Unsupervised Learning Eigenstate Phases of Matter
Steven Durr, Sudip Chakravarty

TL;DR
This paper demonstrates that unsupervised clustering algorithms can effectively identify eigenstate phases of matter in the transverse-field Ising model without prior knowledge or labeled data, matching results from supervised methods.
Contribution
The study introduces an unsupervised learning approach for phase identification that requires no assumptions about the number of phases or labeled training data.
Findings
Unsupervised clustering accurately identifies phases of matter.
Results agree with supervised learning methods.
Method requires no prior phase information.
Abstract
Supervised Learning has been successfully used to produce phase diagrams and identify phase boundaries when local order parameters are unavailable. Here, we apply unsupervised learning to this task. By using readily available clustering algorithms, we are able to extract the distinct eigenstate phases of matter within the transverse-field Ising model in the presence of interactions and disorder. We compare our results to those found through supervised learning and observe remarkable agreement. However, as opposed to the supervised procedure, our method requires no strict assumptions concerning the number of phases present, no labeled training data, and no prior knowledge of the phase diagram. We conclude with a discussion of clustering and its limits.
Click any figure to enlarge with its caption.
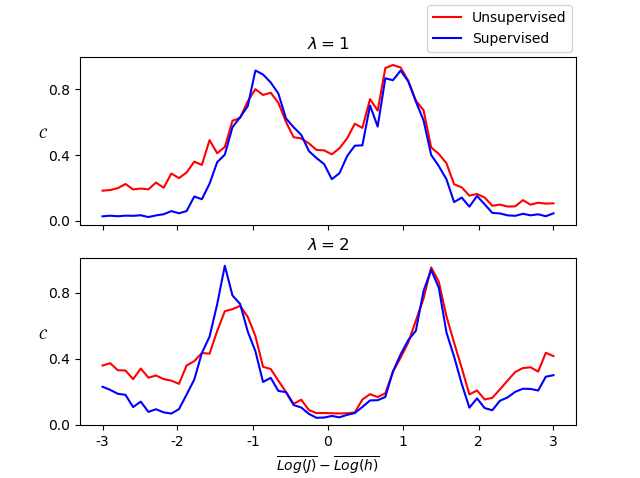 Figure 1
Figure 1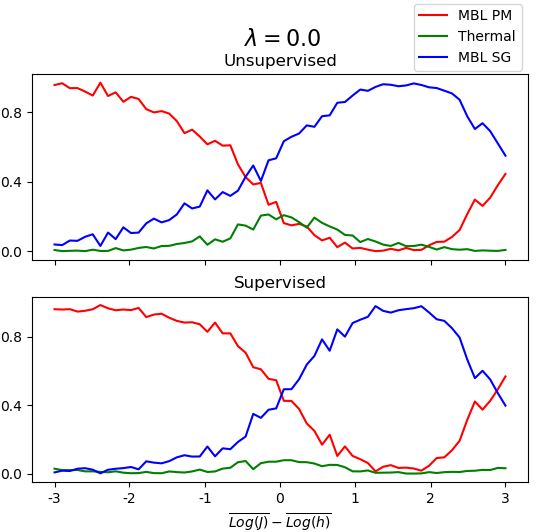 Figure 2
Figure 2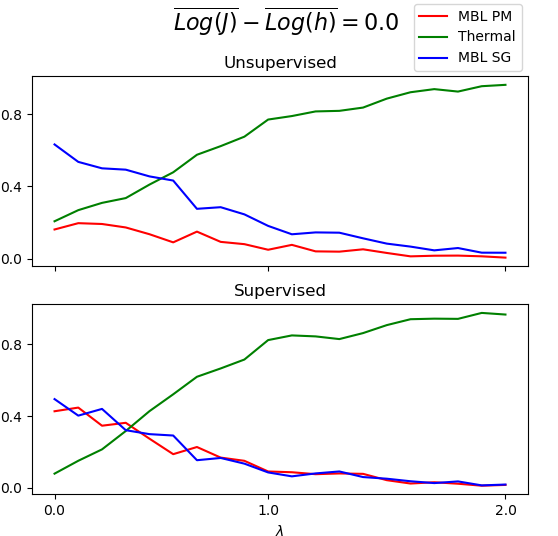 Figure 3
Figure 3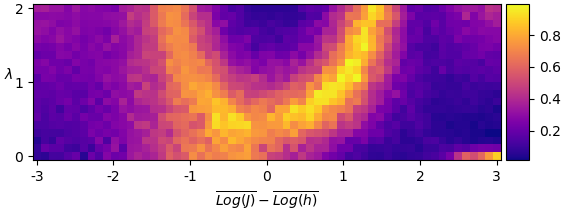 Figure 4
Figure 4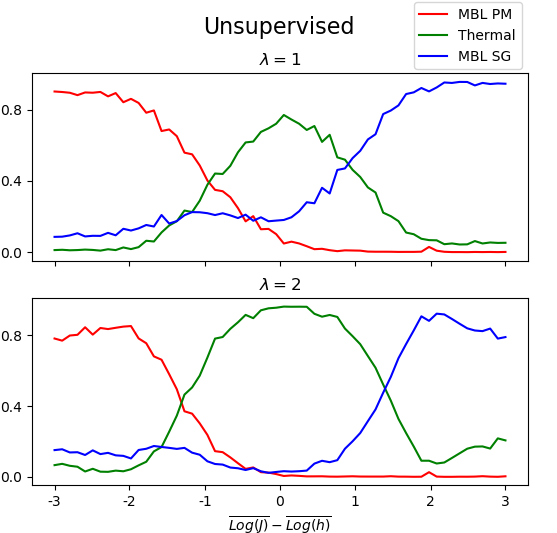 Figure 5
Figure 5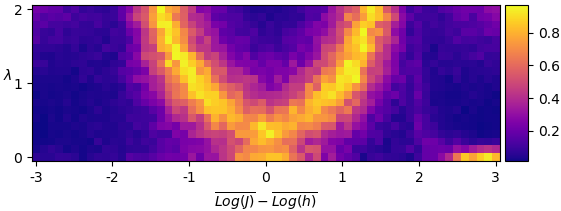 Figure 6
Figure 6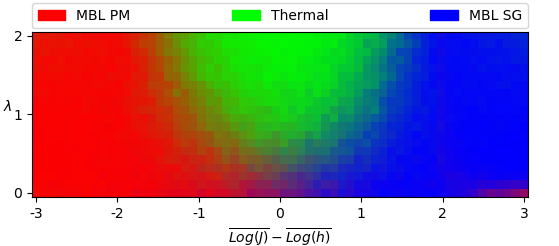 Figure 7
Figure 7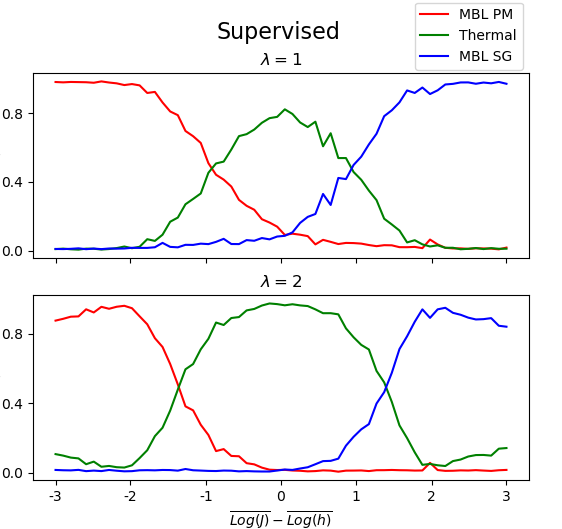 Figure 8
Figure 8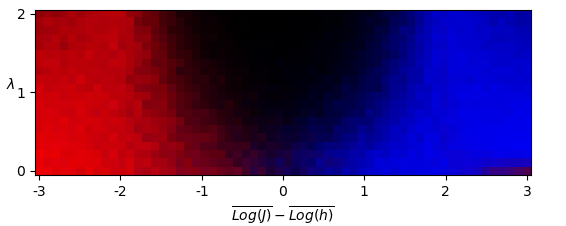 Figure 9
Figure 9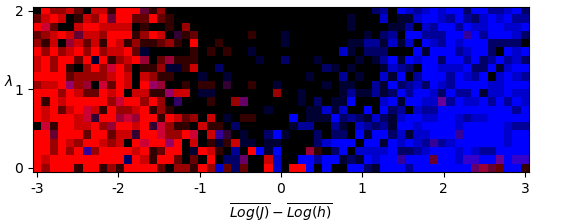 Figure 10
Figure 10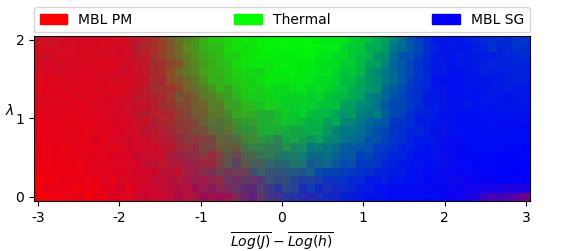 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Unsupervised Learning Eigenstate Phases of Matter
Steven Durr
Sudip Chakravarty
Mani L Bhaumik Institute for Theoretical Physics
Department of Physics and Astronomy, University of California Los Angeles, Los Angeles, California 90095, USA
Abstract
Supervised Learning has been successfully used to produce phase diagrams and identify phase boundaries when local order parameters are unavailable. Here, we apply unsupervised learning to this task. By using readily available clustering algorithms, we are able to extract the distinct eigenstate phases of matter within the transverse-field Ising model in the presence of interactions and disorder. We compare our results to those found through supervised learning and observe remarkable agreement. However, as opposed to the supervised procedure, our method requires no strict assumptions concerning the number of phases present, no labeled training data, and no prior knowledge of the phase diagram. We conclude with a discussion of clustering and its limits.
††preprint: APS/123-QED
I Introduction
Recently, machine learning has been applied to the task of identifying phases of matter – particularly in scenarios in which local order parameters are not available Venderley et al. (2018); Jönsson (2018); Carrasquilla and Melko (2017); Schindler et al. (2017); Wetzel (2017); Araki et al. (2019); Rodriguez-Nieva and Scheurer (2018); Casert et al. (2019); Jadrich et al. (2018); Wang (2016); Wetzel and Scherzer (2017); Broecker et al. (2017a, b); Zhang and Kim (2017); Carleo and Troyer (2017); Liu and van Nieuwenburg (2018); Zhang et al. (2017); Ohtsuki and Ohtsuki (2017); van Nieuwenburg et al. (2017); Hu et al. (2017); Huembeli et al. (2018). Approaches have largely focused on the application of supervised learning. Using this technique, data is sampled from points in parameter space known to belong to a certain phase. Some function (often a neural network) is then trained to predict the phase given input data. If the function is able to effectively generalize, it is then possible to apply it to data coming from points across the parameter space. This allows one to produce a phase diagram, and gain insight into the underlying physics.
Techniques from unsupervised learning have also been shown to be effective at identifying phases Wetzel (2017); Rodriguez-Nieva and Scheurer (2018); Jadrich et al. (2018); Wang (2016); Wetzel and Scherzer (2017); Broecker et al. (2017a); Casert et al. (2019); Hu et al. (2017); Huembeli et al. (2018). When applied to the 2D Ising model, for instance, tools such as autoencoders have been able to extract a local order parameter Wang (2016); Hu et al. (2017). In addition, clustering techniques have been used to accurately distinguish spin data known to correspond to distinct topological sectors Rodriguez-Nieva and Scheurer (2018).
Here, we expand on work applying unsupervised learning towards identifying phases. Using readily available clustering algorithms, we explore the parameter space of a system known to display many-body localization and eigenstate phase transitions. In particular, the problem we study has been effectively treated using supervised learning Venderley et al. (2018); Jönsson (2018), which, when compared to conventional techniques, was able to predict the sharpest phase boundary to date Venderley et al. (2018).
We therefore use this supervised approach as a starting point from which to compare our unsupervised method, and find that we are able to produce highly similar results. Notably, our method relies on no separate training data, no prior knowledge of the phase space, and even no explicit assumption of the number of phases present.
We conclude with a discussion of what can be learned from this success, as well as the role and usefulness of machine learning algorithms for the task of identifying phases.
II Clustering Many-Body Localized Phases
Generally, an isolated interacting quantum system is said to display many-body localization (MBL) if it fails to thermalize under its own unitary time evolution. On the other hand, a quantum system is said to be thermal if it is able to serve as its own heat bath. Different MBL phases exist, displaying different symmetries and topological order. The transition of a state among these thermal and MBL phases represents a dynamic eigenstate phase transition – for which an extensive theoretical description does not currently exist.
Here we use clustering algorithms to analyze eigenstate phase transitions within the transverse-field Ising model in the presence of interactions and disorder:
[TABLE]
Above, are the Pauli matrices and and are log-normal distributions with respective means and , and the standard deviations of their logarithms equal to . We use open boundary conditions and a length spin chain.
The limits of this model have been studied, and are known to exhibit different eigenstate phases Huse et al. (2013); Pekker et al. (2014); Kjäll et al. (2014); Fisher (1995). In particular, for , the system is expected to exhibit a many-body localized paramagnetic phase (MBL PM). In this limit, MBL PM eigenstates roughely correspond to product states in the basis (e.g. ). In the opposite limit of the system is expected to be in a many-body localized spin-glass phase (MBL SG). Here, states resemble global superpositions of spins in the basis with frozen domain walls (e.g. ). In the limit of the system is expected to be in a thermal phase. In addition, the model is self dual about . Therefore, up to the effects of finite size and open boundary conditions, we should observe symmetry about this point in the phase diagram.
Supervised learning has been used to study this model Venderley et al. (2018); Jönsson (2018) and determine phase boundaries with more precision. In Venderley et al. (2018), the authors demonstrate that supervised learning can accurately identify phase boundaries with a high degree of clarity. Therefore, to evaluate the success of our analysis, we will compare our results to those found through the use of supervised learning following the procedure of Venderley et al. (2018).
II.1 Producing Data
We vary two parameters: and , and obtain data for a grid of points in parameter space where and Venderley et al. (2018). At each point, we obtain the Hamiltonian and find its eigenvectors 111We exclude the highest and lowest 10% of the eigenvectors to reduce potential deviation from the trend of a given phase. For each eigenvector, , we can calculate the reduced density matrix as follows:
We consider the system to be split into two parts: region A containing the middle spins, and region B containing the outer . We then trace over the states of B to obtain the reduced density matrix:
[TABLE]
The of the eigenvalues of would give us the entanglement spectrum – known to carry information concerning many body localization Geraedts et al. (2016); Pal and Huse (2010); Bauer and Nayak (2013). The eigenvalues of themselves are probabilities, giving us a vector in dimensions with elements summing to .
There exist established distance metrics motivated by information theory for expressing the similarity of two probability distributions. For this reason, combined with the additional benefit of having the data live in a compact region, we use the probability vectors corresponding to the eigenvalues of the reduced density matrix as our data for clustering. We take our distance metric between two probability vectors to be the Jensen-Shannon distance Endres and Schindelin (2003), which is a bounded metric expressing similarity between probability distributions.
Therefore, for each disorder realization and each point in parameter space, we calculate an array of lists containing reduced density matrix eigenvalues (one list of eigenvalues for each eigenvector). Here we generate disorder realizations and evaluate Hamiltonians at points in parameter space.
II.2 Clustering Data
We collect samples of our data, each with elements taken at each of the positions in parameter space ( elements per sampling).
As a first step, we apply the HDBSCAN clustering algorithm McInnes et al. (2017) (Hierarchical Density-Based Spatial Clustering of Applications with Noise) to run an exploratory analysis and identify structure within the data set. HDBSCAN is ideal for exploratory clustering due to its lack of hard assumptions about the data. In particular, it does not assume clusters to be convex, nor does it assume a set number of clusters to search for. A more complete discussion of HDBSCAN can be found in the appendix.
We next set HDBSCAN’s two main parameters. We set the minimum cluster size (min_cluster_size) by using a rough prior concerning the size of the smallest cluster we expect to see. This clearly varies based on application. Here we specify that we are interested in finding clusters which comprise at least of the total data set. This gives us a minimum cluster size of elements.
A suitable value for the min_samples parameter can be set by evaluating the density-based validation score Moulavi et al. across a range. The value of min_samples, however, is observed to have little effect on the clustering. By identifying cluster labels with their phase space positions, we may then obtain a corresponding phase diagram (Fig. 1).
By examination, we can see that there are two observed clusters which may be ordered by their average value. We then apply HDBSCAN to all samples, and note that in over of samples, two such clusters were formed – the remaining forming only a single cluster. We discard these, identify clusters by their weighted order, and average over samples to obtain a phase diagram (Fig. 2).
By inspection, we can identify three regions of the phase diagram: two to the left and right identified as clusters, and a third in the center considered noise.
HDBSCAN does not attempt to allocate every element into a cluster. Rather, it assumes that data sets may contain sparse noise not belonging to any particular cluster. Here, we can see that the data HDBSCAN considers noise may instead form a third, more sparse cluster.
To investigate this, we apply an algorithm known as spectral clustering Pedregosa et al. (2011) (discussed in more detail in the appendix). While still not assuming convexity of clusters, spectral clustering allows us to include assumptions about the number of clusters to form within the data. We repeat the above procedure, taking the number of clusters to form to be , and again using Jensen-Shannon distance. Averaging over samples, we obtain a total phase diagram (Fig. 3).
III Analysis of Results
We see that the sparse data considered noise by HDBSCAN was successfully identified as a third cluster. Physically, we do expect three phases to be present: two clusters corresponding to a many-body localized paramagnetic phase and a many-body localized spin-glass phase (referred to as MBL PM and MBL SG, respectively), and one cluster corresponding to a thermal phase which conforms to the eigenstate thermalization hypothesis.
Up to the effects of finite system size and open boundary conditions, we expect our phase diagram to be symmetric under , and for the phases to exist in the general regions identified within the phase diagram. Therefore, we appear to have formed clusters corresponding to each of these predicted phases.
III.1 Comparison to Supervised Learning
Following the procedure outlined in Venderley et al. (2018) and using the framework of TensorFlow Abadi et al. (2015), we produce a phase diagram for the system by applying a trained neural network to our data. We can then compare this to the phase diagram found through unsupervised learning.
We train a neural network on a set of simulated data emanating from three points in , space:
[TABLE]
These correspond to the MBL SG, MBL PM, and Thermal phases, respectively. After training, we apply the neural network to data from across the parameter space and use the resulting phase predictions to produce a phase diagram (Fig. 4).
To measure uncertainty in a phase assignment, in Venderley et al. (2018) the authors define a quantity . If each point on the final phase diagram has a corresponding probability vector, , then is defined as . Here , and Q is the set of points of extremal phase uncertainty: , , , and . is then the value of normalized by its maximum possible value.
We calculate this measure for both the unsupervised (Fig. 5) and the supervised (Fig. 6) approaches, and compare the two.
Qualitatively, the two diagrams are similar. We examine this agreement by taking slices of at constant . Again, we find agreement at both and (Fig. 7). Note, however, that the supervised method produces consistently lower values of away from phase transitions.
We also observe agreement at , where both methods observe the same asymmetry at = 3, present potentially due to open boundary conditions and finite-size effects (Fig. 11).
IV Discussion
Here, we have outlined an unsupervised method to study the phase space of a system demonstrating MBL transitions. Our method applies readily available clustering algorithms to segment phase space into three regions. Specifically, we apply HDBSCAN and spectral clustering to the eigenvalues of reduced density matrices, using Jensen-Shannon distance as a metric for clustering.
When compared to the corresponding result obtained through supervised learning, we find remarkable agreement between the phase boundaries that both methods predict. Both techniques are able to produce these meaningful results using small data sets. Here we relied on a set of only disorder realizations. Our method, however, requires no strict assumptions about the number of clusters present, no labeled training data, and no prior knowledge of the phase diagram.
In the case of supervised learning applied to eigenstate phases, it is not readily apparent which features are being extracted from the data that would indicate the presence of a particular phase. Therefore, this is a black box method – an issue present in many applications of machine learning. In our use of clustering, the same problem exists.
When applying a clustering algorithm, data is segmented into groups according to each algorithm’s implicit conception of what a cluster comprises. Moreover, there does not exist – and cannot exist Kleinberg (2003) – a satisfying universal axiomatic approach to define the goals of clustering. Rather, trade-offs between different clustering criteria are intrinsic. These trade-offs can be seen in practice. Clustering algorithms often fail to perform when the ideal clusters are of very different sizes, different densities, and different shapes. Algorithms which perform well in one of these situations may fail in another.
Choosing a function to express the similarity between two elements (i.e. a distance function) also often relies on heuristics. Distance functions can be chosen based on the nature of the data at hand and the goal of the clustering. Other tools from unsupervised learning can be effective here. Autoencoders, for instance, map elements from an original space to a latent space. Spatial separation of two data points in the latent space then corresponds to some meaningful difference between the two initial elements. A set of words, for example, can be mapped to vectors in a latent space. Spatial similarity between vectors in this latent space (e.g. cosine similarity) corresponds to similarity in meanings of the words. Forming clusters in this latent space can then yield meaningful groupings.
From the perspective of clustering, there does not necessarily exist an a priori ‘correct’ partitioning of the data. The optimal clustering of data is instead dependent on the application. HDBSCAN uses a quantified heuristic expressing hierarchical depth within the data to determine the number of clusters to form. Other methods to determine the optimal number of clusters are also available, but all rely on optimizing some conception (either stated explicitly or implied) of what a cluster should be.
With these concerns in mind, when using a clustering algorithm whose optimization criteria is without a direct mapping to physics, one cannot be immediately sure that the resulting partitioning of physical data must usefully correspond to distinct physical categories. Nonetheless, we have demonstrated that the clustering procedure applied here has yielded useful results. Our goal, however, is not to show that clustering techniques accurately and reliably extract MBL phase boundaries. Rather, it is to show that meaningful relationships within physical data can be quickly and cheaply explored by using reasonably applied clustering techniques.
This work was supported in part by funds from David S. Saxon Presidential Term Chair at UCLA.
V Appendix
V.1 High level Overview of Relevant ML
Supervised Learning
Supervised learning makes use of a function, , to classify data into categories.
[TABLE]
with parameters , as well as sets of labeled training data – each representative of its corresponding category of data. We wish to interpret the output of to obtain the probability that a data point, , belongs to the data set. To do this, we normalize using the softmax function:
[TABLE]
And interpret
[TABLE]
We then use the training data sets to find optimal parameters , such that for , is maximized, while for , is minimized. This is achieved through the minimization of some loss function which characterizes the error of the prediction (for example, cross entropy).
If care is taken to avoid overfitting and each training set is sufficiently representative of its corresponding category of data, then can be interpreted as a function which probabilistically categorizes our data into sets. In particular, is often chosen to take the form of a neural network.
Unsupervised Learning
In unsupervised learning, we do not require data to be labeled. Rather, we follow a procedure to extremize some quantity in order to identify structure present in the data. Clustering is a form of unsupervised learning whose goal is to separate data into groups such that elements within a group are in some sense similar, and elements between groups are different.
Different clustering algorithms use different approaches to group data. Below, we describe some meaningful differences in approaches that clustering algorithms can take.
Parametric vs Density-Based
Parametric clustering algorithms assume (either implicitly or explicitly) that the data takes a certain form. This could be that the clusters are convex (as assumed by algorithms such as k-means) or that the pdf from which the data points are drawn are sums of Gaussians (as assumed by a Gaussian mixture model). Furthermore, these models generally assume knowledge of the number of clusters present in advance.
On the other hand, density-based clustering assumes that the data is generated according to a probability distribution and seeks to identify connected components of level sets of the pdf. In practice, these algorithms separate high density regions of the data from low density regions. Connected components of these high density regions are then considered clusters.
Flat vs Hierarchical
Flat clustering algorithms require us to set a parameter identifying the ‘granularity’ of the clusters we would like to form. For parametric algorithms, this could correspond to specifying the number of clusters to form in the data (i.e. the resolution of clustering). For density-based clustering algorithms, this might correspond to choosing which level set of the pdf to use in clustering. Different level sets may then yield different connected components.
Hierarchical clustering algorithms avoid setting a granularity parameter. Rather, they construct a hierarchy of groupings, with similar clusters merging into one another as we decrease the resolution.
HDBSCAN
HDBSCAN is a density-based clustering algorithm which also uses tools from hierarchical clustering. It builds upon DBSCAN, a flat density-based algorithm, and can be ideal for exploratory clustering.
In exploring an unknown data set, we would like our clustering algorithm to make as few assumptions about the data as possible. These include assumptions about the number of clusters present, as well as the shape of those clusters.
As the HDBSCAN algorithm is density-based, it does not assume that clusters must be of a specific form. In addition, instead of assuming a specific number of clusters to find, HDBSCAN uses a hierarchical analysis of the data to quantify the ‘depth’ of potential clusters. Its hierarchical technique allows HDBSCAN to predict which clusters to form, based on how resilient their presence is under variation of the clustering resolution. Furthermore, HDBSCAN does not attempt to segment each point into a cluster. Rather, it assumes that clusters may be surrounded by lower density noise.
HDBSCAN has two parameters: min_cluster_size, and min_samples. The min_cluster_size parameter simply puts a lower bound on the size of clusters to form. min_samples is less intuitive. It expresses how conservative or aggressive a given clustering of the data should be. A greater value corresponds to a more conservative clustering and more points being declared as noise. Its value generally does not radically affect the final partitioning. However, some quantitative reference for a suitable value of min_samples can be found by applying the density-based validation score to resulting clusters.
Spectral Clustering
Spectral clustering is a density-based clustering algorithm related to manifold learning and the DBSCAN algorithm. It allows the user to include specific assumptions concerning the number of clusters to form. Spectral clustering approaches separating and grouping data as a graph partitioning problem. Given a distance metric, , the algorithm generates a similarity matrix. Typically this is done using a Gaussian kernel similarity function:
[TABLE]
Where corresponds to the size of neighborhoods expected to form within the data.
The algorithm then computes the Laplacian matrix of the resulting graph and collects the first eigenvectors. Data is then projected to the dimensional vector space spanned by these eigenvectors and clustered in this space using a more simple algorithm (such as k-means). This process corresponds to moving to a vector space in which position expresses connectivity, and clustering in this space.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Venderley et al. (2018) J. Venderley, V. Khemani, and E.-A. Kim, Physical review letters 120 25 , 257204 (2018).
- 2Jönsson (2018) M. Jönsson, Detecting the Many-Body Localization Transition with Machine Learning Techniques , Master’s thesis (2018).
- 3Carrasquilla and Melko (2017) J. Carrasquilla and R. G. Melko, Nature Physics 13 , 431 (2017) . · doi ↗
- 4Schindler et al. (2017) F. Schindler, N. Regnault, and T. Neupert, Phys. Rev. B 95 , 245134 (2017) . · doi ↗
- 5Wetzel (2017) S. J. Wetzel, Phys. Rev. E 96 , 022140 (2017) . · doi ↗
- 6Araki et al. (2019) H. Araki, T. Mizoguchi, and Y. Hatsugai, Phys. Rev. B 99 , 085406 (2019) . · doi ↗
- 7Rodriguez-Nieva and Scheurer (2018) J. F. Rodriguez-Nieva and M. S. Scheurer, ar Xiv:1805.05961 (2018), ar Xiv:1805.05961 .
- 8Casert et al. (2019) C. Casert, T. Vieijra, J. Nys, and J. Ryckebusch, Phys. Rev. E 99 , 023304 (2019) . · doi ↗