TL;DR
This paper introduces a GAN-based system that generates realistic handwritten word images conditioned on text sequences, aiming to augment training data for handwriting recognition systems.
Contribution
It presents a novel GAN architecture with an auxiliary recognition network to control generated text content, improving synthetic data quality for training handwriting recognition models.
Findings
Generated images are realistic on French and Arabic datasets.
Synthetic images slightly improve recognition system performance.
The method effectively controls the textual content of generated handwriting.
Abstract
State-of-the-art offline handwriting text recognition systems tend to use neural networks and therefore require a large amount of annotated data to be trained. In order to partially satisfy this requirement, we propose a system based on Generative Adversarial Networks (GAN) to produce synthetic images of handwritten words. We use bidirectional LSTM recurrent layers to get an embedding of the word to be rendered, and we feed it to the generator network. We also modify the standard GAN by adding an auxiliary network for text recognition. The system is then trained with a balanced combination of an adversarial loss and a CTC loss. Together, these extensions to GAN enable to control the textual content of the generated word images. We obtain realistic images on both French and Arabic datasets, and we show that integrating these synthetic images into the existing training data of a text…
Click any figure to enlarge with its caption.
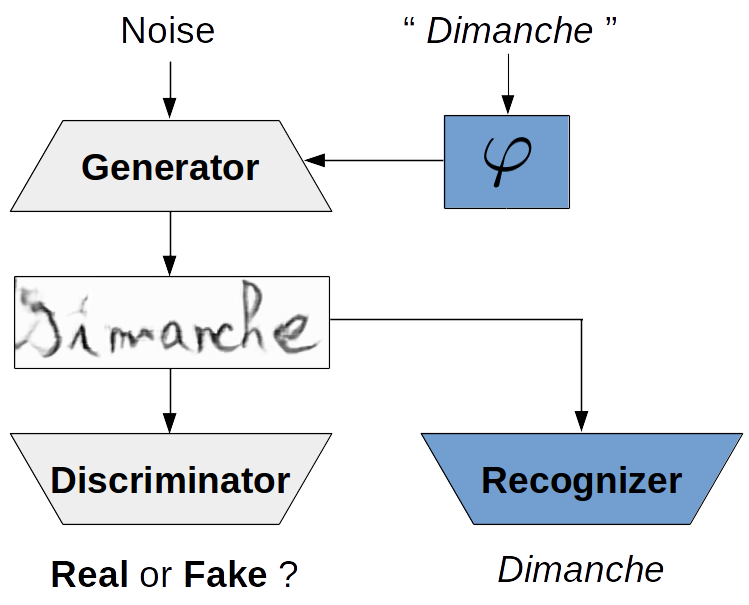 Figure 1
Figure 1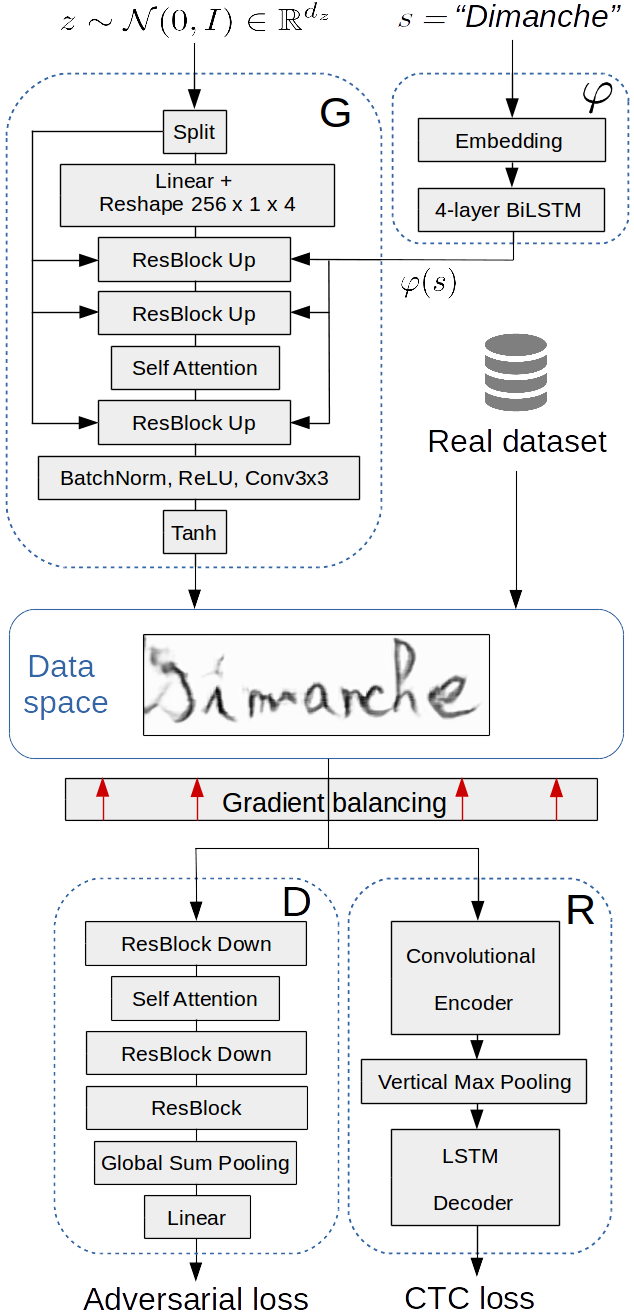 Figure 2
Figure 2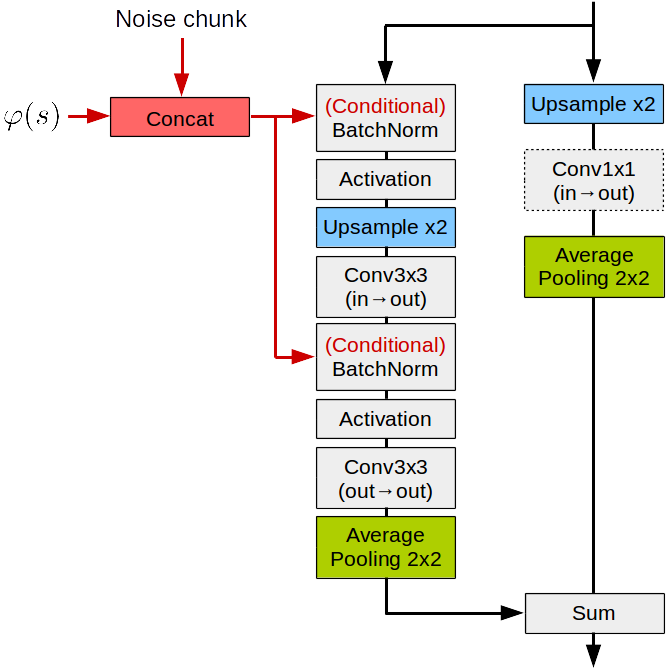 Figure 3
Figure 3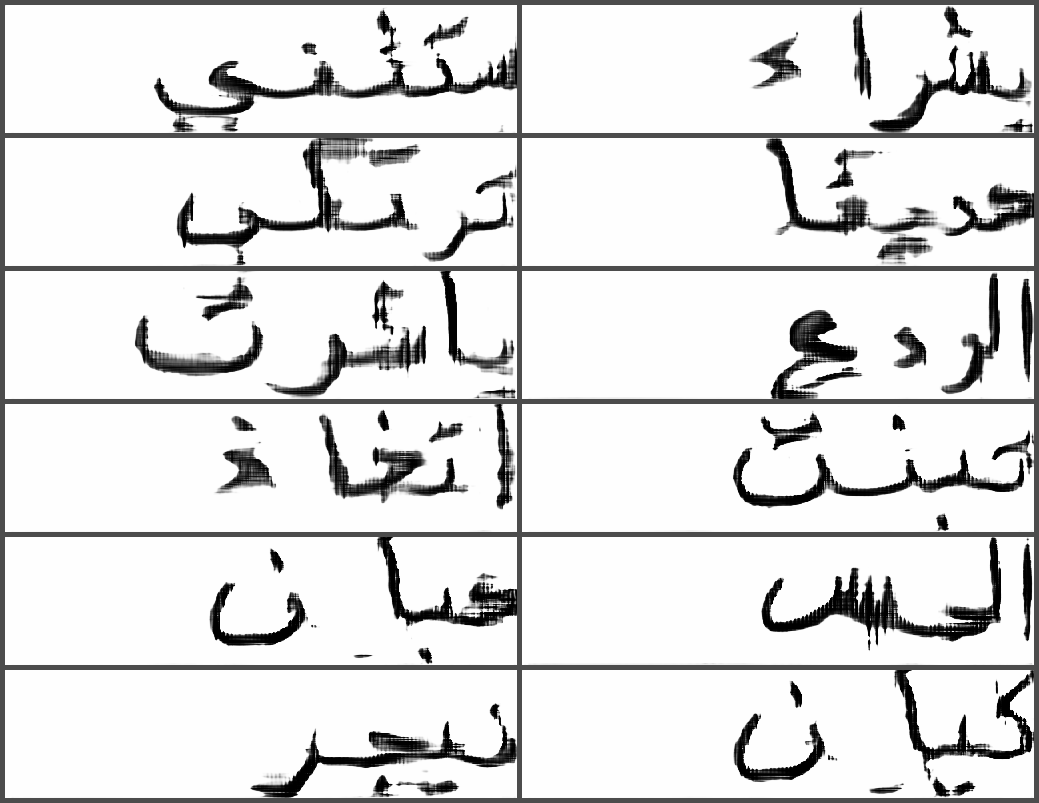 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10| Dataset | Language | Images | Words | Characters |
|---|---|---|---|---|
| RIMES | French | 129414 | 6780 | 86 |
| OpenHaRT | Arabic | 710892 | 65575 | 77 |
| FID | GS | Images | |
|---|---|---|---|
| None | 141.35 |
|
|
| 0.1 | 72.93 |
|
|
| 10 | 222.47 |
|
|
| 1 | 23.94 |
|
| Adversarial Loss | FID | GS |
|---|---|---|
| GAN | 36.32 | |
| LSGAN | 116.09 | |
| Geometric GAN | 23.94 |
| FID | GS | |
|---|---|---|
| Without self-attention | 67.86 | |
| With self-attention | 23.94 |
| FID | GS | |
|---|---|---|
| First linear layer | 42.23 | |
| CBN layers | 23.94 |
| Data | ED | WER |
|---|---|---|
| RIMES only | 4.34 | 12.1 |
| RIMES + 100k | 4.03 | 11.9 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsConnectionist Temporal Classification Loss · Sigmoid Activation · Tanh Activation · Convolution · Long Short-Term Memory · Dogecoin Customer Service Number +1-833-534-1729
Adversarial Generation of Handwritten Text Images Conditioned on Sequences
Eloi Alonso
A2iA SA, Paris, France
École des Ponts ParisTech
Bastien Moysset
A2iA SA, Paris, France
Ronaldo Messina
A2iA SA, Paris, France
Abstract
State-of-the-art offline handwriting text recognition systems tend to use neural networks and therefore require a large amount of annotated data to be trained. In order to partially satisfy this requirement, we propose a system based on Generative Adversarial Networks (GAN) to produce synthetic images of handwritten words. We use bidirectional LSTM recurrent layers to get an embedding of the word to be rendered, and we feed it to the generator network. We also modify the standard GAN by adding an auxiliary network for text recognition. The system is then trained with a balanced combination of an adversarial loss and a CTC loss. Together, these extensions to GAN enable to control the textual content of the generated word images. We obtain realistic images on both French and Arabic datasets, and we show that integrating these synthetic images into the existing training data of a text recognition system can slightly enhance its performance.
I Introduction
Having computers able to recognize text from images is an old problem that has many practical applications, such as automatic content search on scanned documents. Transcribing printed text is now a reliable technology. However, automatically recognizing handwritten text is still a hard and open problem. Unlike printed text, cursive handwriting cannot be segmented into individual characters, since their boundaries are ill-defined. Graves et al. [1] introduced the Connectionist Temporal Classification (CTC), a loss enabling to train neural networks to recognize sequences without explicit segmentation. Today, in order to deal with such a complex problem, state-of-the-art solutions [2, 3] are all based on deep neural networks and the CTC loss.
The supervised training of these neural networks requires large amounts of annotated data; in our case, images of handwritten text with corresponding transcripts. However, annotating images of text is a costly, time-consuming task. We therefore propose a system to reverse the annotation process: starting from a given word, we generate a corresponding image of cursive text. We first tackle the challenge of generating realistic data, and then address the question of using such synthetic data to train neural networks in order to improve the performance of handwritten text recognition.
The problem of generating images of handwritten text has already been addressed in the past. Many techniques [4] are based on a collection of templates of a few characters, either human-written or built using Bezier curves. These templates are possibly perturbed and finally concatenated. However, this class of solutions, that simply concatenates character models, cannot faithfully reproduce the distribution of real-world images. It is also complex to have templates that are generic enough to result in truly cursive text. Alternatively, following the online approach, we can consider the handwriting as a trajectory, typically recorded with pen computing. In this setting, the model aims at producing a sequence of pen positions to generate a given word. Graves et al. [5] use a Long Short-Term Memory (LSTM) [6, 7] recurrent neural network to predict such a sequence, and let the network condition its prediction on the target string to synthesize handwriting. However, this method does not allow to deal with some features useful for offline recognition, such as background texture or line thickness variations.
Generative Adversarial Networks (GAN) [8] offer a powerful framework for generative modeling. This architecture enables the generation of highly realistic and diverse images. The original GAN does not allow any control over the generated images, but many works [9, 10, 11] proposed a modified GAN for class-conditional image generation. However, we want to condition our generation on the sequence of characters to render, not on a single class. Closer to our goal, Reed et al. [12] conditions the generation on a textual description of the image to be produced. In addition to a random vector, their generator receives an embedding of the description text, and their discriminator is trained to classify as fake a real image with a non-matching description, to enforce the generator to produce description-matching images.
To the best of our knowledge, there is only one work [13] on a GAN for text image synthesis. While our generation process is directly conditioned on a sequence of characters, this method follows a style transfer approach, resorting to a CycleGAN [14] to render images of isolated handwritten Chinese characters from a printed font.
Data augmentation techniques based on distortion and additive noise do not allow to enlarge the textual contents of the training data. Moreover, having control of the generated text enables the creation of training material that covers even rare sequences of characters, which can be expected to improve the recognition performance. This, combined with the intrinsic diversity, provides a strong motivation to use a conditional GAN for the generation of cursive text images.
In this paper, we make the following contributions:
- •
We propose an adversarial architecture, schematically represented in Fig. 1, to generate realistic images of handwritten words.
- –
We use bidirectional LSTM recurrent layers to encode the sequence of characters to be produced.
- –
We introduce an auxiliary network for text recognition, in order to control the textual content of the generated images.
- •
We obtain realistic images on both French and Arabic datasets.
- •
Finally, we slightly improve text recognition performance on the RIMES dataset [15], using a neural network trained on a dataset extended with synthetic images.
II Proposed adversarial model
We introduce here our adversarial model for handwritten word generation. Section II-A gives the general idea and defines the training objectives of the different parts. We detail the network architectures in Section II-B and describe our optimization settings in Section II-C.
II-A Auxiliary Recognizer Generative Adversarial Networks
A standard GAN [8] comprises a generator () and a discriminator () network, shown in gray in Fig. 1. maps a random noise to a sample in the image space. is trained to discriminate between real and generated (fake) images. Adversarially, is trained to produce images that fails to discriminate correctly. These networks hence have competing objectives.
In order to control the textual content of the generated images, we modify the standard GAN as follows. First, we use a recurrent network () to encode , the sequence of characters to be rendered in an image. takes this embedding as a second input. Then, in the vein of [10], the generator is asked to carry out a secondary task. To this end, we introduce an auxiliary network for text recognition (). We then train to produce images that is able to recognize correctly, thereby completing its original adversarial objective with a “collaboration” constraint with . We use the hinge version of the adversarial loss [16] and the CTC loss [1] to train this system. Formally, , , and are trained to minimize the following objectives:
[TABLE]
with the joint distribution of real [image, word] pairs, a prior distribution on input noise and a prior distribution of words, potentially different from the word distribution of the real dataset.
II-B Networks architecture
Fig. 2 and the text below describe the architecture of networks , , and . The residual blocks (ResBlocks) we used are detailed in Fig. 3.
The network first embeds each character of the sequence in , then encodes it with a four-layer bidirectional LSTM [6, 7] recurrent network (with a hidden state of size 128). is the output of the last bidirectional LSTM layer.
The network is derived from [11]. The input noise, of dimension 128, is split into eight equal-sized chunks. The first one is passed to a fully connected layer of dimension 1024, whose output is reshaped to (with the convention ). Each of the seven remaining chunks is concatenated with the embedding , and fed to an up-sampling ResBlock through Conditional Batch Normalization (CBN) [17] layers (see Fig. 3). The consecutive ResBlocks have the following number of filters: 256, 128, 128, 64, 32, 16, 16. A self-attention layer [18] is used between the fourth and the fifth ResBlocks. We add a final convolutional layer and a tanh activation in order to obtain a image.
The network is made up of seven down-sampling ResBlocks (with the following number of filters: 16, 16, 32, 64, 128, 128, 256), a self-attention layer between the third and the fourth ResBlocks, and a normal ResBlock (with 256 filters). We then sum the output along horizontal and vertical dimensions and project it on .
The auxiliary network is a Gated Convolutional Network, introduced in [2] (we used the “big architecture”). This network consists in an encoder of five convolutional layers, with Tanh activations and convolutional gates, followed by a max pooling on the vertical dimension and a decoder made up of two stacked bidirectional LSTM layers.
II-C Optimization settings
We used spectral normalization [22] in and , following recent works [18, 11, 22] that found that it stabilizes the training. We optimized our system with the Adam algorithm [23] (for all networks: ) and we used gradient clipping in and . We trained our model for several hundred thousand iterations with mini-batches of 64 images of the same type, either real or generated.
While processes one real batch and one generated batch per training step, is trained with real data only, to prevent it from learning how to recognize generated (and potentially false) images of text. To train the networks and , we first produce a batch of “fake” images , and then pass it through and . learn from the gradients and coming from these two networks. Since and have different architectures and losses, the norms of and can differ by several orders of magnitudes (we observed that is typically to times greater than ). To have learn from both and , we found it useful to balance the two gradients before propagating them to . Therefore, we apply the following affine transformation to :
[TABLE]
With and being the mean and the standard deviation of . controls the relative importance of with respect to and is set to in our model. The concrete impact of this transformation is discussed in Section III-B1.
III Results
III-A Experimental setup
In our experiments, we use images of handwritten words obtained with the following preprocessing: we isometrically resize the images to a height of 128 pixels, then remove the images of width greater than 512 pixels and finally, pad them with white to reach a width of 512 pixels for all the images (right-padding for French, left-padding for Arabic). Table I summarizes the meaningful characteristics of the two datasets we work with, namely the RIMES [15] and the OpenHaRT [24] datasets, while Fig. 4 shows some images from these two datasets.
To reflect the distribution found in natural language, the words to be generated are sampled from a large list of words (French Wikipedia for French, OpenHaRT for Arabic). For the text recognition experiments on the RIMES dataset (Section III-D), we use a separate validation dataset of 6060 images.
We evaluate the performance with Fréchet Inception Distance (FID) [25] and Geometry Score (GS) [26]. FID is widely used and gives a distance between real and generated data. GS compares the topology of the underlying real and generated manifolds and provides a way to measure the mode collapse. For these two indicators, lower is better. In general, we observed that FID correlates with visual impression better than GS. For each experiment, we computed FID (with 25k real and 25k generated images) and GS (with 5k real and 5k generated images, 100 repetitions and default settings for the other parameters) every 10000 iterations and trained the system with different random seeds. We then chose independently the best FID and the best GS among the different runs. To verify the textual content, we relied on visual inspection. To measure the impact of data augmentation on the text recognition performance, we used Levenshtein distance at the character level (Edit Distance) and Word Error Rate.
III-B Ablation study
For all the experiments in this section, we used the RIMES database described in Section III-A.
III-B1 Gradient balancing
When training the networks , the norms of the gradients coming from and may differ by several orders of magnitudes. As mentioned in Section II, we found it useful to balance these two gradients. Table II reports FID, GS and a generated image for different gradient balancing settings.
Without gradient balancing, we observed that was typically to times greater than , meaning that the learning signal for is biased toward satisfying . As a result, the word “réparer” is clearly readable, but the FID is high (141.35) and the generated image is not realistic (the background is noisy, the letters are too far apart).
With , is much smaller than , meaning that and take little account of the auxiliary recognition task. As illustrated by the second image in Table II, we lose control of the textual content of the generated image. FID is better than before, but still high (72.93). In a way, the generated image is quite realistic, since the background is whiter and the writing more cursive.
On the contrary, when setting to 10, and mostly learn from the feedback of and the generation is thus successfully conditioned on the textual content. In fact, we can distinguish the letters of “réparer” in the third generated image in Table II. However, as we are focusing on optimizing the generation process to have a minimal CTC cost, we observe strong visual artifacts that remind of the one obtained by Deep Dream generators [27]. FID is much higher (222.47) and the resulting images are very noisy, as demonstrated by the third image in Table II.
The best compromise corresponds to . We obtain the best FID of 23.94 and GS of , while the generated image is both readable and realistic. For all other experiments, we set to 1.
III-B2 Adversarial loss
Using the network architecture described in Section II, we test three different adversarial training procedures: the “vanilla” GAN [8] (GAN), the Least Squares GAN [28] (LSGAN) and the Geometric GAN [16, 18, 11], used in our model. FID and GS are reported in Table III.
As shown in Table III, Geometric GAN leads to the best performance in terms of FID and GS. LSGAN fails to produce text-like outputs in three out of five trials. The low FID for vanilla GAN indicates that it produces realistic images. The high GS in Table III shows that both GAN and LSGAN suffer from a style collapse, and we observed that the textual content was not controlled. The trends given by FID and GS have been successfully confirmed by visual inspection of the generated samples.
III-B3 Self-attention
We use a self-attention layer [18], in both the generator and the discriminator, as it may help to keep coherence across the full image. We trained our model with and without this module to measure its impact.
Without self-attention, we still obtain realistic samples with correct textual content, but using self-attention improves performance both in terms of FID and GS, as shown in Table IV.
III-B4 Conditional Batch Normalization
As described in Section II, is provided a noise chunk and through each CBN layer. Another reasonable option, closer to [10], is to concatenate the whole noise with , and feed it to the first linear layer of (in this scenario, CBN is replaced with standard Batch Normalization). Table V reports FID and GS for these two solutions.
FID and GS in Table V indicates that feeding the generator inputs through CBN layers improves realism and reduces mode collapse. The visual inspection of the generated samples confirmed these trends and showed that the other solution prevents from correctly conditioning on the textual content.
III-C Generation of handwritten text images
We trained the model detailed in Section II on the two datasets described in Section III-A, RIMES and OpenHaRT.
Fig. 5 and Fig. 6 display some randomly generated (not cherry-picked) samples in French and Arabic respectively. For these two languages, we observe that our model is able to produce images of cursive handwriting, successfully conditioned on variable-length words (even if some words remain barely readable, e.g. le and olibrius in Fig. 5). The typography of the individual characters is varied, but we can detect a slight collapse of writing style among the images. For French, as we trained the generator to produce words from all Wikipedia, we are able to successfully synthesize words that are not present in the training dataset. In Fig. 5 for instance, the words olibrius, inventif, ionique, gorille and ski are not in RIMES, while Dimanche, bonjour, malade and golf appear in the corpus but with a different case.
III-D Data augmentation for handwritten text recognition
We aim at evaluating the benefits of generated data to train a model for handwritten text recognition. To this end, we trained from scratch a Gated Convolutional Network [2] (identical to the network described in Section II-B) with the CTC loss, RMSprop optimizer [29] and a learning rate of . We used the validation data described in III-A for early stopping.
Table VI shows that extending the RIMES dataset with data generated with our adversarial model brings a slight improvement in terms of Edit Distance and Word Error Rate. Note that using only GAN-made synthetic images for training the text recognition model does not yield competitive results.
IV Conclusion
We presented an adversarial model to produce synthetic images of handwritten word images, conditioned on the sequence of characters to render. Beyond the classical use of a generator and a discriminator to create plausible images, we employ recurrent layers to embed the word to condition on, and add an auxiliary recognition network in order to generate an image with legible text. Another crucial component of our model lies in balancing the gradients coming from the discriminator and from the recognizer when training the generator.
We obtained realistic word images in both French and Arabic. Our experiments showed a slight reduction in error rate for the French model trained on combined data.
An immediate continuation of our experiments would be to train the described model on more challenging datasets, with textured background for instance. Furthermore, deeper investigation to reduce the observed phenomenon of style collapse would be a significant improvement. Another important line of work is to extend this system to the generation of line images of varying size.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Graves, S. Fernandez, F. Gomez, and J. Schmidhuber, “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Nets,” ICML , 2006.
- 2[2] T. Bluche and R. Messina, “Gated Convolutional Recurrent Neural Networks for Multilingual Handwriting Recognition,” ICDAR , 2017.
- 3[3] J. A. Sanchez, V. Romero, A. H. Toselli, M. Villegas, and E. Vidal, “Icdar 2017 competition on handwritten text recognition on the read dataset,” ICDAR , 2017.
- 4[4] R. I. Elanwar, “The state of the art in handwriting synthesis,” Int. Conf. on New Paradigms in Electronics & information Technology , 2013.
- 5[5] A. Graves, “Generating sequences with recurrent neural networks,” ar Xiv preprint ar Xiv:1308.0850 , 2013.
- 6[6] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation , 1997.
- 7[7] F. A. Gers, J. A. Schmidhuber, and F. A. Cummins, “Learning to forget: Continual prediction with lstm,” Neural Computation , 2000.
- 8[8] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” NIPS , 2014.
