Detecting changes in the covariance structure of functional time series with application to fMRI data
Christina Stoehr, John A D Aston, Claudia Kirch

TL;DR
This paper develops nonparametric change point detection methods for covariance stationarity in functional time series, specifically applied to resting state fMRI data to identify deviations in brain connectivity.
Contribution
It introduces new tools for detecting covariance changes in functional time series, combining dimension reduction with full-structure tests, tailored for fMRI data analysis.
Findings
Methods effectively detect change points in simulated data.
Application to fMRI data reveals deviations in brain connectivity.
Full-structure tests outperform dimension-reduction methods in certain scenarios.
Abstract
Functional magnetic resonance imaging (fMRI) data provides information concerning activity in the brain and in particular the interactions between brain regions. Resting state fMRI data is widely used for inferring connectivities in the brain which are not due to external factors. As such analyzes strongly rely on stationarity, change point procedures can be applied in order to detect possible deviations from this crucial assumption. In this paper, we model fMRI data as functional time series and develop tools for the detection of deviations from covariance stationarity via change point alternatives. We propose a nonparametric procedure which is based on dimension reduction techniques. However, as the projection of the functional time series on a finite and rather low-dimensional subspace involves the risk of missing changes which are orthogonal to the projection space, we also consider…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9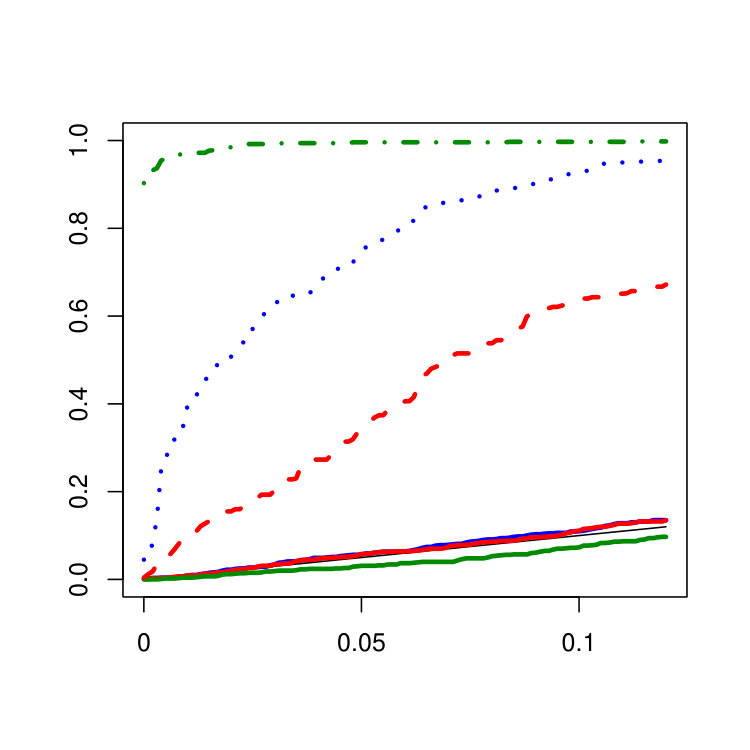 Figure 10
Figure 10 Figure 11
Figure 11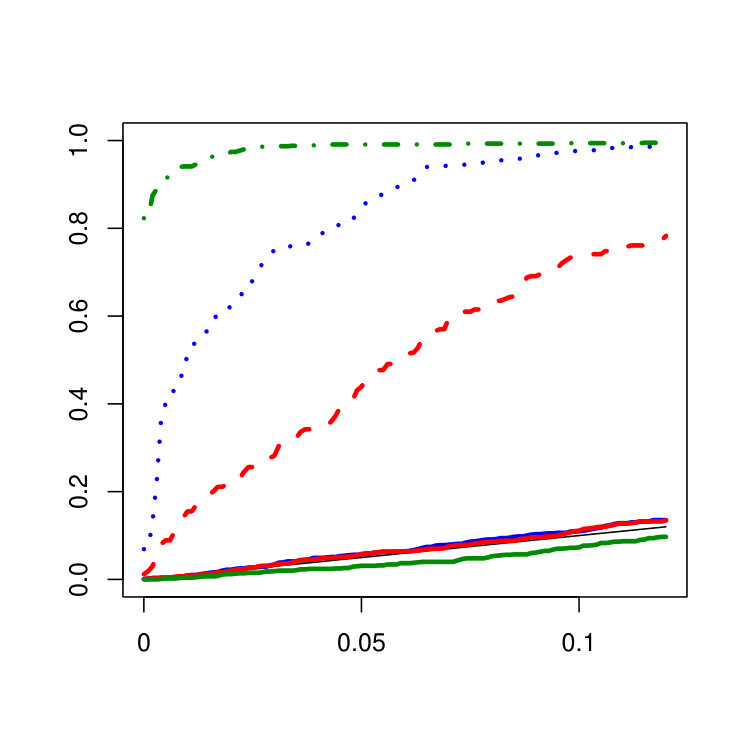 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16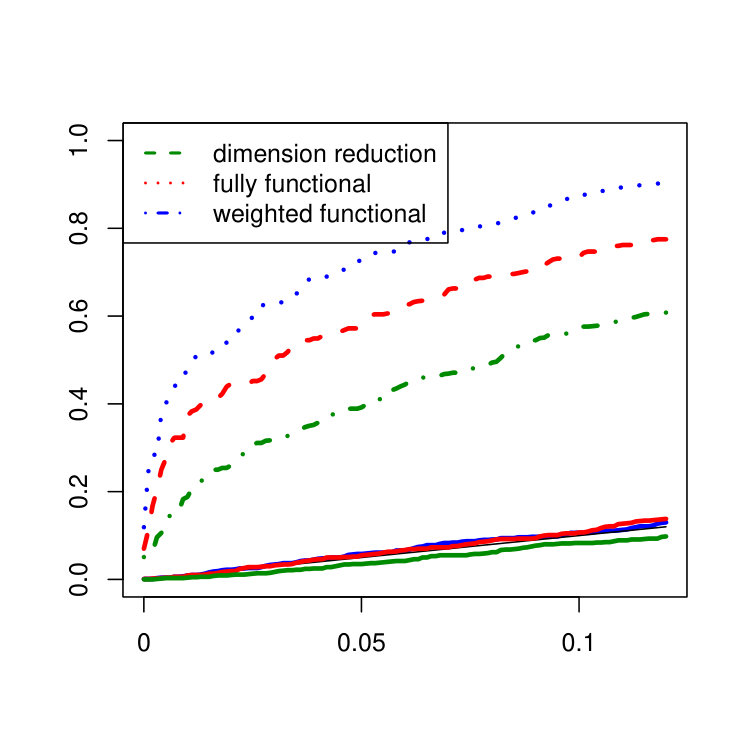 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20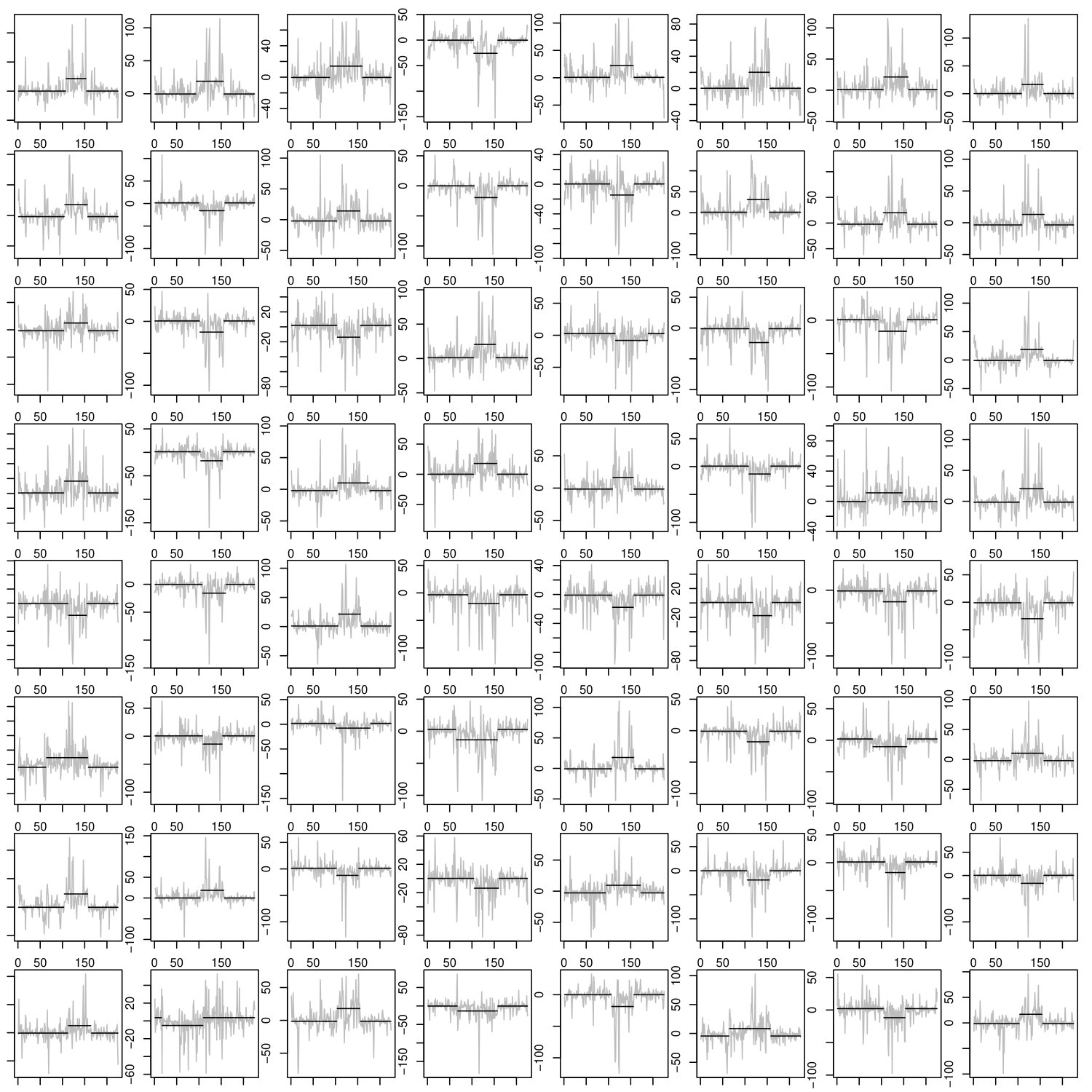 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24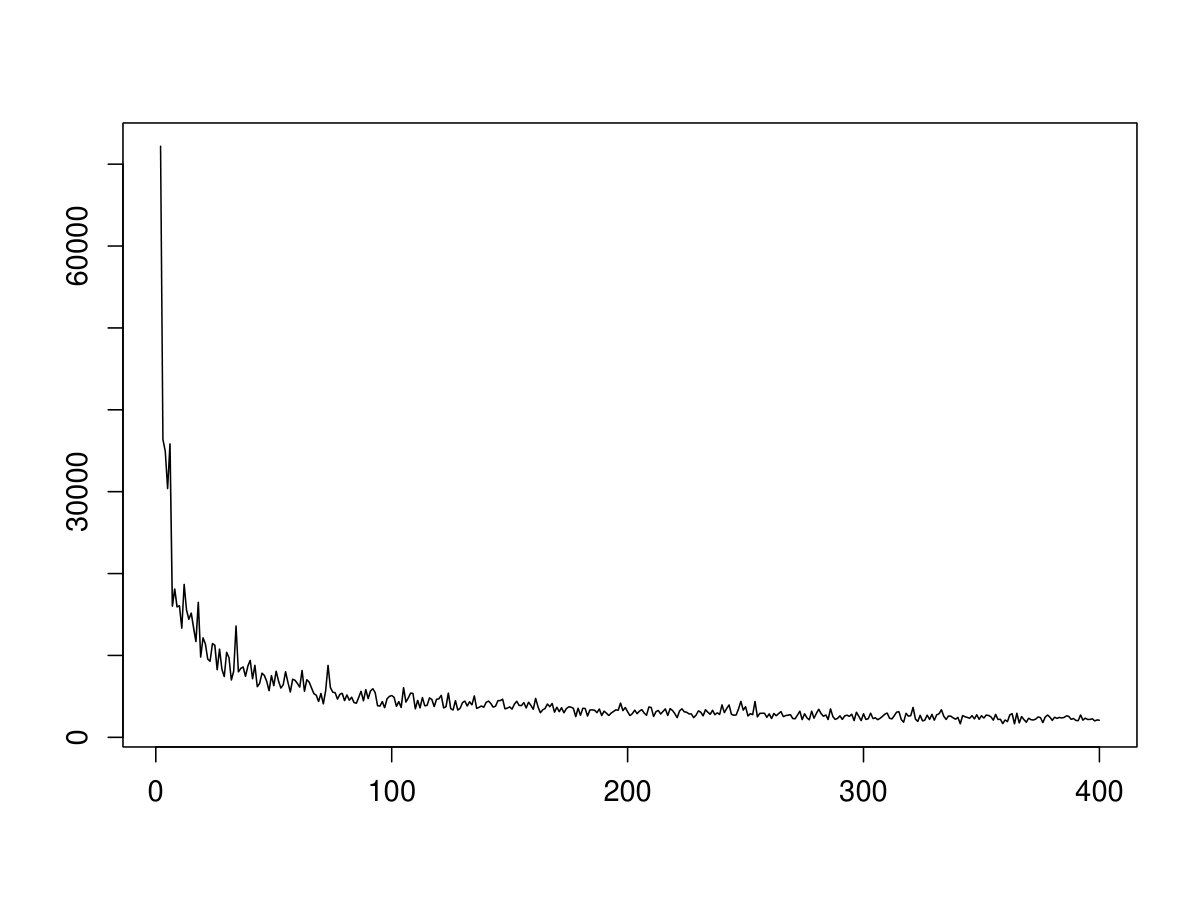 Figure 25
Figure 25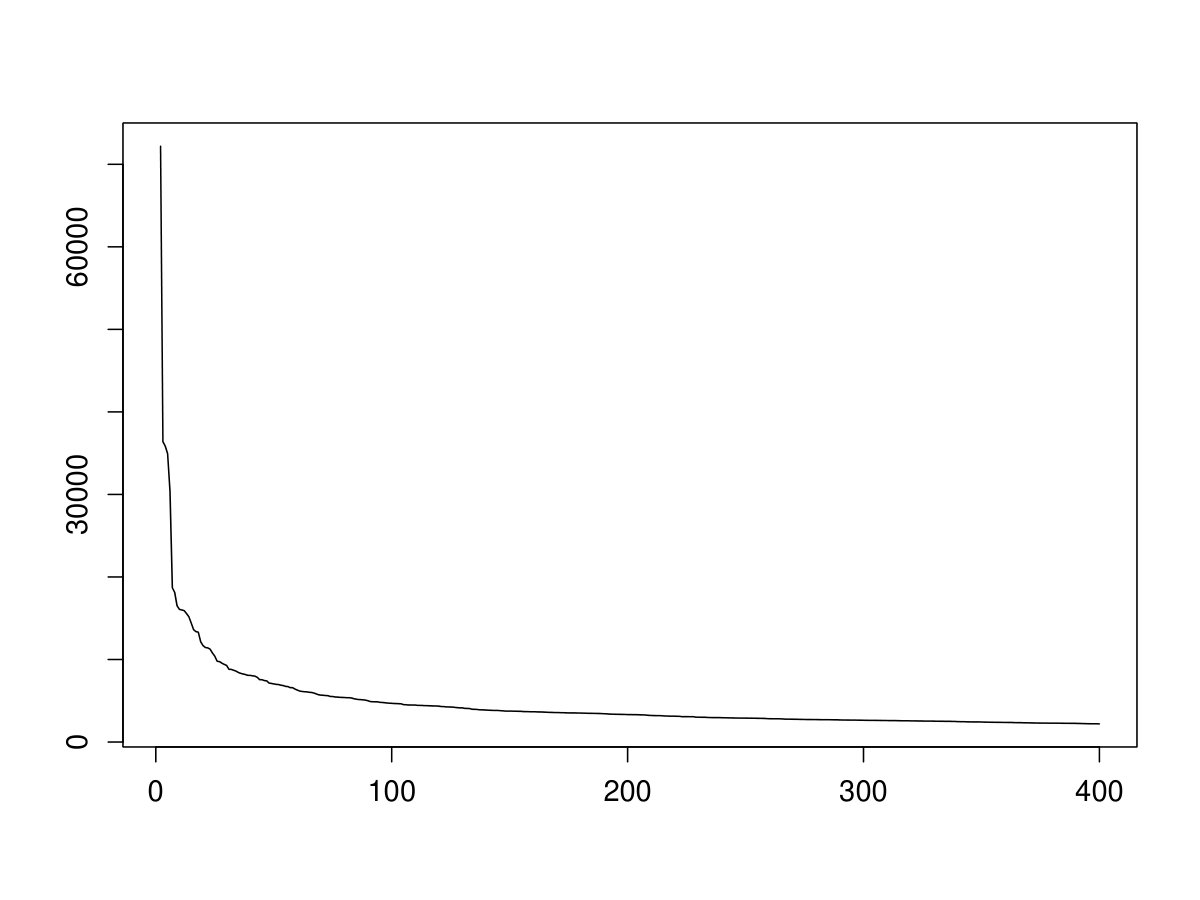 Figure 26
Figure 26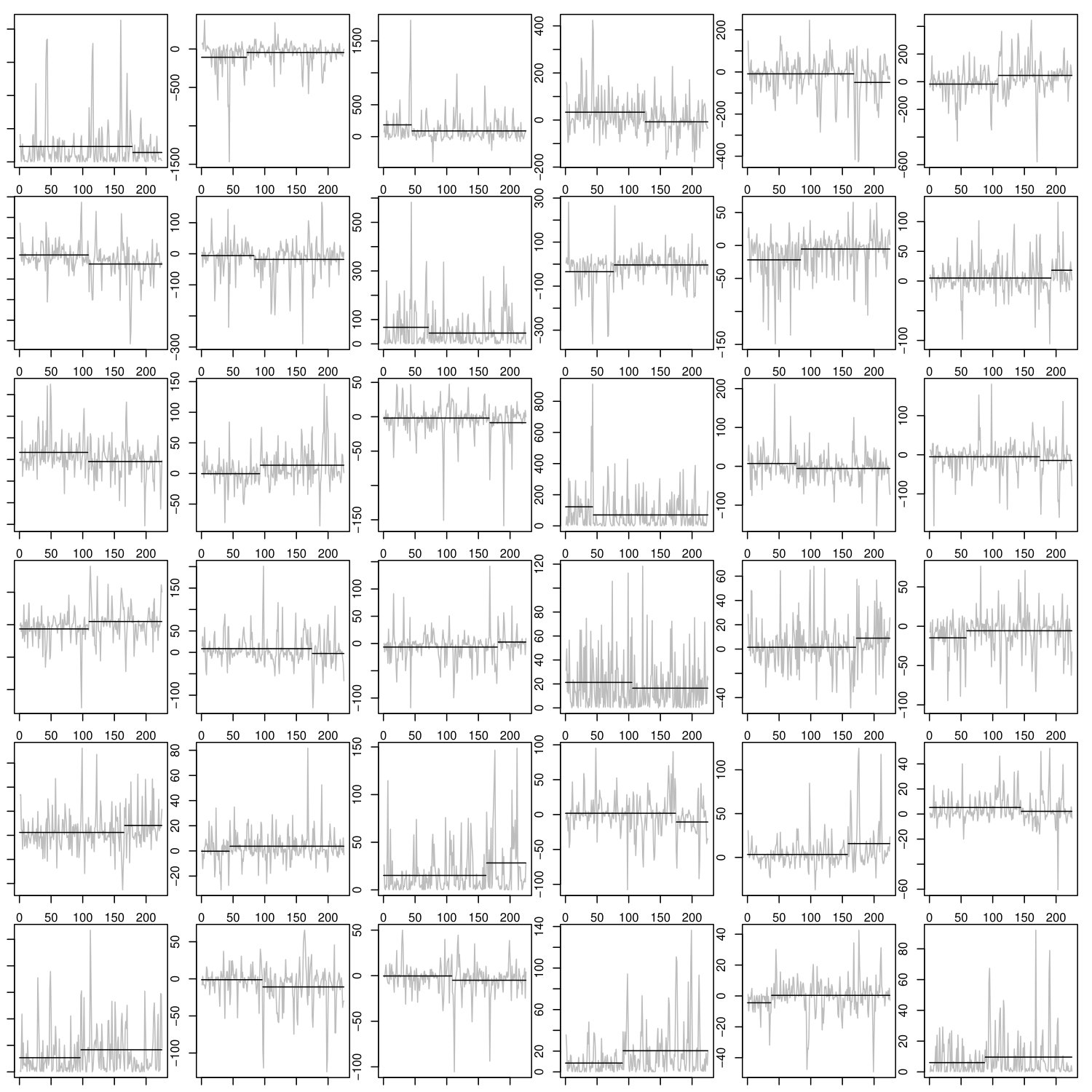 Figure 27
Figure 27Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Detecting changes in the covariance structure of functional time series with application to fMRI data
Christina Stoehr111 Ruhr-Universität Bochum, Department of Mathematics, Bochum, Germany; [email protected]
John A D Aston222 University of Cambridge, Statistical Laboratory, Cambridge, UK
Claudia Kirch333 Otto-von-Guericke University Magdeburg, Institute for Mathematical Stochastics, Magdeburg, Germany, 444 Center for Behavioral Brain Sciences (CBBS), Magdeburg, Germany
Abstract
Functional magnetic resonance imaging (fMRI) data provides information concerning activity in the brain and in particular the interactions between brain regions. Resting state fMRI data is widely used for inferring connectivities in the brain which are not due to external factors. As such analyzes strongly rely on stationarity, change point procedures can be applied in order to detect possible deviations from this crucial assumption. In this paper, we model fMRI data as functional time series and develop tools for the detection of deviations from covariance stationarity via change point alternatives. We propose a nonparametric procedure which is based on dimension reduction techniques. However, as the projection of the functional time series on a finite and rather low-dimensional subspace involves the risk of missing changes which are orthogonal to the projection space, we also consider two test statistics which take the full functional structure into account. The proposed methods are compared in a simulation study and applied to more than 100 resting state fMRI data sets.
Keywords: Change point analysis, covariance change, functional data, resting state fMRI, functional time series, dimension reduction
1 Introduction
Functional Magnetic Resonance Imaging (fMRI) is a widely used technique to capture brain activity. An fMRI dataset consists of a sequence of three-dimensional images related to the contrast of oxygenated and deoxygenated hemoglobin, the so called BOLD signal, that are recorded every few seconds. fMRI facilitates a noninvasive real time functional brain mapping with a high spatial resolution and thus yields large amounts of data requiring the development of appropriate statistical methodologies. fMRI scans can be obtained related to a task or in a resting state where the person is told to go through the scanning procedure without thinking of anything while not falling asleep. Resting state data is used to analyze brain activities excluding external factors where the examination of the covariance structure between brain regions is of particular interest as it is associated with neural connectivity. Such analyses strongly rely on the assumption that resting state data is first and second order stationary. This assumption is by no means guaranteed as it might happen, for example, that during the scan the person suddenly remembers something such that the mean activities deviate from their resting state baseline in some areas of the brain. If such a scan is then used for analyzing connectivities without taking a possible change into account, the results will be contaminated by the mean change leading to wrong conclusions. Therefore, in [2], Aston and Kirch developed testing procedures to detect deviations from mean stationarity. However, it is not only deviations from mean stationarity but also deviations from covariance stationarity that will contaminate the analysis and ultimately the conclusions. Therefore, in this paper, we develop tools to test for deviations from covariance stationarity in fMRI data which will be modeled as functional time series. This means that each observation of the time series, in this case each 3-d image of the brain, can be viewed as a function. Indeed, taking into consideration that the brain works as a single unit with spatial dependencies, it is a natural approach to model each image as a discretized observation of a functional response. In contrast, a voxelwise approach requires a difficult adaption for multiple testing and may miss signals that are very small in any voxel but considerably large if information across voxels is used. Dependencies in time, i.e. between subsequent images, which are also present in fMRI data, can be captured by a time series structure. Lifting the multivariate observations to a functional space makes them mathematically easier to handle as one can exploit functional properties, such as smoothness, making use of many well established statistical techniques.
The statistical analysis of functional data is currently a rapidly progressing field of research as an increasing number of applications provides data which can be modeled in such a way. The methodology developed in this paper is widely applicable beyond the considered application of fMRI data, hence also of independent interest in functional data analysis in general. We adapt a nonparametric approach where we tackle the problem by means of a change point procedure without assuming any parametric spatial or temporal correlation structure. Such nonparametric methods become more and more refined in the analysis of functional data (cf. [15] and [17]). Nonparametric tests for at most one change (AMOC) in the mean function have been considered for independent observations in [3] and [7] as well as for weakly dependent data in [16]. Aston and Kirch [1] extend these results to a more general class of dependency structures and also consider epidemic changes where the mean function returns to its original state after some time.
The analysis of functional connectivity data is a very active field of research in neuroimaging. The detection of change points in the observed data without assuming the specifications of the experiment to be known is of particular interest. In this context, Cribben et al. [11] propose a data-driven approach, the so called Dynamic Connectivity Regression (DCR), for detecting changes in the functional connectivity between a set of brain regions and estimate a connectivity graph for each temporal interval between the change points. They use resampling methods in order to decide whether a change is significant. With a view to single-subject data, DCR is further developed in [12]. In this paper we develop statistical procedures for the detection of deviations from covariance stationarity in functional time series that can be applied to fMRI data without being restricted to predefined regions of interest.
The paper is organized as follows: In Section 2 we propose a procedure based on dimension reduction techniques such as principal component analysis, to detect deviations from covariance stationarity. The test statistics and their asymptotic behavior are investigated in Section 2.3. The proposed procedures require the estimation of the long-run covariance which is statistically unstable. Using a missspecified estimator is a possible solution but leads to an unknown limit distribution such that resampling procedures, as described in Section 2.4, are unavoidable. Alternative test statistics which take the full functional structure into account without reducing the dimension are discussed in Section 2.5. The different procedures proposed in this paper are compared in a simulation study in Section 3. The application to fMRI data is presented in Section 4. Additional technical details, proofs and further results from the data analysis are given in the supplementary material.
2 Testing for changes in the covariance structure of functional data
We assume that the observations are obtained from a functional time series with the respective mean function being constant over time, i.e.
[TABLE]
where denotes the time point and a spatial coordinate in a compact set . The constant mean function is given by while the random fluctuations are represented by with which is not necessarily stationary but can have a time-dependent covariance structure as detailed in Section 2.1. as well as all elements of are assumed to be square integrable on . The mean stationarity can be checked previously as described in [2].
The covariance structure of a functional time series is determined by the covariance operator respectively the covariance kernel as given in the following definition.
Definition 1**.**
Let be a functional time series, where is a compact set. The square integrable covariance operator is defined by
[TABLE]
where is the covariance kernel of
2.1 Change point model
First consider the at most one change (AMOC) alternative given by
[TABLE]
with and for some and . According to this model, the covariance change occurs at the unknown time point . The covariance kernel before the change as well as the change in covariance are both unknown.
Assumption 1**.**
Assume that for as in (2.1) it holds
- (i)
* with*
[TABLE]
is approximable **[16]* and hence, in particular, stationary and ergodic.*
- (ii)
* is ergodic with*
[TABLE]
As we do not assume to be stationary, the time series after the change is allowed to have starting values from a different distribution. approximability is a nonparametric concept of dependence which provides the necessary mathematical tools for the proofs and is satisfied for a large class of time series. Full details can be found in [16].
Testing for covariance stationarity against the AMOC alternative can be described by the following hypotheses:
[TABLE]
In order to obtain a test for more general alternatives of nonstationarities in the covariance, we consider the following epidemic alternative:
[TABLE]
with and for some . It would also be possible to allow for contaminated starting values in the time series after the change. This alternative can be viewed as a better approximation to the expected kind of deviation from covariance stationarity.
2.2 Dimension reduction techniques
A common approach in functional data analysis is the transition to a multivariate setting by projecting the data into a -dimensional space spanned by an orthonormal basis . In this case, the projection scores are obtained by
[TABLE]
As we aim at assessing the above functional testing problem by applying a multivariate testing procedure to the projection scores we first need to verify if a change in the covariance structure of the observed functional time series implies a change in the covariance of the scores. To this end, we observe
[TABLE]
Thus, a necessary condition for the covariance change to be visible in the projection scores is
[TABLE]
In contrast to other applications we do not require the dimension reduction technique to explain a large amount of the variation of the data but to yield a good signal-to-noise ratio where the signal is determined by .
Principal component analysis
Principal component analysis (PCA) is a widely used data driven dimension reduction technique which projects the functional data on the subspace spanned by the first principal components explaining the most variance of any subspace of size . Let be the non-negative decreasing sequence of eigenvalues of the covariance operator and a set of corresponding orthonormal eigenfunctions defined by
[TABLE]
By Mercer’s Lemma, see Lemma 1.3 in [9], the covariance kernel can be expressed as
[TABLE]
and the Karhunen-Loève expansion, see Theorem 1.5 in [9], yields
[TABLE]
where the scores given by are uncorrelated and centered with variance . As the covariance kernel is unkown, PCA is usually conducted based on the empirical covariance function
[TABLE]
where Under the null hypothesis, the empirical covariance function estimates the actual covariance kernel whereas under the alternative it converges to a contaminated limit as stated in (B.7) in the supplementary material. As projection basis we determine the eigenfunctions of belonging to the largest eigenvalues and obtain the projection scores by
[TABLE]
with For more details on functional principal component analysis, in particular for the consistency of the empirical eigenvalues and eigenfunctions, see, for example, [17].
Separable covariance structure
As fMRI data is collected voxelwise ( voxels), using the empirical covariance function requires the calculation and storage of an -dimensional matrix in addition to the respective eigenanalysis. While this is computationally infeasible, one can show that there is a one-to-one correspondence between the eigenvalues and eigenvectors of the spatial covariance matrix () and that of the time domain (). As the eigenanalysis in the time domain requires less computational effort. However, this relationship also reveals that the number of nonzero eigenvalues is limited by the sample size and hence indicates a considerable loss of precision when using the nonparametric covariance estimator. Based on those considerations, Aston and Kirch [2] suggest to use a separable covariance structure in the estimation procedure given by
[TABLE]
In this work, we adopt this approach of estimating the covariance matrix separately in each direction ( resp. resp. ) and calculate the respective eigenvalues and eigenfunctions. The projection basis can then be obtained by the tensor product of the first eigenfunctions of each direction. Even if the actual covariance structure is not separable we obtain a valid projection such that the proposed dimension reduction can be applied for our purposes. While this is an obvious simplification, most smoothing techniques in fMRI make use of tensor based formulations leading to very similar implicit assumptions.
2.3 Test statistic and statistical properties
We assess the functional testing problem by testing for a change in the covariance structure of the d-dimensional estimated score vectors. As proposed by Aue et al. in [4] we construct the test statistic based on the following version of the traditional CUSUM-statistic for the AMOC alternative:
[TABLE]
We consider the test statistic
[TABLE]
where is an estimator for the long-run covariance under . We assume that is consistent under the null hypothesis and
[TABLE]
where is some positive-definite matrix which can differ from . For the epidemic change point alternative we propose the test statistic
[TABLE]
with While we consider sum-type test statistics throughout this paper the respective results for max-type test statistics obtained as the maximum over the quadratic forms resp. can be found in Section A in the supplementary material.
Behavior under the null hypothesis
We allow for a weak dependency structure by assuming the observed functional time series to be approximable. Effectively, this means the time series can be well approximated (in an sense) by an -dependent one (see Definition 2.1 in [16]) - a property that many of the usual time series models possess.
Theorem 1**.**
Let Assumption 1 (i) be satisfied. Additionally, we assume that the first eigenvalues of are separated, i.e. . Then, the following asymptotics hold under the null hypothesis if is a consistent estimator for the long-run covariance .
[TABLE]
where and are independent standard Brownian bridges.
Based on this result we can now determine the critical value as -quantile of the respective limit distribution. This can be done by using Monte Carlo simulations. However, it is notoriously difficult to estimate the long-run covariance (see discussion in [2]). In this case, i.e. if is not consistent or the convergence too slow to be appropriate for small samples, the limit distributions in Theorem 1 are no longer true.
Behavior under the alternative hypothesis
Condition (2.3) is examined for two exemplary alternatives, where the projection basis is determined based on principal component analysis. The following Lemma states that, under the alternative, the empirical covariance function converges to a contaminated limit .
Lemma 1**.**
Under Assumption 1 it holds
[TABLE]
where .
Example 1** (Change does not affect eigenfunctions).**
We consider a covariance change that does not affect the eigenfunctions, i.e. the covariance kernel after the change has the same eigenfunctions as the covariance kernel before the change:
[TABLE]
*where and are the eigenfunctions and eigenvalues of and with for some l=1,…,d.
Condition (2.3) is fulfilled as it holds (see Section B in the supplementary material)*
[TABLE]
Assuming that the eigenvalues of are separated, the change is still detectable if the eigendirections are estimated based on the empirical covariance function (see (B)).
Example 2** (Additive noise term).**
In this example, a covariance change in the functional time series occurs due to an additive noise term in the scores of the first m leading eigendirections. More precisely, it holds with
[TABLE]
where with are independent and identically distributed with mean 0 and and independent of . In this setting, it holds (see Section B in the supplementary material)
[TABLE]
for . Hence, condition (2.3) is fulfilled if for some . According to (B.13) the change can be detected by projecting on the subspace spanned by the first eigendirections of the empirical covariance kernel if
[TABLE]
for at least one pair , where are the eigenfunctions of .
Estimation of the long-run covariance
The estimation of the long-run covariance matrix is a challenging issue in change point analysis. In the case where are independent under the long-run covariance reduces to the covariance, i.e.
[TABLE]
The components of the scores are known to be uncorrelated. However, this does not necessarily imply a diagonal long-run covariance as, in general, the squared components are not uncorrelated. By additionally assuming that the scores are Gaussian we get a diagonal long-run covariance depending only on the eigenvalues of the covariance kernel which can be estimated by the eigenvalues of the estimated covariance kernel. More precisely, it holds (see Section B in the supplementary material for proof):
[TABLE]
However, when dealing with a time series structure and non-Gaussian structure one has to estimate the full long-run covariance. Usual estimators, such as the Bartlett estimator, lead to problems, in particular if the dimension is large compared to the sample size (see [2]). Aston and Kirch [2] conclude that the change point procedure becomes more stable and conservative if one only corrects for the long-run variance, i.e. the diagonal of the long-run covariance matrix. In our case, this approach leads to the following test statistic:
[TABLE]
where is an estimator for the inverse of the diagonal matrix given by the diagonal elements of . This test statistic is not pivotal in the sense that the asymptotic critical value depends on the unknown correlation structure. As a consequence, this approach requires resampling procedures. As detailed in the next section we apply a circular block bootstrap where we estimate the long-run variance of the bootstrap samples by the block sample variance given in (2.10). The estimator for the test statistic has to be chosen carefully with respect to its interaction with the estimator used for the bootstrap statistic. We decide to estimate the long-run variance for the test statistic with the block estimator in (2.9) as, based on simulations, this seems to yield the most stable size in comparison to, for example, the flat-top kernel estimator introduced in [20] with automatic bandwidth selection.
2.4 Resampling procedures
The critical values of change point procedures are usually chosen based on the limit distribution of the test statistic under the null hypothesis. Resampling methods can be applied to get a better small sample performance but cannot be avoided if the limit distribution is non-pivotal and cannot be estimated otherwise, as is the case in our example. Previous work on resampling procedures for functional time series include [18] for independent data and [21] as well as [14] for dependent Hilbert space-valued random variables. Recently, in [19], a sieve-type bootstrap procedure for functional time series based on a vector autoregressive representation of the scores has been introduced.
In order to prove the validity of a bootstrap procedure it has to be shown that, given the observations, the bootstrap test statistic has the same limit distribution as the actual test statistic under the null hypothesis and thus leads to the same asymptotic critical values. For a good power behavior under alternatives, it is important to take into account that the underlying observations may contain a change. Ideally, the respective limit distribution holds under the null hypothesis as well as under the alternative showing that the bootstrap test is asymptotically equivalent to the asymptotic test. Theoretical justifications for the bootstrap procedure providing better small sample behavior are mainly available for simple test statistics such as the mean (see for example [23]). Therefore, simulation studies are usually performed in order to assess the size and power of a bootstrap procedure. In this work, we apply the bootstrap to the projections as resampling the functional observations would require the estimation of the covariance kernel for each bootstrap sample which is computationally infeasible. Whether this leads to theoretically justifiable bootstrap procedures remains to be seen in future work.
As discussed above, due to the non-pivotal limit distribution, resampling procedures are required to obtain critical values for our test. Aston and Kirch [2] obtained reasonable results by applying multivariate block bootstrap procedures for the corresponding mean change procedure. We apply a circular block bootstrap to the dimensional sequence of the score products. In order to correct the data for a possible change we first estimate the change point in each component as follows:
[TABLE]
Thus, we can estimate the uncontaminated data by
[TABLE]
where and We estimate the long-run variance of the original test statistic by
[TABLE]
where we use the same blocklength as in the following bootstrap procedure. We split the whole sequence of length n circularly into overlapping subsequences of length and repeat the following steps B times to obtain the bootstrap statistics :
- (1)
Draw the starting points of the blocks as realizations of
[TABLE]
- (2)
Generate a bootstrap sample by
[TABLE]
where if
- (3)
Calculate residuals of the bootstrap sample of length n analogously to (2.8).
- (4)
Calculate by
[TABLE]
- (5)
Calculate the bootstrap statistic by
[TABLE]
with
We obtain the critical values as the upper -quantiles of the B realizations . The validity of the corresponding multivariate block bootstrap has been shown in [24] taking possible changes into account. In the functional setting this should carry over as long as the eigenvalues are well separated but a detailed theoretic analysis is beyond the scope of this paper.
2.5 Some alternative test statistics
The main drawback of change point procedures based on dimension reduction techniques is their inability to detect changes which are orthogonal to the projection space as given by condition (2.3) for the covariance change. Furthermore, the asymptotic distributions do not yield reasonable small sample approximations if the dimension of the projection space is chosen too large. This is particularly problematic when testing for a covariance change as the procedure is based on the -dimensional product vector when projecting on a d-dimensional subspace. Even if we only use the first two leading eigenfunctions of each direction in the separable dimension reduction and thus risk missing possible changes which do not occur in this very limited number of eigendirections we project on a 8-dimensional subspace and obtain 36-dimensional product vectors. Taking 3 eigenfunctions in each direction results in a 378-dimensional product vector which is considerably larger than the sample size and thus problematic for the multivariate procedure. This motivates us to consider fully functional test statistics. Recall that after reducing the dimension, the test statistic as given in (2.7) is based on
[TABLE]
with as given in (2.5), and is an estimator for . The weight corrects for different variances in the time series of the score products making smaller changes in components with smaller variances better visible for the test statistic. This approach is related to the likelihood ratio statistic in the multivariate case. However, the price to pay is that changes - even big ones - in score components other than the first d will not be detected at all. This seems quite unnatural. Therefore, we consider alternative test statistics related to the procedures proposed in [10] and [6] for the mean change problem which take the full functional structure into account. An obvious and well defined alternative to reducing the dimension is
[TABLE]
which takes all scores of the basis expansion into account but without correcting for different variances as the multivariate test statistic does. Due to the squared summability of the eigenvalues, this infinite sum is well defined. In order to keep the advantage of in terms of the weights improving the visibility of changes in components with smaller variances while not risking to miss a change due to dimension reduction we suggest the following weighting
[TABLE]
where is the estimated variance of the first squared score component. This additive constant is needed for bounding the denominator of the weights away from zero and is chosen such that the test statistic is scale invariant. By (2.6) for independent Gaussian scores the variance of the first squared score component is given by which is the largest element in the long-run covariance matrix.
We calculate the critical values with an analogous the bootstrap procedure as described in Section 2.4. For the weighted functional procedure the long-run variances are estimated for each bootstrap sample with the block estimator as in step (4) whereas we keep the variance of the first squared score component fixed. Analogously to the multivariate procedure we also use the block estimator (2.9) for estimating the long-run covariance for the test statistics.
Remark 1**.**
* is related to the statistic , where*
[TABLE]
with . More precisely, some calculations show (see (B) in the supplementary material) that
[TABLE]
In contrast to , this statistic contains all combinations of twice such that the cross-covariances have double weights compared to the variances. This is an artefact when dealing with a bivariate symmetric function which does not occur in the mean change problem. In accordance with we construct the functional statistic such that each combination is only contained once.
3 Simulation study
In the following simulation study we assess the empirical size and power of the proposed procedures. As there are no mathematical justifications for the bootstrap procedures for the functional test statistics available yet, the simulation study is of particular interest to evaluate their performance. Independent innovations of length are generated using a Fourier basis with basis functions on , where followed by pairs of and for . The scores are independent and normally distributed with standard deviations . Following the simulation study in [6] we consider the following settings:
- Setting 1 (small number of nonzero eigenvalues): for and for .
- Setting 2 (fast decay of eigenvalues using): .
- Setting 3 (slow decay of eigenvalues using): .
Functional autoregressive time series are simulated where the linear operator can be represented as a -matrix that is applied to the coefficients of the basis representation via (for further details see [5]). In this simulation study we use the operator with on the diagonal and on the superdiagonal and the subdiagonal which has infinity norm such that the resulting functional autoregressive time series is stationary. A covariance change at the time point is inserted in the first leading eigendirections for by adding a common additive noise term with variance according to Example 2. The variance of the noise term is chosen such that for all m. In view of the application to fMRI data in Section 4 the multivariate procedure is applied to the projections on the subspace spanned by the first 8 eigendirections of the empirical covariance function. The plots in Figure 7 show the empirical size and the size corrected power for the different procedures obtained based on N=1000 repetitions with B=1000 bootstrap iterations each.
The multivariate procedure is very conservative in all settings whereas the size of the functional procedures is mostly larger but closer to the nominal level except for setting 1. However, it should be mentioned that for independent data (see Figure 7 in the supplementary material) all procedures keep the level very well in all settings. As expected by construction, the procedure based on PCA fails to detect the change in setting 1 for increasing m as most of the change is orthogonal to the first 8 eigendirections which are still dominating the contaminated covariance kernel. The advantage of the procedures which take the full functional structure into account is clearly visible here. The opposite power behavior can be observed for the fast decay of eigenvalues in setting 2, where the procedure based on PCA is superior to the functional procedures. In particular the unweighted functional procedure has problems to detect the change in this setting. In setting 3, the functional procedures have good power for all choices of m. In applications where one aims to explain a large amount of the variability of the data via PCA, a slow decay of eigenvalues as in setting 3 usually leads to a bad performance. However, this is not true when PCA is applied for change point detection if the change leads to an increased variability in the affected directions which is true for the alternative in this simulation study. Hence, directions which are affected by the change but orthogonal to the uncontaminated subspace are more likely to be chosen by PCA if the eigenvalues are flat. This effect can be observed when comparing the power of the multivariate procedure for in setting 2 and 3. For the power of the multivariate procedure is slightly better in setting 2 than in setting 3 as for the fast decay of eigenvalues the change occurs in those eigendirections which already clearly dominate in the uncontaminated subspace. Across all situations considered in this simulation study except for setting 1 with the weighted functional procedure outperforms the unweighted functional procedure. Hence, the weighted functional procedure behaves not only as a compromise between the other two procedures but even more as a promising improvement of the unweighted functional approach.
Discussion
The above simulation study reveals that the functional test statistics with critical values obtained by the block bootstrap described in Section 2.4 can be liberal for dependent data. This is mostly a small sample effect which did not occur in simulations of longer time series (T=500). However, even for the sample size in the present simulations, the size is reasonable up to a nominal level of and the procedures seem to be suitable for the purpose of the application in this paper. We do not expect them to cause too many false rejections and we are in particular interested in a good power behavior in order to avoid nonstationarities to contaminate subsequent analyzes. For future work, it would be of great interest to investigate the mathematical validity of this bootstrap approach as well as develop procedures that improve the behavior of the functional procedures for dependent data and can also deal with stonger dependency structures.
4 Application to resting state fMRI data
In [2] a subset of 198 scans from the 1000 Connectome Resting State Data555The data is publicly available from the International Neuroimaging Data-Sharing Initiative (INDI) at http://fcon_1000.projects.nitrc.org. which have all been recorded at the same location (Beijing, China) are tested for an epidemic mean change. We test for deviations from covariance stationarity in those 118 data sets among these where no epidemic mean change was detected at a level of in the previously mentioned work. Each scan consists of a three-dimensional image of size ( voxels) recorded every 2 seconds at 225 time points. As usual in fMRI data analysis, each data set is preprocessed by voxelwise removing a polynomial trend of order 3 to correct for technical effects as for example scanner drift. We apply the separable covariance estimation and for the multivariate procedure we reduce the dimension by projecting on the 8-dimensional subspace obtained by taking the first two eigenfunctions in each direction.
4.1 Implementation of the functional procedures
In practice, the sums in (2.12) and (2.13) are finite as we cut after the number N of strictly positive eigenvalues obtained by principal component analysis. In the above simulation study we obtained but for the fMRI data sets the separable covariance estimation yields . For the functional test statistics all combinations of the score components have to be taken into account. As the number of those combinations is of order this is computationally infeasible, in particular with regard to the fact that the test statistic also has to be calculated for every single bootstrap sample. However, as the variances of the score products rapidly decrease, most of the score products only have a negligible influence on the value of the test statistic in comparison to those with large variances and can thus be omitted.
Figure 3 shows the 200 largest variances of the score products after correcting for a possible change in decreasing order exemplarily for one subject. The variance of the first squared score component is approximately 10 times larger than the second one and is thus omitted in this plot for a better visibility. It can clearly be seen that the variances strongly decrease and quickly level off at a magnitude which is only a small fraction of the larger variances. We make use of this observation to solve the computational problem discussed above where the main idea is to only consider those score products that have a sufficiently large variance compared to the variance of the first squared score component. However, estimating this ratio by calculating the empirical variance of the residuals for each of the combinations is still very time consuming. Therefore, we use a preselection step where we predict which combinations could possibly exceed a certain threshold based on the variances of the single score components. More precisely, we proceed as follows:
- (1)
For each calculate
[TABLE]
where is the estimated residual of obtained as in (2.8). Determine for
[TABLE]
This estimation of the ratio is based on the Gaussian approximation as given in (2.6). While this is only correct in the Gaussian case and if the separability assumption is correct, according to some preliminary analysis (see Figure 3) it at least approximates the order of magnitude in the misspecified case. Figure 3 shows the variances of the score products ordered according to their approximations given by the products of the variances of the single components.
- (2)
Perform the following steps for each :
- (2.1)
Estimate the ratio nonparametrically (without relying on Gaussanity or the separability assumption) by
[TABLE]
where is the estimated residual of the product obtained analogously to (2.8).
- (2.2)
If continue with step (2.3), else skip this combination and continue with step (2.1) for the next combination.
- (2.3)
Update
[TABLE]
with , where K is the block length of the respective bootstrap procedure and .
- (3)
Calculate the test statistics:
We additionally applied the procedure with to the resting state fMRI data and the results are similar to those obtained for . Hence, there is no need to further reduce the threshold as there is already no considerable loss of information when reducing it from to . In the preselection step we find those combinations for which with a very conservative threshold . In the above example the predicted ratio is at most times larger than the actual ratio such that is indeed very conservative. We calculate the critical values analogously to the bootstrap procedure described in Section 2.4. For the weighted procedure the long-run variances are estimated for each bootstrap sample with the block estimator as in step (4) whereas we keep the variance of the first squared score component fixed.
4.2 Results
In this section, we refer to the -values obtained for and a blocklength of . The results of the data analysis are illustrated exemplary by the score products of certain subjects as a change in the covariance structure is visible as a mean change in the products which is indicated by the black line in the plots. However, as the functional procedures are, on average, based on around 10000 score products, the plots are limited to the 64 most significant products in the sense of having the smallest -values which are obtained by componentwise calculating the -values for the weighted functional statistic based on the respective bootstrap components. The main findings of the data analysis can be summarized as follows, for further details see D in the supplementary material:
- •
When testing for the AMOC alternative at a level of , the null hypothesis of covariance stationarity is rejected for of the data sets by the multivariate procedure, for by the unweighted functional procedure and for by the weighted functional procedure. The functional procedures always lead to similar results whereas the multivariate procedure implies different test decisions in some cases. Those deviation occur in both directions and are explained in more detail in the supplementary material. As an example, in sub12220 a covariance change is detected by all considered procedures with -values of at most . Figure 4 shows the 64 most significant components of the score products for the weighted functional procedure. The estimated global change point is
- •
There are some data sets with epidemic changes. For example, sub08816 is not significant when testing for the AMOC alternative with a -value of for the multivariate procedure and at least for the functional procedures whereas the test for the epidemic alternative yields -values which are smaller than for the functional procedures. Figure 5 shows the 64 most significant components of the score products for the epidemic alternative. The respective plots for the AMOC alternative can be found in Figure 9 in the supplementary material.
- •
Some data sets contain outliers which cause the rejection of the null hypothesis. For example, testing for an epidemic change in sub08992 yields -values smaller than for all considered procedures. Figure 6 reveals that the procedure picks the outlier as epidemic change in form of a very small interval. The mean of this interval is obviously much larger than the mean of the remaining observations and additionally always at the same position determined by the outlier such that the test for an epidemic change is significant. Although, in this case, the rejection of the null hypothesis is not due to an actual change in the covariance structure, an outlier constitutes a deviation from stationarity which contaminates the subsequent analyzes if they are not robust. On the other hand, if the data is only involved in analyses which require stationarity but are robust against outliers, it would be of interest to have robust change point procedures such as in [13] for the univariate mean change problem. At this point it should be mentioned that even though for the AMOC alternative the null hypothesis is not rejected for sub08992 (see Figure 10 in the supplementary material) the procedures proposed in this work are not robust against outliers as all of them are based on the empirical covariance. For another setting, for example if the outlier occurs rather at the beginning of the observations, the null hypothesis of stationarity might also be rejected for the AMOC alternative which is the case for sub08455 (see Figure 11 in the supplementary material).
5 Concluding remarks
In this paper, different methods for detecting devtiations from stationarity in the covariance structure of functional time series have been introduced and investigated with the main focus on applications to fMRI data. Dimension reduction via projections is a very common approach in functional time series analysis and enables the application of a multivariate change point procedure. We derived the asymptotic distribution of the test statistic based on the projection scores for the AMOC alternative as well as for the epidemic alternative. This asymptotic procedure requires the estimation of the long-run covariance which is statistically unstable but can be avoided by using resampling procedures. We applied a circular block bootstrap to obtain the critical values for an adapted test statistic where we only correct for the diagonal elements of the long-run covariance. This gave us a reasonable approach for detecting changes in the covariance structure of fMRI data which, however, comes with the risk of missing changes that are orthogonal to the projection subspace. As alternative solution we provided two test statistics which both take the full functional structure into account and differ with respect to the weighting. The unweighted functional test statistic has been derived from the -norm of the functional partial sum process without additional weights. In contrast to that, the weights in the multivariate procedure correct for differenct variances of the components. We incorporate this idea into the functional approach by proposing the weighted functional test statistic. Simulations confirmed that this statistic indeed improves the unweighted functional procedure in different situations and is thus a very promising approach for the detection of change points in functional data analysis, not only for detecting changes in the covariance as considered in this paper but, in an analogous version, also for the mean change problem. A mathematical investigation of this test statistic, as for example deriving the asymptotic distribution, will be of future interest. While the validity of the multivariate block bootstrap has been proven in [24], it still has to be shown for the functional procedures. However, the simulation study already indicates their reasonable performance. The application of the proposed methods to resting state fMRI data has shown that taking possible nonstationarities in the covariance structure into account is crucial. Although we only considered data sets where no mean change was detected the null hypothesis of covariance stationarity was still rejected in more than one third of the cases. Many of those nonstationarities have been detected when testing for the AMOC alternative while in some cases the epidemic alternative seemed to be more appropriate. For some data sets, the null hypothesis was rejected due to outliers, so that the development of more robust methods is of future interest.
Acknowledgements
This work was supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - 314838170, GRK 2297 MathCoRe. The first author would like to thank the German Academic Exchange Service (DAAD) for supporting her visit in Cambridge. The second author was supported by the Engineering and Physical Sciences Research Council (UK) grants EP/K021672/2, EP/N031938/1 as well as EP/N014588/1. The authors would like to thank the Isaac Newton Institute for Mathematical Sciences for support and hospitality during the programme Statistical Scalability (supported by EPSRC grant numbers EP/K032208/1 and EP/R014604/1).
The authors (especially JA) thank Wenda Zhou (Columbia) for his helpful discussions, particularly of his independent derivation of the change point statistics using PCA for covariances under iid settings that were produced as part of his Cambridge Part III essay.
Supplementary material
This supplement contains additional technical details, proofs and further results from the data analysis.
Appendix A Max-type test statistics
An alternative to the sum-type statistics discussed in the main paper are the following max-type statistics. For the procedure based on dimension reduction such a statistic is given by
[TABLE]
for the AMOC-alternative and
[TABLE]
for the epidemic alternative. The asymptotic distributions under the null hypothesis are stated in the following theorem.
Theorem 2**.**
Let be approximable with . Then, the following asymptotics hold under the null hypothesis if is a consistent estimator for the long-run covariance :
[TABLE]
where and are independent standard Brownian bridges.
Appendix B Proofs
Theorem 3**.**
Let be orthonormal eigenfunctions of and be orthonormal eigenfunctions of , where both sets of eigenfunctions are arranged according to the respective eigenvalues in decreasing order. Furthermore, assume that the eigenvalues of are separated, i.e. .
- a)
If , it holds for
[TABLE]
where .
- b)
If , it holds for
[TABLE]
Proof.
Observing that
[TABLE]
the assertions follow with Theorem 2.1 in [1]. ∎
Proof of Theorem 1 and 2.
We first show that the approximability is passed on to the projection scores. Let be the -approximations for an approximable sequence . The sequence with components is m-dependent as is -dependent. Furthermore, it holds with the Cauchy-Schwarz inequality, similarly to the proof of Theorem 5.1 in [16],
[TABLE]
where denotes the Euklidean norm. Thus, the score vectors with components are approximable and it holds with Theorem A.2 in [4] and the continuous mapping theorem
[TABLE]
where is a -dimensional centered Gaussian process with covariance function . The convergence in (B.1) still holds true if the projection basis is obtained based on the empirical covariance kernel. More precisely, it holds for and with the Cauchy-Schwarz inequality
[TABLE]
By Lemma 2.3 b) in [1] and the separation of the eigenvalues of the assumptions of Theorem 3 b) are fulfilled such that we obtain
[TABLE]
Lemma 2.1 in [16] yields that is approximable and with the invariance principle in [8] we obtain
[TABLE]
It follows that
[TABLE]
Hence, (B) yields
[TABLE]
We obtain the same limit distribution if we replace by as in our statistics. Indeed, with the notations we obtain
[TABLE]
as it holds with the ergodic theorem (see, for example, [22])
[TABLE]
Combining (B.1), (B.4) and (B) we obtain
[TABLE]
and the assertions follow by the continuous mapping theorem. ∎
Behaviour under alternatives
Proof of Lemma 1.
We split the empirical covariance as follows:
[TABLE]
Now, observe that
[TABLE]
Furthermore, it holds
[TABLE]
by (B.6), where one needs to note that this assertion remains true under the alternative which can easily be seen by splitting the time series at the change point. By the ergodic theorem it holds
[TABLE]
Hence, we obtain
[TABLE]
and analogously
[TABLE]
As
[TABLE]
where , it follows that
[TABLE]
∎
Example 1
In this setting, condition (2.3) is fufilled as it holds
[TABLE]
and thus
[TABLE]
By (B.8) each is an eigenfunction of with eigenvalue . It follows with the Cauchy-Schwarz inequality
[TABLE]
with Theorem 3 a) and . Hence, we get
[TABLE]
This shows that the change is detectable if the eigendirections are estimated based on the empirical covariance function.
Example 2
First observe that, as is independent of and as the score components are uncorrelated,
[TABLE]
Hence, it holds with (2.4) for
[TABLE]
such that the change in the covariance kernel is given by
[TABLE]
For it holds
[TABLE]
Hence, condition (2.3) is fufilled. Analogously to (B) we obtain
[TABLE]
showing that the change is detectable if the eigendirections are estimated based on the empirical covariance function if for at least one pair .
Long-run covariance for Gaussian scores
Assuming a normal distribution, the components of the score vectors are independent. This leads to
[TABLE]
With , we obtain
[TABLE]
Functional test statistic
The representation of the -norm of the functional partial sum process in terms of the projection scores as stated in Remark 1 is obtained by
[TABLE]
Appendix C FurthersSimulations
Figure 7 shows the empirical size and the size corrected power where the procedures considered in this paper are applied to the independent innovations of the simulation study in Section 3 in the main paper using Efron’s Bootstrap to obtain the critical values.
Appendix D Further results of the data analysis
In this section, we give some additional results of the analysis of the 1000 Connectome Resting State Data in order to complement the main findings that are reported in Section 4.2 in the main paper. In the following we will make some remarks on the comparison of the -values for the different procedures. First, it should be mentioned that the -values obtained by the two functional procedures are consistent, meaning that in most of the cases they imply the same test decision and if they lead to different test decisions at a certain level the -values are nevertheless of the same magnitude, i.e. for one procedure the -value is slightly below and for the other procedure it slightly exceeds . Regarding the comparison of the multivariate procedure with the functional procedures we observed that they lead to different test decisions in some cases. On the one hand, the multivariate procedure is not able to detect changes which are orthogonal to the projection subspace. On the other hand, false alarms can occur as the few components which are considered after reducing the dimension might contain some irregularities which lead to a rejection of the null hypothesis but are not significant when considering the full functional structure. This can be observed, for example, when analyzing sub34943. The multivariate procedure detects a deviation from covariance stationarity in the 8-dimensional time series of the scores but the null hypothesis is not rejected by the functional procedures. Figure 8 shows the 36 score products which are considered in the multivariate procedure. Calculating the componentwise -values of the weighted functional procedure which includes 1083 score products for it turns out that more than one third of the 36 components considered in the multivariate procedure belong to the 100 smallest -values of the weighted functional procedure.
In Section 4.2 we have seen that for some data sets, as for example sub08816, the epidemic alternative is more appropriate. In addition to Figure 5 in the main paper, Figure 9 shows the 64 most significant score products for the AMOC alternative. A visual inspection of those two figures suggests that the epidemic model is indeed more suitable in this case. Furthermore, the small -values are reasoned by the fact that the epidemic changes in the single components tend to be aligned.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. A. D. Aston and C. Kirch. Detecting and estimating changes in dependent functional data. Journal of Multivariate Analysis , 109:204–220, 2012.
- 2[2] J. A. D. Aston and C. Kirch. Evaluationg stationarity via change-point alternatives with applications to fmri data. The Annals of Applied Statistics , 6(4):1906–1948, 2012.
- 3[3] A. Aue, R. Gabrys, L. Horváth, and P. Kokoszka. Estimation of a change-point in the mean function of functional data. Journal of Multivariate Analysis , 100:2254–2269, 2009.
- 4[4] A. Aue, S. Hörmann, and L. Horváth. Break detection in the covariance structure of multivariate time series models. The Annals of Statistics , 37:4046–4087, 2009.
- 5[5] A. Aue, D. Norinho, and S. Hörmann. On the prediction of stationary functional time series. Journal of the American Statistical Association , 110(509):378–392, 2015.
- 6[6] A. Aue, G. Rice, and O. Sönmez. Detecting and dating structural breaks in functional data without dimension reduction. 2017+. preprint on https://arxiv.org/pdf/1511.04020.pdf.
- 7[7] I. Berkes, R. Gabrys, L. Horváth, and P. Kokoszka. Detecting changes in the mean of functional observations. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 71:927–946, 2009.
- 8[8] I. Berkes, L. Horváth, and G. Rice. Weak invariance principles for sums of dependent random functions. Stochastic Processes and their Applications , 123:385–403, 2013.