TL;DR
This paper introduces a new query learning algorithm for residual symbolic finite automata (RSFAs), which combine properties of SFAs and RFAs to efficiently learn automata over large alphabets, outperforming existing methods.
Contribution
The paper presents the first efficient query learning algorithm for RSFAs, enabling more succinct automata representations and improved learning efficiency over large alphabets.
Findings
The algorithm efficiently learns RSFAs over huge alphabets.
RSFAs can be exponentially smaller than deterministic finite automata.
Learning RSFAs outperforms existing algorithms for deterministic SFAs.
Abstract
We propose a query learning algorithm for residual symbolic finite automata (RSFAs). Symbolic finite automata (SFAs) are finite automata whose transitions are labeled by predicates over a Boolean algebra, in which a big collection of characters leading the same transition may be represented by a single predicate. Residual finite automata (RFAs) are a special type of non-deterministic finite automata which can be exponentially smaller than the minimum deterministic finite automata and have a favorable property for learning algorithms. RSFAs have both properties of SFAs and RFAs and can have more succinct representation of transitions and fewer states than RFAs and deterministic SFAs accepting the same language. The implementation of our algorithm efficiently learns RSFAs over a huge alphabet and outperforms an existing learning algorithm for deterministic SFAs. The result also shows that…
Click any figure to enlarge with its caption.
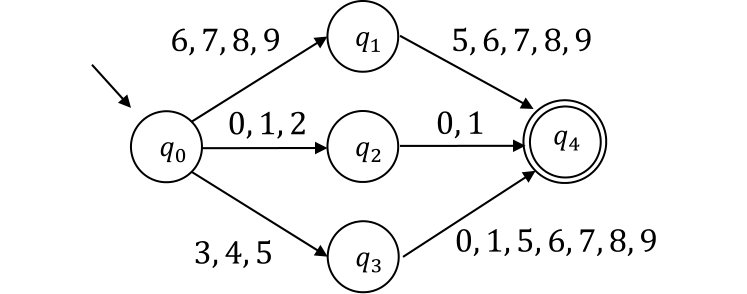 Figure 1
Figure 1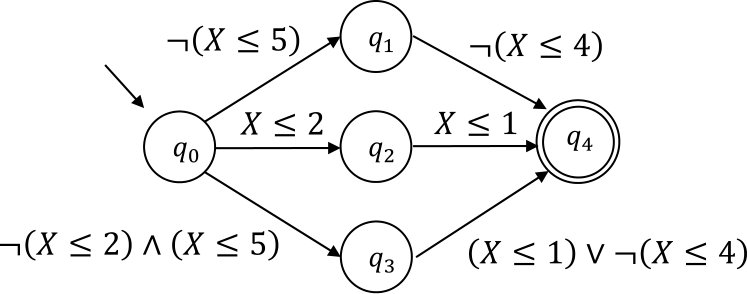 Figure 2
Figure 2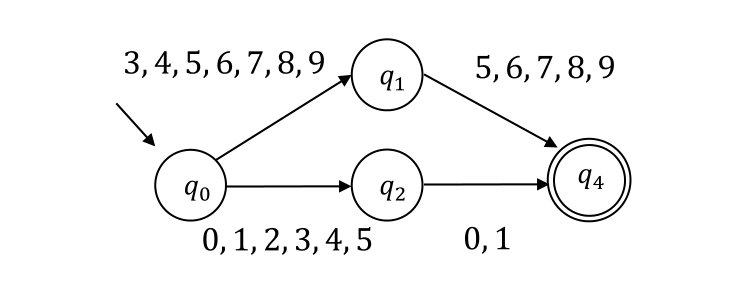 Figure 3
Figure 3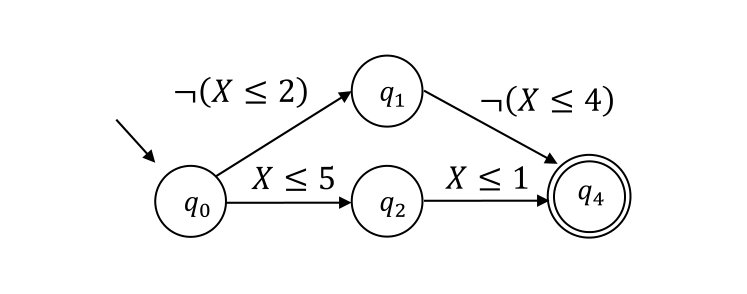 Figure 4
Figure 4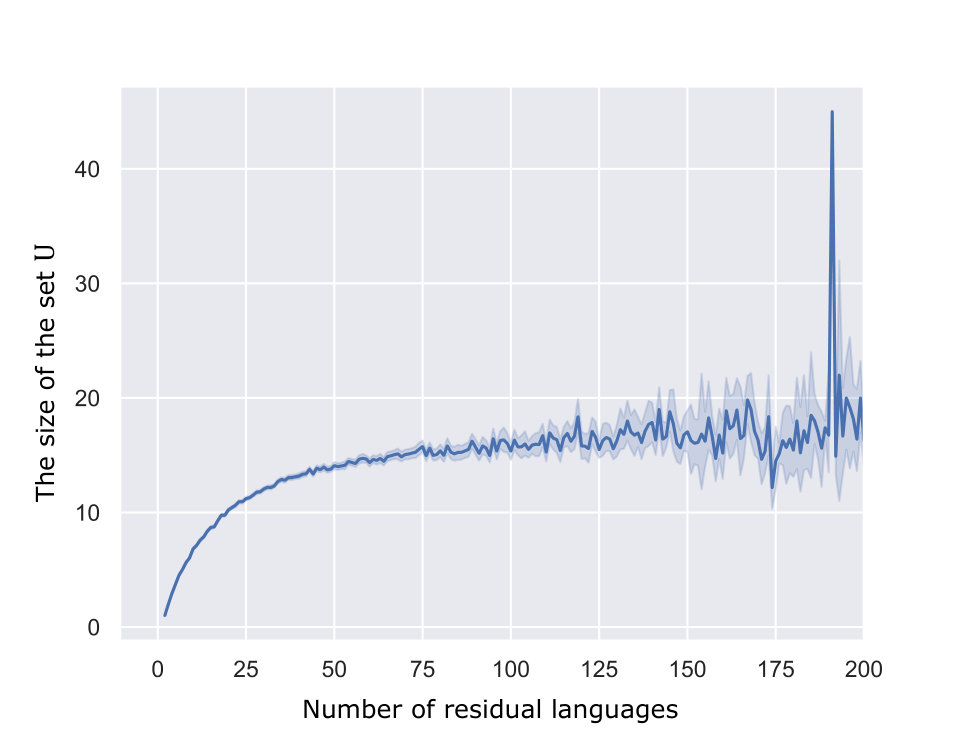 Figure 5
Figure 5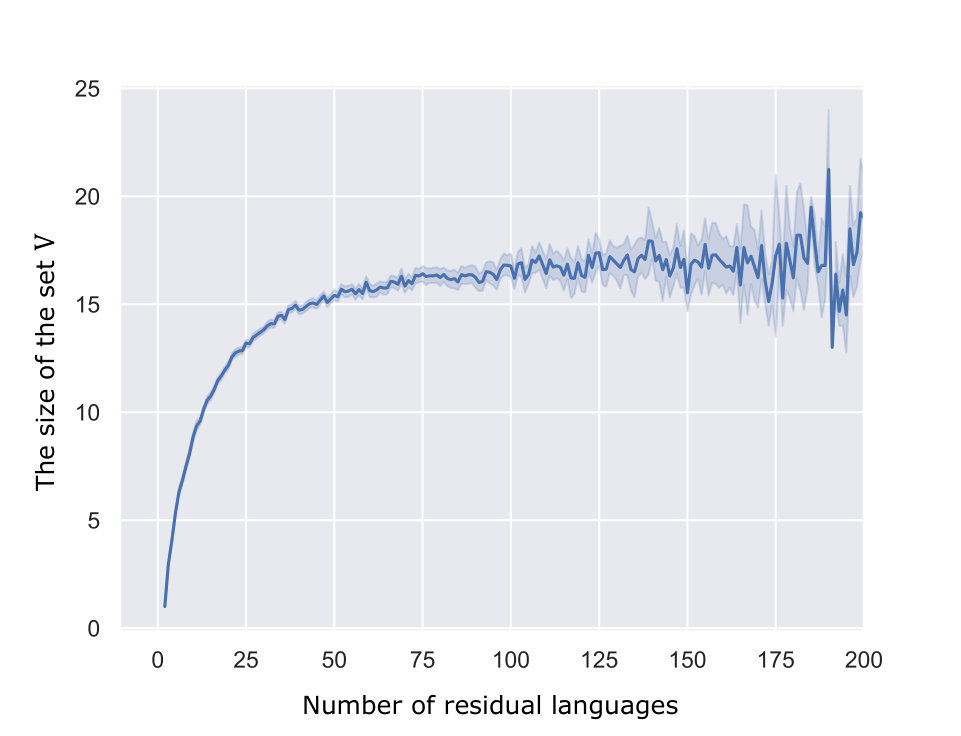 Figure 6
Figure 6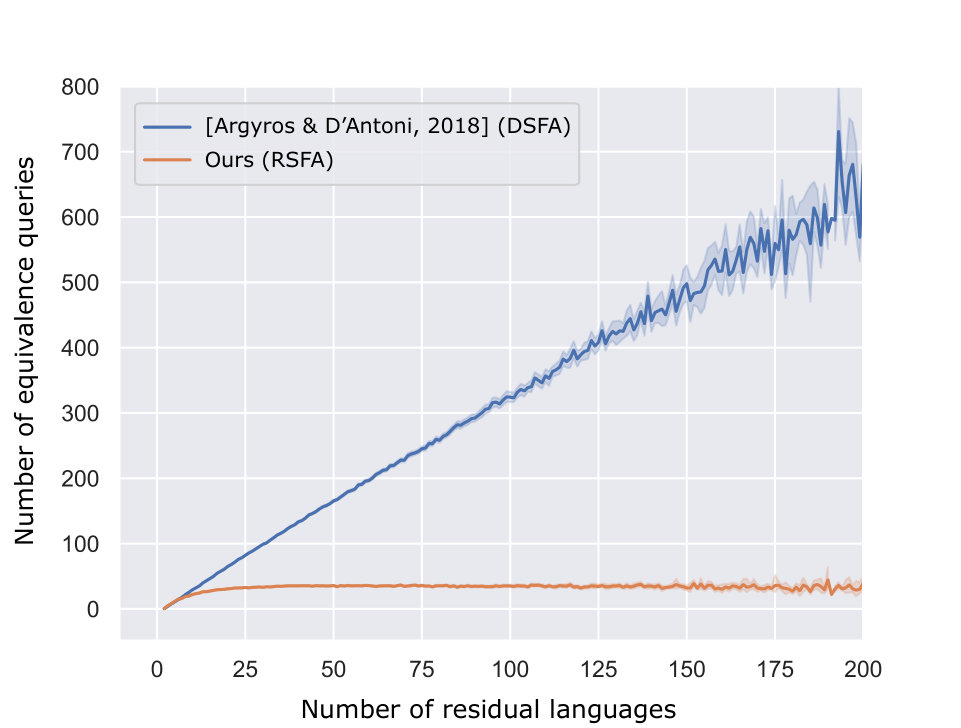 Figure 7
Figure 7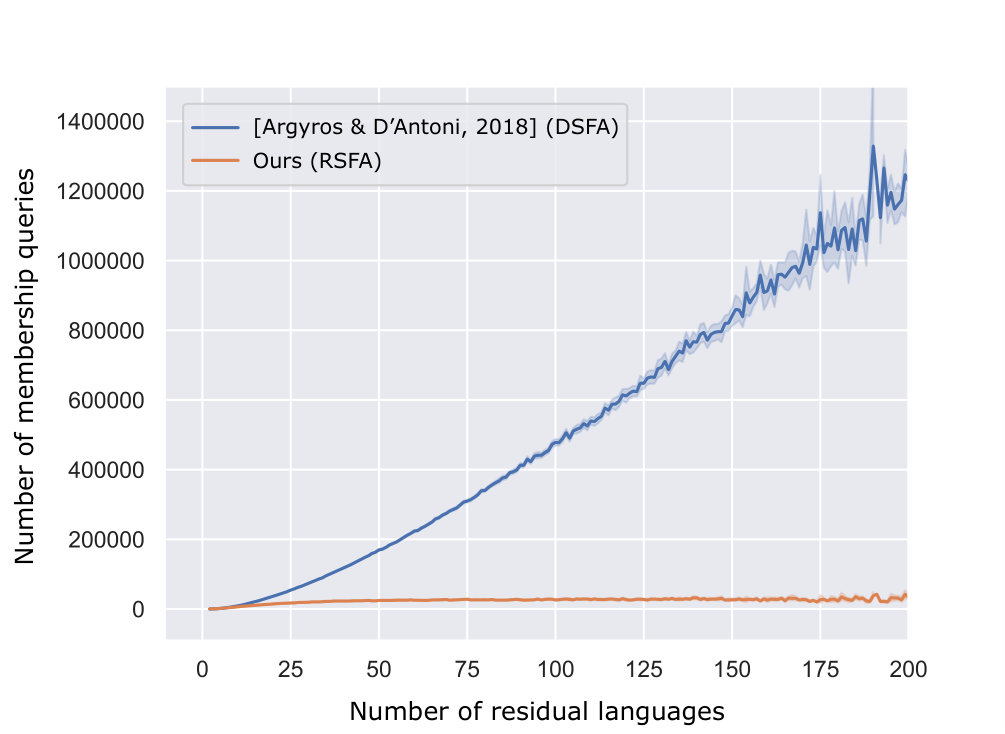 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Query Learning Algorithm for
Residual Symbolic Finite Automata
Kaizaburo Chubachi
[email protected] Graduate School of Information Sciences, Tohoku University, Japan
Diptarama Hendrian
[email protected] Graduate School of Information Sciences, Tohoku University, Japan
Ryo Yoshinaka
[email protected] Graduate School of Information Sciences, Tohoku University, Japan
Ayumi Shinohara
[email protected] Graduate School of Information Sciences, Tohoku University, Japan Graduate School of Information Sciences, Tohoku University, Japan
Abstract
We propose a query learning algorithm for residual symbolic finite automata (RSFAs). Symbolic finite automata (SFAs) are finite automata whose transitions are labeled by predicates over a Boolean algebra, in which a big collection of characters leading the same transition may be represented by a single predicate. Residual finite automata (RFAs) are a special type of non-deterministic finite automata which can be exponentially smaller than the minimum deterministic finite automata and have a favorable property for learning algorithms. RSFAs have both properties of SFAs and RFAs and can have more succinct representation of transitions and fewer states than RFAs and deterministic SFAs accepting the same language. The implementation of our algorithm efficiently learns RSFAs over a huge alphabet and outperforms an existing learning algorithm for deterministic SFAs. The result also shows that the benefit of non-determinism in efficiency is even larger in learning SFAs than non-symbolic automata.
1 Introduction
Learning regular languages has been extensively studied because of its wide varieties of applications in many fields such as pattern recognition, model checking, data mining and computational linguistics [11]. Angluin [2] presented an algorithm which learns the minimum deterministic finite automaton (DFA) accepting an unknown target language using membership queries (MQs) and equivalence queries (EQs). An MQ asks whether a string selected by the learner is a member of the target language or not. An EQ asks whether the learner’s hypothesis automaton accepts exactly the target language or not. If not, the learner gets a counterexample from the symmetric difference of the hypothesis and target languages. A teacher who can answer those two types of queries is called a minimally adequate teacher (MAT). A number of different learning algorithms working under the MAT model have been designed for regular languages [13, 14, 20]. These works have been found in applications such as specification generation [12, 17] and model verification [15]. Recently, the algorithm is also used to extract a DFA representing behavior of recurrent neural networks [22].
In such applications, alphabets tend to be extremely large and structured. The size of DFA representation grows linearly in the size of the alphabet and the number of queries needed to learn a language over the alphabet also grows linearly. Such difficulty can be alleviated by using symbolic finite automata (SFAs) [21]. An SFA has transitions that carry predicates over a Boolean algebra. By using an algebra and its predicates suitable for the languages to represent, we can make the representing SFA and learning processes for them more efficient. For example, the edge from to is labeled with in the DFA in Fig. 1(a), while the symbolic representation of it will be in Fig. 1(b), where is a free variable for which an input character is substituted. One of the first query learning algorithms targeting some types of SFAs has been proposed by Mens and Maler [18]. Their algorithm assumes a stronger teacher than MAT, but it works efficiently over large ordered alphabets such as or . After that, several query learning algorithms which work under the standard MAT model have been proposed [4, 5, 10, 16]. In particular, the algorithm given by Argyros and D’Antoni [4] is quite generic. It learns SFAs over any algebra when an efficient learning algorithm for the underlying algebra is available. For example, as there exists a learning algorithm for binary decision diagrams (BDDs) [19], SFAs whose transitions carry BDDs can be learned by the algorithm.
Another way to represent a regular language compactly is to introduce non-determinism. Denis et al. [8] have proposed residual finite automata (RFAs), which are a special kind of non-deterministic finite automata, and presented nice properties of them including the fact that an RFA can be exponentially smaller than the minimum DFA accepting the same language. Figure 1(c) shows an RFA that accepts the same language as the DFA in Figure 1(a). Bollig et al. [7] proposed an Angluin style learning algorithm for RFAs based on those nice properties and their experimental results demonstrated that needs fewer queries than in practice.
In this paper, we propose a learning algorithm for non-deterministic SFAs, which we call residual symbolic finite automata (RSFAs) to pursue further compact representations and efficient learning. Figure 1(d) shows an example of an RSFA. The algorithm can be seen as a combination of [4] and [7]. We prove that our algorithm learns target languages using RSFAs under the MAT model and present upper bounds on the numbers of EQs and MQs required. We also present experimental results that compare our algorithm with . We observe that the proposed algorithm asks much fewer EQs and MQs than like Bollig et al. [7] have demonstrated for non-symbolic automata. Yet, as we will discuss in more detail in Section 5, the impact looks significantly bigger in the learning of SFAs than non-symbolic automata.
As a byproduct of our algorithm analysis, we propose an improvement for that reduces the worst case query complexity.
2 Preliminaries
2.1 Learning under Minimally Adequate Teacher
Query learning (also called active learning) is a learning model where the learner constructs a representation of an unknown target language by actively asking queries about the language. A most representative setting is learning under a minimally adequate teacher (MAT), proposed by Angluin [2]. For a target language over an alphabet , a MAT answers two types of queries. The first type is a membership query (MQ), whose instance is a string selected by the learner. The answer to an MQ on , denoted by , is if and otherwise. The second type is an equivalence query (EQ), whose instance is a hypothesis that represents a language . The answer to an EQ is “yes” if the language is equal to the target language . Otherwise, the answer is a counterexample from the symmetric difference arbitrarily chosen by the teacher. For convenience, we say that an algorithm learns a class of representations if it finally acquires a representation in that represents an arbitrary target language in .
Angluin has proposed a polynomial time algorithm for learning deterministic finite automata (DFA). Her algorithm has been improved in theoretical and practical query efficiency and memory efficiency [13, 20].
2.2 Residual Finite Automata
An (-free) non-deterministic finite automaton (NFA) is a quintuple , where is a finite alphabet, is a finite set of states, is the set of initial states, is the set of final states, and is the transition function. An NFA is called deterministic (DFA) if for all and . The transition function is extended to so that and for , and . We use to denote . A string is accepted by if . For each state , the language accepted by is . The language accepted by is .
A language is a residual language of if there exists such that . The set of residual languages of is denoted by . A residual finite automaton (RFA) [8] is an NFA such that for every state . In other words, each state of an RFA accepts a residual language of . It is not necessary that every residual language of must be accepted by a single state. A residual language is the union of languages accepted by the states reached by reading from the initial states. Denis et al. [8] showed that an RFA can be exponentially smaller than the minimum DFA accepting the same language.
A language over a (possibly infinite) alphabet is called prime in a class of languages if it is not equal to the union of the languages it strictly contains, i.e., . The set of primes in is denoted by . Denis et al. [8] showed that an RFA has the minimum number of states among RFAs accepting the same language if and only if and for each . Such an RFA is called reduced, since no states can be deleted without changing its language. Each state of the reduced RFA corresponds to a unique prime residual language of . For a regular language , the canonical RFA of is where , , and . The canonical RFA is reduced and has saturated transitions (i.e. no transition can be added without modifying the language accepted by the RFA).
Bollig et al. [7] has proposed an algorithm for learning RFAs extending Angluin’s algorithm for DFAs. It constructs (an RFA isomorphic to) the canonical RFA of the target language. The theoretical upper bound on the number of queries required by is higher than for the same regular language. However, their experimental results show that practically makes fewer queries than does.
2.3 Symbolic Finite Automata
Symbolic finite automata (SFAs) are finite automata which have more expressive transitions than NFAs. In an SFA, transitions carry unary predicates over an effective Boolean algebra on a (typically huge or infinite) alphabet . Transitions whose predicates are satisfied by the read character are executed.
An effective Boolean algebra is a tuple , where is an alphabet, is a set of unary predicates closed under the Boolean connectives, and is a denotation function such that (i) , (ii) , and (iii) for all , , and . We assume it is decidable whether for any and moreover there is an effective procedure to find an element of unless .
An SFA is a quintuple , where is an effective Boolean algebra, is a finite set of states, is the set of initial states, is the set of final states, is the finite transition relation. When the transition edge from to has a predicate label , i.e., , this means that the transition is executed when is satisfied by the reading character. That is, induces the transition function such that for and . We extend to in the same way as for (non-symbolic) FAs. Without loss of generality, we may assume that each pair of states has just one predicate such that , since and is closed under union. Let for . The language accepted by is . An SFA is called deterministic if and for all and . SFAs inherit many virtues of (non-symbolic) FAs. For example, one can effectively obtain the minimum DSFAs from SFAs and decide equivalence of two SFAs [21].
Argyros and D’Antoni [4] have given a MAT learner for deterministic SFAs (DSFAs), assuming that a MAT learner for is available. That is, can learn for an arbitrary predicate with a MAT. The algorithm uses instances of to identify the predicate label of the transition edge from to and pretends to be a MAT for those predicate learner instances. Through communication between those predicate learners and the real MAT for the DSFA, it constructs a hypothesis DSFA. Accordingly, the query complexity of depends on the design of . In general, it requires very much less MQs than classical MAT learners using DFAs, when the alphabet is big but finite. If the alphabet is infinite, classical MAT learners have no hope to learn the language.
The target of this paper is residual symbolic finite automata (RSFAs). An RSFA is an SFA such that for every state . It is called reduced if and for each .
3 Learning Algorithm for Residual Symbolic Finite Automata
Our learning algorithm for RSFAs can be seen as a combination of the RFA learner [7] and the DSFA leaner [4]. This section presents how those can be combined and how the new difficulties raised by the combined setting shall be solved.
Our algorithm uses an observation table [2], which is used by . An observation table is where is a prefix-closed set of strings, is a set of strings, and is a map . For each and , we make if and otherwise for all and by asking an MQ on the string . An observation table can be viewed as a two-dimensional table whose entry is for and . Let for . To observe the relationship among residual languages is a key to acquire a (reduced) RFA for the target language , but we cannot directly handle . However, we can have a finite approximation . The algorithm builds a hypothesis based on this information. Compared to the one constructed by , our observation table differs in two points: (1) the domain of is rather than and (2) is not necessarily suffix-closed. The first change is inevitable to handle huge alphabets. The second is an improvement from . Giving up the idea of keeping suffix-closed reduces the size of and consequently the number of MQs.
Our algorithm builds a hypothesis SFA using the observation table and instances of the predicate learning algorithm, checks necessary conditions of the hypothesis to be an RSFA, asks an EQ and then updates the hypothesis by modifying the observation table and/or talking with the predicate learners. This procedure is repeated until an EQ is answered “yes”. The pseudo-code of our algorithm is shown in Algorithm 1. The hypothesis is rebuilt from scratch when the observation table is updated. Our algorithm assigns null to the variable if the hypothesis has to be rebuilt.
At the beginning of the main loop, our algorithm calls Algorithm 2 to build a hypothesis with , and , using the observation table . In order to construct , similarly to , we use the MAT learning algorithm for the underlying algebra . After Algorithm 2 creates instances of for all pairs of states , Algorithm 3 communicates with each by pretending to be a MAT to obtain a transition predicate from to . To avoid confusion with EQs and MQs from our algorithm to the MAT, we use small capital letters eq and mq for equivalence queries and membership queries from a predicate learner to our algorithm, respectively. When asks an mq on , our algorithm answers if and otherwise. When asks an eq on , our algorithm determines the transition predicate from to to be . An answer to the eq from the predicate learner will be generated by analyzing the built transitions or a counterexample for an EQ on the hypothesis automaton in the following steps. Execution of the predicate learner is suspended until a counterexample for the eq is found. When the algorithm is trying to answer an mq on from a predicate learner , if happens to be a new prime in , is extended to , and the procedure of building hypothesis restarts from the beginning.
After building a hypothesis, we check the following three conditions on the hypothesis by Algorithm 4 and modify the hypothesis if necessary, before raising an EQ. Those conditions ensure that our final output hypothesis will be a reduced RSFA.
- •
Condition 1: For and , implies .
- •
Condition 2: For and , we have .
- •
Condition 3: For and , we have iff .
Note that, in , the automaton derived from an observation table always satisfies essentially the same conditions as above, which ensures that finally acquires the canonical RSA for the learning target language. The difference comes from the fact that makes a transition so that if and only if . On the other hand, the predicate on the transition edge from to is determined by in our setting, which ensures no special properties required to have the conditions. Therefore, we need additional processes to check the three conditions.
If some of the conditions is not satisfied, we modify the observation table or the transition relation so that the conditions shall be satisfied. The transition relation is updated by giving a counterexample to a predicate learner’s eq and receiving a new predicate hypothesis from it. For Condition 1, recall that for all if and only if implies , i.e., , for all . By assumption, this can be confirmed effectively and when , one can find a witness . Condition 2 can be checked by naively executing transitions reading all from initial states. By performing this in length ascending order, if Condition 2 fails, one can find with , and such that and , thanks to the prefix-closedness of . Condition 3 can also be checked by naively executing transitions reading all from each . Note that, since is not necessarily suffix-closed, differently from the previous case, we do not perform this in the length ascending order. If some is found to falsify the condition, i.e. , we find a suffix of with , which is not necessarily in , such that for all and for some . Such a suffix can be found with MQs using binary search on the suffixes of , since for all and for some . Then, using such and , we modify the hypothesis. Note that by employing this technique, the query efficiency of [7], which requires to be suffix-closed, can be improved (Corollary 1).
When the hypothesis is confirmed to satisfy the three conditions above, the algorithm asks an EQ. We prove in Section 4 that if the hypothesis passes the equivalence test, it is a reduced RSFA.
When a counterexample is given to an EQ, we process the counterexample. Algorithm 5 is a modification of for our non-deterministic hypothesis. At First, we check whether . If not, shall be refined by adding to . If it is the case, we find a decomposition of such that , and . We have and because and is a counterexample such that . This implies . Therefore, such a decomposition can be found with MQs using binary search on the decompositions of . This is a non-deterministic extension of the binary search technique in [20] for learning DFAs. Then, we can refine the transition from led by .
4 Correctness and Termination
Although our hypothesis is not guaranteed to be always an RFSA, the algorithm will eventually terminate and return a reduced RSFA accepting the target language.
Theorem 1**.**
When the hypothesis passes the equivalence test, is a reduced RSFA accepting the target language .
One can prove Theorem 1 in the essentially same manner as for [7].
In order to evaluate the query complexity of our algorithm, we first discuss how many mqs and eqs a predicate learner may make. Let be the set of letters that is expected to learn, in accordance with how our learner answers mqs from . To find a predicate for , we refer to the minimum DSFA that accepts the learning target . Note that is constructible from an arbitrary SFA for [21]. Let and , where is the transition function induced by .111To be strict, the DSFA should be written as and is a singleton set according to what we have defined in the preliminary section, but here we follow the conventional notation for deterministic automata. Then we have where is the predicate on the edge from to . Therefore, is indeed capable of learning and there are bounds on the numbers of eqs and mqs that makes, which we write as and , respectively.
For each , let . Then, the set of denotations of predicates that may appear in an automaton built by the learner during the learning process is represented as . Then the numbers of eqs and mqs that each predicate learner may make are bounded by and , respectively.
Theorem 2**.**
Let and be the length of the biggest counterexample to an EQ returned by the MAT. Then, the proposed algorithm returns a reduced RSFA accepting using after raising at most EQs and MQs.
Proof.
At first, we will prove that the observation table cannot be extended beyond times. Following [7], we create a tuple of measures where , , , , . After each extension of the table, either (1) is increased or (2) is increased by and, simultaneously, is increased by at most or (3) stays the same and decreases or increase. However, , , cannot increase beyond . Therefore, cannot be extended beyond times.
Recall that is updated only when a counterexample to some predicate learner is found. Such counterexamples are found at most times without extending . can be bounded by . Thus, is updated at most times without extending . Therefore, The algorithm must always reach an EQ and terminate after making at most EQs.
The algorithm asks MQs for (1) filling the observation table after extending the table, (2) answering mqs from predicate learners at Line 3 of Algorithm 3, (3) checking for a counterexample at Line 5 of Algorithm 5, (4) finding a decomposition of a counterexample at Line 5 of Algorithm 5, (5) finding a suffix of which does not satisfy Condition 3 at Line 4 of Algorithm 4, and (6) the other purpose, where we check one or two rows for deciding whether to extend the observation table or to update the transition relation, after finding a decomposition of a counterexample or when one of the three conditions is found to be unsatisfied.
The total number of MQs used for (1) is , because and is bounded by and , respectively. Concerning (2), we use at most MQs for each intermediate observation table . Thus, MQs are asked in total. We perform (3) and (4) at most times. For each event, (3) uses MQs and (4) uses MQs. All in all, MQs are asked for (3) and (4). Each time (5) happens, MQs are raised, and (5) happens times. In total, MQs are asked for (5). For each decision of (6), MQs are used, and it takes place times. Hence, MQs are made for (6). Therefore, the algorithm asks at most MQs. ∎
A query complexity comparison among previous algorithms and our algorithm for related classes of automata is shown in Table 1. The query complexity of the proposed algorithm is higher than that of [4], especially for MQs. This is also true in the non-symbolic case. However, Bollig et al. [7] showed that in practice learning RFAs requires less queries than learning DFAs. In Section 5, we show that it is also the case in the learning of RSFAs and DSFAs.
We remark that the query efficiency of [7] can be improved by using our technique. The algorithm [7] adds all the suffixes of a counterexample to , which makes suffix-closed and rather large. Suffix-closedness of ensures the correctness of . Namely, the property is used in the proof of Lemma 2 of [6], which states that Condition 3 of our paper always holds for . That is, by employing our counterexample processing and Condition 3 assurance procedure, the upper bound of the size of the table is improved from to with additional MQs (binary search with MQs can occur times).
Corollary 1**.**
Canonical RFAs can be learned using EQs and MQs.
5 Experiments
To evaluate the practical performance of our algorithm, we compare it with Argyros and D’Antoni’salgorithm for DSFAs [4]. They implemented their algorithm on the open-source librarysymbolicautomata. Our algorithm is also implemented on the same library.
5.1 Setting
We generated learning target languages as follows, which can be seen as the symbolic counterpart of the languages given by Denis et al. [9] for comparing DFAs and RFAs. Denis et al. used NFAs over a two-letter alphabet for generating random regular languages. We use non-deterministic (not necessarily residual) SFAs over the entire 32-bit integers, i.e. . SFAs we use are on the inequality algebra over , whose atomic predicates are of the form for some , where is the free variable, and their semantics is given by . Using negation, intersection and union, predicates define unions of intervals. We abbreviate to . We also implemented a MAT learning algorithm for the algebra and used it as . It learns arbitrary subsets by asking at most eqs and mqs using binary search where is the number of “borders” in the set . SFAs are randomly generated using four parameters: the number of states, the number of transitions per state, and the probabilities and for each state of being an initial and final state, respectively. For each state , we randomly pick a destination state and two integers such that and add to . This addition is performed times for each state permitting duplication of the destination state. If we choose the same state twice or more as a destination of a state , the transition predicate from to will be the union of two or more randomly chosen intervals. We used the parameters , and in our experiments.222The source code is available at https://github.com/ushitora/RSFA-QueryLearning.
5.2 Results
We generated 50,000 non-deterministic SFAs and let our algorithm learn the languages defined by those SFAs. Figures 2(a) and (b) show the average numbers of EQs and MQs raised by our algorithm relative to the number of the residual languages, respectively. The results are in contrast with our worst case analysis in Theorem 2. Our algorithm makes much fewer queries than . The gap between the numbers of the queries made by and our algorithm looks even bigger than that between those by and observed in the experiments performed by Bollig et al. [7] and by Angluin et al. [3]. In the remainder of this section, we discuss why using non-deterministic version should be more beneficial in the learning of symbolic automata than non-symbolic automata.
5.3 Analyses and Discussions
Denis et al. [9] have observed that most languages of randomly generated NFAs have few prime residual languages, i.e., the number of states of a reduced RFA tends to be much fewer than that of the minimum DFA for the same language. Even in the middle of the learning process, hypotheses built by our learner tend to be smaller than the ones by (c.f. Fig. 3(a)), in spite of the worst case analysis. This tendency should be essentially the same in the non-symbolic and symbolic cases. However, the automaton size has a bigger effect on the query complexity in the symbolic case than in the non-symbolic case. Recall that most MQs and EQs to the MAT are used to answer mqs and eqs from the predicate learners when learning SFAs. We have predicate learners if our current hypothesis has states. As a consequence, the benefit in the query complexity to reduce the number of states in a hypothesis automaton is much bigger in SFA learning and thus using residual automata is quite advantageous.
In addition, when learning RSFAs, we are granted to be flexible to some extent in identification of transition predicates. Concerning a transition from to , let and . For any with , changing the transition predicate between and to does not change the language defined by the automaton. That is, when learning an RSFA, as long as the predicate learner outputs a predicate satisfying , the RFSA constructed using that output may pass the equivalence test. For instance, in the inequality algebra, when consists of many intervals, a “lazy” predicate whose semantics consists of fewer intervals may be accepted, which can be achieved with fewer queries. This nature is not observed neither in RFAs nor DSFAs.
At last, we present another observation that explains why learning residual automata can be more efficient than deterministic ones, which applies to the non-symbolic case, too. To answer each mq from a predicate learner, our algorithm uses MQs to the MAT. Figure 3(b) shows the average of in our experiments. In the worst case analysis, may increase up to , but in most of these experiments, is much smaller than , which keeps the number of MQs in our algorithm small. An element is added to for denying at least one inclusion relation of a pair of rows, which occurs times in the worst case. In practice, one added element to may falsifies inclusions for many pairs of residual languages, while there is a lot of pairs between which inclusion properly hold, which will never been denied. Therefore, tends to be much smaller than the worst case, and it saves many MQs by our algorithm.
Acknowledgement
The research is supported by JSPS KAKENHI Grant Number JP18K11150.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1]
- 2[2] Dana Angluin (1987): Learning Regular Sets from Queries and Counterexamples . Information and Computation 75(2), pp. 87–106, 10.1016/0890-5401(87)90052-6 . · doi ↗
- 3[3] Dana Angluin, Sarah Eisenstat & Dana Fisman (2015): Learning Regular Languages via Alternating Automata . In: Proceedings of the 24th International Conference on Artificial Intelligence , IJCAI’15, AAAI Press, pp. 3308–3314.
- 4[4] George Argyros & Loris D’Antoni (2018): The Learnability of Symbolic Automata . In: Computer Aided Verification (CAV 2018) , pp. 427–445, 10.1007/978-3-319-63121-98 . · doi ↗
- 5[5] George Argyros, Ioannis Stais, Aggelos Kiayias & Angelos D. Keromytis (2016): Back in Black: Towards Formal, Black Box Analysis of Sanitizers and Filters . In: IEEE Symposium on Security and Privacy (SP 2016) , pp. 91–109, 10.1109/SP.2016.14 . · doi ↗
- 6[6] Benedikt Bollig, Peter Habermehl, Carsten Kern & Martin Leucker (2008): Angluin-Style Learning of NFA . Technical Report LSV-08-28, Laboratoire Spécification et Vérification.
- 7[7] Benedikt Bollig, Peter Habermehl, Carsten Kern & Martin Leucker (2009): Angluin-Style Learning of NFA . In: Proceedings of the 21st International Joint Conference on Artificial Intelligence , pp. 1004–1009.
- 8[8] François Denis, Aurélien Lemay & Alain Terlutte (2002): Residual finite state automata . Fundamenta Informaticae 51(4), pp. 339–368.
