Towards Corner Case Detection for Autonomous Driving
Jan-Aike Bolte, Andreas B\"ar, Daniel Lipinski, Tim Fingscheidt

TL;DR
This paper proposes a system framework for detecting critical corner cases in video data from moving vehicles, addressing robustness issues in autonomous driving systems by identifying unusual and potentially dangerous situations.
Contribution
It introduces a formal definition of corner cases and a versatile system framework for online and offline detection from vehicle-mounted cameras, extending beyond fixed-camera scenarios.
Findings
Framework effectively detects corner cases in driving videos.
Applicable to both online real-time and offline data screening.
Enhances robustness of autonomous driving systems.
Abstract
The progress in autonomous driving is also due to the increased availability of vast amounts of training data for the underlying machine learning approaches. Machine learning systems are generally known to lack robustness, e.g., if the training data did rarely or not at all cover critical situations. The challenging task of corner case detection in video, which is also somehow related to unusual event or anomaly detection, aims at detecting these unusual situations, which could become critical, and to communicate this to the autonomous driving system (online use case). Such a system, however, could be also used in offline mode to screen vast amounts of data and select only the relevant situations for storing and (re)training machine learning algorithms. So far, the approaches for corner case detection have been limited to videos recorded from a fixed camera, mostly for security…
Click any figure to enlarge with its caption.
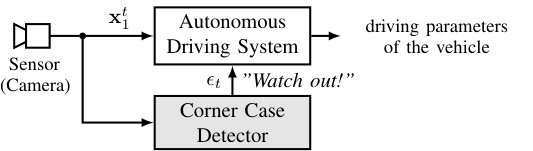 Figure 0
Figure 0 Figure 1
Figure 1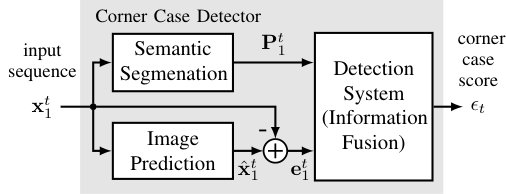 Figure 2
Figure 2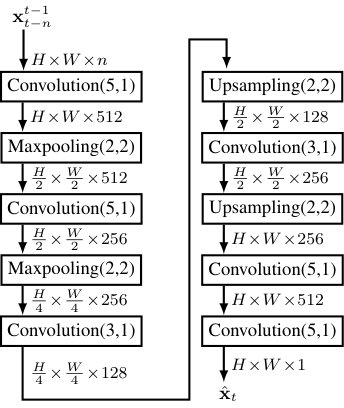 Figure 3
Figure 3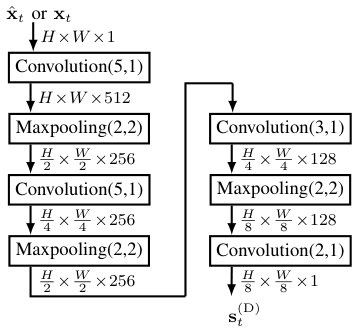 Figure 4
Figure 4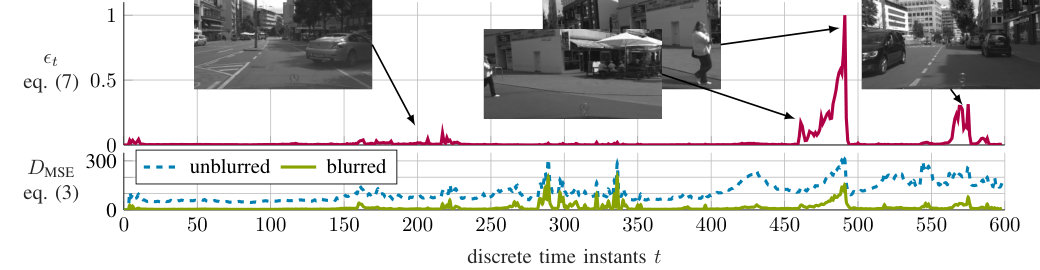 Figure 5
Figure 5 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10| No. | Class | No. | Class | No. | Class |
|---|---|---|---|---|---|
| 1 | Road | 8 | Traffic sign | 15 | Truck |
| 2 | Sidewalk | 9 | Vegetation | 16 | Bus |
| 3 | Building | 10 | Terrain | 17 | Train |
| 4 | Wall | 11 | Sky | 18 | Motorcycle |
| 5 | Fence | 12 | Person | 19 | Bicycle |
| 6 | Pole | 13 | Rider | ||
| 7 | Traffic light | 14 | Car |
| Model | MSE | PSNR | SSIM | # Parameters |
|---|---|---|---|---|
| PredNet | 319.19 | 23.41 | 0.795 | 6,909,818 |
| Pred. AE | 209.78 | 25.53 | 0.721 | 7,209,089 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Towards Corner Case Detection for Autonomous Driving
Jan-Aike Bolte*∗, Andreas Bär∗, Daniel Lipinski∘* and Tim Fingscheidt*∗* *∗Jan-Aike Bolte, Andreas Bär and Tim Fingscheidt are with the Institute for Communications Technology, Technische Universität Braunschweig, Schleinitzstr. 22, 38106 Braunschweig, Germany {j.bolte, a.baer, t.fingscheidt}@tu-bs.de∘*Daniel Lipinski is with Volkswagen Group Research - Automated Driving, Berliner Ring 2, 38440 Wolfsburg, Germany [email protected]
Abstract
The progress in autonomous driving is also due to the increased availability of vast amounts of training data for the underlying machine learning approaches. Machine learning systems are generally known to lack robustness, e.g., if the training data did rarely or not at all cover critical situations. The challenging task of corner case detection in video, which is also somehow related to unusual event or anomaly detection, aims at detecting these unusual situations, which could become critical, and to communicate this to the autonomous driving system (online use case). Such a system, however, could be also used in offline mode to screen vast amounts of data and select only the relevant situations for storing and (re)training machine learning algorithms. So far, the approaches for corner case detection have been limited to videos recorded from a fixed camera, mostly for security surveillance. In this paper, we provide a formal definition of a corner case and propose a system framework for both the online and the offline use case that can handle video signals from front cameras of a naturally moving vehicle and can output a corner case score.
I INTRODUCTION
The recent developments in machine learning also led to significant advancements in current autonomous driving systems. These systems more and more rely on deep learning techniques that use huge datasets for training, e.g., learning from this data how to behave in certain situations. The use of black-box deep learning systems poses a risk, which became apparent through the latest real-world accidents with autonomous cars being involved [1, 2]. Such accidents may occur, if the training data did rarely or not at all cover certain situations [3], a typical case, when issues due to machine learning can be expected [4]. The goal of a corner case detection system is to detect unusual situations111In defining a ”situation”, we follow the definition by Ulbrich et al. [5], ”a situation is the entirety of circumstances, which are to be considered for the selection of an appropriate behaviour pattern at a particular point of time.” either in this training data, or, in a second step, online in an autonomous vehicle. The video signal from a monocular vehicle camera represents a part of the situation. For humans it is possible to distinguish normal from unusual events, even when they only have available the video from a mono vehicle camera. Therefore, it should also be possible to design a corner case detection system that can evaluate situations based on video data only.
Corner case detection brings advantages both in offline as well as in online systems. In an online approach the corner case detection system can be employed as a redundant warning function accompanying an autonomous driving system, where it provides information about how unusual the current situation is (see Fig. 1 (a)). In an offline approach, the corner case detection system can be used to parse through vast amounts of collected video data and returns only a user-defined amount of unusual data. This can be used as a data selection procedure for large-scale data recordings, where it is undesirable to store too much redundant or irrelevant data. These selected corner cases can then be used for a more focused training of autonomous driving systems, tackling the problem of underrepresented critical training data, e.g., by oversampling the corner cases [6].
A major challenge in the development of a corner case detection system is that the detection of corner cases is an ill-defined problem, since there is no universally accepted definition of what a corner case actually is. Corner case detection is closely related to anomaly detection [7] and novelty detection [8], and these two disciplines are already very close to each other. Anomaly detection typically refers to the detection of samples during inference that do not conform with an expected normal behavior. To figure out what is abnormal, a world model can be trained on normal data so that any deviation from that learned behavior will be marked as an anomaly. Novelty detection is similar in the sense that a world model is trained on normal data. Any data that deviates from the already seen data is marked as a novelty. These novelties can be either anomalies or just samples that were not included in the training data. If enough diverse training data is available to train a world model that represents normality sufficiently well, any novelty will be an anomaly. If not, any anomaly is a novelty, but not any novelty is necessarily an anomaly.
The core idea of our work is that the online corner case detection provides self-awareness and a criticality measure for a perception module by an advantageous combination of a semantic segmentation with a video-based prediction error, under the hypothesis that non-predictive relevant objects in vicinity to the car’s expected future trajectory is a corner case. Our contribution with this work is threefold, as we propose a formal definition of what a corner case in the context of perception in autonomous driving might be, secondly, we point out domain-specific challenges regarding corner case or anomaly detection in videos from car-mounted cameras that record scenes with a highly dynamic content and challenging ego motion. Thirdly, we propose a technical framework that will allow to develop corner case detection systems.
The paper is structured as follows. In Section II we present related work in the field of anomaly detection, image prediction, and semantic segmentation. In Section III we propose a definition of a corner case. In Section IV we introduce the corner case detection system concept along with employed datasets and measures. Finally we will present the results of some first experiments in Section V, before we provide conclusions in Section VI.
II RELATED WORK
The corner case detection system that is proposed in this work has a modular structure, consisting of subsystems, which can be (partly) adopted from other research fields. As mentioned in Section 1, we employ an image prediction method in combination with a semantic segmentation to tackle the problem of corner case detection, being closely related to anomaly detection.
II-A Anomaly Detection
Literature offers a wide variety of approaches for the detection of unusual events. Most of them fall under the terms of anomaly detection or novelty detection [9, 7, 8]. Driven by the rapid development in the field of deep learning, many recent methods follow the reconstruction-based approach by unsupervised training of neural networks, exploiting the important advantage that vast mounts of unlabeled data can be used in training [10, 11, 12, 13, 14, 15, 16, 17, 18]. The unsupervised training is typically applied to datasets that contain a large number of normal samples and a negligible small amount of abnormal samples. We assume that we are given a sequence , where denotes the frame at the discrete frame index , and is the length of the sequence. In this case the reconstruction-based method learns a model of normality , given the training dataset , consisting of several sequences. The trained model is used to assign a novelty or abnormality score to the test dataset . Various forms of autoencoder (AE) networks can be used to train such a model.
There are also some special approaches to anomaly detection in the context of autonomous driving or unmanned vehicles. Lin et al. [19] used the Mahalanobis distance to measure the distance of mutliple sensor data vectors, thereby identifying the unusual events. However, their approach was not image-based and thus is not suitable for our work. Another approach is to employ particle filtering and maximum likelihood methods for anomaly detection [20], but again this approach is not suitable for image-based anomaly detection.
As a more general approach to anomaly detection, Munawar et al. [17] trained a spatio-temporal anomaly detection system for surveillance of industrial robots using a deep convolutional neural network (DCNN). They use a biologically plausible system for anomaly detection according to Egner et al. [21], where an anomaly is determined on the basis of expectation and surprise. Accordingly, an unusual video frame can be identified by its deviation from the predicted frame. Liu et al. [18] used a future frame prediction with spatial and motion constraints based on generative adversarial networks (GANs).
Encouraged by these results, we will choose a simple reconstruction-based approach but will employ a predictively trained model of normality. Different to all image-based approaches mentioned above that were evaluated on datasets with a stationary camera, the ego motion of the vehicle makes the datasets in autonomous driving research much more challenging. We therefore will now consider various image prediction approaches for automotive datasets.
II-B Image Prediction
The task of predicting future frames in videos with parametric models that were trained in an unsupervised manner was rarely approached before the work of Ranzato et al. [22]. Inspired by language modeling they introduced a baseline approach for extrapolating future frames that used features learned from video signals in an unsupervised fashion. It seemed to have been the first model that was able to generate realistic predictions of video sequences. Srivastava et al. [23] introduced a long short-term memory autoencoder (LSTM-AE) that performed predictions on image patches, or so-called percepts, that are extracted by a preceding convolutional neural network (CNN). They showed that the predictive training even improved results in a classification task for action recognition. Mathieu et al. [24] used a multi-scale architecture and an objective function that incorporated an adversarial loss and the differences in image gradients. Pătrăucean et al. [25] used a convolutional LSTM-AE. They designed a spatio-temporal video autoencoder to emulate the human visual short-term memory in a basic form. The first real model for long-term prediction was introduced by Lu et al. [26]. They designed a novel objective function and an autoencoder structure with LSTMs. However, again, all predictive approaches mentioned before have in common that they only evaluate their models on datasets with stationary cameras. In the context of automotive image prediction the well-known prediction network PredNet [27] can capture key aspects of both movement of the ego vehicle and movement of the objects in the visual sequences.
In our experiments, we will evaluate PredNet and a predictive autoencoder that is based on the network proposed in [13], since the authors already used it for anomaly detection with a reconstruction-based approach. We will adopt the network and will propose an adversarially trained predictive approach for corner case detection.
II-C Semantic Segmentation
The aim of semantic segmentation is the semantic labeling of each pixel of an input image. Current state-of-the-art architectures for semantic segmentation rely on the concept of fully convolutional networks (FCNs), introduced by [28]. Here, a classifier, pre-trained on the ImageNet database [29], is modified for semantic segmentation. Typical classifiers in state-of-the-art models for semantic segmentation [30, 31, 32, 33, 34] are residual networks (ResNets) [35]. The appropriate amount of context is crucial for semantic segmentation. One common way of dealing with this problem is the use of dilated convolution [36] to enlarge the receptive field in deeper layers [30, 31, 32, 33, 34]. Further multi-scale context is addressed by some state-of-the-art architectures [30, 31, 33, 37, 34] via combining the feature extractor with a pyramid pooling module. To restore the original resolution, all models are designed in a encoder-decoder fashion. One simple approach is to use bilinear interpolation of the network prediction as the decoder part [30, 31, 37, 34], while other approaches use more complex operations such as transposed convolution [32, 38], or the additional use of low-level features through skip connections [33, 39].
Recently, along with a major interest in practical implementations, efficient semantic segmentation architectures with regard to computation and memory cost have been introduced. To address the memory problem, [34] proposes in-place activated batch normalization (InPlace-ABN), a memory-efficient approach in the training process through combining the leaky rectified linear unit (leaky ReLU) with batch normalization [40]. In [33, 41] depthwise separable convolutions are used to reduce the number of parameters and therefore computation cost and memory usage, while [38] proposes factorized convolution in combination with residual connections to obtain a similar effect.
We base our own segmentation network on the DeepLabv3 [31] with some improvements, since it is one of the best performing networks on the Cityscapes dataset.
III CORNER CASE DEFINITION
A consequence of the so-far missing universally accepted definition of a corner case is that there is also no explicit metric existing. Motivated by [17], we will use a predictive approach for corner case detection. The idea is that if a novel or abnormal or critical suddenly occurring situation is technically predictable, it will not pose a major problem to an autonomous driving system, which will then naturally take care of adequate actions. Therefore, for us this would be a don’t care situation, although some might view it as a corner case. So our focus is on technically unpredictable situations. However, it is important to note that not each unpredictable situation in the field of autonomous driving is necessarily a corner case. An aircraft that suddenly enters the camera image in the sky may not be predictable, but luckily in most cases it will be irrelevant for the driving task. As opposed to that, pedestrians, cyclists and other moving objects on the ground are highly relevant classes. Beyond that, even a pedestrian acting in some highly unpredictable manner may be irrelevant for the driving task if it happens at a sufficiently large distance from the vehicle or its future trajectory.
We therefore propose that a corner case is given if there is a relevant object (class) in relevant location that a modern autonomous driving system cannot predict. Therefore, the relevance of a corner case results from the three aspects noted in Figure 2. The relevance of objects and locations, as well as aspects of prediction, will be discussed in the next section.
IV TOWARDS CORNER CASE DETECTION: FRAMEWORK AND MEASURES
As a working hypothesis we assume that it is possible to detect corner cases with a camera-based system, because, as already mentioned, it is also possible for a human to distinguish normal from unusual events, even when only the video from a mono vehicle camera is available. We limit this work to the detection of non-predictive situations in the context of autonomous driving, meaning a camera in movement. Following our definition of a corner case we need a system that combines the three important aspects (Fig. 2): (1) First, we need an image prediction that gives us the prediction errors for each new frame. (2) Second, we need a semantic segmentation of the input frame that allows us to classify and localize the objects in the scene, with moving objects being considered as relevant (see Table 1), and (3) third, we need a detection system that processes the information from both image prediction and semantic segmentation by information fusion, comprising a check, whether the non-predictable (e.g., jumping) relevant class (e.g., pedestrian) is in a relevant location (will cross trajectory). The following subsections describe each part of the corner case detector that is illustrated in Figure 3, along with the datasets we employ for training, and related measures.
IV-A Semantic Segmentation
Semantic segmentation of images aims at finding a transformation that partitions the input image into semantically related parts, by assigning each pixel to a specific class. As motivated in Section II, we adopt a segmentation network based on the DeepLabv3 [31] with some improvements from WideResNet38 [32], which is pre-trained on the ImageNet corpus. To be more specific, we replace ResNet50 [35] inside DeepLabv3 by WideResNet38. This is similiar to the approach in [34], with the difference, that we don’t incorporate the proposed InPlace-ABN. Further, we do a few common modifications in semantic segmentation to WideResNet38 [31, 32]: First, we remove the classification layer of WideResNet38 and connect the remaining network to the segmentation head of DeepLabv3. Second, to control the output stride (ratio between input resolution and output resolution) we decrease the stride of several convolutions from two to one in a bottom-up fashion and increase the dilation rate instead. Third, in contrast to [32], we do not incorporate dropout in our segmentation framework as we observed lower performance results otherwise.
The input image with image pixel , where is the set of gray values, and are the image height and width in pixels and is the number of color channels from set , is fed into a fully-convolutional neural network. It maps the input to output scores , where denotes the set of classes with cardinality and . For each pixel position , the third dimension of the output scores provides a posterior probability (score) for each class . Here, is the set of pixel indices in the image, and the number of pixels. Taking the argmax over the output scores we obtain the mask , which gives us a pixel-wise classification of the frame for time .
As a metric, the mean intersection over union (mIoU) is employed [42], which measures the accuracy of the segmentation mask and is defined as the mean of the frame-wise
[TABLE]
where are the numbers of true positive, false positive, and false negative pixels, respectively, in frame .
Modern neural networks have been shown to be overconfident in their classifications [43]. This can pose a problem on system components used for semantic segmentation or object detection, since even unknown objects will be classified as one of the known classes. In a future corner case detection system this will be solved by a single-frame anomaly detection.
IV-B Image Prediction
As already mentioned, image prediction is an essential part of the corner case detection system. Modern autonomous driving systems already predict trajectories of other traffic participants. To identify corner cases in video streams, it is essential to understand the underlying states and dynamics within the given situations. This high-level abstraction can be learned by predictive models. For the image prediction approach we train a model that receives consecutive frames to compute a prediction of the current frame. As a metric for the corner case, we now calculate an error
[TABLE]
between the predicted image and the actual image (subtraction symbol in Figure 2), with elements . Following Mathieu et al. [24], we use the following metrics to evaluate the prediction models. The mean-squared error (MSE) distance is then given by
[TABLE]
Additionally we employ the peak signal-to-noise ratio (PSNR), which is defined by
[TABLE]
where shall denote the squared maximum possible value of the color channel image intensities, e.g., for 8-bit image formats with . Both metrics can also be applied to color images, where the metric is evaluated for each color channel separately, and then averaged. As a third metric, we use the structural similarity index measure (SSIM), which is a metric for perceived image quality being introduced by Wang et al. [44]. The SSIM measures the perceptual difference between the original and the predicted image and is, unlike the other two metrics, based on visible structures in the image.
IV-C Detection System
In the detection system, information from both of the two previous processing steps is combined. As its output the system generates a corner case score for each input frame , exploiting also past frames . Along with , in principle also a localization of the corner case in the image can be performed. If we recall the definition of the corner case in Figure 1, we remember that we consider a corner case consisting of the logical AND combination of three aspects. The semantic segmentation provides the class and location information and the image prediction provides the predictability. To identify a relevant location, in a real system, typically one would use a perception approach based on a light detection and ranging (LIDAR) sensor to assign depth information to the image pixels [45, 46]. On the basis of that, a time to collision on a pixel basis can be estimated [47]. For the purpose of this work, however, instead we adopt a rather simple approach for the reason of conciseness of presentation and evaluation. We simply assume that objects being further above the bottomline of the image are more distant to the ego vehicle.
The error map (2) from the image prediction gives us a value of non-predictability for each pixel. Since we are for now only interested in the moving classes, we simply set the error of those pixels that do not belong to one of these moving classes to zero, given the following formula:
[TABLE]
where denotes the set of all relevant classes for the corner case detection. In our case, we use the eight classes that are printed in bold in Table I. The squared errors of the relevant classes are then weighted depending on their distance from the bottom of the image and summed up resulting in an error score
[TABLE]
with being the row index (bottom-up) of pixel . Thereby, our simple definition of a relevant location weights the bottom row squared errors by a one, and the top row squared errors of the relevant classes by a zero. Finally, the corner case score is obtained by normalizing the error score to a value range from 0 to 1 using
[TABLE]
where denotes a set of time instants. For the online approach it may be , or all time instants of the validation data. For the offline approach may contain all time instants of the video material currently being analyzed. If a localization of the corner case in the frame is needed, is obtained by (6) with summation over small patches of the window. We therefore subdivide the image into patches of the same size, e.g., pixels. The patch size can be adjusted by the user, depending on how exactly he desires to localize the corner cases. The error scores of each of the patches can then also be normalized to a range between 0 and 1.
Finally, the obtained corner case score is subject to thresholding. An appropriate threshold value has to be identified on validation data to tune the desired behavior of the detector regarding the false acceptance rate and the false rejection rate. In an offline system, can be chosen by the user in order to control the amount of detected corner cases in the data.
V DATASET, TRAINING, AND QUALITATIVE EVALUATION OF THE CORNER CASE DETECTION SYSTEM FRAMEWORK
V-A Dataset
We train both the segmentation and image prediction network on the Cityscapes dataset [48] that contains a diverse set of street scene images recorded in 50 different cities, being a widely used benchmark for semantic segmentation not only for autonomous driving research. The dataset is labeled with 19 classes that are used during training and inference (see Table 1). They denote the set . The Cityscapes dataset [48] offers a benchmark suite that serves as a baseline for future improvements in image segmentation. For the purpose of this conceptual paper, the image prediction is trained on the three demo videos provided by the dataset.
V-B Semantic Segmentation
We mainly adopted the training protocol from Chen et al. [31]. For optimization, we used the stochastic gradient descent with momentum and a learning rate with polynomial decay:
[TABLE]
where is the current learning rate at iteration , is the initial learning rate, the maximum number of iterations, and exponent . For data augmentation we perform random resizing in the range , left-right flipping, and cropping of the input image with a crop size of 700x700. With this configuration and our reimplementations we were able to fit a batch of size and using an output stride of and , respectively, on an Nvidia Geforce GTX 1080 Ti.
The training itself is organized in a two-stage fashion. In the first stage, we set the output stride to and train the network parameters, including the batch statistics, for 90,000 iterations with a batch of size and an initial learning rate . In the second stage, we set the output stride to , freeze the batch statistics in the corresponding layers, and fine tune for an additional 120,000 iterations with a reduced batch of size and a reduced initial learning rate .
We evaluate our segmentation results by using the fine-tuned stage-two model and computing the mean intersection over union (mIoU, see (1)) between the network prediction and the ground truth with an output stride of . We use multiple parallel fine-tuned models, which are fed by input images with three different scales , resulting in score maps for each class and scale . These score maps are resized to the original input size and are fused by summation for each class separately across all scales .
Our network was solely trained on the finely annotated training images from the Cityscapes dataset. It achieves a competitive mIoU of 78.4% on the Cityscapes evaluation set, being quite close to the best approaches known today.
V-C Image Prediction
For the image prediction task we tested two models to find out which one works best for the difficult conditions in automotive applications. The first model is the well-known PredNet [27] and the second is an autoencoder network that is based on the network proposed by Hasan et al. [13].
To gain a quick first insight into the employment of image prediction the three demo videos provided by the Cityscapes dataset were used as training data for both prediction networks.
Both networks were trained on the three demo videos provided by the Cityscapes dataset. The networks were trained in a leave-one-out scheme, where they were trained on two of the three videos and the test was performed on the third, unseen video. The training and testing was done for each combination of the three videos and the test results on the respective unseen video were averaged. For the exemplary test we limit ourself to the demo videos of the Cityscapes dataset, since our segmentation network was trained on this dataset and therefore we can definitely expect good performance on images from this domain.
For the PredNet, we used the standard architecture and training protocol as described by Lotter et al. [27]. For the predictive AE we adopted the architecture proposed by Hasan et al. [13] with some improvements to refine the predictions. The architecture is shown in Figure 4. Typically a normal AE is trained using the MSE loss. It was shown that this leads to blurry predictions [24, 49], which can be overcome by incorporating an adversarial loss. We added a discriminator network to the training procedure. The discriminator network uses the same architecture as the encoder network of the AE, extended with a patch-wise classification (also known as local adversarial loss) as proposed by [50], where the discriminator network is trained to classify the real images or predicted images of the image prediction network w.r.t. the respective classes, with being the class upon which the discriminator decides. The architecture of the discriminator network is shown in Fig. 5.
The loss of the generator and of the discriminator are added in the loss function
[TABLE]
with being the standard MSE loss, being the adversarial loss, and the weighting factor determining the influence of the adversarial loss on the overall loss. and denote the weights of the generator network, in this case the image prediction network, and the discriminator, respectively.
We found a major improvement in stability of the training by using a cyclic learning rate as proposed by [51]. We used the stochastic gradient descent and started the training with a learning rate of the generator and then periodically increased the learning rate of the generator to and decreased it back again. The period showed the best results. The learning rate of the discriminator did not follow the cyclic protocol and was set to . The maximum learning rate is also subject to an exponential decay after each epoch with an exponent of . The batch size for the training is set to . For the training, the original Cityscapes images were downsampled to a resolution of pixels and converted to greyscale.
The results in Table II show that the quality of the predictions from both networks are not far apart from each other for both PSNR and SSIM. In our experiment, however, the predictive autoencoder provides clearly a better MSE. We decide to use the predictive adversarial AE, since it is a simple feed-forward architecture that can be easily modified for further experiments and also provides the better MSE, which is closely related to the measure that we use for corner case detection.
V-D Detection System
As already mentioned, the task of corner case detection was an ill-defined problem lacking useful metrics so far. This is the reason why our approach to corner case detection relies on a clear definition of what a corner case is (Fig. 2), which is then conceptually implemented by a respective modular structure (Fig. 3), where two of the modules follow well-known quality metrics (see Sections IV.A and IV.B).
Typical metrics for the third module, namely the detection system, such as the false acceptance rate (FAR), false rejection rate (FRR) or the area under curve (AUC) of the receiver operation characteristic (ROC) can only be applied if (human-)labeled test data is available. To the best of our knowledge, there is no dataset of labeled corner cases for autonomous driving available so far. Therefore, in this work, we show exemplary results that were achieved on demo video material from the Cityscapes dataset.
Fig. 6 shows some exemplary results of (3) (lower subfigure) and the final corner case score (7) (upper subfigure) on the demo video stuttgart_00 of the Cityscapes dataset. A problem with the image prediction module is that the squared error was considerably higher in image regions with high frequencies.
We have therefore low-pass-filtered both the real image and the predicted image with a Gaussian kernel filter with kernel size and calculated the squared error afterwards. In the lower subfigure the MSE (3) is depicted without such blurring (blue, dashed) and with blurring (green, solid). The effect of blurring both the predicted image and the real image with a Gaussian kernel filter before subtraction (2) is that it helps to achieve in the many ordinary situations, while potential corner cases lead to fewer clearly observable periods of being larger than zero.
The plot in the upper subfigure (red, solid) shows the corner case score that is calculated according to (7). The corner case score is based on the MSE of the blurred images (6). It can be seen, that the system focuses on the relevant classes and suppresses high MSE values for non-relevant objects, when there are either no relevant classes or they are all predictable. Marked are three exemplary situations yielding medium to high corner case scores. In the first situation, the preceding car is turning right and the driver of the ego vehicle is taking a slight left turn to overtake the other car. In the second situation, a pedestrian is suddenly crossing the street in a road curve, a potentially dangerous situation. The third situation is an oncoming car that is not predictable for our system and close to the ego vehicle, which in our case leads to a high corner case score. It can be seen that the woman immediately crossing in a road curve produces the highest corner case score in our system, a situation, which indeed can be considered a corner case.
VI CONCLUSIONS
In this work we proposed a formal definition for a corner case that is applicable to autonomous driving. We consider that a corner case is given, if there is a non-predictable relevant object/class in relevant location. Each of the three aspects of our definition is covered by a module in the proposed corner case detector. The semantic segmentation to identify relevant objects and the image prediction are both subsystems that can be improved on their own. Their performance can be easily compared to knew methods due to widely accepted metrics in the respective research fields. For the third subsystem, the detection system, we presented a conceptual framework, which showed promising results in preliminary qualitative experiments. It also showed the urgent need for data that covers labeled corner cases. Accordingly, the next step of our work is to record videos of (arranged) corner cases along with labels in order to be able to also quantitatively evaluate the entire detection system.
VII ACKNOWLEDGMENT
The authors gratefully acknowledge support of this work by Volkswagen Group Research, Wolfsburg, Germany.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] National Transportation Safety Board, “Preliminary Report Highway HWY 18MH 010,” May 2018.
- 2[2] National Transportation Safety Board, “Preliminary Report Highway HWY 18FH 011,” June 2018.
- 3[3] Y. Tian, K. Pei, S. Jana, and B. Ray, “Deep Test: Automated Testing of Deep-Neural-Network-Driven Autonomous Cars,” ar Xiv preprint ar Xiv:1708.08559 , 2017.
- 4[4] P. Koopman and M. Wagner, “Challenges in Autonomous Vehicle Testing and Validation,” SAE International Journal of Transportation Safety , vol. 4, no. 1, pp. 15–24, Apr. 2016.
- 5[5] S. Ulbrich, T. Menzel, A. Reschka, F. Schuldt, and M. Maurer, “Defining and Substantiating the Terms Scene, Situation, and Scenario for Automated Driving,” in Proc. of ITS , Canary Islands, Spain, Sept. 2015, pp. 982–988.
- 6[6] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: Synthetic minority over-sampling technique,” Journal of Artificial Intelligence Research (JAIR) , vol. 16, pp. 321–357, 2002.
- 7[7] V. Chandola, A. Banerjee, and V. Kumar, “Anomaly Detection: A Survey,” ACM Computing Surveys , vol. 41, no. 3, pp. 15:1–15:58, July 2009.
- 8[8] M. Pimentel, D. Clifton, L. Clifton, and L. Tarassenko, “A Review of Novelty Detection,” Signal Processing , vol. 99, pp. 215 – 249, June 2014.