TL;DR
This paper introduces Reward Augmented Imitation Learning (RAIL), a novel approach that enhances multi-agent imitation learning to better capture emergent traffic behaviors in driving scenarios, with proven convergence guarantees.
Contribution
The paper proposes RAIL, integrating reward augmentation into multi-agent imitation learning, enabling better modeling of emergent behaviors while maintaining convergence guarantees.
Findings
RAIL improves the modeling of emergent traffic behaviors.
The method outperforms traditional imitation learning in local and emergent metrics.
Convergence guarantees are preserved with reward augmentation.
Abstract
Recent developments in multi-agent imitation learning have shown promising results for modeling the behavior of human drivers. However, it is challenging to capture emergent traffic behaviors that are observed in real-world datasets. Such behaviors arise due to the many local interactions between agents that are not commonly accounted for in imitation learning. This paper proposes Reward Augmented Imitation Learning (RAIL), which integrates reward augmentation into the multi-agent imitation learning framework and allows the designer to specify prior knowledge in a principled fashion. We prove that convergence guarantees for the imitation learning process are preserved under the application of reward augmentation. This method is validated in a driving scenario, where an entire traffic scene is controlled by driving policies learned using our proposed algorithm. Further, we demonstrate…
Click any figure to enlarge with its caption.
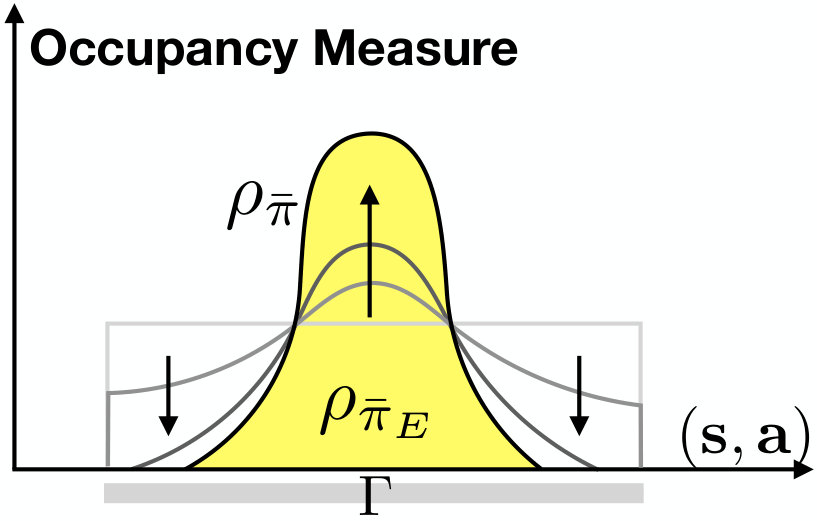 Figure 1
Figure 1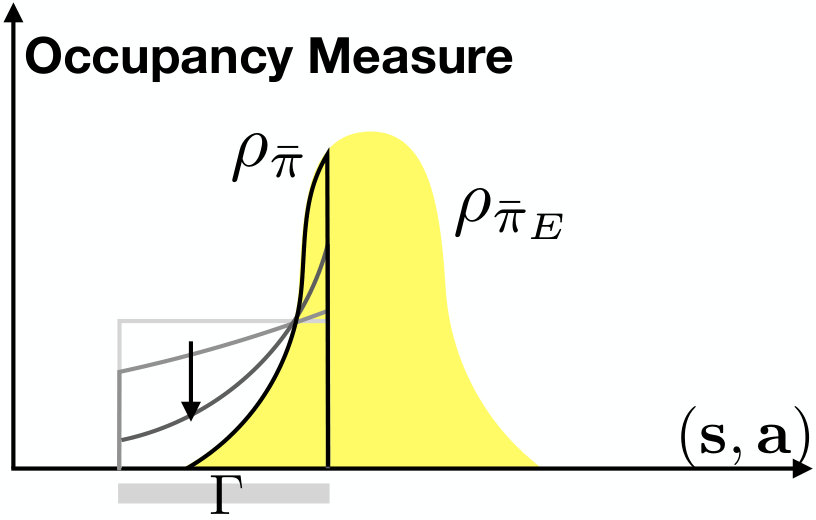 Figure 2
Figure 2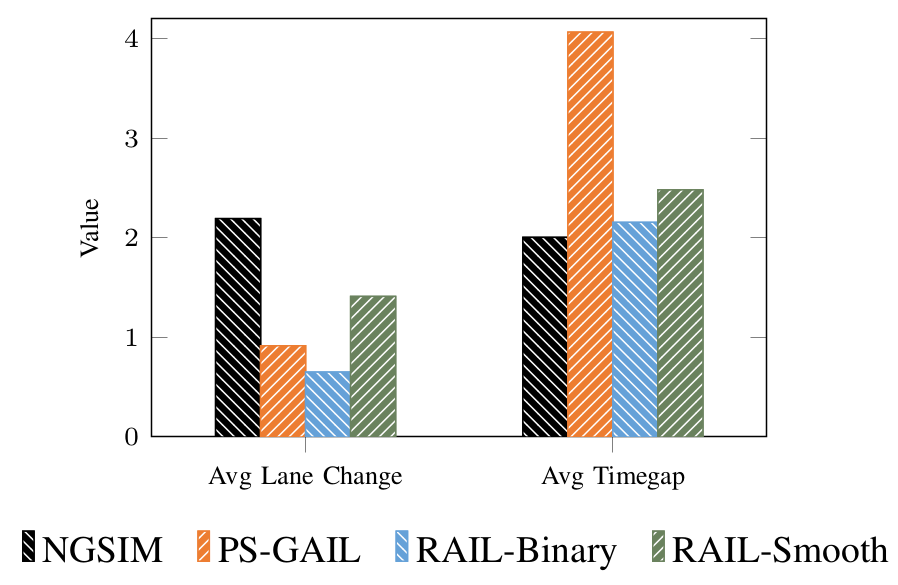 Figure 3
Figure 3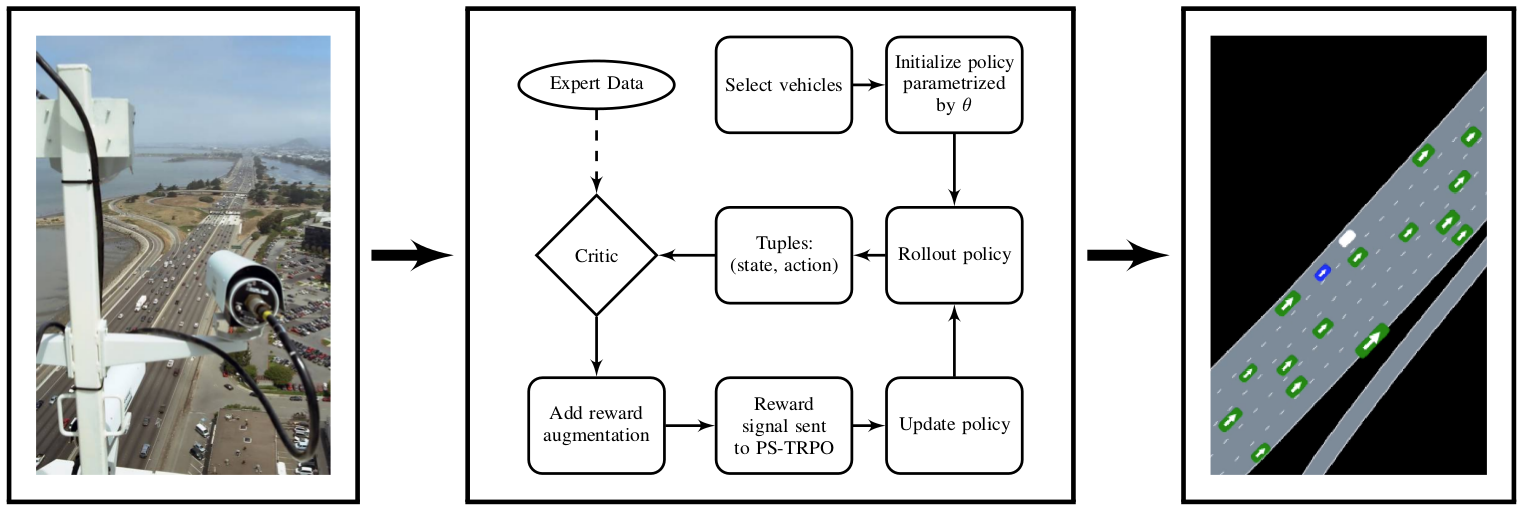 Figure 4
Figure 4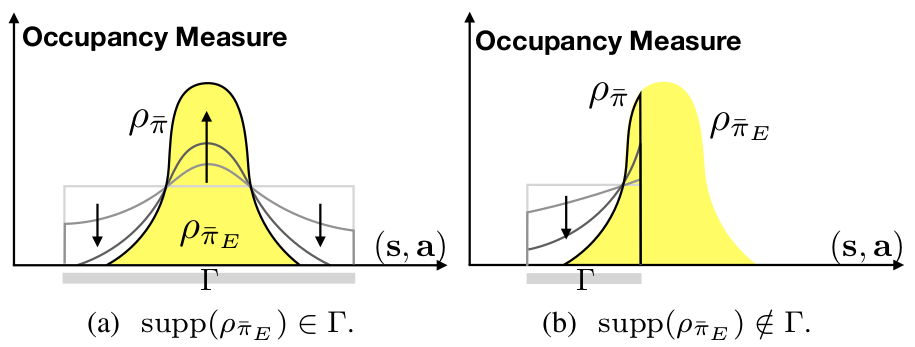 Figure 5
Figure 5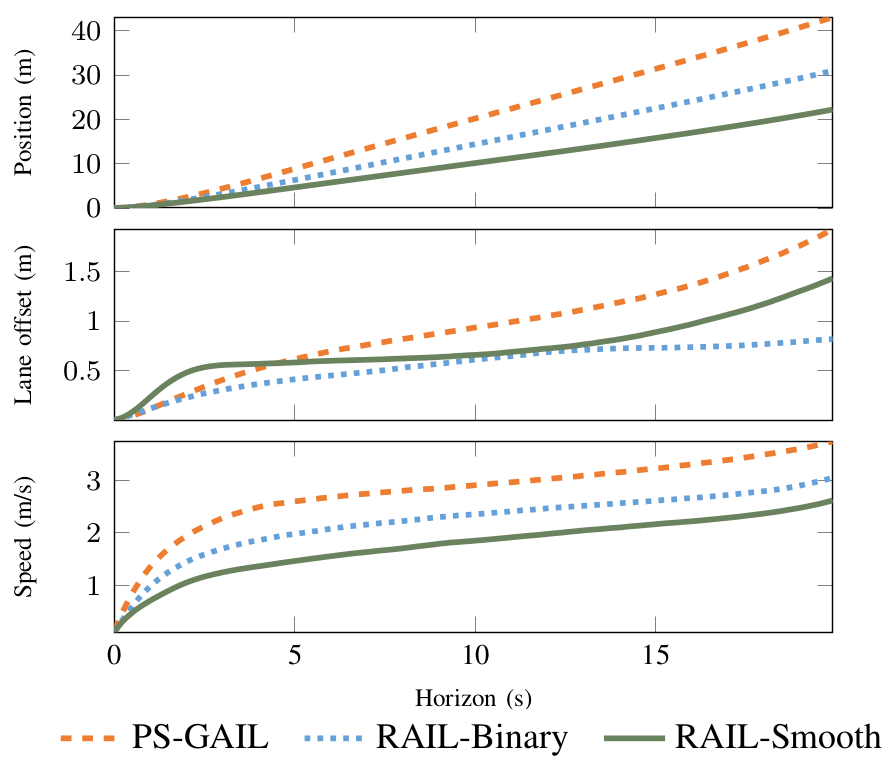 Figure 6
Figure 6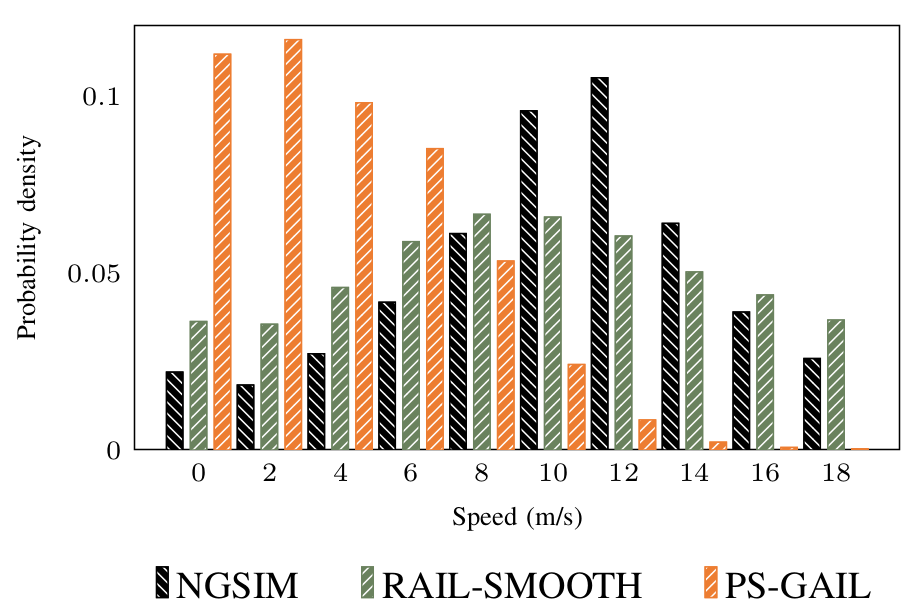 Figure 7
Figure 7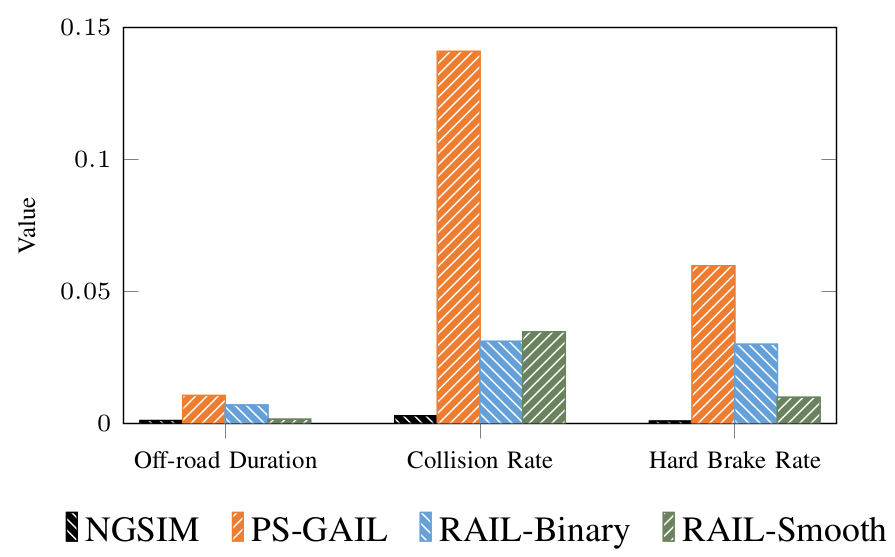 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Simulating Emergent Properties of Human Driving
Behavior
Using Multi-Agent Reward Augmented Imitation Learning
Raunak P. Bhattacharyya, Derek J. Phillips, Changliu Liu,
Jayesh K. Gupta, Katherine Driggs-Campbell, and Mykel J. Kochenderfer R. Bhattacharyya, D. Phillips, C. Liu, J.K. Gupta, and M.J. Kochenderfer are with the Stanford Intelligent Systems Laboratory in the Department of Aeronautics and Astronautics at Stanford University, Stanford, CA 94305, USA (email: {raunakbh, djp42, changliuliu, jayeshkg, mykel}@stanford.edu}). K. Driggs-Campbell is with the Department of Electrical and Computer Engineering at the University of Illinois at Urbana-Champaign, Urbana, IL 61801 (email: [email protected]).
Abstract
Recent developments in multi-agent imitation learning have shown promising results for modeling the behavior of human drivers. However, it is challenging to capture emergent traffic behaviors that are observed in real-world datasets. Such behaviors arise due to the many local interactions between agents that are not commonly accounted for in imitation learning. This paper proposes Reward Augmented Imitation Learning (RAIL), which integrates reward augmentation into the multi-agent imitation learning framework and allows the designer to specify prior knowledge in a principled fashion. We prove that convergence guarantees for the imitation learning process are preserved under the application of reward augmentation. This method is validated in a driving scenario, where an entire traffic scene is controlled by driving policies learned using our proposed algorithm. Further, we demonstrate improved performance in comparison to traditional imitation learning algorithms both in terms of the local actions of a single agent and the behavior of emergent properties in complex, multi-agent settings.
I Introduction
Robot learning from human demonstrations has been a subject of significant interest in recent years [1]. Imitation learning has been applied to vehicle navigation, humanoid robots, and computer games [2]. This paper focuses on imitation learning for building reliable human driver models.
The autonomous driving literature has established that it is infeasible to build a statistically significant case for the safety of a system solely through real-world testing [3, 4]. Validation through simulation is an alternative to real-world testing, with the ability to evaluate vehicle performance in large numbers of scenes quickly, safely, and economically [5]. This paper seeks to extend state of the art imitation learning to improve our ability to accurately generate realistic driving scenarios. In such safety critical settings, representative models of human driving behavior are essential in the validation of autonomous driving systems.
Human driving situations are inherently multi-agent in nature. Typical human driving scenes are composed of several vehicles that interact to exhibit emergent patterns of traffic behavior that cannot be easily predicted from the properties of the individual vehicles alone. For example, given two very similar initial scenes, the vehicles can reach very different configurations after just a few seconds because small changes in states can quickly compound into large differences in the resulting vehicle behaviors and motion pattern. Reliable human driver models must be capable of imitating these emergent properties of traffic behavior.
Generative Adversarial Imitation Learning (GAIL) [7] has recently been used to model human driving behavior. GAIL performs well when imitating the driving behavior in single agent settings [8], outperforming behavioral cloning and rule-based driver models (e.g., IDM+MOBIL [9]). However, GAIL does not scale to imitating the behavior of multiple human driven vehicles because the multi-agent setting leads to the problem of covariate-shift [10].
The PS-GAIL algorithm uses the framework provided by recent work extending GAIL to the multi-agent setting [11], borrowing ideas from the PS-TRPO algorithm [12]. PS-GAIL outperforms GAIL in terms of imitation performance and scalability in imitating multiple interacting human driven vehicles [10]. However, PS-GAIL has significant room for improvement in terms of imitation performance, specifically in terms of reducing undesirable traffic phenomena arising out of interactions between vehicles, such as off-road driving, collisions, and hard braking.
This paper modifies the GAIL approach to enable the use of external rewards in the multi-agent setting. The resulting algorithmic procedure improves imitation performance compared to PS-GAIL in three ways. First, it performs better at reproducing individual driving behaviors. Second, resulting policies exhibit reductions in undesirable traffic phenomena such as collisions and offroad driving. Third, emergent properties of multi-agent driving, such as lane changes and spacing between vehicles, are shown to approach human driving behavior.
While using shaped rewards in the context of imitation learning has been proposed previously [13, 14, 15, 16], this paper differs from the existing literature in two aspects. First, we propose directly considering the imitation learning problem in the multi-agent setting using parameter sharing. Second, this approach penalizes undesirable traffic phenomena through reward augmentation, and assesses the resulting impact on emergent properties of multi-agent driving behavior.
This paper makes the following contributions: (1) We propose a mathematical formulation for incorporating metrics of undesirable traffic phenomena as constraints in the problem of finding policies through imitation learning; (2) We provide a framework for the designer of the imitation learning agent to provide prior knowledge in the form of reward augmentation to help the learning process; and (3) We demonstrate the RAIL algorithm in a case study of modeling human driving behavior and compare the imitation performance against results from existing algorithms.
The link to the github repository containing the source code for the experiments can be found at https://github.com/sisl/ngsim_env.
II Problem Definition
We consider the problem of imitation learning in a multi-agent setting. The objective is to improve imitation performance by expanding the scope of the imitation algorithm to include imitation of emergent properties. We hypothesize that by imitating both the local and emergent behaviors, the resulting policy will improve our ability to mimic human behaviors in a multi-agent setting.
II-A Formulation
We formulate highway driving as a sequential decision making task, in which the driver obeys a stochastic policy that maps observed road conditions to a probability distribution over driving actions [17, 18]. Given a dataset consisting of a sequence of state-action tuples demonstrating highway driving and a class of policies parameterized by , we adopt imitation learning to infer this policy.
We use the multi-agent extension of Markov decision processes adapted to the imitation learning framework [11, 19]. Suppose there are agents. The state, action, and policy of agent are denoted , , and , respectively. The state, action, and policy of the multi-agent system are denoted , , and . The state space and the action space of the multi-agent system are denoted and , respectively. In the remainder of this paper, we use and without the subscripts to refer to the single agent scenario. We make some simplifying assumptions to the general Markov Games framework, which include agents being homogeneous (every agent has the same action and observation space), each agent getting independent rewards (as opposed to there being a joint reward function), and the reward function being the same for all the agents, as motivated in [10].
We define the -discounted state occupancy measure of a policy by , where is the probability of landing in state at time , when following starting from . When convenient, we will overload notation for state-action occupancy measure: , where is the probability of executing action in state . We denote the support of the occupancy measure as where .
Consider a multi-agent policy , which maps the multi-agent system state in to a distribution over the multi-agent action space . Given the demonstrated data , we need to ensure that the greatest difference between and is small. The difference is measured between the demonstrated trajectory and the roll-out trajectory given in a finite time horizon. Using the GAIL framework, our goal is to minimize the distance between the occupancy measures and . Further, to ensure centralized training with decentralized control, and to provide prior knowledge, we introduce parameter sharing [12] and reward augmentation [20].
Mathematically, introducing parameter-sharing and reward augmentation poses two constraints on the function space of the policy . For parameter-sharing, we are enforcing that for any and , where denotes the policy for single agent. Hence, . For reward augmentation, we require that belongs to a certain set such that undesired actions are discouraged. For example, the vehicle should not drive off road, collide with others, or brake too hard. Such undesired state-action pairs are denoted as belonging to the set . The constraint on the policy is denoted by :
[TABLE]
Considering Wasserstein distance [21], the following constrained minimax problem for imitation learning is formulated:
[TABLE]
where the critic, , learns to output a high score when encountering pairs from , and a low score when encountering pairs from . should be optimized for all functions.
II-B Solution Approach
The constrained minimax is solved by transforming the problem to an unconstrained form. The constraint for parameter sharing is naturally encoded by sharing the same policy for all agents. The constraint for reward augmentation is enforced by adding a reward augmentation regularizer in the function. Thus, the unconstrained problem becomes:
[TABLE]
where is the penalty, and is an indicator function that is non-zero if and only if . The penalty can either be a constant value or a barrier function. We have binary penalty when is constant, and smooth penalty when is a continuous function that reaches zero on the boundary of the set . Note that the term \mathbb{E}_{\pi}\mathopen{}\mathclose{{}\left[D(\mathbf{s},\mathbf{a})}\right] is different from \mathbb{E}_{\bar{\pi}}\mathopen{}\mathclose{{}\left[D(\mathbf{s},\mathbf{a})}\right], where the former notation requires that all agents use the same policy with shared parameters.
We are now ready to introduce an algorithm to solve the problem as formulated above. This algorithm is called Reward Augmented Imitation Learning (RAIL, cf. Risk Averse Imitation Learning [22]). We parameterize the single agent policy using and the critic using . The parameterized policy and critic are denoted by and , respectively. Under this parametrization, the objective function becomes:
[TABLE]
To solve for the desired , the following two steps are performed iteratively:
Step 1: maximize . Similar to single agent GAIL, this step involves the rollout and the update of the critic .
Step 2: minimize policy . This step is where the constraints are taken into account.
Algorithm 1 provides the pseudo code that enacts the above two step procedure and incorporates the reward augmentation by providing penalties.
II-C Theoretical Analysis: Convergence and Optimality
This section shows the convergence and optimality of the constrained minimax problem using non-parameterized policy and critic. In the following discussion, the occupancy measure refers to the state-action occupancy measure. Given the occupancy measure , we have
[TABLE]
where and are rollout data from the policy . By Proposition 3.1 of [7], there is a one-to-one correspondence between the policy and the occupancy measure .
The minimax objective function (2) can be re-written as
[TABLE]
where is the constraint on the occupancy measure equivalent to (1) with
[TABLE]
and is a marginal occupancy measure by integrating out for in .
Theorem II.1
The solution converges in measure by iteratively solving the minimax problem (6) if the following conditions hold:111In practice, these assumptions may not exactly hold.
* and have enough capacity (representing all functions);* 2. 2.
* attains the optimal value at each iteration;* 3. 3.
* is updated so as to improve the criterion .*
Moreover, the solution converges in measure to the optimal solution of the following problem:
[TABLE]
Proof:
If (6) is unconstrained, i.e., is the whole occupancy measure space, [24] and [21] have shown that the solution converges by iteratively solving the unconstrained minimax problem if the three conditions hold.
Consider the constrained version of the optimization. Since both the objective function (6) and the constraint (7) are convex in , the constraints will not affect convergence, as long as the three conditions are satisfied.222We are dealing with the function space which contains . The convexity means: for any and satisfying (7), their linear interpolation also satisfy (7) for any . It is easy to verify that this condition is true for any , i.e., if and are [math] on , then should also be [math] on . Hence, the convexity of the constraint is not affected by the shape of . The solution of the inner maximization in (6) is . Then, in the limit, the problem
[TABLE]
converges to (8) in measure. ∎
According to Theorem II.1, if the demonstrated data satisfy the constraint , then in the limit. Consider the case that the demonstrated data does not satisfy . The constraint for parameter sharing introduces an averaging effect, i.e., the learned single agent policy is an average of the demonstrated single agent policy for all . The demonstrated single agent policy is a marginal occupancy measure by integrating out for in . The average effect results from identity permutation during minimization of the two norm in (8). The constraint for reward augmentation introduces a truncation effect, which shrinks the support of such that . The truncation effect is illustrated in Fig. 2.
Normally, the constraint from reward augmentation is satisfied in the demonstration data. For example, the vehicles do not drive off the road. However, the constraint from parameter sharing may not be satisfied by the demonstrated data, i.e., the assumption that all vehicles are homogeneous may not hold. Then, as discussed above, the learned policy takes an average over different policies. Therefore, reward augmentation improves the learning performance in practice, since it encodes prior knowledge.
III Experiments and Results
We use the results from PS-GAIL as a baseline to compare against the RAIL algorithm by learning policies and calculating specific metrics, as described in Section III-C. We train three policies for each set of parameters that we want to compare, selecting the best performing policy based on the results of policy rollouts in the -agent training environment. The results presented in Section III-D are extracted by evaluating our policies in the same manner, but on scenes sampled from the held-out testing dataset.
III-A Environment
We evaluate our algorithm using the same simulator as is used in the development of PS-GAIL [10]. The simulator allows us to sample initial scenes from real traffic data and then simulate for at . The most important feature of this simulator is that expert vehicles observed in the real data can be replaced with policy controlled agents, crucial to both learning a good policy and evaluating final policies. We replace vehicles from the initial scene with vehicles driven by the learned policy. Another crucial component of the simulator is the extraction of features from the environment which are then fed into the policy controller as observations. The agent’s decisions are translated into actions, which the simulator uses to determine the next state.
We run our experiments on data from the Next Generation Simulation (NGSIM) project [6]. This dataset is split into three consecutive sections of driving data for a fixed section of highway 101 in California. We use the first section as the training dataset, from which we learn our policies. The remaining two sections are used for testing and evaluating the quality of the resulting policies.
III-B Reward Augmentation
Reward augmentation combines imitation learning with reinforcement learning and helps improve state space exploration of the learning agent. Part of the reinforcement learning reward signal comes from the critic based on imitating the expert, and another signal comes from the externally provided reward specifying the prior knowledge of the expert [13].
The reward augmentation in our experiments is provided in the form of penalties.
III-B1 Binary Penalty
The first method of reward augmentation that we employ is to penalize states in a binary manner, where the penalty is applied when a particular event is triggered. To calculate the augmented reward, we take the maximum of the individual penalty values. For example, if a vehicle is driving off the road and colliding with another vehicle, we only penalize the collision. This will also be important when we discuss smoothed penalties.
We explore penalizing three different behaviors. First, we give a large penalty to each vehicle involved in a collision. Next, we impose the same large penalty for a vehicle that drives off the road. Finally, performing a hard brake (acceleration of less than ) is penalized by only . The penalty formula is shown in Eq. 10. We denote the smallest distance from the ego vehicle to any other vehicle on the road as (meters), where . We also define the closest distance from the ego vehicle to the edge of the road (meters): . We allow to be negative if the vehicle is off the road. Finally, let be the acceleration of the vehicle, in . A negative value of indicates that the vehicle is braking. Now, we can formally define the binary penalty function:
[TABLE]
The relative values of the penalties indicate the preferences of the designer of the imitation learning agent. For example, in this case study, we penalize hard braking less than the other undesirable traffic phenomena.
III-B2 Smooth Penalty
In this case, we provide a smooth penalty for off-road driving and hard braking, where the penalty is linearly increased from a minimum threshold to the previously defined event threshold for the binary penalty.
For off-road driving, we linearly increase the penalty from [math] to when the vehicle is within of the edge of the road. For hard braking, we linearly increase the penalty from [math] to for acceleration between and .
III-C Metrics
We assess the imitation performance of our driving policies at three levels. These are imitation of local driving behavior, reduction of undesirable traffic phenomena, and imitation of emergent properties of multi-agent driving. First, to measure imitation of local vehicle behaviors, we use a set of Root Mean Square Error (RMSE) metrics that quantify the divergence between the trajectories generated by our learned policies and the real trajectories in the dataset. We calculate the RMSE between the original human driven vehicle and its replacement policy driven vehice in terms of the position, lane offset, and speed. A perfect policy would have RMSE values close to [math] for the entire rollout duration.
Second, to assess the undesirable traffic phenomena that arise out of vehicular interactions as compared to local, single vehicle imitation, we extract metrics that quantify hard braking, collisions, and offroad driving. It is important to note that these undesirable traffic phenomena were explicitly incorporated into the formulation of penalty based reward augmentation provided to the RAIL algorithm. We also extract these metrics of undesirable traffic phenomena for the NGSIM driving data and compare them against the metrics obtained from rollouts generated by our driving policies.
Third, to quantify imitation of driving properties that are emergent in that they are not explicitly modeled in the RAIL formulation, we assess metrics of emergent properties. These are the average number of lane changes per vehicle, the average timegap per vehicle, and the distribution of speed over all vehicles. The timegap for a vehicle is defined as the time spacing (in seconds) to the vehicle in front of it. These metrics of emergent driving properties are calculated for the NGSIM driving data and compared against metrics obtained from rollouts generated by our driving policies.
III-D Results
We compare our proposed algorithm, RAIL, against PS-GAIL. For comparisons between PS-GAIL, traditional GAIL, and rule-based models, we guide the reader to [8, 10]. The policies generated using RAIL were obtained using for the binary penalty, and for the smoothed penalties. These values were determined to be the best after performing a hyperparameter search on penalty values ranging from [math] and .
Figure 3 shows the RMSE values for speed, lane offset and position of the vehicle driven by imitation learned policies varying with increasing time horizon of the simulation rollout. Policies learned using RAIL show lower values of RMSE as compared to PS-GAIL throughout the rollout duration. Further, between the two RAIL policies, it is observed that smoothing the penalties improves the RMSE performance. Thus, RAIL outperforms PS-GAIL in imitating local driving behavior of individual vehicles.
Figure 4 illustrates the number of undesirable traffic phenomena through the metrics of collisions, hard braking, and offroad driving in case of NGSIM data, and policies trained using PS-GAIL and RAIL. The results show that policies learned using RAIL are less likely to lead vehicles into extreme decelerations, off-road driving, and collisions. Additionally, for the case where we provide smooth penalties (off-road duration and hard brake), we see significant reductions in the associated metrics as compared to PS-GAIL.
Figures 5 and 6 show the imitation performance of policies in terms of emergent properties of driving behavior. Average number of lane changes per agent, and average timegap per agent are illustrated in Fig. 5. While it can be argued that the results showing improvements in reducing undesirable traffic phenomena in Fig. 4 can be attributed directly to penalizing via reward augmentation, the properties of driving reported in Fig. 5 are truly emergent in that they arise out of vehicular interactions that are not explicitly accounted for in the imitation learning formulation. Policies trained using reward augmentation result in driving behavior that leads to emergent properties that are closer to human demonstrations as compared to the baseline policies trained using PS-GAIL.
The distribution of speeds over all the vehicles in the trajectory is shown in Fig. 6. The speed values over the trajectory have been normalized and presented as a probability distribution. Policies trained using reward augmentation provide speed distributions more closely matching the NGSIM data. Further, the mode of the distribution is closer to human demonstrations in case of RAIL.
IV Conclusions
This paper discusses the problem of imitation learning in multi-agent settings in the context of autonomous driving. The goal of this paper is to create reliable models of human driving behavior that can imitate emergent properties of driving behavior arising out of local vehicular interactions. Specifically, we provide a framework for multi-agent imitation learning in terms of policy optimization with added constraints using GAIL. We demonstrate improved performance in learning human driving behavior models as measured by both local and emergent imitation performance. The main contribution of this paper was including reward augmentation in the imitation learning framework as an added reinforcement signal to the learning agent. Using externally specified rewards, the designer of the learning agent can provide prior knowledge to guide the training process. This imitation learning procedure was demonstrated using the RAIL algorithm.
Simulation experiments were performed on learned driving policies from human driving demonstrations in the NGSIM dataset. These experiments were performed in the multi-agent setting where multiple cars in the NGSIM scenes were replaced by the vehicles driven using polcies learned using RAIL. Resulting metrics such as root mean square error, off-road duration, collision rates and hard brake rate were used to assess the imitation performance. The results obtained showed better imitation performance using reward augmentation as compared to previous multi-agent results, especially in terms of imitating emergent properties of driving behavior, as measured by lane changes, timegap and speed distributions of the resulting driving behavior. Further, this paper also provided theoretical convergence guarantees in the reward augmented imitation learning framework.
A limitation of this approach is that it does not capture different types of driving behavior. Future work will include latent states to capture different driving styles and enable learning different policies for different agents. Another interesting extension of this work would focus on populating driving scenarios with these models trained using imitation learning. Such scenarios will enable validation of autonomous cars driven using planning algorithms by simulating interactive driving behavior between autonomous vehicles and human driven vehicles. Finally, policies trained using the RAIL algorithm will be deployed in simulation with an autonomous vehicle for validation testing.
Acknowledgments
We thank Blake Wulfe and Jeremy Morton for useful discussions. Toyota Research Institute (TRI) provided funds to assist the authors with their research, but this article solely reflects the opinions and conclusions of its authors and not TRI or any other Toyota entity.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] B. D. Argall, S. Chernova, M. Veloso, and B. Browning, “A survey of robot learning from demonstration,” Robotics and Autonomous Systems , vol. 57, no. 5, pp. 469–483, 2009.
- 2[2] A. Hussein, M. M. Gaber, E. Elyan, and C. Jayne, “Imitation learning: A survey of learning methods,” ACM Computing Surveys (CSUR) , vol. 50, no. 2, pp. 1–35, 2017.
- 3[3] ISO, “ISO 26262: Road vehicles-functional safety,” International Standard ISO/FDIS , 2011.
- 4[4] P. Koopman and M. Wagner, “Challenges in autonomous vehicle testing and validation,” SAE International Journal of Transportation Safety , vol. 4, no. 1, pp. 15–24, 2016.
- 5[5] J. Morton, T. Wheeler, and M. J. Kochenderfer, “Closed-loop policies for operational tests of safety-critical systems,” IEEE Transactions on Intelligent Transportation Systems , pp. 317–328, 2018.
- 6[6] J. Colyar and J. Halkias, “US highway 101 dataset, Tech. Rep. FHWA-HRT-07-030, Jan. 2007.
- 7[7] J. Ho and S. Ermon, “Generative adversarial imitation learning,” in Advances in Neural Information Processing Systems (NIPS) , 2016, pp. 4565–4573.
- 8[8] A. Kuefler, J. Morton, T. A. Wheeler, and M. J. Kochenderfer, “Imitating driver behavior with generative adversarial networks,” in IEEE Intelligent Vehicles Symposium (IV) , 2017, pp. 204–211.
