A changepoint approach for the identification of financial extreme regimes
Chiara Lattanzi, Manuele Leonelli

TL;DR
This paper introduces a novel changepoint model for financial tail analysis that dynamically detects regime shifts in extreme market behavior, improving tail risk estimation over traditional static models.
Contribution
It extends extreme value mixture models to incorporate distributional changepoints, enabling more accurate tail estimation in changing financial regimes.
Findings
Outperforms static models in financial tail risk detection
Effectively identifies multiple extreme regimes in market data
Provides uncertainty measures for changepoint and threshold estimates
Abstract
Inference over tails is usually performed by fitting an appropriate limiting distribution over observations that exceed a fixed threshold. However, the choice of such threshold is critical and can affect the inferential results. Extreme value mixture models have been defined to estimate the threshold using the full dataset and to give accurate tail estimates. Such models assume that the tail behavior is constant for all observations. However, the extreme behavior of financial returns often changes considerably in time and such changes occur by sudden shocks of the market. Here we extend the extreme value mixture model class to formally take into account distributional extreme changepoints, by allowing for the presence of regime-dependent parameters modelling the tail of the distribution. This extension formally uses the full dataset to both estimate the thresholds and the extreme…
Click any figure to enlarge with its caption.
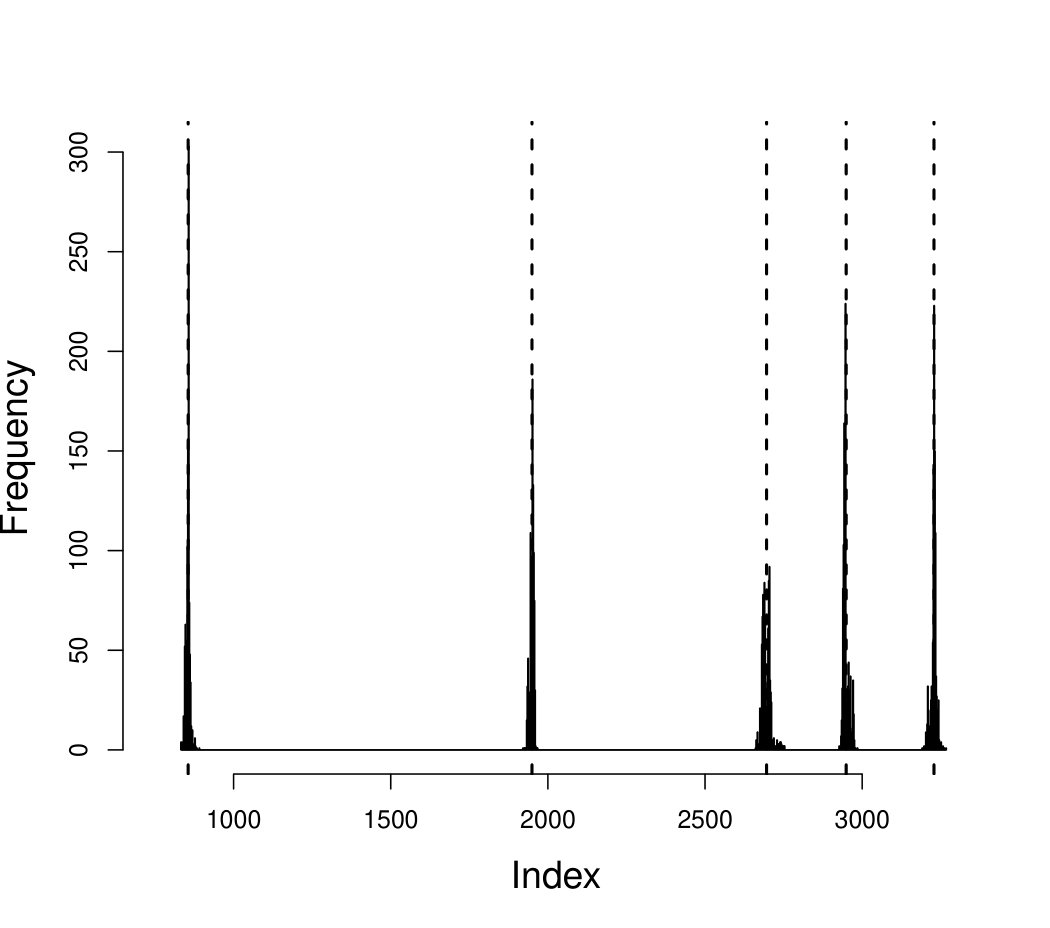 Figure 1
Figure 1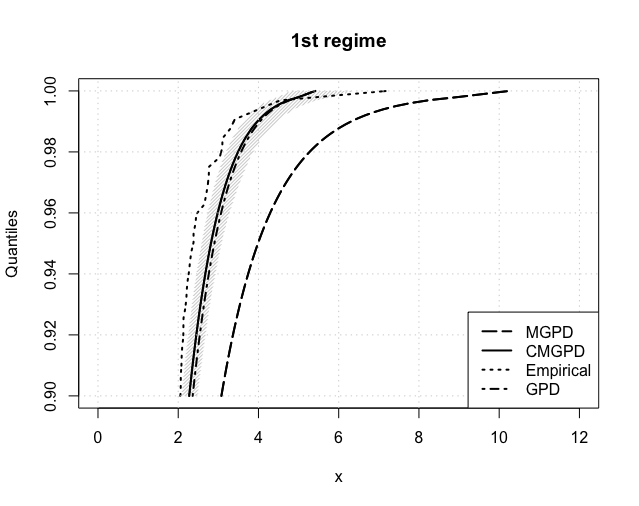 Figure 2
Figure 2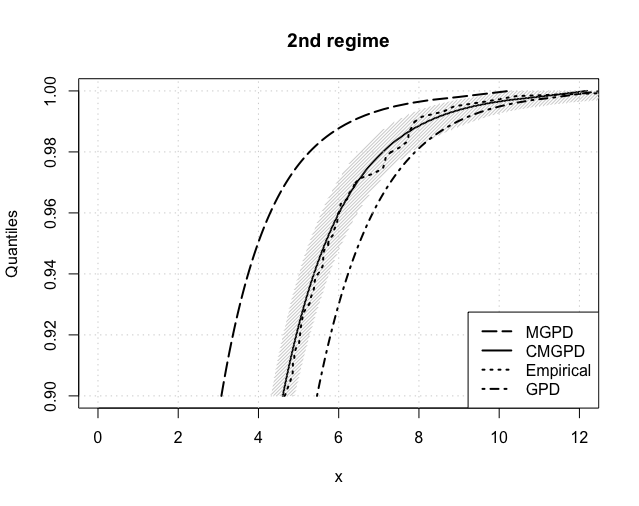 Figure 3
Figure 3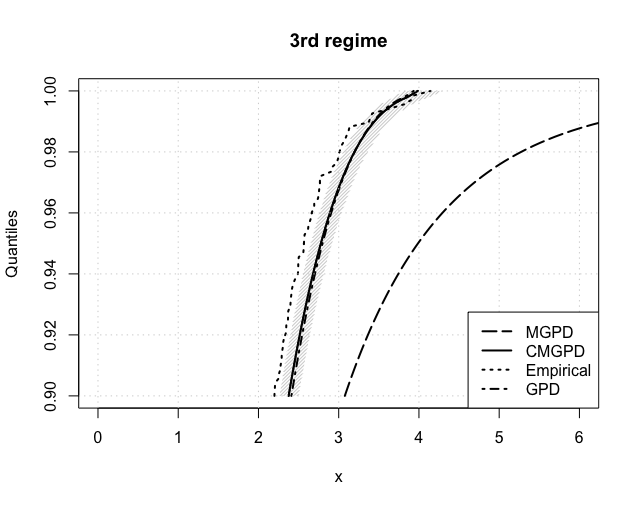 Figure 4
Figure 4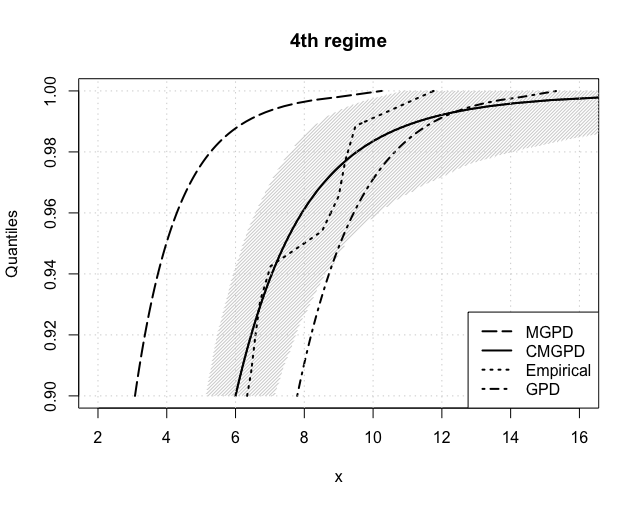 Figure 5
Figure 5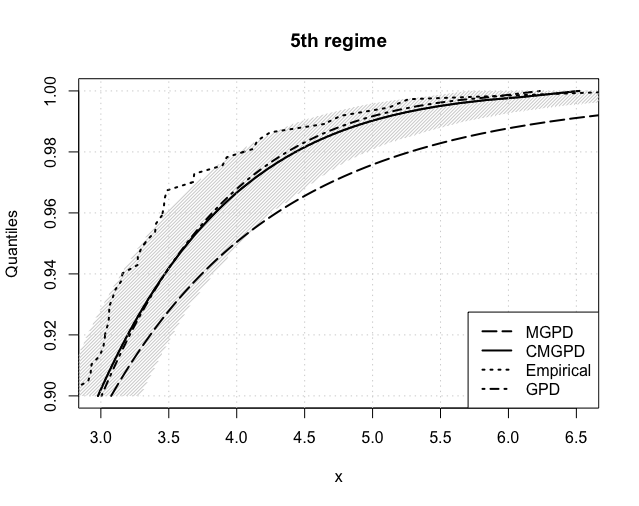 Figure 6
Figure 6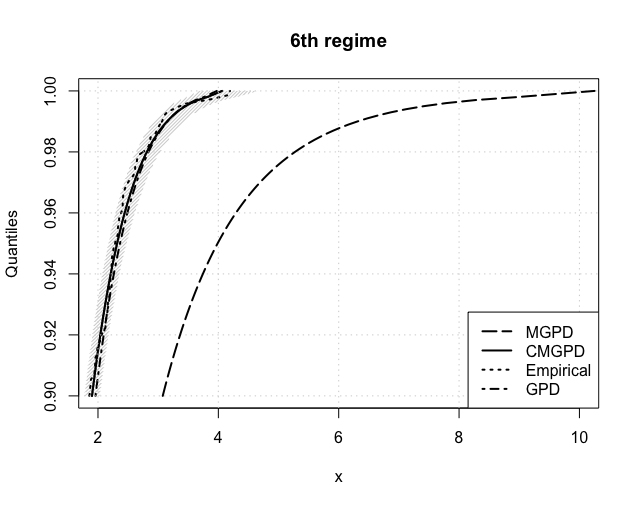 Figure 7
Figure 7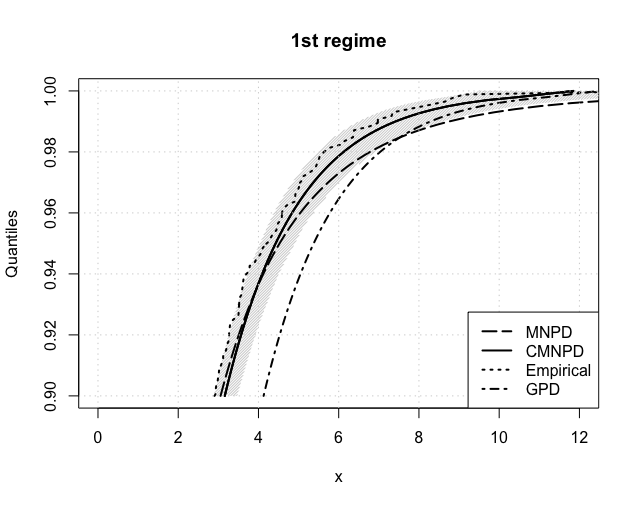 Figure 8
Figure 8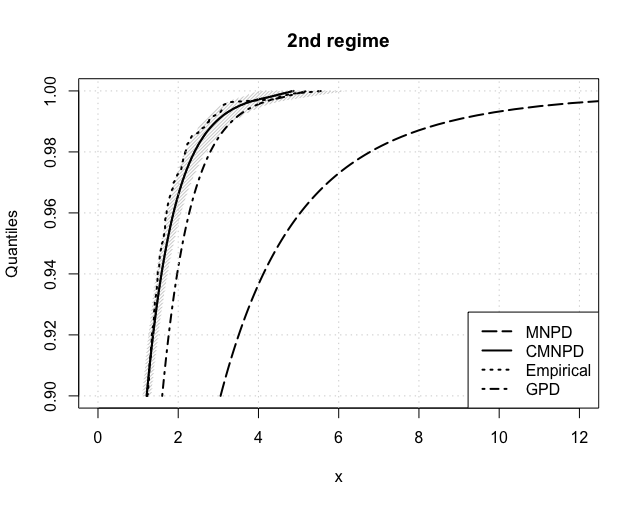 Figure 9
Figure 9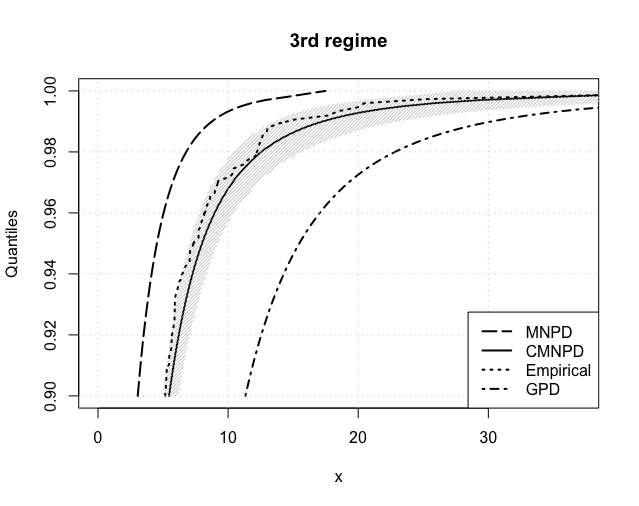 Figure 10
Figure 10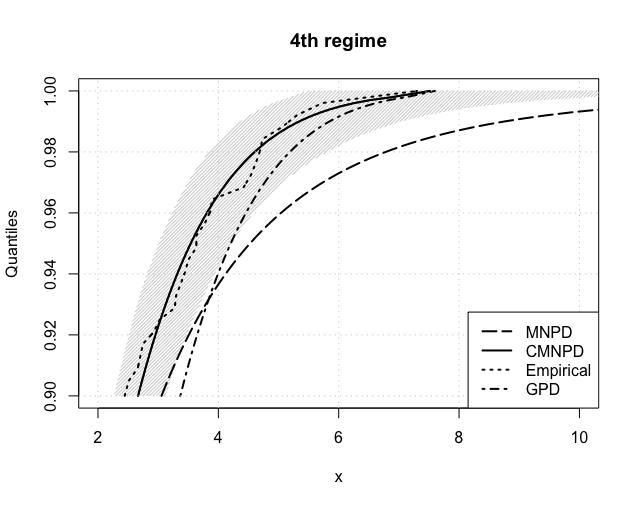 Figure 11
Figure 11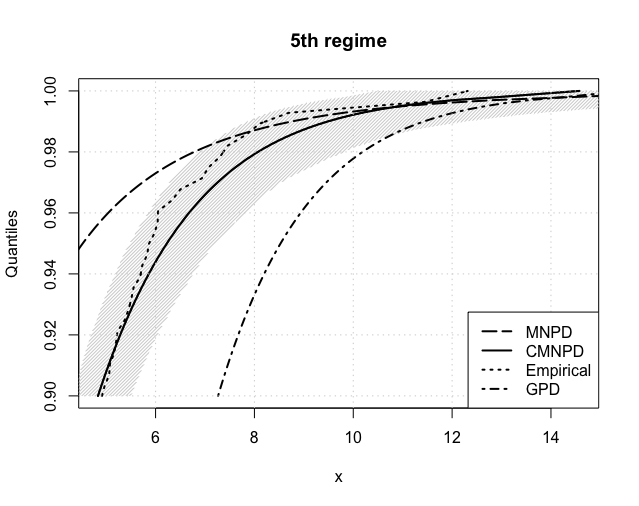 Figure 12
Figure 12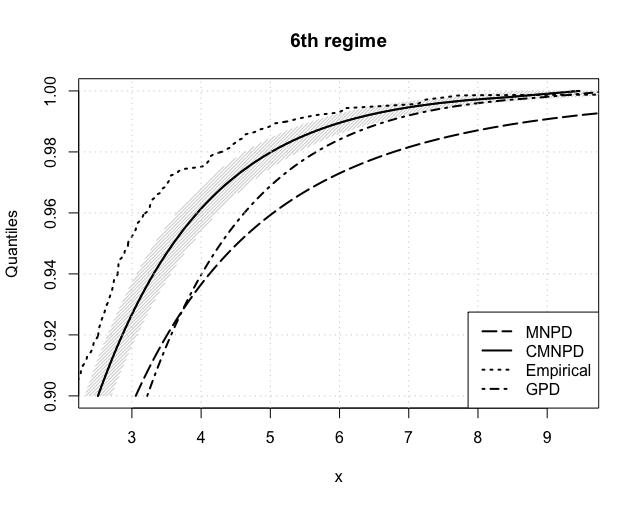 Figure 13
Figure 13 Figure 14
Figure 14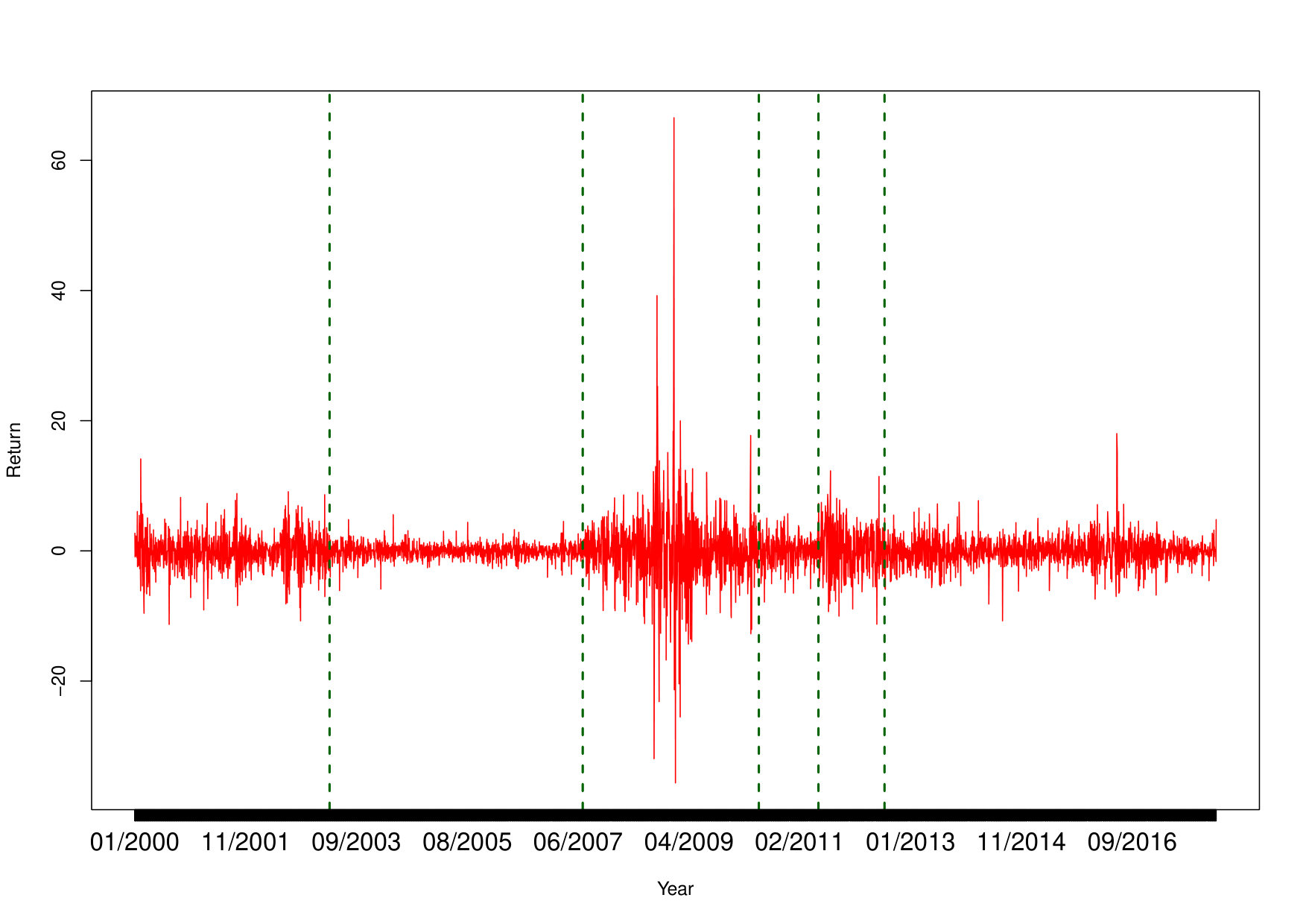 Figure 15
Figure 15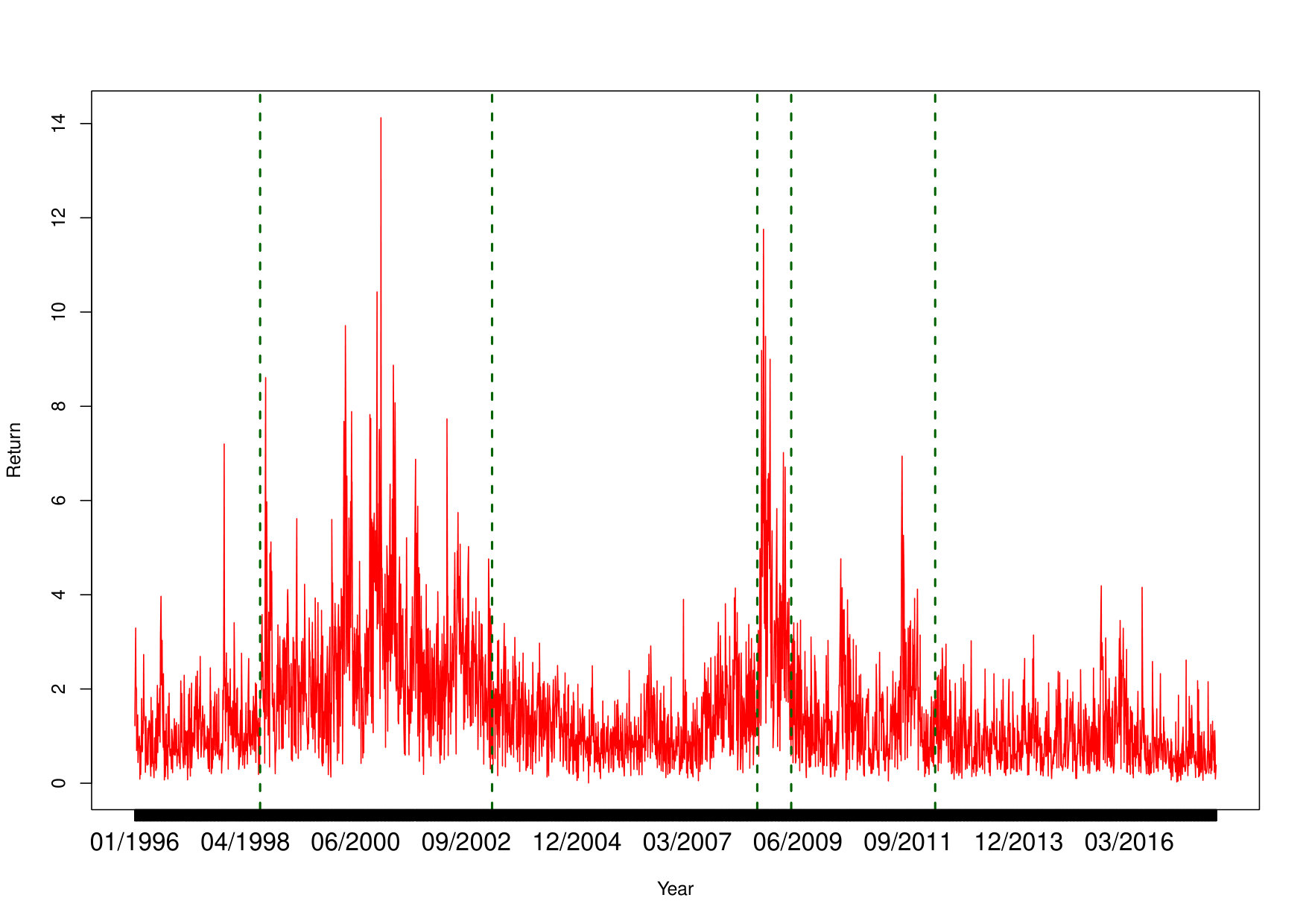 Figure 16
Figure 16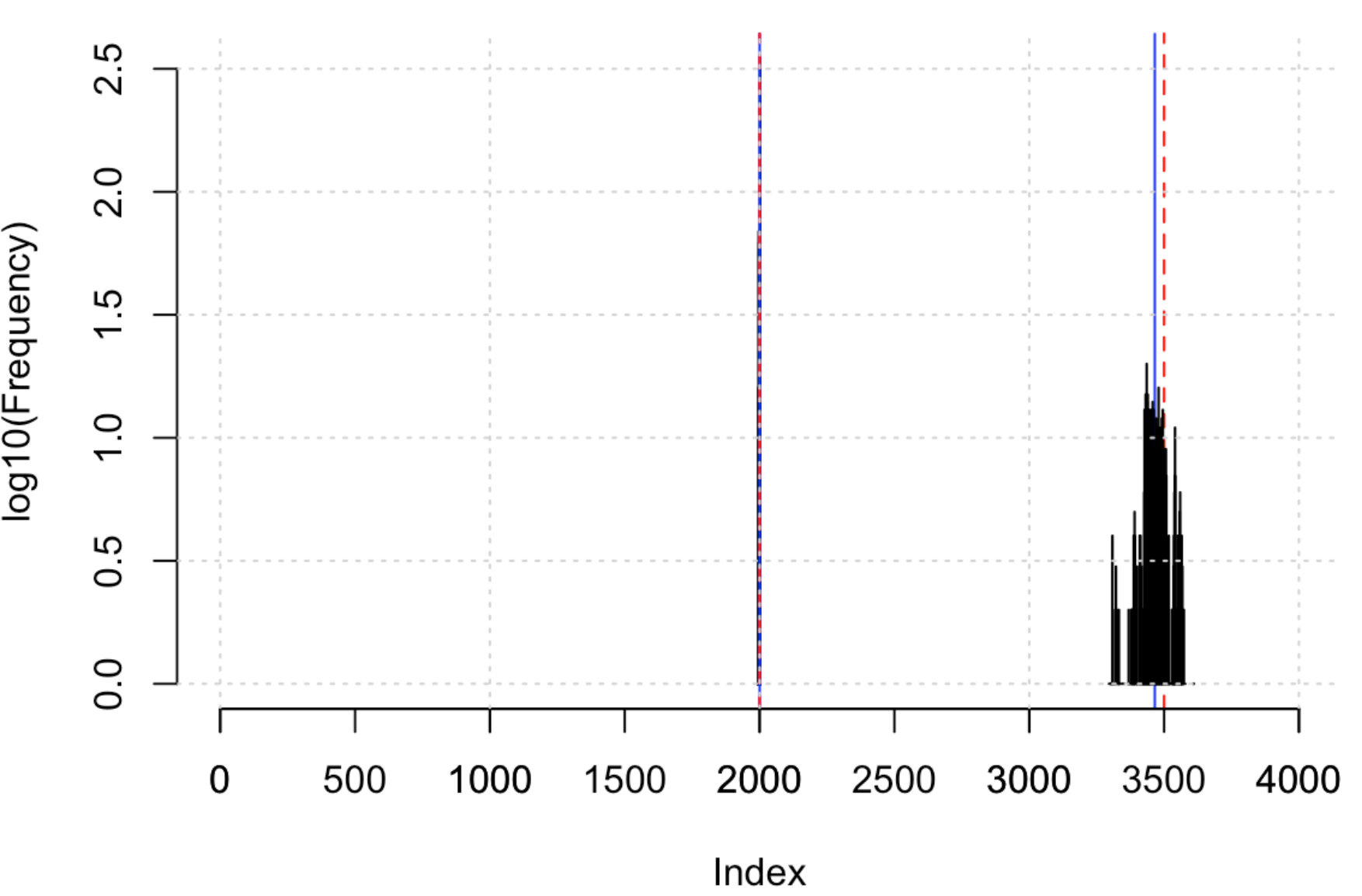 Figure 17
Figure 17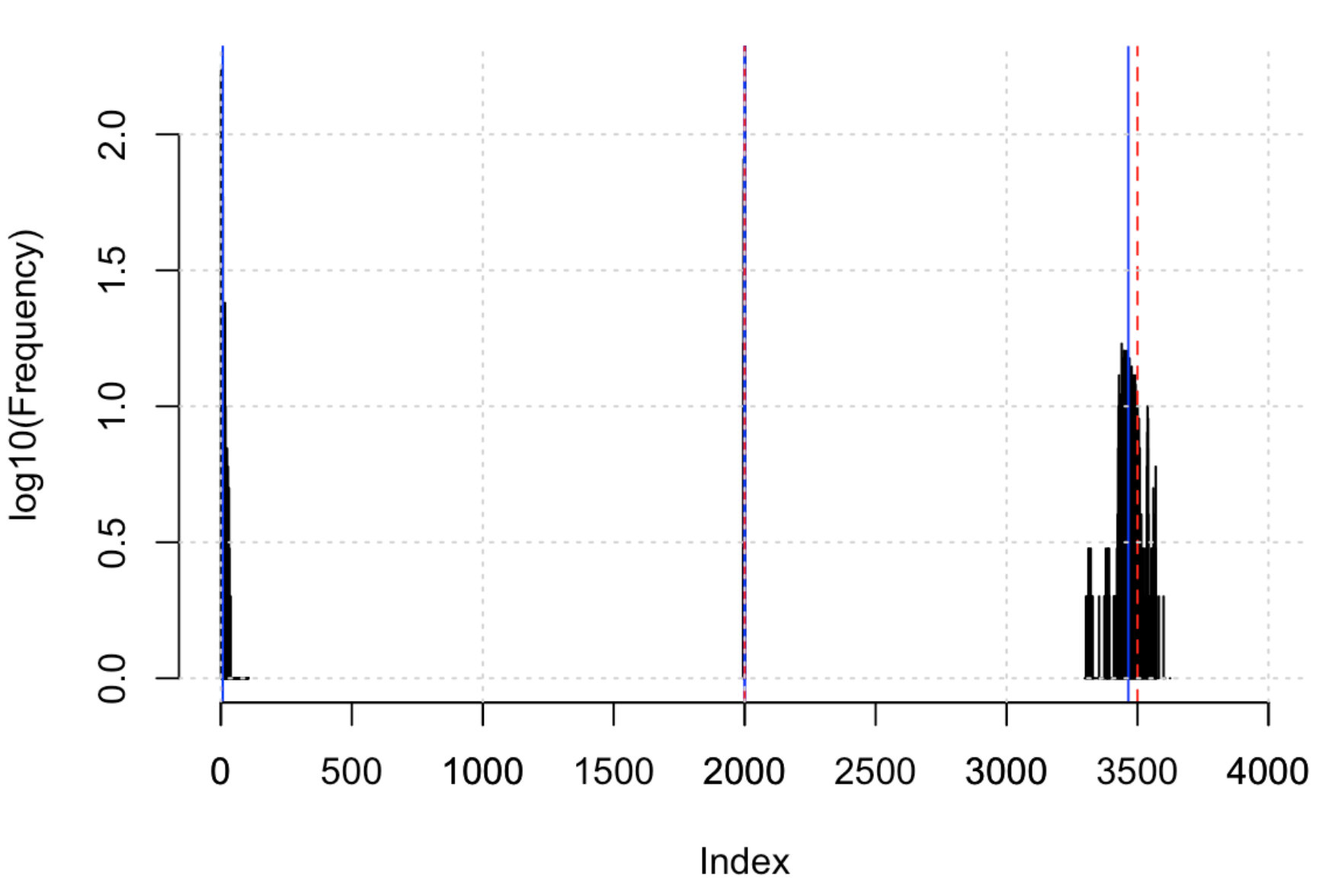 Figure 18
Figure 18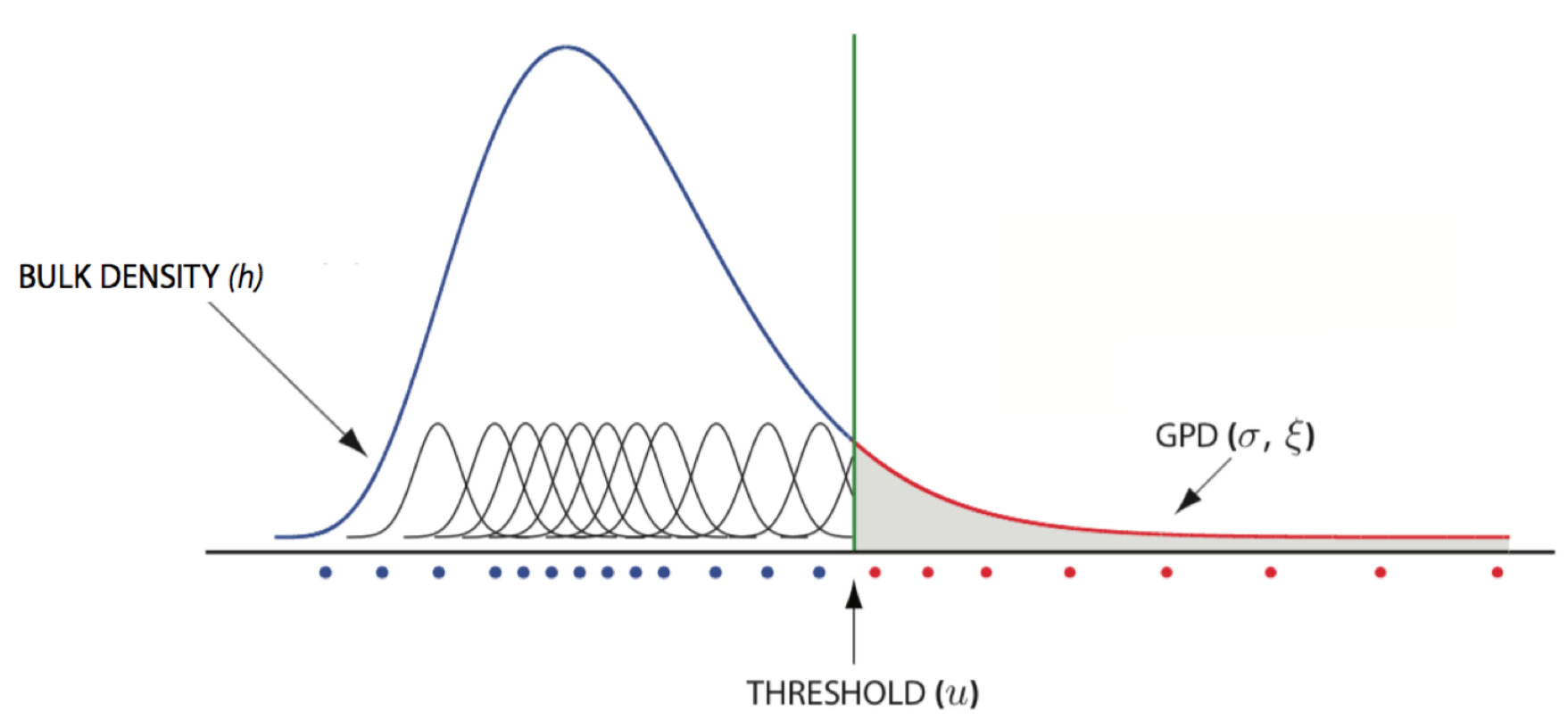 Figure 19
Figure 19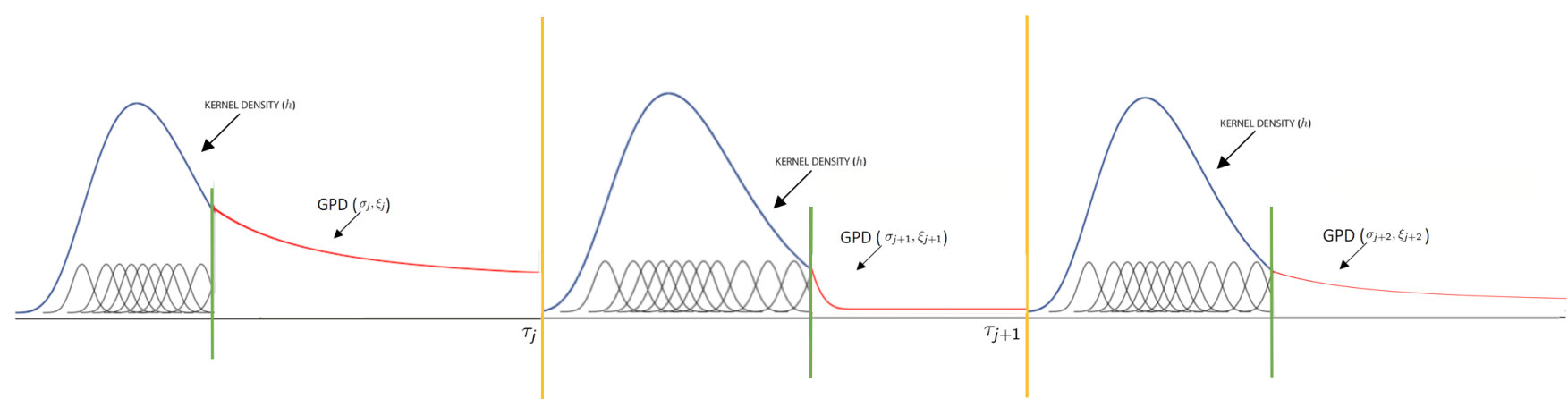 Figure 20
Figure 20 Figure 21
Figure 21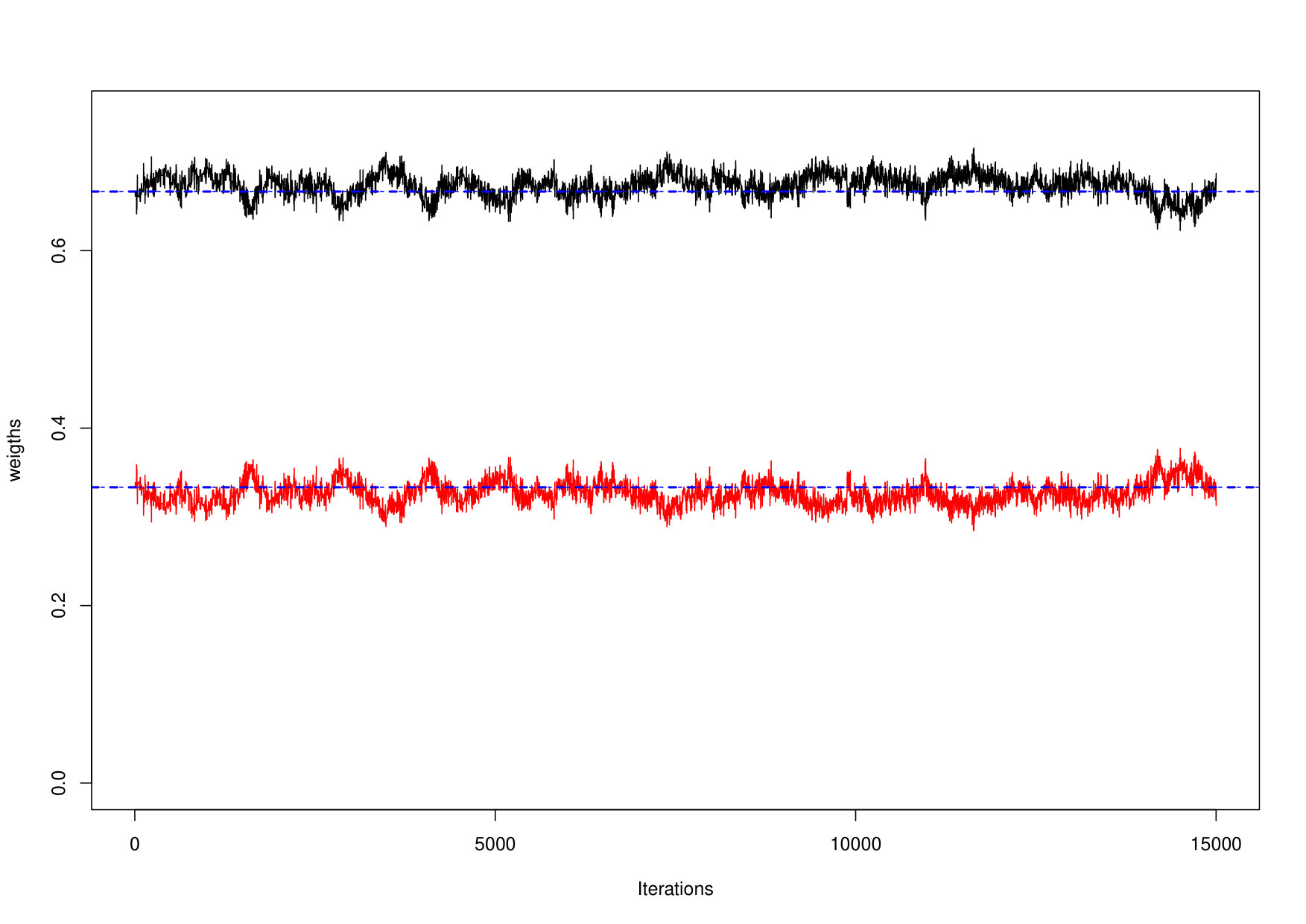 Figure 22
Figure 22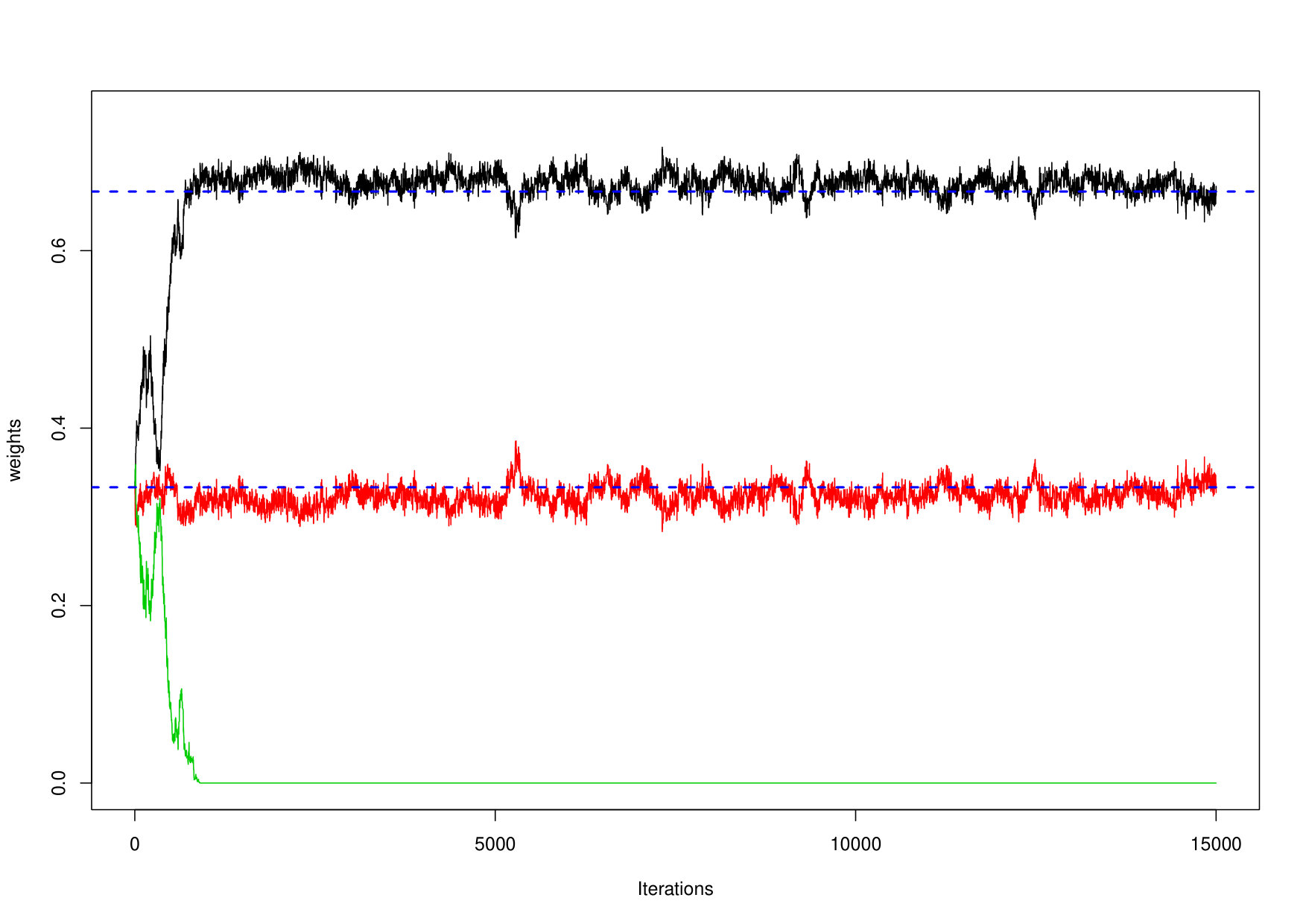 Figure 23
Figure 23| Data | Model | BIC | DIC | WAIC |
| CMGPD | MGPD2 | 21212.55 | 21148.29 | 22037.79 |
| CMGPD | CMGPD | 20414.07 | 20361.69 | 20366.07 |
| CMGPD | CMGPD | 20309.73 | 20255.33 | 20262.07 |
| CMGPD | CMGPD | 20320.46 | 20255.15 | 20263.74 |
| MGPD2 | MGPD2 | 22654.83 | 22592.46 | 22595.90 |
| MGPD2 | CMGPD | 22649.49 | 22574.54 | 22597.84 |
| Parameter | |||
|---|---|---|---|
| MGPD2 | 0.30 (0.23,0.39) | ||
| CMGPD | -0.38 (-0.43,-0.31) | 0.01 (-0.11,0.18) | 0.49 (0.29,0.76) |
| Parameter | |||
| MGPD2 | 1.09 (0.99,1.21) | ||
| CMGPD | 0.48 (0.43,0.53) | 0.98 (0.80,1.19) | 1.52 (1.12,1.96) |
| Parameter | |||
| MGPD2 | 6.99 (6.99,7.00) | ||
| CMGPD | 6.99 (6.99,7.00) | 8.02 (8.00,8.04) | 9.07 (8.80,9.25) |
| MGPD2 | 0.43 (0.33,0.55) | 2.02 (1.76,2.46) | 8.28 (7.82,9.44) | |||
| CMGPD | 0.09 (-0.50,0.59) | 0.45 (0.35,0.59) | 1.72 (0.15,4.01) | 2.04 (1.77,2.52) | 9.07 (7.37,12.93) | 8.39 (8.00,9.37) |
| Model | BIC | DIC | WAIC |
|---|---|---|---|
| MGPD1 | 7527.67 | 7488.93 | 7329.53 |
| CMGPD | 7492.97 | 7408.87 | 7203.87 |
| CMGPD | 6696.19 | 6615.71 | 6776.51 |
| CMGPD | 6719.61 | 6612.89 | 7106.92 |
| CMGPD | 918 (702,1036) | 1336 (921,1599) | 1602 (1581,1636) | 1645 (1626,1673) | ||
| CMGPD | 323 (318,327) | 915 (907,929) | 1594 (1588,1598) | 1681 (1668,1695) | 2049 (2008,2094) | |
| CMGPD | 4 (1,8) | 323 (318,326) | 915 (907,926) | 1595 (1590,1598) | 1679 (1667,1690) | 2029 (2006,2092) |
| -0.08 (-0.12,-0.08) | 0.04 (-0.06,0.19) | -0.30 (-0.35,-0.22) | 0.04 (-0.3,0.63) | -0.12 (-0.20,-0.002) | -0.14 (-0.20,-0.06) |
| 0.95 (0.83,1.08) | 1.42 (1.12,1.66) | 1.25 (1.09,1.42) | 2.00 (1.04,3.28) | 1.32 (1.06,1.59) | 0.86(0.78,0.97) |
| 0.30 (0.27,0.39) | 2.00 (1.82,2.44) | 0.32 (0.22,0.43) | 3.31 (2.28,4.05) | 0.44 (0.24,0.65) | 0.22 (0.20,0.23) |
| Model | BIC | DIC | WAIC |
|---|---|---|---|
| MNPD1 | 22425.55 | 22422.27 | 22289.93 |
| CMNPD | 21510.00 | 21413.04 | 21462.25 |
| CMNPD | 21424.62 | 21356.38 | 21381.23 |
| CMNPD | 21429.53 | 21345.34 | 21392.57 |
| 0.01 (-0.08,0.10) | 0.04 (-0.04,0.13) | 0.37 (0.16,0.61) | -0.12 (-0.31,0.08) | -0.01 (-0.25,0.32) | -0.02 (-0.06,0.03) |
| 1.79 (1.57,2.03) | 0.67 (0.58,0.76) | 2.36 (1.79,3.10) | 1.63 (1.23,2.09) | 2.07 (1.37,3.09) | 1.65 (1.52,1.78) |
| -0.008 (-0.02,0.0002) | 0.000 (-0.005,0.0006) | 3.12 (2.23,3.82) | -0.14 (-0.15,0.32) | 3.00 (2.31,3.6) | -0.46 (-0.48,-0.43) |
| Shortfall | Approach | regime | regime | regime | regime | regime | regime |
|---|---|---|---|---|---|---|---|
| ES5% | Empirical | 5.87 | 2.30 | 13.15 | 4.63 | 7.40 | 4.50 |
| NormFit | 5.16 | 2.11 | 11.80 | 4.40 | 7.39 | 4.03 | |
| CMNPD | 6.29 (5.56,7.19) | 2.49 (2.23,2.83) | 14.97 (11.50,21.30) | 4.65 (3.85,5.99) | 8.29 (6.98,10.61) | 5.13 (4.73,5.55) | |
| ES1% | Empirical | 8.40 | 3.58 | 25.45 | 5.86 | 10.28 | 7.52 |
| NormFit | 6.68 | 2.74 | 15.20 | 5.15 | 9.01 | 5.22 | |
| CMNPD | 9.34 (7.85,11.45) | 3.78 (3.22,4.56) | 30.93 (19.80,55.32) | 6.30 (4.89,9.03) | 10.71 (9.10,18.80) | 7.55 (6.86,8.37) |
| Value-at-Risk | Approach | regime | regime | regime | regime | regime | regime |
|---|---|---|---|---|---|---|---|
| VaR5% | Expected | 42 | 54 | 37 | 13 | 14 | 70 |
| CMNPD | 40 | 43 | 32 | 14 | 10 | 38 | |
| GARCH-EVT | 41 | 40 | 54 | 7 | 15 | 65 | |
| VaR1% | Expected | 8 | 10 | 7 | 2 | 3 | 14 |
| CMNPD | 6 | 9 | 7 | 2 | 2 | 8 | |
| GARCH-EVT | 9 | 13 | 16 | 2 | 2 | 19 | |
| VaR0.5% | Expected | 4 | 5 | 3 | 1 | 1 | 7 |
| CMNPD | 3 | 4 | 3 | 1 | 1 | 7 | |
| GARCH-EVT | 8 | 8 | 12 | 2 | 2 | 15 | |
| VaR0.1% | Expected | 1 | 1 | 1 | 0 | 0 | 1 |
| CMNPD | 1 | 1 | 1 | 0 | 0 | 2 | |
| GARCH-EVT | 4 | 3 | 6 | 1 | 1 | 6 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFinancial Risk and Volatility Modeling · Market Dynamics and Volatility · Monetary Policy and Economic Impact
A changepoint approach for the identification of financial extreme regimes
Chiara Lattanzi
Dipartimento di Scienze Statistiche, Universitá di Bologna
and
Manuele Leonelli
School of Mathematics and Statistics, University of Glasgow
Part of this work was carried out during CL final year project of the double-degree program in Statistics between the University of Bologna and the University of Glasgow.
Abstract
Inference over tails is usually performed by fitting an appropriate limiting distribution over observations that exceed a fixed threshold. However, the choice of such threshold is critical and can affect the inferential results. Extreme value mixture models have been defined to estimate the threshold using the full dataset and to give accurate tail estimates. Such models assume that the tail behavior is constant for all observations. However, the extreme behavior of financial returns often changes considerably in time and such changes occur by sudden shocks of the market. Here we extend the extreme value mixture model class to formally take into account distributional extreme changepoints, by allowing for the presence of regime-dependent parameters modelling the tail of the distribution. This extension formally uses the full dataset to both estimate the thresholds and the extreme changepoint locations, giving uncertainty measures for both quantities. Estimation of functions of interest in extreme value analyses is performed via MCMC algorithms. Our approach is evaluated through a series of simulations, applied to real data sets and assessed against competing approaches. Evidence demonstrates that the inclusion of different extreme regimes outperforms both static and dynamic competing approaches in financial applications.
Keywords: Extreme value mixture models; Financial returns; GPD distribution; High quantiles; Threshold estimation.
1 Introduction
The financial market is characterized by periods of turbolence where extreme events shock the system, potentially leading to huge profit losses. For this reason it is fundamental to understand and predict the tail distribution of financial returns. As claimed in Rocco (2014), a portfolio is more affected by a few extreme movements in the market than by the sum of many small movements. This motivates risk managers to be primarily concerned with avoiding big unexpected losses. The tool to perform inference over such unexpected events is extreme value theory (EVT) which provides a coherent probabilistic framework to model the tail of a distribution. Standard EVT methods require returns to be independent and identically distributed and their application is based on a number of assumptions which are usually hard to verify in practice.
Extreme value mixture models (Scarrott and MacDonald, 2012) have been introduced to overcome this second deficiency of EVT. These do not require any arbitrary assumption. Although some non-stationary extensions exist (e.g. Nascimento et al., 2016), such models are not capable of explicitly taking into account the structure of financial returns which are often destabilized by shocks concurring with periods of different extreme behaviors.
We introduce here a new class of models, termed changepoint extreme value mixture models, which, whilst not requiring any of the arbitrary assumptions usually made in EVT, are also able to formally represent different extreme regimes caused by financial shocks. We demonstrate below that this approach not only correctly identifies the location of such shocks, but also gives model-based uncertainty measures about these.
Inference is carried out within the Bayesian paradigm using the MCMC machinery (Gamerman and Lopes, 2006), enabling us to straightforwardly deliver a wide variety of estimates and predictions of quantities of interest, e.g. high quantiles.
Before formally defining our approach, univariate EVT and non-stationary (extreme) models are reviewed to highlight the relevance and the novelty of our methodology.
1.1 Extreme value theory
A common approach to model extremes, often referred to as peaks over threshold, studies the exceedances over a threshold. A key result to apply this methodology is due to Pickands (1975) which states that if a random variable X with endpoint is in the domain of attraction of a generalized extreme value distribution then , where is the distribution function (df) of the generalized Pareto distribution (GPD). The df is defined as
[TABLE]
for and , where the support is if and if . Therefore, the GPD is bounded if and unbounded from above if . The application of this result in practice entails first the selection of a threshold beyond which the GPD approximation appears to be tenable and then the fit of a GPD over data points that exceed the chosen threshold. Thus only a small subset of the data points, those beyond the chosen threshold, are formally retained during the inferential process.
The choice of the threshold over which to fit a GPD is hard and arbitrary. Although tools to guide this choice exist (Davison and Smith, 1990; DuMouchel, 1983), inference can greatly vary for different thresholds (Scarrott and MacDonald, 2012; Tancredi et al., 2006).
1.2 Extreme value mixture models
To overcome the difficulties associated with the selection of a threshold, a variety of models called extreme value mixture models (Scarrott and MacDonald, 2012) have been recently defined, which formally use the full dataset and do not require a fixed threshold. These combine a flexible model for the bulk of the data below the threshold, a formally justifiable distribution for the tail and uncertainty measures for the threshold.
The density function of an extreme value mixture model can be generally defined as
[TABLE]
where is the density, parametrized by , of the bulk, i.e. the portion of data below the threshold , its is df and is the GPD density function with parameters , which models the tail of the distribution above the threshold . Figure 1 illustrates the typical form of an extreme value mixture model using a flexible model for the bulk of the distribution, often defined as a mixture of density functions.
The first proposal to use the full dataset to estimate both the threshold location and the tail of the distribution is due to Behrens et al. (2004), which used a Gamma for the bulk. Since then a variety of proposal for the bulk have been used, including a Normal distribution (Carreau and Bengio, 2009), an infinite mixture of Uniforms (Tancredi et al., 2006), a mixture of Gammas (Nascimento et al., 2012) and a kernel estimator (MacDonald et al., 2011).
Nascimento et al. (2012) demonstrated that nothing is lost in extreme estimation by using the full dataset in cases where the determination of the threshold is easy. Conversely, when uncertainty about the threshold location is high, extreme value mixture models outperform the standard peaks over threshold approach.
1.3 Non-stationary extremes
The above methods assume that all observed data come from a same underlying distribution independently. However, in financial, as well as ecological, applications the structure and amplitude of extremes events usually changes through time. For this reason, inference over financial extremes is often carried out using dynamic models. In this direction, Bollerslev (1987) used a GARCH(1,1) model with Student-T innovations to explicitly take into account of the longer tails often encountered in financial datasets.
Dynamic models based on EVT then started to appear. For instance, McNeil and Frey (2000) proposed a two-stage approach where dependence is first removed using a GARCH model followed by GPD estimation to the assumed independent residual innovations. In a Bayesian setting, Huerta and Sansó (2007) proposed a hierchical dynamic model based on the generalized extreme value (GEV) distribution, whilst Zhao et al. (2011) defined a GARCH model directly over the GEV parameters. Dynamic extensions of extreme value mixture models have been recently defined (Lima et al., 2018; Nascimento et al., 2016), but in our experience these often require fine tuning of their parameters to work reliably.
Although the above approaches take into account the time dependent nature of rare events, in financial settings extreme variations occur by sudden shocks caused by exogenous agents as described, for instance, by Caldara et al. (2016) and Dierckx and Teugels (2010). Financial returns typically show clusters of observations in the tails, a phenomenon often termed volatility clustering. For this reason, inference can be expected to be more accurate by formally taking into account the nature of financial extreme events.
Changepoint models allow for changes of the model distribution at multiple unknown time points and therefore can be faithfully used to represent and make inference over financial shocks. Some of the first changepoint models using the Bayesian MCMC machinery are due to Albert and Chib (1993) and Carlin et al. (1992), which were extended to multiple changepoints in Stephens (1994). Since then the number of changepoint models proposed in the literature has increased dramatically (see e.g Bauwens et al., 2017; Giordani and Kohn, 2008; Ko et al., 2015). However, changepoint models which explicitly study distributional changes in the structure of the extremes are very limited.
In the frequentist setting, Dierckx and Teugels (2010) and Jarušková and Rencová (2008) defined an hypothesis testing routine to investigate the presence of changepoints in GPD and GEV distributions, respectively. In the Bayesian setting, Nascimento and Moura e Silva (2017) developed MCMC algorithms to identify changepoints in GEV models. Here we propose a highly flexible, new approach for inference over extremes which not only estimates the location of extreme changepoints but also the structure of the extremes within each regime by using the full dataset and without requiring any ad-hoc assumptions.
1.4 Outline of the paper
Our approach and inferential routines are next described in Section 2. Section 3 presents a simulation study to both investigate their performance and address the issue of model choice. In Section 4 our methodology is applied to two real-world financial applications: 2-days maxima absolute returns of the NASDAQ stock and negative daily returns of the Royal Bank of Scotland (RBS) stock. We conclude with a discussion.
2 Changepoint extreme value mixture models
Let be a series of time-ordered observations. The probability density function of a changepoint extreme value mixture model is defined as
[TABLE]
where is a model parametrized by for the bulk below the threshold , its df, a GPD density whose parameters are , the changepoint locations, and . The parameters of the GPD vary according to the regime in which the observations above the regime-dependent threshold are situated, whilst the bulk distribution is common to all regimes and does not vary. Thus the changepoints mark a distributional change in the extremes only, and not on the overall distribution of the data. The changepoints are integer values corresponding to the index of an observations that mark a sudden change in the distribution of the data. In this setting, and : thus there are inner changepoints and extreme regimes. Figure 2 gives an illustration of the newly defined model class: whilst the bulk distribution is common to all regimes, the GPD distribution for the tail changes between regimes, alternating between periods of heavy and light tails.
Changepoint extreme value mixture models have the very useful property of a parametric closed form for expected return levels above the threshold in each regime. The expected return level for each period in time is defined as the quantile, i.e. the value for which an equal or higher value is expected to occur once every periods of time. From Nascimento et al. (2012), a return above the threshold in regime is given by
[TABLE]
The model definition in equation (2) is general and for practical purposes it needs to be refined by a specific choice of density . Next we present two possible choices based on finite mixtures that we use in our applications in Section 4, but in general can be any density over which Bayesian inference can be carried out.
2.1 The CMGPD model
When the common distribution for the bulk is a finite mixture of Gammas, we say that the changepoint extreme value mixture model is a CMGPD model, where denotes the number of mixture components and the number of different extreme regimes. The CMGPD model extends the MGPD of Nascimento et al. (2012) to include extreme changepoints. A finite mixture of Gammas is defined as , where is a Gamma density parametrized by the mean and the shape , i.e.
[TABLE]
with and such that . The parametrization in terms of mean and shape parameters is used to solve identifiability issues (Wiper et al., 2001). In this setting , where is the Gamma df. The CMGPD model can be used to fit data over the positive real line, as for instance absolute financial returns.
The bulk density could be straightforwardly extended to an infinite mixture model (using e.g. the approach of Fúquene Patiño, 2015), but this is not required: as demonstrated in Dey et al. (1995) and Rousseau and Mengersen (2011) only as small number of mixture components have non-zero weights in practical applications. Furthermore, in our experience, for financial returns one component only is usually necessary.
2.2 The CMNPD model
The CMNPD model is similarly defined to the CMGPD, with the difference that the bulk distribution is now a finite mixture of normal distributions. Formally, , where is the normal density with mean and variance . Thus this model is used in financial applications where interest is in one tail only, for instance to predict negative losses. It extends the model of Carreau and Bengio (2009) to take into account of distributional extreme changepoints.
2.3 Prior distribution
The model definition is completed by assigning prior distributions to the parameters. GPD parameters of different regimes are a priori assumed independent. In regime , the prior distribution for is the non-informative prior of Castellanos and Cabras (2007) defined as .
The priors for the different regimes’ thresholds are independent Normal distributions as suggested by Behrens et al. (2004). The prior means are placed around the 90th data quantile while the prior variances are chosen so that the 95% prior credibility interval ranges a priori from the 50th to the 99th data quantiles, in symbols .
The changepoints are given an non-informative discrete uniform distribution subject to the restriction , as suggested by Stephens (1994):
[TABLE]
The prior distribution for the bulk density parameter depends on the model used. In both cases the weights are given a Dirichlet prior with parameter . For the CMGPD model, the parameters of the Gammas are non-informative and given as in Nascimento et al. (2012). Each shape parameter is given an independent Gamma prior , where are chosen to give a large prior variance. The prior for the Gamma means is , where is the inverse Gamma density, is a normalizing constant and and are chosen to give a large prior variance. The order restriction over the means is set to ensure identifiability.
For the CMNPD model, priors for the normal mixture parameters are given as follows. The prior for the means is given conditionally on the variances as , where is chosen to give a large prior variance and . This choice is motivated by the symmetry of financial returns, so to assure the closeness of the means to 0, and by identifiability issues. Each mixture variance is independently given a Gamma distribution, i.e. where again hyperparameters are chosen to be non-informative.
The overall prior for a changepoint extreme value mixture model can be written as . All priors used are non-informative, giving enough flexibility for the influence of the likelihood in the estimation process.
2.4 Posterior inference
For a sample the log-posterior of the CMGPD model is
[TABLE]
For the CMNPD model the log-posterior can be easily deduced by substituting and in equation (4) with and respectively.
Inference cannot be performed analytically and approximating MCMC algorithms are used. Parameters are divided into blocks and updating of the blocks follows Metropolis-Hastings steps since full conditionals have no recognizable form. Proposal variances are tuned via an adaptive algorithm as suggested in Roberts and Rosenthal (2009). Details are given in Appendix A. All algorithms are implemented in R.
Summaries of financial extreme returns can be straightforwardly computed from the posterior distribution. Common measures used for financial losses are the Value-at-Risk (VaR) and the expected shortfall (ES). VaR is generally defined as the risk capital sufficient to cover losses from a portfolio over a holding period of a fixed number of days. It corresponds to the quantile over a certain time horizon and is denoted as VaRp. ES, or tail conditional expectation, is defined as the potential size of a loss exceeding a specif VaRp. It corresponds to the expectation conditional on observing values larger than VaRp. For changepoint extreme value mixture models, the expected shortfall in the -th regime takes the closed form
[TABLE]
where is the Value-at-Risk in regime .
Both VaR and ES are highly non-linear functions of the model’s parameters (see equations (3) and (5)). Thus their posterior distribution cannot be derived analytically. However, the MCMC machinery enables us to derive an approximated distribution for any function of the models’ parameters, as demonstrated in our applications in Section 4.
3 Simulation study
A simulation study is conducted next with two main purposes: first, to assess the identifiability of the models proposed; second, to validate model selection criteria. For brevity we report here the results for data generated from CMGPD and MGPD, but the same results were observed for CMNPD and MNPD. Two samples of 5000 observations were generated, one from a MGPD2, the other from a CMGPD, where the subscript denotes the number of mixture components and the superscript the number of extreme regimes. In both datasets the mixture parameters are , and . For the MGPD data, GPD parameters were fixed at and , whilst the threshold was placed at the theoretical quantile of the Gamma mixture (7.99).
The simulated observations from CMGPD had changepoint locations . The regime-dependent GPDs were chosen so that , and the regimes’ thresholds were placed respectively at the (6.99), (7.99) and (9.22) theoretical quantiles.
Simulations were run on a PC with processor 2,7 GHz Intel Core i5 and 8 Gb RAM. For all simulations, the codes ran for 15000 iterations, with a burn-in of 5000 and thinning every 10, giving a posterior sample of 1000. Convergence was assessed by running parallel chains with different starting values and then comparing the resulting estimates. Details about these can be found online111Posterior samples from the simulation study, as well as from the real data applications reported in Section 4, are available at the following links: https://lattanzichiara.shinyapps.io/CMGPDdt2chains/ (CMGPD data), https://lattanzichiara.shinyapps.io/MGPD2chains/ (MGPD2 data), https://lattanzichiara.shinyapps.io/CMGPD-NDAQ/ (NASDAQ data) and https://lattanzichiara.shinyapps.io/CMNPD-RBS/ (RBS data)..
In all cases, to reduce the number of models to be compared, the number of mixture components was first chosen by fitting MGPDl and CMGPD for various . As already shown in Nascimento et al. (2012) and Leonelli and Gamerman (2017), the correct number of mixture components can be retrieved from the posterior sample since the weights of all extra components are estimated as zero. This is demonstrated in Figure 3 where the weight of the third component quickly converges to zero.
Having fixed the number of mixtures, models with varying changepoints’ numbers were fitted to the simulated datasets. As already discussed in Leonelli and Gamerman (2017), standard model selection criteria often fail to identify the correct model in the setting of extreme value mixture models. This is shown in Table 1 where BIC (Schwarz, 1978) and DIC (Spiegelhalter et al., 2002) fail to select the true model. Conversely, the true generating model is always preferred by the WAIC of Watanabe (2010). This criterion has been shown to be particularly robust for mixtures and non-identifiable models.
The number of regimes can be further identified when fitting CMGPD with non-necessary changepoints since the exceeding locations converge to values very close to [math], or another changepoint, depending on the starting values of the MCMC algorithm, as noted in Nascimento and Moura e Silva (2017). This can be seen in Figure 4. When a CMGPD model is estimated over CMGPD data, the two changepoints are correctly identified, whilst the third is located close to zero. Conversely, fitting a CMGPD model over CMGPD data the only changepoint is estimated around the true changepoint giving a larger distributional change: in this case the one at associated to a switch from an upper bounded distribution to an unbounded one. The histograms further show that in all cases, uncertainty about the strongest changepoint is limited, whilst the posterior distribution for the changepoint located at has a larger variance. The same conclusion can be drawn when fitting a CMGPD model over MGPD2 data, since the posterior mean of the only changepoint is with 95% credibility interval .
Having ensured that the true model can be correctly chosen, the identifiability of the parameters is investigated next. As in Nascimento et al. (2012) all bulk parameters are correctly estimated (see the online apps for further details). But more interestingly, Table 2 demonstrates that tail parameters are well estimated for all regimes when using data simulated from the CMGPD model. When an MGPD2 model is fitted over this dataset, each tail parameter is estimated around an average value of those of all regimes. When the CMGPD model is fitted over MGPD2 data, the parameters associated to the non-empty regime well estimate the true tail parameters, as shown in Table 3.
Given the use of non-informative priors, there is a clear indication that the likelihood can correctly identify the true values. In particular, the estimation of the tail parameters is highly successful evidencing the ability of the model to recover varying tail behavior.
4 Applications
4.1 NASDAQ absolute daily returns
The first financial dataset considered consists of daily returns of NASDAQ stock values from January 1996 to December 2017. Daily returns are considered in their absolute value and, in order to avoid excess return clustering, maxima of sets of 2 days were considered for a total of 2768 observations. The aim is the estimation of volatility of the composite index over time comparing the MGPD and the CMGPD approaches.
The number of Gamma components for the bulk was first investigated and it was observed that only one component is needed. To choose the number of changepoints we resort to information criteria and posterior locations. The most reliable WAIC criterion favors a model with 6 regimes as reported in Table 4, which also includes evidence that a changepoint approach outperforms the static one. This is confirmed in Table 5 reporting the posterior distribution of the changepoints: the posterior mean of the first CMGPD changepoint equals 4, thus giving an empty regime and confirming the optimality of CMGPD.
The posterior means of changepoints from the CMGPD model are located on July 1998, April 2003, August 2008, May 2009 and April 2012 as shown in Figure 5. An alternation of regimes with low/medium volatility and high volatility can be noticed, so different tail parameters and returns are to be expected. The regimes with the higher volatility are concurrent to the main events which shook the US stock market in the past 20 years: the second regime show the result of the Dotcom-bubble-burst and the instability after 9/11 while the fourth regime is the direct consequence of the 2008 subprime mortgage crisis.
Table 6 summarizes the posterior distribution of the CMGPD tail parameters. This demonstrates the flexibility of our approach of discriminating between periods of high and low volatility: in the and regimes the estimates of the scale and shape parameters are larger than all other regimes demonstrating higher level of stress of the market. The values of the estimated thresholds suggest a particular behaviour of this dataset: the , , , regimes resemble more a GPD distribution than a MGPD. As a result, the estimated thresholds for these regimes are very close to 0. The flexibility of the model proposed enable us to take this into account without any complication.
The expected return levels, for , are reported in Figure 6 for each estimated regime. The CMGPD estimates and their 95% confidence interval (shaded area) are fairly close to the empirical ones in all regimes, thus confirming the goodness of our estimation routines. Returns were further estimated using the MGPD and the GPD (using the threshold estimated by the CMGPD). The CMGPD estimates are always closer to the empirical values than the MGPD ones. Furthermore the GPD estimates overlays the CMGPD ones in all the regimes with a low threshold, whilst in the others CMGPD clearly outperforms GPD. Thus the use of the full dataset, divided into extreme regimes, leads to better posterior estimates.
4.2 Royal Bank of Scotland daily returns
The second financial dataset considered is the Royal Bank of Scotland (RBS) stock daily returns from January 2000 to February 2018 for a total of 4635 observations. In this case positive and negative returns are modeled at the same time and we focus on the estimation of the lower tail (a change of sign is applied for convenience). The estimation efficiency of MNPD and CMNPD models are now investigated. For all models it was first observed that only one Normal component is needed.
Again all model selection criteria favor a changepoint approach compared to the static one, as reported in Table 7 and the WAIC chooses a model with 6 regimes. This is also confirmed by the posterior distribution of the first CMNPD changepoint, located at the beginning of the series with a posterior mean of and 95% credibility interval .
The regimes estimated from the CMNPD model are reported in Figure 7. The estimated changepoint are located on April 2003, July 2007, June 2010, June 2011 and August 2012 with posterior distributions shown in Figure 8. The regimes show different magnitude in losses, with tail parameters reported in Table 8. The first and last three regimes represent periods of medium-sized losses, whilts the second one represents a period of high stability. The third regime is by far the most interesting: it is concurrent to the UK’s biggest bank failure in history culminated to the Blue Monday Crash in January 2009. The bank eventually managed to survive thanks to the UK bank rescue package issued by the Government. This is the only regime with a clear heavy tail behaviour (). The value of is constant among the regimes, with the exception of the second regime whose value of indicates lower volatility.
Figure 9 reports the crucial VaR estimates from 5% to 0.1% for each regime. The same conclusions can be drawn as in the NASDAQ case, with the CMNPD outperfoming both the MNPD and GPD approaches. Table 9 further summarizes our estimates of the expected shortfall at both 5% and 1%. These are compared with the so-called NormFit approach: as reported in Chang et al. (2011) and Gilli and Këllezi (2006) the Basel accord formalizes that financial firms estimate VaR using a normal hypothesis, which is then multiplied by a ‘safety factor’ of 3 to take account of tail’s heaviness. Whilst NormFit estimates are comparable to ours at the 5% level, they highly underestimate risk at the 1% level.
The CMNPD model is compared to the GARCH-EVT approach of McNeil and Frey (2000) via backtesting: we compare the actual losses at time with the estimated VaR at time . The backtesting is based on a moving window such that at each time , a new set of GARCH(1,1) parameters, residuals and GPD based quantile are estimated. Table 10 reports the number of expected VaRp violations in each regime, equal to with the number of observations in a regime, and the violations observed from CMNPD and GARCH-EVT. The CMNPD model always outperforms GARCH-EVT in estimating violations for high-volatility regimes (e.g, the and ) and in very-high quantiles scenarios (VaR0.5% and VaR0.1%). Thus CMNPD better estimates the occurrence of very rare events than the GARCH-EVT approach.
5 Conclusions
The financial literature asserts that not only extreme behaviour may change considerably in time, but also that these variations occur by sudden shocks which deeply affect volatility scenarios. This work puts forward a changepoint generalisation of extreme value mixture models with the ability of detecting multiple changepoints in the tail distribution. The inclusion of regime-dependent GPD parameters enables the switch between light and heavy-tailed behaviour explaining well periods of financial stress and market instability.
Due to the semiparametric nature of the models proposed, Bayesian methods are used. Despite the use of vague prior information, our inferential routines recover the correct parameter values, whilst giving uncertainty measures about crucial parameters such as thresholds and changepoint locations. Model choice is easily performed due to the inherent ability of the model to detect the number of mixture components for the bulk and, most importantly, the number of changepoints.
Our approach outperforms in financial applications all the static and dynamic methods considered for comparison. Since financial markets are heavily affected by unexpected and abrupt variations, extreme regimes are well-captured using changepoint tools, identifying periods of changing volatility. Return levels, VaR and ES measures are well estimated by our approach, making it a very powerful tool in a real-data context. Their effectiveness in other fields, for instance environmental and medical applications, is yet to be explored.
Although the number of changepoints is correctly identified by model selection criteria, models with a different number of changepoints need to be fitted. We are currently exploring approaches to estimate , the number of changepoints, within our MCMC routines. Recent proposals use the hidden changepoint representation of Chib (1998) coupled with a Dirichlet process (e.g. Ko et al., 2015). However these fail in our context because the acceptance of a new changepoint location is based on a subset of the observations. Because our changepoints discriminate only tail behaviour, such subsets do not include enough information to identify their location. More promising is the development of reversible jump MCMC algorithms (Green, 1995), which have already been successfully applied in changepoint applications, although not in the context of extremes.
Appendix A MCMC Algorithms
A.1 CMGPD
Sampling is carried out in blocks with Metropolis-Hastings proposals. A parameter with a superscript denotes its value at the -th iteration of the algorithm. Let , , , and . We denote , and similarly for other parameters. Recall that and . At each iteration , parameters are updated as follows:
Sampling : The proposal transition kernel for each , , where is the total number of regimes, is given by a truncated Normal where is a variance appropriately chosen to ensure chain mixing and is the maximum of the observations in . So, with probability , where
[TABLE]
, and .
Sampling : The proposal transition kernel for each , , depends on the value of . If , then is sampled from the Gamma distribution where is the variance of the proposal distribution appropriately chosen to ensure chain mixing. If , then is sampled from a . So, with probability where, if ,
[TABLE]
and if ,
[TABLE]
, and .
Sampling : The thresholds are sampled from a distribution where is the minimum of the observations in if and if . The lower limit of the truncation is chosen to satisfy the sample space of the GPD. The variance is chosen to ensure appropriate chain mixing. So with probability , where
[TABLE]
, and .
**Sampling : ** The proposal kernel for , , where is the number of mixture components, is taken as the Gamma distribution , where is chosen to ensure appropriate chain mixing. So with probability , where
[TABLE]
, and .
**Sampling : ** The proposal kernel for , , is taken as the Gamma distribution where is chosen to ensure appropriate chain mixing. So with probability , where
[TABLE]
, and .
**Sampling : **The vector of weights is proposed from a Dirichlet , where is chosen to ensure chain mixing. So, with probability , where:
[TABLE]
and .
**Sampling : ** The proposal transition kernel for each , , is given by a truncated Normal , where is a chosen to ensure chain mixing. So, with probability , where
[TABLE]
, and .
A.2 CMNPD
The steps for the CMNPD are the same as for the CMGPD with the only difference that the parameters of the mixture of normals now need to be estimated, i.e. the means and the variances . In this case . At each iteration , the normal parameters are updated as follows:
Sampling : The proposal kernel for , , is taken as the Gamma distribution where is chosen to ensure appropriate chain mixing. So with probability , where
[TABLE]
, and .
**Sampling : ** The proposal kernel for , , is taken as the Gamma distribution where is chosen to ensure appropriate chain mixing. So with probability , where
[TABLE]
, and .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Albert and Chib (1993) Albert, J. H. and S. Chib (1993). Bayes inference via Gibbs sampling of autoregressive time series subject to Markov mean and variance shifts. J. Bus. Econ. Stat. 11 (1), 1–15.
- 2Bauwens et al. (2017) Bauwens, L., J. Carpantier, and A. Dufays (2017). Autoregressive moving average infinite hidden Markov-switching models. J. Bus. Econ. Stat. 35 (2), 162–182.
- 3Behrens et al. (2004) Behrens, C. N., H. F. Lopes, and D. Gamerman (2004). Bayesian analysis of extreme events with threshold estimation. Stat. Model. 4 (3), 227–244.
- 4Bollerslev (1987) Bollerslev, T. (1987). A conditionally heteroskedastic time series model for speculative prices and rates of return. Rev. Econ. Stat. 69 , 542–547.
- 5Caldara et al. (2016) Caldara, D., C. Fuentes-Albero, S. Gilchrist, and E. Zakrajšek (2016). The macroeconomic impact of financial and uncertainty shocks. Eur. Econ. Rev. 88 , 185–207.
- 6Carlin et al. (1992) Carlin, B. P., A. E. Gelfand, and A. F. M. Smith (1992). Hierarchical Bayesian analysis of changepoint problems. J. R. Stat. Soc. C 41 , 389–405.
- 7Carreau and Bengio (2009) Carreau, J. and Y. Bengio (2009). A hybrid Pareto model for asymmetric fat-tailed data: the univariate case. Extremes 12 (1), 53–76.
- 8Castellanos and Cabras (2007) Castellanos, M. E. and S. Cabras (2007). A default Bayesian procedure for the generalized pareto distribution. J. Stat. Plan. Infer. 137 (2), 473–483.