A Machine Learning based Robust Prediction Model for Real-life Mobile Phone Data
Iqbal H. Sarker

TL;DR
This paper introduces a robust machine learning prediction model for real-life mobile phone data that effectively identifies and removes noisy instances to enhance prediction accuracy, using a dynamic noise threshold and decision trees.
Contribution
The paper presents a novel noise filtering approach using naive Bayes and Laplace estimator tailored to individual user behavior, improving mobile data prediction models.
Findings
Improved precision, recall, and F-measure on real mobile datasets.
Effective noise removal enhances model accuracy.
Decision tree classifier performs well on cleaned data.
Abstract
Real-life mobile phone data may contain noisy instances, which is a fundamental issue for building a prediction model with many potential negative consequences. The complexity of the inferred model may increase, may arise overfitting problem, and thereby the overall prediction accuracy of the model may decrease. In this paper, we address these issues and present a robust prediction model for real-life mobile phone data of individual users, in order to improve the prediction accuracy of the model. In our robust model, we first effectively identify and eliminate the noisy instances from the training dataset by determining a dynamic noise threshold using naive Bayes classifier and laplace estimator, which may differ from user-to-user according to their unique behavioral patterns. After that, we employ the most popular rule-based machine learning classification technique, i.e., decision…
Click any figure to enlarge with its caption.
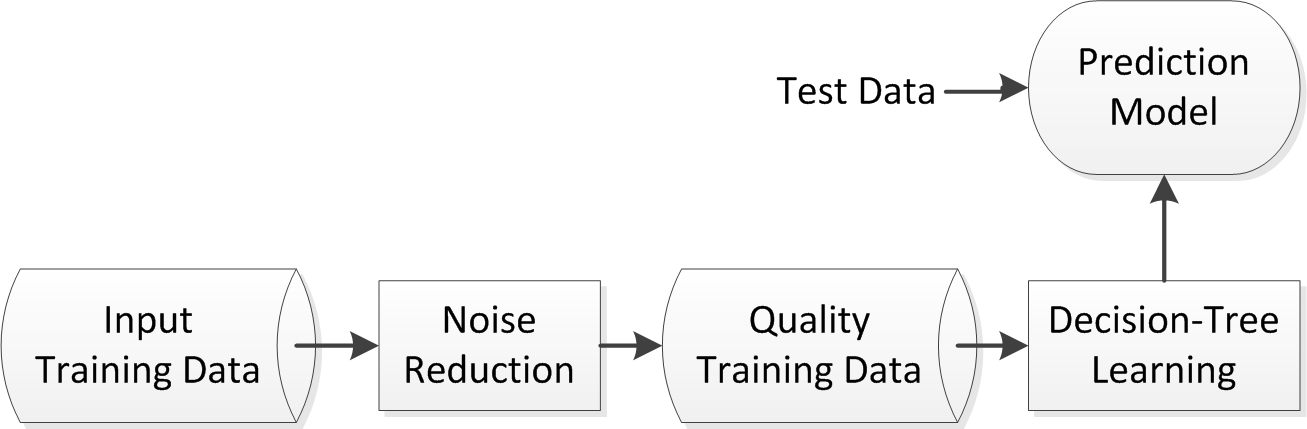 Figure 1
Figure 1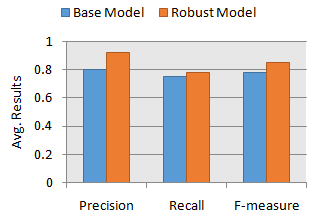 Figure 2
Figure 2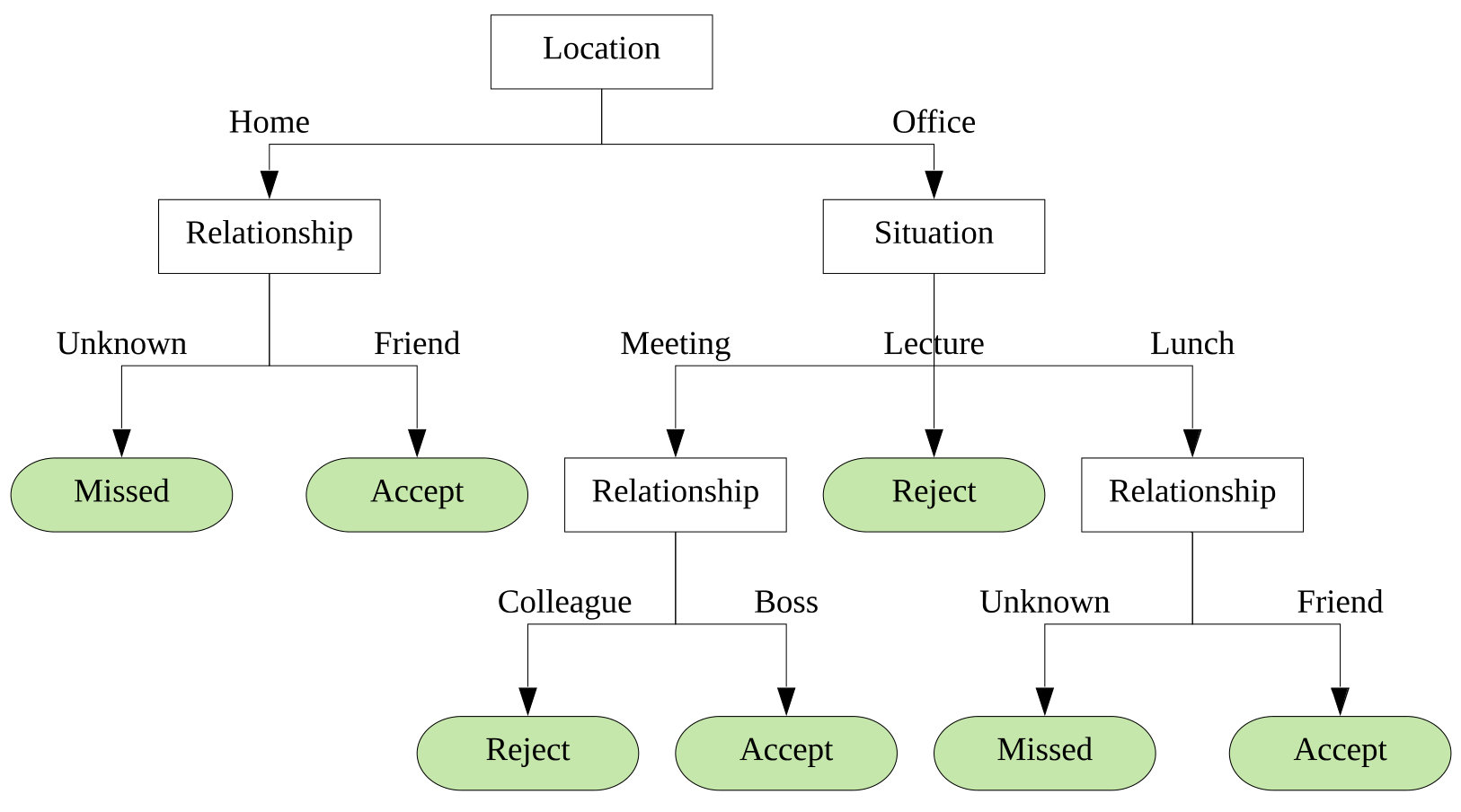 Figure 3
Figure 3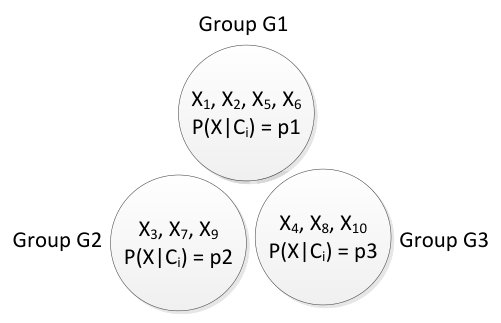 Figure 4
Figure 4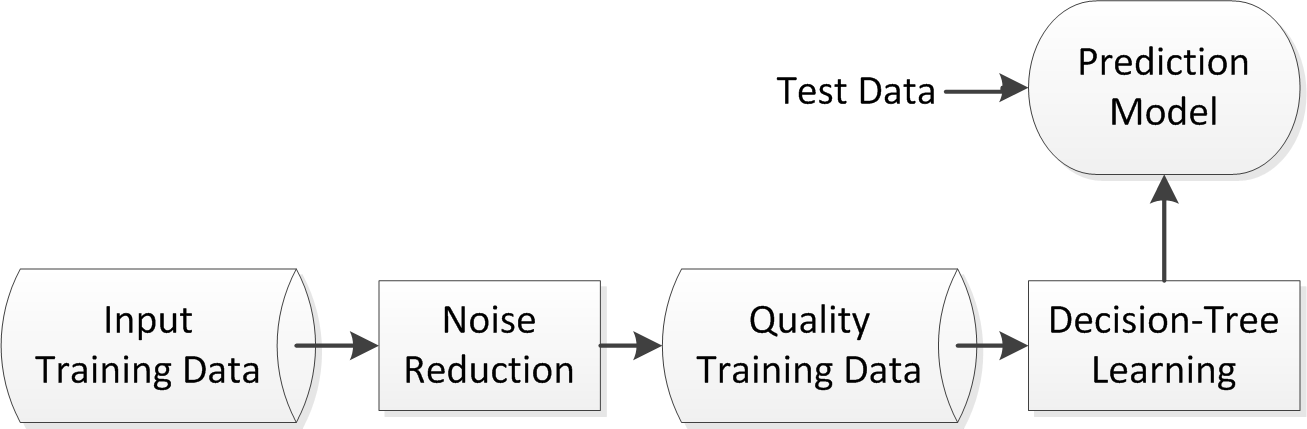 Figure 5
Figure 5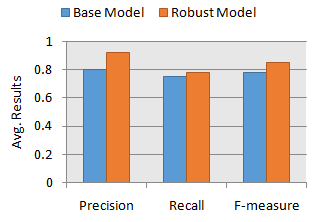 Figure 6
Figure 6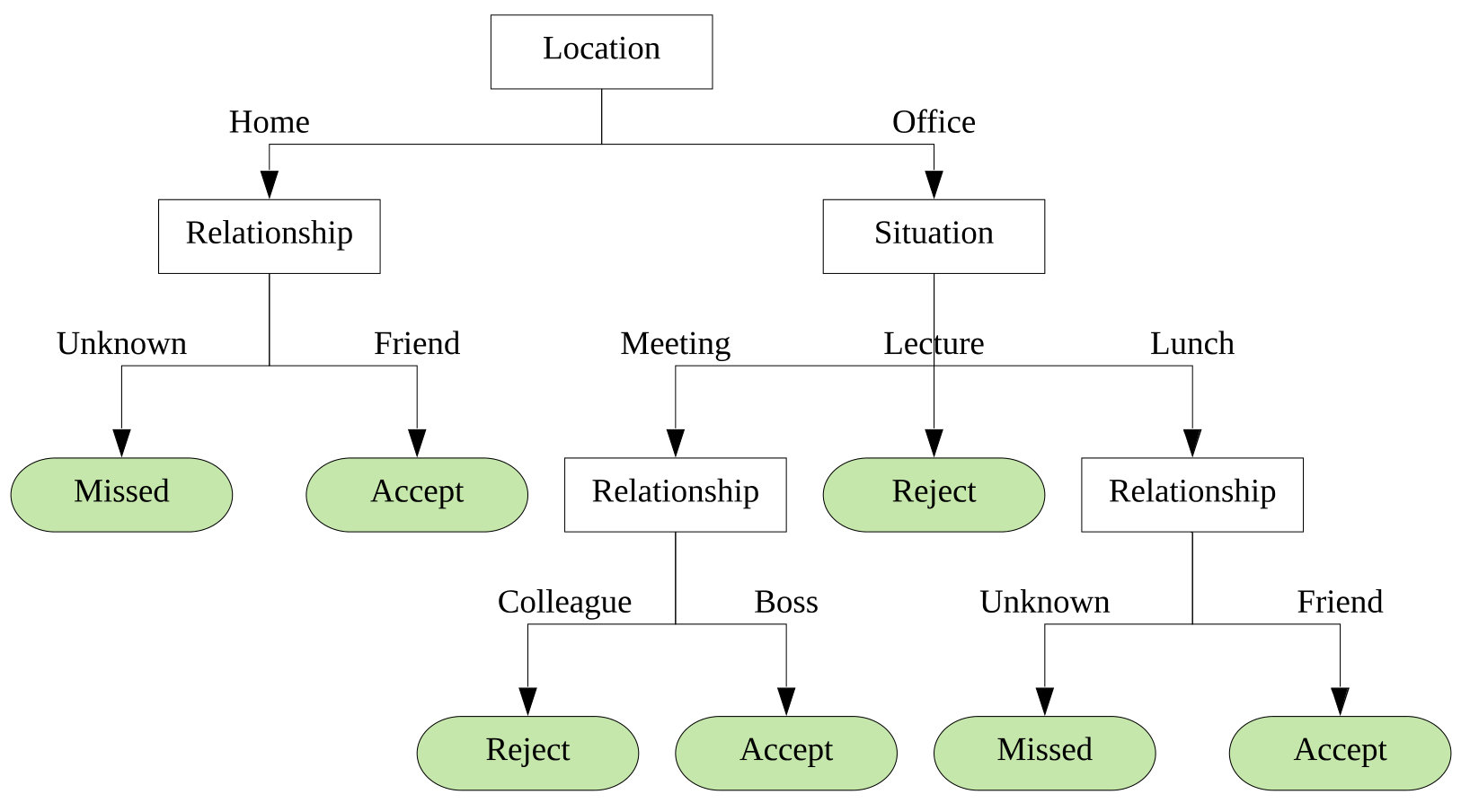 Figure 7
Figure 7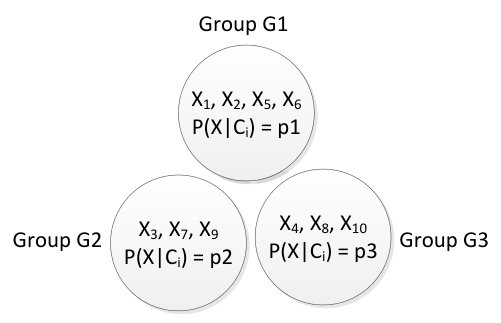 Figure 8
Figure 8| DayName TimeSegment | User Location | Social Situation | Social Relationship | Phone Call Behavior |
| Fri[S1] | Office | Meeting | Friend | Reject |
| Fri[S1] | Office | Meeting | Colleague | Reject |
| Fri[S1] | Office | Meeting | Boss | Accept |
| Fri[S1] | Office | Meeting | Friend | Reject |
| Fri[S2] | Home | Dinner | Friend | Accept |
| Wed[S1] | Office | Seminar | Unknown | Reject |
| Wed[S1] | Office | Seminar | Colleague | Reject |
| Wed[S1] | Office | Seminar | Mother | Accept |
| Wed[S2] | Home | Dinner | Unknown | Accept |
| Probability | Value |
| P(behavior = Reject) | 5/9 |
| P(behavior = Accept) | 4/9 |
| Probability | Value |
| 3/5 | |
| 1/4 | |
| 0/5 | |
| 1/4 | |
| 2/5 | |
| 1/4 | |
| 0/5 | |
| 1/4 | |
| 5/5 | |
| 2/4 | |
| 0/5 | |
| 2/4 | |
| 3/5 | |
| 1/4 | |
| 2/5 | |
| 1/4 | |
| 0/5 | |
| 2/4 | |
| 2/5 | |
| 1/4 | |
| 2/5 | |
| 0/4 | |
| 0/5 | |
| 1/4 | |
| 0/5 | |
| 1/4 | |
| 1/5 | |
| 1/4 |
| Mobile Phone Dataset (individual users) | Data Size (instances) | Time Period of User Activities |
| DS01 | 9204 | 9 months |
| DS02 | 5121 | 4 months |
| DS03 | 506 | 2 months |
| DS04 | 8518 | 9 months |
| DS05 | 2982 | 6 months |
| DS06 | 7040 | 6 months |
| DS07 | 1578 | 3 months |
| DS08 | 8606 | 4 months |
| DS09 | 7752 | 9 months |
| DS10 | 3798 | 9 months |
| Context Category | Context Examples |
| Temporal Context | User’s activity occuring date (YYYY-MM-DD), time (hh:mm:ss), period (e.g., 1 hour, 10:00am-12:00pm), weekday (e.g., Monday), weekend (e.g., Saturday), etc. |
| Spatial Context | User’s coarse level location such as at office, work, home, market, on the way, restaurant, vehicle, playground etc. |
| Social Context | User’s social relationship between individuals such as mother, friend, family, colleague, boss, significant one, unknown, etc. |
| Call Activities | Answering an incoming call, Decline an incoming call, Missed call, and making an Outgoing call |
| Mobile Phone Dataset (individual users) | Noisy Instances |
| DS01 | 5.23% |
| DS02 | 3.52% |
| DS03 | 2.03% |
| DS04 | 4.12% |
| DS05 | 0.24% |
| DS06 | 4.89% |
| DS07 | 3.49% |
| DS08 | 4.70% |
| DS09 | 5.35% |
| DS10 | 4.67% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHuman Mobility and Location-Based Analysis · Data Stream Mining Techniques · Data Management and Algorithms
A Machine Learning based Robust Prediction Model for Real-life Mobile Phone Data
Iqbal H. Sarker∗
Department of Computer Science and Engineering,
Chittagong University of Engineering and Technology, Bangladesh.
Department of Computer Science and Software Engineering,
Swinburne University of Technology,
Melbourne, VIC-3122, Australia.
Abstract
Real-life mobile phone data may contain noisy instances, which is a fundamental issue for building a prediction model with many potential negative consequences. The complexity of the inferred model may increase, may arise over-fitting problem, and thereby the overall prediction accuracy of the model may decrease. In this paper, we address these issues and present a robust prediction model for real-life mobile phone data of individual users, in order to improve the prediction accuracy of the model. In our robust model, we first effectively identify and eliminate the noisy instances from the training dataset by determining a dynamic noise threshold using naive Bayes classifier and laplace estimator, which may differ from user-to-user according to their unique behavioral patterns. After that, we employ the most popular rule-based machine learning classification technique, i.e., decision tree, on the noise-free quality dataset to build the prediction model. Experimental results on the real-life mobile phone datasets (e.g., phone call log) of individual mobile phone users, show the effectiveness of our robust model in terms of precision, recall and f-measure.
keywords:
Mobile data mining, machine learning, noise, user behavior modeling, contexts, personalization, prediction model, intelligent systems.
††journal: Journal: Internet of Things: Engineering Cyber-Physical Human Systems (Elsevier),
1 Introduction
Nowadays, mobile phone is considered as an essential device of our daily life, as people around the world communicate with each other via mobile phones. According to ITU (International Telecommunication Union), nearly 96.8% of the world population has been covered by the cellular network coverage, and this coverage even increases up to 100% of the population in many countries, particularly, in the developed countries like USA, Australia, Canada, UK etc. in the world [48]. In another statistics, Sarker et al. [33] have shown that users’ interest on “Mobile Phones” is more and more than other platforms like “Desktop Computer” or “Tablet Computer” over time. People use mobile phones for various purposes such as voice communication, Internet browsing, apps using, e-mailing, SNS, instant messaging etc. [26]. The smart mobile phones have the ability to log such activities of individual mobile phone users and corresponding contextual information from different sources, such as phone logs [38], electronic calendars [40], or sensors. In this paper, we mainly focus on individuals’ diverse phone call activities in order to build our robust prediction model utilizing their real-life mobile phone data, e.g., phone call log.
Building an effective prediction model utilizing individual’s phone log data is important, as this model can be used to develop various context-aware personalized mobile applications, such as intelligent interruption management system, smart notification management system, intelligent mobile recommender system etc, in order to assist them intelligently in their daily activities. However, the real-life mobile phone data may contain noisy instances that may affect on the inferred prediction model, and thereby decrease the effectiveness in terms of prediction accuracy, in these systems. Thus, a robust prediction model is a key requirement to build such intelligent systems, which is able to handle noisy instances in mobile phone data and can perform effectively for providing personalized services to assist individuals’ in their various day-to-day situations in their real world life.
For the purpose of building a data-driven robust prediction model to predict individual’s phone call behavior, we use phone log data that consists of individuals’ diverse phone call activities, e.g., Accept, Reject, Missed, or making Outgoing call [36], and corresponding contextual information, such as temporal context, spatial context, or social context that have an influence on individuals to make a call handling decision in the real world [41]. For instance, say, on Monday, in the morning a mobile phone user typically rejects (user behavior) the incoming calls if she is in a meeting at her office; however, she accepts (user behavior) if the incoming call is from her elderly mother. Hence, “Monday morning” is an example of temporal context, “at office” represents user location which is an example of spatial context, and the interpersonal relationship “mother”, and social situation “meeting” are the social contexts relevant to that user. According to [7], “context is any information that can be used to characterize the situation of an entity, e.g., an individual mobile phone user”. Such contextual information may differ from application-to-application according to their relevancy in applications [34]. For instance, social relational context might be relevant for one application, say, call interruption management system [36], whereas, it may not be relevant for another type of application, say, mobile notification management system [21].
In the area of mining mobile phone data, both association learning [1], and classification learning [29] are the most common and popular techniques to build a rule-based user behavior model. However, association learning, e.g., Apriori [1] produces a large number of redundant rules that makes the prediction model more complex and ineffective [12] [44]. Thus, in this paper, we focus on rule-based classification technique, e.g., decision tree, that can play an important role to build an effective prediction model for individual mobile phone users utilizing their real-life mobile phone data based on multi-dimensional contexts. However, to achieve higher prediction accuracy of the inferred decision-tree based model is challenging. The reason is that classification learning technique requires a quality training data set to build an effective prediction model free from outliers or noise [6]. Typically, real-world datasets may contain noise or inconsistency instances that may cause over-fitting problem that reduce the prediction accuracy, and consequently, make the prediction model ineffective. Thus, the presence of noise in the dataset is an important issue to effectively modeling mobile user behavior [34]. According to [13], “noise is anything that obscures the relationship between the features (contexts) in an instance and it’s corresponding behavior class”. According to [13], it is evident that decision trees are badly impacted by noise. Hence, we summarize the effects of noisy instances in the real-life mobile phone data for predicting user behavior as follows:
- •
It may create unnecessary prediction rules that are not interesting to the users and make the rule-set unnecessarily larger.
- •
The complexity of the inferred decision tree based model may increase, due to the number of unnecessary training samples represented as noise.
- •
The presence of noise or inconsistency instances in the dataset may cause over-fitting problem of the decision tree-based model, and thus decrease it’s prediction accuracy.
Therefore, a noise elimination process is required before applying the decision tree classification technique to make the prediction model robust, in order to improve the prediction accuracy. According to [53], the performance of a machine learning classification technique depends on two significant factors. First one is the quality of the training data that is used to build the model, and Second one is the competence of the machine learning technique. Therefore, identification and elimination of the noisy instances from a training dataset are required to ensure the quality of the training data in order to build an effective model.
In this paper, we address the above mentioned issues and present a robust prediction model in order to improve the prediction accuracy. In our robust model, we first calculate the conditional probability for all the instances using naive Bayes classifier and laplace estimator. After that, we dynamically determine a noise threshold according to individual’s unique behavioral patterns, which may differ from user-to-user. Using this noise threshold, we identify the noisy instances that are unnecessary to build an effective model. Finally, we we employ the prominent rule-based machine learning technique, e.g., decision tree, on the noise-free quality data, to generate a set of prediction rules based on relevant multi-dimensional contexts, for the purpose of building a rule-based effective prediction model.
The contributions are summarized as follows:
- •
We determine a noise threshold dynamically by analyzing individual’s unique behavioral patterns, for the purpose of identifying inconsistency instances in the dataset.
- •
We present a machine learning based robust prediction model that effectively predicts individual’s phone call behaviors based on multi-dimensional contexts, utilizing their real-life mobile phone data.
- •
Our experiments on mobile phone datasets show that this robust model is more effective for predicting user behavior, while comparing with other base models in the area of mining mobile phone data.
This paper significantly revises and extends our earlier paper [43] in several directions: (i) defining and formulating the problem statement clearly in terms of mathematical notation; (ii) summarizing a number of base modeling approaches that utilize real-life mobile phone data; (iii) designing a decision tree based model and extracting the prediction rules based on multi-dimensional contexts; (iv) conducting additional experiments on real-life mobile phone datasets of individuals; (v) highlighting our key observations in terms of model effectiveness; and finally (vi) summarizing a number of real-world applications of the prediction model for the benefit of end mobile phone users.
The rest of the paper is organized as follows. Section 2 reviews the related work. We define and formulate the problem statement in Section 3. We give an overview about the Naive Bayes classifier and Laplace estimator that are used in our model, in Section 4 and Section 5 respectively. We present our robust prediction model in section 6. We report the experimental results in Section 7. In section 8, we discuss our key observations. We also summarize a number of real life applications of our model in Section 9 Finally, Section 10 concludes this paper and highlights the future work.
2 Related Work
Due to the popularity of smart mobile phones with advanced features and context-aware technology, analyzing real-life mobile phone data to model users’ behavioral activities, has become an active research area in the current world. A number of researchers have used mobile phone data in order to model and predict user behavior for various purposes. However, these approaches are not robust as they do not take into account the issues of noisy or inconsistence instances in the mobile phone data while building the prediction model based on contexts. For instance, Song et al. [46] present a study on users’ search behavior in order to improve searching relevance based on the log data. Rawassizadeh et al. [30] propose a scalable approach utilizing multiple sensor data, for the purpose of mining the daily behavioral patterns of the users. Mukherji et al. [22] propose an intelligent modeling approach based on multi-dimensional contexts utilizing the mobile phone data. Bayir et al. [2] propose an approach for smartphone applications in order to provide the web-based personalized service. In [24], Paireekreng et al. have proposed an approach for building personalization mobile game recommendation system. These approaches utilize mobile phone data to build their models based on multi-dimensional contexts. However, they do not take into account the robustness to build their models, in which we are interested in.
Besides these approaches, in [21], Mehrotra et al. propose a novel interruptibility management system based on mobile phone data. In their approach, they first learns users’ preferences based on multi-contexts about how the users respond with the mobile notifications utilizing mobile phone data. Xu et al. [50] have presented a prediction model for the purpose of predicting app usages behavior of mobile phone users. Zhu et al. [52] have presented an approach for the purpose of recommending mobile usages based on relevant contexts utilizing the mobile context log data. In [51], Yu et al. investigate how to exploit user context logs for the purpose of building the personalized context-aware recommendation system through topic models. In [45], Shin et al. propose an prediction model to predict mobile apps based on mobile phone data.
In addition to these approaches, a number of models based on mobile phone data have been presented for different purposes. For example, an intelligent intrusion administration framework [54], making application prefetch commonsense on cell phones [25], mining continuous co-event designs on the cell phones [47], mining versatile client propensities [20] are displayed dependent on cell phone information. Ozer et al. [23] propose a way to deal with foresee the area and time of cell phone clients by utilizing consecutive example mining systems. In [8], Do et al. present a structure for anticipating where clients will go and which application they will use in the following by misusing the rich relevant data from cell phone sensors. In [11], Farrahi et al. utilize expansive scale cell phone information for examining their day by day schedule practices. In [19], Karatzoglou et al. utilize cell phone information in their versatile application suggestion framework. Phithakkitnukoon et al. [28] utilize cell phone information in their investigation to recognize human every day action designs.
In order to predict mobile user navigation patterns, Halvey et al. [14] have done their investigation dependent on cell phone information. In their methodology, they fundamentally center around transient setting, as this is a standout amongst the most critical setting sway on client conduct. Phithakkitnukoon et al. [27] structure a versatile telephone call expectation display using cell phone information. In [18], Jang et al. have done their investigation dependent on cell phone information and demonstrated that clients application uses conduct may differ from client to client after some time. In [16], Henze et al. propose a way to deal with locate the best time to convey the portable applications dependent on cell phone information. To identify the appropriate day and age of dynamic applications, Xu et al. [49] propose a methodology by investigating the cell phone information. In [3], Bohmer et al. present a way to deal with recognize the pinnacle time of normal application utilizations as per client conduct using their cell phone information.
These approaches discussed above utilize mobile phone data to build their models for different purposes. However, they do not take into account the robustness, i.e., issues of inconsistency or noise in the datasets, in their models. Unlike these works, we present a machine learning based robust prediction model that eliminates the noisy instances from the real-life mobile phone data, in order to make the model more effective by improving the prediction accuracy.
3 Definitions and Problem Statement
This section defines the main notions concerning our robust prediction model in order to predict individuals’ diverse phone call activities utilizing their mobile phone data. In the following, the notion of mobile phone dataset having phone call activities of individuals with multi-dimensional contexts, is formally stated.
Definition 1. (Mobile phone data). Let be a set of contexts and the set of corresponding domains. A mobile phone dataset is a collection of records, where - **
- (i)
each record is a set of pairs , where , and . For example, if represents the context ‘spatial’, then an example of is ‘at office’. 2. (ii)
each , also called attribute (context), may occur at most once in any record in DS, and 3. (iii)
each record has a particular user activity with mobile phones (e.g., reject phone call).
The mobile phone dataset defined above, represents the behavioral data as it contains individual’s phone call activities, e.g., rejecting an incoming phone call, in a particular context, e.g., at office.
Definition 2. (Phone Call Activity). Let, be a set of activity related to the phone calls of an individual user , each action represents a particular activity for that user.
In the real world, the common phone call activities of an individual mobile phone user are - (i) answering an incoming phone call, i.e., ‘Accept’, (ii) decline the incoming phone call by the user, i.e., ‘Reject’, (iii) the phone rings but the user misses the call, i.e., Missed, and (iv) making a phone call to a particular person, i.e., ‘Outgoing’ [35]. Each such phone call activity is represented as defined above.
As each activity of an individual user is associated with a particular timestamp (e.g., YYYY-MM-DD hh:mm:ss) recorded by the device, the temporal context can play a primary role to model individual’s phone call behavior. Mobile phone records such type of exact temporal information for each activity of an individual, which represents as a time-series that is continuous real-valued. A formal definition of time-series is stated in the following.
Definition 3. (Time-Series). A time-series is a sequence of data points ordered in time such that , where are individual observations, each of which contains real-value data and is the number of observations in a time-series [39].
To use time-series data as a temporal context in our robust prediction model, there is a need of time interval, even if only a small interval, e.g., five minutes. The reasons is that exact time is not informative for modeling and predicting user behavior [39]. Moreover, individuals’ day-wise behavior are not identical. For instance, one’s phone call behaviors on Monday might be different with her Tuesday’s behavior because of her day-to-day situations in the real world. Thus, a day-wise time segment, e.g., Friday[09:00-11:00] that represents the similar behavioral characteristics of an individual mobile phone user in that time period, could be useful. As we aim to build our robust prediction model based on multi-dimensional contexts, in the following, we define the other contexts relevant to our model.
Definition 4. (Multi-dimensional Contexts). Let be a set of contexts having influence to make a phone call decision in the real world and the set of corresponding domains related to phone call activity of an individual user . Each context represents a part of the multi-dimensional contexts. In addition to the temporal context discussed above, the spatial context can be considered as another dimension of contexts relevant to individual’s phone call behavior. For instance, an individual’s phone call behavior at her ‘office’ may be well different from her behavior when she is at ‘home’, which represents an example of spatial context. Some examples of these coarse level locations [32] [9] are office, home, market, store, restaurant, vehicle etc. that can be used to model individual mobile phone users’ behavior.
In addition to the above spatio-temporal contexts, social contexts or interpersonal relationship between individuals, mother, might have also an influence on individual mobile phone users to make phone call decisions [36]. For example, a user typically ‘rejects’ an incoming phone call during an event official meeting, however, she ‘answers’ if the incoming call comes from her ‘elderly mother’. Thus, the interpersonal relationship between the caller and the callee has a strong influence to handle phone call decision.
Definition 5. (Interpersonal Relationship). If is a caller and is a callee, then the social relational bonding between and represents the interpersonal relationship in their real life.
According to [36], there are several interpersonal relationships, such as mother, family, friend, colleague, boss, significant one, or unknown, can play a strong role to model user phone call behavior of individual mobile phone users in the real world.
Definition 6. (Noise). Noise is anything that obscures the relationship between the features or contexts in an instance and it’s phone call behavior class. The presence of noisy instances in the training dataset makes the machine learning based behavior prediction model ineffective in terms of prediction accuracy.
Definition 7. (Quality Mobile Phone Data). Let, is the total number of instances in the mobile phone data, is the number of noisy instances, then - represents the quality data that is used to build our robust prediction model for individuals.
Problem Statement. With the above definitions, the main problem we are addressing in this paper is stated as follows:
Given, a mobile phone dataset containing real-life mobile phone data of an individual mobile phone user. Our goal is to identify and eliminate the noisy instances from and to model individual’s behavior based on the relevant multi-dimensional contexts utilizing the quality data , in order to predict more accurately. In this paper, we present a robust prediction model for the given dataset , using machine learning techniques, such as naive Bayes classifier, rule-based decision tree classifier, for solving this problem.
4 Naive Bayes Classifier
In our robust prediction model, we use Naive Bayes classifier (NBC) to calculate the class conditional probabilities for a given contextual information, in order to identify the noisy instances from the training dataset. NBC in one of the most popular classifiers in the area of data mining and machine learning, which is well-known as a simple probabilistic based method that is able to calculate the class membership probabilities [15]. In NBC, the effect of a contextual attribute in the dataset on a given class is also independent of those of other attributes.
Let represents a training set of data instances having the contextual attributes and corresponding behavioral class labels. Each instance in the dataset is represented by an n-dimensional context vector, , where n represents the number of attributes of an instance and represented as . Say, there are number of behavior classes in the dataset, and represented as . For a test case of an instance, , the NBC will predict that belongs to the class with the highest conditional probability, conditioned on . That is, the naive Bayes classifier predicts that the instance belongs to the class , if and only if [15] -
for
The class for which is maximized is called the Maximum Posteriori Hypothesis and defined as [15]:
[TABLE]
In Bayes theorem shown in Equation 1, as is a constant for all classes, only needs to be maximized. If the class prior probabilities are not known, then it is commonly assumed that the classes are likely equal, that is, , and therefore we would maximize . Otherwise, we maximize . The class prior probabilities are calculated by , where is the number of training instances of class in . To compute in a dataset with many attributes is extremely computationally expensive. Thus, the naive assumption of class-conditional independence is made in order to reduce computation in evaluating . This presumes that the attributes’ values are conditionally independent of one another, given the class label of the instance, i.e., there are no dependence relationships among attributes. Thus, Equation 2 and Equation 3 are used to produce [15].
[TABLE]
[TABLE]
In Equation 2, refers to the value of attribute for instance . Therefore, these probabilities can be easily estimated from the training instances. If the attribute value, , is categorical, then is the number of instances in the class with the value for , divided by , i.e., the number of instances belonging to the class .
To predict the class label of instance is evaluated for each class . The naive Bayes classifier predicts that the class label of instance is the class , if and only if [15] -
for and
In other words, the predicted class label is the class for which is the maximum. NBC has also two main advantages: (a) it requires only one scan of the training data to calculate the probability, and (b) it is easy to use to classify a class according to that probability, which makes the Naive Bayes classifier more popular in the area of classification to predict or classify the class in a given dataset. For instance, for a given particular contexts (office, meeting) in the mobile phone dataset, this classifier is able to predict the behavior (say, reject phone call) by calculating the corresponding conditional probability scanning the relevant contexts over the dataset. However, this classifier is unable to predict the actual behavior class with zero probability [15]. In our robust model, we resolve this issue by using laplace estimator that is discussed in next section.
5 Laplace Estimator
As in naive Bayes classifier discussed above, we calculate as the product of the probabilities , based on the independence assumption and class conditional probabilities, we will end up with a probability value of zero for some . This may happen if the attribute value is never observed in the training data for a particular class . Therefore, the generated Equation 3 becomes zeros for such attribute value regardless the values of other attributes. Thus, naive Bayes classifier is unable to predict the class of such test instances. In order to resolve such issues in our model, we use Laplace estimator [4] to scale up the values by smoothing factor. In Laplace-estimate, the class probability is defined as [4]:
[TABLE]
where is the number of instances satisfying , is the number of training instances, is the number of classes and .
Let’s consider a phone call behavior example, for the behavior class ‘reject’ in the training data containing 1000 instances, we have 0 instance with , 990 instances with , and 10 instances with . The probabilities of these contexts are 0, 0.990 (from 990/1000), and 0.010 (from 10/1000), respectively. On the other hand, according to equation 4, the probabilities of these contexts would be as follows:
, ,
In this way, we obtain the above non-zero probabilities, rounded up to three decimal places, respectively using Laplace estimator defined above. The “new” probability estimates are close to their “previous” counterparts, and these values can be used for further processing in our model.
6 Methodology: Our Robust Prediction Model
In this section, we present our robust prediction model for real-life mobile phone data of individual users, in order to improve the prediction accuracy of a machine learning based model.
6.1 Approach Overview
In our robust model, we first effectively identify and eliminate the noisy instances from the training dataset by determining a dynamic noise threshold that may differ from user-to-user according to their unique behavioral patterns. After that, we employ the most popular rule-based machine learning technique, i.e., decision tree, on the noise-free quality dataset to build the prediction model. Figure 1 shows an overview of our robust prediction model that utilizes real-life mobile phone data of individual users.
To achieve our goal, we first use naive Bayes classifier (NBC) discussed above as the basis for noise identification as it calculates the class conditional probability for a given contextual information. Based on such probability values for the contexts and their possible combinations in the datasets, we identify the inconsistency in the dataset. As we aim to build prediction model based on multi-dimensional contexts, such as temporal, spatial, or social context according to the given dataset, the assumption used in NBC for zero probabilities is often unrealistic for predicting individual’s phone call behavior [42], which is mentioned earlier. Thus, we further use Laplace-estimator [4] discussed above to estimate the conditional probability of contexts. After that, we calculate the “noise-threshold” using the generated probability values, in order to identify the noisy instances. As individual’s phone call behavioral patterns are not identical in the real world, this noise-threshold may differ according to individual’s unique behavioral patterns.
Once we have identified noisy instances, we eliminate those from the training dataset to get a noise-free quality data set that is used to build our robust model. After that, we employ the most popular C4.5 decision tree learning technique [29] to generate a set of rules, in order to build our robust prediction model that improves the prediction accuracy while predicting individual’s phone call behavior in multi-dimensional contexts.
6.2 Dynamic Threshold Calculation and Noise Detection
In this section, we discuss our dynamic threshold based noise detection technique using both the naive Bayes classifier (NBC) and laplace estimator, which may differ from user-to-user according to their behavioral patterns, mentioned earlier. Using NBC, we first calculate the conditional probability for each attribute by scanning the training contextual data. Table 1 shows an example of the mobile phone dataset consisting of user phone call behavior, and corresponding multi-dimensional contexts. Each instance contains four attribute or context values (e.g., time, location, situation, and social relationship between the caller and callee) and corresponding phone call behavior, e.g., Reject or Accept call activities. Based on this information, Table 2 and Table 3 report an example of the prior probabilities for each behavior class and conditional probabilities, respectively. Using these probabilities, we calculate the conditional probability for each given instance. As NBC was implemented under the independence assumption, it estimates zero probabilities if the conditional probability for a single context is zero. In such cases, we apply Laplace-estimator [4] to estimate the conditional probability of contexts.
Once we have calculated conditional probability for each instance, we differentiate between the purely classified instances and misclassified instances using these values. “Purely classified” instances are those for which the predicted class and the original class is same. If different class is found then the instances are considered as “misclassified” [10]. After that, we generate the instance groups by taking into account all the distinct probabilities as separate group values. Figure 2 shows an example of instance groups for the instances , where consists of 5 instances with probability , consists of 3 instances with probability , and finally consists of 3 instances with probability . We then identify the group among the purely classified instances for which the probability is minimum. This minimum probability is considered as “noise-threshold”. Finally, the instances in misclassified list differentiated earlier, for those the probability does not satisfy the noise threshold, are identified as noise.
The process for identifying noise is set out in Algorithm 1. Input data includes training dataset: , which contains a set of training instances and their associated class labels and output data is the list of noisy instances. For each class, we calculate the prior probabilities . After that for each attribute value, we calculate the class conditional probabilities . For each training instance, we calculate the conditional probabilities . We then check whether it is non-zero. If we get zero probabilities, we then recalculate the conditional probabilities using Laplace Estimator. Based on these probability values, we then check whether the instances are misclassified or purely classified and store all misclassified instances with corresponding probabilities in . Similarly, we also store all purely classified instances with corresponding probabilities in . We then identify the minimum probability from as noise threshold. Finally, this algorithm returns a set of noisy instances for a particular dataset.
Rather than arbitrarily determine the threshold, our algorithm dynamically identifies the noise threshold according to individual’s behavioral patterns and identify noisy instances based on this threshold. As individual’s phone call behavioral patterns are not identical in the real world, this noise-threshold for identifying noisy instances changes dynamically according to individual’s unique behavioral patterns.
6.3 Decision Tree based Model and Rule Generation
In this section, we discuss our decision-tree based prediction model for generating a set of rules. It is developed based on a basic C4.5 algorithm [29]. Given a training dataset, , where represents the sample size. Each instance is represented by an n-dimensional attribute vector, , depicting measurements made on the instance from attributes, respectively, . The training data also belong to a set of classes . A decision tree is a rule-based classification tree associated with , which is a structure that includes a root node, internal nodes, leaf nodes, and their associate arcs. The topmost node in the tree is called the root. Each internal node denotes a test on a context attribute, , (e.g., social relationship), and each leaf node denotes the behavioral outcome class, , of that test which is represented by a behavior class label (e.g., reject phone call). Each arc is associated with a particular context value, e.g., friend as a social relationship context. After building the complete decision tree, rules are extracted from the tree for the purpose of using in prediction for a particular test case.
Figure 3 shows an example of such a decision tree for multi-dimensional contexts, where locational context values are , interpersonal social relational context values are , social situation values are , and user phone call behavior classes are . Once the tree has been generated, rules are extracted by traversing the tree from root node to each leaf node. The followings are the examples of the produced rules generated from the tree, shown in Figure 3.
Rule states that the user misses the incoming calls from unknown people, when she is at home. However, accepts the incoming calls at home if the calls come from her friends, which is stated in Rule . Similarly, Rule states that the user rejects the incoming calls of her colleagues, when she is in a meeting at her office. However, she accepts the incoming calls from her boss, which is stated in Rule . Similarly, the other rules state the behaviors of the user in other relevant contexts. These generated rules based on relevant multi-dimensional contexts are able to predict individual’s phone call behavior, and can be used to build a context-aware intelligent system, to assist them in their daily activities.
7 Experiments and Evaluation
In this section, we describe our experimental results for the real-life mobile phone datasets of individual users. We also present an experimental evaluation comparing our robust prediction model with the existing approaches for predicting user phone call behavior.
7.1 Real-life Mobile Phone Dataset
We have conducted experiments on ten phone log datasets collected by Massachusetts Institute of Technology (MIT) for their Reality Mining project [9]. Each dataset represents the phone call activities of an individual mobile phone user. These individuals are faculty, staff, and students. The datasets include people with different types of calling patterns and call distributions. These datasets contain multi-dimensional contexts, such as temporal, location, and social context, and corresponding phone call activities of individuals. Table 4 describes each call log dataset represented as for ten individual mobile phone users respectively.
7.2 Data-Preprocessing
Hence, we pre-process the raw data available in the dataset. As seen in the dataset, the mobile phone records both accepting and rejecting calls as incoming calls, we distinguish accept and reject calls by using the call duration. According to [37], if the call duration is greater than 0 then the call has been accepted; if it is equal to 0 then the call has been rejected. Overall, we take into account four types of phone call behavioral classes, such as accept/answer call, reject/decline call, missed call, and making an outgoing call, of all the individuals. In Table 5, we summarize all these activities (behavior classes) and corresponding contextual information that are taken into account in our experiments. In order to pre-process the temporal data for building this model, we use our earlier bottom-up behavior-oriented time segmentation (BOTS) technique [39] that extracts individual’s behavior oriented time segments according to the similar behavioral characteristics. For instance, Friday[09:00-11:00], Monday[12:00-13:00], Saturday[15:30-18:45] are the examples of the generated segments using this technique. We also generate data-centric social relational context using mobile phone data, where “each unique mobile phone number represents a particular one-to-one relationship” [36]. For instance, mother’s phone number (047XXXX231) represents one relation (), while friend’s phone number (047XXXX232) represents another relation () etc.
7.3 Evaluation Metric
In order to measure the prediction accuracy, we compare the predicted response with the actual response (i.e., the ground truth) and compute the accuracy in terms of:
- •
Precision: ratio between the number of phone call behaviors that are correctly predicted and the total number of behaviors that are predicted (both correctly and incorrectly). If TP and FP denote true positives and false positives then the formal definition of precision is [15]:
[TABLE]
- •
Recall: ratio between the number of phone call behaviors that are correctly predicted and the total number of behaviors that are relevant. If TP and FN denote true positives and false negatives then the formal definition of recall is [15]:
[TABLE]
- •
F-measure: a measure that combines precision and recall is the harmonic mean of precision and recall. The formal definition of F-measure is [15]:
[TABLE]
7.4 Evaluation Results
To evaluate our model, we employ the most popular cross validation technique, N-fold [15], in machine learning, where we use N=10 to measure the outcome. The 10-fold cross validation breaks data into 10 sets. It trains the prediction model on 9 sets and tests it’s performance using the remaining one set. This repeats 10 times and we take a mean accuracy rate.
To show the effectiveness of our robust model, we compare the prediction results of existing approaches with our model, in terms of precision, recall and f-measure, defined earlier. In our experiment, existing approaches are those that use real-life mobile phone data for modeling without taking into account the robustness, i.e, the quality of the training data for modeling. For the purpose of effectiveness comparison with our robust model, we represent such type of existing works as ‘Base Model’, shown in Figure 4. In order to make fare comparison of both models, we use the same datasets described above, in our experiments. Figure 4 shows the overall impact of noisy instances in mobile phone data on the effectiveness of the prediction model. In Table 6, we also show the number of noisy instances identified by our approach for an iteration, which have an impact on the overall prediction accuracy. For another iteration, the number of noisy instances may change. The reason is that, we use 10-fold cross validation technique for evaluation, where 90% data is used as training data to build the model in each iteration. In another iteration, the training data is changed according to the procedure of N-fold cross validation, and consequently, the number of noisy instances may also change.
To show the overall effectiveness in terms of prediction accuracy of our robust model, Figure 4 shows the relative comparison of precision, recall and f-measure, by calculating the average results for all the datasets described earlier. If we observe Figure 4, we find that our robust model consistently outperforms base model for predicting individual’s phone call behavior in terms of precision, recall and f-measure. The main reason is that existing base models do not take into account the robustness while predicting user behavior, and the resulting accuracy is consequently low. On the other-hand, our robust model effectively handles the noisy instances by analyzing the behavioral patterns of individual mobile phone users, and thus improves the prediction accuracy in relevant contexts.
8 Discussion
Overall, our robust prediction model is completely individualized and behavior-oriented. Contrasted with the existing applicable methodologies, the user behavior prediction accuracy in terms of precision, recall and f-measure, is improved when our robust prediction model is applied, as shown in Figure 4. Although, the robust model is a two-step process, it is effective while demonstrating user behavior using real life cell phone information. The following are few key discoveries from our study.
- •
Real-world datasets may contain noisy instances. Such noisy instances may diminish the precision of expectations, increment the multifaceted nature of model induction process because of noisy training samples. To recognize such cases, determining a noise threshold according to individual’s unique behavioral patterns is the key term in our methodology. However, the threshold can differ from user-to-user, as the behavioral patterns of individual mobile phone users are not identical in the real world.
- •
Machine learning based approaches, such as using Naive Bayes classifier and Laplace Estimator can play an important role for identifying and eliminating noisy instances from the training dataset, in order to prepare the quality training data for an effective modeling. Such techniques also can help to calculate the dynamic noise-threshold by analyzing the given contextual data, in order to identify the noisy instances.
- •
We have observed a significantly lower prediction accuracy when using the base model compared to our robust model. The reason is that existing base models do not take into account the impact of noisy instances in their models. Consequently, the prediction results found using base models have low precision, recall and f-measure, shown in Figure 4.
- •
Our approach does not depend on any particular number of contexts. However, we take into account temporal, spatial, and social contexts, as these are relevant to our problem domain. For another problem domain in mobile phones, the corresponding relevant contexts can be used in our approach.
9 Real-Life Applications
As our model is able to predict future behavior of individual mobile phone users based on relevant contextual information utilizing their mobile phone data, this model can be used in various real-life applications to assist them intelligently. Hence, we summarize a number of relevant applications. These are:
- •
Intelligent Voice Communication: Managing incoming call interruptions can be an important application of this model. For this, phone call log data having different types of behaviors with incoming phone calls in different contexts, is needed to build the model. Such application will be helpful for individual mobile phone users to assist them in their daily activities, as mobile phones are considered to be ‘always on, always connected’ device in the real world, but the users are not always attentive and responsive to incoming phone calls, because of their various day-to-day situations [5]. Such call intrusions may make humiliating circumstance in an official situation, e.g., meeting, as well as influence in different exercises like inspecting patients by a specialist or driving a vehicle and so on. These call interferences may likewise diminish laborer execution, expanded blunders and worry in a workplace [26]. Therefore, in order to minimize such interruptions, a robust model utilizing individual’s phone call response behavioral data collected from related sources having relevant contexts such as temporal, spatial, social or interpersonal relationship between caller and callee, can be used to build an intelligent call interruption management system. Similarly, building robust model utilizing outgoing call related data can be used to build a smart call reminder system that can help to keenly looks through the attractive contact from the substantial contact list and reminds the user to make a phone call to a specific individual in a specific settings.
- •
Mobile Notification Management: Notifications are a core feature of mobile phones [31]. In the real world, a variety of smart mobile applications use notifications in order to inform the the users about various kinds of events, such as the arrival of a message, a new comment on their posts on social networks, like Facebook, LinkedIn, Twitter, the updating availability of an application like WhatsApp, Skype, Viber, various news or just to send them reminders or alerts [31]. However, many of them (mobile phone notifications) are neither useful nor relevant to the interests of the users. As a result, such useless notifications are considered disruptive and potentially annoying to the users [21] [17]. Individual’s behavioral rules based on user’s contextual information, might be able to manage such notifications intelligently. For examples, one individual always dismisses promotional email notifications; she accepts birthday reminder notifications of Facebook mostly at night, when she is at home; does not accept Viber or Whatsapp notifications from unknown persons at office. Therefore, building robust model utilizing individual’s notification handling behavioral data collected from related sources having relevant contexts such as temporal, spatial, notification type, can be used to build an intelligent notification management system.
- •
Mobile Recommendation System: Mobile recommender system is one of the most important applications of user behavior model, as it helps the user to find the most satisfying service by reducing search effort and information overload. For instance, a particular mobile app recommendation among a huge number of installed apps (e.g., Multimedia, Facebook, Gmail, Youtube, Skype, Game, Microsoft outlook, etc.) according to users current contextual information (temporal, spatial or others), and preference could be useful for the users. For this relevant mobile phone data having various contexts and corresponding app usages can be used for building the app recommendation model for the purpose of identifying which app is preferred by a particular user under a certain context to provide personalized context-aware recommendation of different mobile phone apps for the mobile phone users. Similarly, other recommendation services can be generated from relevant mobile phone data using our robust model in order to get better prediction accuracy in various contexts.
10 Conclusion and Future Work
In this paper, we have presented a robust prediction model for the real-life mobile phone data, in order to improve the prediction accuracy. In our robust model, we have effectively handled the noisy instances from the training dataset by determining a dynamic noise threshold using naive Bayes classifier and laplace estimator, which may differ from user-to-user according to their unique behavioral patterns. In order to build the complete model, we have also employed the most popular rule-based machine learning technique, i.e., decision tree, on the noise-free quality dataset. Experimental results on multi-contextual phone call log datasets indicate that compare to the existing approaches, our robust model improves the prediction accuracy in terms of precision, recall and f-measure.
In future work, we plan to use this model for building real-world mobile applications discussed above, to assess the effectiveness of this model in application level.
Acknowledgment
The author would like to thank Prof. Jun Han, Swinburne University of Technology, Australia, Dr. Alan Colman, Swinburne University of Technology, Australia, and Dr. Ashad Kabir, Charles Sturt University, Australia for their relevant discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Rakesh Agrawal and Ramakrishnan Srikant. Fast algorithms for mining association rules. In Proceedings of the International Joint Conference on Very Large Data Bases, Santiago Chile, pp. ∼ similar-to \sim 487–499. , volume 1215, 1994.
- 2[2] Murat Ali Bayir, Murat Demirbas, and Ahmet Cosar. A web-based personalized mobility service for smartphone applications. The Computer Journal , 54(5):800–814, 2010.
- 3[3] Matthias Böhmer, Brent Hecht, Johannes Schöning, Antonio Krüger, and Gernot Bauer. Falling asleep with angry birds, facebook and kindle: a large scale study on mobile application usage. In Proceedings of the International Conference on Human computer interaction with mobile devices and services, Stockholm, Sweden, 30 August - 2 September, pp. ∼ similar-to \sim 47–56. ACM, New York, USA , 2011.
- 4[4] Bojan Cestnik et al. Estimating probabilities: a crucial task in machine learning. In ECAI , volume 90, pages 147–149, 1990.
- 5[5] Yung-Ju Chang and John C Tang. Investigating mobile users’ ringer mode usage and attentiveness and responsiveness to communication. In Proceedings of the International Conference on Human-Computer Interaction with Mobile Devices and Services, Copenhagen, Denmark, 24-27 August, pp. ∼ similar-to \sim 6–15. ACM, New York, USA , 2015.
- 6[6] Luis Daza and Edgar Acuna. An algorithm for detecting noise on supervised classification. In Proceedings of WCECS-07, the 1st World Conference on Engineering and Computer Science , pages 701–706, 2007.
- 7[7] Anind K Dey. Understanding and using context. Personal and ubiquitous computing , 5(1):4–7, 2001.
- 8[8] Trinh Minh Tri Do and Daniel Gatica-Perez. Where and what: Using smartphones to predict next locations and applications in daily life. Pervasive and Mobile Computing , 12:79–91, 2014.