A Machine Learning Artificial Neural Network Calibration of the Strong-Line Oxygen Abundance
I-Ting Ho

TL;DR
This paper introduces a neural network-based calibration method for determining oxygen abundance in HII regions, outperforming traditional linear models and effectively reproducing galaxy metallicity patterns.
Contribution
It presents the first application of neural networks to calibrate strong-line oxygen abundance, capturing complex non-linear relationships more accurately than previous methods.
Findings
Neural network models outperform linear calibrations in predicting oxygen abundance.
The new calibration reproduces galaxy metallicity gradients and mass-metallicity relations.
Complex models are preferred given the current sample size.
Abstract
The HII region oxygen abundance is a key observable for studying chemical properties of galaxies. Deriving oxygen abundances using optical spectra often relies on empirical strong-line calibrations calibrated to the direct method. Existing calibrations usually adopt linear or polynomial functions to describe the non-linear relationships between strong line ratios and Te oxygen abundances. Here, I explore the possibility of using an artificial neural network model to construct a non-linear strong-line calibration. Using about 950 literature HII region spectra with auroral line detections, I build multi-layer perceptron models under the machine learning framework of training and testing. I show that complex models, like the neural network, are preferred at the current sample size and can better predict oxygen abundance than simple linear models. I demonstrate that the new calibration can…
Click any figure to enlarge with its caption.
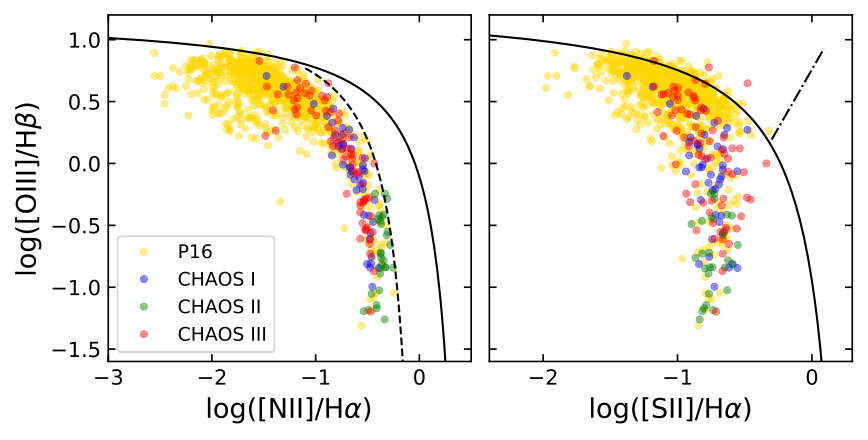 Figure 1
Figure 1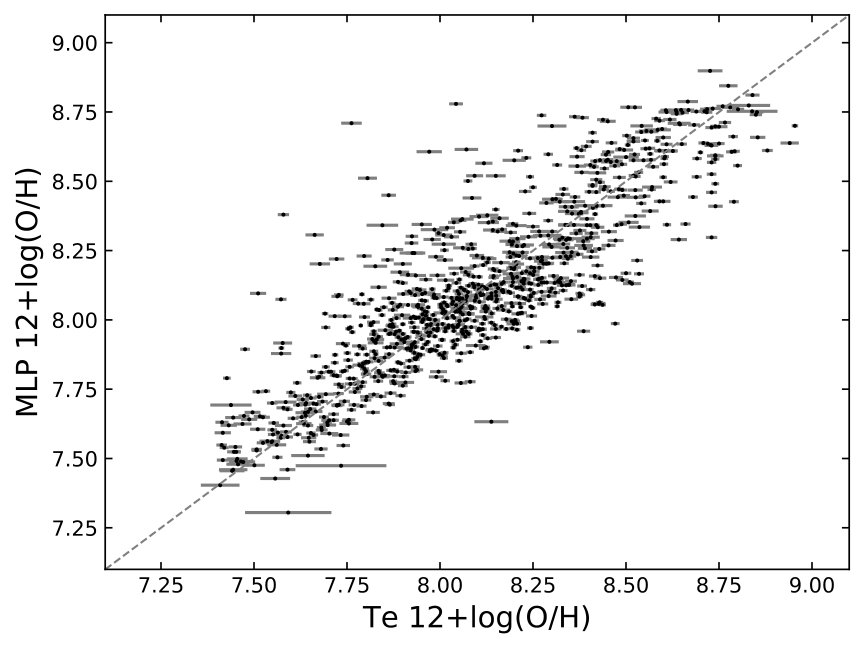 Figure 2
Figure 2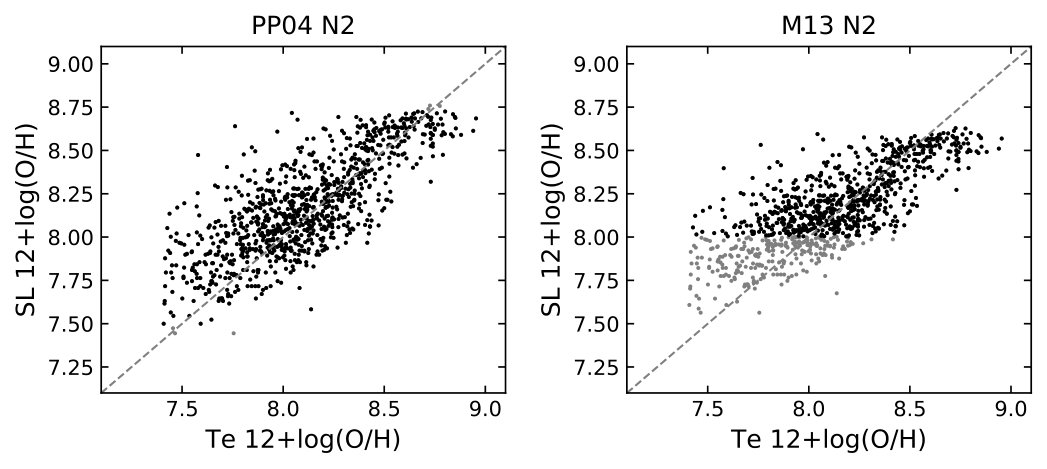 Figure 3
Figure 3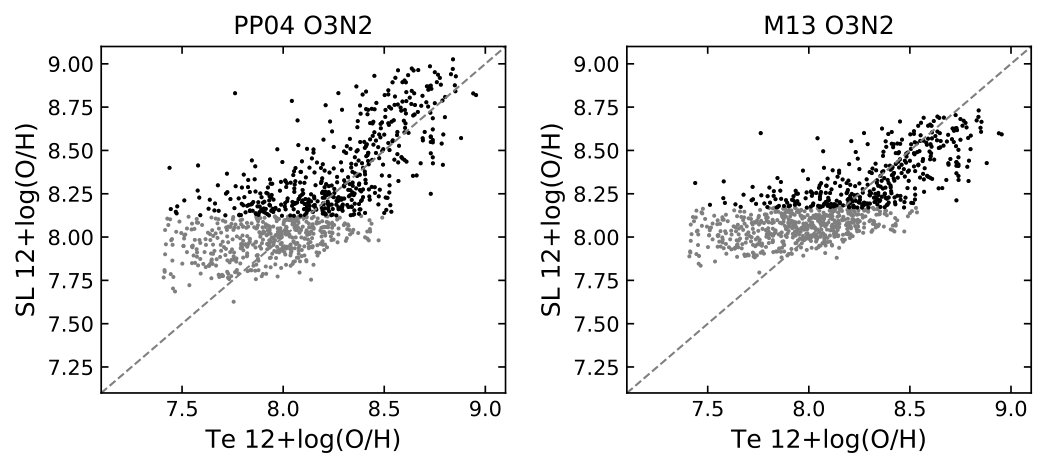 Figure 4
Figure 4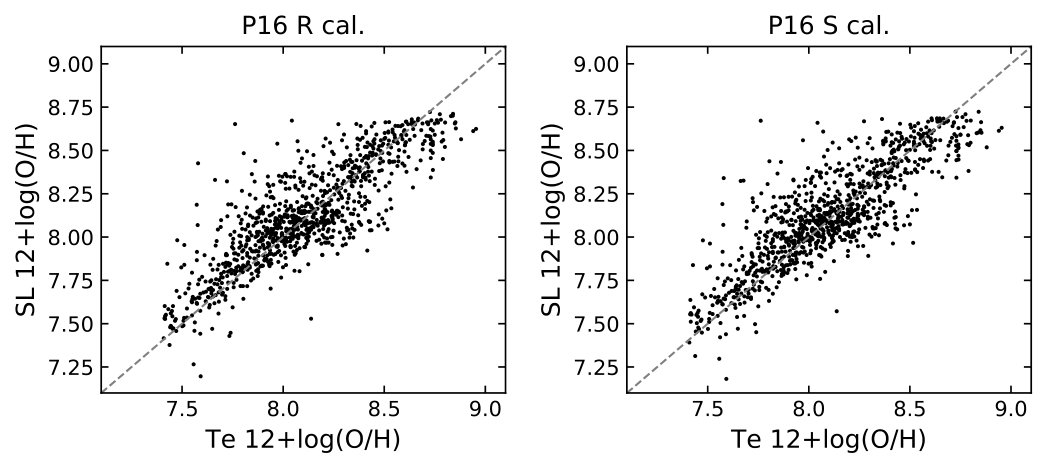 Figure 5
Figure 5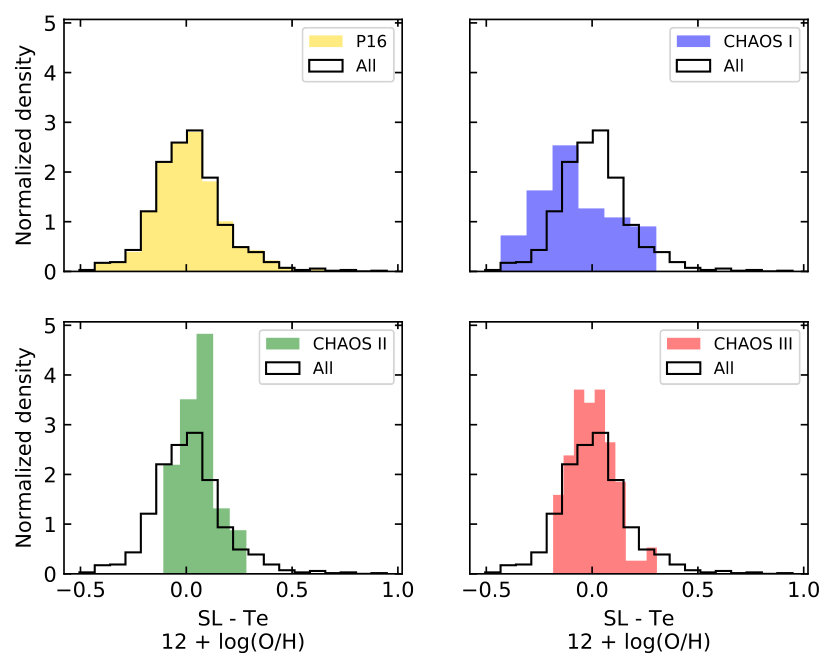 Figure 6
Figure 6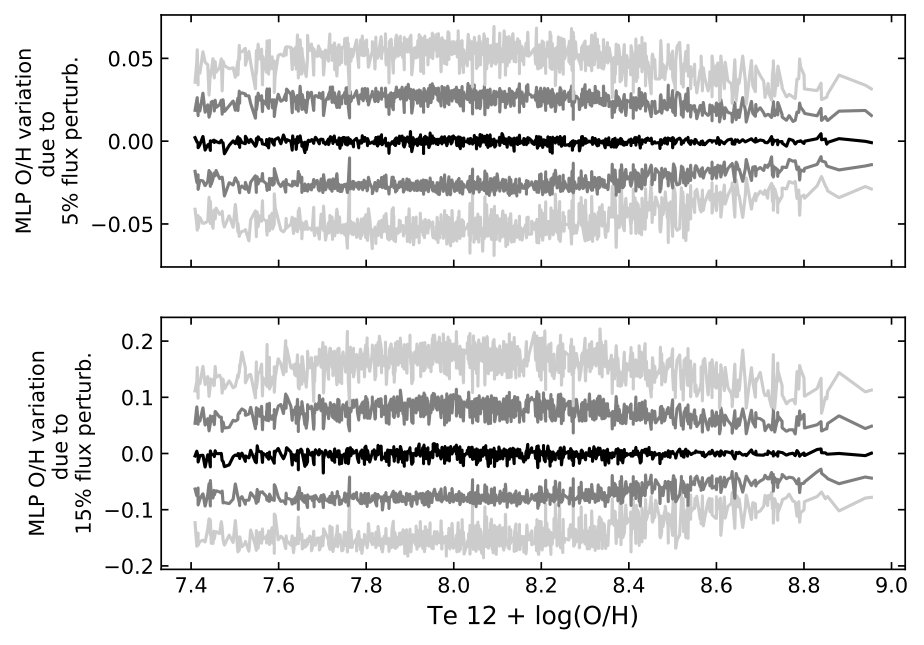 Figure 7
Figure 7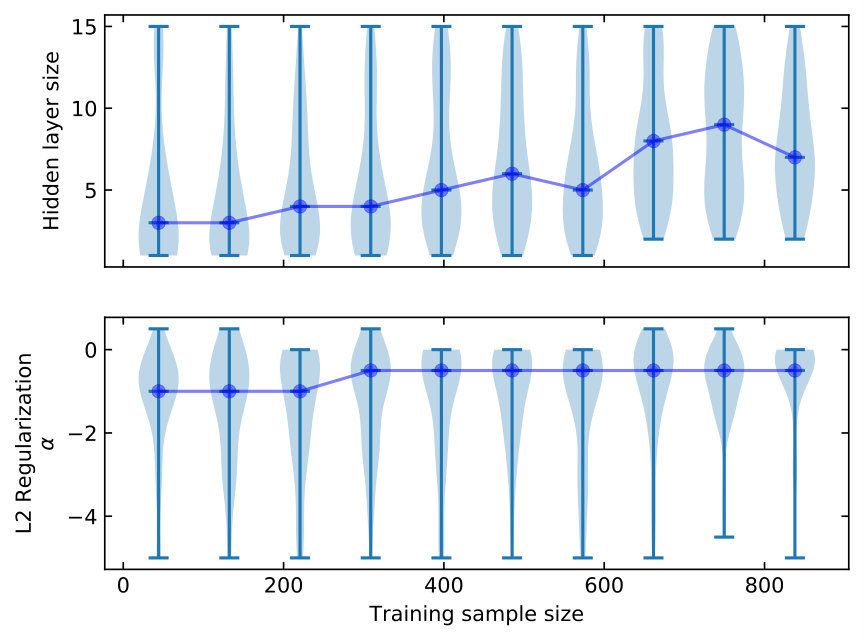 Figure 8
Figure 8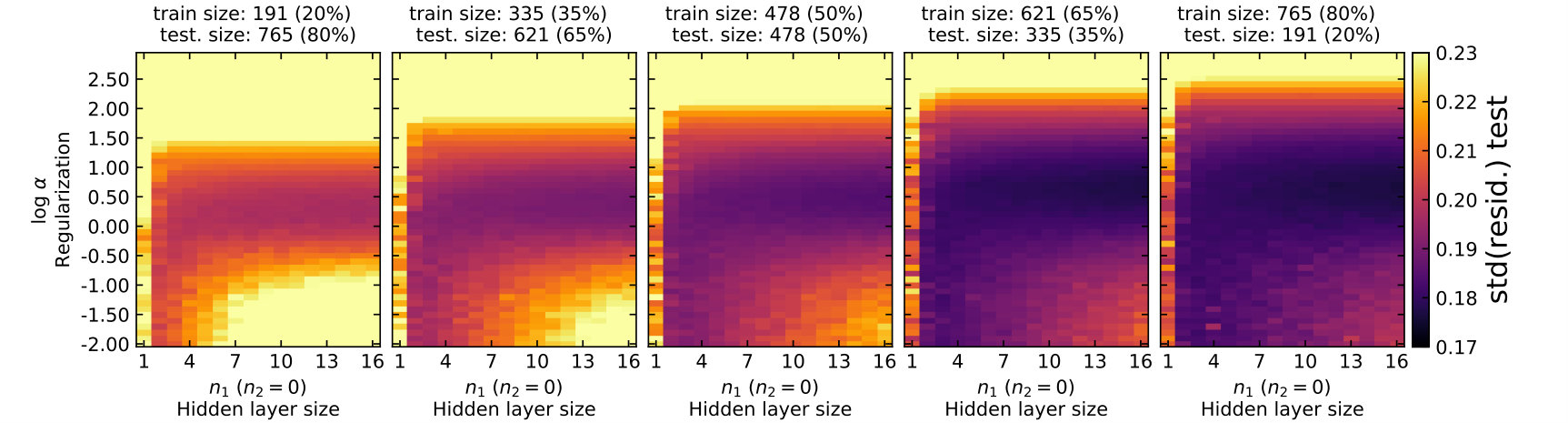 Figure 9
Figure 9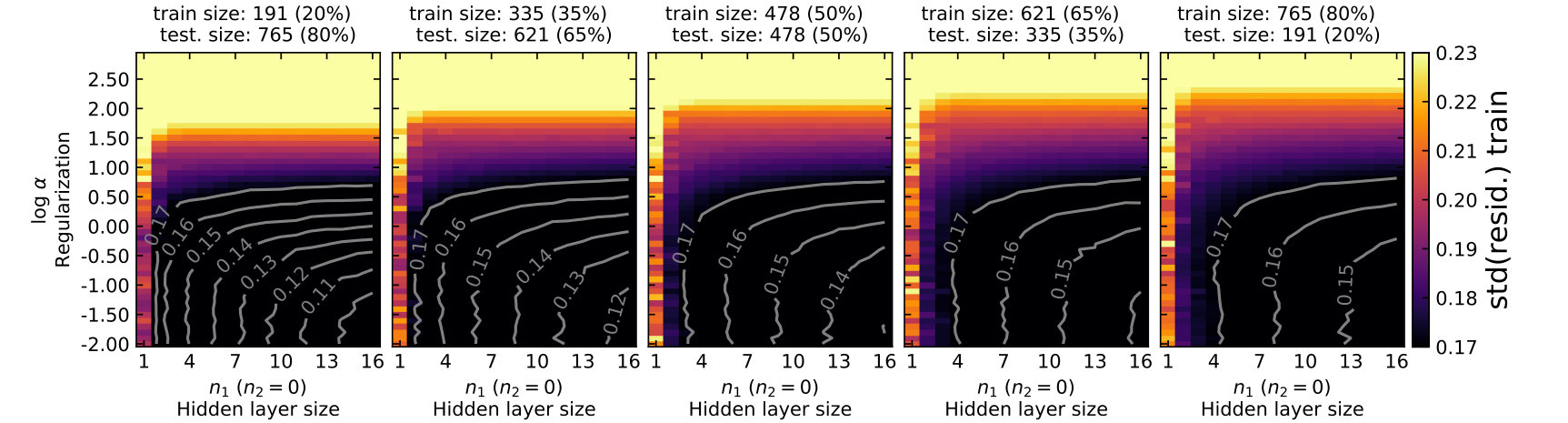 Figure 10
Figure 10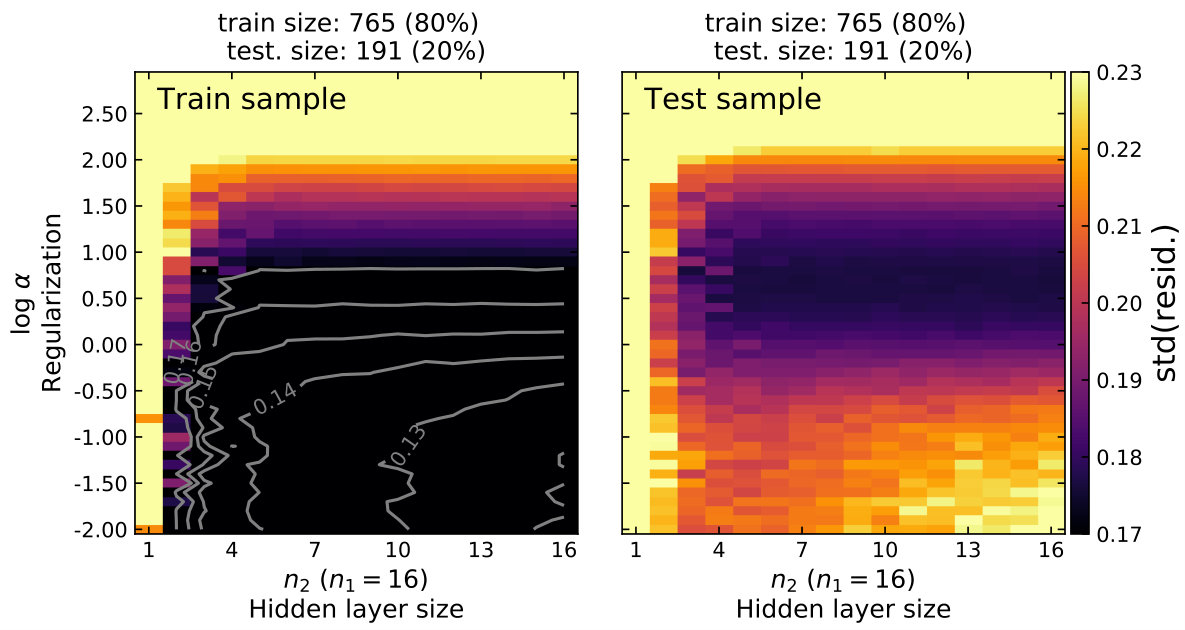 Figure 11
Figure 11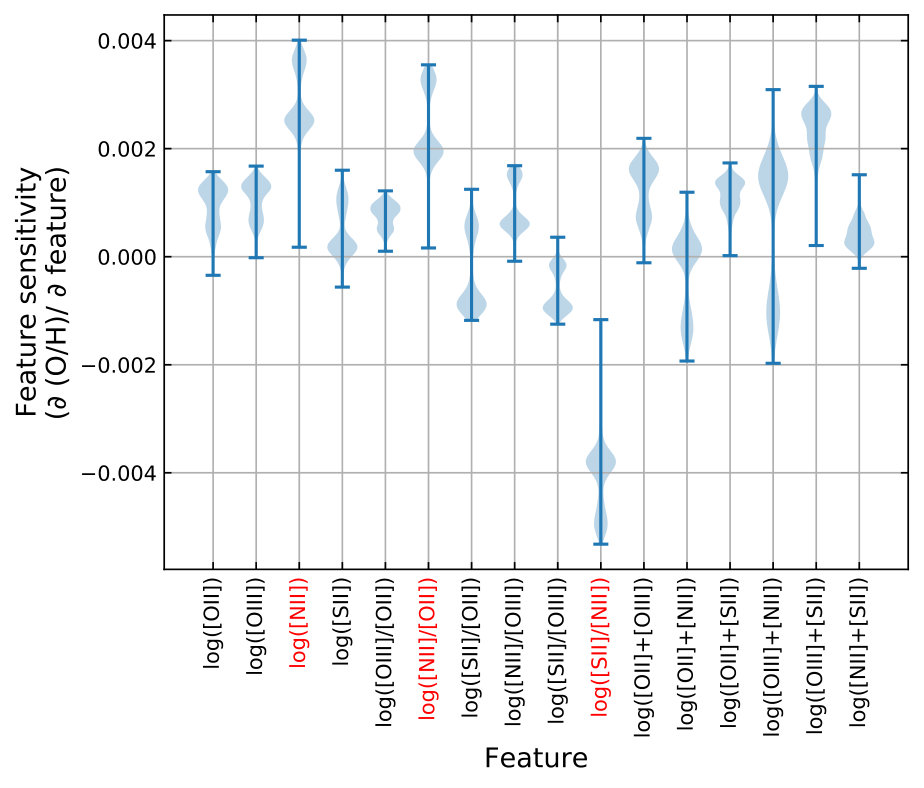 Figure 12
Figure 12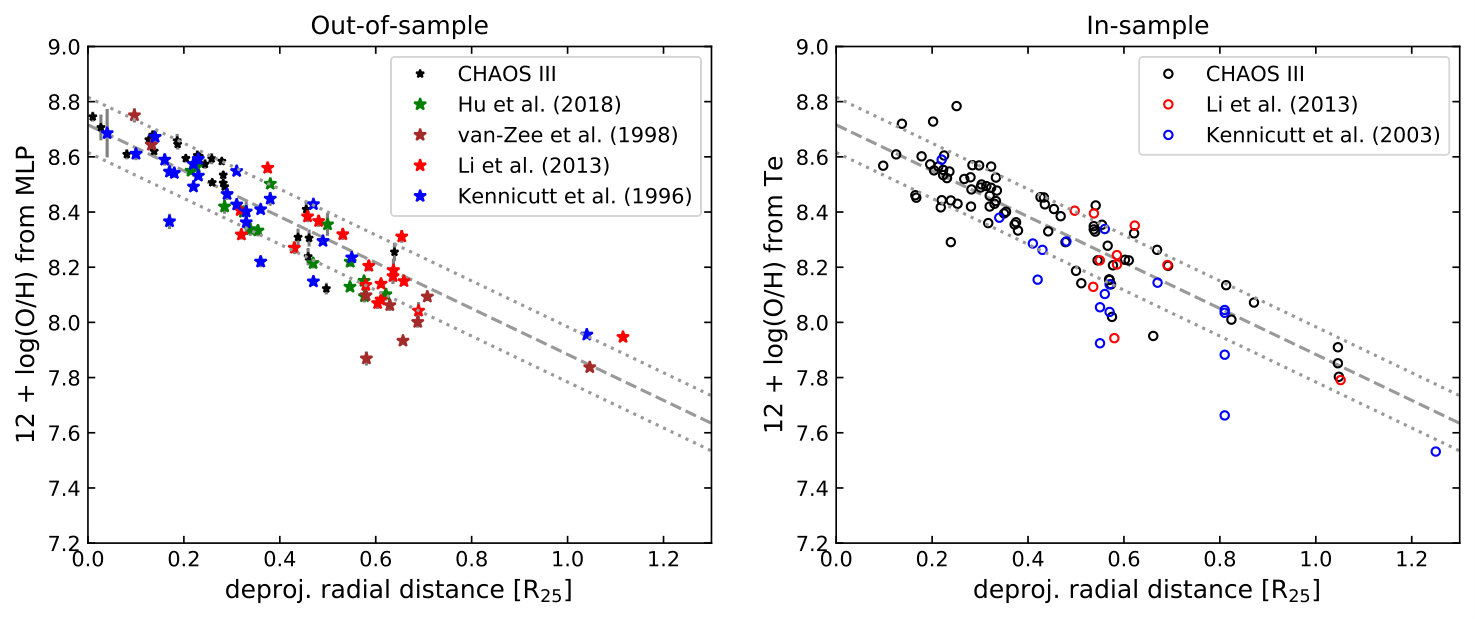 Figure 13
Figure 13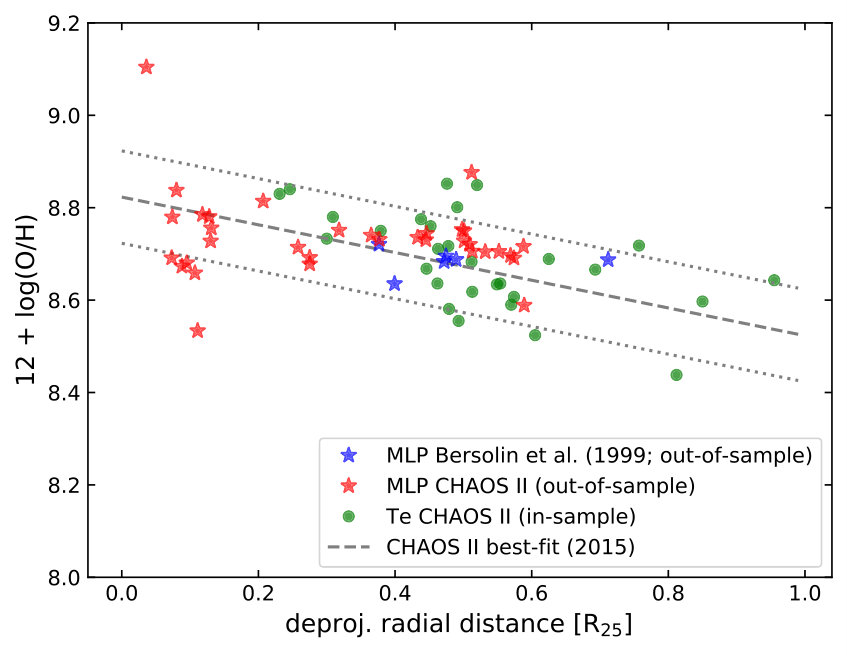 Figure 14
Figure 14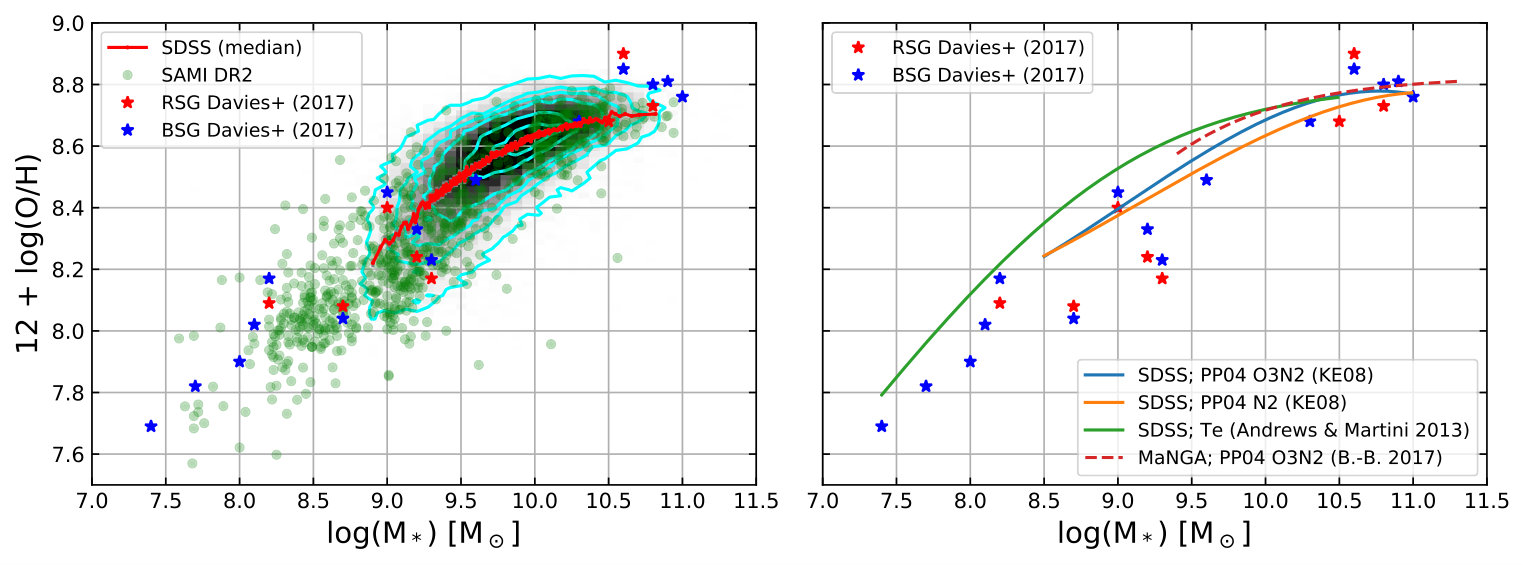 Figure 15
Figure 15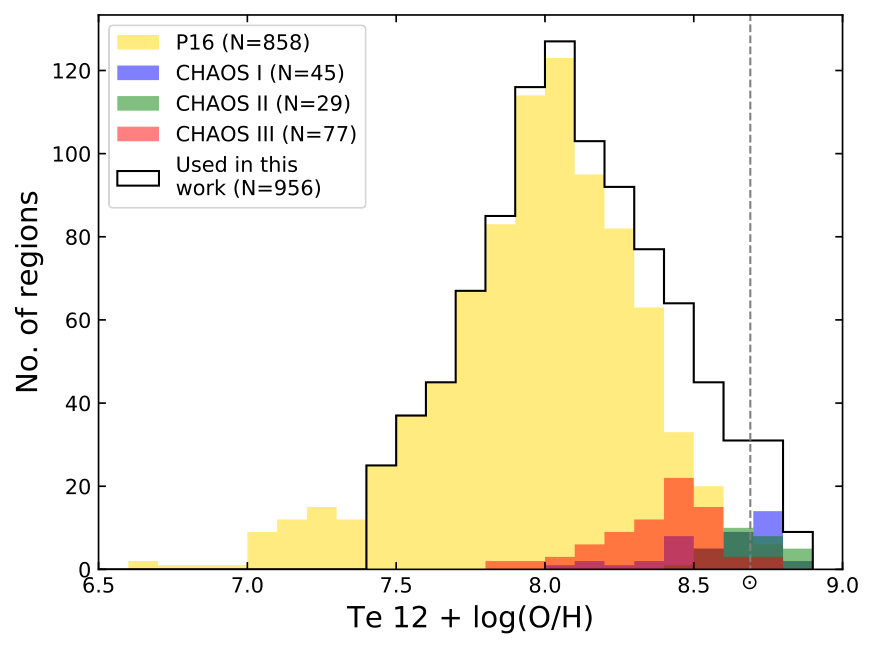 Figure 16
Figure 16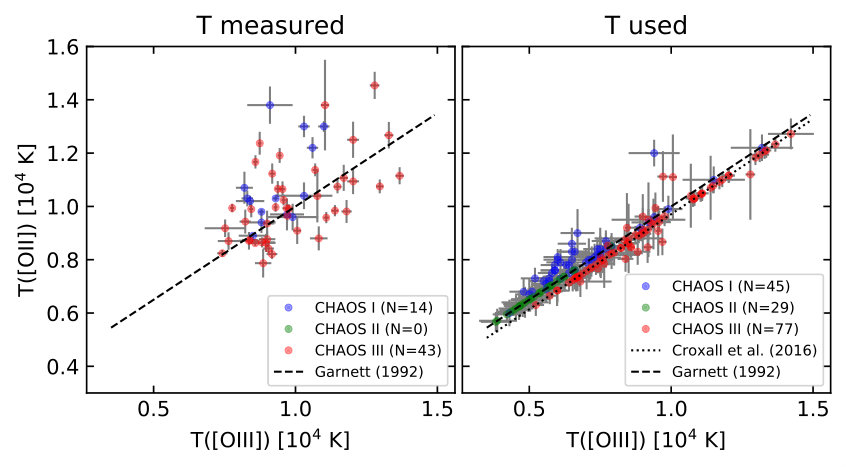 Figure 17
Figure 17| Type | Line ratio |
|---|---|
| Single line | [O ii], [O iii], [N ii], [S ii] |
| Ratio of line pairs | [O iii]/[O ii], [N ii]/[O ii], [S ii]/[O ii], |
| [N ii]/[O iii], [S ii]/[O iii], [S ii]/[N ii] | |
| Sum of line pairs | ([O ii]+[O iii]), ([O ii]+[N ii]), |
| ([O ii]+ [S ii]), ([O iii]+[N ii]), | |
| ([O iii]+[S ii]), ([N ii]+[S ii]) | |
| 1. All lines are normalized to H | |
| 2. The input features are the logarithmic of the line ratios | |
| Method | Median | Mean | Standard deviation |
|---|---|---|---|
| MLP (this work) | |||
| O3N2 (PP04) | |||
| O3N2 (M13) | |||
| N2 (PP04) | |||
| N2 (M13) | |||
| R cal. (P16) | |||
| S cal. (P16) |
| Method | Median | Mean | Standard deviation |
|---|---|---|---|
| MLP (this work) | |||
| O3N2 (PP04) | |||
| O3N2 (M13) | |||
| N2 (PP04) | |||
| N2 (M13) | |||
| R cal. (P16) | |||
| S cal. (P16) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A Machine Learning Artificial Neural Network Calibration of the Strong-Line Oxygen Abundance
I-Ting Ho (何宜庭),1
1Max Planck Institute for Astronomy, Königstuhl 17, 69117 Heidelberg, Germany E-mail: [email protected]
(Accepted XXX. Received YYY; in original form ZZZ)
Abstract
The H ii region oxygen abundance is a key observable for studying chemical properties of galaxies. Deriving oxygen abundances using optical spectra often relies on empirical strong-line calibrations calibrated to the direct method. Existing calibrations usually adopt linear or polynomial functions to describe the non-linear relationships between strong line ratios and oxygen abundances. Here, I explore the possibility of using an artificial neural network model to construct a non-linear strong-line calibration. Using about 950 literature H ii region spectra with auroral line detections, I build multi-layer perceptron models under the machine learning framework of training and testing. I show that complex models, like the neural network, are preferred at the current sample size and can better predict oxygen abundance than simple linear models. I demonstrate that the new calibration can reproduce metallicity gradients in nearby galaxies and the mass-metallicity relationship. Finally, I discuss the prospects of developing new neural network calibrations using forthcoming large samples of H ii region and also the challenges faced.
keywords:
ISM: abundances – HII regions – galaxies: ISM – methods: data analysis
††pubyear: ????††pagerange: A Machine Learning Artificial Neural Network Calibration of the Strong-Line Oxygen Abundance–A Machine Learning Artificial Neural Network Calibration of the Strong-Line Oxygen Abundance
1 Introduction
The H ii region oxygen abundance, a proxy for the metallicity of the interstellar medium (ISM), is a key quantity for studying chemical evolution of galaxies. Oxygen is the most common heavy element in the ISM (after helium and lithium). Together with other relatively abundant elements (e.g. nitrogen, sulfur), they produce a wealth of emission lines in the optical wavelength which are useful for constraining the ISM chemical abundances. Observing these optical emission lines has allowed us to significantly advance our understanding of fundamental chemical characteristics of star-forming galaxies, such as the oxygen abundance gradient (e.g. Searle, 1971; Zaritsky et al., 1994; Sánchez et al., 2014; Ho et al., 2015) and the mass-metallicity relationship (e.g. Lequeux et al., 1979; Tremonti et al., 2004; Zahid et al., 2013).
Although observing emission lines from H ii regions is relatively straight-forward, deriving accurate oxygen abundances is non-trivial. A variety of methods is available in the literature (see reviews by Stasińska 2004 and Peimbert et al. 2017); however, large systematic differences between different methods exist and the disagreement remains unresolved (Kewley & Ellison, 2008). One of the more accurate ways is through measuring the electron temperature () and density () of the line-emitting gas (see Pérez-Montero 2017 for a tutorial). This method, known as the direct method, is built on the physical basis that the emissivity of collisionally excited lines (CELs) depends strongly on . When and are known, ionic abundances can be inferred from CEL to hydrogen recombination line ratios. The total elemental abundance can subsequently be derived by accounting for unseen stages of ionisation. In this method, can be easily determined using the density-sensitive doublets [O ii] and [S ii]. However, constraining requires detecting auroral lines originating from transitions between upper energy levels, e.g. [O iii], [N ii]. A key limitation of the direct method comes from the faintness of the auroral lines, typically 2 orders of magnitude dimmer than the H line.
It is worth noting that the direct method is not perfect and has an important caveat. Oxygen abundances estimated base on recombination lines (RLs) are almost always higher than those from the CELs, by about 0.2 to 0.3 dex (e.g. Peimbert, 2003; Esteban et al., 2002; Esteban et al., 2009; García-Rojas & Esteban, 2007). One possible origin of this so-called “abundance discrepancy factor” problem is the presence of significant temperature, density, and possibly chemical composition fluctuation inside nebulae , which affect the direct method morer than the RL method . The CELs are expected to originate from relatively low metallicity, high , and low density regions inside a nebula, leading to an underestimate of the overall metallicity (see Peimbert et al. 2017 for a review). Recent spectroscopic studies of blue and red supergiant stars in nearby galaxies, however, report stellar oxygen abundances more consistent with gas-phase abundances measured from the direct method than the RLs (Bresolin et al. 2016 and references therein).
The faintness of the auroral lines severely limits its practical use when observations do not achieve excellent signal-to-noise ratios. Empirical strong-line calibrations are developed and have gained popularity among those using shallower (spectroscopic survey) data to study chemical properties of galaxies. Strong line indexes sensitive to metallicity, such as 111 (Pilyugin, 2001; Pilyugin & Thuan, 2005), O3N2222, N2333 (Pettini & Pagel, 2004; Marino et al., 2013), 444 (Maiolino et al., 2008; Curti et al., 2017), have been calibrated to the metallicity. In general, metallicities derived from high quality H ii spectra (or in some cases integrated galaxy spectra) are plotted against a selected strong line index. A simple linear or polynomial function is fit to the data and then reported as an empirical calibration.
The simplest cases are the linear calibrations of the O3N2 and N2 indexes. For the diagnostic, more complex functions are needed because the index is known to be double valued in metallicity (e.g. Pagel et al., 1979; Pagel et al., 1980; Kobulnicky & Kewley, 2004). In this situation, either two functions are fit separately to the upper and lower branches or a high-order polynomial is adopted. Photoionisation models, however, suggest that all these indexes have secondary dependency with the ionisation parameter (e.g. Kewley & Dopita, 2002; Dopita et al., 2013). It is likely that, by including more line ratios, the calibration dispersion can be reduced.
It is non-trivial to include additional line ratios into the calibrations and find suitable analytical formulae. Steps moving from 1- or 2-dimensional calibrations (where one or two line ratios are used) to high-dimensional calibrations (where multiple line ratios are fit simultaneously) have been taken in various work (e.g. Maiolino et al., 2008; Curti et al., 2017). A particularly efficient approach was taken by Pilyugin & Grebel (2016). Pilyugin & Grebel recognised that the metallicity-dependent index N2 exhibits a secondary correlation with the excitation parameter P555, particularly at high (low metallicities). By carefully designing the fitting formulae, Pilyugin & Grebel (2016) were able to develope two 3-dimensional calibrations: an R calibration using [O ii], [O iii] and [N ii], and an S calibration using [O iii], [N ii] and [S ii].
Another shortcoming of fitting one index at a time is that different indexes are sensitive to metallicity in different ranges, and the scatters could also be different. When multiple diagnostic indexes are available in a spectrum, different metallicities can be reported by using different indexes (and calibrations). A practical approach is to combine the different metallicities by taking the mean or minimising the in the space defined by the selected diagnostics (Curti et al., 2017; Maiolino et al., 2008).
Calibrating strong-line to metallicities is fundamentally searching for a function that can map the measured line ratios to metallicities using a set of well-characterised sample. This function is likely to have a high dimensionality (e.g. Vogt et al., 2014). The linear or polynomial fits in the literature describe only projections of this complex function onto certain index space. Here, I present an exploratory work of using a neural network model to recover the underlying function. The main goal of this work is to examine the possibility of fitting an arbitrarily complex, non-linear model to existing data (approximately 950 H ii regions) and improving the calibration accuracy by directly “learning” from the data. By performing supervised learning under a machine learning framework, I will “train” a strong line calibration that is data-driven and has no built-in physics. I will show that my first-try model can deliver reasonably good performance, even exceeding most popular literature strong-line calibrations. I will demonstrate that the neural network model can capture line ratios that are known to be sensitive to metallicity in photoionisation models, and successfully reproduce the well-characterised metallicity gradient and mass-metallicity relationship. I will end the article by discussing the prospect of this new approach and some challenges faced ahead.
Through out the paper, the following convention is followed: [O ii] = [O ii], [O iii] = [O iii], [N ii] = [N ii], and [S ii] = [S ii]. The best-fit neural network model and corresponding python wrapper script is publicly available at https://github.com/hoiting/OxygenMLP.The fluxes and oxygen abundances (as well as their original references) adopted in training and testing are also stored in the online repository.
2 Methods: combining literature auroral line data and a simple artificial neural network
2.1 Sample
The H ii region sample is drawn from two sources, containing originally 1009 oxygen abundances estimated based on auroral line(s). A sub-sample of 956 regions forms the final sample for this study.
The first source is 858 literature H ii region data compiled first by Pilyugin et al. (2012) and Pilyugin & Grebel (2016). An updated version of this literature compilation is adopted here. The sample contains 797 regions where the [O iii] line is detected and 151 regions the [N ii] is detected. A small fraction of the sample has both auroral lines 90. The oxygen abundances are derived following the prescription described in Pilyugin et al. (2012) and assuming the commonly adopted t2 – t3 scaling relationship (Campbell et al., 1986; Garnett, 1992). When both auroral lines are detected which yields two estimates of the oxygen abundance, the average is adopted. The second source comes from the on-going CHemical Abundances Of Spirals (CHAOS) survey conducted with the Multi-Object Double Spectrograph (MODS) on the Large Binocular Telescope (LBT). In total, 151 H ii regions are drawn the three CHAOS publications, 45 from Berg et al. (2015, CHAOS \Romannum1), 29 from Croxall et al. (2015, CHAOS \Romannum2) and 77 from Croxall et al. (2016, CHAOS \Romannum3). The oxygen abundances tabulated in their Tables 5, 5, and 4 are adopted, respectively.
Figure 1 presents the sample distributions. The P16 sample contains mostly low-metallicity regions that produce bright [O iii]. The CHAOS survey fills in the high-metallicity regime by virtue of the sensitivity of MODS and its capability to probe multiple auroral lines simultaneously ([O iii], [N ii], [S iii], [O ii] and [S ii]).
To arrive at the final, working sample (956 regions), an abundance cutoff of 7.4 is imposed to remove the long low-metallicity tail. This is to avoid the calibration being affected by the sparse sampling in a relatively large metallicity space. Figure 2 shows where the working sample lies in the BPT line ratio space (Baldwin et al., 1981).
2.1.1 Bootstrapping
The working sample does not uniformly cover the metallicity range of [7.4, 8.9], despite removing the low metallicity tail and including the high-metallicity CHAOS regions. To avoid the fitting being biased by the non-uniform distribution, I bootstrap the working sample to generate uniformly distributed samples.
The (non-uniform) working sample is first sorted and grouped in bins of approximately 30 regions. In each bin, new samples are drawn randomly (with replacement) and added to the bin such that the new sample number is proportional to the width of the bin. This re-sampling is done for every bin, except for the reference bin where the bin width is the narrowest. The reference bin defines the targeted bin-width to sample number ratio. The bootstrapped samples, each containing 2516 regions, are adopted to fit neural network models and quantify their performance. Performing analysis on the bootstrapped samples is equivalent to imposing higher weights on regions having high or low metallicities.
2.2 Multi-layer perceptron
I build a simple, feed-forward artificial neural network using the multi-layer perceptron (MLP) framework. A schematic of the network architecture is shown in Figure 3. The MLP is constructed using scikit-learn666http://scikit-learn.org/ (Pedregosa et al., 2011) version v0.19.2 in python3. The fully-connected MLP has three components: input layer, hidden layer(s), and output layer.
The input layer ingests “features”, i.e. logarithmic line ratios, from the training data. The 16 features (based on strong forbidden lines) are listed in Table 1. Here, all the line fluxes are normalised to H and the logarithmic line ratios are adopted as the input features. To optimise the MLP performance, the 16 inputs are first passed through standard scaler functions such that the means are zero and the standard deviations are unity.
The 16 features are selected by taking possible arithmetic combinations of line ratios, i.e. single line, ratio of line pairs and sum of line pairs. Some of the features are line ratios well-known to be sensitive to metallicity. For example, the [N ii], [N ii]/[O ii], and [N ii]/[O iii] are popular diagnostics (e.g. Kewley & Dopita, 2002; Pettini & Pagel, 2004). The combination of [S ii]/[N ii] and [N ii] is also shown to be a robust metallicity indicator (Dopita et al., 2016). [O iii]/[O ii] is known to be sensitive to both ionisation parameter and metallicity (e.g. Kewley & Dopita, 2002). [O ii] + [O iii], or equivalently , is yet another widely adopted metallicity indicator (Pagel et al., 1979). The rest of the features are not traditionally adopted in metallicity diagnostics. These line ratios could be sensitive to other physical properties of the ISM which may help improve the predication of metallicity. The intention is to test if by non-linearly combining these features using the neural network, a better model could emerge.
In the hidden layers, each neuron is a simple perceptron with the output being passed through an activator function. Each perceptron performs a simple calculation
[TABLE]
where and (i.e. weight and bias) are the model variables and are input from the previous layer. The rectified linear unit is adopted as the activator function that adds nonlinearity to the model. That is:
[TABLE]
In other words, each neuron in the hidden layers ingests outputs of the previous layer, , and performs the calculation
[TABLE]
Two models are explored below: one hidden layer with neurons and two hidden layers with (,) neurons. The final, best model has only one hidden layer.
The output layer comprises of one single perceptron with no activator function attached. The perceptron in the output layer is used to predict the targeted unknown quantity, i.e. oxygen abundance.
The MLP framework described above is controlled by two hyper-parameters. The first parameter is the number of neurons in the hidden layers, and . A larger number of neurons in the hidden layers allows the model a higher degree of complexity. Since complex models are prone to over-fitting the data, a second parameter , the L2 penalty parameter (for regularisation), is introduced. At a fixed (,), of zero imposes no prior on all the possible models under the MLP configuration. A non-zero, positive penalises the chi-square by the sum of the weight squares (multiplied by ), effectively guiding the fitting towards models with neuron weights closer to zero.
2.3 Train and test the neural network
Training the MLP network was done using the standard solver implemented in scikit-learn. The weights of the perceptrons are initialised randomly, and then a limited-memory version of the Broyden-Fletcher-Goldfarb-Shanno algorithm was adopted to minimise the loss function. The minimisation terminated when the the loss function did not improve by for two consecutive iterations. Since the training sample is moderate in size, all the training sample was used simultaneously without performing any stochastic minimisation using mini-batches.
2.3.1 Hyper-parameter tuning
In general, hyper-parameter tuning is required to avoid over-training a neural network, i.e. using a model too complex for the available data, resulting in the model to “remember the answers by-heart”. This problem is usually avoided by withholding a part of the data to test the model performance, and tuning the complexity of the model until the model performs equally well on data that it has and has not seen (i.e. training and testing samples). Below, I systematically investigate how the two hyper-parameters affect the network performance. This investigation will be done at different sample sizes to further understand whether more complex models can be adopted with increasing sample sizes.
For a give combination of hyper-parameters and train-sample size, a training sample is randomly drawn from the working sample and the remaining data are used for testing. Both the training and testing samples are bootstrapped (separately) to avoid the non-uniformity discussed in Section 2.1.1. After the model is trained, the standard deviation of the residuals, i.e. predicted versus metallicities, is adopted to quantify the model performance. Both the residuals of the training and testing sets are calculated to quantify the in- and out-of-sample performance, respectively.
To avoid my analysis being biased by the random components described above, i.e. the random weight initialisation, the random drawing of train/test samples and the bootstrap re-sampling, the sample drawing and fitting are repeated 100 times with different random states. This yields 100 performance pairs at each hyper-parameter grid point. The mean values are presented henceforth to understand the appropriate hyper-parameters and MLP performance.
2.3.2 One hidden layer
I start by training a network with only one hidden layer and neurons. I explore a grid of hyper-parameters with from 1 to 16 neurons with a step of 1, and from to with a step of 0.1. I explore the parameter grids using five different training sample sizes, from 20% (191) to 80% (765) of the working sample in a step of 15% (143). In Figures 4 and 5, I present the in- and out-of-sample performance at different sample sizes and model complexity, respectively. The sample size increases from the left to the right panels. Within each panel, the model complexity increases with increasing and decreasing .
In Figure 4, for a given sample size the in-sample performance in general improves with increasing model complexity. For a given model complexity, more training data leads to worse performance. That is, when the sample size becomes larger, a more complex model is required to improve the in-sample performance.
Figure 5 shows the out-of-sample performance. In general, models that are either too simple or too complex (i.e. close to the edge of the parameter space explored) have poor performance. At each sample size, there is a family of models that can perform equally well. With increasing sample size, the achievable best-performance improves. That is, with more H ii regions complex models can be developed, which achieve better out-of-sample performance.
To avoid over-fitting the data, the hyper-parameters need to be chosen to deliver comparable in-and and out-of-sample performance with the latter being as good as possible. This can be done by comparing Figures 4 and 5. At a given sample size, the appropriate model complexities can be achieved by different combinations of , networks with fewer neurons and less regularisation (smaller and ) or with more neurons and more regularisation (larger and ). The parameter of approximately appears to avoid over-training over a wide range of .
Finally, it is worth noting that the models are not optimal in all five sample sizes. Even with little regularisation, the single neuron model is still too simple to fully extract information from the data. The performance difference between and models is increasingly more obvious with increasing sample size. The single neuron model describes essentially linear combinations of the 16 logarithmic line ratios. Some existing strong line calibrations only fit linear combinations of logarithmic line ratios to the data, e.g. using the N2 or O3N2 indexes. These calibrations are similar to the single neuron models. This suggests that properly trained MLP models with more than one neuron will out-perform these literature calibrations. In other words, given the available literature samples complex models utilising multiple line ratios could better calibrate strong line metallicity than those using only one or two line ratio pairs.
2.3.3 Two hidden layers
The performance of a single hidden-layer network saturates at large . It is worth exploring whether including a second hidden-layer could further increase the network performance. Here, I fix to 16 and systematically explore the network performance at different and . This exploration is done only for the 80%/20% train/test split. As before, 100 models with different random states are trained for each grid point. In Figure 6, I show the mean performance of the 100 realisations.
Figure 6 demonstrates that with the inclusion of a second hidden layer, the in-sample performance improves further, from 0.15 dex in the right panel of Figure 4 to 0.12 dex. However, the out-of-sample performance remains virtually the same. This suggests that at the current sample size, an additional hidden layer is not critical for fitting the data.
2.3.4 Best MLP model
I have demonstrated how the hyper-parameters and sample size affect the choice of model complexity, and showed that one hidden layer is sufficient for the current sample size. Here, I train the final MLP model using all the H ii region sample, without withholding any data for testing. I adopt the hyper-parameters . This parameter combination delivers in- and out-of-sample performance of approximately 0.18 and 0.18, respectively, for the 80%/20% train/test split (right panels in Figures 4 and 5). Given more training data for the final model, these hyper-parameters should deliver an appropriate model complexity that does not over-fit the data. As before, I train 100 models with different random states to avoid being biased by the random components in the fitting process. Henceforth, I will report the median value of the predictions from the 100 models.
In Figure 7, I compare input metallicities with those predicted by the MLP model from strong lines. The error bars show the 1 standard deviations of the 100 predictions. In general, the spread in metallicity due to the random components in the fitting process is much smaller than the dispersion of the calibration. Figure 7 suggests that the best MLP model performs reasonably well over a wide range of metallicity.
2.3.5 Feature sensitivity
Extracting physical interpretation from neuron weights and biases is known to be difficult. However, it is worth investigating how sensitive different features are to the output to understand their importance to the network. The sensitivity analysis can be achieved by computing the partial derivative of the output with respect to the input features.
Using the best MLP model, I perturb one feature at a time while keeping the other features unchanged and compute the changes in the output metallicity. The small perturbation is set to 3% of the standard deviation of the input feature of the working sample. The response of the model to the perturbations is calculated for the entire working sample. Figure 8 presents histograms of the resulting changes in the output metallicities in the form of a “violin” plot. The top three features that the network output is most sensitive to are [S ii]/[N ii], [N ii]/[O ii], and [N ii] (deviate most from zero). Interestingly, photoionisation models have demonstrated that the [N ii]/[O ii] ratio is a good metallicity diagnostic (at above 0.2 solar) due to its insensitivity to ionisation parameter (Kewley & Dopita, 2002; Dopita et al., 2013). The combination of [N ii]/[S ii] and [N ii]/H is also suggested by Dopita et al. (2016) to be an excellent diagnostic that is insensitive to ISM pressure and ionisation parameter. The neural network appears to rely more heavily on features that are also important in diagnostics developed from photoionisation models, despite that this information is not given a priori. This demonstrates the ability of the neural network to directly “learn” from the data.
3 Results
3.1 Compare with other calibrations
It is worth comparing the MLP performance with other literature strong line calibrations to examine the putative improvement. Below, I apply different strong line diagnostics to the working H ii region sample and quantify their performance using the metallicity residuals, i.e. strong-line versus metallicity.
In Figure 9, I compare the strong line diagnostics using the O3N2 and N2 indexes calibrated by Pettini & Pagel (2004)777For the N2 calibration, the linear fit is adopted. and Marino et al. (2013). The H ii regions with indexes beyond the diagnostic limits are shown in grey. The calibrations provide 1D linear functions describing simple relationships between the input indexes and metallicity. Although the O3N2 and N2 indexes are not explicitly included in my feature list (Table 1), equivalent line ratios, [N ii]/[O iii] and [N ii]/H, are a part of the input features. In Figure 9, I also compare the R and S calibrations developed by P16. These two calibrations each ingests three forbidden to Balmer line ratios. The R calibration uses [O ii], [O iii], and [N ii], and the S calibration [O ii], [S ii], and [N ii]. These calibrations describe more complex 3D mappings from line ratios to metallicity.
In Tables 2 and 3, I quantify the residual distributions of the different calibrations. Table 2 tabulates the median, mean, and standard deviation derived from the entire sample. Since a large fraction of the sample was adopted to construct the R.- and S.- calibrations, a second comparison in Table 3 is done using only the CHAOS sample that has on average a higher metallicity than the P16 sample (see Figure 1). Even with the very simple architecture (Figure 3) and virtually picking the input features blindly, the MLP out-performs almost all the calibrations with its smallest median, mean, and standard deviation (Table 2). In Table 3, the MLP standard deviation is slightly larger than the R. calibration but its mean and median are smaller. The improvement of MLP over other literature calibrations is somehow marginal (a few to 30 percent in dispersion), however, the prediction accuracy of the ANN method increases with increasing sample size, as demonstrated in Figure 5. It is likely that when a larger training sample is available, the prediction accuracy can be improved further (see Section 4).
Below, I will apply the MLP calibration to H ii region and galaxy integrated spectra to reproduce metallicity gradient and the mass-metallicity relationship (MZR), two of the most fundamental chemical characteristics of star-forming galaxies.
3.2 Abundance gradients in nearby galaxies
I apply the MLP calibration to a sample of H ii regions in M101. The M101 galaxy is chosen because of its rich literature H ii region data and its well-behaved radial gradient that covers a wide range of metallicity. The MLP calibration is applied to only regions that the model has not seen before. Theses include 25, 9, 18, and 24 regions from Croxall et al. (2016), van Zee et al. (1998), Li et al. (2013) and Kennicutt & Garnett (1996), respectively. The auroral lines were undetected in these regions. An additional 15 regions from the recent work by Hu et al. (2018, their Table 1) is also included.
In Figure 10, I show the metallicity gradient from the MLP calibration in the left panel. For reference, I show the metallicities from Croxall et al. (2016), Li et al. (2013) and Kennicutt et al. (2003) in the right panel. These H ii regions are in the training sample. In both panels, the grey dashed lines indicate the best-fit gradient from Croxall et al. (2016). Figure 10 demonstrates that the MLP calibration produces a reasonable metallicity gradient and comparable scatter, compared with the method.
In Figure 11, a similar comparison for M51 is presented. Here, the out-of-sample regions are taken from the CHAOS survey (Croxall et al., 2015) that do not have auroral line detections. Additionally, 6 regions from the long-slit observations of Bresolin et al. (1999) are also included (the other 7 regions with low S/N on the diagnostic lines are excluded). The MLP abundances of the out-of-sample regions appear to follow the best-fit abundance gradient derived from the in-sample CHAOS II regions, demonstrating the robustness of the metallicity predicted by the MLP calibration.
3.3 Mass-metallicity relationship
I now apply the MLP calibration to integrated spectra of galaxies to reproduce the mass-metallicity relationship. This is done with large numbers of spectra from the Sloan Digital Sky Survey (SDSS; Abazajian et al. 2009) and the SAMI Galaxy Survey (Croom et al., 2012; Bryant et al., 2015). The SDSS line fluxes (DR7) are taken from the MPA-JHU catalog888http://www.mpa-garching.mpg.de/SDSS/DR7/. The sample selection follows Zahid et al. (2013) that includes covering fraction (), redshift (), and line ratio criteria (reject AGN base on Kauffmann et al. 2003 and Kewley et al. 2006) to ensure only star-forming galaxies remain in the sample. Galaxies with S/N less than 3 in any of the diagnostic lines are also removed. The line fluxes are extinction corrected using H/H Balmer decrement and the extinction law by Cardelli et al. (1989). In total, about 49,000 galaxies are further analysed.
The SAMI data are taken from the data release 2 (Scott et al., 2018). Aperture spectra of 1 effective radius are adopted. Extinction correction also follows the Cardelli et al. extinction curve using the H/H Balmer decrement. Similarly, AGNs are removed using the [N ii]/H and [O iii]/H line ratios (Kauffmann et al., 2003; Kewley et al., 2006) and a S/N criterion of 3 is imposed. In total, 868 SAMI galaxies are used.
In the left panel of Figure 12, I present the mass-metallicity relationship derived from SDSS and SAMI spectra using the MLP calibration. In the right panel of Figure 12, I show the mass-metallicity relationships from applying the PP04 O3N2 and N2 calibrations to SDSS spectra (Kewley & Ellison, 2008). I also show the relationship derived from oxygen auroral lines measured in SDSS stacked spectra (Andrews & Martini, 2013). In both panels, the blue and red star symbols indicate the mass-metallicity relationship derived from blue and red supergiant stars (BSGs and RSGs) in nearby galaxies (Davies et al. 2017 and references therein). The MLP calibration yields reasonable slope and the zero point of the mass-metallicity relationship and follows closely the BSG/RSG relationship over 1 order of magnitude in oxygen abundance.
4 Prospect and Challenge
I have demonstrated that by fitting literature H ii region data with one of the simplest form of neural network, i.e. the multi-layer perceptron, it is possible to calibrate a strong-line diagnostic that performs reasonably well over a wide range of oxygen abundance. The MLP calibration performs equally well as the R and S calibrations by Pilyugin & Grebel (2016) and out performs some popular literature calibrations base on N2 and O3N2.
The very first, simple attempt of this methodology demonstrates the prospect of applying this approach to large datasets coming in the near future. In particular, Figures 4 and 5 suggest that with larger training samples complex models can be developed and more accurately predict oxygen abundance. Although in this work I only develop a calibration requiring five strong forbidden lines, customised calibrations can be easily developed and their performance quantified by following the same work-flow.
The non-linear nature of the neural network, to an arbitrarily complex degree, delivers several advantages for developing strong-line diagnostics. It is no longer critical to navigate through high-dimensional space via a series of 2-dimensional projections. For example, it is common practice to first select a primary feature sensitive to metallicity and search in the residuals for potential correlations with other line ratios. Non-linear correlation can also be more easily captured. For example, existing calibrations using the index sometimes provide two different fits for the upper and lower branches due to the turn-over of the index with metallicity (e.g. Pilyugin, 2001; Pilyugin & Thuan, 2005). Such upper/lower branch separation is integrated automatically in the MLP model. Furthermore, different line ratios are often sensitive to metallicity in different metallicity intervals. The MLP model adapts to this internally without needing to fit different indexes over different intervals and report the fit parameters and the applicable intervals (e.g. Curti et al., 2017). This makes both the development and application of a calibration more straightforward.
In this work, no attempt was made to optimise the choice of input features. The input features are picked virtually blindly base on possible arithmetic operations of the strong lines. While some features are known to be sensitive to metallicity, others might carry only limited information. It is thus expected that the network can perform even better with an optimised input feature set. The optimisation can be guided by Figure 8 but will require some trial-and-error by, for example, dropping one feature at a time and re-training the network and re-tuning the hyper-parameters. This is because that the network may response to feature trimming non-linearly and many existing features are degenerate.
Some additional features might also be important and are currently missing. For example, the electron density of the nebula, traced by either the to ratio or the to ratio, is a fundamental, yet missing physical quantity. The ionisation parameter is another important quantity that could improve metallicity calibration. Although the ionisation parameter in principle is encoded in the to ratio already seen by the model, the ratio is also sensitive to metallicity (e.g. Kewley & Dopita, 2002). The to ratio is another key feature for passing the ionisation parameter information to the model given its insensitivity to metallicity (e.g. Kewley & Dopita, 2002). These line ratios are currently missing in my attempt due to their non-uniform availability in the literature. Exploring the importance of these features using coming data from, for example, the CHAOS Project may be fruitful.
Despite the prospect and advantages of the neural network over traditional calibration methods, there are limitations and challenges. The predictive power of a neural network depends heavily on the quality and quantity of the training sample. The training sample in this work has only 43 H ii regions (4.5%) more metal rich than 12+log(O/H) = 8.69 (solar), only 3 regions (0.3%) above 8.87 (1.5 solar), and no regions above 8.99 (2 solar). The lack of high metallicity training data is directly reflected in the mass-metallicity relationship (Figure 12). The SDSS and SAMI galaxies have no MLP oxygen abundances larger than approximately 12+log(O/H) = 8.8 or 1.3 solar. The mass-metallicity relationship from the blue and red supergiants, however, reaches up to 12+log(O/H) = 8.9. The systematic underestimate of MLP metallicities for the high-metallicity and high-mass galaxies results in the SDSS median mass-metallicity relationship to saturate at approximately 12+log(O/H) = 8.7 at the high-mass end. Furthermore, a low-metallicity floor of 7.4 was also imposed due to the sparse sampling in the low-metallicity end (see Section 2.1). The lack of high and low metallicitiy training data puts a fundamental constraint on the interval where the calibration is reliable. For most literature calibrations, extrapolating the calibrations outside the applicable metallicity interval can be easily visualised, and in some cases justified by comparing with photoionisation models (e.g. Maiolino et al., 2008). Nonetheless, the non-linear nature of the neural network puts a fundamental constraint on making predictions outside the parameter space populated by the training sample.
The uniformity of the training data is also key to the quality of the predicted metallicity. Non-uniformly analysed or low quality input data will introduce noise and bias to the network. Artefacts arose from non-uniform analysis can already been noticed in my MLP model. In Figure 13, I present the residuals of H ii regions from different sources. The P16 residual distribution is very similar to the overall residual distribution, because the P16 sample comprises the majority (84%) of the working sample. The CHAOS distributions, however, are noticeably different from the overall distribution, with CHAOS I significantly skewed to negative residuals and CHAOS II and III more consistent with the overall distribution.
The differences come from how the oxygen abundances are derived from auroral line measurement(s). In the P16 sample, the temperature scaling relationship of Garnett (1992) is always used to infer the high- or low-state oxygen temperatures. In fact, 92% and 19% of the P16 sample have T([O iii]) and T([N ii]) measured from the [O iii] and [N ii] lines, respectively. As in the two-zone model, T([O ii]) is approximated by T([N ii]). A small fraction of the sample (11%) has both auroral lines detected and the mean of the two metallicities is adopted. In the CHAOS Project, multiple auroral lines are typically detected in each regions. Different auroral lines and scaling relationships are adopted to determine the low and high state temperatures. For the low state, T([O ii]) is usually approximated by T([N ii]) even when T([O ii]) is measured. For the high state, CHAOS I prioritizes T([S iii]) over T([O iii]) while CHAOS III adopts the opposite. CHAOS II has no [O iii] detections and adopts T([S iii]). When only one of the two states is measured, scaling relationships are adopted. CHAOS I and II adopt the G92 relationships, and CHAOS III adopts updated relationships fit to their sample. These various factors determine the final T([O ii]) and T([O iii]) used for calculating the oxygen abundances. Figure 14 shows the T([O ii]) and T([O iii]) “used” (right panel) and those “measured” (left panel). For the CHAOS II and III sample, the temperatures used in determining oxygen abundances lie close to the G92 scaling relationship, consistent with the P16 sample. This consistency is directly reflected in the residual distributions in Figure 13. A significant fraction of the CHAOS I sample, however, falls systematically above the G92 scaling relationship, resulting in the skewed residual distribution in Figure 13.
In general, there is an unavoidable trade-off between sample uniformity and sample size. In this exploratory work, sample size is prioritized over uniformity. Thus, all the CHAOS samples are included even though a significant fraction (56%) has no [O iii] detections. Nonetheless, it is expected that in the next few years, uniform analyses on large samples will be feasible by virtue of emerging high quality H ii region catalogs. The CHAOS Project has detected multiple auroral lines in a few tens H ii regions in each of the three published galaxies. With a sample size of a dozen nearby galaxies, close to 1,000 H ii regions are expected. Large IFU surveys of nearby galaxies with 10-m class telescope (e.g. the MUSE/VLT large program by the PHANGS collaboration999https://sites.google.com/view/phangs/home; Kreckel et al. 2018; Ho et al. in preparation) will also report auroral line metallicities. The Local Volume Mapper of the planned SDSS V survey will detect auroral lines in thousands of H ii regions in M31, M33, LMC, SMC, and the Galaxy (Kollmeier et al., 2017). These coming data will significantly improve the quality and quantity of the training data (even at super solar abundances), allowing both an increase of neural network complexity and its predictive accuracy.
Acknowledgements
I thank Prof. Pilyugin for sharing the literature auroral line data. This work would not have been possible without the sample he collected through out the years. I am also deeply grateful to the support of an MPIA fellowship that enables this exploratory work. Additionally, I would like to thank H. Jabran Zahid, Po-Feng Wu, Rolf-Peter Kudritzki and Danielle Berg for their feedback and help at various stages of this project.
Appendix A Variation of MLP prediction due to line flux uncertainty
Non-linear models often response non-linearly with input perturbations. In the presence of measurement noise, the non-linearity could be an undesirable characteristic for calibration. To understand how the MLP model reacts to measurement uncertainties of the input line fluxes, I perform Monte Carlo simulations. Gaussian noises are added to the four line fluxes ([O ii], [O iii], [N ii], and [S ii]) and the resulting features are adopted to derive MLP abundances. Five hundred realisations are created for each of the 956 regions. Two noise levels are considered, 5% and 15% flux perturbations. The resulting difference between MLP abundances derived using noise-free and noisy features is shown in Figure 15. For the 5% and 15% perturbations, the MLP abundance fluctuations are approximately 0.025 and 0.08 dex. There is no appreciable bias in the medians. That is, adding noise to the line fluxes does not seem to skew the resulting MLP abundances in a statistically significant way.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Abazajian et al. (2009) Abazajian K. N., et al., 2009, Ap JS , 182, 543 · doi ↗
- 2Andrews & Martini (2013) Andrews B. H., Martini P., 2013, Ap J , 765, 140 · doi ↗
- 3Baldwin et al. (1981) Baldwin J. A., Phillips M. M., Terlevich R., 1981, PASP , 93, 5 · doi ↗
- 4Barrera-Ballesteros et al. (2017) Barrera-Ballesteros J. K., Sánchez S. F., Heckman T., Blanc G. A., The Ma NGA Team 2017, Ap J , 844, 80 · doi ↗
- 5Berg et al. (2015) Berg D. A., Skillman E. D., Croxall K. V., Pogge R. W., Moustakas J., Johnson-Groh M., 2015, Ap J , 806, 16 · doi ↗
- 6Bresolin et al. (1999) Bresolin F., Kennicutt Jr. R. C., Garnett D. R., 1999, Ap J , 510, 104 · doi ↗
- 7Bresolin et al. (2016) Bresolin F., Kudritzki R.-P., Urbaneja M. A., Gieren W., Ho I.-T., Pietrzyński G., 2016, Ap J , 830, 64 · doi ↗
- 8Bryant et al. (2015) Bryant J. J., et al., 2015, MNRAS , 447, 2857 · doi ↗