Detecting causality in multivariate time series via non-uniform embedding
Ziyu Jia, Youfang Lin, Zehui Jiao, Yan Ma, Jing Wang

TL;DR
This paper introduces LM-PMIME, a new information-theoretic method for detecting causality in multivariate time series, improving accuracy especially in weakly coupled and chaotic systems.
Contribution
The paper presents LM-PMIME, a novel non-uniform embedding approach that combines low-dimensional mutual information approximation with a mixed search strategy.
Findings
Outperforms PMIME in simulations of stochastic and chaotic systems.
Effective in detecting causality with weak coupling.
Successfully applied to epilepsy electrocorticographic data.
Abstract
Causal analysis based on non-uniform embedding schemes is an important way to detect the underlying interactions between dynamic systems. However, there are still some obstacles to estimate high-dimensional conditional mutual information and form optimal mixed embedding vector in traditional non-uniform embedding schemes. In this study, we present a new non-uniform embedding method framed in information theory to detect causality for multivariate time series, named LM-PMIME, which integrates the low-dimensional approximation of conditional mutual information and the mixed search strategy for the construction of the mixed embedding vector. We apply the proposed method to simulations of linear stochastic, nonlinear stochastic, and chaotic systems, demonstrating its superiority over partial conditional mutual information from mixed embedding (PMIME) method. Moreover, the proposed method…
Click any figure to enlarge with its caption.
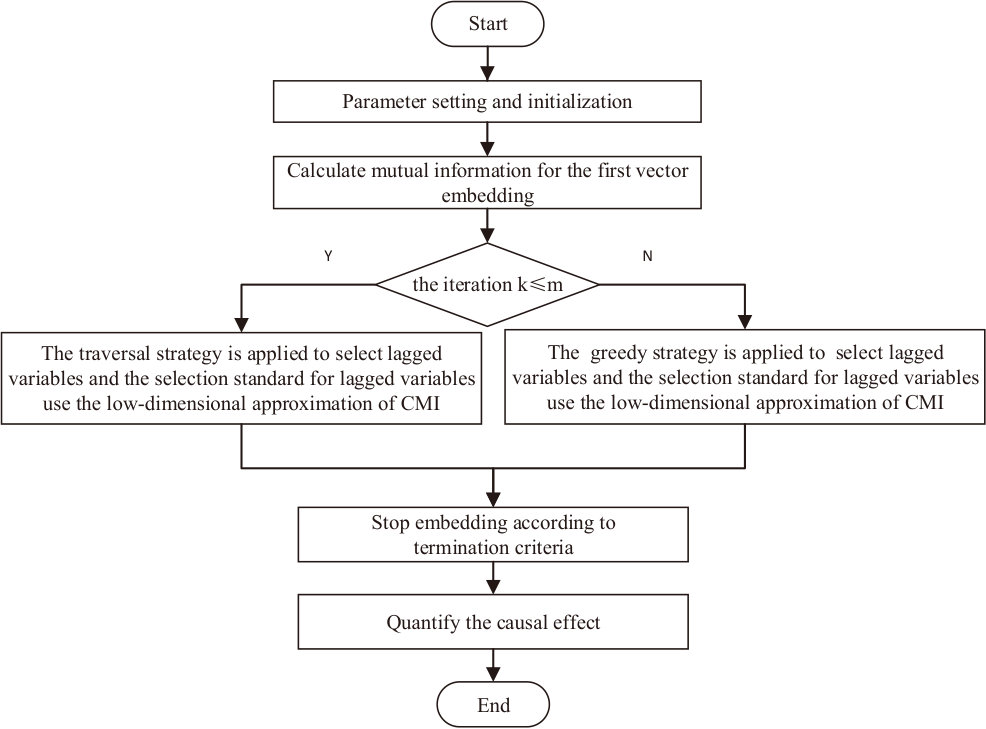 Figure 1
Figure 1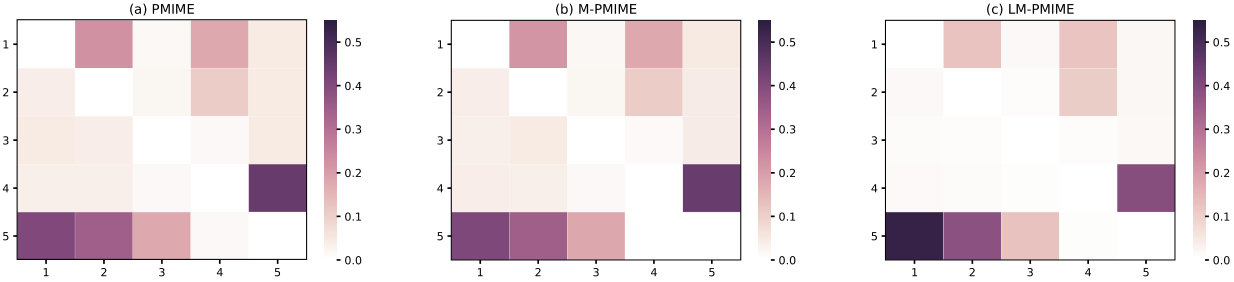 Figure 2
Figure 2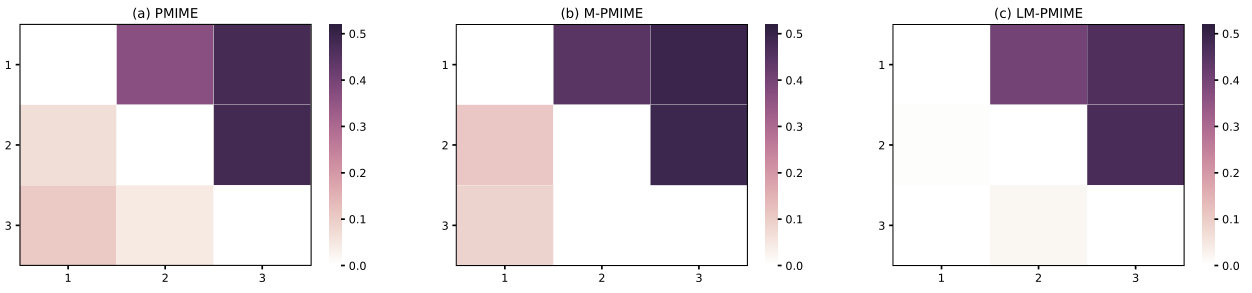 Figure 3
Figure 3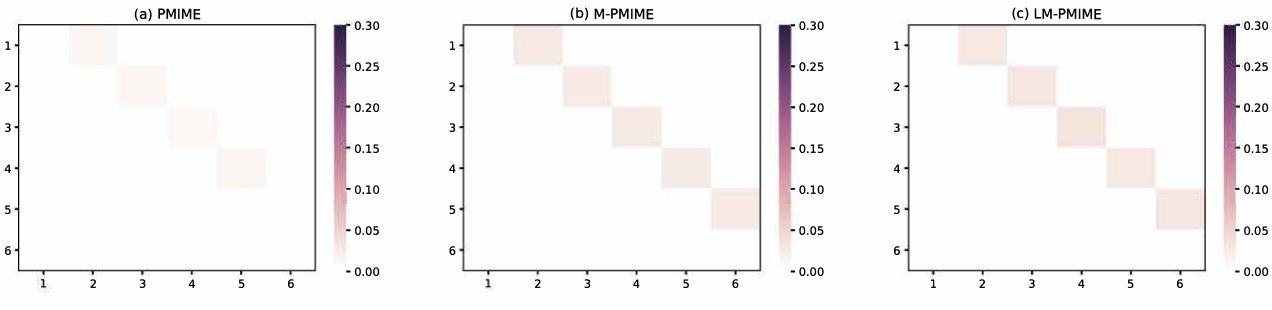 Figure 4
Figure 4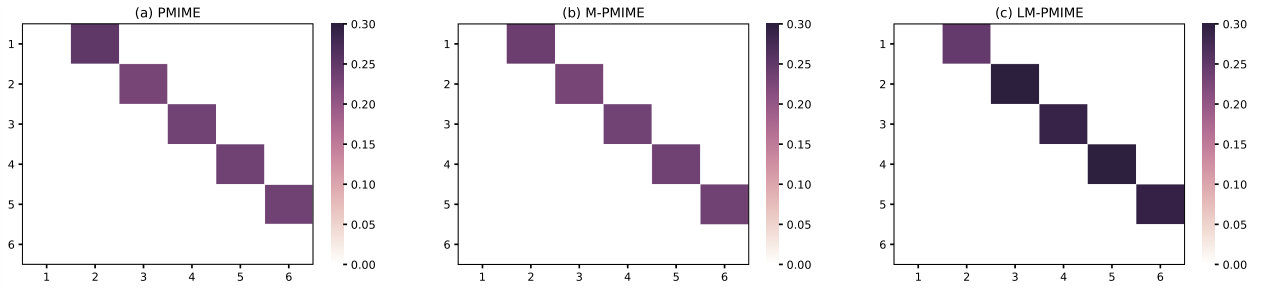 Figure 5
Figure 5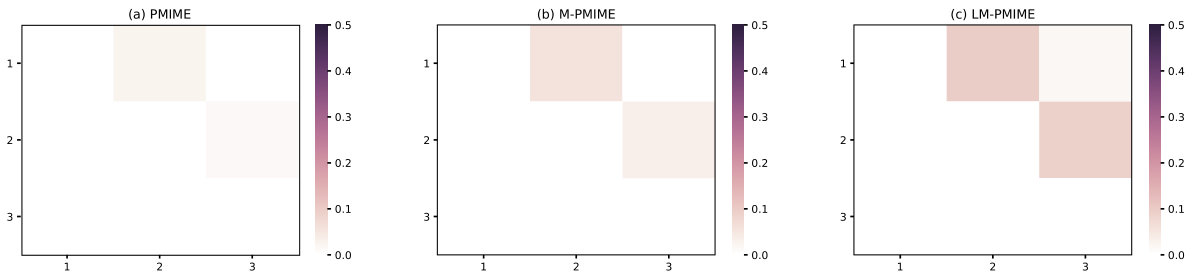 Figure 6
Figure 6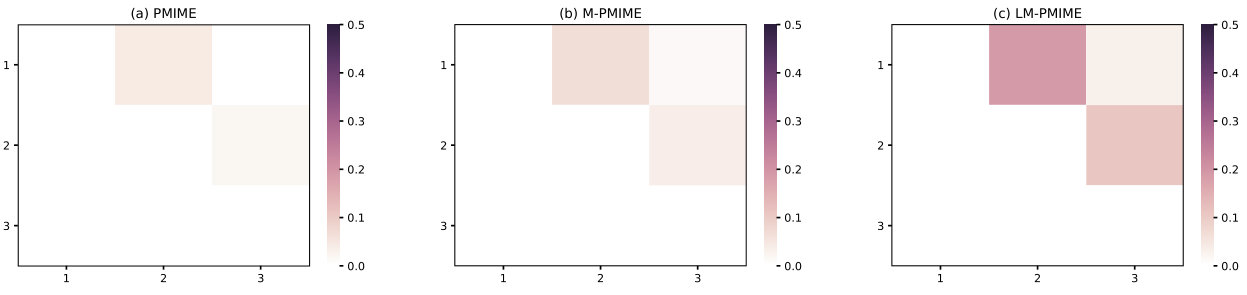 Figure 7
Figure 7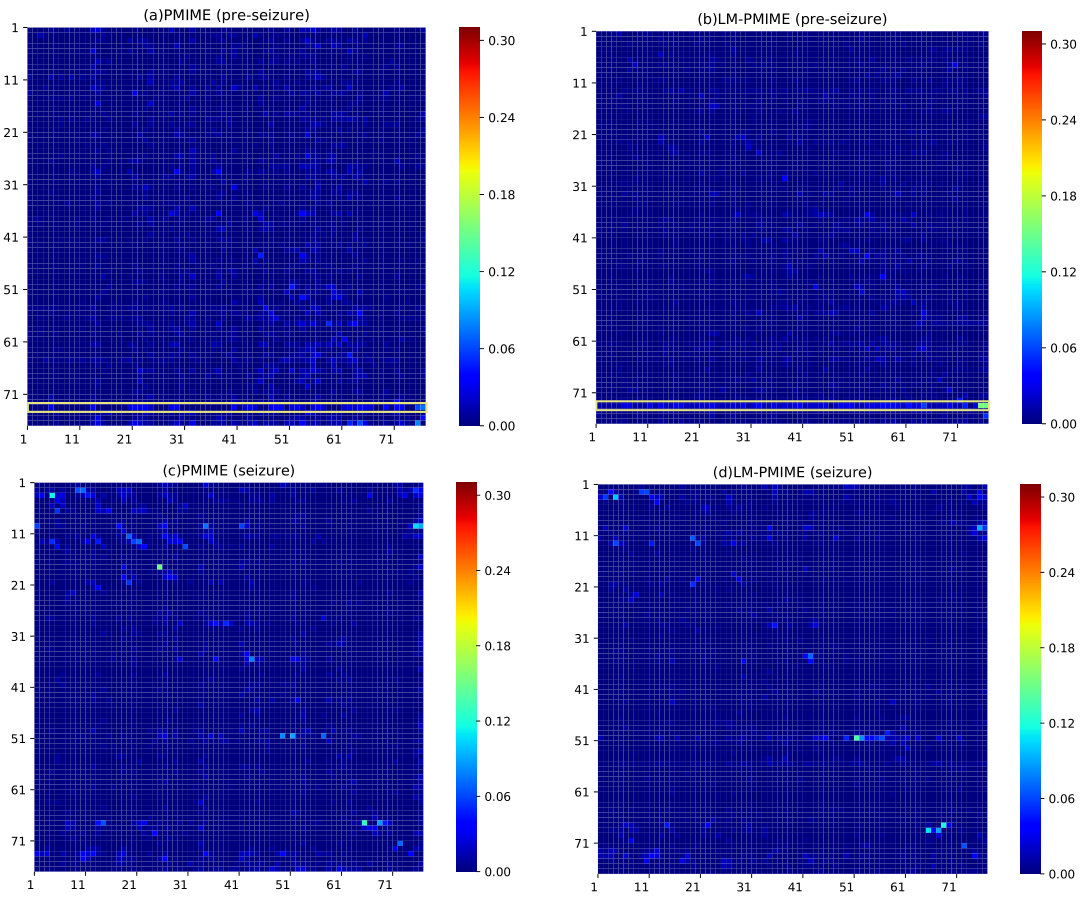 Figure 8
Figure 8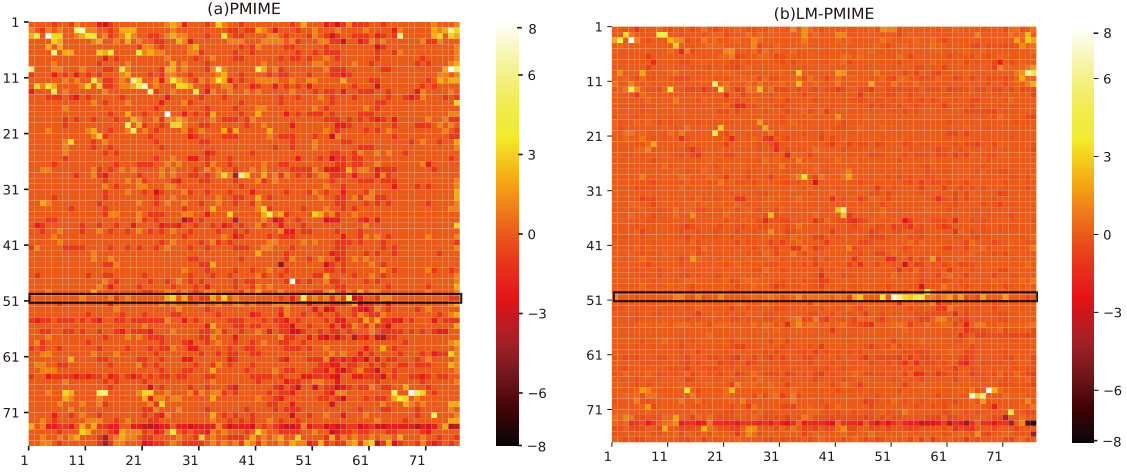 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Detecting causality in multivariate time series via non-uniform embedding
Ziyu Jia1, Youfang Lin1, Zehui Jiao1, Yan Ma2, Jing Wang*∗,1*
1 School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, PR China
2 Division of Interdisciplinary Medicine and Biotechnology, Department of Medicine,
Beth Israel Deaconess Medical Center/ Harvard Medical School, Boston, MA, USA
Abstract
Causal analysis based on non-uniform embedding schemes is an important way to detect the underlying interactions between dynamic systems. However, there are still some obstacles to estimating high-dimensional conditional mutual information and forming optimal mixed embedding vector in traditional non-uniform embedding schemes. In this study, we present a new non-uniform embedding method framed in information theory to detect causality for multivariate time series, named LM-PMIME, which integrates the low-dimensional approximation of conditional mutual information and the mixed search strategy for the construction of the mixed embedding vector. We apply the proposed method to simulations of linear stochastic, nonlinear stochastic, and chaotic systems, demonstrating its superiority over partial conditional mutual information from mixed embedding (PMIME) method. Moreover, the proposed method works well for multivariate time series with weak coupling strengths, especially for chaotic systems. In the actual application, we show its applicability to epilepsy multichannel electrocorticographic recordings.
Keywords: causal analysis; non-uniform embedding; multivariate time series; conditional mutual information.
1. Introduction
In recent years, various time series analysis methods have been proposed to identify interactions between complex systems[1]. The study of causality, in particular, has attracted wide attention of researchers. There are two classic methods in the time series causal analysis: Granger causality [2] and transfer entropy [3, 4]. Both methods are based on time series prediction for causal analysis. In addition, the relationship between Granger causality and transfer entropy is demonstrated [5]: the two methods are equivalent under Gaussian assumptions. Furthermore, Hlavackova-Schindler [6] extends the equivalence of the two causality methods for generalized Gassian processes which satisfy some additional condition on probability density distributions.
With the development of multivariate state space reconstruction, different embedding schemes [7, 8, 9, 10, 11] are used in Granger causality and transfer entropy. The common idea of those embedding schemes is to reconstruct the past of the whole system represented by all variables with reference to the target variable, in order to form a mixed embedding vector containing the most significant past variables to explain the target variable. Non-uniform embedding schemes are proposed to overcome the problems of arbitrariness and redundancy in uniform embedding schemes [9, 12]. Vlachos et al. propose a causality measure based on the mixed embedding scheme for bivariate time series: the conditional mutual information from mixed embedding (MIME) [13]. Kugiumtzis et al. extend the measure MIME to multivariate time series and form the partial MIME (PMIME) [14]. The PMIME addresses successfully the problem of detecting direct causal effects in the multivariate variables. In addition, it is gradually applied to complex systems such as physiology [15, 16] and finance [17, 18].
Although the causal analysis based on non-uniform embedding schemes has practical advantages, there are still some key shortcomings that need to be overcome. One shortcoming is the curse of dimensionality, which makes the estimation of mutual information inaccurate as the dimension of the embedded space increases [19, 20, 21, 22]. Another shortcoming is related to the mixed embedding vector. The greedy strategy uses a sequential forward approach to select the lagged variables and finally form the mixed embedding vector [9, 13, 14]. That is to say, the lagged variables that have been embedded will not be changed in the mixed embedding vector. As the iteration increases, more lagged variables are selected until the final mixed embedding vector is formed. Therefore, the inaccuracy of the initial embedding will have a large impact on the results. The above shortcomings will be highlighted when there are multivariate time series of weak causal coupling strengths in practical applications.
In this paper, we put forward a new non-uniform embedding method named LM-PMIME for multivariate time series according to the low-dimensional approximation of conditional mutual information and the mixed search strategy. The main idea of the proposed method is to reduce the dimension of the embedded space by replacing the original estimate with a low-dimensional approximation of conditional mutual information. In addition, a mixed strategy, which has taken the place of the greedy strategy, was adopted as an embedded strategy to optimize the initial embedding. The proposed method works well for multivariate time series with weak coupling strengths.
The rest of the paper is organized as follows. In Section 2, we present the whole structure of multivariate non-uniform embedding in accordance with the low dimensional approximation of CMI and a mixed search strategy. In Section 3, we perform a large number of simulation experiments in order to verify the effectiveness of the proposed method. In Section 4, by analyzing the electrocorticographic (ECoG) recordings from an epileptic patient, the applicability of the proposed method to actual data is shown. Finally, a summary is presented in Section 5.
2. Method
In this section, we first introduce the traditional PMIME method. Then we expound a low dimensional approximation of conditional mutual information and a mixed search strategy. Finally, we present the LM-PMIME method for multivariable non-uniform embedding.
2.1. PMIME Method
Partial conditional mutual information from mixed embedding (PMIME), a generalization of conditional mutual information from mixed embedding (MIME) for bivariate time series [13], is developed by Kugiumtzis et al. [14] to estimate the directional coupling in multivariate time series. Let variables constitute an overall dynamical system . Suppose that the driving subsystem is and the target subsystem is . In other words, the current value of variable is affected by the past of variable . represent the remaining subsystems.
We estimate the causal effect of on conditioned by . It is necessary to form a set of variables representing the past of the subsystems. The lags of , and are sought within a range given by a maximum lag for each variable, e.g., for and for . is defined as the set of all lagged variables at time , containing the parts of and the same for and . It is usually assumed that the maximum lag for all variables is the same (). The larger the value of , the more lagged variables are included in . The key step of the PMIME method is to form the mixed embedding vector using non-uniform embedding. Greedy forward selection and a stopping criterion are applied to the process of embedding. The detailed method is described below as follows :
An empty embedding vector is initialized. 2. 2.
At the first iteration = 1, the embedding vector is selected most related to :
[TABLE]
where represents mutual information. Mutual information is estimated by the k-nearest neighbors (k-NNs) method. Then we have . At the same time, is removed from . 3. 3.
At the iteration , the mixed embedding vector is augmented by the component of , giving most information about additionally to the information already contained in . will be tested by a standard through computing the maximum conditional mutual information (CMI), , i.e., at the iteration , , where the conditional mutual information is estimated by the k-NNs estimator, and the mixed embedding vector is . By using greedy forward method, each will be embedded in the already embedded vector until the process stops. The termination criterion is quantified as :
[TABLE]
where the threshold and the general value of is 0.95 or 0.97 in [13, 14]. That is, the additional information of selected at the iteration is not large enough. The embedding process will stop and we have the mixed embedding vector . And any combination of the lagged variables may be included in . 4. 4.
To quantify the causal effect of on conditioned by the other variables in , the index is defined as
[TABLE]
where represents the component of in . And it is the same with and . The causal effect of to depends on the components of in .
*2.2. The Proposed Method *
*2.2.1. Low Dimensional Approximation of CMI *
As the dimension of mixed embedding vector increases, the estimation of CMI becomes less reliable. Because of an increasing volume of state space, the estimation of entropy rates progressively decrease towards zero [23]. Therefore, in order to overcome the problems caused by computing high-dimensional CMI, the low-dimensional approximation of CMI is a better alternative. The low-dimensional approximation can improve the accuracy of conditional mutual information estimation and reduce the computational cost.
The low-dimensional approximation of CMI is studied by researchers in the field of information theory based on feature selection [24, 25, 26, 27, 28, 30]. Brown et al. [21] emphasize that lots of feature selection heuristics are all approximate iterative maximisers of the conditional likelihood, which can be interpreted in a unifying framework of conditional likelihood maximisation under certain assumptions of independence. Consequently, the methods are summarized as a parameterized general standard:
[TABLE]
where the difference between different standards depends on the parameters ( and ) . For example, the JMI standard [25] can be obtained with . and are different in standards such as MRMR standard [27], and CIFE standard [28]. Recent studies have shown that higher-order feature interactions are considered to optimize feature selection standard. Therefore, we need to consider the second-order interactions between the features compared to Eq (4), such as [22].
[TABLE]
where and . Using Eq (5), the original high-dimensional mutual information based standard can be decomposed into a set of low-dimensional MI quantities. We apply this low-dimensional approximation to the selection of lagged variables.
*2.2.2. Mixed Search Strategy *
An applicable search strategy is important for building the mixed embedding vector. Because the greedy search strategy has high computational efficiency and good practicability, it has become the preferred strategy for embedding. However, the greedy strategy uses a sequential forward approach to select lagged variables, which rely heavily on the initial embedded vector. That is to say, the initial embedded vector is not accurate and the subsequent selection will get worse.
In order to solve the above problem, we propose a mixed strategy to avoid inaccuracies in the initial embedding. The mixed strategy consists of two strategies: the traversal strategy and the greedy strategy. The application of the strategy is determined by defining a strategy adjustment factor . Assuming that a number of iterations is , the traversal strategy is applied when . For example, when using the traversal strategy, it is necessary to calculate the possible combinations of all lagged variables before determining the mixed embedding vector of the current step. That is to say, we need to calculate combinations in total, and then select the combination of largest conditional mutual information as the mixed embedding vector of the current step. The greedy strategy is applied when . This strategy is the same as the one used by the PMIME method.
*2.2.3. LM-PMIME Method *
We put forward the LM-PMIME method for estimating the directional coupling in multivariate time series according to the low-dimensional approximation of conditional mutual information and the mixed search strategy. In the LM-PMIME method, the mixed strategy determines the way to select lagged variables. But whether the variable will be embedded depends on the low dimensional approximation of conditional mutual information. Fig.1 is an illustration of the flow of the LM-PMIME method.
The detailed LM-PMIME method is as follows:
Initialize an empty embedding vector . 2. 2.
At the first iteration = 1, the embedding vector is selected most related to :
[TABLE]
Then we have . 3. 3.
At the iteration , will be tested by a standard through computing the maximum value of the low dimensional approximation of CMI.
[TABLE]
where and . The traversal strategy is applied to select , i.e., at the iteration and , needs to be selected. First, clear the already embedded vector and calculate combinations in total. Then select the combination of largest conditional mutual information as of the current step. Finally, . 4. 4.
At the iteration , greedy strategy is used. Each will be embedded in the already embedded vector until the process stops. The standard of low dimensional approximation is still used before stopping. 5. 5.
The termination criterion is quantified as:
[TABLE]
where the threshold and threshold near 1, e.g. , allows the inclusion of a new component in the mixed embedding vector even if the augmented vector explains very little of the information on that was not explained at the previous step. The general value of is 0.95 or 0.97 in [13, 14]. That is, the additional information of selected at the iteration is not large enough. The embedding process will stop and we have the mixed embedding vector . In addition, any combination of the lagged variables may be included in . 6. 6.
To quantify the causality strength of on conditioned by the other variables in , the index is defined as :
[TABLE]
where represents the component of in . And it is the same with and . The causality strength of to depends on the components of in . The presence of components of in the mixed embedding vector indicates that has some effect on the evolution of and then the derived information measure causality strength is positive, whereas the absence indicates no effect and then causality strength is exactly zero. In addition, the is considered significant if it is positive in the PMIME method and proposed method.
Figure 1 The Flow chart of the LM-PMIME method.
3. Simulation study
In this section, we perform a series of causal analysis simulation experiments using linear stochastic, nonlinear stochastic, and chaotic systems. The experiments compare the differences between the proposed LM-PMIME method and the traditional PMIME method for time series with different lengths or coupling strengths. The experiments also add a comparison method M-PMIME, which improve the search strategy without using low-dimensional approximation.
We calculate all methods on 100 realizations from each system to assess statistically the sensitivity and specificity of the methods. The connections between variables are classified as coupled directions and uncoupled directions to compute the confusion matrix: (ture positives), (false positives), (true negatives), and (false negatives), where sensitivity = , specificity = , and F1 score = .
The accuracy of the estimated mutual information is vital for embedding vector selection [27]. The two most common methods for estimating mutual information are the histogram and kernel methods. The former one is time efficient but not highly accurate [31]. The latter one has higher accuracy but comes with huge computational pressure [32]. We applied the k-nearest neighbors (k-NNs) method to estimate mutual information, because the k-NNs estimator is suitable for high-dimensional data [33].
In the following results, the performance of LM-PMIME and a comparison to M-PMIME and PMIME are presented for multivariate time series with different lengths or coupling strengths.
*3.1. Linear multivariate stochastic process *
The first system is a linear vector autoregressive (VAR) process which is composed of order 4 in 5 time series (model 1 in [34]).
[TABLE]
where , , are Gaussian noise with zero mean and unit covariance matrix. , , , , , , and are the true causal connections in this process.
Figure 2 Matrix representation of causality for the linear VAR process. Retrieved by traditional PMIME method (a), M-PMIME method (b), and LM-PMIME method (c) with k-NNs estimator. The length of the time series is 512. is used for the M-PMIME method and the LM-PMIME method. The remaining parameters of the three methods are the same (). Color maps for the mean values of coupling measurements are obtained from 100 realizations of the linear VAR process. The direction of causal influence is from row to column in the matrix. The true causal connections in this linear VAR process are at the matrix elements (1, 2), (1, 4), (2, 4), (4, 5), (5, 1), (5, 2) and (5, 3).
We use and , which matches the larger lag for the three methods in the process. In addition, the LM-PMIME method and the M-PMIME method use the parameter . The results from linear VAR process with the time series length of 512 are shown in Fig 2. The direction of causal influence is from row to column in the matrix representation, e. g. the causal connection is represented as (1, 2) in the matrix representation. Hence, true causal connections in this process are at the matrix elements (1, 2), (1, 4), (2, 4), (4, 5), (5, 1), (5, 2) and (5, 3). The mean values of coupling measured by the three methods are positive and high on these matrix elements. It is proved that the three methods have good sensitivity to true couplings. However, Fig 2 shows that there are lots of false positives in the traditional method using high-dimensional CMI. In contrast, the LM-PMIME method has better performance than the other two methods, because the method reduces false positives. The sensitivity, specificity, and F1 score are obtained from 100 realizations of linear VAR process with varying length of time series. The values of the specific indexs are listed in Table I. The F1 score of LM-PMIME method has better results on linear VAR process with different time series lengths. Furthermore, the F1 score calculated by the LM-PMIME method increases as the length of the time series increases. These better results are likely due to the great improvement of specificity by the proposed method. At the same time, the F1 score reflects that PMIME method and M-PMIME method have achieved similar results in the linear VAR process. It shows that the mixed strategy does not work in this process. However, the following experiments show that the mixed strategy works well on the chaotic system.
TABLE I Sensitivity, specificity, and F1 score are obtained from 100 realizations of linear VAR process with varying length of time series for the three different methods. and are the parameters common to the three methods. In addition, the LM-PMIME method and the M-PMIME method use the parameter .
[TABLE]
3.2. Nonlinear multivariate stochastic process
The nonlinear VAR process is of order 1 in three variables (model 7 in [35]).
[TABLE]
The true causal connections in NLVAR3 (1) are , , . The results obtained from 100 realizations of the nonlinear VAR process are shown in Fig 3 for , , . The strategy adjustment factor determines the application of the strategies for LM-PMIME method and M-PMIME method. The true causal connections in are represented at the matrix elements (1,2), (1,3), and (2,3). For the three methods, the mean values of coupling measurements on these matrix elements are positive and high. It turns out that all methods have good sensitivity to true couplings. But there are many false positives in the traditional methods using high-dimensional CMI. Hence, the LM-PMIME method significantly outperforms the others. The sensitivity, specificity, and F1 score are obtained from by gradually increasing the time series length from 256 to 1024. The values of the specific indexs are listed in Table II. The F1 score of LM-PMIME method has better results on with different time series lengths. In addition, the F1 score will increase as the length of the time series increases. The low-dimensional approximation of CMI can greatly improve specificity, although mixed strategy does not work in .
Figure 3 Matrix representation of causality for . Retrieved by traditional PMIME method (a), M-PMIME method (b), and LM-PMIME method (c) with k-NNs estimator. The length of the time series is 512. is used for the M-PMIME method and the LM-PMIME method. The remaining parameters of the three methods are the same (, ). Color maps for the mean values of coupling measurements are obtained from 100 realizations of . The direction of causal influence is from row to column in the matrix. The true causal connections in are at the matrix elements (1,2), (1,3), (2,3).
TABLE II Sensitivity, specificity, and F1 score are obtained from 100 realizations of with varying length of time series for the three different methods. and are the parameters common to the three methods. In addition, the LM-PMIME method and the M-PMIME method use the parameter .
[TABLE]
3.3. Coupled Henon maps
The system of coupled chaotic Henon maps defined as
[TABLE]
, where , are the true causal connections in the coupled chaotic Henon maps. The results from 100 realizations of the coupled Henon maps with the coupling strength are shown in Fig 4 for , , , , . In addition to this, the results of only changing the coupling strength are shown in Fig 5. The true causal connections in the coupled Henon maps are at the matrix elements (), where . There is almost no false positive for all methods. However, Fig 4 and Fig 5 illustrate that the proposed methods have better performance than the traditional method when there are true causal connections. All methods will detect stronger causal connections as the coupling strength of the system increases. The sensitivity, specificity, and F1 score are obtained from coupled Henon maps with the variables from 3 to 9. The values of the specific indexs are listed in Table III and Table IV. The results show that the F1 score of the LM-PMIME method is higher than the others when the coupling strength is low. Although the F1 score may be affected by the number of variables in the simulation experiments, the F1 score for the LM-PMIME method is above 0.9. The LM-PMIME method and the M-PMIME method greatly improve the specificity, especially the former method. It is proved that both low-dimensional approximation of CMI and the mixed strategies play an important role in coupled Henon maps when the coupling strength is low.
Figure 4 Matrix representation of causality for variables of the coupled Henon maps (). Retrieved by traditional PMIME method (a), M-PMIME method (b), and LM-PMIME method (c) with k-NNs estimator. The length of the time series is 1024. is used for the M-PMIME method and the LM-PMIME method. The remaining parameters of the three methods are the same (, ). Color maps for the mean values of coupling measurements are obtained from 100 realizations of the coupled Henon maps. The direction of causal influence is from row to column in the matrix. The true causal connections in the coupled Henon maps are at the matrix elements (), where .
Figure 5 Matrix representation of causality for variables of the coupled Henon maps (). Retrieved by traditional PMIME method (a), M-PMIME method (b), and LM-PMIME method (c) with k-NNs estimator. The length of the time series is 1024. is used for the M-PMIME method and the LM-PMIME method. The remaining parameters of the three methods are the same (, ). Color maps for the mean values of coupling measurements are obtained from 100 realizations of the coupled Henon maps. The direction of causal influence is from row to column in the matrix. The true causal connections in the coupled Henon maps are at the matrix elements (), where .
TABLE III Sensitivity, specificity, and F1 score are obtained from 100 realizations of variables of the coupled Henon maps () for the three different methods. and are the parameters common to the three methods. In addition, the LM-PMIME method and the M-PMIME method use the parameter .
[TABLE]
TABLE IVSensitivity, specificity, and F1 score are obtained from 100 realizations of variables of the coupled Henon maps () for the three different methods. and are the parameters common to the three methods. In addition, the LM-PMIME method and the M-PMIME method use the parameter .
[TABLE]
3.4. Coupled Lorenz system
Next we study a chaotic system of three coupled identical Lorenz oscillators defined as
[TABLE]
where . The differential equations by the explicit Runge-Kutta (4,5) method are solved in MATLAB. In addition, the time series are generated at a sampling time of 0.05 time units. The true causal connections in the three coupled Lorenz oscillators are , where .
The results from 100 realizations of the three coupled Lorenz oscillators with the coupling strength are shown in Fig 6, for , , , . In addition, The sensitivity, specificity, and F1 score are listed in Table V. The values of the specific indexs are obtained from the three coupled Lorenz oscillators with varying length of time series from 256 to 1024 and the remaining parameters are the same. The F1 scores of the proposed methods are much higher than the traditional PMIME method. The M-PMIME method performs best when the time series is short. That is to say, the mixed strategy plays a role in improving the F1 score. However, the F1 score of the LM-PMIME method is the highest as the length of the time series increases.
Figure 6 Matrix representation of causality for the three coupled Lorenz oscillators. Retrieved by traditional PMIME method (a), M-PMIME method (b), and LM-PMIME method (c) with k-NNs estimator. The length of the time series is 512 with coupling strength . is used for the M-PMIME method and the LM-PMIME method. The remaining parameters of the three methods are the same (, ). Color maps for the mean values of coupling measurements are obtained from 100 realizations of the three coupled Lorenz oscillators. The direction of causal influence is from row to column in the matrix. The true causal connections in the three coupled Lorenz oscillators are at the matrix elements (), where .
TABLE V Sensitivity, specificity, and F1 score are obtained from 100 realizations of the three coupled Lorenz oscillators () with varying length of time series for the three different methods. and are the parameters common to the three methods. In addition, the LM-PMIME method and the M-PMIME method use the parameter .
[TABLE]
The sensitivity, specificity, and F1 score are obtained from 100 realizations of the three coupled Lorenz oscillators with coupling strength from 1 to 5 for the three different methods. The length of the time series is 512 and , , . The values of sensitivity, specificity, and F1 score are listed in Table VI. The results show that the LM-PMIME method performs best when the coupling strength is low, such as =1. Although the F1 score of the traditional PMIME method increases as the coupling strength increases, it is still much worse than the proposed methods. Fig 7 is the matrix representation of causality for the three coupled Lorenz oscillators with coupling strength . The true causal connections are () in the matrix elements, where . Only for the LM-PMIME method, the mean values of coupling measurements on these matrix elements are positive and high.
Figure 7 Matrix representation of causality for the three coupled Lorenz oscillators. Retrieved by traditional PMIME method (a), M-PMIME method (b), and LM-PMIME method (c) with k-NNs estimator. The length of the time series is 512 with coupling strength . is used for the M-PMIME method and the LM-PMIME method. The remaining parameters of the three methods are the same (, ). Color maps for the mean values of coupling measurements are obtained from 100 realizations of the three coupled Lorenz oscillators. The direction of causal influence is from row to column in the matrix. The true causal connections in the three coupled Lorenz oscillators are at the matrix elements (), where .
TABLE VI Sensitivity, specificity, and F1 score are obtained from 100 realizations of the three coupled Lorenz oscillators () with coupling strength from 1 to 5 for the three different methods. and are the parameters common to the three methods. In addition, the LM-PMIME method and the M-PMIME method use the parameter .
[TABLE]
4. Application
In this section, we show the applicability of the proposed LM-PMIME method to actual electrocorticographic (ECoG) data. That is to say, the causal analysis method is adopted to explore key contacts of the human subject with intractable epilepsy and assist doctors in the diagnosis and treatment of the disease. A public dataset from the human subject (a 39-year-old woman with medically refractory complex partial seizures) is used. The dataset contains 8 seizure epochs and 8 pre-seizure epochs. Each epoch contains 76 time series obtained from the 8-by-8 electrode grid and two depth electrodes with six contacts each. In addition, the duration of each epoch is 10s and the length of each time series is 4000 (More details about the data are given in [36]).
We use PMIME method and LM-PMIME method to analyze the seizure data and the pre-seizure data. The data is recorded at a fixed sampling rate of 400 Hz, which is downsampled to 100 Hz. To assess the causal matrices of different physiological states estimated by each method, we compute the average causal strengths (the mean values of the coupling measurements over all epochs in the same physiological state) as shown in Fig. 8. The brighter the colors are, the more signifincant causal connections are. As a result, it is obvious from the causal matrics of LM-PMIME method that contact 73 has more impact on the other contacts, highlighting that it is the key contact in the pre-seizure data [see Fig. 8(b)]. However, the traditional PMIME method has led to a lot of false positives [see Fig. 8(a)]. Fig. 9 illustrates the difference of total numbers of significant connections between the seizure state and the pre-seizure state. The proposed method highlights the key contact 50 [see Fig. 9(b)] and these discovered key contacts are consistent with many researchers [36, 37, 38].
Figure 8 Results for multivariate electrocorticographic (ECoG) data. Matrices of causalities reflect the pre-seizure state (top) and the seizure state (down) estimated by the PMIME method and the LM-PMIME method. The causal strengths are averaged (the mean values of the coupling measurements over all epochs in the same physiological state). Contacts 1 to 64 belong to an 8-by-8 electrode grid, and contacts 65 to 76 belong to two depth electrodes. The direction of causal influence is from row to column in the matrices. The brighter colors indicate more significant values. The key contact is marked by a rectangular box. The parameter and are set for the different methods.
Figure 9 Results for multivariate electrocorticographic (ECoG) data. Matrices reflect the difference of total numbers of significant connections between the seizure state and the pre-seizure state (seizure minus pre-seizure). The numbers are respectively summed from 8 seizure epochs and 8 pre-seizure epochs. Contacts 1 to 64 belong to an 8-by-8 electrode grid, and contacts 65 to 76 belong to two depth electrodes. The direction of causal influence is from row to column in the matrices. The brighter colors indicate more significant values. The key contact is marked by a rectangular box. The parameter and are set for the different methods.
We observe that LM-PMIME method gives an obvious causal driver located at the contact 73 from the second depth electrode strip in the pre-seizure data. Therefore, the contact 73 may be associated with seizures. Although not yet clinically observable, it has been suggested that the second depth electrode primarily affect cortical activity in [37, 38]. In addition, the proposed method successfully identifies a key contact from the data: contact 50, which exhibits the most significant change in the betweenness centrality. The contact is considered the primary target of therapeutic intervention in [38], because contacts with statistically significant increases in betweenness centrality may lead to seizures. In contrast, traditional PMIME method leads to a large number of false positives, so key contacts cannot be highlighted.
5. Discussion and conclusion
In this paper, we have put forward a new non-uniform embedding method named LM-PMIME for multivariate time series. We present effective modifications for the well-known non-uniform embedding method: PMIME, which quantifies causality by means of information theoretic measures. The advantage of the non-uniform embedding compared with uniform embedding is that it can reduce the dimension of the state space by selecting the relevant variables which contribute the most to explain the target variable. Therefore, it has been proved that the non-uniform embedding process is more flexible for state space reconstruction [9, 13, 39]. However, there are still some obstacles to estimating high-dimensional CMI and forming optimal mixed embedding vector in the traditional non-uniform embedding methods. The proposed LM-PMIME method overcomes the above shortcomings of traditional methods. The effectiveness and applicability of the LM-PMIME method are demonstrated by a large number of experiments. Furthermore, the LM-PMIME method works well for multivariate time series with weak coupling strengths, especially for chaotic systems. The usefulness of the LM-PMIME method for multivariate time series is illustrated by the analysis of actual ECoG data.
The major contribution of the proposed LM-PMIME method, which is based on the low-dimensional approximation of conditional mutual information and the mixed search strategy, is that improves the traditional non-uniform embedding methods. The curse of dimensionality is avoided by replacing the original estimate with a low-dimensional approximation of conditional mutual information. In addition, a mixed strategy instead of the greedy strategy is used as an embedded strategy to solve the problem of initial embedding inaccuracy. Hence, the mixed embedding vector becomes more parsimonious by maximizing the correlation with the target variable and minimizing the redundancy between the selected variables. In order to form the optimal mixed embedded vector, there are also other propositions. For example, in [20] a preselection scheme for subsets of causal predictors is used to search an optimal subset and detect the synergetic variables. In addition, many researchers adopt the OCE algorithm [40] or the PCMCI [29] algorithm to estimate the causal graphs. Different from these preselection methods, the LM-PMIME method relies on both the low-dimensional approximation and the mixed search strategy to improve the conditions. In all simulation systems, the LM-PMIME method performs better than the traditional methods according to the F1 score. Because of the complexity of chaotic systems, true causality is often difficult to detect. However, the LM-PMIME method significantly improves the sensitivity in chaotic systems. In the remaining simulation systems, the LM-PMIME method reduces false positives and increases the specificity. The experiments also adopt the comparison method M-PMIME, which improves the search strategy without using low-dimensional approximation. By the M-PMIME method, it can be found that the mixed search strategy works well in chaotic systems, especially the systems with low coupling strengths. In addition, the low-dimensional approximation of conditional mutual information plays an important role in linear and nonlinear systems. Therefore, we combine both the low-dimensional approximation of conditional mutual information and the mixed search strategy to form a new non-uniform embedding method LM-PMIME for multivariate time series.
In this study, the proposed LM-PMIME method, a causal analysis method, has great potential to be adopted in other applications, e.g. prediction of dynamic systems. We will further study the non-uniform embedding method and extend its applications.
Acknowledgement
Financial supports by National Natural Science Foundation of China (61603029), and the Fundamental Research Funds for the Central Universities (2018RC002) are gratefully acknowledge.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] García P, Mujica R. A local approach for information transfer[J]. Communications in Nonlinear Science and Numerical Simulation, 2019, 70: 326-333.
- 2[2] Granger C W J. Investigating causal relations by econometric models and cross-spectral methods[J]. Econometrica: Journal of the Econometric Society, 1969: 424-438.
- 3[3] Marko H. The bidirectional communication theory–a generalization of information theory[J]. IEEE Transactions on communications, 1973, 21(12): 1345-1351.
- 4[4] Schreiber T. Measuring information transfer[J]. Physical Review Letters, 2000, 85(2): 461.
- 5[5] Barnett L, Barrett A B, Seth A K. Granger causality and transfer entropy are equivalent for Gaussian variables[J]. Physical Review Letters, 2009, 103(23): 238701.
- 6[6] Schindlerova K. Equivalence of Granger Causality and Transfer Entropy: A Generalization[J]. Applied Mathematical Sciences, 2011, 5: 3637–3648.
- 7[7] Mao X, Shang P. Transfer entropy between multivariate time series[J]. Communications in Nonlinear Science and Numerical Simulation, 2017, 47: 338-347.
- 8[8] Montalto A, Stramaglia S, Faes L, et al. Neural networks with non-uniform embedding and explicit validation phase to assess Granger causality[J]. Neural Networks, 2015, 71: 159-171.