Sparsity Constrained Distributed Unmixing of Hyperspectral Data
Sara Khoshsokhan, Roozbeh Rajabi, Hadi Zayyani

TL;DR
This paper introduces a novel distributed optimization algorithm for hyperspectral spectral unmixing that incorporates sparsity constraints, improving the estimation of endmembers and abundances in hyperspectral images.
Contribution
It proposes a sparsity constrained distributed unmixing algorithm using diffusion LMP strategy, with analysis for various LMP powers and norms, advancing hyperspectral data analysis methods.
Findings
The proposed algorithm outperforms existing methods in spectral unmixing accuracy.
Distributed approach effectively handles large hyperspectral datasets.
Sparsity constraints improve endmember and abundance estimation.
Abstract
Spectral unmixing (SU) is a technique to characterize mixed pixels in hyperspectral images measured by remote sensors. Most of the spectral unmixing algorithms are developed using the linear mixing models. To estimate endmembers and fractional abundance matrices in a blind problem, nonnegative matrix factorization (NMF) and its developments are widely used in the SU problem. One of the constraints which was added to NMF is sparsity, that was regularized by Lq norm. In this paper, a new algorithm based on distributed optimization is suggested for spectral unmixing. In the proposed algorithm, a network including single-node clusters is employed. Each pixel in the hyperspectral images is considered as a node in this network. The sparsity constrained distributed unmixing is optimized with diffusion least mean p-power (LMP) strategy, and then the update equations for fractional abundance and…
Click any figure to enlarge with its caption.
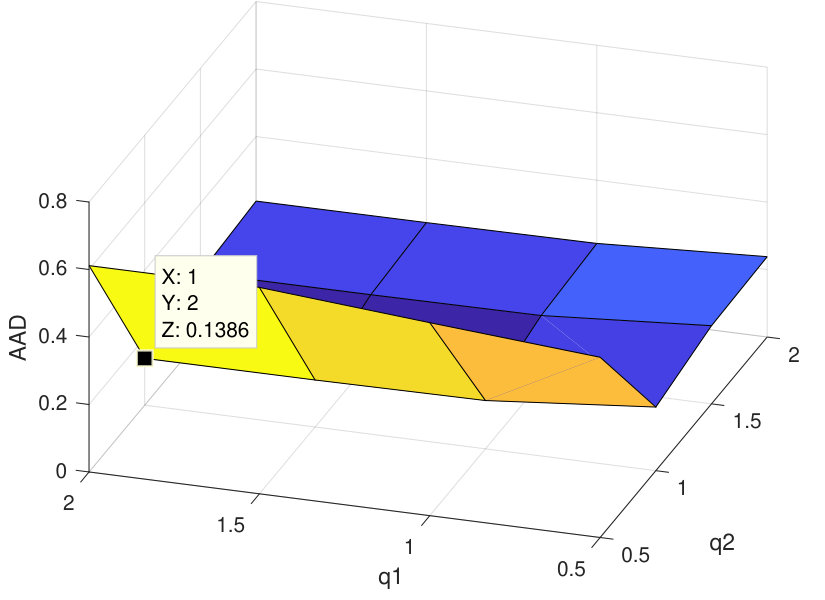 Figure 1
Figure 1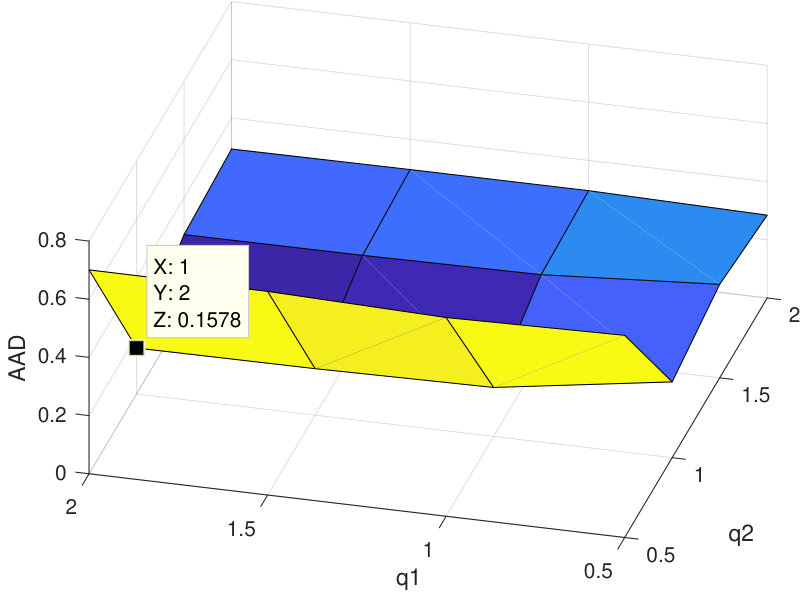 Figure 2
Figure 2 Figure 3
Figure 3 Figure 10
Figure 10 Figure 9
Figure 9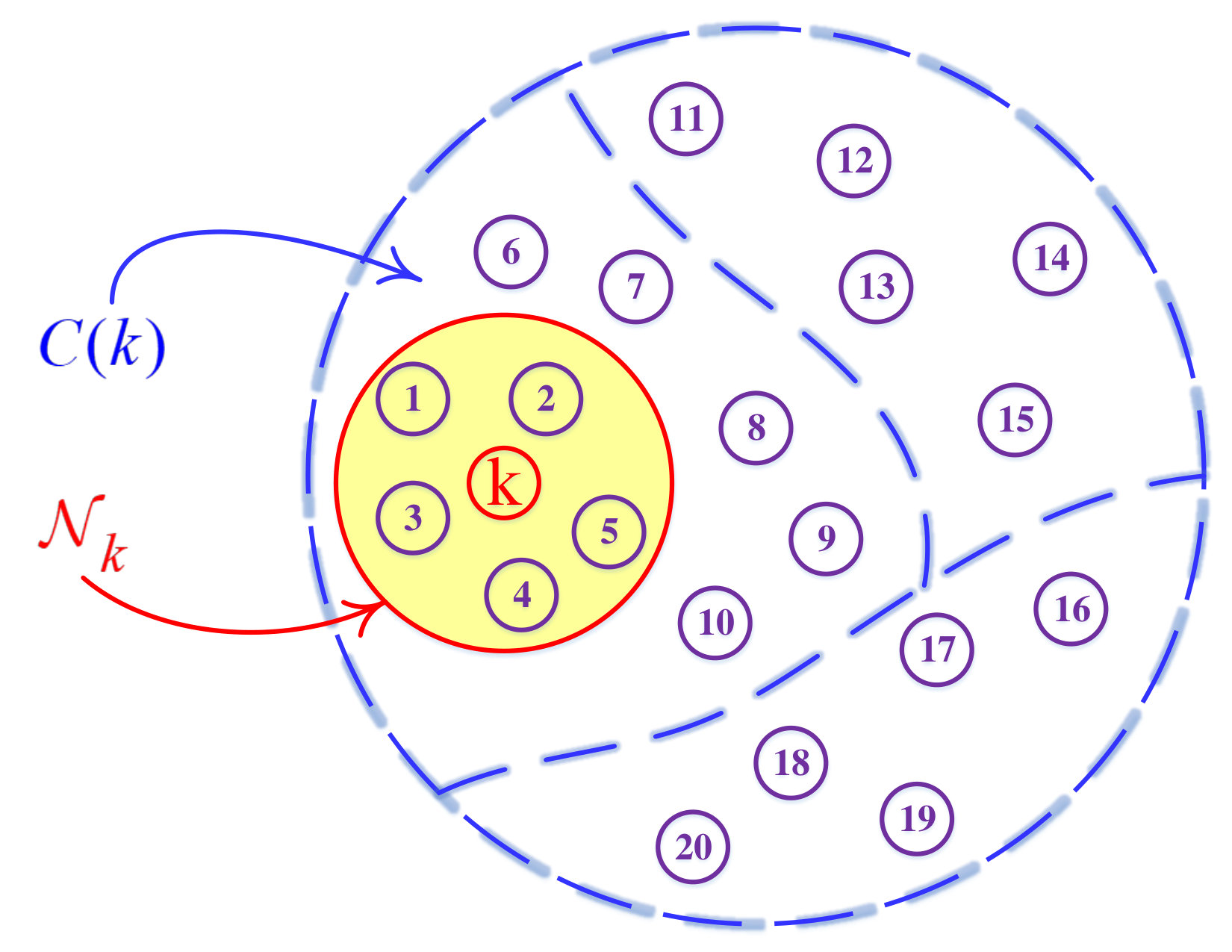 Figure 6
Figure 6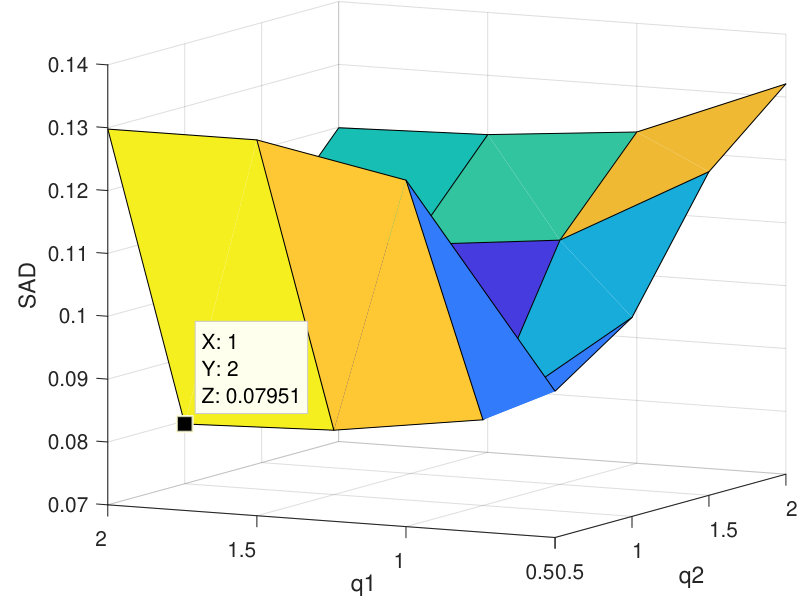 Figure 7
Figure 7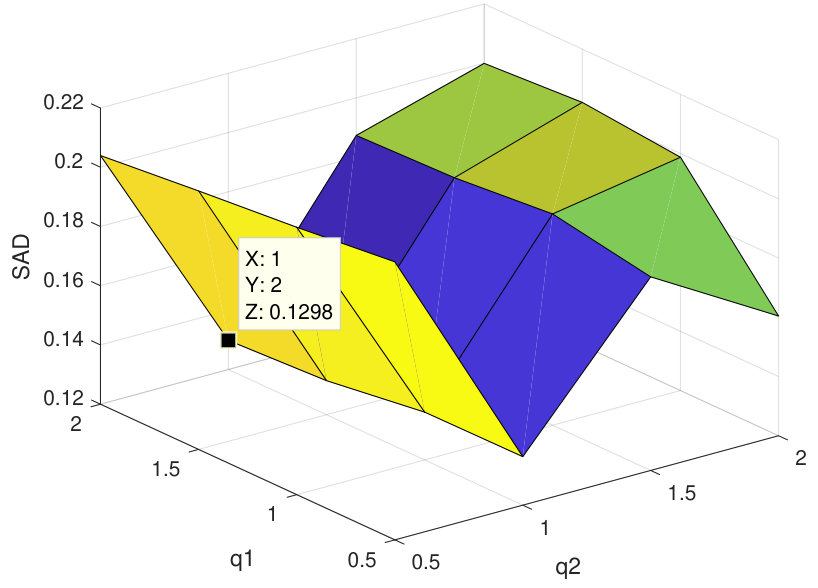 Figure 8
Figure 8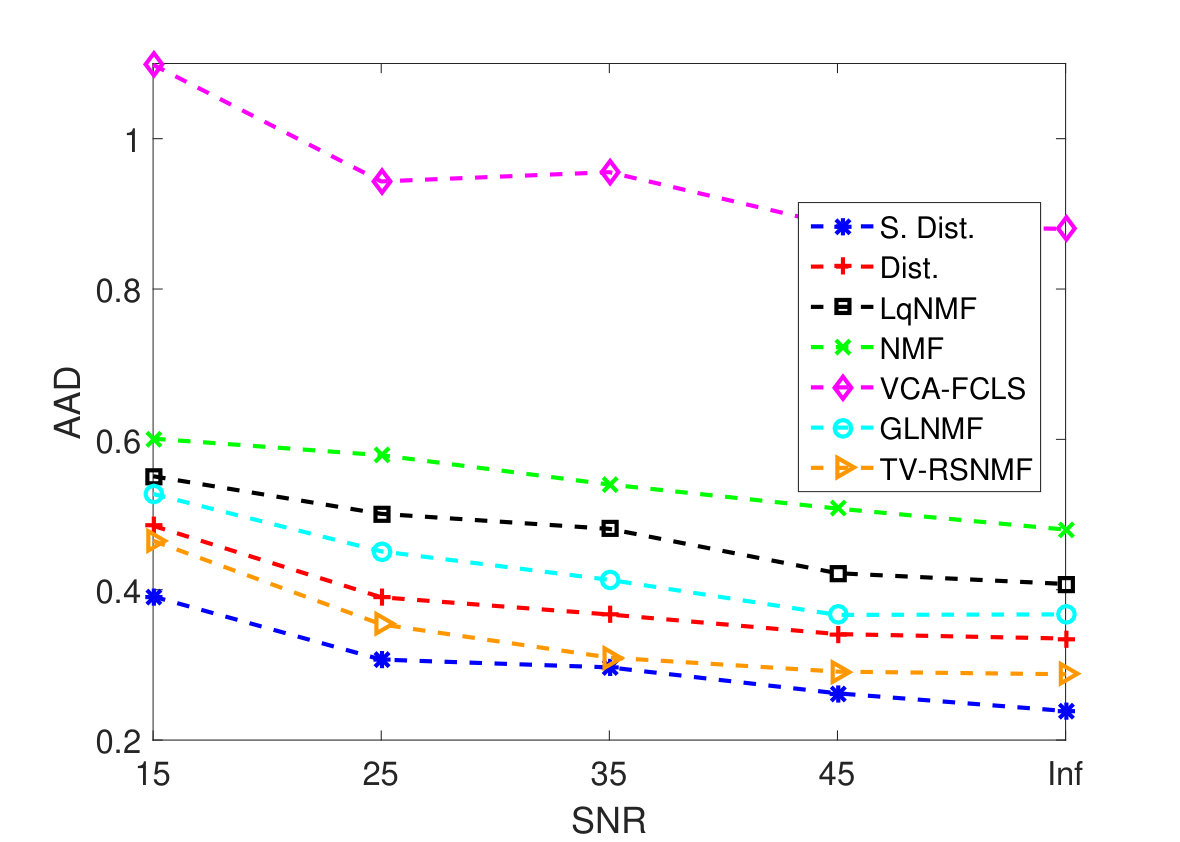 Figure 9
Figure 9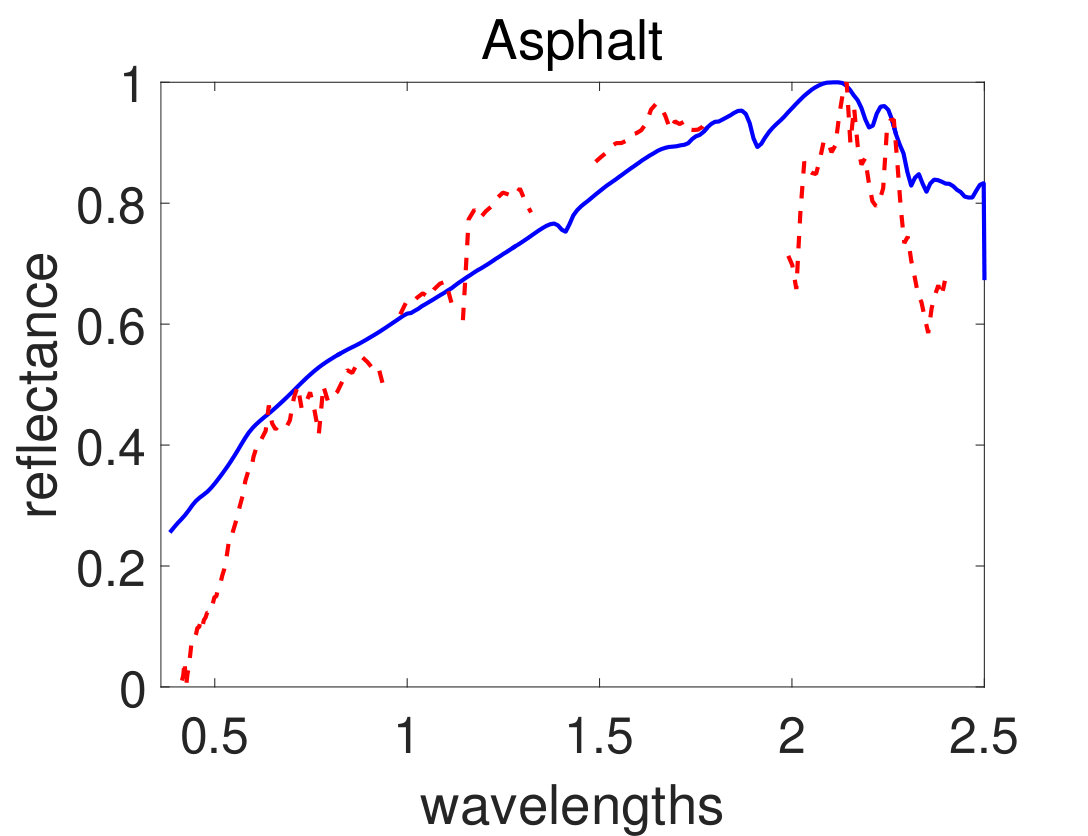 Figure 10
Figure 10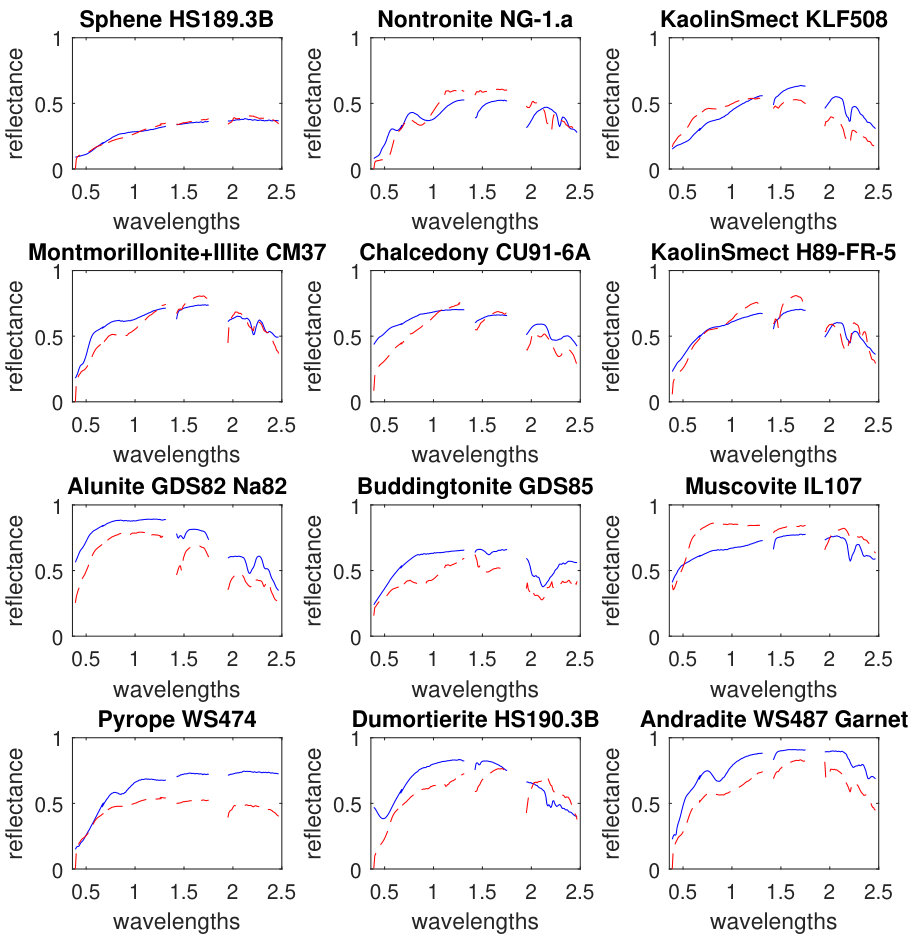 Figure 11
Figure 11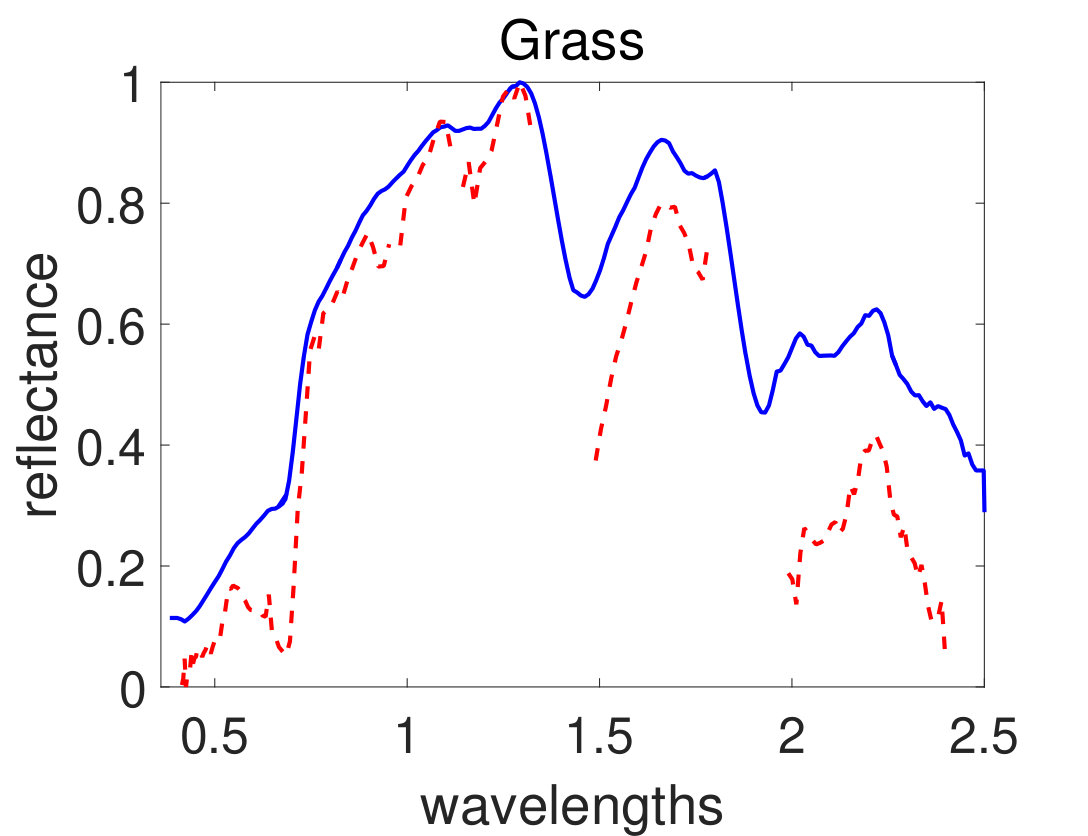 Figure 12
Figure 12 Figure 13
Figure 13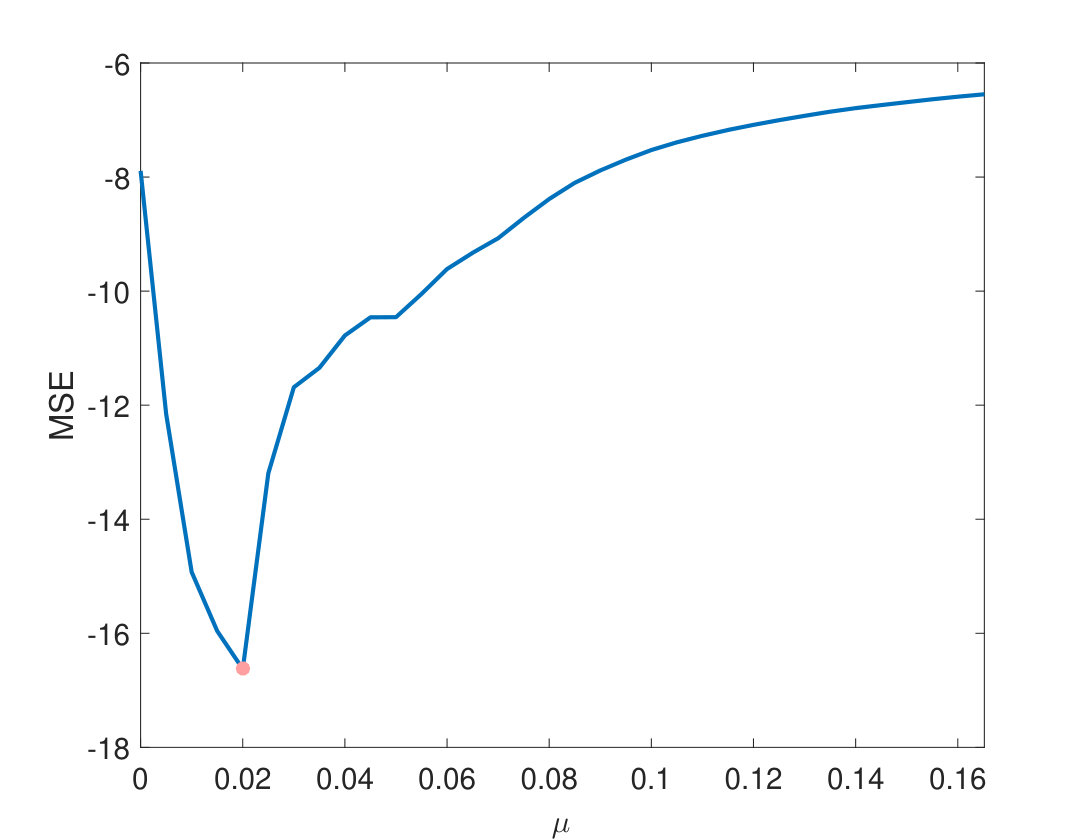 Figure 14
Figure 14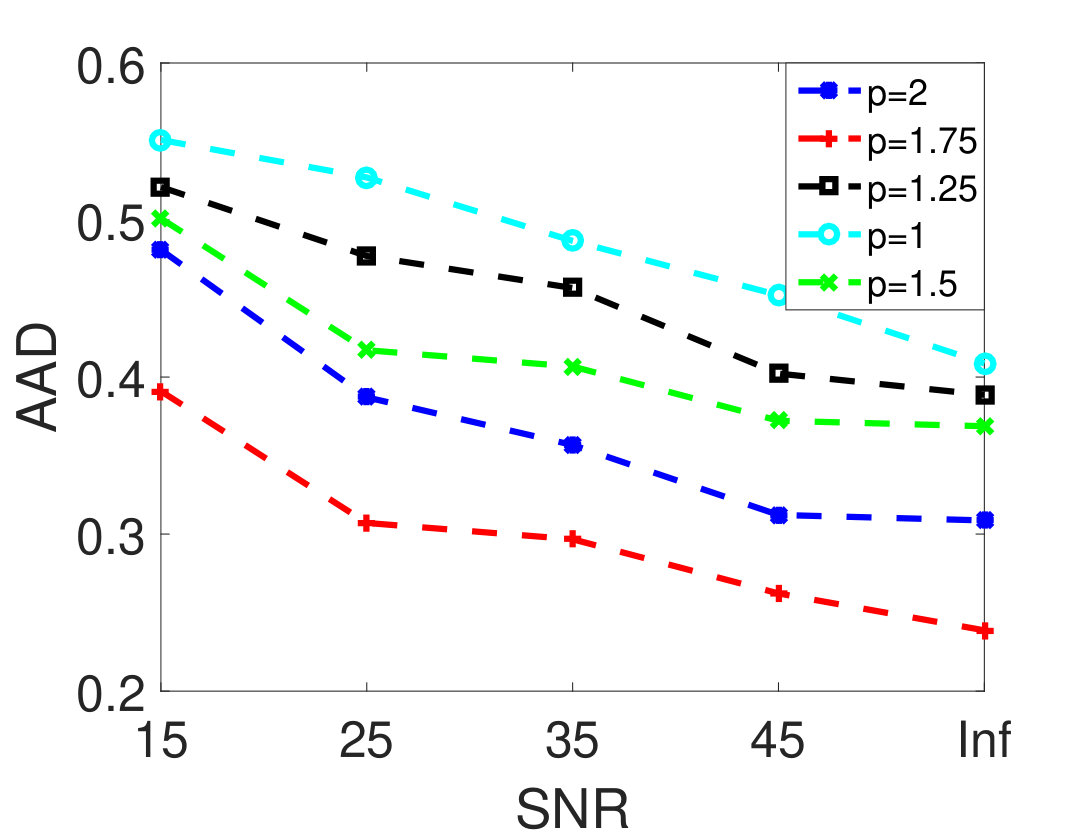 Figure 15
Figure 15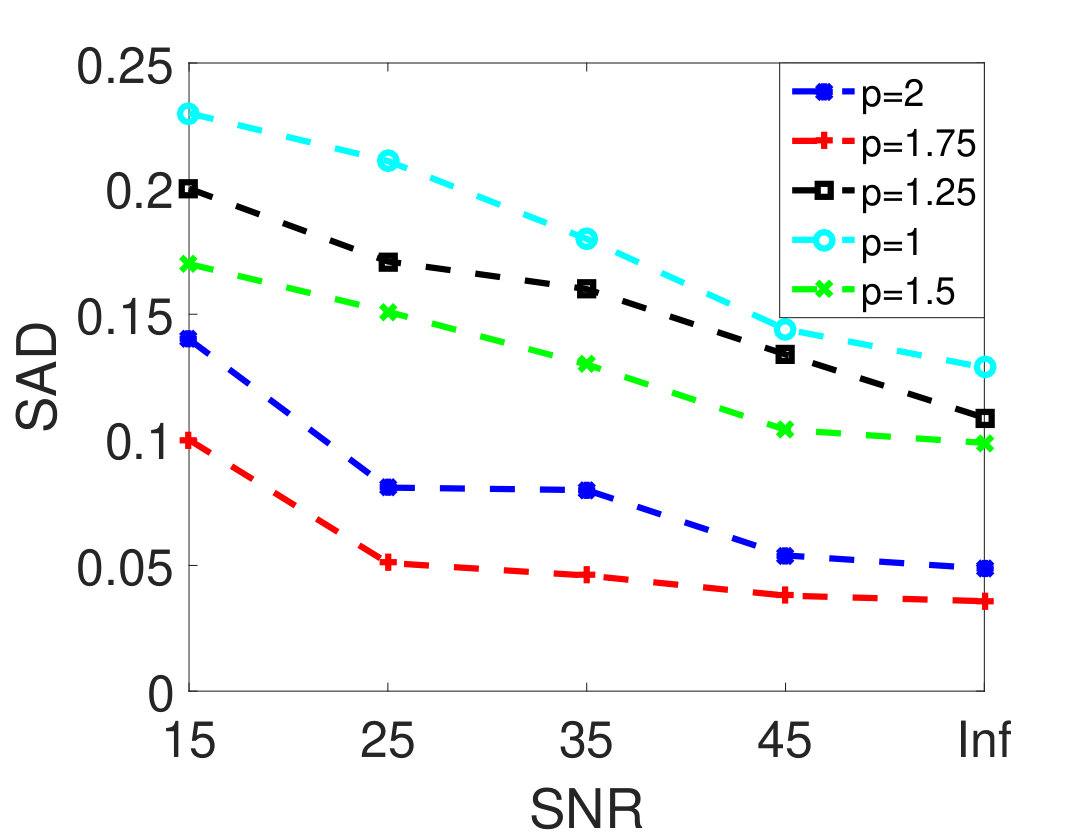 Figure 16
Figure 16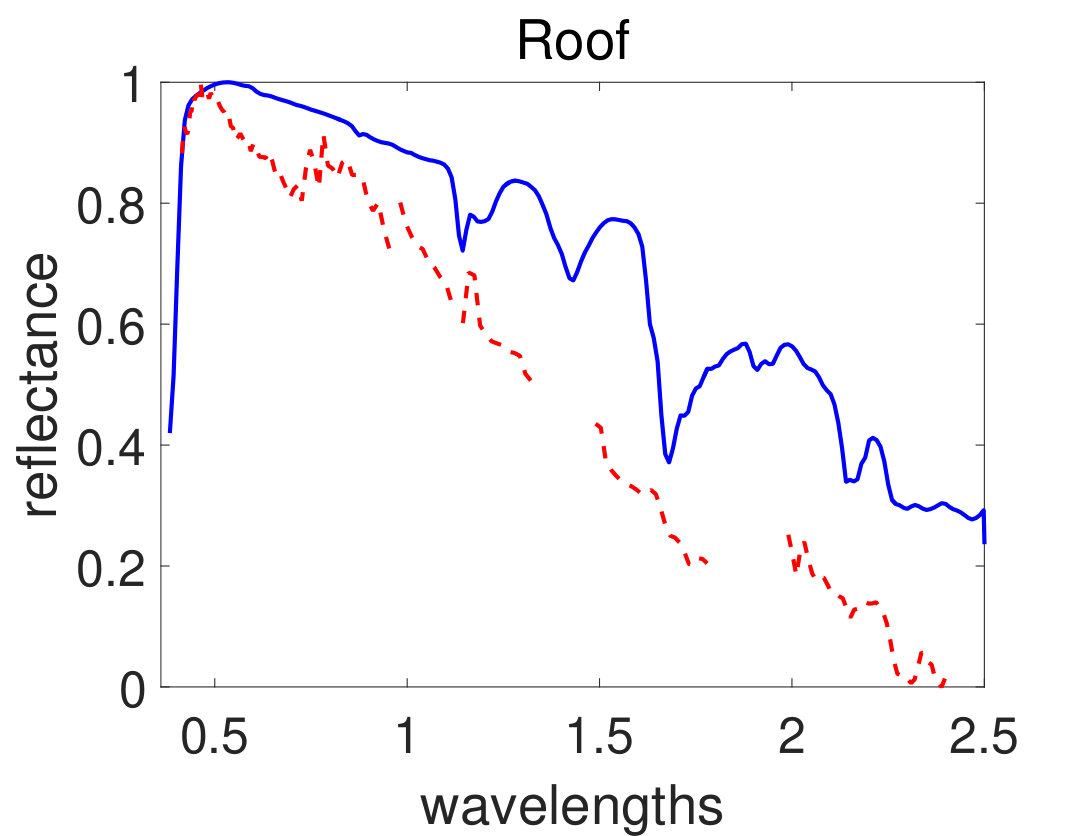 Figure 17
Figure 17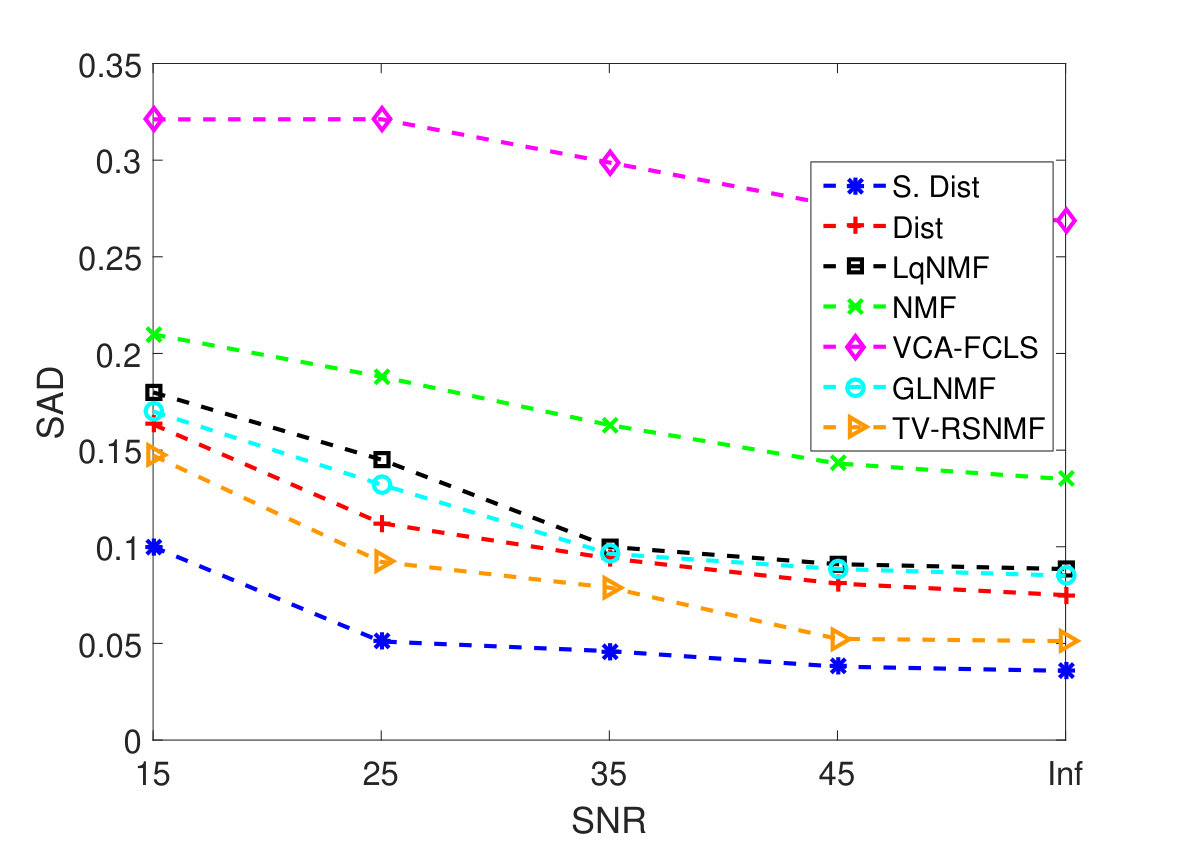 Figure 18
Figure 18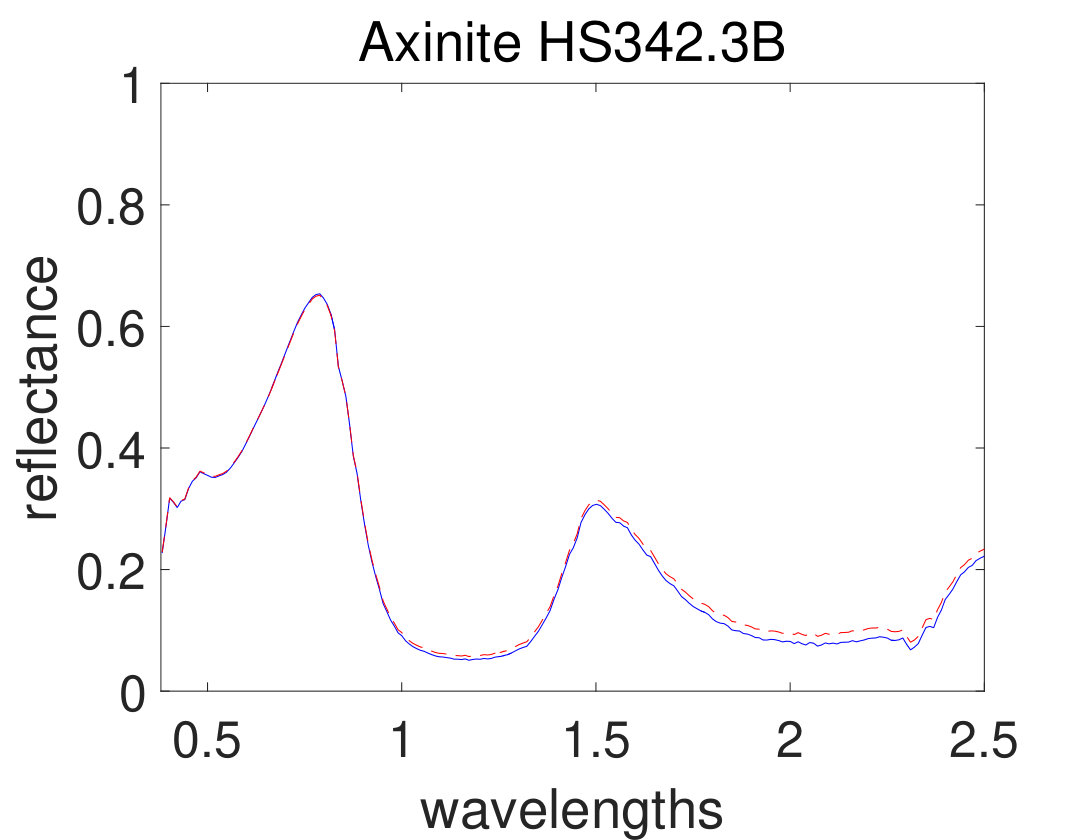 Figure 19
Figure 19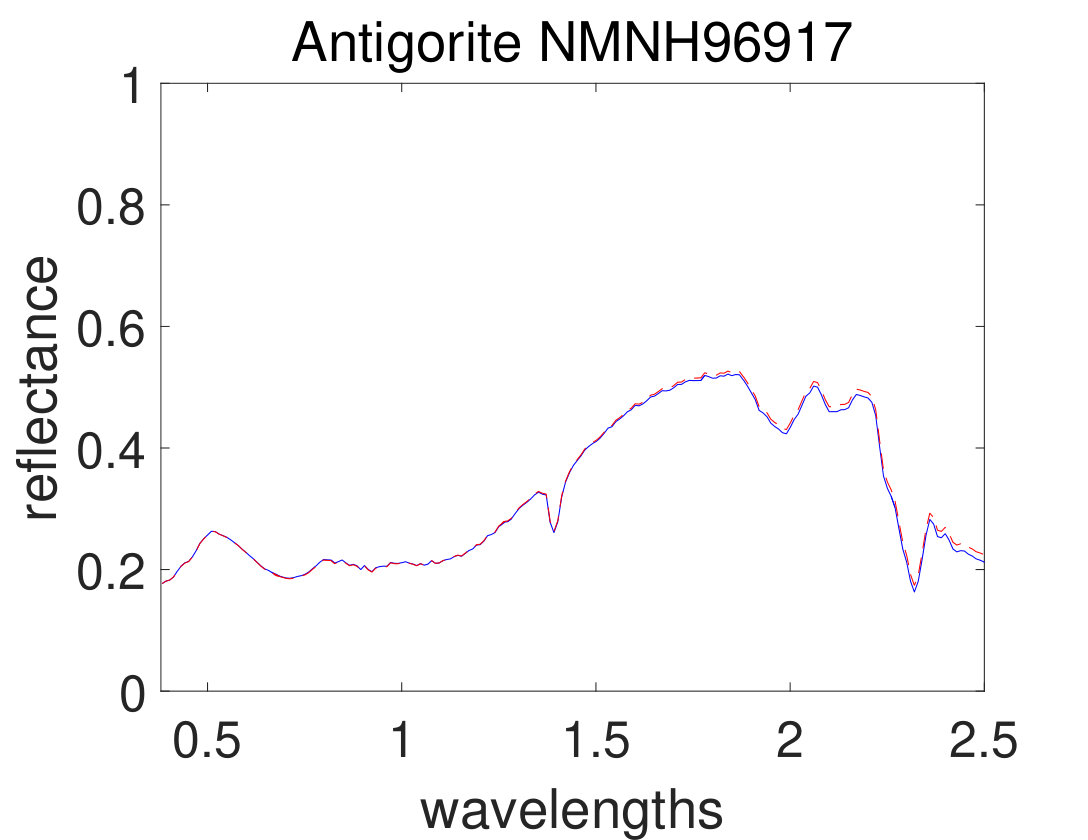 Figure 20
Figure 20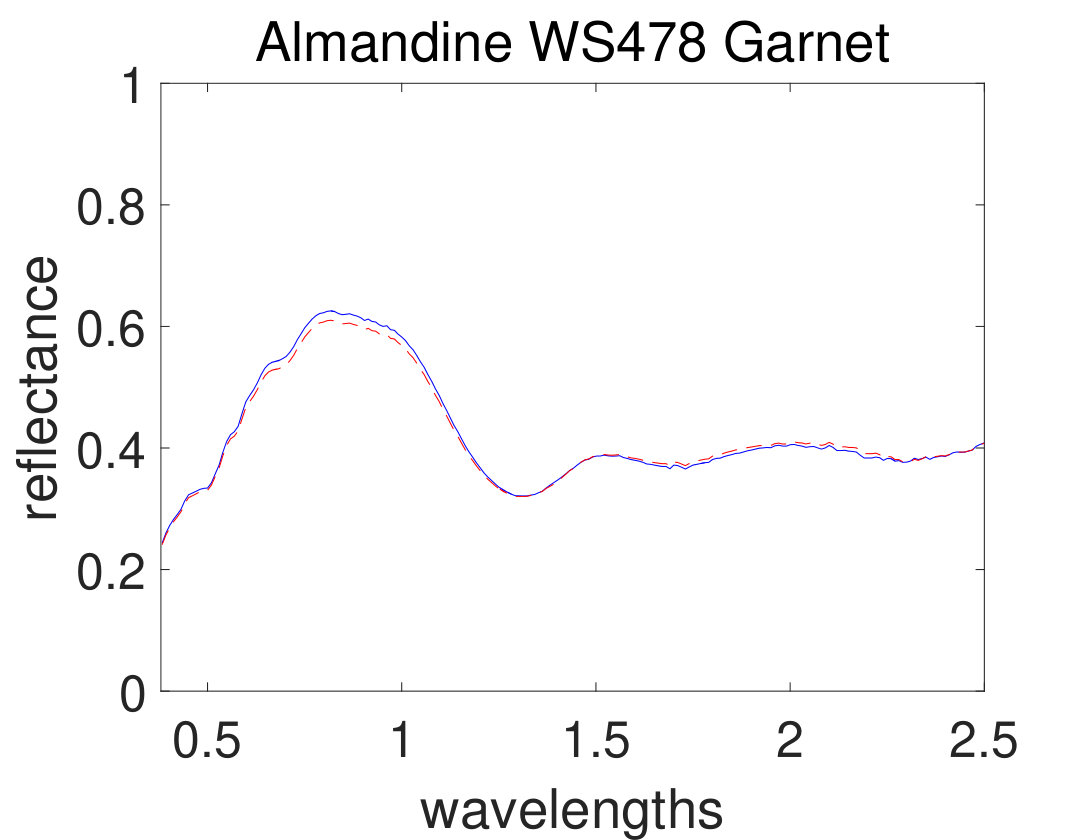 Figure 21
Figure 21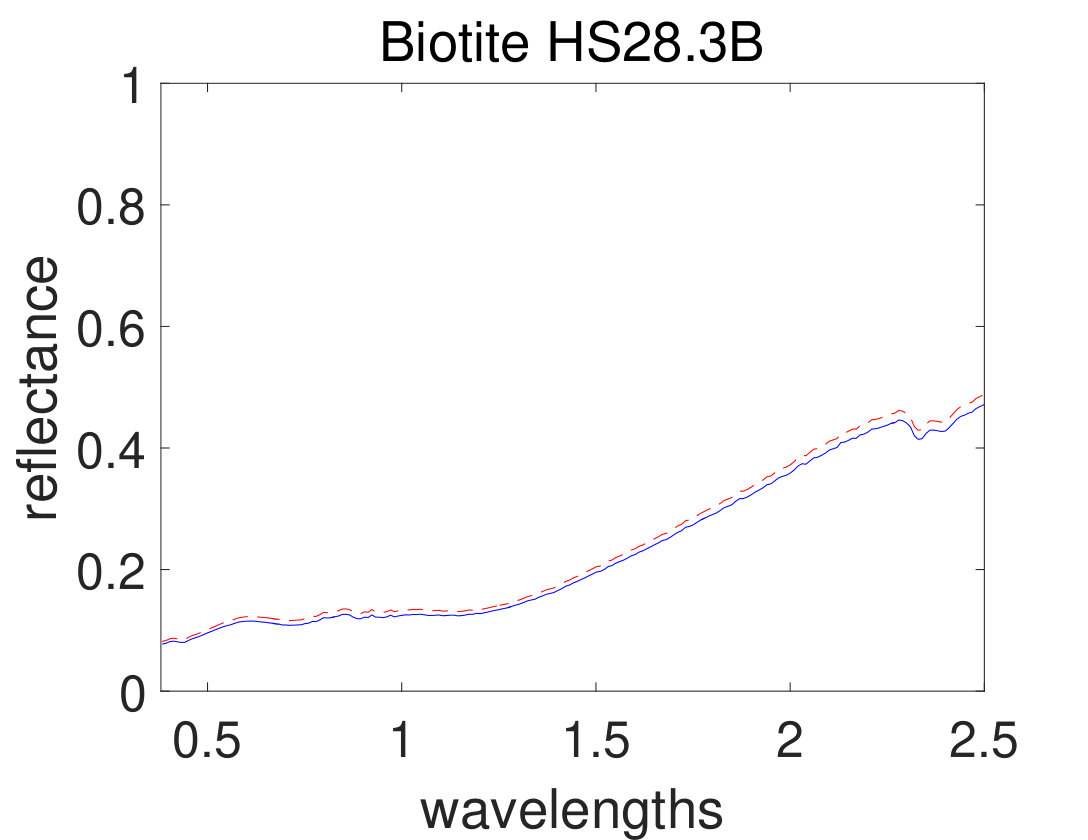 Figure 22
Figure 22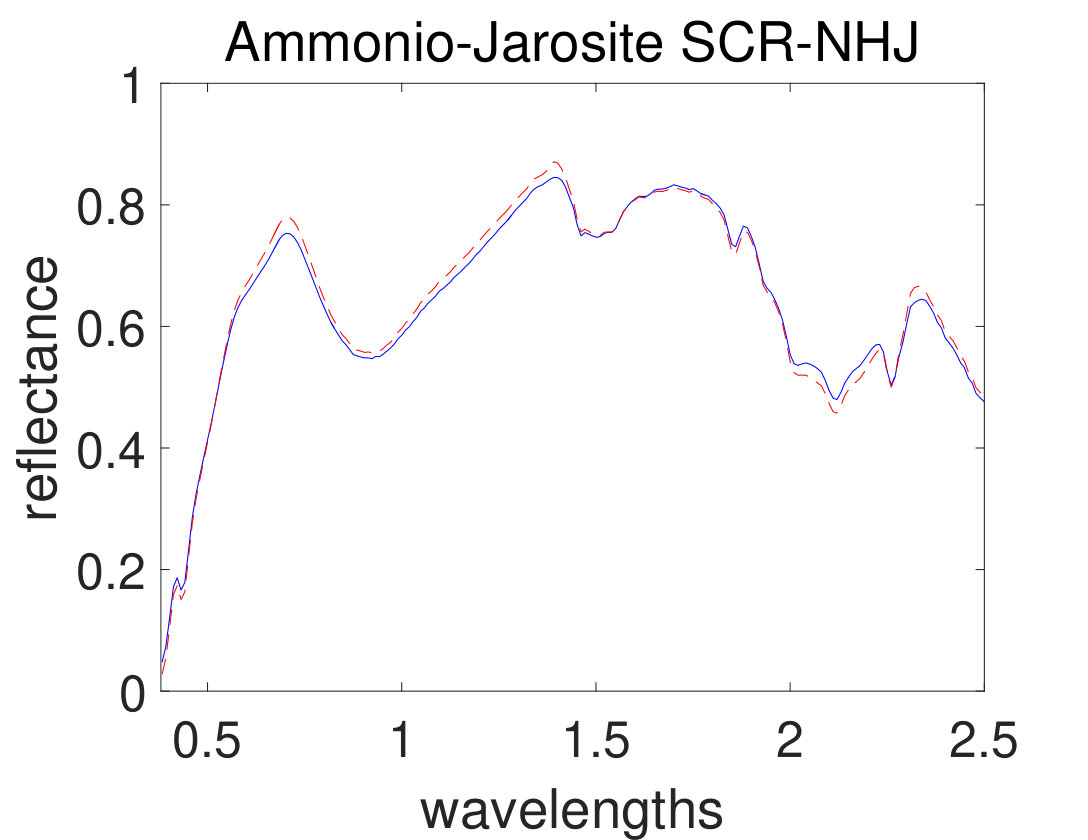 Figure 23
Figure 23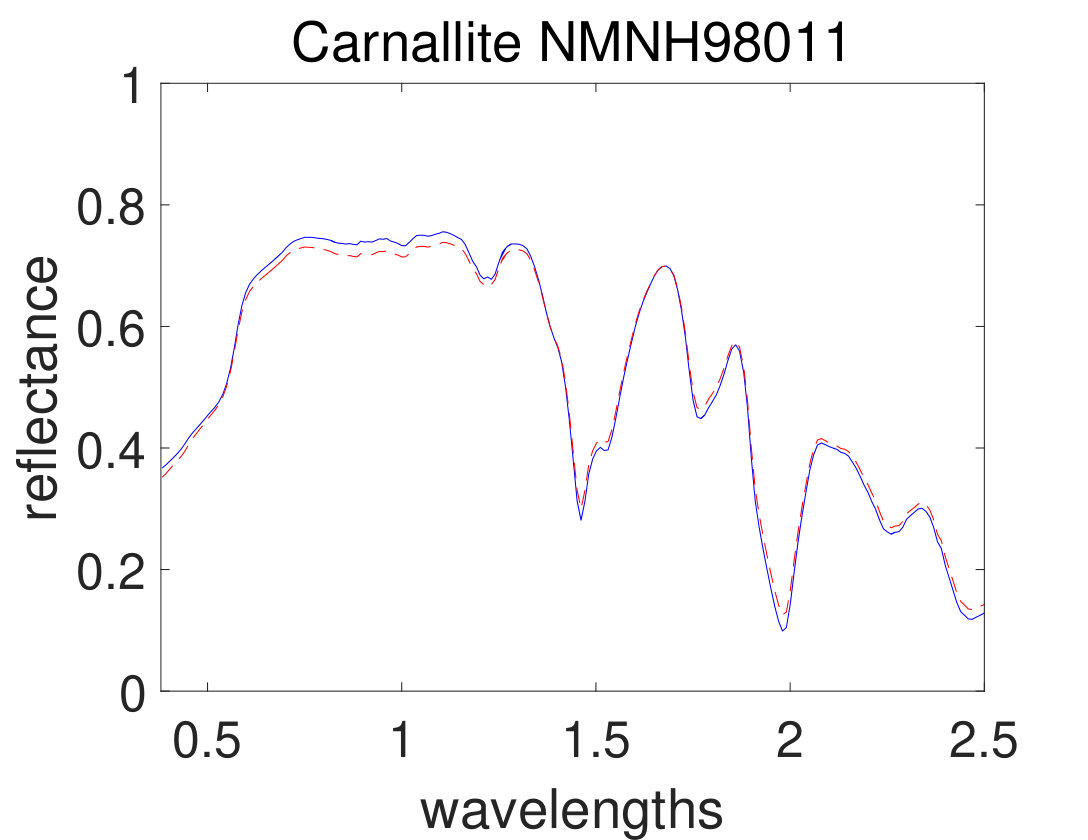 Figure 24
Figure 24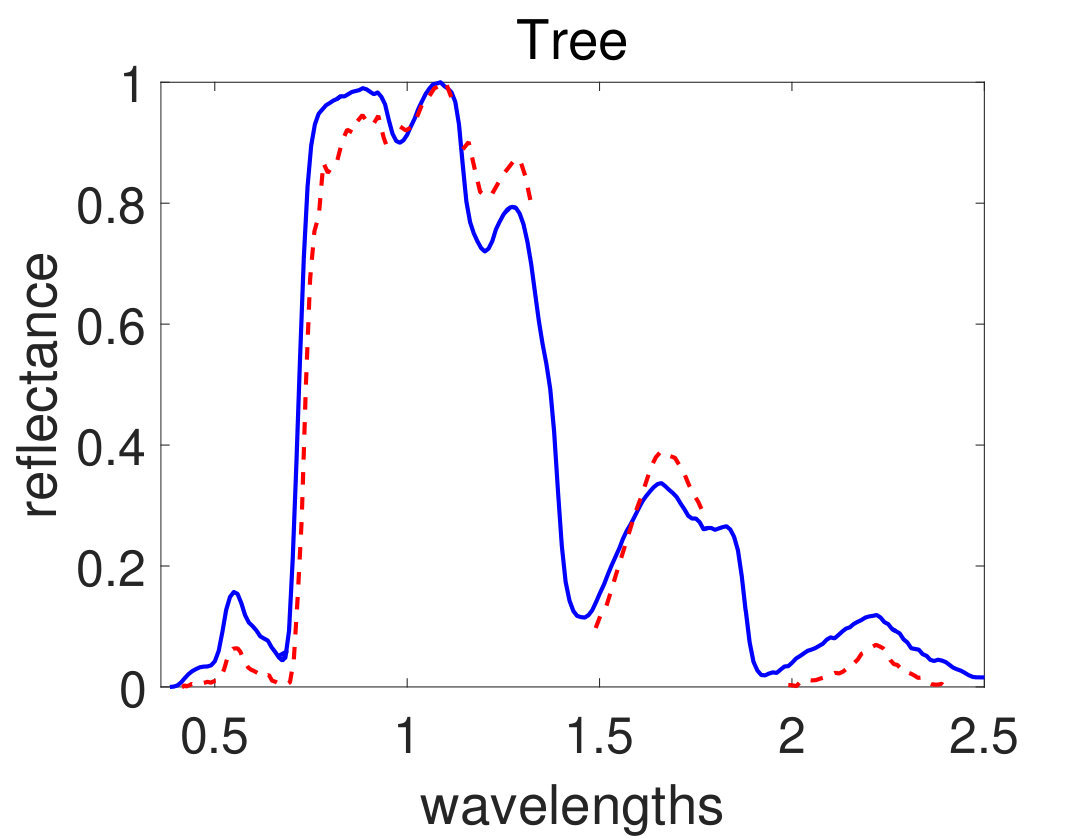 Figure 25
Figure 25| Methods | Addition | Multiplication | Division | Complexity order |
|---|---|---|---|---|
| NMF | ||||
| -NMF | ||||
| GLNMF | ||||
| TV-RSNMF | ||||
| Distributed | ||||
| Proposed alg. |
| Methods | Running time (second) |
|---|---|
| NMF | 33.5161 |
| -NMF | 10.8671 |
| GLNMF | 54.6483 |
| TV-RSNMF | 40.3321 |
| Distributed | 104.5395 |
| Sparse. Distributed | 65.1102 |
| materials | VCA-FCLS | -NMF | GLNMF | TV-RSNMF | Distributed | Proposed alg. |
| Sphene | 0.3091 | 0.2143 | 0.1913 | 0.1583 | 0.1561 | 0.1205 |
| Nontronite | 0.2622 | 0.2518 | 0.1842 | 0.1803 | 0.1944 | 0.1538 |
| KaolinSmect #1 | 0.2498 | 0.1653 | 0.1638 | 0.1731 | 0.2370 | 0.1421 |
| Montmorillonite | 0.2609 | 0.2318 | 0.2184 | 0.2159 | 0.3571 | 0.2163 |
| Chalcedony | 0.1934 | 0.1995 | 0.1649 | 0.1588 | 0.1603 | 0.1881 |
| KaolinSmect #2 | 0.3258 | 0.2542 | 0.2594 | 0.2576 | 0.2873 | 0.2512 |
| Alunite | 0.3601 | 0.3458 | 0.2841 | 0.2551 | 0.3813 | 0.2158 |
| Buddingtonite | 0.2402 | 0.1693 | 0.2068 | 0.2034 | 0.2514 | 0.1778 |
| Muscovite | 0.3917 | 0.1584 | 0.1471 | 0.1563 | 0.4682 | 0.1826 |
| Pyrope | 0.2851 | 0.3361 | 0.3148 | 0.2392 | 0.2132 | 0.2385 |
| Dumortierite | 0.2311 | 0.2453 | 0.2632 | 0.2686 | 0.3381 | 0.2917 |
| Andradite | 0.4492 | 0.3829 | 0.3021 | 0.3136 | 0.3711 | 0.2963 |
| rmsSAD | 0.3049 | 0.2562 | 0.2317 | 0.2207 | 0.2998 | 0.2131 |
| materials | VCA-FCLS | -NMF | GLNMF | TV-RSNMF | Distributed | Proposed alg. |
| Roof | 0.4671 | 0.3461 | 0.3486 | 0.3327 | 0.3831 | 0.3294 |
| Tree | 0.2711 | 0.1492 | 0.1673 | 0.1572 | 0.2052 | 0.1521 |
| Asphalt | 0.3077 | 0.2984 | 0.2096 | 0.2054 | 0.2469 | 0.2118 |
| Grass | 0.2089 | 0.1461 | 0.1283 | 0.1249 | 0.1344 | 0.1019 |
| rmsSAD | 0.3279 | 0.2512 | 0.2291 | 0.2198 | 0.2588 | 0.2161 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRemote-Sensing Image Classification · Advanced Image Fusion Techniques · Remote Sensing and Land Use
Sparsity Constrained Distributed Unmixing of Hyperspectral Data
Sara Khoshsokhan, Roozbeh Rajabi, and Hadi Zayyani The authors are with the Communications and Electronics Department, Faculty of Electrical and Computer Engineering, Qom University of Technology, Qom, Iran (e-mail: [email protected]; [email protected]; [email protected]). Dr. Zayyani is also with the School of Electrical and Computer Engineering, Shiraz University, Shiraz, Iran.
Abstract
Spectral unmixing (SU) is a technique to characterize mixed pixels in hyperspectral images measured by remote sensors. Most of the spectral unmixing algorithms are developed using the linear mixing models. To estimate endmembers and fractional abundance matrices in a blind problem, nonnegative matrix factorization (NMF) and its developments are widely used in the SU problem. One of the constraints which was added to NMF is sparsity, that was regularized by norm. In this paper, a new algorithm based on distributed optimization is suggested for spectral unmixing. In the proposed algorithm, a network including single-node clusters is employed. Each pixel in the hyperspectral images is considered as a node in this network. The sparsity constrained distributed unmixing is optimized with diffusion least mean p-power (LMP) strategy, and then the update equations for fractional abundance and signature matrices are obtained. Afterwards the proposed algorithm is analyzed for different values of LMP power and norms. Simulation results based on defined performance metrics illustrate the advantage of the proposed algorithm in spectral unmixing of hyperspectral data compared with other methods.
Index Terms:
Spectral unmixing, hyperspectral images, sparsity constraint, LMP strategy, remote sensing, distributed optimization.
I Introduction
Remote sensors gather data by detecting the energy that is reflected from the Earth. Recent advances in remote sensing have paved the way for the development of hyperspectral sensors. One of the challenges in hyperspectral imaging is mixed pixels. Pixels in a scene constituting a single material are called pure pixels and other pixels containing more than one material are called mixed pixels [1]. So, the recorded spectrum of a single pixel is a mixture of some material spectra in the scene, named endmembers. The contribution of each endmember for a given pixel is weighted by its fractional abundance [2]. Decomposition of the mixed pixels is known as spectral unmixing (SU) problem [3]. Most of the spectral unmixing methods are based on linear mixing model (LMM), in which it is assumed that the recorded spectrum of a particular pixel, is linearly mixed by endmembers which exist in the pixel. In return, several researches have done by adopting nonlinear mixing model. In this model, considered pixel is generated from a nonlinear function of fractional abundances of endmembers [4], [5]. If the number of endmembers that are present in the scene and its signatures, are unknown, the SU problem becomes a blind source separation (BSS) problem [6].
Several SU methods have been proposed in different models. Unmixing methods can be categorized into three class of approaches: geometrical, statistical and sparse regression based methods [7]. Pixel purity index (PPI) [8], N-FINDR [9], simplex volume maximization [10], convex cone analysis (CCA) [11], successive projections algorithm (SPA) [12], principal component analysis (PCA) [13], vertex component analysis (VCA) [14], [15] and robust minimum volume simplex analysis [16] are some of convex geometric methods. They are based on the pure pixel assumption, where the simplex volume is considered as a criterion for detection of endmembers. Also, some of the methods such as independent component analysis (ICA) [17] use statistical models to solve the SU problem. Approaches like SUnSAL and C-SUnSAL [18] that work based on variable splitting and augmented Lagrangian, robust sprase unmixing (RSU) using [19] and double reweighted sparse regression and total variation (DRSU-TV) [20] are examples of sparse regression based approaches.
Nonnegative matrix factorization (NMF) [21], [22] is another practical method of unmixing, which decomposes the data into two nonnegative matrices. Recently, this basic method was developed by adding some constraints, such as the minimum volume constrained NMF (MVC-NMF) method [2], graph regularized NMF (GNMF) [23] and manifold regularized sparse NMF (GLNMF) [24]. GLNMF is a two steps approach including sparse constraint and graph regularization. NMF with local smoothness constraint (NMF-LSC) [25] and total variation regularized reweighted sparse NMF (TV-RSNMF) [26] are the methods in which the total variation regularizer is embedded into the reweighted sparse NMF. Also, some new NMF-based algorithms such as robust collaborative NMF [27], estimate the number of endmembers, in addition to spectral signatures and fractional abundances. One of the constraints that has been used to improve performance of NMF methods is sparsity constraint applied to NMF cost function using regulaizers [6], or using another constraint such as smooth and sparse regularization proposed in [28]. Since the number of endmembers present at each mixed pixel is normally scanty compared with the number of total endmembers, the problem becomes sparse [29]. So, the abundance matrix has many zero elements, and it has a large degree of sparsity. Using regularization in NMF, the authors in [6] proposed the -NMF algorithm, which enforces the sparsity of endmember abundances. Another method is proposed in [30] based on difference of and norm in conjunction with total variation regualrization. Overall, NMF approaches that exploit two-block alternating optimization (AO) offer good performance to solve hyperspectral unmixing problem [31]. Recently, multilayer NMF (MLNMF) [32, 33] and deep NMF [34] has been proposed to use in hyperspectral unmixing problems that can effectively decompose observation matrix in different layers to reduce reconstruction error.
As another approach, the distributed strategy has been used for utilization of neighborhood information as spatial information. This can be advantageous, because the neighboring pixels may be correlated. Spatial information has been used in different ways in spectral unmixing [35], including total variation spatial regularization for sparse hyperspectral unmixing [36]. There are some distributed strategies such as consensus strategies [37], incremental strategies [38] and diffusion strategies [39]. In this paper, a diffusion strategy is used because it has strong stability over adaptive networks [40, 41]. Diffusion least mean p-power (LMP) strategy has been proposed in [42] and used in different applications like system identification [43], robust sparse recovery [44].
To solve a distributed problem, a network is considered. There are three types of networks: 1) a single-task network, that nodes estimate a common unknown and optimum vector, 2) a multitask network, in which each node estimates its own optimum vector and 3) a clustered multitask network includes clusters that each of them has to estimate a common optimum vector [40]. Unmixing problem is a multitask problem where each pixel is considered to be a node. Here, we first consider the general case, where there is a clustered multitask network and each cluster has an optimum vector (fractional abundance vector) that should be estimated. Then we will reduce that to a multitask case.
The main contributions of this paper are as follows,
• Sparsity constraint has been added to the distributed method for spectral unmixing and LMP strategy is used,
• The cost function has been generalized using and norms,
• Simultaneous estimation of spectral signatures and fractional abundances using NMF method has been added to distributed unmixing.
This paper is organized as follows. In section II, we introduce the proposed method and optimize it. Section III includes an introduction of datasets. Section IV provides simulation results and the last section gives conclusions.
II Distributed Unmixing of Hyperspectral Data With Sparsity Constraint
In this section, a new method that utilizes sparsity constraint and neighborhood information is proposed. First, we express linear mixing model in subsection II.A, then the sparsity constrained distributed cost functions are formulated in II.B, and finally, we use them to solve SU problem in II.C.
II-A Linear Mixing Model (LMM)
To solve the SU problem, we focus on a simple but representative model, named LMM. In this model, there exists a linear relation between the endmembers that are weighted by their fractional abundances, in the scene. Mathematically, this model is described as and the matrix form of this equation can be written as:
[TABLE]
where is an observed data vector for th pixel, is an observed data matrix, is the signature matrix, is the fractional abundance vector for th pixel, is the fractional abundance matrix, is assumed as an additive noise vector of -th pixel of the image and is an additive noise matrix where , and denote the number of endmembers, bands and pixels, respectively.
In the SU problem, fractional abundance vectors have two constraints in each pixel, abundance sum to one constraint (ASC) and abundance nonnegativity constraint (ANC) [45], which are as follows, for endmembers in a scene.
[TABLE]
Where is the fractional abundance of the -th endmember in the -th pixel of the image. Fractional abundances of endmembers are nonnegative values and endmembers present in a mixed pixel cover all area of that mixed pixel, hence they add up to one. Note that, in a BSS problem, only the observed vector is known and we aim to determine the two other matrices ( and in equation (1)).
II-B Distributed Cost Functions and Optimization
As explained earlier, three types of networks containing single task, multitask and clustered multitask networks are supposed. First, nodes are considered in a clustered multitask network and an optimum vector at node is estimated. A global cost function using LMP with power [42], , is defined as follows:
[TABLE]
where is the expectation operator. Then, to minimize the cost function, the following equation is written, using the iterative steepest-descent solution [46]:
[TABLE]
where is the fractional abundance vector of the th node in the th iteration, is a step-size parameter, and the algorithm make small jumps, using an optimum value of . This optimum value causes stability and depends on the cost function. The algorithm will diverge with a too large value of , and will take a long time to converge with a too small value. is iteration number and is the gradient operator with respect to , is the complex conjugate operator, then after computing complex gradient and substituting it into (4), the following iterative equation is obtained:
[TABLE]
where is the error signal.
Since the neighborhood information has not been used yet, the equation (5) is not distributed. In a distributed network, relationships between neighboring nodes are used to improve accuracy. In this article, we utilize the norm:
[TABLE]
There are different criteria to measure sparsity of hyperspectral images [47, 6]. In this paper we generalized sparsity norm and used the regularizer for sparsity constraint:
[TABLE]
Note that, the solution determined from global cost function, needs to have access to information over the entire network, but the nodes can be considered to have availability only to information of their neighbors. Thus, for solving this problem, the following local cost function for th pixel is defined, using LMP and adding the (6) and (7) constraints:
[TABLE]
where is a vector equals to , the symbol is the set difference, shows nodes that are in the neighborhood of node , that is in the cluster (see Figure 1). denotes a regularization parameter [40], that controls the effect of neighborhood term, is a scalar value that weights the sparsity function [6], and the nonnegative coefficients are normalized spectral similarity which is obtained from correlation of data vectors [40]. The coefficients are computed as introduced in [6], [40]:
[TABLE]
where is a vector denoting the th band of the hyperspectral image ().
[TABLE]
where includes neighbors of node except itself, and is computed as [40]:
[TABLE]
Now, to minimize the cost function of (LABEL:eq:_10), using steepest-descent in equation (4), we have:
[TABLE]
As explained earlier, the SU is a multitask problem that is adopted as Figure 1 using single node clusters. Therefore, (LABEL:eq:_19) with adoption of LMP strategy, is simplified to:
[TABLE]
Hence, this recursive equation can be used to update fractional abundance vectors in SU problems.
II-C Spectral Unmixing Updating Equations
Similar to the NMF algorithm, the least mean p-power error should be minimized with respect to the signatures and abundances matrices, subject to the non-negativity constraint [48]. So, the following equation is denoted, using matrix notation:
[TABLE]
where and are the signature and fractional abundances matrices, respectively, and Y denotes the Hyperspectral data matrix. Then, based on described equations of the sparsity constrained distributed unmixing, the neighborhood and sparsity terms are added to (14) as follows:
[TABLE]
This cost function is minimized with respect to , using multiplicative update rules [48], then recursive equation of signature matrix is obtained as:
[TABLE]
And the recursive equation of fractional abundances has been obtained already in accordance with (LABEL:eq:_s) as follows:
[TABLE]
where operator projects vectors onto a simplex, that adopt the ASC and ANC constraints for abundance vectors. The operator has been defined in [49]. Another significant point in implementation of the algorithm is stopping criteria. This approach will be stopped until the maximum number of iteration (), or the following stopping criteria is reached.
[TABLE]
where and are cost function values for two consecutive iterations and has been set to in our experiments. Now, the proposed approach is summarized in Algorithm 1.
A usual way for evaluation of algorithms is computational cost. TABLE I shows comparison of computational complexity order for each iteration between NMF, -NMF, GLNMF, TV-RSNMF, distributed unmixing and the proposed method. The complexity of sparsity constrained distributed unmixing with is presented in the last row. It should be noticed, the proposed approach becomes more complicated with non integer values of , and .
III Datasets
In this paper, the proposed algorithm is tested on synthetic and real datasets. This section introduces a real dataset that recorded with hyperspectral sensors and a synthetic dataset that are generated using spectral libraries.
III-A Synthetic Images
To generate synthetic data, some spectral signatures are chosen from a digital spectral library (USGS) [50], that include 224 spectral bands, with wavelengths from 0.38\mu$$m to 2.5\mu$$m. Size of intended images is 6464, and one endmember is contributed in spectral signature of each pixel, randomly. Pixels of this image are pure, so to have an image containing mixed pixels, a low pass filter is considered. It averages from abundances of endmembers in its window, so that the LMM would be confirmed. The size of this window controls degree of mixing [2]. With smaller dimension of the window and more endmembers in the image, degree of sparsity is increased.
III-B Real Data
III-B1 AVIRIS Cuprite
The real dataset that the proposed method is applied on it, is hyperspectral data captured by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) over Cuprite, Nevada. This dataset has been used since the 1980s. AVIRIS spectrometer has 224 channels and covers wavelengths from 0.4\mu$$m to 2.5\mu$$m. Its spectral and spatial resolutions is about 10 and 20, respectively [51]. 188 bands of these 224 bands are used in the experiments. The other bands (covering bands 1, 2, 104-113, 148-167, and 221-224) have been removed which are related to water-vapor absorption or low SNR bands. Figure 2 illustrates a pseudo color image of this dataset.
III-B2 HYDICE Urban
Now, turn our attention to another real dataset that is urban HYDICE hyperspectral image. There are 210 bands in this dataset, that covers wavelengths from 0.4\mu$$m to 2.5\mu$$m. After removing water-vapor absorption or low SNR bands (including 1-4, 76, 87, 101-111, 136-153, and 198-210), only 162 bands are used in the experiments. There are just 4 distinguished materials in HYDICE Urban image, asphalt, roof, tree and grass [52]. Figure 2 illustrates a pseudo color image of this real dataset.
IV Experiments and Results
In this section firstly evaluation criteria are introduced and then the proposed algorithm is justified and parameter selection is done using experiments on synthetic data. Then to verify results of the proposed algorithm on real datasets, it is applied on AVIRIS cuprite and HYDICE urban datasets.
IV-A Evaluation Criteria
In this section, for quantitative comparison between the proposed method with different values of , and , also between proposed and the other methods, the performance metrics such as spectral angle distance () and abundance angle distance () [2] are used. They are defined as:
[TABLE]
where is the estimation of spectral signature vectors and is the estimation of fractional abundance vectors.
IV-B Experiments on Synthetic Data and Parameter Selection
First, the proposed algorithm has been applied on synthetic data. to generate this dataset, six signatures of USGS library have been selected randomly, using a 33 low pass filter and containing no pure pixels. Then, the zero mean Gaussian noise with seven different levels of SNR has been added to generated data, and performance metrics have been computed by averaging 20 Monte-Carlo runs. To choose the best value of in our experiments, we used the procedure of APPENDIX, and then according to Figure 3, the best value of this parameter has been set equal to 0.02. Also, value of has been considered equal to 0.1 [40], to gain the best results. In the experiments it is assumed that number of endmembers are preknown, however this parameter can be determined by algorithms like HySime [53].
As the first experiment, Figure 4 shows the and performance metrics of proposed method in various , and values versus different levels of SNR. Figure 4 and 4 depict that the algorithm with in red plus-dashed line eventuates the best result. Values of have been chosen in accordance with [42]. Also, in Figure 4, 4, 4 and 4, the best values of and are equal to 2. Then the proposed algorithm and some other algorithms such as VCA-FCLS [14], NMF [22], -NMF [6], GLNMF [24], TV-RSNMF [26] and distributed unmixing [40], have been applied on generated synthetic dataset. The comparison of performance metrics of these seven different methods has been shown in Figure 5 and 5, where metrics of proposed algorithm with the best results for , and values based on Figure 4, is star-dashed line and excels other methods. The superiority of distributed algorithms in star-dashed and plus-dashed lines, represents preference of using neighborhood information because of correlation between neighboring pixels. TABLE II shows the average of running time of NMF, -NMF, GLNMF, TV-RSNMF, distributed unmixing and proposed method, when , and have been chosen. These results have been obtained using MATLAB R2015b with Intel Core i5 CPU at 2.40 GHz and 4 GB memory. This table shows that one of the main advantages of sparse representation is its efficiency and improvement in running time. As the last experiment on synthetic data, Figure 6 is illustration of original and estimated spectral signatures for 6 endmembers, when the SNR is set to .
IV-C Experiments on Real Data
Afterwards, the proposed algorithm has been applied on AVIRIS Cuprite and HYDICE Urban real datasets described in section III. In the experiments, stopping criteria parameters have been set as follows: the maximum number of iterations is set equal to 200 and the cost function error parameter in (18) has been set to . The parameter setting are as follows: , , , and . Figure 7 and 8 show simulation results of spectral signatures for AVIRIS and HYDICE datasets respectively. The number of materials in the AVIRIS Cuprite and HYDICE Urban scenes has been considered to be 12 and 4 respectively based on previous works on these datasets. Figure 9 and 10 show simulation results of abundance fractions for AVIRIS and HYDICE datasets respectively. To compare quantitatively, performance metric of six related methods applied on these datasets have been summarized in TABLE III and IV for AVIRIS and HYDICE datasets respectively. In these tables the results of proposed algorithm appear in the last column and show the best value.
V Conclusion and Future Work
Hyperspectral remote sensing is a prominent research topic in data processing. The purpose of spectral unmixing is decomposition of pixels in the scene into their constituent materials. This paper used the sparsity constrained distributed unmixing method that improved estimation of spectral signature of endmembers and their abundances. This new algorithm considered sparsity and neighborhood information. In our experiments, the best power of LMP and norms have been found, using AAD and SAD performance metrics. Simulation results on synthetic and real datasets illustrated better performance of proposed approach compared with VCA-FCLS, NMF, -NMF, GLNMF, TV-RSNMF and Distributed Unmixing methods. Furthermore, the algorithm of this paper achieved faster convergence in comparison with the distributed method. Also by obtaining optimum and values and adding optimum norm of sparsity constraint, the proposed method gained about 25% and 79% improvement of SAD and AAD respectively, in SNR25 toward distributed method. In this paper, the neighborhood information has been used as spatial information, however spectral information can be useful in the SU problem. Therefore, using clustering algorithms as a preprocessing step, and then adopting the clustered multitask network model for the distributed unmixing method, is expected to eventuate better results. Additionally, recently proposed multilayer or deep NMF structures can also be used in conjunction with the proposed method to gain better results.
Acknowledgment
The authors would like to acknowledge editor, associate editor, and five anonymous reviewers for their helpful comments, and Dr. Mehdi Korki for his useful suggestions to improve the revised paper.
Mean Error Convergence Analysis
Here the stochastic behavior of the proposed algorithm is studied. First, the weight error vector is defined as , where is optimum abundance vector [54]. We collect information from all pixels and these vectors are stacked by as follows , and .
Then we can write the following equation using these expressions and the recursive equation of (LABEL:eq:_19) with constant values of , and , that is chosen equal to 2, 1 and 1, respectively:
[TABLE]
where we can define [40] that is the Kronecker product [55], and is a matrix with components, is a diagonal matrix defined as and is a vector .
Now by taking expectation from both side of (LABEL:eq:_nu1), the following equation is obtained:
[TABLE]
where is taken as with and .
Then the proposed algorithm converges, if the following inequality is satisfied [56]:
[TABLE]
where is spectral radius of its matrix argument, and according to the following definition of block maximum norm for any vector [56], and its properties, we get:
[TABLE]
Since is a right stochastic matrix [40], we have .
So, the inequality of (22) is simplified to:
[TABLE]
Note that, the spectral radius is used, because its argument is a diagonal Hermitian matrix. Therefore upper bound of is obtained as:
[TABLE]
where is the maximum eigenvalue of its argument. Afterwards this upper bound is achieved equal to 0.1652, using the synthetic dataset in our experiments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] H. K. Aggarwal and A. Majumdar, “Hyperspectral unmixing in the presence of mixed noise using joint-sparsity and total variation,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 9, no. 9, pp. 4257–4266, 2016.
- 2[2] L. Miao and H. Qi, “Endmember extraction from highly mixed data using minimum volume constrained nonnegative matrix factorization,” IEEE Transactions on Geoscience and Remote Sensing , vol. 45, no. 3, pp. 765–777, 2007.
- 3[3] S. Mei, M. He, Y. Zhang, Z. Wang, and D. Feng, “Improving spatial–spectral endmember extraction in the presence of anomalous ground objects,” IEEE Transactions on Geoscience and Remote Sensing , vol. 49, no. 11, pp. 4210–4222, 2011.
- 4[4] R. Heylen, M. Parente, and P. Gader, “A review of nonlinear hyperspectral unmixing methods,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 7, no. 6, pp. 1844–1868, 2014.
- 5[5] B. Yang, B. Wang, and Z. Wu, “Nonlinear hyperspectral unmixing based on geometric characteristics of bilinear mixture models,” IEEE Transactions on Geoscience and Remote Sensing , vol. 56, no. 2, pp. 694–714, 2018.
- 6[6] Y. Qian, S. Jia, J. Zhou, and A. Robles-Kelly, “Hyperspectral unmixing via L 1 / 2 subscript 𝐿 1 2 {L}_{1/2} sparsity-constrained nonnegative matrix factorization,” IEEE Transactions on Geoscience and Remote Sensing , vol. 49, no. 11, pp. 4282–4297, 2011.
- 7[7] J. M. Bioucas-Dias, A. Plaza, N. Dobigeon, M. Parente, Q. Du, P. Gader, and J. Chanussot, “Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 5, pp. 354–379, April 2012.
- 8[8] C.-I. Chang and A. Plaza, “A fast iterative algorithm for implementation of pixel purity index,” IEEE Geoscience and Remote Sensing Letters , vol. 3, no. 1, pp. 63–67, 2006.