Emulating Human Developmental Stages with Bayesian Neural Networks
Marcel Binz, Dominik Endres

TL;DR
This paper investigates whether Bayesian Neural Networks emulate human developmental stages by analyzing their learning progress across various tasks and comparing it with developmental psychology findings.
Contribution
It demonstrates that Bayesian Neural Networks exhibit developmental stages similar to humans, suggesting shared principles in knowledge acquisition.
Findings
Bayesian Neural Networks show stages of learning similar to infants.
Developmental patterns in models align with psychological research.
Results support common principles in human and machine learning.
Abstract
We compare the acquisition of knowledge in humans and machines. Research from the field of developmental psychology indicates, that human-employed hypothesis are initially guided by simple rules, before evolving into more complex theories. This observation is shared across many tasks and domains. We investigate whether stages of development in artificial learning systems are based on the same characteristics. We operationalize developmental stages as the size of the data-set, on which the artificial system is trained. For our analysis we look at the developmental progress of Bayesian Neural Networks on three different data-sets, including occlusion, support and quantity comparison tasks. We compare the results with prior research from developmental psychology and find agreement between the family of optimized models and pattern of development observed in infants and children on all…
Click any figure to enlarge with its caption.
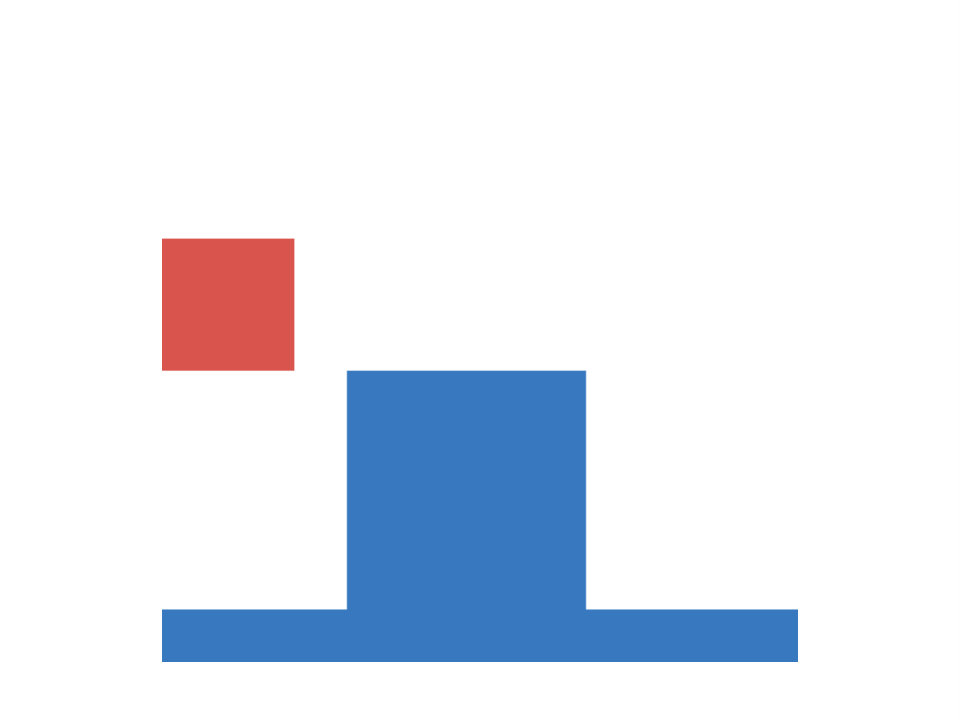 Figure 1
Figure 1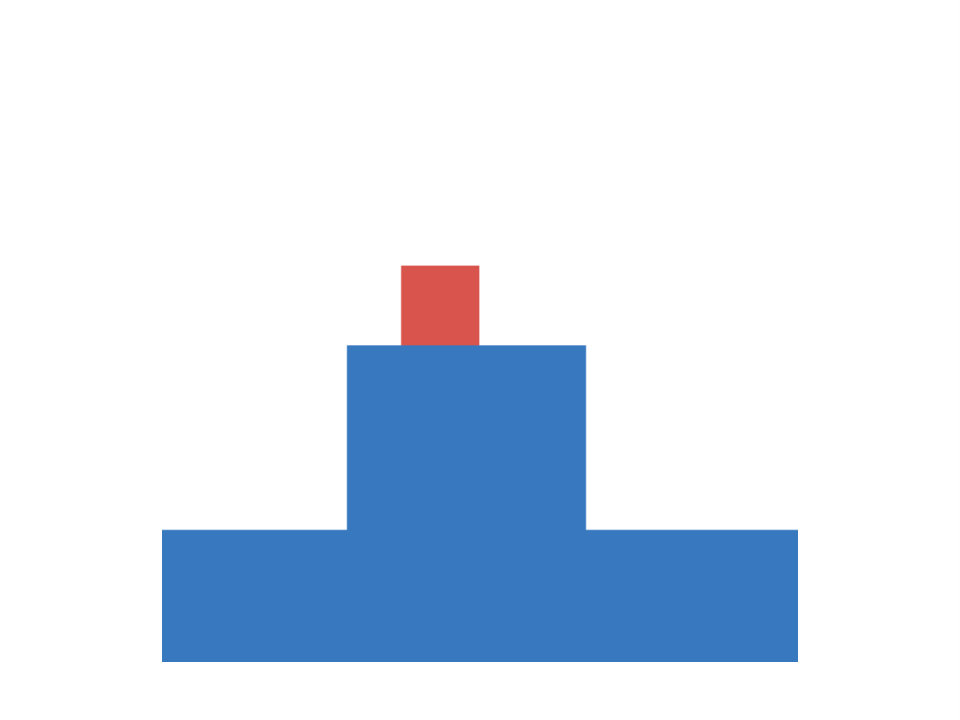 Figure 2
Figure 2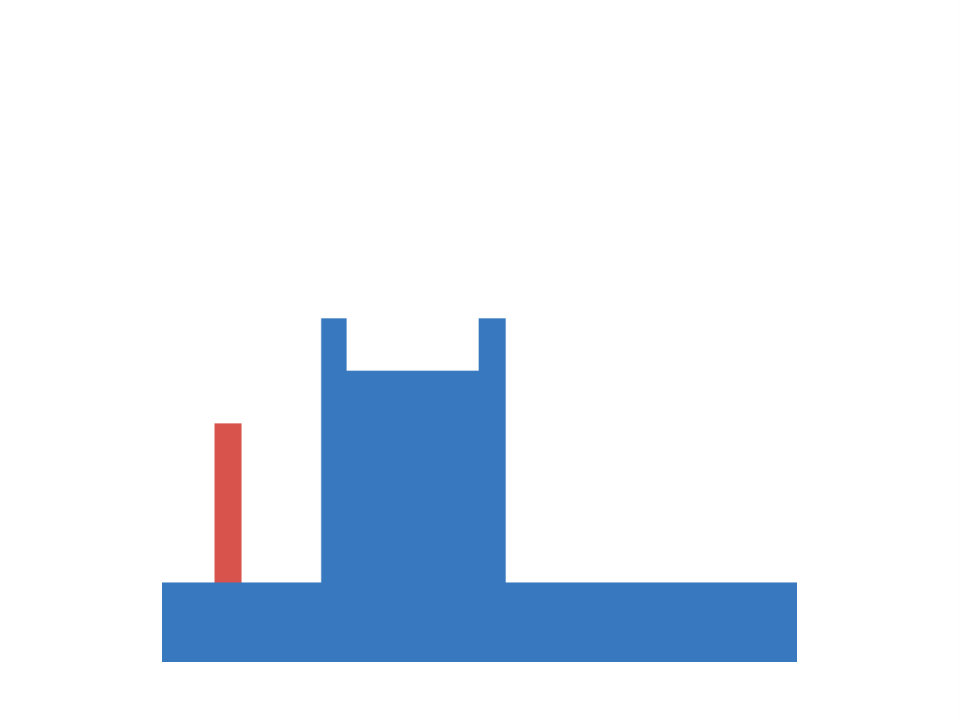 Figure 3
Figure 3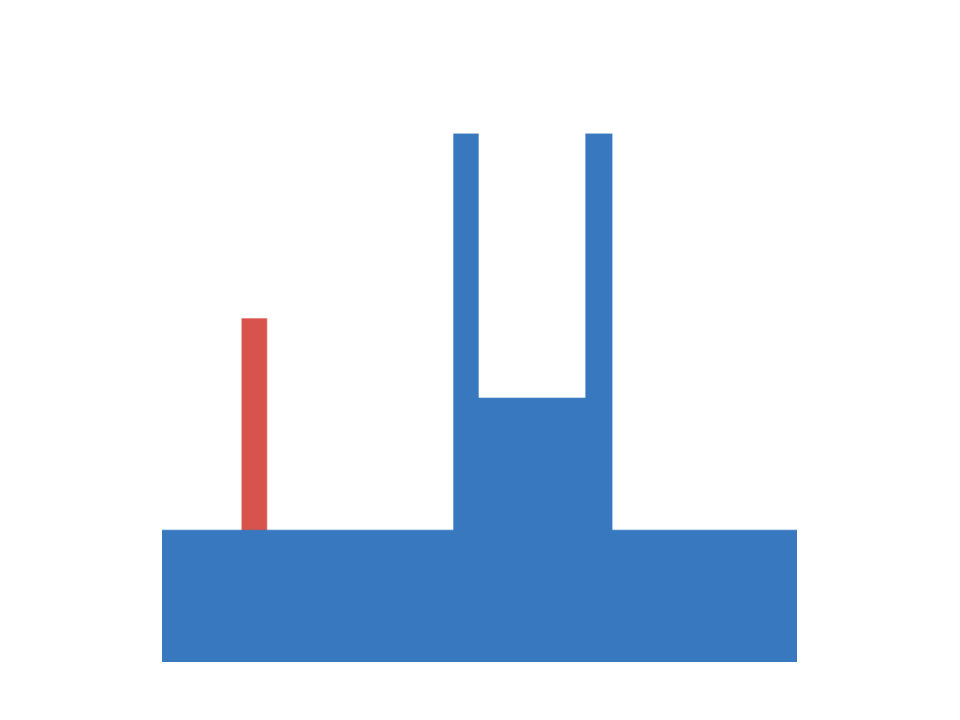 Figure 4
Figure 4 Figure 5
Figure 5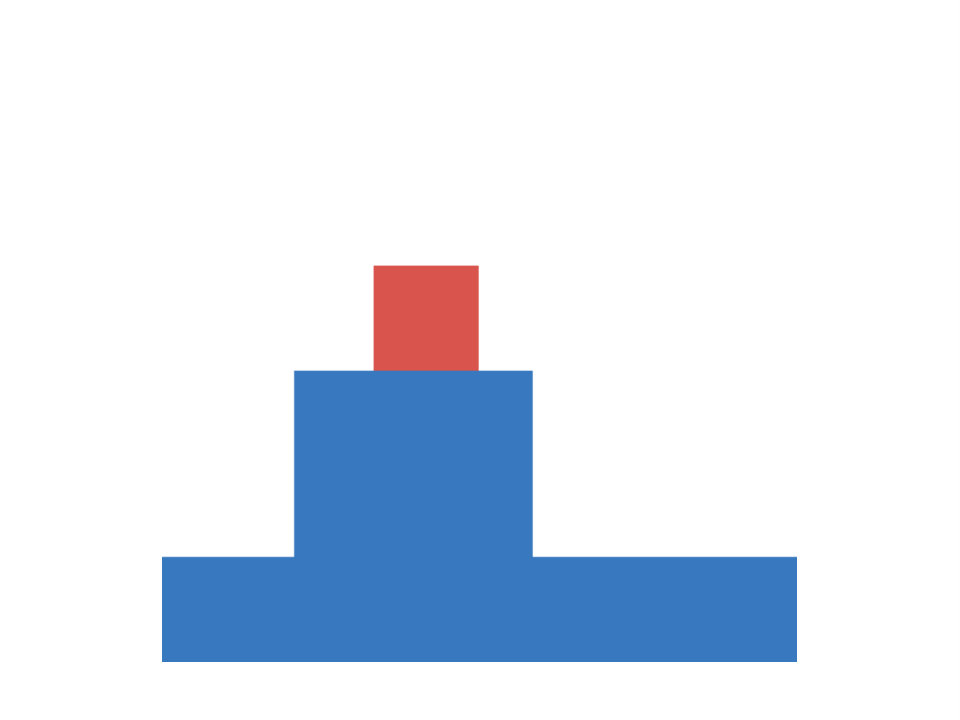 Figure 6
Figure 6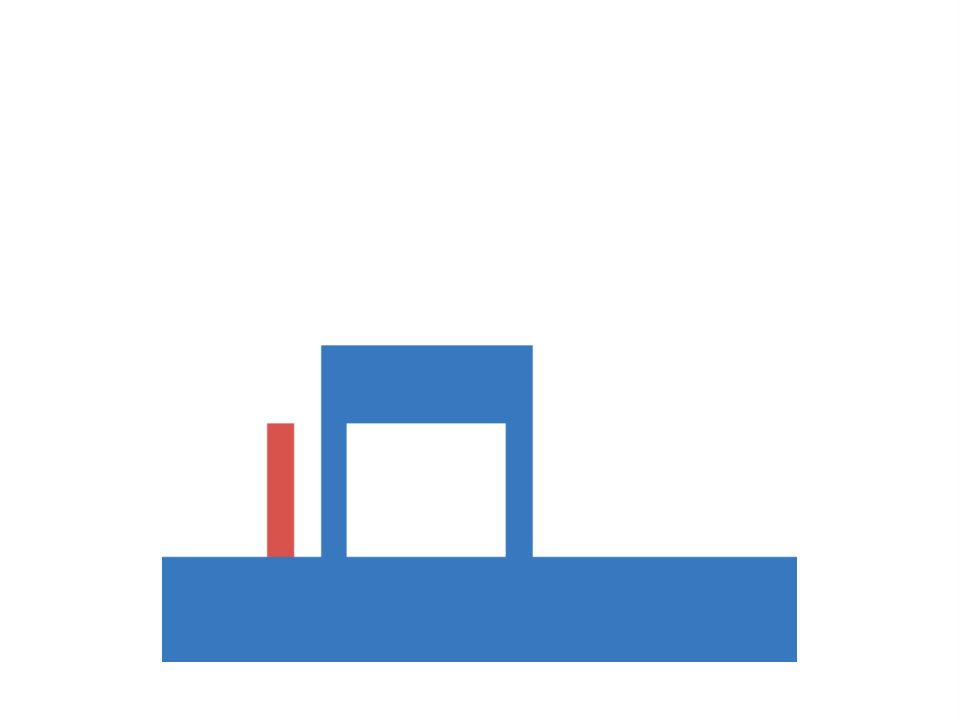 Figure 7
Figure 7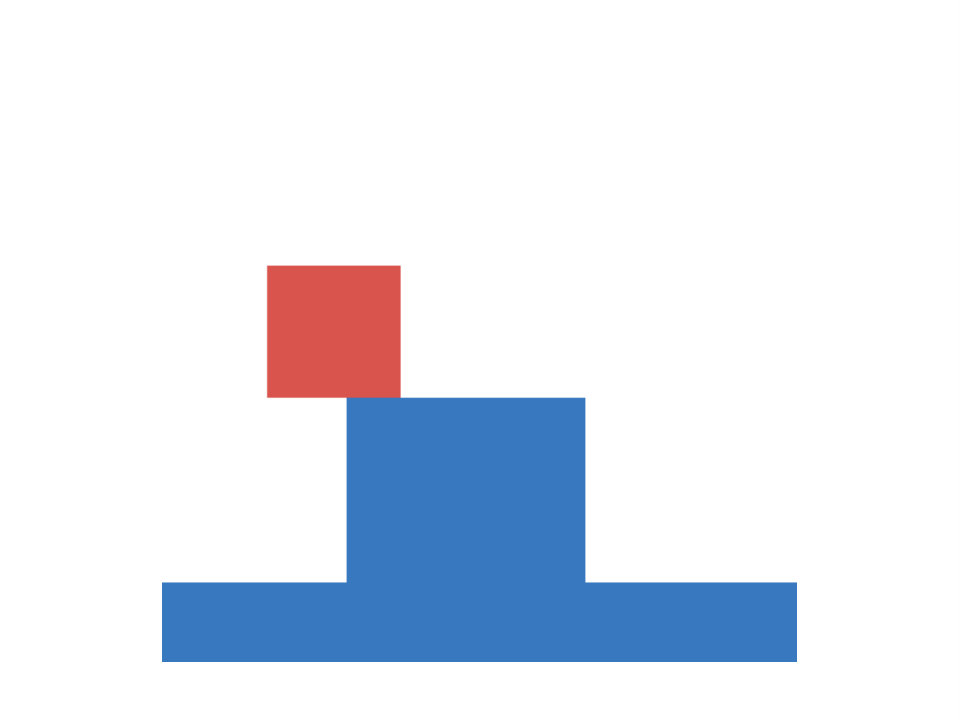 Figure 8
Figure 8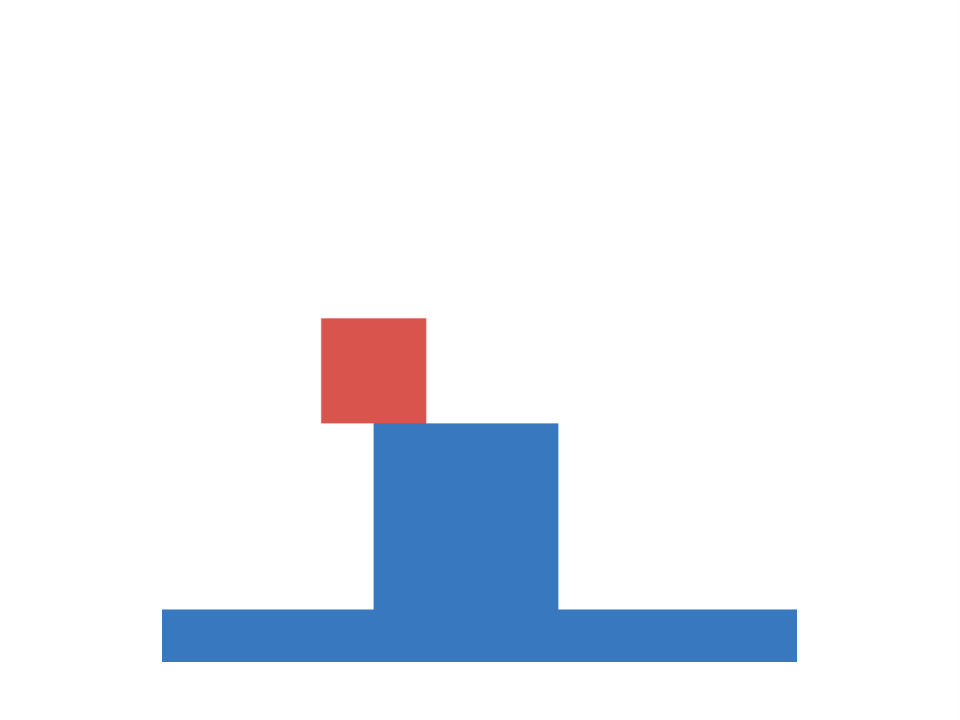 Figure 9
Figure 9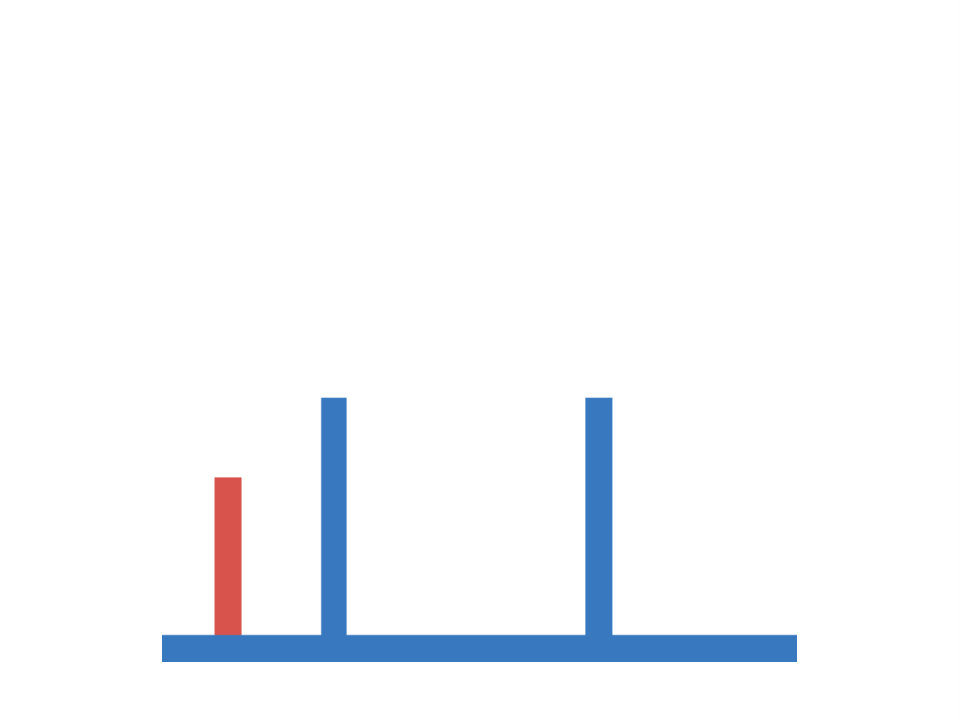 Figure 10
Figure 10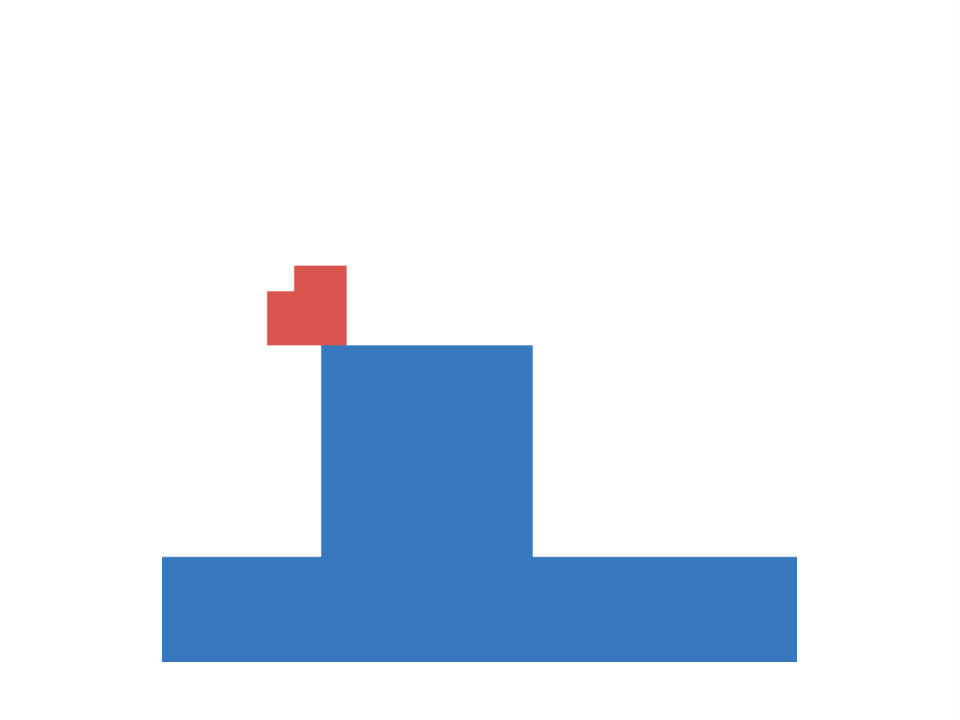 Figure 11
Figure 11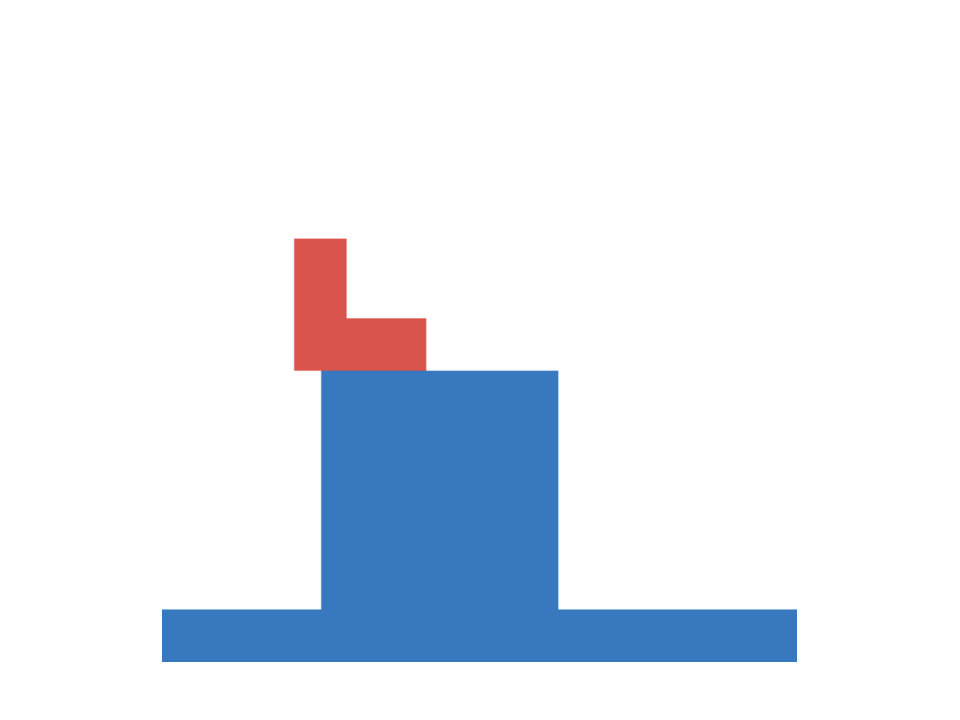 Figure 12
Figure 12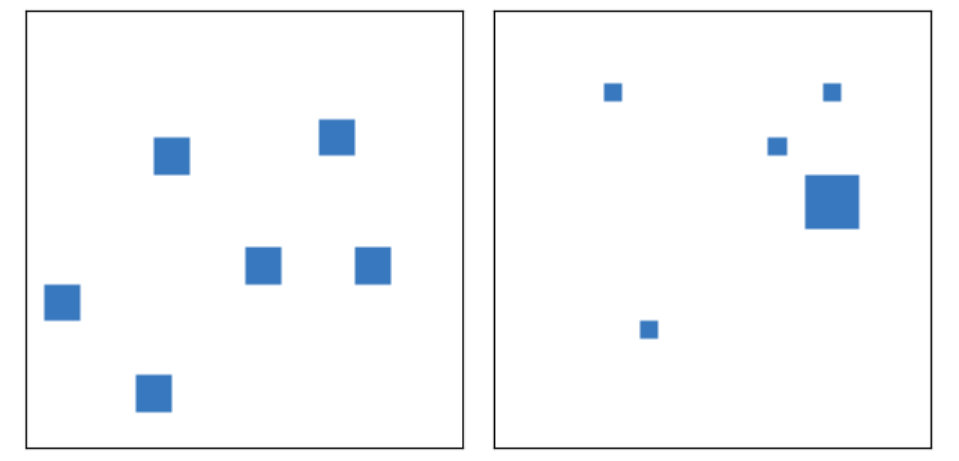 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17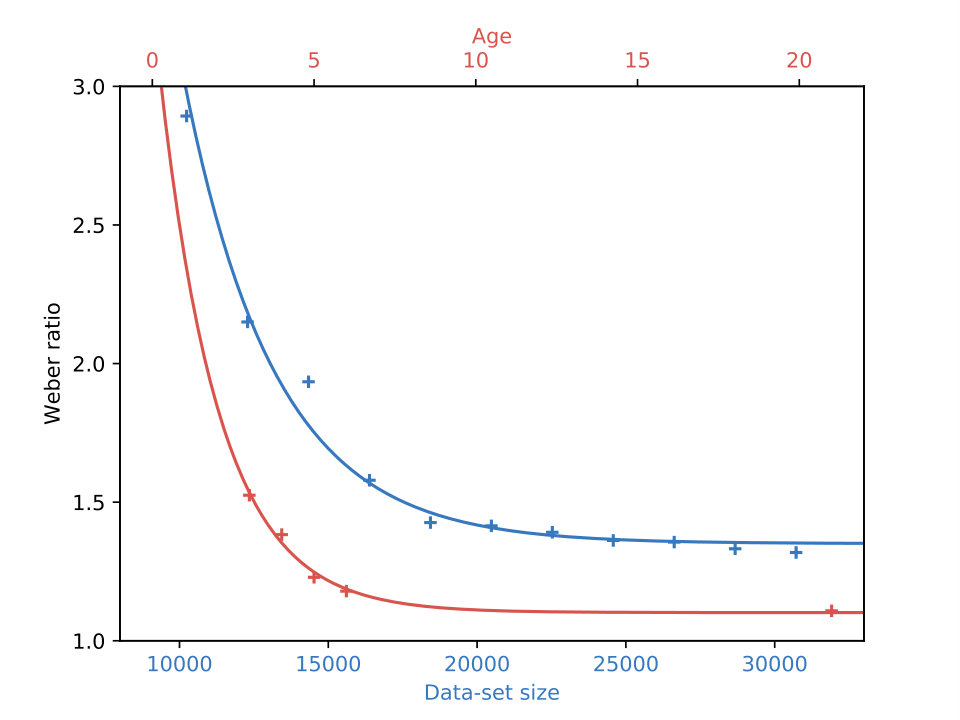 Figure 18
Figure 18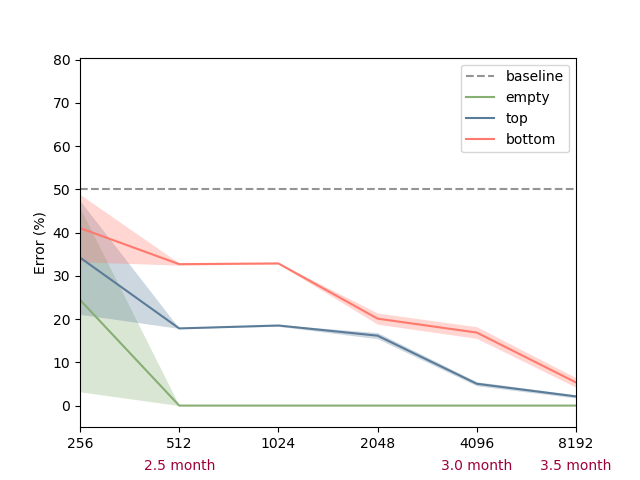 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21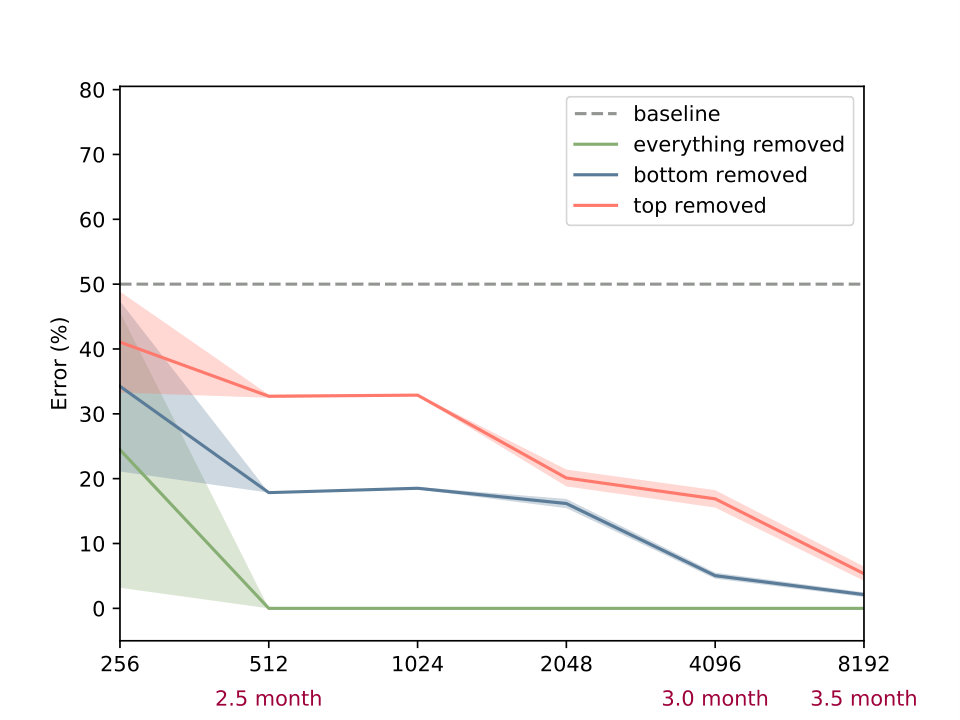 Figure 22
Figure 22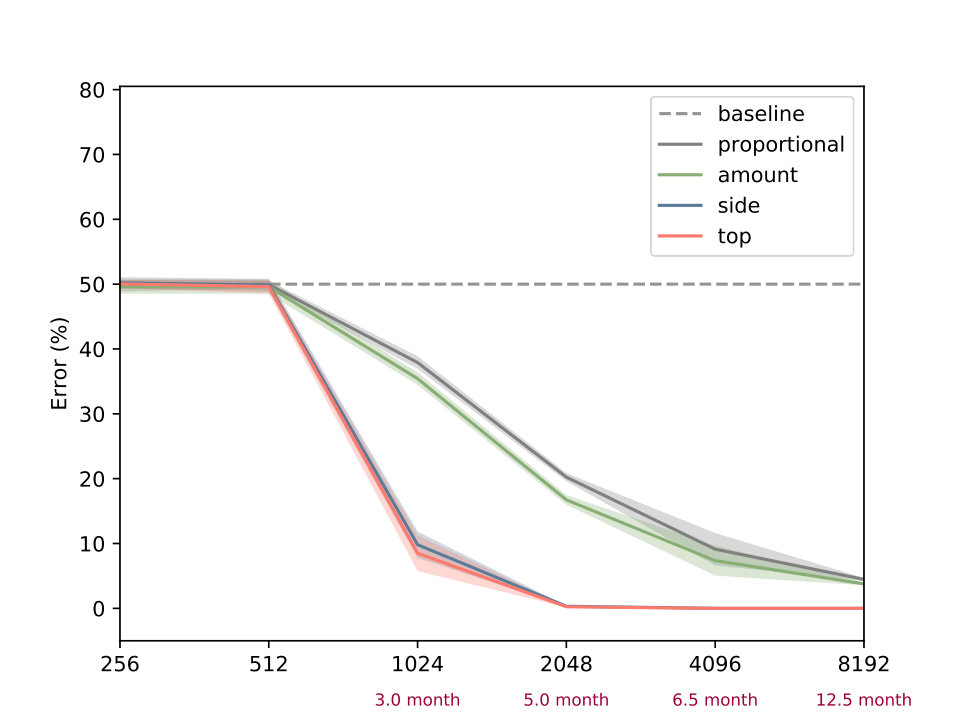 Figure 23
Figure 23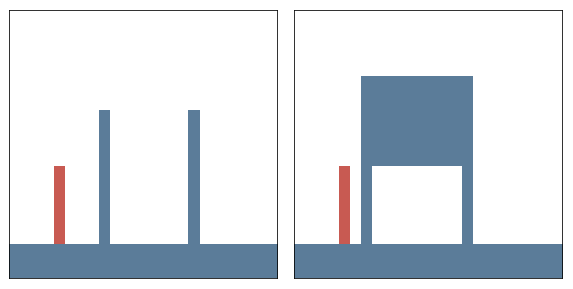 Figure 24
Figure 24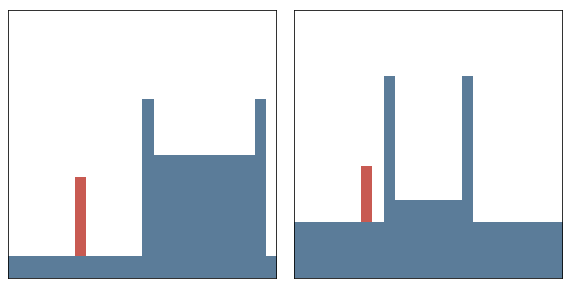 Figure 25
Figure 25 Figure 26
Figure 26Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBayesian Modeling and Causal Inference · Neural Networks and Applications · Gaussian Processes and Bayesian Inference
Emulating Human Developmental Stages with Bayesian Neural Networks
Marcel Binz ([email protected])
Department of Psychology, Theoretical Neuroscience Group
Philipps-Universität Marburg \ANDDominik Endres ([email protected])
Department of Psychology, Theoretical Neuroscience Group
Philipps-Universität Marburg
Abstract
We compare the acquisition of knowledge in humans and machines. Research from the field of developmental psychology indicates, that human-employed hypothesis are initially guided by simple rules, before evolving into more complex theories. This observation is shared across many tasks and domains. We investigate whether stages of development in artificial learning systems are based on the same characteristics. We operationalize developmental stages as the size of the data-set, on which the artificial system is trained. For our analysis we look at the developmental progress of Bayesian Neural Networks on three different data-sets, including occlusion, support and quantity comparison tasks. We compare the results with prior research from developmental psychology and find agreement between the family of optimized models and pattern of development observed in infants and children on all three tasks, indicating common principles for the acquisition of knowledge.
Keywords: Core knowledge; developmental psychology; intuitive physics; approximate number system; machine learning, deep learning, variational inference, normative models
Introduction
The theory of core knowledge in developmental psychology identifies several domains, that build the foundations of human cognition (?, ?, ?). Typically physics, actions, numbers, space and social interactions are listed among the core domains. Knowledge in these areas is present starting from early stages of childhood and serves as the basis for learning during later life. Research in developmental psychology over the past decades equipped us with a solid understanding about the acquisition of such knowledge. Different stages of development have been identified for a wide range of phenomena. Insights across studies suggest, that established rules generally start with a simple hypothesis before becoming more sophisticated over time (?, ?).
We investigate whether current machine learning systems show generalization behavior reminiscent of human infants and children at different stages of development. For this purpose, we assume that the amount of data available to the learning algorithm is proportional to human age. The class of models we focus on are Bayesian Neural Networks (BNNs), that are trained through variational inference. Neural networks have the desirable property of being able to approximate an arbitrary complex mapping given enough capacity, while Bayesian inference captures normative principles of how to update an initial belief in the light of new evidence. The specific choice of variational inference and neural networks is mainly due to convenience reasons, and we hypothesize, that many different combinations of universal function approximators and Bayesian learning would lead to comparable results.
Our experiments focus on two of the established core domains: physics and numbers. We consider two experiments involving intuitive reasoning about the laws of physics (?, ?) and one examining the approximate number system, which is responsible for forming fast, but imprecise, representations of quantities (?, ?). In all three cases we observe pattern in our models, that share similarities with the development progress during childhood, as we increase the data-set size.
There has been a recent interest in replicating reasoning capabilities from the core domains in artificial systems. Prior work regarding intuitive physics has considered generative (?, ?, ?) as well as discriminative models (?, ?). Both classes of models are often able to reach performance levels comparable to those of adults on specific tasks. Another core domain, that has received some attention within the computational modelling community, is the one of intuitive psychology. Here, for example, ? (?) suggest to employ Bayesian inverse planning for inferring mental states of other agents. In contrast to the aforementioned prior work, we are interested in the differences between optimal models for varying data-set sizes and how these differences compare to observations made in developmental psychology. Existing work on modelling the development of intuitive physics is limited to descriptive models, such as list of rules (?, ?) or decision trees (?, ?). In contrast to this, our approach is based on normative principles and we ask the question, whether observed stages emerge naturally in complex artificial learning systems.
In the next section we provide a short technical overview of neural networks and variational inference. This is followed by a description of the three experiments under examination. For each experiment we outline the given task, the empirical observations made in the developmental psychology literature and how we construct an artificial data-set. We finally provide a comparison between the developmental progress of children at different ages and that of optimized models for different data-set sizes. We conclude the article with a discussion of the obtained results and an outlook of the future interaction between the areas of machine learning and developmental psychology.
Methods
Deep Learning
Neural networks are parametric function approximators, that combine linear transformations and non-linear activation functions in alternating fashion:
[TABLE]
where . corresponds to the input and to an estimate of the target . Parameters of the model are commonly updated via gradient descent on a loss function, usually some form of negative log-likelihood. The power of neural networks stems from their ability to approximate any continuous function on a compact subset of .
Variational Inference
The task of learning model parameters can also be stated as a Bayesian inference problem:
[TABLE]
for a given data set , with inputs and targets . Bayes’ theorem defines how we should update our beliefs as more information becomes available. As the influence of the prior vanishes, while for we can only rely on prior assumptions. In our context we assume that experience (i.e. ) increases with age and hence we use an approximation to Equation 1 with data-sets of varying size to represent agents of different age.
Equation 1 is in general hard to compute for models of useful complexity. Variational inference offers a tractable approximation to Equation 1 (?, ?). Let be a distribution with parameters , that approximates the true posterior . Formulating the problem as a minimization of the Kullback-Leibler (KL) divergence between and leads to the evidence lower bound (ELBO):
[TABLE]
which can be maximized with respect to using standard optimization techniques.
In order to be able to scale to large data-sets Equation 2 is often approximated using batches of size M, with the log-likelihood term being scaled appropriately:
[TABLE]
Note, that only the first term of the ELBO depends on the data-set size , while the second term is independent of it. Hence the divergence term will dominate for small data-sets, leading to models that closely reflect our prior assumptions. In this work we employ priors, that promote simple functions. Therefore, our models are able to capture successively more complex functions with increasing data-set size.
Implementational Details
All models consist of layers with hidden layer sizes and ELU activation functions (?, ?), unless otherwise mentioned. Inputs correspond to flattened images of the scene and targets are dependent on the current task. We place a group horseshoe prior, which can be viewed as a continuous relaxation of a spike-and-slab prior (?, ?), over all parameters:
[TABLE]
and represent the approximate posterior through a fully factorized distribution as proposed in (?, ?). The sparsity hyperparameter of the horseshoe prior is fixed to . During training we approximate the expectation of the log-likelihood term with a single sample from and make use of the local reparametrization trick (?, ?). Gradient-based optimization is performed using Adam (?, ?) with batches consisting of samples. Results reported after training correspond to a Monte-Carlo estimate using 100 samples from .
Experiments
In this section we present an analysis of the proposed model on three different tasks adopted from the developmental psychology literature. The first two tasks involve reasoning about physical events (occlusion and support), while the last is concerned with the intuitive representation of quantities. For each task we include a summary of empirical observations made in children, alongside a comparison between these results and our models. Code for performing all experiments and generating artificial data-sets is publicly available111https://github.com/marcelbinz/Developmental-Stages-of-BNNs.
Occlusion Events
The first task under investigation is concerned with occlusion events. It is based on an experiment conducted by ? (?). Each scene consists of a cylinder and a screen in form of a rectangular plane. During experimental manipulation the cylinder is moved back and forth behind the screen, while parts of the screen are removed. There are three different experimental conditions, each differing in which part of the screen is removed (top, bottom or everything removed). A depiction of the setup is shown in Figure 1 (left). We are interested in infants’ ability to judge, whether the cylinder remains visible as it moves behind the screen, which is measured via violation-of-expectation methods (?, ?). In violation-of-expectation methods gazing times for physically implausible events are measured. High gazing times for such events indicate, that children are surprised by the observation, which is interpreted as a violation of their expectation of what should have happened.
Empirical evidence indicates, that infants form an initial concept based on a behind/not-behind distinction starting from the age of 2.5 months. At this stage they have learned, that the cylinder remains visible while moving past the screen, if the entire middle section of the screen is removed. They do not expect the cylinder to be visible in the other two conditions. This initial concept is refined during later stages of development. At the age of three months they also predict to see parts of the cylinder, if only the bottom part of the screen is removed. The knowledge of 3.5 months olds additionally extends to screens with removed top fractions. Note, that the last condition is more challenging compared to the other two, as it involves a comparison of heights between the cylinder and the lower connection of the screen (if the connection height is lower than the cylinder, the cylinder will be visible, otherwise it will not be visible). Baillargeon et al. conclude from these observations, that infants start with initially simple rules about the laws of physics (behind/not-behind distinction), which become successively more sophisticated over time (reasoning about relative heights).
We construct an artificial version of this task as follows. Each input corresponds to a image with three channels, containing segregated information about the floor, the cylinder and the screen respectively. Input images show an initial configuration of the scene, in which the cylinder is located on the left side of the screen. Each target indicates the visibility of the cylinder when passing behind the screen, as it is moved towards the right side of the image. Cylinder height and position, screen position and size and floor level are determined randomly. We generate a training and test set, each consisting of 10000 data-points. Figure 1 (center) shows examples for each of the conditions. Both sets include 2000 images for each of the three condition, as well as 4000 baseline images (nothing of the screen is removed). This is to ensure, that both (cylinder is visible) and (cylinder is not visible) are represented in equal fractions, i.e. the chance of guessing correctly is 50 percent.
We train otherwise identical models for until convergence and report results averaged over ten random seeds. The resulting performances on the artificial data-set are visualized in Figure 1 (right). We observe, that the percentage of incorrect predictions, similar to the developmental progress in infants, decreases first in the easier conditions. The network is able to predict visibility of the cylinder reliably (with less than ten percent errors), if the entire middle section of the screen is removed, for larger than 512. For larger than 4096 it is additionally able to predict the correct targets, if the bottom part is removed (corresponding to knowledge of a three months old). This extends to the condition, in which the top part is removed for (corresponding to knowledge of a 3.5 months old). Hence we conclude, that in this task the family of BNNs recovers the order of developmental stages observed in infants.
Support Events
Next we take a closer look at infants’ knowledge of support events, for which we adopt another experiment of ? (?). In this task a scene consists of a box and a platform. The box is presented in different positions relative to the platform and the experimenter measures (via violation-of-expectation methods), if infants are able to predict, whether the given configuration is stable or not. Four different conditions are investigated. In the first the box is positioned either on top of the platform or some distance away from it. This condition requires a simple contact/no-contact distinction to make reliable predictions about the stability of the configuration. The second condition involves a distinction between different types of contact. Here the box connects with the platform either on the top (as before) or on the side. The third condition requires judgments based on the amount of contact, i.e. the box is only partially positioned on the platform. The final condition adds an additional layer of complexity, as it involves reasoning about non-rectangular shapes. The different conditions are summarized in Figure 2 (left).
According to ? (?), from three months onward infants knowledge about the stability of a configuration is captured through a contact/no-contact distinction. At this stage they expect the box to be stable if and only if it touches the platform in some way. This initial hypothesis is than refined, as they grow older. At the age of around five months infants begin to distinguish between different types of contacts. They realize, that the box will only be stable, if it positioned above the platform, but not if it touches it on the side. Starting with an age of 6.5 months they are able to take into account the center of mass of simple objects (rectangular boxes) when reasoning about stability. This is extended to more complex, asymmetrical shapes at an age of roughly twelve months. As in the occlusion task, infants start with an initially simple hypothesis of how the laws of physics work, which is subsequently refined to better fit the observed data.
In our artificial version of this task inputs are represented as images with three channels (one for platform, box and floor) and targets are a binary indicator of the stability of the given configuration. Floor level as well as the size and position of the platform and the box are randomized. Again we generate a training set of 10000 samples and an equally large test set. In both sets 2500 data-points belong to each of the described conditions. Within each condition the amount of stable and unstable configurations is balanced, leading to a chance of 50 percent for guessing correctly. Example configurations are shown in Figure 2 (center).
As before we train otherwise identical models for until convergence and report result averaged over ten random seeds. Inspecting Figure 2 (right) we observe, that the family of BNNs first discovers solutions to the easier conditions (those where the box is positioned fully on the platform or on the side of it). If we increase to or more, they are also able to reason reliably about stability in both of the center of mass conditions. Note, that the error rate decreases slower, when being exposed to the more complex, L-shaped objects, although this difference is only marginal. We conclude, that the models show pattern similar to the developmental progress of infants, as we increase the data-set size, akin to the observation from experiment 1, although not as pronounced.
Approximate Number System
Moving away from probing knowledge about physical laws, we next inspect a different domain: children’s intuitive counting abilities (?, ?). A single trial consists of two images, each containing between 1 and 10 items, and the goal is to determine quickly, i.e. without to much deliberation time, which of the two images contains the larger quantity of items. The display time is adjusted depending on age, such that it is short enough to prevent serial counting. Objects within a trial are identical, but are selected from a set of different objects across trials. Two conditions either control for average item size or the summed continuous area. An example trial from the original task is shown in Figure 3 (left).
Experimental data for this task has been obtained for three to six years olds, as well as for adults (?, ?). Human perception is sensitive to the ratio between amounts of objects in the two images and not their difference, i.e. it follows a Weber-Fechner law. Levels of accuracy are measured for different ratios of objects, ranging from 1.11 (10:9) to 2.0 (2:1), from which Weber ratios are estimated. The Weber ratio is the smallest ratio, where a participant is able to identify the correct stimulus in more than 75 percent of the cases. Empirical results indicate, that the Weber ratio decreases during childhood and our ability to distinguish similar stimuli improves over time. Prior work (?, ?) estimates Weber ratios of around 1.53 in three years olds, which improves to 1.38 in four years olds, to 1.23 in five years olds, to 1.18 in six years olds and to 1.11 in adults. Overall the decrease of Weber ratios is well described through an exponential function of age (see Figure 3, right).
We created an artificial version of this task, with inputs corresponding to two images. For simplicity images contain only rectangular objects and the difference in quantity within a pair of images is always one. Targets are the number of objects in each images and the final prediction is obtained by comparing expected values between the two estimates. Object sizes are randomly drawn from and their position is randomized, such that neighbouring objects do not overlap. We controlled for an equal expected, total area between both images as done in the second condition of the original task. Both training and test set contain 6000 samples for each ratio from 10:9, 9:8, 8:7, 7:6, 6:5, 5:4, 4:3, 3:2, 2:1. Examples are provided in Figure 3 (center).
We train one model for each value from . Hidden layers have 512 units in this experiment and we found it helpful to initialize weights for all models from a pretrained network. For the resulting models we calculate Weber ratios after estimating accuracy levels of 75 percent via linear interpolation and visualize the results in Figure 3 (right). We observe an improvement of Weber ratios as the data-set size increases and conclude, that our models also follow a Weber-Fechner law. The resulting progression is well described through an exponential function222, with corresponding to data-set size or age. of data-set size, a characteristic shared with the curve obtained from human participants. There is however a small gap between the overall model performance in the artificial task and that of human participants in the original one, even for large data-sets.
Discussion
We investigated the progress of Bayesian Neural Networks with access to increasingly large data-sets on three different tasks. In all three examples we find an at least partial agreement between the development of our artificial learning systems and findings from the developmental psychology literature. However we also observe some considerable differences. The best performing BNNs in the quantity comparison task, for example, do not reach the level of human adults. We attribute this effect to difficulties for standard neural networks architectures on relational reasoning tasks and hypothesize that recent advances in visual relational reasoning (?, ?) could close this gap. In general we interpret our results as additional evidence for Bayesian theories of cognition and learning (?, ?).
The discriminative models employed in this work require large amounts of input-target pairs to obtain the desired result. Children on the other hand have to operate in a much more data-efficient manner, as they do not have constant access to a teacher providing correct targets. One approach to resolve the question of sources, that children use for learning, are generative models, which are able to discover underlying structures without explicitly provided targets. Whether our results transfer to generative models remains to be seen. Indeed applying generative models in this context would enable us to measure performance in artificial systems directly via violation-of-expectation methods, as was done with infants in two of our examples. In the future it would be natural to extend our work to more realistic settings and apply different architectures, such as recurrent or convolutional networks.
We believe there are exciting opportunities for research on the intersection of machine learning and developmental psychology. On one hand insights from developmental psychology can provide guidelines of how to build more intelligent, human-like systems. The machine learning framework on the other hand enables researchers to formulate normative theories, that can be empirically verified. We already see some progress in these areas. Examples include the usage of violation-of-expectation methods for probing the knowledge of deep networks (?, ?) or the proposal to select training curricula for machine learning systems, based on how children obtain samples (?, ?).
Acknowledgments
This work was supported by the DFG GRK-RTG 2271 ’Breaking Expectations’.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Baillargeon Baillargeon Baillargeon, R. (2002). The acquisition of physical knowledge in infancy: A summary in eight lessons. Blackwell handbook of childhood cognitive development , 1 (46-83), 1.
- 2Baillargeon, Li, Ng, Yuan Baillargeon et al. Baillargeon, R., Li, J., Ng, W., Yuan, S. (2009). An account of infants’ physical reasoning. Learning and the infant mind , 66–116.
- 3Baillargeon, Spelke, Wasserman Baillargeon et al. Baillargeon, R., Spelke, E. S., Wasserman, S. (1985). Object permanence in five-month-old infants. Cognition , 20 (3), 191–208.
- 4Baker, Saxe, Tenenbaum Baker et al. Baker, C. L., Saxe, R., Tenenbaum, J. B. (2009). Action understanding as inverse planning. Cognition , 113 (3), 329–349.
- 5Battaglia, Hamrick, Tenenbaum Battaglia et al. Battaglia, P. W., Hamrick, J. B., Tenenbaum, J. B. (2013). Simulation as an engine of physical scene understanding. Proceedings of the National Academy of Sciences , 201306572.
- 6Chang, Ullman, Torralba, Tenenbaum Chang et al. Chang, M. B., Ullman, T., Torralba, A., Tenenbaum, J. B. (2016). A compositional object-based approach to learning physical dynamics. ar Xiv preprint ar Xiv:1612.00341 .
- 7Clevert, Unterthiner, Hochreiter Clevert et al. Clevert, D.-A., Unterthiner, T., Hochreiter, S. (2015). Fast and accurate deep network learning by exponential linear units (elus). ar Xiv preprint ar Xiv:1511.07289 .
- 8Griffiths, Kemp, Tenenbaum Griffiths et al. Griffiths, T. L., Kemp, C., Tenenbaum, J. B. (2008). Bayesian models of cognition.