Dual-modality seq2seq network for audio-visual event localization
Yan-Bo Lin, Yu-Jhe Li, Yu-Chiang Frank Wang

TL;DR
This paper introduces AVSDN, a deep neural network that jointly processes audio and visual data for precise localization of events in videos, outperforming recent methods in both supervised and weakly supervised scenarios.
Contribution
The paper presents a novel dual-modality seq2seq network that effectively integrates audio and visual features for event localization in videos, applicable in various supervision settings.
Findings
Outperforms recent deep learning approaches in experiments
Effective in both fully supervised and weakly supervised settings
Learns global and local event information from combined audio-visual data
Abstract
Audio-visual event localization requires one to identify theevent which is both visible and audible in a video (eitherat a frame or video level). To address this task, we pro-pose a deep neural network named Audio-Visual sequence-to-sequence dual network (AVSDN). By jointly taking bothaudio and visual features at each time segment as inputs, ourproposed model learns global and local event information ina sequence to sequence manner, which can be realized in ei-ther fully supervised or weakly supervised settings. Empiricalresults confirm that our proposed method performs favorablyagainst recent deep learning approaches in both settings.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2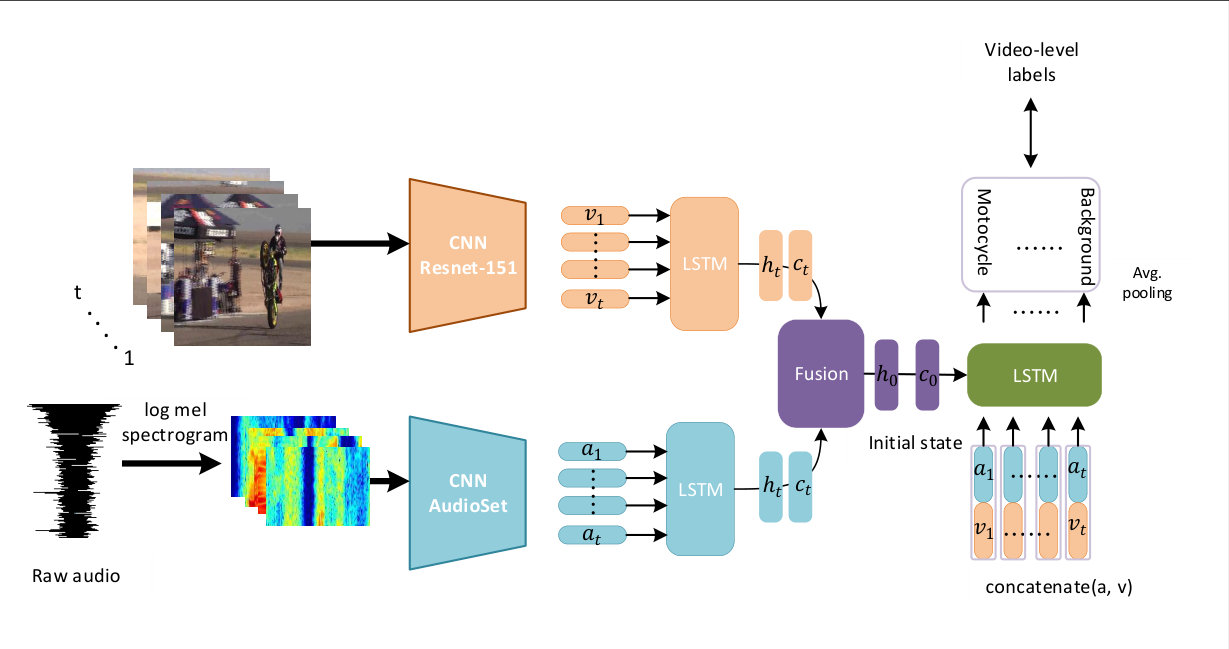 Figure 3
Figure 3 Figure 4
Figure 4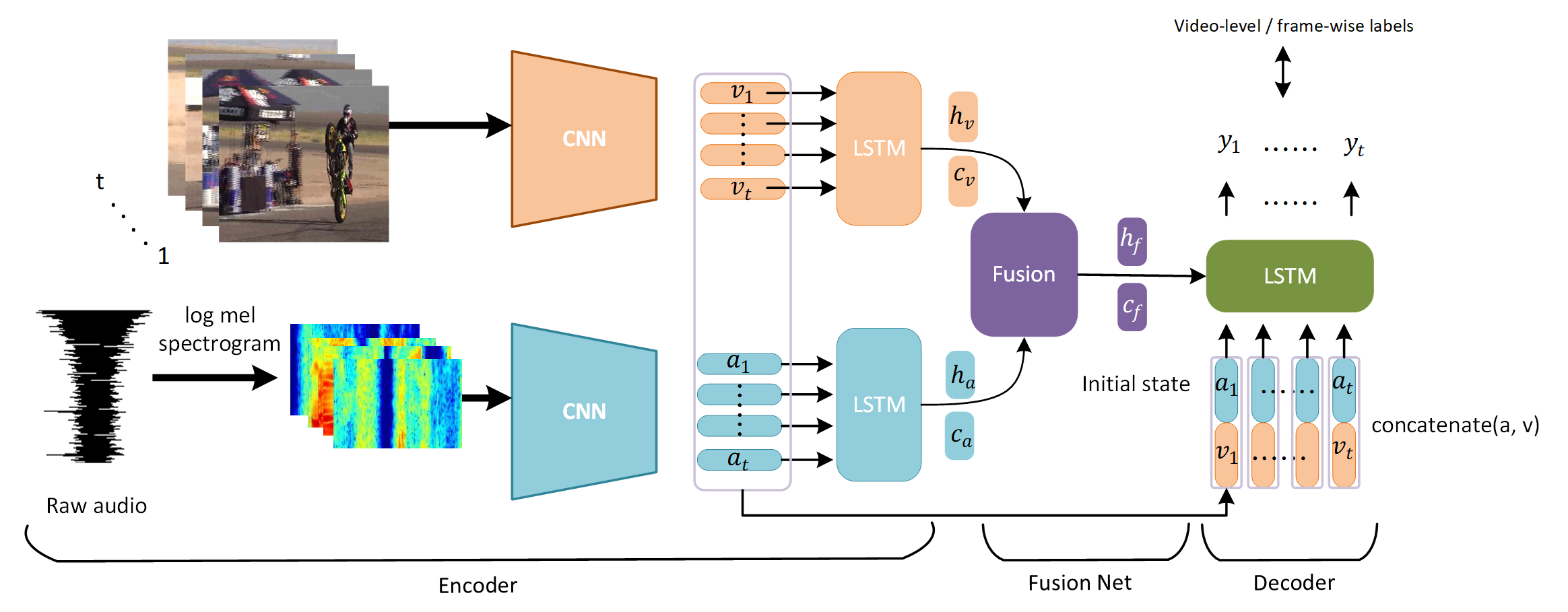 Figure 5
Figure 5 Figure 0
Figure 0| Method | Accuracy (%) | Remarks |
|---|---|---|
| AVEL [13] | 59.5 | audio only |
| 55.3 | visual only (VGG16) | |
| 71.4 | audio+visual (VGG16) | |
| 72.7 | audio+visual w/ att (VGG16) | |
| 65.0 | visual only (ResNet-152) | |
| 74.0 | audio+visual (ResNet-152) | |
| 74.7 | audio+visual w/ att (ResNet-152) | |
| AVSDN | 75.4 | audio+visual (ResNet-152) |
| Method | Accuracy (%) | Remarks |
|---|---|---|
| AVEL[13] | 53.4 | audio only |
| 52.9 | visual only (VGG16) | |
| 63.7 | audio+visual (VGG16) | |
| 66.7 | audio+visual w/ att (VGG16) | |
| 63.4 | visual only (ResNet-152) | |
| 71.6 | audio+visual (ResNet-152) | |
| 73.3 | audio+visual w/ att (ResNet-152) | |
| AVSDN | 74.2 | audio+visual (ResNet-152) |
| Method | Accuracy (%) |
|---|---|
| Visual input only | 70.2 |
| Audio input only | 70.9 |
| Audio + Visual (label guided) | 72.6 |
| Fusion (Ours) | 74.2 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMusic and Audio Processing · Speech and Audio Processing · Video Analysis and Summarization
dual-modality seq2seq network for Audio-Visual event localization
Abstract
Audio-visual event localization requires one to identify the event which is both visible and audible in a video (either at a frame or video level). To address this task, we propose a deep neural network named Audio-Visual sequence-to-sequence dual network (AVSDN). By jointly taking both audio and visual features at each time segment as inputs, our proposed model learns global and local event information in a sequence to sequence manner, which can be realized in either fully supervised or weakly supervised settings. Empirical results confirm that our proposed method performs favorably against recent deep learning approaches in both settings.
**Index Terms— ** Audio-Video Features, Dual Modality, Event Localization, Deep Learning
1 Introduction
While a substantial amount of visual and auditory signals can be observed in real-world activities, several studies in neurobiology and human perception suggest that the perceptual benefits of integrating visual and auditory information are extensive. For computational models, they reflect in lip reading [1], where correlations between speech and lip movements provide a strong cue for linguistic understanding. In sound synthesis [2], where physical interactions with different types of material give rise to plausible sound patterns. In spite of these advanced models, they are still limited to some constrained domains. Hence, some works [3, 4, 5, 6] have begun to learn the correspondence between the visual scene and the sound, achieving the cross-modality scenario. However, such cross-modality learning methods typically assume that the audio and visual contents in a video are always presented and matched. Such assumptions might not be practical for analyzing/understanding unconstrained videos in the real world.
Audio-visual event localization addresses the task of matching both visible and audible components in a video for identifying the event of interest, as depicted in Fig. 1. Recently, some multi-modal deep networks for joint audio-visual representation have been studied [7, 8, 9]. Aside from works in representation learning, audio-visual cross-modal synthesis is studied in [10, 11], and associations between natural image scenes and accompanying free-form spoken audio captions are explored in [12]. However, how to handle learned audio and visual features for audio-video event jointly localization remains a challenging issue (i.e., hearing a dog barking and seeing a dog in the video simultaneously). To this end, [13] introduce such novel problem of audio-visual event localization in unconstrained videos. As shown in Fig. 1, they define an audio-visual event as an event that is both visible and audible in a video segment. In addition, they further collect an Audio-Visual Event (AVE) dataset to systemically investigate three temporal localization tasks: supervised and weakly-supervised audio-visual event localization, and cross-modality localization. Nevertheless, they only consider temporal relationship within video or audio data, and no cross-modality relationship is observed.
To address this challenging task, we propose an end-to-end deep learning framework of Audio-Visual sequence-to-sequence dual network (AVSDN). Based on sequence to sequence (seq2seq) [14] and autoencoder, our network architecture takes both audio and visual data at each time segment as inputs and exploits global and local event information in a seq2seq manner. More importantly, our model can be learned in a fully or weakly supervised settings, i.e., ground truth event labels observed in the frame or video levels. While the technical details of our proposed networks will be presented in Sec. 2, contributions of our work are highlighted as follows:
- •
We propose a unique end-to-end trainable network for audio-visual event localization, which can be learned in fully or weakly supervised settings.
- •
Our proposed model jointly takes visual and audio data as inputs. By exploiting this cross-modality information across time, such encoded global features will be conditioned on the decoder for event localization.
- •
Experimental results demonstrate that our proposed model performs favorably against state-of-the-art approaches on the challenging AVE dataset.
2 Proposed Method
2.1 Problem Formulation
Supervised event localization. In supervised settings, one needs to predict video events every second given audio and visual tracks. As mentioned in Section 1, non-background labels are determined only if visual and audio events are jointly observed. To this end, the segment-wised (every second) labels are given as , where denotes total event categories. The number of total categories is which includes one background label ,and is the time segment of one video. In supervised setting, segment-wise labels are observed during the training phase.
Weakly-supervised event localization. Compared with the aforementioned supervised task, we can only access the video-level event labels in a weakly-supervised manner. The video-level event labels are processed by averaging the segment event labels , where is the length of a video. For the weakly-supervised task, we can lower the reliance on the well-annotated labels and evaluate the robustness of our proposed framework.
2.2 Audio-Visual Sequence-to-sequence Dual Network (AVSDN)
To address the audio-visual event localization problem in both supervised and weakly-supervised problems, we propose a novel framework named Audio-Visual sequence-to-sequence dual network (AVSDN). Based on seq2seq [14] and autoencoder, our network architecture takes both audio and visual data at each time segment as inputs and exploits global and local event information in a seq2seq manner.
As shown in Fig 2, the framework is composed of three components: encoder modules for learning visual and audio representations, fusion network for producing global video representation, and decoder to take global and local features for event localization. More details about the three components in AVSDN can be obtained as follows:
Encoder: learning global visual and audio representations. The encoder, which is the first part of our network AVSDN, is aimed to extract global visual and audio representations for fusion network.
Before learning the global features, we have to obtain the segment visual and audio representations by utilizing CNNs. To better learn the visual and audio embedding features, our CNNs are learned from the large-scale dataset (ImageNet [15] and AudioSet [16]) which are highly shown useful for vision and audition tasks. To be specific, for visual frames we sample a frame and obtain the visual representation from pre-trained ResNet-152 [17], which has been trained on ImageNet. On the other hand, for one raw audio, we convert one segment to log mel spectrogram and extract an audio representation each 1s from VGGish [18] trained on AudioSet.
In order to further learn the global visual and audio representations, we now utilize the Long Short-Term Memory (LSTM) [19], which is known to exploit long-range temporal dependencies, to generate encoded temporal representation sequence. Generally, the most common implementation of vanilla LSTM [20] includes various gate mechanisms such as input gate, forget gate, output gate, memory state, and hidden state etc. The utilized LSTM unit in our proposed model is illustrated in Eq. (1).
[TABLE]
Each time step in Eq. (1) denotes subscript , and denotes the given input of time step . , and are forget, input and output gate’s activation vector respectively. and are hidden and cell state of the LSTM unit. When , and would be the initial values. , and are weight matrices and bias vector which can be learned during train phase. Where and refer the number of input features and number of hidden units. Element-wise product is denoted by . Activation function: is sigmoid function and is hyperbolic tangent function.
Eventually, all the audio and visual segments are the inputs of the two designed LSTM (audio and video separately). Hence, the last time step of hidden and cell state can be generated as the global representations of audio and visual tracks.
Fusion network: learning video event representation.
After obtaining the audio and visual global representations, our goal is to convert these two representations into one video event representation. To perform such a fusion mechanism, our fusion network is designed to fuse cross-modality features which are built based on dual multimodal residual network (DMRN) fusion block [13]. As mentioned above, the last time step of hidden and cell state from encoder can be given as the representations of audio and visual tracks. Following [13], with time step , audio and visual hidden state (, ) and cell state (, ) can be fused with Eq.(2). After fusion hidden and cell state, these fused state will be the initial state of the decoder LSTM (one LSTM of right-half Fig.2).
[TABLE]
where is denoted as hyperbolic tangent function and is multilayer perceptrons (MLP) with parameters . The cell states can be fused like hidden states. The fused states, and , turn to be the initial states in our decoder. Because compared with vanilla LSTM, a representative initial state can benefit a LSTM for prediction [14]. Thus, we take the fused states for the initialization for the decoder.
Decoder: localization of video events using global and local cross-modality representations. Generally, our decoder is aimed to perform the supervised and weakly-supervised event localization. Thus, given both the fused global representations from the fused network and local features of audio and video, our decoder will generate the corresponding labels segment-wisely. The architecture of our decoder is a single LSTM. Different from each encoder, the inputs of the decoder are concatenated features which are global and local cross-modality representations. We concatenate and which are audio and visual segment features from pre-trained CNN. Our decoder is designed to not only learn spatial cross-modality representations but temporal ones. Especially weakly supervised setting, we can only access to the video-level labels in the training phase. All the individual predictions will be aggregated by average pooling in Eq.(3),
[TABLE]
where are the predictions from the last fully connected layer of our model. The average prediction over softmax function can be the probability distribution of the event category. For both the weakly-supervised and supervised setting, the predicted probability distribution can be optimized by video-level labels through binary cross-entropy.
3 experiments
3.1 Dataset
Following [13], we consider Audio-Visual Event(AVE) [13] dataset (a subset of Audioset [16]) for experiments. This AVE dataset includes 4143 videos with 28 categories and videos are labeled with audio-visual events every second. AVE dataset covers wide range domain events (e.g., Church bell, Dog barking, Truck, Bus, Clock, Violin, etc.).
3.2 Comparison results
For both fully supervised and weakly-supervised audio-visual event localization, we apply frame-wise accuracy as an evaluation metric in both supervised and weakly-supervised settings. We compute the percentage of correct matchings over all the testing frames as prediction accuracy to evaluate the performance of audio-visual event localization.
In this paper, we use different visual pre-trained embedding compared with Tian et al [13]. Visual pre-trained embedding in Tian et al is VGG16 [21]. Thus, we re-implement the model with ResNet-152 [17] visual pre-trained embedding and show each one modality results. In a fully supervised manner, all the frame-wise labels are used during training. In Table LABEL:table:STOA, our model has better results compared with state-of-the-art methods even if the model [13] is with cross-modality attention mechanism [22] which can find the audio location in the video scene [13, 4]; In a weakly supervised manner, Table LABEL:table:STOA_weak shows our model outperforms other methods as well. Compared with the supervised task, our model can tickle noise labels better. We give an example of our visualization comparison with the existing method in Fig. 3.
3.3 Ablation studies
In this section, we will discuss the results on the different initial state for decoder LSTM. In Table LABEL:table:ab, first-two rows show the results which initial state is only from visual or audio content respectively. Further, we want to explore whether encoder LSTM can learn global event information or not. With the last hidden states from visual and audio modality individually, these hidden states are guided by video-level labels through a simple multilayer perceptron (MLP). The third row in Table LABEL:table:ab shows the result is improved compared with only one modality. However, extra loss functions for guiding the last hidden states are not needed. The last hidden states are well-learned during the training of our AVSDN.
4 conclusion
In this work, we proposed Audio-Visual sequence-to-sequence dual network (AVSDN) for video event localization, which can be learned in fully or weakly supervised fashions. Our network takes both audio and visual local features, together with integrated global representation, to perform event localization in a sequence to sequence manner. From the experimental results, the use of our network and its design can be successfully verified.
Acknowledgements. This work is supported by the Ministry of Science and Technology of Taiwan under grant MOST 107-2634-F-002-010.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Joon Son Chung, Andrew W Senior, Oriol Vinyals, and Andrew Zisserman, “Lip reading sentences in the wild.,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017.
- 2[2] Andrew Owens, Phillip Isola, Josh Mc Dermott, Antonio Torralba, Edward H Adelson, and William T Freeman, “Visually indicated sounds,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016.
- 3[3] Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, and In So Kweon, “Learning to localize sound source in visual scenes,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2018.
- 4[4] Relja Arandjelović and Andrew Zisserman, “Objects that sound,” in Proceedings of the European Conference on Computer Vision (ECCV) , 2018.
- 5[5] Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh Mc Dermott, and Antonio Torralba, “The sound of pixels,” in Proceedings of the European Conference on Computer Vision (ECCV) , 2018.
- 6[6] Relja Arandjelovic and Andrew Zisserman, “Look, listen and learn,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV) , 2017.
- 7[7] Di Hu, Xuelong Li, et al., “Temporal multimodal learning in audiovisual speech recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016.
- 8[8] Xitong Yang, Palghat Ramesh, Radha Chitta, Sriganesh Madhvanath, Edgar A Bernal, and Jiebo Luo, “Deep multimodal representation learning from temporal data,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017.