Securing Downlink Massive MIMO-NOMA Networks with Artificial Noise
Ming Zeng, Nam-Phong Nguyen, Octavia A. Dobre, and H. Vincent Poor

TL;DR
This paper enhances the security of massive MIMO-NOMA networks by using artificial noise, optimizing power allocation, and analyzing secrecy performance, demonstrating significant improvements over conventional methods.
Contribution
It introduces a novel artificial noise scheme with joint power optimization for secure massive MIMO-NOMA networks, including asymptotic analysis and energy efficiency maximization.
Findings
Artificial noise significantly improves secrecy performance.
Joint power allocation enhances sum secrecy rates.
Proposed algorithms outperform baseline methods in simulations.
Abstract
In this paper, we focus on securing the confidential information of massive multiple-input multiple-output (MIMO) non-orthogonal multiple access (NOMA) networks by exploiting artificial noise (AN). An uplink training scheme is first proposed with minimum mean squared error estimation at the base station. Based on the estimated channel state information, the base station precodes the confidential information and injects the AN. Following this, the ergodic secrecy rate is derived for downlink transmission. An asymptotic secrecy performance analysis is also carried out for a large number of transmit antennas and high transmit power at the base station, respectively, to highlight the effects of key parameters on the secrecy performance of the considered system. Based on the derived ergodic secrecy rate, we propose the joint power allocation of the uplink training phase and downlink…
Click any figure to enlarge with its caption.
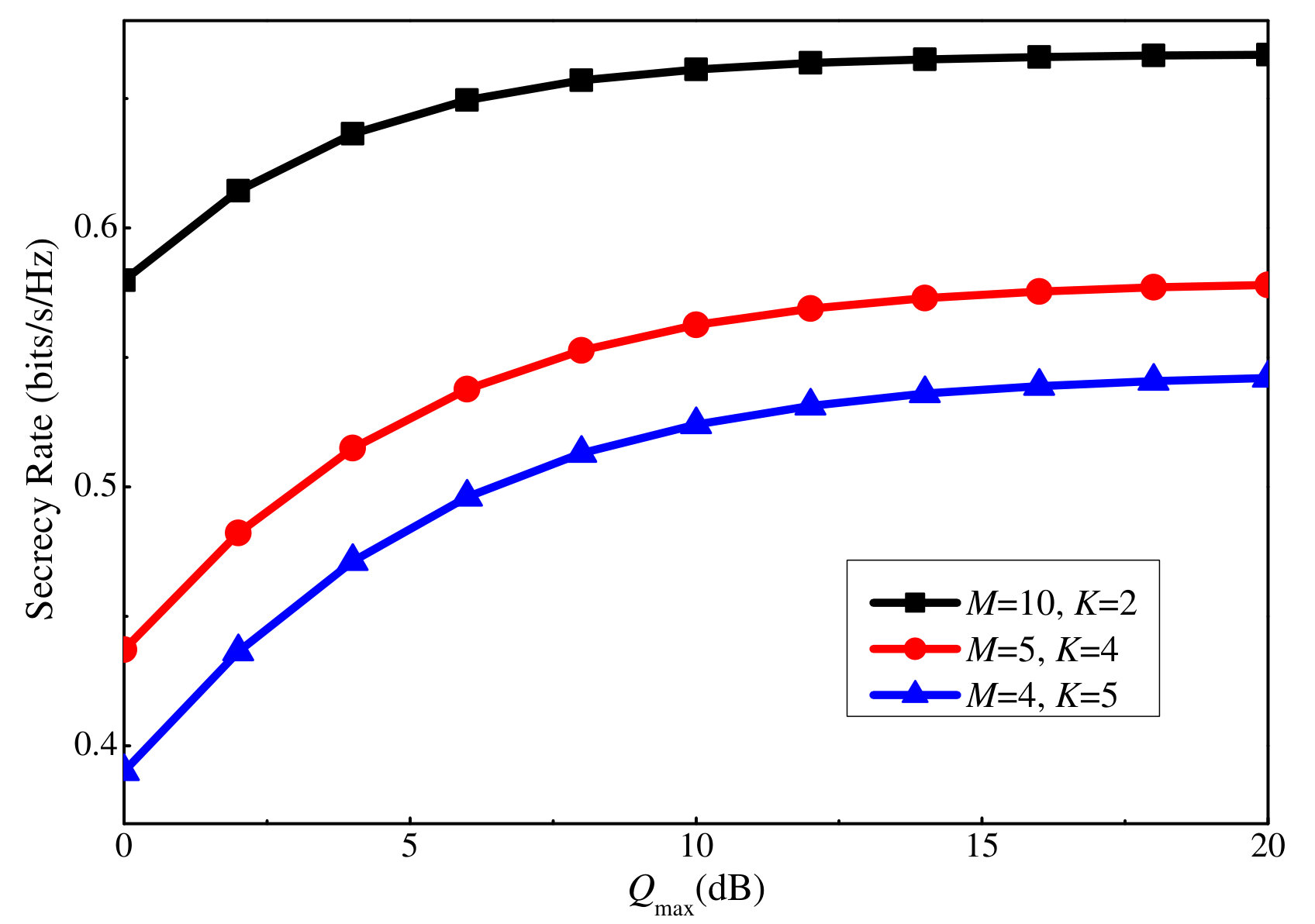 Figure 1
Figure 1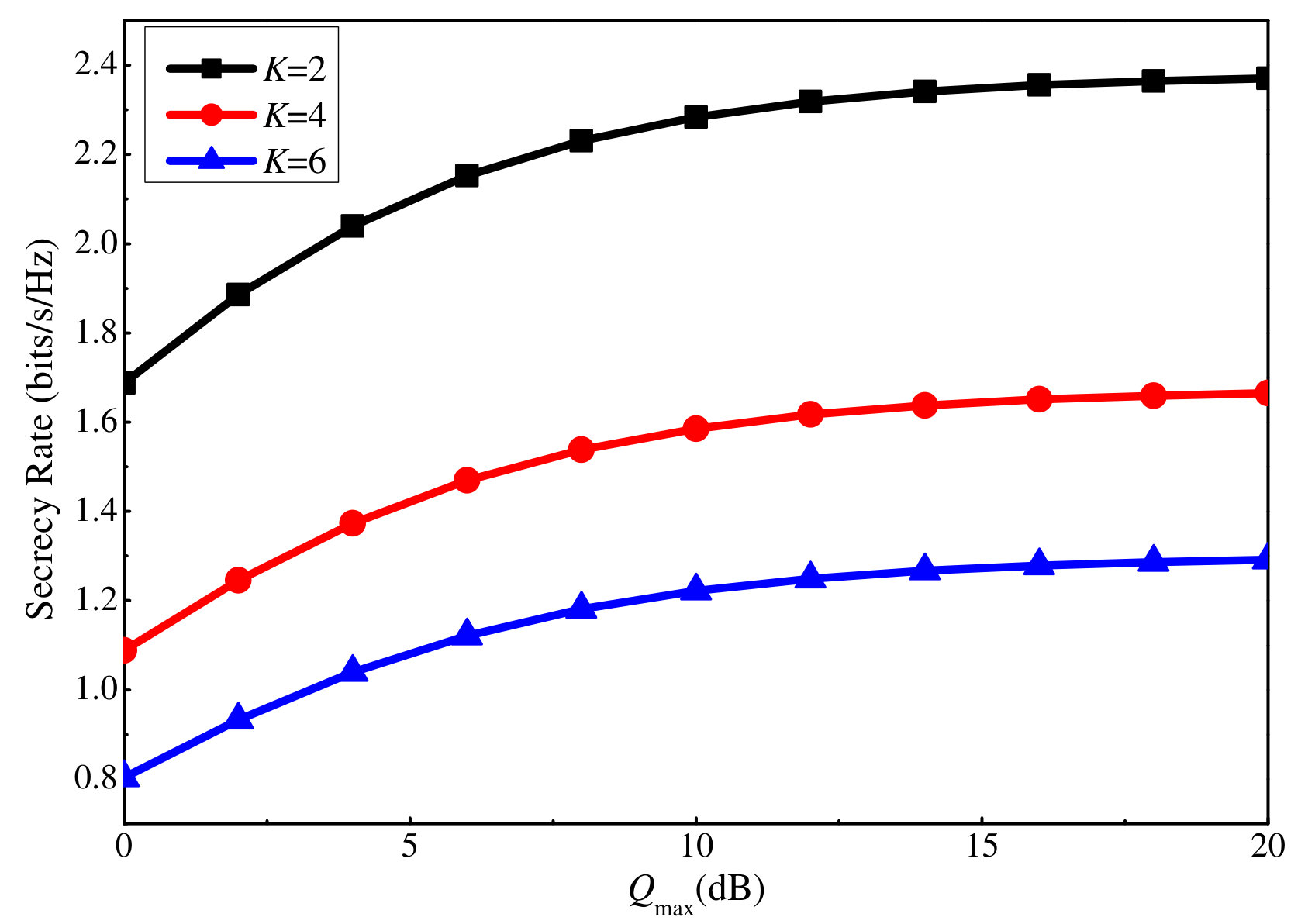 Figure 2
Figure 2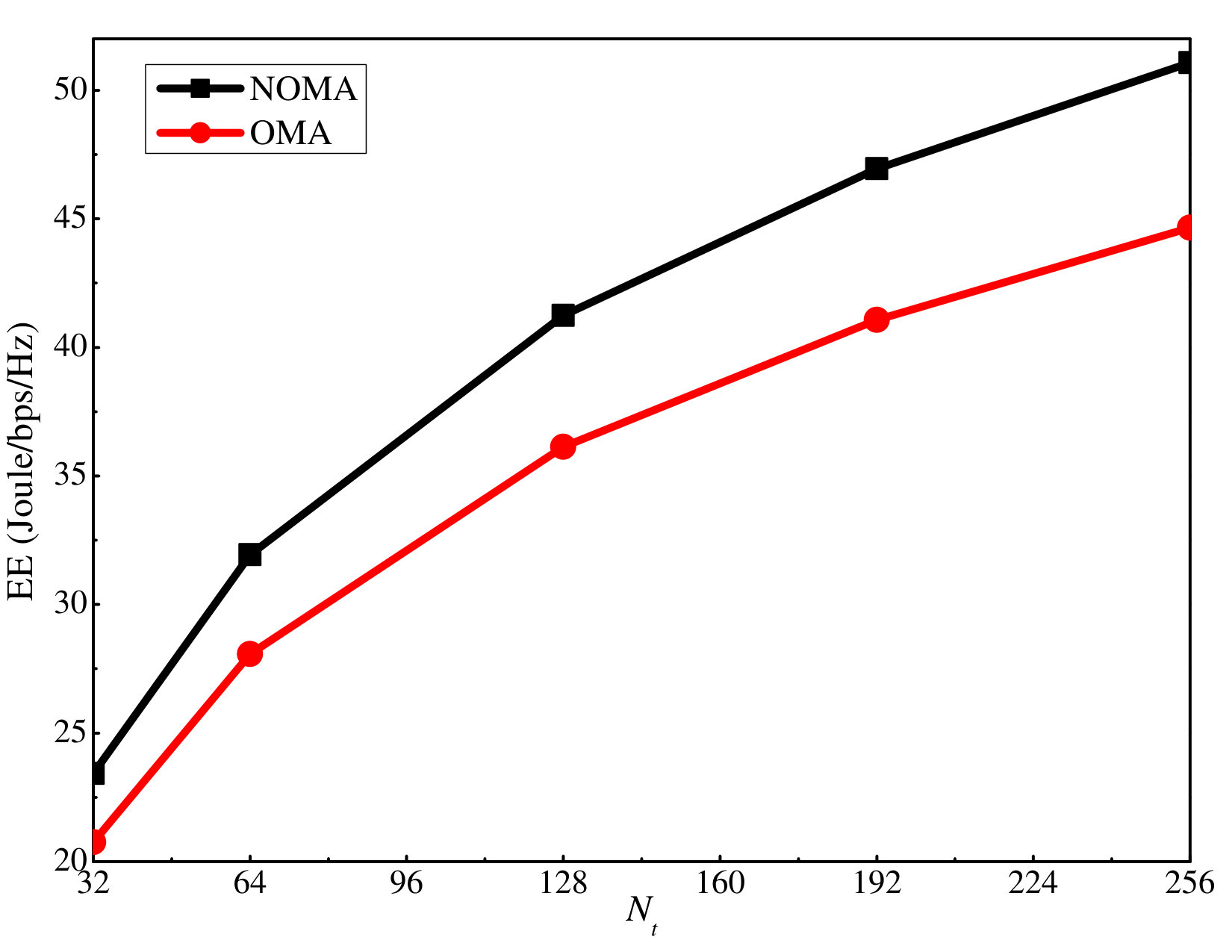 Figure 3
Figure 3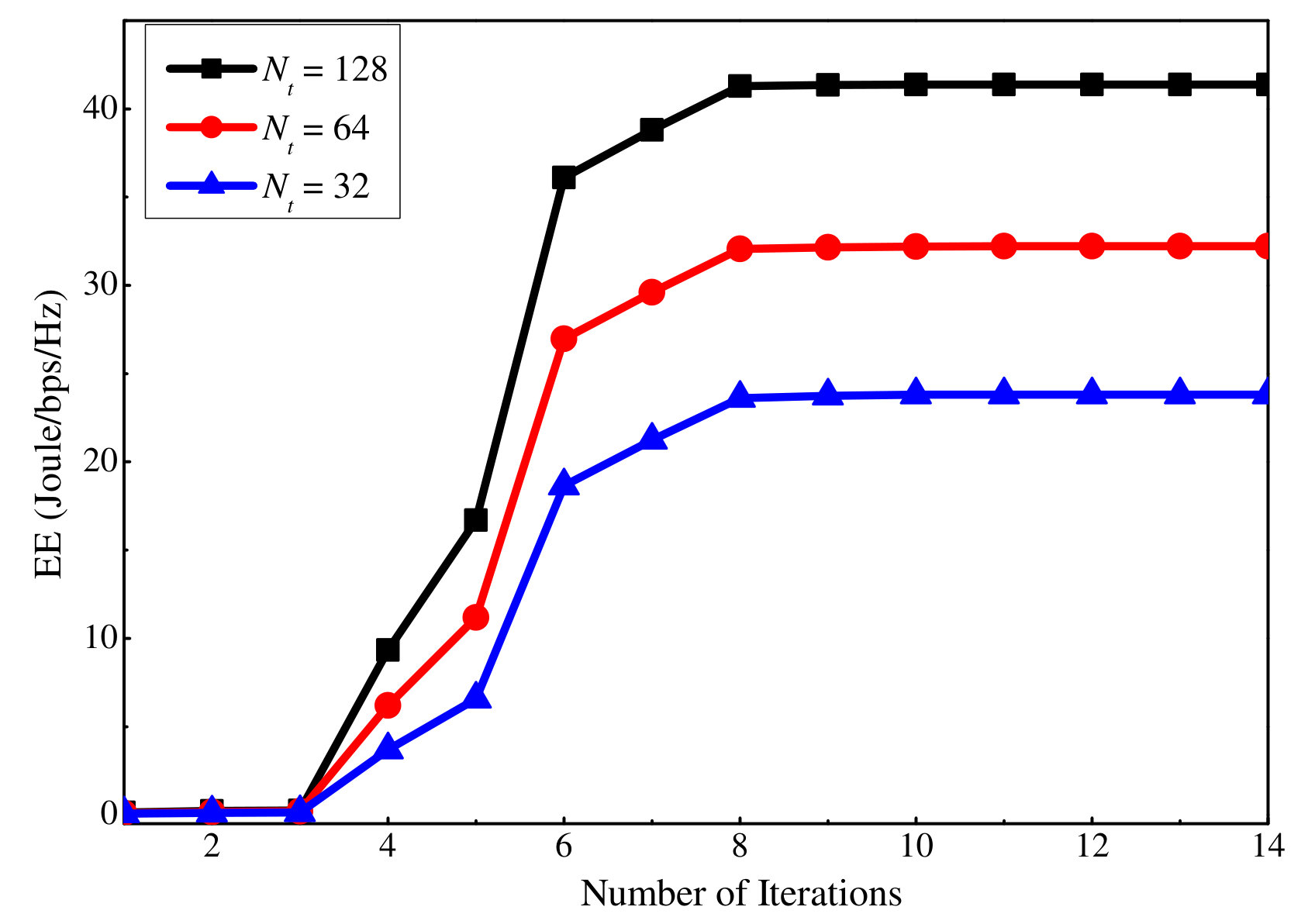 Figure 4
Figure 4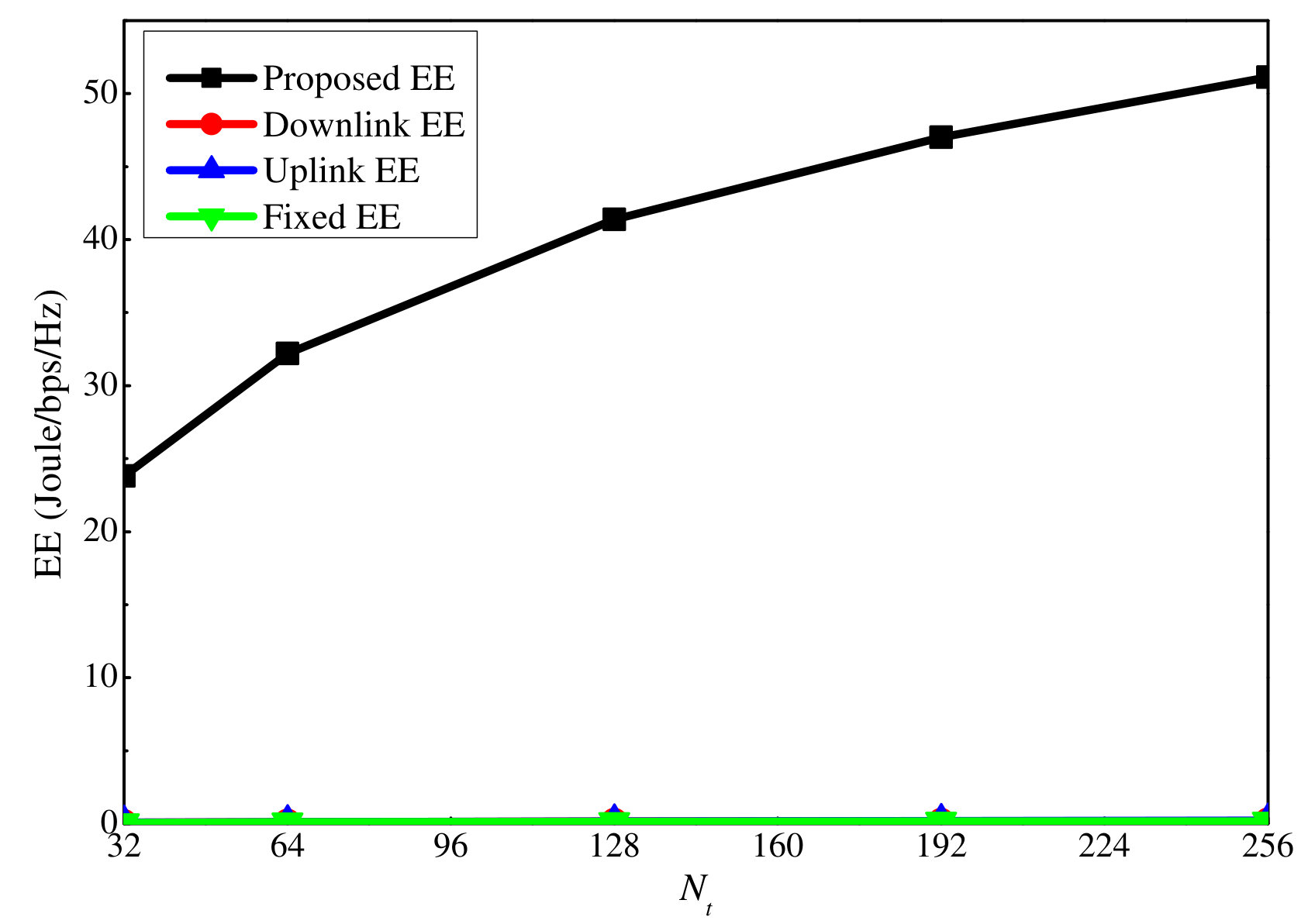 Figure 5
Figure 5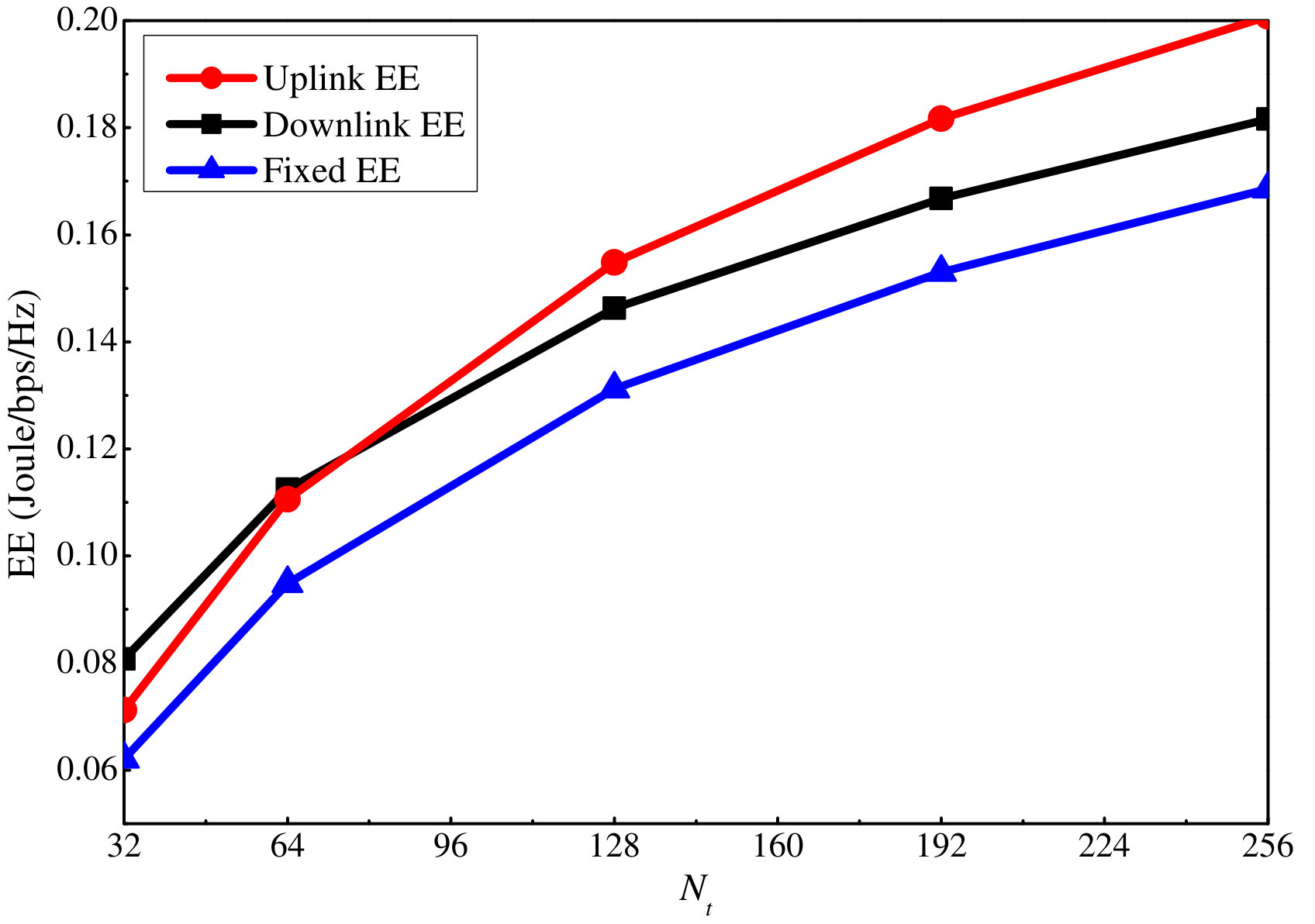 Figure 6
Figure 6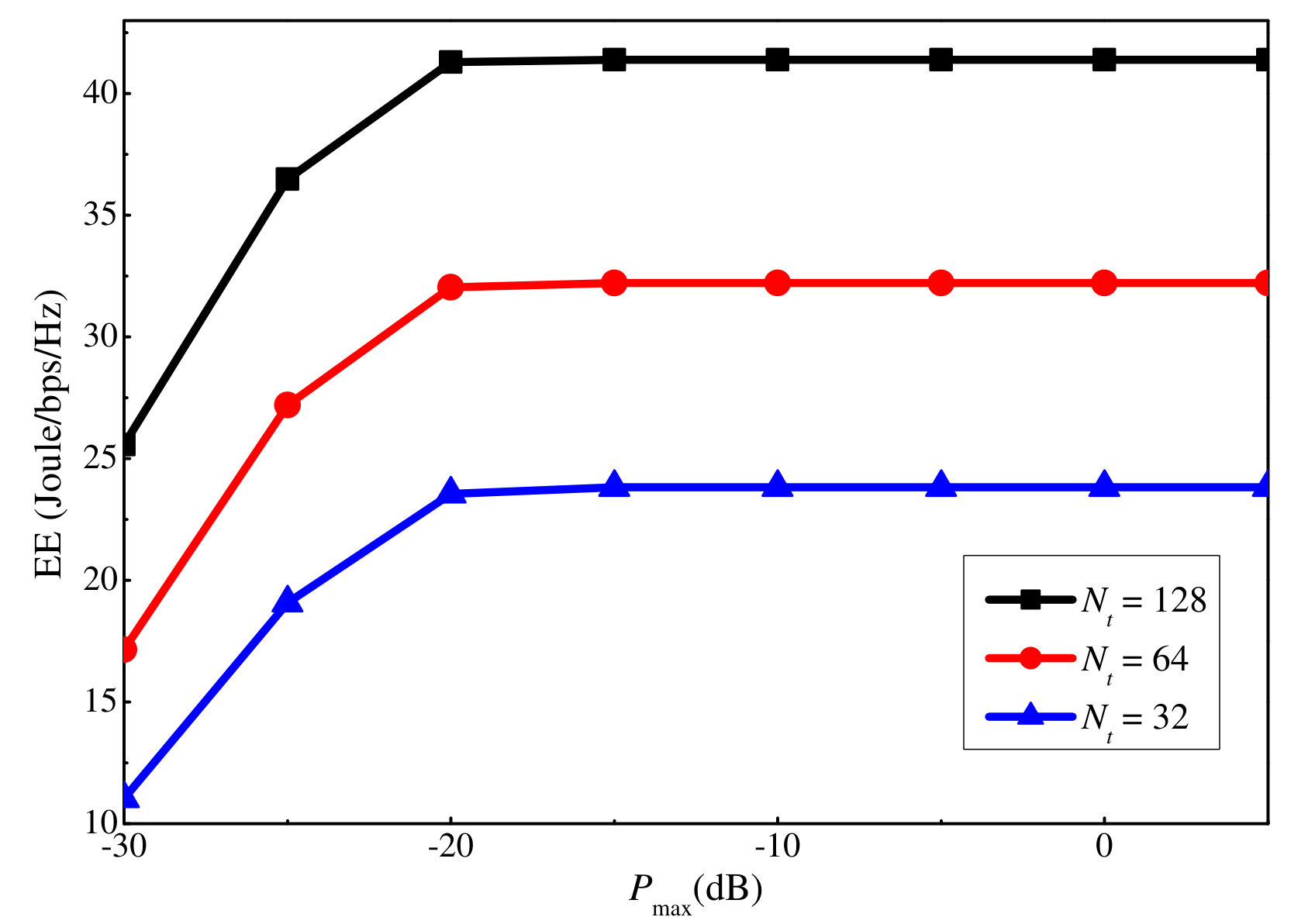 Figure 7
Figure 7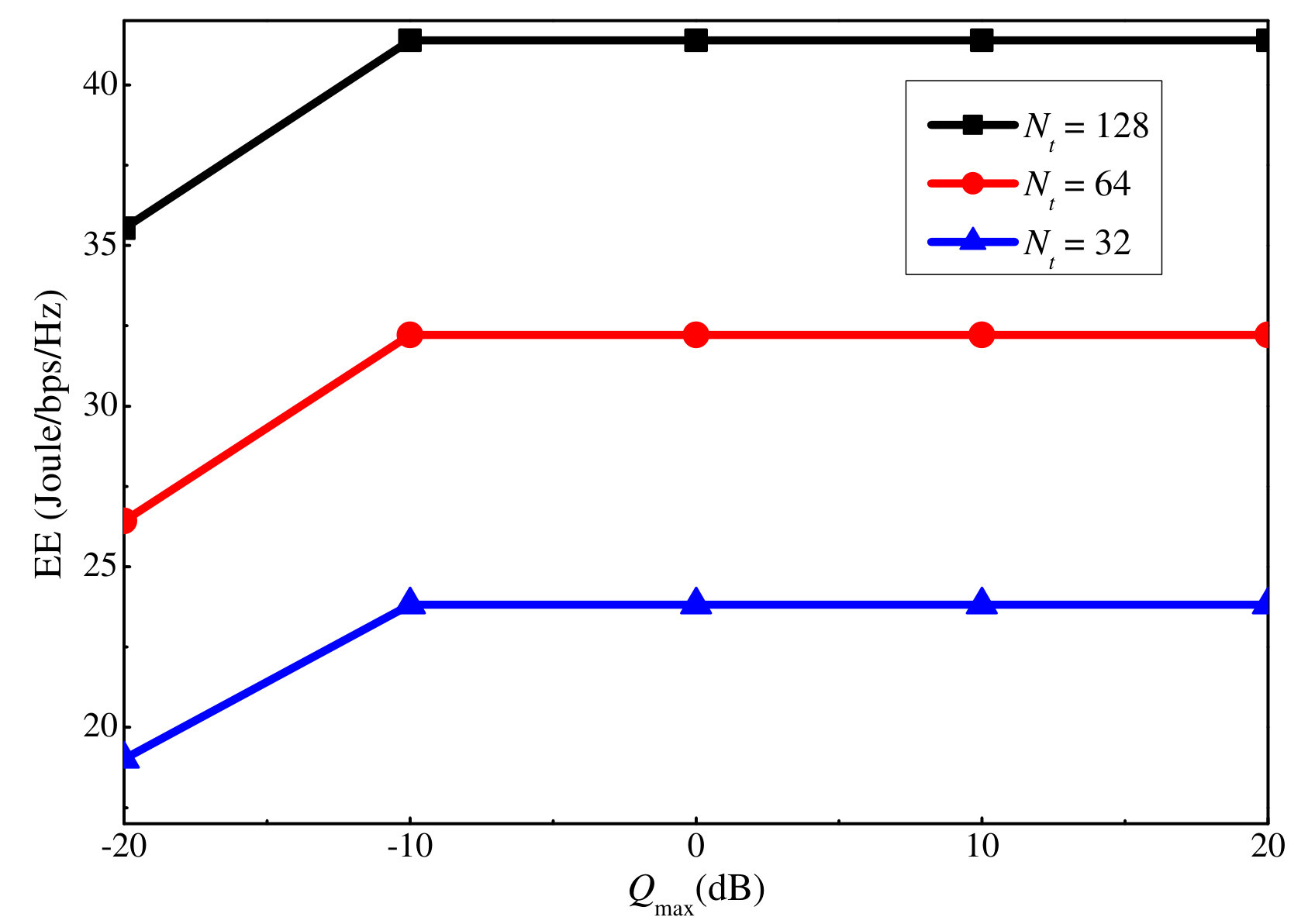 Figure 8
Figure 8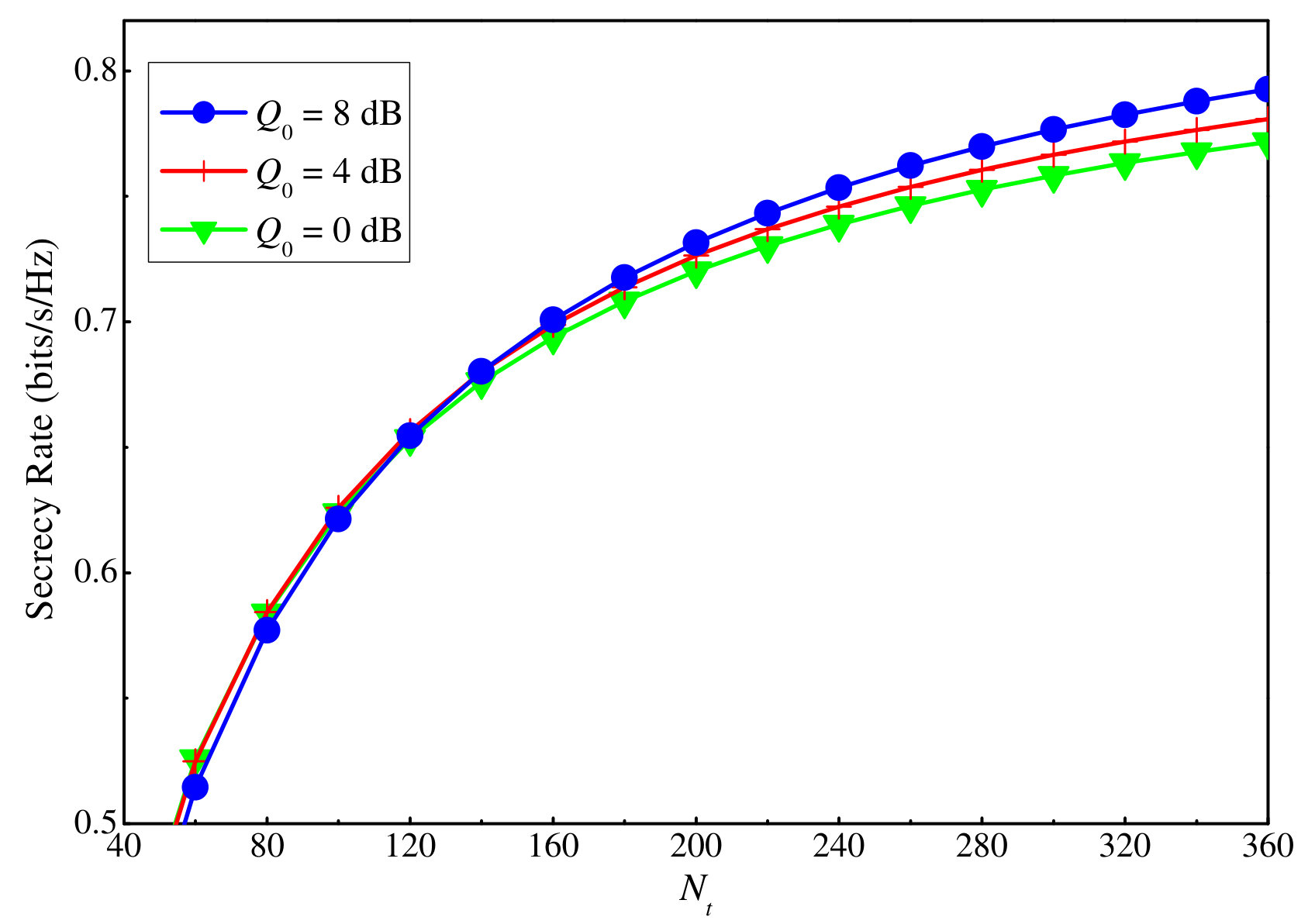 Figure 9
Figure 9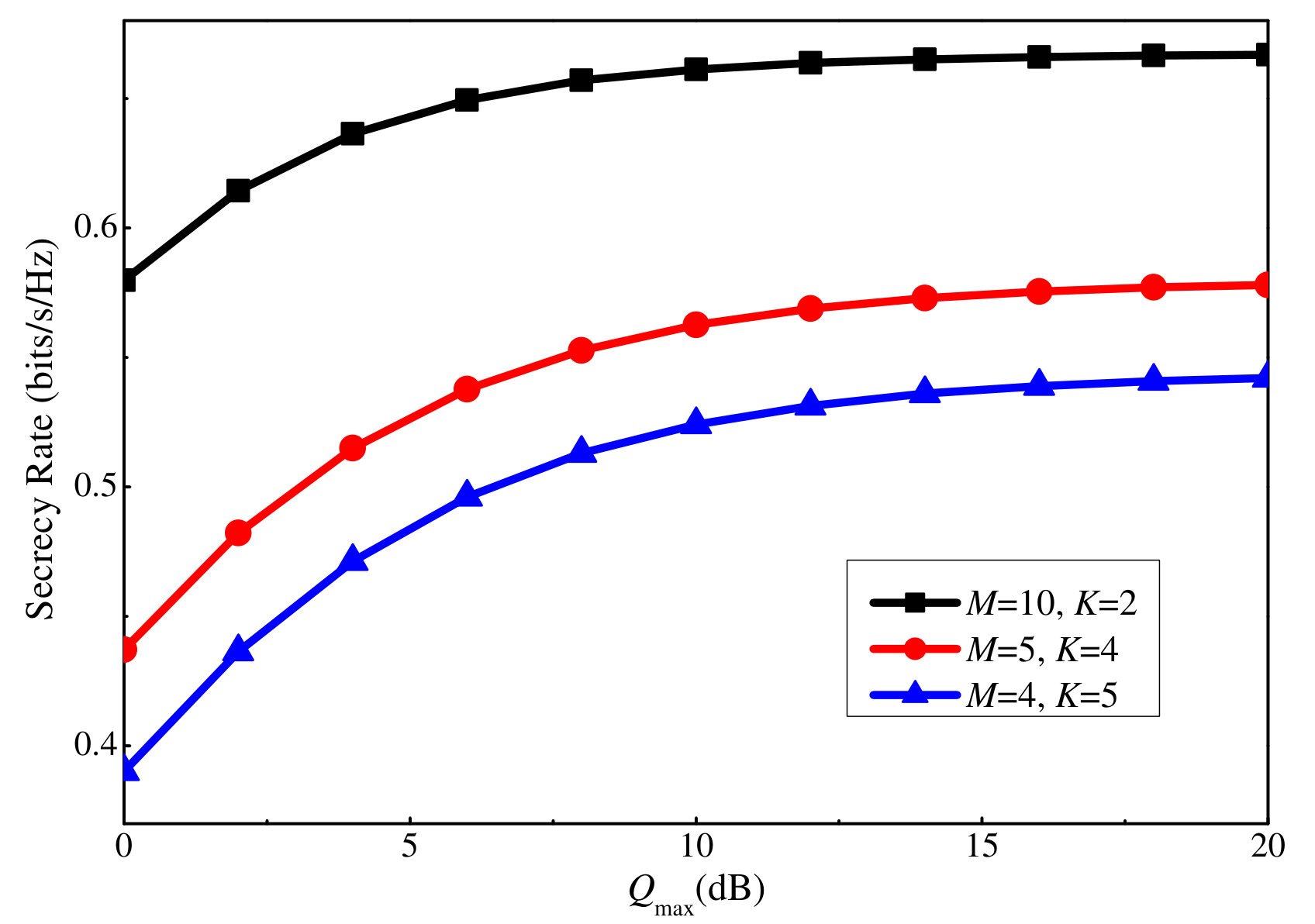 Figure 10
Figure 10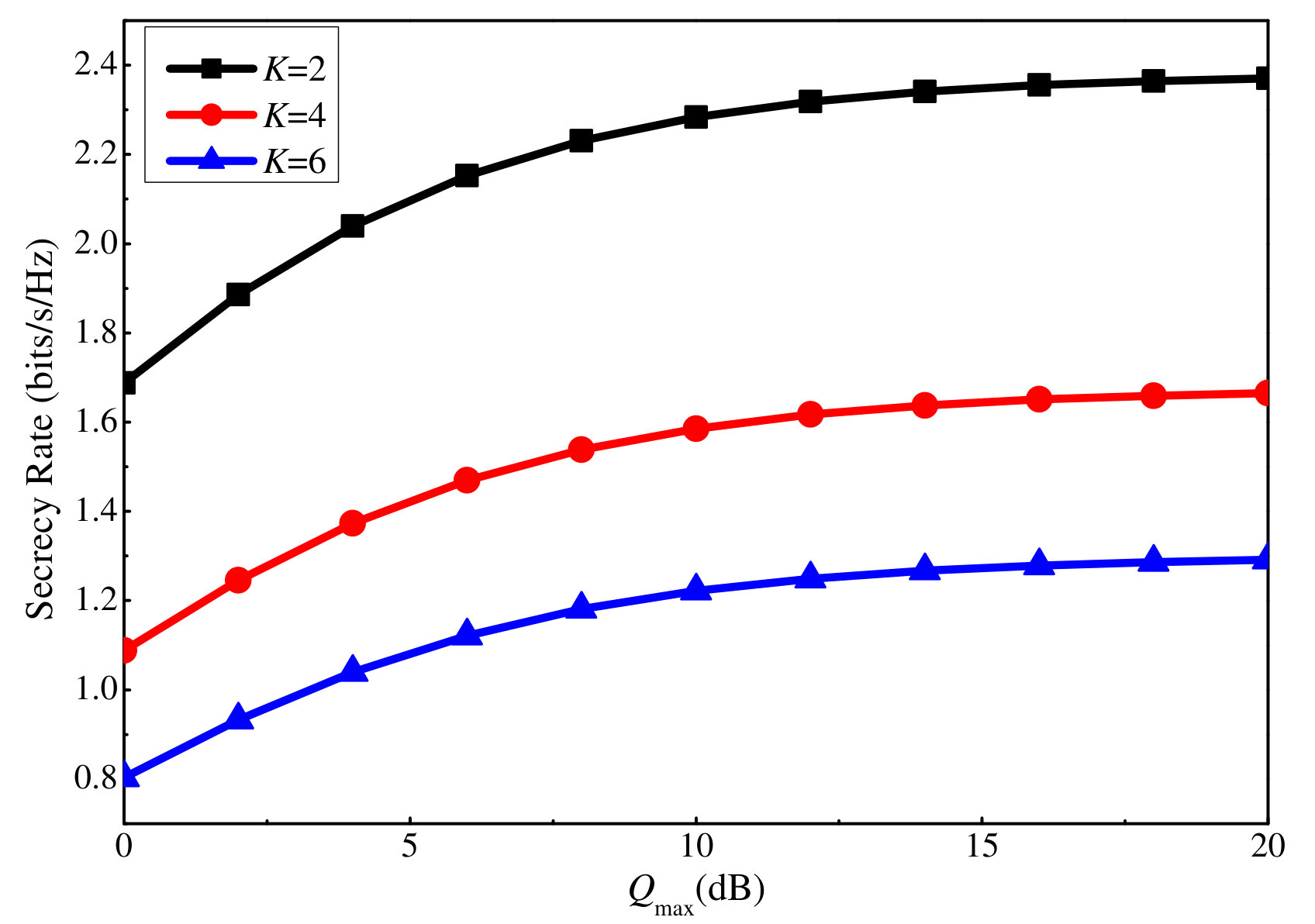 Figure 11
Figure 11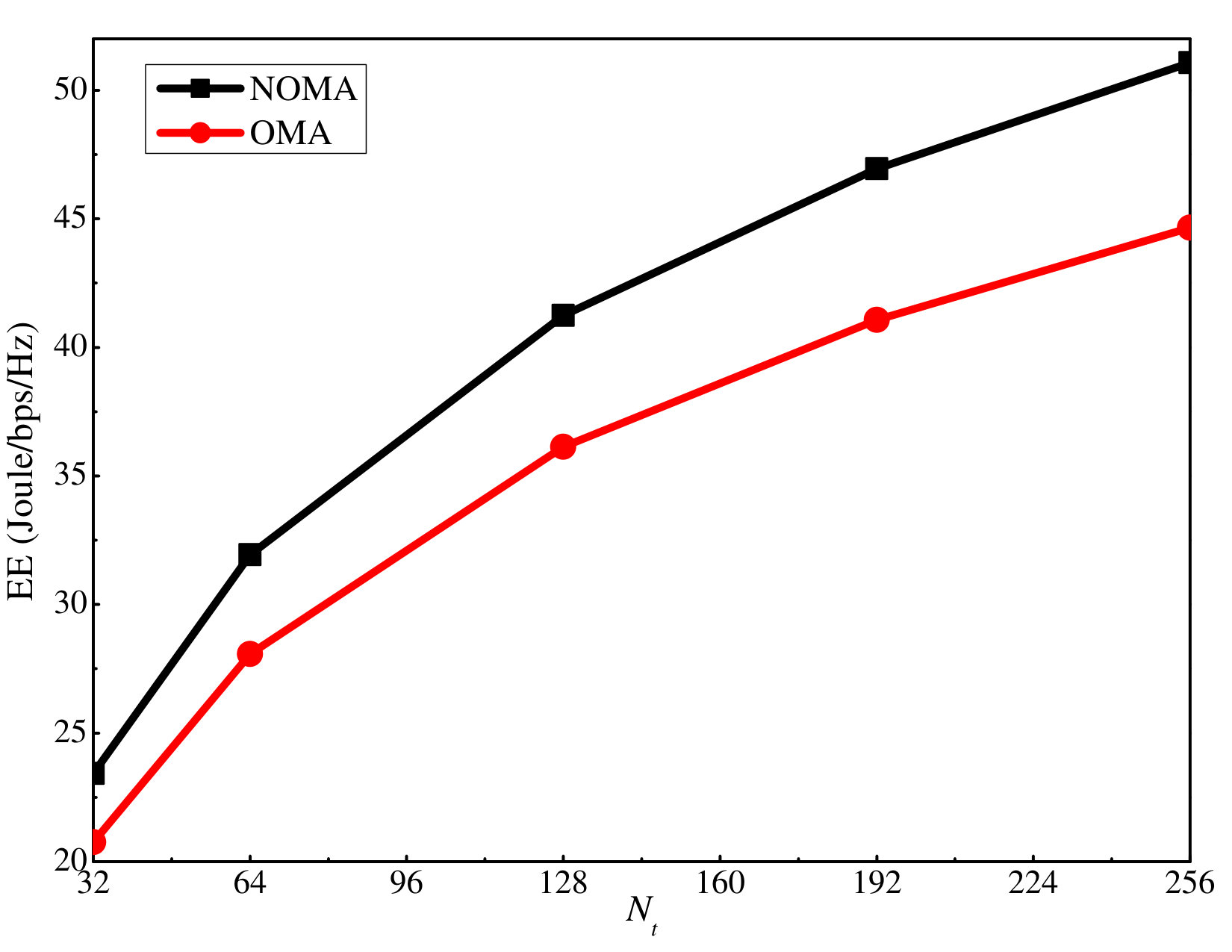 Figure 12
Figure 12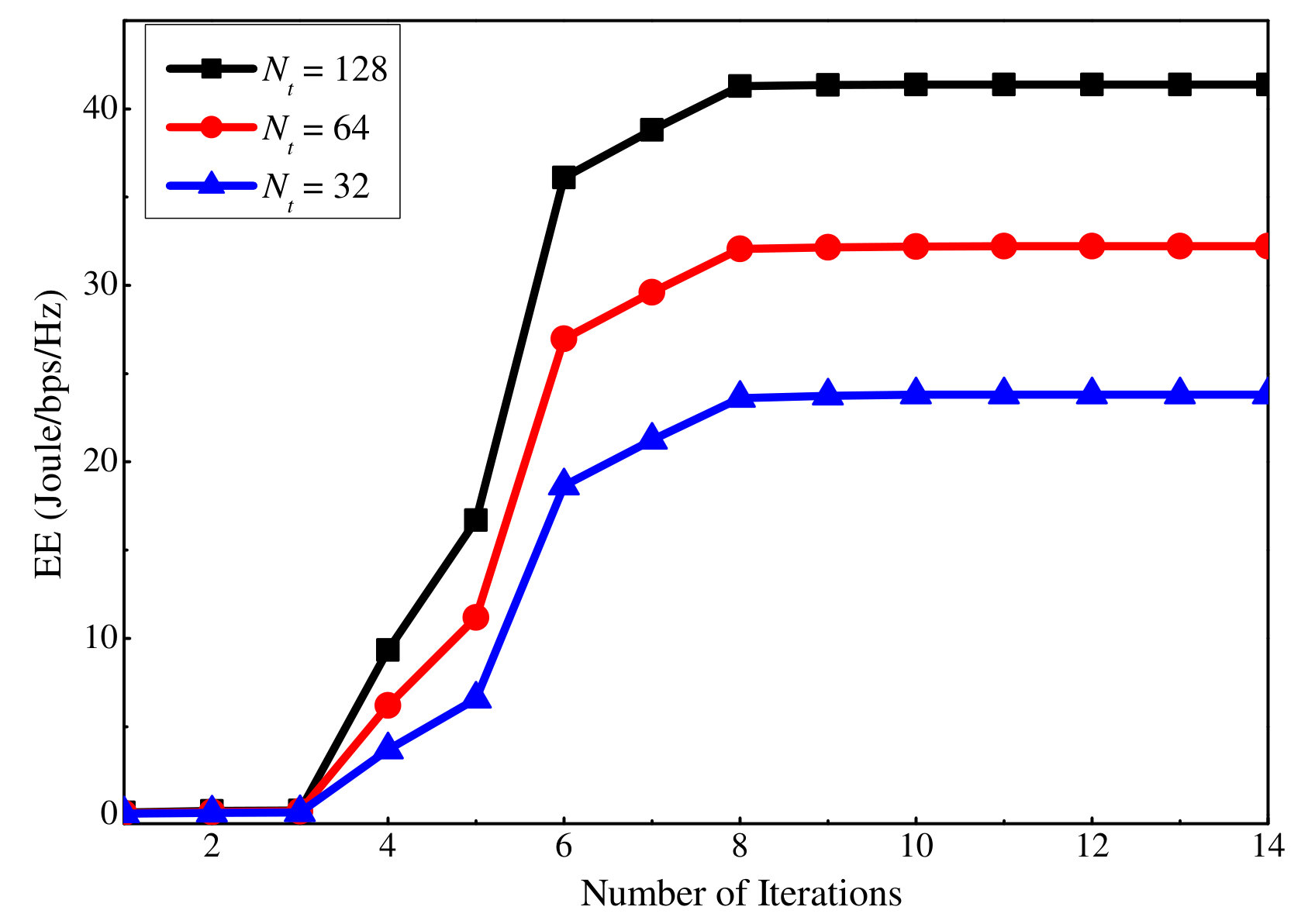 Figure 13
Figure 13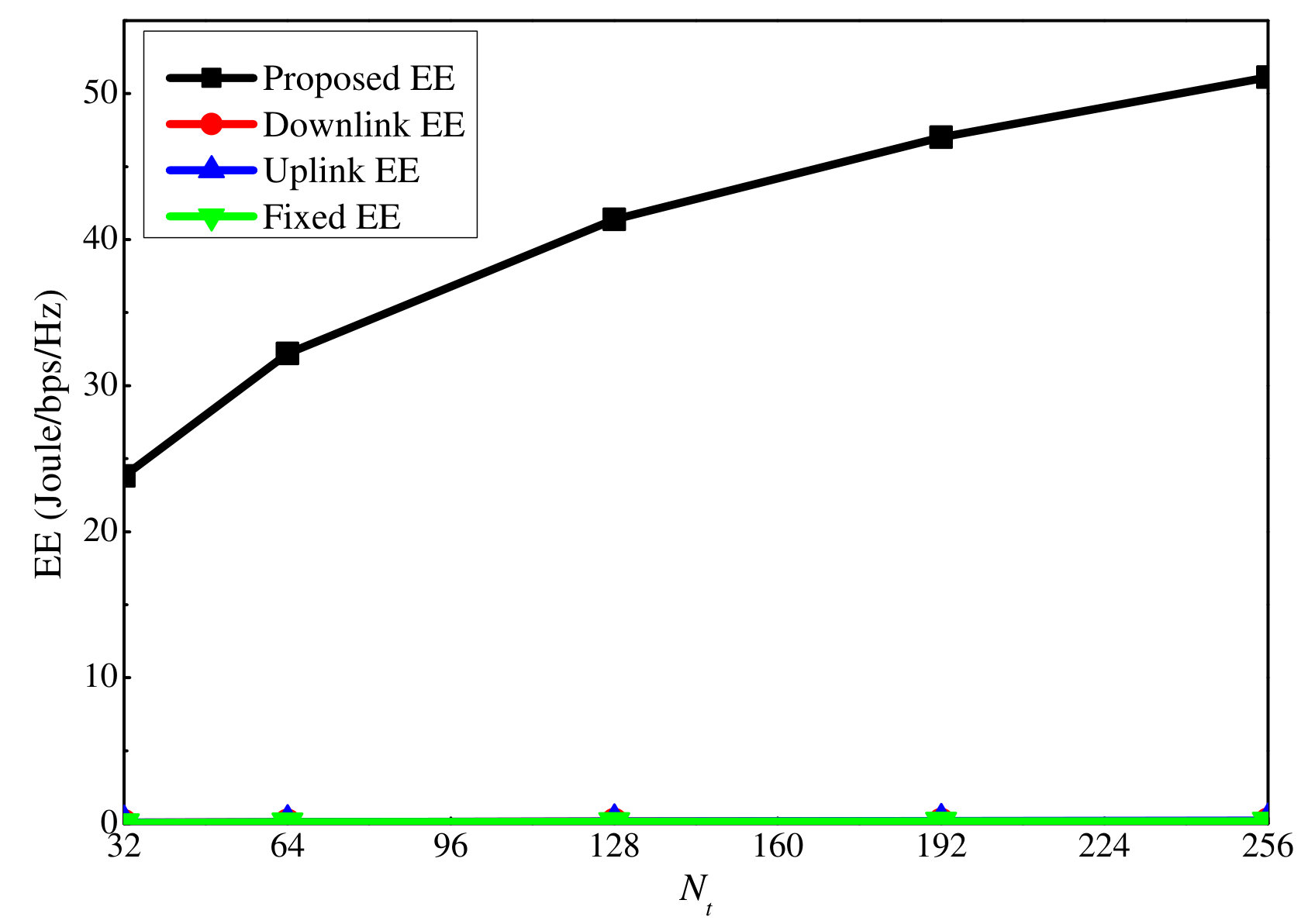 Figure 14
Figure 14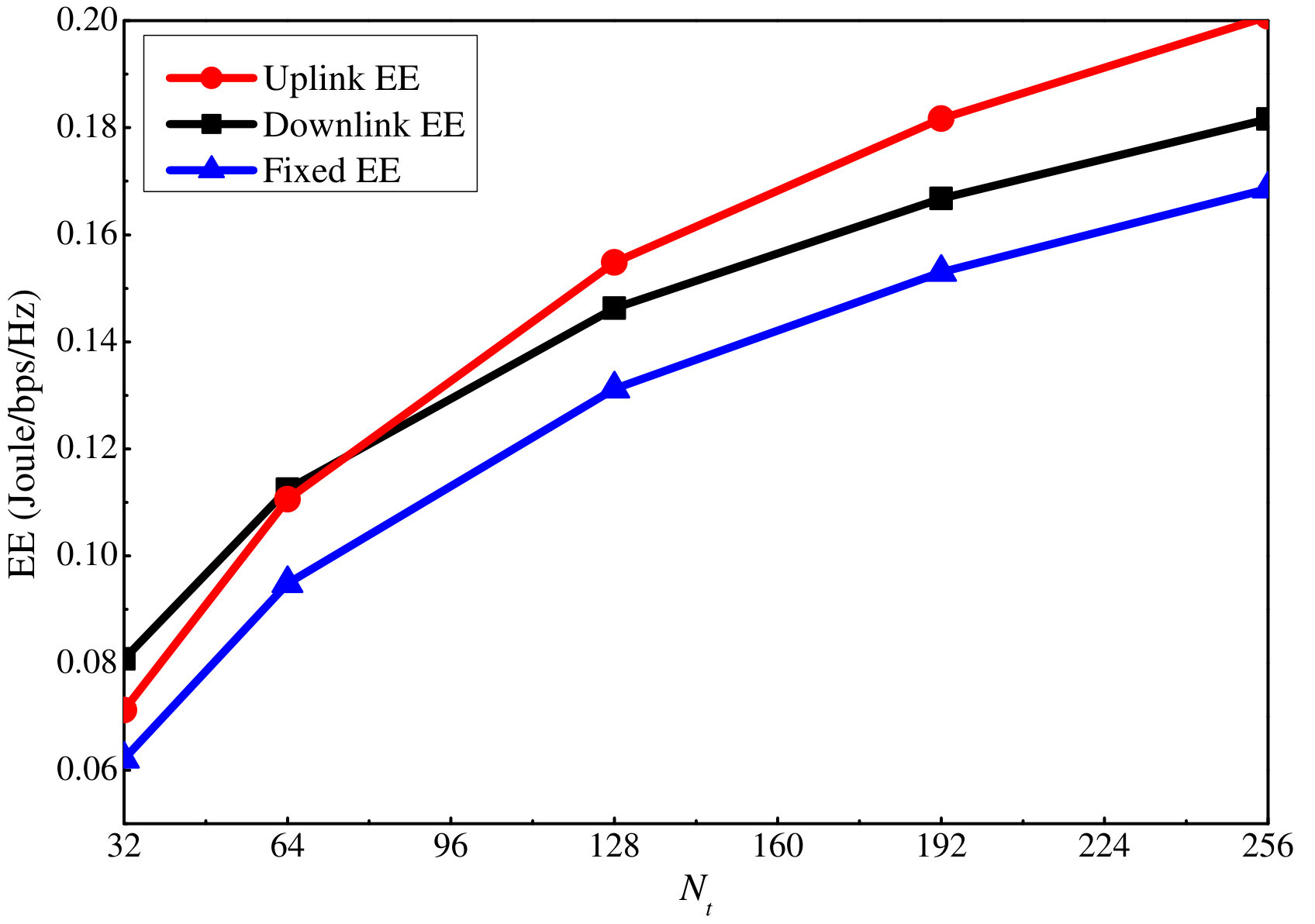 Figure 15
Figure 15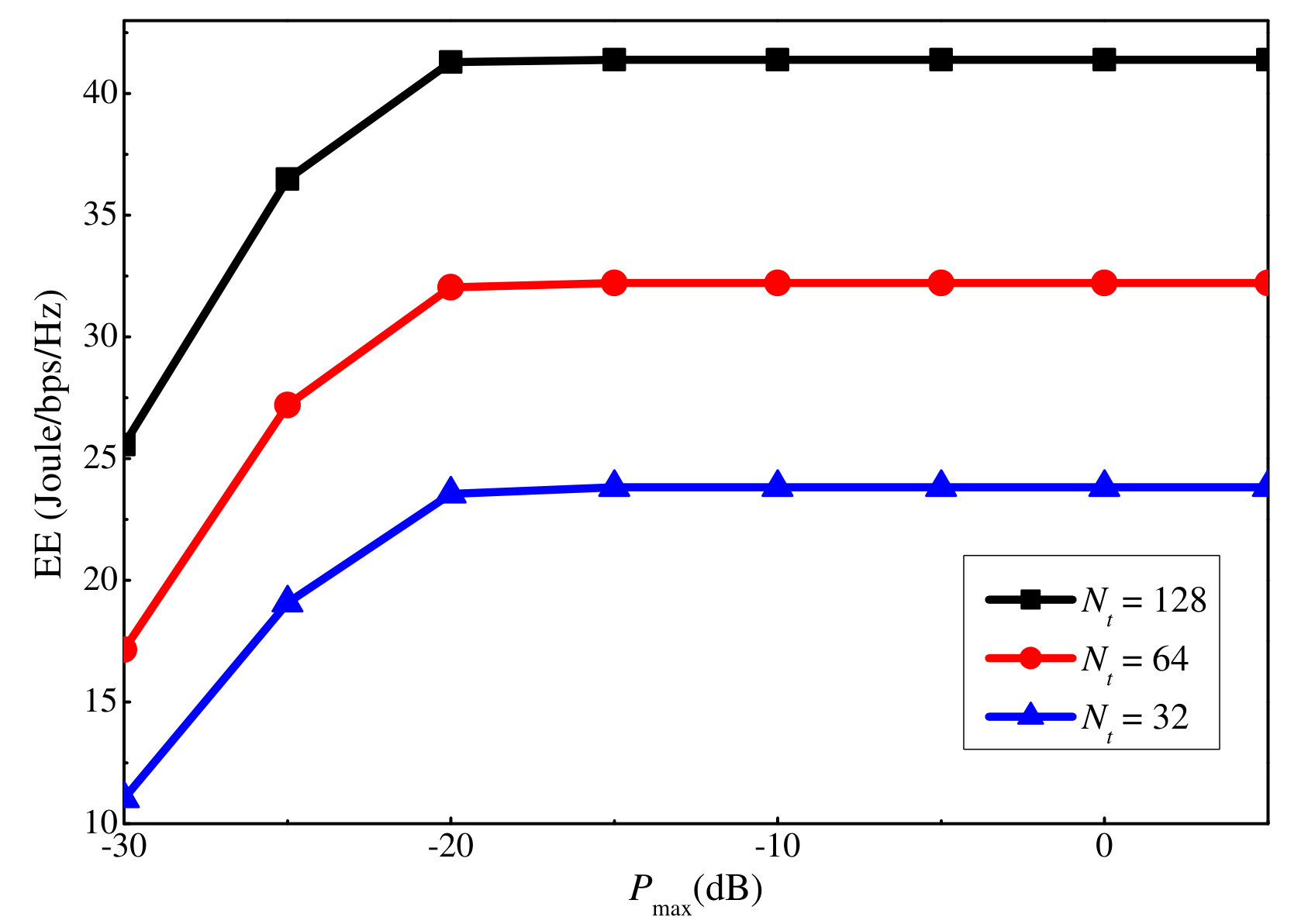 Figure 16
Figure 16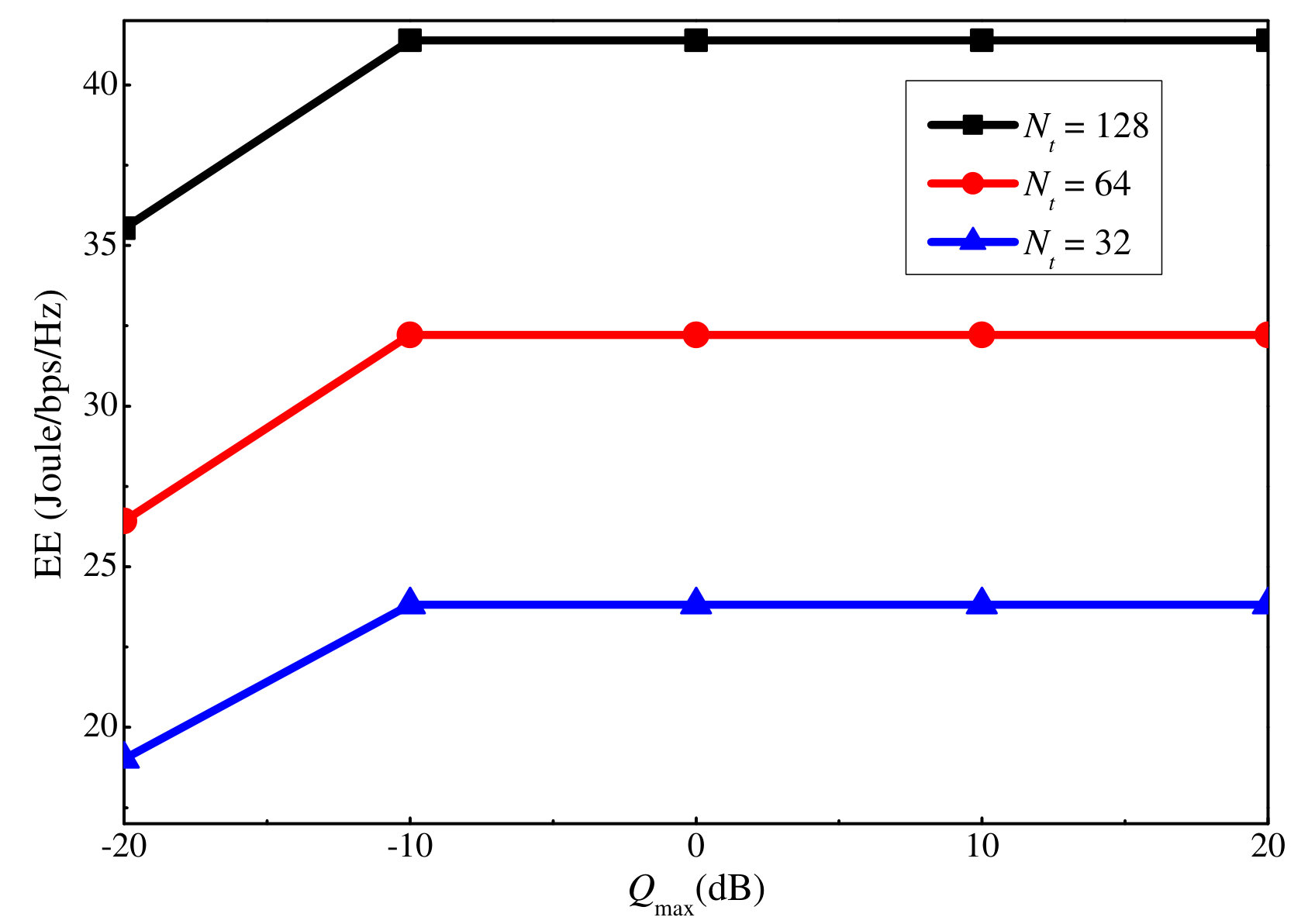 Figure 17
Figure 17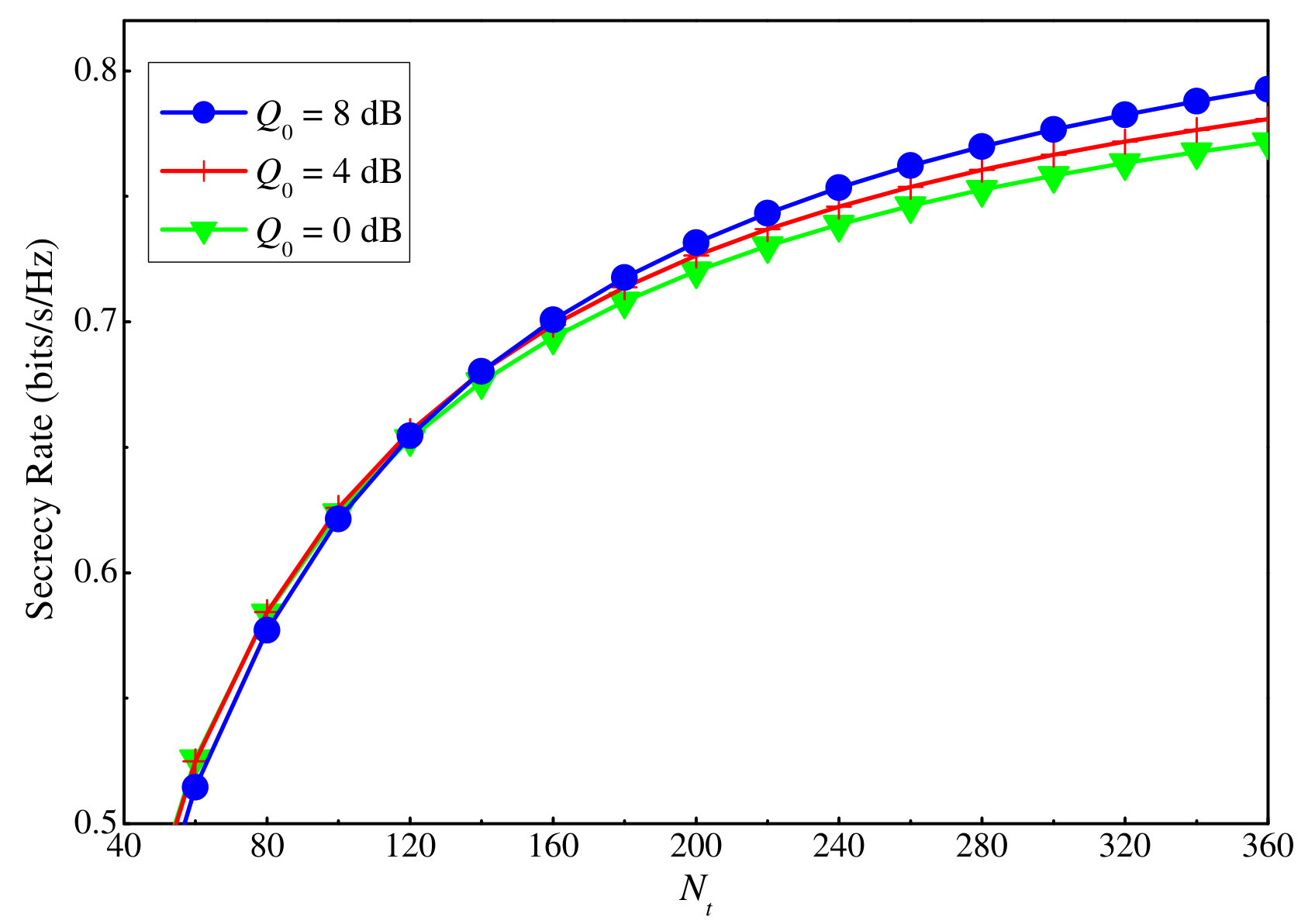 Figure 18
Figure 18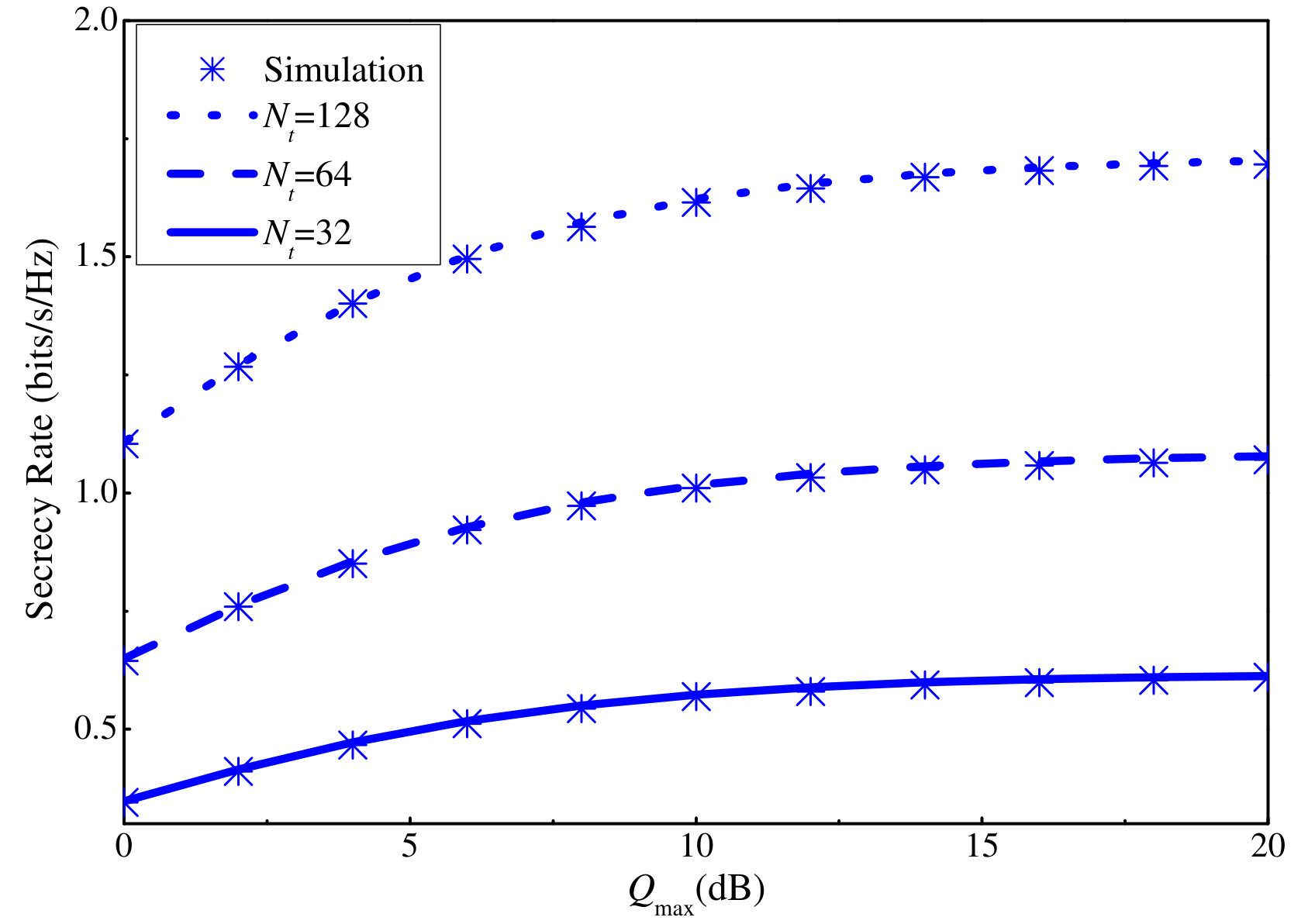 Figure 19
Figure 19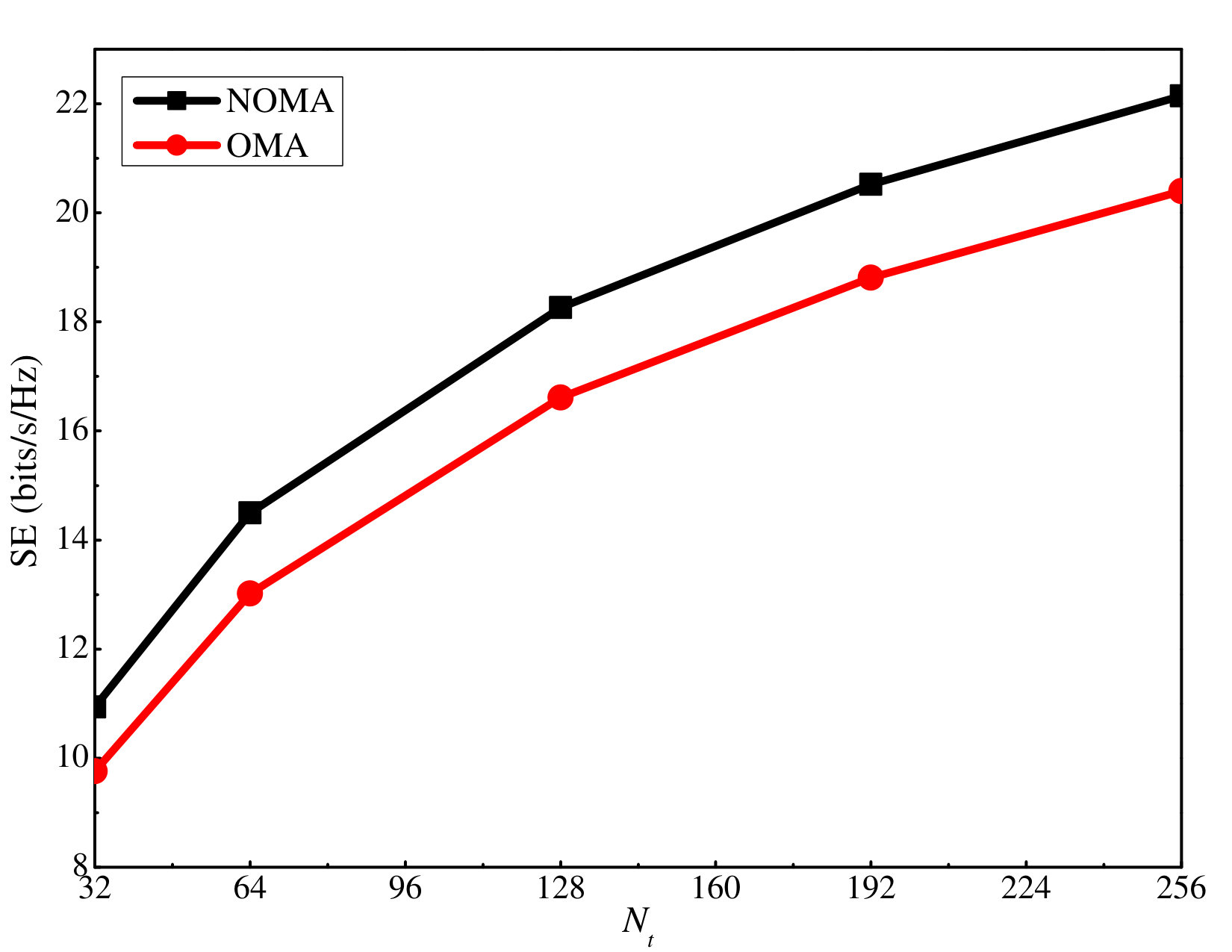 Figure 20
Figure 20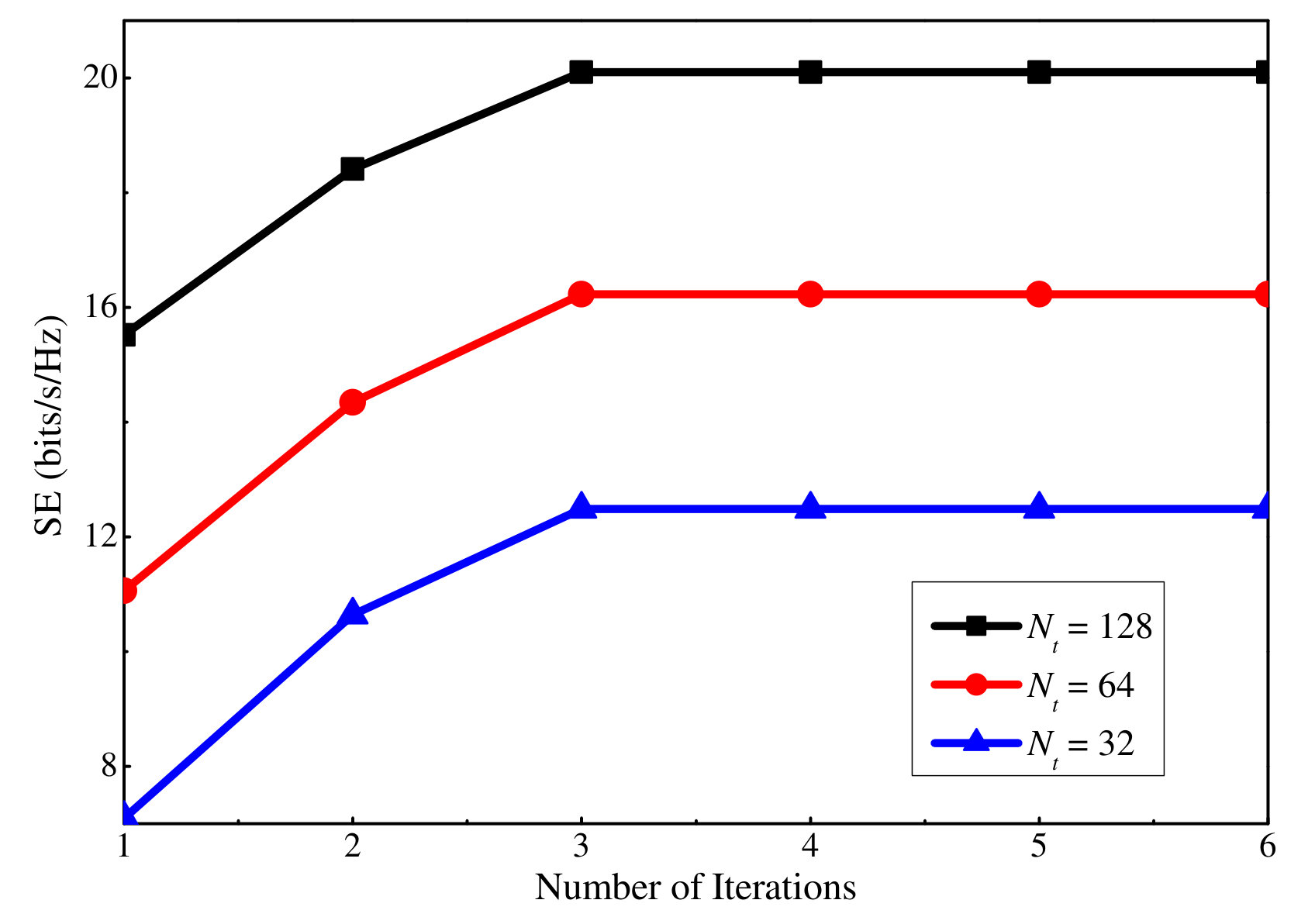 Figure 21
Figure 21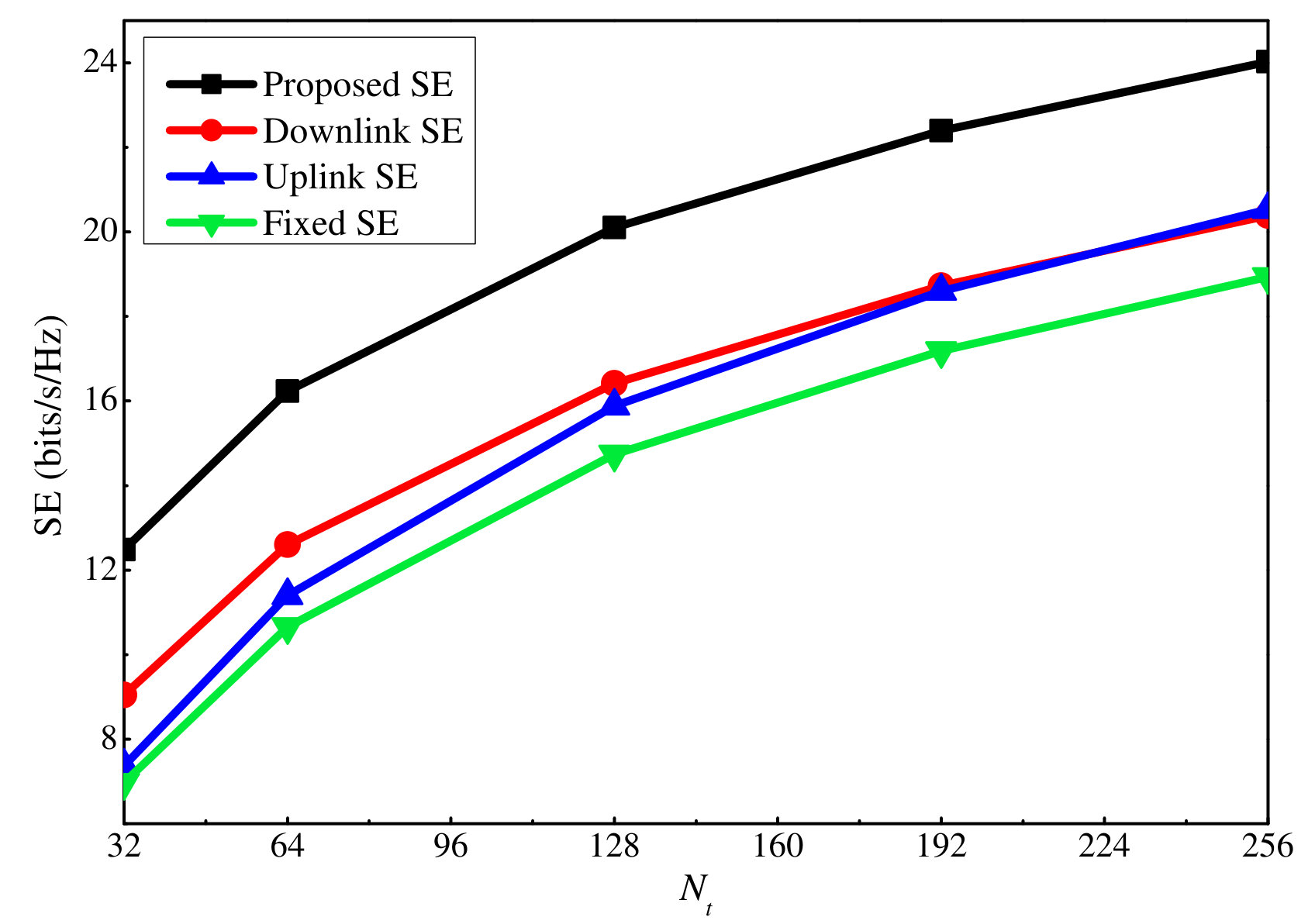 Figure 22
Figure 22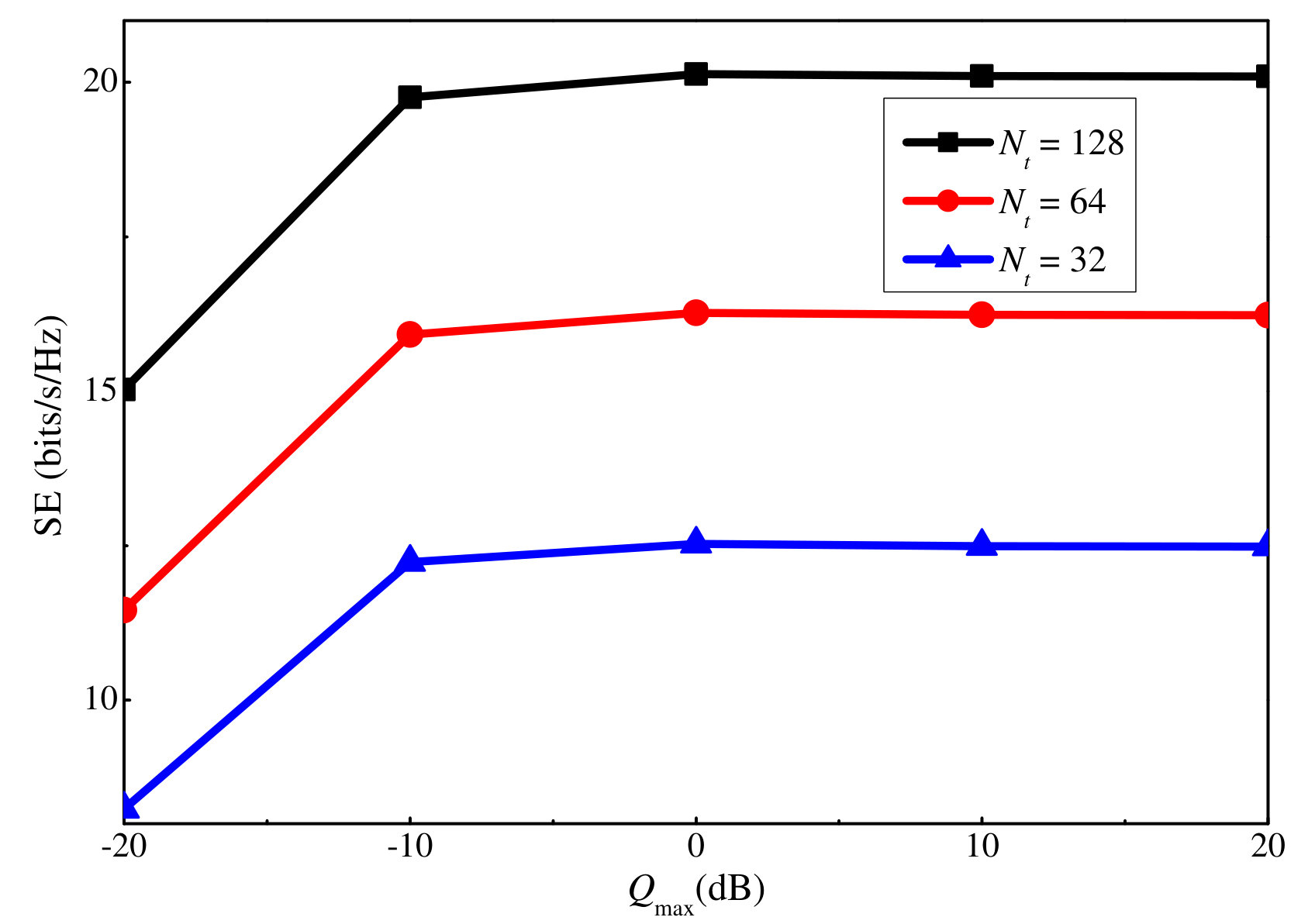 Figure 23
Figure 23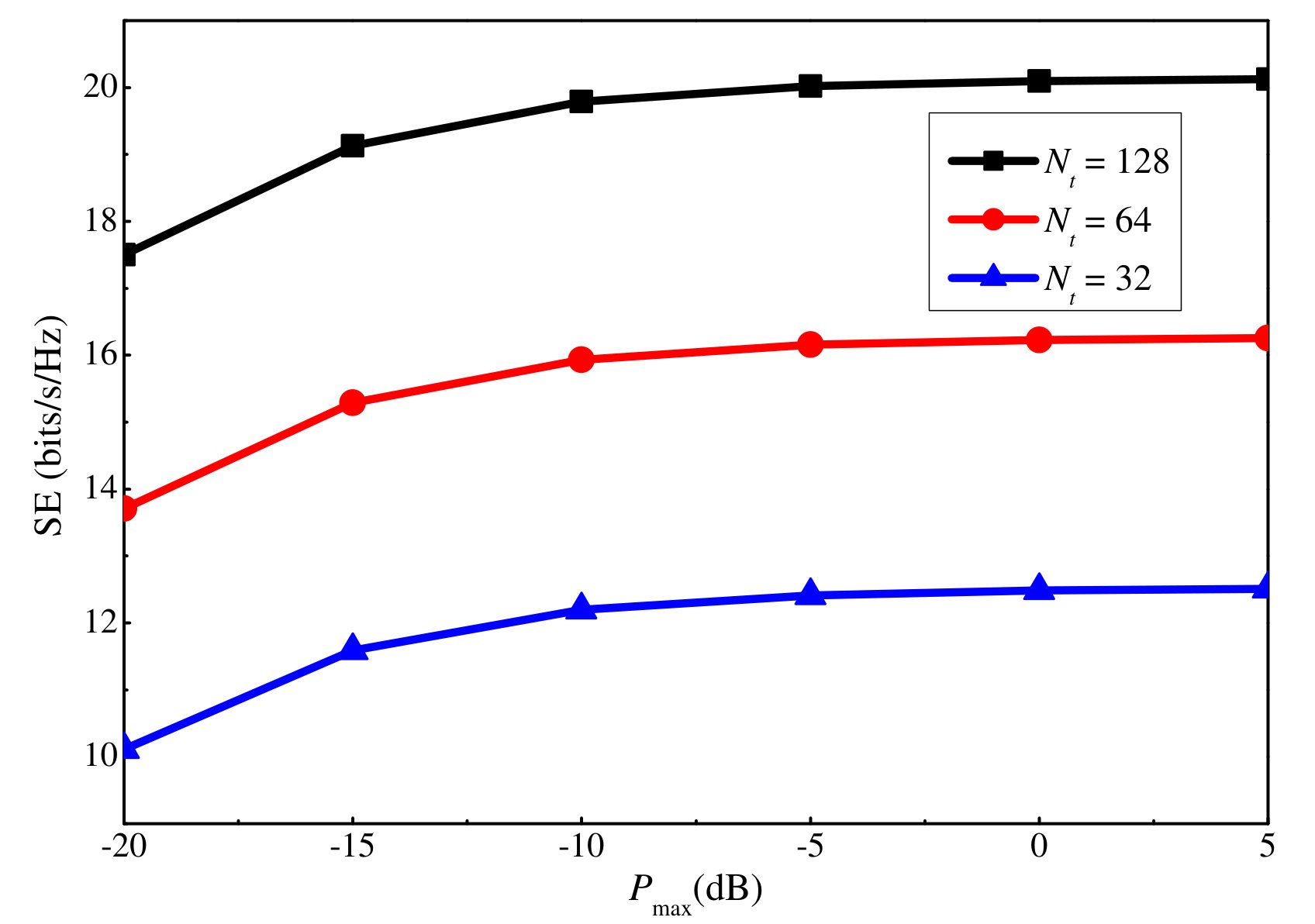 Figure 24
Figure 24 Figure 25
Figure 25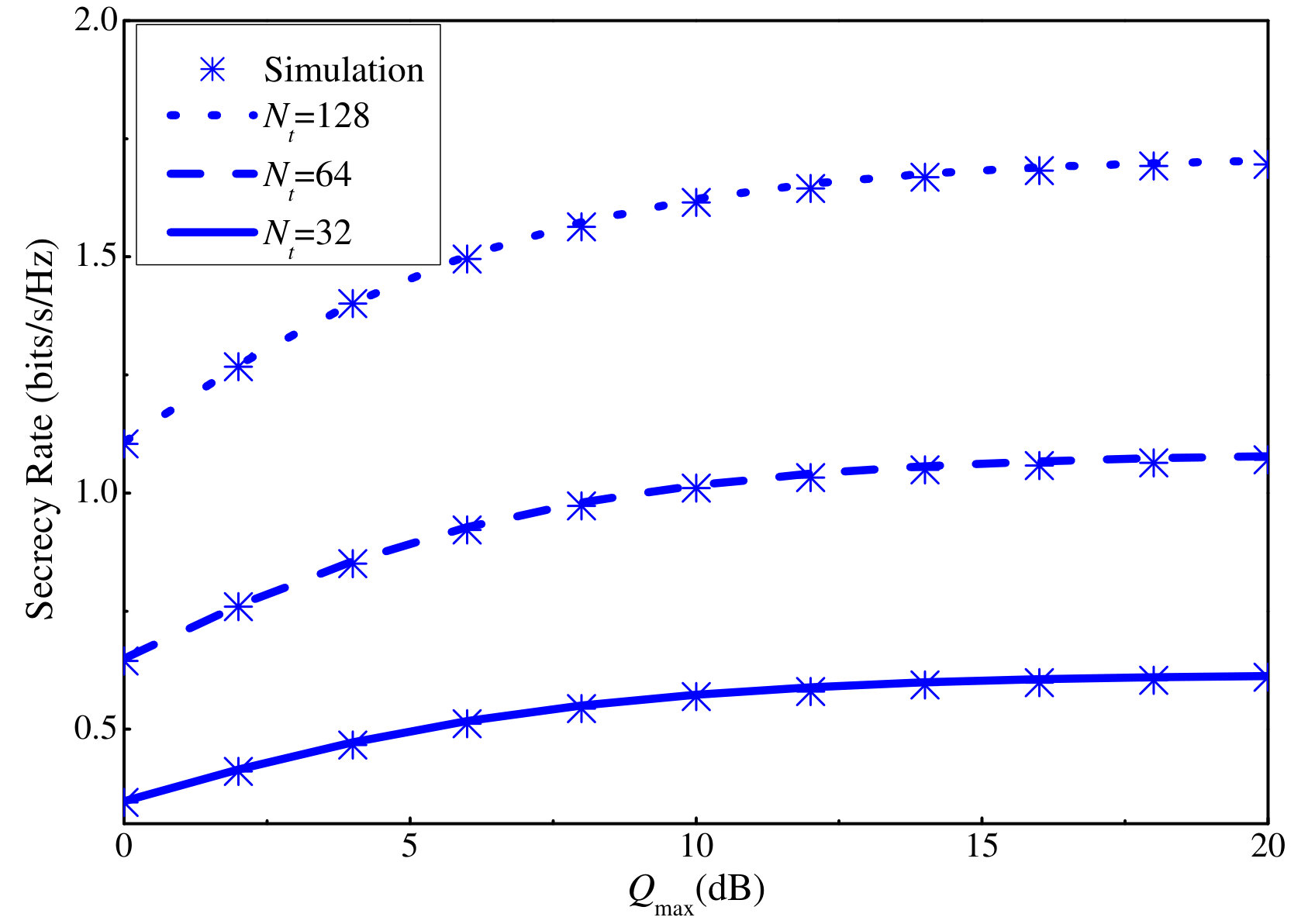 Figure 26
Figure 26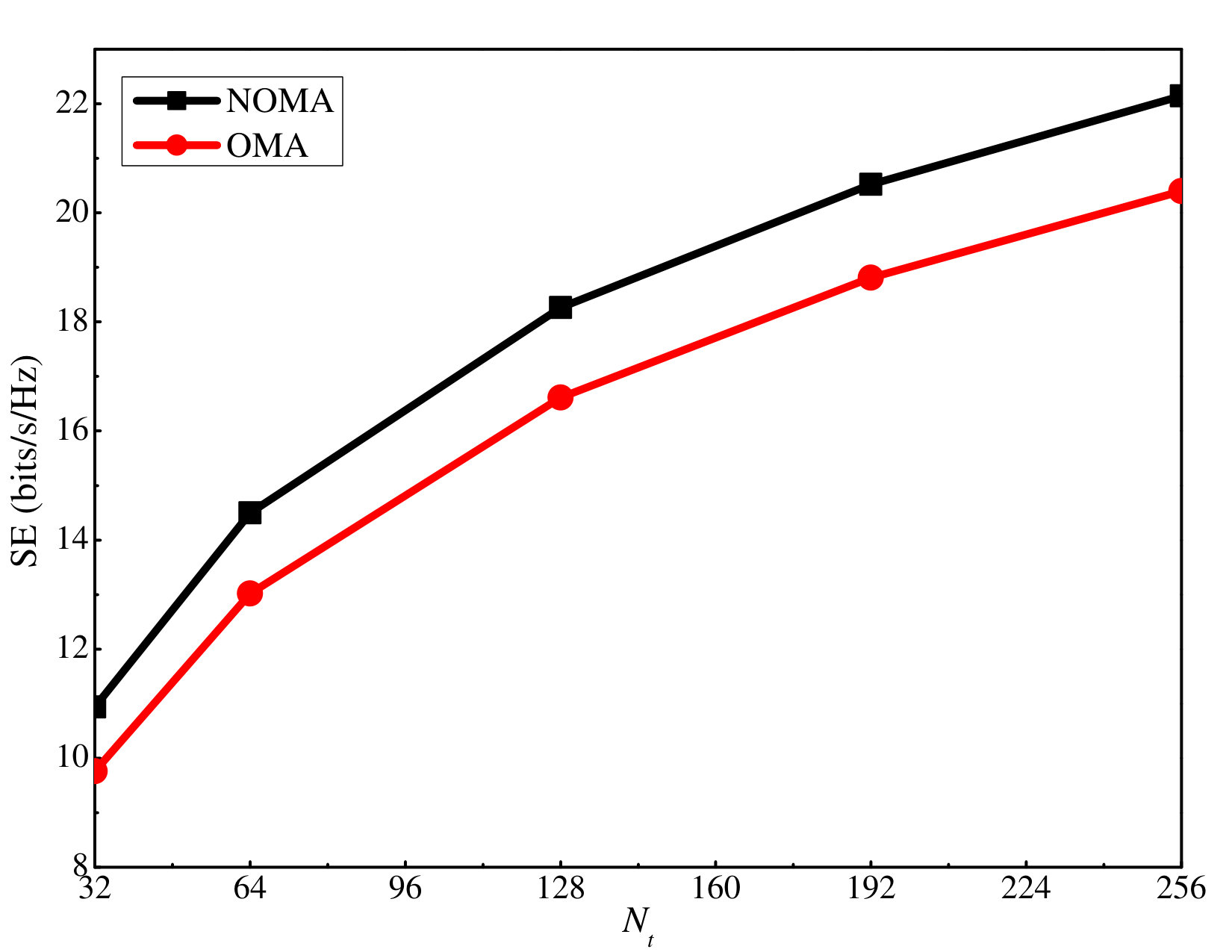 Figure 27
Figure 27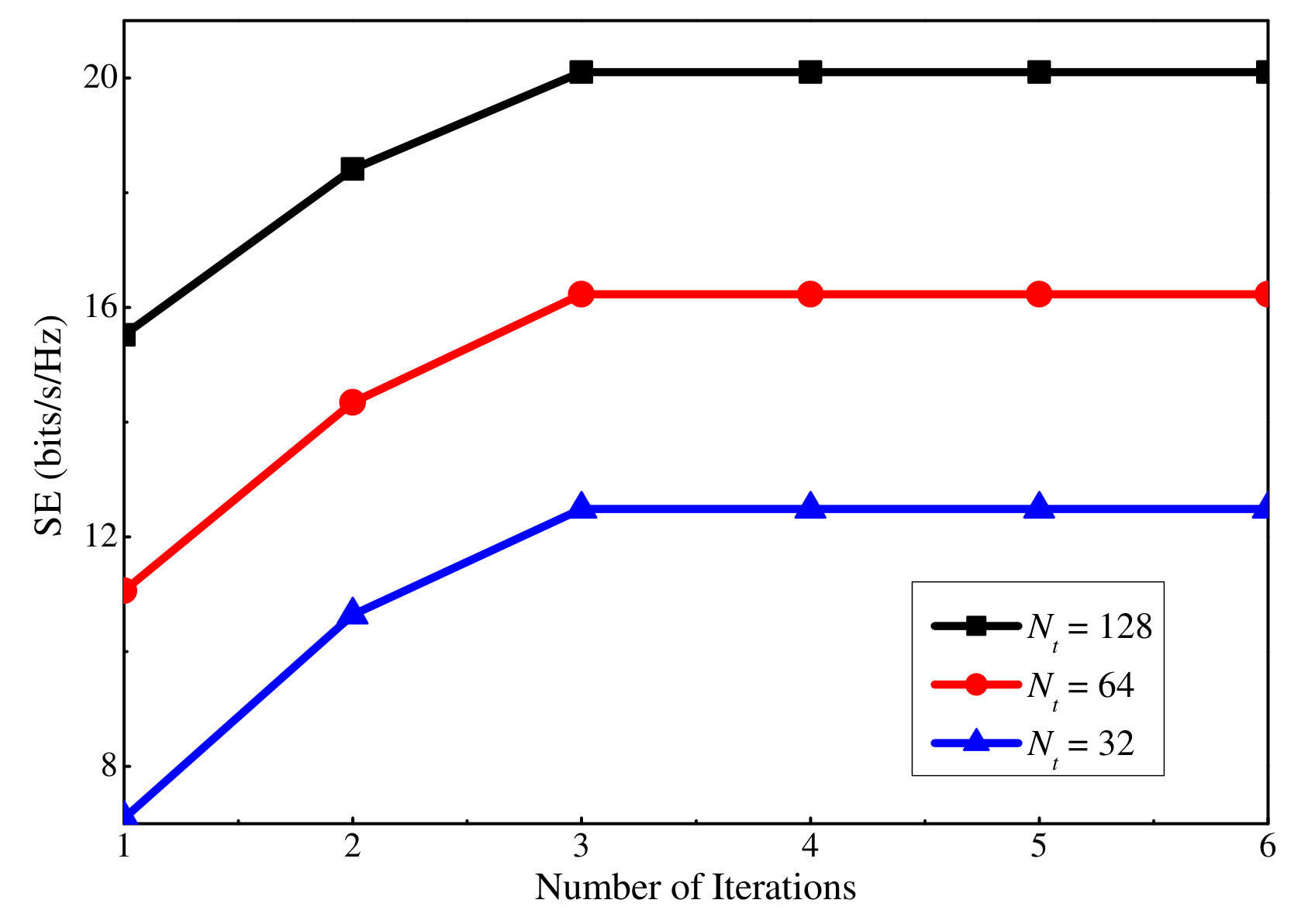 Figure 28
Figure 28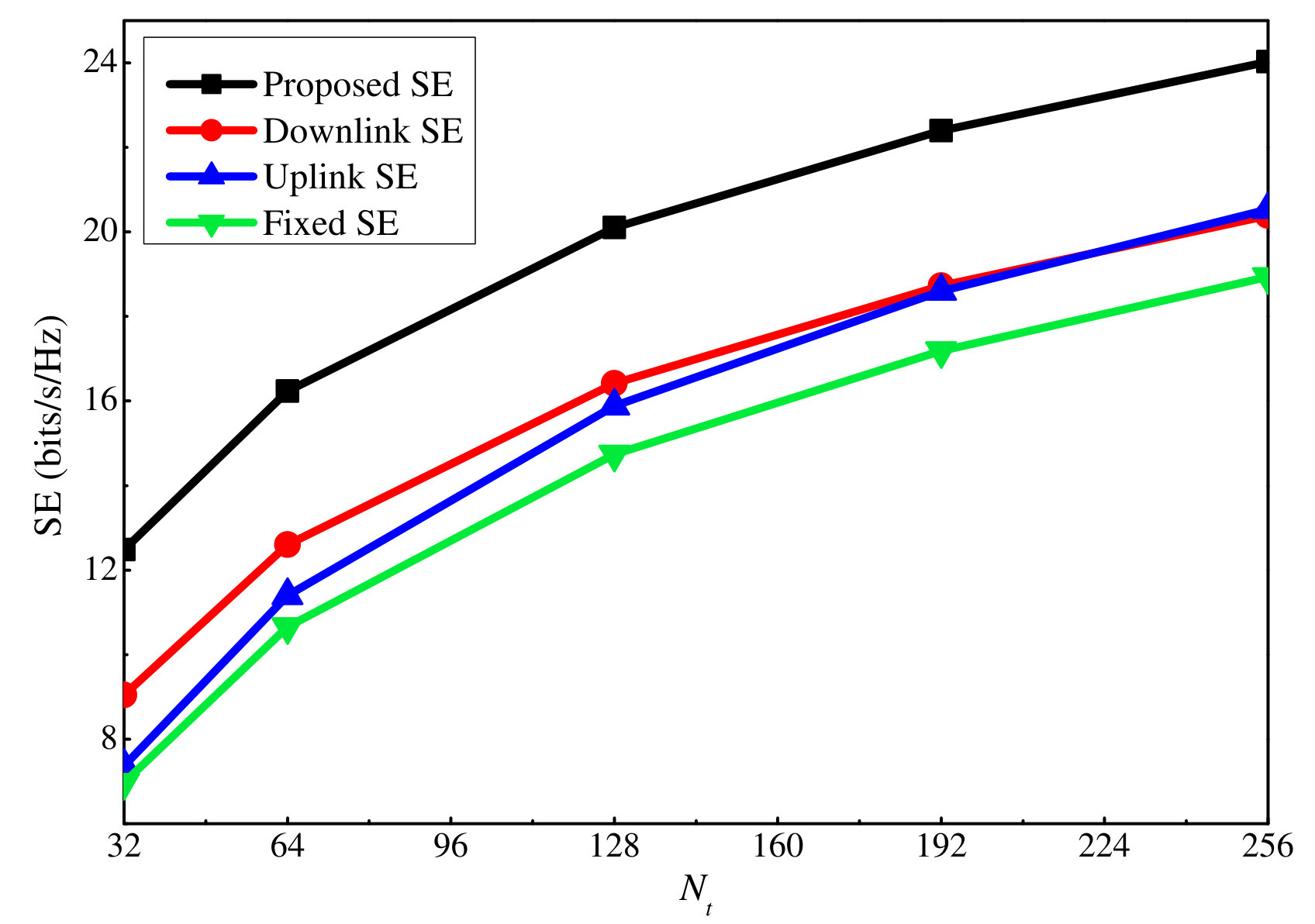 Figure 29
Figure 29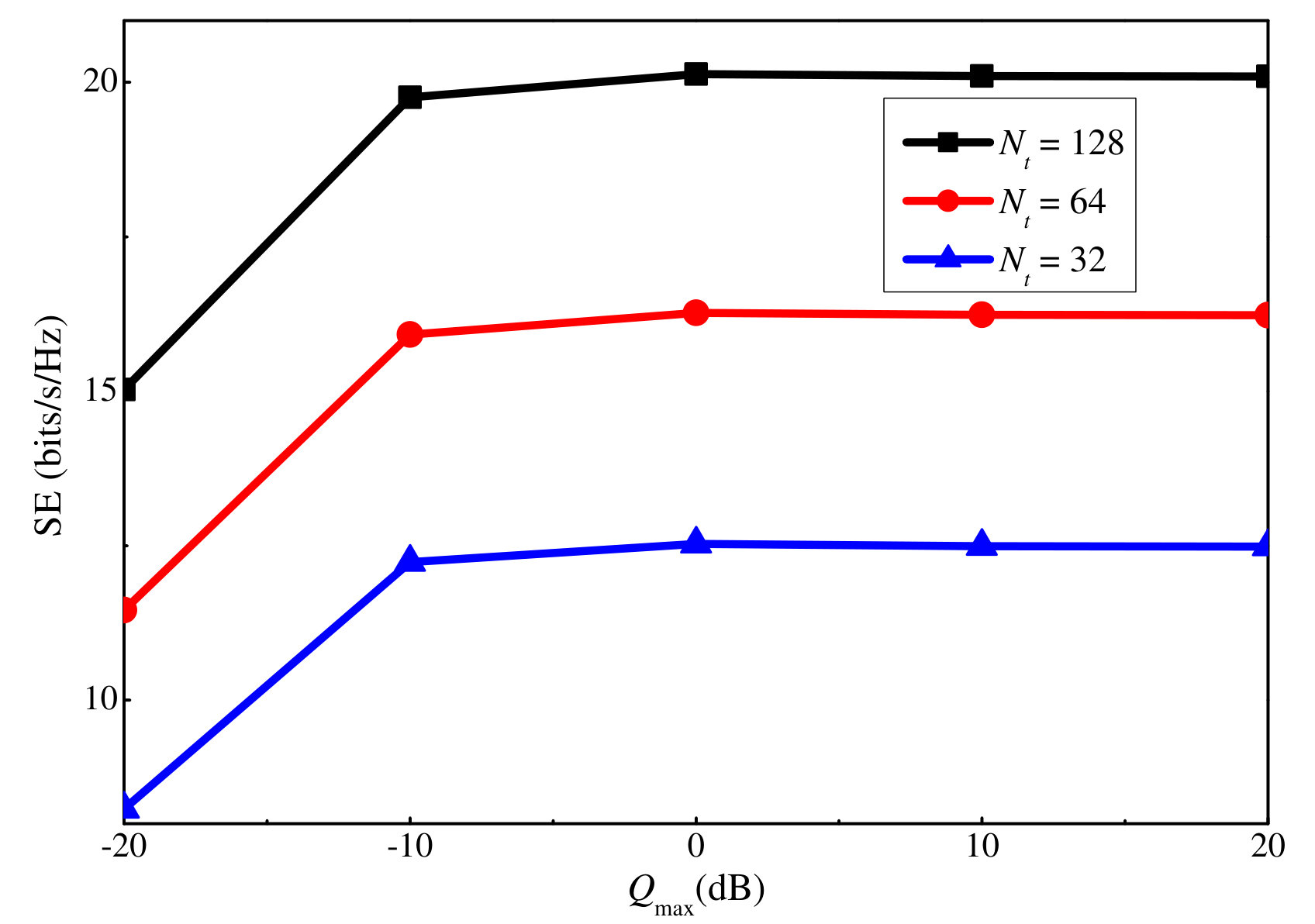 Figure 30
Figure 30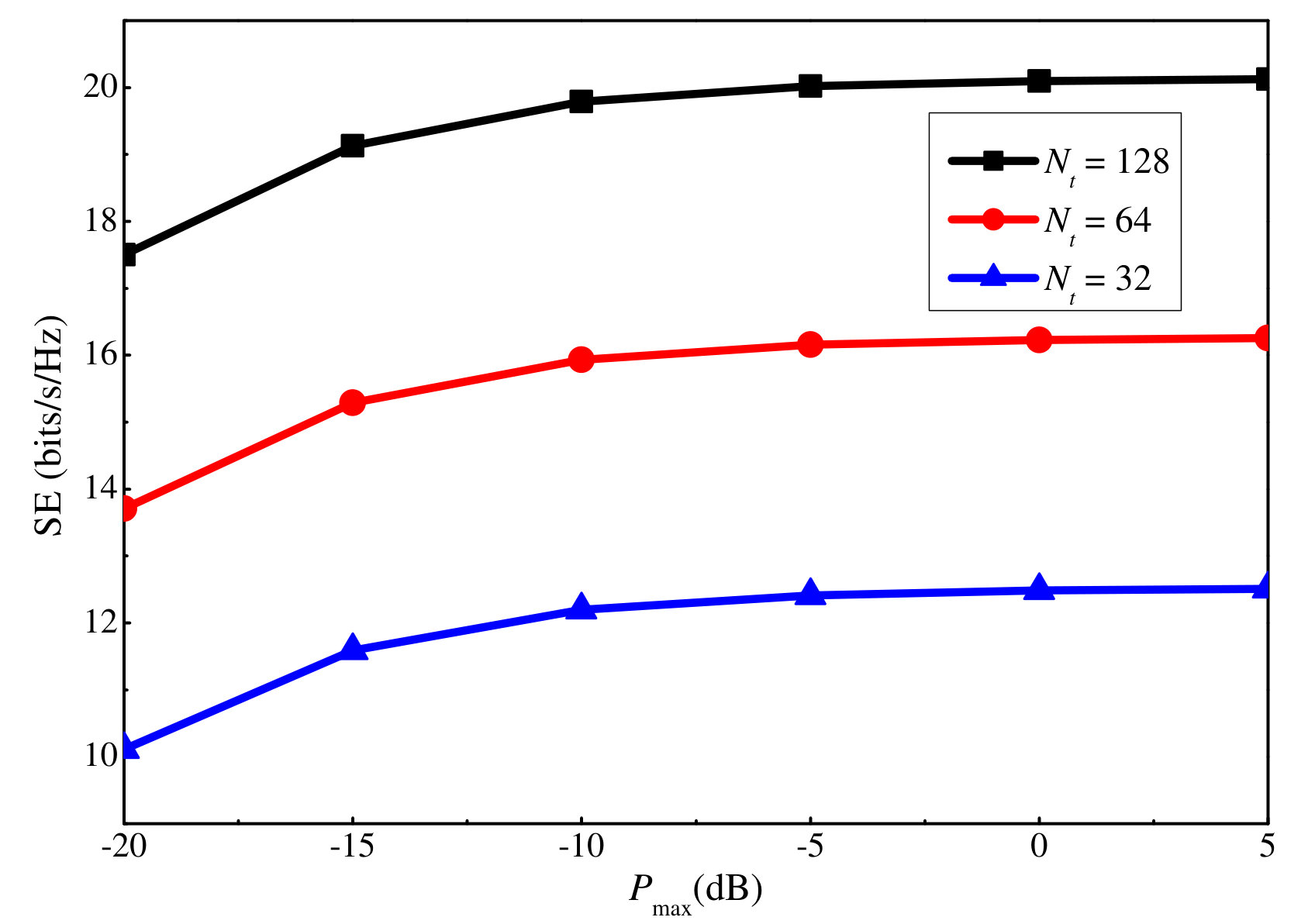 Figure 31
Figure 31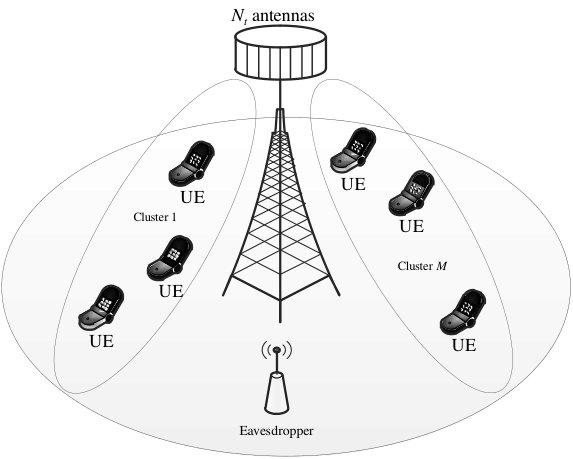 Figure 32
Figure 32Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Securing Downlink Massive MIMO-NOMA Networks with Artificial Noise
Ming Zeng, Nam-Phong Nguyen, Octavia A. Dobre, and H. Vincent Poor This work was supported in part by the Natural Sciences and Engineering Research Council of Canada (NSERC) through its Discovery program, and in part by the U.S. National Science Foundation under Grants CCF-093970 and CCF-1513915. M. Zeng, N.-P. Nguyen, and O. A. Dobre are with Memorial University, Canada. (e-mail: {mzeng, nnguyen, odobre}.mun.ca). N.-P. Nguyen is also with Hanoi University of Science and Technology, Vietnam (email: [email protected]).H. V. Poor is with the Electrical Engineering Department, Princeton University, Princeton, NJ, USA (e-mail: [email protected]). All authors contributed equally to the article.
Abstract
In this paper, we focus on securing the confidential information of massive multiple-input multiple-output (MIMO) non-orthogonal multiple access (NOMA) networks by exploiting artificial noise (AN). An uplink training scheme is first proposed with minimum mean squared error estimation at the base station. Based on the estimated channel state information, the base station precodes the confidential information and injects the AN. Following this, the ergodic secrecy rate is derived for downlink transmission. An asymptotic secrecy performance analysis is also carried out for a large number of transmit antennas and high transmit power at the base station, respectively, to highlight the effects of key parameters on the secrecy performance of the considered system. Based on the derived ergodic secrecy rate, we propose the joint power allocation of the uplink training phase and downlink transmission phase to maximize the sum secrecy rates of the system. Besides, from the perspective of security, another optimization algorithm is proposed to maximize the energy efficiency. The results show that the combination of massive MIMO technique and AN greatly benefits NOMA networks in term of the secrecy performance. In addition, the effects of the uplink training phase and clustering process on the secrecy performance are revealed. Besides, the proposed optimization algorithms are compared with other baseline algorithms through simulations, and their superiority is validated. Finally, it is shown that the proposed system outperforms the conventional massive MIMO orthogonal multiple access in terms of the secrecy performance.
Index Terms:
Non-orthogonal multiple access (NOMA), massive multiple-input multiple-output (MIMO), physical layer security, artificial noise (AN).
I Introduction
The development of Internet-of-Things demands massive connectivity over the limited radio spectrum. This requires the next generation wireless networks deploy new multiple access technologies with better spectral efficiency[1]. Recently, non-orthogonal multiple access (NOMA) has been introduced as a solution for this challenge [2, 3]. Power-domain NOMA allows multiple users to share the same time-frequency resource simultaneously by using superposition coding and advanced interference cancellation techniques, such as successive interference cancellation (SIC)[4, 5, 6]. As a result, NOMA can enhance the capacity of a network in both spatial and temporal dimensions [7, 8, 9, 10]. However, from the security viewpoint, sharing the same time-frequency resource among users imposes secrecy challenges.
Traditionally, the security issues have been handled at the higher layers using encryption approaches. However, the development of computing technologies and the tremendous growth in the number of wireless devices have surfaced the vulnerability of the conventional encryption methods [11]. As a result, physical layer security (PLS) has been introduced as an additional protecting layer to the conventional encryption methods for securing confidential information [12]. The principle of PLS is to take advantage of the randomness of the wireless channels to restrain the illegitimate side from overhearing the legitimate users [13]. The community has shown a great interest in applying PLS to NOMA networks. In[14], the authors investigated the secrecy outage probability (SOP) of NOMA relay networks with two types of relay, i.e., amplify-and-forward and decode-and-forward. The paper revealed that in the high signal-to-noise ratio regime, the SOP of the considered NOMA relay network converges to a constant value. In [15], the secrecy performance of a stochastic NOMA network was considered, by modelling its users’ locations using stochastic geometry. The results showed that the secrecy diversity order of the considered system is determined by that of the user pair with a poorer channel. In [16], the authors derived a closed-form solution for maximizing the secrecy sum rate of the NOMA while taking the users’ quality of service requirements into consideration. In [17], the authors investigated a NOMA system in the presence of an external eavesdropper. The SOP of the considered system was derived and used to optimize the decoding order, transmission rates, and allocated power. These studies have laid the initial foundation for exploiting PLS in NOMA networks.
Recently, massive multiple-input multiple-output (MIMO) has become one of the key technologies for 5G network [18, 19, 20]. By deploying hundreds of antennas at the base station (BS) to serve tens of users, massive MIMO exploits the high spatial resolution and large array gain to greatly enhance the throughput, spectral efficiency, and energy efficiency (EE) [21, 22, 23]. Massive MIMO networks are suggested to operate in time division duplex to address pilot contamination by exploiting channel reciprocity [18]. In massive MIMO networks, the BS can obtain the knowledge of the channel state information (CSI) via uplink training sequences of the users and employ this knowledge to precode the transmit data. The combination of massive MIMO and NOMA seems to be naturally matched since it can offer a great performance enhancement for a large number of users [24]. However, there are some challenges of this combination. Since the number of orthogonal sequences for the uplink training phase is limited, the massive number of users has to be grouped in clusters. In a cluster, users share the same training sequence. As a consequence, the quality of the uplink training phase can be compromised. Therefore, the spatial resolution is decreased, which can lead to leakage of the confidential information. There have been several studies of PLS for massive MIMO-NOMA networks. In [25], the authors have investigated the secrecy performance of a NOMA massive MIMO network in the presence of an active eavesdropper. The inter-user interference was utilized to enhance the secrecy performance of the network. Artificial noise (AN) has proven its effectiveness to secure the legitimate side from malicious attempts [26, 27]. Recently, in [28], the authors have proposed a joint alignment of multi-user constellations and AN to secure the massive MIMO-NOMA networks. By using a water filling power allocation between the constellation and AN, the error rate of the legitimate user is eliminated with a large number of antennas at the receiver, while the error rate of the eavesdropper approaches a floor when the number of eavesdropper’s antennas is large. So far, it is the only work that deploys AN in NOMA networks. Therefore, the role of AN in massive MIMO-NOMA networks is far from being well-understood.
In this paper, we propose an AN-based PLS method for the massive MIMO-NOMA networks in the presence of a passive eavesdropper. In order to secure the downlink transmission, the BS uses its knowledge of CSI to precode the confidential information and inject the AN, which is different from [25]. Besides, because of the high complexity of the uplink training phase in the massive MIMO-NOMA networks, the AN approaches in [26, 27] are not suitable. Therefore, in this paper, the AN is injected in the null-space of the effective channels of the clusters in the downlink transmission phase. To emphasize the role of the uplink training process on the secrecy performance of the considered system, the CSI knowledge at the BS is the result of an estimation process that is more practical than the assumption of perfect CSI in other existing work on PLS for massive MIMO-NOMA networks. To the best of our knowledge, this is the first work using AN to secure massive MIMO-NOMA networks when taking imperfect channel estimation into account. The contributions of this paper can be summarized as follows:
- •
We demonstrate a framework to analyze the secrecy performance of an AN-aided massive MIMO-NOMA network while taking the imperfect channel estimation into consideration. In particular, the ergodic secrecy rates for users are derived. The asymptotic expressions of the legitimate and illegitimate rates for a large number of antennas and high transmit power at the BS are also obtained. Note that the AN-aided massive MIMO-OMA network is a special case of the proposed system. The analysis expressions can be applied directly with the number of users in each cluster being equal to one.
- •
The results reveal that by using a sufficiently large number of antennas at the BS, the AN only affects the eavesdropper. In addition, when the transmit power at the BS is sufficiently high, the secrecy performance of a user depends on the AN, the intra-cluster interference, and the channel estimation error of its cluster.
- •
In order to further exploit the interference and AN, we study the maximization of the sum ergodic secrecy rate (SE) and the maximization of the EE in terms of the ergodic secrecy rates. In this work, the EE is defined as the sum ergodic secrecy rate over the total transmit power, which includes both the uplink and downlink powers. For the SE maximization problem, we first decompose it into two sub-problems, i.e., uplink and downlink power allocation (PA), based on alternating optimization. Then, we address each sub-problem using difference of convex (DC) programming. The EE maximization problem is of fractional form, and can be transformed into a series of SE maximization problems, which can be solved accordingly. Numerical results show that the proposed algorithms can significantly enhance the performance of the considered system, compared with other baseline algorithms.
The rest of this paper is organized as follows. The system and channel models are described in Section II. The analytical expressions for the ergodic secrecy rates of the considered system are developed in Section III. In Section IV, the optimization problems are proposed, and the solutions are discussed in Section V. The numerical results and discussions are presented in Section VI. Finally, we conclude the paper in Section VII.
Notations
Superscript stands for the conjugate transpose. The expectation operation and Frobenius norm are denoted by and , respectively. denotes the -dimensional identity matrix. indicates complex normal distribution with mean and variance.
II System and Channel Models
As shown in Fig. 1, we consider the downlink transmission in a massive MIMO-NOMA system, which includes one -antenna BS, multiple single-antenna end users (UEs) that are grouped into clusters with users, , in the -th cluster, and one passive single-antenna eavesdropper. Before performing the downlink transmission, the BS needs the network’s CSI to precode the information and inject the AN. Besides, the users also require knowledge of the precoding to decode the confidential information. Therefore, the BS and users exchange CSI and precoding knowledge in the training phases.
II-A Training Phases
II-A1 Uplink training
During one coherence interval duration of samples, the users simultaneously send training sequences to the BS. Users in the same cluster employ the same training sequence. In order to prevent the training sequence of each cluster from interfering with each other, all clusters are assigned mutually orthogonal training sequences of length samples, where . The -th cluster training sequence is denoted by a vector , where , . The received training signal at the BS is
[TABLE]
where is the transmit power of the -th UE of the -th cluster, is the large-scale fading, is the small-scale fading, , and the elements of represent the additive white Gaussian noise (AWGN). Since is known at the BS, the BS pre-processes the received signal as follows:
[TABLE]
where is the effective channel for the -th cluster.
The BS uses the minimum mean squared error (MMSE) technique to estimate .111The use of MMSE has been widely addopted in massive MIMO system [19, 20]. The estimate of is [25]
[TABLE]
The relation between and is
[TABLE]
where is the error vector, which is independent of . Besides, [25].
Remark 1
For each cluster, the error of the estimation process depends on the uplink transmit power of each user, the number of users in a cluster, the large-scale fading, and the length of the training sequences. This error can be reduced by decreasing the number of users in a cluster. However, this leads to an increase in the number of clusters, and further yields more orthogonal training sequences, which are limited in certain cases, e.g., crowded stadium, busy city center, etc.
After the estimation process, the BS uses the estimates of the cluster’s effective channels to precode. In this paper, we assume that the BS employs the maximal ratio transmission (MRT) precoder, which is simple and nearly optimal in massive MIMO networks [20]. The precoder is defined as
[TABLE]
II-A2 Downlink training
The downlink training phase is similar to the uplink training phase, except that the BS uses the obtained precoder to beam the downlink pilots to the clusters. Since the downlink pilots are known at the users, these users can estimate accurately their effective channel gains, i.e., . We assume that the estimation process at users is perfect.222This assumption is reasonable since it has been proven that at a sufficiently high transmit power, the error of the channel estimation process at the receiver is sufficiently small and can be neglected [27]. Without loss of generality, the users’ effective channel gains of the -th cluster are ordered as follows:
[TABLE]
During this phase, the eavesdropper also obtains its effective channel gain, i.e., , where is the large-scale fading and is the small-scale fading vector corresponding to the eavesdropper.
II-B NOMA Downlink Transmission
In order to perform NOMA downlink transmission, the BS conducts superposition coding for each cluster. The superposition coding for the -th cluster is as follows:
[TABLE]
where is the transmit power allocated to UEm,k, and is the corresponding transmitted signal, satisfying . For securing the confidential information, the BS injects AN into the transmitted signals. The BS combines all cluster signals as follows:
[TABLE]
where and are the precoding vector and AN vector for the -th cluster, respectively, , ; is the power allocated for the AN and is the AN signal of the -th cluster, .
The received signal at the UEm,k is
[TABLE]
where is the AWGN at UEm,k.
The eavesdropper tries to intercept the confidential information of UEm,k. The received signal at the eavesdropper is
[TABLE]
where is the AWGN at the eavesdropper.
III Secrecy Performance Analysis
In this section, we derive the ergodic secrecy rate of UEm,k from its ergodic legitimate rate and its corresponding ergodic eavesdropping rate.
III-A Ergodic Secrecy Rate
The ergodic secrecy rate of UEm,k is
[TABLE]
where . This approximation is reasonable in massive MIMO systems owing to the channel hardening property [29]. The achievable rate of UEm,k is
[TABLE]
where denotes the expectation operator and , with
[TABLE]
where step holds true because , is the gamma function, step is based on the fact that has a scaled Chi distribution with degrees of freedom by a factor of [27]. Therefore, , and step is obtained by using the approximation [30].
Further, for in the expression of are given in (III-A), (III-A) and (III-A), respectively on the top of the next page. Note that step in (III-A) is obtained because and is independent of .
It can be seen that denotes the desired signal leakage due to the imperfect uplink channel estimation, while represents the intra-cluster interference after SIC and the AN leakage. In addition, expresses the inter-cluster interference and AN.
Remark 2
Note that perfect SIC is assumed to obtain . That is, the -th user first decodes and subtracts the interfering signals from the -th to the -th user in sequence, and then demodulates its desired signal . In other words, the residual intra-cluster interference is only from the users with stronger channel gains, i.e., the first user to the -th user. In practice, owing to channel estimation error, hardware limitation, low signal quality, and so on, the decoding error of the weak interfering signal may occur. Consequently, there exists residual interference from the weak users after SIC, namely imperfect SIC. This residual interference is similar to the intra-cluster interference. As shown in [31, 32, 33], the residual interference can be modeled as a linear function of the power of the interfering signal, and the coefficient of imperfect SIC can be obtained through long-term measurements. As a result, the ergodic secrecy rate in the presence of imperfect SIC can be directly derived by adding the term of residual interference in .
The ergodic eavesdropping rate corresponding to UEm,k is
[TABLE]
where , with
[TABLE]
Therefore, can be simplified as (18) on the top of the next page.333It is possible to extend this work to the case of multiple eavesdroppers or multi-antenna eavesdropper since (18) can be applied to each eavesdropper or each antenna of a multi-antenna eavesdropper. The secrecy performance in these cases is determined by the strongest eavesdropper or the strongest eavesdropping antenna.
By comparing the intra-cluster interference terms in and , i.e., and , we can observe that the intra-cluster interference has less impact on the legitimate users owing to SIC. This helps to achieve a higher secrecy rate.
III-B Asymptotic Secrecy Performance
In this subsection, increasing the number of antennas and the transmit power at the BS are respectively studied to reveal insights into the considered system.
III-B1 Large Number of Antennas at the BS
We first investigate the impact of a large number of antennas at the BS on the secrecy performance. From (18), we can observe that the eavesdropping rate is independent of the number of antennas at the BS. When this number is large, the legitimate rate is expressed as
[TABLE]
Remark 3
When the number of antennas at the BS is sufficiently large, the secrecy rate converges to a constant value. At the legitimate side, the effect of imperfect CSI, fading, inter-cluster interference, and AN leakage is negligible because of channel hardening. The legitimate rate depends only on the intra-cluster transmit powers. Meanwhile, the eavesdropping rate suffers from noise, interferences, and fading. Obviously, by using AN, the secrecy performance can be guaranteed in this scenario.
III-B2 High Transmit Power at the BS
In order to reveal the impact of the transmit power at the BS, the transmit power for each user is set proportional to the maximum transmit power of the BS, i.e., , where is the maximum transmit power at the BS and . When is large, the legitimate rate and the eavesdropping rate are respectively approximated as (III-B2) and (21) on the top of the next page.
Remark 4
When the transmit power at the BS is high, we can observe that:
- •
The secrecy rate converges to a constant value. This value is independent of fading and the maximum transmit power.
- •
The legitimate rate and the eavesdropping rate suffer from the same amount of inter-cluster interference and inter-cluster AN. In other words, the secrecy rate is independent of the inter-cluster interference and inter-cluster AN.
- •
The eavesdropper is affected by the AN more heavily than the legitimate user. This effect depends on the uplink training process. Recalling Remark 1, we can conclude that the secrecy performance depends on the number of available orthogonal pilots.
IV Optimization Problems
In this section, we consider the optimization of the uplink and downlink PA to fully exploit the potential of the proposed secure massive MIMO-NOMA network. Two system level criteria are respectively considered, i.e., the SE maximization and the EE maximization.
IV-A SE Maximization
First, we aim to maximize the SE for the considered system, which is formulated as
[TABLE]
where and denote the matrix for the uplink and downlink power, respectively. Equations (22ab) and (22ad) represent the maximum transmit power constraint for each user in uplink and the total power constraint in downlink, respectively. Note that there exists a one-to-one mapping between and .
IV-B EE Maximization
We also consider maximization of EE, defined as the sum ergodic secrecy rate over the total transmit power, which includes both the uplink and downlink power [34, 35, 36]. Moreover, for uplink and downlink power, both fixed circuit power and dynamic transmit power are considered [37, 38]. We denote the overall circuit power of the system as . Then, the EE is given as
[TABLE]
Accordingly, the EE optimization problem can be expressed as
[TABLE]
V Proposed Solutions
V-A SE Maximization
Problem (22a) is clearly non-convex, owing to the non-convex objective function. Moreover, it can be seen that the uplink power and downlink power are coupled in the objective function. This coupling makes (22a) difficult to handle. To address it, we propose to decompose the original problem into the following two sub-problems:
V-A1 Uplink Power Allocation for Channel Estimation
For this sub-problem, we assume that the downlink power is appropriately allocated to the users and the AN, i.e., is known and given. Then, the original problem can be simplified as
[TABLE]
V-A2 Downlink Power Allocation for Data Transmission
Likewise, here we assume that the uplink power is appropriately allocated to the users, i.e., is known and given. Then, the original problem is re-expressed as
[TABLE]
For sub-problem (1), since is given, it can be seen that is a constant. Then, we only need to consider . After some mathematical manipulations, can be expressed as
[TABLE]
where , , .
On this basis, we further transform as (V-A2) on the top of the next page.
Note that is a constant, which does not affect the solution and can be removed. Then, (25) can be re-expressed as
[TABLE]
where both functions and are concave. Thus, the objective is a DC function. The gradient of at is given by
[TABLE]
The following procedure generates a sequence of improved feasible solutions [39, 40]. Initialized from a feasible , is obtained as the optimal solution of the following convex problem at the -th iteration:
[TABLE]
Note that (V-A2) can be efficiently solved by available convex software packages [41]. Moreover, since there exists no inter-cluster interference, the sum rate maximization can be done in parallel for each cluster, i.e., the system sum rate maximization equals to the cluster sum rate maximization.
After solving the above problem, we can obtain the value for . Accordingly, we can obtain . On this basis, for sub-problem (2), after some mathematical manipulations, can be expressed as (V-A2) on the top of the next page.
Note that in (V-A2), , , and .
The gradient of at is given by (32) on the top of the next page.
Next, let us consider , which can be re-written as
[TABLE]
The gradient of at is given by
[TABLE]
The following procedure generates a sequence of improved feasible solutions [39, 40]. Initialized from a feasible , is obtained as the optimal solution of the following convex problem at the -th iteration:
[TABLE]
Note that (V-A2) can also be efficiently solved by available convex software packages [41].
Now we have solved the two sub-problems. We repeat them after each other until convergence. Then, for those users with negative rates, we set their rates to zero following the operation. The specific procedure is summarized in Algorithm 1.
V-B EE Maximization
It is clear that (24) belongs to a fractional problem, which can be transformed into a series of parametric subtractive-form subproblems as (36) on the top of the next page based on Dinkelbach algorithm [42].
Note in (36), is a non-negative parameter. Starting from , can be updated by , where , and are the updated rates and power after solving (36). As shown in [42], keeps growing as increases. When is smaller than a certain threshold, e.g., , the iterations terminate, and the obtained is the maximum EE of (24).
Then, the problem lies in how to solve (36) for a given . It is clear that (36) is similar to the sum rate maximization problem (22a), except for the extra linear part in the objective function. Adding a linear part does not affect the way of solving the problem, and thus, we can apply the proposed sum rate maximization here directly. The specific procedure is summarized in Algorithm 2.
V-C Complexity and Convergence
The proposed SE maximization algorithm includes inner and outer iterations. For the inner iteration, i.e., the DC programming, its convergence has been shown in [40, 39]. For the outer iteration, on one hand, the SE increases or remains unchanged for both the uplink and downlink PA; on the other hand, there exists an upper bound for the SE. Therefore, the outer iteration terminates within a limited number of iterations, i.e., the proposed SE maximization algorithm always converges.
The proposed EE maximization algorithm also includes inner and outer iterations. For the inner iteration, i.e., the SE maximization, its convergence has been shown above. For the outer iteration, i.e., the fractional programming, it always converges to the stationary and optimal solution [42]. Therefore, the proposed EE maximization algorithm always converges.
Now, we discuss the computational complexity of the proposed algorithms. First, we look at the proposed SE maximization algorithm. Denote the number of iterations for solving the uplink and downlink PA as and , respectively. The corresponding number of dual variables for solving (V-A2) and (V-A2) is denoted as and , respectively. Then, if the number of outer iteration is , the overall computational complexity of the proposed SE maximization algorithm is . Next, we consider the proposed EE maximization problem. Denote its outer iteration as , then it can be easily shown that the overall computational complexity of the proposed EE maximization algorithm is .
VI Numerical Results
In this section, we firstly investigate the behavior of the system without PA to highlight the effects of key parameters on the secrecy performance in subsection VI-A. The effectiveness of our proposed PA algorithms is then evaluated in subsection VI-B.
VI-A Fixed PA
Without loss of generality, we consider the following scenario. The total transmit power is allocated for information transmission and for AN. The effect of varying the AN power allocation will be shown later in Fig. 3. The power is equally assigned to each user, and the AN power for each cluster is the same. units and units. for each user is a random value between 0 and 100 and satisfies the condition , while that for the illegitimate user is fixed to 10. Unless explicitly mentioned, this setup is kept throughout the section.
Without loss of generality, the ergodic secrecy rate of the user in the cluster is selected to show in Fig. 2. The number of cluster is and the number of users in a cluster is .444The subscript in is dropped since the same number of users is considered in clusters. It can be seen that the approximation in (III-A) and the simulation results match very well. Throughout the numerical results section, this approximation will be used. Besides, when the total transmit power at the BS increases, the secrecy rate at a user converges to a constant value. This is because of the interference and AN within the cluster and from other clusters. In addition, we can also observe that an increase in the number of antennas at the BS can lift the secrecy performance. The reason is that by increasing the number of antennas, the spatial transmitting beams become sharper, which leads to a decrease in inter-cluster interference and AN leakage, and an increase in the desired signal. The next figure will reveal how to take advantage of this property to enhance secrecy performance.
In Fig. 3, we demonstrate the advantage of combining AN and massive MIMO technique in NOMA networks. In this setup, the transmit power assigned to each user is dB, and the AN power is varied as dB. The number of clusters is with users in a cluster. We can observe that when the number of transmit antennas is sufficiently large, the more the AN allocated power is, the better the secrecy performance at the user is. The main reason is that for the legitimate side, the channel hardening property of massive MIMO technique helps reducing the AN leakage and the inter-cluster interference at each cluster. Meanwhile, the secrecy performance of the eavesdropper decreases when the AN power increases.
Figures 4 and 5 depict the effect of clustering on the secrecy performance. In Fig. 4, the total number of users is , which are clustered into three scenarios: , , and . The total transmit power for each scenario is the same. The results show that the smaller the number of users in a cluster is, the better the secrecy performance at a user is. Meanwhile, in Fig. 5, the scenario of limited number of orthogonal sequences is shown. In this scenario, we assume that the number of available orthogonal sequences is , therefore, the number of clusters is . The number of users in a cluster is varied as to highlight its effect on the secrecy performance of a cluster. It is observed that although the transmit power for each user is identical and the AN power for each cluster is the same, the cluster with more users has smaller total secrecy rate than the ones with a smaller number of users. The reason is that when the number of users in a cluster is small, the error of the uplink training process at this cluster is also small. As a consequence, the beam of the BS for this cluster is more precise, followed by a decrease in intra-cluster interference and AN leakage. This also reduces the imposed interference from this cluster to other clusters. In other words, for a better secrecy performance of each user and cluster, it is crucial to keep the number of users in a cluster small (minimum is two users for NOMA networks).
VI-B Optimized PA
In the following, we investigate the effectiveness of the proposed SE and EE maximization algorithms. We consider a scenario with four clusters, each with three users, i.e., and . The simulation parameters are as follows: dB, dB. units. The large scale channel gain for each user is a random value between 0 and 100, while that for the illegitimate user is fixed to 10.
First, we investigate the effectiveness of the proposed SE maximization algorithm, referred to as Proposed SE. We compare it with three baseline algorithms, as follows: Downlink SE, which allocates the maximum uplink power to each user, and on this basis, performs PA for the downlink transmission as the Proposed SE. In contrast, the Uplink SE first allocates of the total downlink power to the users equally, and of the total downlink power to the AN equally. Then, uplink power is optimized as the Proposed SE. Fixed SE allocates the maximum uplink power for each user, equal downlink power allocation among the users, and the AN as in the above subsection. As shown in Fig. 6, the SE provided by all four algorithms grows with the number of transmit antennas. Moreover, among them, it can be seen that Proposed SE achieves the best performance, followed by Downlink SE, Uplink SE, and Fixed PA. This fully reveals the necessity of performing power optimization for the considered system. Furthermore, both uplink and downlink PA are required to achieve the best performance. Nonetheless, by comparing Downlink SE and Uplink SE, we can conclude that an appropriate allocation of the downlink power may play a larger role in the current setting.
To further show the effect of the uplink and downlink power on the achieved SE, Figs. 7 and 8 plot the SE versus the maximum uplink and downlink power, respectively. is respectively considered in each case. It is clear that the SE increases with both the maximum uplink and downlink powers. The former is because increasing the maximum uplink power leads to a more precise channel estimation result, which improves the beamforming sharpness and thus, the SE. The latter is because more power is available for data transmission. However, after a certain point, the increase becomes minor for both power values. This can be explained by the logarithmic relation between the power and user rate. Moreover, for the downlink power, increasing it also leads to a larger illegitimate rate and intra-cluster interference. Besides, by comparing the three antenna scenarios, we can conclude that increasing the number of antennas can significantly increase the SE.
Next, we investigate the proposed EE algorithm. Here dB. We first compare the proposed EE maximization algorithm with the other three baseline algorithms when dB and dB. According to Fig. 9, the EE for the other algorithms is quite small compared with the proposed algorithm. This is because when dB and dB, the power level is quite high, and thus, a large part of the available power is not used to maximize the EE. However, for the three baseline algorithms, at least one of the uplink and downlink power is fully consumed according to the setting. This leads to low EE. Figure 10 only shows these three algorithms, and it can be seen that all of them increase with the antenna number as the proposed algorithm.
Similar to the SE, we also show how the EE varies with the maximum uplink and downlink power in Figs. 11 and 12, respectively. For both cases, the EE first grows with the maximum power constraint, and after a certain threshold, i.e., dB and dB, it remains unchanged even if the maximum power constraint continues to grow. This is because the slow increases in the SE cannot compensate for the power increment when the power is high, and thus, no more power will be consumed by the users to maximize the EE. By comparing the EE figures with the sum rate ones, i.e., Fig. 7 versus Fig. 11, and Fig. 8 versus Fig. 12, we can observe that the EE reaches the turning point at a smaller power value than the sum rate. This is because after the sum rate increment over the power declines to a certain value, no more extra power is used to maximize the EE.
The baseline massive MIMO-OMA can be considered as a special case of the proposed massive MIMO-NOMA scheme with just one user in each cluster. Accordingly, the legitimate achievable rate of the -th user is:
[TABLE]
where , , , , is the downlink power for the -th user, is the AN power for the -th user, is the large scale fading of the -th user, , is the length of training sequences that is the same as the NOMA case, and is the uplink transmit power of the -th user. The achievable eavesdropping rate corresponding to the -th user is:
[TABLE]
The achievable secrecy rate of the -th user is
[TABLE]
In simulations, to compare the proposed massive MIMO-NOMA with the baseline massive MIMO-OMA, we consider a scenario with four clusters and two users in each cluster. TDMA is used for the baseline massive MIMO-OMA, and thus, each user in one cluster is only served half the time. Fig. 13 shows the corresponding SE and EE comparison between the considered schemes. It is clear that the proposed scheme outperforms the baseline massive MIMO-OMA when the number of antennas at the BS increases, which shows its superiority.
Finally, Figs. 14 and 15 show how many iterations are required for the proposed SE and EE maximization algorithms to converge, respectively. Note that here an iteration means solving either the uplink or the downlink DC programming problem, which requires to solve an average of five convex problems according to the simulation. Results for three different antenna numbers are presented when dB and dB. It can be seen that a small number of iterations are required for the proposed SE and EE maximization algorithms to converge.
VII Conclusion
In this paper, an AN-aided scheme has been proposed to ensure secrecy in massive MIMO-NOMA networks. The ergodic secrecy rate and its asymptotic value have been derived to spotlight the roles of key parameters on the secrecy performance of the considered system. The results have revealed that with a sufficiently large number of transmit antennas at the BS, only the illegitimate side is affected by the AN. In addition, when the transmit power at the BS is high, the secrecy performance of a user is independent of the inter-cluster interference and AN and is determined by the uplink training process, which depends on the number of users in a cluster, the uplink transmit power, and the large-scale fading. Besides, the results also suggest to keep the number of users in a cluster small for a better secrecy performance at each user and cluster. Furthermore, numerical results validate that our proposed optimization algorithms can obtain significant improvements over the baseline algorithms, i.e., Uplink PA, Downlink PA and Fixed PA, in terms of the sum ergodic secrecy rate and energy efficiency. This fully reveals the necessity of performing power optimization for the considered system, and the effectiveness of the proposed algorithms. Finally, from the perspective of sum ergodic secrecy rate and its energy efficiency, our proposed system surpasses the conventional massive MIMO-OMA system.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] V. W. S. Wong et al., Key Technologies for 5G Wireless Systems . Cambridge, UK: Cambridge University Press, 2017.
- 2[2] S. M. R. Islam, M. Zeng, and O. A. Dobre, “NOMA in 5G systems: Exciting possibilities for enhancing spectral efficiency,” IEEE 5G Tech. Focus, vol. 1, no. 2, May 2017. [Online]. Available: 307 http://5g.ieee.org/tech-focus .
- 3[3] S. M. R. Islam, M. Zeng, O. A. Dobre, and K. Kwak, “Resource allocation for downlink noma systems: Key techniques and open issues,” IEEE Wireless Commun. Mag. , vol. 25, no. 2, pp. 40–47, April 2018.
- 4[4] S. M. R. Islam et al., “Power-domain non-orthogonal multiple access (NOMA) in 5G systems: Potentials and challenges,” IEEE Commun. Surv. Tuts. , vol. 19, no. 2, pp. 721–742, Second quarter 2017.
- 5[5] M. Zeng, G. I. Tsiropoulos, O. A. Dobre, and M. H. Ahmed, “Power allocation for cognitive radio networks employing non-orthogonal multiple access,” in Proc IEEE Globecom , Washington DC, USA, Dec. 2016.
- 6[6] Z. Wei, D. W. K. Ng, J. Yuan, and H. Wang, “Optimal resource allocation for power-efficient mc-noma with imperfect channel state information,” IEEE Trans. Commun. , vol. 65, no. 9, pp. 3944–3961, Sep. 2017.
- 7[7] M. Zeng, A. Yadav, O. A. Dobre, G. I. Tsiropoulos, and H. V. Poor, “Capacity comparison between MIMO-NOMA and MIMO-OMA with multiple users in a cluster,” IEEE J. Sel. Areas Commun. , vol. 35, no. 10, pp. 2413–2424, Oct. 2017.
- 8[8] ——, “On the sum rate of MIMO-NOMA and MIMO-OMA systems,” IEEE Wireless Commun. Lett. , vol. 6, no. 4, pp. 534–537, Aug. 2017.