TL;DR
This paper introduces a novel hierarchical model combining Predictive Coding and Sparse Coding to simulate early visual cortex processing, capturing neural organization, feedback effects, and contour integration in image recognition.
Contribution
It presents the Sparse Deep Predictive Coding (SDPC) model that unifies neural and representational feedback effects in early vision processing, a novel integration of PC and SC.
Findings
SDPC exhibits realistic receptive fields in V1 and V2.
Feedback reorganizes neural interaction maps akin to Gestalt principles.
SDPC improves image disambiguation under noise conditions.
Abstract
Both neurophysiological and psychophysical experiments have pointed out the crucial role of recurrent and feedback connections to process context-dependent information in the early visual cortex. While numerous models have accounted for feedback effects at either neural or representational level, none of them were able to bind those two levels of analysis. Is it possible to describe feedback effects at both levels using the same model? We answer this question by combining Predictive Coding (PC) and Sparse Coding (SC) into a hierarchical and convolutional framework. In this Sparse Deep Predictive Coding (SDPC) model, the SC component models the internal recurrent processing within each layer, and the PC component describes the interactions between layers using feedforward and feedback connections. Here, we train a 2-layered SDPC on two different databases of images, and we interpret it…
Click any figure to enlarge with its caption.
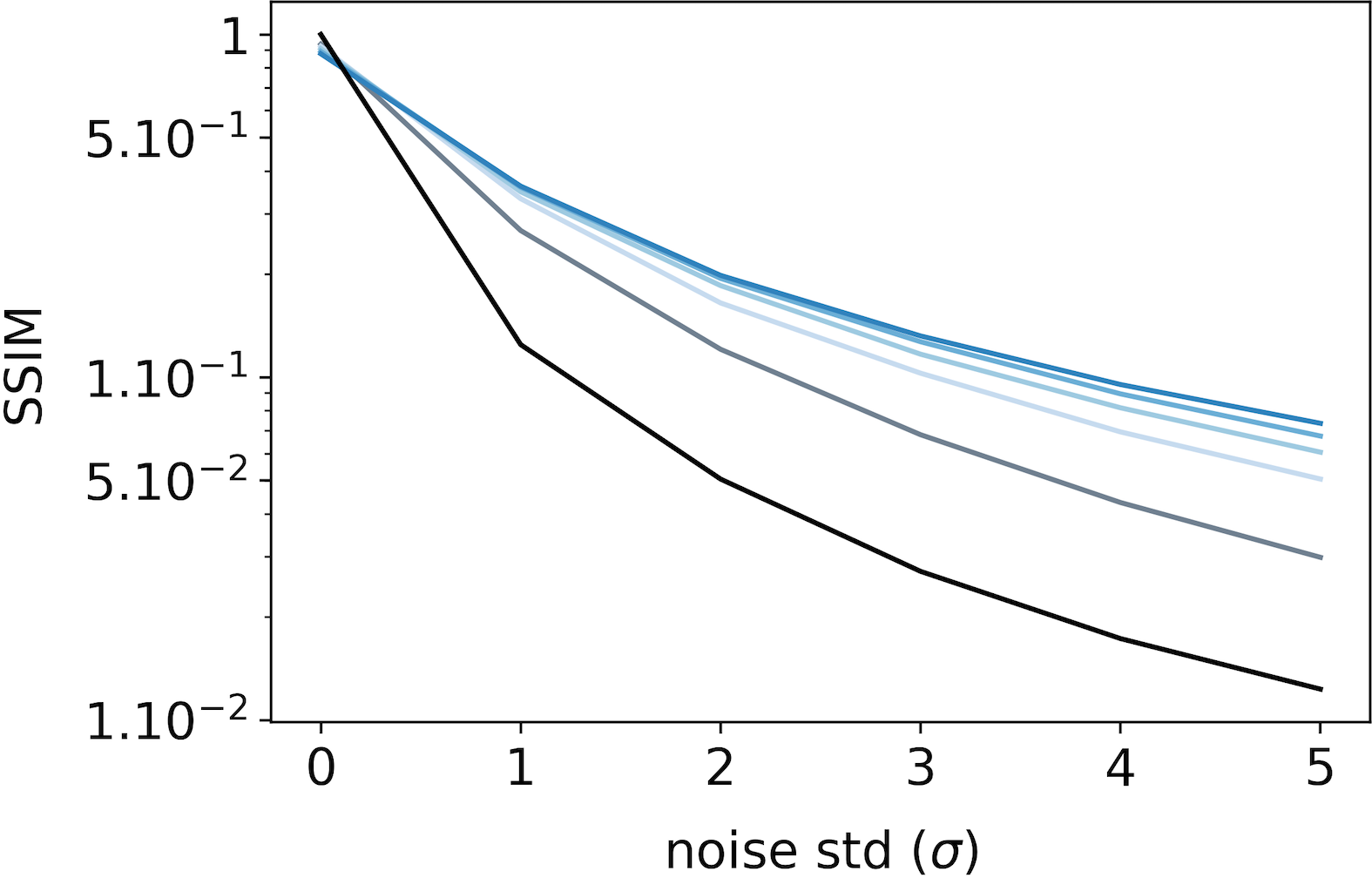 Figure 10
Figure 10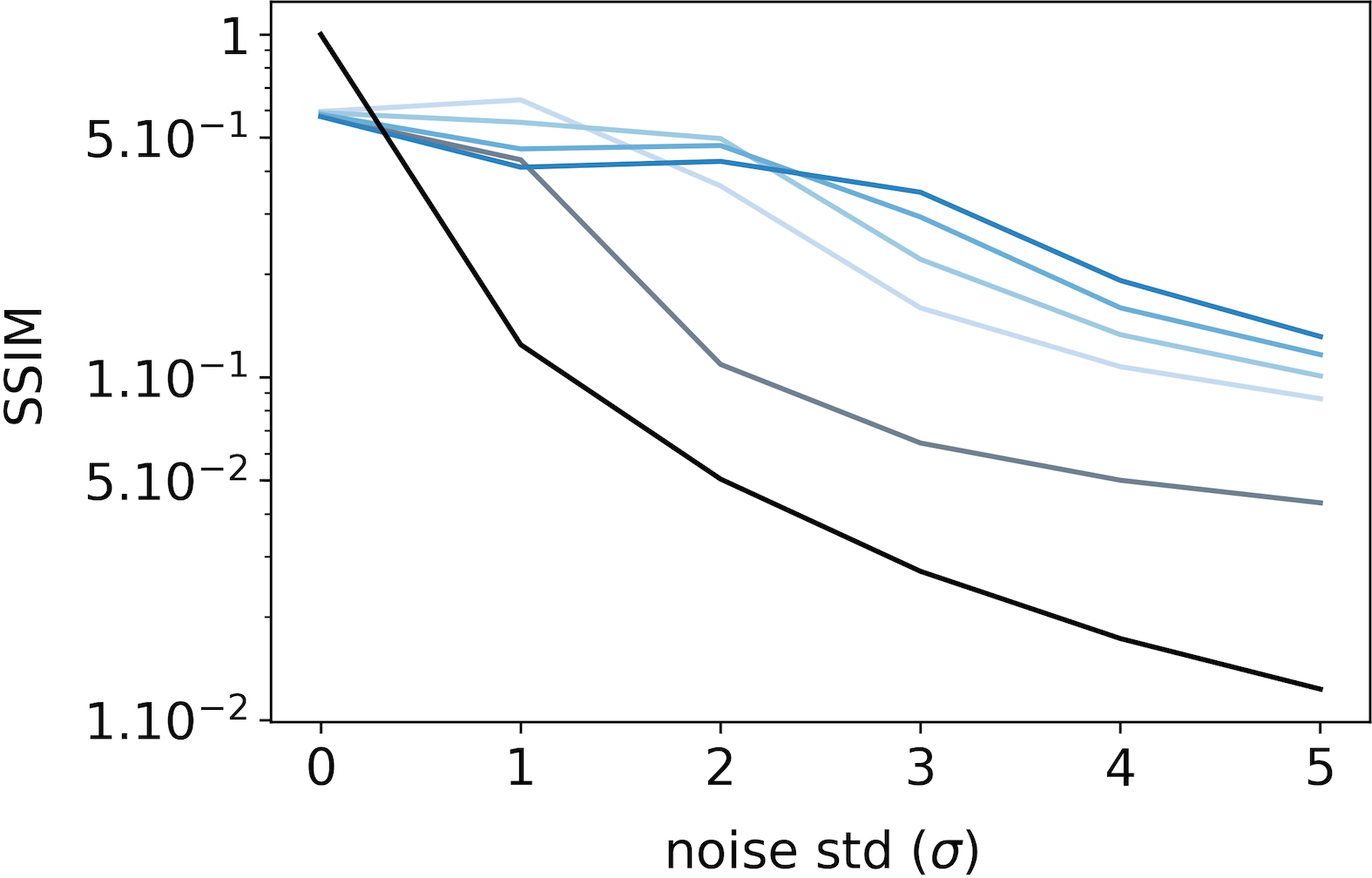 Figure 10
Figure 10 Figure 10
Figure 10 Figure 10
Figure 10 Figure 10
Figure 10 Figure 10
Figure 10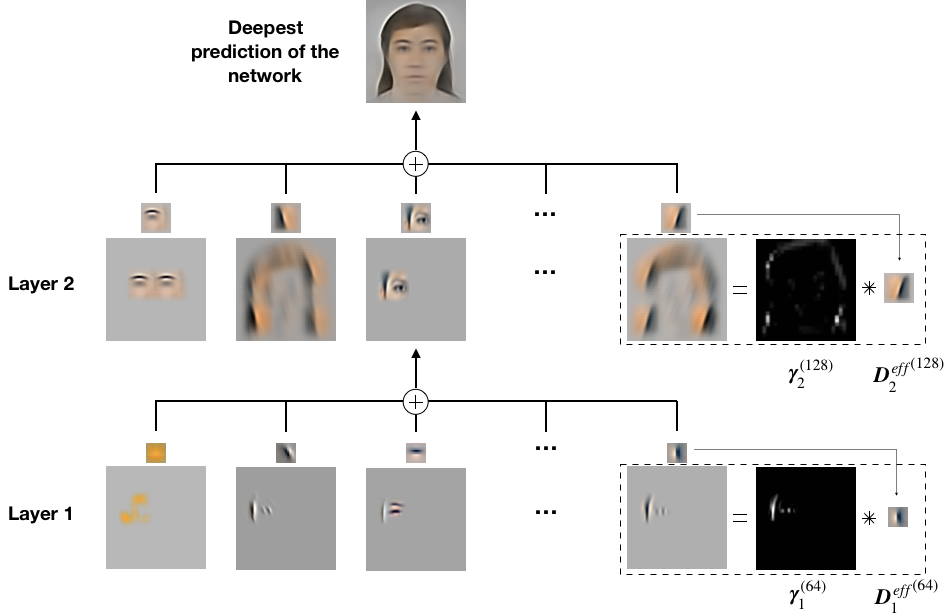 Figure 11
Figure 11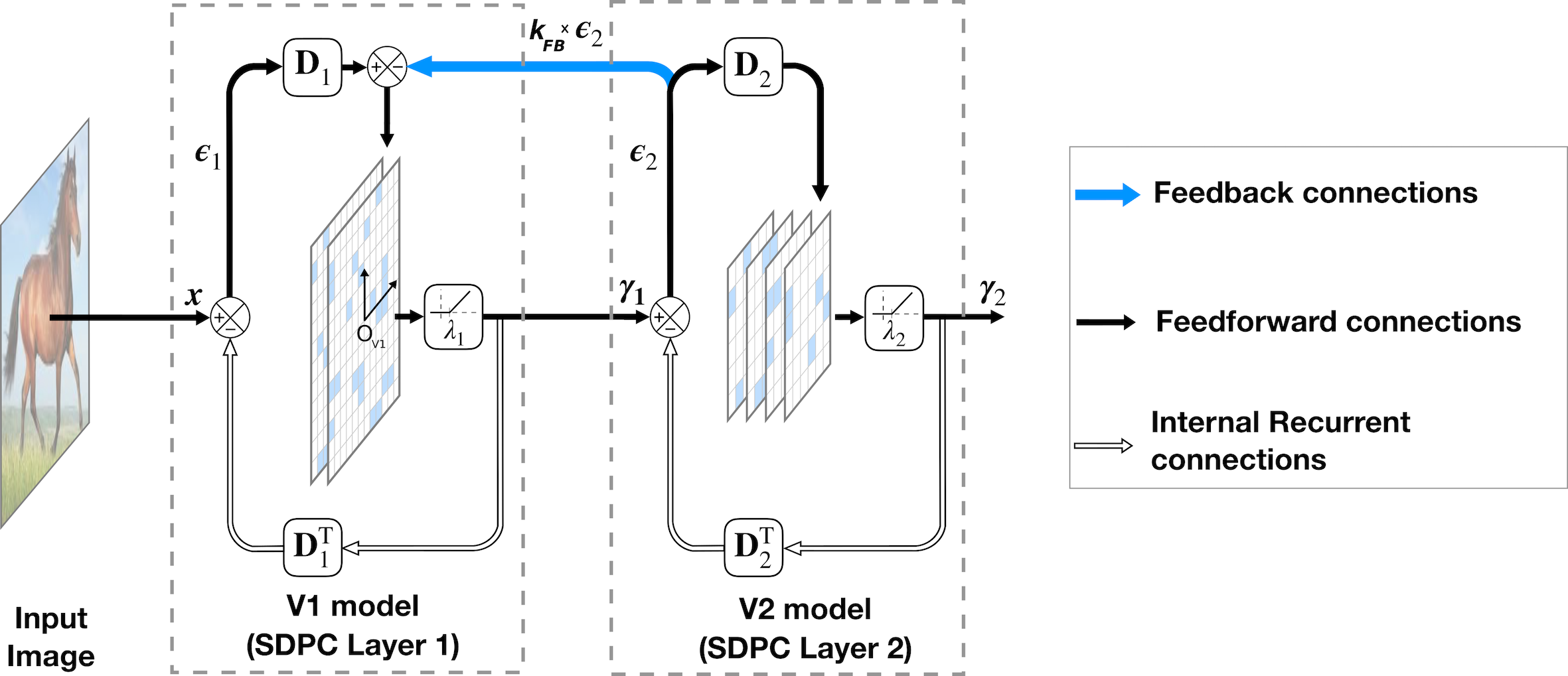 Figure 1
Figure 1 Figure 2
Figure 2 Figure 2
Figure 2 Figure 2
Figure 2 Figure 2
Figure 2 Figure 2
Figure 2 Figure 2
Figure 2 Figure 2
Figure 2 Figure 2
Figure 2 Figure 2
Figure 2 Figure 2
Figure 2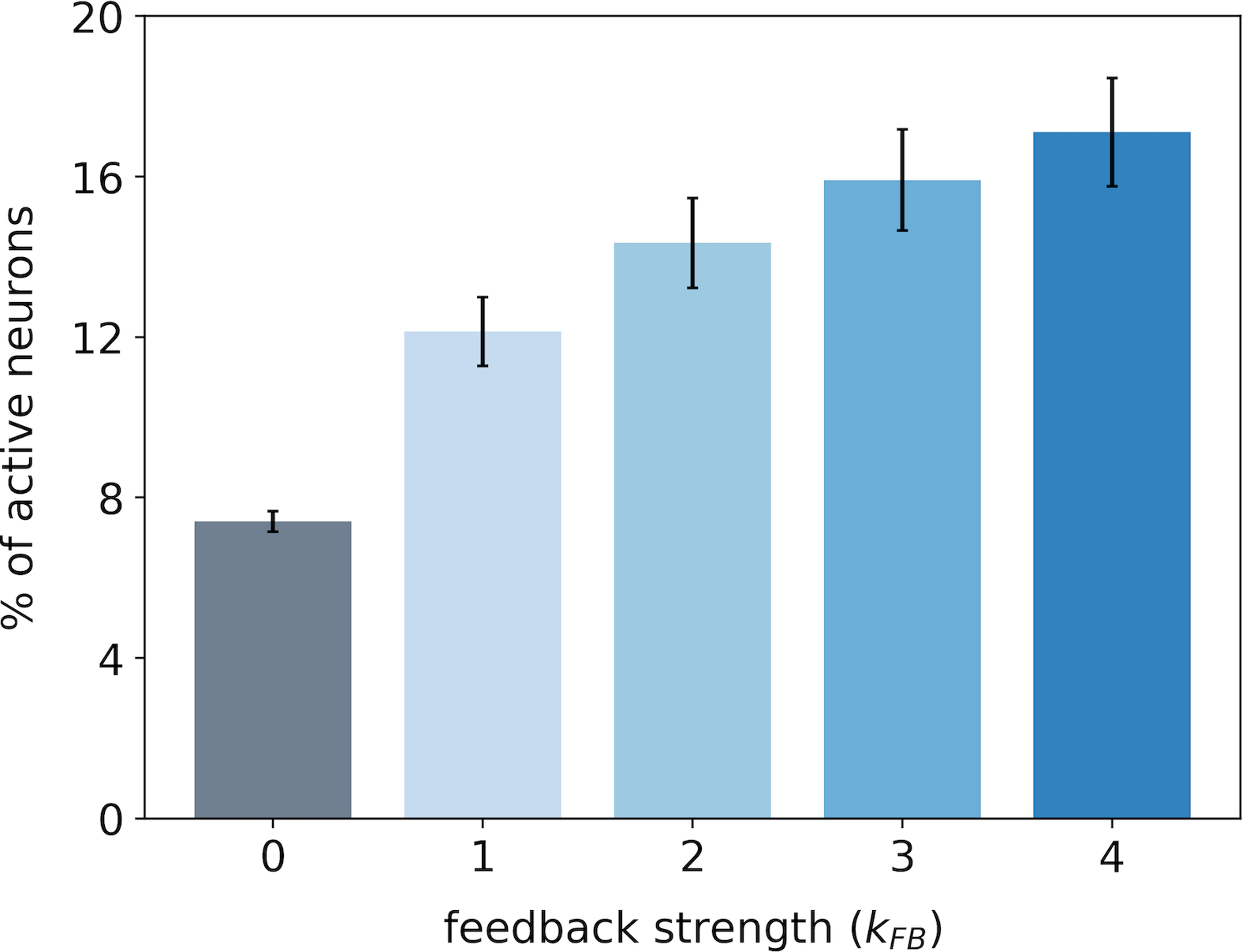 Figure 3
Figure 3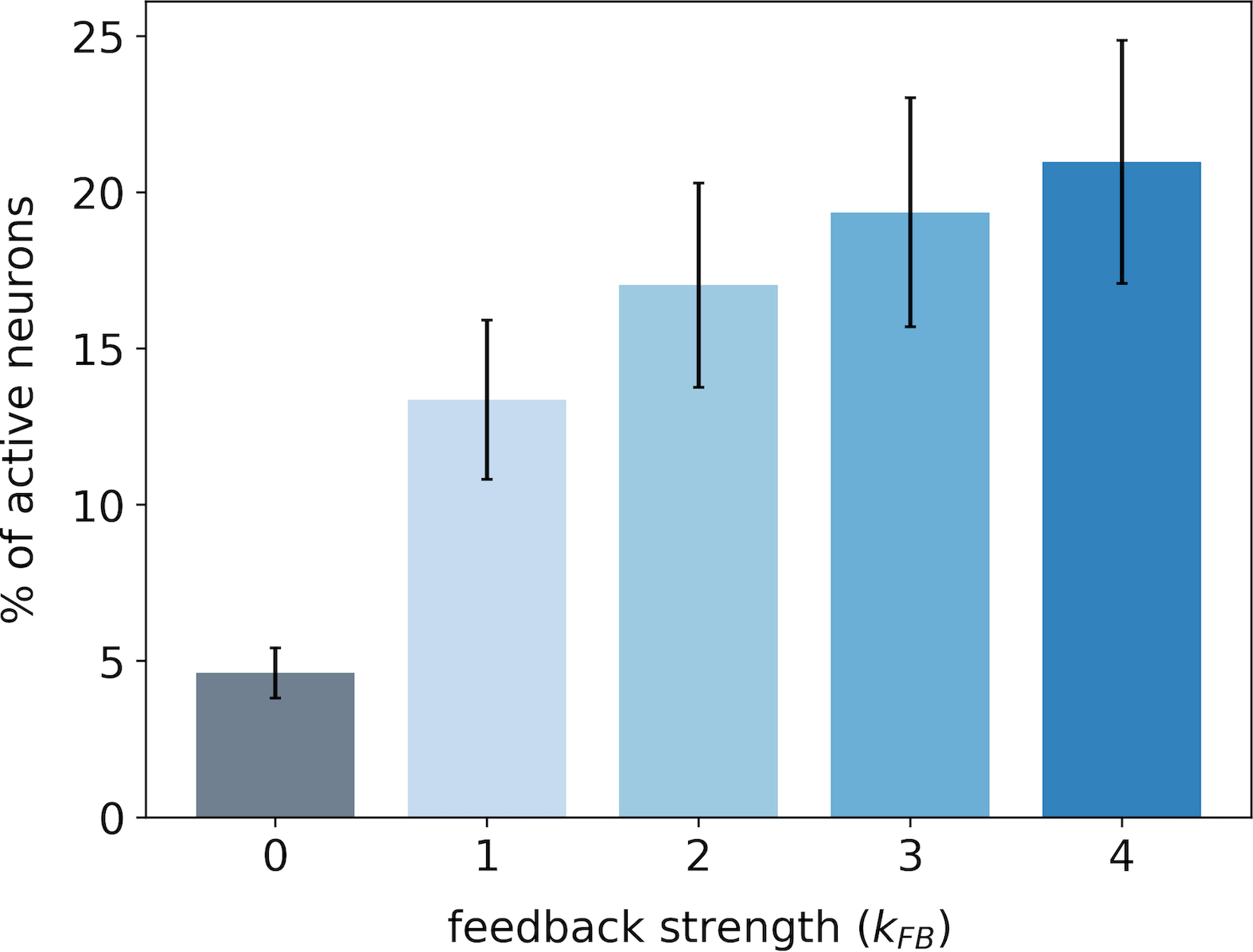 Figure 3
Figure 3 Figure 3
Figure 3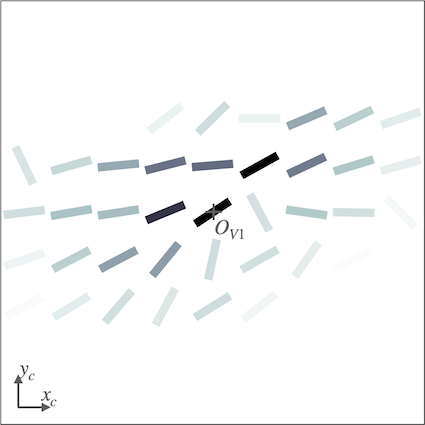 Figure 4
Figure 4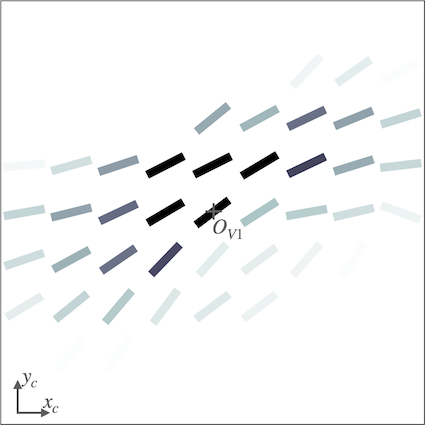 Figure 4
Figure 4 Figure 4
Figure 4 Figure 4
Figure 4 Figure 5
Figure 5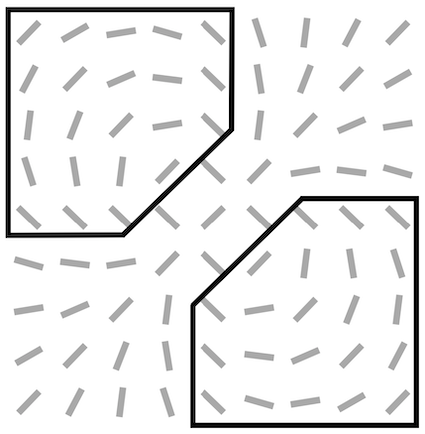 Figure 5
Figure 5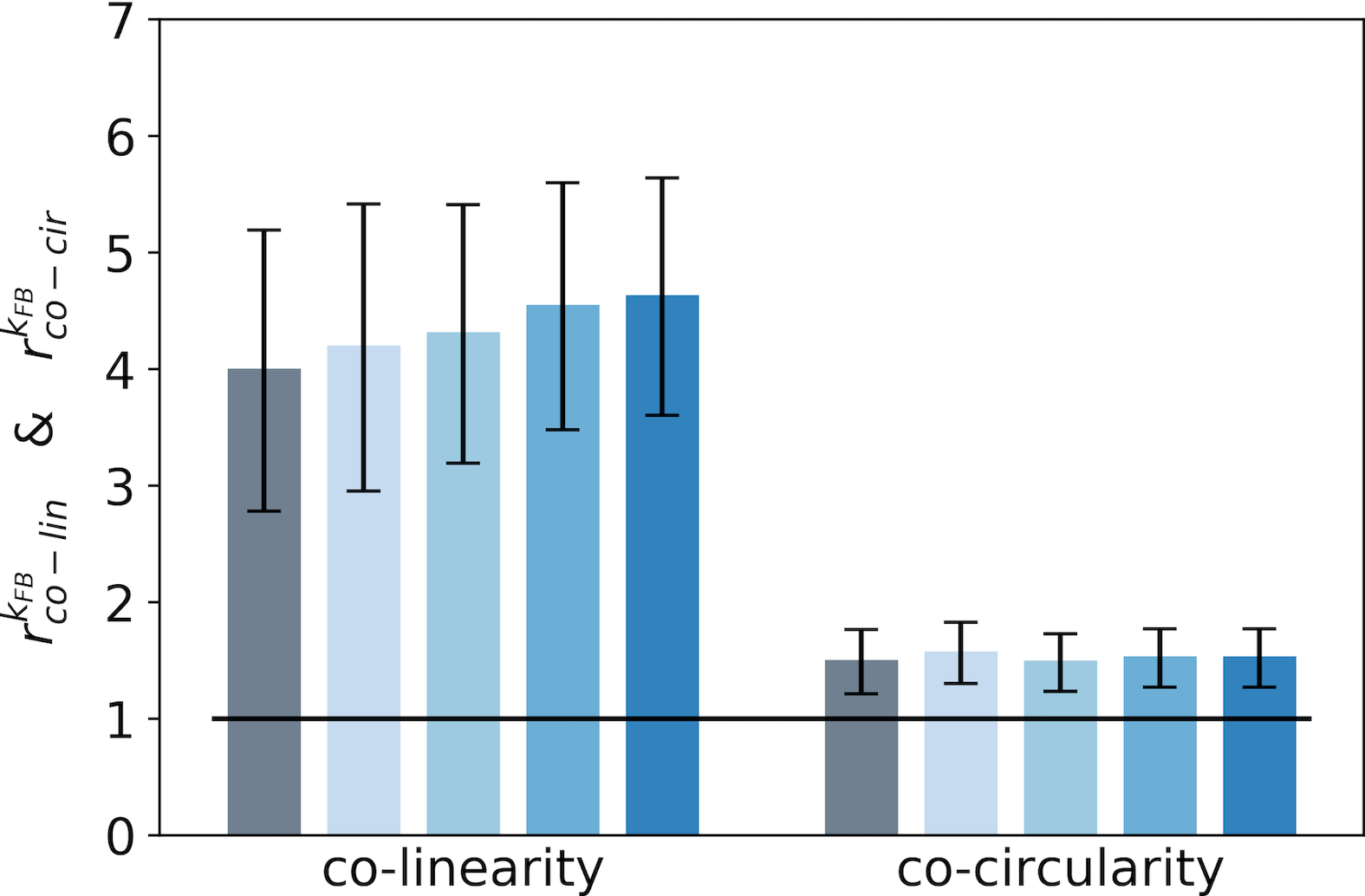 Figure 5
Figure 5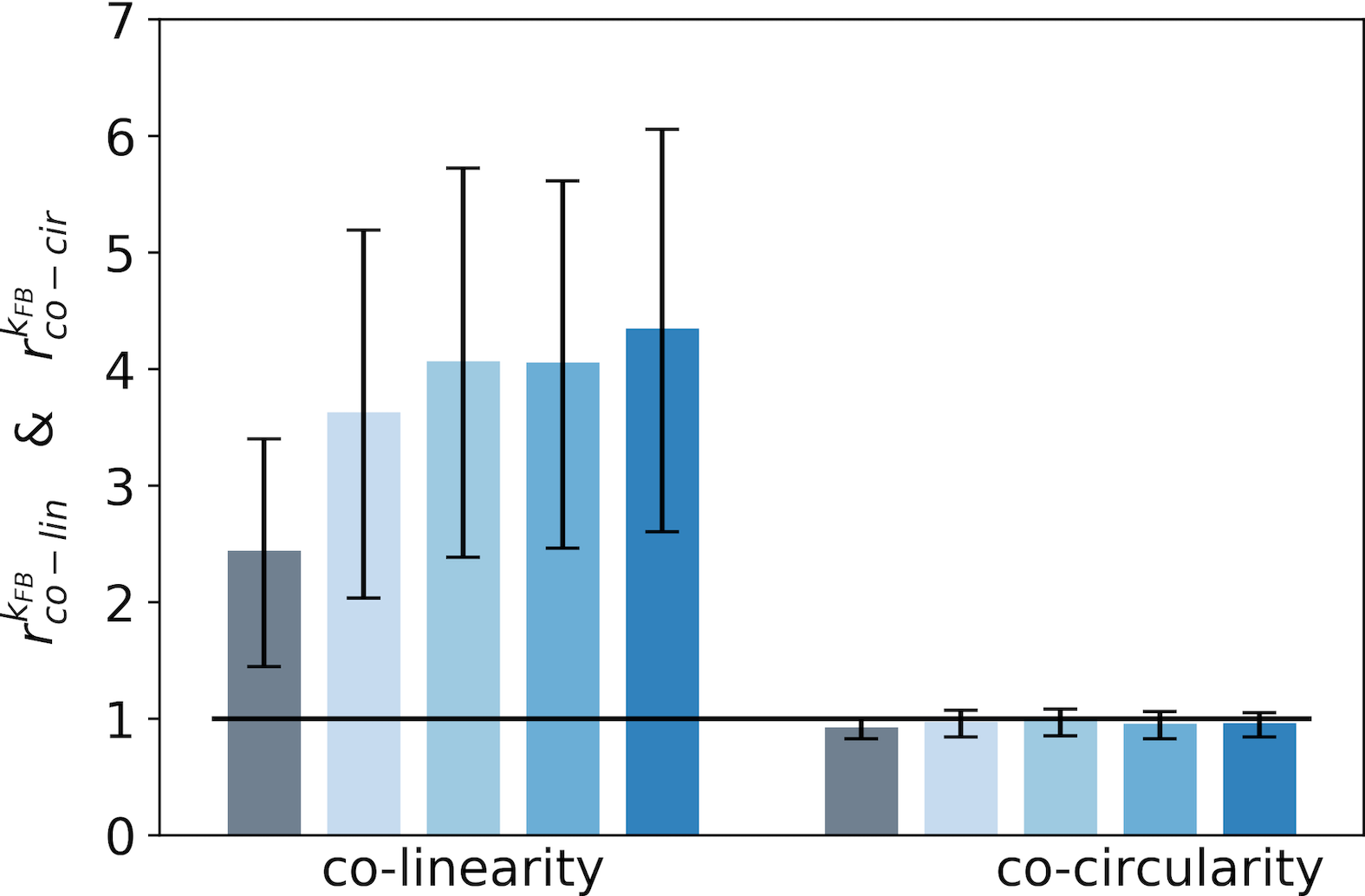 Figure 5
Figure 5 Figure 5
Figure 5 Figure 6
Figure 6 Figure 6
Figure 6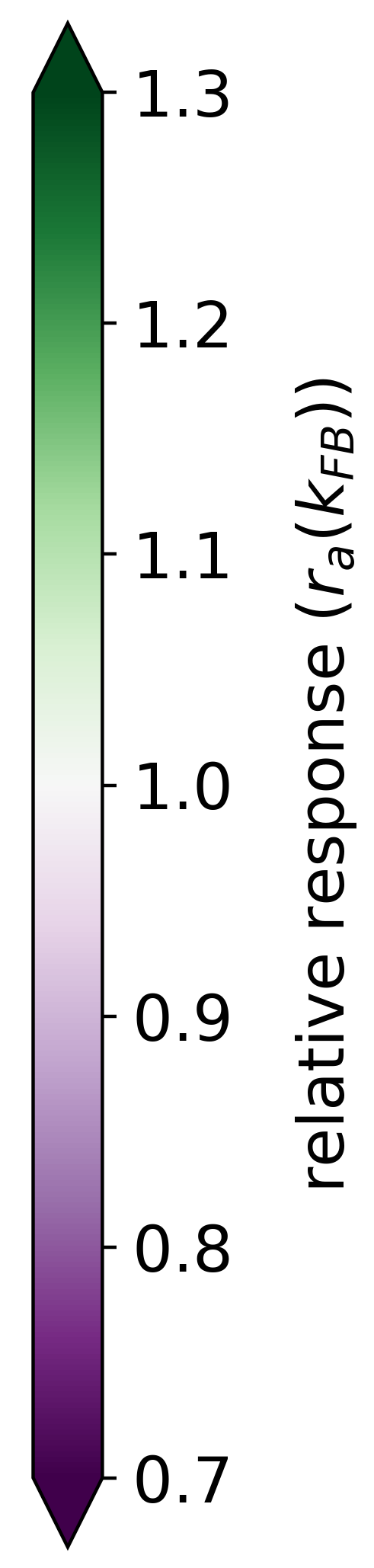 Figure 6
Figure 6 Figure 7
Figure 7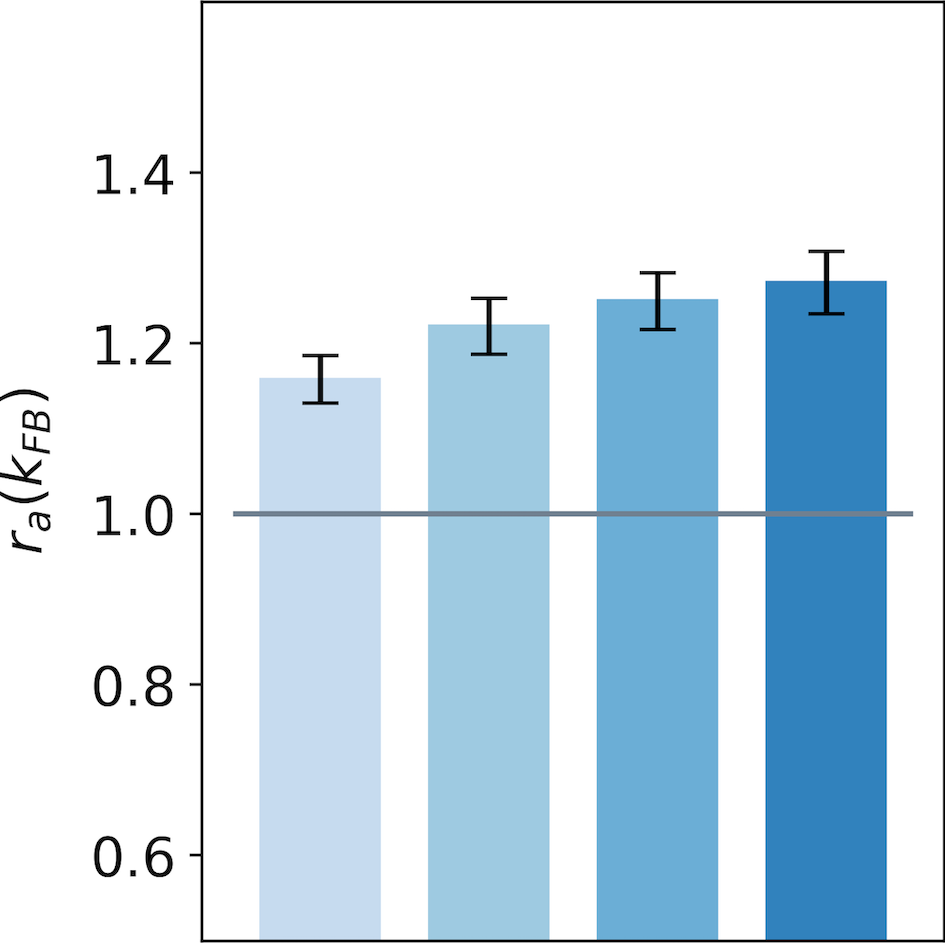 Figure 7
Figure 7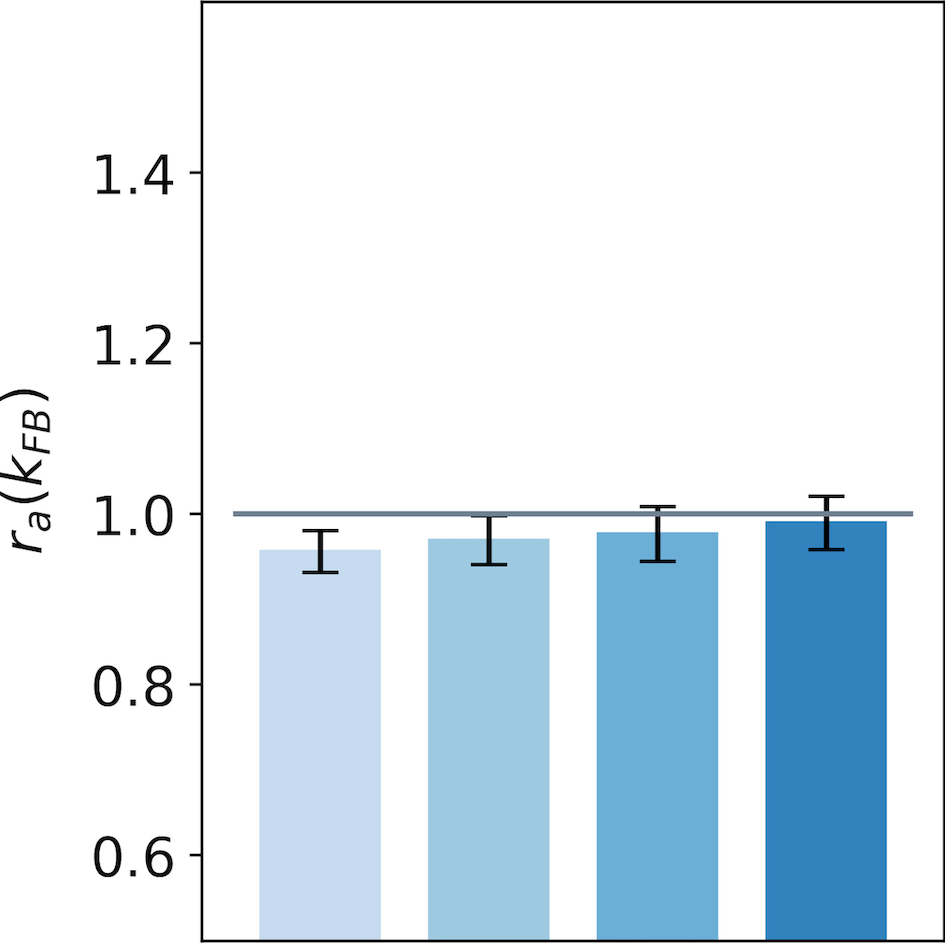 Figure 7
Figure 7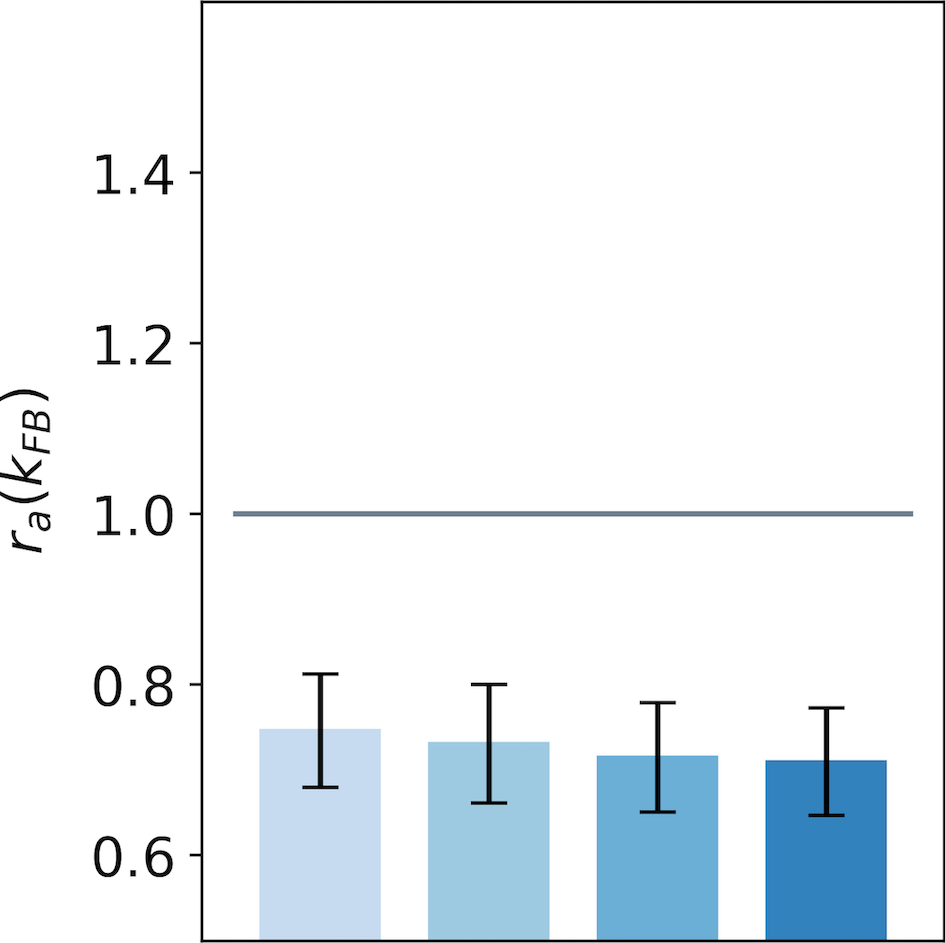 Figure 7
Figure 7 Figure 7
Figure 7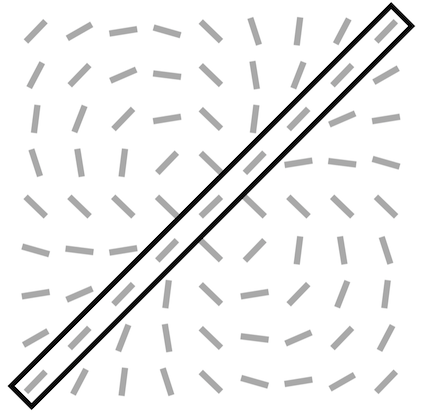 Figure 8
Figure 8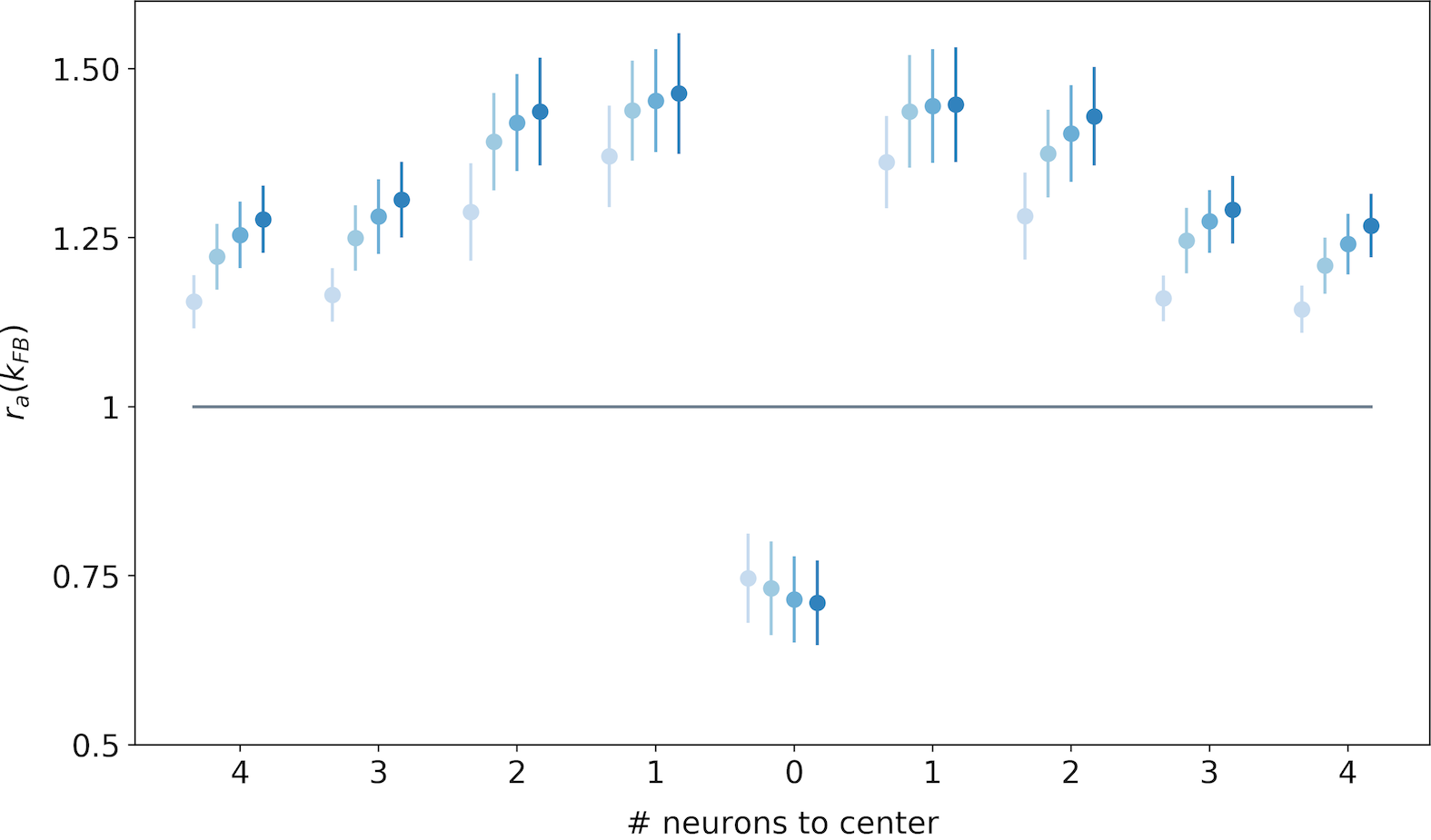 Figure 8
Figure 8| DataBase | |||
| CFD | STL-10 | ||
| network param. | size | [64, 1, 9, 9] (3) | [64, 3, 8, 8] (2) |
| size | [128, 64, 9, 9] (1) | [128, 64, 8, 8] (1) | |
| 0.4 | |||
| 1.2 | |||
| 5e-3 | 5e-3 | ||
| training param. | # epochs | 250 | 250 |
| 1e-4 | 1e-4 | ||
| 5e-3 | 5e-3 | ||
| momentum | 0.9 | 0.9 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
Methodspc
Sparse Deep Predictive Coding captures contour integration capabilities of the early visual system
Victor Boutin1,2*, Angelo Franciosini1, Frederic Chavane1, Franck Ruffier2, Laurent Perrinet1
1 Aix Marseille Univ, CNRS, INT, Inst Neurosci Timone, Marseille, France
2 Aix Marseille Univ, CNRS, ISM, Marseille, France
- corresponding author: [email protected]
Abstract
Both neurophysiological and psychophysical experiments have pointed out the crucial role of recurrent and feedback connections to process context-dependent information in the early visual cortex. While numerous models have accounted for feedback effects at either neural or representational level, none of them were able to bind those two levels of analysis. Is it possible to describe feedback effects at both levels using the same model? We answer this question by combining Predictive Coding (PC) and Sparse Coding (SC) into a hierarchical and convolutional framework. In this Sparse Deep Predictive Coding (SDPC) model, the SC component models the internal recurrent processing within each layer, and the PC component describes the interactions between layers using feedforward and feedback connections. Here, we train a 2-layered SDPC on two different databases of images, and we interpret it as a model of the early visual system (V1 & V2). We first demonstrate that once the training has converged, SDPC exhibits oriented and localized receptive fields in V1 and more complex features in V2. Second, we analyze the effects of feedback on the neural organization beyond the classical receptive field of V1 neurons using interaction maps. These maps are similar to association fields and reflect the Gestalt principle of good continuation. We demonstrate that feedback signals reorganize interaction maps and modulate neural activity to promote contour integration. Third, we demonstrate at the representational level that the SDPC feedback connections are able to overcome noise in input images. Therefore, the SDPC captures the association field principle at the neural level which results in better disambiguation of blurred images at the representational level.
Author summary
One often compares biological vision to a camera-like system where an image would be processed according to a sequence of successive transformations. In particular, this “feedforward” view has been the building-block of popular architectures in deep-learning. However, neuroscientists have long stressed that more complex information flow is necessary to reach natural vision efficiency. In particular, recurrent and feedback connections in the visual cortex allow to integrate contextual information in our representation of visual stimuli. These modulations have been observed both at the low-level of neural activity and at the higher level of perception. In this study, we present an architecture that describes biological vision at both levels of analysis. It suggests that the brain uses feedforward and feedback connections to compare the sensory stimulus with its own internal representation. In contrast to classical deep learning approaches, our model learns interpretable features. Moreover, it demonstrates that feedback signals modulate neural activity to promote good continuity of contours. Finally, the same model can disambiguate images corrupted by noise. To the best of our knowledge, this is the first time that the same model describes the effect of recurrent and feedback modulations at both neural and representational levels.
Introduction
Visual processing of objects and textures has been traditionally described as a pure feedforward process that extracts local features. These features become increasingly more complex and task-specific along the hierarchy of the ventral visual pathway [1, 2]. This view is supported by the very short latency of evoked activity observed in monkeys (\mathrm{ms}$$) in higher-order visual areas [3, 4]. This feed-forward flow of information is sufficient to account for object categorization in the IT cortical area [5]. Although this feedforward view of the visual cortex was able to account for a large scope of electrophysiological [6, 7] and psychophysical [8] findings, it does not take advantage of the high density () and diversity of feedback connections observed in the anatomy [9, 10, 11].
Feedback connections, but also horizontal intra-cortical connections are known to integrate contextual modulations in the early visual cortex [12, 13, 14]. At the neurophysiological level, it was observed that activity in the ’silent’ regions surrounding the classical Receptive Field (RF) tends to either suppress or facilitate the neural activity in the center of the RF. These so-called ’Center/Surround’ modulations are known to be highly stimulus specific [15]. For example, when gratings are presented to the visual system, feedback signals tend to suppress horizontal connectivity which is thought to better segregate the shape of the perceived object from the ground (figure-ground segregation) [16, 17]. In contrast, when co-linear and co-oriented lines are presented, feedback signals facilitate horizontal connections such that local edges are grouped towards better shape coherence (contour integration) [18]. Interestingly, both figure-ground segregation and contour integration are directly derived from the Gestalt principle of perception. In particular, contour integration is known to follow the Gestalt rule of good continuation as mathematically formalized by the concept of association field [19]. This association field suggests that local edges tend to align toward a co-circular geometry. Besides being central in natural image organization [20], association fields might also be implemented in the connectivity within the V1 area [21, 22] and play a crucial role in contour perception [19, 23]. At the psychophysical level, the temporal decoupling between feedforward and feedback connections allowed experimenters to investigate the effect of feedback connection [24, 25]. In particular, it was demonstrated that short-range feedback connections (originating in the ventral visual area and targeting V1) play a crucial role in the recognition of degraded images [26]. These pieces of biological evidence suggest that feedforward models are not sufficient to account for the context-dependent behavior of the early visual cortex and urge us to look for more complex, recurrent models.
From a neurophysiological perspective, Predictive Coding (PC) might be a good candidate to describe inter-layer interaction between feedforward and feedback connections. Rao & Ballard [27] were the first to leverage Predictive Coding (PC) into a hierarchical framework and to combine it with Sparse Coding. On one hand, PC describes the brain as a Bayesian ’machine’ that consistently updates its internal model of the world to infer the possible physical causes of a given sensory input [28]. PC suggests that top-down connections convey predictions about the activity in the lower level while bottom-up processes transmit prediction error to the next higher level. In particular, PC models were able to describe center-surround antagonism in the retina [29] and extra-classical RFs effects observed in the early visual cortex [27]. In addition, studies have investigated the correspondence between cortical micro-circuitry and the connectivity implied by the PC theory [30, 31]. Later, PC has been generalized into a unified brain theory for perception and action [32, 33, 34]. On the other hand, Sparse Coding (SC) might be considered as a framework to describe local computations in the early visual cortex. Olshausen & Field demonstrated that a SC strategy was sufficient to account for the emergence of features similar to the Receptive Fields (RFs) of simple cells in the mammalian primary visual cortex [35]. These RFs are spatially localized, oriented band-pass filters [36]. Furthermore, SC could also be considered as a result of a competition mechanism that explains sensory input in terms of a small number of possible causes. SC implements an ’explaining away’ strategy [37] by suppressing alternative explanations and selecting only the dominant causes.
At the higher representational level, several models have accounted for feedback effects in psychophysical experiments. O’Reilly and colleagues presented a model, called LVis, to describe recurrent processing during object recognition [38]. The LVis model was used to describe the results of psychophysical experiments in which subjects had to recognize objects degraded by occlusion or contrast reduction under a backward-masking setting [26]. Interestingly, the LVis model fitted the psychophysical findings: feedback connections greatly improved object recognition in degraded images and exhibited no significant improvement in classification performance when images of objects were not degraded [26, 39]. Another study uses recurrent convolutional neural networks to dissociate the role of feedforward, feedback, and horizontal connectivity in different kinds of degraded object recognition tasks (cluttered and noisy stimuli) [40]. The authors demonstrated that while horizontal and feedforward connectivity were enough to account for good classification under modest degradation of stimuli, the feedback connection was necessary to reach higher performance for heavily degraded inputs.
To the best of our knowledge, there is no model accounting for feedback effect at both neural level and representational level. In this paper, we use a Sparse Deep Predictive Coding (SDPC) model that combines Predictive Coding and Sparse Coding in a hierarchical and convolutional framework. We first briefly introduce the 2-layered SDPC network used to conduct all the experiments of the paper, and we show the results of the training of the SDPC on two different databases. Next, we investigate the feedback effects at the ’neural’ level. We show how feedback signals in SDPC account for a reshaping of V1 neural population both in terms of topographic organization and activity level. Then, we probe the effect of feedback at the representational level. In particular, we investigate the ability of the feedback connection to denoise corrupted input. Finally, we discuss the results obtained with the SDPC model in the light of the psychophysical and neurophysiological findings observed in neuroscience.
Results
In our mathematical description of the proposed model, italic letters are used as symbols for scalars, bold lowercase letters for column and bold uppercase letters for MATRICES. j refers to the complex number such that .
Brief description of the SDPC
Given a hierarchical generative model for the formation of images, the core objective of Hierarchical Sparse Coding (HSC) is to retrieve the parameters and the internal states variables that best explain the input stimulus. As any perceptual inference model, HSC attempts to solve an inverse problem (Eq. 1), where the forward model is a hierarchical linear model:
[TABLE]
The number of layers of our model is denoted and is the sensory input (i.e. image). The sparsity at each layer is enforced by a constraint on the pseudo-norm of the internal state variable . Finally, and are respectively the prediction error and the weights (i.e. the parameters) at each layer .
To tighten the link with neuroscience, we impose to be non-negative and we force to have a convolutional structure. It allows us to interpret as a retinotopic map describing the neural activity at layer . In addition, could be viewed as the synaptic weights between layers whose activity is represented by and . When projected into the visual space (see Eq. 7), dictionaries could also be interpreted as a set of Receptive Fields (RFs). We call the back-projection of into the visual space (see Fig. S7). Note that RFs in the visual space get bigger for neurons located in deeper layers (that is, on layers further away from the sensory layer). To visualize the information represented by each layer, we back-project into the visual space (see Eq. 8). We call this projection a ’representation’ and it is denoted by .
One possibility to solve the problem defined by Eq. 1 in a neuro-plausible way is to use the Sparse Deep Predictive Coding (SDPC) model (see Model and Methods). The SDPC model combines local computational mechanisms to learn the weights and infer internal state variables. It leverages recurrent and bi-directional connections (feedback and feedforward) through the Predictive Coding (PC) theory. SDPC consists in minimizing, for each layer the loss function defined by Eq. 2 :
[TABLE]
In Eq. 2, is a parameter we introduce to tune the strength of the feedback connection and controls the sparsity level within each layer.
In this paper, we aim at modeling the early visual cortex using a -layered version of SDPC (see Fig. 1). Consequently, we denote the first and second layer of the SDPC as the V1 and V2 model, respectively. In particular, corresponds to the activity-map in V1 and to V2’s activity-map. We refer to the V1 space as the retinotopic space described by , and it is symbolized with a small coordinate system centered in (see Fig. 1).
We train the SDPC on different datasets: a face database (CFD) and a natural images database (STL-10). In this paper, all presented results are obtained with a SDPC network trained with a feedback strength equal to (i.e =1). Once trained, and when specified, we vary the feedback strength to evaluate its effect on the inference process. Note that we have also experimented to equate the feedback strength during learning and inference, and the results obtained are extremely similar to those obtained when the feedback strength was set to during the SDPC training. For both databases, all the presented results are obtained on a testing set that is different from the training set (except when we describe the training in the section entitled ’SDPC learns localized edge-like RFs in V1 and more specific RFs in V2’. All network parameters and database specifications are listed in the ’Model and Methods’ section.
SDPC learns localized edge-like RFs in V1 and more specific RFs in V2
In this subsection, we present the results of the training of the SDPC model on both STL-10 and CFD databases with a feedback strength equal to (Fig. 2). First-layer Receptive Fields (RFs) exhibit two different types of filters: low-frequency filters, and higher frequency filters that are localized, band-pass and similar to Gabor filters (Fig. 2-B and Fig. 2-G). The low-frequency filters are mainly encoding for textures and colors whereas the higher frequency ones describe contours. Second layer RFs (Fig. 2-D and Fig. 2-I) are built from a linear combination of the first layer RFs. For both databases, the second layer RFs are bigger than those in the first layer (approximately times bigger for both databases). We note that for the CFD database the second layer RFs present curvatures and specific face features, whereas on the STL-10 database they only exhibit longer oriented edges. This difference is mainly coming from the higher variety of images composing the STL-10 database: the identity of objects, their distance, and their angle of view are more diverse than in the CFD database. On the contrary, as the CFD database is composed only of well-calibrated centered faces, the SDPC model is able to extract curvatures and features that are common to all faces. In particular, we observe on the CFD database the emergence of face-specific features such as eyes, nose and mouth that are often selected by the model to describe the input (second layer RFs are ranked by their activation probability in a descending order in Fig. 2-D and Fig. 2-I). All the first layer RFs and the second layer RFs learned by the SDPC on both databases are available in the Supporting information section (Fig. S1 for STL-10 and Fig. S2 for CFD). The first layer reconstruction on both databases (Fig. 2-C and Fig. 2-H) are highly similar to the input image (Fig. 2-A and Fig. 2-F). In the second layer reconstructions (Fig. 2-E and Fig. 2-J), the details like textures and colors are faded and smoothed in favor of more pronounced contours. In particular, the contours of the STL-10 images reconstructed by the second layer of the SDPC are sketched with a few oriented lines.
Effect of the feedback at the neural level
We now vary the strength of the feedback connection to assess its impact on neural representations when an image is presented as a stimulus. The strength of the feedback, , is a scalar ranging from [math] to . When is set to [math], the feedback connection is suppressed, in other words, the neural activity in the first layer is independent of the neural activity at the second layer. Inversely, when feedback signals are strongly amplified such that it reinforces the interdependence between the neural activities of both layers. As a consequence, varying the feedback strength should affect the first layer activity. The objective of this subsection is to study this effect on the organization of V1 neurons (i.e. the first layer of the SDPC).
SDPC feedback recruits more neurons in the V1 model
In the first experiment, we monitor the median number of active neurons in our V1 model when varying the feedback strength on both databases. The medians are computed over images of STL-10 database (Fig. 3-A) and images of CFD database (Fig. 3-B). In this paper, we use the median Median Absolute Deviation (MAD) instead of the classical mean standard deviation to avoid assuming that samples are normally distributed [42]. For the same reason, all the statistical tests are performed using the Wilcoxon signed-rank test. It will be denoted when the null hypothesis is rejected. In this notation is the number of samples and is the corresponding probability value (p-value). In contrast, we will formalize the test by when the null hypothesis cannot be rejected.
For both databases, we observe that the percentage of active neurons increases with the strength of the feedback. In particular, we note a strong increase in the number of activated neurons when we restore the feedback connection (from to ): + and + for STL-10 and CFD databases, respectively. Incrementally amplifying the feedback strength above further increases the number of active neurons in the first layer even if the effect is sublinear. All the increases in the percentage of recruited neurons with the feedback strength are significant as quantified with statistical tests between all pairs of feedback strength: for STL-10 database and for CFD database. For each database, we notice that the inter-stimuli variability, as illustrated by error-bars, is lower when the feedback connection is removed: with versus with for the STL-10 database and with versus with for the CFD database. The results of this first experiment suggest that as the feedback gets stronger, the number of recruited neurons becomes larger.
SDPC feedback signals reorganize the interaction map of the V1 model
We investigate the effect of feedback on the neural organization in our V1 model when the SDPC is trained on natural images (i.e. STL-10 database). The V1 activity-map () being a high-dimensional tensor, it is a priori difficult to visualize its internal organization. We define the notion of interaction map to reduce the neural activity to two state variables at every position on the V1 space: the resulting orientation and activity. Using interaction map allows us to represent in 2D the state of the network surrounding a given central position. We choose the location of the center of the interaction map such that neurons, at this position, are strongly responsive to a given orientation. This orientation is called the central preferred orientation and denoted . Interaction maps are denoted , the maps of resulting orientations and activities are denoted and \big{|}\boldsymbol{\bar{a}}\big{|}, respectively. The computation of the interaction maps is detailed in the subsection ’Interaction maps analysis’ of the section ’Model and Methods’ .
For all feedback strengths and different central preferred orientations, we observe that the interaction maps are highly similar to association fields [19]: most of the orientations of the interaction map are co-linear and/or co-circular to the central preferred orientation (see Fig. 4 for one example of this phenomenon and Fig. S3 for more examples with =1). In addition, interaction maps exhibit a strong activity in the center and towards the end-zone of the central preferred orientation. We define the end-zone as the region covering the axis of the central preferred orientation, and the side-zone as the area covering the orthogonal axis of the central preferred orientation. The activity of the interaction map in the side-zone is lower compared to the activity in the end-zone. We notice qualitatively that the orientations of the interaction maps are less co-linear to the central preferred orientation when feedback is suppressed (i.e. ). In other words, when feedback is active, the interaction map looks more organized compared to the interaction map generated without feedback (see Fig. 4 for a striking example of this phenomenon).
We next quantify this organizational difference for different levels of feedback strength by estimating the co-linearity and the co-circularity deviation of the interaction map in both regions: the end-zone and the side-zone. To perform such an analysis, we measure the co-linearity deviation of the interaction map from the central preferred orientation, denoted (see Eq. 15 in section Model and Methods). In addition, we measure the co-circularity deviation of the interaction map from a map of orientations that are co-circular to the central preferred orientation (see Eq. 16 in section Model and Methods).
When feedback is suppressed (ie ), we measure a median co-linearity deviation equal to [math] and [math] in the end-zone and in the side-zone of the interaction map, respectively (the medians are computed over all the central preferred orientations). These measures are to be compared with the marginal co-linearity, i.e the median co-linearity deviation outside the interaction map. We report a marginal co-linearity of [math] in both regions (as computed with a spatially shuffled version of the V1 activity-map). Consequently, orientations inside the interaction map are more co-linear to the central preferred orientation than orientations located outside of the interaction map. Still without feedback, we measure a median co-circularity deviation equal to [math] and [math] in the end-zone and the side-zone of the interaction map, respectively. The marginal co-circularity, i.e the median co-circularity deviation outside the interaction map is equal to [math] in both regions. Thus, orientations located in the end-zone of the interaction map are more co-circular to the central preferred orientation than orientations located outside the interaction map. In contrast, side-zone orientations in the interaction map are equally co-circular to the central preferred orientation that orientations located outside of the interaction map.
For a given feedback strength , we synthesize these results by introducing two ratios to compare the respective precisions in co-linearity ( in Eq. 17 in section Model and Methods) and co-circularity ( in Eq. 18 in section Model and Methods). These are derived by dividing the marginal co-linearity/co-circularity deviation by the co-linearity/co-circularity deviation in the interaction map.
We report these two ratios for the end-zone (Fig. 5-A) and the side-zone (Fig. 5-B). As a first observation, for all feedback strengths the end-zone orientations in the interaction map are both more co-linear and co-circular to the central preferred orientation than orientations located outside the interaction map (as computed by the marginal baseline, see Fig. 5-A). This increase of co-linearity and co-circularity compared to the baseline in the end-zone is significant for all feedback strengths (). All increases of co-linearity between and are also significant as reported by pair-wise statistical test (). In contrast, the increases in co-linearity between the rest of the feedback strength are not significant as measured by the minimum p-value of all pair-wise statistical tests (). Concerning the side-zone and for all feedback strengths, orientations in the interaction map are significantly more co-linear to the central preferred orientation compared to the marginal co-linearity (see Fig. 5-B) (). Interestingly, the increases of co-linearity between and in the side-zone are also significant as quantified by pair-wise statistical tests (). Besides, the co-circularity in the side-zone is at the marginal level or below. However, this observation is not significant as reported by the maximum p-value of all pair-wise statistical test (). In addition, we observe that the feedback strength has a strong effect on the co-linearity in the side-zone and a smoother effect on the co-linearity in the end-zone. While the relative co-linearity w.r.t. marginal co-linearity is strong in the end-zone it is weaker in the side-zone when feedback is suppressed. The feedback signals in the side-zone tend to catch-up with the co-linearity level in the end-zone. Our analysis suggests that interaction maps without feedback are both co-linear and co-circular in the end-zone of the interaction map, but only slightly co-linear and not co-circular in the side-zone. Interestingly, increasing the feedback strength tends to orientate the side-zone of the interaction map co-linearly to the central preferred orientation.
SDPC feedback signals modulate the activity within the interaction map
To study the effect of the feedback on the level of activity within the interaction map, we introduce the ratio between the activity with a certain feedback strength and the activity when the feedback is suppressed (see Eq. 19 in section Model and Methods). Coloring the interaction map using a color scale proportional to allows us to identify which part of the map is more activated with the feedback. First, we observe qualitatively that the interaction map in the end-zone is more strongly activated when the feedback connection is active. On the contrary, the side-zone exhibited weaker activities when feedback is turned on (see Fig. 6 and Fig. S4 for examples of this phenomenon with =1). Note also that the activity in the center of the interaction map, which corresponds to the classical RF area, is lowered when feedback is active.
We now generalize, refine and quantify these qualitative observations. We include a third region of interest, the center of the interaction map, to confirm the decreasing activity observed qualitatively at this location. We report the median of the ratio over all central preferred orientations, for the end-zone, the side-zone and the center. This analysis is repeated for a feedback strength ranging from to (see Fig. 7).
We observe an increase of the activity in the end-zone of the interaction map with feedback compared to the end-zone of the interaction without feedback (see Fig. 7-A). This increase is significant as quantified by all pair-wise statistical tests with the baseline (). For larger feedback strengths, we observe a higher activity in the end-zone which is also significant (all pair-wise statistical tests between all feedback strengths (). For example, in the end-zone, the median activity over all the central preferred orientations is 16% and 25% higher with a respective feedback strength of and compared to the median when feedback is suppressed. This suggests that the feedback signals excite neurons in the end-zone of the interaction map. In contrast, we observe a slight decrease of activity in the side-zone of the interaction map with feedback active compared to when feedback is suppressed (see Fig. 7-B). The decrease compared to the baseline is significant as well as the increase between the different feedback strengths as quantified by all pair-wise statistical tests (). The center of the interaction map exhibits a significant decrease in activity compared to the baseline (). In addition, the larger the feedback strength, the weaker the activity in the center of the interaction map (). For example, we report a decrease from -28% for to -34% for compared to the activity in the center of the interaction map without feedback (see Fig. 7-C).
We report the spatial profile of the median activity along the axis of the central preferred orientation (see Fig. 8). For all distances from the center, the activity along the central preferred orientation axis of interaction map is significantly higher than the activity without feedback (all pair-wise statistical tests with the baseline: ). The only exception is in the center of the interaction map, where the activity is weaker when feedback is active (see also Fig. 7-C). This inhibition in the center of the map compared to the baseline is significant as quantified with pair-wise statistical tests (). Even if activities for along the central preferred orientation are always higher than the activity with , they tend to decrease with distance to the center. Especially, for , the neurons located just near the center exhibit a response higher than the same neurons without feedback. With the same feedback strength, this increase of activity w.r.t to no feedback is reduced to when the neurons are located 4 neurons away from the center. At a given position different from the center, increasing the feedback strength significantly increases the activity as quantified by all pair-wise statistical test ().
Our results exhibit three different kinds of modulations in the interaction map due to feedback signals. First, the activity in the center of the map is reduced with the feedback. Second, the activity in the end-zone, and more specifically along the axis of the central preferred orientation is increased with the feedback. Third, the activity in the side-zone is reduced with the feedback.
Effect of the feedback at the representational level
After investigating the effect of feedback at the lowest level of neural organization, we now explore its functional and higher-level aspects. In particular, this subsection is dealing with the denoising ability of the feedback signal.
SDPC feedback signals improve input denoising
To evaluate the denoising ability of the feedback connection, we feed the SDPC model with increasingly more noisy images of the STL-10 and CFD databases. Then, we compare the resulting representations () with the original (non-degraded) image. To do this comparison, we conduct two types of experiments: a qualitative experiment that visually displays what has been represented by the model (see Fig. 9-A on STL-10 and Fig. 10-A on CFD), and a quantitative experiment measuring the similarity between representations of noisy and original images (see Fig. 9-B & C on STL-10 and Fig. 10-B & C on CFD). These two experiments are repeated for a noise level () ranging from [math] to and a feedback strength () varying from [math] to . The similarity between images is computed using the median structural similarity index (SSIM) [43] over and images for the STL-10 and CFD database, respectively. The SSIM index varies from [math] to such that the more similar the images, the closer the SSIM index is to . For comparison, we include a baseline (see the black curves in Fig. 7) which is computed as the SSIM index between original and noisy images for different levels of noise.
We first observe that whatever the feedback strength, the first layer representations of the original image (first row, column 2 to 6 in Fig. 9-A for STL-10 and Fig. 10-A for CFD) are relatively similar to the input image itself. This observation is supported by a SSIM index close to for all feedback strengths ( in Fig. 9-B for STL-10 and Fig. 10-B for CFD). On the contrary, second layer representations look more sketchy and exhibited fewer details than the image they represent (first row, column 7 to 11 in Fig. 9-A for STL-10 and Fig. 10-A for CFD). This is also quantitatively backed by a SSIM index fluctuating around for the STL-10 database ( in Fig. 9-C) and for the CFD database ( in Fig. 10-C). Interestingly, when input images are corrupted with noise (i.e. when ), and whatever the feedback strength, first layer representations systematically exhibit higher SSIM index than the baseline (Fig. 9-B for STL-10 and Fig. 10-B for CFD). This denoising ability of the SDPC, even without feedback is significant as reported by the pair-wise statistical tests with the baseline for both databases ( for STL-10 database, and for the CFD database). More importantly, the higher the feedback strength, the higher the SSIM index. In particular, on the STL-10 database, when the input is highly degraded by noise (), the SSIM is for the baseline, for , for and for (see Fig. 9-B). This improvement of the denoising ability with higher feedback strength when is also significant as quantified by the pair-wise statistical tests between all feedback strength (). The inter-image variability of the SSIM of first layer representation as quantified by the MAD is low compared to the median SSIM on the STL-10 database (see Fig. S5-C). In the CFD database, for a highly degraded input (), the SSIM is for the baseline, for , for and for . On the CFD database, the increases of the first layer SSIM with the feedback strength when inputs are highly degraded () are significative as measured by all the pair-wise statistical tests between all feedback strength (). Inter-image variability of the SSIM of the first layer representation is also lower than the corresponding median on the STL-10 database (see Fig. S6-C). It is interesting to observe that even if the second layer representations are less detailed and more sketchy than the first layer reconstructions, they offer a piece of valuable information, in the form of feedback signals, that allow these first layer to better denoise the input. To conclude this subsection, we conducted a qualitative and a quantitative analysis of the denoising ability of the feedback connection. Our results suggest that feedback improves the denoising ability of the first layer. Especially, as feedback gets stronger, then the first layer is more able to properly recover from a degraded input.
Discussion
Herein, we have conducted computational experiments on a 2-layered Sparse Deep Predictive Coding (SDPC) model. The SDPC leverages feedforward and feedback connections into a model combining sparse coding and predictive coding. As such, the SDPC learns the causes (i.e. the features) and infers the hidden states (i.e. the activity maps) that best describe the hierarchical generative model giving rise to the visual stimulus (see. Fig. 8 for an illustration of this hierarchical model and Eq. 1 for its mathematical description).
We use this model of the early visual cortex to assess the effect of the early feedback connection (i.e feedback from V2 to V1) through different levels of analysis. At the neural level, we have shown that feedback connections tend to recruit more neurons in the first layer of the SDPC. We have introduced the concept of interaction map to describe the neural organization in our V1-model. Interestingly, the interaction maps generated when natural images are presented to the model are very similar to association fields. In addition, interaction maps allow us to describe the neural reorganization due to feedback signals. In particular, we have observed that feedback signals align neurons in the side-zone of the interaction map co-linearly to the central preferred orientation. At the activity level, we observed main kind of feedback modulatory effects. First, the activity in the center of the interaction map is decreased. Second, the activity in the end-zone and more specifically along the axis of the central preferred orientation is increased. Third, the activity in the side-zone is reduced. At the representational level, we have investigated the role of feedback signals when input images are degraded using Gaussian noise. We have demonstrated that higher feedback strengths allow better denoising ability. In this section, we interpret these computational findings in light of current neuroscientific knowledge.
SDPC learns cortex-like RFs while performing neuro-plausible computation
The SDPC model satisfies some of the computational constraints that are thought to occur in the brain: notably local computation and plasticity [44]. The locality of the computation is ensured by Eq. 3: the new state of a neural population (whose activity is represented by ) only depends on its previous state (), the state of adjacent layers ( and ) and the associated synaptic weights ( and ). Similarly, the update of the synaptic weights (), described by Eq. 6, is exclusively based on the pre-synaptic and post-synaptic activity (respectively and ). The learning process could then be assimilated to an Hebbian learning. Not only the processing but also the result of the training exhibits tight connections with neuroscience. The first-layer RFs (Fig. 2-B for the STL-10 database and Fig. 2-G for the CFD database) are similar to the V1 simple-cells RFs, which are oriented Gabor-like filters [45, 46]. Olshausen & Field have already demonstrated, in a shallow network, that oriented Gabor-like filters emerge from sparse coding strategies [35], but to the best of our knowledge, this is the first time that such filters are exhibited in a 2-layers network combining Predictive Coding and Sparse Coding. This architecture allows us to observe an increase in specificity of the neuron’s RFs with the depth of the network. This observation is even more striking when the SDPC is trained on the CFD database, which presents less variability compared to the STL-10 database. On CFD, second layer RFs exhibit features that are highly specific to faces (eyes, mouth, eyebrows, contours of the face). Interestingly, it was demonstrated with neurophysiological experiments that neurons located in deeper regions of the central visual stream are also sensitive to that particular face features [47, 48].
Functional interpretation of the observed V1 interaction maps
At the electrophysiological level, it has been demonstrated that as early as in the V1 area, feedback connections from V2 could either facilitate [12] or suppress [16] lateral interactions. In particular, these modulations help V1 neurons to integrate contextual information from a larger part of the visual field and play a crucial role in contour integration [49]. It was assumed that association fields were represented in V1 to perform such a contour integration [21]. Interestingly, the SDPC first-layer interaction maps exhibited a co-linear and co-circular neural organization very similar to association fields even without feedback (see Fig. 4). We formulate the hypothesis that this specific organization is mainly related to the statistics of edge co-occurrence in natural images [20]. Nevertheless, the modulation of neural activity within the interaction map mediated by feedback goes towards a better contour integration. Indeed, the increase of activity in the end-zone and the decrease of activity in the side-zone seem to be optimal to integrate smooth and close contours [50] (see Fig. 6, Fig. 7 and Fig. 8). In addition, the organizational feedback modulation in the interaction map revealed that feedback signals tend to reorganize the side-zone to promote orientations that are co-linear to the central preferred orientation (see Fig. 5). This organization may provide an optimal substrate to integrate dynamic stimuli along two axes: a parallel one with apparent motion-like sequence of oriented stimuli moving along the end-zone direction [42, 51, 52], and a perpendicular one for oriented stimuli moving perpendicular to their orientation. Interestingly, oriented Gabors moving in an apparent sequence along the parallel axis are perceived as faster as Gabors moving along the orthogonal axis [52]. Furthermore, aligning the side-zone region to the preferred orientation could also contribute to the aperture problem [53] and the observed bias for perceiving oriented bars as moving in direction perpendicular to their orientation [54, 55].
Do lateral interactions increase the sparseness of neural activity in V1?
In this paper, we have assumed that recurrent internal processing could be modeled using sparse coding. Is it a realistic hypothesis? One of the main roles of sparse coding is to enforce competition among neurons: it suppresses weakly activated neurons to promote strongly activated ones. In other words, sparse coding performs ’explaining away’. Interestingly, when stimuli (blobs) were presented at different locations and timings, it has been observed in monkeys’ area V1 that a suppressive wave tends to spatially disambiguate the positions of the stimuli [56]. This effect was attributed to lateral interactions (due to the spatio-temporal properties of the effect) and can be thought as such an explaining away mechanism. Other studies have also demonstrated that lateral interactions exacerbate competition in cortical columns with different orientations or ocular dominance [57, 58, 59]. Therefore, our sparse coding model accounts for one possible function of lateral interaction. Nevertheless, the sparse coding algorithm we use (i.e. FISTA, see section ’Model and Methods’) doesn’t allow to explicitly learn a lateral connectivity matrix. Consequently, one might consider other sparse coding algorithms including lateral connection weights to provide a more accurate model of cortical columns [60].
SDPC feedback accounts for object processing in V1 with degraded images
Psychophysical experiments using backward masking demonstrated that categorization performances were substantially impaired when a mask followed a highly degraded stimulus (by occlusion or contrast reduction) [26, 39]. This suggests that feedback is crucial to recognize degraded image. In this paper, we demonstrate a similar result by assessing the representations of the first layer of the SDPC when the model is fed with increasingly more noisy images and with different feedback strengths. In particular, we show that feedback connections from V2 to V1 have the ability to denoise corrupted images (see Fig. 10 and Fig. 11). In addition, the previously mentioned psychophysical studies suggest that feedback connections are not bringing any change in recognition accuracy when non-degraded images are presented to the subjects [26, 39]. In contrast, the SSIM between the original image and the first layer representation when the SDPC is fed with non-degraded image exhibits a slight decrease, but significant enough, when the feedback strength is increased. We formulate the hypothesis that this discrepancy is mainly coming from the fixed value we give to the feedback strength parameter. Feedback is strongly subject to attentional modulation, and a recent study has suggested that attention can be understood as a mechanism weighting feedback connections using the level of uncertainty [61]. Therefore, one might consider replacing the scalar with a precision matrix proportional to the prediction error at each layer. Said differently, if the first layer prediction error is very low, feedback signals should be weak as no higher-layer information are needed to faithfully represent the sensory input. On the contrary, if the first layer prediction error is high, the feedback connection should be strong enough to bring additional information from higher-layer to compensate for the high uncertainty in the first layer. Extending the SDPC framework with a finer-grained feedback weighting should greatly improve its performance and tighten that particular link with neuroscience.
Concluding remarks
In this study, we have shown that the first layer of the SDPC model represents the visual input similarly to V1. We have also demonstrated that feedback from V2 may modulate the interaction map in such a way to promote contour integration. This improvement in contour integration with feedback strength resulted in a better representation when noisy images were presented to the SDPC. Note that the proposed SDPC is a simplified version of perceptual inference models based on free-energy optimization [33, 32]. While free-energy estimates the entire distribution of error and prediction signals, our SDPC only assesses their most likely values. One interesting perspective would be to extend the SDPC to make it fit the precision-weighted message passing implemented in the free-energy framework. In general, we foresee great perspectives to such a description of the brain both in computational neuroscience to understand perceptual mechanisms and in artificial intelligence for tasks like denoising, classification or inpainting.
Model and Methods
In this section, we detail the Sparse Deep Predictive Coding (SDPC) model. We first explain how the SDPC is directly related to the Predictive Coding (PC) theory. Next, we describe the mathematics behind the inference and the learning process. We then explicit the back-projection mechanism used to interpret and visualize inference and learning results. We also describe the databases and the network parameters we adopted to train the SDPC. Finally, we detailed all the calculations needed to generate interaction maps.
SDPC Model
From Predictive Coding to Sparse Deep Predictive Coding
Fig. 1 shows the architecture of a 2-layered SDPC model that takes an image as an input. As the SDPC is relying on the Predictive Coding (PC) theory [27], it is continuously generating top-down predictions such that the neural population at one level () predicts the neural activity at the lower level (). The prediction from a higher level is sent through a feedback connection to be compared to the actual neural activity. This elicits a prediction error, , that is forwarded to the following layer to update the population activity towards improved prediction. This dynamical process repeats throughout the hierarchy until the bottom-up process no longer conveys any new information. We force the weights of the feedforward connection () to be reciprocal to the weights of the feedback connection () [27, 62]. We also impose a convolutional structure to to strengthen the proximity with the overlapping RFs observed in the visual cortex. For the sake of clarity, in the mathematical description of our model, we replaced the convolution by a matrix product. The rigorous equivalence between discrete convolution and matrix product could be easily demonstrated by transforming into a Toeplitz-structured matrix. Mathematically, the SDPC solves the hierarchical inverse problem formulated in Eq. 1 by minimizing the loss function defined in Eq. 2. This optimization process is separated in two different but related steps: inference and dictionary learning. The inference process consists in finding a sparse activity map of the input considering the synaptic weights are fixed. Once the activity map has been estimated the next step is to update the synaptic weights to better fit the dataset. We iterate these two processes until the convergence is reached.
Inference
To obtain a convex cost, we relax the constraint in Eq. 1 into a -penalty. It defines, therefore, a loss function that could be minimized using first-order methods like Iterative Shrinkage Thresholding Algorithms (ISTA) [63]. ISTA is proven to be computationally cheap and offers fast convergence rate. In practice, we use an accelerated version of the ISTA algorithm called FISTA. One inference step used to update is shown in Eq. 3
[TABLE]
In Eq. 3, denotes a non-negative soft thresholding operator, as defined in Eq. 4. is the learning rate of the inference process, it is computed as the inverse of the largest eigenvalue of [63]. is the state of the neural population at layer and time . is a scalar tuning the sparsity of the activity map .
[TABLE]
Fig. 1 shows how we can interpret the update scheme described in Eq. 3 as one loop of the inference process of a recurrent layer. This recurrent layer forms the building block of the Sparse Deep Predictive Coding (SDPC) network (see Algo.S 2 for the complete pseudo-code of the SDPC inference process). We initialize all the activity maps to zero at the beginning of the inference process. We consider the inference process is finalized once all the activity maps have reached a stability criterion. Our stability criterion consists in a threshold () on the relative variation of each activity map (Eq. 5).
[TABLE]
Dictionary learning
The SDPC learns the synaptic weights using a Stochastic Gradient Descent (SGD) on . Eq. 6 describes on step of the dictionary learning process.
[TABLE]
In Eq. 6, is the set of synaptic weights at time step and is its learning rate. At the beginning of the learning, all weights are initialized using the standard normal distribution (mean [math] and variance ). The learning step takes place after the convergence of the inference process is achieved (see Algo. 1). It was demonstrated that this alternation of inference and learning offers reasonable convergence guarantee [64]. After every dictionary learning step we -normalize each weight to avoid any redundant solution.
Back-projection mechanism
Interestingly, the dictionaries could be used to project (or back-project) the activity of a neural population and their associated synaptic weights into the next (or previous) level. Due to their high dimensionality, the weights or difficult to interpret and visualize for as they represent a structure into an intermediate feature space at layer . To overcome this limitation, we back-project the weights into the input space, which is the visual space [64]. This back-projection, called effective dictionary and denoted by , could be interpreted as the set of Receptive Fields (RFs) of the neurons located in layer i. Mathematically, the effective dictionaries are described in Eq. 7, and illustrated by Fig. S7.
[TABLE]
Similarly, we defined as the back-projection into the visual space of the hidden states variable (Eq. 8). This mechanism is used to reconstruct the input image from one intermediate layer.
[TABLE]
Databases
We train our SDPC model on two different databases: The Chicago Face Database (CFD) [65] and STL-10 [66].
Chicago Face Database (CFD). CFD consists of high-resolution ( px), color, standardized photographs of Black and White males and females between the ages of and years. We re-sized the pictures to px to keep reasonable computational time. The CFD database is partitioned into batches of 10 images. This dataset is split into a training set composed of images and a testing set of images.
STL-10 database. The STL-10 dataset is an image recognition dataset developed for unsupervised feature learning and composed of color photographs with a resolution of px representing animals (bird, cat, deer, dog, horse, monkey) and non-animals (airplane, car, ship, truck). The images are highly diverse (different view-point, background…) and could be considered as natural images. The set is partitioned into a training set of images and a testing test of images.
All the curves, images and histograms presented in this paper are generated using the testing set. The training set is used only to learn the synaptic weights. All these databases are pre-processed using Local Contrast Normalization (LCN) and whitening. LCN is inspired by neuroscience and consists in a local subtractive and divisive normalization [41]. In addition, we use whitening to reduce dependency between pixels.
Network parameters
Networks and training parameters of the SDPC model are summarized in the table Table. 1 for CFD and STL-10 databases.
We used PyTorch 1.0 [67] to implement, train, and test the SDPC model. The codes of the model and all the simulations that generate the result of this paper are available at ’www.github.com/XXX/XXX’.
Interaction maps analysis
Using the intrinsic invariance to translations of CNNs and the fact that learned filters are in majority edge-like filters, we define the notion of interactions map to reduce the neural activity to two state variables at every position on the V1 space: the resulting orientation and activity. Using interaction map allows us to represent in 2D the state of the network surrounding a given central position. We choose the location of the center of the interaction map such that neurons, at this position, are strongly responsive to a given orientation. This orientation is called the central preferred orientation and denoted . Interaction maps are denoted .
To mathematically define the resulting orientations and activities of the interaction map, it is convenient to interpret the V1 activity-map as a 3-dimensional tensor, in which the first dimension corresponds to one specific orientation and the two last dimensions describe the V1 space. Eq. 9 formalizes this interpretation using complex number representation.
[TABLE]
In Eq. 9, denotes the orientation of the filters. In practice, we estimate by fitting the first layer RFs with Gabor filters [68]. Note that textural and low-frequency filters are poorly fitted and are removed (we remove out of filters). For each orientation, we adjust the V1 activity-map surrounding the central preferred orientation with a marginal activity. The marginal activity is computed by extracting the mean neighborhood in a spatially shuffled version of the V1 activity-map. Said differently, the marginal activity, denoted , is a spatial average over the activity of neurons that respond to one given orientation . The adjusted activity is called and its computation is defined in Eq. 10.
[TABLE]
In Eq. 10, (, ) denotes the coordinates of the V1-space neighboring the central preferred orientation, and (, ) represents the V1-space outside this neighborhood. At each position of the V1-space surrounding the central preferred orientation, the interaction map is computed as the weighted average over all the orientations of the adjusted activity vector (see Eq. 11). We denote and \big{|}\boldsymbol{\bar{a}}\big{|} the resulting orientation and activity of the interaction map, respectively (see Eq. 12).
[TABLE]
We use a circular weighted average to compute the resulting orientation (see Eq. 13) and activity (see Eq. 14) of the interaction map.
[TABLE]
For each image, we average interaction maps with the same central preferred orientation. The centers of these maps correspond to the locations, in the V1-space, showing the strongest response to the given central preferred orientation. The size of the interaction map is set to cover the second layer neurons’ RFs. In practice, our interaction maps have a size in the V1 space. The interaction maps obtained for each image are finally averaged over images of the STL-10 testing set. We iterate this analysis for different feedback strengths ranging from [math] to .
We measure the co-linearity deviation of the interaction map with a circular difference between the central preferred orientation () and the orientation of the interaction map (see Eq. 15). The co-circularity deviation is quantified using a circular difference between a map of orientations that are co-circular to the central preferred orientation and the angle of the interaction map (see Eq. 16) [69]. We simplify the calculation of the co-circular angle map in Eq. 16 by centering the coordinate in the middle of the interaction map (the co-circular map is shown in the top right corner of the Fig. 5-A and Fig. 5-B).
[TABLE]
For a given feedback strength , we synthesize our results by introducing two ratios to compare the respective precisions in co-linearity ( in Eq. 17) and co-circularity ( in Eq. 18). In those equations, the marginal co-linearity and co-circularity are denoted and , respectively. To facilitate the interpretation of these ratios, we make sure they are following the same evolution than a precision measure. For example, if an interaction map exhibits a higher co-linearity with the central preferred orientation, then the corresponding will be necessarily over .
[TABLE]
To compare this relative activity with or without feedback, we introduce the ratio (see Eq. 19).
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 11. Riesenhuber M, Poggio T. Hierarchical models of object recognition in cortex. Nature neuroscience. 1999;2(11):1019.
- 22. Di Carlo JJ, Zoccolan D, Rust NC. How does the brain solve visual object recognition? Neuron. 2012;73(3):415–434.
- 33. Bullier J. Integrated model of visual processing. Brain research reviews. 2001;36(2-3):96–107.
- 44. Lamme VA, Roelfsema PR. The distinct modes of vision offered by feedforward and recurrent processing. Trends in neurosciences. 2000;23(11):571–579.
- 55. Fabre-Thorpe M, Richard G, Thorpe SJ. Rapid categorization of natural images by rhesus monkeys. Neuroreport. 1998;9(2):303–308.
- 66. Freedman DJ, Riesenhuber M, Poggio T, Miller EK. A comparison of primate prefrontal and inferior temporal cortices during visual categorization. Journal of Neuroscience. 2003;23(12):5235–5246.
- 77. Rust NC, Mante V, Simoncelli EP, Movshon JA. How MT cells analyze the motion of visual patterns. Nature neuroscience. 2006;9(11):1421.
- 88. Serre T, Wolf L, Bileschi S, Riesenhuber M, Poggio T. Robust object recognition with cortex-like mechanisms. IEEE Transactions on Pattern Analysis & Machine Intelligence. 2007;(3):411–426.
