On the usage of the probability integral transform to reduce the complexity of multi-way fuzzy decision trees in Big Data classification problems
Mikel Elkano, Mikel Uriz, Humberto Bustince, Mikel Galar

TL;DR
This paper introduces a distributed fuzzy partitioning method using the probability integral transform to simplify multi-way fuzzy decision trees in Big Data classification, maintaining accuracy with fewer leaves.
Contribution
It proposes a novel approach combining the probability integral transform with fuzzy partitioning to reduce decision tree complexity in Big Data scenarios.
Findings
Maintains classification accuracy with up to 6 million fewer leaves.
Effectively transforms data distribution for simplified fuzzy partitioning.
Enhances scalability of fuzzy decision trees in Big Data contexts.
Abstract
We present a new distributed fuzzy partitioning method to reduce the complexity of multi-way fuzzy decision trees in Big Data classification problems. The proposed algorithm builds a fixed number of fuzzy sets for all variables and adjusts their shape and position to the real distribution of training data. A two-step process is applied : 1) transformation of the original distribution into a standard uniform distribution by means of the probability integral transform. Since the original distribution is generally unknown, the cumulative distribution function is approximated by computing the q-quantiles of the training set; 2) construction of a Ruspini strong fuzzy partition in the transformed attribute space using a fixed number of equally distributed triangular membership functions. Despite the aforementioned transformation, the definition of every fuzzy set in the original space can be…
Click any figure to enlarge with its caption.
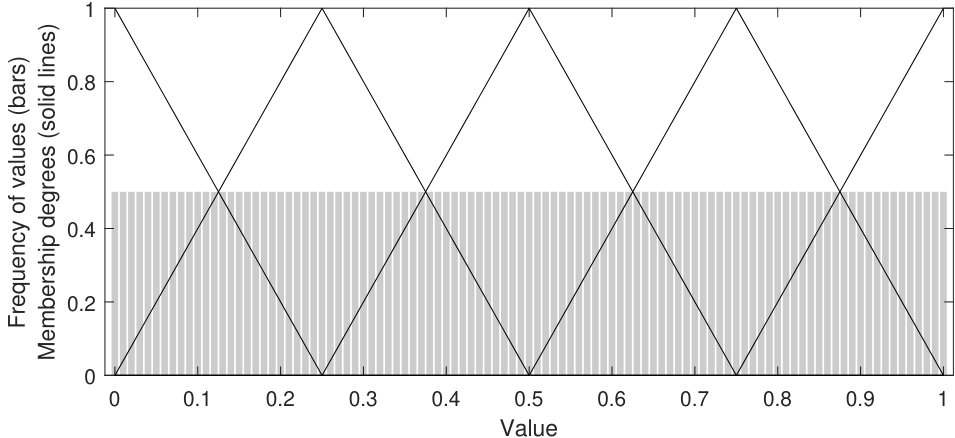 Figure 1
Figure 1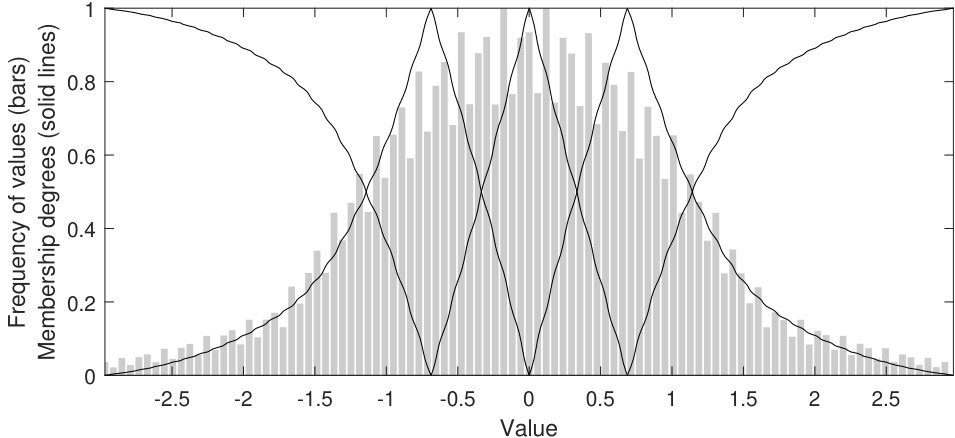 Figure 1
Figure 1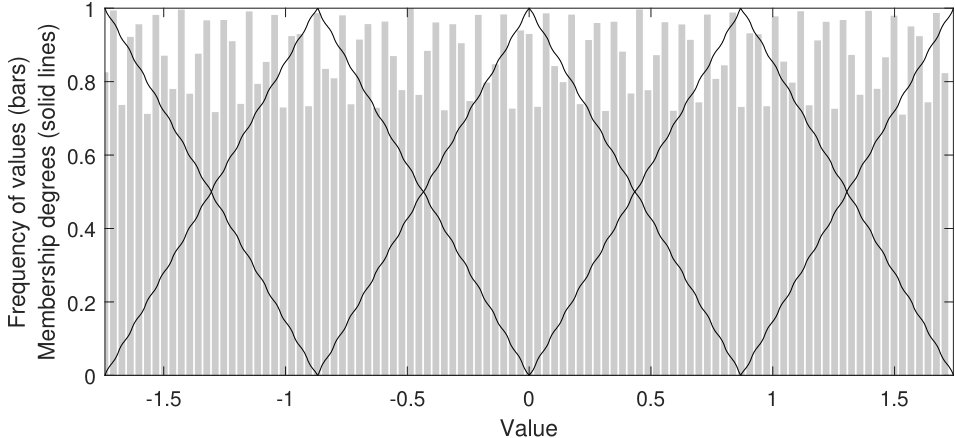 Figure 1
Figure 1| Dataset | #Instances | #Attributes | #Classes | |||
|---|---|---|---|---|---|---|
| R | I | C | T | |||
| BNG | 1,000,000 | 8 | 6 | 0 | 14 | 2 |
| HEPM | 10,500,000 | 28 | 0 | 0 | 28 | 2 |
| HIGGS | 11,000,000 | 28 | 0 | 0 | 28 | 2 |
| SUSY | 5,000,000 | 18 | 0 | 0 | 18 | 2 |
| Positive prediction | Negative prediction | |
|---|---|---|
| Positive class | True Positive (TP) | False Negative (FN) |
| Negative class | False Positive (FP) | True Negative (TN) |
| Accuracy rate % | ||||
|---|---|---|---|---|
| Dataset | FMDT | FMDT5 | FMDT7 | FMDT9 |
| BNG | 80.23±0.05 | 86.79±0.06 | 86.93±0.07 | 86.97±0.06 |
| HEPM | - | 91.13±0.02 | 91.25±0.02 | 91.33±0.02 |
| HIGGS | 71.54±0.02 | 70.61±0.02 | 71.32±0.03 | 71.69±0.03 |
| SUSY | 79.29±0.05 | 79.15±0.04 | 79.49±0.04 | 79.66±0.04 |
| AUC | ||||
| Dataset | FMDT | FMDT5 | FMDT7 | FMDT9 |
| BNG | .7896±.0004 | .8649±.0006 | .8658±.0007 | .8662±.0007 |
| HEPM | - | .9113±.0002 | .9125±.0002 | .9133±.0002 |
| HIGGS | .7143±.0001 | .7033±.0002 | .7114±.0003 | .7155±.0003 |
| SUSY | .7859±.0004 | .7847±.0004 | .7880±.0004 | .7898±.0004 |
| Number of leaves | ||||
|---|---|---|---|---|
| Dataset | FMDT | FMDT5 | FMDT7 | FMDT9 |
| BNG | 83,044 | 1,211 | 4,807 | 9,492 |
| HEPM | - | 2,854 | 13,472 | 43,339 |
| HIGGS | 6,414,575 | 3,005 | 15,876 | 53,489 |
| SUSY | 5,225,134 | 2,977 | 14,989 | 49,038 |
| Avg. depth | ||||
| Dataset | FMDT | FMDT5 | FMDT7 | FMDT9 |
| BNG | 3.02 | 4.67 | 5.00 | 4.35 |
| HEPM | - | 4.52 | 4.03 | 3.93 |
| HIGGS | 3.25 | 5.00 | 5.00 | 4.89 |
| SUSY | 3.68 | 5.00 | 5.00 | 4.76 |
| Avg. number of fuzzy sets | ||||
| Dataset | FMDT | FMDT5 | FMDT7 | FMDT9 |
| BNG | 6.04 | 5.00 | 7.00 | 9.00 |
| HEPM | - | 5.00 | 7.00 | 9.00 |
| HIGGS | 13.01 | 5.00 | 7.00 | 9.00 |
| SUSY | 22.60 | 5.00 | 7.00 | 9.00 |
| Partitioning | ||||
|---|---|---|---|---|
| Dataset | FMDT | FMDT5 | FMDT7 | FMDT9 |
| BNG | 58 | 41 | 40 | 40 |
| HEPM | - | 295 | 292 | 294 |
| HIGGS | 252 | 273 | 274 | 276 |
| SUSY | 110 | 77 | 72 | 77 |
| Learning | ||||
| Dataset | FMDT | FMDT5 | FMDT7 | FMDT9 |
| BNG | 25 | 23 | 22 | 24 |
| HEPM | - | 149 | 158 | 153 |
| HIGGS | 4,984 | 176 | 167 | 158 |
| SUSY | 1,282 | 76 | 75 | 77 |
| Total time | ||||
| Dataset | FMDT | FMDT5 | FMDT7 | FMDT9 |
| BNG | 84 | 65 | 63 | 65 |
| HEPM | - | 445 | 450 | 448 |
| HIGGS | 5,238 | 450 | 441 | 435 |
| SUSY | 1,392 | 154 | 148 | 155 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
On the usage of the probability integral transform to reduce the complexity of multi-way fuzzy decision trees in Big Data classification problems
Mikel Elkano123, Mikel Uriz12, Humberto Bustince123, Mikel Galar123
1Department of Automatics and Computation, Public University of Navarre, 31006 Pamplona, Spain
2GIARA, Navarrabiomed, Complejo Hospitalario de Navarra (CHN), Universidad Pública de Navarra (UPNA), IdiSNA
Irunlarrea 3, 31008 Pamplona, Spain
3Institute of Smart Cities, Public University of Navarre, 31006 Pamplona, Spain
Emails: {mikel.elkano, mikelxabier.uriz, bustince, mikel.galar}@unavarra.es
Abstract
We present a new distributed fuzzy partitioning method to reduce the complexity of multi-way fuzzy decision trees in Big Data classification problems. The proposed algorithm builds a fixed number of fuzzy sets for all variables and adjusts their shape and position to the real distribution of training data. A two-step process is applied : 1) transformation of the original distribution into a standard uniform distribution by means of the probability integral transform. Since the original distribution is generally unknown, the cumulative distribution function is approximated by computing the q-quantiles of the training set; 2) construction of a Ruspini strong fuzzy partition in the transformed attribute space using a fixed number of equally distributed triangular membership functions. Despite the aforementioned transformation, the definition of every fuzzy set in the original space can be recovered by applying the inverse cumulative distribution function (also known as quantile function). The experimental results reveal that the proposed methodology allows the state-of-the-art multi-way fuzzy decision tree (FMDT) induction algorithm to maintain classification accuracy with up to 6 million fewer leaves.
Index Terms:
Fuzzy Decision Trees; Probability Integral Transform; Quantile Function; MapReduce; Apache Spark; Big Data
††publicationid: pubid:
©2018 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. Citation information: DOI 10.1109/BigDataCongress.2018.00011, 2018 IEEE International Congress on Big Data (BigData Congress)
I Introduction
Decision trees (DTs) [1] are popular non-parametric supervised machine learning tools used for classification and regression tasks. They have been applied in a wide variety of problems such as finance [2], image classification [3], intrusion detection [4], astronomy [5], bioinformatics [6], or medicine [7]. The main feature of DTs is the ability to explain the reasoning behind their decisions by means of tree-like graphs. Each node is a question or a test on an attribute (e.g. is ?), each branch represents the answer or the outcome of the test, and terminal nodes (or leaves) contain the final decisions. Trees are usually built by applying a top-down strategy called recursive partitioning [1], in which input data is recursively partitioned (split) into two or more sub-spaces that increase the homogeneity of class distributions. In the case of continuous attributes, the tree induction algorithm can apply either a brute-force search to test all possible cut points or a discretization process to split the attribute domain into a discrete set of intervals (also called bins). Since brute-force solutions might be too computationally heavy when dealing with Big Data problems, discretization strategies are usually applied to speed up the algorithm and reduce the model complexity.
Fuzzy logic [8] has proven to be an effective way to enhance the classification performance of machine learning algorithms when dealing with uncertainty, including decision trees [9, 10, 11]. In fuzzy decision trees (FDTs), a continuous attribute is characterized by a fuzzy variable instead of a discrete set of intervals. Therefore, a given input value might belong to one or more fuzzy sets with a certain membership degree and activate multiple branches at the same time. This way, the FDT is able to create soft decision boundaries and handle smooth transitions between adjacent intervals. In addition to classification performance, fuzzy logic allows the user to translate the whole tree into a number of IF-THEN rules composed of human-readable linguistic labels such as ”IF Temperature is High AND Sugar level is Very low THEN Class = Sick”, which might improve the interpretability of the model.
In the context of Big Data, the excessive time and space requirements of FDTs seriously affect the scalability of these algorithms. Segatori et al. came up with a MapReduce solution consisting of a new fuzzy partitioning method (discretizer) and a distributed FDT learning scheme [12]. The discretizer generates a strong triangular fuzzy partition for each continuous attribute based on fuzzy entropy, which is then used to construct the tree. The authors proposed two versions of FDT that differ in the splitting strategy: the binary (or two-way) FDT (FBDT) and the multi-way FDT (FMDT). The former recursively partitions the attribute space into two subspaces (child nodes), while the latter might generate more than two subspaces. Although accurate, the solution of Segatori et al. generally builds large and complex trees containing hundreds of thousands of leaves.
In this work, we present a new fuzzy partitioning method that reduces the complexity of trees constructed by the FMDT scheme, in terms of both the number of fuzzy sets used per variable and the number of leaves. The proposed algorithm applies the probability integral transform [13, 14] to adjust a fixed number of fuzzy sets to the real distribution of the training data. This transformation allows the algorithm to convert the variables of the training set into (approximately) uniform random variables regardless of their original distribution. Next, the Ruspini strong fuzzy partitions [15] are built in the new transformed dataset using equally distributed triangular membership functions. The resulting fuzzy sets are then used by the original FMDT to construct the tree.
In order to assess the benefits of our proposal, we carried out an empirical study using 4 Big Data classification problems available at UCI [16] and OpenML111https://www.openml.org/search?type=data repositories. We compared the accuracy rate and the model complexity of FMDT when using the original and the proposed fuzzy partitioning methods. The experimental results show a significant reduction in model complexity when applying our strategy.
This paper is organized as follows. Section II recalls the basics of the MapReduce algorithm and the Apache Spark framework and briefly describes the distributed solution of Segatori et al. to build FDTs for Big Data. In Section III we introduce the proposed fuzzy partitioning method. The experimental framework and the analysis of the results are shown in Sections IV and V, respectively. Finally, Section VI contains concluding remarks.
II Preliminaries
In this section we recall some concepts about the MapReduce algorithm and the Apache Spark framework (Section II-A) and we briefly describe the distributed solution presented by Segatori et al. to build fuzzy decision trees for Big Data (Section II-B).
II-A MapReduce and Apache Spark
MapReduce is a programming paradigm [17] for processing large-scale datasets in a distributed fashion. It is composed of two stages called Map and Reduce, which are executed by the so-called mappers and reducers, respectively:
Map stage: input data is partitioned into several logical splits that are associated with certain physical blocks (preferably with local ones, in favor of data locality). Each split is then processed by a single mapper on a given computing node. The mapper transforms the input data into multiple key-value pairs and calls the map() function (defined by the user) for each pair. The result of this function is another key-value pair that is part of the so-called intermediate data. Finally, this intermediate data is prepared to be sent to the reducers by applying the following operations:
- (a)
Sorting and Merging: outputs are sorted by key and all the values corresponding to the same key are merged in a list of values. 2. (b)
Partitioning: a target reducer is selected for each key. 3. (c)
Shuffle: previous intermediate data is copied to the reducers. 2. 2.
Reduce stage: the reducer is responsible for aggregating the outputs of the mappers when they all have finished. To this end, all the key-value pairs received from the mappers are sorted and merged by key. Then, the reduce() function (defined by the user) is called for every single key, where all its values are aggregated. Finally, the reducer returns the final result for each key.
Spark [18] was introduced as a generalization and an extension of the MapReduce paradigm. It is built around the concept of Resilient Distributed Datasets (RDDs) [19], which represent distributed immutable data (partitioned data) and lazily evaluated operations (transformations). The execution of a user-defined algorithm consists of a sequence of stages composed of a number of transformations that are split into tasks. One stage consists only of transformations that do not require any shuffling/repartitioning process (e.g., map and filter operations). Tasks are executed by the so-called executors, which represent independent processes in the Java Virtual Machine (JVM) of a worker node. Finally, the result of all transformations is obtained by calling an action that computes and returns the result to the driver node. This data flow allows the user to run an indefinite number of MapReduce jobs within the same main program, supporting a wide variety of algorithms and methods.
II-B Fuzzy decision trees for Big Data
Decision trees (DTs) [1] are popular supervised machine learning algorithms used for both classification and regression. In this work we focus on classification tasks, which consist in building a model called classifier that is able to classify unlabeled (unknown) examples (also called instances), on the basis of a training set containing previously labeled examples. Each example contained in the training set belongs to a class ( being the number of classes of the problem) and is characterized by a set of variables (also called attributes or features), where each variable can take on any value contained in the set . Therefore, the construction of a classifier consists in finding a decision function that maximizes the classification accuracy.
A DT is a directed acyclic graph where each internal node is a test on an attribute, each branch represents the outcome of the test, and each terminal node (or leaf) contains the final decision (class label). DTs are usually built by applying a top-down recursive partitioning [1] of the attribute space. The selection of the attribute considered in the decision node is based on metrics that measure the difference between the level of homogeneity of the class labels contained in the parent and child nodes. For continuous attributes, either brute-force solutions or discretization strategies can be applied. The former test all the possible cut points in the training set, while the latter divide the attribute domain into a discrete set of intervals (also called bins). Since brute-force strategies are computationally heavy, the DTs designed for Big Data usually apply discretization methods to speed up the algorithm and reduce the model complexity.
Fuzzy decision trees (FDTs) [9, 10] make use of fuzzy logic [8] to better deal with uncertainty and create soft decision boundaries that improve classification performance. FDTs use fuzzy partitions to characterize continuous attributes instead of considering a discrete set of intervals. As a consequence, a given input value might belong to one or more fuzzy sets with a certain membership degree and activate multiple branches at the same time. Fuzzy partitions allow FDTs to handle smooth transitions between adjacent intervals in continuous attributes, which might lead to more accurate predictions when handling numeric data. When classifying a new example , the strength of activation of each leaf (called matching degree) is computed. To this end, the matching degree of every internal node must be calculated as well. Given the current node that considers as the splitting attribute, the matching degree between and is computed as:
[TABLE]
where is a T-norm, is the membership degree of to the fuzzy set associated with the node , and is the matching degree between and the parent node . Next, the association degree of with the class at the leaf node is calculated as:
[TABLE]
where is the matching degree between and the leaf node and is the class weight associated with at . Different definitions have been proposed for in the literature [20]. In this work we consider
[TABLE]
where is the set of all training examples belonging to the class . Finally, the class label of is predicted according to different criteria, the most common being the following:
- •
Maximum matching: the class corresponding to the maximum association degree is returned.
- •
Weighted vote: the sum of all association degrees is computed for each class. The one getting the maximum sum is predicted.
The excesive time and space requirements of FDTs can cause serious scalability issues when tackling large-scale problems. In this work, we consider the distributed solution proposed by Segatori et al. in [12] to build FDTs for Big Data, which comprises two stages:
Fuzzy partitioning. A strong triangular fuzzy partition is constructed for each continuous attribute based on fuzzy entropy. To this end, the algorithm selects the candidate fuzzy partition that minimizes the fuzzy entropy and splits the attribute domain into two subsets in a recursive fashion, until a stopping condition is met. Although accurate, the partitions built by this methodology might contain many fuzzy sets per variable, increasing the complexity of the model. 2. 2.
FDT learning. An FDT is built by applying one of the two splitting strategies considered by the authors: the binary (or two-way) FDT (FBDT), which always generates two child nodes, or the multi-way FDT (FMDT), which might create more than two child nodes. Another difference is that in FBDTs an attribute can appear several times in the same path. Both methods use the fuzzy information gain [21] for the attribute selection. In this work we focus on FMDTs.
The whole pipeline is built on top of Apache Spark and the MLlib [22] machine learning library and is publicly available at GitHub222https://github.com/BigDataMiningUnipi/FuzzyDecisionTreeSpark.
III Applying the probability integral transform to reduce the complexity of multi-way fuzzy decision trees
In this work we propose a new distributed fuzzy partitioning method that reduces the complexity of FDTs generated by the FMDT algorithm presented in [12]. The proposed solution replaces the original partitioning method used by FMDT without altering the FDT learning algorithm. The goals of our approach are the following:
- •
To build a few fuzzy sets per attribute. The original method adds fuzzy sets to the fuzzy partition until the fuzzy information gain is below a certain threshold, increasing the complexity of the model. Our approach uses a fixed number of fuzzy sets for all attributes.
- •
To adjust the fuzzy sets to the real distribution of the attributes. The proposed solution modifies both the shape and the position of the fuzzy sets to enhance the discrimination capability of the model.
In order to achieve the aforementioned goals, we propose a two-step algorithm consisting of a pre-processing stage that directly leads to a self-adaptive fuzzy partitioning process:
- •
Pre-processing: the variables of the training set are converted into standard uniform random variables by applying the probability integral transform theorem [13, 14], described in Theorem 1. This theorem states that any continuous random variable can be converted into a standard uniform random variable.
Theorem 1**.**
If is a continuous random variable with cumulative distribution function (CDF) and if , then is a uniform random variable on the interval [0,1].
Proof.
Suppose that is a function of where is differentiable and strictly increasing. Thus, its inverse uniquely exists. The CDF of can be derived using
[TABLE]
and its density is given by
[TABLE]
This procedure is called the CDF technique and allows the distribution of to be derived as follows:
[TABLE]
∎
However, since the original distribution of the training set is unknown, we cannot compute the exact CDF. Instead, we propose computing the -quantiles of the training set to obtain an approximate CDF. To this end, for each variable, all the values are sorted and each quantile is extracted. If is smaller than the number of examples in the training set, the CDF of a certain value is linearly interpolated on the interval [, ], being the first quantile greater than the value. If the value is smaller than the first quantile () or greater than the last quantile (), the CDF is 0 or 1, respectively. This way, the new transformed dataset will be approximately uniform regardless of the original distribution. Of course, the transformation of the testing set is performed by interpolating the CDF using the quantiles extracted from the training set.
- •
Partitioning: a Ruspini strong fuzzy partition [15] is created by uniformly distributing a fixed number of triangular membership functions across the interval [0,1]. It is worth noting that the definition of every single fuzzy set in the original space can be recovered by applying the inverse cumulative distribution function or quantile function [23]. In this case, for every point defining the triangular membership function, we would linearly interpolate the corresponding value between the two closest quantiles by computing the inverse of the linear function used to compute the CDF. Figure 1 shows an illustrative example of how fuzzy sets are distributed in the original and transformed spaces of the attribute jet_1_eta and jet_1_phi of HIGGS. Solid lines and bar plots represent the membership functions of the fuzzy sets and the original distribution of the variables, respectively.
Notice that both steps (pre-processing and partitioning) are closely interrelated. Given that, from our point of view, a Ruspini strong fuzzy partition with equally distributed membership functions is a suitable way to model a uniform distribution, our hypothesis is that if we are able to transform any attribute into a uniform distribution and likewise carry out the inverse process, we would obtain a self-adapted partition for the original distribution of each attribute. Interestingly, this result is obtained without specifically developing a new partitioning method. The whole pipeline is written in Scala 2.11333http://www.scala-lang.org/ on top of Apache Spark 2.0.2 and is publicly available at GitHub444https://github.com/melkano/uniform-fuzzy-partitioning under the GPL license.
IV Experimental framework
In this section, we first describe the datasets and performance metrics used to evaluate the methods considered in the experiments (Section IV-A). Next, we specify the parameters and the environment configuration used for the executions of the algorithms (Section IV-B).
IV-A Datasets and performance metrics
In order to develop the experimental study, we considered 4 Big Data classification problems available at UCI [16] and OpenML555https://www.openml.org/search?type=data repositories. Table I shows the description of the datasets indicating the number of instances (#Instances), real (R)/integer(I)/categorical(C)/total(T) attributes (#Attributes), and classes (#Classes). The names of BNG Australian (BNG) and HEPMASS (HEPM) have been shortened. All the experiments were carried out using a 5-fold stratified cross-validation scheme. To this end, we randomly split the dataset into five partitions of data, each one containing 20% of the examples, and we employed a combination of four of them (80%) to train the system and the remaining one to test it. Therefore, the result of each dataset was computed as the average of the five partitions.
Classification performance was measured based on the so-called confusion matrix (Table II), which stores the number of correctly classified and misclassified examples for each class.
From this matrix we can obtain the following four metrics:
- •
True positive rate: percentage of correctly classified positive examples.
[TABLE]
- •
True negative rate: percentage of correctly classified negative examples.
[TABLE]
- •
False positive rate: percentage of misclassified negative examples.
[TABLE]
- •
False negative rate: percentage of misclassified positive examples.
[TABLE]
Based on these metrics, the classification performance of each method was measured with the well-known accuracy rate and the Area Under the ROC Curve (AUC) [24], which are defined as:
[TABLE]
[TABLE]
IV-B Parameters and environment configuration
As for the parameters used for FMDT, we set the values suggested by the authors in the original paper:
- •
Measure to compute the impurity of nodes: fuzzy entropy
- •
T-norm: product
- •
Maximum number of bins for numeric attributes: 32
- •
Maximum depth of the tree: 5
- •
= 0.1%; = 0.02 ; = 10
The computing cluster used for running the algorithms is composed of 6 slave nodes and a master node connected via 1Gb/s Ethernet LAN network. Half of the slave nodes have 2 Intel Xeon E5-2620 v3 processors at 2.4 GHz (3.2 GHz with Turbo Boost) with 12 virtual cores in each one (where 6 of them are physical). The other half are equipped with 2 Intel Xeon E5-2620 v2 processors at 2.1 GHz with the same number of cores as the previous ones. The master node is composed of an Intel Xeon E5-2609 processor with 4 physical cores at 2.4 GHz. All slave nodes are equipped with 64 GB of RAM memory, while the master works with 32 GB of RAM memory. With respect to the storage specifications, all nodes use Hard Disk Drives featuring a read/write performance of 128 MB/s. The entire cluster runs on top of CentOS 6.5 + Apache Hadoop 2.6.0 + Apache Spark 2.0.2.
We found that using more than 24 cores had a negative impact on runtimes when setting the configuration recommended by the authors. Consequently, the number of cores used in the experiments was 24 and we assigned 4 cores to every single executor in order to ensure full HDFS write throughput while minimizing memory replication overhead (e.g. broadcast variables).
V Experimental study
In order to assess the performance of our approach, we carried out an empirical study covering three aspects: classification performance (Table III), model complexity (Table IV), and runtimes (Table V). In all cases we consider four methods: the original FMDT proposed by Segatori et al. in [12] and three different configurations of the proposed method that differ in the number of fuzzy sets () used for numeric attributes (denoted as FMDTX). We must point out that the original FMDT ran out of memory while tackling HEPMASS due to the excessive number of leaves built during training, and thus no results are given for this method on HEPMASS.
Tables III and IV reveal that the proposed fuzzy partitioning method (FMDTX) is able to maintain the classification performance of FMDT while leading to significantly simpler models. The different configurations of our approach yield similar results in terms of accuracy rate and AUC (except for HIGGS), although there is a positive trend in favor of the usage of more fuzzy sets. However, using more fuzzy sets often causes the learning algorithm to build more leaves, which increases the model complexity. Next, we analyze the results obtained on each dataset separately:
- •
BNG: the proposed method improves the accuracy rate and the AUC of FMDT by 6% and 8%, respectively. Although the trees built by FMDTX are deeper, they have 8-80K times fewer leaves than FMDT’s.
- •
HEPM: the original FMDT builds too many leaves to handle this dataset on the cluster described in Section IV-B and ran out of memory during the experiments. This fact suggests that our approach is a potential solution to avoid the explosion in the number of leaves during the induction of FDTs.
- •
HIGGS: the classification performance of FMDT5 on this dataset drops by nearly 1% with respect to the rest of methods, which reveals that 5 fuzzy sets are not enough to capture the complexity of this problem. However, the rest of configurations (FMDT7 and FMDT9) are able to maintain the classification performance of FMDT with trees composed of 15K and 50K leaves, respectively, while FMDT generates 6M leaves. Furthermore, the original fuzzy partitioning method builds almost twice as many fuzzy sets as FMDT7.
- •
SUSY: all the configurations perform similarly to FMDT in terms of discrimination capability. However, our method leads to simpler trees composed of 3K, 15K, and 50K leaves, while FMDT builds 5M leaves. In this case, the difference between the number of fuzzy sets used by each method is even larger, since FMDT uses nearly 23 fuzzy sets on average for each attribute.
Table V shows the time required by each method to perform three different stages: the partitioning process, the FDT induction, and the whole learning algorithm. In general, there are no significant differences among the methods when it comes to the partitioning stage, though the proposed algorithm is 30% faster than the original method on SUSY. However, when the FDT induction is considered, the reduction in model complexity coming from the proposed fuzzy partitioning algorithm results in much faster runtimes.
VI Concluding remarks
In this work we have presented a new distributed fuzzy partitioning method that reduces the model complexity of multi-way fuzzy decision trees (FDTs) in Big Data classification problems. The proposed algorithm consists in transforming the original training set in such a way that all numeric variables follow an approximately standard uniform distribution. To this end, the probability integral transform is applied, which states that any continuous random variable can be converted into a standard uniform random variable based on the original cumulative distribution function (CDF). Since the CDF is generally unknown, we approximate this function by computing the -quantiles of the training set and linearly interpolating between such quantiles. After this transformation, Ruspini strong fuzzy partitions are created by equally distributing a fixed number of triangular membership functions across the [0,1] interval. To recover the points defining the fuzzy sets in the original space, the inverse cumulative distribution function or quantile function can be applied. The proposed two-step partitioning process is able to adjust both the position and shape of fuzzy sets to the real distribution of training data.
In order to test the performance of our approach, we carried out an empirical study focused on the MapReduce FDT induction algorithm introduced by Segatori et al. for Big Data. To this end, we replaced the fuzzy partitioning method used in the original paper with the proposed algorithm, without modifying the FDT learning stage. The experimental results reveal that the proposed methodology leads to simpler FDTs that maintain classification performance while providing much faster runtimes.
Acknowledgment
This work has been supported by the Spanish Ministry of Science and Technology under the project TIN2016-77356-P.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. R. Quinlan, C 4.5: Programs for Machine Learning . San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1993.
- 2[2] M.-Y. Chen, “Predicting corporate financial distress based on integration of decision tree classification and logistic regression,” Expert Systems with Applications , vol. 38, no. 9, pp. 11 261–11 272, 2011.
- 3[3] C.-C. Yang, S. Prasher, P. Enright, C. Madramootoo, M. Burgess, P. Goel, and I. Callum, “Application of decision tree technology for image classification using remote sensing data,” Agricultural Systems , vol. 76, no. 3, pp. 1101–1117, 2003.
- 4[4] X.-B. Li, “A scalable decision tree system and its application in pattern recognition and intrusion detection,” Decision Support Systems , vol. 41, no. 1, pp. 112–130, 2005.
- 5[5] N. Ball, R. Brunner, A. Myers, and D. Tcheng, “Robust machine learning applied to astronomical data sets. I. Star-galaxy classification of the sloan digital sky survey DR 3 using decision trees,” Astrophysical Journal , vol. 650, no. 1, pp. 497–509, 2006.
- 6[6] D. Che, Q. Liu, K. Rasheed, and X. Tao, “Decision tree and ensemble learning algorithms with their applications in bioinformatics,” Advances in Experimental Medicine and Biology , vol. 696, pp. 191–199, 2011.
- 7[7] J. Sanz, D. Paternain, M. Galar, J. Fernandez, D. Reyero, and T. Belzunegui, “A New Survival Status Prediction System for Severe Trauma Patients Based on a Multiple Classifier System,” Computer Methods and Programs in Biomedicine , vol. 142, no. C, pp. 1–8, 2017.
- 8[8] L. Zadeh, “Fuzzy sets,” Information and Control , vol. 8, no. 3, pp. 338 – 353, 1965.