TL;DR
LOSOGRAD is a simple, fast algorithm that automatically adjusts the learning rate during neural network training, making it more robust to initial settings while maintaining competitive performance.
Contribution
The paper introduces LOSSGRAD, an easy-to-implement method for automatically optimizing step-size in gradient descent based on local quadratic approximation.
Findings
Insensitive to initial learning rate choices
Achieves results comparable to existing methods
Simple and fast to implement
Abstract
In this paper, we propose a simple, fast and easy to implement algorithm LOSSGRAD (locally optimal step-size in gradient descent), which automatically modifies the step-size in gradient descent during neural networks training. Given a function , a point , and the gradient of , we aim to find the step-size which is (locally) optimal, i.e. satisfies: Making use of quadratic approximation, we show that the algorithm satisfies the above assumption. We experimentally show that our method is insensitive to the choice of initial learning rate while achieving results comparable to other methods.
Click any figure to enlarge with its caption.
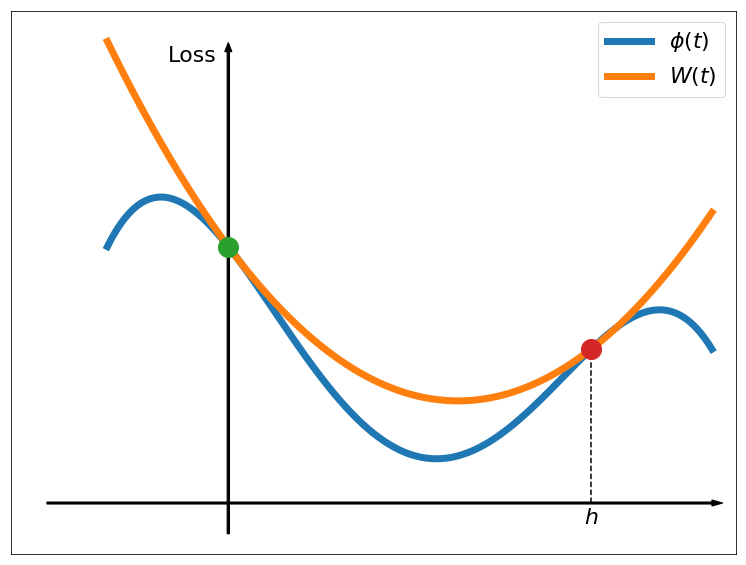 Figure 1
Figure 1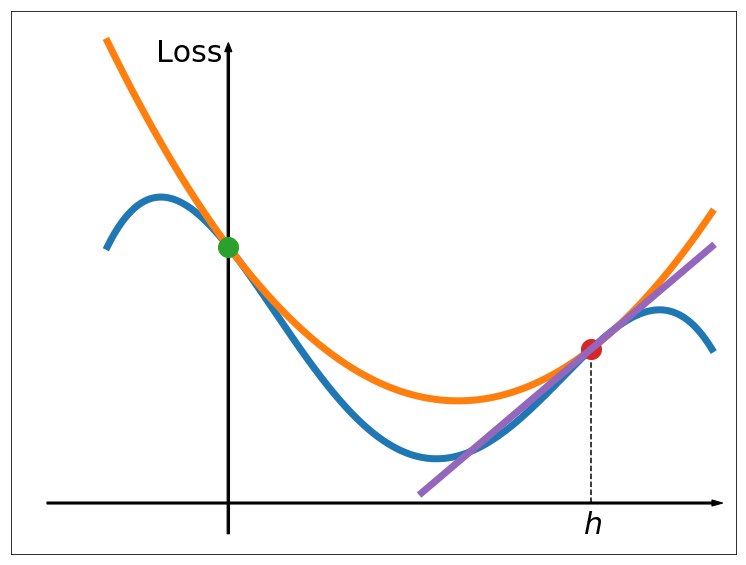 Figure 2
Figure 2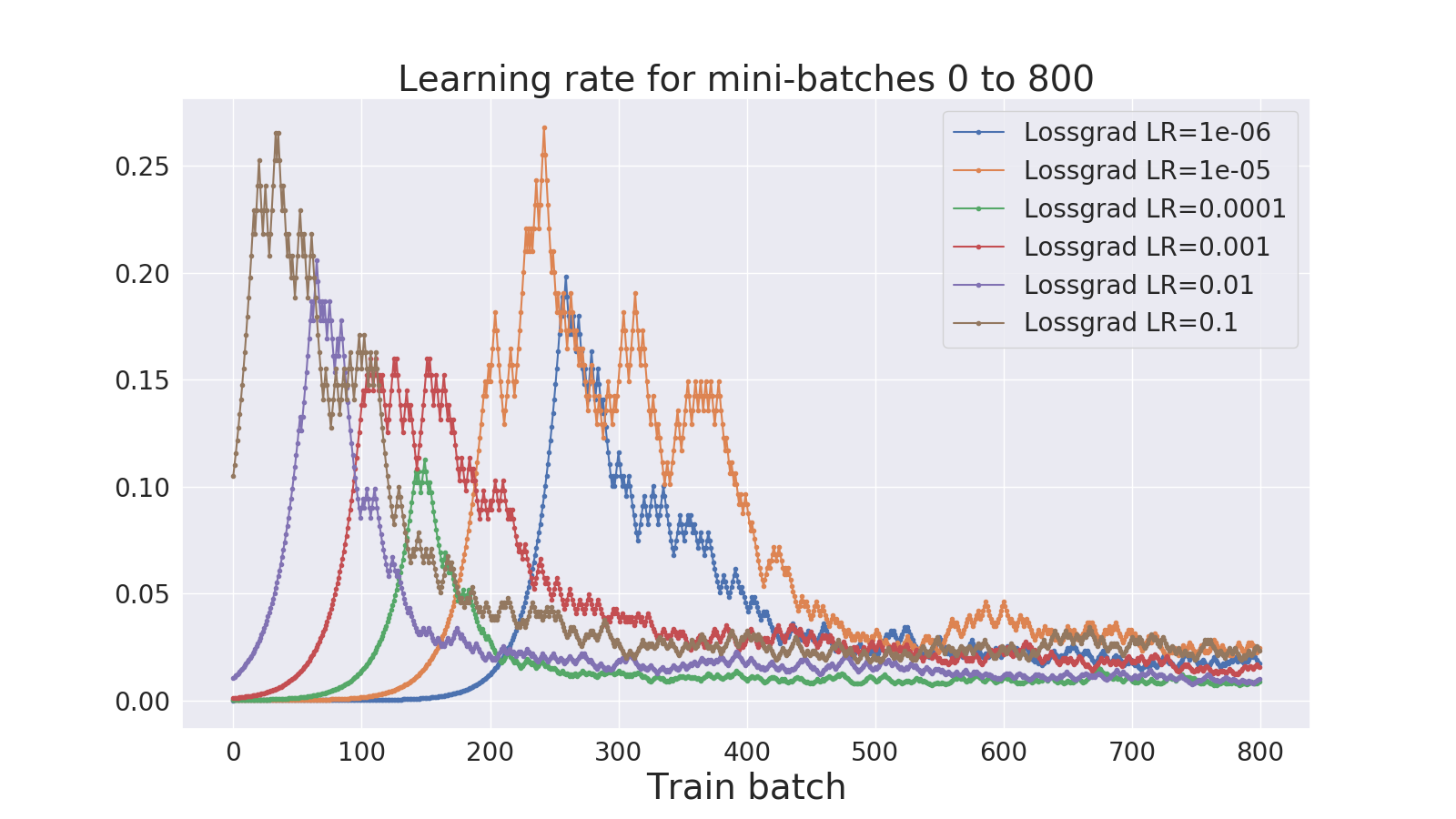 Figure 3
Figure 3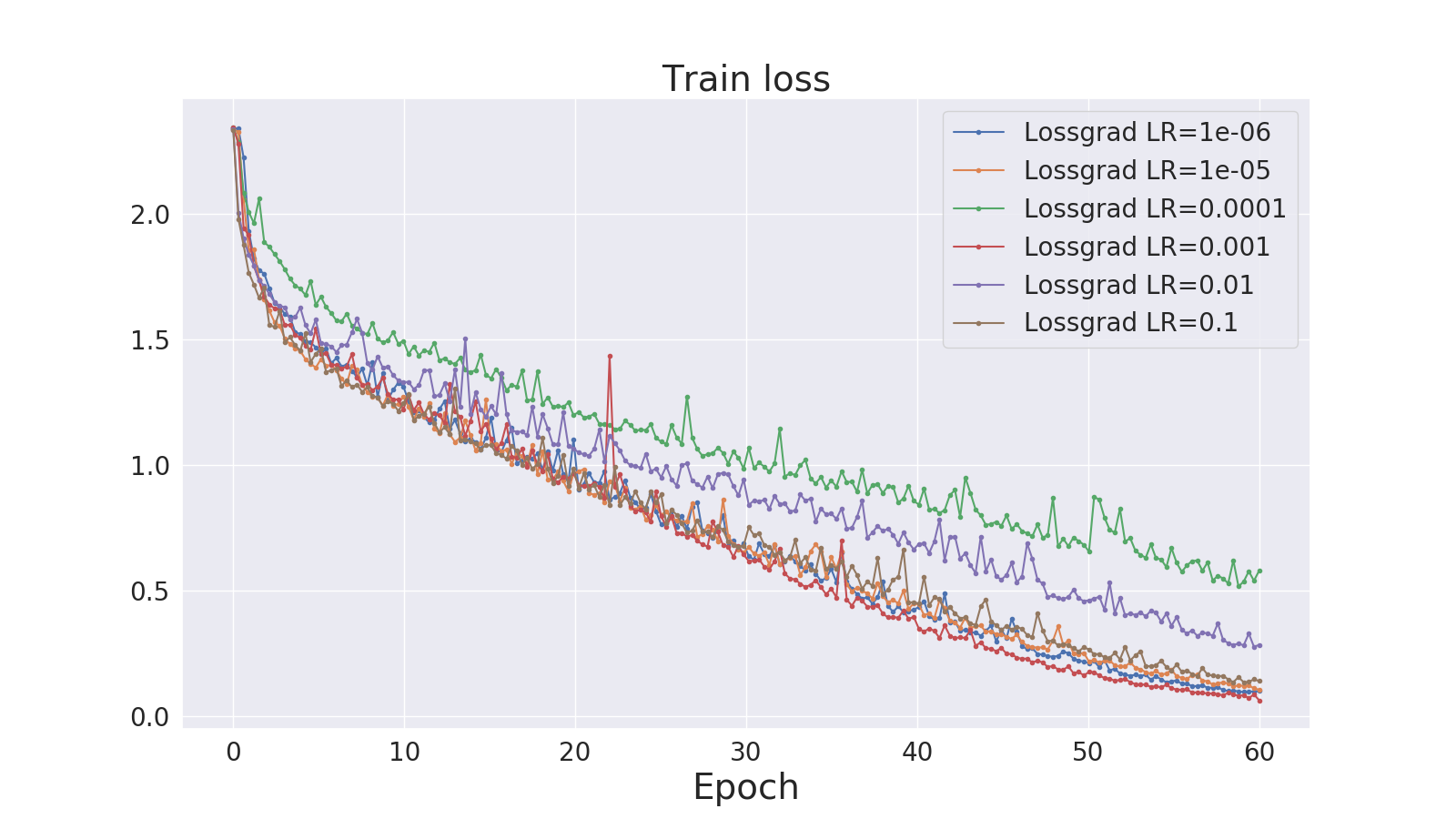 Figure 4
Figure 4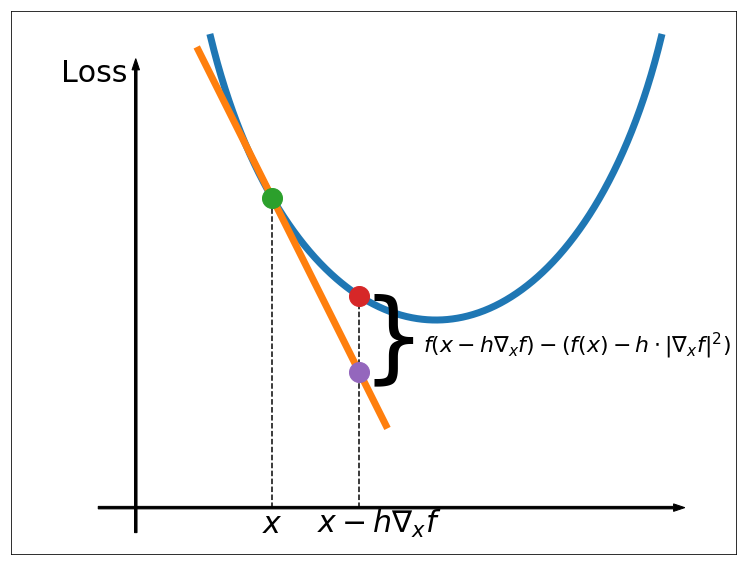 Figure 5
Figure 5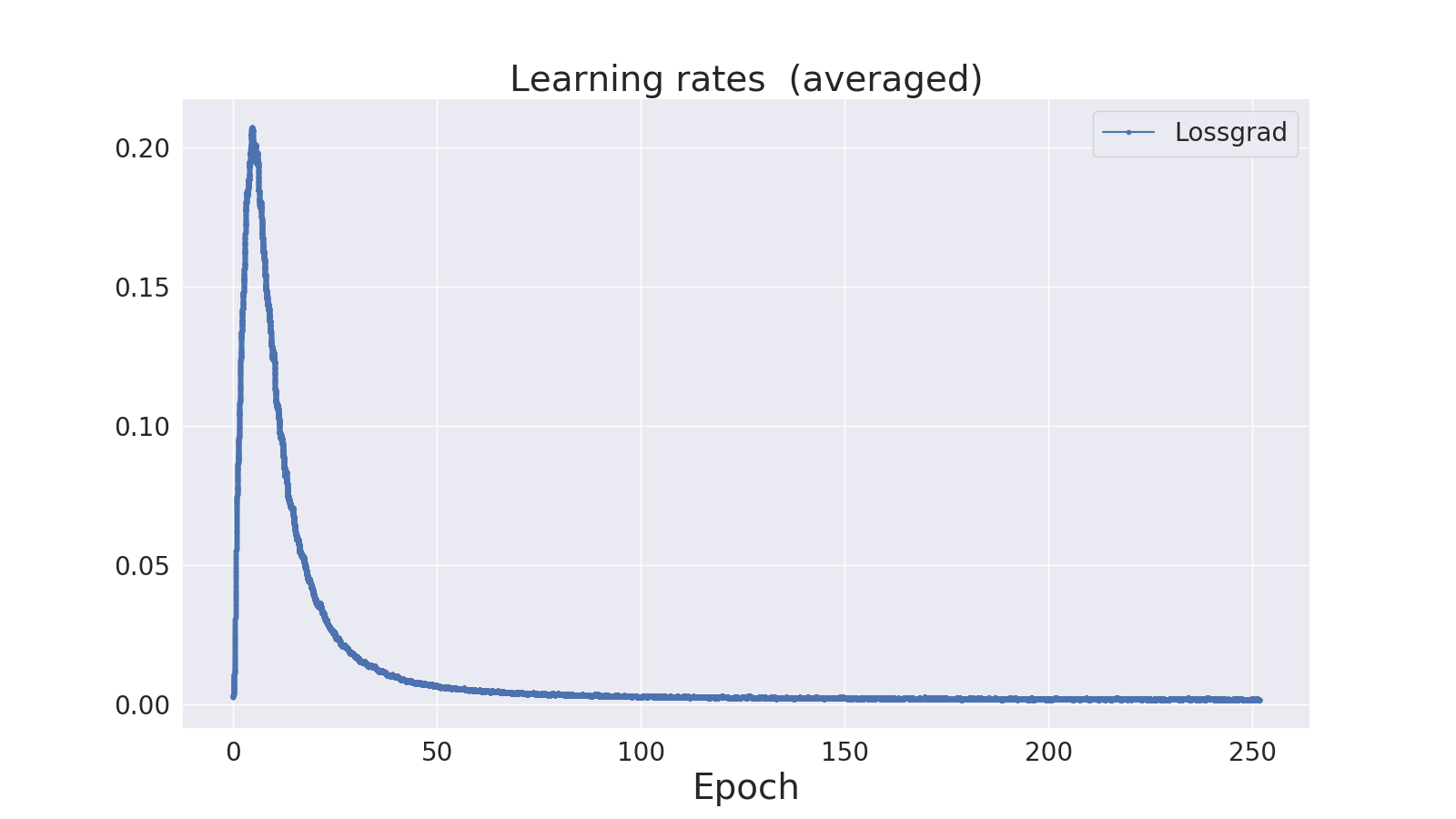 Figure 6
Figure 6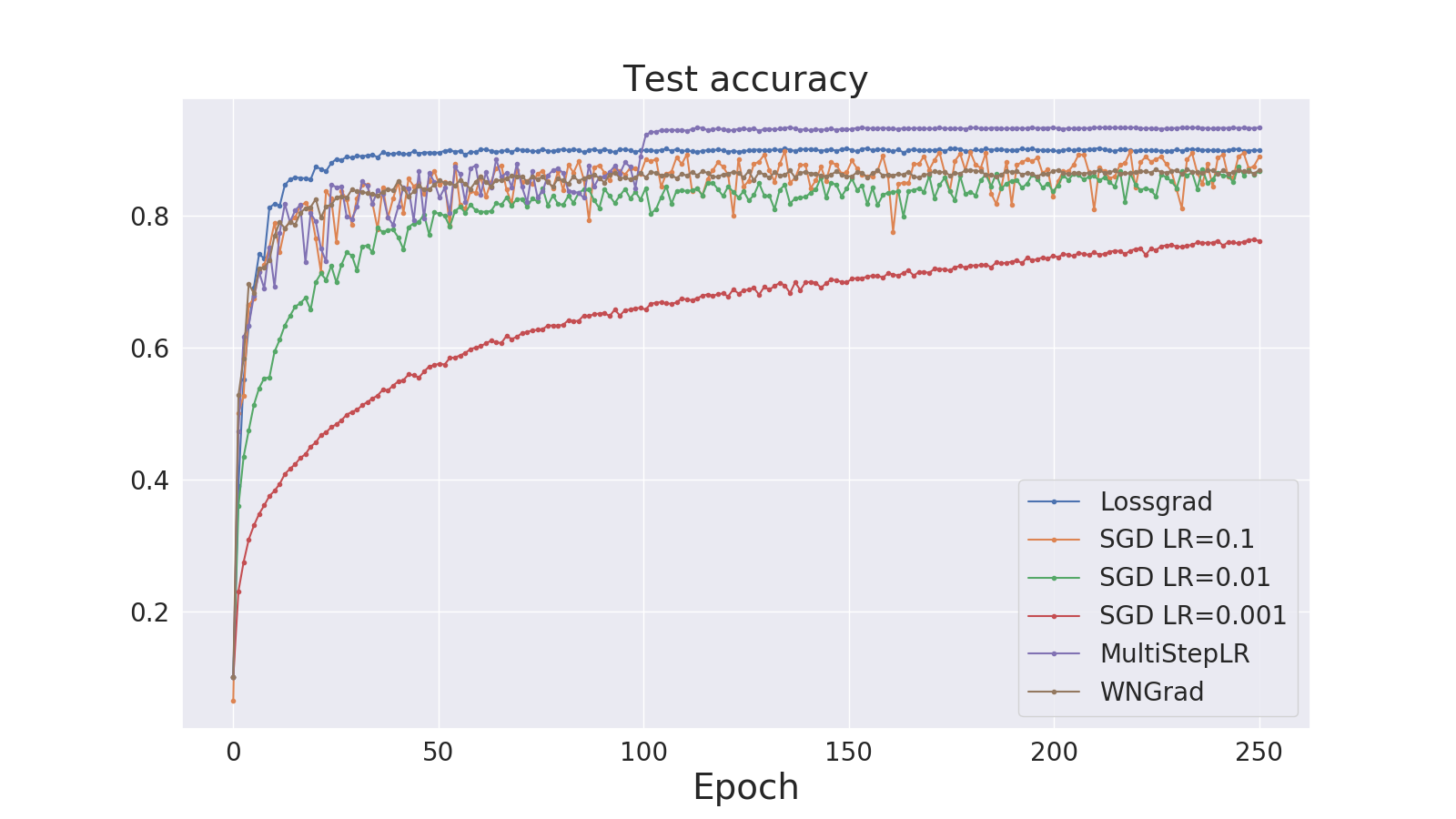 Figure 7
Figure 7| Test loss | Test acc. | |
|---|---|---|
| Lossgrad c=1.001 | 2.737 | 0.655 |
| Lossgrad c=1.005 | 2.870 | 0.673 |
| Lossgrad c=1.01 | 1.995 | 0.658 |
| Lossgrad c=1.05 | 1.165 | 0.665 |
| Lossgrad c=1.1 | 1.862 | 0.661 |
| Lossgrad c=1.2 | 2.830 | 0.643 |
| Train loss | Test loss | |
|---|---|---|
| SGD LR=2.0 | 0.018 | 0.019 |
| SGD LR=4.0 | 0.013 | 0.013 |
| SGD LR=16.0 | 0.010 | 0.010 |
| StepLR | 0.015 | 0.016 |
| Trapezoid | 0.012 | 0.012 |
| WNGrad | 0.023 | 0.023 |
| Lossgrad | 0.022 | 0.022 |
| Test loss | Test acc. | |
|---|---|---|
| SGD LR=0.05 | 0.66 | 0.623 |
| SGD LR=0.1 | 0.359 | 0.845 |
| SGD LR=0.5 | 0.297 | 0.875 |
| scheduled | 0.299 | 0.874 |
| WNGrad | 0.567 | 0.726 |
| Lossgrad | 0.583 | 0.708 |
| MNIST | Fashion-MNIST | CIFAR | ||||
|---|---|---|---|---|---|---|
| Type | Outputs | Type | Outputs | Type | Kernel | Outputs |
| Linear | 500 | Linear | 200 | Conv2d | 5x5 | 28x28x30 |
| ReLU | ReLU | MaxPool2d | 2x2 | 14x14x30 | ||
| Linear | 300 | Linear | 100 | ReLU | ||
| ReLU | ReLU | Conv2d | 5x5 | 10x10x40 | ||
| Linear | 100 | Linear | 50 | MaxPool2d | 2x2 | 5x5x40 |
| ReLU | ReLU | ReLU | ||||
| Linear | 10 | Linear | 100 | Conv2d | 3x3 | 3x3x50 |
| ReLU | ReLU | |||||
| Linear | 200 | Linear | 250 | |||
| ReLU | ReLU | |||||
| Linear | 784 | Linear | 100 | |||
| Sigmoid | ReLU | |||||
| Linear | 10 | |||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
lossgrad**: automatic learning rate in gradient descent**
Bartosz Wójcik1
Łukasz Maziarka2
Jacek Tabor2
1Faculty of Physics, Mathematics and Computer Science
Cracow University of Technology
2Faculty of Mathematics and Computer Science
Jagiellonian University
e-mail: [email protected], [email protected], [email protected]
Abstract
In this paper, we propose a simple, fast and easy to implement algorithm lossgrad (locally optimal step-size in gradient descent), which automatically modifies the step-size in gradient descent during neural networks training. Given a function , a point , and the gradient of , we aim to find the step-size which is (locally) optimal, i.e. satisfies:
[TABLE]
Making use of quadratic approximation, we show that the algorithm satisfies the above assumption. We experimentally show that our method is insensitive to the choice of initial learning rate while achieving results comparable to other methods.
keywords:
gradient descent, optimization methods, adaptive step size, dynamic learning rate, neural networks
1 Introduction
Gradient methods, with the stochastic gradient descent at the head, play a basic and crucial role in nonlinear optimization of artificial neural networks. In recent years many efforts have been devoted to better understand and improve existing optimization methods. This led to the widespread use of the Momentum method [10] and learning rate schedulers [17], as well as to creation of new algorithms, such as AdaGrad [1], AdaDelta [18], RMSprop [13], Adam [4].
These methods, however, are not without flaws, as they need an extensive tuning or costly grid search of hyperparameters, together with suitable learning rate scheduler – too large step-size may result in instability, while too small may be slow in convergence and may lead to stuck in the saddle points [12].
As the choice of the proper learning rate is crucial, in this paper we aim to find such step which is locally optimal with respect to the direction of the gradient. Our ideas were motivated by l4 algorithm [11], which however apply the idea globally, as it computes the linearization of the loss function at the given point and proceeds to the global root of this linearization. Furthermore, unlike the wngrad [15], our algorithm can both increase and decrease the learning rate values.
Our algorithm is similar in principle to the line search methods as its aim is to adjust the learning rate based on function evaluations in the selected direction. Line search methods however, perform well only in a deterministic setting and require a stochastic equivalent to perform well with SGD [8]. In opposite to this, lossgrad is also intended to work well in a stochastic setting. The difference is that our algorithm changes the step-size after taking the step thus never requiring any copying of potentially large amounts of memory for network weights.
2 LOSSGRAD
The method we propose is based on the idea of finding a step-size which is locally optimal, i.e. we follow the direction of the gradient to maximally minimize the cost function. Thus given a function (which we want to minimize), a point and the gradient111Clearly, we can use an arbitrary direction provided by some minimization method instead of the gradient in place of , we aim to find the step-size which is (locally) optimal, i.e. satisfies:
[TABLE]
A natural problem of how to practically realize the above search emerges. This paper is devoted to the examination of one of the possible solutions.
We assume that we are given a candidate from the previous step (or some initial choice in the first step). A crucial role is played by investigation of the connection between the value of after the step size and the value given by its linearized prediction (see Figure 1):
[TABLE]
We implicitly assume here that (if this is not the case, we replace by ).
Our idea relies on considering the loss function in a direction :
[TABLE]
and fitting a quadratic function , which coincides with at the end points and has the same derivative at zero (see Figure 2), i.e. such that:
[TABLE]
Then we get:
[TABLE]
Remark 1**.**
To compute we need the knowledge of the gradient and the evaluation of at (the predicted next point in which we will arrive according to the current value of the step-size). Consequently, in the case when (i.e. in the case of gradient methods), we need to additionally compute . Then the value simplifies to:
[TABLE]
The derivative of function at point is given by:
[TABLE]
This means that if:
[TABLE]
the derivative of function at point is negative, and therefore we should increase the step-size to further minimize (see Figure 2). On the other hand, if :
[TABLE]
the derivative of function at point is positive, and therefore we should decrease the step-size to further minimize .
In our method, increasing (decreasing) the step-size takes place by multiplication of the current learning rate by the learning rate adjustment factor (). One can find the lossgrad algorithm pseudocode in algorithm 1. Notice that using our method does not involve almost any additional calculations.
3 LOSSGRAD asymptotic analysis in two dimensions
In the following section we show, how this process behaves for the quadratic form , where and is a symmetric positive matrix. Observe that in this case lossgrad can be seen as the approximation of the exact solution to equation (1). Therefore in this section, we study how the minimization process given in (1) works for quadratic functions.
To obtain exact formula we now apply the orthonormal change of coordinates in which has the simple form:
[TABLE]
where are the eigenvalues of .
Starting from the random point , which gradient is equal to , we have:
[TABLE]
[TABLE]
After taking the derivative we have:
[TABLE]
[TABLE]
As our goal is to find , we equate the derivative to zero:
[TABLE]
Since , we have:
[TABLE]
To see how this process behaves after a greater number of steps, we assume that . We consider the function which transports the point to its next iteration:
[TABLE]
Then
[TABLE]
[TABLE]
[TABLE]
where , and thus . By taking the worst possible case we obtain that the above minimizes for , so we obtain an estimate for the convergence:
[TABLE]
Notice that this is invariant to data and function scaling (i.e. ).
Remark 2**.**
One can easily observe that the estimation (4) gives the upper bound for a decrease rate of the solution to any standard gradient descent method with a fixed learning rate. Whether the same holds for the method in is an open problem.
4 Experiments
We tested lossgrad in multiple different setups. First, we explore the algorithm’s resilience on the choice of initial learning rate and its behavior for a range of different LR adjustment factor values. Then we proceed to test the algorithm’s performance on fully connected networks on MNIST classification and Fashion-MNIST [16] autoencoder tasks. Convolutional neural networks are tested on CIFAR-10 [5] classification task using ResNet-56 architecture [2]. We also evaluate our optimizer for an LSTM model [3] trained on Large Movie Review Dataset (IMDb) [7]. Finally, we test lossgrad on Wasserstein Auto-Encoder with Maximum Mean Discrepancy-based penalty [14] on CelebA dataset [6]. Network architectures and all hyperparameters used in experiments are listed in the appendix A
In our experiments we tried to compare lossgrad with wngrad [15] and l4 applied to SGD [11]. We found out that l4 based on vanilla SGD is extremely unstable both on standard and tuned parameters on almost all datasets and network architectures, so we do not present the results here. For each experiment we also tested standard SGD optimizer with a range of learning rate hyperparameters, including a highly tuned one. For comparison, we also included SGD with scheduled learning rate if that enhanced the results. Because dropout heavily affects lossgrad’s stability, we decided not to use it in our experiments.
We test the initial learning rate with values ranging between and for a convolutional neural network on CIFAR-10 with the rest of the settings staying the same. Resulting test loss values are presented in Fig. 3 on the right, while the first 800 batches’ step size values are presented on the left. Irrespectively of the initial learning rate chosen, the step size always converges to values around for this experiment setup. Thus, the need for tuning is practically eliminated, and this property makes the algorithm noticeably attractive.
As lossgrad requires one hyperparameter, we explore which values are appropriate. This is tested by training a convolutional neural network on CIFAR-10 dataset, using our optimizer parameterized with a different value each time, with the rest of the settings staying the same. We evaluated the following hyperparameter values: . We found that low and high values tend to cause unstable behavior. According to these results, the rest of the experiments in this paper use and initial learning rate set to .
Tab. 2 and Tab. 4 presents the results for fully connected network trained on MNIST and an autoencoder trained on Fashion-MNIST, respectively. We noticed the occurrence of sudden spikes in loss (classification accuracy drops and subsequent recoveries) in case of classification on MNIST, but not when training an autoencoder on Fashion-MNIST. The spikes correspond to learning rate peaks, which suggests that temporarily too high step size causes the learning process to diverge.
Fig. 4 presents test accuracy and averaged step size (learning rate) when training a ResNet-56 network on CIFAR-10, while Tab. 4 presents the results summary. Even with low initial learning rate, lossgrad still manages to achieve results better than SGD, being beaten only by optimized scheduled SGD. Note the step size spike at the beginning of the training process. This spike consistently appears at the beginning of the training in nearly every setup tested in this paper. This result is in line with many learning rate schedulers used in the training of neural networks, that increase the step-size at the beginning of the training and then, after few epochs, they decrease the step-size value [17].
Results for LSTM trained on IMDb dataset are presented in Tab. 6. Here, for the vanilla SGD, a higher learning rate is preferred. lossgrad selects a very low step-size instead (below after the initial peak) and manages only to achieve better results than untuned SGD.
Finally, the results for WAE-MMD are presented in Tab. 6. The originally used optimizer (Adam) and scheduler combination from [14] is marked as ,,original”. Properly tuned SGD, as well as WNGrad, yield better results than lossgrad, which chooses a very low step size for this problem.
We provide an implementation of the algorithm with basic examples of usage on a git repository: https://github.com/bartwojcik/lossgrad.
5 Conclusion
We proposed lossgrad, a simple optimization method for approximating locally optimal step-size. We analyzed the algorithm behavior in two dimensions quadratic form example and tested it on a broad range of experiments. Resilience on the choice of initial learning rate and the lack of additional hyperparameters are the most attractive properties of our algorithm.
In future work, we aim to investigate and possibly mitigate the loss spikes encountered in the experiments, as well as work on increasing the algorithm’s effectiveness. A version for momentum SGD and Adam is also an interesting topic for exploration that we intend to pursue.
Appendix A Network architecture, hyperparameters and datasets description
Tab. 7 presents the architecture used for image classification on CIFAR-10 dataset. This architecture was used to obtain the results presented in Fig. 3 and Tab. 2. We initialized the neuron weights using a normal distribution with a standard deviation and bias weights with a constant . The minibatch size was set to 100 and cross entropy was chosen as the loss metric. The model was trained for 60 epochs with c hyperparameter set to in the learning rate convergence experiment and for 120 epochs with an initial learning rate of in the second experiment. We preprocessed the CelebA dataset by resizing its images to 64x64 and discarding labels.
Tab. 7 also contains the architectures used for image classification on MNIST dataset and for autoencoder training on Fashion-MNIST dataset. We trained both networks for 30 epochs with the rest of the hyperparameters being the same as in CIFAR-10 experiment. For MNIST, we selected the following learning rate values: for SGD and for WNGrad. For Fashion-MNIST, we tested the following learning rate values: for SGD and for WNGrad. We also evaluated two scheduled optimizers. The first one linearly increases the learning rate from [math] to in epoch 10, stays constant until epoch 15 and decreases afterward (trapezoidal). The second one starts with and is multiplied by after 20 epochs. Mean square error was used as the loss function.
ResNet-56 architecture is described in [2]. We trained the network for 250 epochs, used random cropping and inversion when training and applied weight decay with . The learning rate values we used were: for SGD, for WNGrad, with multiplier after epochs 100 and 150 for step scheduled SGD. We set the mini-batch size to 128 in this experiment.
For IMDb experiments, we used a pretrained embedding layer, trained with GloVe algorithm [9] on 6 billion tokens available from torchtext library. Its 100 element output was fed to 1 layer of bidirectional LSTM with 256 hidden units for each direction. The final linear layer transformed that to scalar output. We set as the learning rate for wngrad , , , for SGD and also tested a scheduled SGD with learning rate initially set to and then decreasing to after 10 epochs.
The architecture for WAE-MMD is the same as in [14]. Minibatch size was set to 64, mean square error was selected as a loss function and the network was trained for 80 epochs. We set as the initial learning rate for WNGrad and for SGD.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research , 12(Jul):2121–2159, 2011.
- 2[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 770–778, 2016.
- 3[3] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation , 9(8):1735–1780, 1997.
- 4[4] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. ar Xiv preprint ar Xiv:1412.6980 , 2014.
- 5[5] Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, Citeseer, 2009.
- 6[6] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision , pages 3730–3738, 2015.
- 7[7] Andrew L Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies-volume 1 , pages 142–150. Association for Computational Linguistics, 2011.
- 8[8] Maren Mahsereci and Philipp Hennig. Probabilistic line searches for stochastic optimization. In Advances in Neural Information Processing Systems , pages 181–189, 2015.
