An Optimal Gauss-Markov Approximation for a Process with Stochastic Drift and Applications
Giacomo Ascione, Giuseppe D'Onofrio, Lubomir Kostal, Enrica Pirozzi

TL;DR
This paper develops an optimal approximation method for stochastic differential equations with stochastic drift using calculus of variations, with applications to neural activity modeling.
Contribution
It introduces a novel approach to approximate SDEs with stochastic drift via Ornstein-Uhlenbeck processes, ensuring existence, uniqueness, and bounds for the approximation.
Findings
Existence and uniqueness of the approximation under general power cost functionals
Bounds on the approximation quality
Application to neural activity modeling
Abstract
We consider a linear stochastic differential equation with stochastic drift. We study the problem of approximating the solution of such equation through an Ornstein-Uhlenbeck type process, by using direct methods of calculus of variations. We show that general power cost functionals satisfy the conditions for existence and uniqueness of the approximation. We provide some examples of general interest and we give bounds on the goodness of the corresponding approximations. Finally, we focus on a model of a neuron embedded in a simple network and we study the approximation of its activity, by exploiting the aforementioned results.
Click any figure to enlarge with its caption.
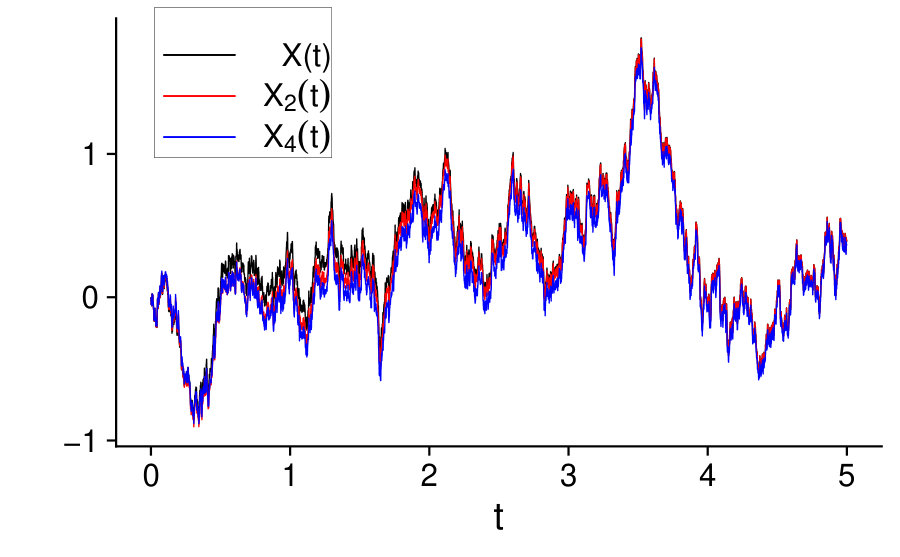 Figure 1
Figure 1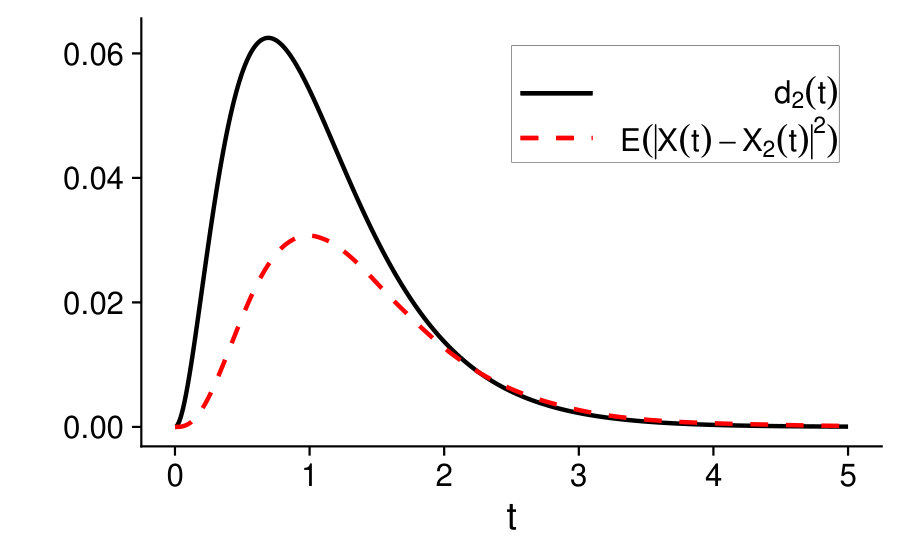 Figure 2
Figure 2| Single Shot | ||||
|---|---|---|---|---|
| Poisson | ||||
| Compound Poisson | ||||
| Brownian Motion | ||||
| Ornstein-Uhlenbeck |
| Exponential Case | ||||
|---|---|---|---|---|
| Gamma Case | ||||
| No Assigned Distribution |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
An optimal Gauss-Markov approximation for a process with stochastic drift and applications
Giacomo Ascione
Giuseppe D’Onofrio
Lubomir Kostal
Enrica Pirozzi
Dipartimento di Matematica e Applicazioni “Renato Caccioppoli”, Università degli Studi di Napoli Federico II, 80126 Napoli, Italy
Dipartimento di Matematica “G. Peano”, Università degli Studi di Torino, Via Carlo Alberto 10, 10123 Torino, Italy
Institute of Physiology of the Czech Academy of Sciences, Videnska 1083, 14220 Prague 4, Czech Republic
Abstract
We consider a linear stochastic differential equation with stochastic drift. We study the problem of approximating the solution of such equation through an Ornstein-Uhlenbeck type process, by using direct methods of calculus of variations. We show that general power cost functionals satisfy the conditions for existence and uniqueness of the approximation. We provide some examples of general interest and we give bounds on the goodness of the corresponding approximations. Finally, we focus on a model of a neuron embedded in a simple network and we study the approximation of its activity, by exploiting the aforementioned results.
keywords:
Stochastic differential equations; Optimality conditions; Shot noise; Neuronal models
††journal: Stochastic Processes and their Applications
1 Introduction
For more than a century stochastic differential equations (SDEs) have played a key role in the description of fluctuating phenomena belonging to different areas of applied mathematics ([1],[2]). Here, we consider the following SDE in which the drift is characterized by a stochastic process independent of :
[TABLE]
where are chosen to guarantee existence and uniqueness of the strong solution of the equation. These equations are of interest in many applications. In mathematical finance stochastic volatility is used to model option pricing to represent that volatility varies with respect to strike price and expiry ([3],[4]). In time series analysis the stochastic trend is used in a difference equation. This is a discrete counterpart of the SDE (1) ([5]). In computational neuroscience they model networks of interacting neurons in the presence of random synaptic weights ([6], [7], [8]). The present work also stems from neuronal modeling (see [9], [10], [11], [12], [13], [14], [15]): one can model the membrane potential of a neuron through a stochastic process solving
[TABLE]
where is the resting potential, is the characteristic time constant of the neuron and is a process representing the collection of the stimuli the neuron under consideration receives from other neurons or from its own activity.
In the first part of this paper we study some features of the solution of Equation (1). Since the process depends on , it can be non Markov and/or non Gaussian. This work is mainly focused on obtaining an optimal (in a sense that will be specified later) Gauss-Markov (GM) approximation of the process . This approximation strategy enables one to use the extensive theoretical results on GM processes (see for instance [16, 17, 18, 19]). Indeed, finding a good approximating GM process with a small approximation error allows one to use the integral equation approach to study the first passage time of the approximating process in place of the actual one.
To find the “best” approximating GM process we look for the minimizer of a general cost functional , here usually a functional, among all Ornstein-Uhlenbeck type processes.
To do that, we solve the minimization problem in a very general setting. Using results of calculus of variations, we show that the minimizer exists and it is unique inside the aforementioned class, requiring relatively mild conditions. Moreover, the Euler-Lagrange equation and the transversality condition of the approximation problem are obtained. The proofs are generalizations in a probabilistic setting of the main tools of the theory of Direct Methods of Calculus of Variations (see [20]), referring in particular to the relaxation of a problem. The Euler-Lagrange equation and the transversality condition are instead found by using an approach that is typical to the Classical Methods of Calculus of Variations (see [21]). In particular we consider, in the familiy of all suitable cost functionals, power costs that are shown to satisfy the needed assumptions. Power costs represent the integral mean power error of the approximation. For instance, the second power cost is the integral of mean square error of approximation, whose minimizer gives a continuous-time version of a least mean square approximation.
Some examples are given in the cases in which is a step function, a Poisson process, a compound Poisson process, a shot noise, a Brownian motion or an Ornstein-Uhlenbeck process. Finally, we propose a stochastic neuronal model for the description of the firing activity of a neuron subject to the inputs coming from other neurons. Our example corresponds to the case in which is a shot noise, that is to say where are i.i.d. random variables, distributed as a given variable with , independent of , are i.i.d. random variables independent of and and is the response function, such that . The stochastic nature of the drift in the model equation is due to the stochastic behavior of the inputs received from the other neurons that occur randomly in time and in space (see for instance [22, 15, 23, 24]). In a theoretical context, we can adopt a specified distribution function for and whereas in the application context a distribution function may be one of the unknowns of the problem. This case is investigated in Section 5. We stress that, although used here in the neuronal modeling context, the results obtained about the approximation are completely general for equations like (1). The paper is structured as follows:
In Section 2 we introduce the target equation and the approximation problem;
- 2.
In Section 3 we describe the problem in a more general setting and prove some sufficient and necessary conditions for existence and uniqueness of the approximation;
- 3.
In Section 4 we provide some examples of general interest;
- 4.
In Section 5 we construct a simple neuronal model and we use the previous results to find the approximating Gauss-Markov process for the membrane potential;
- 5.
Finally, in Section 6 we summarize the work and we give some concluding remarks.
2 The linear equation and the class
2.1 The linear equation
Let be a probability space endowed with the (completed) natural filtration of the standard Brownian motion . Let us consider the following stochastic differential equation in a time interval , for a fixed ,
[TABLE]
with stochastic process adapted to such that its sample paths belong to , a damping rate, and . Let us denote by the space of the stochastic processes adapted to with sample paths a.s. in and by , for some , the space of the stochastic processes adapted to with sample paths a.s. in such that . For simplicity we will assume to be independent from . In the examples the function will be a negative constant.
Since Eq.(2) is a linear equation, one can ensure the existence of a unique strong solution (see for instance [1]). In particular one has the following result:
Proposition 2.1**.**
The map given by
[TABLE]
where
[TABLE]
is an injection that associates to the unique strong solution of Equation (2).
The well-posedness of , i.e. existence and uniqueness of the strong solution, follows from [1, Theorem and ]. Later we will prove that is an injection.
Given a generic , we can split the process in two parts. Indeed, if we set
[TABLE]
we have
[TABLE]
In particular is an Ornstein-Uhlenbeck process independent of . Its mean and covariance are given by
[TABLE]
On the other hand, if is a Riemann-integrable Gaussian process (for instance if it admits continuous sample paths), then is also Gaussian and independent of . By Equation (4) we conclude that, in such case, is a Gaussian process. In general could be neither Markov nor Gaussian.
Let us state this easy Lemma.
Lemma 2.2**.**
Let such that . Then
[TABLE]
Moreover, if is such that , then
[TABLE]
The proof follows from the application of Fubini’s theorem.
The previous Lemma, together with the independence of and and Equation (4), gives us the following Proposition.
Proposition 2.3**.**
If is such that then
[TABLE]
and, for
[TABLE]
2.2 The class
A particular solution of (2) is achieved when is a degenerate stochastic process (i.e. a deterministic function). Indeed, for a function let us consider the equation
[TABLE]
The solution map can be still used, since we can consider by identifying any deterministic function with the constant stochastic process for any . Thus we have that
[TABLE]
By using Equation (4), we have that is a deterministic function, hence it does not play any role in the auto-covariance function of , which is now determined by (5). is Gaussian since it is a sum of independent Gaussian processes and Markov property is ensured by the fact that is solution of (8). Now we define the class of processes of the form for some .
Definition 2.1**.**
The Ornstein-Uhlenbeck class is defined as
[TABLE]
We will denote to state that .
As already mentioned in the introduction, a Gauss-Markov process is easier to handle than processes of the form for general , and many existing tools and results about these processes can be exploited. Thus it is interesting to understand how can we best approximate a general solution of (2) with a process .
2.3 The approximation problem
Let us consider a process and let us introduce a cost functional on the class , defined, for any , as
[TABLE]
for some functions and , where . The cost functional represents the mean cost we are going to pay for approximating the process with a process . The function will be used to represent the running cost of the approximation, while is the final cost. To find the best approximation means that we want to find a process such that
[TABLE]
By using the definition of the solution map in Proposition 2.1 and Equation (4), one obtains
[TABLE]
where
[TABLE]
This means that actually
[TABLE]
Let us now consider the space of absolutely continuous functions on (see [25, Sections and ]), i.e.
[TABLE]
and let us define the map such that
[TABLE]
This map is a bijection between and since it associates to the unique Caratheodory solution (see [26, Theorem and of Section ]) of the Cauchy problem
[TABLE]
On the other hand for any we have
[TABLE]
For any process we have, by Equation (4), . The fact that is a bijection proves the injectivity of . Moreover, is bijective and .
Now we can define a new functional directly on (that we will still denote with ) that is the composition of the functional , the map and the inverse solution map on , and is given by
[TABLE]
for . Being the maps and bijections, finding the minimizer of in gives us the best approximating process .
We can study these kind of cost functionals as particular cases of the more general cost functional
[TABLE]
In particular, we want to find a such that
[TABLE]
In the following section we show that under some hypotheses this problem admits a unique solution and we find some necessary conditions that will be the main tools to actually find the minimizer .
3 Optimality conditions and existence of the solution of the approximation problem
3.1 The main result
Let us state the problem in its full generality. Let us consider the stochastic process with a.s. continuous paths and let us define the probability measure flow where denotes the law of a random variable . Fix and define
[TABLE]
For any measurable set define the section for fixed . Then let us define the set function as follows
[TABLE]
It is not difficult to check that is a measure.
One can also show that for any measurable function we have
[TABLE]
Consider now the functions
[TABLE]
and define the functional as
[TABLE]
We want to solve the following problem:
[TABLE]
where the admissible set is defined as
[TABLE]
We will consider the following assumptions, that we will explain while proving the main result:
- A1
There exists a function such that ;
- A2
The functions and defined in (13) are non-negative for any ;
- A3
For fixed the map is in ;
- A4
For any compact set there exists a function such that
[TABLE]
- A5
For fixed the map is in ;
- A6
For any compact set there exists a function such that
[TABLE]
- A7
For any fixed , the map is strictly convex, decreasing as and increasing as ;
- A8
There exist two constants , a function and an exponent such that for any and with
[TABLE]
- A9
The map is proper or constant;
- A10
The map is convex;
- A11
The function
[TABLE]
is in , where is such that is at most finite, and
[TABLE]
for any ;
- A12
The function
[TABLE]
belongs to , where is a solution of
[TABLE]
defined for , where is at most a finite set;
- A13
It holds true that
[TABLE]
- A14
Given the (unique) solution of
[TABLE]
then it also holds
[TABLE]
Although numerous, these assumptions are not so strict, neither unusual, as we will see later. Indeed, we will show that an important family of cost functions (the power costs) satisfies all the assumptions, depending on the regularity of the process .Now we state the main result of the paper.
Theorem 3.4**.**
Under assumptions , there exists a unique solution of (15) and it is the unique solution of Equations
[TABLE]
and
[TABLE]
From a probabilistic point of view by Equations (17) and (18) we are asking for to be, on average, a critical point of the running cost and the final cost . Furthermore, under our assumptions, one can show that Equation (17) can be also written as
[TABLE]
that is to say that is also a critical point of the mean of the running cost. The same holds for the final cost.
The proof of Theorem 3.4 will be given in Subsections 3.2, 3.3, and 3.4. The proof is structured as follows:
First, in Subsection 3.2 we find necessary optimality conditions in terms of Equations (17) and (18), which are the Euler-Lagrange equation and the Transversality Condition of the function (see for instance [21, Chapter ]), by using Assumptions ;
- 2.
In Subsection 3.3, to obtain an existence result, we need to relax the problem, in the spirit of Calculus of Variations (see for instance [20, Section ]), by introducing a more general functional on a more general admissible set. For the relaxed functional we are able to prove lower semicontinuity and then existence of the minimizer, by using Assumptions ;
- 3.
In Subsection 3.4 we show that exactly one of the minimizers belong to the admissible set and thus it is a minimizer of the original problem, by using the whole set of Assumptions and completing the proof of the Theorem.
3.2 Necessary optimality conditions
In this section we perform the first step of our plan. Indeed, by using Assumptions we will prove that any minimizer of in solves Equations (17) and (18). These equations will be the main tools to actually find a minimizer for . We have the following optimality conditions, by means of the Euler-Lagrange equation and the transversality condition. The proof follows the ideas of [21, Theorem Part ], adapted to our case.
Theorem 3.5**.**
Under Assumptions , let be a solution of the problem (15). Then is solution of Equations (17) and (18).
Proof.
Let us first observe that if is a minimizer for , then, by Assumption , . In particular
[TABLE]
and thus almost surely. In particular we can use Fubini’s theorem to obtain
[TABLE]
First of all, let us fix and define . Since , then we have that
[TABLE]
Now observe that since , then uniformly as . In particular let us consider a tubular neighbourhood of , i.e.
[TABLE]
and a compact set such that . Then there exists a such that for the couples and then . Hence we have, by Assumption ,
[TABLE]
Taking the mean and then integrating with respect to time in the right hand side we have, by Equation (12),
[TABLE]
In particular we can use Fubini’s theorem to obtain
[TABLE]
and then is almost surely in . This implies that is almost surely in and in particular
[TABLE]
Consider the function and observe that it admits a minimum in . Let us show that is in . To do this, let us consider the function
[TABLE]
such that
[TABLE]
and observe that, being a function in by Assumption , we have
[TABLE]
and in particular
[TABLE]
thus we have a uniform (with respect to ) bound on the derivative of . By differentiation under the integral sign we have that and
[TABLE]
Now, by Fermat’s theorem, we know that and then, by the fact that we arbitrarily chose ,
[TABLE]
By Fundamental Lemma of Calculus of variation (see [20, Theorem ]), Equation (19) implies
[TABLE]
Now let us choose again . Working as before on , by using also Assumption (since ) we have
[TABLE]
As done before, let us introduce a function and let us define the function
[TABLE]
to obtain
[TABLE]
Now let us show that is in . To do that, we only need to work with . We have, by Assumption ,
[TABLE]
and then
[TABLE]
Thus we can differentiate under the integral sign, obtaining
[TABLE]
By using Fermat’s Theorem, we have and then
[TABLE]
However, we already proved that , hence, since we have arbitrarily chosen
[TABLE]
from which we finally obtain
[TABLE]
∎
Remark 3.6*.*
Let us observe that Assumption is a non-triviality assumption, to avoid functionals of the form . Assumption is used instead to avoid the case . Concerning Assumptions , they are typical Assumptions of regularity and integrability of the local Lipschitz constant.
3.3 Existence of a minimizer for a relaxed problem
Now we introduce a relaxed problem. Indeed, we are not able to prove directly existence of the minimizer in the admissible set . Hence we will “enlarge” this set and extend the functional in order to prove an existence result. This relaxation technique is typical of direct methods of Calculus of Variations (see [20]). From now on we will split the functional in two parts
[TABLE]
such that .
As we will see, the problem is in the functional, since we are only able to prove weak lower-semicontinuity of this functional on the space , which is quite larger than . The proof of the next Lemma mimics the one of [20, Theorem ].
Lemma 3.7**.**
Consider and suppose we have a sequence , a function such that in . If is convex , then
[TABLE]
Proof.
First of all, let us observe that since is continuous in , then if in we have, by Fatou’s Lemma,
[TABLE]
so in particular is strong lower semicontinuous.
Now, if the theorem is trivial. Suppose then and suppose we are working with a subsequence (that, for the ease of the reader, we will still call ) such that . Fix and observe that there exists a such that for we have . Now, by Mazur’s Theorem [20, Theorem ] we know that there exists a sequence of integers with and for each a vector with such that, if we pose
[TABLE]
we have in . However, by convexity of in (by also using Fubini’s theorem) we have
[TABLE]
Taking the on , from the strong lower semi-continuity, we have
[TABLE]
Finally, we can send to conclude. ∎
The latter result shows us that if we want to use an approach via minimizing sequences to find a minimizer, we can do this by substituting for some to . However, functions are not defined on single points, thus for any , is not well-defined. Hence we need to split the action of and , the first on , the second simply on . From now on, our admissible set will be composed of couples where and . Let us define the relaxed admissible set
[TABLE]
and the relaxed functional
[TABLE]
for . Then the relaxed problem is given by
[TABLE]
Now we can move to the next step, that is proving that the relaxed problem (20) admits a solution.
Lemma 3.8**.**
Under Assumption , Problem (20) admits a solution.
Proof.
Let us first consider the case in which is a proper map. If , the solution is trivial. Thus let us suppose . Let us then consider a sequence such that . In particular we can suppose that
[TABLE]
First of all, we have that
[TABLE]
By Fubini’s Theorem we have that
[TABLE]
Now let us define . By using Assumption we have
[TABLE]
and then
[TABLE]
At the same time we have
[TABLE]
Thus we have, by summing Equations (21) and (22)
[TABLE]
and then, by Banach-Alaoglu theorem [27, Theorem ] (and the fact that is reflexive [27, Theorem ]), there exists a such that (up to a subsequence) in .
Moreover, by the weak lower-semicontinuity of we have
[TABLE]
Now, we also have that
[TABLE]
thus, since is a proper map by Assumption , there exists such that . Thus there exists such that (up to a subsequence) . Moreover, we have that for any , posing
[TABLE]
hence we can use dominated convergence theorem to conclude that
[TABLE]
Finally, we have that
[TABLE]
If the map is constant, the term in is actually a dummy term and it is useless in the minimization problem. Hence we can neglect it and the statement still holds true. ∎
Remark 3.9*.*
We did not use but only the fact that for any fixed the map is convex. The final formulation of is needed to guarantee that if and are solutions, then in .
Let us also recall that, with the same strategy used before, we can show the following necessary optimality conditions for the minima of the relaxed problem.
Lemma 3.10**.**
Let be a solution of the problem (20). Then, under assumptions ,
[TABLE]
and
[TABLE]
3.4 Gain of regularity
The solutions we found for the relaxed problem at this stage cannot be used for the original problem:
while we want it in ;
- 2.
is not well-defined, but, even if it were, we are not sure that, in any case, .
For these reasons we have to show that we can gain regularity of the solution, in the sense that we can find a solution of the relaxed problem (20) that is more regular than simply for some .
First of all, let us show that, under our assumptions, the first part of the solution is unique and continuous, while can only vary in an interval.
Lemma 3.11**.**
Under Assumptions , there exists a unique and a unique interval such that for any the couple is a solution of the problem (20). Moreover admits a continuous modification in for which the equation (23) holds for any .
Proof.
Since the map is convex by Assumption , we know that must be a convex set, hence, being non-empty by the previous theorem, it must be an interval . Moreover the strict convexity of the map given by Assumption ensures that the minimizer (that exists by the previous theorem) is unique.
Concerning the continuity, fix and consider such that are points for which Equation (23) is satisfied. We obviously have
[TABLE]
Now observe that there exists a subsequence of that converges to . In particular, taking the limit on such subsequence, we have, by Assumption ,
[TABLE]
In the same way, we also have
[TABLE]
Now, since is strictly convex for any , we know that is injective, thus for any the equation
[TABLE]
admits a unique solution and then . We have shown that is well-defined. Now let us observe that being decreasing as and increasing as , by Assumption . Thus we have . Now let us distinguish two cases. If is one of the point in which the necessary condition (23) is already satisfied, we have, by uniqueness of the solution of Equation (25), and then is continuous in .
If is not one of these points, we can modify on in such a way that . Being the set of for which the necessary condition is not satisfied a zero-measure set, we can conclude that admits a continuous modification in . ∎
It is still not enough: we do not want to be simply continuous, but absolutely continuous. However, under our hypotheses we do not only obtain that is absolutely continuous, but we can exploit its derivative (almost everywhere).
Lemma 3.12**.**
Under Assumptions , let be a solution of (20). Then .
Proof.
By the Implicit Function Theorem (see [28, Theorem ]) we know that defined in Equation (16) of Assumption is actually the derivative of where it is defined. In particular let us denote , , and for . For any and we have and, being continuous in such interval, for any . Fix a . Let us observe that for any
[TABLE]
thus, by the dominated convergence theorem (being in ) and by the continuity of we have, by taking ,
[TABLE]
Moreover, if we consider we can show in the same way that
[TABLE]
Now let us consider . If for some we have, by Equation (26),
[TABLE]
Otherwise there exists such that and we have, by both Equations (26) and (27),
[TABLE]
Thus, for any , we have
[TABLE]
concluding the proof. ∎
Remark 3.13*.*
Let us stress that Assumption can be lightened by asking instead that except for a set that is at most finite.
Now, for to be in , we only need to ask that and , where is the optimal interval for . This is done by introducing the Assumptions .
Lemma 3.14**.**
Under Assumptions , (15) admits a unique solution .
Proof.
Let us consider first the relaxed problem. Thus we have that there exists a unique function and an interval such that for any the couple is solution of (20). By Lemma 3.11 we know that . Moreover, by Lemma 3.12 we know that . By Assumption and uniqueness of the solution of equation (25) we have that , hence . Finally, we have that is the unique solution of (17) for and then, by Assumption ,
[TABLE]
Being the map convex, the map is increasing and then . Thus the couple is solution of the relaxed Problem (20) and then is solution of Problem (15). Uniqueness follows from the fact that for each , Equation (23) admits a unique solution. ∎
This last Lemma ends the proof of Theorem 3.4. The only thing we have to observe is that by implicit function theorem and Assumptions , we know that Equation (17) admits a unique solution that, in such case, has to be the minimizer we are looking for.
3.5 Power cost functionals
Let us give a practical example. We want to solve the approximation problem of Section 3 for some particular cost functions. By power cost functionals we mean functionals induced by constant and, for a fixed , for any and ,
[TABLE]
We can show the following result that will be useful in the applications.
Proposition 3.15**.**
Let us fix and suppose that
The process ;
The function belongs to .
* almost surely for any ;*
* is continuous.*
*Fix for some constant and let be as in Equation (28). Then the Problem (15) with running cost function (28) and constant final cost admits a unique solution . The same holds if .
If , then, under hypotheses and , for or and defined as before, there exists a unique solution of (15).*
Proof.
Without loss of generality, let us always suppose that . As function of we have, by Equation (28),
[TABLE]
Let us also denote the respective functional as . By definition of in Equation (3) and Jensen’s inequality we have
[TABLE]
and in particular, since the right-hand side is continuous, we have that . Let us now check the hypotheses of Theorem 3.4.
- A1
This is verified for , since ;
- A2
This hypothesis is verified by definition of and ;
- A3
For any fixed the map belongs to and
[TABLE]
- A4
Let and observe that
[TABLE]
Since is well defined and belongs to (by Hölder’s inequality), we have that .
- A5,A6
These are obvious since ;
- A7
The map is strictly convex, decreasing as and increasing as since the function has these properties;
- A8
Observe that we have
[TABLE]
hence
[TABLE]
Thus we can conclude that
[TABLE]
where belongs to ;
- A9,A10
These hypotheses are obviously satisfied by ;
- A11
Let us observe that
[TABLE]
Let us fix , and distinguish three cases. If then and we have
[TABLE]
If and we have (since the function is concave if restricted to or )
[TABLE]
thus in this case
[TABLE]
If and then we can suppose and . In this case
[TABLE]
The same holds for and . Finally, for we have . By using these estimates and the estimate in hypothesis , we can differentiate under the integral sign, obtaining
[TABLE]
Let us observe that, by Remark (3.13), we actually need to show that at most in a finite set, where is the unique solution of
[TABLE]
that is Equation (17) in this case. Let us first consider the case in which . Since, by , for any almost surely, for any in almost surely. In such case, cannot be negative for all thus . Then we have, recalling Equation (29),
[TABLE]
For we have instead
[TABLE]
without using .
- A12
For , let us observe that
[TABLE]
Since, by , we have that is continuous in , we can observe that the function
[TABLE]
is continuous in , thus is in .
The case is simpler. We have that Equation (29) becomes
[TABLE]
thus we know that
[TABLE]
By Fubini’s theorem we know that
[TABLE]
Thus we have, since ,
[TABLE]
which is uniquely defined since the map is a bijection. Finally, since we have
[TABLE]
and then
[TABLE]
we get
[TABLE]
that is continuous in and then in .
- A13
Since we have
[TABLE]
- A14
This hypothesis is obviously satisfied since .
The proof of Assumptions , for are analogous to the ones for , while , and follow from the structure of . ∎
The previous example shows that our result includes, as a special case, the well-known fact that the expected value minimizes the mean square error. Moreover, in this case it is easy to obtain a bound on the minimum in terms of the variance of . Indeed we have
[TABLE]
However we have by Jensen’s inequality
[TABLE]
thus we have
[TABLE]
In particular, if , we have that the minimum approximation error is bounded for .
One can obtain also a point-wise estimate on the distance between the processes, given by
[TABLE]
Let us recall that, despite Problem (15) admits a unique solution, the relaxed Problem (20) could still admit more than a solution. For instance, if we consider the functional induced by and , Problem (15) admits as unique solution, while Problem (20) admits as solution for any . On the other hand, if is strictly convex, then also the relaxed Problem (20) admits a unique solution. This is the case of the functional induced by and . Indeed Problem (15) admits as unique solution and Problem (20) admits as unique solution. Finally, let us observe that if Assumption is not satisfied, then the Problem (20) could admit a solution while (15) could not. Indeed, if we consider the funcitonal induced by and , Problem (20) admits as unique solution , while Problem (15) admits a unique solution if and only if , otherwise there are no absolutely continuous functions that satisfies simultaneously Equations (17) and (18).
4 Examples
In order to provide some examples of application of Theorem 3.4, in particular of Proposition 3.15, let us consider Eq. (2) with for some . Let us study the optimal approximation for some particular choices of . In particular we will denote with the original process and with the optimal Gauss-Markov approximation with respect to the power cost functional . In the examples we will consider the approximations and . Let us recall that, by Proposition 3.15, while Equation (29) for becomes
[TABLE]
Let us also recall that the approximating process solves the SDE
[TABLE]
where
[TABLE]
is, by Theorem 3.4 and Proposition 3.15, the unique zero of Equation (34). Thus we can evaluate it numerically by using bisection method. We will not have explicit expression of in the following examples.
4.1 A single shot as a drift.
Let
[TABLE]
where with . To ensure that is adapted to the filtration we have to ask for to be a Markov time with respect to that filtration. By definition of in Equation (3), we have
[TABLE]
where is the indicator function of the (stochastic) interval . Let us in particular observe that is a Markov process. Moreover, by using Proposition 2.1 (or Equation (4)) we have
[TABLE]
Let us also observe that
[TABLE]
hence we obtain
[TABLE]
Finally, is obtained by solving Equation (35), thus we have
[TABLE]
Observing that
[TABLE]
we have, by Equation (32),
[TABLE]
It is not difficult to check that thus is uniformly bounded by . To evaluate , we need , solution of Equation (34). In Figure 1, on the left, we plot some sample trajectories of , and , with the same realization of the white noise process. In particular to plot we solved numerically Equation (34) to obtain . In Figure 1, on the right, we plot a simulated curve of the function and we compare it to the bound given in Equation (39). We observe that as increases, the simulated error and the bound tend to coincide and go to [math]. The fact that the error should go to [math] can be also observed from Figure 1 on the left, since as increases the trajectories of and overlap. This is due also by the nature of in Equation (37), which goes to as increases and so does its mean, thus leaving the stochastic part only to that is common between and .
4.2 A Poisson process as drift.
Let be the stochastic drift process with a Poisson process with parameter adapted to the filtration . In this case one has . By definition of in Equation (3) we have
[TABLE]
where last equality follows from with the jump times of the process , hence, from Proposition 2.1 we have that
[TABLE]
The process is obtained by solving (35) with , obtaining
[TABLE]
Concerning the upper bound for the punctual distance, we have, by Equation (32),
[TABLE]
This time, does not belong to . However, it is not difficult to check that there exists a constant such that for large enough.
4.3 A Compound Poisson process as drift.
Let be the stochastic drift process where is a Poisson process adapted to the filtration with parameter and is a sequence of i.i.d. random variables, distributed as a given variable , which are also independent from . Let us also suppose that are measurable with respect to for any and for any . By definition of in Equation (3) we have
[TABLE]
where are the jump times of the process , hence, by Proposition 2.1, we have
[TABLE]
The process is then obtained by solving Equation (35) with :
[TABLE]
Moreover, since , we have, by Equation (32),
[TABLE]
As for the case of the Poisson process, also in this case there exists a constant such that for large enough.
4.4 A Shot Noise as drift.
Let be a random variable with positive integer values measurable with respect to for any , i.i.d. random variables independent of , measurable with respect to for any , and distributed as and i.i.d. almost surely positive absolutely continuous random variables that are Markov times with respect to , distributed as a fixed random variable and independent of the and . Moreover, let us consider a function (called response function) such that for any . Let us denote by the probability density function of . Let us consider the stochastic process as drift process. In this case , by Equation (3), is given by
[TABLE]
and then the process , by Equation (4),
[TABLE]
Now let us recall that
[TABLE]
where
[TABLE]
Solving Equation (35) we get
[TABLE]
Finally, since
[TABLE]
where
[TABLE]
we obtain, from Equation (32),
[TABLE]
Let us observe that if is distributed as a Poisson random variable with parameter , then and we have
[TABLE]
An interesting case is given by . In the neuronal modeling context, a process of this kind goes under the name of shot noise. It plays a key role in the description of neuronal networks dynamics as described in the next section.
4.5 A Brownian motion as drift.
Let where is a Brownian motion adapted to and independent of , and . By definition of in Equation (3) we have
[TABLE]
that solves the equation
[TABLE]
By Proposition 2.1 we have
[TABLE]
Since , solving (35), we have
[TABLE]
Note that is the same as the approximant we obtain in the Poisson case. However, since , we have, by Equation (32),
[TABLE]
which is independent of . Thus if , the upper bound given by is stricter than the one in the Poisson process case; vice-versa if .
Concerning , in general, if hypothesis of Proposition 3.15 does not hold, one could check if Equation (34) admits a triple zero only for an at most finite set of . However, the case of a Gaussian drift term is particular since we can show the following Proposition:
Proposition 4.16**.**
If is a Riemann-integrable Gaussian process and hypotheses and of Proposition 3.15 for for some hold, then Problem (15) with running cost and constant final cost, or final cost , admits a unique solution .
Proof.
Let us first observe that if satisfies hypotheses and of Proposition 3.15 for , then it satisfies the same hypotheses for . Moreover, being a Riemann-integrable Gaussian process, also is a Gaussian process. Now let us observe that Equation (29) for becomes
[TABLE]
Let us add and subtract in the left-hand side of Equation (45) to achieve
[TABLE]
However, being Gaussian, we have and then Equation (46) becomes
[TABLE]
Thus, substituting the result of Equation (47) in Equation (45) we get
[TABLE]
whose solution is given by , concluding the proof. ∎
Hence the processes and (and any for ) coincide in the case of a Gaussian drift.
Finally, let us observe that even in this case can grow at most quadratically with respect to the time horizon .
4.6 An Ornstein-Uhlenbeck process as drift.
Let be the stochastic drift process with the OU process solution of the following SDE
[TABLE]
where , , with .
In this case we have, by Equation (3),
[TABLE]
that is solution of
[TABLE]
and, by Prop 2.1 and Equation (4),
[TABLE]
Recalling that we have , by solving Equation (35), as
[TABLE]
Since we also have
[TABLE]
we obtain, by Equation (32),
[TABLE]
Let us observe that in such case the mean cumulative error of approximation is asymptotically bounded by a constant, i.e.
[TABLE]
where , thus can grow at most linearly with respect to the time horizon.
4.7 Numerical results
We considered six examples of possible choices for the drift. In the first four cases the resulting process is not Gaussian, while in the last two it is. For each example (except the Shot Noise case), we evaluate numerically the quantities , for and . is the integral mean square error of approximation of with the process , while is the integral mean fourth-power error of approximation of with the process . In general we expect, from Theorem 3.4, for , and . As shown in Table 1, this inequality holds strictly in the first three cases, while it is an equality on the last two (in bold in Table 1). This latter fact is justified by Proposition 4.16, since for Gaussian drifts. To obtain each quantity, we used the formula
[TABLE]
to avoid the simulation of the whole trajectories of the processes , and , which could lead to numerical errors. While is known explicitly, has been obtained by solving numerically Equation (34). Since (34) is a simple polynomial equation, we used for each the bisection method to evaluate , with a precision of . We set , , , , , . In the compound Poisson case, we used with . The simulation time step is and the time horizon . For each example sample paths have been produced.
The case of the Shot Noise will be discussed in the next section.
5 A model of a neuron embedded in a neuronal network
In this section we will focus on an application of Theorem 3.4 to neuronal modeling described by the linear Equation (2).
In particular, we are interested in the dynamics of a neuron embedded in a network of neurons. We assume that the neuron under study receives impulses from the other neurons, whenever they fire for the first time. We say that a neuron fires when its membrane potential exceeds a critical value: after the crossing, the value of the membrane potential is reset to its resting state and the dynamics starts anew. This process generates an electrical impulse that is transferred to the neurons that are connected to it. For this reason the membrane potential can be modelled as a leaky RC circuit with a drift characterizing the input stimuli. The membrane potential of each neuron of the network is then modelled by the following stochastic differential equation:
[TABLE]
where is the characteristic time of the membrane, is a constant injected stimulus and determines the amplitude of the baseline noise.
Concerning the embedded neuron, we assume that the stimuli it receives can be described by a function that is exponentially decreasing in time, with a characteristic time (suppose for simplicity that ). The initial amplitude of each stimulus is stochastic, represented by a family of i.i.d. random variables . The stochastic differential equation that describes the dynamics of this neuron is of shot noise type:
[TABLE]
where is the first firing time of the -th neuron of the network. In Figure 2 we have a schematization of this model. Equations (48) and (49) are the classical Itô stochastic differential equation for the stochastic diffusion Leaky Integrate and Fire (LIF) model (see, for instance, [22, 15, 30]). In particular, Equation (49) admits a stochastic drift of the form
[TABLE]
where we suppose that and are i.i.d. and independent of each other. This is the driving term of the stimulus that neuron under study receives from the first-layer neurons (see Figure 2). All the other smaller inputs and changes in the environment are summarized by the Brownian noise. With the independence assumption we are supposing that the neurons described by the processes are not communicating. This is a reasonable assumption: such physiological behaviour is common in the synaptic organization of the sensory neurons. An example of such behaviour is given by the sensory neurons of the olfactory bulb: such neurons are homogeneous and, neglecting eventual ephaptic coupling (which in general is insufficient to stimulate an action potential), independent from each other until their axons form a spherical structure named glomerulus, which carries all of such stimulus and is connected to the mitral cell [31, 32, 33]. Another example of this behaviour is given by the photoreceptors of the retina, which are independent from each other and only linked to the retinal horizontal cell [33, 34].
in Equation (50) is an example of shot noise with response function given by
[TABLE]
Let us then observe that, by Equation (40), with the choice of given by (51), we get
[TABLE]
and then, by solving Equation (49), we obtain
[TABLE]
Now we consider some choices for the distribution of the first firing times , as proposed in the literature, and we show the corresponding approximating processes .
5.1 The Exponential Case.
Let us suppose that is an exponential random variable (see, e.g., [17]) with parameter . By definition of in Equation (41), of in Equation (43), and the choice of the response function as in Equation (51), we get
[TABLE]
and then, by using Equation (42), we get
[TABLE]
Moreover, by using Equation (44), we get
[TABLE]
with . Moreover, , thus the approximation error is bounded by .
5.2 The Gamma Case.
Gamma distribution is also a popular choice for the interspike interval distribution (see, e.g., [11]). Let us consider as a Gamma random variable with rate and shape parameter , i.e . By definition of in Equation (41), of in Equation (43), and the choice of the response function as in Equation (51), we get
[TABLE]
where is the lower incomplete Gamma function
[TABLE]
By using Equation (42), we get
[TABLE]
can be obtained from Equation (44) by using and given in Equation (53). The expression is omitted here due to its length, but one can show that and , thus is bounded by . In Table 2 we show some numerical evaluations of for and . As expected from Theorem 3.4, we have for .
6 Concluding remarks
In this work we studied the problem of approximating solutions of linear SDEs with stochastic drift by using Ornstein-Uhlenbeck type processes, as introduced in Section 2. In particular, in Section 3, we showed sufficient and necessary conditions for existence and uniqueness of an optimal approximation (with respect to a suitable, but general, cost functional). Moreover, in Subsection 3.5, we show that a wide class of cost functionals (i.e. the power cost functionals with ) satisfies Theorem 3.4.
In Section 4, these results have been applied to some examples that are of interest in the classical literature. Some specific features of the approximations are highlighted in such examples. For instance, for the simplest example in Subsection 4.1, we plot the simulated sample paths for , and in Figure 1, on the left. On the right of Figure 1 we also plotted the pointwise mean square error together with its bound . The examples in Subsections 4.2, 4.3 and 4.5 exhibit the same (eventually up to some constant) approximating process with respect to the quadratic cost, highlighting the exclusive dependence on the mean of the drift in such case. However, the performance of the approximation is strictly related to the variance of the processes describing the drift. In Subsection 4.6 we also provided an upper bound for a temporal-mean of the mean-square error, showing in this case that such mean is bounded by a constant. It is actually easy to show that this behavior appears every time the function is in , equivalently if the drift process concentrates around its asymptotic mean. Moreover, in Subsection 4.5 we proved that for Gaussian drift terms the approximations and for any coincide. In Subsection 4.7 we compare the behaviour of and on and for the examples of Section 4, giving both a confirmation of Theorem 3.4 and some quantitative information on the approximation error.
Finally, the example in Subsection 4.4 is of interest in the frame of neuronal modeling. Indeed, we provide a model for a single neuron embedded in a neuronal network in Section 5. In such case, we specialize the response function of the shot noise process and we study the approximation of the membrane potential process. Indeed, as we did for Section 4, we evaluated the approximation errors and on the processes and under some suitable assumptions on the spiking times of the first layer of neurons and finally without any assumptions on them, by simulating the whole network.
The novelty of our findings is that in our case no hypotheses of ergodicity of the process ([35],[36],[37]) is asked, nor we use slow-fast dynamic techniques ([38], [39]), nor we increase asymptotically the number of neurons as in the mean field theory approach ([6],[40], [7], [41], [42]).
If on one hand the lack of assumptions on the drift process makes the result very general, on the other hand our approach does not easily lead to explicit solutions, since Equation (17) could be impossible to solve in closed form and numerical evaluations are needed.
The study of the approximation problem with a stochastic time horizon, depending eventually on the process itself, as, for instance, first passage times through some fixed thresholds, will be the subject of future studies.
Acknowledgements
We thank the anonymous reviewers whose comments have greatly improved this manuscript. This research is partially supported by MIUR - PRIN 2017, project Stochastic Models for Complex Systems, no. 2017JFFHSH, by Gruppo Nazionale per il Calcolo Scientifico (GNCS-INdAM), by Gruppo Nazionale per l’Analisi Matematica, la Probabilità e le loro Applicazioni (GNAMPA-INdAM) and by the Czech Science Foundation project 20-10251S.
References
- [1]
I. Karatzas, S. E. Shreve, Brownian Motion and Stochastic Calculus, Springer, 1998.
- [2]
B. Oksendal, Stochastic Differential Equations: an Introduction with Applications, Springer Science & Business Media, 2013.
- [3]
M. H. Davis, Complete–market models of stochastic volatility, Proceedings of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences 460 (2041) (2004) 11–26.
- [4]
P.-L. Lions, M. Musiela, Correlations and bounds for stochastic volatility models, in: Annales de l’Institut Henri Poincare (C) Non Linear Analysis, Vol. 24, Elsevier, 2007, pp. 1–16.
doi:10.1016/j.anihpc.2005.05.007.
- [5]
L. A. Gil-Alana, Testing of stochastic trends, seasonal and cyclical components in macroeconomil time series, Communications for Statistical Applications and Methods 12 (1) (2005) 101–115.
doi:10.5351/CKSS.2005.12.1.101.
- [6]
P. Grazieschi, M. Leocata, C. Mascart, J. Chevallier, F. Delarue, E. Tanré, Network of interacting neurons with random synaptic weights, ESAIM: Proceedings and Surveys 65 (2019) 445–475.
- [7]
O. Faugeras, J. Maclaurin, E. Tanré, The meanfield limit of a network of Hopfield neurons with correlated synaptic weights, arXiv preprint arXiv:1901.10248.
- [8]
S. Ostojic, N. Brunel, V. Hakim, Synchronization properties of networks of electrically coupled neurons in the presence of noise and heterogeneities, Journal of computational neuroscience 26 (3) (2009) 369.
doi:10.1007/s10827-008-0117-3.
- [9]
P. C. Bressloff, Stochastic neural field theory and the system-size expansion, SIAM Journal on Applied Mathematics 70 (5) (2010) 1488–1521.
- [10]
G. D’Onofrio, P. Lansky, E. Pirozzi, On two diffusion neuronal models with multiplicative noise: the mean first-passage time properties, Chaos: An Interdisciplinary Journal of Nonlinear Science 28 (4) (2018) 043103.
- [11]
P. Lansky, L. Sacerdote, C. Zucca, The Gamma renewal process as an output of the diffusion leaky integrate-and-fire neuronal model, Biological cybernetics 110 (2-3) (2016) 193–200.
- [12]
P. Lansky, P. Sanda, J. He, The parameters of the stochastic leaky integrate-and-fire neuronal model, Journal of Computational Neuroscience 21 (2) (2006) 211–223.
doi:10.1007/s10827-006-8527-6.
- [13]
E. Pirozzi, Colored noise and a stochastic fractional model for correlated inputs and adaptation in neuronal firing, Biological cybernetics 112 (1-2) (2018) 25–39.
doi:10.1007/s00422-017-0731-0.
- [14]
J. Touboul, Bifurcation analysis of a general class of nonlinear integrate-and-fire neurons, SIAM Journal on Applied Mathematics 68 (4) (2008) 1045–1079.
- [15]
H. C. Tuckwell, Introduction to Theoretical Neurobiology: Volume 2, Non-Linear and Stochastic Theories, Vol. 8, Cambridge University Press, 1988.
- [16]
C. Mehr, J. McFadden, Certain properties of Gaussian processes and their first-passage times, Journal of the Royal Statistical Society: Series B (Methodological) 27 (3) (1965) 505–522.
- [17]
A. Buonocore, L. Caputo, E. Pirozzi, L. M. Ricciardi, The first passage time problem for Gauss-diffusion processes: algorithmic approaches and applications to LIF neuronal model, Methodology and Computing in Applied Probability 13 (1) (2011) 29–57.
doi:10.1007/s11009-009-9132-8.
- [18]
E. Di Nardo, A. Nobile, E. Pirozzi, L. Ricciardi, A computational approach to first-passage-time problems for Gauss–Markov processes, Advances in Applied Probability 33 (2) (2001) 453–482.
- [19]
A. Buonocore, L. Caputo, G. D’Onofrio, E. Pirozzi, Closed-form solutions for the first-passage-time problem and neuronal modeling, Ricerche di Matematica 64 (2) (2015) 421–439.
doi:10.1007/s11587-015-0248-6.
- [20]
B. Dacorogna, Direct Methods in the Calculus of Variations, Vol. 78, Springer Science & Business Media, 2007.
- [21]
B. Dacorogna, Introduction to the Calculus of Variations, World Scientific Publishing Company, 2014.
- [22]
P. Dayan, L. F. Abbott, Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems, MIT press, 2001.
- [23]
M. F. Carfora, E. Pirozzi, Stochastic modeling of the firing activity of coupled neurons periodically driven, in: Conference Publications, Vol. 2015, American Institute of Mathematical Sciences, 2015, p. 195.
- [24]
M. F. Carfora, E. Pirozzi, Linked Gauss-diffusion processes for modeling a finite-size neuronal network, Biosystems 161 (2017) 15–23.
doi:10.1016/j.biosystems.2017.07.009.
- [25]
H. Royden, P. Fitzpatrick, Real analysis (4th Edtion), New Jersey: Printice-Hall Inc, 2010.
- [26]
E. A. Coddington, N. Levinson, Theory of Ordinary Differential Equations, Tata McGraw-Hill Education, 1987.
- [27]
H. Brezis, Functional analysis, Sobolev spaces and partial differential equations, Springer Science & Business Media, 2010.
- [28]
S. G. Krantz, H. R. Parks, The implicit function theorem: history, theory, and applications, Springer Science & Business Media, 2012.
- [29]
R Core Team, R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria (2019).
URL https://www.R-project.org/
- [30]
L. Sacerdote, M. T. Giraudo, Stochastic integrate and fire models: a review on mathematical methods and their applications, in: Stochastic biomathematical models, Springer, 2013, pp. 99–148.
doi:10.1007/978-3-642-32157-3_5.
- [31]
G. Ascione, M. F. Carfora, E. Pirozzi, A stochastic model for interacting neurons in the olfactory bulb, Biosystems 185 (2019) 104030.
doi:10.1016/j.biosystems.2019.104030.
- [32]
K. Mori, H. Nagao, Y. Yoshihara, The olfactory bulb: coding and processing of odor molecule information, Science 286 (5440) (1999) 711–715.
doi:10.1126/science.286.5440.711.
- [33]
G. M. Shepherd, The Synaptic Organization of the Brain, 1990.
- [34]
J. P. Keener, J. Sneyd, Mathematical Physiology: Systems Physiology. II, Springer, 2009.
- [35]
S.-J. Liu, M. Krstic, Stochastic Averaging and Stochastic Extremum Seeking, Springer Science & Business Media, 2012.
- [36]
J. Jacod, A. Shiryaev, Limit Theorems for Stochastic Processes, Vol. 288, Springer Science & Business Media, 2013.
- [37]
N. Limnios, V. S. Koroliuk, Stochastic Systems in Merging Phase Space, World Scientific, 2005.
- [38]
N. Berglund, B. Gentz, Noise-Induced Phenomena in Slow-Fast Dynamical Systems: a Sample-Paths Approach, Springer Science & Business Media, 2006.
- [39]
W. Liu, M. Röckner, X. Sun, Y. Xie, Averaging principle for slow-fast stochastic differential equations with time dependent locally Lipschitz coefficients, Journal of Differential Equations 268 (6) (2020) 2910–2948.
doi:10.1016/j.jde.2019.09.047.
- [40]
P. Robert, J. Touboul, On the dynamics of random neuronal networks, Journal of Statistical Physics 165 (3) (2016) 545–584.
doi:10.1007/s10955-016-1622-9.
- [41]
O. Faugeras, E. Soret, E. Tanré, Asymptotic behaviour of a network of neurons with random linear interactions.
URL https://hal.archives-ouvertes.fr/hal-01986927
- [42]
F. Flandoli, E. Priola, G. Zanco, A mean-field model with discontinuous coefficients for neurons with spatial interaction, Discrete & Continuous Dynamical Systems - A 39 (1078-0947 2019 6 3037) (2019) 3037.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] I. Karatzas, S. E. Shreve, Brownian Motion and Stochastic Calculus, Springer, 1998.
- 2[2] B. Oksendal, Stochastic Differential Equations: an Introduction with Applications, Springer Science & Business Media, 2013.
- 3[3] M. H. Davis, Complete–market models of stochastic volatility, Proceedings of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences 460 (2041) (2004) 11–26. doi:10.1098/rspa.2003.1233 . · doi ↗
- 4[4] P.-L. Lions, M. Musiela, Correlations and bounds for stochastic volatility models, in: Annales de l’Institut Henri Poincare (C) Non Linear Analysis, Vol. 24, Elsevier, 2007, pp. 1–16. doi:10.1016/j.anihpc.2005.05.007 . · doi ↗
- 5[5] L. A. Gil-Alana, Testing of stochastic trends, seasonal and cyclical components in macroeconomil time series, Communications for Statistical Applications and Methods 12 (1) (2005) 101–115. doi:10.5351/CKSS.2005.12.1.101 . · doi ↗
- 6[6] P. Grazieschi, M. Leocata, C. Mascart, J. Chevallier, F. Delarue, E. Tanré, Network of interacting neurons with random synaptic weights, ESAIM: Proceedings and Surveys 65 (2019) 445–475. doi:10.1051/proc/201965445 . · doi ↗
- 7[7] O. Faugeras, J. Maclaurin, E. Tanré, The meanfield limit of a network of Hopfield neurons with correlated synaptic weights, ar Xiv preprint ar Xiv:1901.10248.
- 8[8] S. Ostojic, N. Brunel, V. Hakim, Synchronization properties of networks of electrically coupled neurons in the presence of noise and heterogeneities, Journal of computational neuroscience 26 (3) (2009) 369. doi:10.1007/s 10827-008-0117-3 . · doi ↗