TL;DR
This paper reviews and empirically compares state-of-the-art sparse feature selection methods, highlighting their accuracy, false detection rates, and computational efficiency across various noise and correlation regimes.
Contribution
It provides a comprehensive empirical evaluation of recent sparse regression algorithms, including integer optimization and Boolean relaxation, with insights into their practical performance and computational costs.
Findings
Integer optimization and Boolean relaxation closely achieve ideal accuracy and false detection rates.
All methods have comparable computational times to glmnet for Lasso.
Proper methods recover true features with increasing sample size.
Abstract
In this paper, we review state-of-the-art methods for feature selection in statistics with an application-oriented eye. Indeed, sparsity is a valuable property and the profusion of research on the topic might have provided little guidance to practitioners. We demonstrate empirically how noise and correlation impact both the accuracy - the number of correct features selected - and the false detection - the number of incorrect features selected - for five methods: the cardinality-constrained formulation, its Boolean relaxation, regularization and two methods with non-convex penalties. A cogent feature selection method is expected to exhibit a two-fold convergence, namely the accuracy and false detection rate should converge to and respectively, as the sample size increases. As a result, proper method should recover all and nothing but true features. Empirically, the…
Click any figure to enlarge with its caption.
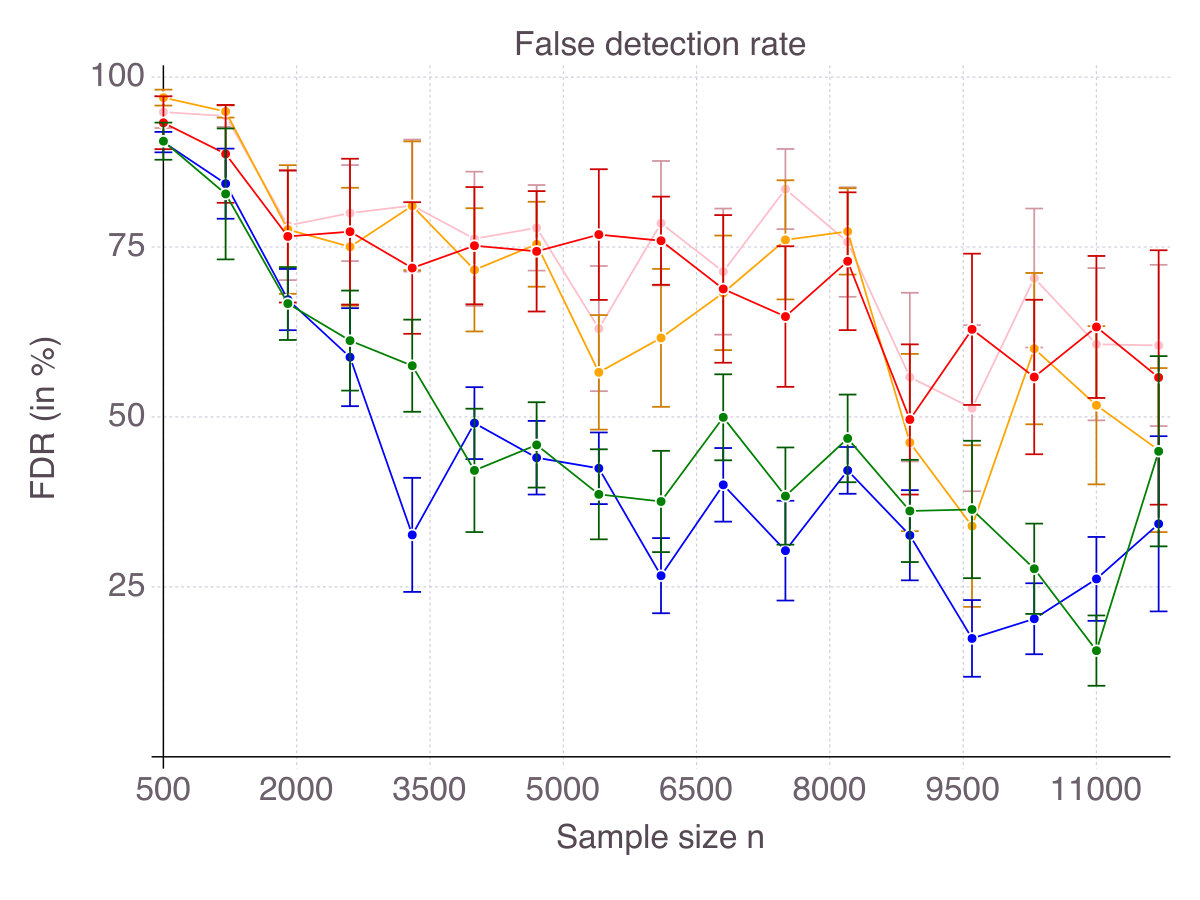 Figure 1
Figure 1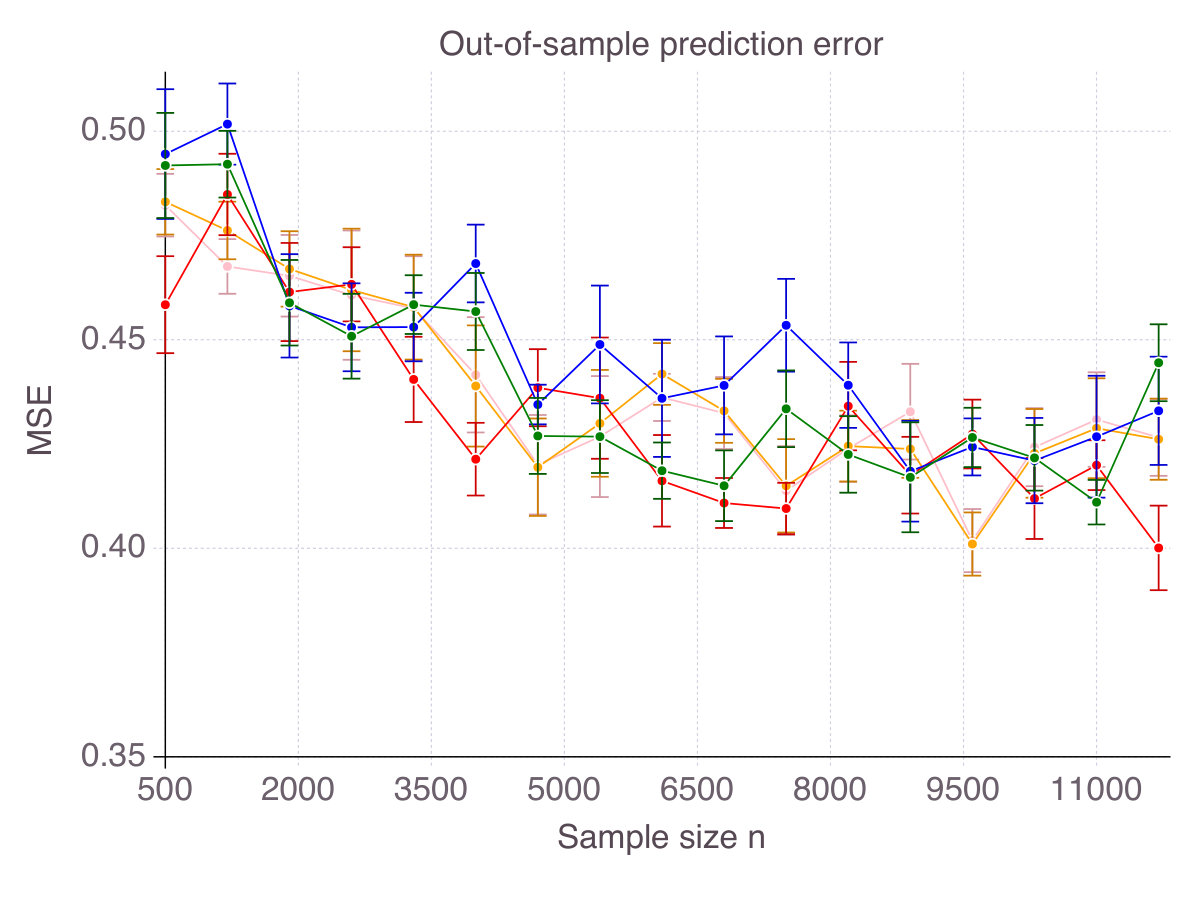 Figure 2
Figure 2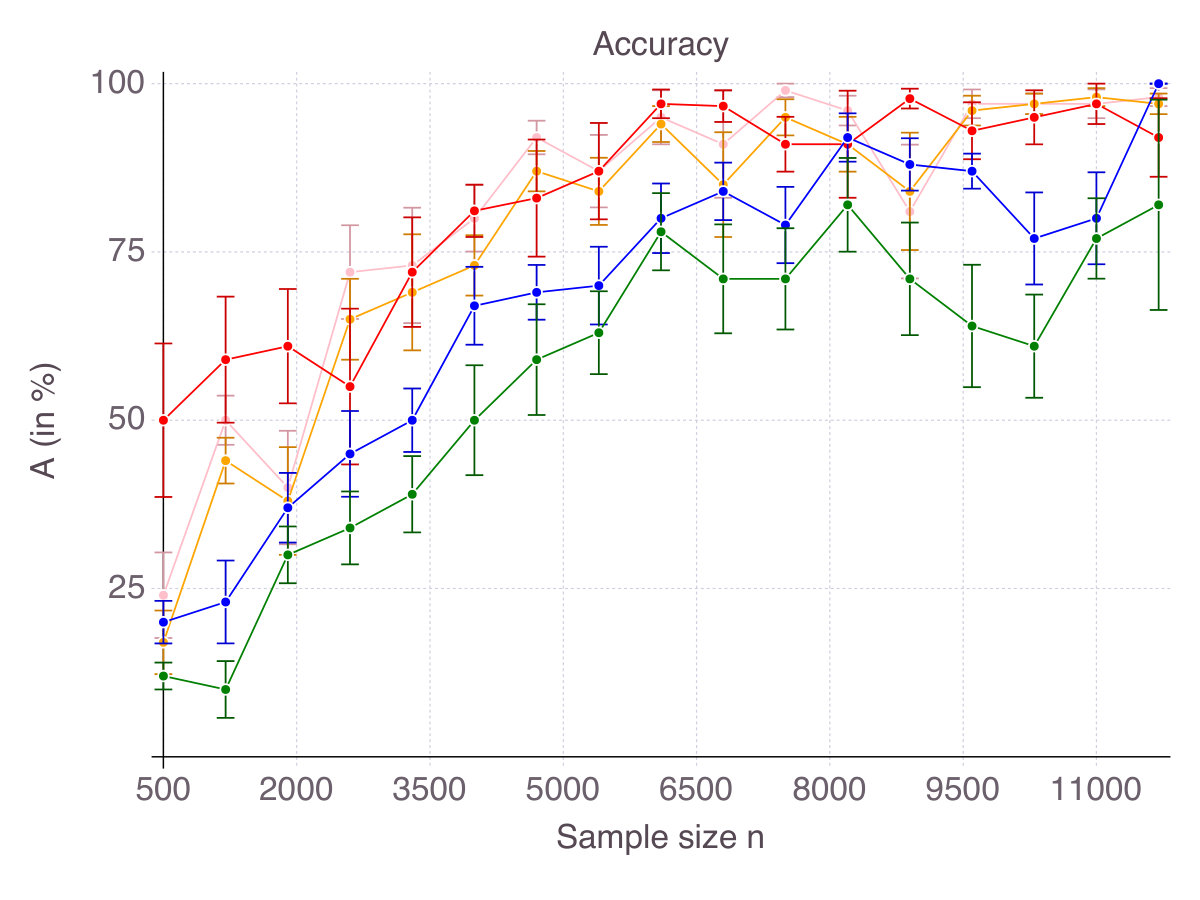 Figure 3
Figure 3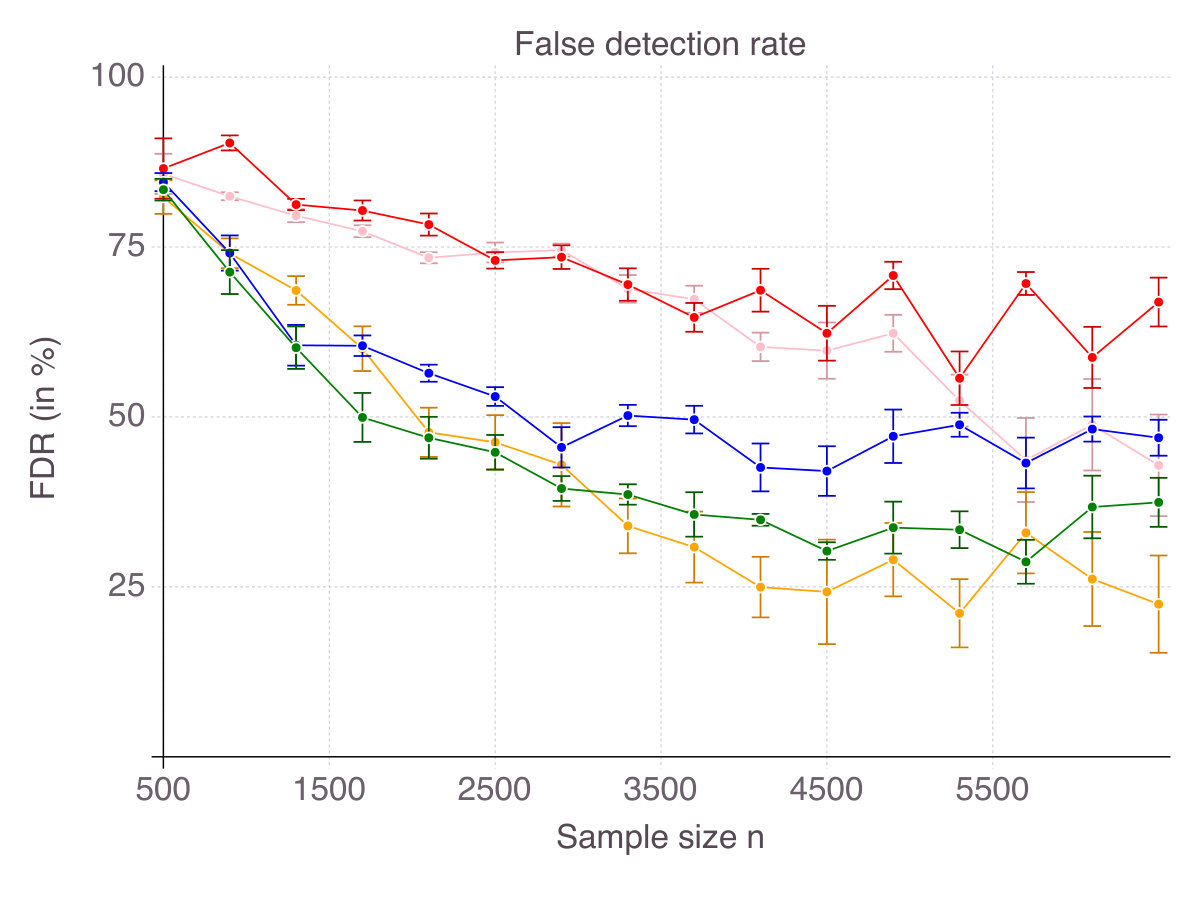 Figure 4
Figure 4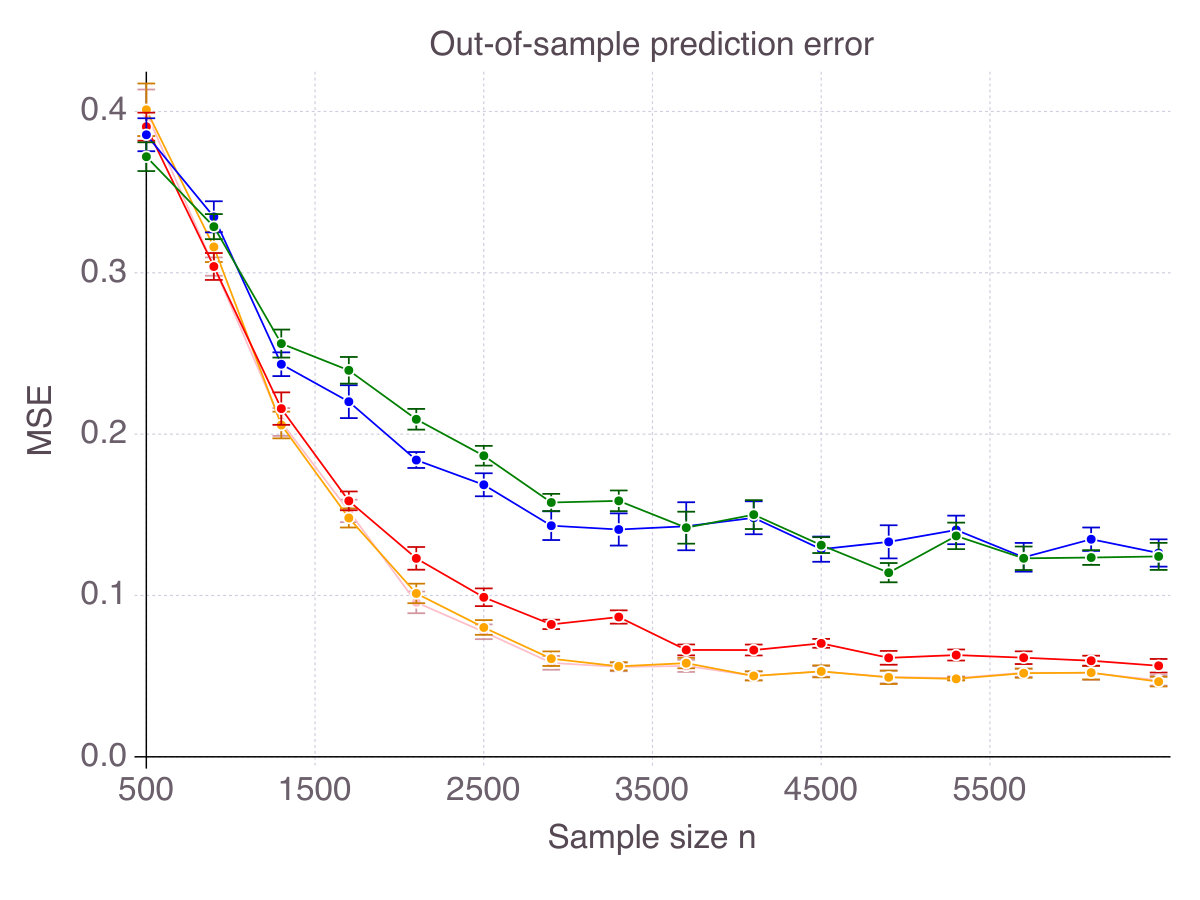 Figure 5
Figure 5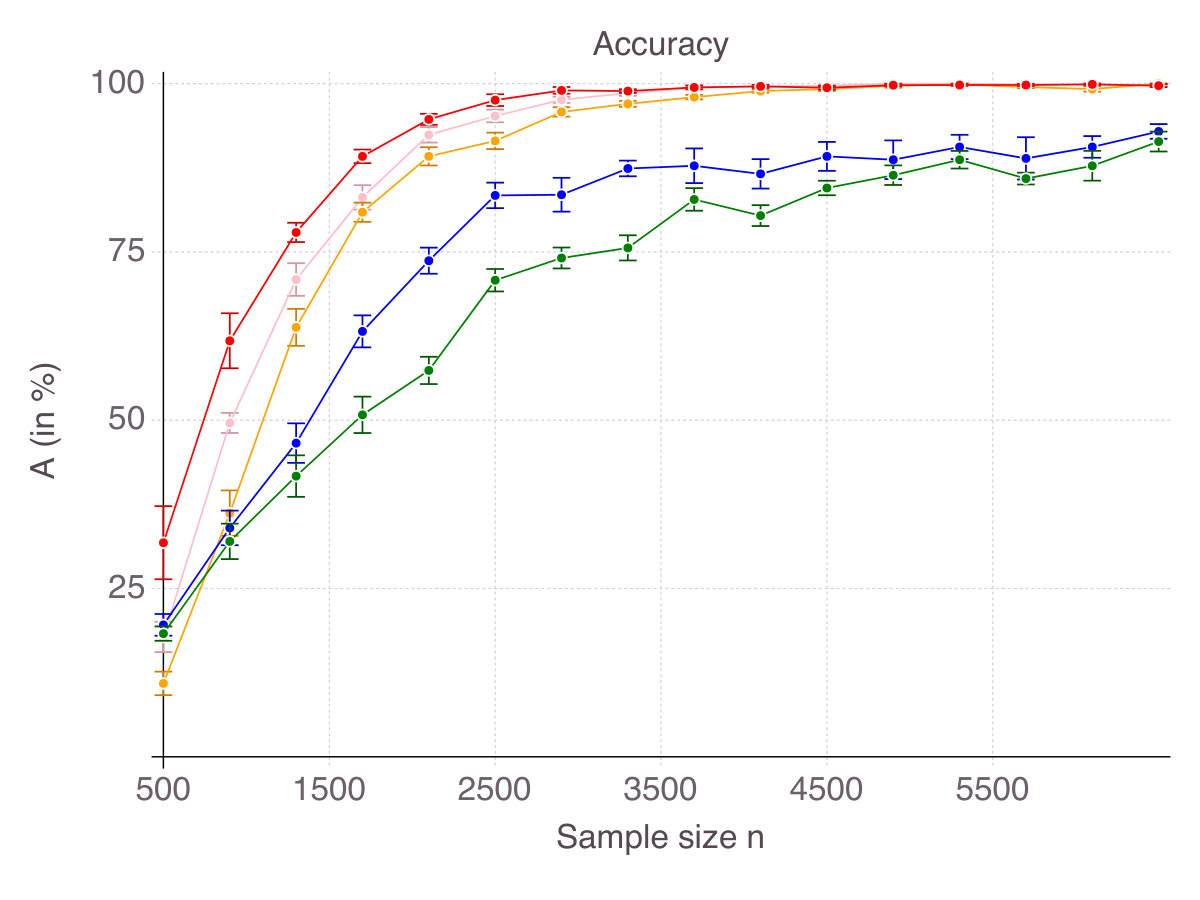 Figure 6
Figure 6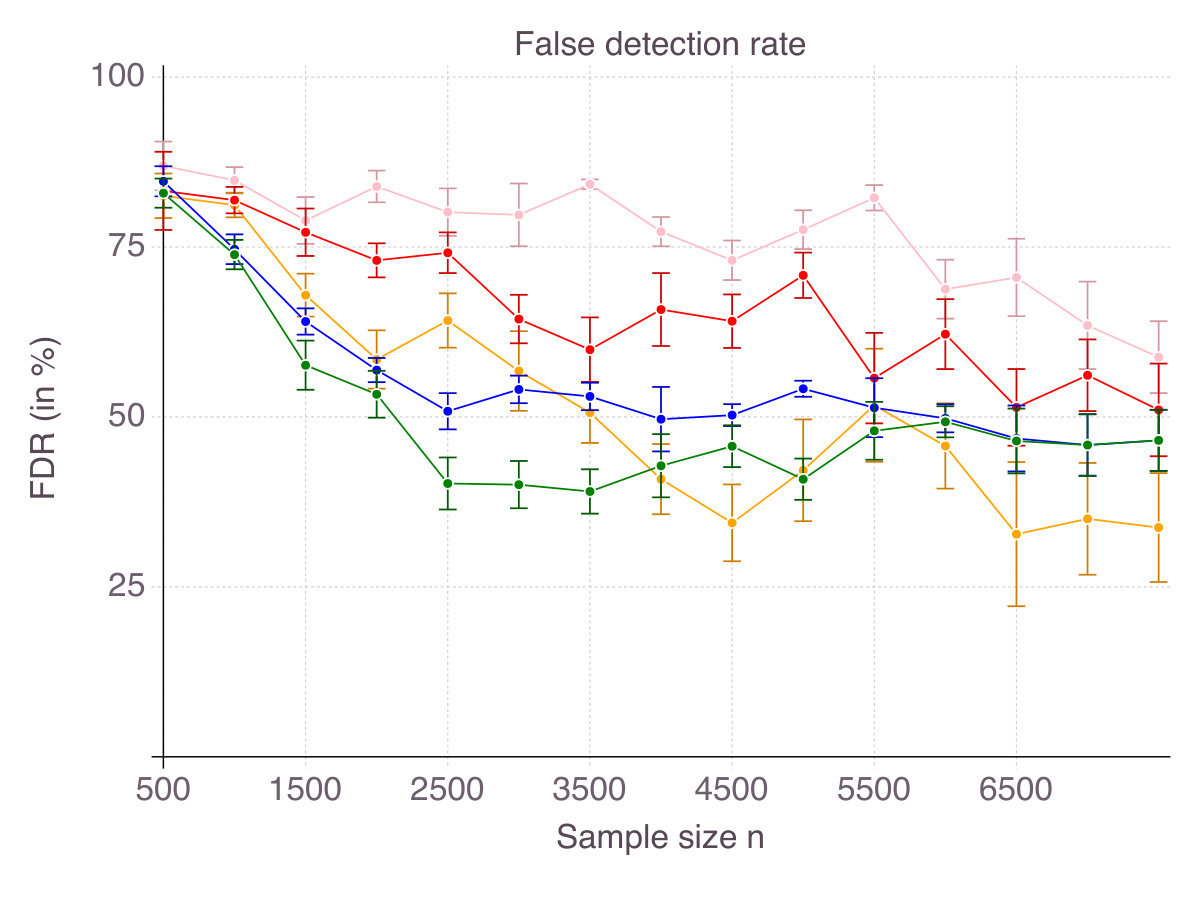 Figure 7
Figure 7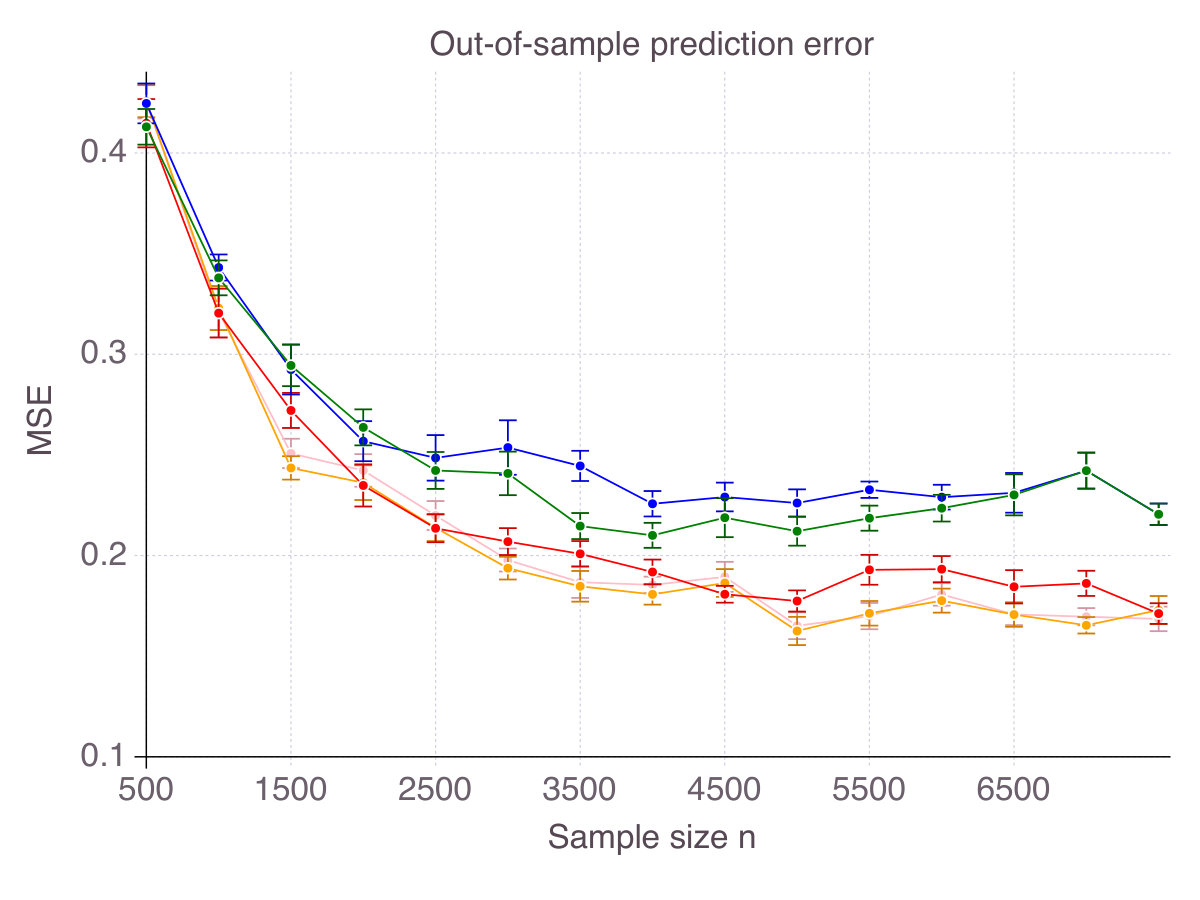 Figure 8
Figure 8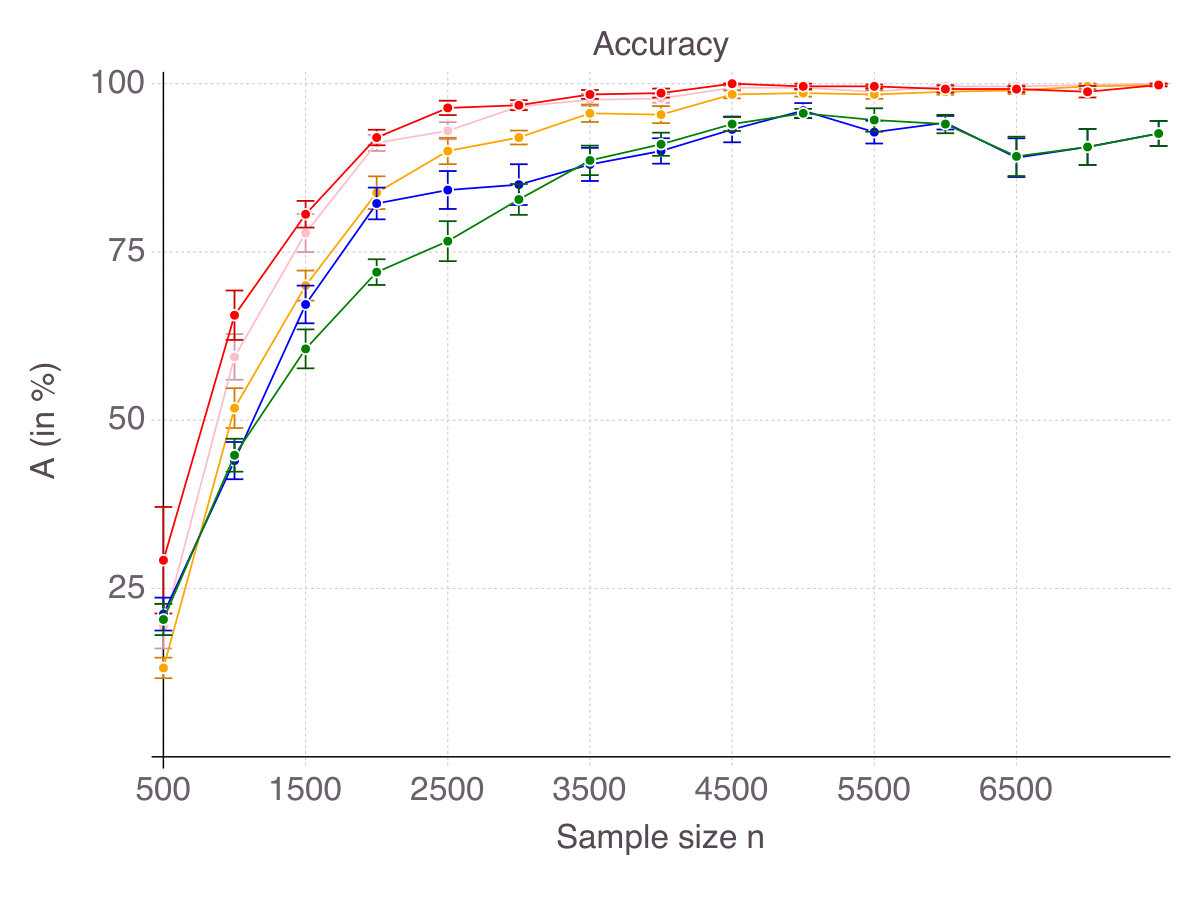 Figure 9
Figure 9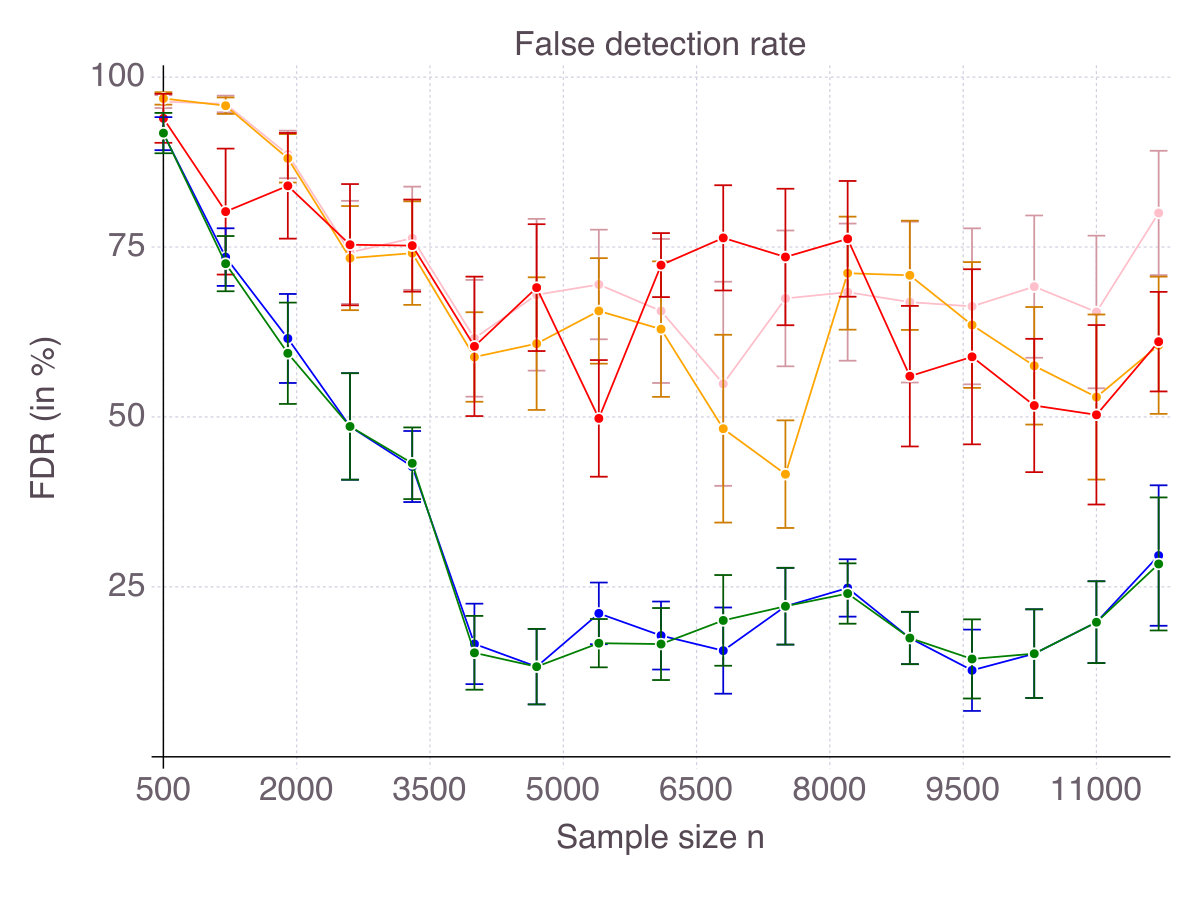 Figure 10
Figure 10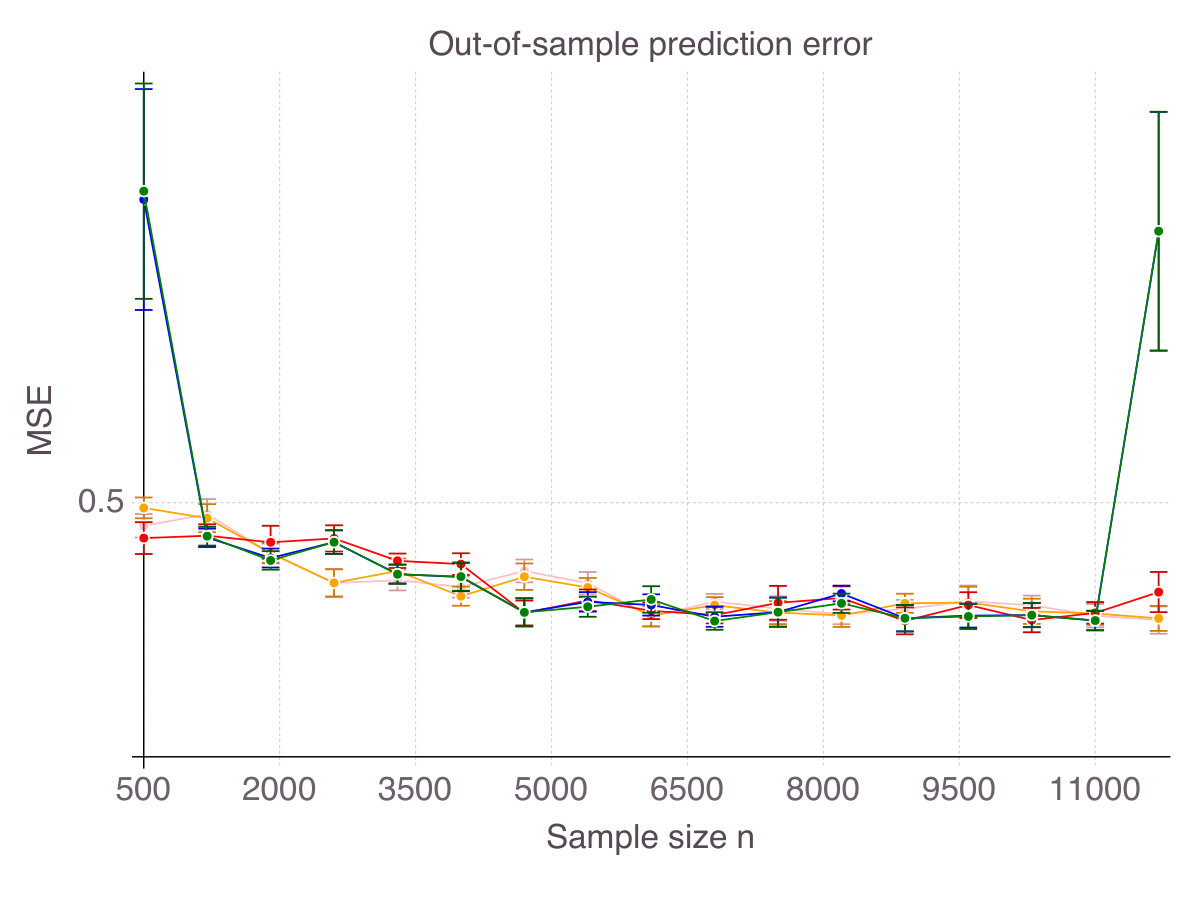 Figure 11
Figure 11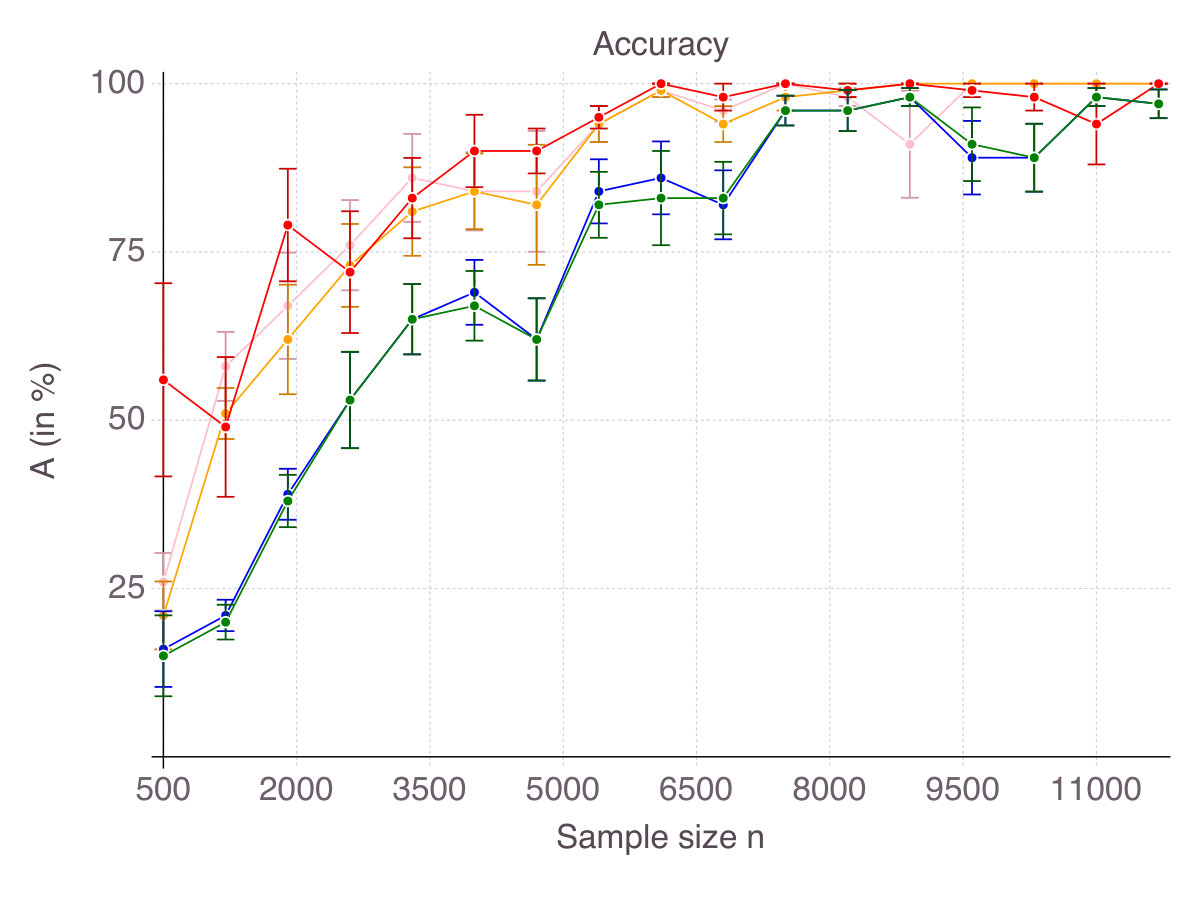 Figure 12
Figure 12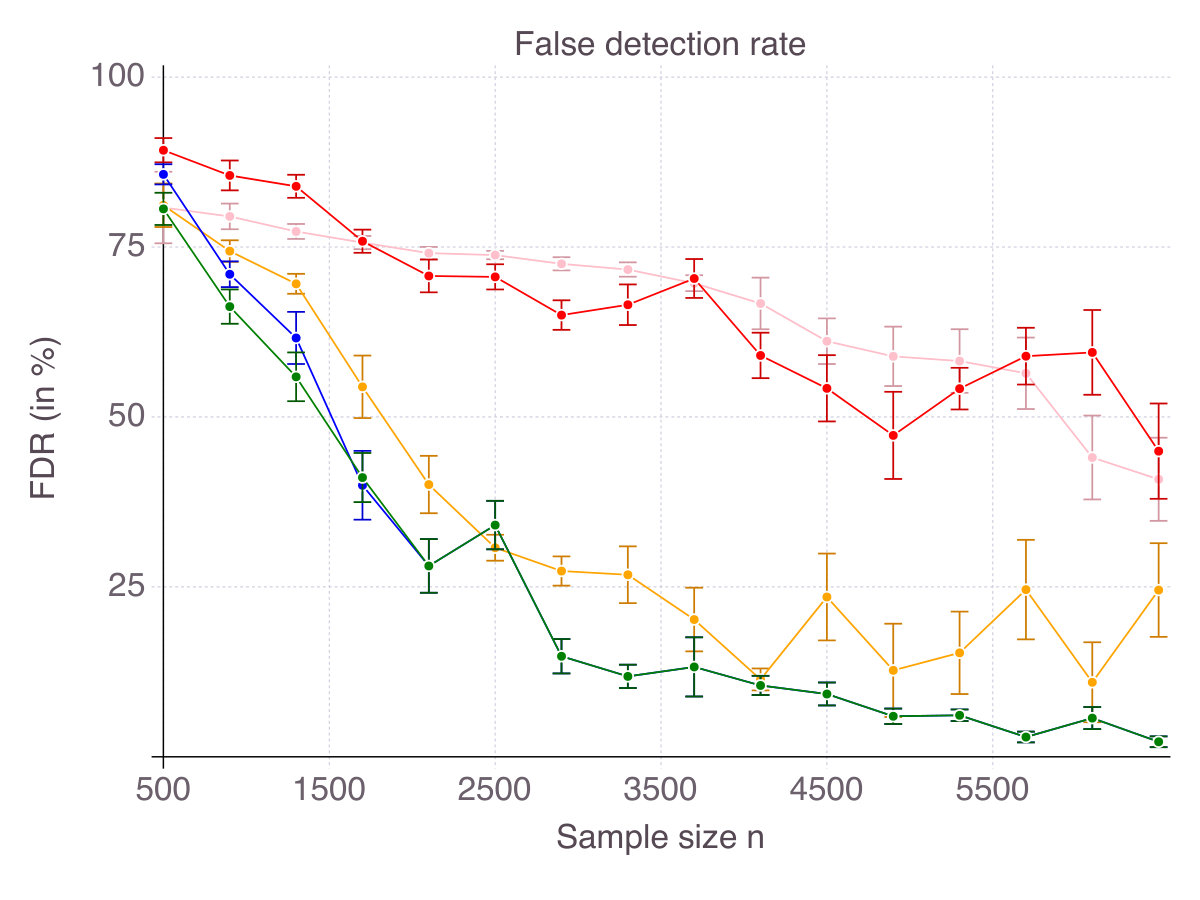 Figure 13
Figure 13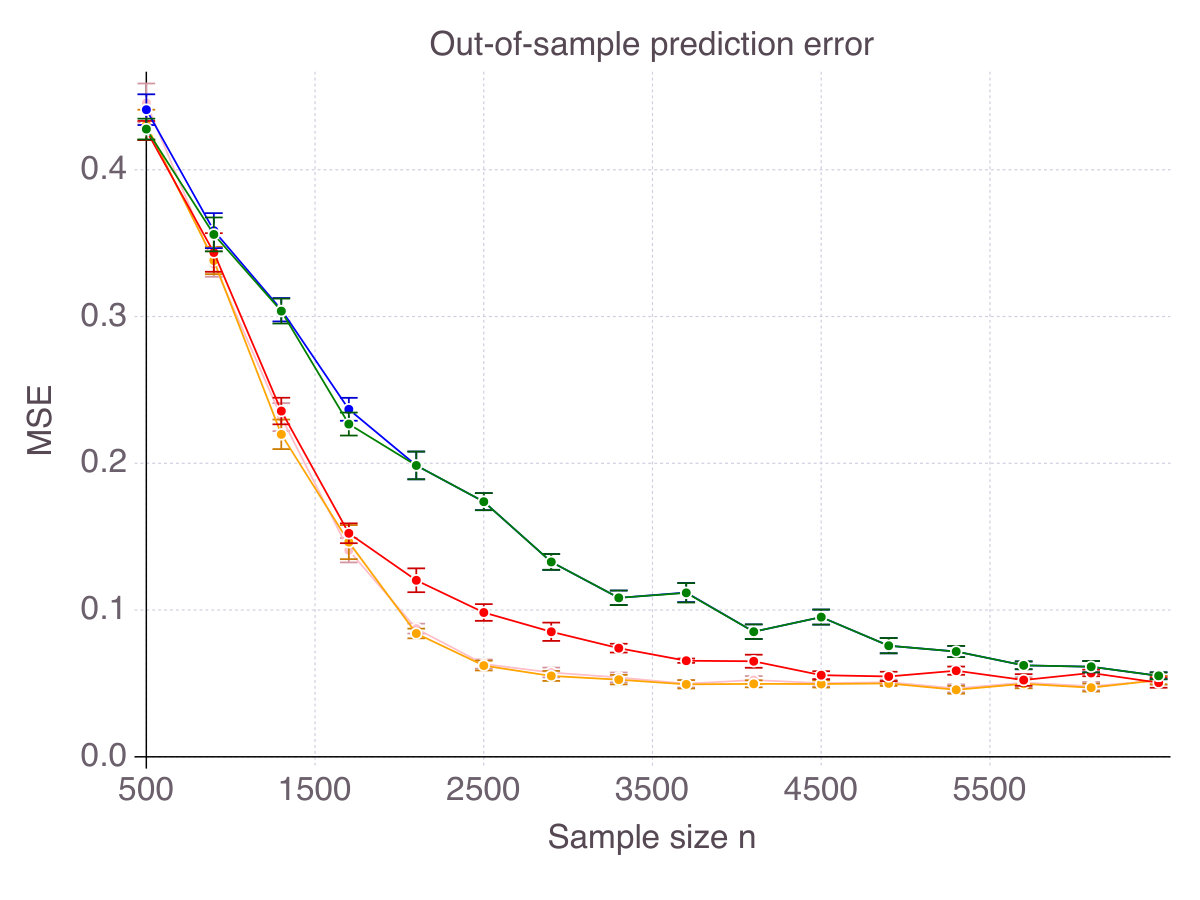 Figure 14
Figure 14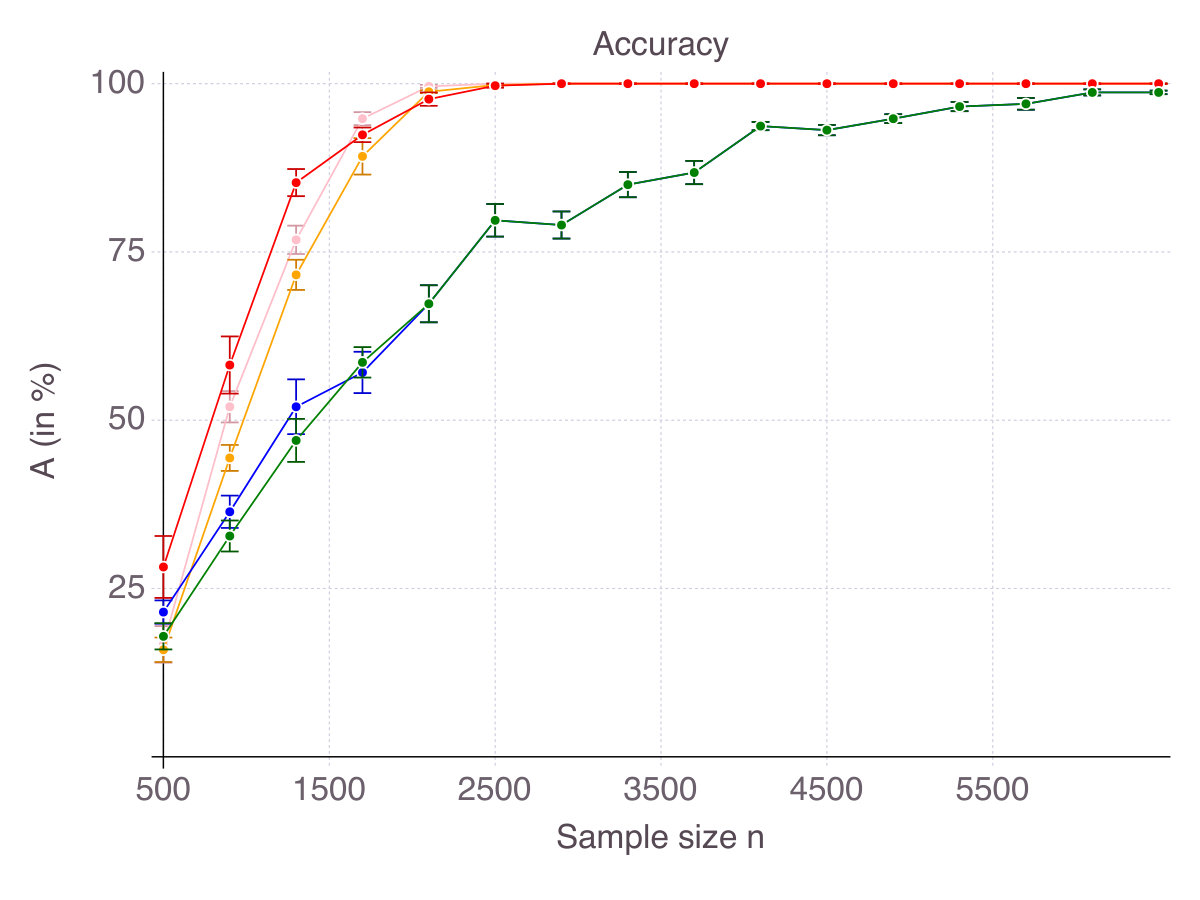 Figure 15
Figure 15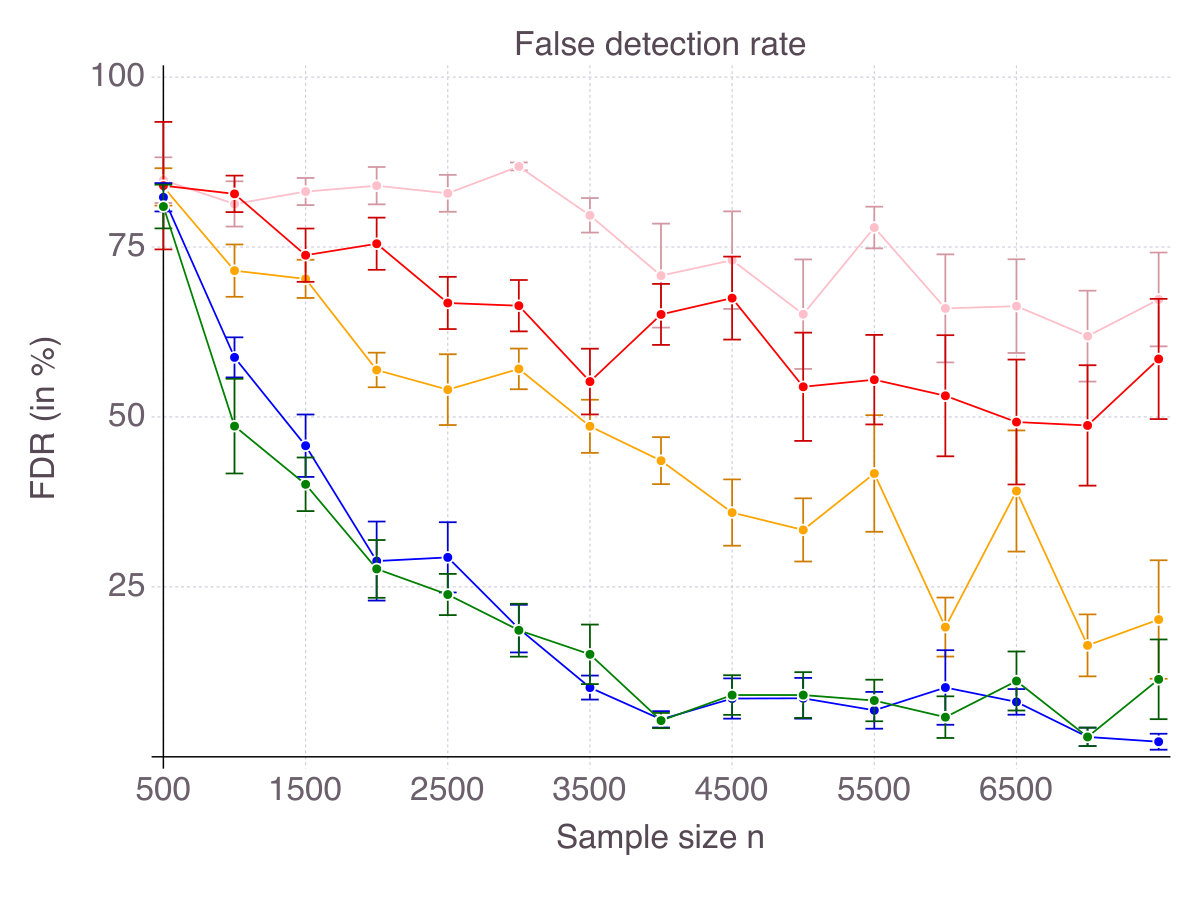 Figure 16
Figure 16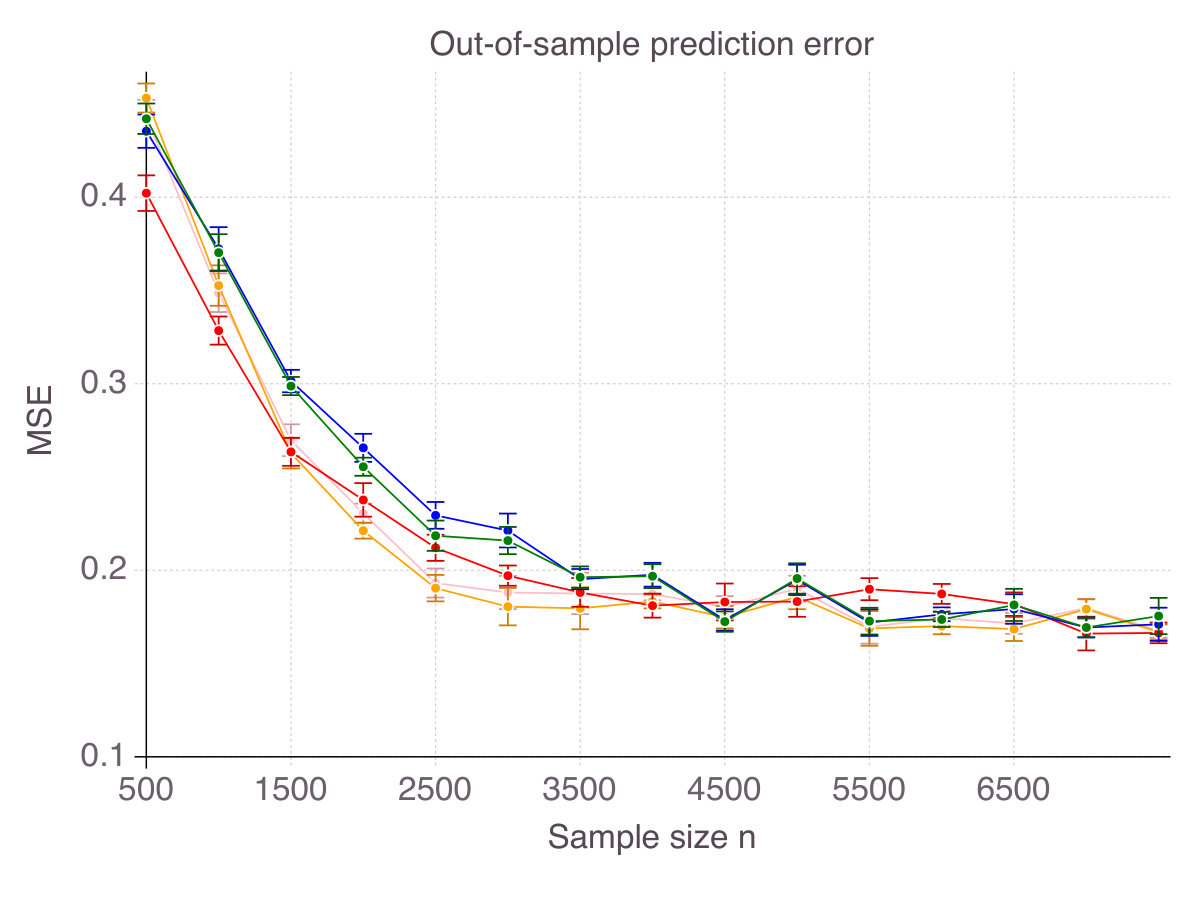 Figure 17
Figure 17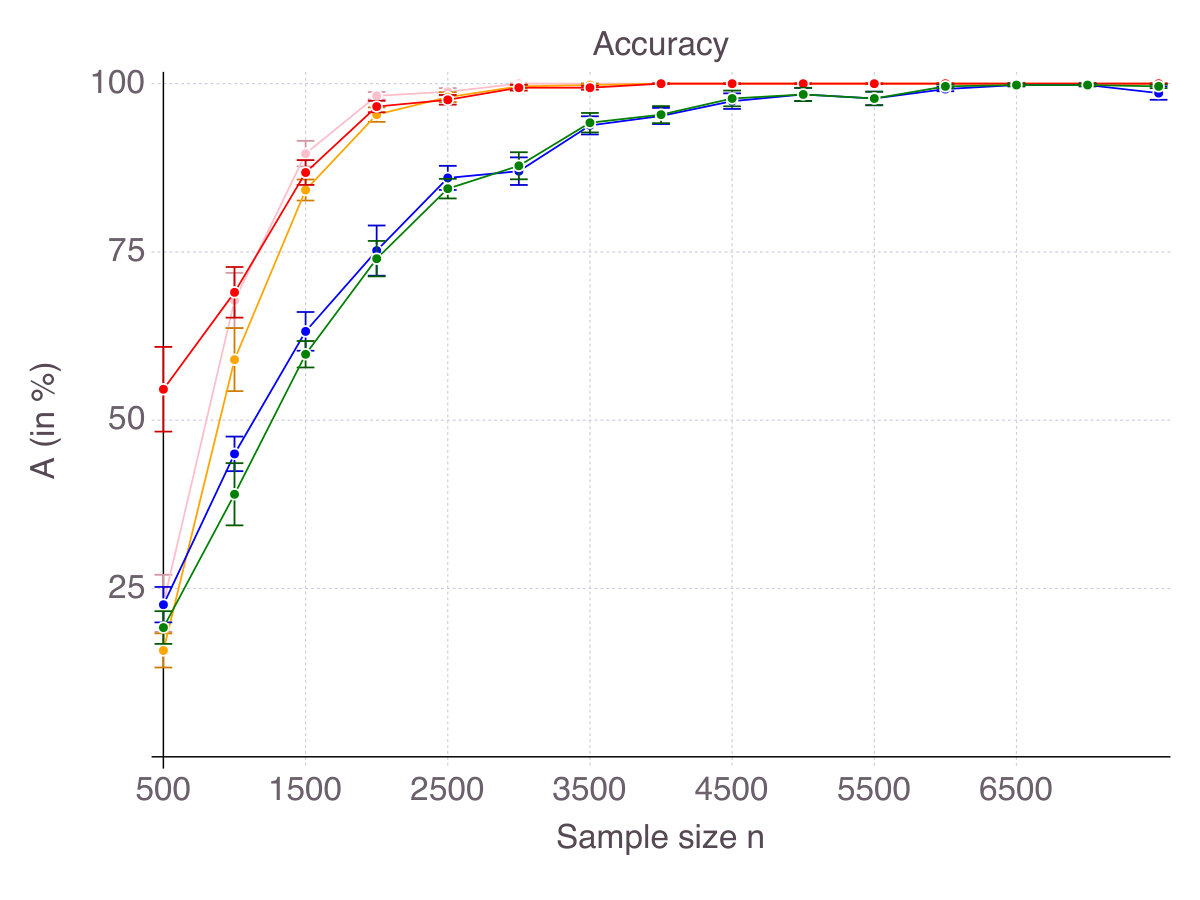 Figure 18
Figure 18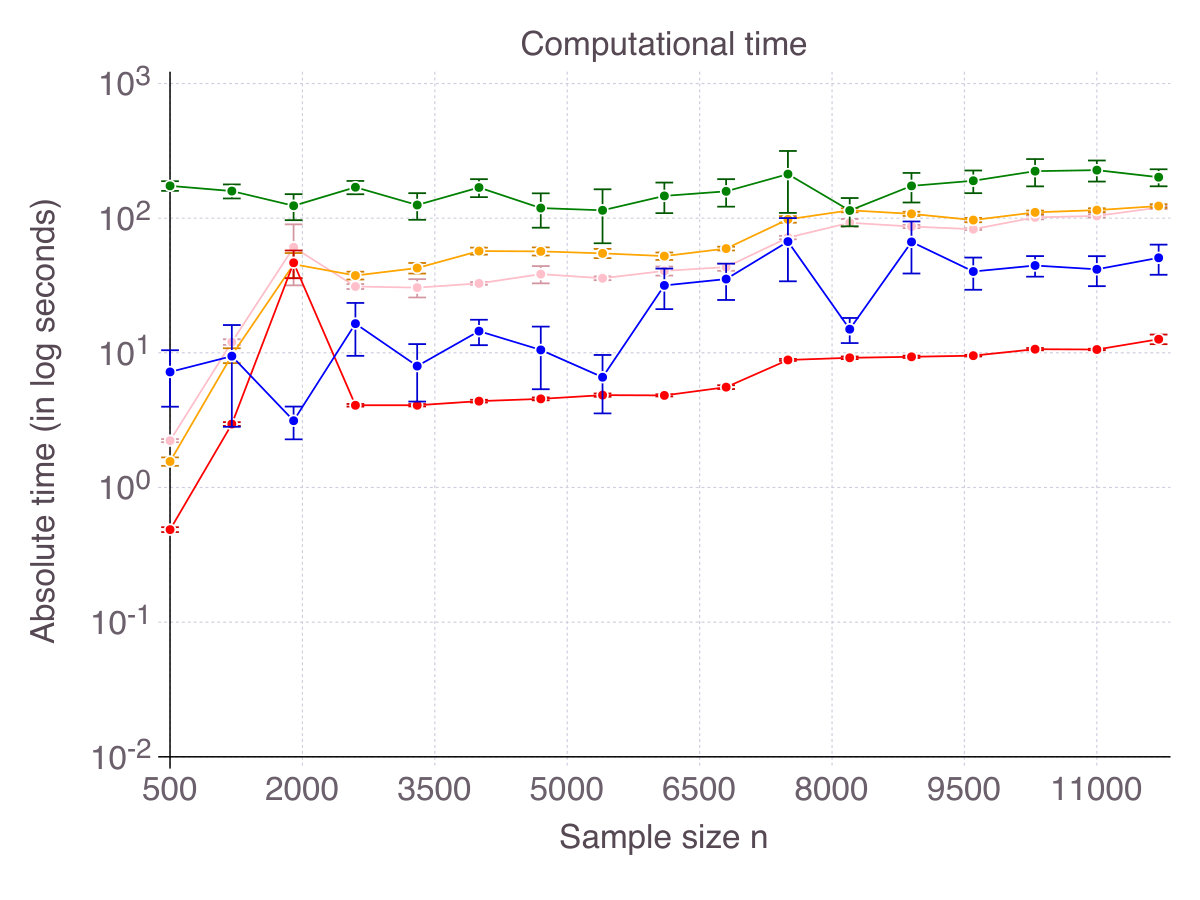 Figure 19
Figure 19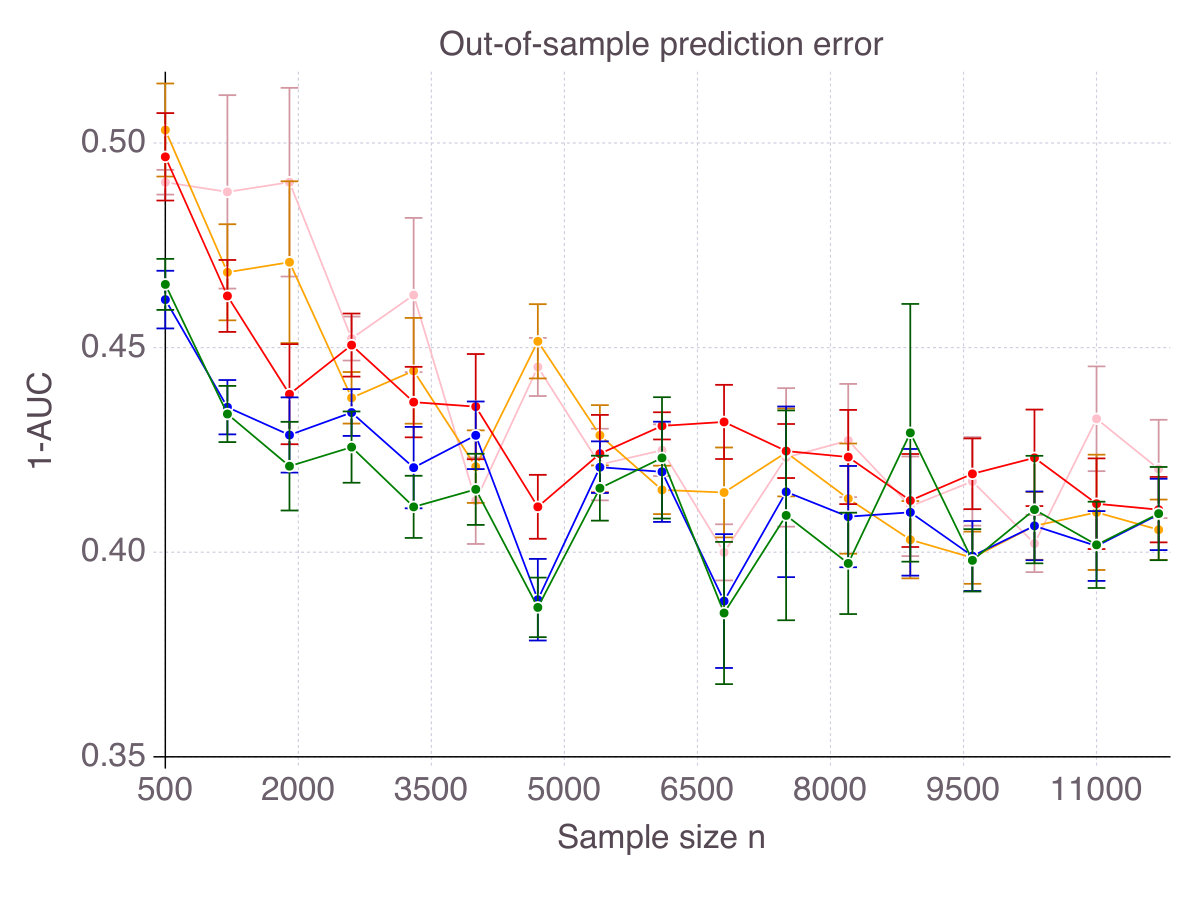 Figure 20
Figure 20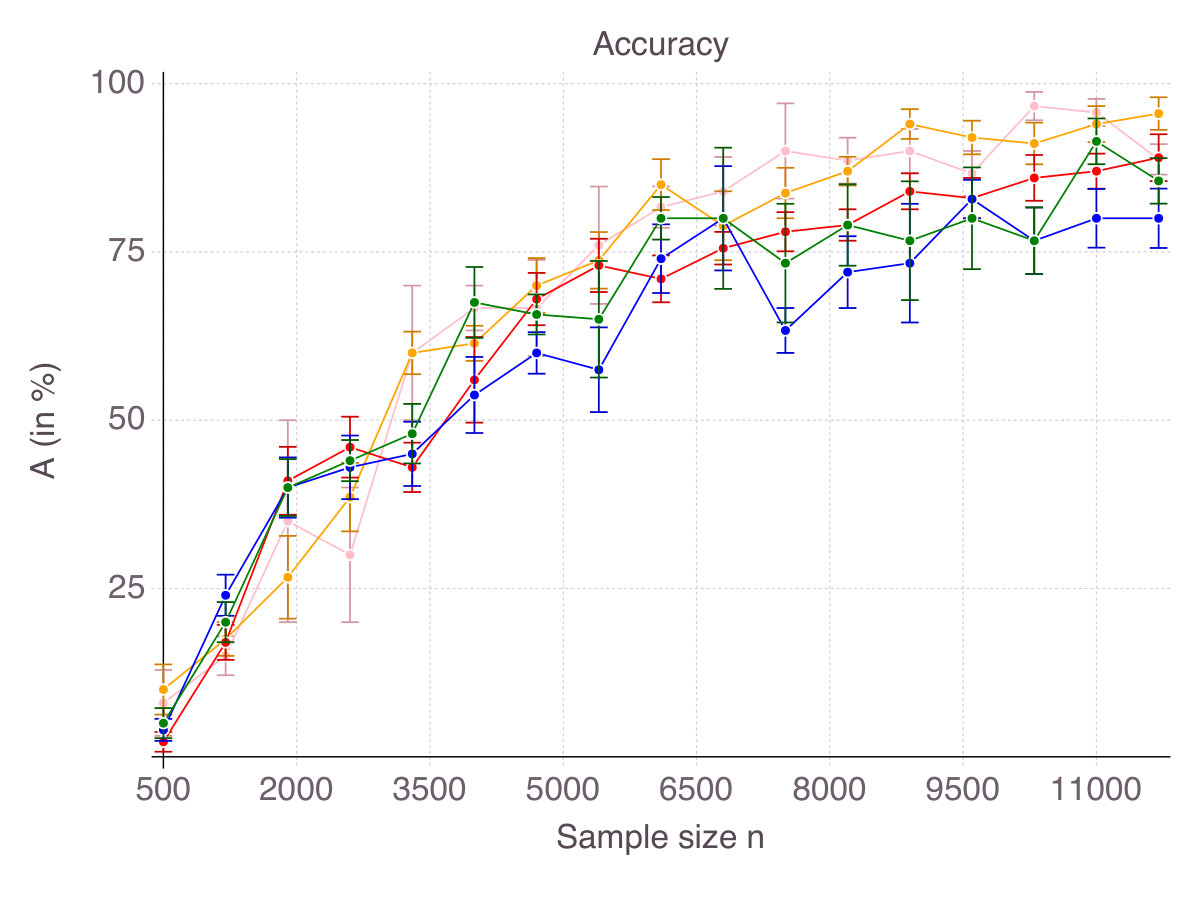 Figure 21
Figure 21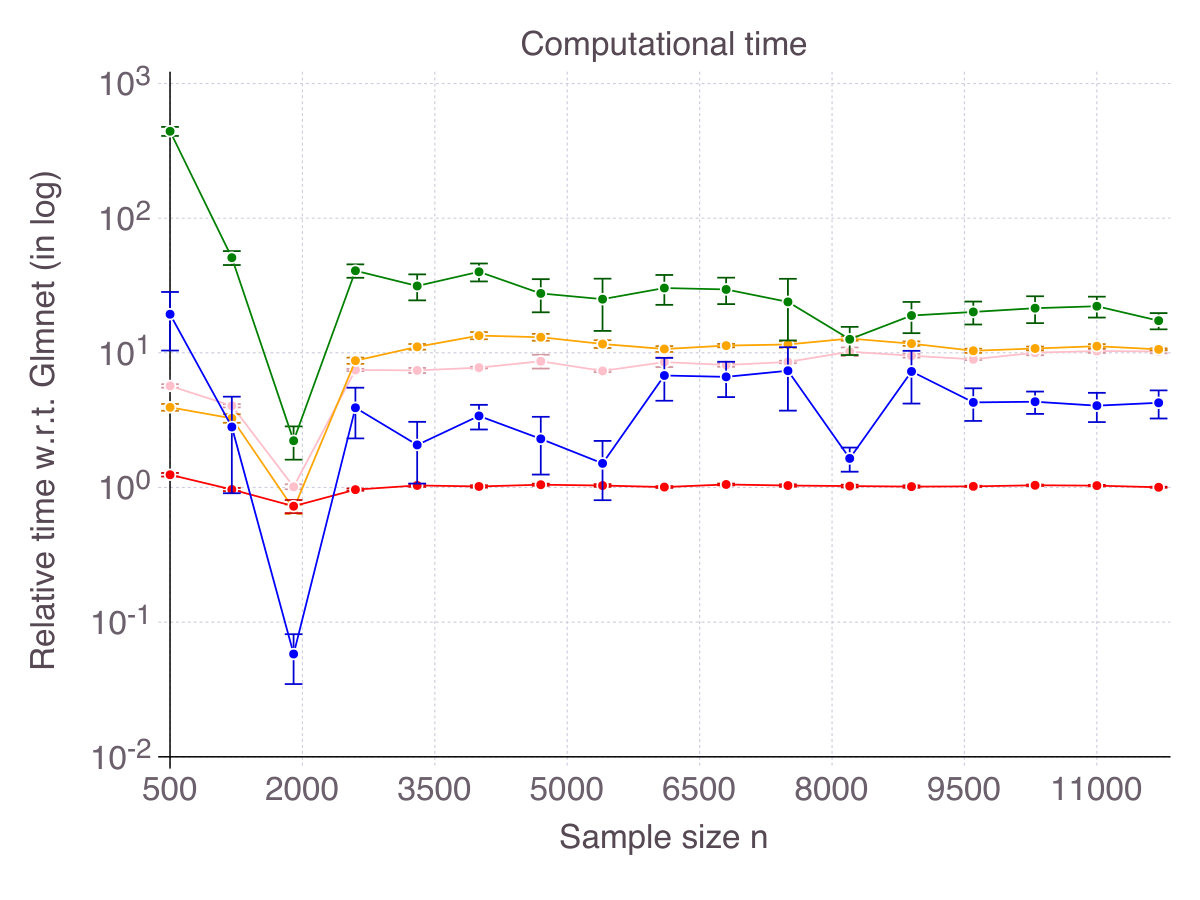 Figure 22
Figure 22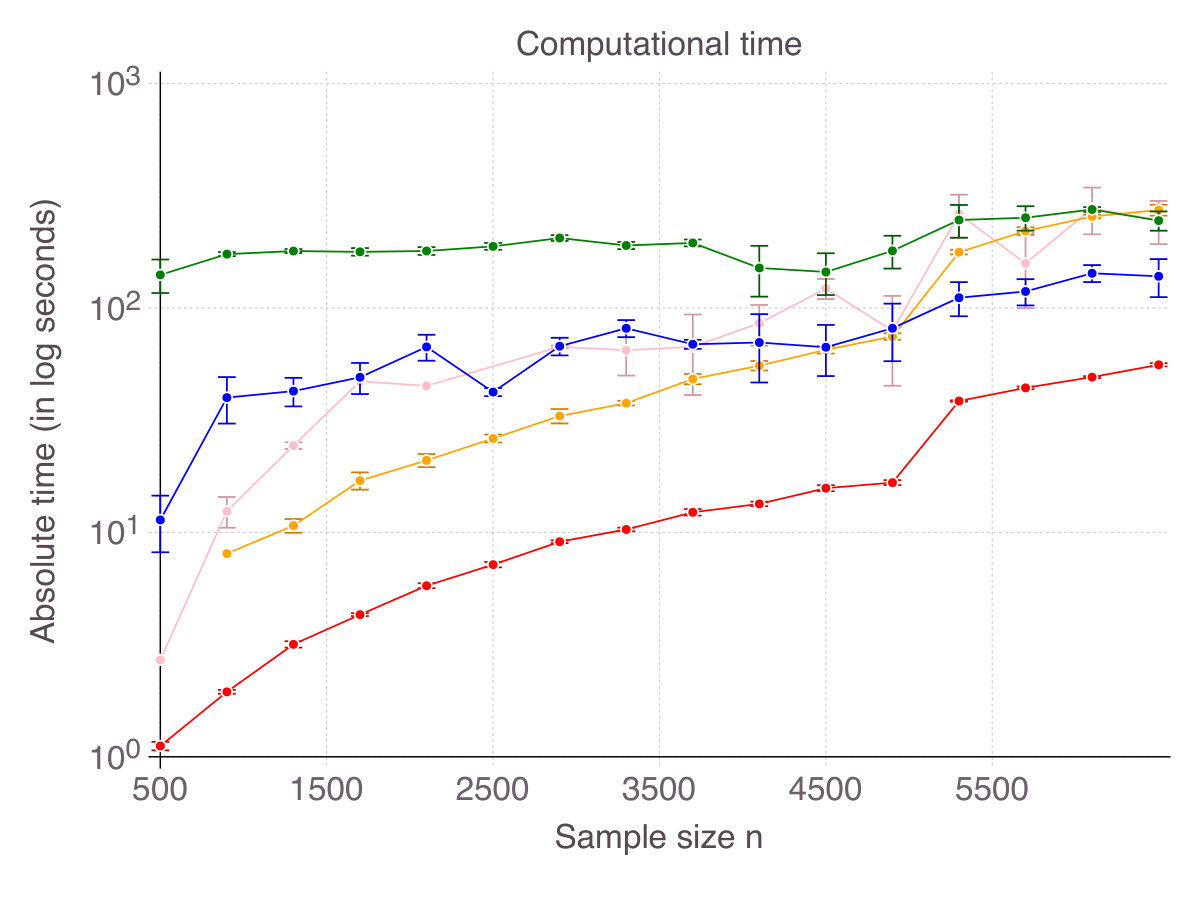 Figure 23
Figure 23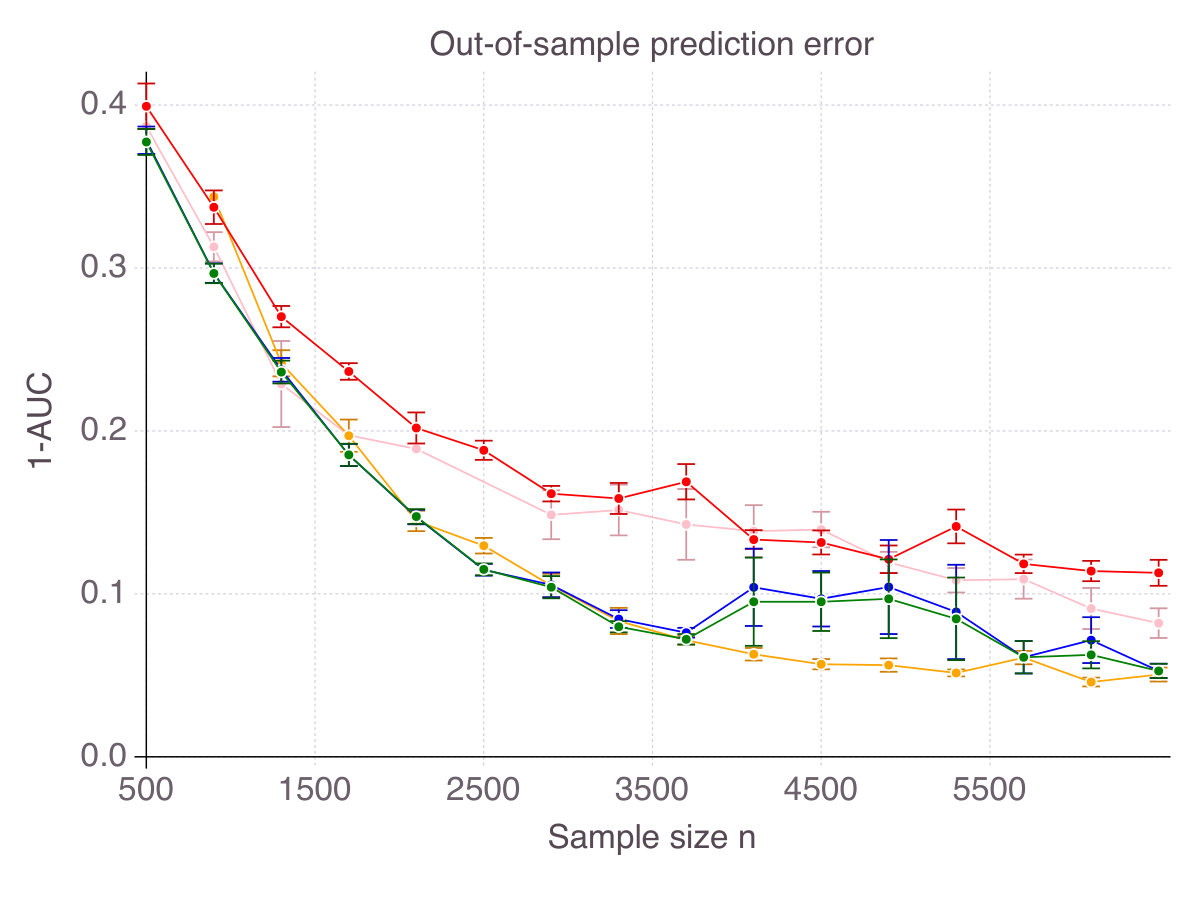 Figure 24
Figure 24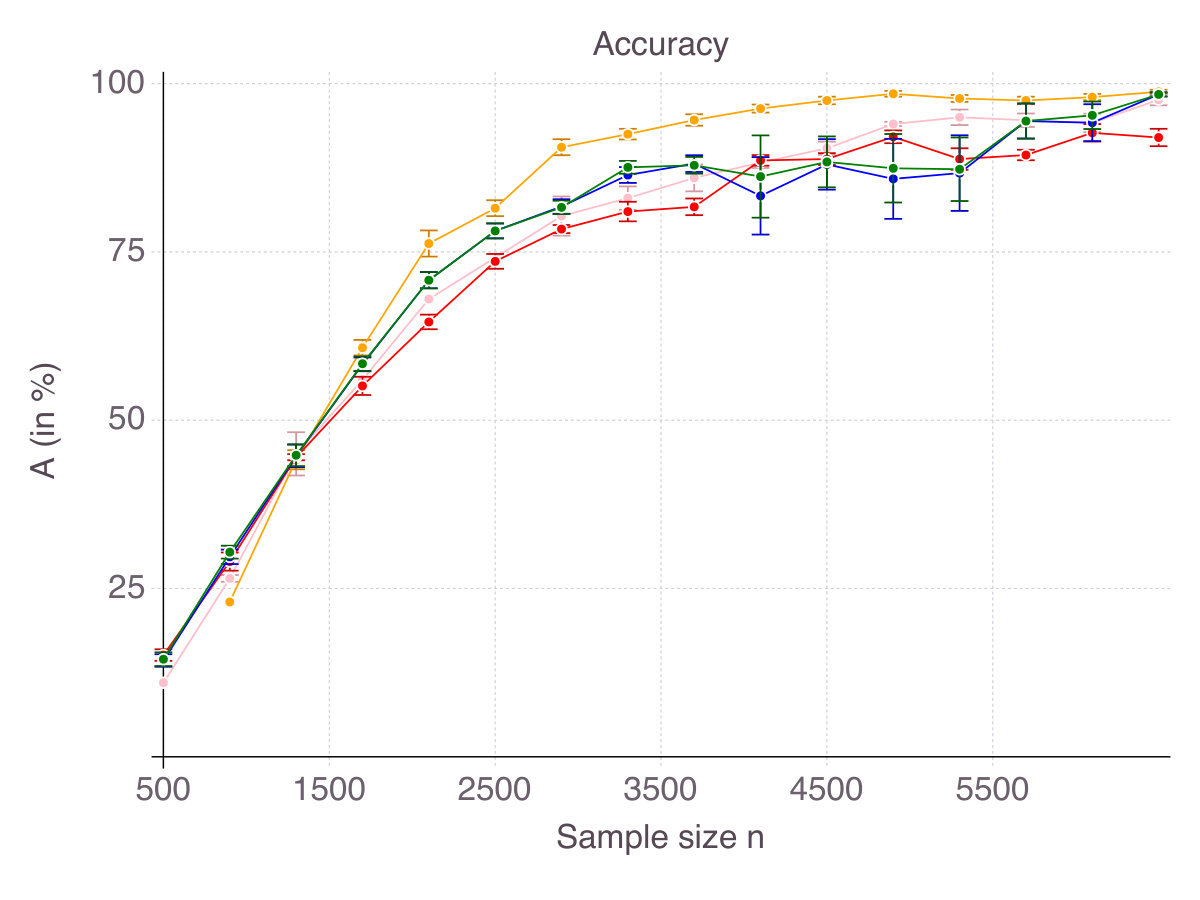 Figure 25
Figure 25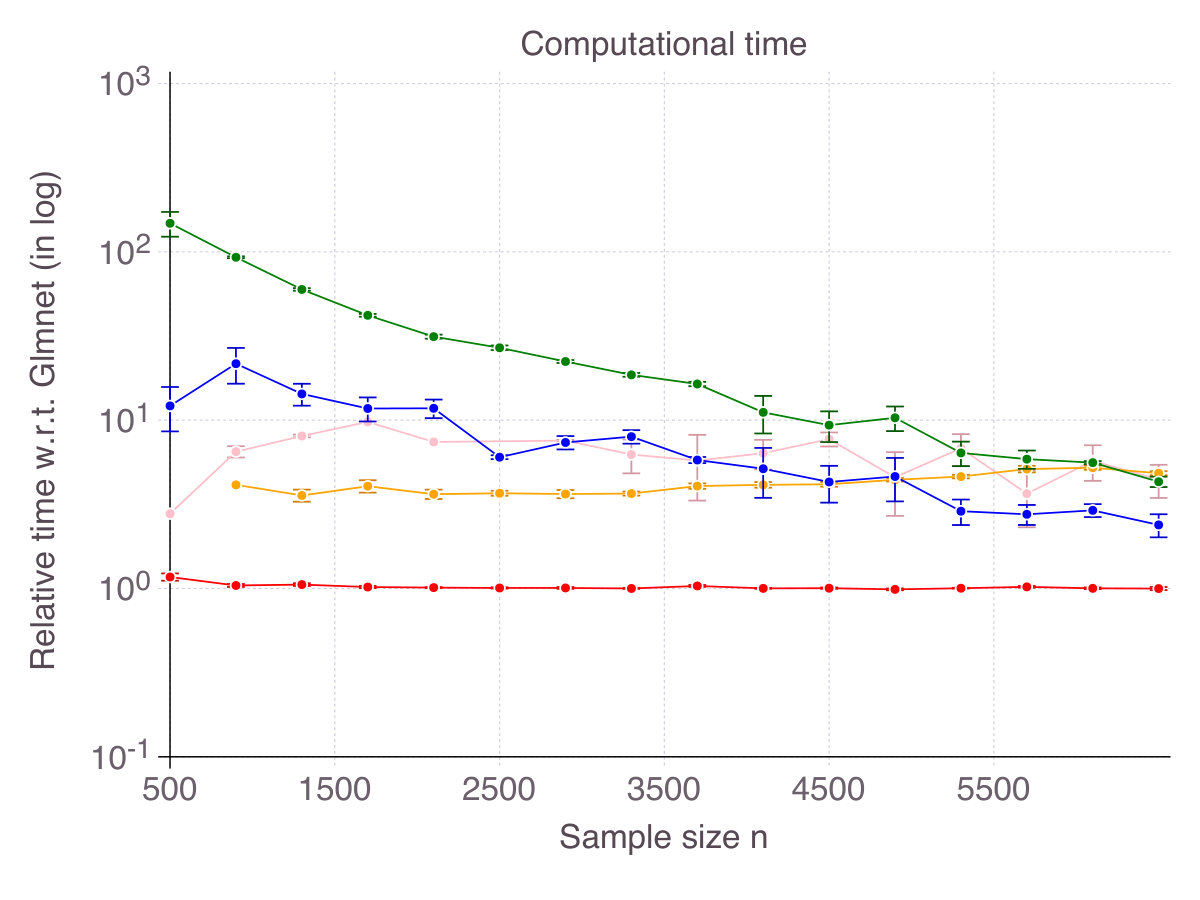 Figure 26
Figure 26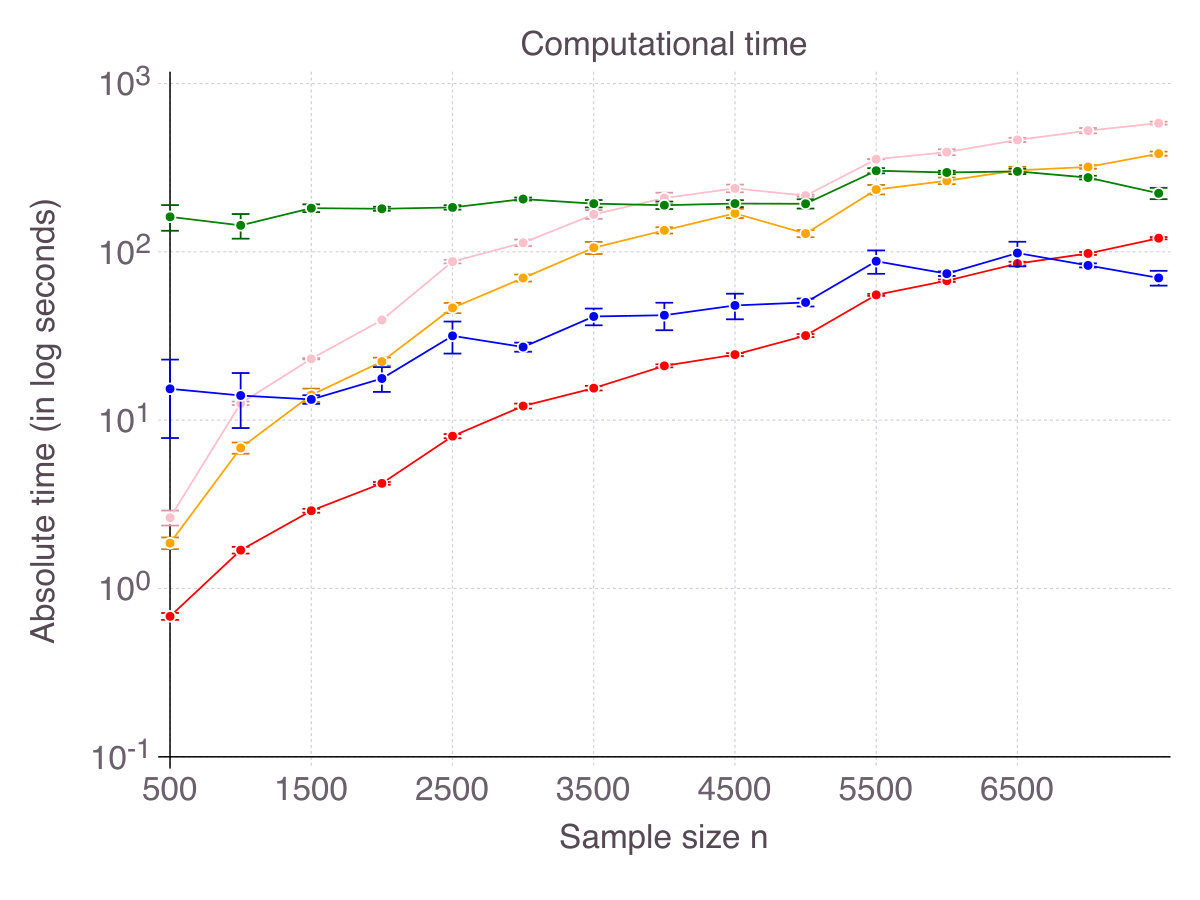 Figure 27
Figure 27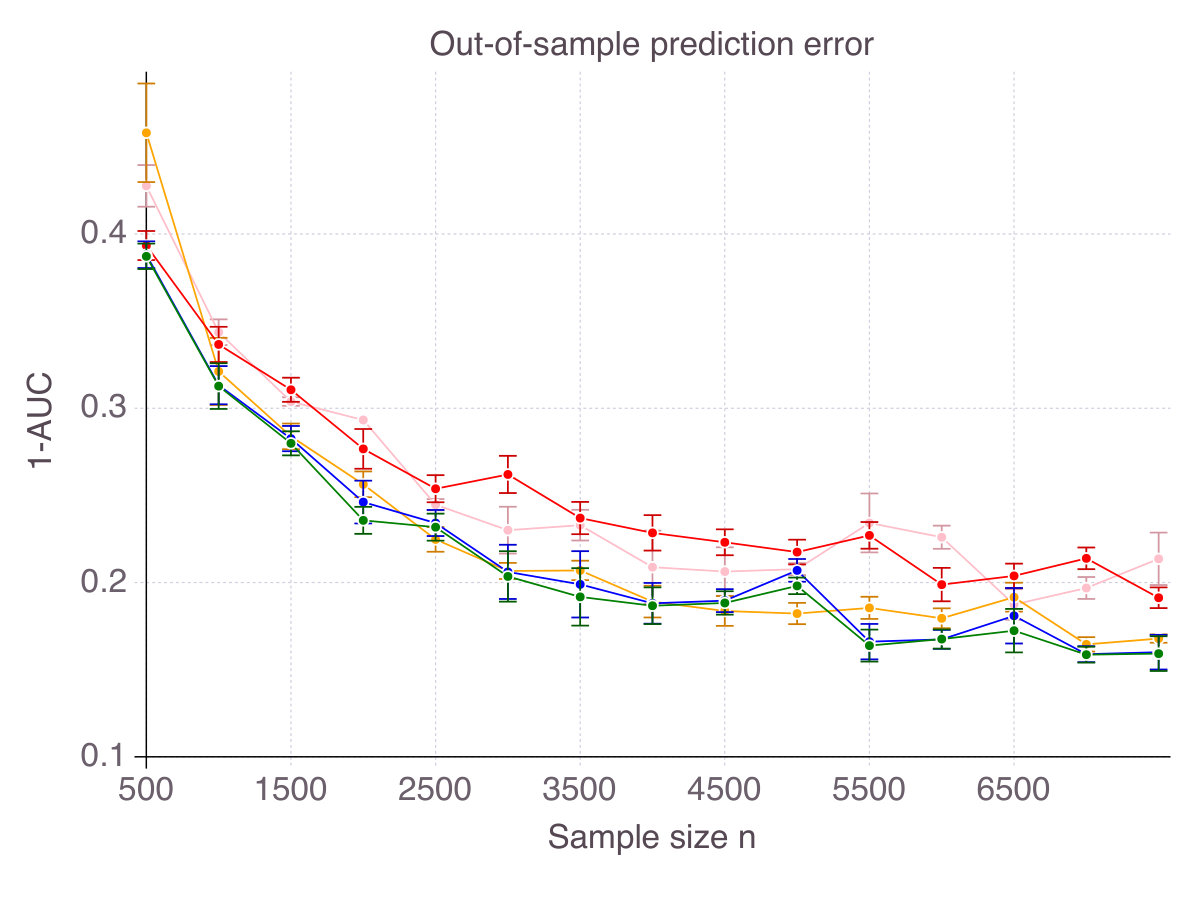 Figure 28
Figure 28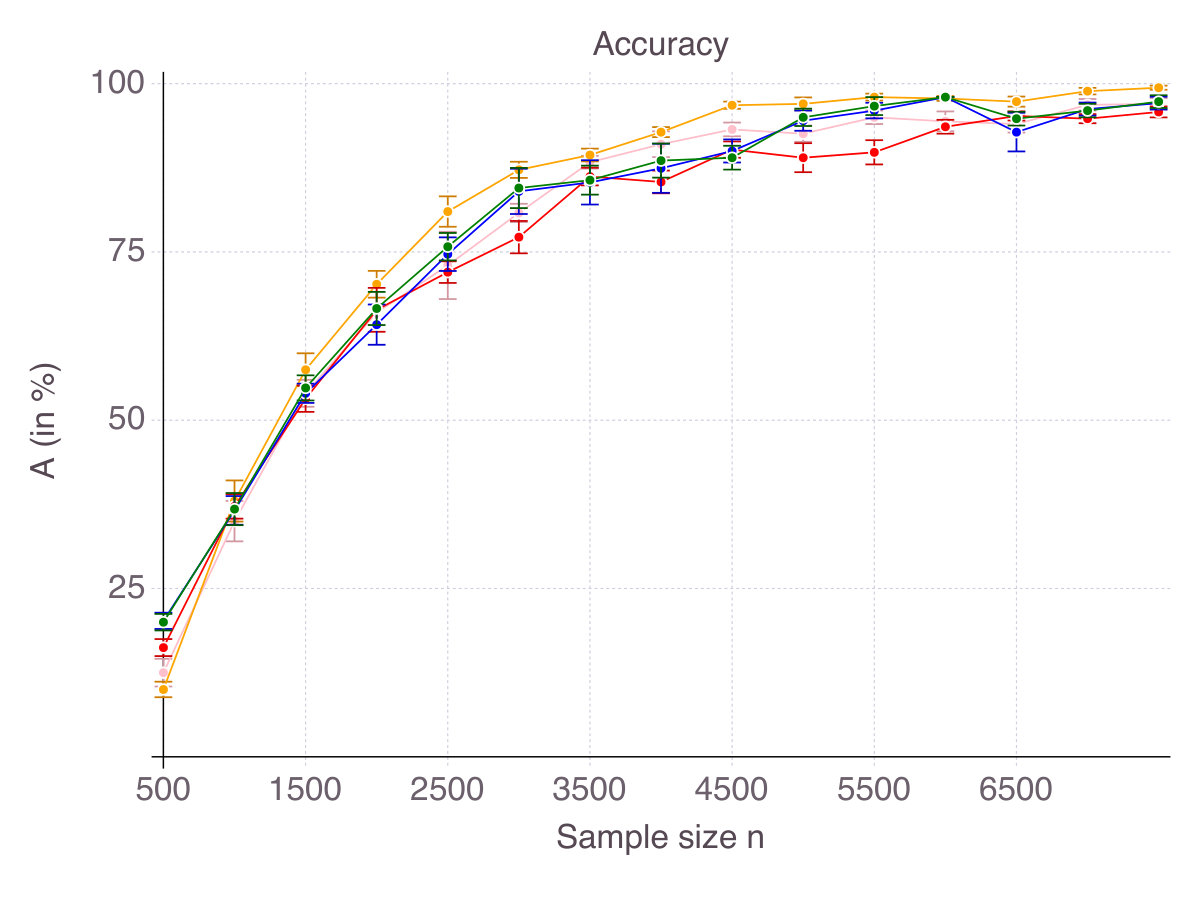 Figure 29
Figure 29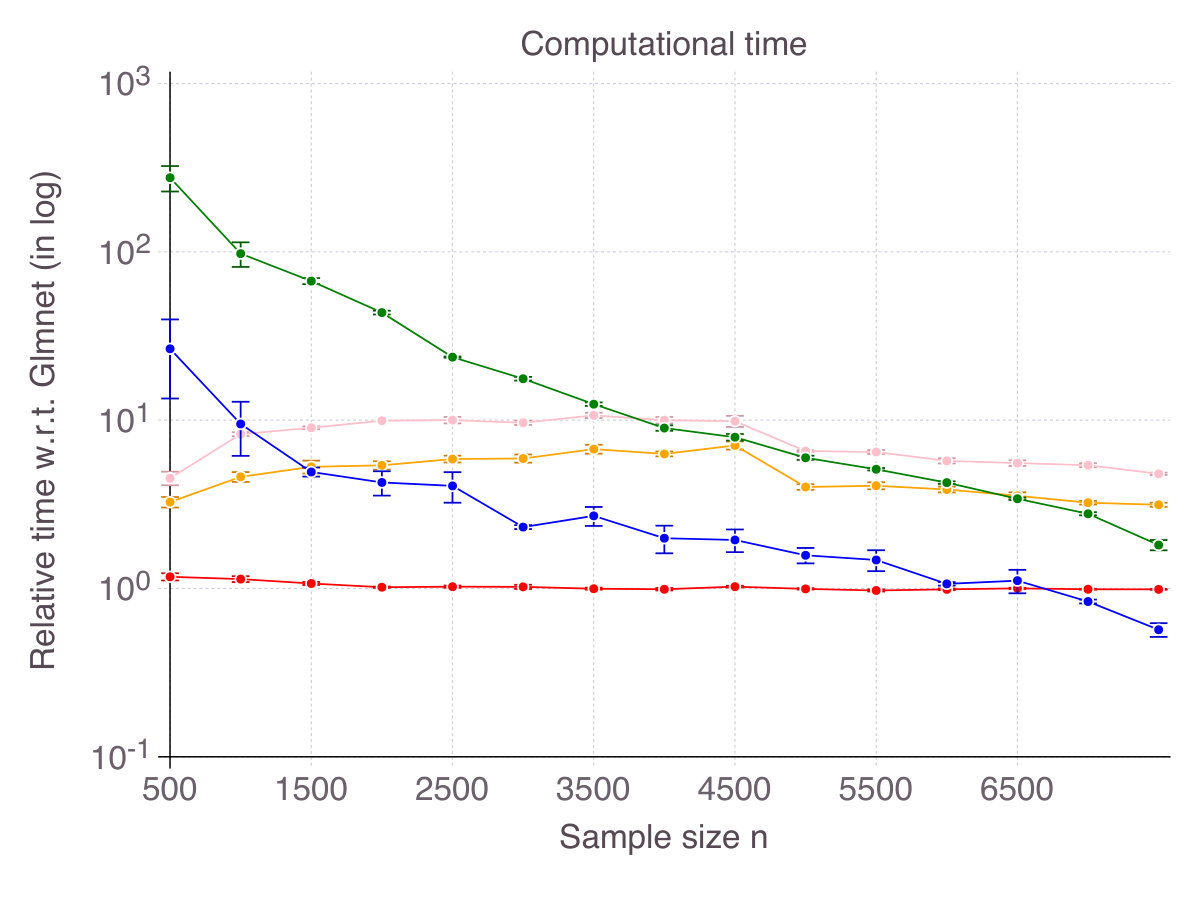 Figure 30
Figure 30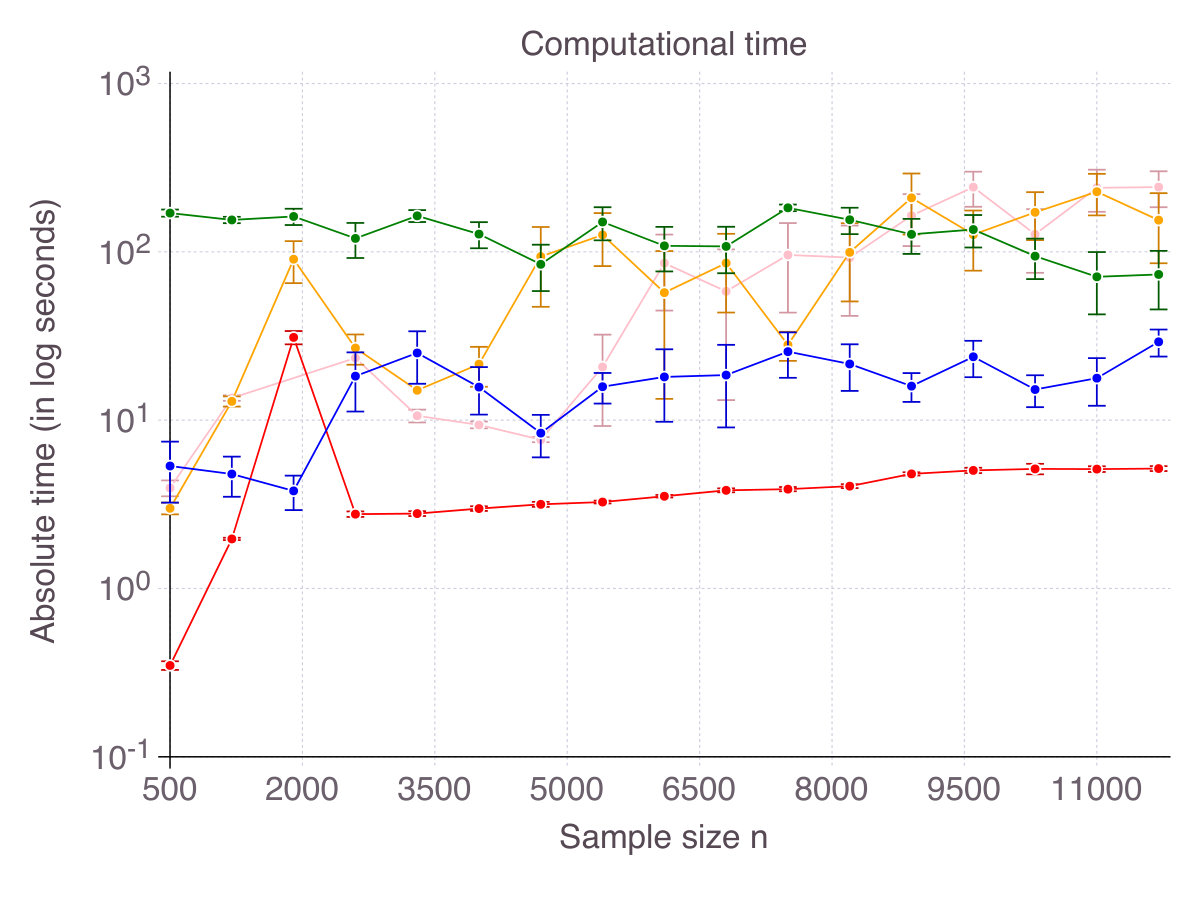 Figure 31
Figure 31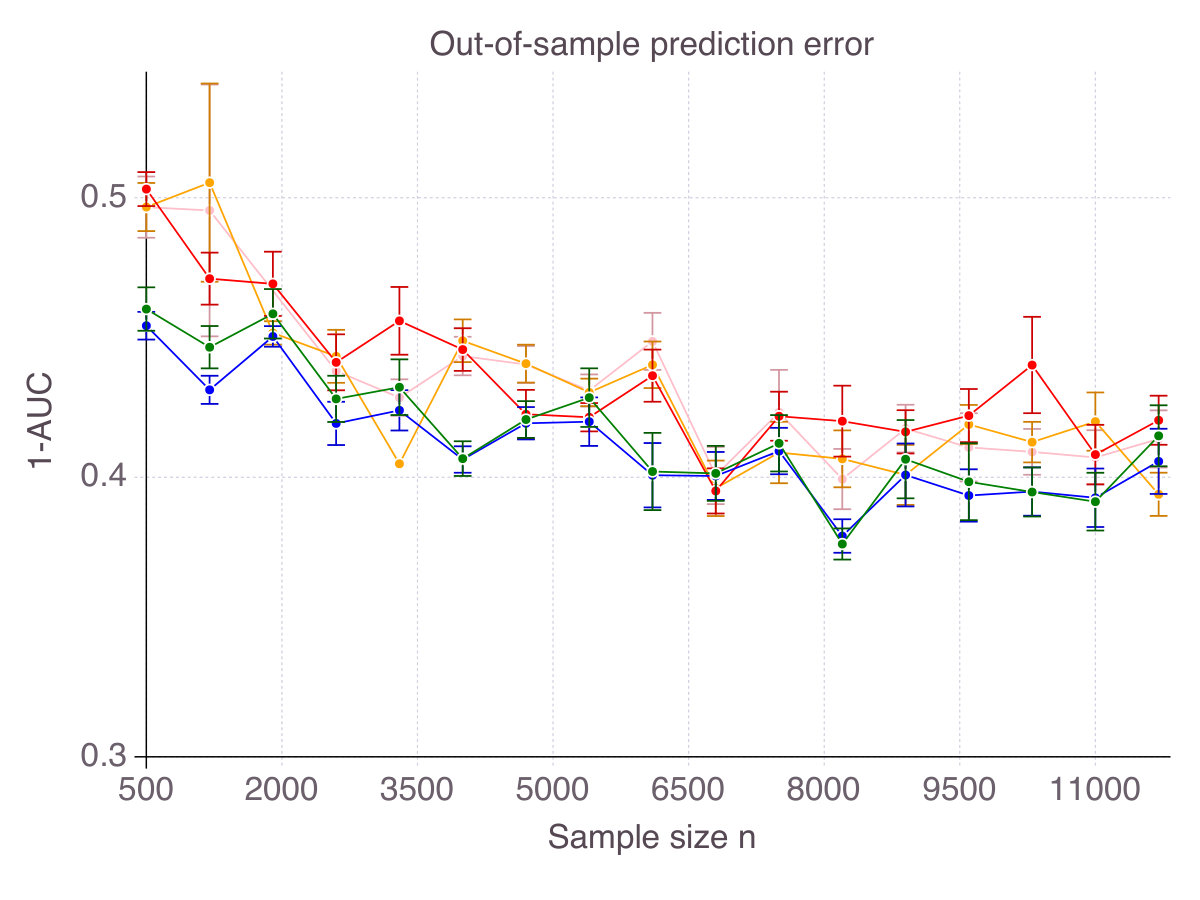 Figure 32
Figure 32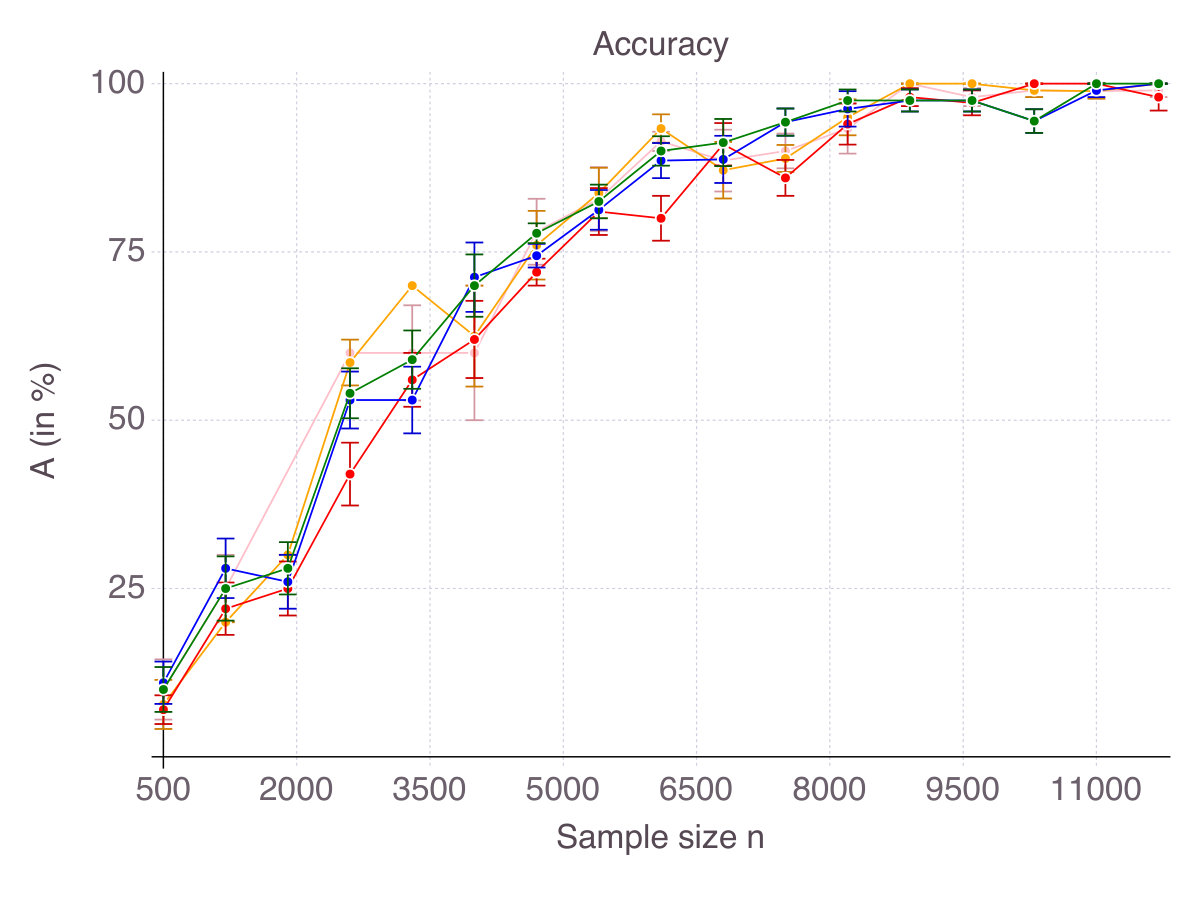 Figure 33
Figure 33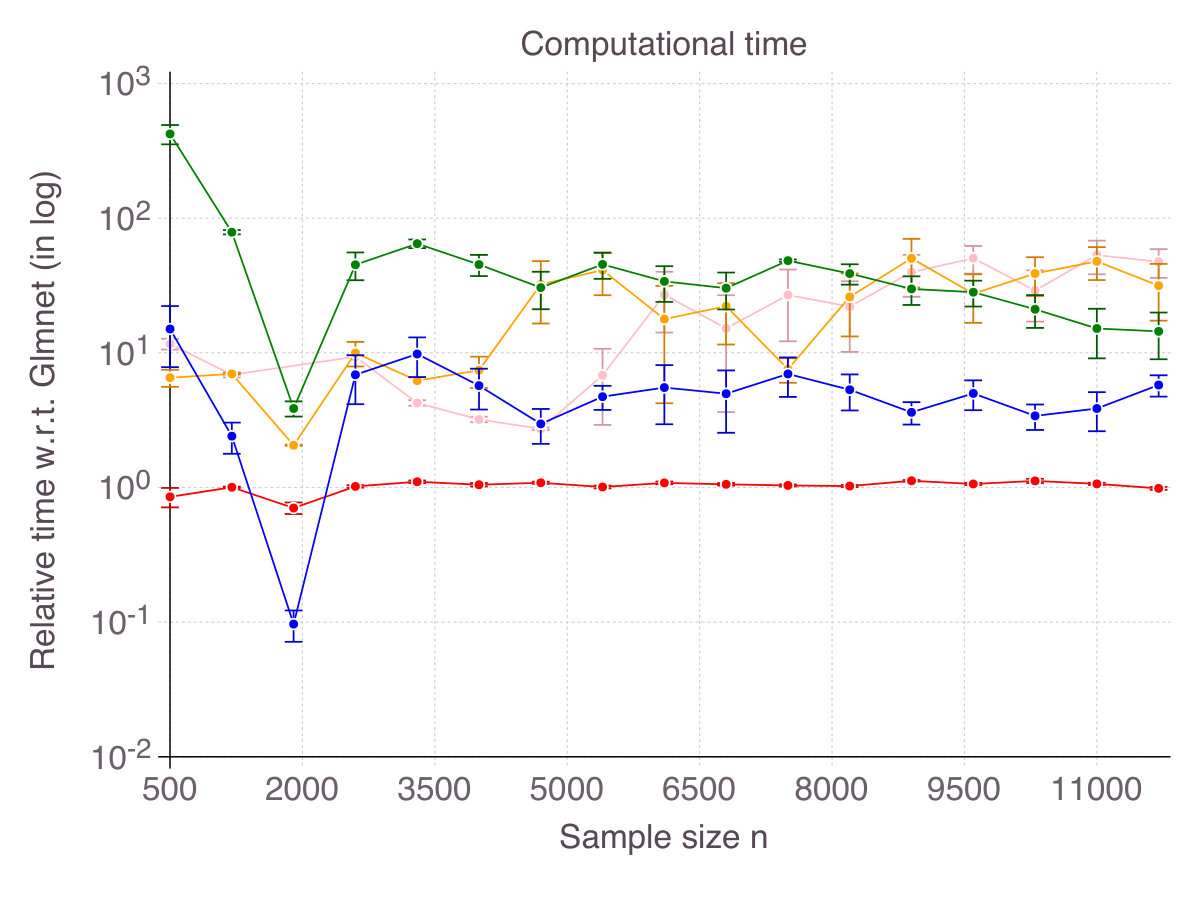 Figure 34
Figure 34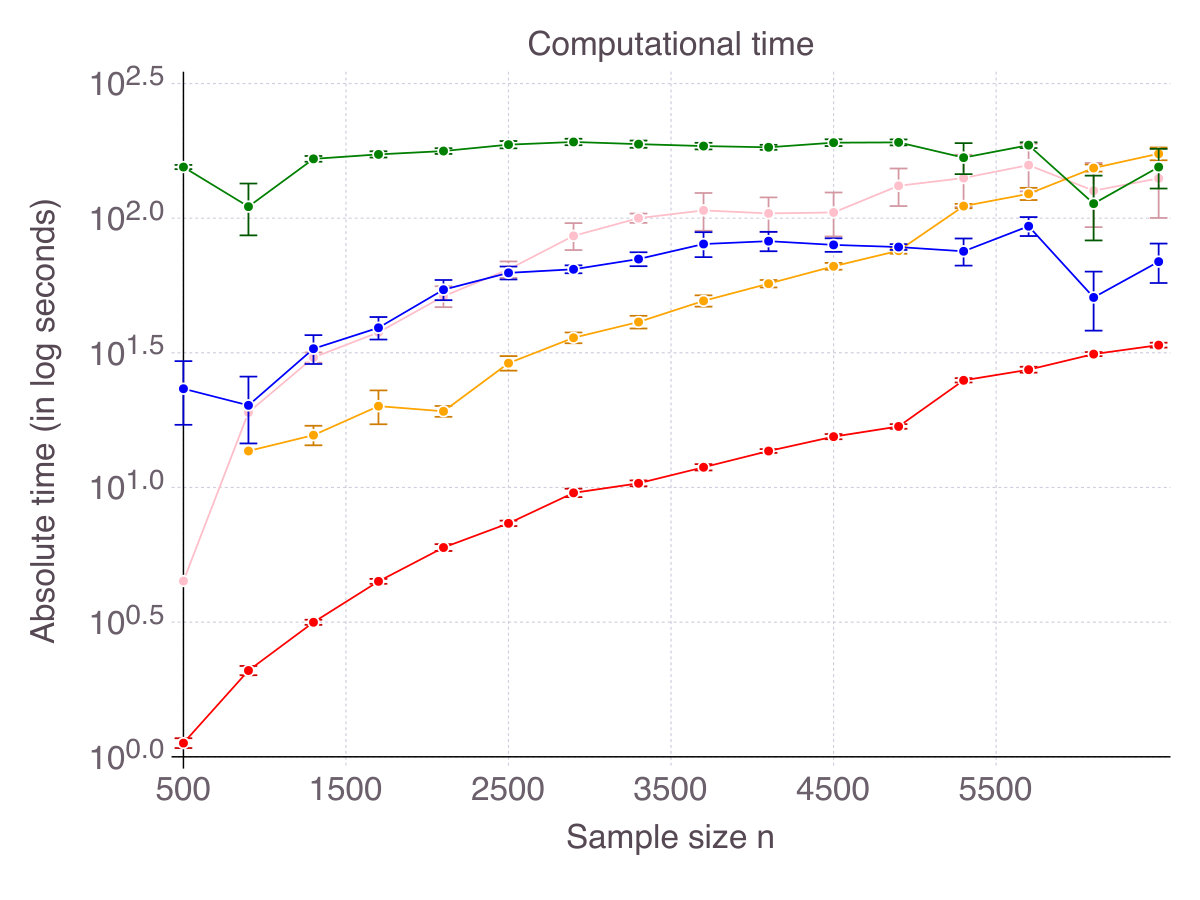 Figure 35
Figure 35| Method | Loss | Fenchel conjugate |
|---|---|---|
| Ordinary Least Square | ||
| Logistic loss | ||
| 1-norm SVM - Hinge loss |
| Low correlation | High correlation | |
|---|---|---|
| Low noise | ||
| Medium noise | ||
| High noise |
| Low noise | |
|---|---|
| Medium noise | |
| High noise |
| Low correlation | High correlation | |
|---|---|---|
| Low noise | ||
| Medium noise | ||
| High noise |
| Low noise | |
|---|---|
| Medium noise | |
| High noise |
| Method | Sparsity | Out-of-sample |
|---|---|---|
| Exact sparse | ||
| Boolean relaxation | ||
| Lasso | ||
| ENet | ||
| MCP | ||
| SCAD |
| Method | Pros and Cons |
|---|---|
| Exact sparse | Very good /. Convergence robust to noise/correlation. |
| Commercial solver and extra computational time. | |
| Boolean relaxation | Good /. Convergence robust to noise/correlation. |
| Heuristic. | |
| Lasso/ENet | Whole regularization path at no extra cost. |
| very sensitive to noise. very sensitive to correlation. | |
| MCP | Excellent . |
| Unstable . | |
| SCAD | Very good . |
| Unstable . sensitive to correlation. |
| Method | Loss | Fenchel conjugate |
|---|---|---|
| Logistic loss | ||
| 1-norm SVM - Hinge loss | ||
| 2-norm SVM | ||
| Least Square Regression | ||
| 1-norm SVR | ||
| 2-norm SVR |
| Loss function | time (in s) | |||
|---|---|---|---|---|
| Least Squares | ||||
| Least Squares | ||||
| Least Squares | ||||
| Least Squares | ||||
| Hinge Loss | ||||
| Hinge Loss | ||||
| Hinge Loss | ||||
| Hinge Loss |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Sparse regression: Scalable algorithms and empirical performance
Dimitris Bertsimas, Jean Pauphilet, Bart Van Parys
{dbertsim,jpauph,vanparys}@mit.edu
Operations Research Center, MIT, Cambridge, MA, USA
(February, 2019)
Abstract
In this paper, we review state-of-the-art methods for feature selection in statistics with an application-oriented eye. Indeed, sparsity is a valuable property and the profusion of research on the topic might have provided little guidance to practitioners. We demonstrate empirically how noise and correlation impact both the accuracy - the number of correct features selected - and the false detection - the number of incorrect features selected - for five methods: the cardinality-constrained formulation, its Boolean relaxation, regularization and two methods with non-convex penalties. A cogent feature selection method is expected to exhibit a two-fold convergence, namely the accuracy and false detection rate should converge to and [math] respectively, as the sample size increases. As a result, proper method should recover all and nothing but true features. Empirically, the integer optimization formulation and its Boolean relaxation are the closest to exhibit this two properties consistently in various regimes of noise and correlation. In addition, apart from the discrete optimization approach which requires a substantial, yet often affordable, computational time, all methods terminate in times comparable with the glmnet package for Lasso. We released code for methods that were not publicly implemented. Jointly considered, accuracy, false detection and computational time provide a comprehensive assessment of each feature selection method and shed light on alternatives to the Lasso- regularization which are not as popular in practice yet.
1 Introduction
The identification of important variables in regression is valuable to practitioners and decision makers in settings with large data sets of high dimensionality. Correspondingly, the notion of sparsity, i.e., the ability to make predictions based on a limited number of covariates, has become cardinal in statistics. The so-called cardinality-penalized estimators for instance minimize the trade-off between prediction accuracy and number of input variables. Though computationally expensive, they have been considered as a relevant benchmark in high-dimensional statistics. Indeed, these estimators are characterized as the solution of the NP-hard problem
[TABLE]
where is an appropriate convex loss function, such as the ones reported in Table 1 (p. 1). The covariates are denoted by the matrix , whose rows are the ’s, and the response data by . Here, denotes the 0-pseudo norm, i.e., the number of non-zero coefficients of . Alternatively, one can explicitly constrain the number of features used for prediction and solve
[TABLE]
which is likewise an NP-hard optimization problem [38]. For decades, such problems have thus been solved using greedy heuristics, such as step-wise regression, matching pursuits [36], or recursive feature elimination (RFE) [27].
Consequently, much attention has been directed to convex surrogate estimators which tend to be sparse, while requiring less computational effort. The Lasso estimator, commonly defined as the solution of
[TABLE]
and initially proposed by Tibshirani [43] is widely known and used. Its practical success can be explained by three concurrent ingredients: Efficient numerical algorithms exist [16, 21, 1], off-the-shelf implementations are publicly available [22] and recovery of the true sparsity is theoretically guaranteed under admittedly strong assumptions on the data [45]. However, recent works [42, 18] have pointed out several key deficiencies of the Lasso regressor in its ability to select the true features without including many irrelevant ones as well. In a parallel direction, theoretical work in statistics [44, 46, 24] has identified regimes where Lasso fails to recover the true support even though support recovery is possible from an information theoretic point of view.
Therefore, new research in numerical algorithms for solving the exact formulation (2) directly has flourished. Leveraging recent advances in mixed-integer solvers [6, 4], Lagrangian relaxation [40], cyclic coordinate descent [30], or cutting-plane methods [5, 7], these works have demonstrated significant improvement over existing Lasso-based heuristics. To the best of our knowledge, the exact algorithm proposed by Bertsimas and Van Parys [5], Bertsimas et al. [7] is the most scalable method providing provably optimal solutions to the optimization problem (2), at the expense of potentially significant computational time and the use of a commercial integer optimization solver.
Another line of research has focused on replacing the norm in the Lasso formulation by other sparsity-inducing penalties which are less sensitive to noise or correlation between features. In particular, non-convex penalties such as smoothly clipped absolute deviation (SCAD) [17] and minimax concave penalty (MCP) [50] have been proposed. Both SCAD and MCP have the so-called oracle property, meaning that they do not require a priori knowledge of the sparsity pattern to achieve an optimal asymptotic convergence rate, which is theoretically appealing. From a computational point of view, coordinate descent algorithms [8] have shown very effective, even though lack of convexity in the objective function hindered their wide adoption in practice.
Convinced that sparsity is an extremely valuable property in high-impact applications where interpretability matters, and conscious that the profusion of research on the matter might have caused confusion and provided little guidance to practitioners, we propose with the present paper a comprehensive treatment of state-of-the-art methods for feature selection in ordinary least square and logistic regression. Our goal is not to provide a theoretical analysis. On the contrary, we selected and evaluated the methods with an eye towards practicality, taking into account both scalability to large data sets and availability of the implementations. In some cases where open-source implementation was not available, we released code on our website, in an attempt to bridge the gap between theoretical advances and practical adoption. Statistical performance of the methods is assessed in terms of Accuracy (),
[TABLE]
i.e., the proportion of true features which are selected, and False Discovery Rate (),
[TABLE]
i.e., the proportion of selected features which are not in the true support.
1.1 Outline and contribution
Our key contributions can be summarized as follows:
- •
We provide a unified treatment of state-of-the-art methods for feature selection in statistics. More precisely, we cover the cardinality-constrained formulation (2), its Boolean relaxation, the Lasso formulation and its derivatives, and the MCP and SCAD penalty. We did not include step-wise regression methods, for they may require a high number of iterations in high dimension and exist in many variants.
- •
Encouraged by theoretical results obtained for the Boolean relaxation of (2) by Pilanci et al. [40], we propose an efficient sub-gradient algorithm to solve it and provide theoretical rate of convergence of our method.
- •
We make our code freely available as a Julia package named SubsetSelection. Our algorithm scales to problems with or and within minutes, while providing high-quality estimators.
- •
We compare the performance of all methods on three metrics of crucial interest in practice: accuracy, false detection rate and computational tractability, and in various regimes of noise and correlation.
- •
More precisely, under the mutual incoherence condition, all methods exhibit a convergence in accuracy, that is the proportion of correct features selected converges to as the sample size increases, in all regimes of noise and correlation. Yet, on this matter, cardinality-constrained and MCP formulations are the most accurate. As soon as mutual incoherence condition fails to hold, -based estimators are inconsistent with , while non-convex penalties eventually perfectly recover the support.
- •
In addition, we also observe a convergence in false detection rate, namely the proportion of irrelevant features selected converging to [math] as the sample size increases, for some but not all methods: The convex integer formulation and its Boolean relaxation are the only methods which demonstrate this behavior, in low noise settings and make the fewest false discoveries in other regimes. In our experiments, Lasso-based estimators return at least of non-significant features. MCP and SCAD have a low but strictly positive false detection rate (around in our experiments) as increases and in all regimes.
- •
In terms of computational time, the integer optimization approach is unsurprisingly the most expensive option. Nonetheless, the computational cost is only one or two orders of magnitude higher than other alternatives and remains affordable in many real-world problems, even high-dimensional ones. Otherwise, the four remaining codes terminate in time comparable with the glmnet implementation of the Lasso, that is within seconds for and .
In Section 2, we present each method, its formulation, its theoretical underpinnings and the numerical algorithms proposed to compute it. In each case, we point the reader to appropriate references and open-source implementations. We propose and describe our sub-gradient algorithm for the Boolean relaxation of (2) also in Section 2. Appendix A provides further details on our implementation of the algorithm, its scalability and its applicability to cardinality-penalized estimators (1) as well. In Section 3 (and Appendix B), we compare the methods on synthetic data sets for linear regression. In particular, we observe and discuss the behavior of each method in terms of accuracy, false detection rate and computational time for three families of design matrices and at least three levels noise. In Section 4 (and Appendix C), we apply the methods to classification problems on similar synthetic problems. We also analyze the implications of the feature selection methods in terms of induced sparsity and prediction accuracy on a real data set from genomics.
1.2 Notations
In the rest of the paper, we denote with e the vector whose components are equal to one. For , denotes the norm defined as
[TABLE]
For any -dimensional vector , we denote with the th largest component of . Hence, we have
[TABLE]
2 Sparse regression formulations
In this section, we introduce the different formulations and algorithms that have been proposed to solve the sparse regression problem. We focus on the cardinality-constrained formulation, its Boolean relaxation, the Lasso and Elastic-Net estimators, the MCP and SCAD penalty.
2.1 Integer optimization formulation
As mentioned in introduction, a natural way to compute sparse regressors is to explicitly constrain the number of non-zero coefficients, i.e., solve
[TABLE]
where is an appropriate loss function, appropriate in the sense that is convex for any . In this paper, we focus on Ordinary Least Square (OLS), logistic regression and Hinge loss, as presented in Table 1 on page 1. Unfortunately, such a problem is NP-hard [38] and believed to be intractable in practice. The original attempt by Furnival and Wilson [23] using "Leaps and Bounds" scaled to problems with in the . Thanks to both hardware improvement and advances in mixed-integer optimization solvers, Bertsimas et al. [6], Bertsimas and King [4] successfully used discrete optimization techniques to solve instances with in the s within minutes. More recently, Bertsimas and Van Parys [5], Bertsimas et al. [7] proposed a cutting plane approach which scales to data sizes of with in the s for ordinary least square and in the s for logistic regression. To the best of our knowledge, our approach is the only method which scales to instances of such sizes, while provably solving such an NP-hard problem.
2.1.1 Convex integer formulation
Bertsimas and Van Parys [5], Bertsimas et al. [7] consider an -regularized version of the initial formulation (2),
[TABLE]
where is a regularization coefficient. From a statistical point of view, this extra regularization, referred to as ridge or Tikhonov regularization, is needed to account for correlation between features [31] and mitigate the effect of noise. Indeed, regularization and robustness are two intimately connected properties, as illustrated by Bertsimas and Fertis [3], Xu et al. [48]. In addition, Breiman et al. [9] proved that subset selection is a very unstable problem and highlighted the stabilizing effect of Ridge regularization. Introducing a binary variable to encode the support of and using convex duality, problem (3) can be shown equivalent to a convex integer optimization problem as stated in the following theorem.
Theorem 1**.**
[7, Theorem 1]** For any convex loss function , problem (3) is equivalent to
[TABLE]
where is the Fenchel conjugate of the loss function [see 2, chap. 6.4], as reported in Table 1. In particular, the function is continuous, linear in and concave in .
In the special case of OLS, the function is a quadratic function in
[TABLE]
where . As a result, the inner maximization problem can be solved in closed form: The maximum is attained at and the objective value is
[TABLE]
2.1.2 Cutting-plane algorithm
Denoting
[TABLE]
which is a convex function in , the cutting-plane algorithm solves the convex integer optimization problem
[TABLE]
by iteratively tightening a piece-wise linear lower approximation of . Pseudo-code is given in Algoritm 1 (p. 1). Proof of termination and details on implementation can be found in Bertsimas and Van Parys [5] for regression and Bertsimas et al. [7] for classification. This outer-approximation scheme was originally proposed by Duran and Grossmann [15] for general nonlinear mixed-integer optimization problems.
2.1.3 Implementation and publicly available code
A naive implementation of Algorithm 1 would solve a mixed-integer linear optimization problem at each iteration, which can be as expensive as explicit enumeration of all feasible supports . Fortunately, with modern solvers such as Gurobi [26] or CPLEX [12], this outer-approximation scheme can be implemented using lazy constraints, enabling the use of a single Branch-and-Bound tree for all subproblems.
The algorithm terminates when the incumbent solution is -optimal for some fixed tolerance level (we chose in our simulations). We also need to impose a time limit on the algorithm. Indeed, as often in discrete optimization, the algorithm can quickly find the optimal solution, but spends a lot of the time proving its optimality. In our experiment, we fixed a time limit of seconds for regression and seconds for classification. Such choices were guided by confidence in the quality of the initial solution we provide to the algorithm (which we will describe in the next section) as well as time needed to compute and for a given support .
The formulation (3) contains two hyper-parameters, and , to control for the amount of sparsity and regularization respectively. In practice, those parameters need to be tuned using a cross-validation procedure. Since the function to minimize does not depend on , any piece-wise linear lower approximation of computed to solve (3) for some value of can be reused to solve the problem at another sparsity level. In recent work, Kenney et al. [33] proposed a combination of implementation recipes to optimize such search procedures. As for , we apply the procedure described in Chu et al. [11], starting with a low value (typically scaling as ) and inflate it by a factor at each iteration.
To bridge the gap between theory and practice, we present a Julia code which implements the described cutting-plane algorithm publicly available on GitHub111https://github.com/jeanpauphilet/SubsetSelectionCIO.jl. The code requires a commercial solver like Gurobi or CPLEX and our open-source package SubsetSelection for the Lagrangian relaxation, which we introduce in the next section. We also call the open-source library LIBLINEAR [19] to efficiently compute in the case of Hinge and logistic loss.
2.2 Lagrangian relaxation
As often in discrete optimization, it is natural to consider the Boolean relaxation of problem (4)
[TABLE]
and study its tightness, as done by Pilanci et al. [40].
2.2.1 Tightness result
The above problem is recognized as a convex/concave saddle point problem. According to Sion’s minimax theorem [41], the minimization and maximization in (5) can be interchanged. Hence, saddle point solutions of (5) should satisfy
[TABLE]
Since is a linear function of , a minimizer of can be constructed easily by selecting the smallest components of the vector . If those smallest components are unique, the so constructed binary vector must be equal to and hence the relaxation (5) is tight. In fact, the previous condition is necessary and sufficient as proven by Pilanci et al. [40]:
Theorem 2**.**
[40, Proposition 1]** The Boolean relaxation (5) is tight if and only if there exists a saddle point such that the vector has unambiguously defined largest components, i.e., there exists such that .
This uniqueness condition in Theorem 2 seems often fulfilled in real-world applications. It is satisfied with high probability, for instance, when the covariates are independent [see 40, Theorem 2]. In other words, randomness breaks the complexity of the problem. Similar behavior has already been observed for semi-definite relaxations [32, 49]. Such results have had impact in practice and propelled the advancement of convex proxy based heuristics such as Lasso. Efficient algorithms can be designed to solve the saddle point problem (5) without involving sophisticated discrete optimization tools and provide a high-quality heuristic for approximately solving (4) that could be used as a good warm-start in exact approaches.
2.2.2 Dual sub-gradient algorithm
In this section, we propose and describe an algorithm for solving problem (5) efficiently and make our code available as a Julia package. Our algorithm is fast and scales to data sets with in the s, which is two orders of magnitude larger than the implementation proposed by Pilanci et al. [40].
For a given , maximizing over cannot be done analytically, with the noteworthy exception of ordinary least squares, whereas minimizing over for a fixed reduces to sorting the components of and selecting the smallest. We take advantage of this asymmetry by proposing a dual projected sub-gradient algorithm with constant step-size, as described in pseudo-code in Algorithm 2. denotes the step size in the gradient update and the projection operator over the domain of . At each iteration, the algorithm updates the support by minimizing with respect to , being fixed. Then, the variable is updated by performing one step of projected sub-gradient ascent with constant step size . The denomination "sub-gradient" comes from the fact that at each iteration is a sub-gradient to the function at .
In terms of computational cost, updating requires operations for computing the sub-gradient plus at most operations for the projection on the feasible domain. The most time-consuming step in Algorithm 2 is updating which requires on average operations.
The final averaging step is critical in sub-gradient methods to ensure convergence of the algorithm in terms of optimal value [see 2, chap. 7.5].
Theorem 3**.**
[2, chap. 7.5]** Assume the sequence of sub-gradients is uniformly bounded by some constant , and that the set of saddle point solutions in (5) is non-empty. Then,
[TABLE]
where denotes the distance of the initial point to the set of saddle point solutions .
As for any sub-gradient strategy, with an optimal choice of step size 222., Theorem 3 proves a convergence rate in terms of objective value, which is disappointingly slow. However, in practice, convergence towards the optimal primal solution is more relevant. In that metric, our algorithm performs particularly well as numerical experiments in Sections 3 and 4 demonstrate. The key to our success is that the optimal primal solution is estimated using partial minimization
[TABLE]
as opposed to averaging
[TABLE]
as studied by Nedić and Ozdaglar [39] and commonly implemented for sub-gradient methods. In addition, even though we are solving a relaxation, we are interested in binary vectors , which can be interpreted as a set of features. To that extend, averaging would not have been a suitable option since the averaged solution is neither binary, nor -sparse. With the extra cost of computing for all past iterates as well as , one can also decide to return the support vector with the lowest value. This can only produce a better approximation of .
2.2.3 Implementation and open-source package
The algorithm terminates after a fixed number of iterations which is standard for sub-gradient methods. In our case, however, the quality of the primal variable should be the key concern. By computing at each iteration and keeping track of the best upper-bound , one can use the duality gap or the number of consecutive iterations without any improvement on the upper-bound as alternative stopping criteria. Computing increases the cost per iteration, with the hope of terminating the algorithm earlier. By default, our implementation stops after iterations or when the duality gap is .
The constant step size rule is difficult to implement in practice. Indeed, as seen in Theorem 3, an optimal step size should depend on quantities that are hard do estimate a priori, namely and . In particular for logistic loss, can be arbitrarily large. Instead, one can use an adaptive stepsize rule such as
[TABLE]
We implemented such a rule and refer to Bertsekas [2, chap. 7.5] for proofs of convergence and alternative choice.
We apply the same grid-search procedures as for the cutting-plane algorithm in order to cross-validate the hyperparameters and .
We make our code publicly available as a Julia package named SubsetSelection and source repository can be found on GitHub333https://github.com/jeanpauphilet/SubsetSelection.jl. Our code implements Algorithm 2 for six loss functions including those presented in Table 1. The package consists of one main function, subsetSelection, which solves problem (5) for a given value of . The algorithm can be extended to more loss functions, and cardinality-penalized estimators as well, as described in Appendix A.
2.3 Lasso - relaxation
Instead of solving the NP-hard problem (1), Tibshirani [43] proposed replacing the non-convex -pseudo norm by the convex -norm which is sparsity-inducing. Indeed, extreme points of the unit ball are -sparse vectors. The resulting formulation
[TABLE]
is referred to as the Lasso estimator. More broadly, -regularization is now a widely used technique to induce sparsity in a variety of statistical settings [see 28, for an overview]. Its popularity has been supported by an extensive corpus of theoretical results from signal processing and high-dimensional statistics. Since the seminal work of Donoho and Huo [13], assumptions needed for the Lasso estimator to accurately approximate the true sparse signal are pretty well understood. We refer to reader to Candes et al. [10], Meinshausen and Bühlmann [37], Zhao and Yu [51], Wainwright [45] for some of these results. In practice however, those assumptions, namely mutual incoherence and restricted eigenvalues conditions, are quite stringent and hard to verify. In addition, even when the Lasso regressor provably converges to the true sparse regressor in terms of distance and identifies all the correct features, it also systematically incorporates irrelevant ones, a behavior observed and partially explained by Su et al. [42] and of crucial practical impact.
2.3.1 Elastic-Net formulation
The Lasso formulation in its original form (6) involves one hyper-parameter only, which controls regularization, i.e., robustness of the estimator against uncertainty in the data [see 48, 3]. At the same time, the norm in the Lasso formulation (6) is also used for its fortunate but collateral sparsity-inducing property. Robustness and sparsity, though related, are two very distinct properties demanding a separate hyper parameter each. The ElasticNet (ENet) formulation proposed by Zou and Hastie [52]
[TABLE]
addresses the issue by adding an regularization to the objective. For , problem (7) is equivalent to the Lasso formulation (6), while corresponds to Ridge regression. Although this extra regularization reduces bias and improves prediction error, it does not significantly improve feature selection, as we will see on numerical experiments in Section 3. In our view, this is due to the fact that -regularization primarily induces robustness of the estimator, through shrinkage of the coefficients [3, 48]. In that perspective, it leads to first-rate out-of-sample predictive performance, even in high-noise regimes [see 29, for extensive experiments]. Nonetheless, the feature selection ability of -regularization ought to be challenged.
2.3.2 Algorithms and implementation
For -regularized regression, Least Angle Regression (LARS) [16] is an efficient method for computing an entire path of solutions for various values of the parameter, exploiting the fact that the regularization path is piecewise linear. More recently, coordinate descent methods [20, 47, 21] have successfully competed with and surpassed the LARS algorithm, especially in high dimension. Their implementation through the glmnet package [22] is publicly available in R and many other programming languages. In a different direction, proximal gradient descent methods have also been proposed, and especially the Fast Iterative Shrinkage Thresholding Algorithm (FISTA) proposed by Beck and Teboulle [1].
2.4 Non-convex penalties
Recently, other formulations have been proposed, of the form
[TABLE]
where is a function parametrized by and , which control respectively the tradeoff between empirical loss and regularization, and the shape of the function. We will consider two popular choice of penalty functions , which are non-convex and are proved to recover the true support even when mutual incoherence condition fails to hold [34].
2.4.1 Minimax Concave Penalty (MCP)
The minimax concave penalty of Zhang [50] is defined on by
[TABLE]
for some and . The rationale behind the MCP can be explained in the univariate OLS case: In the univariate case, MCP and -regularization lead to the same solution as , while the MCP is indeed equivalent to hard-thresholding when . In other words, in one dimension or under the orthogonal design assumption, the MCP produces the so-called firm-shrinkage estimator introduced by Gao and Bruce [25], which should be understood as a continuous tradeoff between hard- and soft-thresholding.
2.4.2 Smoothly Clipped Absolute Deviation (SCAD)
Fan and Li [17] orginally proposed the smoothly clipped absolute deviation penalty, defined on by
[TABLE]
for some and . The rationale behing the SCAD penalty is similar to the MCP but less straightforward. We refer to Fan and Li [17] for a comparison of SCAD penalty with hard-thresholding and -penalty and to Breheny and Huang [8] for a comparison of SCAD and MCP.
2.4.3 Algorithms and implementation
For such non-convex penalties, Zou and Li [53] designed a local linear approximation (LLA) approach where, at each iteration, the penalty function is linearized around the current iterate and the next iterate is obtained by solving the resulting convex optimization problem with linear penalty. Another, more computationally efficient, approach has been proposed by Breheny and Huang [8] and implemented in the open-source R package, ncvreg. Their algorithm relies on coordinate descent and the fact that the objective function in (8) with OLS loss is convex in any , the other being fixed. For logistic loss, they locally approximate the loss function by a second-order Taylor expansion at each iteration and use coordinate descent to compute the next iterate.
3 Linear regression on synthetic data
In this section, we compare the aforementioned methods on synthetic linear regression data where the ground truth is known to be sparse. The convex integer optimization algorithm of Bertsimas and Van Parys [5], Bertsimas et al. [7] (CIO in short) was implemented in Julia [35] using the commercial solver Gurobi 7.5.0 [26], interfaced using the optimization package JuMP [14]. The Lagrangian relaxation is also implemented in Julia and openly available as the SubsetSelection package (SS in short). We used the implementation of Lasso/Enet provided by the glmnet package [22], available both in R and Julia. We also compared to MCP and SCAD penalty formulations implemented in the R package ncvreg [8]. The computational tests were performed on a computer with Xeon @2.3GhZ processors, 1 CPUs, 16GB RAM per CPU.
3.1 Data generation methodology
The synthetic data was generated according to the following methodology: We draw independent realizations from a -dimensional normal distribution with mean and covariance matrix . We randomly sample a weight vector with exactly non-zero coefficient. We draw i.i.d. noise components from a normal distribution scaled according to a chosen signal-to-noise ratio . Finally, we compute . With this methodology, we are able to generate data sets of arbitrary size , sparsity , correlation structure and level of noise . The signal-to-noise ratio relates to the percentage of variance explained (). Indeed, Hastie et al. [29] showed that
[TABLE]
Accordingly, we will consider values ranging from () to ().
3.2 Metrics and benchmarks
Statistical performance of the methods is assessed in terms of Accuracy (),
[TABLE]
i.e., the proportion of true features which are selected, and False Discovery Rate (),
[TABLE]
i.e., the proportion of selected features which are not in the true support. We refer to the quantities in the numerators as the number of true features () and false features () respectively. One might argue that accuracy as we defined it here is a purely theoretical metric, since on real-world data, the ground truth is unknown and there is no such thing as true features. Still, accuracy is the only metric which assesses feature selection only, while derivative measures such as predictive power depend on more factors than the features selected alone. Moreover, accuracy has some practical implications in terms of interpretability and also in terms of predictive power: Common sense and empirical results suggest that better selected features should yield diminished prediction error. To that end, we also compare the performance of the methods in terms of out-of-sample Mean Square Error
[TABLE]
which will be the metric of interest on real data. Note that the sum can be taken over the observations in the training (in-sample) or test set (out-of-sample).
Practical scalability of the algorithms is assessed in terms of computational time. In order to provide a fair comparison between methods that are not implemented in the same programming language, we report computational time for each algorithm relative to the time needed to compute a Lasso estimator with glmnet in the same language and on the same data. For these experiments, we fixed a time limit of seconds for the cutting-plane algorithm and considered iterations of the sub-gradient algorithm for the Boolean relaxation.
3.3 Synthetic data satisfying mutual incoherence condition
We first consider Toeplitz covariance matrix . Such matrices satisfy the mutual incoherence condition, required by -regularized estimators to be statistically consistent. We compare the performance of the methods in six different regimes of noise and correlation described in Table 2 (p. 2).
3.3.1 Feature selection with a given support size
We first consider the case when the cardinality of the support to be returned is given and equal to the true sparsity for all methods, while all other hyper-parameters are cross-validated on a separate validation set. In this case, accuracy and false discovery rate are complementary. Indeed, in this case
[TABLE]
which leads to so that we may consider accuracy by itself.
As shown on Figure 1 (p. 1), all methods converge in terms of accuracy. That is their ability to select correct features as measured by smoothly converges to with an increasing number of observations . Noise in the data has an equalizing effect on all methods, meaning that noise reduces the gap in performance. Indeed, in high-noise regimes, all methods are comparable. On the contrary, correlation is discriminating: High correlation strongly hinders the performance of Lasso/ENet, moderately those of SCAD and very slightly CIO, SS and MCP methods. Among all methods, -regularization is the less accurate, selects fewer correct features than the four other methods and is sensitive to correlation between features. SCAD provides modest improvement over ENet in terms of accuracy, in comparison with CIO, SS and MCP. Unsurprisingly, we observe a gap between the solutions returned by the cutting-plane method and its Boolean relaxation, gap which decreases as noise increases. All things considered, CIO and the MCP penalization are the best performing method in all six regimes, with a fine advantage for CIO.
Figure 2 on page 2 reports relative computational time compared to glmnet in log scale. It should be kept in mind that we restricted the cutting-plane algorithm to a -second time limit and the sub-gradient algorithm to iterations. All methods terminate in times of one to two orders of magnitude larger than glmnet (seconds for the problem size at hand), contradicting the common belief that -penalization is the only tractable alternative to exact subset selection. Computational time for the discrete optimization algorithm CIO and sub-gradient algorithm SS highly depends on the regularization parameter . For low , which are suited in high noise regimes, the algorithm is extremely fast, while it can take as long as a minute in low noise regimes. This phenomenon explains the relative comparison of SS with glmnet in Figure 2. For this is an important practical aspect, we provide detailed experiments regarding computational time in Appendix B.1. As previously mentioned, stopping the algorithm SS after a consecutive number of non-improvements can drastically reduce computational time. Empirically, this strategy did not hinder the quality of the solution in regression settings, but was not as successful in classification setting, so we did not reported its performance. As CIO has a fixed time limit independent of , the relative gap in terms of computational time with glmnet narrows as sample size increases.
Finally, though a purely theoretic metric, accuracy has some intuitive and practical implications in terms of out-of-sample prediction. To support our claim, Figure 3 (p. 3) represents the out-of-sample for all five methods, as increases, for the six noise/correlation settings of interest. There is a clear connection between performance in terms of accuracy and in terms of predictive power, with CIO performing the best. Still, good predictive power does not necessarily imply that the features selected are mostly correct. SCAD, for instance, seems to provide a larger improvement over ENet in terms of predictive power than in accuracy. Similarly, SS dominates MCP in terms of out-of-sample MSE, while this is not the case in terms of accuracy.
3.3.2 Feature selection with cross-validated support size
We now compare all methods when is no longer given and needs to be cross-validated from the data itself.
For each value of , each method fits a model on a training set for various levels of sparsity , either explicitly or by adjusting the penalization parameter. For each sparsity level , the resulting classifier incorporates some true and false features. Figure 4 (p. 4) represents the number of true features against the number of false features for all five methods, for a range of sparsity levels , all other hyper-parameters being tuned so as to minimize on a validation set. To obtain a fair comparison, we used the same range of sparsity levels for all methods. Some methods only indirectly control the sparsity through a regularization parameter and do not guarantee to return exactly features. In these cases, we calibrated as precisely as possible and used linear interpolation when we were unable to get the exact value of we were interested in. From Figure 4, we observe that in low correlation settings, CIO and MCP strictly dominate ENet, SCAD and SS. There is no clear winner between CIO and MCP. When noise is low, CIO tends to make less false discoveries, while the latter is generally more accurate, but the difference between all methods diminishes as noise increases. In high correlation settings, no method clearly dominates. CIO, SS and MCP are better for small support size , while ENet and SCAD dominate for larger supports. In high noise and high correlation regimes though, Enet and SCAD seem to clearly dominate their competitors. In practice however, one does not have access to "true" features and cannot decide on the value of based on such ROC curves. As often, we select the value which minimizes out-of-sample error on a validation set. To this end, Figure 5 (p. 5) visually represents validation as a function of for all five methods.The vertical black line corresponds to . For each method, is identified as the minimum of the out-of-sample curve. From Figure 5, we can expect the Lasso/ENet and SCAD formulations to select many irrelevant features, while CIO, SS and MCP are relatively close to the true sparsity pattern.
As a result, for every , each method selects features, some of which are in the true support, others being irrelevant, as measured by accuracy and false detection rate respectively. Figures 6 (p. 6) and 7 (p. 7) report the results of the cross-validation procedure for increasing . In terms of accuracy (Figure 6), all five methods are relatively equivalent and demonstrate a clear convergence: as . The first to achieve perfect accuracy is ENet, followed by SCAD, MCP, CIO and then SS. On false detection rate however (Figure 7), the methods rank in the opposite order. Among all five, CIO and SS achieve the lowest with as low as in low noise settings and around when noise is high. On the contrary, ENet persistently returns around of incorrect features in all regimes of noise and correlation. Concerning MCP and SCAD, in low noise regimes, false detection rate quickly drops as sample size increases. Yet, for large values of , we observe a strictly positive on average (around in our experiments) and high variance, suggesting that feature selection with these regularizations is pretty unstable. As noise increases, for those methods remains significant (around ), with a fine advantage of MCP over SCAD. In our opinion, this is due to the fact that MCP and SCAD, just like Lasso/ENet, do not enforce sparsity explicitly, like CIO or SS do, but rely on regularization to induce it.
3.4 Synthetic data not satisfying mutual incoherence condition
We now consider a "hard" correlation structure, i.e., a setting where the standard Lasso estimator is inconsistent. Fix , and a scalar 444in our experiment we take . Define as a matrix with ’s on the diagonal, ’s in the first positions of the th row and column, and [math]’s everywhere else. Such a matrix does not satisfy mutual incoherence [see 34, Appendix F.2. for a proof]. As opposed to the previous setting, we fix , and compute noisy signals, for increasing noise levels (see Table 3 p. 3). In this setting, the -penalty result in an estimator that puts nonzero weight on the th coordinate, while MCP and SCAD penalties eventually recover the true support [34].
3.4.1 Feature selection with a given support size
We first consider the case when the cardinality of the support to be returned is given and equal to the true sparsity . In this setting, -estimators are expected to always return at least incorrect feature, while MCP and SCAD will provably recover the entire support [34].
As shown on Figure 8 (p. 8), we observe empirically what theory dictates: The accuracy of ENet reaches a threshold strictly lower than . Non-convex penalties MCP and SCAD, on the other hand, see their accuracy converging to as increases. Cardinality-constrained estimators CIO and SS, which are also non-convex, behave similarly, although no theory like Loh and Wainwright [34] exists, to the best of our knowledge. As far as accuracy is concerned (left panel), CIO dominates all other methods. Interestingly, while ENet is the least accurate in the limit , it is sometimes more accurate than non-convex penalties for smaller values of .
We report computational time in Appendix B.2.1.
3.4.2 Feature selection with cross-validated support size
Behavior of the methods when is no longer given and needs to be cross-validated from the data itself is very similar to the case where satisfies the mutual incoherence condition. To avoid redundancies, we report those results in Appendix B.2.2.
3.5 Real-world design matrix
To illustrate the implications of feature selection on real-world applications, we consider an example from genomics. We collected data from The Cancer Genome Atlas Research Network555http://cancergenome.nih.gov on lung cancer patients. The data set consists of gene expression data for each patient. We discarded genes for which information was only partially recorded so there is no missing data. We used this data as our design matrix and generated synthetic noisy outputs , for 10 uniformely log-spaced values of , as in Hastie et al. [29] (Table 4 p. 4).
We held of patients in a test set ( patients). We used the remaining patients as a training and validation set. For each algorithm, we computed models with various degrees of sparsity and regularization on the training set, evaluated them on the validation set and took the most accurate model. Figure 9 (p. 9) represents the accuracy and false detection rate of the resulting regressor, for all methods, as increases. ENet ranks the highest both in terms of number of true and false features. On the contrary, MCP is the least accurate, while making fewer incorrect guesses. CIO, SS, SCAD demonstrate in-between performance. Nevertheless, differences in feature selection does not translate into significant differences into predictive power in this case (see Figure 20 in Appendix B.3 page 20).
As previously mentioned, these results are the conclusion of a cross-validation procedure to find the right value of . In Figure 10 (p. 10), we represent the ROC curve corresponding to four of the ten regimes of noise. For low noise, ENet is dominated by SCAD, SS, MCP and CIO. As noise increases however, ENet gradually improves and even dominates all methods in very noisy regimes. These ROC curves are of little interest in practice, where true features are unknown - and potentially do not even exist. They raise, in our view, interesting research questions about the cross-validation procedure and its ability to efficiently select the "best" model.
3.6 Summary and guidelines
In this section, we compared five feature selection methods in regression, in various regimes of noise and correlation, and under different design matrices. Based on those extensive experiments, we can make the following observations:
- •
As far as accuracy is concerned, non-convex methods should be preferred over -regularization for they provide better feature selection, even in the absence of the mutual incoherence condition. In particular, MCP, the cutting-plane algorithm for the cardinality-constrained formulation, and its Boolean relaxation have been particularly effective in our experiments.
- •
In terms of false detection rate, cardinality-constrained formulations improve substantially over ENet and SCAD, and moderately over MCP.
- •
Computational time might still be the limiting factor in the use of such methods in practice. To that matter, publicly available software, such as the ncvreg package for SCAD and MCP estimators and our package SubsetSelection for the Boolean relaxation, should be advertised to practitioners since they compete with glmnet, which remains the gold standard for tractability. For time can be a crucial bottleneck in practice, we provide detailed experiments regarding computational time and scalability of the algorithms in Appendix B.1.
- •
In practice, we should recommend using a combination of all these methods: Lasso or ENet can be used as first feature screening/dimension reduction step, to be followed by a more computationally expensive non-convex feature selection method if time permits.
- •
While Lasso/ENet performs poorly in low noise settings, its competes and sometimes dominates other methods as noise increases. This observation supports the view that -regularization is, first and foremost, a robustness story [3, 48]: Through shrinkage of the coefficients, the penalty reduces variance in the estimator and improves out-of-sample accuracy, especially in presence of noise. Experiments by Hastie et al. [29] even suggested that Lasso outperforms cardinality-constrained estimators in high noise regimes. Our experiments suggest that their observations are still valid but less obvious as soon as the best subset selection estimator is regularized as well (with an penalty in our case).
4 Synthetic and real-world classification problems
In this section, we compare the five methods included in our study on classification problems. For implementation considerations, we use CIO and SS with the Hinge loss and ENet, MCP and SCAD with the logistic loss.
4.1 Methodology and metrics
Synthetic data is generated according to the same methodology as for regression, except that we now compute the signal according to
[TABLE]
instead of previously.
On synthetic data, feature selection is assessed in terms of accuracy and false detection rate as in the previous section. Prediction accuracy, on the other hand, is assessed in terms of Area Under the Curve (). The corresponds to the area under the receiver operating characteristic curve, which represents true positive rate against false positive rate. The ranges from (for a completely random classifier) to . This area also corresponds to the probability that a randomly chosen positive example is correctly ranked with higher suspicion than a randomly chosen negative example. Correspondingly, is a common measure of prediction error for real-world data.
4.2 Synthetic data satisfying mutual incoherence condition
In this section, we consider consider Toeplitz covariance matrix , which satisfy mutual incoherence condition. We compare the performance of the methods in six different regimes of noise and correlation described in Table 5 (p. 5).
4.2.1 Feature selection with a given support size
We first conducted experiments where the cardinality of the support to be returned is given and equal to the true sparsity for all methods. We report the results in Appendix C.1.1.
4.2.2 Feature selection with cross-validated support size
We now compare the methods on cases where the support size needs to be cross-validated from data.
For every , each method selects features, some of which are in the true support, others being irrelevant, as measured by accuracy and false detection rate respectively. Figures 11 (p. 11) and 12 (p. 12) report the results of the cross-validation procedure for increasing . In terms of accuracy (Figure 11), all methods increase in accuracy as increases, although CIO and SS converge significantly slower than ENet, MCP and SCAD. However, this lower accuracy comes with the benefit of a strictly lower false detection rate (Figure 12).
4.3 Synthetic data not satisfying mutual incoherence condition
As for regression, we now consider the covariance matrix that does not satisfy mutual incoherence [34], in three regimes of noise (see Table 6 p. 6).
We consider the case when the cardinality of the support to be returned is given and equal to the true sparsity .
Results are shown on Figure 13 (p. 13) and corroborate our previous observations in the case of regression: the accuracy of ENet reaches a threshold strictly lower than . Non-convex penalties MCP and SCAD, on the other hand, will see their accuracy converging to , yet for a fixed there are not necessarily more accurate than ENet. Cardinality-constrained estimators CIO and SS dominate all other methods, with a clear edge for CIO.
4.4 Real-world design matrix
To illustrate the implications of feature selection on real-world applications, we re-consider the example from genomics we introduced in the previous section. Our lung cancer patients naturally divide themselves into two groups, corresponding to different tumor types. In our sample for instance, patients () suffered from Adenocarcinoma while the remaining patients () suffered from Squamous Cell Carcinoma, making our data amenable to a binary classification task. Our goal is to identify a genetic signature for each tumor type, which only involves a limited number of genes, to better understand the disease or narrow the search for potential treatment for instance. We held of patients from both groups in a test set ( patients). We used the remaining patients as a training and validation set. For each algorithm, we computed models with various degrees of sparsity on the training set, evaluated them on the validation set and took the most accurate model. Table 7 reports the induced sparsity and out-of-sample accuracy in terms of on the test set for each models. Results correspond to the median values obtained over ten different training/validation splits. Compared to the regression cases, we now have a real-world design matrix and real world signals as well.
The first conclusion to be drawn from our results is that the all the feature selection methods considered in this paper, including the convex integer optimization formulation, scale to sizes encountered in real-world impactful applications. MCP and SCAD provide the sparsest classifiers with median sparsity of and respectively. At the same time, they achieve the lowest prediction accuracy, which questions the relevance of the genes selected by those methods. The -based formulations, Lasso and ENet, reach an above with and genes respectively. In comparison, CIO and SS have similar accuracy while selecting respectively only and genes.
5 Conclusion
In this paper, we provided a unified treatment of methods for feature selection in statistics. We focused on five methods: the NP-hard cardinality-constrained formulation (3), its Boolean relaxation, -regularized estimators (Lasso and Elastic-Net) and two non-convex penalties, namely the smoothly clipped absolute deviation (SCAD) and minimax concave penalty (MCP).
In terms of statistical performance, we compared the methods based on two metrics: accuracy and false detection rate. A reasonable feature selection method should exhibit a two-fold convergence property: the accuracy and false detection rate should converge to and [math] respectively, as the sample size increases. Jointly observed, these two properties ensure the method selects all true features and nothing but true features.
Most of the literature on feature selection so far has focused solely on accuracy, from both a theoretical and empirical point of view. Indeed, on that matter, our observations match existing theoretical results. When mutual incoherence condition is satisfied, all five methods attain perfect accuracy, irrespective of the noise and correlation level. As soon as mutual incoherence fails to hold however, -regularized estimators do not recover all true features, while non-convex formulations do. In all our experiments, Lasso-based formulations are the least accurate and sensitive to correlation between features, while cardinality-constrained formulation and the MCP non-convex estimator are the most accurate. As far as accuracy is concerned, we observe a clear distinction between convex and non-convex penalties, which echoes in our opinion the distinction between robustness and sparsity. Robustness is the property of an estimator to demonstrate good out-of-sample predictive performance, even in noisy settings, and convex regularization techniques are known to produce robust estimators [3, 48]. When it comes to sparsity however, non-convex penalties are theoretically more appealing, for they do not require stringent assumptions on the data [34]. Because both properties should deserve attention, we believe - and observe - that the best approaches are those combining a convex and a non-convex component. The -regularization on its own is not sufficient to produce reliably accurate feature selection.
In real-world applications, false detection rate is at least as important as accuracy. We were able to observe a zero false detection rate for Lasso-based formulations only under the mutual incoherence condition and in low noise settings where . Otherwise, false detection rate remains strictly positive and stabilizes above (we observed this behavior as early as for ). False detection rate for non-convex penalties MCP and SCAD quickly drops as increases, but remains strictly positive (around ) and highly volatile, even for large sample sizes. The exact sparse formulation is the only method in our study which clearly outperforms all other methods, in all settings, and both for regression and classification, with the lowest false detection rate. Its Boolean relaxation demonstrates a similar behavior but less acute, especially in classification. In our opinion, such an observation speaks in favor of formulations that explicitly constrain the number of features instead of using regularization to induce sparsity. In practice, one could use Lasso or non-convex penalties as a good feature screening method, that is to discard irrelevant features and reduce the dimensionality of the problem. Nonetheless, in order to select relevant features only, we highly recommend the use of cardinality-constrained formulation or its relaxation, depending on available computing resources. Table 8 (p. 8) summarizes the advantages and disadvantages we observed for each method.
Those observations would be of little use if the best performing method were neither scalable nor available to practitioners. To that end, we released the code of a cutting-plane algorithm which solves the exact formulation (3) in minutes for and in the s. Though computationally expensive, this method requires only one to two orders of magnitude more time than other methods. We believe this additional computational cost is affordable in many applications and justified by the resulting improved statistical performance. For more time-sensitive applications, its Boolean relaxation provides a high-quality approximation. We proposed a scalable sub-gradient algorithm to solve it and released our code in the Julia package SubsetSelection, which can compete with the glmnet implementation of Lasso in terms of computational time, while returning statistically more relevant features. With SubsetSelection, we hope to bring to the community an easy-to-use and generic feature selection tool, which addresses deficiencies of -penalization but scales to high-dimensional data sets.
Appendix A Extension of the sub-gradient algorithm and implementation
From a theoretical point of view, the boolean relaxation of the sparse learning problem is often tight, especially in the presence of randomness or noise in the data, so that feature selection can be expressed as a saddle point problem with continuous variables only. This min-max formulation is easier to solve numerically than the original mixed-integer optimization problem (3) because the original combinatorial structure vanishes. Our proposed algorithm benefits from both tightness of the Boolean relaxation and integrality of optimal solutions. In this section, we present the Julia package SubsetSelection which competes with the glmnet implementation of Lasso in terms of computational time, while returning statistically more relevant features, in terms of accuracy but more significantly in terms of false discovery rate. With SubsetSelection, we hope to bring to the community an easy-to-use and generic feature selection tool, which addresses deficiencies of -penalization but scales just as well to high-dimensional data sets.
A.1 Cardinality-constrained formulation
In this paper, we have proposed a sub-gradient algorithm for solving the following boolean relaxation
[TABLE]
where
[TABLE]
is a linear function in and concave function in . The function depends on the loss function through its Fenchel conjugate . In this paper, we mainly focused on OLS and logistic loss but the same methodology could be applied to any convex loss function. Indeed, the package SubsetSelection supports all loss functions presented in Table 9.
At each iteration, the algorithm updates the variable by performing one step of projected gradient ascent with step size , and updates the support by minimizing with respect to , being fixed. Since satisfies , and is linear in , this partial minimization boils down to sorting the components of and selecting the smallest. Pseudo-code is given in Algorithm 2.
A.2 Scalability
As experiments in Sections 3 and 4 demonstrated, our proposed algorithm and implementation provides an excellent approximation for the solution of the discrete optimization problem (3), while terminating in times comparable with coordinate descent for Lasso estimators for low values of . Table 10 reports some computational time of SubsetSelection for data sets with various values of , and . The algorithm scales to data sets with s or s within a few minutes. More comparison on computational time are given in Appendix B.1.
A.3 Extension to cardinality-penalized formulation
Our proposed approach naturally extends to cardinality-penalized estimators as well, where the [math]-pseudonorm is added as a penalization term instead of an explicit constraint. Let us consider the -regularized optimization problem
[TABLE]
which corresponds to the estimator (1) in the unregularized limit . Similarly introducing a binary variable encoding the support of , we get that the previous problem (9) is equivalent to
[TABLE]
The new saddle point function is still linear in and concave in . As before, its boolean relaxation
[TABLE]
is tight if the minimizer of with respect to is unique. More precisely, we prove an almost verbatim analogue of Theorem 2.
Theorem 4**.**
The boolean relaxation (11) is tight if there exists a saddle point such that the vector has non-zero entries.
Proof.
The saddle-point problem (11) is a continuous convex/concave minimax problem and Slater’s condition is satisfied so strong duality holds. Therefore, any saddle-point must satisfy
[TABLE]
If there exists such that has non-zero entries, then there is a unique . In particular, this minimizer is binary and the relaxation is tight. ∎
This theoretical result suggests that the Lagrangian relaxation (11) can provide a good approximation for the combinatorial problem (9) in many cases. The same sub-gradient strategy as the one described in Algorithm 2 can be used to solve (11), with a slightly different partial minimization step: Now, minimizing with respect for a fixed boils down to computing the components of and selecting the negative ones, which requires operations. This strategy is also implemented in the package SubsetSelection.
Appendix B Numerical experiments for regression - Supplementary material
In this section, we provide additional material for the simulations conducted in Section 3 on regression examples.
B.1 Synthetic data satisfying mutual incoherence condition
We first consider the case where the design matrix , with a Toeplitz matrix. In particular, satisfies the so-called mutual incoherence condition required by Lasso estimators to be statistically consistent. In this setting, we provide more details about the computational time comparison between algorithms for sparse regression presented in Sections 3.
B.1.1 Impact of the hyper-parameters and
The discrete convex optimization formulation (3) and its Boolean relaxation (5) involve two hyper-parameters: the ridge penalty and the sparsity level .
Intuition suggests that computational time would increase with . Indeed, when , is an obvious optimal solution, while for the problem can become ill-conditioned. We generate problems with , , and and various sample sizes , fix and report absolute computational time as increases in Figure 14 (p. 14). For small values of , both methods terminate extremely fast - within seconds for CIO and in less than seconds for SS. As increases, computational time sharply increases. For CIO, we capped computational time to seconds. For SS, we limited the number of iterations to .
Regarding the sparsity , the size of the feasible space grows as . Empirically, we observe (Figure 15 p. 15) that computational time increases at most polynomially with .
B.1.2 Impact of the signal-to-noise ratio, sample size and problem size
As more signal becomes available, the feature selection problem should become easier and computational time should decrease. Indeed, in Figure 16 (p. 16), we observe that low generally increases computational time for all methods (left panel). The correlation parameter (right panel), however, does not seem to have a strong impact on computational time. In our opinion, with , the effect of correlation on computational time is second order compared to the impact of noise.
Figure 17 (p. 17) represents computational for increasing , being fixed and for increasing , being fixed. As shown, all methods scale similarly with (almost linearly), while CIO and SS are less sensitive to than their competitors.
B.2 Synthetic data not satisfying mutual incoherence condition
We now consider a covariance matrix , which does not satisfy mutual incoherence, as proved in [34].
B.2.1 Feature selection with a given support size
Figure 18 on page 18 reports relative compared to glmnet (left panel) and absolute (right panel) computational time in log scale. As for the case where mutual incoherence is satisfied, all methods terminates within a - factor with respect to glmnet.
B.2.2 Feature selection with cross-validated support size
We compare all methods when is no longer given and needs to be cross-validated from the data itself. Figure 19 on page 19 reports the results of the cross-validation procedure for increasing . In terms of accuracy (left panel), all four methods are relatively equivalent and demonstrate a clear convergence: as . On false detection rate however (right panel), behaviors vary among methods. Cardinality-constrained estimators achieve the lowest false detection rate (), followed by MCP (), SCAD () and then ENet (c.). In case of ENet, this behavior was expected, for -estimators are provably inconsistent, so that must be positive when .
B.3 Real-world design matrix
In this section, we consider a real-world design matrix and generated synthetic noisy signals for 10 levels of noise. Figure 20 (p. 20) represents the out-of-sample of all five methods as increases. As mentioned, the difference in between methods is far less acute than the difference observed in terms of accuracy and false detection.
Appendix C Numerical experiments for classification - Supplementary material
C.1 Synthetic data satisfying mutual incoherence condition
C.1.1 Feature selection with a given support size
We first consider the case when the cardinality of the support to be returned is given and equal to the true sparsity for all methods.
As shown on Figure 21 (p. 21), all methods converge in terms of accuracy. That is their ability to select correct features as measured by smoothly converges to with an increasing number of observations . Compared to regression, the difference in accuracy between methods is much narrower. MCP now slightly dominates all methods, including CIO and SS. The suboptimality gap between the discrete optimization method and its Boolean relaxation appears to be much smaller as well and the two methods perform almost identically.
Figure 22 on page 22 reports relative computational time compared to glmnet in log scale. It should be kept in mind that we restricted the cutting-plane algorithm to a -second time limit and the sub-gradient algorithm to iterations. glmnet is still the fastest method in general, but it should be emphasized that other methods terminate in times at most two orders of magnitude larger, which is often an affordable price to pay in practice. Combined with results in accuracy from Figure 21, such an observation speaks in favor of a wider use of cardinality-constrained or non-convex formulations in data analysis practice. As previously mentioned, for the sub-gradient algorithm, using an additional stopping criterion would drastically cut computational time (by a factor 2 at least) but would also deteriorate the quality of the solution significantly for such classification problems.
Figure 23 (p. 23) represents the out-of-sample error for all five methods, as increases, for the six noise/correlation settings of interest. There is a clear connection between performance in terms of accuracy and in terms of predictive power, with CIO performing the best. Still, better predictive power does not necessarily imply that the features selected are more accurate. As we have seen for instance, MCP often demonstrates the highest accuracy, yet not the highest .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Beck and Teboulle [2009] A. Beck and M. Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM journal on imaging sciences , 2(1):183–202, 2009.
- 2Bertsekas [2016] D. P. Bertsekas. Nonlinear programming, 3rd edition . Athena scientific Belmont, 2016.
- 3Bertsimas and Fertis [2009] D. Bertsimas and A. Fertis. On the equivalence of robust optimization and regularization in statistics. Technical report, Massachusetts Institute of Technology, 2009. Working paper.
- 4Bertsimas and King [2017] D. Bertsimas and A. King. Logistic regression: From art to science. 2017. Statistical Science.
- 5Bertsimas and Van Parys [2017] D. Bertsimas and B. Van Parys. Sparse high-dimensional regression: Exact scalable algorithms and phase transitions. under revision to Annals of Statistics , 2017.
- 6Bertsimas et al. [2016] D. Bertsimas, A. King, and R. Mazumder. Best subset selection via a modern optimization lens. Annals of Statistics , 44(2):813–852, 2016.
- 7Bertsimas et al. [2017] D. Bertsimas, J. Pauphilet, and B. Van Parys. Sparse classification: a scalable discrete optimization perspective. under revision , 2017.
- 8Breheny and Huang [2011] P. Breheny and J. Huang. Coordinate descent algorithms for nonconvex penalized regression, with applications to biological feature selection. Annals of Applied Statistics , 5(1):232–253, 2011.
