Where Do Human Heuristics Come From?
Marcel Binz, Dominik Endres

TL;DR
This paper explores the origins of human heuristics by modeling them as learned, resource-bounded approximations to optimal decision-making, supported by empirical evidence from a bandit task.
Contribution
It introduces a novel meta-learning framework combining RNNs with resource constraints to explain human heuristic strategies.
Findings
Models exhibit patterns similar to human decision-making differences.
Supports the hypothesis that heuristics are learned, resource-bounded approximations.
Connects heuristics to variational inference and MDL principles.
Abstract
Human decision-making deviates from the optimal solution, that maximizes cumulative rewards, in many situations. Here we approach this discrepancy from the perspective of bounded rationality and our goal is to provide a justification for such seemingly sub-optimal strategies. More specifically we investigate the hypothesis, that humans do not know optimal decision-making algorithms in advance, but instead employ a learned, resource-bounded approximation. The idea is formalized through combining a recently proposed meta-learning model based on Recurrent Neural Networks with a resource-bounded objective. The resulting approach is closely connected to variational inference and the Minimum Description Length principle. Empirical evidence is obtained from a two-armed bandit task. Here we observe patterns in our family of models that resemble differences between individual human participants.
Click any figure to enlarge with its caption.
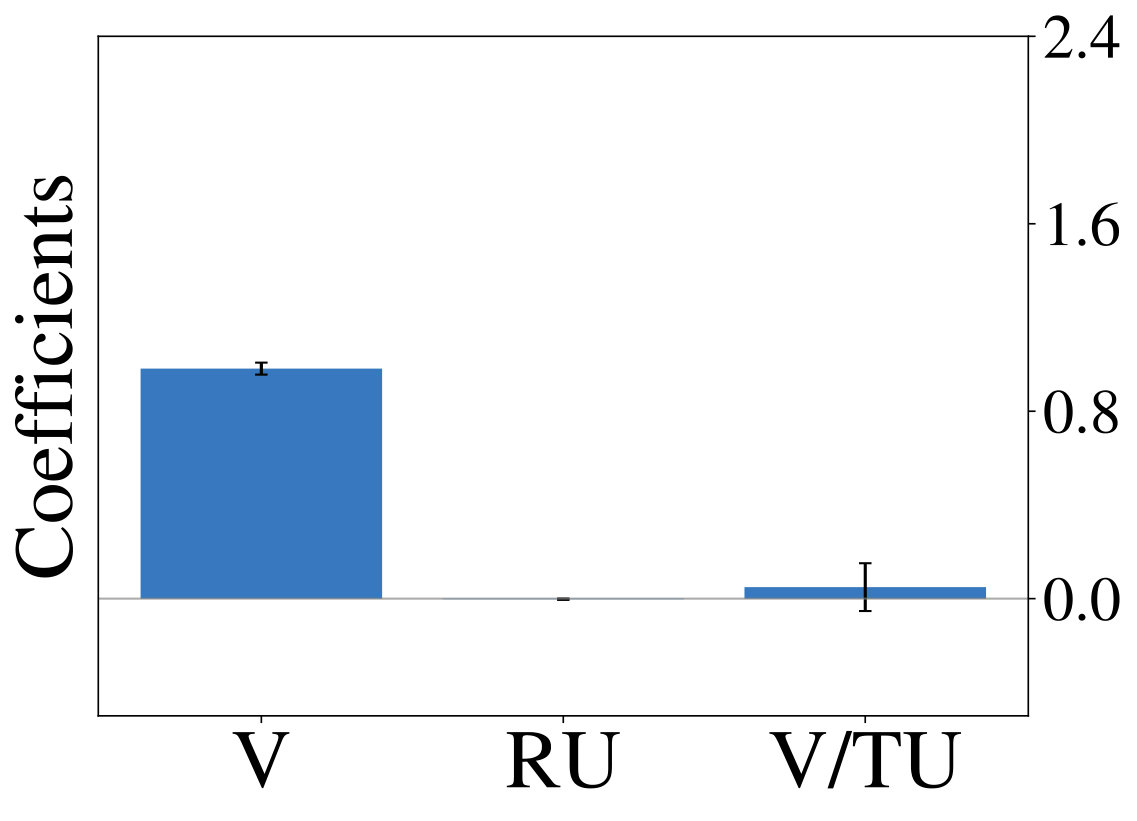 Figure 1
Figure 1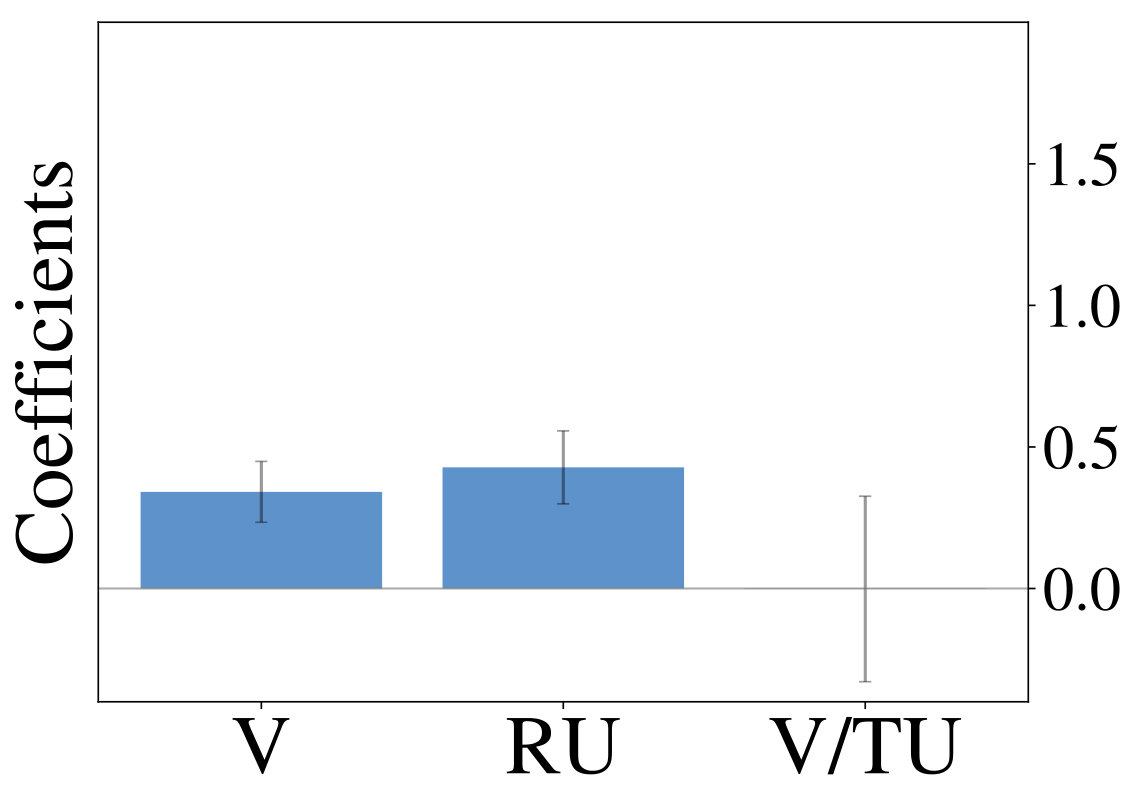 Figure 2
Figure 2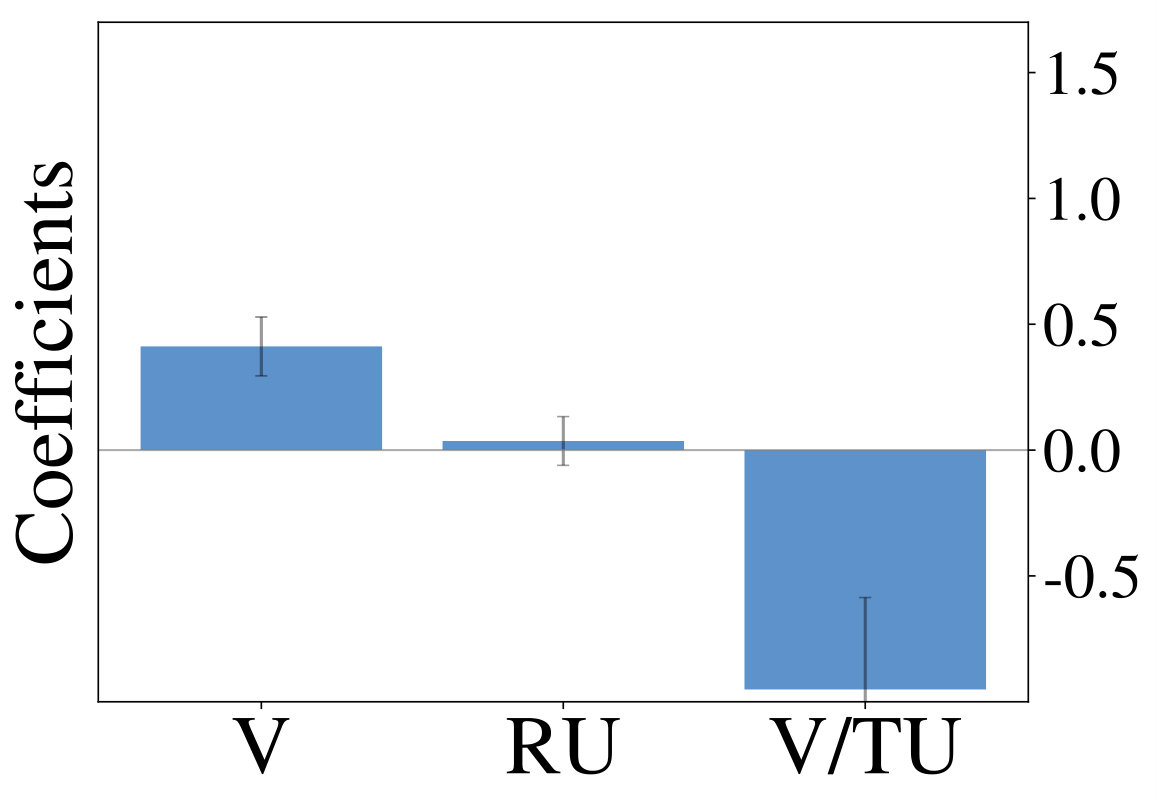 Figure 3
Figure 3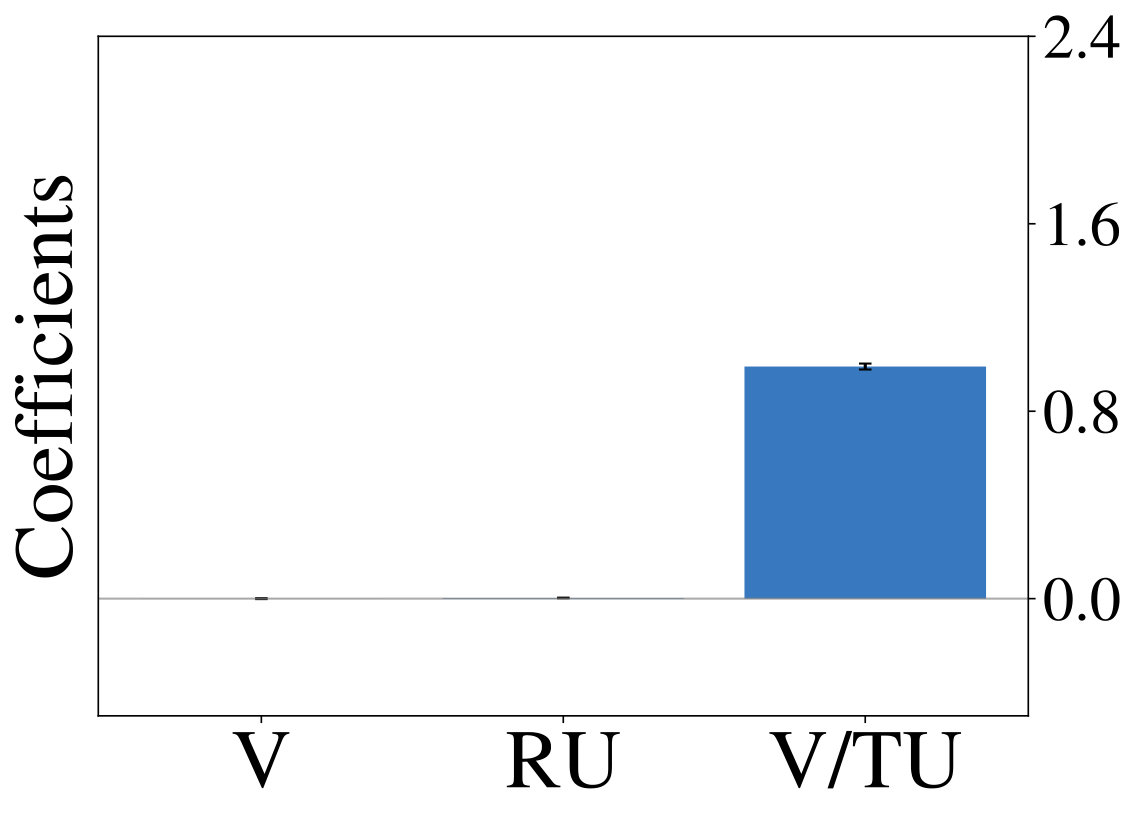 Figure 4
Figure 4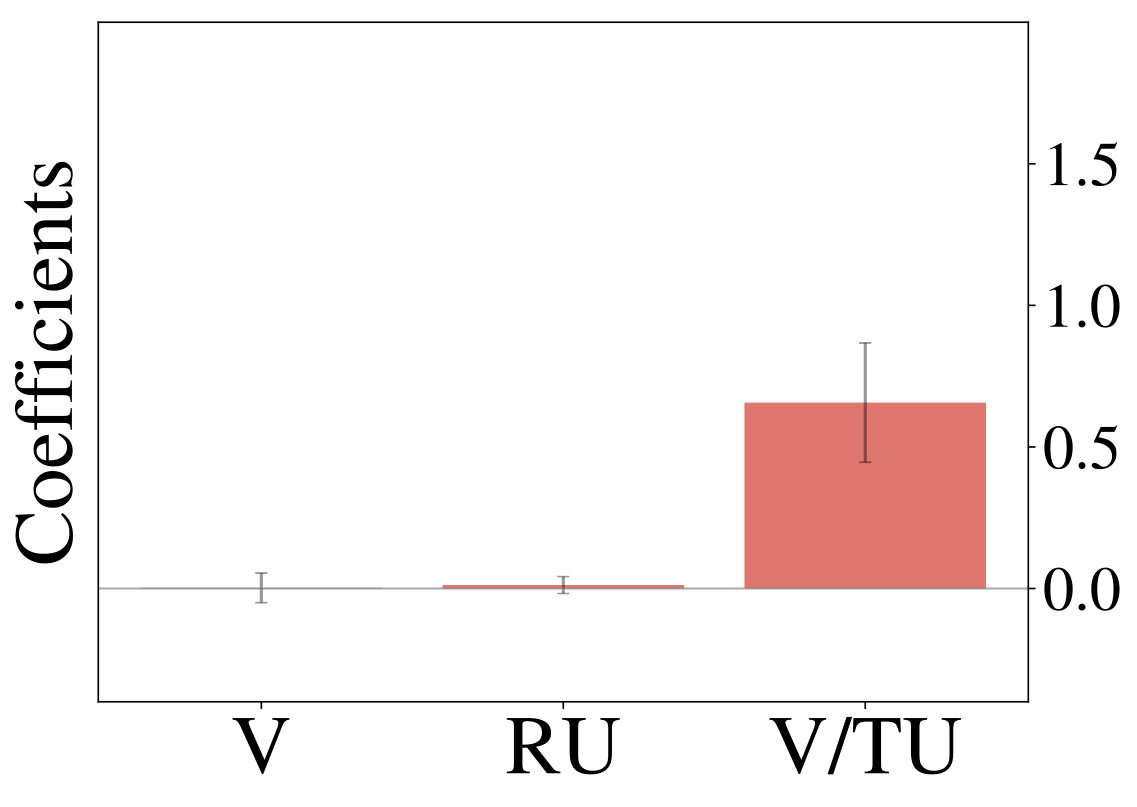 Figure 5
Figure 5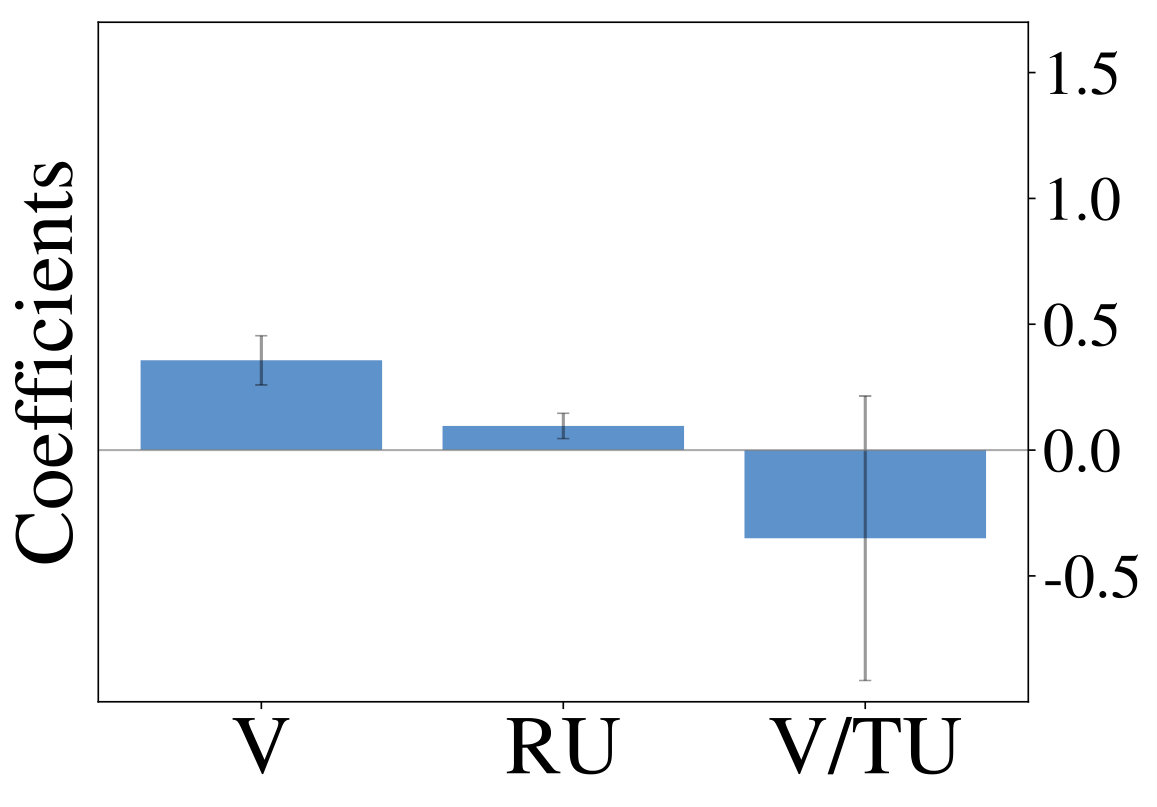 Figure 6
Figure 6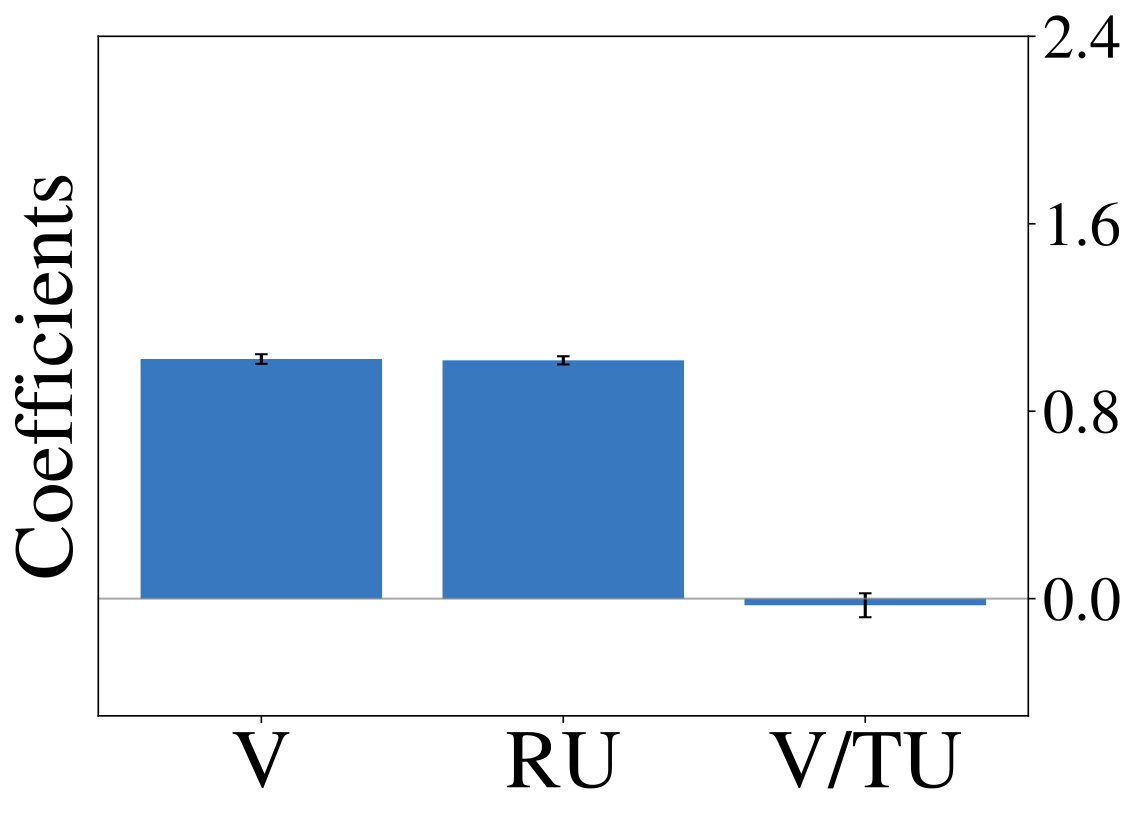 Figure 7
Figure 7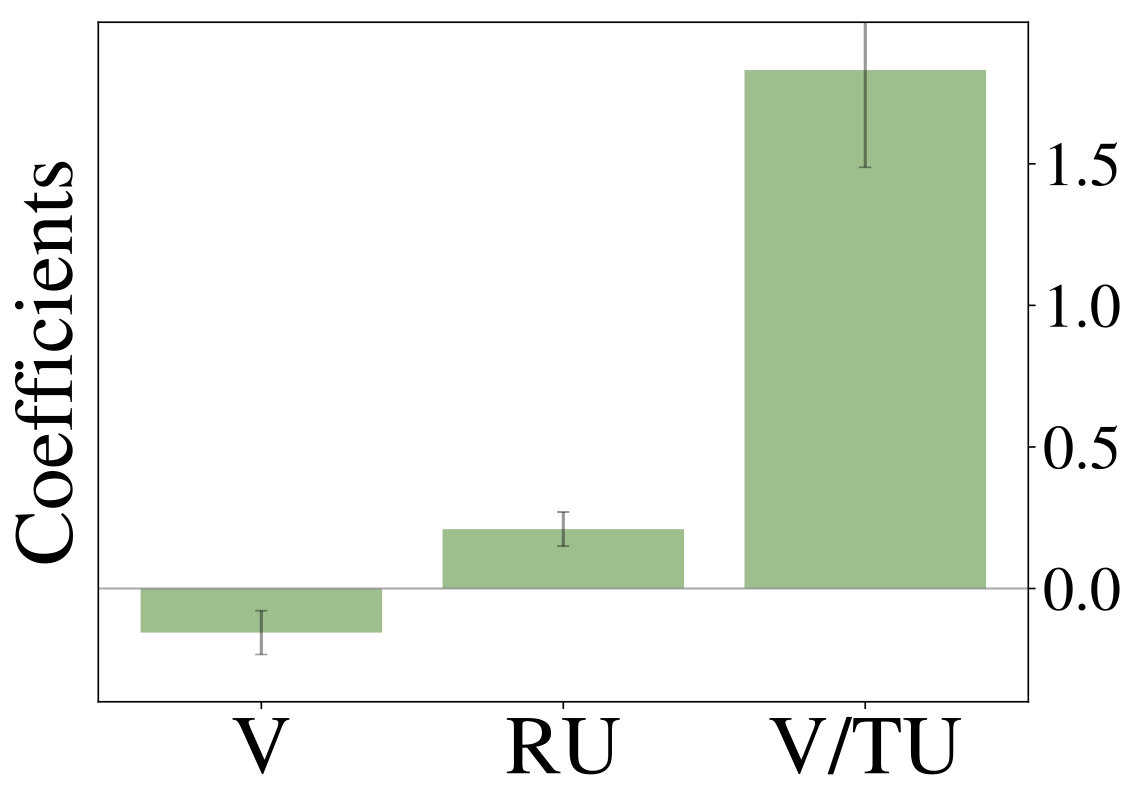 Figure 8
Figure 8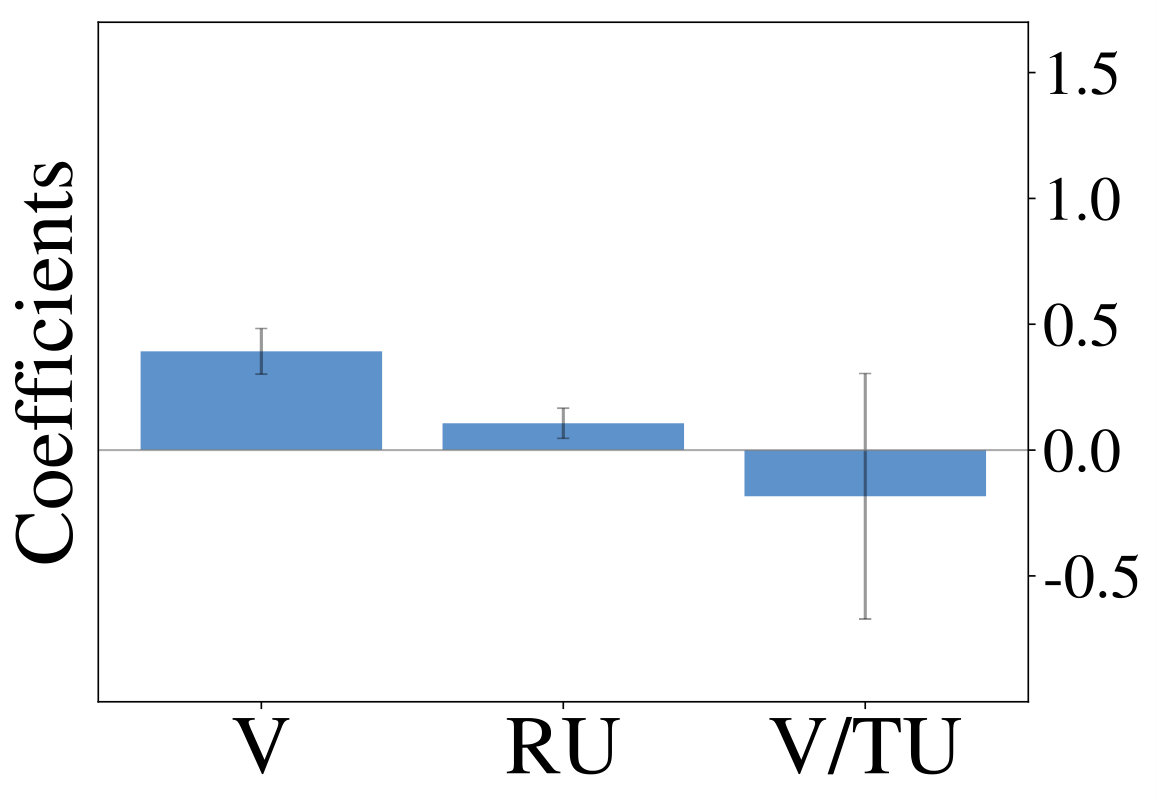 Figure 9
Figure 9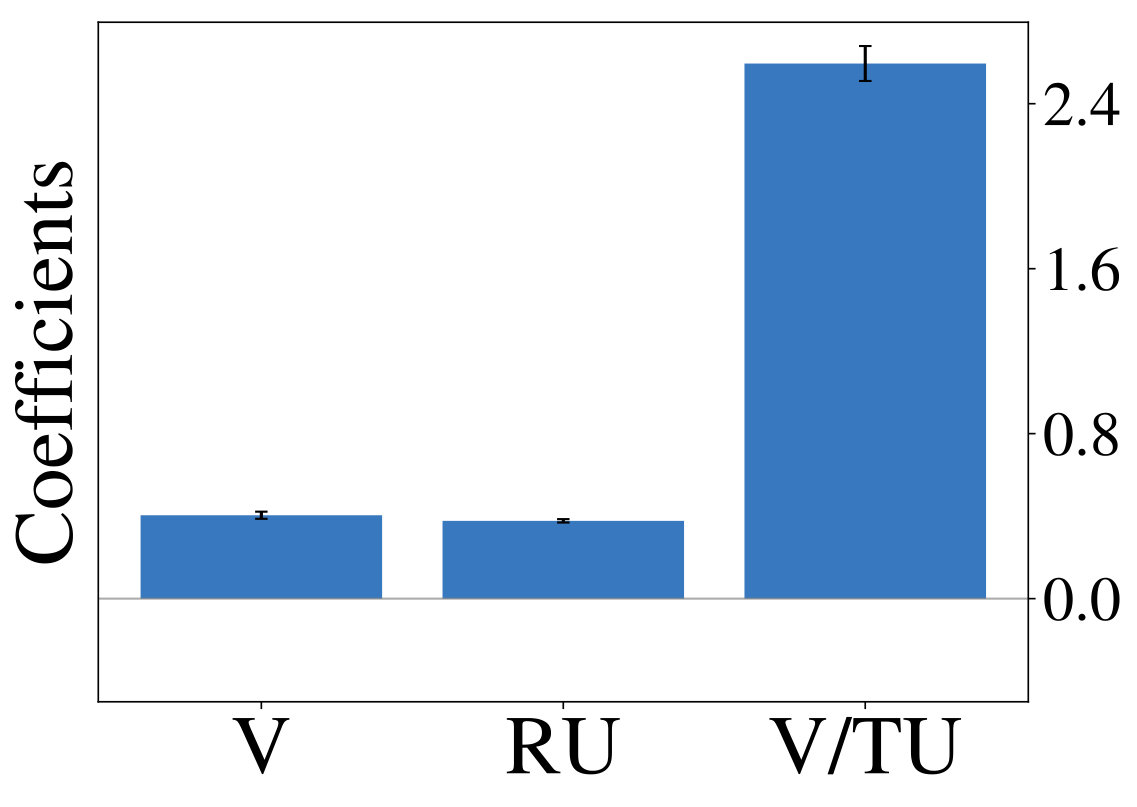 Figure 10
Figure 10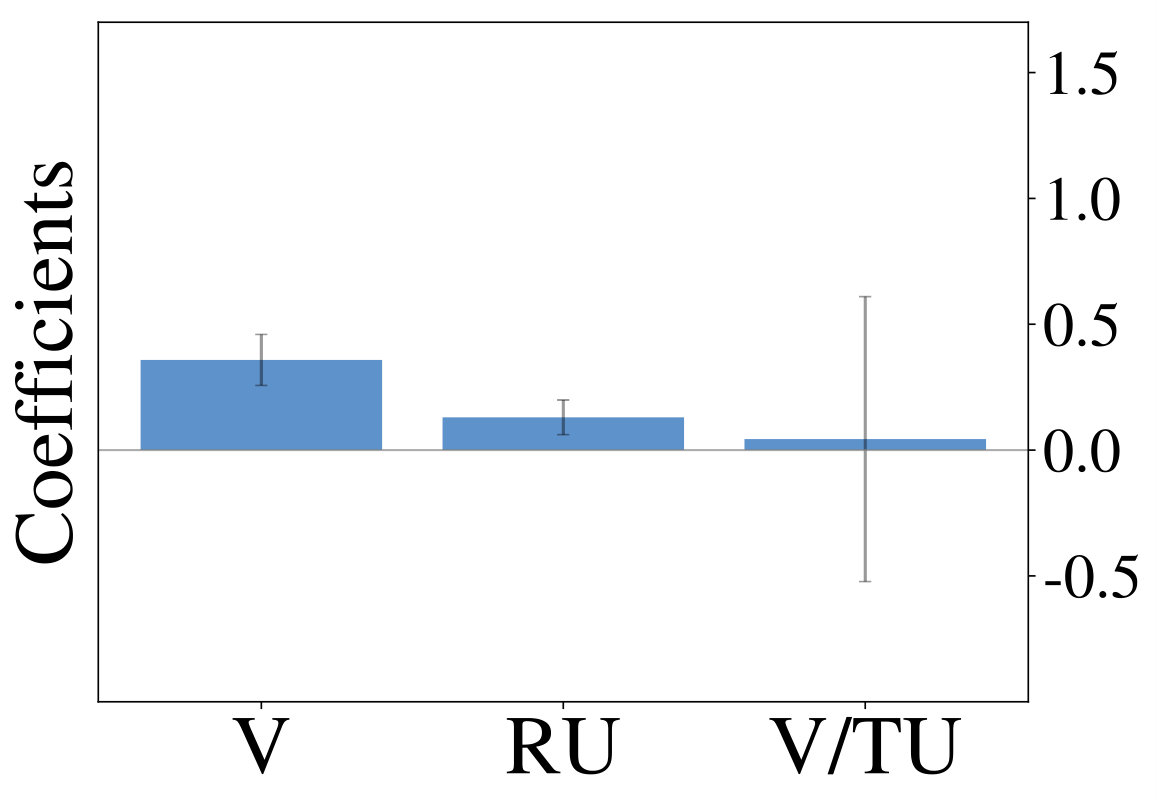 Figure 11
Figure 11 Figure 12
Figure 12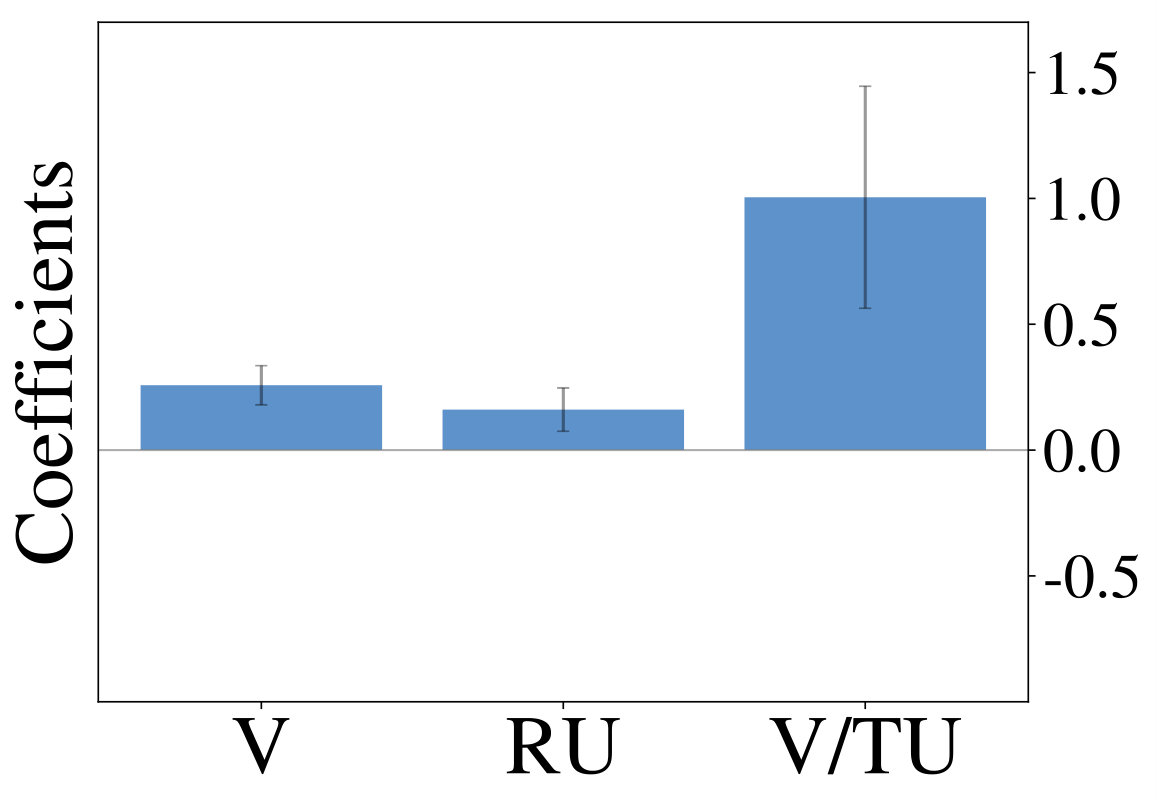 Figure 13
Figure 13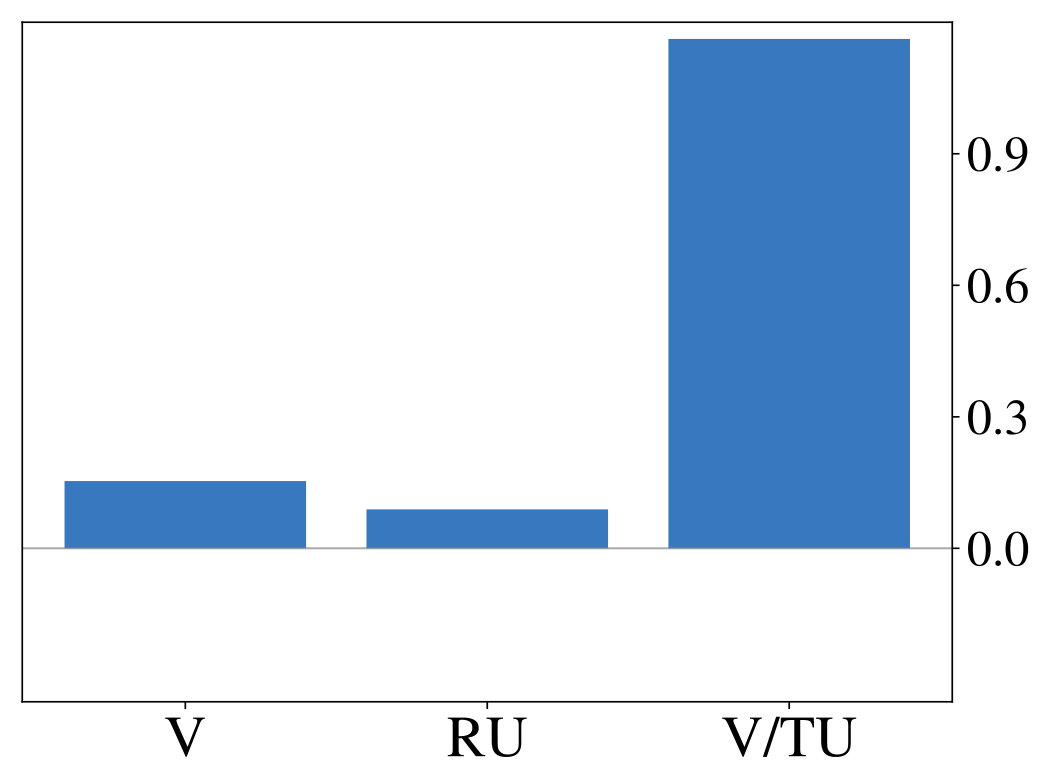 Figure 14
Figure 14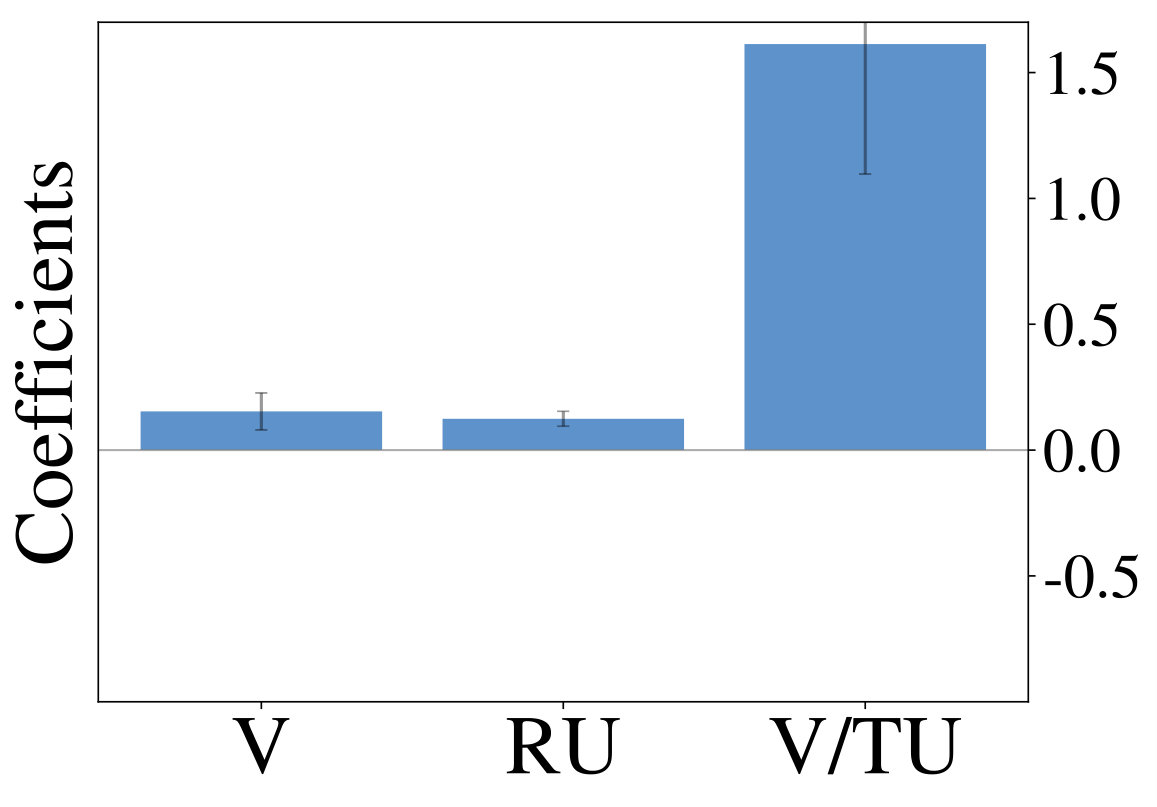 Figure 15
Figure 15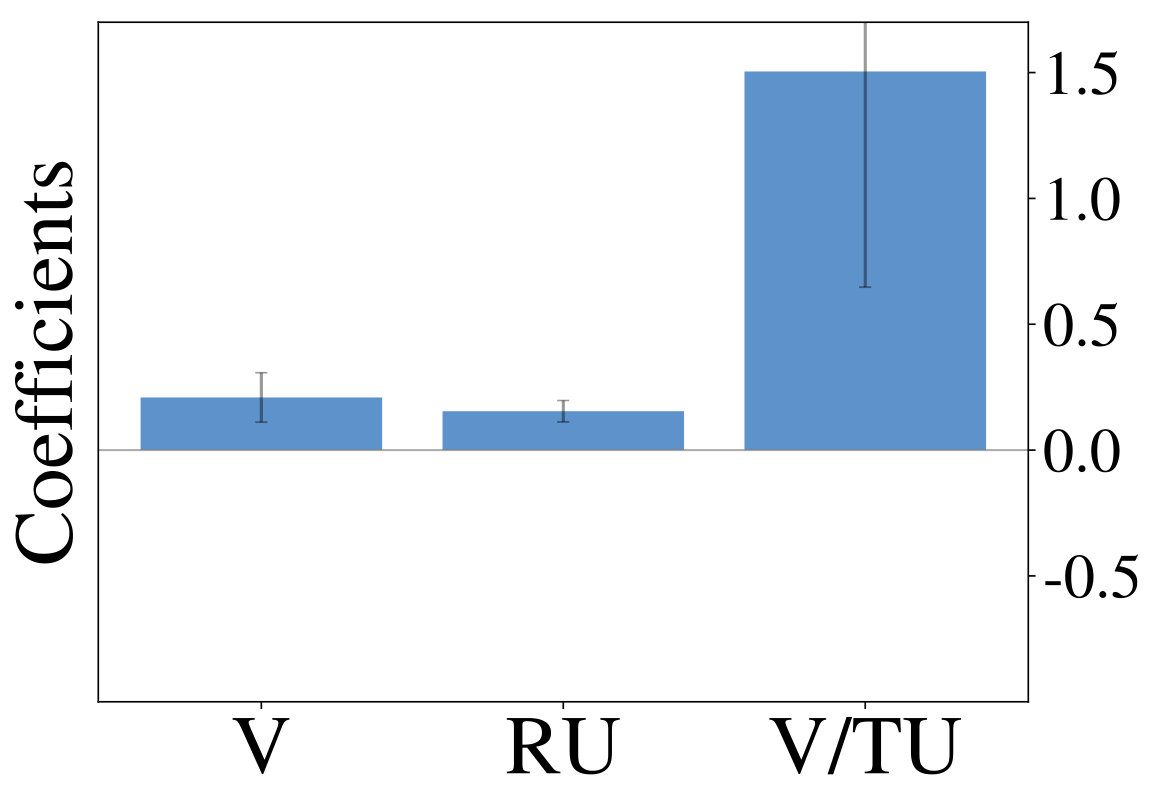 Figure 16
Figure 16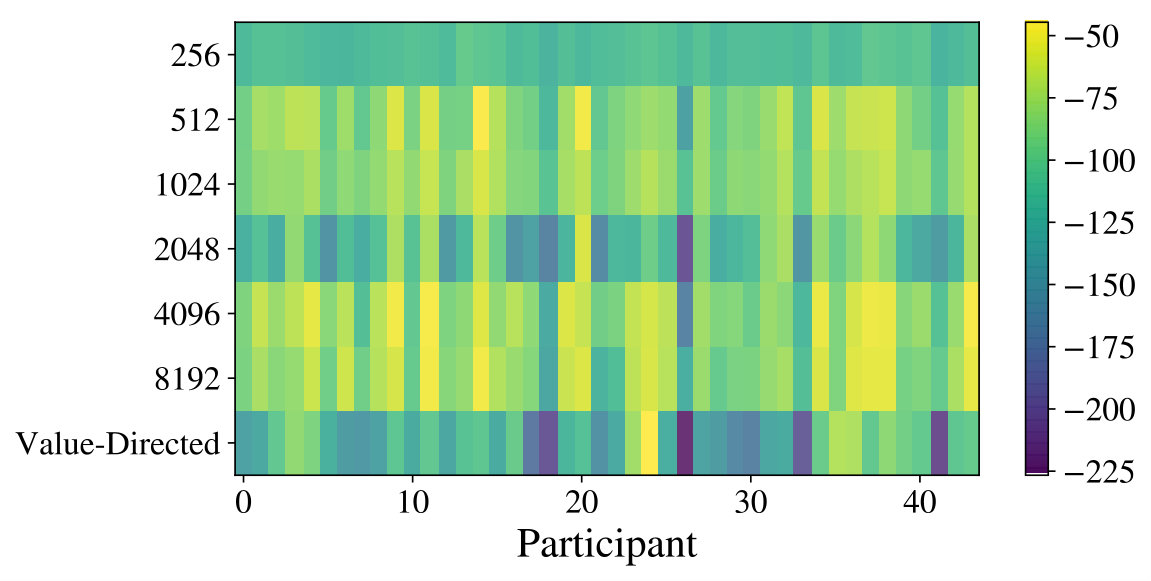 Figure 17
Figure 17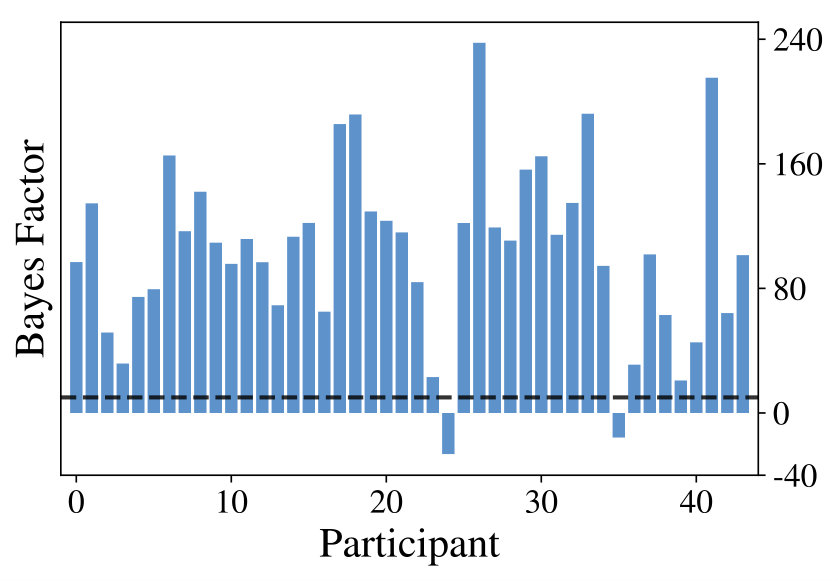 Figure 18
Figure 18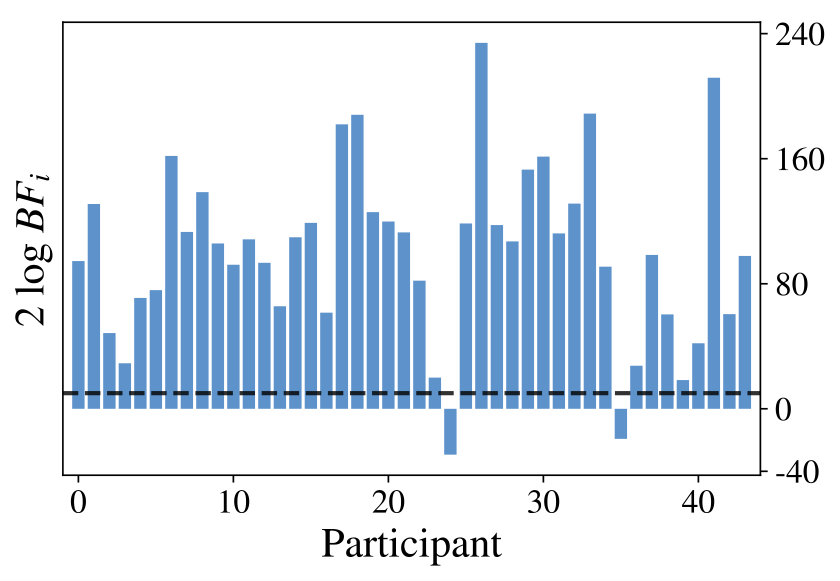 Figure 19
Figure 19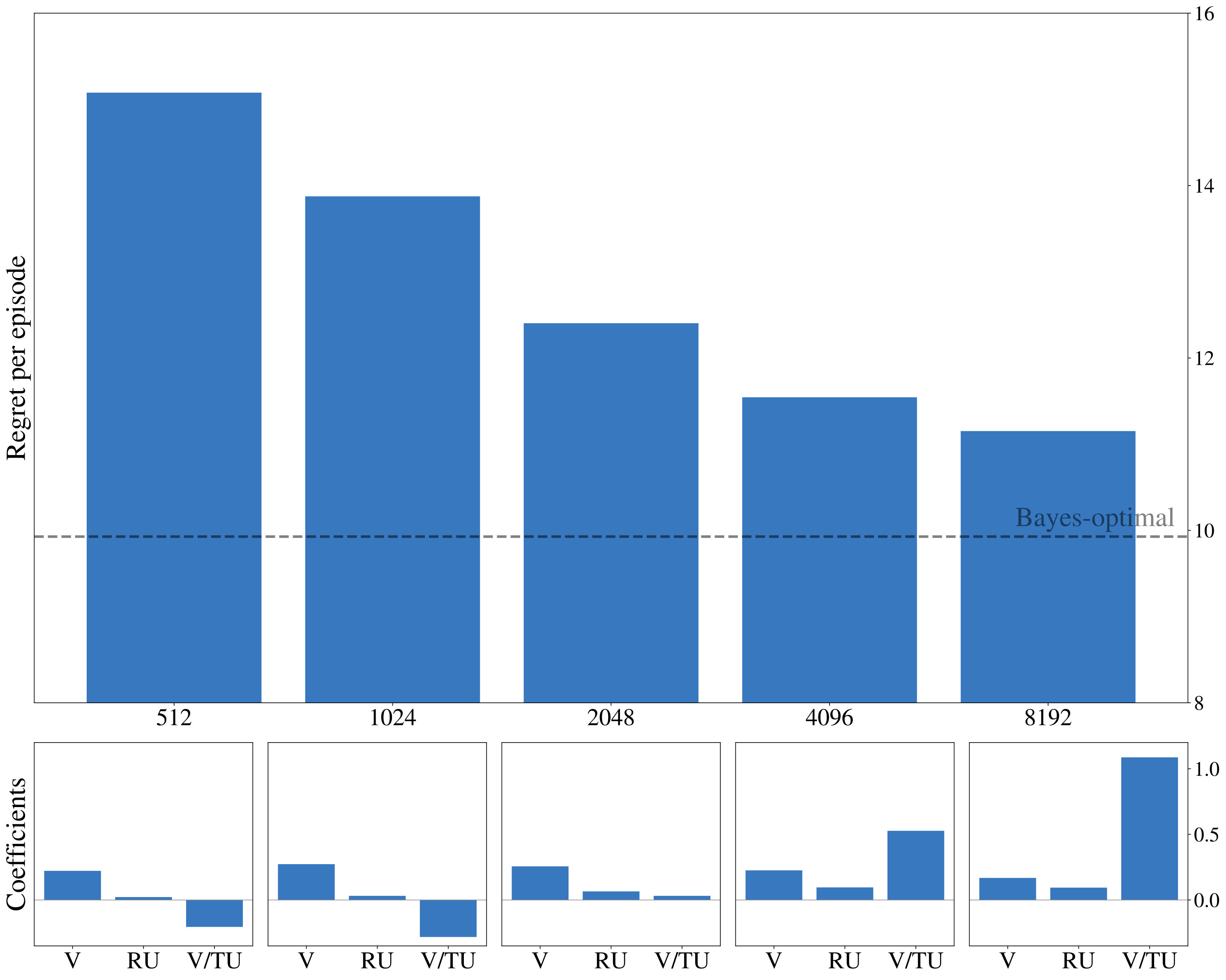 Figure 20
Figure 20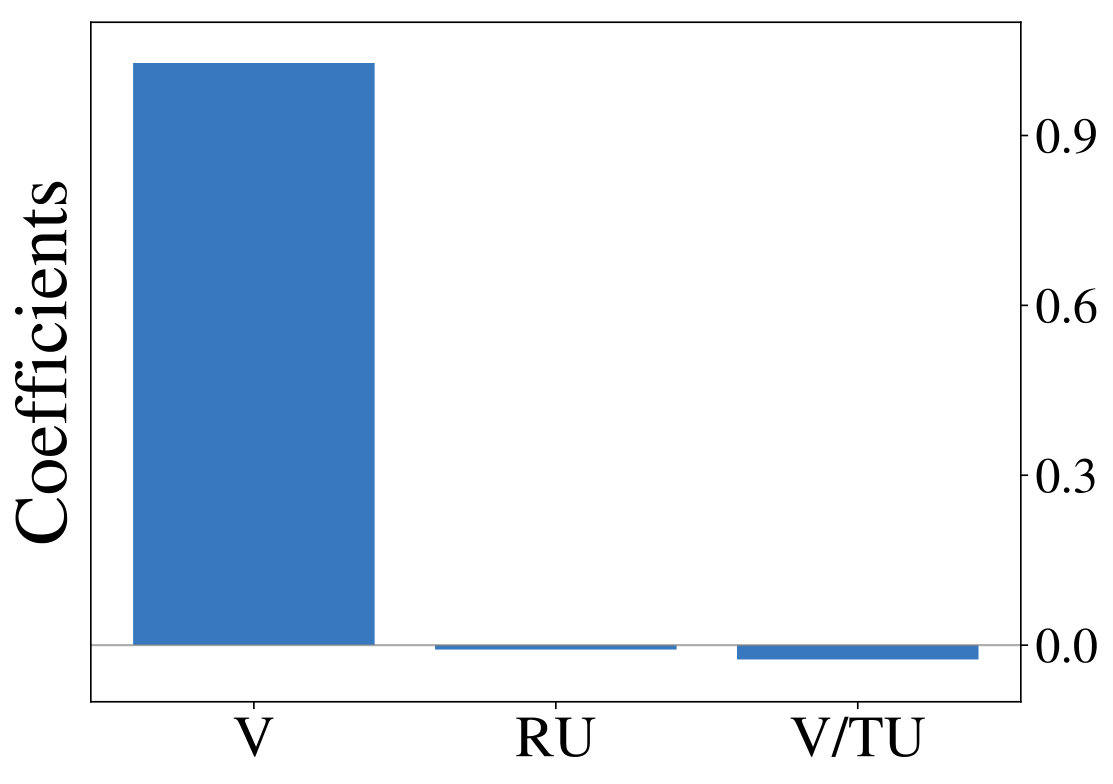 Figure 21
Figure 21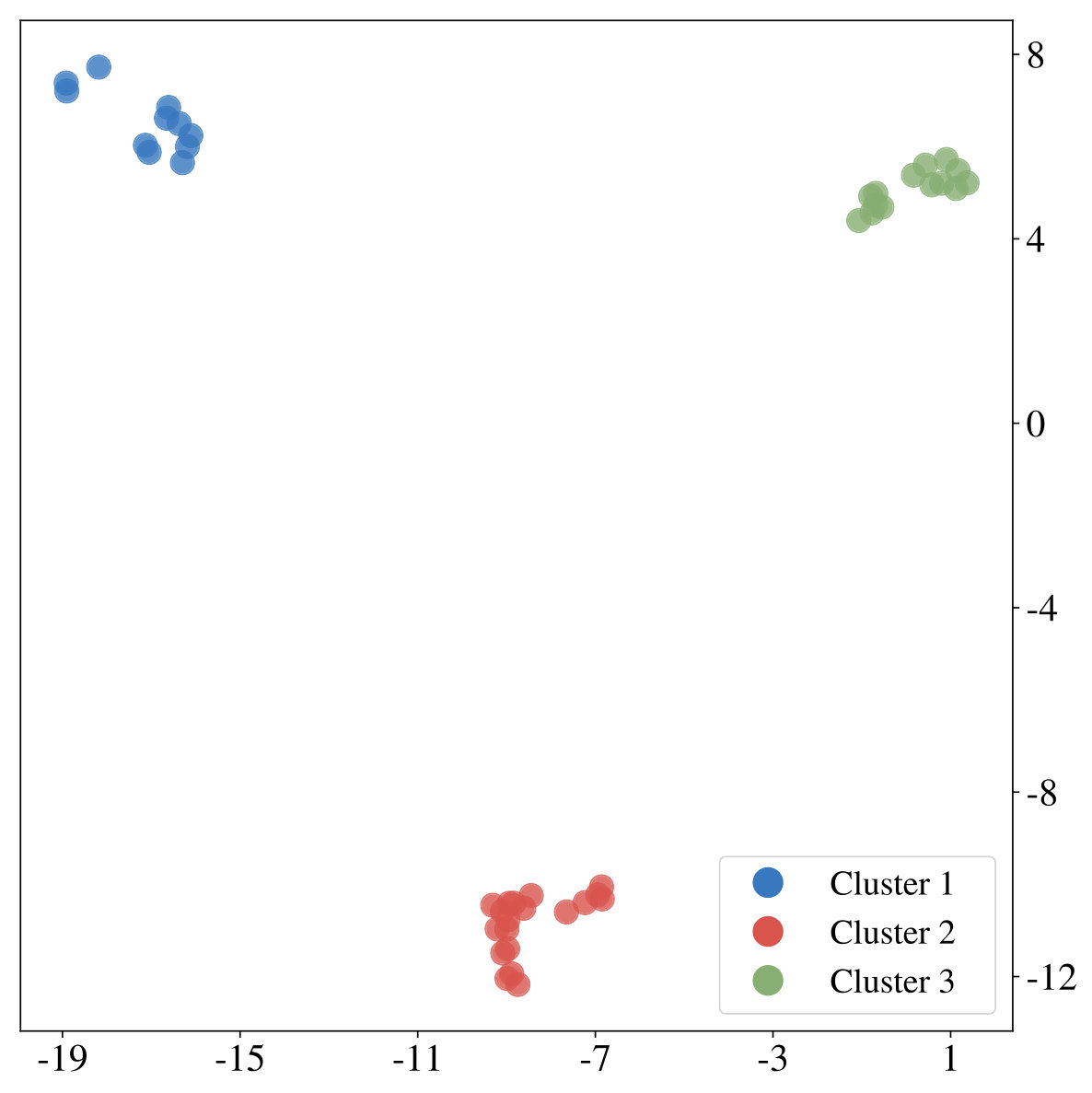 Figure 22
Figure 22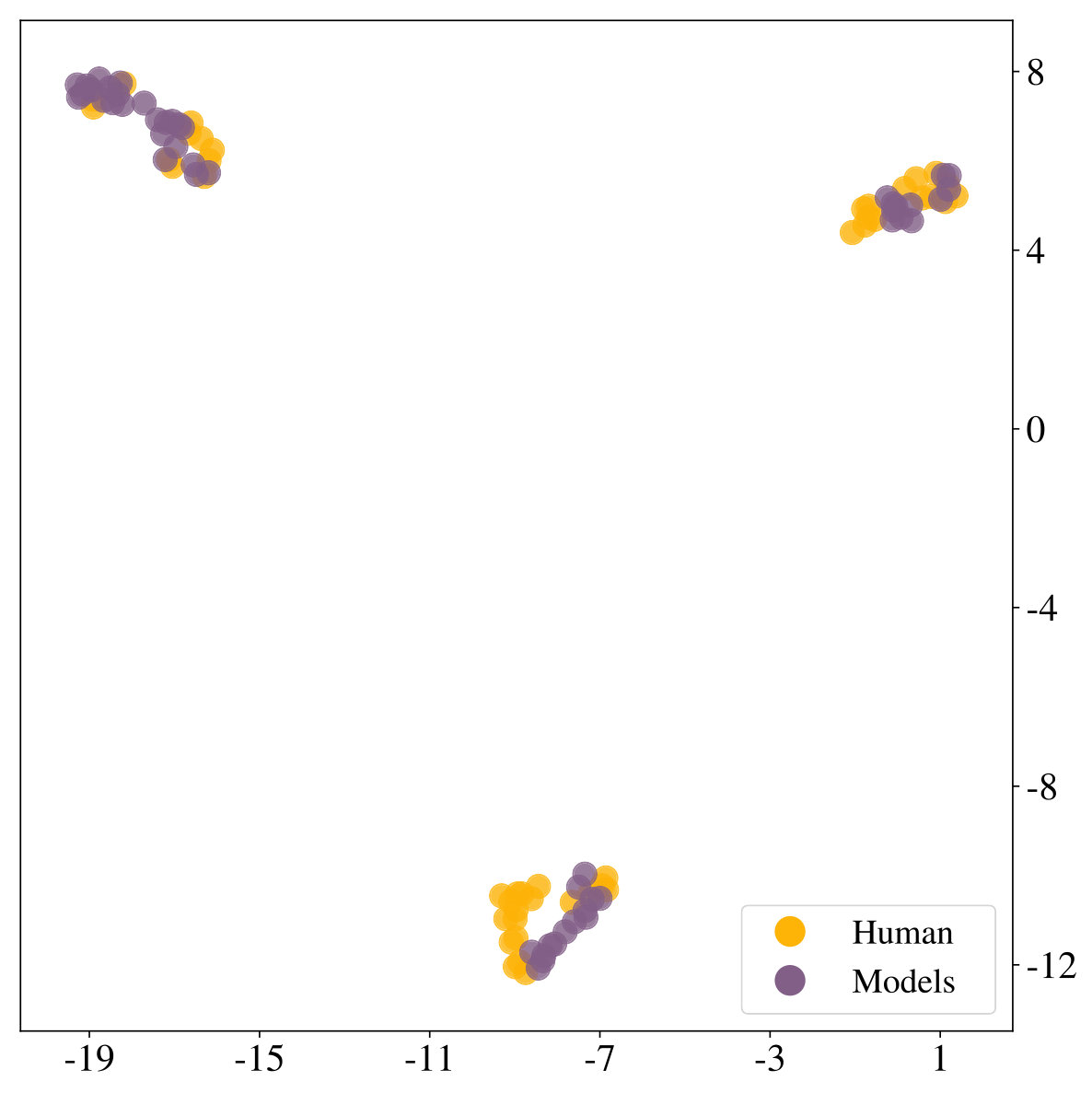 Figure 23
Figure 23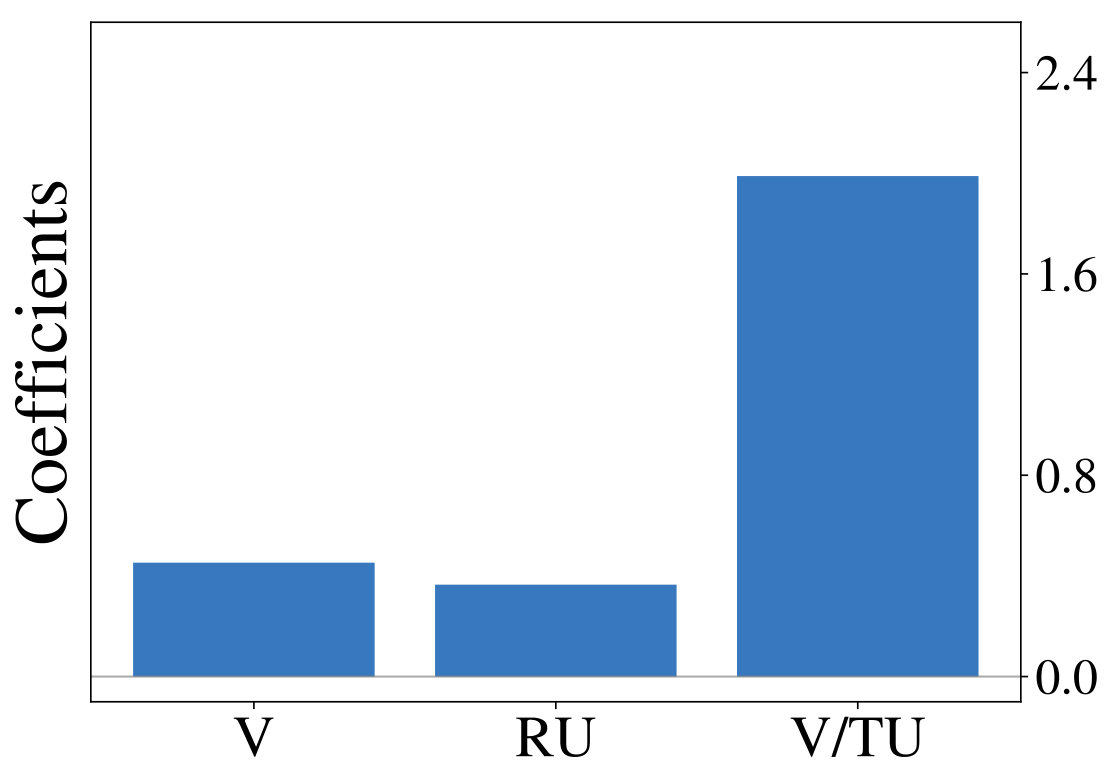 Figure 24
Figure 24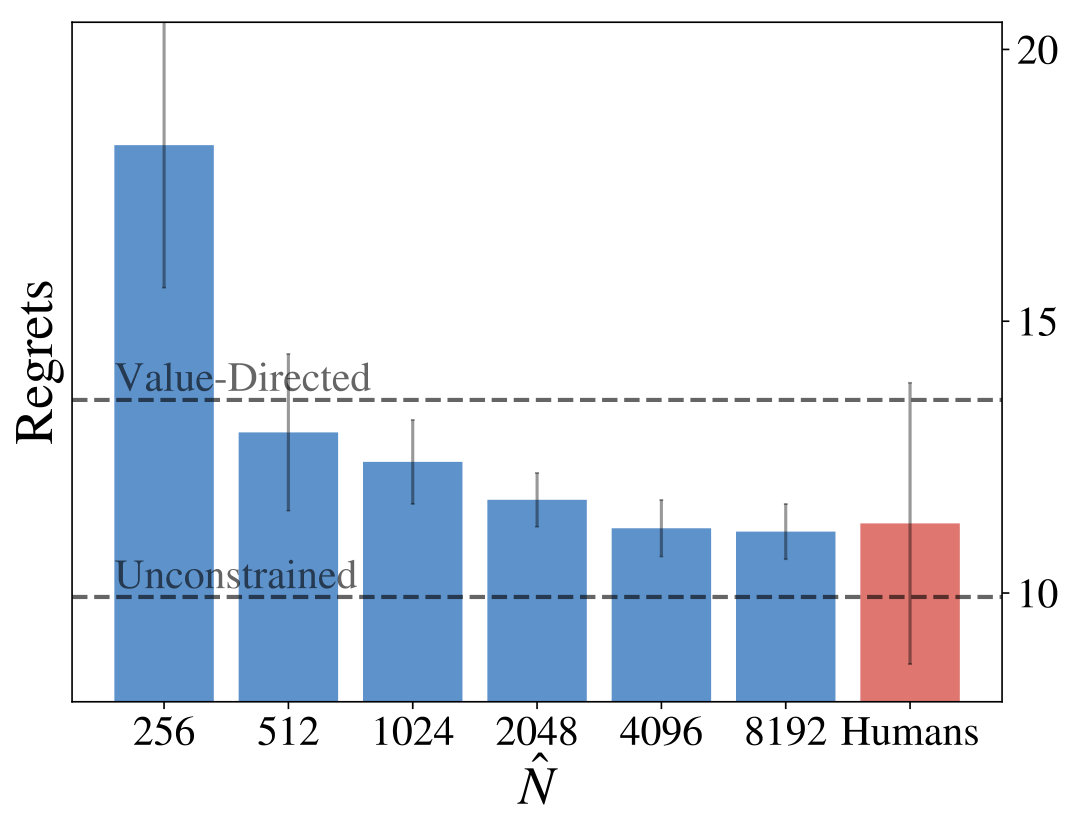 Figure 25
Figure 25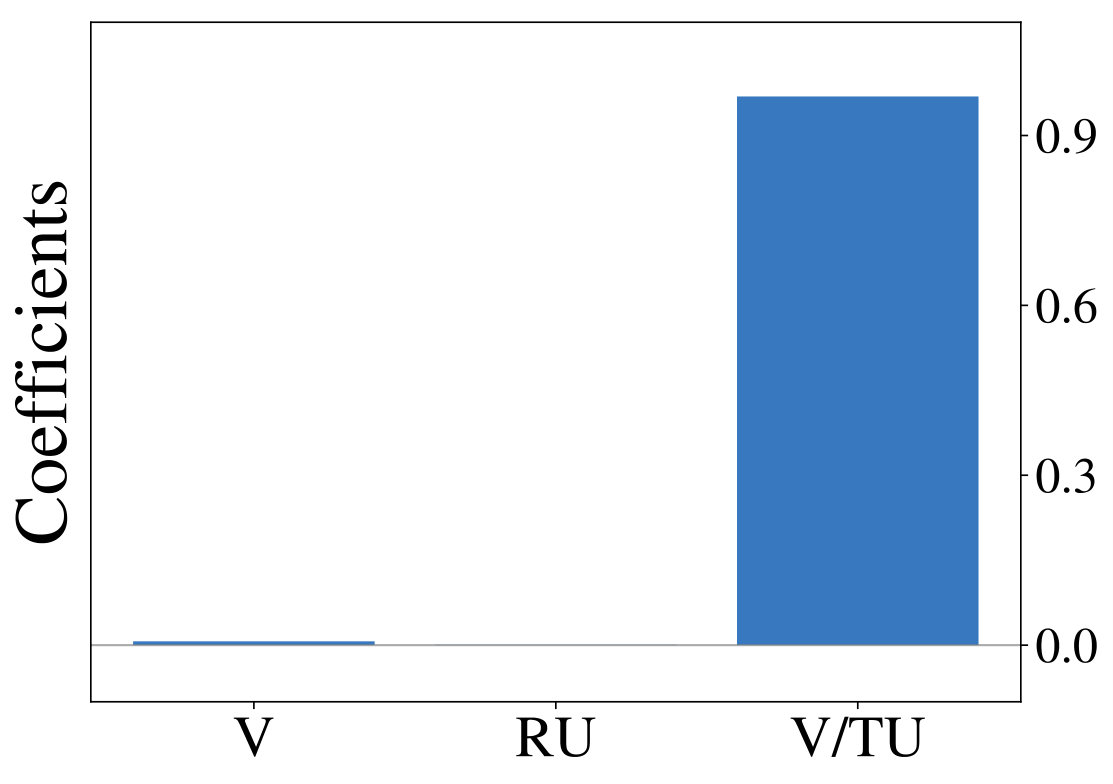 Figure 26
Figure 26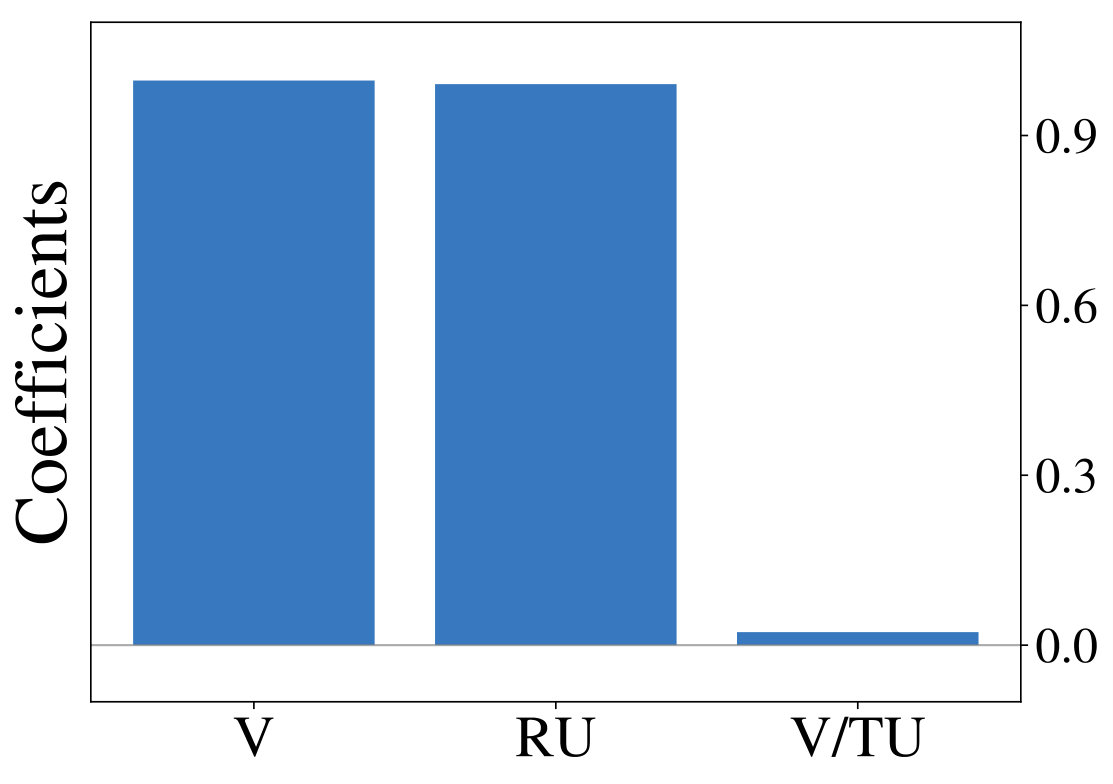 Figure 27
Figure 27Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsExplainable Artificial Intelligence (XAI) · Advanced Bandit Algorithms Research · Machine Learning and Data Classification
Where Do Heuristics Come From?
Marcel Binz ([email protected])
Department of Psychology, Theoretical Neuroscience Group
Philipps-Universität Marburg \ANDDominik Endres ([email protected])
Department of Psychology, Theoretical Neuroscience Group
Philipps-Universität Marburg
Abstract
Human decision-making deviates from the optimal solution, i.e. the one maximizing cumulative rewards, in many situations. Here we approach this discrepancy from the perspective of computational rationality and our goal is to provide justification for such seemingly sub-optimal strategies. More specifically we investigate the hypothesis, that humans do not know optimal decision-making algorithms in advance, but instead employ a learned, resource-constrained approximation. The idea is formalized through combining a recently proposed meta-learning model based on Recurrent Neural Networks with a resource-rational objective. The resulting approach is closely connected to variational inference and the Minimum Description Length principle. Empirical evidence is obtained from a two-armed bandit task. Here we observe patterns in our family of models that resemble differences between individual human participants.
Keywords: Bounded rationality; computational rationality; variational inference; reinforcement learning; meta-learning; individual differences; multi-armed bandit
Introduction
In this work we study human decision-making strategies on a stationary multi-armed bandit task. These are among the simplest sequential decision-making problems, that require reasoning about trade-offs between exploration and exploitation. In the special case of an infinite horizon and geometric discounting their Bayes-optimal solution is the Gittins index strategy (?, ?), while in general it is defined as the result of a planning process in an augmented Markov Decision Process (?, ?). Prior work however suggests, that several heuristics appear to be favourable as a model of human decision-making, when compared to the Bayes-optimal solution (?, ?, ?).
Understanding human cognition in terms of heuristics has been a major theme in cognitive science over the past decades (?, ?, ?, ?). They can be viewed as crude, but realizable, approximations of optimal behavior. Heuristics are thus connected to the idea of rationality under resource constraints, which is commonly referred to as bounded rationality (?, ?), computational rationality (?, ?), or resource-rationality (?, ?). Examples for resource constraints include related prior experience on a given task, limited capacity of our brain or restricted deliberation times. For a more general overview of computational rationality we refer the reader to ? (?). Here we are interested in the hypothesis, that humans employ a learned, resourced-constrained approximation of an optimal decision-making strategy. More specifically we show, that different, potentially sub-optimal, human strategies emerge naturally in artificial learning systems when varying the strength of the constraints placed upon them. For a realization of this principle, we rely on information-theoretic concepts, similar to the approach of ? (?).
We instantiate a particular kind of such resource-rational agents using recent advances from the meta-learning literature (?, ?, ?). In this framework the algorithm to be learned is parametrized by a Recurrent Neural Network (RNN). RNNs are known to be Turing-complete and hence are in theory able to realize any algorithm (?, ?). The RNN is trained on a set of related tasks to act as an independent Reinforcement Learning algorithm for solving the original problem. We treat all parameters of the RNN as random variables and infer approximate posterior distributions by solving a regularized optimization problem. Varying the regularization factor leads to a spectrum of resource-rational algorithms, each possessing different properties. Models with large constraints need to rely more on prior assumptions and thus prefer simple strategies, while models with weaker constraints will approach the optimal solution (up to the representational capabilities of the RNN and the limitations of the meta-learning procedure).
The resulting approach is closely related to the Minimum Description Length (MDL) principle (?, ?, ?), which asserts that the best model is the one, that leads to the best compression of the data, including a cost for describing the model. The bits-back argument establishes a link between the MDL principle and Bayesian learning (?, ?), opening up connections to Bayesian theories of cognition (?, ?). Indeed several heuristics have been recently interpreted as Bayesian models under strong priors (?, ?).
Our hypothesis is validated on a classical two-armed bandit task. However we view multi-armed bandits merely as the first step towards investigating more complex tasks and the proposed algorithm is not limited to any specific problem class. The following section first introduces the framework in more general terms, before considering multi-armed bandits as a special case. We then identify different strategies of human participants and subsequently show how the proposed class of models captures important characteristics of human behavior on both a qualitative and quantitative level. Our results indicate, that the seemingly sub-optimal decision strategies used by humans might be a consequence of the constraints under which these very strategies are learned.
Methods
Reinforcement Learning
Let be a Markov Decision Process (MDP), with a set of states , a set of actions , a joint distribution over the next state and a scalar reward signal, describing the dynamics of the environment, and a discount factor . The objective of a Reinforcement Learning (RL) agent is to find a policy , that maximizes the discounted, expected return without having direct access to the true underlying dynamics .
Learning Reinforcement Learning Algorithms
Following the approach of ? (?, ?) we want to learn a RL algorithm for solving a MDP sampled from a distribution over MDPs. We parametrize the algorithm to be learned with a Recurrent Neural Network (RNN), in form of a Gated Recurrent Unit (?, ?), followed by a linear layer. The set of all model parameters is denoted with in the following. The RNN takes previous actions and rewards as inputs in addition to the current state, making the output a function of the entire history . A good algorithm has to integrate information from the history in order to identify the currently active MDP, based on which it subsequently has to select the appropriate strategy. The RNN is trained to accomplish this using standard model-free RL techniques. In this work we utilize -step Q-Learning (?, ?), although in theory any other algorithm could be applied as well. The RNN implements a freestanding RL algorithm through its recurrent activations after training is completed (the parameters of the RNN are held constant during evaluation). Throughout this work we use the abbreviation LRLA – for learned Reinforcement Learning algorithm – to refer to this kind of model. Alternatively we can view this procedure as a model-free algorithm for partially observable MDPs, where the hidden information consists of the currently active task.
Resource-Rational Decision-Making
We consider maximizing the following regularized objective for inferring a distribution over parameters of LRLAs:
[TABLE]
where the hyperparameter controls how much the posterior is allowed to deviate from the prior in terms of the Kullback-Leibler (KL) divergence. We assume a likelihood , that factorizes over data points and we approximate each factor with a normal distribution of fixed scale : . In our setting corresponds to the RNN output after seeing history and corresponds to the n-step return . The corresponding policy is derived as follows:
[TABLE]
Setting to a specific value can be interpreted as implicitly defining a constraint on . Importantly the KL term determines how much the model parameters can be compressed in theory (?, ?). Hence our models are resource-constrained with regard to a hypothetical lower bound on their storage capacity. Intuitively, if the regularization factor is large, parameters are forced to match the prior closely. In this work we employ priors favoring simple functions, hence models are only allowed to realize more complex functions as .
Bayesian Interpretation
If we set , we recover the evidence lower bound (ELBO) as an objective for performing variational inference. In the setting of large data-sets subsampling techniques are often employed to approximate Equation 1 using mini-batches of size M with an appropriately scaled log-likelihood term:
[TABLE]
If data arrives in sequential fashion, as it does in the RL setting, the data-set size is not known in advance and has to be treated as an additional hyperparameter. This leads to a Bayesian interpretation of Equation 1 even for . For any values of and maximizing Equation 1 is equivalent to performing stochastic variational inference with an assumed data-set size of . In practice we optimize a by scaled version of Equation 1, which leads to as a factor for the KL term.
In the following section we investigate whether we can understand individual differences in human decision-making in terms of optimal solutions to Equation 1 for varying values of . It is worth clarifying, that we are only interested in the computational aspects of this hypothesis, i.e. we want to test, whether human decision-making can be characterized through resource-rational strategies. We do not attempt to answer how this objective is realized on an algorithmic or implementational level.
Technical Details
We maximize Equation 1 using standard gradient-based optimization techniques. For this we simulate environments in parallel and update the model at the end of each episode. All models in this work employ a group horseshoe prior, which can be viewed as a continuous relaxation of a spike-and-slab prior (?, ?), over their weights:
[TABLE]
and we represent the approximate posterior through a fully factorized distribution as proposed in (?, ?). The hyperparameter of the horseshoe prior is fixed to . The horseshoe prior is a sparsity-inducing prior, which causes our models to implement simple functions in absence of any experience. During training we approximate the expectation of the log-likelihood term with a single sample from and make use of the reparametrization trick (?, ?). Resampling of weight matrices is done only at the beginning of an episode as proposed in ? (?, ?). Target values are computed using the maximum a posteriori estimate of a separate target network (?, ?, ?). For additional details we refer the reader to the publicly available implementation111https://github.com/marcelbinz/MDLDQN.
Multi-Armed Bandits
Experiments in the following section involve a multi-armed bandit task. These are MDPs consisting of a single state. At each step an agent selects one out of multiple actions and is rewarded according to an unknown, stationary distribution based on its choice. This interaction is repeated times.
The trade-off between exploiting good options and exploring yet unknown ones is the central theme in multi-armed bandits (and in RL in general). Methods for resolving this exploration-exploitation dilemma can be categorized in two major groups: directed and random exploration strategies. Directed exploration attempts to gather information about uncertain, but learnable, parts of the environment, while random exploration injects stochasticity of some form into the policy. ? (?) showed, that these two principles can be distinguished exactly under certain conditions. For this we consider a two-armed bandit task with normal distributions over both the mean of rewards for each arm and their reward noise at each time-step. Let be an independent normal prior over expected rewards for each action and be the posterior after interactions. Many popular strategies can be formulated using the parameters of these distributions. Define:
[TABLE]
constitutes the estimated difference in value, while and describe relative and total uncertainty respectively. Choice probability in Thompson sampling (an example for random exploration) is only a function of and , while it is a function of and for the UCB algorithm (an example of directed exploration). Figure 1 (middle row) shows definitions of all strategies under consideration. For a given set of observed trajectories one can fit a probit regression model to infer the importance of factors from Equation Multi-Armed Bandits:
[TABLE]
Analyzing the resulting coefficients can reveal, which exploration strategy generated the observations, as shown in Figure 1 (bottom row). We utilize this form of analysis throughout the following sections.
Empirical Analysis
Human Participants
We initially inspect human exploration strategies on a two-armed bandit task with episode length . The mean reward for each action is drawn from at the beginning of an episode and the reward in each step from . Intuitively we expect some participants to be more proficient at the task, for example because they have more experience at related problems (higher ), while the opposite is true for others. We rely on data gathered by ? (?), which contains records of 44 participants, each playing 20 of the aforementioned two-armed bandit problems. Figure 2 (middle) shows the result of fitted probit regression coefficients for individual participants. This analysis reveals three major subgroups within the population, each using a different set of strategies. We visualize coefficients of three example participants (Figure 2, left) and observe, that a large fraction is well-described through Thompson sampling (clusters 2 and 3), while other participants have tendencies towards a mixture of strategies (cluster 1).
Learned Reinforcement Learning Algorithms
Next we show, that optimizing LRLAs with different regularization factors leads to the emergence of diverse exploration pattern. We train otherwise identical models for on the same two-armed bandit task until convergence and report average results over 10 random seeds unless otherwise noted. Equation 1 is approximated with a batch of samples from complete episodes of 16 parallel simulations and gradient-based optimization is performed using Adam (?, ?). Figure 3 (left) shows, that performances continuously improves as increases, confirming our expectation that models become more sophisticated for large . Fitting the aforementioned probit regression model to the resulting policies (Figure 3, right) reveals value-based characteristics at one end of the spectrum. Towards the other end we observe coefficients, that slowly transition to those of the unconstrained ( = 0) model.
Modelling Human Behavior
We are mainly interested in whether the set of resource-constrained LRLAs can help us to understand human behavior on an individual level. To answer this question, we compare the optimized models to human decision-making strategies in terms of the probit regression analysis. We visualize the regression coefficients for 50 models (10 for each value of , excluding ) alongside those of the human participants in Figure 2 (right). Although some parts of the low-dimensional embedding are over- and underrepresented, the overall variation of human exploration strategies is captured by the resource-constrained LRLAs.
Model Comparison
The regression analysis performed so far provides only qualitative indicators for our hypothesis. In order to obtain a quantitative measure for the explanatory power of the proposed hypothesis, we performed a Bayesian model comparison. Figure 4 (left) shows log-likelihoods for each participant and model. We observe, that different participants are modelled best with different values of .
To verify that the class of resource-constrained LRLAs contains a good model, we compute Bayes factors (BF) between the marginal probability of the resource-constrained LRLAs and a value-directed policy:
[TABLE]
where refers to all actions taken by a specific participant and is a prior that corrects for multiple comparisons across different values of . The resulting s (see Figure 4, right) reveal strong evidence for 42 of the 44 participants in favor of the class of resource-constrained LRLAs, when compared with the baseline. This indicates, that one of the models in explains the participant’s behavior much better than the value-directed policy. There are nine participants best described by letting , nine by , 20 by and six by . This heterogeneity highlights, that the model class is able to accomodate individual differences between human participants.
Finally we want to show, that the proposed class of models captures exploration strategies across all participants better than any standard exploration strategy alone. To verify this, we computed Bayes factors between and two baseline exploration strategies: and . We find against Thompson sampling and against UCB, indicating that our class of models is overall better at representing exploration strategies for all participants in comparison to any single, fixed strategy.
Discussion
In this work we proposed a justification for seemingly sub-optimal human strategies in sequential decision-making problems based on the idea of computational rationality. We view human decision-making as an instance of a learned, resource-constrained RL algorithm. This is formalized through learning distributions over parameters of a meta-learning model with a regularized, resource-rational objective. The emerging spectrum of strategies resembles characteristics of human decision-making without being explicitly trained to do so. Additional model comparison suggests, that the resulting resource-constrained LRLAs describe human policies well on a quantitative level. However, the correspondence between human behavior and the LRLA model class is not perfect. Looking at Figure 2 (right) we observe, that some clusters are not represented exactly. Furthermore it remains open, why none of the participants is best described through the model with . Accounting for these observations remains a question for future work.
The analysis on the two-armed bandit task presented in this work can be extended in several ways. Relating deliberation times to regularization factors could, for example, provide additional evidence for our hypothesis. It also remains to be seen whether our conclusions transfer to other sequential decision-making problems beyond the bandit setting. In this context we are especially interested in tasks, where descriptive models of individual human behavior consist of a set of different heuristics. We are also interested in methods, that allow us to disentangle resource-rational behavior from the Bayesian interpretation.
Recent work on model-free meta-learning methods, similar to the one employed in this work, indicates an emergence of model-based behavior (?, ?) and causal reasoning (?, ?) as well as the ability for few-shot learning (?, ?), properties supposedly absent in artificial systems. Having systems capable of such feats, opens the possibility for interesting studies on human cognition.
Acknowledgments
This work was supported by the DFG GRK-RTG 2271 ’Breaking Expectations’.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Cho et al. Cho et al. Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., Bengio, Y. (2014). Learning phrase representations using rnn encoder-decoder for statistical machine translation. ar Xiv preprint ar Xiv:1406.1078 .
- 2Dasgupta et al. Dasgupta et al. Dasgupta, I., Wang, J., Chiappa, S., Mitrovic, J., Ortega, P., Raposo, D., … Kurth-Nelson, Z. (2019). Causal reasoning from meta-reinforcement learning. Retrieved from https://openreview.net/forum?id=H 1lt Q 3R 9KQ
- 3Duan et al. Duan et al. Duan, Y., Schulman, J., Chen, X., Bartlett, P. L., Sutskever, I., Abbeel, P. (2016). Rl 2 : Fast reinforcement learning via slow reinforcement learning. ar Xiv preprint ar Xiv:1611.02779 .
- 4Duff Barto Duff Barto Duff, M. O., Barto, A. (2002). Optimal learning: Computational procedures for bayes-adaptive markov decision processes . Unpublished doctoral dissertation, University of Massachusetts at Amherst.
- 5Fortunato, Blundell, Vinyals Fortunato et al. Fortunato, M., Blundell, C., Vinyals, O. (2017). Bayesian recurrent neural networks. ar Xiv preprint ar Xiv:1704.02798 .
- 6Gal Ghahramani Gal Ghahramani Gal, Y., Ghahramani, Z. (2016). A theoretically grounded application of dropout in recurrent neural networks. In Advances in neural information processing systems (pp. 1019–1027).
- 7Gershman Gershman Gershman, S. J. (2018). Deconstructing the human algorithms for exploration. Cognition , 173 , 34–42.
- 8Gershman, Horvitz, Tenenbaum Gershman et al. Gershman, S. J., Horvitz, E. J., Tenenbaum, J. B. (2015). Computational rationality: A converging paradigm for intelligence in brains, minds, and machines. Science , 349 (6245), 273–278.