A surrogate model for estimating extreme tower loads on wind turbines based on random forest proximities
Mikkel Slot Nielsen, Victor Rohde

TL;DR
This paper introduces a random forest-based surrogate model to estimate extreme tower loads on wind turbines from operational signals, aiding design and safety assessments without relying on traditional regression methods.
Contribution
The paper presents a novel surrogate modeling approach using random forest proximities to estimate extreme loads, improving adaptability in high-dimensional, sparse data environments.
Findings
Effective estimation of tower loads from operational data
Model outperforms traditional regression-based surrogates
Applicable to real-world wind turbine data
Abstract
In the present paper we present a surrogate model, which can be used to estimate extreme tower loads on a wind turbine from a number of signals and a suitable simulation tool. Due to the requirements of the International Electrotechnical Commission (IEC) Standard 61400-1, assessing extreme tower loads on wind turbines constitutes a key component of the design phase. The proposed model imputes tower loads by matching observed signals with simulated quantities using proximities induced by random forests. In this way the algorithm's adaptability to high-dimensional and sparse settings is exploited without using regression-based surrogate loads (which may display misleading probabilistic characteristics). Finally, the model is applied to estimate tower loads on an operating wind turbine from data on its operational statistics.
Click any figure to enlarge with its caption.
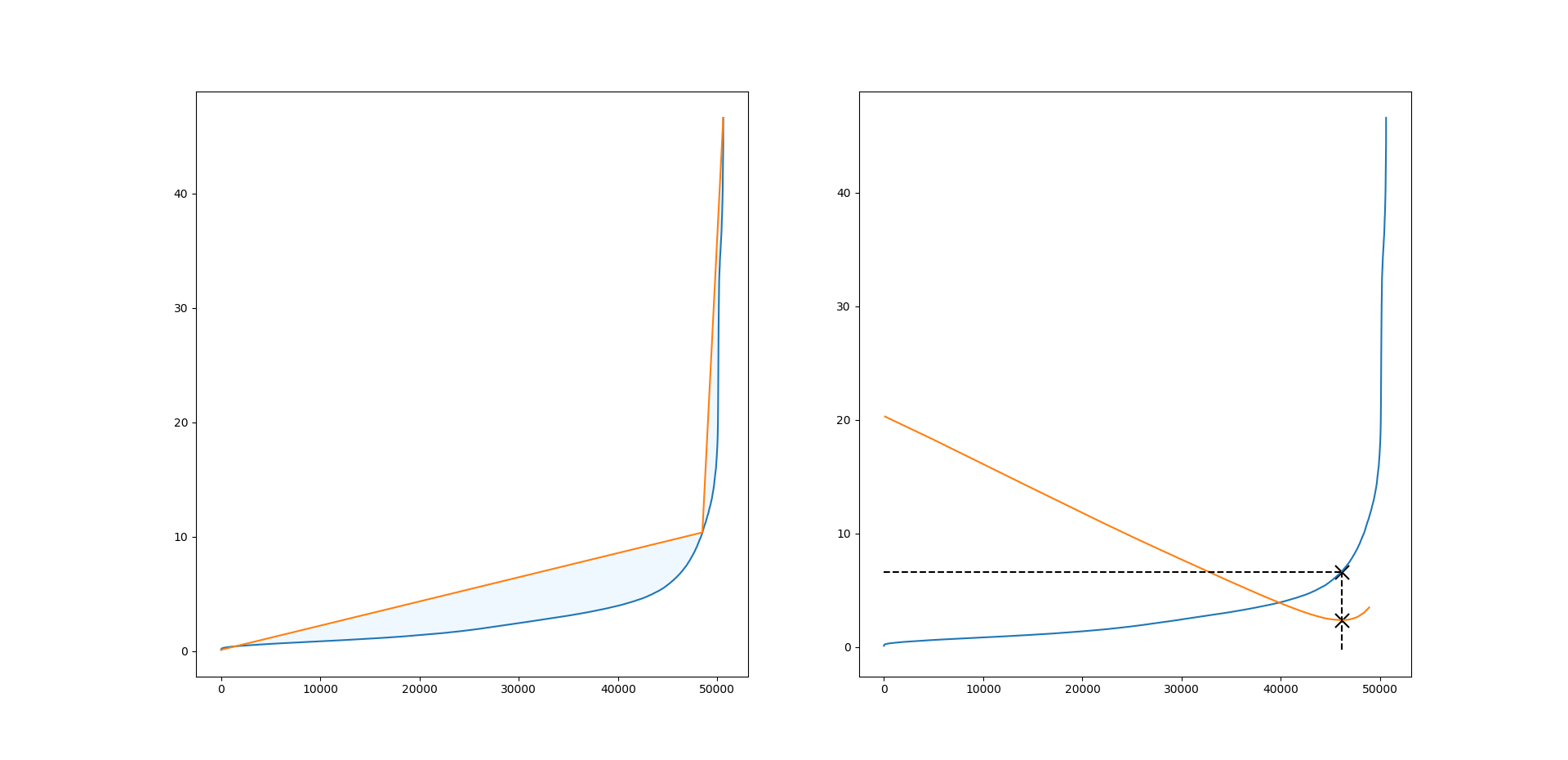 Figure 1
Figure 1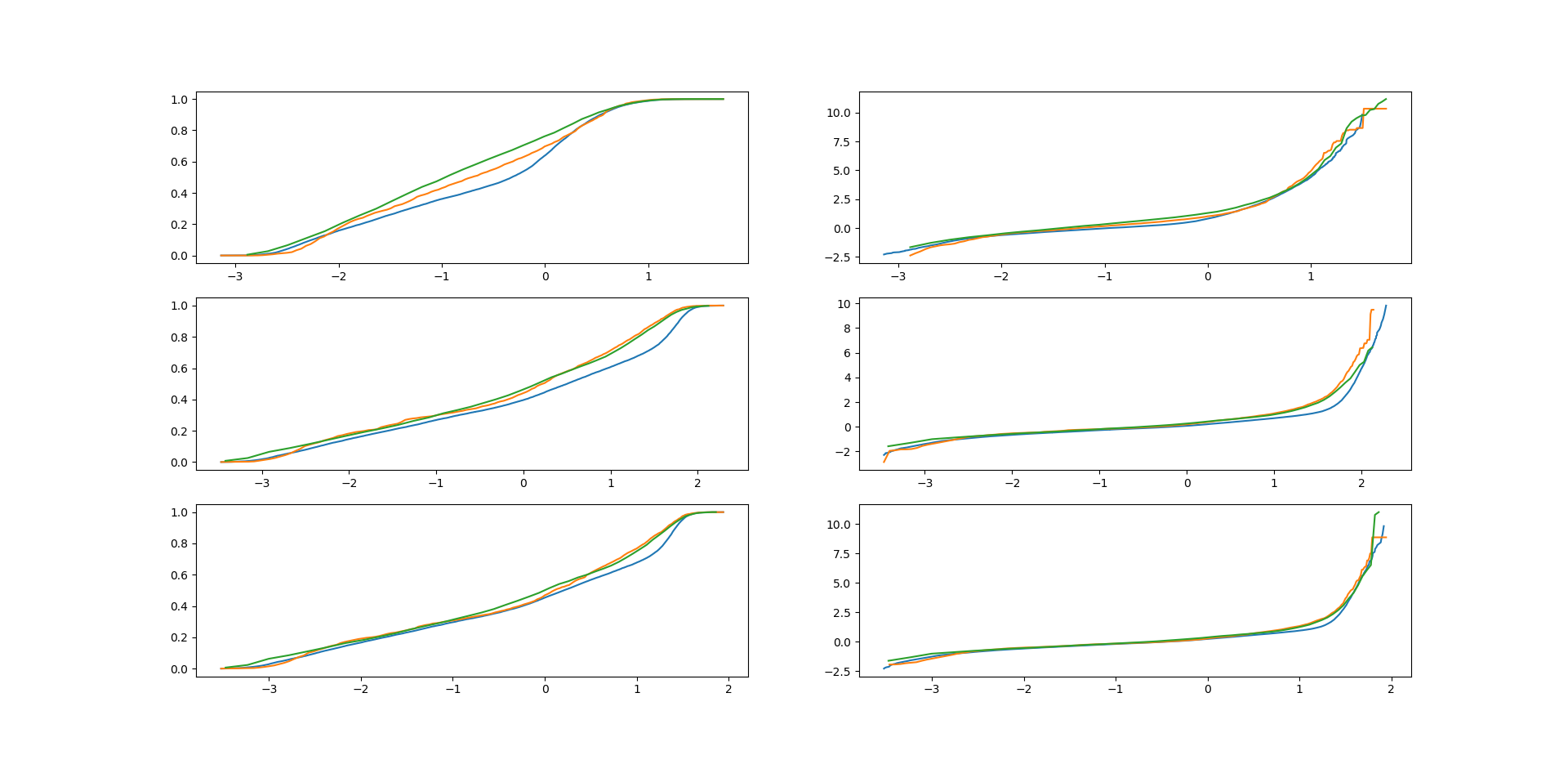 Figure 2
Figure 2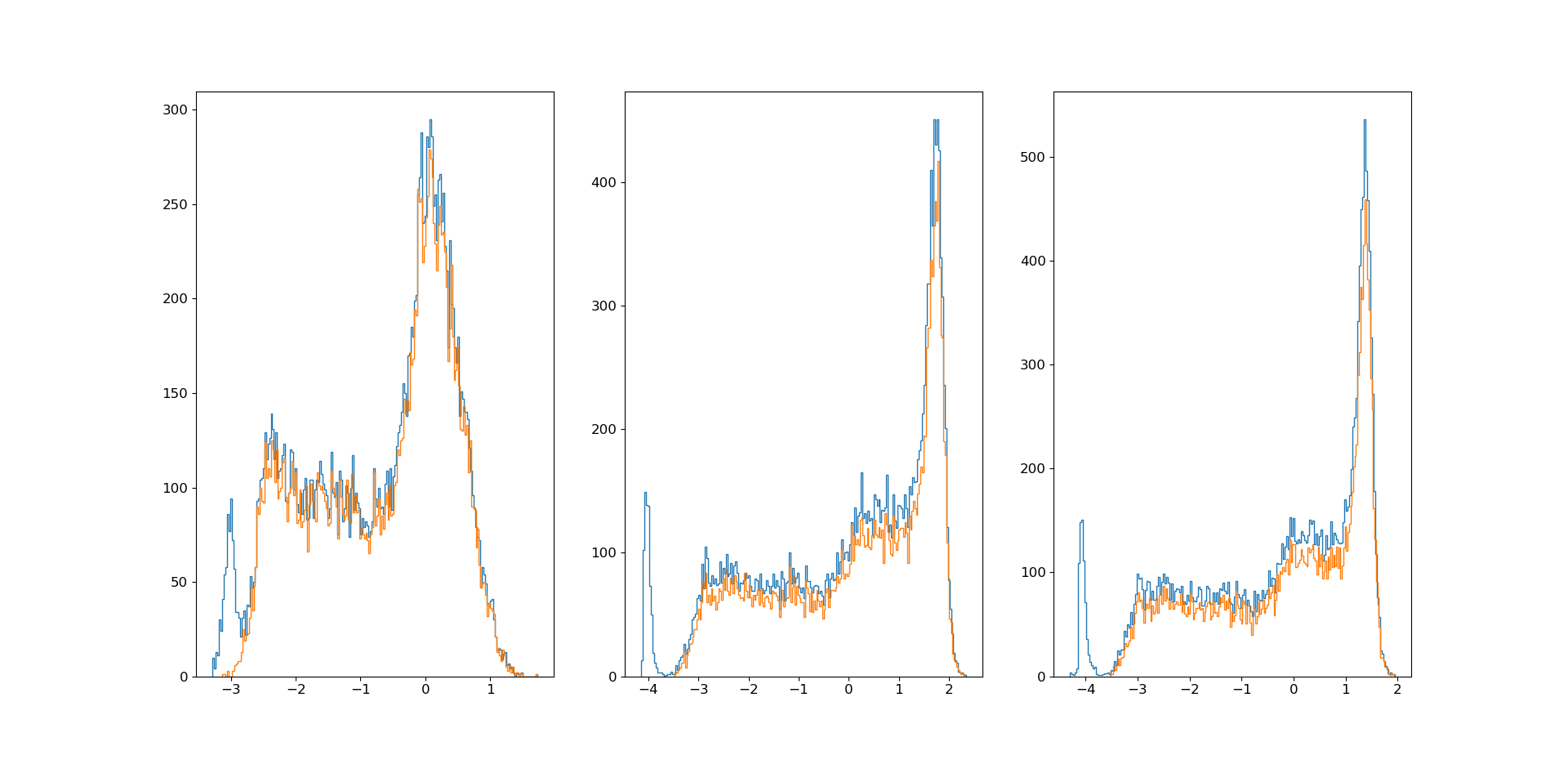 Figure 3
Figure 3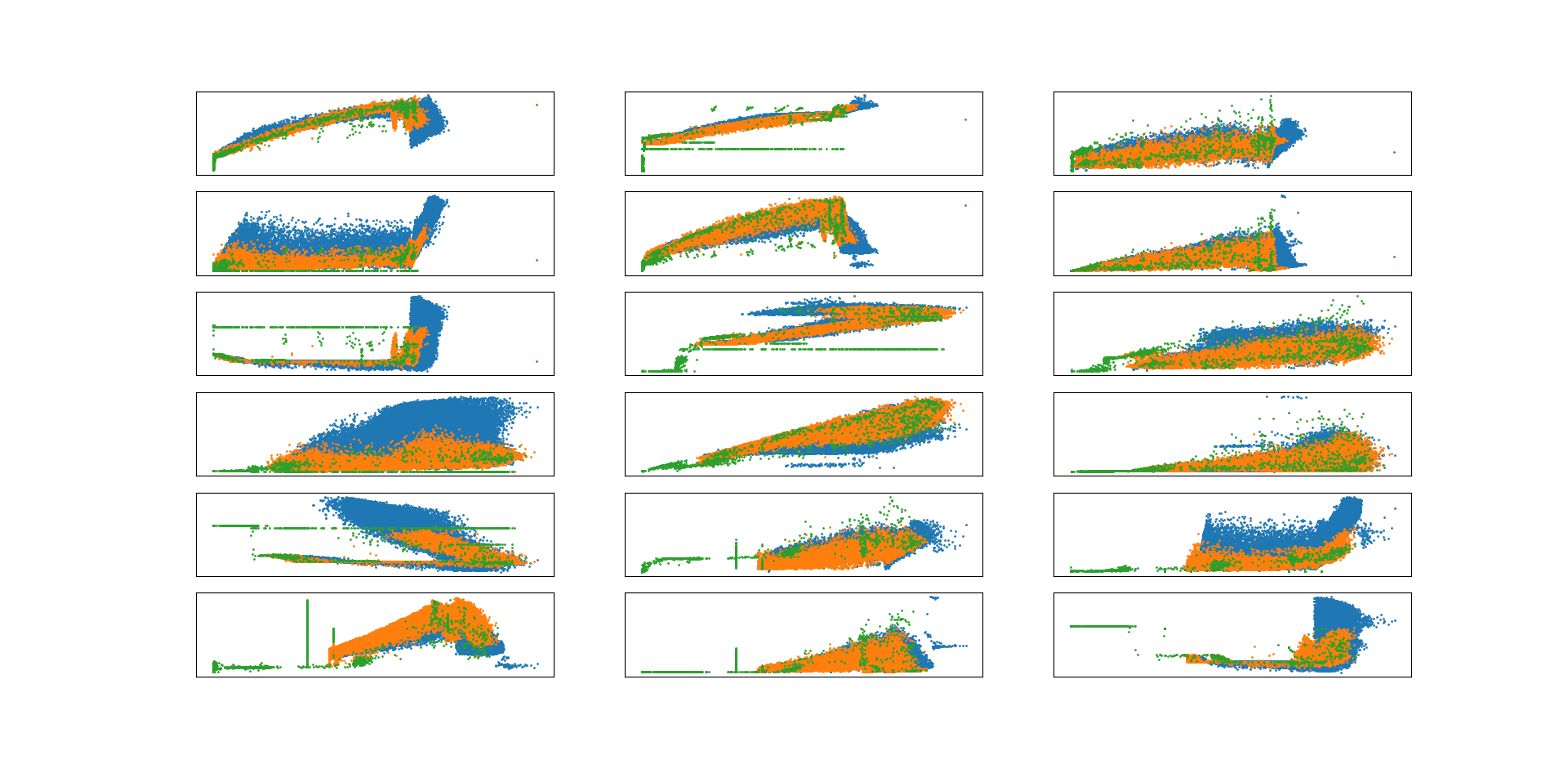 Figure 4
Figure 4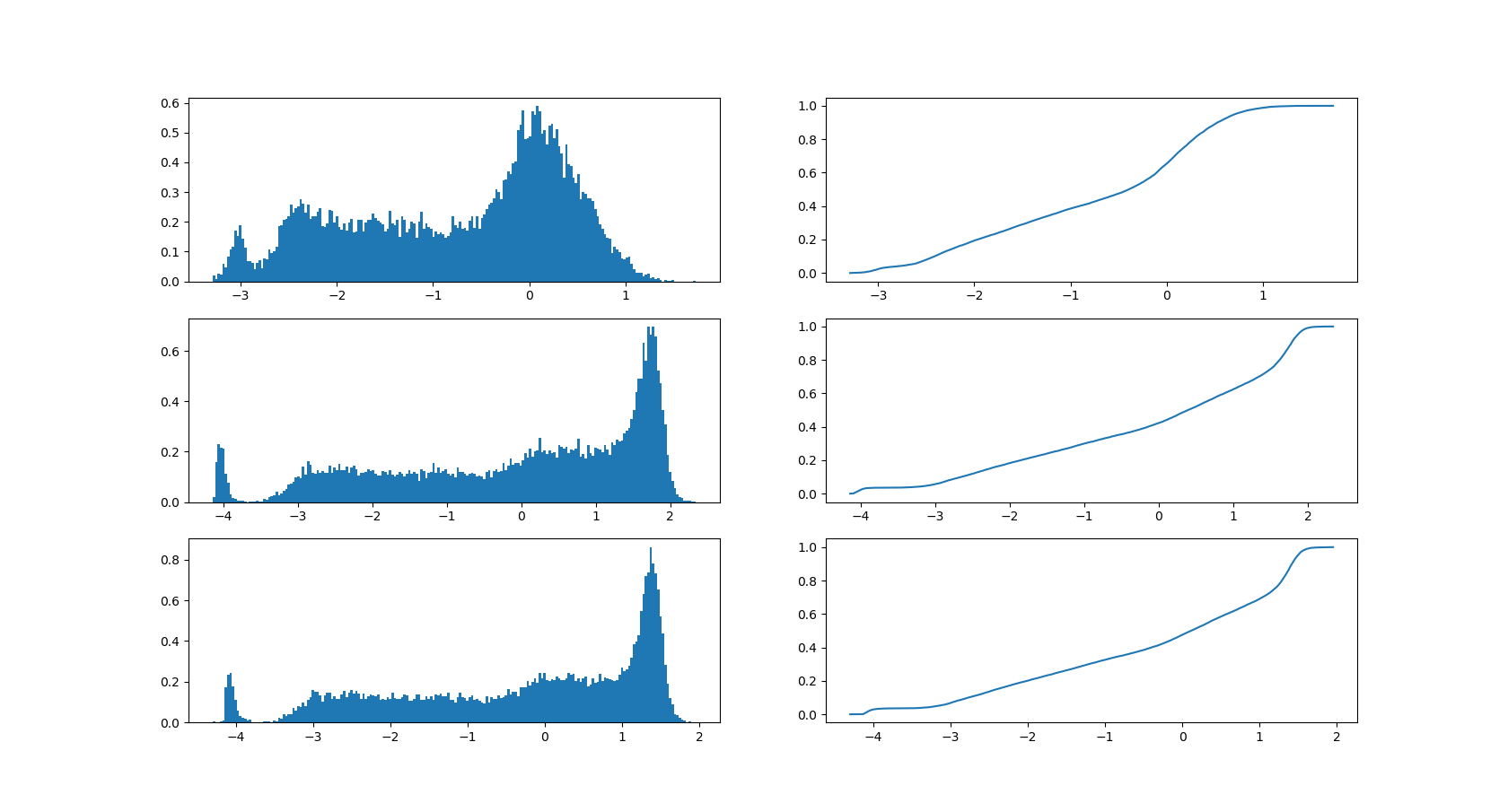 Figure 5
Figure 5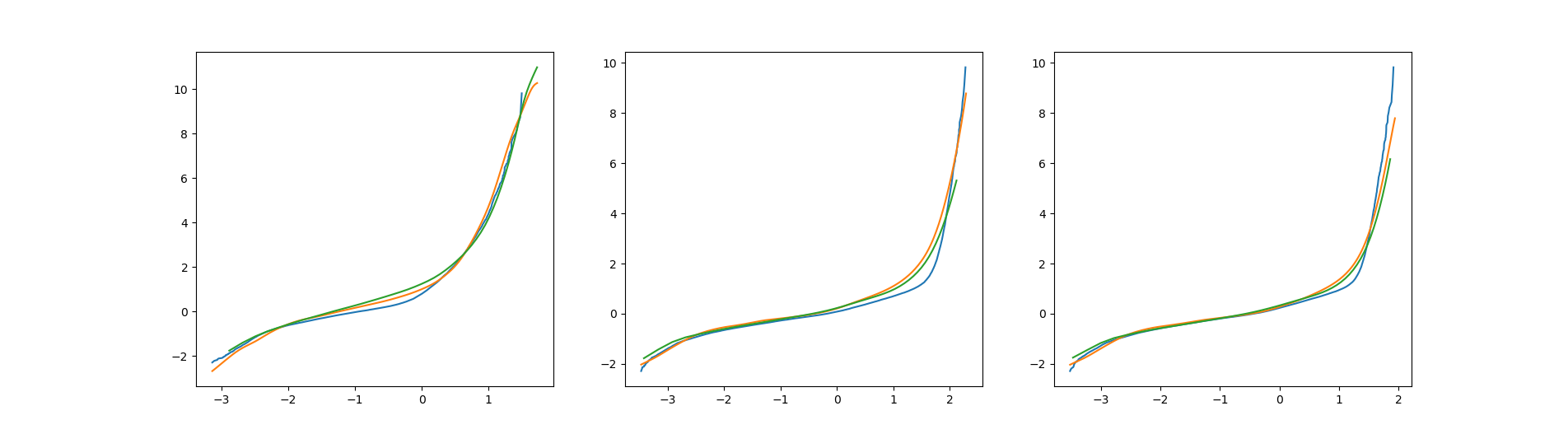 Figure 6
Figure 6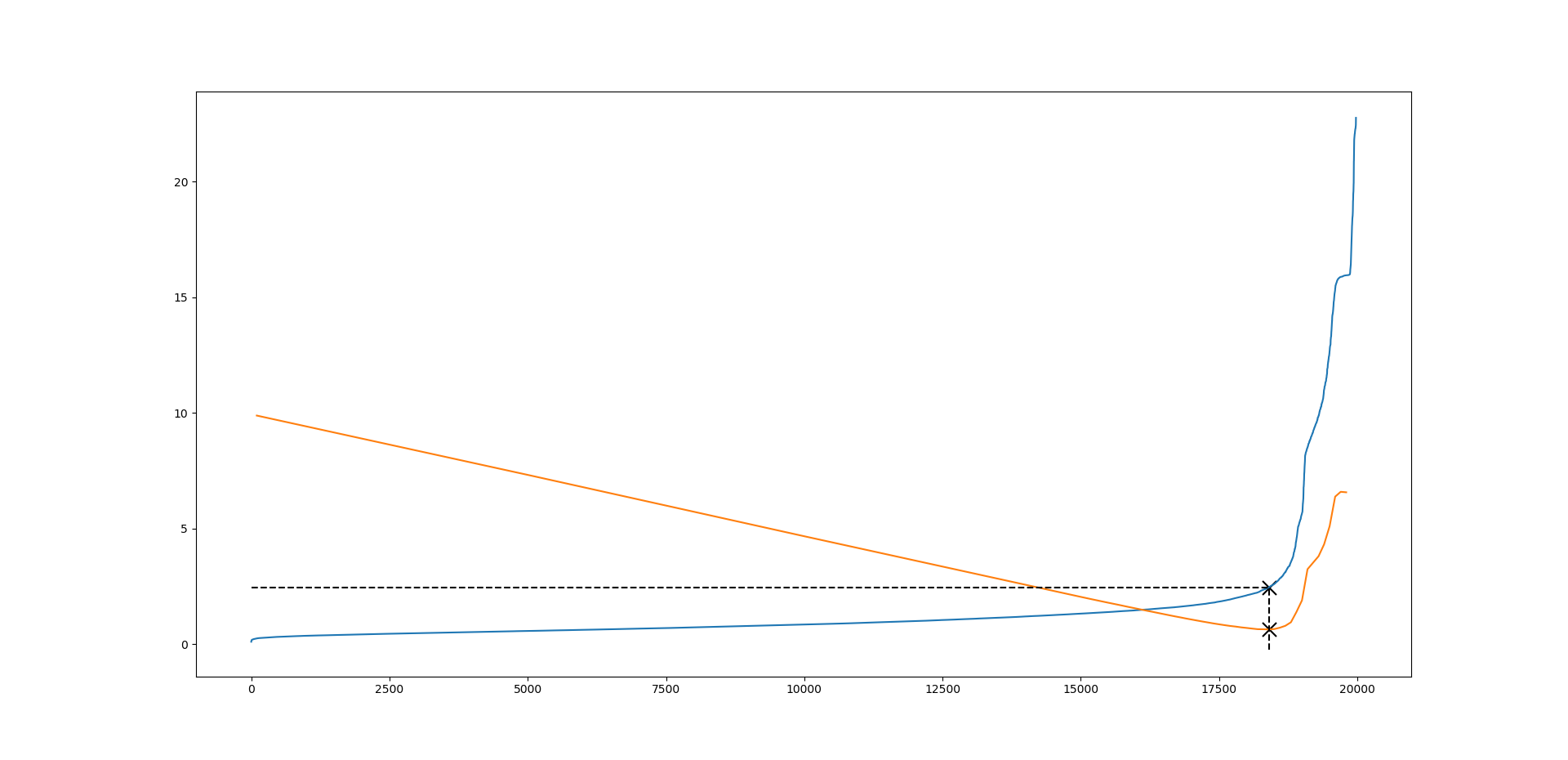 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
A surrogate model for estimating extreme tower loads on wind turbines based on random forest proximities
Mikkel Slot Nielsen***Department of Statistics, Columbia University, USA. E-mail: [email protected].
Victor Rohde†††Department of Mathematics, Aarhus University, Denmark.
( )
Abstract
In the present paper we present a surrogate model, which can be used to estimate extreme tower loads on a wind turbine from a number of signals and a suitable simulation tool. Due to the requirements of the International Electrotechnical Commission (IEC) Standard 61400-1, assessing extreme tower loads on wind turbines constitutes a key component of the design phase. The proposed model imputes tower loads by matching observed signals with simulated quantities using proximities induced by random forests. In this way the algorithm’s adaptability to high-dimensional and sparse settings is exploited without using regression-based surrogate loads (which may display misleading probabilistic characteristics). Finally, the model is applied to estimate tower loads on an operating wind turbine from data on its operational statistics.
*MSC 2010 subject classifications: 62P30; 65C20; 91B68
Keywords: extreme load estimation; matching; random forests; surrogate models; wind turbines*
1 Introduction
The aim of this paper is to construct a surrogate model for tower loads on wind turbines based on simulation. By using operational statistics (signals) from a turbine the surrogate model should be able to estimate load distributions and, in particular, extreme loads such as the 50-year return load. Surrogate models are widely employed in engineering science and can, among other things, be used to avoid computational costs caused by additional simulations and to impute missing outputs in measurements. The applications of surrogate models in the context of wind turbines are many, e.g., they are used to characterize energy production and lifetime equivalent fatigue loads ([13]), design and optimize turbine blades ([12]), and design the rotor ([18]). Estimation of extreme loads is also a well-studied area, particularly due to the IEC standards (see, e.g., [15, 19]). However, the possibility of building extreme load estimates on top of surrogate loads has, to the best of our knowledge, not been investigated.
The model must be able to (i) impute surrogate loads which approximately have the true distribution conditional on the signals, and (ii) handle a high-dimensional feature space (many signals). Since it is important to extract other distributional properties than simply the mean of the conditional load, standard prediction-based imputation will not work ([17]). Under the assumption of strong ignorability (in particular, the load distribution is the same for both measurements and simulations conditional on the signals), matching observations with simulations based on signals is a reasonable way to meet (i). However, due to the curse of dimensionality, classical matching techniques, such as -nearest neighbors, will only work well if the dimension of the feature space is small ([2]).
In this paper we propose imputing surrogate loads using random forest proximities. Based on data from an operating wind turbine with several operational statistics and a simulation tool we demonstrate that, by matching signals with simulated values, the random forest proximities can successfully impute tower loads. Moreover, these imputations are precise enough to allow for subsequent estimation of extreme events. Random forest algorithms have become an extremely popular tool in the analysis of high-dimensional data and, by some authors, viewed as the most successful general-purpose algorithm in modern times ([9]). A random forest is an ensemble of decision trees; given a tree-building mechanism, a large number of decision trees is constructed and, finally, trees are aggregated to form the forest. Arguably, the most popular forest is the one introduced by Breiman [4] where each tree is constructed in the following way:
- fnum@enumiitem i(i)
Draw a bootstrap sample (with replacement) from the original data. 2. fnum@enumiitem ii(ii)
Form a finer and finer partition of the feature space by recursively performing splits perpendicular to the axes. Each split is performed by maximizing impurity decrease over a randomly chosen subset of signals of fixed cardinality (see Section 2 and [5] for details). 3. fnum@enumiitem iii(iii)
The partitioning procedure continues as long as each leaf contains a prespecified, and often small, number of observations.
The reason that this algorithm succeeds in large dimensions is that splits are placed in a greedy manner: the split is placed to decrease the impurity within each node as much as possible. As a consequence of this, most splits will be placed along important signals, disregarding directions in the feature space which do not contribute to explaining (the mean of) the output. While the forest is often used for prediction by either voting or averaging across trees, it also induces its own measure of proximity: given two points in the feature space, the proximity is the proportion of trees, where they fall into the same leaf ([3]). Using this measure it is possible to perform reasonable matching of signals even when the ambient dimension of the space is large. Clustering and matching of signals using random forest proximities have been successfully applied in several studies (see, e.g., [14, 20, 21]).
The data set consists of measurements from a wind turbine under normal operation over a period from February 17 to September 30, 2017. Each measurement contains the state of 40 signals corresponding to four types of 10-minute operational statistics measured by 10 different sensors on the turbine. Specifically, the signals are the 10-minute maximum, minimum, mean and standard deviation of blade pitch angles (BLdA, BLdB and BLdC), electrical power (EP), generator speed (GenSp), pitch rates (PR1, PR2 and PR3), and tower top downwind and lateral acceleration (TT_dw and TT_lat). The interest will be in assessing the distribution of the 10-minute maximum downwind bending moment of the tower top, middle and base. Since this particular turbine is part of a measurement campaign, measurements of these loads are in fact available, and they will be used to assess the performance of the model. The model is based on simulated values of both signals and loads.
Section 2 gives a mathematical introduction to random forests and their associated proximity measure. In relation to this, it is discussed how different components affect the proximity measure and, in particular, how to construct the forest so that its induced proximity suits the particular problem in question. Compared to the rest of the paper, this section is rather technical and, hence, the practitioner may turn directly to the application, which is treated in the subsequent sections. Section 3 concerns some initial preparations of the data, such as detecting outliers and checking that simulated values of signals roughly overlap measured values, and Section 4 presents the estimated load distributions and compares them to the true (empirical) distributions. Finally, Section 5 concludes the paper and points out interesting directions for future research.
2 Random forests, the induced proximity measure and matching
In the following we introduce the random forests as well as their proximity measure and discuss their specifications. For details on their theoretical foundations beyond this, see e.g. [3, 4] or [7, Chapter 15] and references therein.
Let be a vector of signals and be the output variable satisfying . Suppose that we have observations available as training data. A (fully grown) decision tree can be associated to a partition of where each contains exactly one of the data points . It is obtained recursively by starting from and then, given that is a node containing at least two data points, a split direction and position are chosen and is defined as , but where is replaced by and . Given a vector of signals , the decision tree returns either the average (regression) or the majority vote (classification) of the observations which fall into the same node in the partition as . Throughout the paper, we will follow the lines of [4] for CART decision trees and choose the feasible split that maximizes the empirical impurity decrease, i.e., is the maximizer of
[TABLE]
over and . Here is a generic node, is the local average, and is a random subset of of fixed cardinality defining the set of feasible split directions in . In particular, the CART trees are built in a greedy manner: splits are placed along directions which contribute the most to explaining the variation of . The degree of greediness can be controlled by .
A random forest (of size ) is simply a collection of decision trees,
[TABLE]
All decision trees are assumed to be grown by the same set of rules, so that their diversity stems from an injected exogenous randomness only. More precisely, one assumes that where are i.i.d. copies of some random variable . The variable could include decisions concerning split direction, position and node, resampling schemes, choice of split among a set of candidates, etc. For Breiman’s original algorithm outlined in Section 1, will include the bootstrap step as well as the random selection of signals performed in each node prior to a split. The proximity of two set of signals with respect to is given by the frequency of trees in the forest where they share the same leaf:
[TABLE]
While (2.2) is the measure implemented in practice, the choice of is set by the modeler and only restricted by computational capabilities, so it is common practice to use the approximation for the sake of interpretation. In words, is the probability that two points fall into the same leaf of a tree grown by using the randomization scheme given the data . While the proximity measure is difficult to work with from a theoretical point of view for many types of forests ([3]), the intuition is clear:
- fnum@enumiiitem i(i)
If trees are built in a greedy manner, most splits are placed along important signals, so can be large even though the two points and are far from each other in Euclidean distance as long as they mainly differ along redundant directions of the feature space. 2. fnum@enumiiitem ii(ii)
If trees are built on many randomly placed splits, is likely to be large only if and are close to each other along all directions of the feature space.
The proximity-based match associated to a vector of signals is the output among the training data where the input has the largest proximity when paired with , i.e., where . The forest should be built in such a way that the distribution of approximately coincides with conditional distribution of given . In the application below we will have measurements of operational statistics operational from a wind turbine and will be the simulations. The corresponding proximity based matches (the surrogate loads) are then used to estimate the CDF of the loads and, by extrapolation, extreme loads. For these results to be reliable it is important that the conditional distribution of given is the same for both simulations and measurements.
We will follow the lines of Breiman’s random forest and use (fully grown) CART trees in the application below, but to reduce the computational costs of implementing the algorithm we skip the bootstrap step. In particular, this means that consists solely of the random selection of signals in each node and that the effects of iiii and iiiii must be balanced by the choice of . On one hand, to be useful in a high-dimensional setting, should be large enough to ensure that important signals can be chosen most of the time. On the other hand, the CART splitting criterion (2.1) is particularly suited for matching conditional means and, thus, it may treat signals which only impact higher order moments of (e.g., its variance) as being redundant. Since we will be interested in obtaining an output which has the same distribution (and not only the same mean) of given , this suggests choosing small enough to ensure that, eventually, splits will be placed along any direction. While can be used as a tuning parameter by the modeler, we will use the default value (cf. [3]) which seems to deliver good performance.
3 Validating the simulation environment
For the simulation environment to work it is necessary that the observed signals could as well have been simulated, i.e., the simulations overlap the measurements. To be a bit more precise, if is the vector of signals and describes whether we draw a measurement () or not (), then we must have that
[TABLE]
This assumption is part of the strong ignorability assumption introduced by Rosenbaum and Rubin [16] in relation to estimating heterogeneous treatment effects.
To accommodate (3.1) we initially detect and exclude signals which, to a great extent, can separate measurements from simulations. These are detected by first obtaining an estimate of the marginal propensity score by running a logistic regression and, next, computing the average of across all measured values of . If is close to 0, signal can almost separate the two environments and should be excluded from the analysis. In Figure 1 we plot for the 40 signals. We see that the value is practically 0 for three signals (TT_dw:mean, TT_dw:min and TT_lat:mean), and five more signals (PR1:std, PR2:std, PR3:std, TT_dw:max and TT_dw:std) have values around 0.1. It is the modeler’s task to set an appropriate threshold; we choose it to be 0.15 and thereby exclude eight signals. To visualize the difference in the marginal distribution of simulations and measurements for the 32 included signals we provide box plots in Figure 2 representing their 0.05, 0.25, 0.50, 0.75 and 0.95 quantiles. Although the masses are concentrated in different regions for some signals, it seems that, overall, simulations overlap measurements on the marginal level.
On the other hand, in Figure 3 we have plotted the excluded signals against the tower top downwind load to illustrate the mismatch between measured and simulated values of those. Specifically, these plots show that the set of measurements is separated from the set of simulations for the three most critical signals, while it is near (and, in some regions, crossing) the boundary for the remaining five excluded signals. Another important observation is that many of the measurements of the excluded signals seem to be almost constant forming strange-looking vertical lines in the two-dimensional plots. Therefore, to a large extent, we suspect the mismatch to be caused by logging errors on these sensors, which supports the decision of discarding them from the subsequent analysis.
On top of this exclusion we identify and exclude measurements which are outliers relative to the simulations. Outlier detection methods have received a lot of attention over decades and, according to Hodge and Austin [8], they generally fall into one of three classes: unsupervised clustering (pinpoints most remote points to be considered as potential outliers), supervised classification (based on both normal and abnormal training data, an observation is classified either as an outlier or not) and semi-supervised detection (based on normal training data, a boundary defining the set of normal observations is formed). We will be using the so-called isolation forest for outlier detection, which belongs to the first class. An isolation forest consists of trees built by splitting along random directions and positions until the simulations are isolated, or until the tree has reached a certain depth. The degree of anomaly for a given measured signal with respect to a tree is inversely related to the number of edges that traverses before it reaches the leaf, and the isolation forest is an average across trees. The intuition behind the isolation forest is that outliers should be easy to isolate. The motivation for choosing this algorithm is, at least, three-fold: (i) it tends to work well in high-dimensional and sparse settings, (ii) it is computationally feasible with a linear time complexity, and (iii) it has shown favorable performance relative to other state-of-the-art methods (e.g., -nearest neighbor based methods). For details about the isolation forest and general outlier detection methods, see [10, 11] and [1, 6, 8, 22], respectively.
By evaluating the isolation forest on each measurement we obtain an anomaly ranking which is used to exclude a certain proportion of the most suspicious measurements. We choose and check the performance of the algorithm through a visual inspection of the two-dimensional projections of the signals. In Figure 4 we have plotted four of these projections. Generally, the algorithm seems to identify most measurements which are not surrounded by simulations in the two-dimensional spaces, i.e., the majority of gray points are surrounded by black points. This statement can be further supported by plotting the simulations on top of measurements (and not only the other way around as in Figure 4). In the following we will discard the outliers without addressing further how to handle these. However, one should observe that many of the observations, which are labeled as outliers, seem to form straight lines in Figure 4. This indicates the presence of logging errors for one or more of the sensors and, thus, should be handled as a missing data problem.
4 Estimating tower loads
After having removed the eight signals in Section 3, which separate measurements from simulations, and discarded the worst outliers in the measurements detected by the isolation forest, we can now impute tower loads by using the random forest proximity measure and the corresponding matching procedure explained in Section 2. In particular, we use the proximity measure induced by Breiman’s random forest built on 500 fully grown decision trees, and we skip the bootstrap step in the tree-growing procedure. Figure 5 shows the empirical CDF based on actual loads and the surrogate CDF based on imputed loads as well as the transform of the CDFs. This transform is natural to consider since loads reflect 10-minute maxima and, thus, the corresponding load distribution should, under suitable conditions, be close to a distribution of GEV type (cf. the Fisher–Tippett–Gnedenko theorem). Indeed, the right tail of the transform of a GEV distribution is either strictly convex (Weibull), strictly concave (Fréchet) or linear (Gumbel). Another reason for plotting this transform is that it puts most attention to the tail of the distribution, which is the important part when estimating extreme loads. To estimate rare (e.g., 50-year) return loads, one will need to extrapolate the tail of the surrogate CDF, e.g., by fitting the tail of a GEV distribution. While we have found promising results in this direction with errors on the 50-year return loads in the range , the performance relies heavily on the employed extrapolation method as well as how much of the tail that is used for extrapolation. Consequently, we have chosen not to include such an analysis here. For details on the extrapolation step, see [15]. Returning to the plots of Figure 5 it appears that the surrogate CDF for the tower top loads mainly differs from the empirical CDF on the interval between and [math], while for the middle and base load the critical region is between and . Although this difference is also reflected in the transform, the plots indicate that extreme load estimation through extrapolation should generally work well, in particular for the tower top. It should be mentioned that plots of similar precision can be obtained for the lateral loads, except for the tower top which seems to be more challenging.
5 Conclusion and future research
In this paper we demonstrated how random forest proximities can be used to obtain surrogate loads and discussed how they can lead to promising estimates of extreme loads. One of the key components of this algorithm is that trees are grown in a greedy manner, and hence it adapts to sparse settings where only few of the included signals have significant explanatory power on loads. Another important component is that loads are imputed by finding the best simulation in terms of proximity and not by prediction (regression).
However, as pointed out in Section 4, there is indeed room for improvement, in particular for the tower middle and base downwind loads and for the tower top lateral loads. While it is difficult to quantify how much is caused by a mismatch between the conditional load distribution of measurements and simulations, it would in any case be natural to consider refinements of the employed algorithm. An interesting direction for future research would be to use an alternative splitting criterion than the CART specification (2.1) in order to favor signals that explain higher order moments of the conditional load distribution. The CART methodology is particularly tailored to detect signals which explain the conditional mean load. Related to this, one could consider other randomization schemes (other specifications of ) and actively use the degree of randomness as a tuning parameter to control the diversity between trees and ensure splits on important signals which are not detected by the splitting criterion.
Acknowledgements
We thank James Alexander Nichols from Vestas (Loads & Control) and Jan Pedersen for fruitful discussions.
Funding
This work was supported by the Danish Council for Independent Research under Grants 4002 - 00003 and 9056 - 00011B.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Irad Ben-Gal. Outlier detection. Data Mining and Knowledge Discovery Handbook , pages 131–146, 2005.
- 2[2] Kevin Beyer, Jonathan Goldstein, Raghu Ramakrishnan, and Uri Shaft. When is “nearest neighbor” meaningful? International Conference on Database Theory , pages 217–235, 1999.
- 3[3] Gérard Biau and Erwan Scornet. A random forest guided tour. TEST , 25(2):197–227, 2016.
- 4[4] Leo Breiman. Random forests. Machine Learning , 45(1):5–32, 2001.
- 5[5] Leo Breiman, Jerome H. Friedman, Richard A. Olshen, and Charles J. Stone. Classification and regression trees . Wadsworth Statistics/Probability Series. 1984.
- 6[6] Guilherme O Campos, Arthur Zimek, Jörg Sander, Ricardo JGB Campello, Barbora Micenková, Erich Schubert, Ira Assent, and Michael E Houle. On the evaluation of unsupervised outlier detection: measures, datasets, and an empirical study. Data Mining and Knowledge Discovery , 30(4):891–927, 2016.
- 7[7] Trevor Hastie, Robert Tibshirani, and Jerome Friedman. The elements of statistical learning: data mining, inference, and prediction . Springer Series in Statistics. Second edition, 2009.
- 8[8] Victoria Hodge and Jim Austin. A survey of outlier detection methodologies. Artificial Intelligence Review , 22(2):85–126, 2004.