TL;DR
This paper introduces a method for real-time, volumetric, instance-aware semantic mapping that detects, tracks, and models 3D objects, including unseen categories, during robotic exploration.
Contribution
It presents a novel incremental approach combining geometric and semantic segmentation for building detailed object-centric maps in real-time.
Findings
Competitive with state-of-the-art methods on public datasets
Capable of discovering objects from unseen categories
Effective in real-world robotic mapping scenarios
Abstract
To autonomously navigate and plan interactions in real-world environments, robots require the ability to robustly perceive and map complex, unstructured surrounding scenes. Besides building an internal representation of the observed scene geometry, the key insight toward a truly functional understanding of the environment is the usage of higher-level entities during mapping, such as individual object instances. We propose an approach to incrementally build volumetric object-centric maps during online scanning with a localized RGB-D camera. First, a per-frame segmentation scheme combines an unsupervised geometric approach with instance-aware semantic object predictions. This allows us to detect and segment elements both from the set of known classes and from other, previously unseen categories. Next, a data association step tracks the predicted instances across the different frames.…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11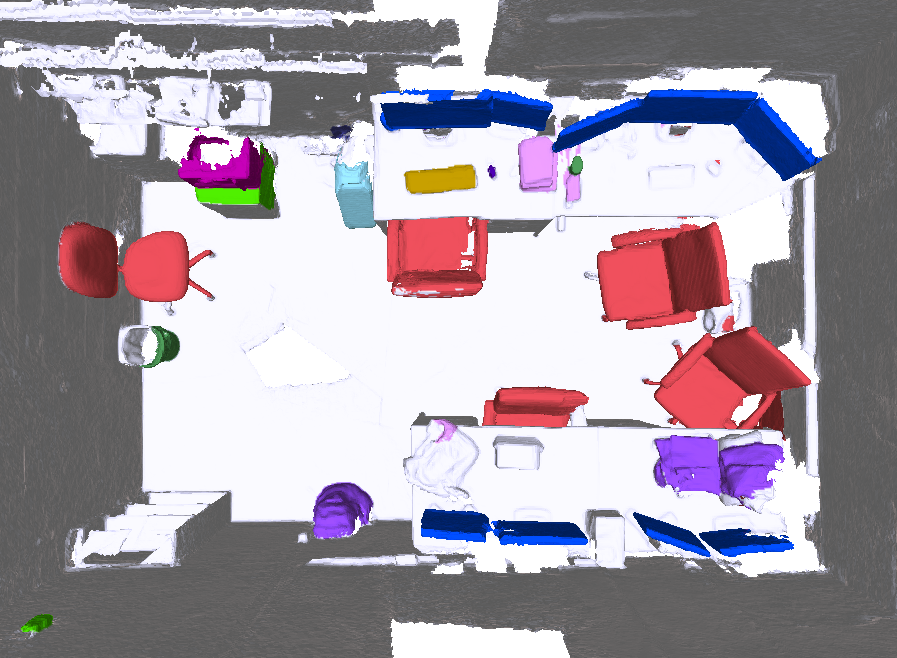 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14| Sequence ID |
Bed |
Chair |
Sofa |
Table |
Books |
Refrigerator |
Television |
Toilet |
Bag |
Average |
Pham et al. [5] |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 011 | - | 75.0 | 50.0 | 100 | - | - | - | - | - | 75.0 | 52.1 |
| 016 | 100 | 0.0 | 0.0 | - | - | - | - | - | - | 33.3 | 34.2 |
| 030 | - | 54.4 | 100 | 55.6 | 14.3 | - | - | - | - | 56.1 | 56.8 |
| 061 | - | - | 100 | 33.3 | - | - | - | - | - | 66.7 | 59.1 |
| 078 | - | 33.3 | - | 0.0 | 47.6 | 100 | - | - | - | 45.2 | 34.9 |
| 086 | - | 80.0 | - | 0.0 | 0.0 | - | - | - | 0.0 | 20.0 | 35.0 |
| 096 | 0.0 | 87.5 | - | 37.5 | 0.0 | - | 0.0 | - | 50 | 29.2 | 26.5 |
| 206 | - | 58.3 | 100 | 60.0 | - | - | - | - | 100 | 79.6 | 41.7 |
| 223 | - | 12.5 | - | 75.0 | - | - | - | - | - | 43.8 | 40.9 |
| 255 | - | - | - | - | - | 75.0 | - | - | - | 75.0 | 48.6 |
| Component | Time (ms) |
|---|---|
| Mask R-CNN * | 407 |
| Depth segmentation * | 753 |
| Data association | 136 |
| Map integration | 276 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery
Margarita Grinvald, Fadri Furrer, Tonci Novkovic, Jen Jen Chung, Cesar Cadena, Roland Siegwart, Juan Nieto This work was supported by ABB Corporate Research, the Amazon Research Awards program, and the Swiss National Science Foundation (SNF) through the National Centre of Competence in Research on Digital Fabrication. *(Corresponding author: Margarita Grinvald.)*The authors are with the Autonomous Systems Lab, ETH Zurich, 8092 Zurich, Switzerland (e-mail: [email protected]; [email protected]; [email protected]; [email protected]; [email protected]; [email protected]; [email protected]).Digital Object Identifier 10.1109/LRA.2019.2923960
Abstract
To autonomously navigate and plan interactions in real-world environments, robots require the ability to robustly perceive and map complex, unstructured surrounding scenes. Besides building an internal representation of the observed scene geometry, the key insight toward a truly functional understanding of the environment is the usage of higher-level entities during mapping, such as individual object instances. This work presents an approach to incrementally build volumetric object-centric maps during online scanning with a localized RGB-D camera. First, a per-frame segmentation scheme combines an unsupervised geometric approach with instance-aware semantic predictions to detect both recognized scene elements as well as previously unseen objects. Next, a data association step tracks the predicted instances across the different frames. Finally, a map integration strategy fuses information about their 3D shape, location, and, if available, semantic class into a global volume. Evaluation on a publicly available dataset shows that the proposed approach for building instance-level semantic maps is competitive with state-of-the-art methods, while additionally able to discover objects of unseen categories. The system is further evaluated within a real-world robotic mapping setup, for which qualitative results highlight the online nature of the method. Code is available at https://github.com/ethz-asl/voxblox-plusplus.
Index Terms:
RGB-D perception, object detection, segmentation and categorization, mapping.
††publicationid: pubid:
2377-3766 © 2019 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.
See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
I INTRODUCTION
Robots operating autonomously in unstructured, real-world environments cannot rely on a detailed a priori map of their surroundings for planning interactions with scene elements. They must therefore be able to robustly perceive the complex surrounding space and acquire task-relevant knowledge to guide subsequent actions. Specifically, to learn accurate 3D object models for tasks such as grasping and manipulation, a robotic vision system should be able to discover, segment, track, and reconstruct objects at the level of the individual instances. However, real-world scenarios exhibit large variability in object appearance, shape, placement, and location, posing a direct challenge to robotic perception. Further, such settings are usually characterized by open-set conditions, i.e. the robot will inevitably encounter novel objects of previously unseen categories.
Computer vision algorithms have shown impressive results for the tasks of detecting individual objects in RGB images and predicting for each a per-pixel semantically annotated mask [1, 2]. On the other hand, dense 3D scene reconstruction has been extensively studied by the robotics community. Combining the two areas of research, a number of works successfully locate and segment semantically meaningful objects in reconstructed scenes while dealing with substantial intra-class variability [3, 4, 5, 6].
Still, these methods can only detect objects from a fixed set of classes used during training, thus limiting interaction planning to a subset of the observed elements. In contrast, purely geometry-based methods [7, 9] are able to discover novel, previously unseen scene elements, under open-set conditions. However, such approaches tend to over-segment the reconstructed objects and additionally fail to provide any semantic information about them, making high-level scene understanding and task planning impractical.
This letter presents an approach to incrementally build geometrically accurate volumetric maps of the environment that additionally contain information about the individual object instances observed in the scene. In particular, the proposed object-oriented mapping framework retrieves the pose and shape of recognized semantic objects, as well as of newly discovered, previously unobserved object-like instances. The proposed system builds on top of the incremental geometry-based scene segmentation approach from our previous work in [7] and extends it to produce a complete instance-aware semantic mapping framework. Figure 1 shows the object-centric map of an office scene reconstructed with the proposed approach.
The system takes as input the RGB-D stream of a depth camera with known pose.111 Please note that the current work focuses entirely on mapping, hence localization of the camera is assumed to be given. First, a frame-wise segmentation scheme combines an unsupervised geometric segmentation of depth images [9] with semantic object predictions from RGB [1]. The use of semantics allows the system to infer the category of some of the 3D segments predicted in a frame, as well as to group segments by the object instance to which they belong. Next, the tracking of the individual predicted instances across multiple frames is addressed by matching per-frame predictions to existing segments in the global map via a data association strategy. Finally, observed surface geometry and segmentation information are integrated into a global Truncated Signed Distance Field (TSDF) map volume. To this end, the Voxblox volumetric mapping framework [10] is extended to enable the incremental fusion of class and instance information within the reconstruction. By relying on a volumetric representation that explicitly models free space information, i.e. distinguishes between unknown space and observed, empty space, the built maps can be directly used for safe robotic navigation and motion planning purposes. Furthermore, object models reconstructed with the voxel grid explicitly encode surface connectivity information, relevant in the context of robotic manipulation applications.
The capabilities of the proposed method are demonstrated in two experimental settings. First, the proposed instance-aware semantic mapping framework is evaluated on office sequences from the real-world SceneNN [8] dataset to compare against previous work on progressive instance segmentation of 3D scenes. Lastly, we show qualitative results for an online mapping scenario on a robotic platform. The experiments highlight the robustness of the presented incremental segmentation strategy, and the online nature of the framework.
The main contributions of this work are:
- •
A combined geometric-semantic segmentation scheme that extends object detection to novel, previously unseen categories.
- •
A data association strategy for tracking and matching instance predictions across multiple frames.
- •
Evaluation of the framework on a publicly available dataset and within an online robotic mapping setup.
II RELATED WORK
II-A Object detection and segmentation
In the context of object recognition in real-world environments, computer vision algorithms have recently shown some impressive results. Driven by the advances in deep learning using Convolutional Neural Network (CNNs) , several architectures have been proposed for detecting objects in RGB images [11, 12]. Beyond simple bounding boxes, the recent Mask R-CNN framework [1] is further able to predict a per-pixel semantically annotated mask for each of the detected instances, achieving state-of-the-art results on the COCO instance-level semantic segmentation task [13].
One of the major limitations of learning-based instance segmentation methods is that they require extensive amounts of training data in the form of annotated masks for the specified object categories. Such annotated data can be expensive or even infeasible to acquire for all possible categories that may be encountered in a real-world scenario. Moreover, these algorithms can only recognize the fixed set of classes provided during training, thus failing to correctly segment and classify other, previously unseen object categories.
Some recent works aim to relax the requirement for large amounts of pixel-wise semantically annotated training data. MaskX R-CNN [14] adopts a transfer method which only requires a subset of the data to be labeled at training time. SceneCut [15] and its Bayesian extension in [2] also operate under open-set conditions and are able to detect and segment novel objects of unknown classes. However, beyond detecting object instances in individual image frames, these methods alone do not provide a comprehensive 3D representation of the scene and, therefore, cannot be directly used for planning tasks such as manipulation or navigation.
II-B Semantic object-level mapping
Recent developments in deep learning have also enabled the integration of rich semantic information within real-time Simultaneous Localization and Mapping (SLAM) systems. The work in [16] fuses semantic predictions from a CNN into a dense map built with a SLAM framework. However, conventional semantic segmentation is unaware of object instances, i.e. it does not disambiguate between individual instances that belong to the same category. Thus, the approach in [16] does not provide any information about the geometry and relative placement of individual objects in the scene. Similar work in [17] additionally proposes to incrementally segment the scene using geometric cues from depth. However, geometry-based approaches tend over-segment articulated scene elements. Thus, without instance-level information, a joint semantic-geometric segmentation is not enough to group parts of the scene into distinct separate objects. Indeed, the instance-agnostic semantic segmentation in these works fails to build semantically meaningful maps to model individual object instances.
Previous work has addressed the task of mapping at the level of individual objects. SLAM++ [18] builds object-oriented maps by detecting recognized elements in RGB-D data, but is limited to work with a database of objects for which exact geometric models need to be known in advance. A number of other works have addressed the task of detecting and segmenting individual semantically meaningful objects in 3D scenes without predefined shape templates [7, 9, 3, 4, 5, 6]. Recent learning-based approaches segment individual instances of semantically annotated objects in reconstructed scenes with little or no prior information about their exact appearance while at the same time handling substantial intra-class variability [3, 4, 5, 6]. However, by relying on a strong supervisory signal of the predefined classes during training, a purely learning-based segmentation fails to discover novel objects of unknown class in the scene. As a result, these methods either fail to map objects that do not belong to the set of known categories and for which no semantic labels are predicted [3, 4, 6], or wrongly assign such previously unseen instances to one of the known classes [5]. In a real-world scenario, detecting objects only from a fixed set of classes specified during training limits interaction planning to a subset of all the observed scene elements.
In contrast, purely geometry-based methods operate under open-set conditions and are able to discover novel, previously unobserved objects in the scene [9, 7]. The work in [9] provides a complete and exhaustive geometric segmentation of the scene. Similarly, the Incremental Object Database (IODB) in [7] performs a purely geometric segmentation from depth data to reconstruct the shape of individual segments and build a consistent database of unique 3D object models. However, as mentioned previously, geometry-based approaches can result in unwanted over-segmentation of non-convex objects. Furthermore, by not providing semantic information, the two methods disallow high-level interaction planning. In addition to a complete geometric segmentation of the scene, the work in [19] performs object recognition on such segments from a database of known objects. While able to discover new, previously unseen objects and to provide for some semantic information, the main drawback lies in the requirement for exact 3D geometric models of the recognized objects to be known. This is not applicable to real-world environments, where objects with novel shape variations are inevitably encountered on a regular basis.
Closely related to the approach presented in this letter is the recent work in [20], with the similar aim of building dense object-oriented semantic maps. The work presents an incremental geometry-based segmentation strategy, coupled with the YOLO v2 [11] bounding box detector to identify and merge geometric segments that are detected as part of the same instance. One of the key differences to our approach is the choice of scene representation. Their system relies on the RGB-D SLAM system from [21] and stores the reconstructed 3D map through a surfel-based representation [22]. While surfels allow for efficient handling of loop closures, they only store the surface of the environment and do not explicitly represent observed free space [23]. That is, a surfel map does not distinguish between unseen and seen-but-empty space, and thus cannot be directly used for planning in robotic navigation or manipulation tasks where knowledge about free space is essential for safe operation [24]. Further, visibility determination and collision detection in surfel clouds can be significantly harder due to the lack of surface connectivity information. Therefore, as with all other approaches relying on sparse point or surfel clouds representations [3, 4], the object-oriented maps built in [20] cannot be immediately used in those robotic settings where an explicit distinction between unobserved space and free space is required.
Conversely, the volumetric TSDF -based representation adopted in this work does not discard valuable free space information and explicitly distinguishes observed empty space from unknown space in the 3D map. In contrast to all previous approaches, the proposed method is able to incrementally provide densely reconstructed volumetric maps of the environment that contain shape and pose information about both recognized and unknown object elements in the scene. The reconstructed maps are expected to directly benefit navigation and interaction planning applications.
III METHOD
The proposed incremental object-level mapping approach consists of four steps deployed at each incoming RGB-D frame: (i) geometric segmentation, (ii) semantic instance-aware segmentation refinement, (iii) data association, and (iv) map integration. First, the incoming depth map is segmented according to a convexity-based geometric approach that yields segment contours which accurately describe real-world physical boundaries (Section III-A). The corresponding RGB frame is processed with the Mask R-CNN framework to detect object instances and compute for each a per-pixel semantically annotated segmentation mask. The per-instance masks are used to semantically label the corresponding depth segments and to merge segments detected as belonging to the same geometrically over-segmented, non-convex object instance (Section III-B). A data association strategy matches segments discovered in the current frame and their comprising instances to the ones already stored in the map (Section III-C). Finally, segments are integrated into the dense 3D map, where a fusion strategy keeps track of the individual segments discovered in the scene (Section III-D). An example illustrating the individual stages of the proposed approach is shown in Figure 2.
III-A Geometric segmentation
Building on the assumption that real-world objects exhibit overall convex surface geometries, each incoming depth frame is decomposed into a set of object-like convex 3D segments following the geometry-based approach introduced in [7]. First, surface normals are estimated at every depth image point. Next, angles between adjacent normals are compared to identify concave region boundaries. Additionally, large 3D distances between adjacent depth map vertices are used to detect strong depth discontinuities. Surface convexity and the 3D distance measure are then combined to generate, at every frame , a set of closed 2D regions in the current depth image and a set of corresponding 3D segments . Figure 2 shows the sample output of this stage.
III-B Semantic instance-aware segmentation refinement
To complement the unsupervised geometric segmentation of each depth frame with semantic object instance information, the corresponding RGB images are processed with the Mask R-CNN framework [1]. The network detects and classifies individual object instances and predicts a semantically annotated segmentation mask for each of them. Specifically, for each input RGB frame the output is a set of object instances, where the -th detected instance is characterized by a binary mask and an object category . Figure 2 shows the sample output of Mask R-CNN.
The segmentation masks offer a straightforward way to associate each of the detected instances with one or more corresponding 3D depth segments . Pairwise 2D overlaps between each and each predicted binary mask are computed as the number of pixels in the intersection of and normalized by the area of :
[TABLE]
For each region the highest overlap percentage and index of the corresponding mask are found as:
[TABLE]
If , the corresponding 3D segment is assigned the object instance label and a semantic category . Multiple segments in assigned to the same object instance label value indicate an over-segmentation of non-convex, articulated shapes being refined through semantic instance information. The unique set of all object instance labels assigned to segments in the current frame is denoted by . All segments for which no mask in the current frame exhibits enough overlap are assigned , denoting a geometric segment for which no semantic instance information could be predicted.
III-C Data association
Because the frame-wise segmentation processes each incoming RGB-D image pair independently, it lacks any spatio-temporal information about corresponding segments and instances across the different frames. Specifically, this means that it does not provide an association between the set of predicted segments and the set of segments . Further, segments belonging to the same object instance might be assigned different label values across two consecutive frames, since these represent mask indices valid only within the scope of the frame in which such masks were predicted.
A data association step is proposed here to track corresponding geometric segments and predicted object instances across frames. To this end, we define a set of persistent geometric labels and a set of persistent object instance labels which remain valid throughout the entire mapping session. In particular, each from the set of segments stored in the map is defined by a unique geometric label through a mapping . At each frame we then look for a mapping that matches predicted segments to corresponding segments . Similarly, within the scope of a frame we seek to define a mapping that matches object instances to persistent instance labels stored in the map.
To track spatial correspondences between segments identified in the current depth map and the set of segments in the global map it is only necessary to consider the set of map segments visible in the current camera view. The pairwise 3D overlap is computed for each and each as the number of points in segment that, when projected into the global map frame using the known camera pose, correspond to a voxel which belongs to segment . For each segment , the highest overlap measure and the index of the corresponding segment are found as,
[TABLE]
Each segment with determines the persistent label mapping for the corresponding maximally overlapping segment from the current depth frame, i.e. . The threshold value is set to 20, and is used to prevent poorly overlapping global map segment labels from being propagated to the current frame. All segments that did not match to any segment are assigned a new persistent label as . It is worth noting that, in contrast to previous work on segment tracking across frames[9], the proposed formulation disallows matching multiple segments in to the same segment . Without such constraint, information about a region in the map that was initially segmented as one now being segmented in two or more parts in the current frame would be lost, thus making it impossible to fix incorrect under-segmentations over time.
We introduce here the notation to denote the pairwise count in the global map between a persistent segment label and a persistent instance label . is used here to determine the mapping from instance labels to instance labels . Specifically, for each segment with a corresponding and no defined yet, the persistent object label with the highest pairwise count is identified. The object label is then mapped to as . Remaining with no mapping found are assigned a new persistent instance label as . Following a similar reasoning as above, multiple labels are prevented from mapping to the same persistent label in order not to discard valuable instance segmentation information from the current frame.
The result of this data association step is a set of 3D segments from the current frame, each assigned a persistent segment label . Further, the corresponding object instance label is matched to a persistent label . Additionally, each segment is associated with the semantic object category predicted by Mask R-CNN (Section III-B).
III-D Map integration
The 3D segments discovered in the current frame, including some which are enriched with class and instance information, are fused into a global volumetric map. To this end, the Voxblox [10] TSDF -based dense mapping framework is extended to additionally encode object segmentation information. After projecting the segments into the global TSDF volume using the known camera pose, voxels corresponding to each projected 3D point are updated to store the incoming geometric segment label information, following the approach introduced in [7]. Additionally, for each integrated into the map at frame with corresponding , the pairwise count between and the object instance and the pairwise count between and the class are incremented as,
[TABLE]
Each 3D segment in the global map volume is then defined by the set of voxels assigned to the persistent label . If the segment represents a recognized, semantically annotated instance then it is also associated with an object label and a corresponding semantic class .
IV EXPERIMENTS
The proposed approach to incremental instance-aware semantic mapping is evaluated on a Lenovo laptop with an Intel Xeon E3-1505M eight-core CPU at 3.00 GHz and an Nvidia Quadro M2200 GPU with 4 GB of memory only used for the Mask R-CNN component. The Mask R-CNN code is based on the publicly available implementation from Matterport,222https://github.com/matterport/Mask_RCNN with the pre-trained weights provided for the Microsoft COCO dataset [13]. In all of the presented experimental setups, maps are built from RGB-D video with a resolution of 640x480 pixels.
To compare against previous work in [5], we evaluate the 3D segmentation accuracy of the proposed dense object-level semantic mapping framework on real-world indoor scans from the SceneNN [8] dataset, improving over the baseline for most of the evaluated scenes. A sample inventory of object models discovered in these scenes is shown to contain recognized, semantically annotated elements, as well as newly discovered, previously unseen objects. Lastly, we report on the runtime performance of the proposed system.
The framework is further evaluated within an online setting, mapping an office floor traversed by a robotic platform. Although the system operates at only 1 Hz, qualitative results in the form of a semantically annotated object-centric reconstruction validate the online nature of the approach and show its benefits in real-world, open set conditions.
IV-A Instance-aware semantic segmentation
Several recent works explore the task of semantic instance segmentation of 3D scenes. The majority of these, however, take as input the full reconstructed scene, either processing it in chunks or directly as a whole. Because such methods are not constrained to progressively fusing predictions from partial observations into a global map but can learn from the entire 3D layout of the scene, these are not directly comparable to the approach presented in this work. Among the frameworks that instead explore online, incremental instance-aware semantic mapping, the work in [5] is, to the best of our knowledge, the only one to present quantitative results in terms of the achieved 3D segmentation accuracy. While a comparison with [5] does not provide any insight into the performance of the proposed unsupervised object discovery strategy, it can help to assess the efficacy of the semantic instance-aware segmentation component of our system.
In their work, Pham et al. [5] report instance-level 3D segmentation accuracy results for the NYUDv2 40 class task, which includes commonly-encountered indoor object classes, as well as structural, non-object categories, such as wall,* window*, door, floor, and ceiling. This set of classes is well-suited for semantic segmentation tasks in which the goal is to classify and label every single element, either voxel of surfel, of the 3D scene. Indeed, the approach in [5] initially employs a purely semantic segmentation strategy, and later clusters the semantically annotated scene into individual instances. However, a set of classes which includes non-object categories does not apply to the object-based segmentation approach proposed in this work. Therefore, rather than training on a class-set that does not meet the requirements and goals of the proposed framework, we relied on a Mask R-CNN model trained on the 80 Microsoft COCO object classes [13]. We then evaluated the segmentation accuracy on the 9 object categories in common between the NYUDv2 40 COCO class tasks. Specifically, we picked the 9 categories that have an unambiguous one-to-one mapping between the two sets.
The proposed approach is evaluated on the 10 indoor sequences from the SceneNN [8] dataset for which [5] reports instance-level segmentation results. For each scene, the per-class Average Precision (AP) is computed using an Intersection over Union (IoU) threshold of 0.5 over the predicted 3D segmentation masks. As [5] only provides class-averaged mean Average Precision (mAP) values, these are compared with mAP averaged over the 9 evaluated categories. The results in Table I show that the proposed approach outperforms the baseline on 7 of the 10 evaluated sequences, however it is worth noting again that the reported mAP values are computed over a smaller set of classes.
Besides evaluating the semantic instance-aware segmentation, Figure 3 additionally shows a sample inventory of selected object instances detected and densely reconstructed across the 10 sequences. Along with recognized, semantically annotated objects, the shown collection includes newly discovered scene elements, highlighting the benefits of the proposed unsupervised object discovery strategy.
Table II shows the running times of the individual components of the framework averaged over the 10 evaluated sequences. The numbers indicate that the system is capable of running at approximately 1 Hz on 640x480 input.
IV-B Online reconstruction and object mapping
The proposed system is evaluated in a real-life online mapping scenario. The robotic setup used for evaluation consists of a collaborative dual arm ABB YuMi robot mounted on an omnidirectional Clearpath Ridgeback mobile base. The platform is equipped with the custom-built visual-inertial sensor described in[25], used only for online localization. Two PrimeSense RGB-D cameras are mounted facing forwards and downwards at 45 degrees, respectively, to capture dense depth maps and color images at an increased effective field of view. The complete setup is shown in Figure 4a.
Within the course of 5 minutes, the mobile base was manually steered along a trajectory through an entire office floor. Real-time poses were estimated through a combination of visual-inertial and wheel odometry and online feature-based localization in an existing map built and optimized with Maplab [26]. During scanning, the RGB-D stream of the two depth cameras is recorded to be later fed through our mapping framework at a frame rate of 1 Hz, emulating real-time on-board operation. That is, any frames that exceed the processing abilities of the system are discarded and not used to reconstruct the object-level map of the scene. The accompanying video illustrates the progressive output of the incremental reconstruction and segmentation of the scene.
Qualitative results for the final object-centric map are shown in Figure 4. Despite only a subset of the incoming RGB-D frames being integrated into the map volume, the resulting reconstruction of the environment densely describes the observed surface geometry. The system is further able to detect recognized objects of known class, and to discover novel, previously unseen object-like elements in the scene. Reconstructed over a trajectory length of over 80 m with a voxel resolution of 2 cm, the entire map fits into 605 MB of memory, which is comparable with the memory usage of the bare Voxblox framework. The final volumetric map additionally provides free space information, relevant for safe planning for robotic navigation and interaction tasks. Such tasks can be carried out in parallel, as the total computational load of the individual components of the framework corresponds to using only 5 out of the 8 CPU cores.
It is worth noting that the quality of the reconstruction in Figure 4 has been in part affected by empirically measured pose estimation errors accumulating up to 0.5 m. Because this work focuses entirely on mapping and assumes localization to be given, we leave the task of quantifying the impact of inaccurate localization on the map quality to future work.
V CONCLUSIONS
We presented a framework for online volumetric instance-aware semantic mapping from RGB-D data. By reasoning jointly over geometric and semantic cues, a frame-wise segmentation approach is able to infer high-level category information about detected and recognized elements, and to discover novel objects in the scene, for which no previous knowledge about their exact appearance is available. The partial segmentation information is incrementally fused into a global map and the resulting object-level semantically annotated volumetric maps are expected to directly benefit both navigation and manipulation planning tasks.
Real-world experiments validate the online nature of the proposed incremental framework. However, to achieve real-time capabilities, the runtime performance of the individual components requires further optimization. A future research direction involves investigating the optimal way to fuse RGB and depth information within a unified per-frame object detection, discovery and segmentation framework.
ACKNOWLEDGMENT
The authors would like to thank T. Aebi for his help in collecting data for the office floor mapping experiment.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask R-CNN,” in 2017 IEEE International Conference on Computer Vision (ICCV) , Oct 2017, pp. 2980–2988.
- 2[2] T. Pham, B. G. Vijay Kumar, T.-T. Do, G. Carneiro, and I. Reid, “Bayesian Semantic Instance Segmentation in Open Set World,” in Computer Vision – ECCV 2018 . Springer International Publishing, 2018, pp. 3–18.
- 3[3] N. Sünderhauf, T. T. Pham, Y. Latif, M. Milford, and I. Reid, “Meaningful Maps With Object-Oriented Semantic Mapping,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , Sep. 2017, pp. 5079–5085.
- 4[4] M. Rünz, M. Buffier, and L. Agapito, “Mask Fusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects,” in 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR) , Oct 2018, pp. 10–20.
- 5[5] Q. Pham, B. Hua, T. Nguyen, and S. Yeung, “Real-Time Progressive 3D Semantic Segmentation for Indoor Scenes,” in 2019 IEEE Winter Conference on Applications of Computer Vision (WACV) , Jan 2019, pp. 1089–1098.
- 6[6] J. Mc Cormac, R. Clark, M. Bloesch, A. Davison, and S. Leutenegger, “Fusion++: Volumetric Object-Level SLAM,” in 2018 International Conference on 3D Vision (3DV) , Sep. 2018, pp. 32–41.
- 7[7] F. Furrer, T. Novkovic, M. Fehr, A. Gawel, M. Grinvald, T. Sattler, R. Siegwart, and J. Nieto, “Incremental Object Database: Building 3D Models from Multiple Partial Observations,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , Oct 2018, pp. 6835–6842.
- 8[8] B. Hua, Q. Pham, D. T. Nguyen, M. Tran, L. Yu, and S. Yeung, “Scene NN: A Scene Meshes Dataset with a N Notations,” in 2016 International Conference on 3D Vision (3DV) , Oct 2016, pp. 92–101.
