Learning continuous Q-Functions using generalized Benders cuts
Joseph Warrington

TL;DR
This paper introduces a model-based algorithm using generalized Benders cuts to approximate the optimal Q-function in continuous control problems, providing finite-iteration guarantees on Bellman error reduction.
Contribution
It presents a novel Benders-based method for continuous Q-function approximation with proven finite-iteration optimality guarantees.
Findings
Algorithm converges to arbitrarily small Bellman error in finite steps.
Guarantees hold for both fixed and online input selection scenarios.
Numerical experiments demonstrate effectiveness on scalar and high-dimensional systems.
Abstract
Q-functions are widely used in discrete-time learning and control to model future costs arising from a given control policy, when the initial state and input are given. Although some of their properties are understood, Q-functions generating optimal policies for continuous problems are usually hard to compute. Even when a system model is available, optimal control is generally difficult to achieve except in rare cases where an analytical solution happens to exist, or an explicit exact solution can be computed. It is typically necessary to discretize the state and action spaces, or parameterize the Q-function with a basis that can be hard to select a priori. This paper describes a model-based algorithm based on generalized Benders theory that yields ever-tighter outer-approximations of the optimal Q-function. Under a strong duality assumption, we prove that the algorithm yields an…
Click any figure to enlarge with its caption.
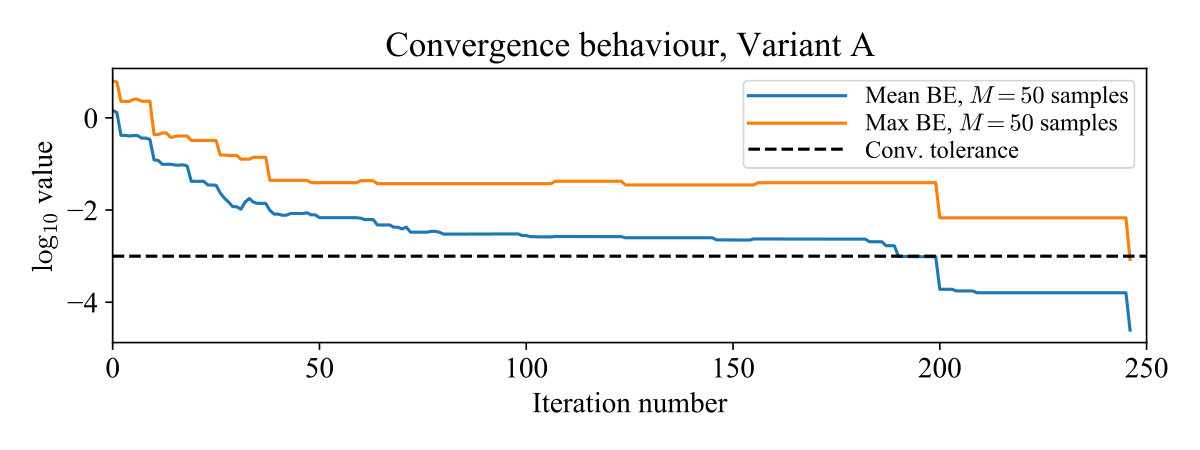 Figure 1
Figure 1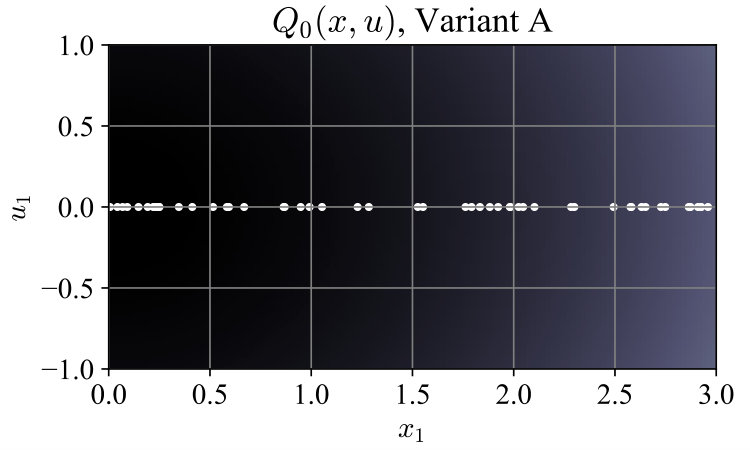 Figure 2
Figure 2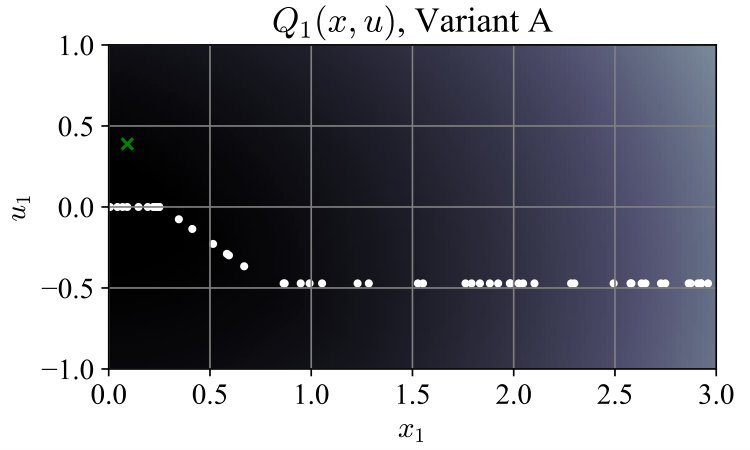 Figure 3
Figure 3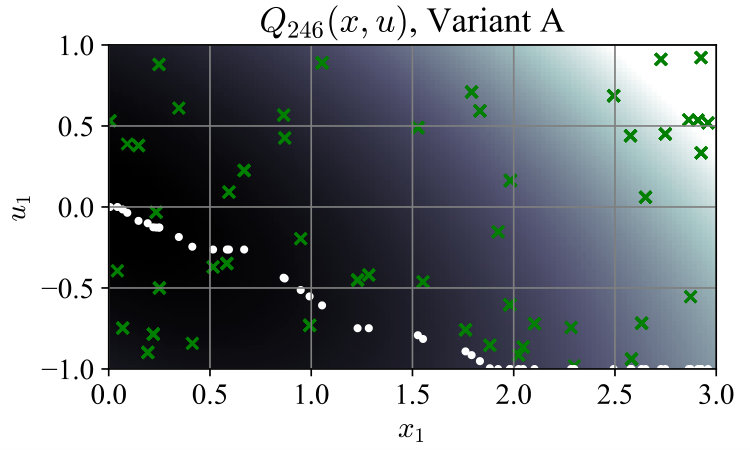 Figure 4
Figure 4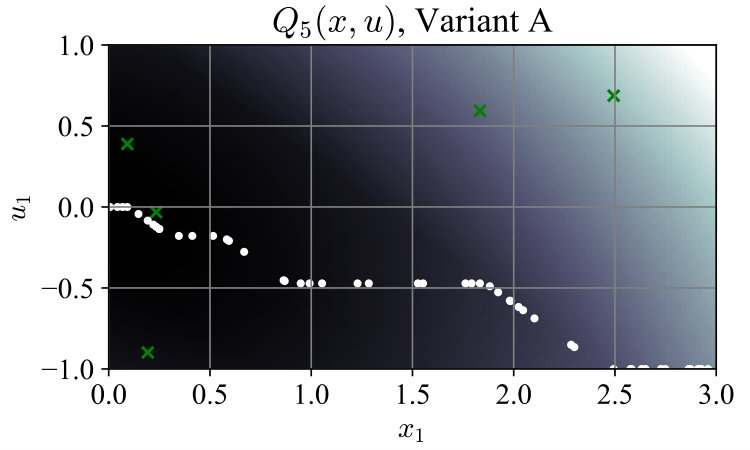 Figure 5
Figure 5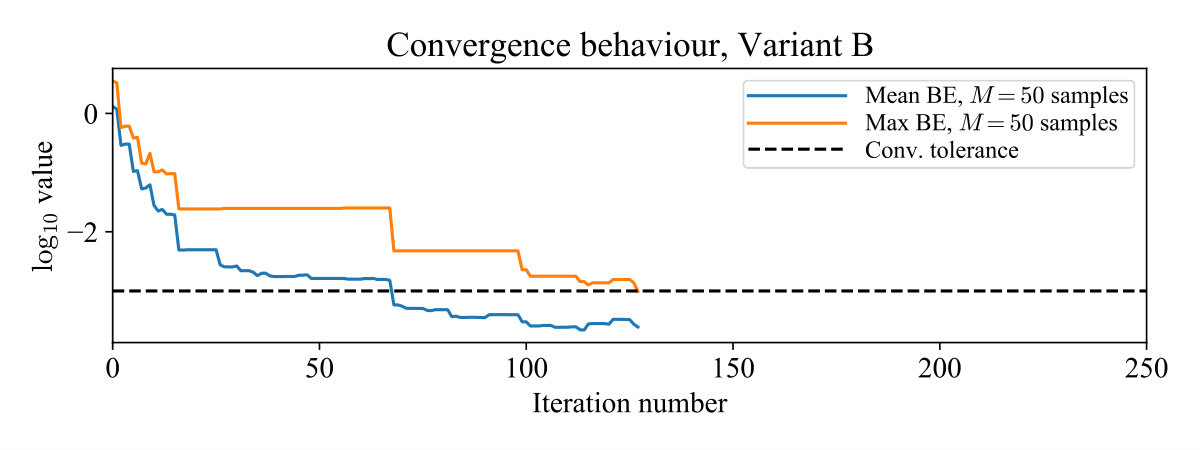 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8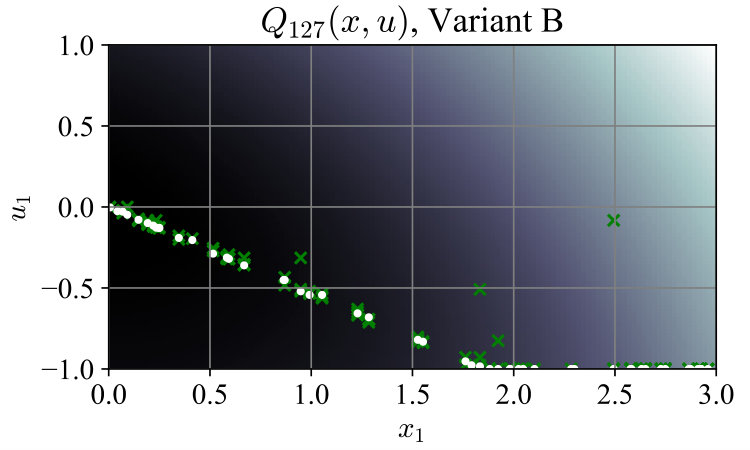 Figure 9
Figure 9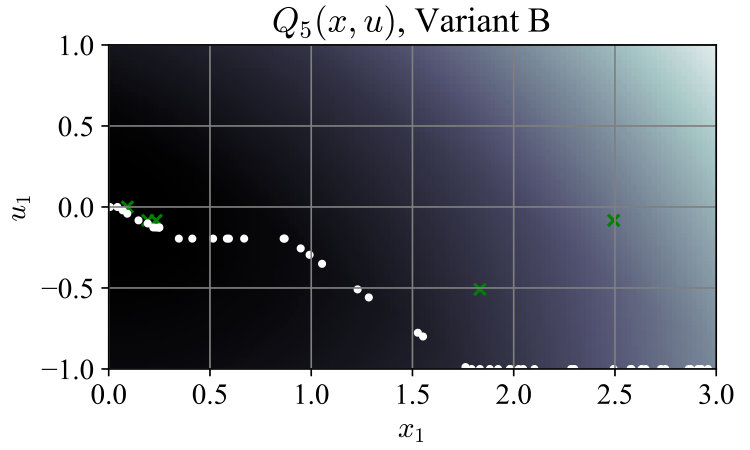 Figure 10
Figure 10| Iterations to | Computation | Number of | |
| termination | time (s) | cuts added 1 | |
| 10 | 217.3 57.9 | 0.313 0.120 | 160.8 31.7 |
| 20 | 485.7 74.5 | 1.054 0.296 | 356.0 71.0 |
| 50 | 1293 193 | 6.083 1.724 | 907.0 163.4 |
| 100 | 2736 491 | 25.09 8.60 | 1828 367 |
| 200 | 6043 1017 | 114.7 34.5 | 3696 626 |
| 500 | 16245 2527 | 777.1 215.3 | 9654 1644 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Learning continuous -functions using generalized Benders cuts
Joseph Warrington The author is with the Automatic Control Laboratory, Swiss Federal Institute of Technology (ETH) Zurich, Physikstrasse 3, 8092 Zurich, Switzerland. Contact: [email protected]
Abstract
-functions are widely used in discrete-time learning and control to model future costs arising from a given control policy, when the initial state and input are given. Although some of their properties are understood, -functions generating optimal policies for continuous problems are usually hard to compute. Even when a system model is available, optimal control is generally difficult to achieve except in rare cases where an analytical solution happens to exist, or an explicit exact solution can be computed. It is typically necessary to discretize the state and action spaces, or parameterize the -function with a basis that can be hard to select a priori. This paper describes a model-based algorithm based on generalized Benders theory that yields ever-tighter outer-approximations of the optimal -function. Under a strong duality assumption, we prove that the algorithm yields an arbitrarily small Bellman optimality error at any finite number of arbitrary points in the state-input space, in finite iterations. Under additional assumptions, the same guarantee holds when the inputs are determined online by the algorithm’s updating -function. We demonstrate these properties numerically on scalar and 8-dimensional systems.
I Introduction
Reinforcement learning (RL) and approximate dynamic programming (ADP) commonly employ so-called -functions to model the costs incurred in the future evolution of a discrete-time system under a given control policy. The -function associated with control policy takes a state and input as parameters, and is equal to the stage costs incurred immediately for plus the costs (typically infinite-horizon with a discount factor) of following policy thereafter.
-functions are widely associated with RL (i.e., model-free learning), thanks to work stemming from Watkins’ -learning algorithm [17]. However, model-free -learning suffers from slow convergence, even despite new insights into optimizing the rate [7]. New work such as [11] is an example of interest in cases where model data, known or itself learned, can improve learning performance for difficult control problems. The present paper is motivated by a desire to learn an approximate -function to control a system with a known model.
Mathematically, -functions have much in common with value (or -) functions, the chief difference being that they are defined on state-input space rather than on the state alone. Although they are generally more expensive to store, their higher-dimensional domain often makes approximate, finitely-parameterized -functions more expressive than -functions [4, Ch. 2].
It is common to discretize continuous problems in order to obtain a finite parameterization of the - or -function [5]. However, performing even one iteration of the canonical algorithms, such as value iteration, then has an undesirable exponential cost. ADP methods have arisen to find more tractable parameterizations of the continuous -function. Several are based on continuous extensions of the “linear programming approach” to ADP [6], in which a valid lower bound on the optimal value function is maximized. Examples include the quadratic lower bound in [14], and the polynomial derived using sum-of-squares techniques in [13]. Approximate -functions represented as the pointwise maximum of multiple lower-bounding functions have been used in [10, 15, 1, 9]. Recent work utilizing a point-wise maximum representation [16] has extended the Benders decomposition argument used for linear multi-stage decision problems in Dual DP (DDP, [12]), to a general nonlinear, infinite-horizon setting.
In this paper we adapt the Benders approach from [16] to learn -functions. We define an algorithm that successively produces tighter approximations of a problem’s optimal -function from below, and prove convergence results for off-policy and policy-driven learning of the -function in this manner. In the former case, pairs are pre-selected at the start of the algorithm, whereas in the latter case, only the points are pre-selected, and the decisions are made according to a policy from the update -function estimate. We then demonstrate the method’s efficacy for test systems.
Section II describes the infinite horizon problem, Section III describes the Benders decomposition approach, and Section IV proposes an algorithm and proves its key properties. Section V presents numerical examples, and Section VI concludes.
II Problem statement
II-A Infinite-horizon control problem
The scope considered is the class of infinite-horizon, discrete-time, deterministic optimal control problems with time-invariant stage cost functions, dynamics, and constraints:
[TABLE]
For each time step we denote the state , and the action, or input, . Sets and are the state and action spaces, and are continuous. Future costs are discounted according to a discount factor , the (non-negative) stage cost function is , and the dynamics are governed by the mapping . There are state-input constraints (1c), parameterized by a vector-valued mapping . The parametric infimum of problem (1) is referred to as the optimal value function (or optimal -function) of the problem.
II-B -functions
We now define -functions and briefly state some of their well-known properties for later use. For more detail, see for example [4, Chapter 2]. Given a policy , its associated -function, , is
[TABLE]
in which the relation holds for , and . The -function is the sum of the stage cost incurred for some initial state and input and , and the infinite sum of (discounted) costs under policy thereafter.
The optimal -function, which we denote , minimizes (2) over policies , and satisfies
[TABLE]
for all . In (3) we use the notation . An associated Bellman operator for -functions, , can be defined as
[TABLE]
On the left-hand side, is to be interpreted as a new function with the same domain as , and evaluated at . Thus, condition (3) can be written for all . If an optimal - and -function exist for problem (1), they are related by , and thus from (3), .
For any approximate -function for which the infimum in (4) is attained, one can define an associated control policy consistent with definition (2):
[TABLE]
The attraction of a -function is that in a wide range of cases it is simpler to solve (5) than it would be to solve, for the same , the full infinite-horizon problem (1), or a finite-horizon truncation thereof, as in Model Predictive Control (MPC) [2].
Lastly, for the benefit of developments in Section III, we note it is easy to show that the operator is monotonic:
[TABLE]
III Benders cuts
III-A Pointwise maximum representation
Let be a function of the following “pointwise maximum” form,
[TABLE]
where is a non-negative integer, and each function is known to satisfy
[TABLE]
Thus for all . From (5) the control policy associated with is simply .
In Section IV we will propose an algorithm that uses to construct an additional function, or “cut” . Under certain assumptions, the new cut satisfies
[TABLE]
Thus the new function, , will be a tighter under-approximation of than . We now derive a Benders-type procedure to achieve this, which is related to that in [16] for -functions.
III-B Duality in operator
We start by taking the dual of the minimization problem solved inside the operator at some point in the state-action space. For a function taking the form (7), the right-hand side of (4) can be written equivalently as
[TABLE]
where the extra variable is introduced to model the successor state explicitly. An epigraph variable can be introduced to replace the inconvenient maximum operator in the objective with separate constraints. This leads to an equivalent problem:
[TABLE]
Assigning the Lagrange multipliers , , and to constraints (9b), (9c), and (9d) respectively, one can form the Lagrangian,
[TABLE]
Following standard procedure, the dual of (9) is then
[TABLE]
where the function
[TABLE]
depends only on the multipliers. Although problem (9) may not be convex, the objective of (10) is always concave [3, §5.2], and weak duality implies for any choice of parameter .
III-C Generalized Benders cut
Given a function of the form (7) such that , suppose that optimal multipliers are attained when (10) is solved with parameter . These can be used to form a new cut with the following attractive properties.
Lemma III.1**.**
The function
[TABLE]
satisfies for all .
Proof.
An optimal dual solution for parameter must in general be a suboptimal solution to problem (10) when any other parameter is used, i.e.,
[TABLE]
Note that is feasible in (10) for all parameters , as the feasible set is independent of the parameter. From weak duality, . As we start with on its domain, we have from the mononoticity property (6) that , and the Bellman optimality condition states that . Combining these relationships we obtain
[TABLE]
and the result follows simply by noting that can refer to any in the argument above. ∎
This proof leverages the (generalized) Benders decomposition argument, which was first developed in [8] to partition a two-stage problem into two subproblems linked by an approximate value function. Here we have used the properties of -functions to accommodate the infinite number of stages in problem (1). A similar result was derived for -functions in [16].
The following properties concern the violation of the Bellman optimality condition (3), or the -Bellman error:
[TABLE]
Lemma III.2**.**
If for all , then for all , where
[TABLE]
Proof.
A simple adaptation of [16, Lemma III.3]. ∎
Lemma III.3**.**
Suppose strong duality holds between problems (9) and (10) and that for all . Then if at some we have , a cut there is strictly improving:
[TABLE]
and the increase is equal to .
Proof.
If strong duality holds, we have , and the new function satisfies . Since the result follows. ∎
Lastly, the following property facilitates a “greedy” cut with respect to some particular location.
Lemma III.4**.**
The Benders cut that yields the greatest increase at , i.e., for which is maximized, is that obtained by solving problem (10) at .
Proof.
The result follows by reversing the roles of and in the proof of Lemma III.1. ∎
IV Benders algorithm for Q-Functions
We propose Algorithm 1 as a means of approximating by generating Benders cuts of the form (11). It starts with , which from (2) trivially lower-bounds , and by Lemmas III.2 and III.3 guarantees for all and for all . New cuts are created at certain points , and Variants A and B differ in how these are chosen:
- A.
Select a list of state-input pairs a priori, and choose a random at each algorithm iteration.
- B.
Select a list of state space points a priori, and within the algorithm pick a random , letting follow from policy (5) parameterized by .
We now state convergence results for both variants.
IV-A Fixed pairs
The following results hold for Variant A. We omit the proofs of both, because they carry across with little modification from the -function results in [16, Thms. III.5 and III.6]:
Theorem IV.1** (Pointwise convergence of ).**
For each for which is finite, there exists a limiting value such that .
Theorem IV.2** (Finite termination of Variant A).**
Suppose the following conditions are met:
- (i)
Strong duality holds for the one-stage problem (9) with parameter each time it is solved, for each . 2. (ii)
* is finite for each pair .*
Then Variant A of Algorithm 1 terminates in finite iterations with probability for any tolerance .
IV-B Fixed , policy-driven
Although Variant A has attractive convergence properties, it learns a -function based only on performance at pre-selected pairs , in the sense of minimizing the -Bellman error there. Variant B instead learns a -function based on performance at pairs in which the is consistent with the policy derived from the learnt -function. One expects this criterion to be more relevant to performance of the final policy, as state-input trajectories will pass closer to these points.
Finite termination of Variant B is our main result, which we now state precisely along with the required assumptions.
Assumption 1**.**
For each , the set of feasible inputs contains an element such that .
This assumption implies is finite for each . Introducing the notation , the following holds:
Theorem IV.3** (Monotone convergence of ).**
Under Assumption 1, the limit exists for each .
Proof.
It follows from Assumption 1 that , and from Lemma III.1, for all . Thus, at each iteration . As the sequence of functions increases monotonically, the sequence must also increase monotonically. This latter sequence is bounded from above, thus the limit exists from the Monotone Convergence Theorem. ∎
An additional performance guarantee for Variant B is available when the following additional assumptions hold.
Assumption 2**.**
For each , set is compact, and each entry of is Lipschitz-continuous on .
Assumption 3**.**
The problem data in (1) is such that the lower-bounding functions generated in Variant B:
- (i)
Maintain strong duality between problems (9) and (10) with parameter at each iteration of the algorithm, with , for all .
- (ii)
Are Lipschitz continuous in with some constant common to all functions , for each .
Assumptions 2 and 3 must be verified for a given problem. A widespread setting where these hold is the constrained, stable linear-quadratic regulator (LQR); see the Appendix.
Theorem IV.4** (Finite termination of Variant B).**
Suppose that in addition to Assumption 1, Assumptions 2 and 3 hold. Then Variant B of Algorithm 1 terminates in finite iterations with probability for any tolerance .
Proof.
Let the sequence of iterations where a given is chosen in line 15 of the algorithm be indexed by . With probability , this sequence is infinitely long for each . We now show that the sequence of -Bellman errors
[TABLE]
is a Cauchy sequence converging to zero for each . As is compact for all , the policy defined in (5) can always be evaluated.
Recall that Lemma III.2 implies for all and . Suppose for the sake of contradiction that the sequence is not a Cauchy sequence converging to [math]. Then there must exist some for which there is no iteration number beyond which . Whenever point is picked in line 15 of the algorithm, the strong duality condition in Assumption 3 and Lemma III.3 together imply that
[TABLE]
If is not a Cauchy sequence, there will be an infinite number of occasions on which
[TABLE]
Furthermore, Assumption 1 and part (ii) of Assumption 3 together imply that
[TABLE]
as is always a lower bound on . Compactness of implies that the volume of the truncated hypograph
[TABLE]
is finite for each ; recall that .
Due to Lipschitz continuity, cut decreases the volume of by an amount that is lower bounded by a function of , , and the input dimension . Thus, this volume cannot be removed infinitely many times from , and we have a contradiction. Cuts made at iterations where some other index is picked in line 15 may also remove some volume from , but this does not affect the argument. Thus is a Cauchy sequence converging to zero, and Algorithm 1 terminates in finite iterations for any . ∎
Therefore, under certain assumptions one need only specify , and Variant B minimizes the -Bellman error at a associated with each that is consistent with policy (5). One then expects the optimal -function to be learnt more accurately around the policy surface than elsewhere in the state-action space.
V Numerical examples
We now report two numerical tests of Algorithm 1. In both cases, systems were of the class C-LQR described in the Appendix, for which finite termination of Variants A and B is guaranteed by Theorems IV.2 and IV.4 respectively, and lower bounding functions are quadratic. All tests used the stage cost , discount rate , and termination tolerance , with encoding an input constraint . Tests were implemented in Python with subproblems solved using Gurobi 7.0.2, on a computer with an Intel i7 CPU at 2.60 GHz and 16 GB RAM.
Scalar system
For ease of visualization, we used the simple system , with , and ran both algorithm variants. In Variant A, contained 50 random states sampled uniformly from the interval , and a random associated with each . In Variant B the associated inputs were dropped to form . Fig. 1 shows convergence of the maximum -Bellman error , with the mean error shown for comparison. Total time spent generating lower-bounding functions was 243 ms for Variant A and 121 ms for Variant B. For this simple system the optimal policy can be computed as . Fig. 2 shows the evolution of at selected iterations; after termination, the policy (5) from Variant B was closer to the optimal policy than that from Variant A. The average closed-loop cost starting from points was also lower at 2.47991, compared to 2.48716 for Variant A, and 2.47968 for the optimal policy.
Higher-dimensional systems
We tested Variant B for systems too large for the optimal policy to be computed exactly. 20 random 8-state, 3-input linear systems were created with . For each system, points in were sampled from a normal distribution with zero mean and variance times the identity matrix, for . Table I reports statistics upon termination. The number of iterations is roughly linear in , while computation time is roughly quadratic. The latter excludes the Bellman error measurement in line 11, on the basis that in practice, the convergence check for which it is used need not be carried out at every iteration.
It is likely that other ways of choosing in line 15, e.g. largest Bellman error, would reduce the number of iterations required, although the assumptions under which finite convergence can be guaranteed may differ. Nevertheless, total times are already modest, and we note that alternative “exact” DP approaches such as value iteration [4, Ch. 2] and explicit MPC [2] are impractically expensive for problems of this size.
VI Conclusion
This paper presented a general algorithm able to learn -functions, in the sense of minimizing Bellman error at arbitrary state space locations, for infinite-horizon problems. Convergence results were provided, both for fixed pairs and for “policy-driven” pairs . A further variant of Algorithm 1 could augment with sequences of states following the policy at each iteration, i.e., . This would potentially learn a -function that approaches around entire trajectories, which is stronger than minimizing in individual locations .
An added attraction of our formulation is that in many cases problem (5) remains convex even when the -function is not convex in the state. Future work will investigate such situations, and consider an extension to stochastic systems.
Acknowledgement
The author thanks Rahul Jain of the University of Southern California for valuable discussions on the topic of this paper.
Appendix A Examples for Assumption 3
An example of a class of problems where Assumptions 2 and 3 hold is that which we refer to as C-LQR, for which:
- •
;
- •
, with ;
- •
, defining decoupled state and input constraints, where the latter are compact;
- •
, meaning “discounted-asymptotically” stable.
Proposition A.1**.**
Any problem of class C-LQR satisfies Assumptions 2 and 3.
Proof.
Assumption 2 is satisfied trivially. The lower-bounding functions in constraint (9d) have the quadratic form
[TABLE]
and thus the problem remains convex at each iteration . A Slater point exists, namely any feasible together with any . Thus the strong duality condition in Assumption 3 holds.
To prove Lipschitz continuity in Assumption 3, one must bound the gradient in -space of the functions for any given . Inspection of problem (9) shows that each new function depends on the existing functions , and (13) shows that, due to -compactness, a Lipschitz constant exists if the sequence is bounded. The KKT optimality conditions of (9) include the stationarity equations
[TABLE]
Without loss of generality, one can redefine the system with a linearly scaled input, and , such that , and then linearly scale the input constraints in such that . Triangle inequalities then yield
[TABLE]
As is compact and is fixed, the norms of and are both bounded by some constants and respectively. Eliminating , one obtains
[TABLE]
Thus, can grow no larger than . As the state and input constraints are decoupled, can be made arbitrarily small by scaling the relevant rows of . Thus the denominator can be made strictly positive, and functions of the form (13) are Lipschitz continuous. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. N. Beuchat, J. C. Warrington, and J. Lygeros. Point-wise Maximum Approach to Approximate Dynamic Programming. In IEEE Conference on Decision and Control , Melbourne, Australia, 2017.
- 2[2] F. Borrelli, A. Bemporad, and M. Morari. Predictive Control for Linear and Hybrid Systems . Cambridge Univ. Press, 2017.
- 3[3] S. Boyd and L. Vandenberghe. Convex Optimization . Cambridge University Press, 2009.
- 4[4] L. Busoniu, R. Babuska, B. De Schutter, and D. Ernst. Reinforcement learning and dynamic programming using function approximators , volume 39. CRC press, 2010.
- 5[5] C. S. Chow and J. N. Tsitsiklis. An optimal one-way multigrid algorithm for discrete-time stochastic control. IEEE Transactions on Automatic Control , 36(8):898–914, 1991.
- 6[6] D. P. de Farias and B. Van Roy. The Linear Programming Approach to Approximate Dynamic Programming. Operations Research , 51(6):850–865, 2003.
- 7[7] A. M. Devraj and S. Meyn. Zap Q-Learning. Advances in Neural Information Processing Systems (NIPS) 30 , pages 2235–2244, 2017.
- 8[8] A. M. Geoffrion. Generalized Benders decomposition. Journal of Optimization Theory and Applications , 10(4):237–260, 1972.