be flexible enough to capture a density close to and, in addition, be simple for efficient optimization. The parametric density which minimizes the KL divergence is
[TABLE]
Unfortunately, Equation 2 cannot be optimized directly since it requires computing a function of . To see this, let us expand the KL divergence using the Bayes’ theorem and noting that does not depend on
[TABLE]
Given that Equation 3 cannot be optimized directly, VI optimizes the alternative objective function
[TABLE]
From Equations 3 and 4 we have that
[TABLE]
Since the KL divergence is non-negative, the expression in Equation 4 is called the evidence lower bound (ELBO). Noting that the ELBO is the negative KL divergence in Equation 3 plus the constant term , it follows that maximizing the ELBO leads to minimizing Equation 2.
It is worth mentioning that the term encourages variational densities to be close to the prior distribution, while the term encourages densities that place their mass on configurations of the latent variables that explain the observed data. The interested reader is referred to [5, 8] for further details.
3.2 The Variational Autoencoder and AEVB algorithm
The Variational Autoencoder, see Figure 1, is a generative model, which aims to learn the distribution of the input data . This means that the VAE can sample from a distribution that it is similar to the one that have generated . In addition, the VAE assumes that latent variables govern the distribution of . In this research, the input data represents the customer data, or a specific grouping of it, and the data transformation of such data is generated by . This data representation of the customer data should capture the customers’ creditworthiness. In this section, we will show how the VAE approximates Equation 5 by maximizing the ELBO. This is done using multilayer perceptron (MLP) networks and stochastic gradient optimization.
The MLPs, which optimze the ELBO, estimate the parameters and in the density functions and , i.e. and . Note that given that the output of the MLPs are and , the stochastic gradient optimization is on and , which are the weights in the MLPs. By doing this, the VAE learns the values of and that maximize the ELBO222It is possible to specify other distributions for and . However, Gaussian distributions are appropriate for our data sets, and we assume a diagonal covariance matrix as in the original VAE..
Specifically, assuming the set of i.i.d vectors , the Auto Encoding Variational Bayesian (AEVB) algorithm [17] learns the parameters jointly using MLP networks, and by performing stochastic gradient descent on the
[TABLE]
for the i’th customer. Therefore, the MLPs for and in Figure 1 have the following form
(7)
where , is the element-wise product, and are the unknown parameters in the MLPs for and respectively.
It is worth mentioning that the latent variable has been reparametrized as a deterministic and differentiable system. The reason is that we need to backpropagate the term in Equation 6. Without the reparametrization, would be inside a sampling operation which cannot be propagated. This means that the AEVB algorithm actually takes the gradient of . The proof of this result can be found in [17].
Note that generates latent variables given and converts them into its original representation. Hence, the former is referred as probabilistic encoder and the latter as probabilistic decoder.
4 Learning Latent Representations
In this section we introduce the motivation for the specific grouping of data that we use to steer a data representation, which encapsulates the customers’ creditworthiness in the latent space of the VAE. The presumption is that given that the AEVB algorithm has converged to the optimal variational density , the latent space should have learned a data representation, which encapsulates the customers’ creditworthiness. Otherwise, the reconstruction would have failed, and the algorithm would not have converged to in the first place.
To quantify creditworthiness, let us first define the ground truth class
[TABLE]
At least 90 days past due, or just 90+dpd, refers to the customers’ payment status, which is known after the performance period is over 333The performance period is the time interval in which if customers are at any moment 90+dpd, then their ground truth class is . Frequently, 12 and 24 months are time intervals used for the performance period. Further, the performance period starts at the moment an applicant signs the loan contract.. This definition is aligned with the Basel II regulatory framework [2].
Let be the j’th set of customers with class labels . Hence,
[TABLE]
where is the Iverson bracket, is the default rate of j’th group of customers.
Given that , we say that group has lower creditworthiness compared to group . In other words, customers in have, on average, higher probability of default. Therefore, in order to identify segments with a different propensity to fall into financial distress, we need to find segments where the average probability of default is different from the rest of the groups. Mathematically, we want to learn a data representation that satisfies
[TABLE]
Now it should be clear that the data transformation that we are looking for, needs to incorporate the class label . In this way, the latent space in the VAE should generate codes that also contain information about . Otherwise, those codes will fail to reproduce .
One such transformation is the Weight of Evidence444Originally, the WoE was introduced by Irving John Good in 1950 in his book Probability and the Weighing of Evidence and it has been used in the logistic regression and Naïve Bayes literature, among others. (WoE) [2, 25], which is defined as
[TABLE]
4.1 The Weight of Evidence
The WoE transformation has been used in credit scoring for a long time [1], and it has become the standard in credit scoring models. The way to estimate it, given that the m’th feature is continuous, is by dividing its values into bins . In the case of categorical variables, the different categories are already these bins. Hence, the WoE for the k’th bin of the m’th feature is
[TABLE]
where is the total number of observations. Note that the number of bins can vary for different features. See chapter 16.2 in [2] or chapter 6 in [25] for more details. Table 1 shows the difference between fine and coarse classing. In the fine classing approach, we create bins, which provide the finest granularity. Then, fine bins with similar risk are binned into smaller groups resulting in the coarse classing. See [2] for more details.
We use the coarse classing WoE transformation555We will simply called it as WoE in the remaining of the paper for brevity. of the input data to tilt the latent space in the VAE towards configurations which encapsulate the propensity to fall into financial distress.
5 Experiments and Results
Our goal with the experiments is threefold. First, we want to show in Section 5.3 that our proposed method is able to learn better representations compared to other methods and that these representations are able to encapsulate the customers’ creditworthiness. Second, we introduce a specific grouping of the data in Section 4, which is used in the supervision stage. Hence, we want to show in Section 5.4 that not any other grouping is able to generate good representations in the latent space. Third, we want to evaluate qualitatively in Section 5.5 the data representation of bank customers analysing the salient dimensions in each clusters.
5.1 Data description
We use three data sets in our experiments; a Norwegian and a Finnish car loan data set provided by Santander Consumer Bank Nordics and the public data set used in the Kaggle competition Give me some credit666Website https://www.kaggle.com/c/GiveMeSomeCredit. These data sets show applicants’ status, financial and demographic factors at the time of application as well as the class label. The performance period for the real data sets is 12 months, while for the public data set it is 24 months. More details about the data sets can be found in Tables A2, A3 and A4.
5.2 Training the VAE and Generating Latent Representations
We train the VAE using the WoE as the input data, and using only the majority class () data. The reason is because we want to have a robust estimate for the default rate in the data representation that we are learning. In addition, using observations from the minority class () did not change the data representation in the latent space in our experiments, which is probably explained by the strong class imbalance in the three data sets.
Hence, we use 30% of the majority class to train the VAE. During training, we generate the latent space for the remaining 70% of the majority class and 100% of the minority class data, see Figure 2. Based on the optimization of the ELBO, together with a heuristic visual comparison of the latent space in the training and test data sets, we select the optimal network architecture as well as the stopping criteria. It is worth mentioning that we observe that the shapes and proportions of the clusters in the training data are similar to the ones in the test data. This is a good indicator that our proposed model learns data representations that generalizes to unseen customers.
The VAE architectures that we tested are shown in Table A1, and the final architecture IDs that we use are arch4, arch4 and arch1 for the Norwegian, Finnish and Kaggle data sets respectively. In addition, we use tanh activations in all hidden layers, linear and sigmoid activations in the output layer for the encoder and decoder respectively, and linear activations in all log layers777We need to use different activation functions depending on the kind of variable that the MLP is handling. See chapter 6 in [11] for more details.. The MLP models are trained with the adagrad optimizer [9] using constant 0.01 learning rate and 0.001 momentum.
Finally, we use the expectation over the latent space for the i’th customer
[TABLE]
as the data representation of bank customers in the latent space of the VAE. Note that it is simply the output in the encoder MLP network, see Equation 7. We also tried the Monte Carlo version of Equation 13 using 100 samples of and Equation 7. The results do not change.
To further analyze the learned data representation of our method, we assign labels to the structure in the two-dimensional latent space. This task can be done manually using a set of if/else rules given the well-defined clustering structure in the latent space. However, we propose an automated version, which is presented in Algorithm 1. The idea is to use the hierarchical clustering algorithm iteratively, generating only two clusters in each iteration. Always preserving the clustering structure in the learned data representation. For this purpose, Algorithm 1 specifies the minimum number of observations in each cluster, denoted by . Similarly, the minimum Euclidean distance between the centroids in the two clusters needs to be specified, and it is denoted by . These two paremeters are data dependent and should be selected in such a way that Algorithm 1 assigns cluster labels preserving the clustering structure in the latent space. The advantage of this approach is that the labelling happens automatically while we train the VAE. Finally, the results of our proposed data representations are shown in Figure 3 and Table 2.
5.3 Latent Data Representations
The first important result to highlight is that using the WoE transformation we learned a data representation with well-defined clusters in the latent space for all three data sets. Analyzing the Norwegian car loan data, we see that about 82% of all customers are in cluster 3, which is the cluster with the smallest default rate. This makes sense since the data set contains only 2 557 customers from the minority class. On the other hand, about 18% of the customers are in clusters with relatively high default rate. Finally, we check whether the default rates are significantly different using the 99% confidence interval for a binomial variable, i.e. , where is the default rate in each cluster, is the corresponding critical value and is the total number of observations in the cluster. With the exception of clusters 1 and 5, the default rate for the other clusters are statistically different. See Table 2.
For the Finnish and Kaggle data sets we observe the same pattern. The majority of the customers are in the cluster with the smallest default rate. However, about 10% of the customers in the Kaggle data are in three clusters with very high default rates. Note that all default rates in the Kaggle data are significantly different. On the other hand, the confidence intervals for the default rates in cluster 1 and 2 for the Finnish data set overlap each other. This is driven by the relatively small number of defaults in the cluster 1, which increases the variance of their default rate estimate.
Further, we use the k-means [20], affinity propagation [10], hierarchical [30], birch [33] and GMM algorithms to cluster the WoE transformations for the Norwegian data set. We specify five clusters as suggested by the VAE. After the clustering is done, we reduce the original dimensional space for the WoE to two dimensions with isomaps [28], kernel PCA [24], t-SNE [13] and PCA [21]. Figure 4 shows the resulting clusters represented by different colors. As can be seen from the figure, none of the clustering algorithms are able to generate non-overlapping clusters.
Finally, we estimate the default probability for customers in the Norwegian data set using three different input data: i) the learned data representation of the VAE, ii) the WoE transformation, and iii) the raw data. We use 70% of the data to estimate the default probability of the remaining 30% of the data. Further, we use the trained VAE from Section 5.2 to generate the latent space of the customers for whom we estimated the default probability. In Figure 5, we show the learned data representation for these customers and we use the three estimated values for the default probability to create a colormap. It is interesting to see that the default probability estimated with the learned data representation reveals a smooth color transition. On the other hand, when the default probability is estimated with the WoE or with the raw data, the colormaps show a relatively random pattern. This result shows that our proposed method is not only able to learn a data representation of customers data, which shows a well-defined clustering structure and captures the customers’ creditworthiness, but which also ranks the default probability across the two dimensions of the latent space.
The well-defined clustering structure of the data representation in the latent space and its ability to capture customers’ creditworthiness, allows our proposed method to generate good representations. These representations express general priors that are particularly useful in the bank industry.
Specifically, our proposed data representation is able to learn the natural clustering and spatial coherence of creditworthiness in the customers data.
5.4 Grouping of the Input Data
Now we want to show that the WoE has valuable information for creating a specific grouping of the input data. Hence, we use different data transformations and, for each of these transformations, we train a new VAE, i.e. for each data transformation, we learn a data representation of the transformed input data using the same architecture in the VAE as in the one used to learn the data representations in Figure 3. Specifically, we generate the latent space for the following data transformations:
PCA: The input data is transformed using principal component analysis with all the principal components, i.e. there is no dimensionality reduction. 2. 2.
Standardization: The input data is standardized by removing the mean and scaling to unit variance. 3. 3.
Fine classing WoE: The input data is transformed into WoE by creating bins with an approximately equal number of customers, i.e. no coarse classing is done by bank analysts. 4. 4.
Input data: Raw data without any transformation.
Figure 6 shows the resulting latent spaces for the data transformations explained above. Interestingly, three of these transformations do not show any clustering structure at all. For the standardized transformation, the clusters have practically the same default rate. Hence, by identifying appealing data transformations and a useful grouping of the input data, it is possible to steer configurations in the latent space of the VAE. In this particular case, these configurations are well-defined clusters with considerably different risk profiles.
5.5 Cluster Interpretation
For the bank industry it is essential to understand which features are most important for the clustering results. To investigate this, we adopt the salient dimension methodology presented in [3] and explained in the Appendix B. This approach identifies features whose values are statistically significant in different clusters, and are called salient dimensions. In what follows, we analyse the salient dimensions for the Norwegian data set. Salient dimensions for the Kaggle and Finnish data sets can be found in Table A5.
The first interesting result in Figure 3 is the pattern of the latent variables for clusters 1 and 5 (both clusters have ), which are located on opposite sides of the two-dimensional space. The salient dimension MaxBucket12 in cluster 1 shows that about of the customers were between 30 and 60 days past due at the moment they applied for the loan, i.e. they are existing customers applying for a new loan. Actually, all customers in cluster 1 are existing customers who are at least 30 days past due. On the other hand, about of the customers in cluster 5 are new applicants. Cluster 2 is also composed of existing customers only. Hence, new applicants lie on the right side, while existing customers on the left hand side of Figure 3.
Now let us see what characterizes cluster 3, which is the cluster with the lowest default rate. Looking at the salient dimension DownPayment%, we can see that the average down payment in this cluster is about , while for the rest of the clusters the average down payment is less than . Further, the salient dimension AgeObject shows that about of the customers in cluster 3 are applying to buy relatively new cars. In contrast, the average percentage of customers, in the other clusters, applying to buy new cars is about .
Cluster 2 has the highest default rate and can be explained by its salient dimension MaxBucket12. About of customers in this cluster are between 1 and 90 days past due, while the percentage of customers in the other clusters in the same interval is only .
Therefore, given that the VAE has learned a business intuitive data representation, the clusters identified for the Norwegian car loan data set can be useful for marketing campaigns, customer relationship management, data and customer management and for credit scoring [2].
6 Conclusion
In this paper, we show that it is possible to steer configurations in the latent space of the Variational Autoencoder (VAE) by transforming the input data and creating a specific grouping of it. Specifically, the Weight of Evidence (WoE) transformation encapsulates the propensity to fall into financial distress and the latent space in the VAE learns a data representation, which shows a well-defined clustering structure that encapsulates the customers’ creditworthiness.
The data representations generated with the VAE express general priors that are particularly useful in the bank industry. Specifically, the data representations are able to learn the natural clustering and spatial coherence of creditworthiness in customers data.
Finally, our proposed method has the advantage of learning a latent data representation, which captures non-linear relationships and, for low dimensional spaces, it can be visualized. In addition, the number of clusters is suggested by the learned representation itself. Furthermore, the VAE can generate the latent configuration of new customers and assign them to one of the existing clusters. This data representation of bank customers, given that their salient dimensions are business intuitive, can be used for marketing, customer, and model fit purposes in the bank industry.
Acknowledgements
The authors would like to thank Santander Consumer Bank for financial support and the real data sets used in this research. This work was also supported by the Research Council of Norway [grant number 260205] and SkatteFUNN [grant number 276428].
Appendices
A Figures and Tables
B Salient Dimensions
Let be the v’th dimension of the i’th vector , where . Further let be the set of in-patterns (within cluster ) and be the set of out-patterns (not within cluster ). Then compute the mean input values
[TABLE]
where returns the cardinality of . Further, compute the difference factors
[TABLE]
and their mean and standard deviations
[TABLE]
Finally, we say that the v’th feature in cluster is a salient dimension if
[TABLE]
or
[TABLE]
where is the number of standard deviations to be used. The value for is defined based on the data set. We use for all three data sets under analysis.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abdou [2009] Abdou, H. A. (2009). Genetic programming for credit scoring: The case of egyptian public sector banks. Expert systems with applications , 36(9):11402–11417.
- 2Anderson [2007] Anderson, R. (2007). The credit scoring toolkit . Oxford University Press.
- 3Azcarraga et al. [2005] Azcarraga, A. P., Hsieh, M.-H., Pan, S. L., and Setiono, R. (2005). Extracting salient dimensions for automatic som labeling. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) , 35(4):595–600.
- 4Bengio et al. [2013] Bengio, Y., Courville, A., and Vincent, P. (2013). Representation learning: A review and new perspectives. IEEE transactions on pattern analysis and machine intelligence , 35(8):1798–1828.
- 5Blei et al. [2017] Blei, D. M., Kucukelbir, A., and Mc Auliffe, J. D. (2017). Variational inference: A review for statisticians. Journal of the American Statistical Association , 112(518):859–877.
- 6Bouchacourt et al. [2018] Bouchacourt, D., Tomioka, R., and Nowozin, S. (2018). Multi-level variational autoencoder: Learning disentangled representations from grouped observations. In Thirty-Second AAAI Conference on Artificial Intelligence .
- 7Bowman et al. [2015] Bowman, S. R., Vilnis, L., Vinyals, O., Dai, A. M., Jozefowicz, R., and Bengio, S. (2015). Generating sentences from a continuous space. ar Xiv preprint ar Xiv:1511.06349 .
- 8Doersch [2016] Doersch, C. (2016). Tutorial on variational autoencoders. ar Xiv preprint ar Xiv:1606.05908 .