A Simple Solution to the Level-Ancestor Problem
Gaurav Menghani, Dhruv Matani

TL;DR
This paper introduces a straightforward method for solving the level-ancestor problem in trees, achieving efficient pre-processing and query times with simplicity suitable for teaching and implementation.
Contribution
It presents a simple, easy-to-understand solution with linear pre-processing and logarithmic query time, contrasting with more complex existing algorithms.
Findings
Pre-processing time is O(n).
Query time is O(log n).
Solution is simple and easy to implement.
Abstract
A Level Ancestory query LA(, ) asks for the the ancestor of the node at a depth . We present a simple solution, which pre-processes the tree in time with extra space, and answers the queries in time. Though other optimal algorithms exist, this is a simple enough solution that could be taught and implemented easily.
Click any figure to enlarge with its caption.
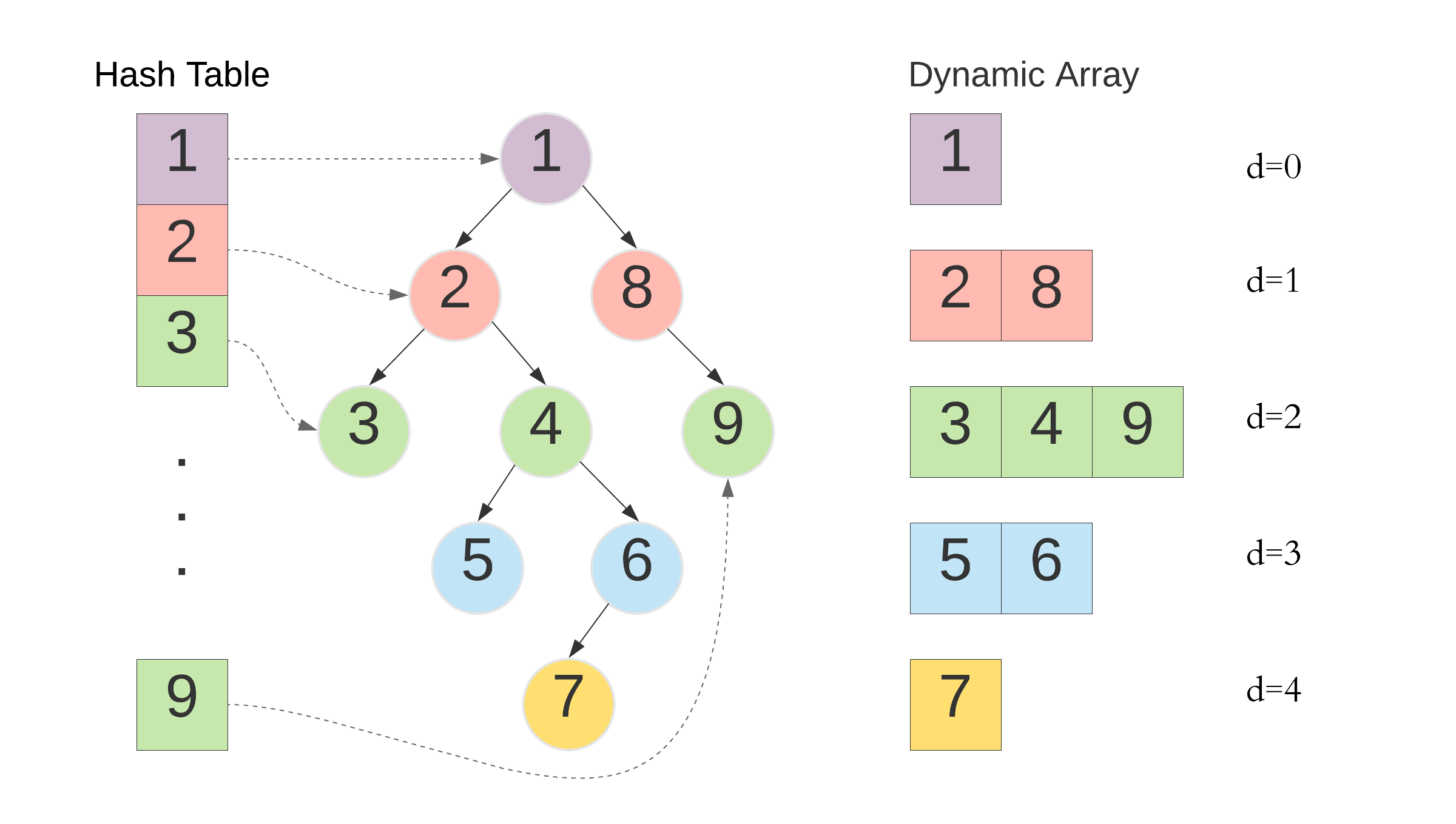 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAlgorithms and Data Compression · Data Mining Algorithms and Applications · Data Management and Algorithms
A Simple Solution to the Level-Ancestor Problem
Gaurav Menghani
Google AI, Mountain View (CA) - 94043
Dhruv Matani
Facebook Inc., Menlo Park (CA) - 94025
Abstract
A Level Ancestory query LA(, ) asks for the the ancestor of the node at a depth . We present a simple solution, which pre-processes the tree in time with extra space, and answers the queries in time. Though other optimal algorithms exist, this is a simple enough solution that could be taught and implemented easily.
1 Introduction
The Level-Ancestor problem has been well-studied [1, 2, 3]. [1] provides a simplified algorithm, that combines two complementary approaches, the Jump Pointer algorithm (to jump half-way to the target height in a hops), and the Ladder algorithm (to cover the remaining height using a single ‘ladder’ in ). However, while the algorithm is simpler and has a much better constant factor than previously published optimal algorithms such as [2], it still requires several non-trivial book-keeping for the preprocessing and query complexity (jump-pointers, ladders, macro-micro tree, and the lookup tables).
While the presented method is equivalent in complexity to the ladder algorithm of [1], it is arguably simple enough for even a junior undergraduate to implement.
2 Our Method
2.1 Preprocessing
We perform a pre-order traversal of the tree we are interested in. We keep a counter initialized to 0.
Each time we see a new node , during the pre-order traversal:
Increment . 2. 2.
Assign as the label of . 3. 3.
Append to the dynamic array associated with the level of . 4. 4.
Insert a pointer to in the hash table with as the key.
It is easy to see that all the four steps are in time. Since they are invoked exactly once for each of the nodes of the tree in its pre-order traversal, the overall complexity of this preprocessing is .
2.2 Observation
The dynamic arrays mentioned in step 3 of the preprocessing will always have the labels in a strictly increasing order. Since we process the nodes in a preorder traversal, when adding a node , all its ancestors would have already been added into their respective dynamic arrays. If is the latest node being processed, all ancestors of would at that time have the largest labels in their respective arrays, but smaller than the label of , since it is the latest node being processed.
By induction, given any node , its ancestor at depth would have the largest label at that depth, but smaller than the label of .
2.3 Query
To answer the query LA(, ):
Retrieve the label associated with the node . 2. 2.
Look up the largest element smaller than in the dynamic array associated with the query depth . 3. 3.
Return the pointer in the hash table for the key .
It is easy to see both steps 1 and 3 are .
Step 2 works because of the observations in section 2.2. Since the dynamic arrays have the labels in strictly increasing order, we can find the largest element smaller than the label in time using binary search. Thus the overall time complexity of the query is .
It is further possible to reduce it by a constant factor to time using [4].
2.4 Summary
We suggest an preprocessing, and query algorithm for the Level Ancestor problem. This is a simple to implement and understand algorithm, with a reasonable space, time, and implementation complexity.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. A. Bender, M. Farach-Colton, The Level Ancestor Problem simplified , 2004.
- 2[2] O. Berkman, U. Vishkin, Finding level-ancestors in trees , 1994
- 3[3] P. Dietz, Finding level-ancestors in dynamic trees. Algorithms and Data Structures , 1991.
- 4[4] D. Matani, Searching Faster Than Binary Search , 2015.