Anytime Heuristic for Weighted Matching Through Altruism-Inspired Behavior
Panayiotis Danassis, Aris Filos-Ratsikas, Boi Faltings

TL;DR
This paper introduces ALMA, a decentralized, altruism-inspired heuristic for the assignment problem that converges quickly and scales efficiently, outperforming centralized algorithms in large, realistic scenarios.
Contribution
The paper proposes a novel altruism-inspired, decentralized heuristic for weighted matching with proven polynomial convergence bounds and demonstrated scalability and efficiency in practical tests.
Findings
ALMA achieves high social welfare in diverse scenarios.
ALMA converges orders of magnitude faster than optimal centralized algorithms.
ALMA scales to hundreds of thousands of agents in urban vehicle coordination.
Abstract
We present a novel anytime heuristic (ALMA), inspired by the human principle of altruism, for solving the assignment problem. ALMA is decentralized, completely uncoupled, and requires no communication between the participants. We prove an upper bound on the convergence speed that is polynomial in the desired number of resources and competing agents per resource; crucially, in the realistic case where the aforementioned quantities are bounded independently of the total number of agents/resources, the convergence time remains constant as the total problem size increases. We have evaluated ALMA under three test cases: (i) an anti-coordination scenario where agents with similar preferences compete over the same set of actions, (ii) a resource allocation scenario in an urban environment, under a constant-time constraint, and finally, (iii) an on-line matching scenario using real…
Click any figure to enlarge with its caption.
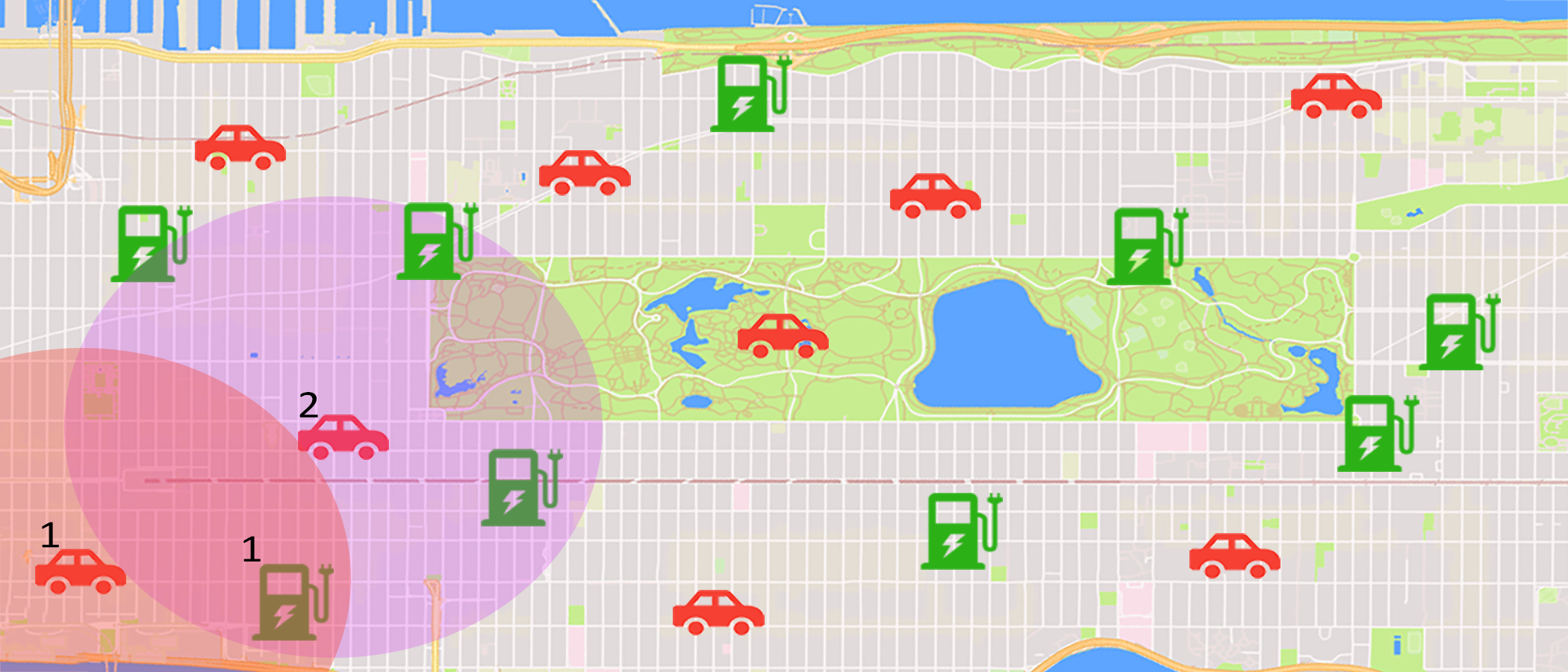 Figure 1
Figure 1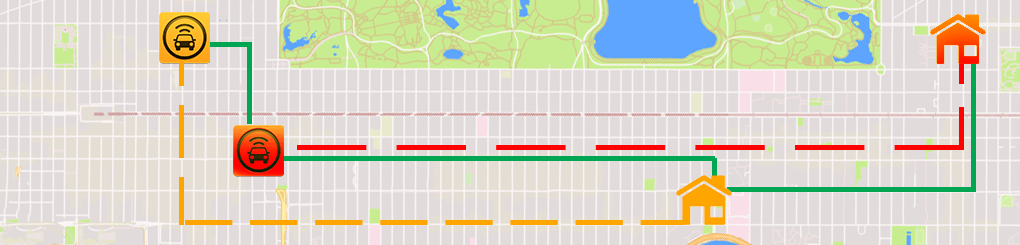 Figure 2
Figure 2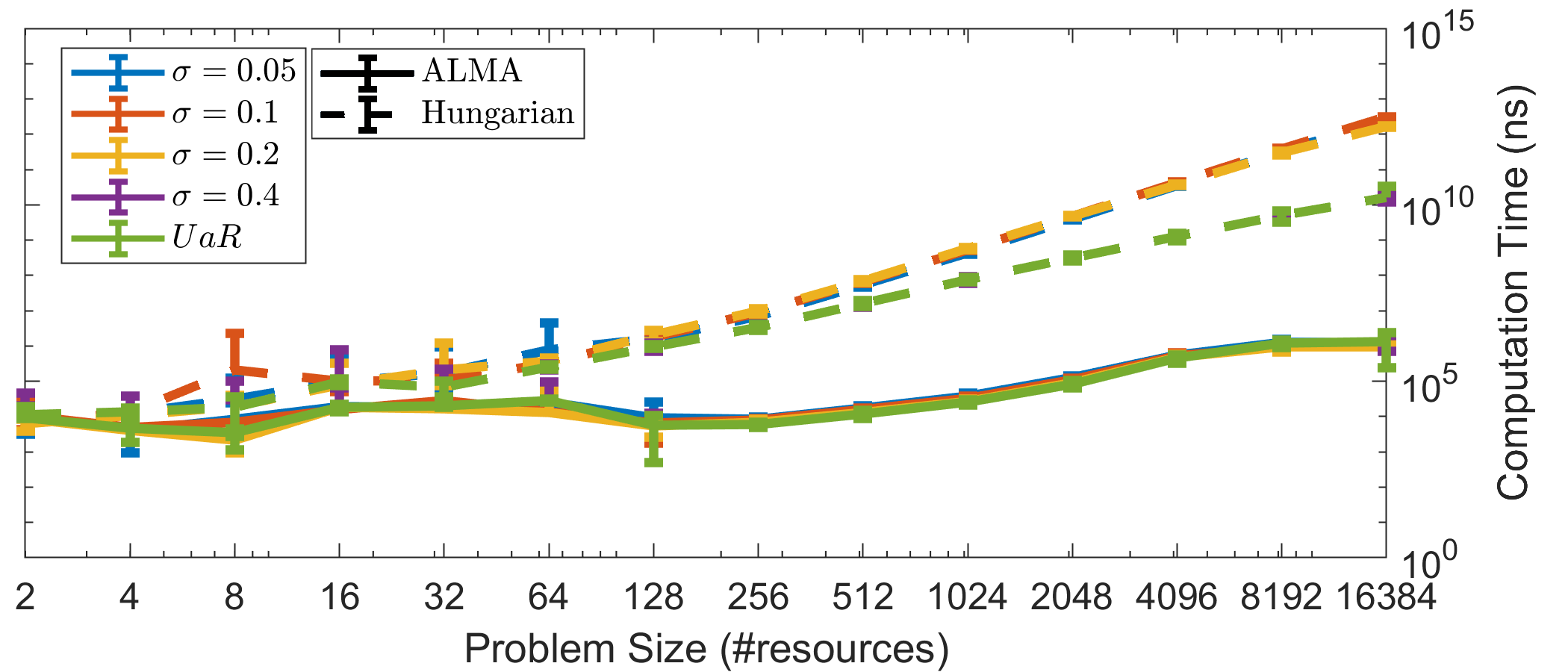 Figure 3
Figure 3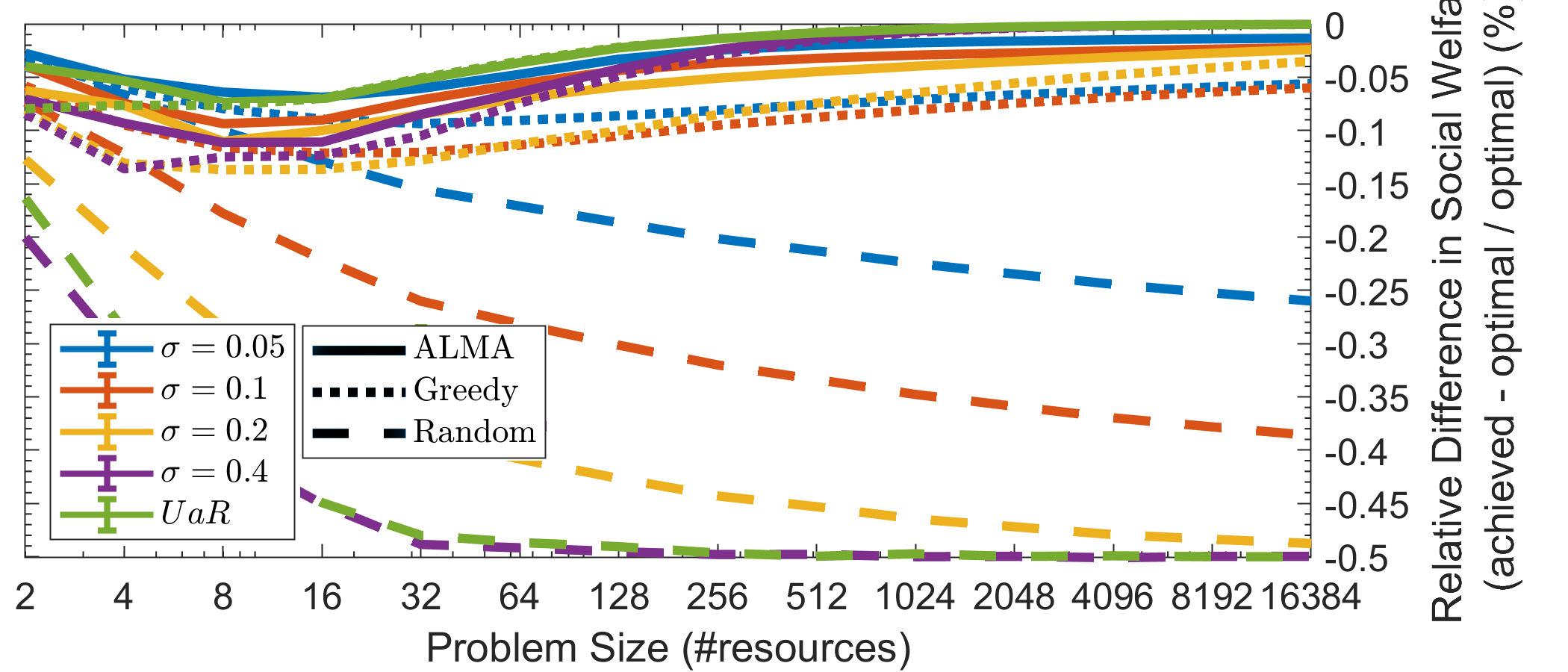 Figure 4
Figure 4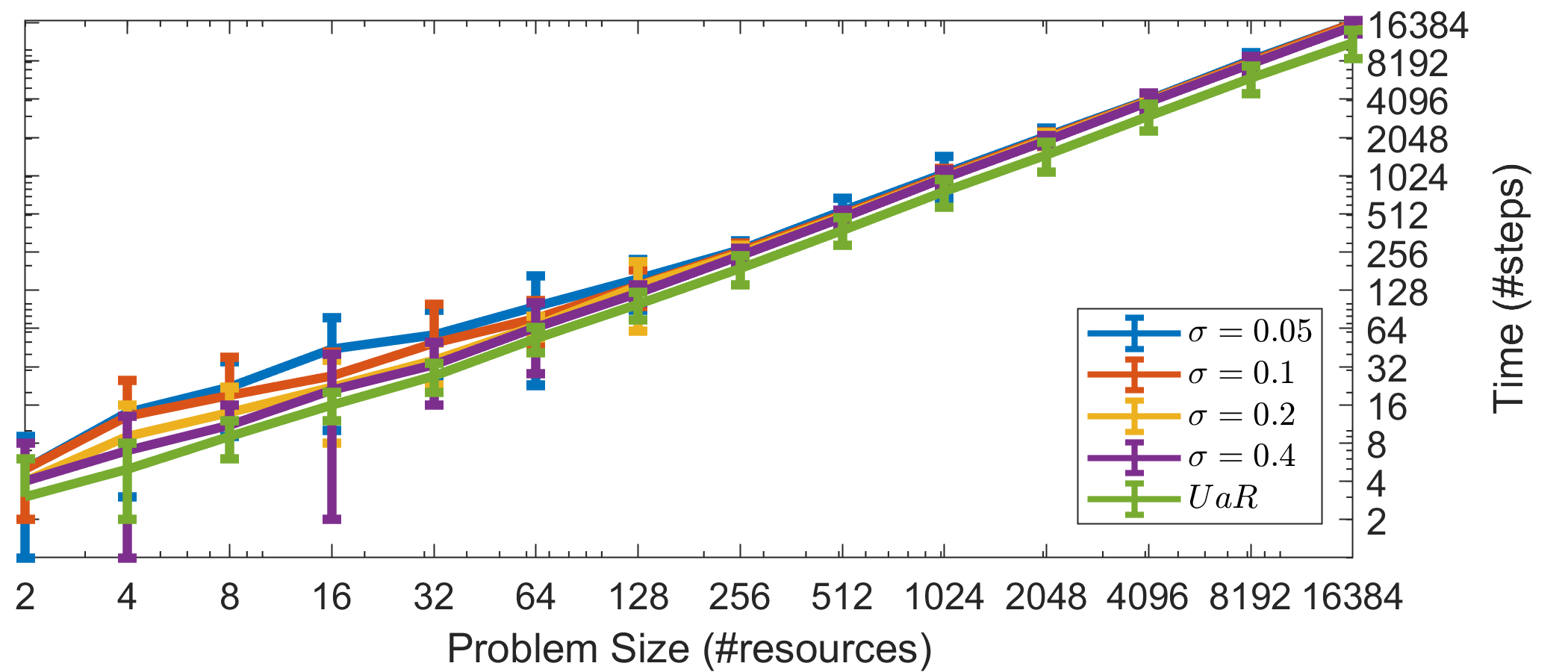 Figure 5
Figure 5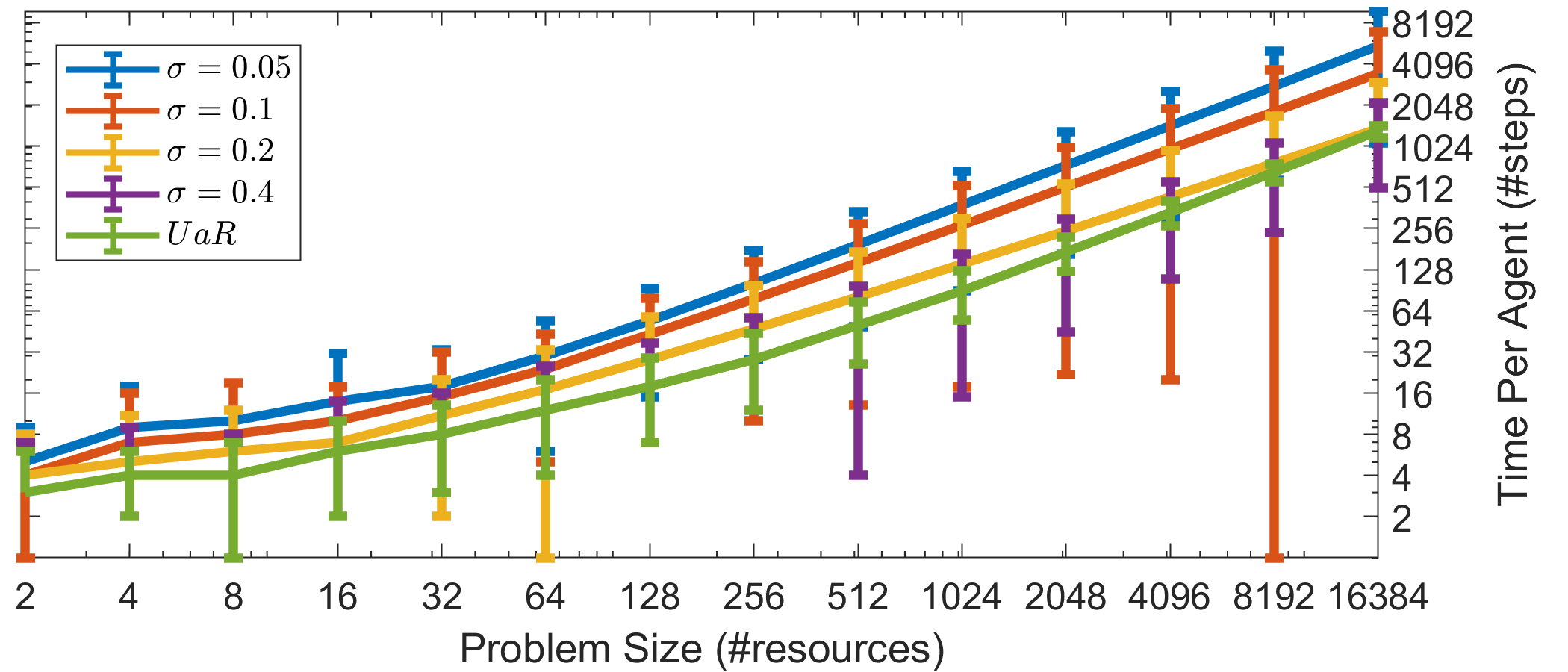 Figure 6
Figure 6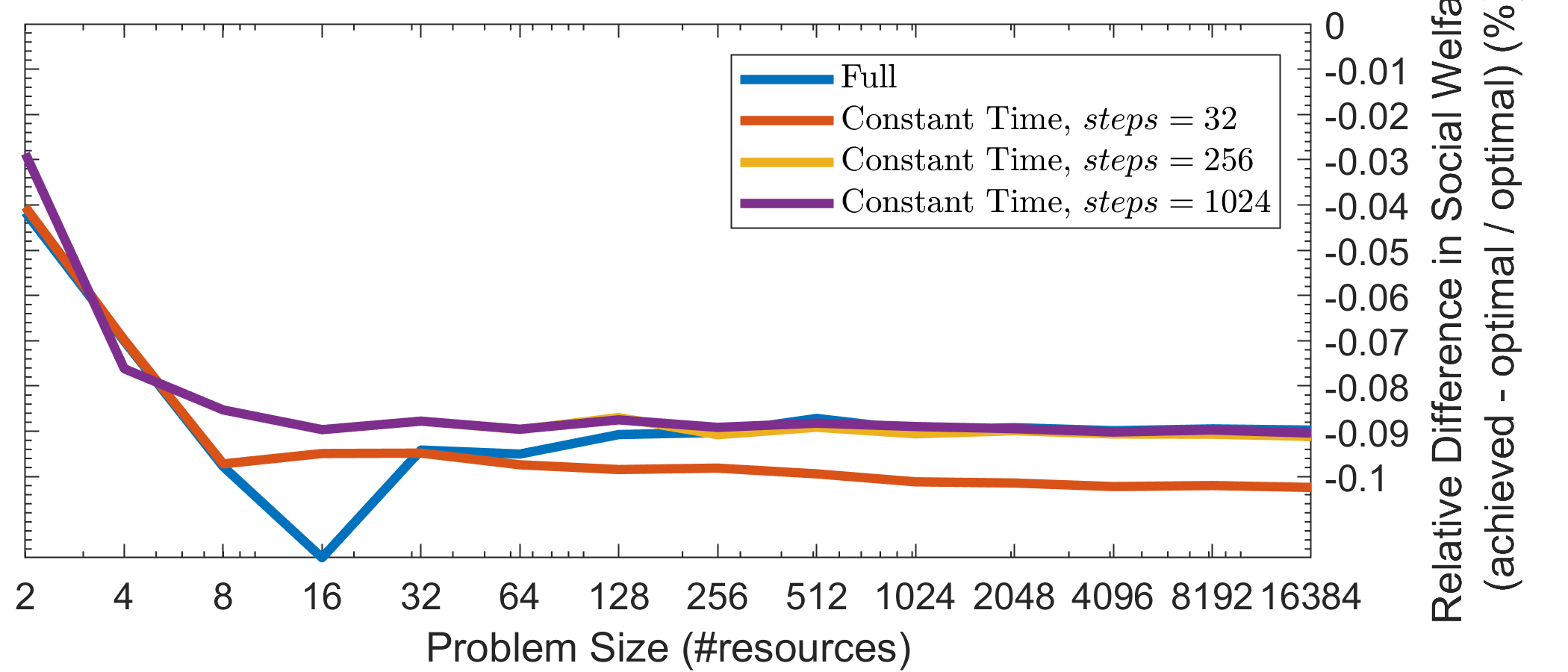 Figure 7
Figure 7 Figure 8
Figure 8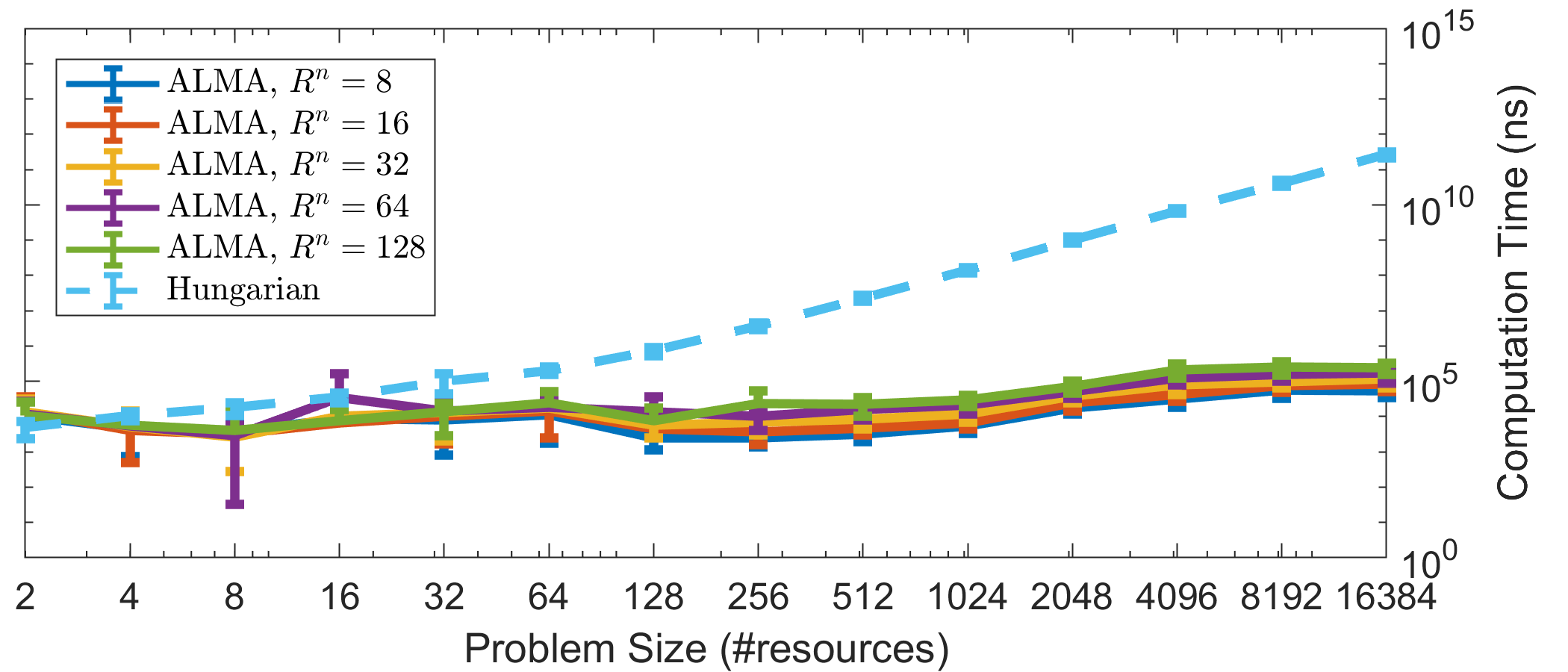 Figure 9
Figure 9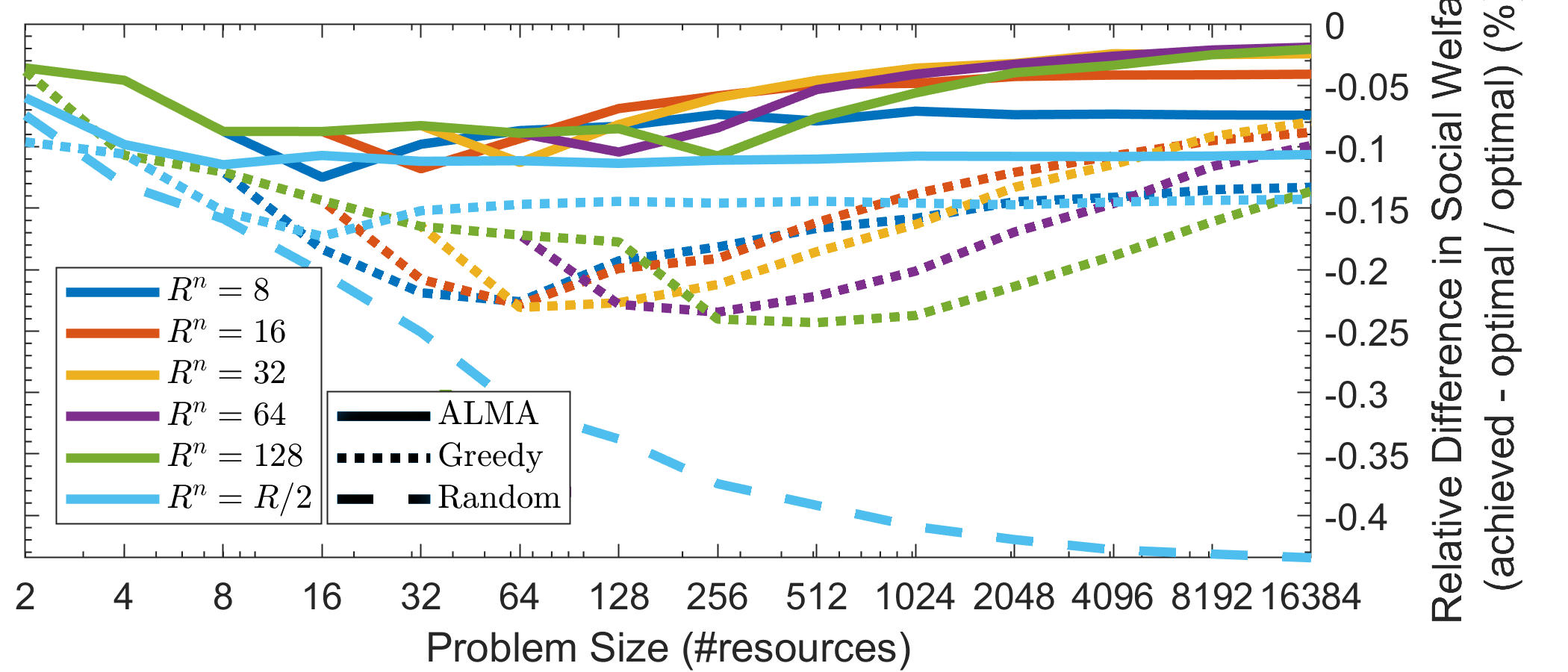 Figure 10
Figure 10 Figure 11
Figure 11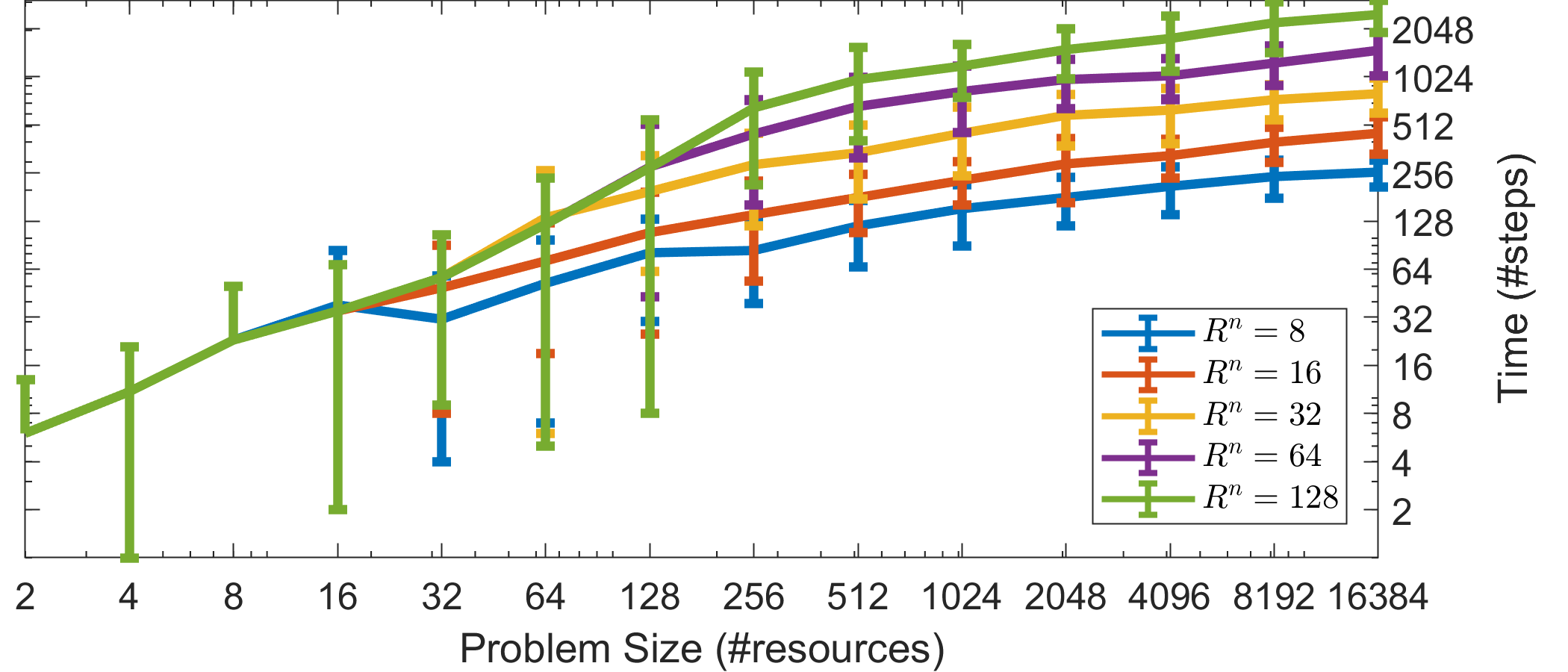 Figure 12
Figure 12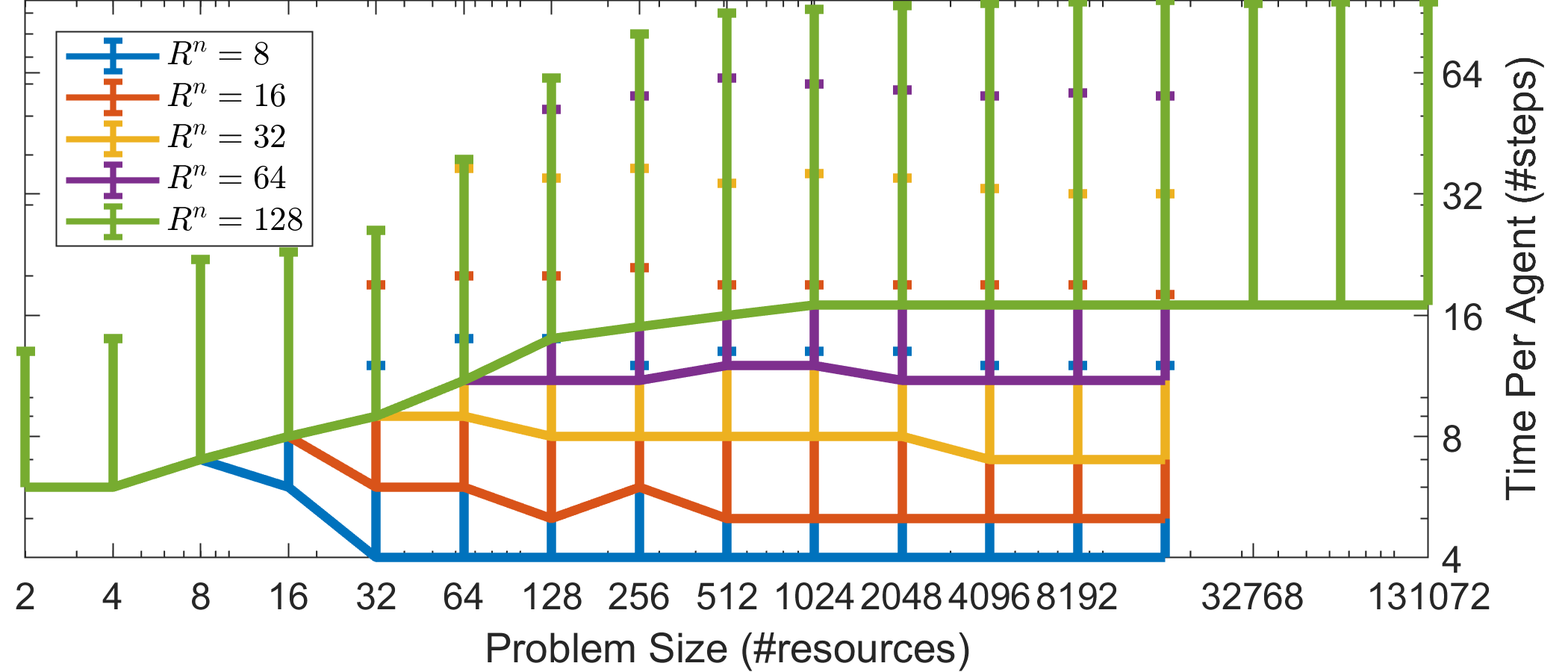 Figure 13
Figure 13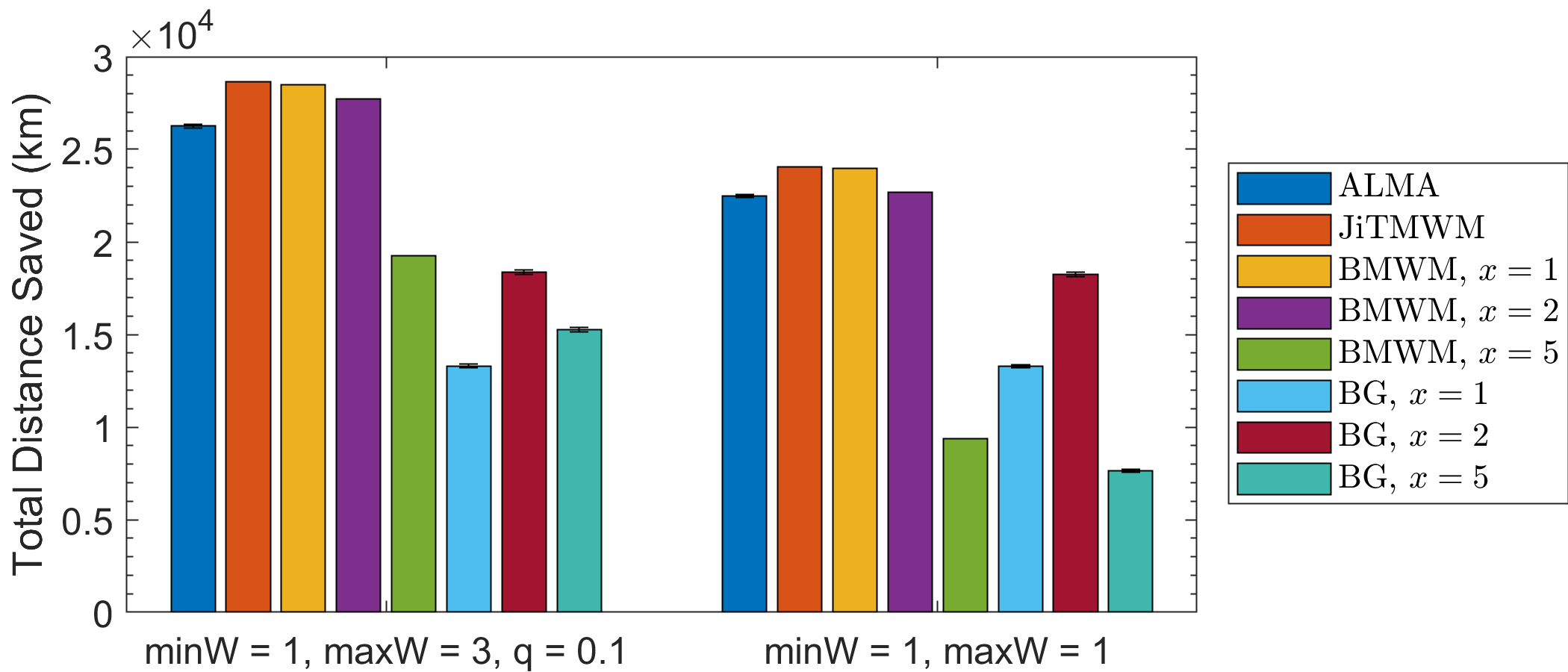 Figure 14
Figure 14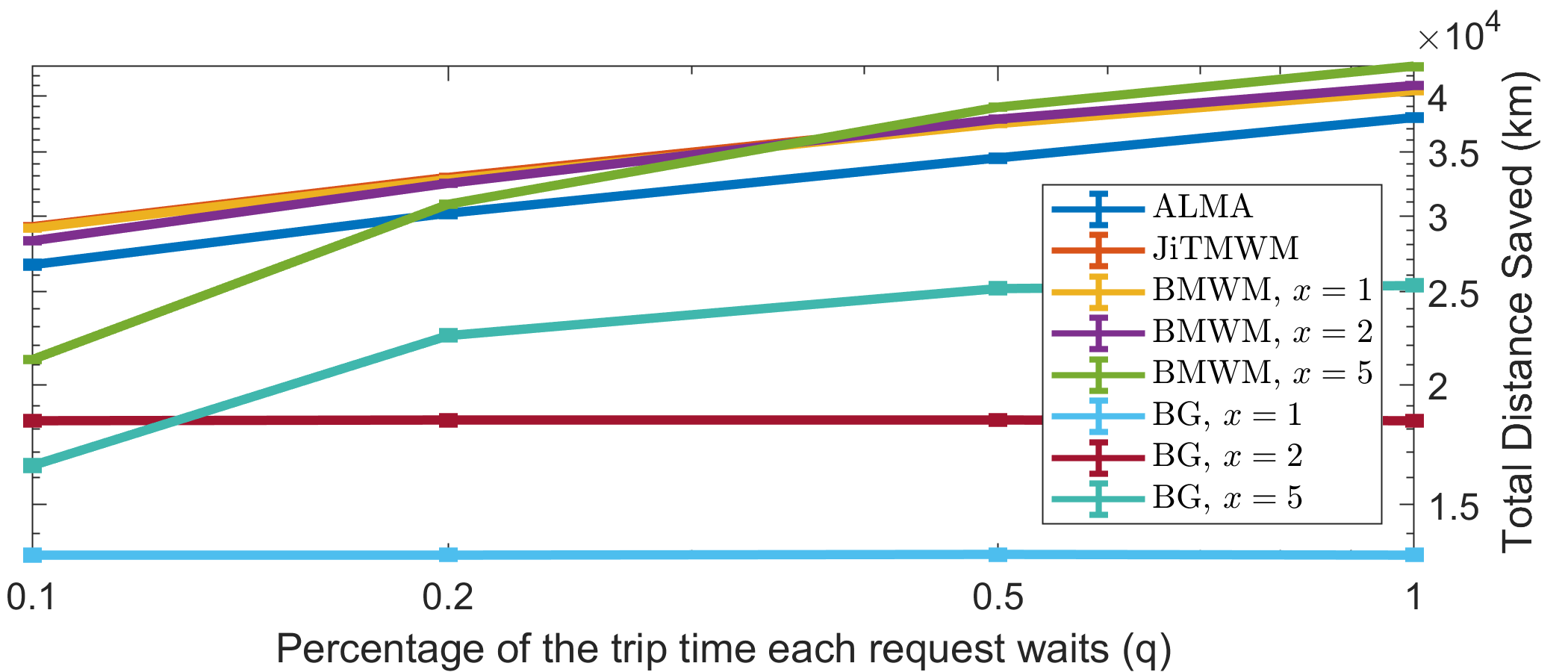 Figure 15
Figure 15| ALMA | JiTMWM | BMWM, | BMWM, | BMWM, | BG, | BG, | BG, | |
|---|---|---|---|---|---|---|---|---|
| 0.7890 | 0.8621 | 0.8568 | 0.8283 | 0.5883 | 0.3991 | 0.5422 | 0.4603 | |
| 0.8491 | 0.9243 | 0.9190 | 0.8663 | 0.3810 | 0.5112 | 0.6891 | 0.3038 | |
| 0.7835 | 0.8528 | 0.8486 | 0.8211 | 0.6221 | 0.3900 | 0.5299 | 0.4840 | |
| 0.7546 | 0.8207 | 0.8158 | 0.8000 | 0.7616 | 0.3399 | 0.4604 | 0.5688 | |
| 0.6939 | 0.7439 | 0.7368 | 0.7448 | 0.7668 | 0.2731 | 0.3714 | 0.5133 | |
| 0.6695 | 0.7390 | 0.7254 | 0.7343 | 0.7706 | 0.2440 | 0.3306 | 0.4606 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
\settopmatter
printacmref=false
\affiliation\institution
Artificial Intelligence Laboratory (LIA), École Polytechnique Fédérale de Lausanne (EPFL)
Anytime Heuristic for Weighted Matching Through Altruism-Inspired Behavior
Panayiotis Danassis, Aris Filos-Ratsikas, Boi Faltings
panayiotis.danassis, aris.filosratsikas, [email protected]
Abstract.
We present a novel anytime heuristic (ALMA), inspired by the human principle of altruism, for solving the assignment problem. ALMA is decentralized, completely uncoupled, and requires no communication between the participants. We prove an upper bound on the convergence speed that is polynomial in the desired number of resources and competing agents per resource; crucially, in the realistic case where the aforementioned quantities are bounded independently of the total number of agents/resources, the convergence time remains constant as the total problem size increases.
We have evaluated ALMA under three test cases: (i) an anti-coordination scenario where agents with similar preferences compete over the same set of actions, (ii) a resource allocation scenario in an urban environment, under a constant-time constraint, and finally, (iii) an on-line matching scenario using real passenger-taxi data. In all of the cases, ALMA was able to reach high social welfare, while being orders of magnitude faster than the centralized, optimal algorithm. The latter allows our algorithm to scale to realistic scenarios with hundreds of thousands of agents, e.g., vehicle coordination in urban environments.
Key words and phrases:
Coordination and Cooperation; Resource Allocation; Multi-agent Learning
1. Introduction
One of the most relevant problems in multi-agent systems (MAS) is finding an optimal allocation between agents. This pertains to role allocation (e.g., team formation for autonomous robots GA (13)), task assignment (e.g., employees of a factory, taxi-passenger matching VCGA (12)), resource allocation (e.g., parking spaces and/or charging stations for autonomous vehicles GC (13)), etc. What follows is applicable to any such scenario, but for concreteness we will refer to the allocation of a set of resources to a set of agents, a setting known as the assignment problem, one of the most fundamental combinatorial optimization problems Mun (57).
When designing algorithms for assignment problems, a significant challenge emerges from the nature of real-world applications, which is often distributed and information-restrictive. For the former part, a variety of decentralized algorithms have been developed GLM (10); IS (17); ZSP (08); BNBA (12), all of which, though, require polynomial in the problem size number of messages. However, inter-agent interactions often repeat no more than a few hundreds of times. Moreover, sharing plans and preferences creates high overhead, and there is often a lack of responsiveness and/or communication between the participants SKKR (10). Achieving fast convergence and high efficiency in such information-restrictive settings is extremely challenging. Yet, humans are able to routinely and robustly coordinate in similar everyday scenarios. One driving factor that facilitates human cooperation is the principle of altruism CR (02); NS (05); Gin (00). Inspired by human behavior, the proposed heuristic is modeled on the principle of altruism. This results to fast convergence to highly efficient allocations, without any communication between the agents.
A distinctive characteristic of ALMA is that agents make decisions locally, based on (i) the contest for resources that they are interested in, (ii) the agents that are interested in the same resources. If each agent is interested in only a subset of the total resources, ALMA converges in time polynomial in the maximum size of the subsets; not the total number of resources. In particular, if the size of each subset is a constant fraction of the total number of resources, then the convergence time is constant, in the sense that it does not grow with the problem size. The same is not true for other algorithms (e.g., the optimal centralized solution) which require time polynomial in the total number of agents/resources, even if the aforementioned condition holds. The condition holds by default in many real-world applications; agents have only local knowledge of the world, there is typically a cost associated with acquiring a resource, or agents are simply only interested in resources in their vicinity (e.g., urban environments). This is important, as the proposed approach avoids having to artificially split the problem in subproblems (e.g, by placing bounds or spatial constraints) and solve those separately, in order to make it tractable. Instead, ALMA utilizes a natural domain characteristic, instead of an artificial optimization technique (i.e., artificial bounds). Coupled to the convergence time, the decentralized nature of ALMA makes it applicable to large-scale, real-world applications (e.g., IoT devices, intelligent infrastructure, autonomous vehicles, etc.).
1.1. Our Results
Our main contributions in this paper are:
(1) We introduce a novel, anytime ALtruistic MAtching heuristic (ALMA) for solving the assignment problem. ALMA is decentralized, completely uncoupled (i.e., each agent is only aware of his own history of action/reward pairs Tal (13)), and requires no communication between the agents.
(2) We prove that if we bound the maximum number of resources an agent is interested in, and the maximum number of agents competing for a resource, the expected number of steps for any agent to converge is independent of the total problem size. Thus, we do not require to artificially split the problem, or similar techniques, to render it manageable.
(3) We provide a thorough empirical evaluation of ALMA on both synthetic and real data. In particular, we have evaluated ALMA under three test cases: (i) an anti-coordination scenario where agents with similar preferences compete over the same set of actions, (ii) a resource allocation scenario in an urban environment, under a constant-time constraint, and finally, (iii) an on-line matching scenario using real passenger-taxi data. In all of the cases, ALMA achieves high social welfare (total satisfaction of the agents) as compared to the optimal solution, as well as various other algorithms.
1.2. Related Work
The assignment problem consists of finding a maximum weight matching in a weighted bipartite graph and it is one of the best-studied combinatorial optimization problems in the literature. The first polynomial time algorithm (with respect to the total number of nodes, and edges) was introduced by Jacobi in the 19th century BJ (65); Oll (09), and was succeeded by many classical algorithms Mun (57); EK (72); Ber (79) with the Hungarian algorithm of Kuh (55) being the most prominent one (see Su (15) for an overview). The problem can also be solved via linear programming Dan (90), as its LP formulation relaxation admits integral optimal solutions PS (82). In Section 3.3, we will apply ALMA on a non-bipartite setting, which corresponds to the more general maximum weight matching problem on general graphs. To compute the optimal in this case, we will use the blossom algorithm of Edm (65) (see LP (09)).
In reality, a centralized coordinator is not always available, and if so, it has to know the utilities of all the participants, which is often not feasible. In the literature of the assignment problem, there also exist several decentralized algorithms (e.g., GLM (10); IS (17); ZSP (08); BNBA (12) which are the decentralized versions of the aforementioned well-known centralized algorithms). However, these algorithms require polynomial computational time and polynomial number of messages (such as cost matrices IS (17), pricing information ZSP (08), or a basis of the LP BNBA (12), etc.). Yet, agent interactions often repeat no more than a few hundreds of times. To the best of our knowledge, a decentralized algorithm that requires no message exchange (i.e., no communication network) between the participants, and achieves high efficiency, like ALMA does, has not appeared in the literature before. Let us stress the importance of such a heuristic: as autonomous agents proliferate, and their number and diversity continue to rise, differences between the agents in terms of origin, communication protocols, or the existence of sub-optimal, legacy agents will bring forth the need to collaborate without any form of explicit communication SKKR (10). Finally, inter-agent communication creates high overhead as well.
ALMA is inspired by the decentralized allocation algorithm of DF (19). Using such a simple learning rule which only requires environmental feedback, allows our approach to scale to hundreds of thousands of agents. Moreover, it does not require global knowledge of utilities; only local knowledge of personal utilities (in fact, we require knowledge of pairwise differences which are far easier to estimate).
2. Altruistic Matching Heuristic
In this section, we define ALMA and prove its convergence properties. We begin with the definition of the assignment problem, and its interpretation in our setting.
2.1. The Assignment Problem
The assignment problem consists of finding a maximum weight matching in a weighted bipartite graph, . In the studied scenario, agents compete to acquire resources. We assume that each agent is interested in a subset of the total resources, i.e., . The weight of an edge represents the utility () agent receives by acquiring resource . Each agent can acquire at most one resource, and each resource can be assigned to at most one agent. The goal is to maximize the social welfare (sum of utilities), i.e.,
[TABLE]
2.2. Learning Rule
This section describes the proposed heuristic (ALMA: ALtruistic MAtching heuristic) for weighted matching. We make the following two assumptions: First, we assume (possibly noisy) knowledge of personal preferences by each agent. Second, we assume that agents can observe feedback from their environment. This is used to inform collisions and detect free resources. It could be achieved by the use of visual, auditory, olfactory sensors etc., or by any other means of feedback from the resource (e.g., by sending an occupancy message). Note here that these messages would be between the requesting agent and the resource, not between the participating agents themselves, and that it suffices to send only 1 bit of information (e.g., 0, 1 for occupied / free respectively).
ALMA learns the right action through repeated trials as follows. Each agent sorts his available resources (possibly ) in decreasing order of utility ( ). The set of available actions is denoted as , where refers to yielding, and refers to accessing resource . Each agent has a strategy () that points to a resource and it is initialized to the most preferred one. As long as an agent has not acquired a resource yet, at every time-step, there are two possible scenarios. If (strategy points to resource ), then agent attempts to acquire that resource. If there is a collision, the colliding parties back-off with some probability. Otherwise, if , the agent choses a resource for monitoring. If the resource is free, he sets . Alg. 1 presents the pseudo-code of ALMA, which is followed by every agent individually. The back-off probability and the next resource to monitor are computed individually and locally based on the current resource and each agent’s utilities, as will be explained in the following section. Finally, note that if the available resources change over time, the agents simply need to sort again the currently available ones.
2.3. Back-off Probability & Resource Selection
Let be totally ordered in decreasing utility under , . If more than one agent compete for resource (step 4 of Alg. 1), each of them will back-off with probability that depends on their utility loss of switching to their respective remaining resources. The loss is given by Eq. 2.
[TABLE]
where denotes the number of remaining resources to be considered. For , the formula only takes into account the utility loss of switching to the immediate next best resource, while for it takes into account the average utility loss of switching to all of the remaining resources. In the remainder of the paper we assume , i.e., . The actual back-off probability can be computed with any monotonically decreasing function on , i.e., . In the evaluation section, we have used two such functions, a linear (Eq. 3), and the logistic function (Eq. 4). The parameter places a threshold on the minimum / maximum back-off probability for the linear curve, while determines the steepness of the logistic curve.
[TABLE]
[TABLE]
Using the aforedescribed rule, agents that do not have good alternatives will be less likely to back-off and vice versa. The ones that do back-off select an alternative resource and examine its availability. The resource selection is performed in sequential order, i.e., , where denotes the resource selected by that agent in the previous round. We also examined the possibility of using a weighted or uniformly at random selection, but achieved inferior results.
2.4. Altruism-Inspired Behavior
ALMA is inspired by the human principle of altruism. We would expect an altruistic person to give up a resource either to someone who values it more, if that resulted in an improvement of the well-being of society CR (02), or simply to be nice to others Sim (16). Such behavior is especially common in situations where the backing-off subject has equally good alternatives. For example, in human pick-up teams, each player typically attempts to fill his most preferred position. If there is a collision, a colliding player might back-off because his teammate is more competent in that role, or because he has an equally good alternative, or simply to be polite; the player backs-off now and assumes that role at some future game. From an alternative viewpoint, following such an altruistic convention leads to a faster convergence which outweighs the loss in utility. Such conventions allow humans to routinely and robustly coordinate in large scale and under dynamic and unpredictable demand. Behavioral conventions are a fundamental part of human societies Lew (08), yet they have not appeared meaningfully in empirical modeling of multi-agent systems. Inspired by human behavior, ALMA attempts to reproduce these simple rules in an artificial setting.
2.5. Convergence
Agents who have not acquired a resource () will not claim an occupied one. Additionally, every time a collision happens, there is a positive probability that some agents will back-off. As a result, the system will converge. The following theorem proves that the expected convergence time is logarithmic in the number of agents and quadratic in the number of resources .
{theorem}
For agents and resources, the expected number of steps until the system of agents following Alg. 1 converges to a complete matching is bounded by (5), where , and is given by Eq. 6.
[TABLE]
[TABLE]
Proof.
To improve readability, we will only provide a sketch of the proof. Please see the appendix for the complete version. The proof is based on CF (11); DF (19).
We first assume that every agent, on every collision, backs-off with the same constant probability . We start with the case of having agents competing for 1 resource and model our system as a discrete time Markov chain. Intuitively, this Markov chain describes the number of individuals in a decreasing population, but with two caveats: the goal (absorbing state) is to reach a point where only one individual remains, and if we reach zero, we restart. We prove that the expected number of steps until we reach a state where either 1 or 0 agents compete for that resource is . Moreover, we prove that with high probability, , only 1 agent will remain (contrary to reaching 0 and restarting the process of claiming the resource), no matter the initial number of agents. Having proven that, we move to the general case of agents competing for resources.
At any time, at most agents can compete for each resource. We call this period a round. During a round, the number of agents competing for a specific resource monotonically decreases, since that resource is perceived as occupied by non-competing agents. Let the round end when either 1 or 0 agents compete for the resource. This will require steps. If all agents backed-off, it will take on average steps until at least one of them finds a free resource. We call this period a break. In the worst case, the system will oscillate between a round and a break. According to the above, one oscillation requires in expectation steps. If , as mentioned in the previous paragraph, in expectation there will be oscillations. For the expected number of oscillations is bounded by . Thus, we conclude that if all the agents back-off with the same constant probability , the expected number of steps until the system converges to a complete matching is .
Next, we drop the constant probability assumption. Intuitively, the worst case scenario corresponds to either all agents having a small back-off probability, thus they keep on competing for the same resource, or all of them having a high back-off probability, thus the process will keep on restarting. These two scenarios correspond to the inner () and outer () probability terms of bound (5) respectively. Let be the worst between the smallest or highest back-off probability any agent can exhibit, i.e., having given by Eq. 6. Using instead of the constant , we bound the expected convergence time according to bound (5). ∎
It is worth noting that the back-off probability in bound (5) does not significantly affect the convergence time. For example, using Eq. 3 with a quite small , the resulting quantities would be at most , and . Most importantly, though, this is a rather loose bound (e.g., agents would rarely back-off with probabilities as extreme as ).
Apart from the convergence of the whole system, we are interested in the expected number of steps any individual agent would require in order to acquire a resource. In real-world scenarios, there is typically a cost associated with acquiring a resource. For example, a taxi driver would not be willing to drive to the other end of the city to pick up a low fare passenger. As a result, each agent is typically interested in a subset of the total resources, i.e., , thus at each resource there is a bounded number of competing agents. Let denote the maximum number of resources agent is interested in, and denote the maximum number of agents competing for resource . By bounding these two quantities (i.e., we consider and to be constant functions of , ), Corollary 2.5 proves that the expected number of steps any individual agent requires in order to claim a resource is independent of the total problem size (i.e., , and ), or, in other words, that the convergence time is constant in these quantities.
*Corollary *\thetheorem
Let , such that , and , such that . The expected number of steps until an agent following Alg. 1 successfully acquires a resource is bounded by (7), where and is given by Eq. 8, independent of the total problem size , .
[TABLE]
[TABLE]
Proof.
The expected number of steps until an agent successfully acquires a resource is upper bounded by the total convergence time of the sub-system he belongs to, i.e., the sub-system consisting of the sets of resources and agents. In such scenario, at most agents can compete for any resource. Using Theorem 2.5 for agents, resources, and worst-case given by any agent in (i.e., Eq 8) results in the desired bound. Note that agents do not compete for already claimed resources (step 8 of Alg. 1), thus the convergence of an agent does not require the convergence of agents of overlapping sub-systems. ∎
3. Evaluation
In this section we evaluate ALMA under various test cases. For the first two, we focus on convergence time and relative difference in social welfare (SW), i.e., . In every reported metric, except for the social welfare, we report the average value out of 128 runs of the same problem instance. Error bars represent one standard deviation (SD) of uncertainty. As a measure of social welfare, we report the cumulative regret of the aforementioned 128 runs, i.e., for runs, the reported relative difference in social welfare is . This was done to improve visualization of the results in smaller problem sizes, where really small differences result in high SD bars (e.g., if = , and = , the relative difference would be for practically the same matching). The optimal matchings were computed using the Hungarian algorithm 111We used Kevin L. Stern’s implementation: https://github.com/KevinStern/.. The third test case is an on-line setting, thus we report the achieved SW (not the relative difference to the optimal), and the empirical competitive ratio (average out of 128 runs, as before). All the simulations were run on 2x Intel Xeon E5-2680 with 256 GB RAM. In Section 3.1 we use the logistic function (Eq. 4) with , while in Sections 3.2 & 3.3 we use the linear function (Eq. 3) with .
It is important to stress that our goal is not to improve the convergence speed of a centralized, or decentralized algorithm. Rather, the computation time comparisons of Sections 3.1 & 3.2 are meant to ground the actual speed of ALMA, and argue in favor of its applicability on large-scale, real-world scenarios. Given the nature of the problem, we elected to use a specialized algorithm to compute the optimal solution, rather than a general LP-based technique (e.g., the Simplex method). Specifically, we opted to use the Hungarian algorithm which, first, has proven polynomial worse case bound, and second, as our simulations will demonstrate, can handle sufficiently large problems.
3.1. Test Case #1: Uniform, and Noisy Common Preferences
3.1.1. Setting
As a first evaluation test case, we cover the extreme scenarios. The first pertains to an anti-coordination scenario in which agents with similar preferences compete over the same set of actions DF (18). For example, autonomous vehicles would prefer the least congested route, bidding agents participating in multiple auctions would prefer the ones with the smallest number of participants, etc. We call this scenario ‘noisy common preferences’ and model the utilities as follows: , where the noise is sampled from a zero-mean Gaussian distribution, i.e., 222Similar results achieved using uniform noise, i.e., .. In the second scenario the utilities are initialized uniformly at random () for each agent and resource.
3.1.2. Convergence Time
Starting with Fig. 1(a), we can see that the convergence time for the system of agents following Alg. 1 is linear to the number of resources . From the perspective of a single agent, Fig. 1(b) shows that on average he will successfully acquire a resource significantly () faster than the total convergence time. This suggest that there is a small number of agents which take longer in claiming a resource and which in turn delay the system’s convergence. We will exploit this property in the next section to present the anytime property of ALMA. Fig. 1(c) shows that ALMA requires approximately 4 to 6 orders of magnitude less computation time than the centralized Hungarian algorithm. Furthermore, ALMA seems to scale more gracefully, an important property for real world applications. Note also that in real-world applications we would have to take into account communication time, communication reliability protocols, etc., which create additional overhead for the Hungarian or any other algorithm for the assignment problem.
3.1.3. Efficiency
The relative difference in social welfare (Fig. 1(d)) reaches asymptotically zero as increases. For a small number of resources, ALMA achieves the worst social welfare, approximately worse than the optimal. Intuitively this is because when we have a small number of choices, a single wrong matching can have a significant impact to the final social welfare, while as the number of resources grow, the impact of an erroneous matching is mitigated. For 16384 resources we lose less than of the optimal. As a reference, Fig. 1(d) depicts the centralized greedy, and the random solutions as well. The greedy solution goes through the participating agents randomly, and assigns them their most preferred unassigned resource. In this scenario, the random solution loses up to of the optimal SW, while the greedy solution achieves similar results to ALMA, especially in high noise situations. This is to be expected, since first, all agents are interested in all the resources, and second, as the noise increases, the agents’ preferences become more distinguishable, more diverse. ALMA is of a greedy nature as well, albeit it utilizes a more intelligent backing-off scheme. Contrary to that, the greedy solution does not take into account the utilities between agents, thus there are scenarios where ALMA would significantly outperform the greedy (e.g., see Section 3.3). Finally, recall that ALMA operates in a significantly harder domain with no communication, limited feedback, and time constraints. In contrast, the greedy method requires either a central coordinator or message exchange (to communicate users’ preferences and resolve collisions).
3.2. Test Case #2: Resource Allocation in a Cartesian Map with Manhattan Distances
Adopting a simple rule allows the applicability of ALMA to large scale multi-agent systems. In this section we will analyze such a scenario. Specifically we are interested in resource allocation in urban environments (e.g., parking spots / charging stations for autonomous vehicles, taxi - passenger matchings, etc.). The aforementioned problems become ever more relevant due to rapid urbanization, and the natural lack of coordination in the usage of resources Var (16). The latter result in the degradation of response (e.g., waiting time) and quality metrics in large cities Var (16).
3.2.1. Setting
Let us consider a Cartesian map representing a city on which are randomly distributed vehicles and charging stations, as depicted in Fig. 2(h). The utility received by a vehicle for using a charging station is proportional to the inverse of their distance, i.e., . Since we are in an urban environment, let denote the Manhattan distance. Typically, there is a cost each agent is willing to pay to drive to a resource, thus there is a cut-off distance, upon which the utility of acquiring the resource is zero (or possibly negative). This is a typical scenario encountered in resource allocation in urban environments, where there are spatial constraints and local interactions.
The way such problems are typically tackled, is by dividing the map to sub-regions, and solving each individual sub-problem. For example, Singapore is divided into 83 zones based on postal codes CN (11), and taxi drivers’ policies are optimized according to those NKL (17); VCGA (12). On the other hand, not placing bounds means that the current solutions will not scale. To the best of our knowledge, we are the first to propose an anytime heuristic for resource allocation in urban environments that can scale in constant time without the need to artificially split the problem. Instead, ALMA exploits the two typical characteristics of an urban environment: the anonymity in interactions and homogeneity in supply and demand Var (16) (e.g., assigning any of two equidistant charging stations to a vehicle, would typically result to the same utility). This results in a simple learning rule which, as we will demonstrate in this section, can scale to hundreds of thousands of agents.
3.2.2. Convergence Time
To demonstrate the latter, we placed a bound on the maximum number of resources each agent is interested in, and on the maximum number of agents competing for a resource, specifically . According to Corollary 2.5, bounding these two quantities should result in convergence in constant time, regardless of the total problem size (R, N). The latter is corroborated by Fig. 2(a), which shows that the average number of time-steps until an agent successfully claims a resource remains constant as we increase the total problem size. Same is true for the system’s convergence time (Fig. 2(b)), which caps as increases. The small increase is due to outliers, as Fig. 2(b) reports the convergence time of the last agent. This results to approximately orders of magnitude less computation time than the centralized Hungarian algorithm (Fig. 2(c)), and this number would grow boundlessly as we increase the total problem size. Moreover, as mentioned, in an actual implementation, any algorithm for the assignment problem would face additional overhead due to communication time, reliability protocols, etc.
3.2.3. Efficiency
Along with the constant convergence time, ALMA is able to reach high quality matchings, achieving less than worse social welfare (SW) than the optimal (Fig. 2(d)). The latter refers to the small bound of . As observed in Section 3.1, with a small number of choices, a single wrong matching can have a significant impact to the final social welfare. By increasing the bound to a more realistic number (e.g., ), we achieve less than worse SW. In general, for resources and different values of , ALMA achieves between loss in SW, while the greedy approach achieves and the random . The behavior of the graphs depicted in Fig. 2(d) for indicate that, as the problem size () increases, the social welfare reaches its lowest value at . To investigate the latter, we have included a graph for increasing (instead of constant to the problem size), specifically . ALMA achieves a constant loss in social welfare (approximately ). The greedy approach achieves loss of , while the random solution degrades towards loss.
Compared to Test Case #1, this is a significantly harder problem for a decentralized algorithm with no communication and no global knowledge of the resources. The set of resources each agent is interested in is a proper subset of the set of the total resources, i.e., (or could be ). Furthermore, the lack of communication between the participants, and the stochastic nature of the algorithm can lead to deadlocks, e.g., in Fig. 2(h), if vehicle 2 acquires resource 1, then vehicle 1 does not have an available resource in range. Nonetheless, ALMA results in an almost complete matching. Fig. 2(e), depicts the percentage of ‘winners’ (i.e., agents that have successfully claimed a resource such that ). The aforementioned percentage refers to the total population () and not the maximum possible matchings (potentially ). As depicted, the percentage of ‘winners’ is more than , reaching up to for . We also employed ALMA in larger simulations with up to agents, and equal resources. As seen in Fig. 2(e), the percentage of winners remains stable at around . Even though the size of the problem prohibited us from running the Hungarian algorithm (or an out-of-the-box LP solver) and validating the quality of the achieved matching, the fact that the percentage of winners remains the same suggests that the relative difference in SW will continue on the same trend as in Fig. 2(d). Moreover, the average steps per agent to claim a resource remains, as proven, constant (Fig. 2(a)). The latter validate the applicability of ALMA in large scale applications with hundreds of thousands of agents.
3.2.4. Anytime Property
In the real world, agents are required to run in real time, which imposes time constraints. ALMA can be used as an anytime heuristic as well. To demonstrate the latter, we compare four configurations: the ‘full’ one, which is allowed to run until the systems converges, and three ‘constant time’ versions which are given a time budget of 32, 256, and 1024 time-steps. In this scenario, we do not impose a bound on , but we assume a cut-off distance, upon which the utility is zero. The cut-off distance was set to of the maximum possible distance, i.e., as the problem size grows, so do the . On par with Test Case #1, the full version converges in linear time. As depicted in Fig. 2(f), the achieved SW is less than worse than the optimal. The inferior results in terms of SW compared to Test Case #1 are because this is a significantly harder problem due to the aforementioned deadlocks. On the other hand though, ALMA benefits from the spatial constraints of the problem. The average number of time-steps an individual agent needs to successfully claim a resource is significantly smaller, which suggest that we can enforce computation time constraints. Restricting to only 32, 256, and 1024 time-steps, results in , , and worse SW than the unrestricted version, respectively. Even in larger simulations with up to agents, the percentage of winners (Fig. 2(g)) remains stable at , which suggests that the relative difference in SW will continue on the same trend as in Fig. 2(f) (we do not suggest that this is the case in any domain. For example, in the noisy common preferences domain of Test Case #1, the quality of the achieved matching decreases boundlessly as we decrease the alloted time. Nevertheless, the aforedescribed domain is a realistic one, with a variety of real-world applications). Finally, the repeated nature of such problems suggests that even in the case of a deadlock, the agent which failed to win a resource, will do so in some subsequent round.
3.3. Test Case #3: On-line Taxi Request Match
In this section we present a motivating test case involving ride-sharing, via on-line taxi request matching, using real data of taxi rides in New York City. Ride-sharing (or carpooling), offers great potential in congestion relief and environmental sustainability in urban environments. In the past few years, several commercially successful ride-sharing companies have surfaced (e.g., Uber, Lyft, etc.), giving rise to a new incarnation of ride-sharing: dynamic ride-sharing, where passengers are matched in real-time. Ride-sharing, though, results to some passenger disruption due to loss in flexibility, security concerns, etc. Compensation comes in the form of monetary incentives, as it allows passengers to share the travel expenses, and thus reduce the cost. Ride-sharing companies account for a plethora of factors, like current demand, prime time pricing, the cost of the route without any ride-sharing, the likelihood of a match, etc. Yet, a fundamental factor of the cost of any shared ride, no matter if it is a company or a locally-organized car sharing scheme, is the traveled distance.
In this test case, we attempt to maximize the total distanced saved, by matching taxi requests of high overlap. Fig. 3 provides an illustrative example. There are two passengers (depicted as yellow and red) with high overlap routes. Each can drive on their own to their respective destinations (dashed yellow and red line respectively), or share a ride (green line) and reduce travel costs.
Dynamic ride-sharing is an inherently on-line setting, as a matching algorithm is unaware of the requests that will appear in the future and needs to make decisions for the requests before they ‘expire’ (a similar setting was studied in ABD*+* (18)). ALMA is highly befitting for such a scenario, as it involves large-scale matchings under dynamic demand, it is highly decentralized, and partially observable.
3.3.1. Setting
We use a dataset 333https://www.kaggle.com/debanjanpaul/new-york-city-taxi-trip-distance-matrix/ of all taxi requests in New York City during one week ({01-01-16 0:00 - 01-07-16 23:59}, 34077 requests in total). The data include pickup and drop-off times, and geolocations. Requests appear (become open) at their respective pickup time, and wait time-steps to find a match. Let a time-step be one minute. After time-steps we call request , critical. If a critical request is not matched, we assume they drive off to their destination in a single passenger ride. Let denote the sets of open, and critical requests respectively, and let . To compute we assume the following: There is a minimum , and a maximum waiting time set by the ride-sharing company, i.e., . Moreover, since each passenger specifies his destination in advance, we can compute the trip time (). Assuming people are willing to wait for a time that is proportional to their trip time, let , where . The parameters , and can be set by the ride-sharing company. We report results on different values for all of the above parameters. For each pair of requests, we compute the driving distance ( of all possible combinations of driving between ’s pickup and drop-off locations) that would be traveled if are matched, i.e., if they share the same taxi. Subsequently, the utility of matching to (distance saved) is (km).
Given the on-line nature of the setting, it might be beneficial to use the following non-myopic heuristic: avoid matching low utility pairs, as long as the requests are not critical, since more valuable pairs might be presented in the future. Thus, if , and , we do not match , . In what follows, we select for each algorithm and for each simulation the value that results in the highest score. To compute the actual trip time, and driving distance, we have used the Open Source Routing Machine 444http://project-osrm.org/, which computes shortest paths in road networks.
3.3.2. Computation of the optimal matching
In this scenario, each request has a dual role, being both an agent and a resource, i.e., we have a non-bipartite graph. For computing the optimal (maximum weight) matching for the employed on-line heuristics, we use the blossom algorithm of Edm (65), which computes a maximum weight matching in general graphs. This enables us to compute the best possible matching among current requests, i.e., requests that have not ‘expired’ at the time of the computation. In fact, the following observation allows us to compute the optimal off-line matching as well, i.e., the best possible matching over the whole time interval. Let be the pick-up time of request and let be the time when it becomes critical. Then, we can redefine the utility of a matching as:
[TABLE]
i.e., the utility is the distance saved if both requests are simultaneously active when matched and otherwise. The latter effectively results in this pair never being matched in an optimal solution. We remark that this clairvoyant matching is not feasible in the on-line setting and serves as a benchmark against which we can compare the performance of on-line algorithms, as is common in the literature of competitive analysis BEY (05). The measure of efficiency, as compared to the off-line optimal, will be the empirical competitive ratio, i.e., the ratio of the social welfare of the on-line algorithm over the welfare of the optimal, as measured empirically for our dataset.
3.3.3. The Blossom Algorithm vs Linear Programming
Contrary to the other test cases, the fact that the graph is not bipartite has implications on how linear programming can be used to compute the optimal solution. In particular, in all of the presented test cases (#1, #2, and #3), one can formulate the problem of computing the optimal solution as an Integer Linear Program (ILP) and then solve it using some general solver like CPLEX 555https://www.ibm.com/analytics/cplex-optimizer. Yet, the computational complexity of solving the aforementioned ILP varies amongst the different test cases.
Solving integer linear programs is generally quite computationally demanding. Thus, it is common to resort to solving the LP relaxation (where the integrality constraints have been ‘relaxed’ to fractional constraints), which can be computed in polynomial time.
In the case of bipartite graphs (such as test cases #1 and #2), the standard LP relaxation admits integer solutions, i.e., solutions to the actual maximum weight bipartite matching problem (because the constraint matrix is totally unimodular). In the case of general (non-bipartite) graphs, this is no longer the case, thus we have to resort to solving the LP relaxation. It is known that the (fractional) optimal solution to the LP relaxation might be better than the (integral) optimal solution to the original ILP formulation (i.e., it has an integrality gap which is larger than , in fact ). In other words, solving the LP relaxation will not provide solutions for the maximum weight matching problem but for an ‘easier version’ with fractional matchings. Thus, comparing against that solution could only give very pessimistic ratios, when the real empirical competitive ratios are much better.
One can derive a different ILP formulation of the problem using more involved constraints (called ‘blossom’ constraints Edm (65)), whose relaxation admits integer solutions (i.e., the integrality gap is now ). However, the latter would result in an exponential number of constraints, and one would need to employ the Ellipsoid method with an appropriately chosen separation oracle to solve it in polynomial time (see (FOW, 02, page 4) for more details]. Overall, the employment of the combinatorial algorithm of Edm (65) for finding the maximum weight matching is a cleaner and more efficient solution.
3.3.4. Benchmarks
Each request runs ALMA independently. ALMA waits until the request becomes critical, and then matches it by running Alg. 1, where , and . In this non-bipartite scenario, if an agent is matched under his dual role as a resource, he is immediately removed. As we explained earlier, it is infeasible for an on-line algorithm to compute the optimal matching over the whole period of time. Instead, we consider just-in-time and in batches optimal solutions. Specifically, we compare to the following AESW (11); ABD*+* (18):
- •
Just-in-time Max Weight Matching (JiTMWM): Waits until a request becomes critical and then computes a maximum-weight matching of all the current requests, i.e .
- •
Batching Max Weight Matching (BMWM): Waits time-steps and then computes a maximum-weight matching of all the current requests, i.e .
- •
Batching Greedy (BG): Waits time-steps and then greedily matches current requests, i.e (ties are broken randomly). Unmatched open requests are removed. For batch size we get the simple greedy approach where requests are matched as soon as they appear.
3.3.5. Efficiency
Starting with the social welfare, Fig. 4 presents the total distance saved (km) for various values of , and . ALMA loses of SW in the pragmatic scenario of Fig. 4(a) (left), and when the requests become critical in just one time-step (Fig. 4(a) (right)). If no bounds are placed on the minimum and maximum waiting time (i.e., ), ALMA exhibits loss of , for various values of (Fig. 4(b)). The above are compared to the best performing benchmark on each scenario (JiTMWM, or BMWM, ). Moreover, it significantly outperforms every greedy approach. In the first scenario the BGs lose between , in the second between , and in the third between .
Once more, it is worth noting that ALMA requires just a broadcast of a single bit to indicate the occupancy of a resource, while the compared approaches require either message exchange for sharing the utility table, or the use of a centralized authority. For example, the greedy solution would require message exchange to communicate users’ preferences and resolve collisions in a decentralized setting, and every batching approach would require a common centralized synchronization clock.
Table 1 presents the empirical competitive ratio for the first day of the week of the employed dataset. As we can see, even in the extreme, unlikely scenarios where we assume that people would be willing to wait for more than 10 or 20 minutes (which correspond to large values of ), ALMA achieves high relative efficiency, compared to the off-line (infeasible) benchmark. These scenarios are favorable to the off-line optimal, because requests stay longer in the system and therefore the algorithm takes more advantage of its foreseeing capabilities (hence, the drop in the competitive ratios is observed in all of the employed algorithms). In particular, ALMA achieves an empirical competitive ratio of for and even better ratios for more realistic scenarios (as large as ). The just-in-time and batch versions of the maximum weight matching perform slightly better, but this is to be expected, as they compute the maximum weight matching on the graphs of the current requests. In spite of the unpredictability of the on-line setting, and the dynamic nature of the demand, ALMA is consistently able to exhibit high performance, in all of the employed scenarios.
4. Conclusion
Algorithms for solving the assignment problem, whether centralized or distributed, have runtime that increases with the total problem size, even if agents are interested in a small number of resources. Thus, they can only handle problems of some bounded size. Moreover, they require a significant amount of inter-agent communication. Humans on the other hand are routinely called upon to coordinate in large scale in their everyday lives, and are able to fast and robustly match with resources under dynamic and unpredictable demand. One driving factor that facilitates human cooperation is the principle of altruism. Inspired by human behavior, we have introduced a novel anytime heuristic (ALMA) for weighted matching in both bipartite and non-bipartite graphs. ALMA is decentralized and requires agents to only receive partial feedback of success or failure in acquiring a resource. Furthermore, the running time of the heuristic is constant in the total problem size, under reasonable assumptions on the preference domain of the agents. As autonomous agents proliferate (e.g., IoT devices, intelligent infrastructure, autonomous vehicles, etc.), having robust algorithms that can scale to hundreds of thousands of agents is of utmost importance.
The presented results provide an empirical proof of the high quality of the achieved solution in a variety of scenarios, including both synthetic and real data, time constraints and on-line settings. Furthermore, both the proven theoretical bound (which guarantees constant convergence time), and the computation speed comparison (which grounds ALMA to a proven fast centralized algorithm), argue for its applicability to large scale, real world problems. As future work, it would be interesting to identify meaningful domains in which ALMA can provide provable worst-case performance guarantees, as well as to empirically evaluate its performance on other real datasets, corresponding to important real-world, large-scale problems.
Appendix A Appendix
A.1. Proof of Theorem 2.5
Theorem 2.5.
For agents and resources, the expected number of steps until the system of agents following Alg. 1 converges to a complete matching is bounded by (10), where and is given by Eq. 11.
[TABLE]
[TABLE]
In this section we provide a formal proof of Theorem 2.5. 666The proof is an adaptation of the convergence proof of [7] and [12]. To facilitate the proof, we will initially assume that every agent, on every collision, backs-off with the same constant probability, i.e.,:
[TABLE]
A.1.1. Case #1: Multiple Agents, Single resource ()
We will describe the execution of the proposed learning rule as a discrete time Markov chain (DTMC) 777For an introduction on Markov chains see [26]. In every time-step, each agent performs a Bernoulli trial with probability of ‘success’ (remain in the competition), and failure (back-off). When agents compete for a single resource, a state of the system is a vector denoting the individual agents that still compete for that resource. But, since the back-off probability is the same for everyone (Eq. 12), we are only interested in how many agents are competing and not which ones. Thus, in the single resource case (), we can describe the execution of the proposed algorithm using the following chain:
Definition \thetheorem.
Let be a DTMC on state space denoting the number of agents still competing for the resource. The transition probabilities are as follows:
[TABLE]
(all the other transition probabilities are zero)
Intuitively, this Markov chain describes the number of individuals in a decreasing population, but with two caveats: The goal (absorbing state) is to reach a point where only one individual remains, and if we reach zero, we restart.
Before proceeding with Theorem 2.5’s convergence proof, we will restate Mityushin’s Theorem [30] for hitting time bounds in Markov chains, define two auxiliary DTMCs, and prove two auxiliary lemmas.
{theorem}
(Mityushin’s Theorem [30]) Let be the absorbing state of a Markov chain . If , and some , then:
[TABLE]
where denotes the hitting time of a state in , starting from state .
Definition \thetheorem.
Let be a DTMC on state space with the following transition probabilities (two absorbing states, 0 and 1):
[TABLE]
(all the other transition probabilities are zero)
Definition \thetheorem.
Let be a DTMC on state space with the following transition probabilities (state 0 the only absorbing state):
[TABLE]
(all the other transition probabilities are zero)
*Lemma *\thetheorem
The expected hitting time of the set of absorbing states , starting from state , of the DTMC of Definition A.1.1 is bounded by .
Proof.
If the DTMC is in state , the next state is drawn from a binomial distribution with parameters . Thus, the expected next state is . Using Theorem A.1.1 with results in the required bound:
[TABLE]
∎
*Corollary *\thetheorem
The expected hitting time of the set of absorbing states , starting from state , of the DTMC of Definition A.1.1 is bounded by .
Proof.
The expected hitting time of the absorbing state of is an upper bound of the expected hitting time of . This is because any path that leads into state 0 in either does not go through state 1 (thus happens with the same probability as in ), or goes through state 1. But, state 1 in is an absorbing state, hence in the latter case the expected hitting time for would be one step shorter. ∎
Let denote the hitting probability of a set of states , starting from state . We will prove the following lemma.
*Lemma *\thetheorem
The hitting probability of the absorbing state , starting from any state , of the DTMC of Definition A.1.1 is given by Eq. 15. This is a tight lower bound.
[TABLE]
Proof.
For simplicity we denote . We will show that for , using induction. First note that since state is an absorbing state, , and that .
The vector of hitting probabilities for a set of states is the minimal non-negative solution to the system of linear equations 16:
[TABLE]
By replacing with the probabilities of Definition A.1.1, the system of equations 16 becomes:
[TABLE]
Base case:
[TABLE]
Inductive step: We assume that . We will prove that .
[TABLE]
We want to prove that:
[TABLE]
which holds since .
The above bound is also tight since , specifically . ∎
Now we can prove the following theorem that bounds the convergence time of the DTCM of Definition A.1.1, which corresponds to the proposed learning rule for the case of a single available resource () and constant back-off probability.
{theorem}
The expected hitting time of the set of absorbing states of the DTMC of Definition A.1.1, starting from any initial state , is bounded by:
[TABLE]
Proof.
Using Lemma A.1.1 we can derive that the DTMC needs in expectation passes until it hits state 1. Each pass requires steps (Corollary A.1.1). Thus, the expected hitting time of state is . ∎
A.1.2. Case #2: Multiple Agents, Multiple resources ()
{theorem}
For agents and resources, assuming a constant back-off probability for each agent, i.e., , the expected number of steps until the system of agents following of Alg. 1 converges to a complete matching is bounded by (19).
[TABLE]
Proof.
At most agents can compete for each resource. We call this period a round. During a round, the number of agents competing for a specific resource monotonically decreases, since that resource is perceived as occupied by non-competing agents. Let the round end when either 1 or 0 agents compete for the resource. Corollary A.1.1 states that in expectation this will require steps.
If all agents backed-off, it will take on average steps until at least one of them finds a free resource. We call this period a break.
In the worst case, the system will oscillate between a round and a break. According to the above, one oscillation requires in expectation steps. If , Lemma A.1.1 states that in expectation there will be oscillations. For the expected number of oscillations is bounded by . Thus, we derive the required bound (19). ∎
A.1.3. Dynamic back-off Probability
So far we have assumed a constant back-off probability for each agent, i.e., . In this section we will drop this assumption. Let . Bound (19) becomes:
[TABLE]
Intuitively, the worst case scenario corresponds to either all agents having a small back-off probability, thus they keep on competing for the same resource, or all of them having a high back-off probability, thus the process will keep on restarting. These two scenarios correspond to the inner () and outer () probability terms of bound (20) respectively. We can rewrite the right part of bound (20) as:
[TABLE]
As seen by Eq. 21, assumes its maximum value on the two extremes, either with a high (), or a low () back-off probability, i.e., . Let be the worst between the smallest or highest back-off probability any agent can exhibit, i.e., having given by Eq. 23. Using instead of the constant , we bound the expected convergence time according to bound (22).
[TABLE]
[TABLE]
This concludes the proof of Theorem 2.5.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1ABD + [18] Itai Ashlagi, Maximilien Burq, Chinmoy Dutta, Patrick Jaillet, Amin Saberi, and Chris Sholley. Maximum weight online matching with deadlines. ar Xiv preprint ar Xiv:1808.03526 , 2018.
- 2AESW [11] Niels Agatz, Alan L Erera, Martin WP Savelsbergh, and Xing Wang. Dynamic ride-sharing: A simulation study in metro atlanta. Procedia-Social and Behavioral Sciences , 17:532–550, 2011.
- 3Ber [79] DP Bertsekas. A distributed algorithmfor the assignment problem. Laboratory for Information and Decision Systems Working Paper, Massachusetts Institute of Technology, Cambridge, MA , 1979.
- 4BEY [05] Allan Borodin and Ran El-Yaniv. Online computation and competitive analysis . cambridge university press, 2005.
- 5BJ [65] CW Borchardt and CGJ Jocobi. De investigando ordine systematis aequationum differentialium vulgarium cujuscunque. Journal für die reine und angewandte Mathematik , 64:297–320, 1865.
- 6BNBA [12] Mathias Bürger, Giuseppe Notarstefano, Francesco Bullo, and Frank Allgöwer. A distributed simplex algorithm for degenerate linear programs and multi-agent assignments. Automatica , 48(9):2298–2304, 2012.
- 7CF [11] Ludek Cigler and Boi Faltings. Reaching correlated equilibria through multi-agent learning. In The 10th International Conference on Autonomous Agents and Multiagent Systems-Volume 2 , pages 509–516. International Foundation for Autonomous Agents and Multiagent Systems, 2011.
- 8CN [11] S. F. Cheng and T. D. Nguyen. Taxisim: A multiagent simulation platform for evaluating taxi fleet operations. In 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology , volume 2, pages 14–21, Aug 2011.