Crowding in humans is unlike that in convolutional neural networks
Ben Lonnqvist, Alasdair D. F. Clarke, Ramakrishna Chakravarthi

TL;DR
This study compares visual crowding effects in humans and deep convolutional neural networks, revealing fundamental differences that challenge the use of DCNNs as models for human object recognition mechanisms.
Contribution
It systematically evaluates crowding in DCNNs using human experimental paradigms, demonstrating key differences and limitations in their similarity to human visual processing.
Findings
Crowding patterns differ significantly between humans and DCNNs.
Human-like invariance to size and target-flanker similarity is absent in DCNNs.
DCNNs likely use mechanisms distinct from humans for object recognition.
Abstract
Object recognition is a primary function of the human visual system. It has recently been claimed that the highly successful ability to recognise objects in a set of emergent computer vision systems---Deep Convolutional Neural Networks (DCNNs)---can form a useful guide to recognition in humans. To test this assertion, we systematically evaluated visual crowding, a dramatic breakdown of recognition in clutter, in DCNNs and compared their performance to extant research in humans. We examined crowding in three architectures of DCNNs with the same methodology as that used among humans. We manipulated multiple stimulus factors including inter-letter spacing, letter colour, size, and flanker location to assess the extent and shape of crowding in DCNNs. We found that crowding followed a predictable pattern across architectures that was different from that in humans. Some characteristic…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4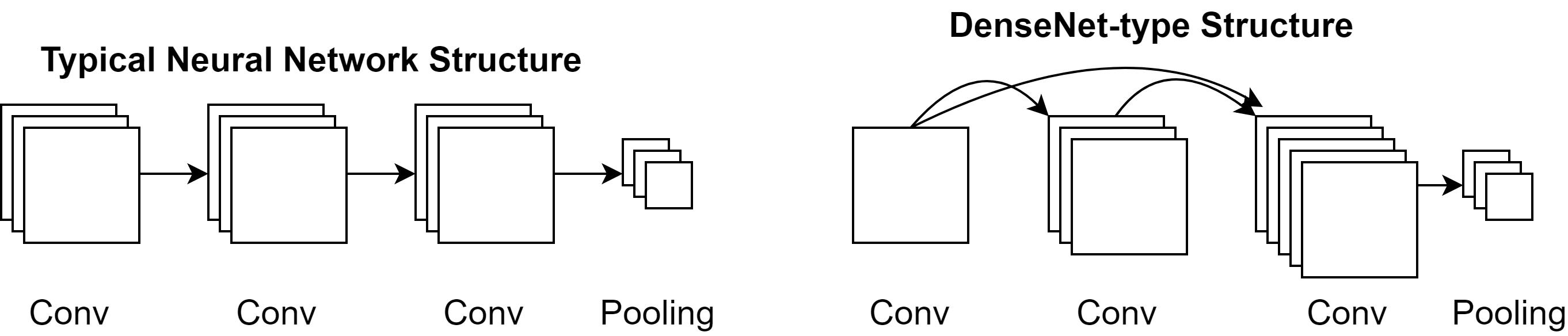 Figure 1
Figure 1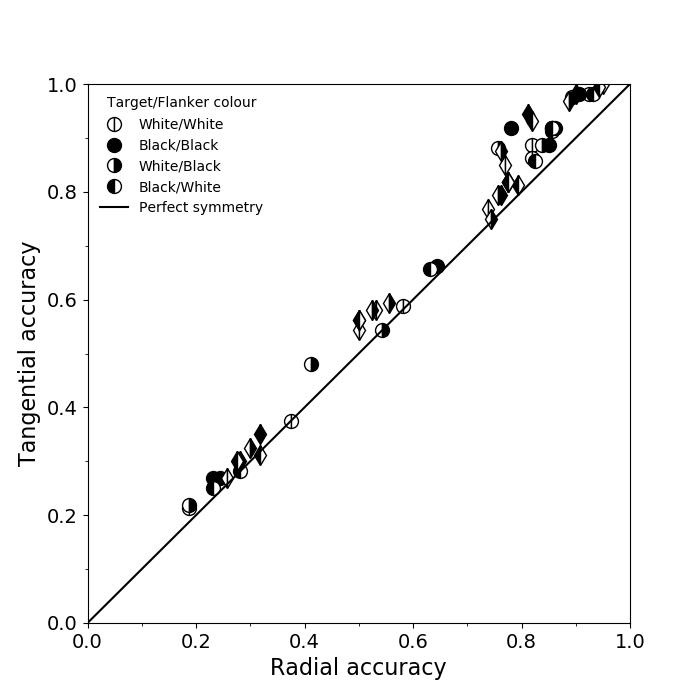 Figure 16
Figure 16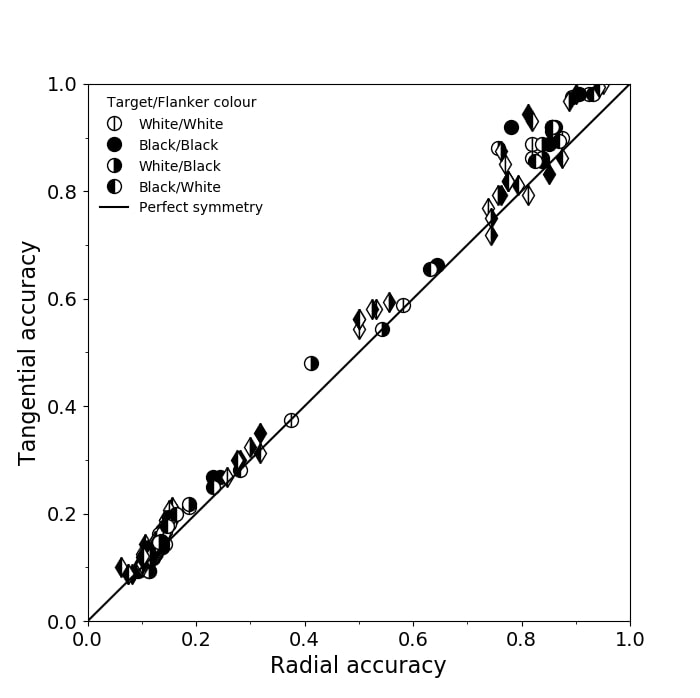 Figure 16
Figure 16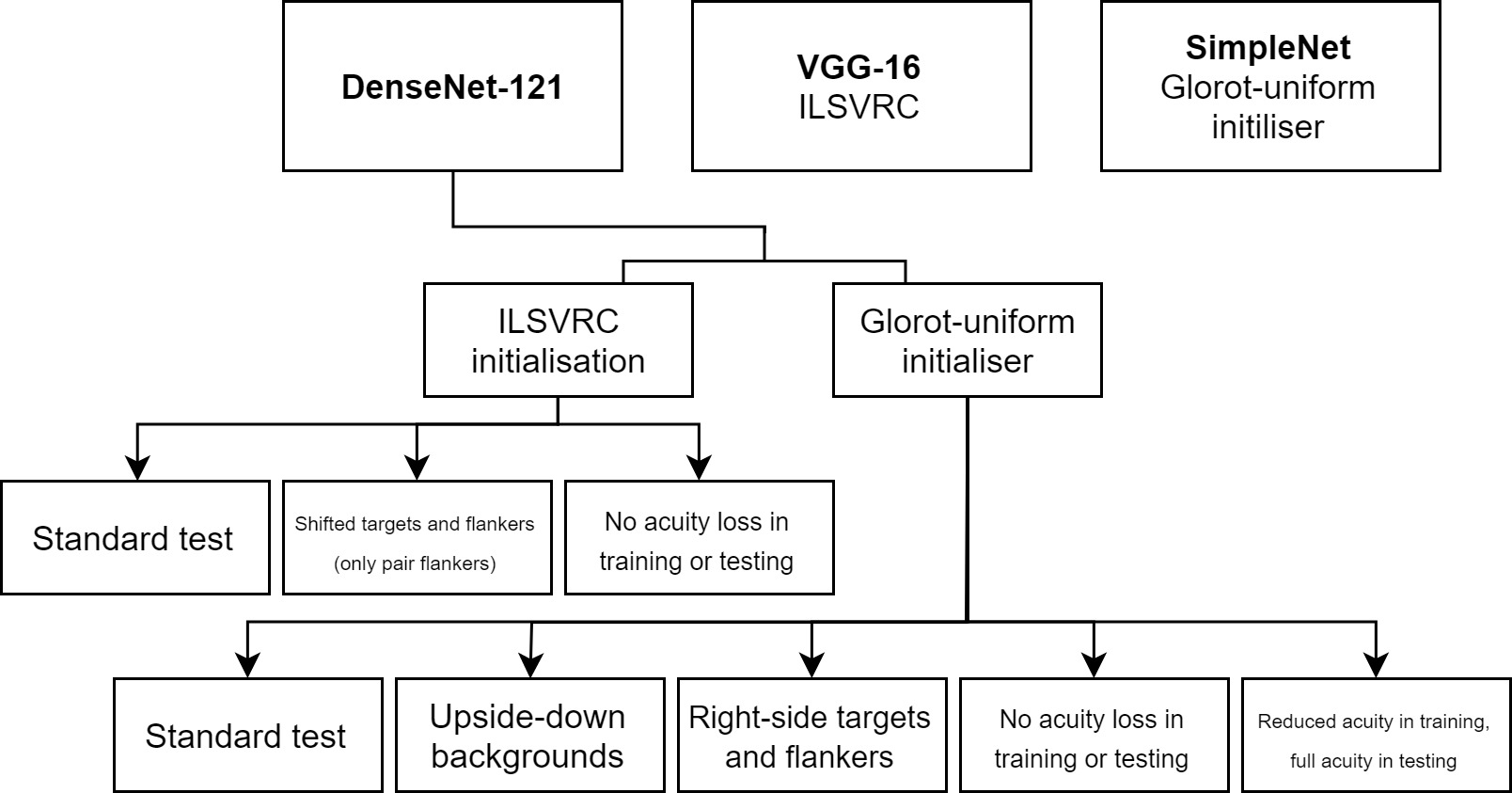 Figure 3
Figure 3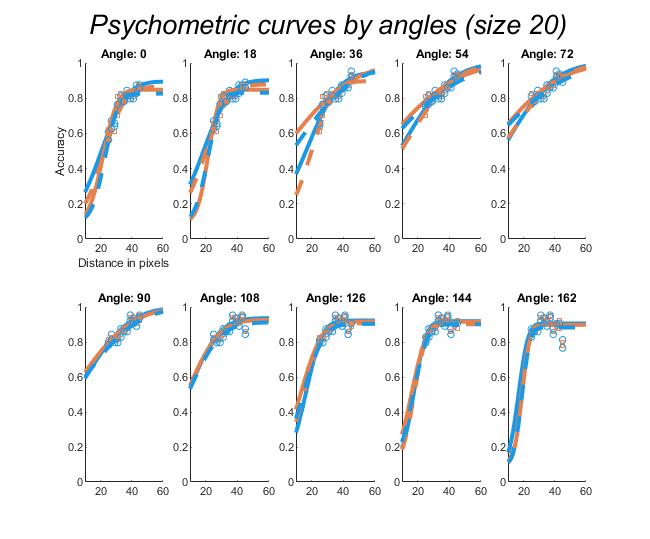 Figure 9
Figure 9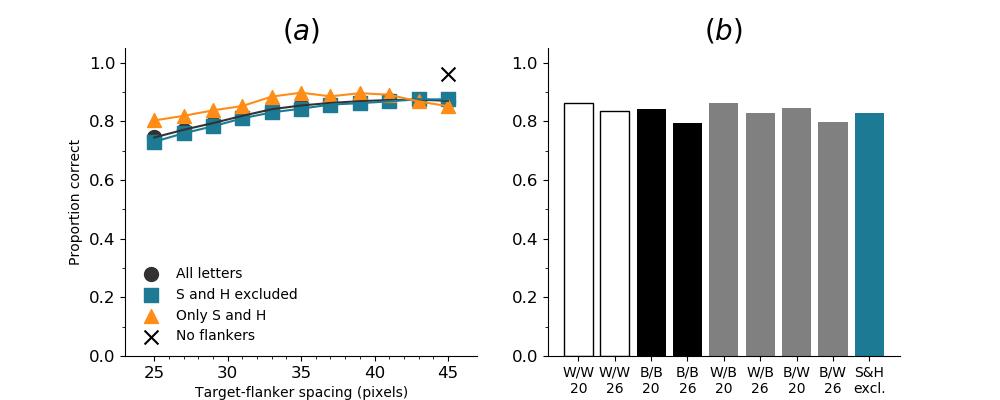 Figure 10
Figure 10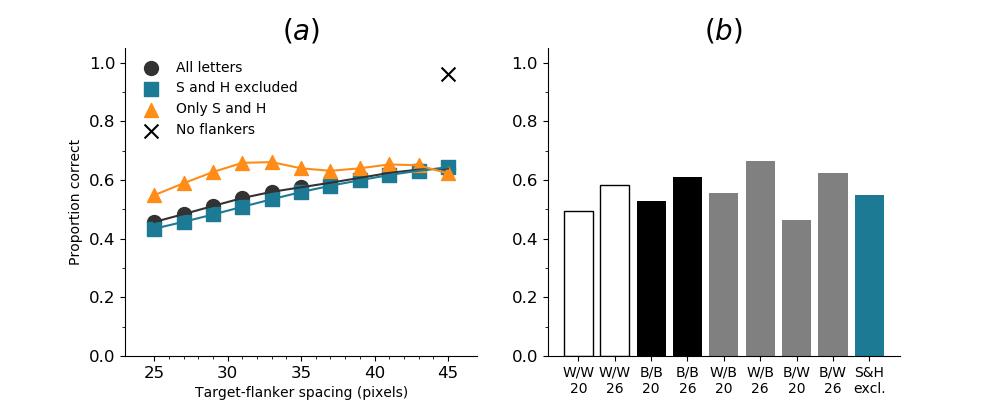 Figure 11
Figure 11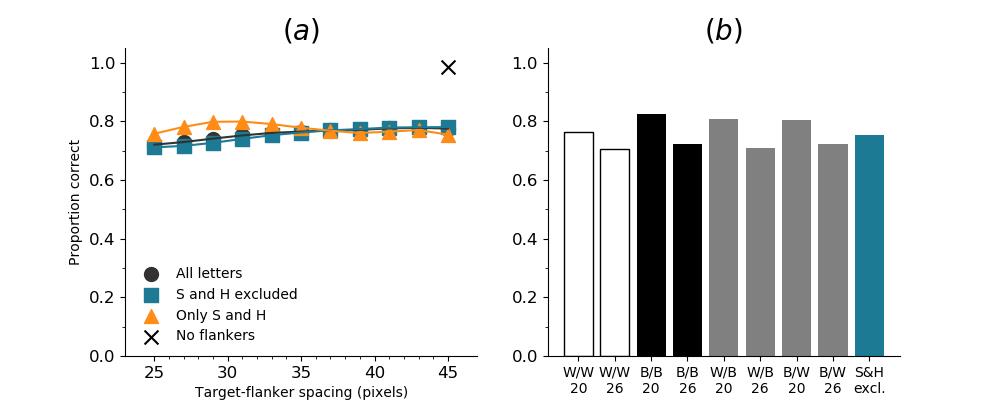 Figure 12
Figure 12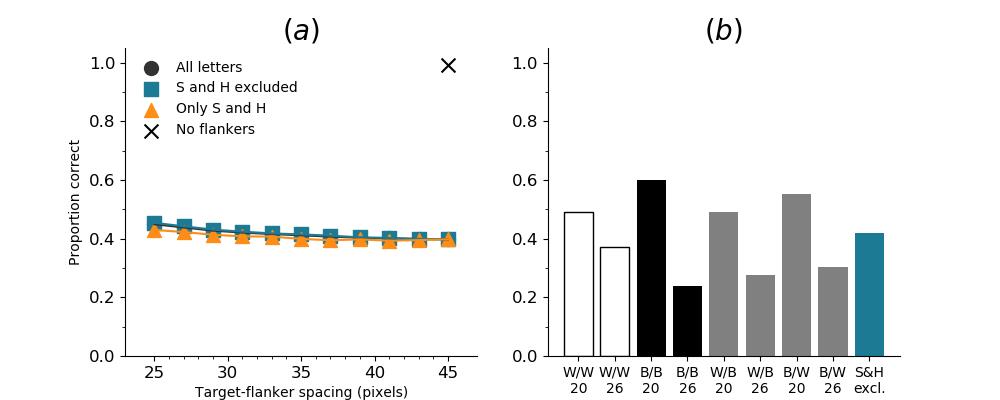 Figure 13
Figure 13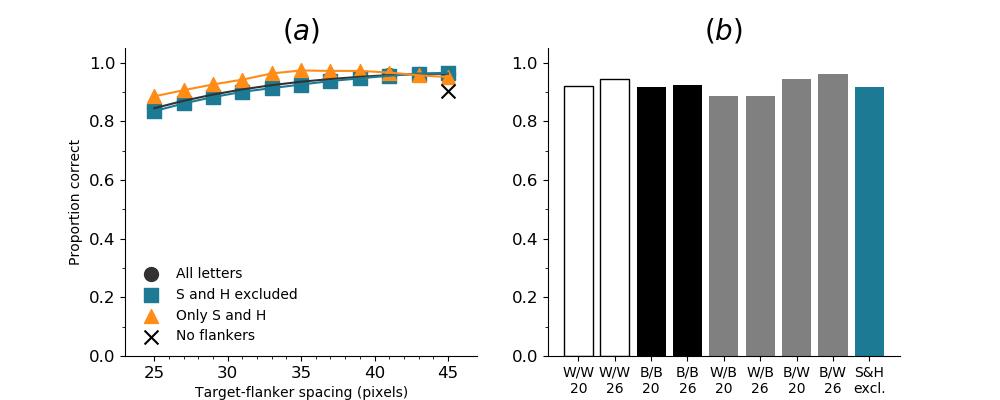 Figure 14
Figure 14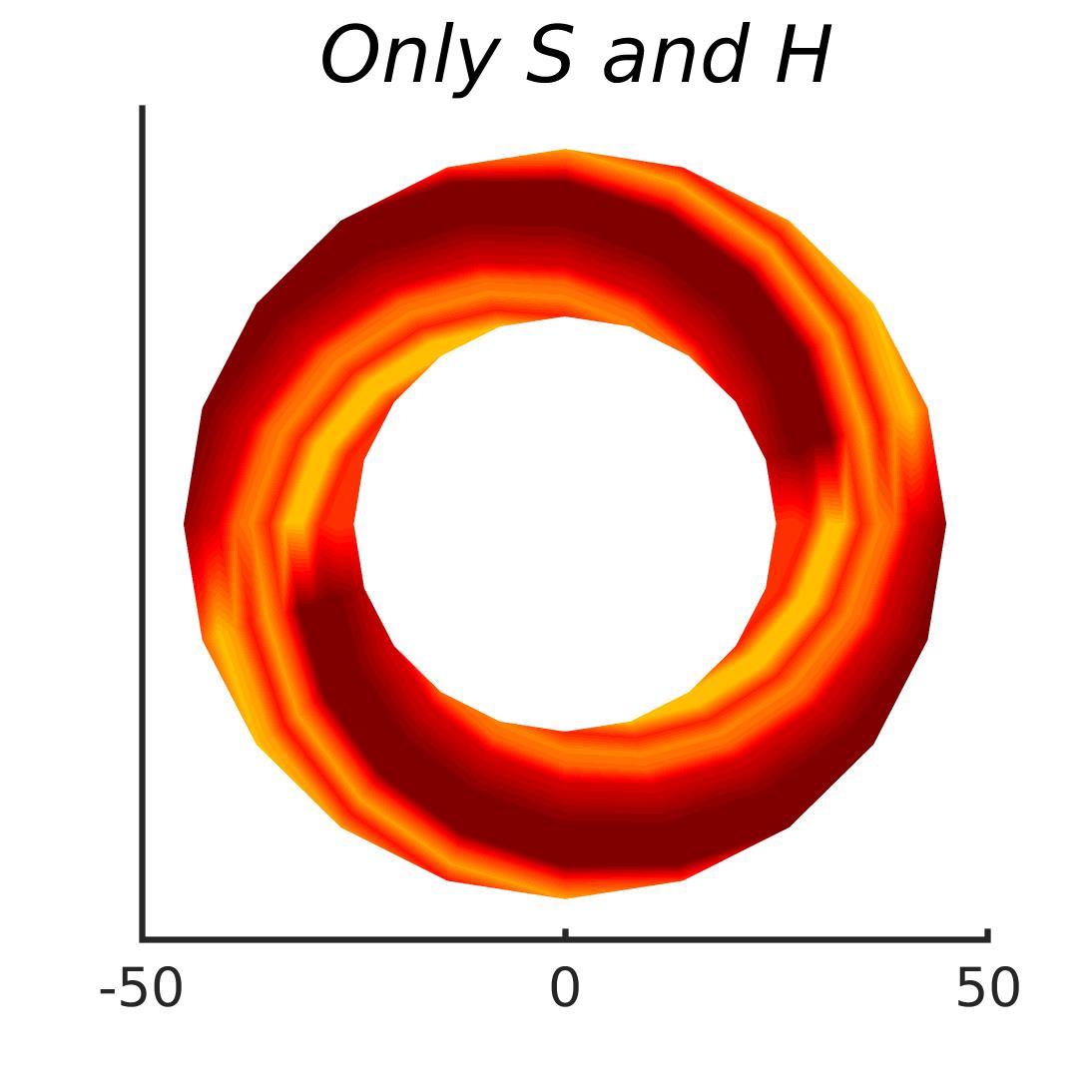 Figure 15
Figure 15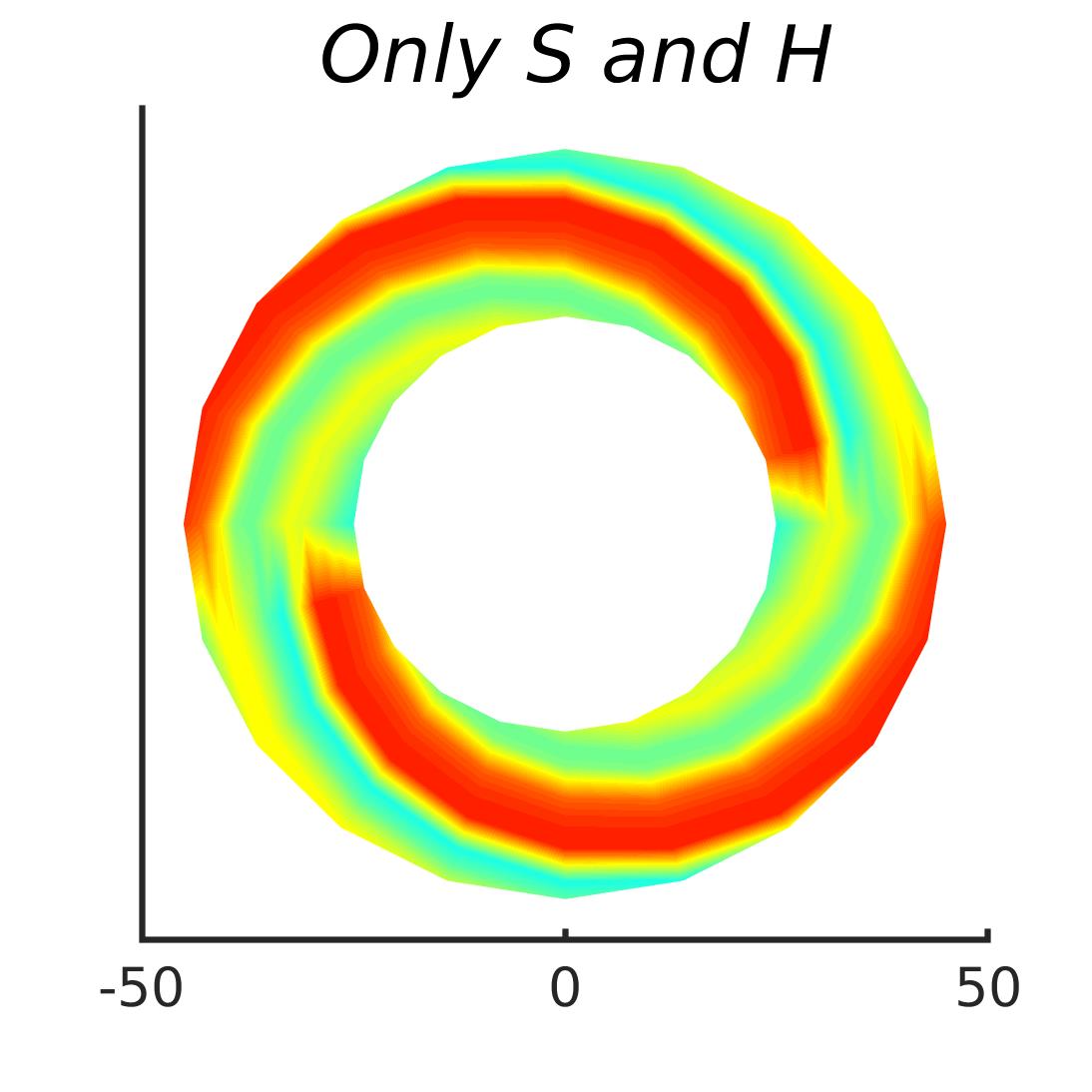 Figure 16
Figure 16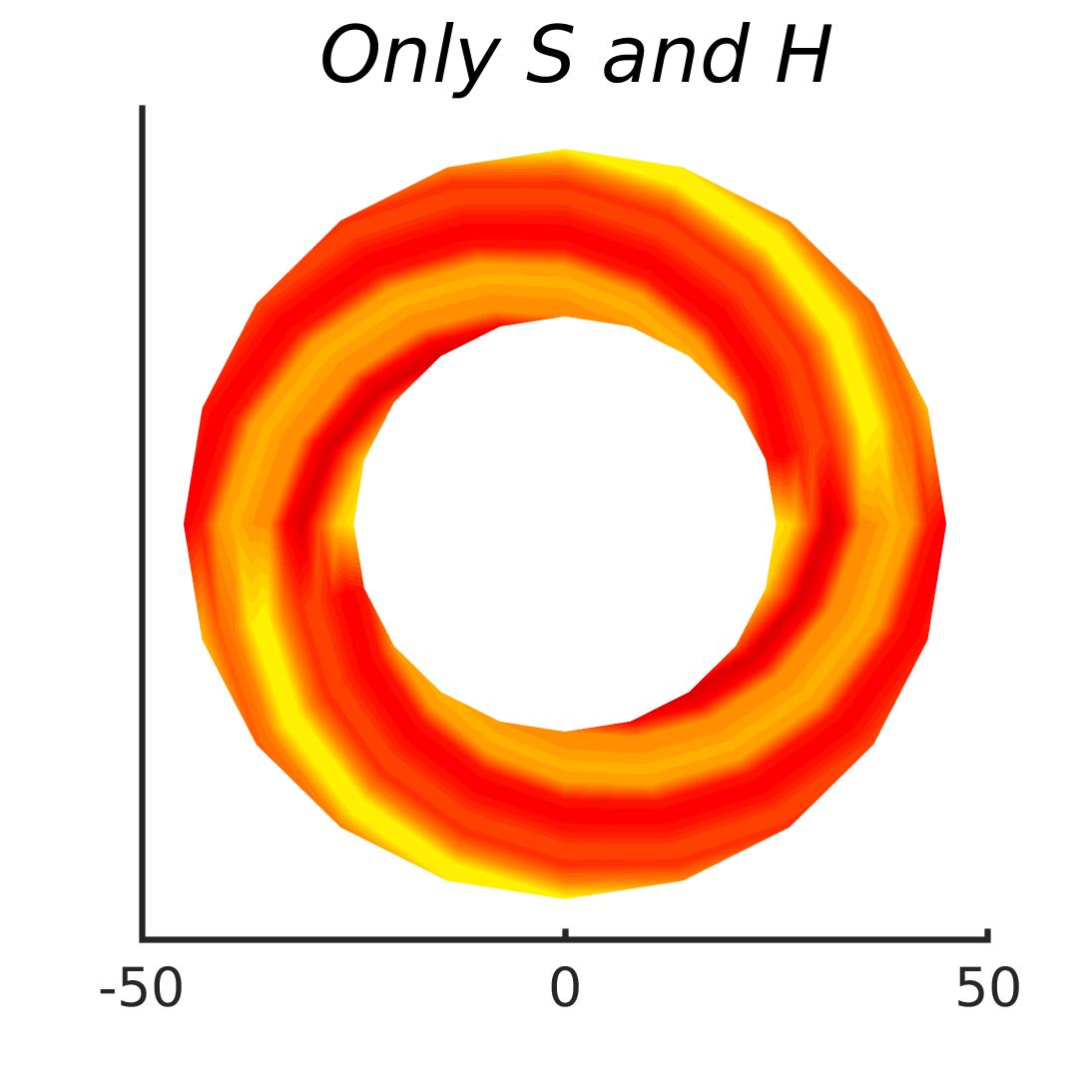 Figure 17
Figure 17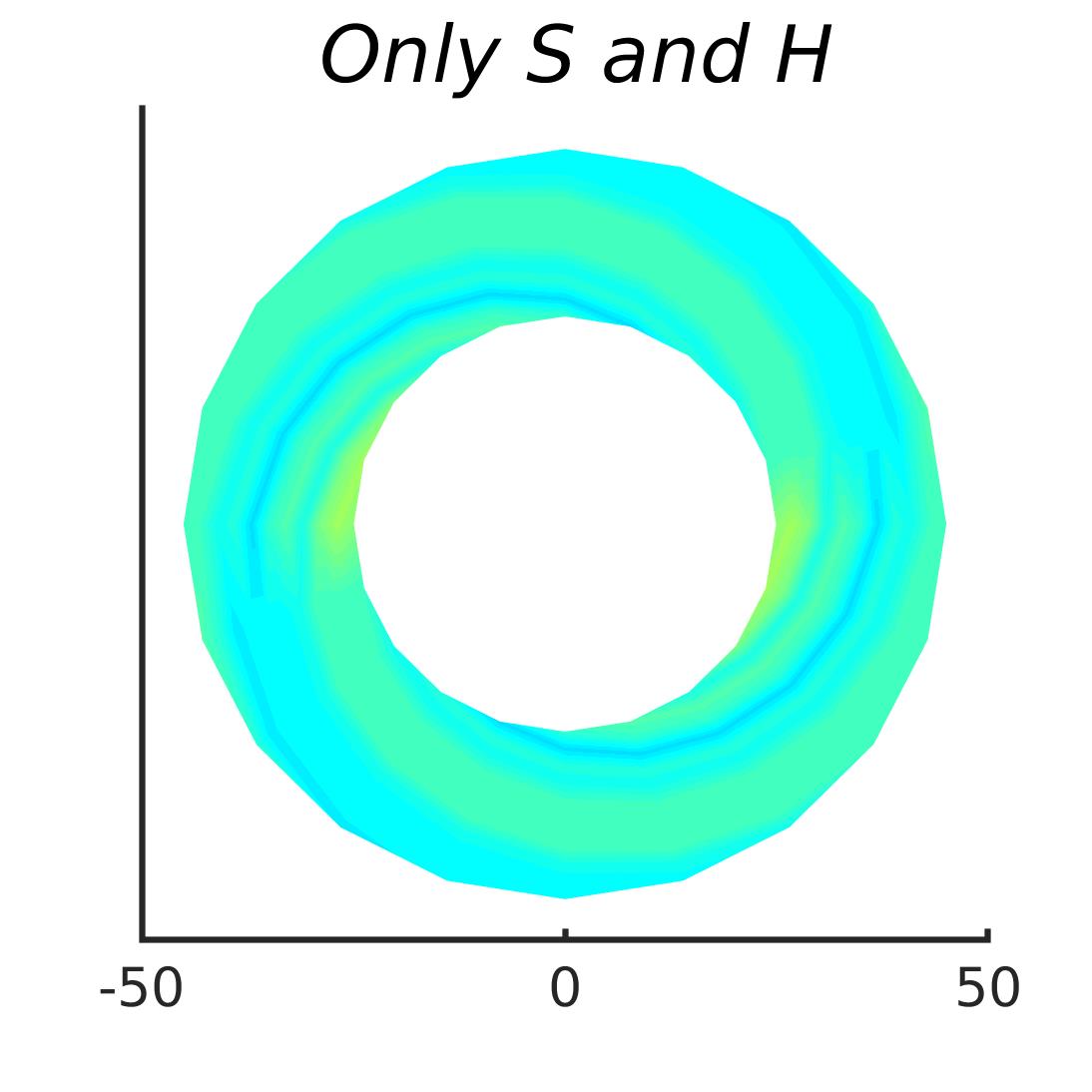 Figure 18
Figure 18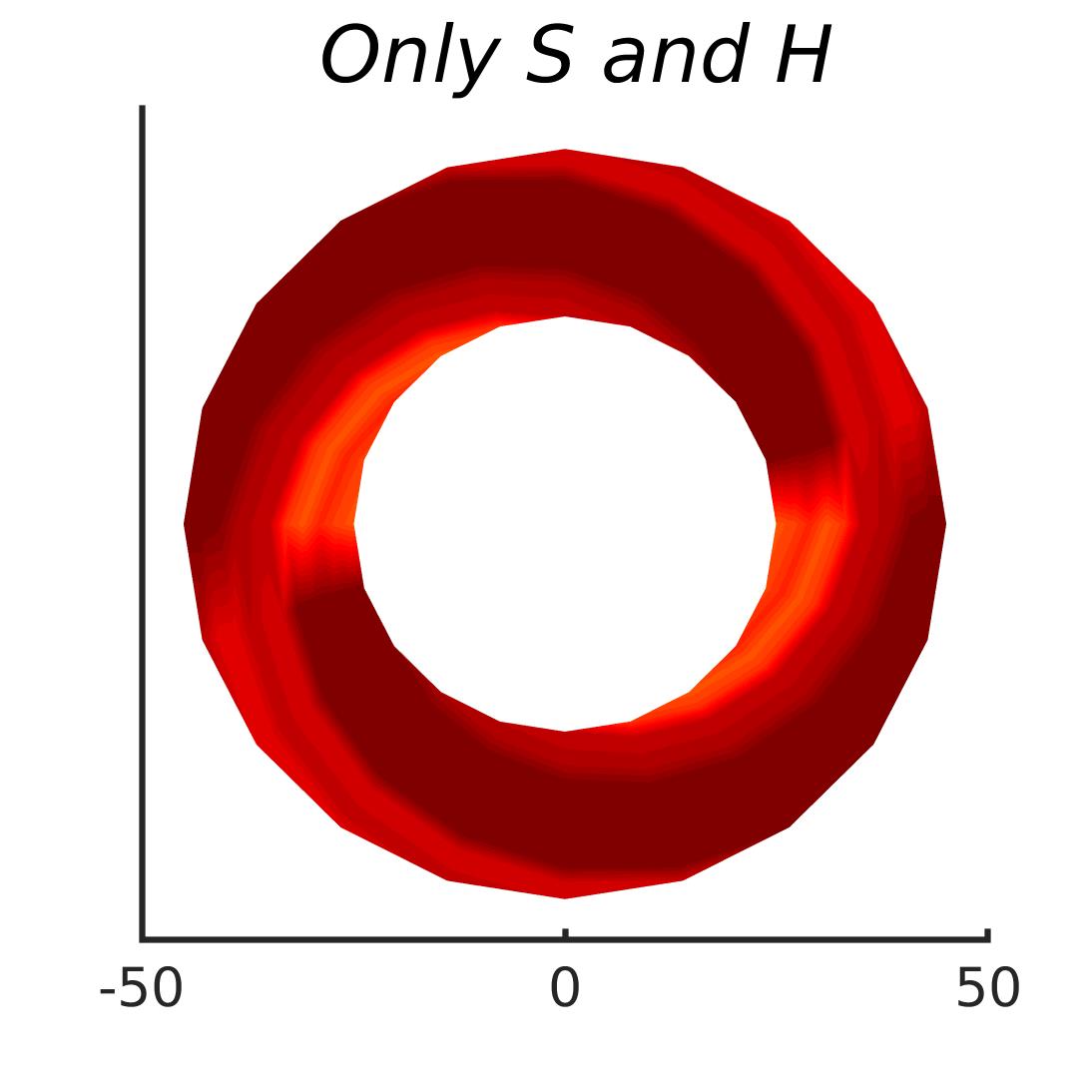 Figure 19
Figure 19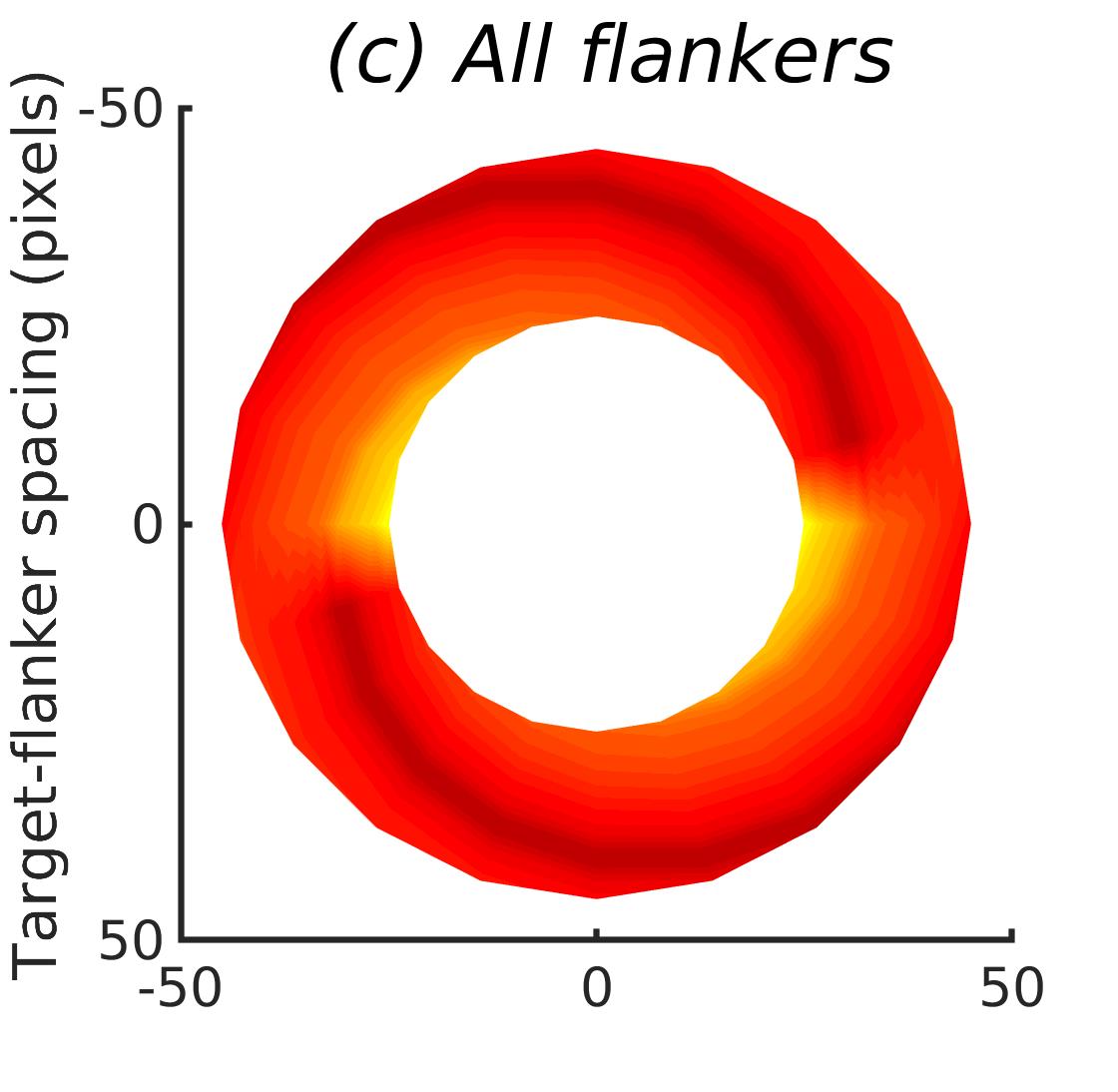 Figure 20
Figure 20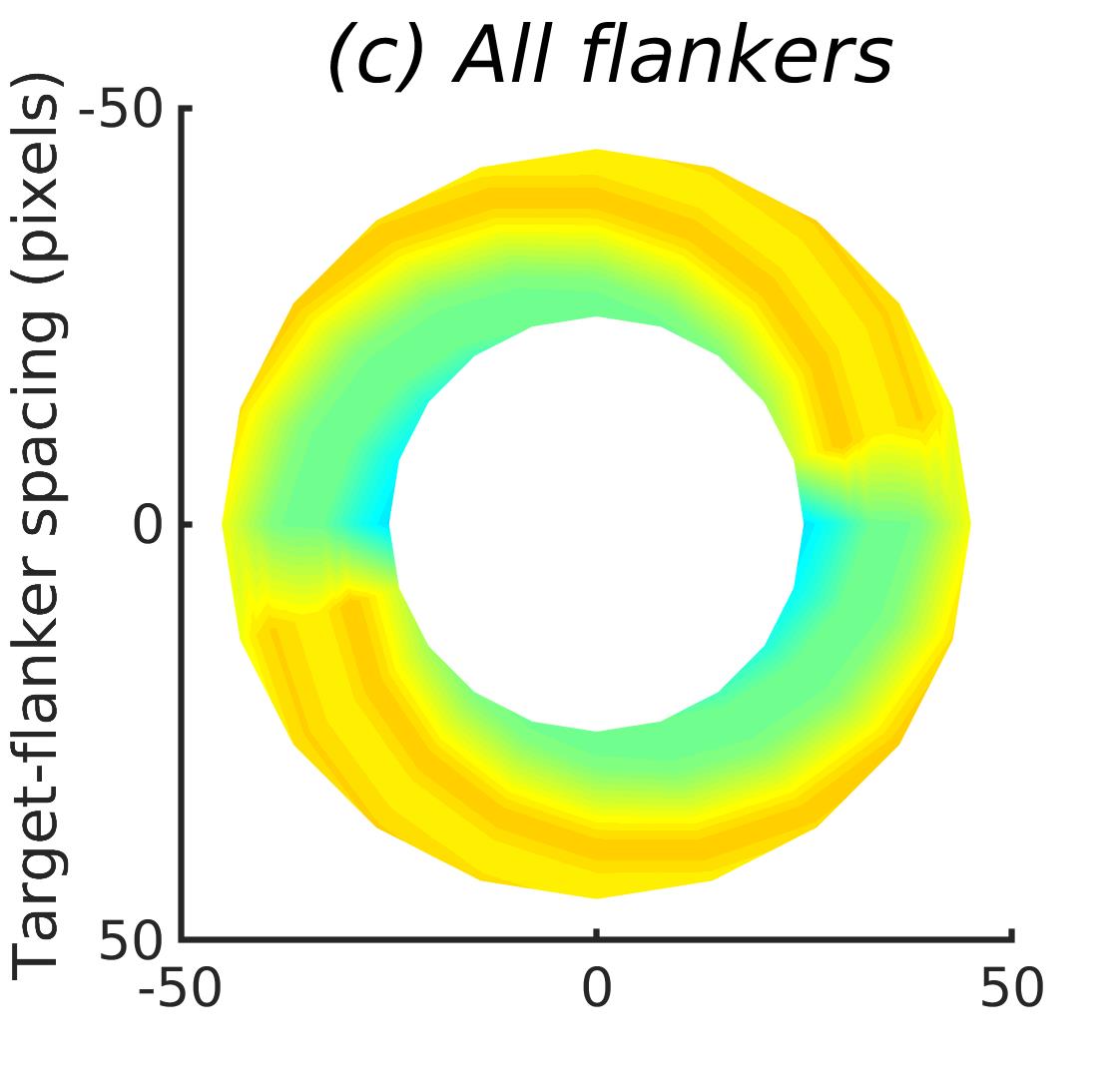 Figure 21
Figure 21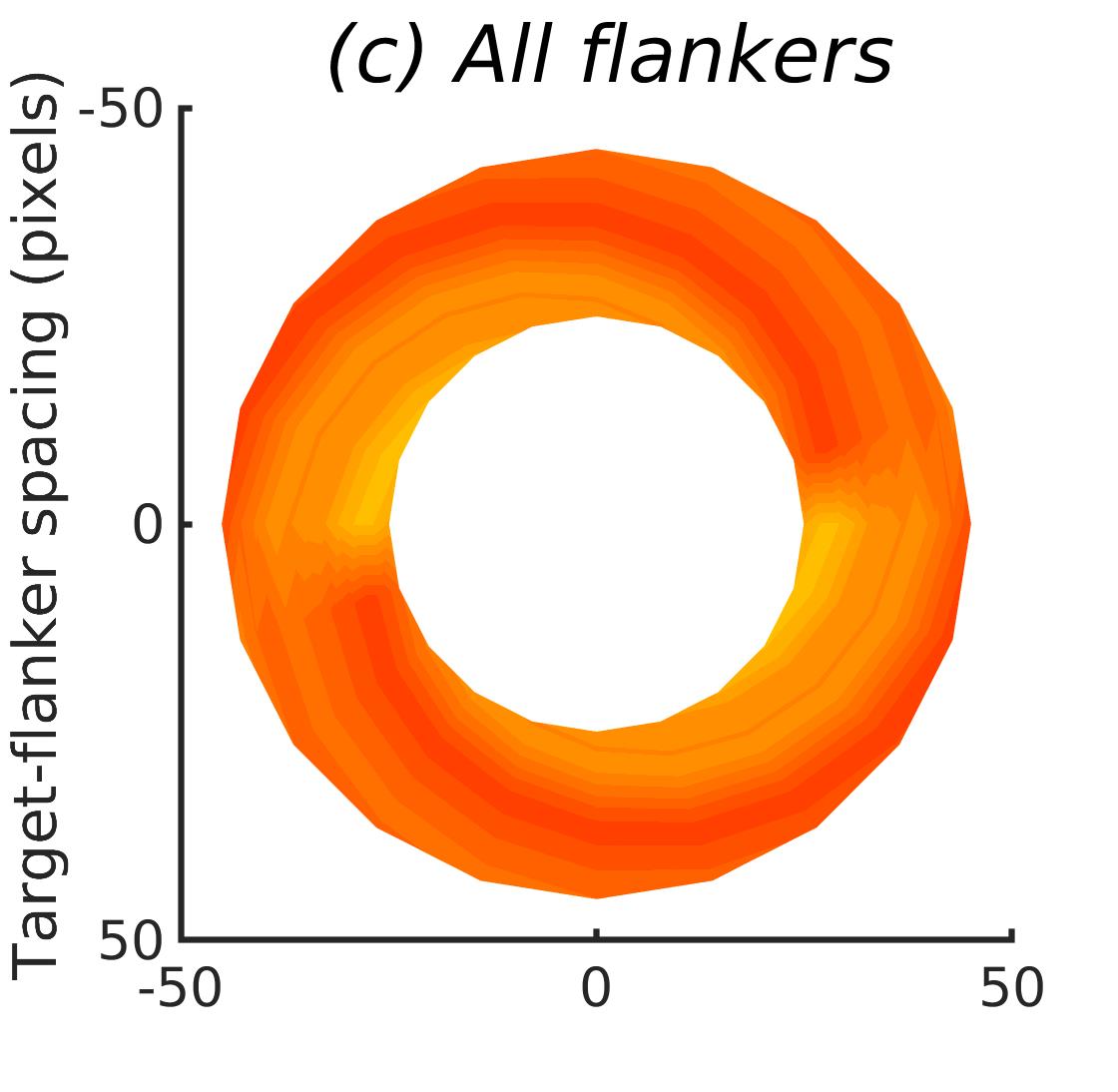 Figure 22
Figure 22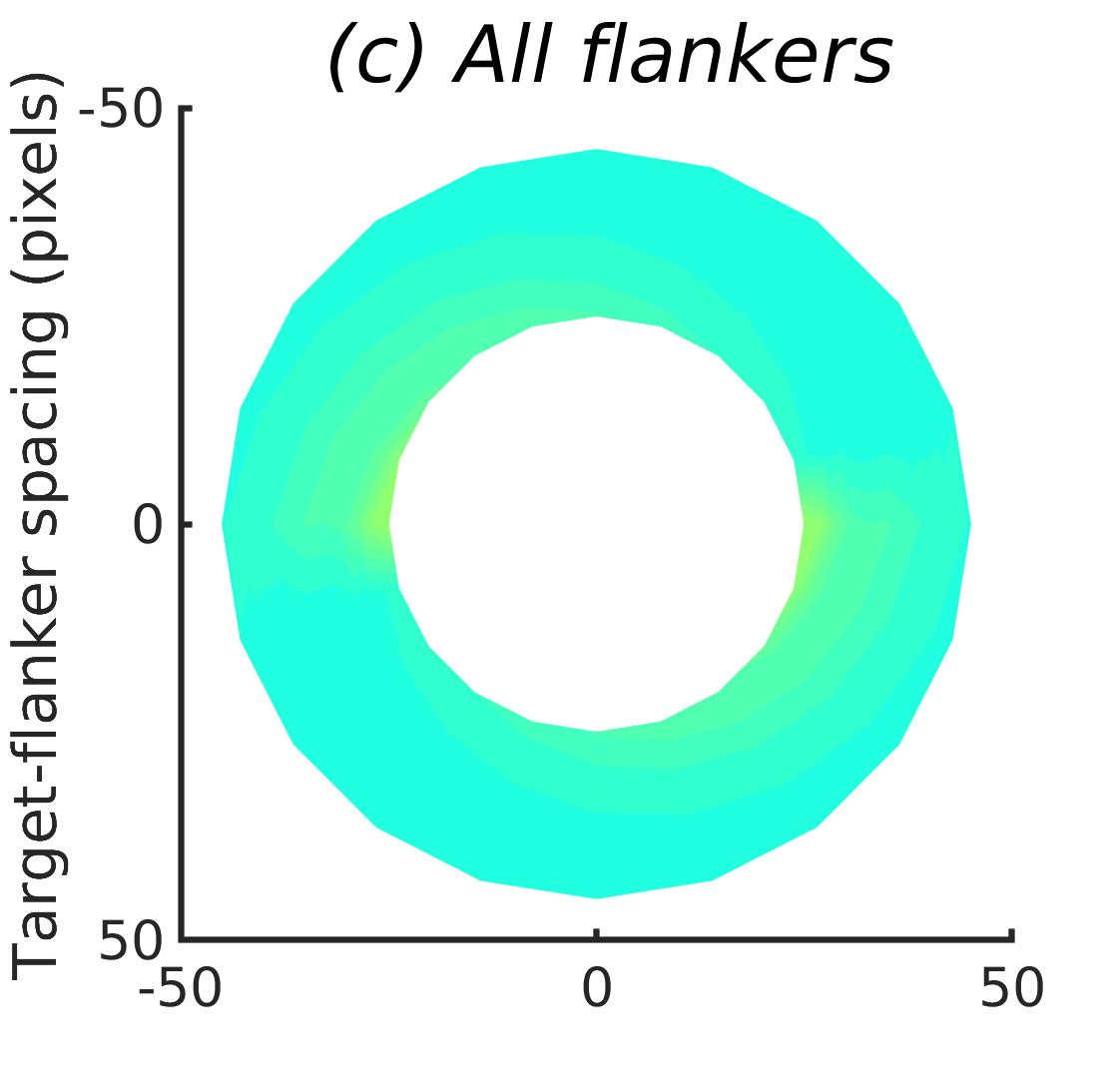 Figure 23
Figure 23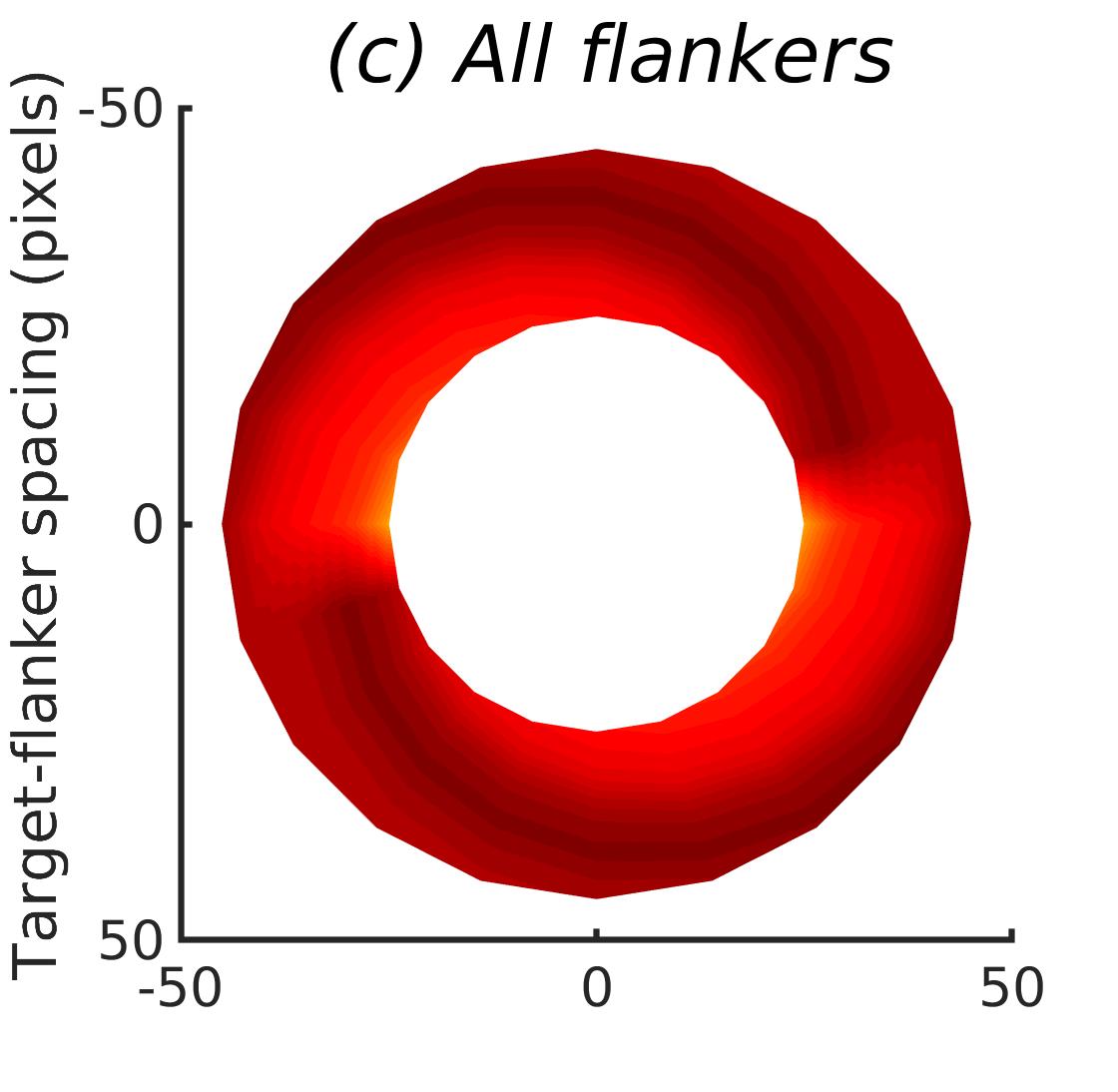 Figure 24
Figure 24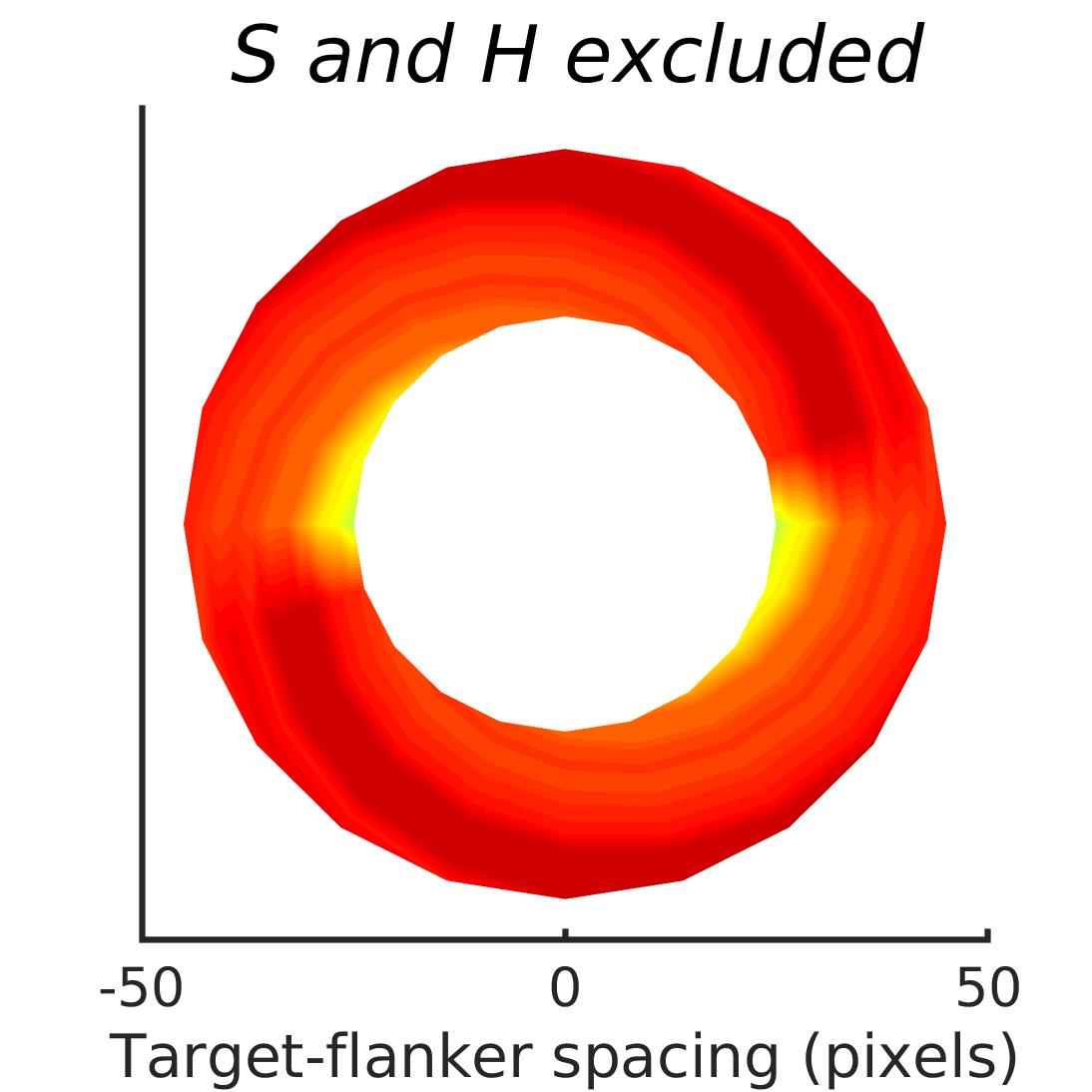 Figure 25
Figure 25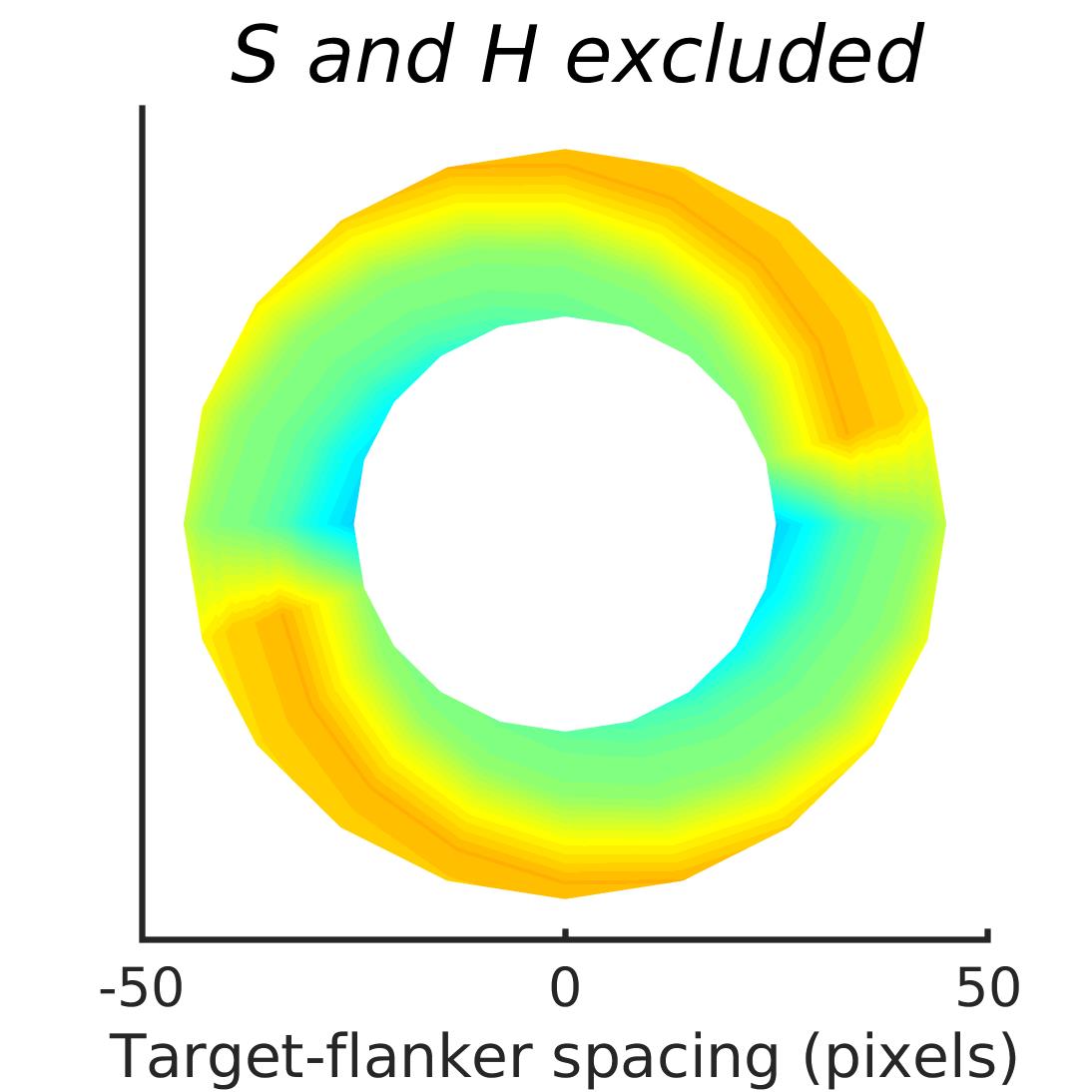 Figure 26
Figure 26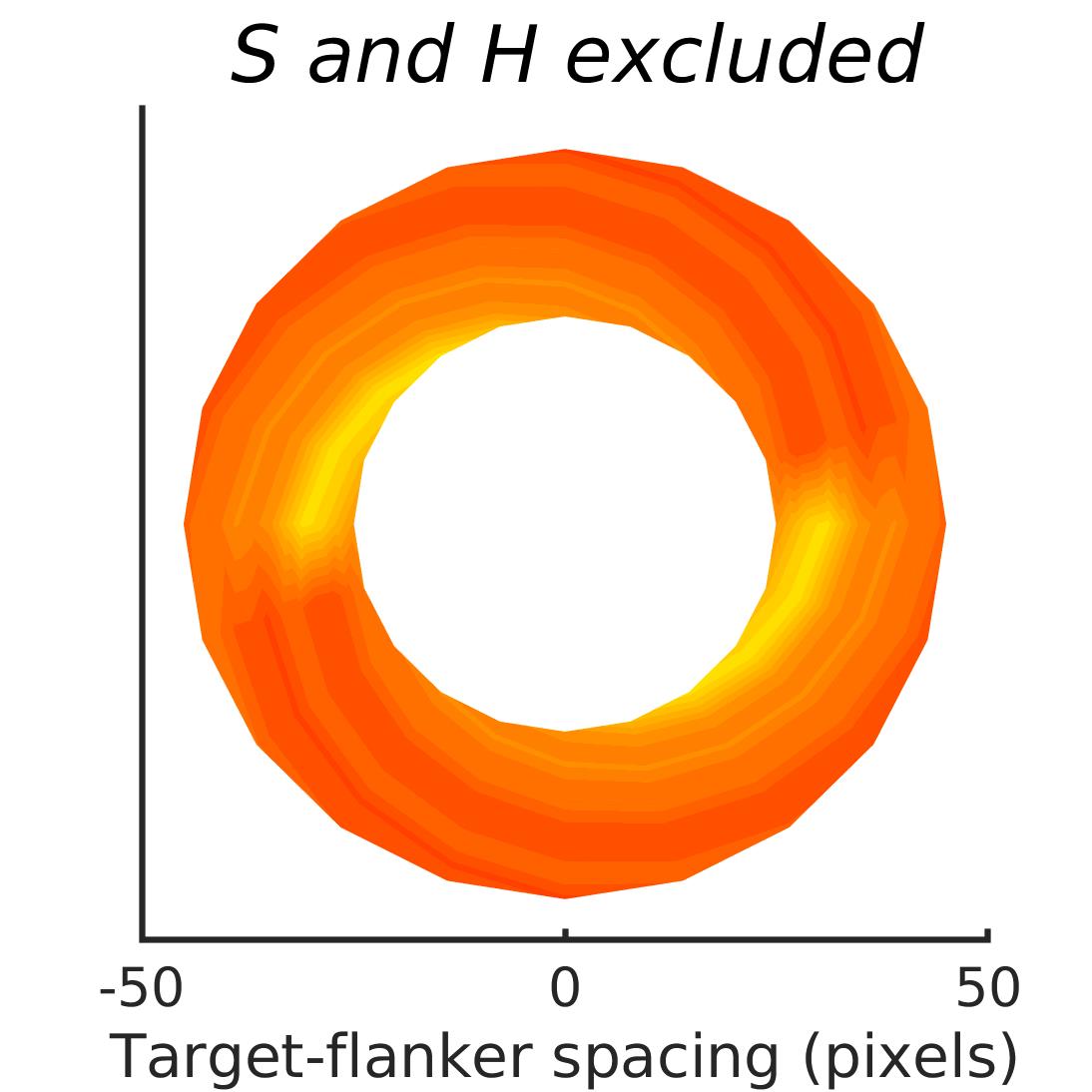 Figure 27
Figure 27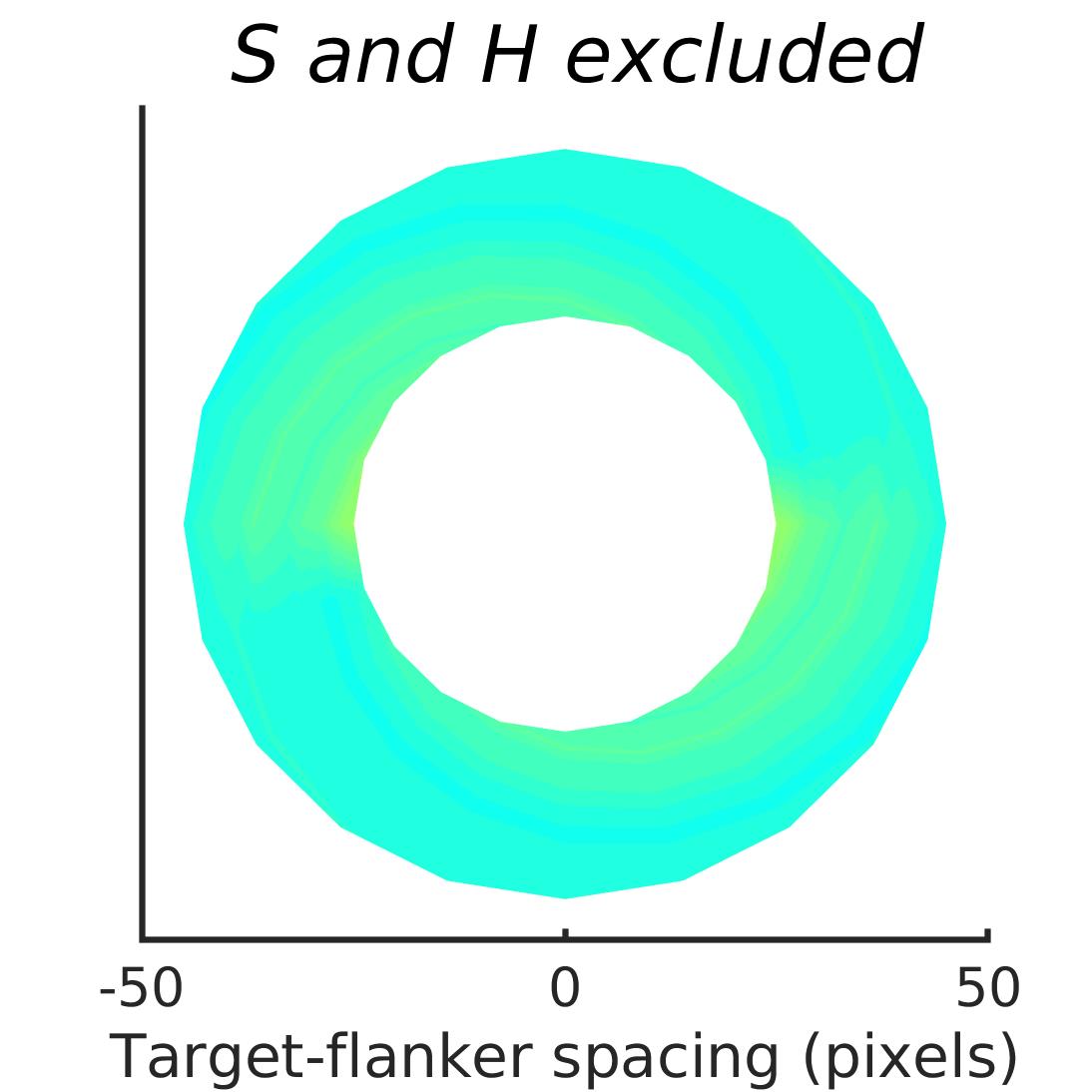 Figure 28
Figure 28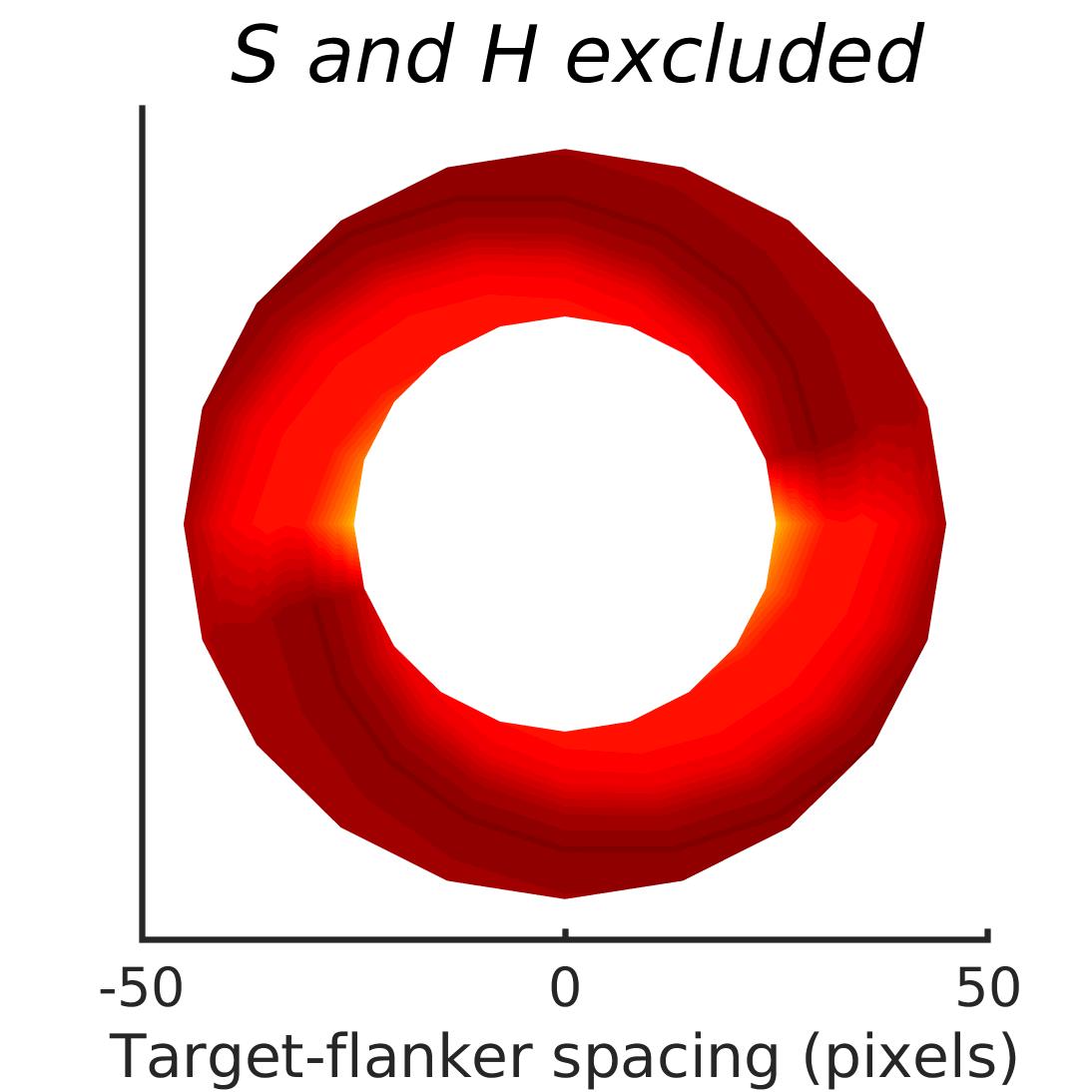 Figure 29
Figure 29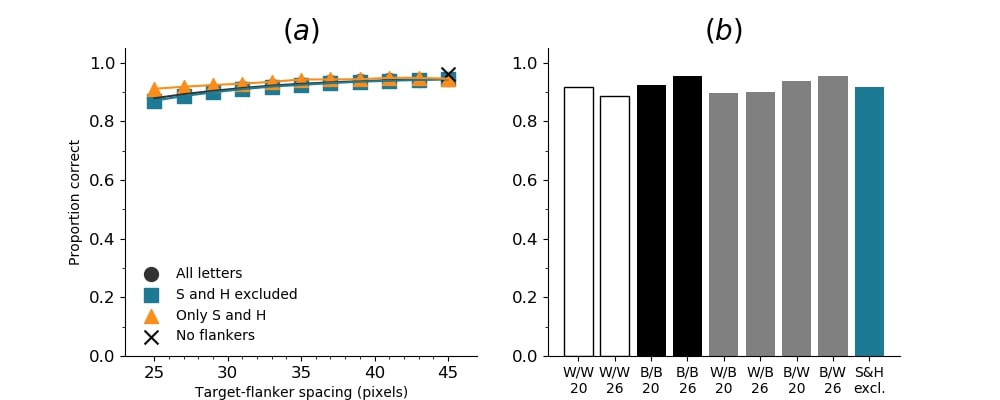 Figure 30
Figure 30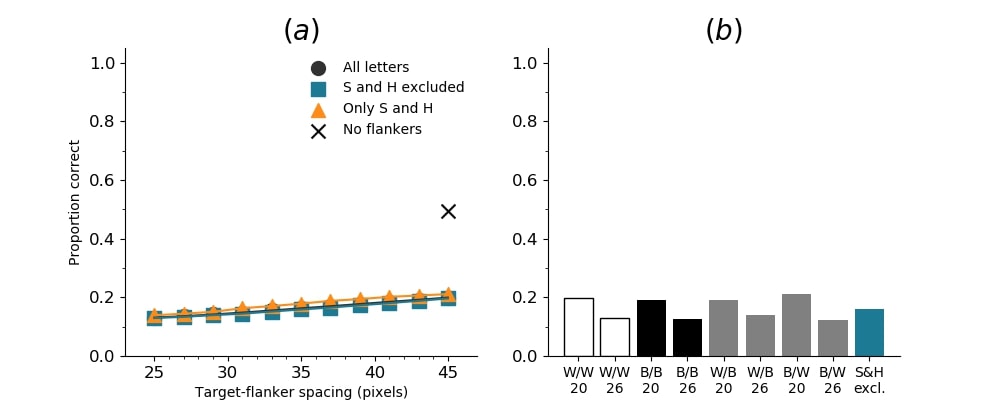 Figure 31
Figure 31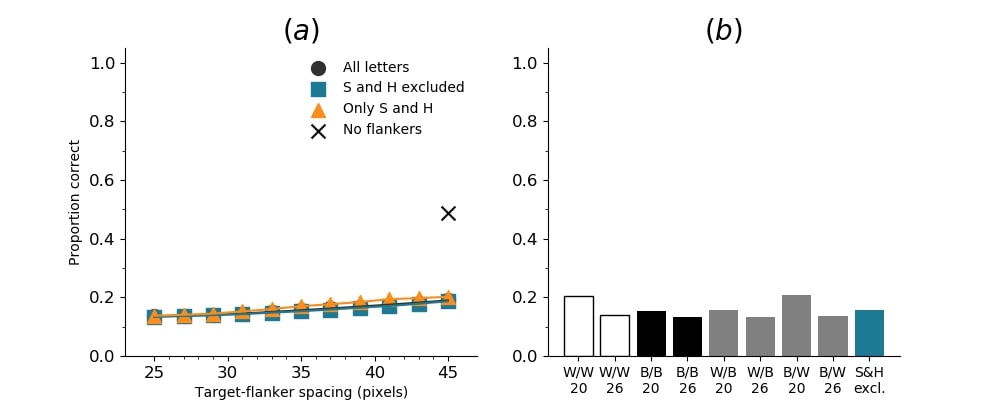 Figure 32
Figure 32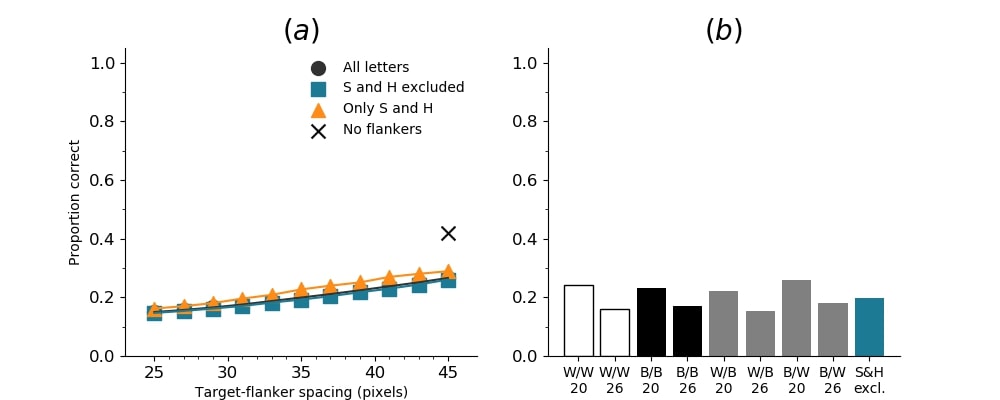 Figure 33
Figure 33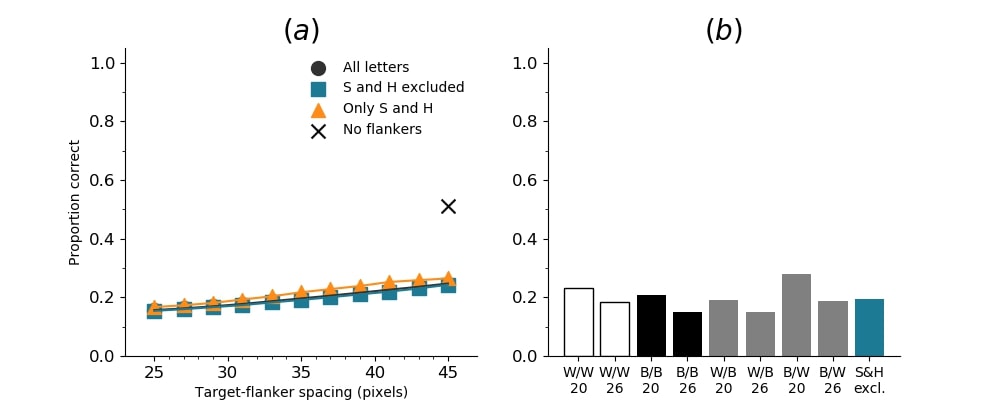 Figure 34
Figure 34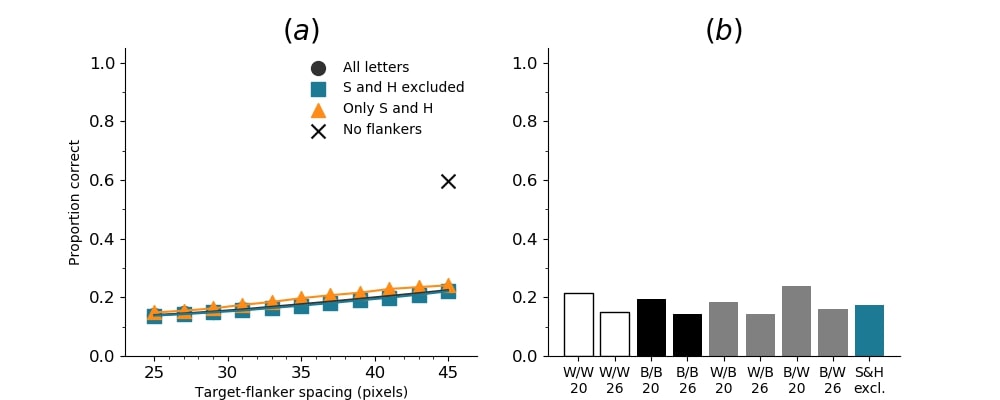 Figure 35
Figure 35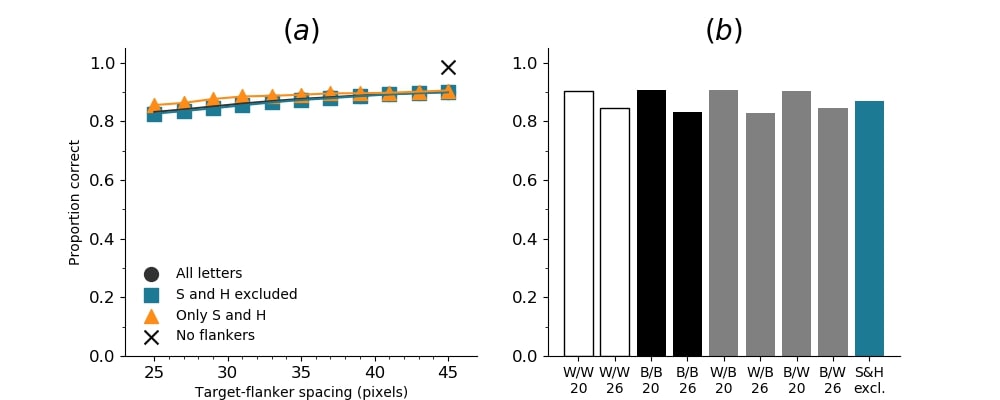 Figure 36
Figure 36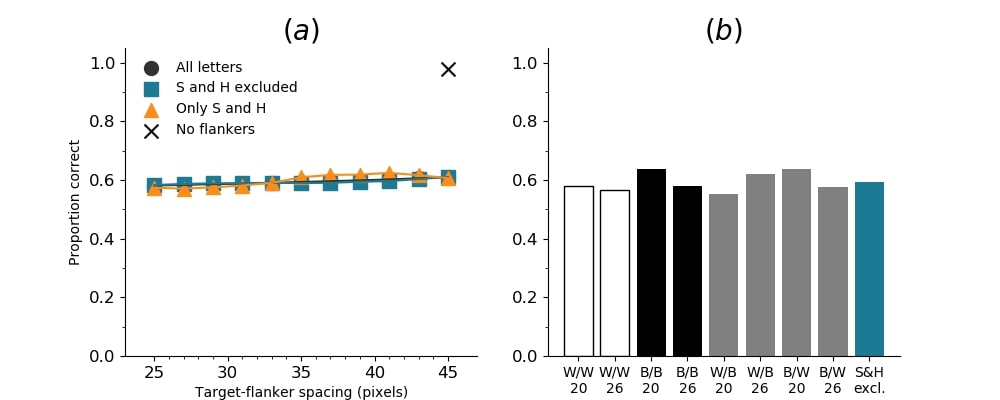 Figure 37
Figure 37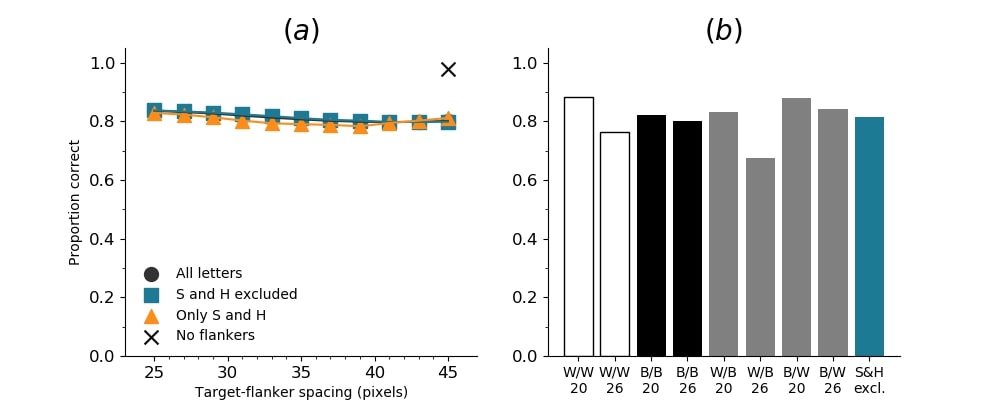 Figure 38
Figure 38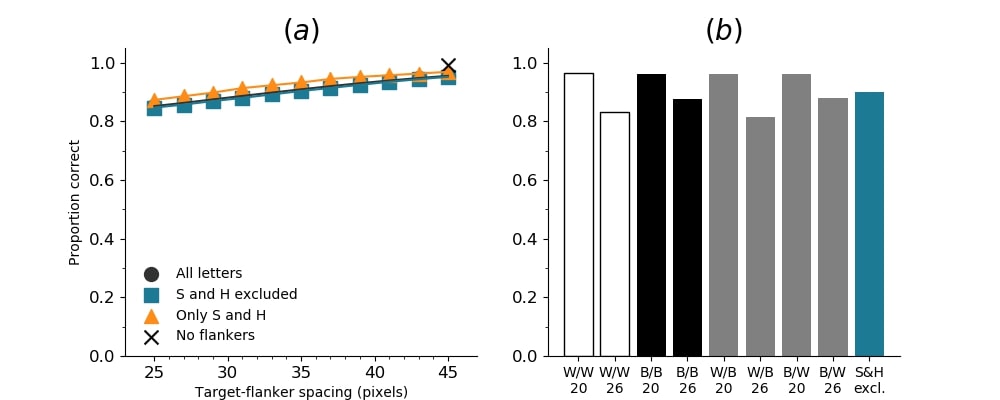 Figure 39
Figure 39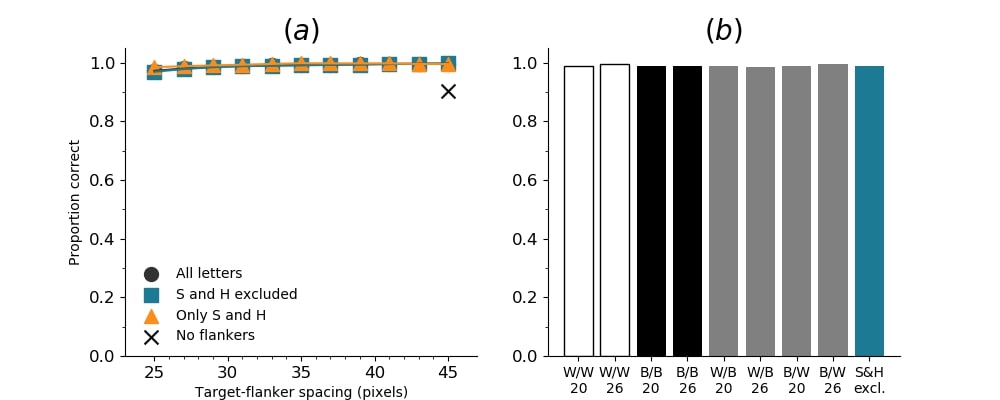 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVisual Attention and Saliency Detection · Face Recognition and Perception · Visual perception and processing mechanisms
\newunicodechar
fifi \newunicodecharffff
Crowding in humans is unlike that in convolutional neural networks
Ben Lonnqvist
Alasdair D. F. Clarke
Ramakrishna Chakravarthi
Business School, University of Aberdeen
Department of Psychology, University of Essex
School of Psychology, University of Aberdeen
Abstract
Object recognition is a primary function of the human visual system. It has recently been claimed that the highly successful ability to recognise objects in a set of emergent computer vision systems—Deep Convolutional Neural Networks (DCNNs)—can form a useful guide to recognition in humans. To test this assertion, we systematically evaluated visual crowding, a dramatic breakdown of recognition in clutter, in DCNNs and compared their performance to extant research in humans. We examined crowding in three architectures of DCNNs with the same methodology as that used among humans. We manipulated multiple stimulus factors including inter-letter spacing, letter colour, size, and flanker location to assess the extent and shape of crowding in DCNNs. We found that crowding followed a predictable pattern across architectures that was different from that in humans. Some characteristic hallmarks of human crowding, such as invariance to size, the effect of target-flanker similarity, and confusions between target and flanker identities, were completely missing, minimised or even reversed. These data show that DCNNs, while proficient in object recognition, likely achieve this competence through a set of mechanisms that are distinct from those in humans. They are not necessarily equivalent models of human or primate object recognition and caution must be exercised when inferring mechanisms derived from their operation.
keywords:
convolutional neural networks , object recognition , crowding
1 Introduction
Recognising objects is a central function of the human visual system and the mechanisms underlying this ability have been extensively studied (DiCarlo et al.,, 2012; Ullman,, 2007). One approach to studying human object recognition is to examine situations where it fails in order to determine the constraints for successful recognition. Visual crowding is one such failure of object recognition in human vision (Bouma,, 1970; Levi,, 2008; Manassi & Whitney,, 2018) where objects that are otherwise recognisable in the visual periphery are rendered unrecognisable when surrounded by similar clutter. Studies on visual crowding have given rise to multi-stage models of object recognition (Pelli et al.,, 2004).
In computer vision, deep convolutional neural networks (DCNNs) have proven to be extremely successful, reaching high accuracy rates in many object recognition and classification tasks (Simonyan & Zisserman,, 2014; Szegedy et al.,, 2014; He et al., 2015a, ; Huang et al.,, 2016). DCCNs are loosely inspired by the human visual system and have been argued to be compelling models of primate object recognition (Cadieu et al.,, 2014; Khaligh-Razavi & Kriegeskorte,, 2014; Güçlü & Gerven,, 2015; Yamins & DiCarlo,, 2016; Bonner & Epstein,, 2017). However, interpreting both the decision process and the relationship between inputs and layers’ outputs is difficult, and many approaches to interpreting and understanding DCNNs have been taken (Zeiler & Fergus,, 2013; Zhang et al.,, 2017). The goal of our paper is not to interpret the low-level details of the DCNN decision process, but rather to investigate if DCNNs suffer from human-like crowding patterns, and if so, whether examining these breakdowns in DCNNs can shed light on the mechanisms of object recognition. If DCNNs are to serve as fruitful models of human neural computations, it is crucial to determine the similarities and differences between human and computer vision models. That is, if DCNNs recognise objects using mechanisms analogous to that in humans, then they too should be subject to the flanker-induced interference observed in humans. It is important to understand the behaviour of crowding in DCNNs not only to help us better understand the human visual system, but also to be able to design more efficient computer vision systems.
The phenomenon of crowding in humans displays certain distinctive features. Here, we highlight the most salient and relevant aspects, which form by no means an exhaustive list of its properties. The most striking observation in crowding is that closer flankers interfere with the identification of a target more than distant flankers; that is, the spacing between targets and their flankers strongly modulates identification performance (Bouma,, 1970; Toet & Levi,, 1992; Pelli et al.,, 2004). Further, for a fixed spacing between a target and its flankers, crowding (interference) is stronger at larger target eccentricities (distance from fixation; Toet & Levi, (1992); Pelli et al., (2004)). Crucially, the flankers interfere with the target over a limited region of space that scales with eccentricity. Under standard circumstances, flankers further than half the target’s eccentricity do not crowd the target. This relationship has been called the Bouma Law (Pelli & Tillman,, 2008). The relationship seems to hold true for a wide range of objects, from simple features such as oriented gratings and colour to complex real-world objects (Berg et al.,, 2007; Wallace & Tjan,, 2011). Additionally, the size of the objects does not seem to affect crowding: small objects crowd each other as much as large objects do (Pelli et al.,, 2004). Hence, it was proposed that the distance between the centres of the objects is more relevant than the distance between edges111Although, there are several caveats to this ‘law’ (Herzog et al.,, 2015; Livne & Sagi,, 2007).. Another interesting characteristic of crowding, alluded to above, is that crowding occurs between similar objects but not dissimilar ones (Kooi et al.,, 1994; Kennedy & Whitaker,, 2010). For example, a black letter is strongly crowded by other black letters, but less so by white letters or filled black circles. Finally, visual crowding displays various asymmetries. The most prominent of these asymmetries is the radial-tangential asymmetry: flankers that are in the radial direction (along the axis connecting the fovea and the target) lead to more interference than flankers that are in the tangential direction (Toet & Levi,, 1992; Petrov & Meleshkevich,, 2011).
Whereas visual crowding has been rigorously tested in humans over the past five decades (Bouma,, 1970; Pelli et al.,, 2004), little is known about crowding in DCNNs. We know of only one previous study, in which Volokitin et al., (2017) argued for the existence of crowding in DCNNs. However, their experiments do not conclusively establish crowding in DCNNs or test their similarity to humans, as their results might be explained by their method to achieve acuity loss, whereby the centres of stimuli are repeatedly sampled with increasingly higher resolution. That is, the models may have exhibited an unnatural preference to process the most central object, which reduced its ability to identify a flanked target. The models used in their research are small-scale and not capable of human-like performance, and might as such not reliably exhibit complex behaviour, such as crowding. Additionally, the methodology used in their research is different from most human crowding research. As such, to establish a conclusive and comparable picture of crowding in DCNNs, more research is needed.
In this paper we take various successful architectures of DCNNs, including ones that have been previously claimed to be comparable to the human visual system (Cichy et al.,, 2016; Güçlü & Gerven,, 2015; Kheradpisheh et al.,, 2016), and investigate the the presence and characteristics of visual crowding using methodology inspired by human crowding research. We will assess the effect of the following on target identification:
The distance between the target and the flankers
- 2.
The position of the target and the flankers
- 3.
The size and contrast polarity of the target and the flankers
- 4.
Different targets and flanker identities
The last two test the effect of similarity. To preview our results, we find that the strength of crowding, defined as flanker-induced reduction in target identification, in DCNNs varies according to the kind of network. However, the results shows a peculiar pattern that appears to be independent of the topology of the network. This pattern is in many ways dissimilar from that in humans. Finally, we discuss how these findings affect our understanding of object recognition in humans and DCNNs, and raise concerns that those employing DCNNs in object recognition tasks should keep in mind.
2 Methods
2.1 Models
We investigated three sets of DCNNs of increasing complexity (and chronology). First, we examined a network that has been widely claimed to possess characteristics similar to that of the human visual system (Cichy et al.,, 2017; Güçlü & Gerven,, 2015; Kheradpisheh et al.,, 2016). That is, the various layers of this network are thought to capture the basic computational processes implemented by the layers of the primate visual system (from V1 to Infero-Temporal Cortex or IT). This network is a variant of the successful AlexNet (Krizhevsky et al.,, 2012) with 5 convolutional layers and 3 fully connected layers, followed by an activation layer; we will call this network SimpleNet throughout. We also investigated the VGG-16 network (Simonyan & Zisserman,, 2014), which is a more successful 16-layer DCNN that uses small (3x3) filters and achieves a deeper network compared to other similar networks of its time. The family of VGG-networks achieved state-of-the-art or near state-of-the-art performance in 2014 image classification and localisation challenges. Finally, we also tested DenseNet-121 (Huang et al.,, 2016), a 121-layer DCNN that takes advantage of two recent advancements in deep learning: batch normalisation (Ioffe & Szegedy,, 2015) and skip connections. The DenseNet-family of networks achieved state-of-the-art performance in many competitive image classification benchmarks while being parameter-efficient. While it is much more successful than the previous two networks, and has a much deeper architecture, it is important to note that the DenseNet-121 has fewer trainable parameters than the VGG-16. We tested these different architectures, and particularly the DenseNet-121, for two reasons. We wanted to test whether networks that are highly successful in recognising objects are in general susceptible to clutter, or if certain networks recognise objects in such a way that they are robust to flanker presence. Second, we wanted to test if networks considered to be similar to the primate visual system also show characteristics of humans, which include crowding. It has been claimed that even deep networks such as DenseNet and ResNet, of which DenseNet is a variant, (He et al., 2015b, ) are comparable to the primate visual system. In fact, recent investigations demonstrate that such networks are superior to older networks such as AlexNet and VGG-16 in terms of correspondence to the primate system (Schrimpf et al.,, 2018). Hence, it is appropriate to test a range of networks to determine if they suffer from crowding.
The DenseNet was of particular interest to us, as it includes skip connections, which are also believed to be present in the human visual cortex (Essen & Maunsell,, 1983). Here, a layer’s feature maps are connected to the filters of all layers that follow it within a given ‘dense block’ (described below). For example, for layers, layer 1’s feature maps are connected to all layers’ inputs up to the th layer. This process is repeated for all layers. DenseNet-121 implements this architecture within ‘dense blocks’, where a set of layers is densely connected (skip connected) to each other, and at the final layer of the block, the feature maps are pooled using max pooling.
In our research, we changed the rectified linear unit (ReLU) activations of the DenseNet and VGG to Leaky ReLU activations to avoid ‘dying neurons’ (neurons which do not allow a gradient to flow through them and end up in a perpetually inactive state) (Xu et al.,, 2015).
We focused our primary attention not on small (either in number of parameters or depth of layers) models, such as those tested by (Volokitin et al.,, 2017), as we wanted to investigate the behaviour of complex networks that have proved to be successful at identifying and categorising real-world images, to understand the patterns of crowding that could emerge from such networks. Additionally, while some have experimented with eccentricity-dependent models (Mnih et al.,, 2014), we limited the scope of our research to better-established DCNN classes.
2.2 Stimuli and Experimental Setup
Two types of stimuli were used in the experiments. The first type was images of places from the Places2 dataset (Zhang et al.,, 2017), which we will refer to as backgrounds. Two classes of backgrounds were used: ruins and neighbourhoods. We used these classes because they are relatively similar in shapes, requiring the networks to construct more general types of filters that might mimic general scene recognition filters, attempting to avoid egregious overfitting of our next type of stimuli.
The second type of stimuli were uniform grey backgrounds with letters fixed in position, which we will call targets. These stimuli are akin to the stimuli used in psychophysical experiments on crowding (Bouma,, 1970; Pelli et al.,, 2004). There were 8 different target letters: {A, B, C, E, G, M, Y, Q}, and each of them was considered a distinct class, making a total of 10 classes of training stimuli (8 letter image classes and 2 background image classes). We chose this set of letters because they are visually dissimilar from each other, which minimises the error rate, particularly when the acuity reduction procedure was applied to images (see Figure 2 (a)), which could have caused confusions between letters. The letters could be of either contrast polarity, near-white and near-black on a grey background, and one of two sizes, 20 and 26 points. All stimuli were 224x224 pixels.
Each network was trained on these 10 classes of images. When trained on letters, a single letter was presented 56 pixels to the left of the centre of the image, that is, midway between the centre and the left border of the stimulus along the horizontal meridian. Similarly, during testing, a target letter was presented at the location it was trained at. It was flanked by one letter or a pair of letters. When two letters were presented, one letter was placed on each side of the target and were identical to each other. The flankers were selected from a set that included all target letters and two additional letters: {S, H}. The pair of flankers were placed diametrically opposite each other on either side of the target. Each pair of flankers was tested at 10 angular locations around the target, each location separated by 18 degrees of rotation, thus covering the entire region around the target. The centre-to-centre distance between a target and each flanker ranged from 25 to 45 pixels in 2-pixel increments. All combinations of target and flanker letters, contrast polarities and sizes were tested. In total, we tested 70,400 combinations of flankers and targets in each experiment. In experiments where we tested the effect of single flankers, the number of tested combinations doubled (20 angular locations instead of 10).
To study crowding in DCCNs, we wished to model human peripheral vision. This is because crowding in humans occurs most noticeably away from the fovea in peripheral vision, where visual acuity and resolution is much lower than in the centre of the visual field. We wanted to provide the DCNNs the same sort of input as the human visual system would receive. Peripheral input is impoverished relative to central input. To model peripheral vision, we used well established relationships in humans regarding acuity and eccentricity (Anstis,, 1974) and reduced acuity logarithmically with distance from the centre of the image in 20 steps, with 1 being full acuity in the centre of the image, and 0.2 being the lowest acuity at the edges of the image. We first took 20 copies of the image and assigned each a value on a logarithmic scale, ranging from 0.2 to 1. We then down-sampled each image by their assigned value, and up-sampled them to their original size using the nearest neighbour algorithm. Finally, we cropped and overlaid the images on top of each other to form a 20-step gradient of acuity reduction (see Figure 2 (a) for an example). We did this to strictly lose information, as crowding in humans is not simply blur (Song et al.,, 2014).
We would like to emphasise that training was done on two kinds of backgrounds and 8 target unflanked letters presented in isolation; flankers were introduced only in the testing stage. Model base performance was evaluated on the set of target letters, and a separate set of validation backgrounds.
2.3 Training
All models for all experiments were trained for 24 hours222This corresponds to roughly 40 epochs on the DenseNet, 80 epochs on the VGG and 200 epochs on the SimpleNet. Although this is an arbitrary time limit, given our configuration these models were run for a sufficient number of epochs to enable good recognition performance, similar to what has been implemented in earlier studies (e.g., Simonyan & Zisserman, (2014). on an NVIDIA Tesla K40c GPU using the Keras library (Chollet et al.,, 2015). The ADAM-optimiser (Kingma & Ba,, 2014) was used with a learning rate of 0.01. Both random initialisation333As a random initialiser, we use the Glorot-uniform initialiser (Glorot & Bengio,, 2010). and ImageNet Large Scale Visual Recognition Competition (ILSVRC) initialisation of weights444ILSVRC initialisation of weights refers to initial weights of the neural network as being set to the weights optimised for the ImageNet Large Scale Visual Recognition Challenge classification task (See Keras documentation; Chollet et al., (2015)). were tested on the DenseNet, random initialisation was tested on the SimpleNet and ILSVRC initialisation on the VGG-16. Random initialisation allowed us to test the network’s characteristics and performance in the absence of influence from outside sources on the system and controlled for the possibility that any results may have been caused by ILSVRC initialisation of weights. Initialising the network with ILSVRC weights allowed us to mimic the types of environments humans are subjected to on a regular basis in addition to testing an already trained network that has been shown to be successful in image categorisation and identification. It is important to note, however, that the ILSVRC weights had been trained without acuity loss, while our training and testing was primarily conducted on stimuli that had been reduced in acuity. When initialising the network with ILSVRC weights, the following procedure for training was taken to allow stable training and avoid ‘gradient nuking’555When using weights optimised for a specific task (e.g. ILSVRC), using them for a different task may cause large gradient updates in the final layers of the network which can cause large changes in the weights of the layers above them. in the upper layers of the network:
Freeze all layers above the last one, initialise learning rate . 2. 2.
When validation loss does not decrease for 2 epochs, open the next layer for training and reduce learning rate by . 3. 3.
When validation loss does not decrease for 2 epochs, open all layers for training and reduce learning rate by . 4. 4.
Training is completed after a total of 24 hours.
3 Results
In our experiments, we did not train the network to recognise targets in the presence of flankers, or letters in the locations where flankers were later placed. Our goal was to present the targets to the models in a specific part of the image, such that it learns to recognise it. We then tested its performance in the presence of flankers. Humans crowding has been attributed to either confusion a fully identified flanker for a target or to combining or pooling the features of both the target and flankers (Strasburger & Malania,, 2013; Hanus & Vul,, 2013). We allowed our models the opportunity to implement either of these processes666Full data-frames of results are available at github.com/benlonnqvist/CNNCrowding..
In Figures 8-11, and Supplementary Figures S12-S17, panel (a) plots accuracy as a function of target-flanker spacing in pixels, collapsed across all stimulus manipulations. In addition, we show unflanked accuracy, which is near-perfect for almost all experiments. Panel (b) plots accuracy for each target-flanker colour combination for both sizes collapsed over all the target-flanker distances. For example, W/B 20 denotes a white target, a black flanker, with letter size 20 points. Additionally, collapsed data when the letters S and H are excluded is shown. Panel (c) plots the shape of crowding—accuracy at each position of the flanker, where the origin of the plot is centred on the target, collapsed over all size and contrast polarity combinations. Accuracy is shown with all flankers, accuracy with the flankers S and H excluded, and accuracy using only the flankers S and H. Separated effects of the the letters S and H are shown as they were not a part of training, and therefore serve as ’novel’ flankers.
In general, letter recognition performance improved with target-flanker distance as expected from human studies, indicating that networks experience at least some form of crowding. However, unlike in humans, this trend was mild, and we also observed peculiar patterns in many of our experiments. We call these peculiar patterns anomalies of crowding, or simply anomalies. An anomaly usually took the form of an unexpected change in performance (e.g. poor accuracy at large target-flanker spacing and better accuracy at short spacing for specific target-flanker configurations). These anomalies were found to be caused primarily by the untrained letters S and H as flankers. However, even after these letters were excluded from analysis, such anomalies persisted. Our findings suggest that only by training and testing a model several times, and by averaging results, can such anomalies be mitigated. Also unlike in humans, the current results showed a strong pattern of crowding along the top-left – bottom-right diagonal in all tests with paired flankers. Interestingly, throughout our experiments no clear pattern of the effect of size or contrast polarity was found. Many models performed better for letter size 20 than for 26, but some exhibited the opposite behaviour. In humans, size has no effect on the strength or extent of crowding, and colour (or similarity) has a strong effect, with different colour flankers causing less crowding than same colour flankers (see Section 1).
3.1 SimpleNet with random initialisation
We trained five independent SimpleNets with unaltered images (no ’acuity loss’) to test the sensitivity of small convolutional networks to different flanker configurations. The primary reason we tested SimpleNet was because of the claimed correspondence between such networks and the primate visual system (Cichy et al.,, 2017; Güçlü & Gerven,, 2015; Kheradpisheh et al.,, 2016). If the two architecture (DCNNs and biological systems) achieve object recognition in comparable ways, then we should see evidence of human-like crowding in SimpleNet. We found that while the networks learned to perform the letter identification task with high accuracy, they suffered greatly from flanker presence. In other words, such networks do suffer from crowding: flankers substantially degrade target identification performance. However, there are noticeable differences between the crowding observed in humans and in the SimpleNets.
Unflanked targets were identified with high accuracy (96.97%), but the presence of a single flanker even at at a large distance from the flanker reduced performance substantially (flanked performance was 35% or lower). In contrast, crowding in humans is quite weak in the presence of a single flanker and is rapidly alleviated with spacing between the target and the flanker (Petrov & Meleshkevich,, 2011). However, for SimpleNet, the overall reduction was dramatic with hardly any improvement with spacing. In fact, extrapolating from the data, the target-flanker distance at which there would be no crowding (where performance is the same as in the unflanked condition) would be 218 pixels, which is approximately the entire width of the image. That is, the model is strongly crowded at almost all distances. In addition, when the flankers presented to the model were untrained (the letters S and H), the pattern of crowding became unpredictable; at certain angular locations, flankers further away caused more crowding than those closer. These are examples of anomalies of crowding, described above. This effect does not occur in humans (Huckauf et al.,, 1999)777However, as mentioned above, we believe that it is possible that such anomalies disappear entirely when a model is trained a large number of times and the results averaged.. These results indicate that DCNNs suffer from crowding in the periphery, that they suffer from crowding up to a much greater distance than humans, and that the effect of target-flanker spacing is weaker than in humans, at least in the range of distances we tested. We attempted to fit psychometric curves (see the Appendix, Figure S13), but the fits were unsuccessful in producing meaningful results, primarily due to the anomalies and a lack of a clear upper asymptote. We also note that all five instantiations of SimpleNet displayed the same pattern of crowding, indicating that these findings were reproducible and not an artefact of the initial settings.
3.2 VGG-16 with ILSVRC initialisation
We also trained a different architecture of network, the VGG-16 (Simonyan & Zisserman,, 2014), to test whether our results are specific to the SimpleNet (and to the DenseNet-121, see below) architecture. We found that while the VGG-16 performed somewhat better in our task (Figure 5), it exhibited the same general patterns and behaviour of crowding as the SimpleNet. This implies that the presence and characteristics of crowding, and by implication, object recognition in DCNNs, is a property of the basic building blocks of DCNNs and not caused by a particular network architecture. Note that in our study VGG-16 was initialised in a completely different way compared to the SimpleNets. Yet, the pattern was the same, with slightly better robustness to flankers888We attempted two runs of this model, but only one converged.. The VGG-16 with ILSVRC initialisation can be considered to be more ’experienced’ with visual stimuli. However, both VGG-16 and our SimpleNet were highly sensitive to the presence of clutter and were insensitive to a large extent to the spacing between the target and the clutter.
3.3 DenseNet-121 with random initialisation
The previous two architectures of models we have tested contained only simple combinations of convolutional, max-pooling, and densely connected layers. To test whether our results are specific to such configurations, or apply more generally to more sophisticated architectures, we tested the DenseNet-121 (Huang et al.,, 2016), a recent architecture that takes advantage of batch normalisation and skip connections. Further, as noted above, DenseNets and ResNest (from which DenseNets are derived) have been argued to have a higher correspondance to the primate visual system than earlier networks such as AlexNet and VGG (Schrimpf et al.,, 2018; NKriegeskorte,, 2017). We trained and tested the DenseNet network extensively under various network and stimulus configurations in order to assess if a highly successful model suffers from crowding and if this crowding is comparable to that in humans, given the claimed correspondence.
Figure 6 shows the results when the network was initialised with random weights and stimuli were degraded to match perceptual input to the human visual system. We found that the DenseNet-121 is much more robust to clutter than the VGG-16 or the SimpleNet. The presence of a single flanker reduces target identification performance, but the drop is not dramatic. Further, increasing the spacing of the flanker from the target ameliorates crowding to the extent that far flankers do not interfere with target identification. The performance of this model is reminiscent of human performance. Interestingly, however, as with the SimpleNet and VGG-16, the strongest interference by a single flanker is not where its acuity is the lowest (the outermost position on the left of the background image along the horizontal meridian), but instead remains on the bottom-diagonal of the target towards the centre of the image. Note that in humans, the strongest interference is observed when the flanker is placed at this outermost location, and not by a flanker closer to the centre of the image (Petrov & Meleshkevich,, 2011).
To determine if the higher interference by a flanker placed along the top-left to bottom-right diagonal and close to the image centre was an artefact of the stimuli used and the training procedure, we trained a new network with the same parameters as before but with the letter stimuli presented on the right side instead of the left. As can be seen in Figure 7, the shape of crowding flips across the vertical axis. That is, it is not the absolute top-left to bottom-right axis that matters, but the presence of a flanker close to the centre of the image, but in the lower visual field that causes the greatest disruption. To replicate these findings, we trained a new model using identical configuration (Figure S18). The general characteristics of crowding in this model remained the same, but it appears that this instantiation of the model (see Figure S18) is more robust to clutter and exhibits minimally reduced performance with increased target-flanker spacing. The reason for this discrepancy is unclear to us. Importantly, however, it is clear from these models and models trained with unaltered images that the pattern of crowding remains the same even with large changes in network and stimulus characteristics, even if the magnitude changes. This magnitude difference can be partially attributed to the image manipulations (’acuity loss’), but not the pattern of results.
3.4 DenseNet-121 with random and ILSVRC initialisations with paired flankers
Psychophysical experiments in humans on crowding are often performed with a pair of flankers, one on either side of the target, rather than a single one (e.g., Bouma, (1970), Freeman et al., (2012)). Hence, we also tested the DenseNet-121 with paired flankers. In these experiments we trained the DenseNet-121 initialised with random and ILSVRC weights, separately. Results are shown in Figures 8 and S12, respectively. We found that the bottom-right flanker that dominates crowding in single-flanker experiments causes the general pattern of crowding to replicate across the horizontal axis (along the top-left to bottom-right axis). It is interesting to note that the model is crowded more by paired flankers at all distances than by single flankers, and does not reach near-unflanked accuracy even at the furthest target-flanker distance. In humans, paired flankers are more effective in interfering with performance than single flankers, and have a larger range of interference. That is, they are more effective even at larger distances. DenseNet-121 appears to mirror that characteristic. Nevertheless, in humans, crowding is eliminated, under similar circumstances, if the distance between the target and the flankers is greater than half the target eccentricity (the distance between the centre of the image and the target), as codified in the ’Bouma Law’ (Pelli & Tillman,, 2008). This is equivalent to a spacing of about 29 pixels in our setup. That is, performance should be the same as in the unflanked condition if flankers are separated from the target by about 29 pixels. This is not the case with the DenseNet model.
3.5 Effect of acuity loss manipulation
As the DenseNet-121 was more robust to flanker interference, we trained and tested the DenseNet-121 with the same hyperparameters on images that had not been reduced in acuity (unaltered images). We found that the general shape of crowding remained the same in all tests but one (pair flankers with ILSVRC initialisation: Figure S15), and barring that experiment the effect of flankers was dramatically reduced. This suggests that the image manipulation cannot explain the pattern of our results, apart from its magnitude. These results also point to the proposal that the pattern of results observed here is inherent to DCNNs.
In the special case of ILSVRC initialisation with a pair of flankers, the performance was much lower than expected (roughly 40%), whereas for most other experiments with acuity loss this ranged from 60-85%. This strange behaviour may have been caused by differences in convergence of the network. In addition to poor performance in the test, the axis of crowding flipped compared to all other experiments. These results closely mimic the effects seen in the SimpleNet tests; robustness to clutter of the DenseNet is higher, and regardless of whether the acuity loss procedure is used, the general characteristics of crowding remain.
We found that while using unaltered images in training and testing can lead to some unpredictable results, such as massive performance drops or improvements with flankers, the general shapes of crowding tended to stay the same. We also found that in the case of experiments trained and tested with unaltered image, anomalies of crowding, described in Section 3.4, largely disappeared when the flankers S and H were excluded from analysis.
Finally, we tested the randomly initialised DenseNet that was trained with acuity loss to see how behaviour changes when the network gains access to full acuity without additional training. Results are shown in Figure 10.
We found that there was no large difference in the general characteristics of crowding regardless of whether the network had reduced acuity during training or during testing. Acuity affected crowding primarily in magnitude, but not in shape or general characteristics, such as the effect of distance on crowding, or the effect of similarity (contrast polarity and size) between the target and flankers.
3.6 Effect of the amount of useful information in a local region
Because our models suffered from crowding to a greater degree in the lower half of the images than in the upper half, we tested whether flipping our background images vertically in training would also flip crowding vertically. It is possible that natural images have diagnostic information in the lower visual field and the network is more sensitive to clutter in that part of the visual field. Results are shown in Figure 11. We found that a relatively large portion of crowding does shift to the upper half of the image, practically equalising the amount of crowding on both halves of the image (59.66% accuracy on the top-half, 59.42% accuracy on the bottom-half). This suggests that the amount of useful information in local regions of a stimulus plays a contributing role in crowding in DCNNs. This effect is the opposite of what is observed in humans. Humans have greater attentional resolution and lower crowding in the lower half of the visual field (Intriligator & Cavanagh,, 2001). Our DCNN models do not. We hypothesise that the networks developed to have greater preference for regions with a higher density of useful information for classification and hence flankers placed in such locations caused more crowding. In other words, the data used to train the networks likely contributes to this effect.
It is interesting to note that while in the randomly initialised single-flanker model with upright background images the models exhibited a greater degree of crowding in the lower portion of the image (89.47% accuracy in the lower half, 95.31% in the upper half), this effect was not entirely reversed when the background images were vertically flipped; the accuracy between the two halves of the stimuli only equalises. We are unable to explain this phenomenon.
3.7 Radial-tangential asymmetry
We examined if the networks demonstrate the radial-tangential asymmetry, where flankers along the radial direction (flankers along the axis connecting the target to the centre of the image) are more influential than tangential flankers. We plotted the accuracy of identification when it was surrounded by the nearest letters along these two axes (Figure 12). We found that crowding is asymmetric in the expected direction—radial flankers crowd more than tangential flankers do, like in humans (Toet & Levi,, 1992; Petrov & Meleshkevich,, 2011). We also find that if the overall accuracy is higher, crowding is more asymmetric than if it is lower.
We also note, as described above, that the networks demonstrate an in-out asymmetry, where there is a difference in effect of the ’inner’ flanker, or flanker closest to the image centre and ’outer’ flanker, or the farthest flanker, The inner flanker appears to be more powerful in disrupting target identification than the outer one. However, the effect is the opposite of what is observed among humans, where the outer flanker is more influential than the inner one.
3.8 Effect of size and contrast polarity
Among humans, contrast polarity, and other cues of similarity, strongly modulates target identification. Objects similar to each other crowd more than dissimilar objects (Kooi et al.,, 1994; Kennedy & Whitaker,, 2010). On the other hand, crowding is not sensitive to object size (Pelli et al.,, 2004). The strength and extent of crowding is comparable for objects of different sizes. Here, we examined if we observe the same pattern of results. In fact, we found no clear effects of size or contrast polarity. Performance was not higher for different polarity letters than it was for same polarity letters (for example, see Figure S3 and Figure S5). However, they showed differences in performance for the two letter sizes. Most networks identified smaller letters than larger letters, however, the opposite pattern was noticeable in other networks.
Some networks, such as the DenseNet-121 with random initialisation (Figure 6 were poor at detecting black targets, but were not modulated by target-flanker similarity. Other networks, such as the DenseNet-121 with random initialisation and with the targets and flankers on the right side (Figure S18) had clear difficulty distinguishing letters of a specific size and colour combination compared to the others. In general, we found no discernible patterns that applied to all models (even within a specific architecture).
3.9 Confusion between targets and flankers
Finally, we analysed the DenseNets’ and VGG’s reported output to examine whether targets were confused with flankers more often than they were confused with other letters. We found that for all single-flanker results there is little difference between the model reporting another target ‘at random’ and the model reporting the flanker letter. On error trials, the flanker is reported 0.0125 percentage points more often than any other single letter, on average.
This finding implies that in our experiments, the DCNNs were highly sensitive to the position of the target and that they were not prone to confuse the flanker as the target. This also rules out the hypothesis that flanker substitution contributes to crowding in DCNNs when DCNNs are trained in a simplistic manner, like it does in humans (Freeman et al.,, 2012; Hanus & Vul,, 2013).
4 Discussion
We investigated crowding in DCNNs and found that they follow a predictable pattern regardless of network topology, size or colour of flankers, or whether images have been reduced in acuity. Overall, we do find that flankers reduce target identification performance, demonstrating that all the networks we tested suffer from crowding. On the other hand, importantly, we found that object recognition in humans has distinctly different characteristics from those exhibited by DCNNs. The pattern of crowding found follows a combination of several factors:
Robustness to flanker interference: We found that the SimpleNet and VGG-16 models were much more susceptible to flanker interference than the DenseNet-121. This suggests that some characteristics unique to the DenseNet (e.g., skip connections, batch normalization, or simply the prsence of more layers) causes the model to be more robust to clutter.
- 2.
Distance of the flanker from the target: In almost all experiments recognition performance for a target surrounded by known flankers strictly follows a positive relationship with distance between them. This suggests that crowding is, at least in part, caused by local pooling of information. This relationship is mild, however, and is in two models reversed (Figures S18 and S15).
- 3.
Flanker substitution versus pooling: Flankers near the image centre (in the lower visual field) cause more crowding than ’outer’ ones, for a given spacing. These letters tend to be less subject to image degradation in our acuity loss manipulation. We suspect that this asymmetry in crowding is therefore due to local pooling, as suggested by Volokitin et al., (2017). In our experiments we also found that target-flanker confusion does not contribute much to crowding, further supporting the hypothesis that local pooling causes crowding in DCNNs under simplistic training regiments. This reason may partly explain why there is more crowding with more foveal flankers than peripheral flankers, unlike in humans (Petrov & Meleshkevich,, 2011; Petrov et al.,, 2007). A caveat to keep in mind is that we also found that acuity loss does not drastically change the patterns of crowding, but instead its magnitude.
- 4.
Amount of useful information in stimuli: The bottom-corner position of the flanker towards the centre of the image caused most crowding in our experiments. In humans, the bottom-half of the visual field has higher resolution and lower crowding (Intriligator & Cavanagh,, 2001). The images of ruins and neighbourhoods we used in training and testing have a sizeable portion of their top-half contain “useless” information, possibly contributing to this effect. Additionally, when the backgrounds were vertically flipped, this bias towards the bottom-half of the image was neutralised. Further support for this argument is given by the fact that in our experiments, the ILSVRC-initialised models were subject to a higher degree of crowding. We suspect that this effect is primarily caused by the training data.
- 5.
Unrecognised clutter: When the networks are subject to flankers they do not recognise, these flankers cause effects that are unpredictable in terms of classification of the target in individual models. Often these stimuli cause a reduction in accuracy in positions and distances which do not follow a clear pattern. However, these effects may be mitigated by training and testing a model several times, and averaging results.
We also observed other dissimilarities in machine and human crowding. In many of our experiments, we found differences in the degree of crowding with differently-sized letters, violating the Bouma Law (Pelli & Tillman,, 2008). Additionally, black letters are not crowded more by other black letters than they are by white letters, and vice versa. In humans, this effect is clear (Kooi et al.,, 1994; Kennedy & Whitaker,, 2010). Despite these differences, crowding in DCNNs and humans share some similarities. For example, the degree of crowding in both DCNNs and humans decreases with increased spacing between a target and its flankers (Bouma,, 1970; Toet & Levi,, 1992; Pelli et al.,, 2004). The radial-tangential asymmetry also shares a resemblance with human crowding asymmetry, with radial flankers crowding the target more (Toet & Levi,, 1992; Petrov & Meleshkevich,, 2011).
We conclude that crowding is present in DCNNs regardless of whether a network is trained on unaltered images or acuity reduced input, and that its magnitude can be reduced by employing a more sophisticated architecture that does not rely only on convolutional, max pooling and densely connected layers. Based on the current evidence, we conjecture that local pooling is the primary source of crowding in DCNNs, and that the position in which crowding occurs is caused by the data the network has been subject to in training. As such, we suggest those who train networks to use data augmentation (Perez & Wang,, 2017) in order to minimise the effect of crowding.
While DCNNs are loosely based on human models of object recognition, and have indeed been considered comparable, they exhibit patterns of behaviour that are substantially different from those in humans. At first glance, both demonstrate flanker induced interference. However, a closer look shows a myriad of differences. We suggest that these differences in behaviour of object recognition between humans and DCNNs are caused by one or several of many neural differences. For example, in the human visual cortex there are many different types of neurons which serve different purposes. The presented DCNNs also do not use recurrent connections—in the human visual cortex, there many recurrent connections, and these recurrent connections contribute enormously to visual processing (Bullier et al.,, 2001). The way in which the human visual system and DCNNs are built are fundamentally different, and our experiments show that they exhibit fundamentally different behaviour in object recognition tasks.
Acknowledgements
We would like to acknowledge the use of a Tesla K40 GPU card that has been donated to Dr M. S. Baptista by Nvidia. We would also like to thank Dr Micha Elsner for helpful discussions.
Supplementary Materials
Supplementary figures
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Anstis, (1974) Anstis, S. M. (1974). Letter: A chart demonstrating variations in acuity with retinal position. Vision Research , 14(7), 589–592.
- 2Berg et al., (2007) Berg, R. v. d., Roerdink, J. B. T. M., & Cornelissen, F. W. (2007). On the generality of crowding: Visual crowding in size, saturation, and hue compared to orientation. Journal of Vision , 7(2), 14–14.
- 3Bonner & Epstein, (2017) Bonner, M. F. & Epstein, R. A. (2017). Coding of navigational affordances in the human visual system. Proceedings of the National Academy of Sciences , (pp. 201618228).
- 4Bouma, (1970) Bouma, H. (1970). Interaction Effects in Parafoveal Letter Recognition. Nature , 226(5241), 177–178.
- 5Bullier et al., (2001) Bullier, J., Hupé, J. M., James, A. C., & Girard, P. (2001). The role of feedback connections in shaping the responses of visual cortical neurons. Progress in Brain Research , 134, 193–204.
- 6Cadieu et al., (2014) Cadieu, C. F., Hong, H., Yamins, D. L. K., Pinto, N., Ardila, D., Solomon, E. A., Majaj, N. J., & Di Carlo, J. J. (2014). Deep Neural Networks Rival the Representation of Primate IT Cortex for Core Visual Object Recognition. PLOS Computational Biology , 10(12), e 1003963.
- 7Chollet et al., (2015) Chollet, F. et al. (2015). Keras. https://keras.io .
- 8Cichy et al., (2017) Cichy, R. M., Khosla, A., Pantazis, D., & Oliva, A. (2017). Dynamics of scene representations in the human brain revealed by magnetoencephalography and deep neural networks. Neuro Image , 153, 346–358.