Speeding up convolutional networks pruning with coarse ranking
Zi Wang, Chengcheng Li, Dali Wang, Xiangyang Wang, Hairong Qi

TL;DR
This paper introduces a fast, general channel pruning framework that uses coarse ranking during fine-tuning to significantly reduce computational costs while maintaining state-of-the-art performance across multiple datasets and architectures.
Contribution
The paper presents a novel, efficient coarse ranking method for channel pruning that can be integrated with various existing pruning techniques, reducing computation time substantially.
Findings
Achieves near state-of-the-art accuracy with much less computation time.
Reduces 75% and 54% of total pruning time on specific benchmarks.
Effective across multiple datasets and network architectures.
Abstract
Channel-based pruning has achieved significant successes in accelerating deep convolutional neural network, whose pipeline is an iterative three-step procedure: ranking, pruning and fine-tuning. However, this iterative procedure is computationally expensive. In this study, we present a novel computationally efficient channel pruning approach based on the coarse ranking that utilizes the intermediate results during fine-tuning to rank the importance of filters, built upon state-of-the-art works with data-driven ranking criteria. The goal of this work is not to propose a single improved approach built upon a specific channel pruning method, but to introduce a new general framework that works for a series of channel pruning methods. Various benchmark image datasets (CIFAR-10, ImageNet, Birds-200, and Flowers-102) and network architectures (AlexNet and VGG-16) are utilized to evaluate the…
Click any figure to enlarge with its caption.
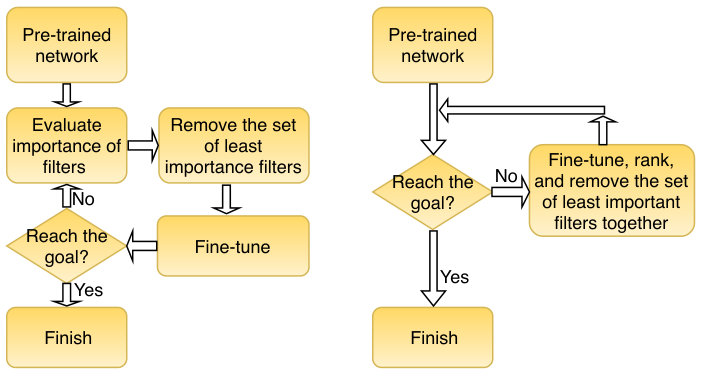 Figure 1
Figure 1| Model | RT (ours) | RT (TE) | TT (ours) | TT (TE) |
|---|---|---|---|---|
| A-C | 0.002 | 5.27 | 171 | 692 |
| V-B | 0.005 | 40.18 | 3098 | 8027 |
| V-F | 0.007 | 18.89 | 1894 | 5023 |
| V-I | 0.006 | 112.39 | 11458 | 24903 |
| Model | Corr (1e-5) | Corr (1e-4) | Variation |
|---|---|---|---|
| A-C | 0.81 0.17 | 0.30 0.23 | 0.96 0.06 |
| V-B | 0.42 0.05 | 0.37 0.04 | 0.78 0.17 |
| V-F | 0.73 0.19 | 0.46 0.16 | 0.88 0.17 |
| V-I | 0.32 0.14 | 0.17 0.07 | 0.69 0.23 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Advanced Neural Network Applications · Adversarial Robustness in Machine Learning
MethodsPruning · 1x1 Convolution · Convolution · Local Response Normalization · Grouped Convolution · *Communicated@Fast*How Do I Communicate to Expedia? · Dropout · Dense Connections · Max Pooling · Softmax
Speeding up convolutional networks pruning with coarse ranking
Abstract
Channel-based pruning has achieved significant successes in accelerating deep convolutional neural network, whose pipeline is an iterative three-step procedure: ranking, pruning and fine-tuning. However, this iterative procedure is computationally expensive. In this study, we present a novel computationally efficient channel pruning approach based on the coarse ranking that utilizes the intermediate results during fine-tuning to rank the importance of filters, built upon state-of-the-art works with data-driven ranking criteria. The goal of this work is not to propose a single improved approach built upon a specific channel pruning method, but to introduce a new general framework that works for a series of channel pruning methods. Various benchmark image datasets (CIFAR-10, ImageNet, Birds-200, and Flowers-102) and network architectures (AlexNet and VGG-16) are utilized to evaluate the proposed approach for object classification purpose. Experimental results show that the proposed method can achieve almost identical performance with the corresponding state-of-the-art works (baseline) while our ranking time is negligibly short. In specific, with the proposed method, and of the total computation time for the whole pruning procedure can be reduced for AlexNet on CIFAR-10, and for VGG-16 on ImageNet, respectively. Our approach would significantly facilitate pruning practice, especially on resource-constrained platforms.
**Index Terms— ** neural network acceleration, channel pruning, coarse ranking, deep neural network
1 Introduction
The over-parameterization of deep convolutional neural networks (DCNN) has become a widely-recognized problem, while they have achieved significant success in a wide range of tasks [1, 2, 3, 4, 5, 6]. In recent years, channel pruning [7, 8, 9, 10, 11] has been proved to be an effective technique to reduce the size of a DCNN while sustaining its performance. It can remove the entire filters, as well as their corresponding feature maps [8, 9, 12], so that no customized hardware are needed [7, 13]. A typical channel pruning procedure is as follows. Given a pre-trained DCNN, all the filters in the DCNN are ranked with a certain criterion and then the lowest ranked (i.e., least important) filters are pruned. Finally, the remaining sub-network is finetuned to alleviate performance loss. The ranking, pruning and fine-tuning are processed iteratively until a target (e.g., a desired pruning ratio or the maximal performance degradation) is satisfied, shown in Fig. 1(top).
An appropriate criterion for ranking filters is considered as playing a dominant role in a successful channel pruning approach. Numerous criteria have been proposed [8, 12, 9, 14], among which, a significant branch is based on data-driven criteria. These approaches usually require a large number of training samples to be fed into the neural network in order to obtain reasonable ranking results, which can be computationally expensive. Our concurrent work shows that a precise filters ranking may not be necessary, since with a certain ranking criterion, pruning relative low-ranked filters can achieve almost identical performance as pruning the lowest-ranked ones. In this paper, we also verify this observation in the experiments (Section 3.1). Inspired by this finding, we propose a novel channel pruning approach based on coarse ranking, which embeds the ranking step into the fine-tuning step by utilizing the intermediate computation results during fine-tuning for ranking purpose. Consequently, ranking time can be significantly reduced. The proposed pipeline is illustrated in Fig. 1(bottom).
We evaluate our approach with various benchmark architectures and datasets for object classification purpose. Experimental results demonstrate that the proposed approach can achieve comparable performance as the baseline, i.e. state-of-the-art approaches with precise ranking in a separate phase. Meanwhile, our ranking time can be reduced to less than second, which is negligibly short, and the overall pruning time is reduced by on AlexNet and around on VGG-16. These results demonstrate that our method can significantly speed up the channel pruning procedure, and can facilitate the pruning practice, especially on resource-limited platforms.
2 Methodology
2.1 The Overall Proposed Innovative Framework
Given a pre-trained DCNN, most existing channel pruning approaches follow an iterative three-step pipeline shown in Fig. 1(top): (1) ranking filters with an importance-based criterion, (2) pruning the least important filters, and (3) fine-tuning the remaining sub-network to alleviate performance loss. With this pipeline, most existing channel pruning methods are devoted to developing sophisticated ranking criteria. Among the numerous criteria, a significant branch is data-driven based criteria that calculate the importance of filters based on the values obtained in the feed-forward, back-propagation, or both passes of the neural network. In order to obtain a precise ranking results, lots of training samples have to be fed into the DCNN and corresponding feed-forward and back-propagation are processed expensively.
Even though we call step (1) as ranking, it actually includes two sub-steps, calculating the importance scores of filters with a certain criterion, and ranking the filters with their scores. What is computationally costly is not ranking a set of values but the process of feed-forward and back-propagation which are required for calculating the importance-based score of filters. Since the feed-forward and back-propagation are also processed during the fine-tuning phase, it is potential to borrow the computation results from fine-tuning instead of calculating them in a separate ranking phase.
Hence, we propose to calculate the importance-based scores of filters with the intermediate computation results from the fine-tuning phase and use these scores to rank filters. We name this ranking approach as coarse ranking. This approach would inevitably result in an imprecise ranking due to the dynamic network weights, which raises concerns that pruning performance would be degraded. However, based on our empirical study, a slightly imprecise ranking can actually achieve comparable performance with precise ranking. More experimental details are presented in Section 3.1. This finding provides a fundamental building block for the proposed innovative framework for channel pruning. The overall proposed framework is shown in Fig. 1(bottom).
2.2 Channel Pruning Methods with Data-driven Criteria
The proposed computationally efficient channel pruning framework works for a series of existing state-of-the-art methods using data-driven criteria for ranking. In the following paragraphs, we introduce several state-of-the-art channel pruning methods. We also present to use Spearman’s rank correlation coefficient [15] to measure the correlation between the baseline (precise ranking) and the proposed method (coarse ranking).
Taylor expansion [9]. Consider a DCNN with convolutional layers, parameterized by , where is the number of filters in the -th layer. Given a training set , the loss function is . The objective of this pruning method is to minimize the loss change when there are at most non-zero filters in the network, parameterized by :
[TABLE]
Suppose are the feature maps of the corresponding filters , then the loss change of removing can be calculated with Eq. 1.
[TABLE]
where and are the losses when is and is not pruned, respectively. The first-order Taylor polynomial at is:
[TABLE]
where the higher order residual , and . Since this approach only consider the first order estimation, is neglected. Thus, Eq. 1 can be rewritten as:
[TABLE]
and can be obtained in the feed-forward and back-propagation passes by feeding a batch of samples to the DCNN. represents the importance of the filter corresponding to .
Mean activation [12]. Suppose is the activation values of the feature map after ReLU. This approach considers the average -norms of the associated feature maps, , calculated by Eq. 2 as the importance scores.
[TABLE]
where is the dimensionality of the feature map.
Rankings correlation. We use the Spearman’s rank correlation coefficient [15] calculated with Eq. 3 to measure the correlation between the proposed coarse ranking and the baseline (precise ranking). This coefficient takes values between , where and indicate absolute negative and positive correlations, respectively.
[TABLE]
where is the number of filters and is the rank difference between the -th filters of two ranking results.
3 Experimental Results
We evaluate the proposed approach with various benchmark network architectures and datasets, including AlexNet [16] on CIFAR-10 [17], VGG-16 [18] on Birds-200 [19], Flowers-102 [20], and ImageNet [21] for image classification purpose. We verify the generality of the proposed approach with two widely-used channel pruning approaches with data-driven criteria for ranking, including Taylor expansion and mean activation, illustrated in Section 2.2. Work [9] demonstrated that Taylor expansion is the state-of-the-art work and outperforms mean activation significantly. Hence, without loss of generality, we mainly utilize Taylor expansion as the baseline and use mean activation as supplementary in the following experiments. For AlexNet, we prune filters and finetune the sub-network for batches at each run; for VGG-16, we prune filters and finetune the sub-network for batches. For all cases, a learning rate of with an SGD optimizer, and a batch size of 64 are used for fine-tuning. We run each experiment times and report the average results and associated standard deviation. Experiments are conducted with Pytorch [22] on NVIDIA Quadro P6000 GPUs and Intel Core i7-6850K CPU (3.60GHz).
3.1 Study of Imprecise Ranking
Our proposed method is built upon the observation that pruning relatively less important filters results in comparable performance with pruning least important filters. Here we verify this finding with comparative study. In specific, we apply Taylor expansion-based criterion to rank filters. In each run of pruning, we compare the performance of different filters selection strategies, including pruning the filters with lowest ranks 1-10 (baseline), and those with relatively low ranks 11-20, 21-30, and 31-40 for AlexNet. Similarly, for VGG-16, the options are filters with ranks 1-50 (baseline), 21-70, 51-100, 81-130, and 101-150. All the other hyper-parameters and configurations remain identical for each pruning strategy. Experimental results are shown in Fig. 2. It is observed that the performances of different filter selection strategies are almost identical with various structures and datasets. These results indicate that it is not necessary to strictly prune the lowest ranking filters, since pruning relatively low ranked filters results in comparable performance. Thus, the overall pruning procedure can be potentially accelerated with a coarse ranking strategy.
3.2 Evaluation with Classification Accuracy
In this subsection, we evaluate our proposed approach that embeds the filter ranking phase into the fine-tuning phase by borrowing the intermediate results of feed-forward and back-propagation from the fine-tuning phase. The Taylor expansion approach is still used as the baseline. In the first run of ranking, since the network has not been through a fine-tuning phase, we randomly select filters to be pruned. After that, we record the intermediate activation values and the corresponding gradients calculated in the feed-forward and back-propagation passes during fine-tuning and use the average results to calculate the importance scores of filters with the Taylor expansion criterion. Therefore, we avoid re-feeding the whole training set to the neural network and re-processing feed-forward and back-propagation in a separate ranking phase, which can save computation significantly.
Experiment results in Fig. 3 show that the proposed approach can achieve almost identical performance with the baseline with various architectures and datasets.
3.3 Evaluation with Computation Time
Furthermore, we evaluate the efficiency of the proposed approach from the perspective of computation time. Specifically, we compare the computation time of the proposed method and the Taylor expansion method in a single iteration of ranking and a complete run of ranking, pruning and fine-tuning, respectively. Since the time used in each run decreases as the pruning procedure goes on, comparing standard deviation is trivial. Therefore, we only report the average computation time in this set of experiments.
The experimental results are shown in Table 1. In all scenarios, the ranking time of our proposed approach is negligibly short, i.e., less than second. Specifically, with AlexNet on CIFAR-10, our method only needs second for one run of ranking while the baseline needs seconds. Moreover, our ranking time increases slightly even though the model grows much deeper (from AlexNet to VGG-16) and the dataset becomes much larger (from CIFAR-10 to ImageNet). However, the corresponding computation time of the baseline method increases significantly.
For a complete run of ranking, pruning and fine-tuning, the total computation time of our approach is seconds while the baseline needs seconds with AlexNet on CIFAR-10. Our method reduces of the computation time, compared with the baseline. For VGG-16, our approach can reduce around of the overall computation time. The percentages of reduced time are different because in the fine-tuning phase, the number of updates varies according to the specific task. For VGG-16, more updates are required to achieve competitive performance.
3.4 Correlation Analysis of Coarse and Precise Rankings
The goal of this section is to study the correlation between the coarse ranking results calculated with our approach and the precise ranking results with Taylor expansion. The Spearman’s rank correlation coefficient described in Section 2.2 is utilized as the measurement.
Firstly, we study the variation of two precise rankings with the same set of hyperparameters, and the results are shown in Table 2 (rightmost column). It is observed that the difference of two precise ranking is noticeable, especially with VGG-16 on ImageNet. This is because training samples are shuffled and are fed into the network with mini-batches. This variation can be considered as a correlation baseline when we evaluate the correlation between precise ranking and coarse ranking in the following paragraph.
We report the correlation between the proposed coarse ranking and the precise ranking in different scenarios, fine-tuning with learning rate and , respectively, shown in Table 2 (2nd and 3rd column). We can observe that the rank correlation between the proposed coarse ranking and precise ranking is close to the correlation baseline (two precise rankings). In specific, the correlation with smaller learning rate is bigger since smaller learning rate leads to smaller change of the network. Besides, the correlation on ImageNet is relatively smaller compared with other datasets, and the probable reason is that ImageNet is a huge dataset containing millions of samples, so it is challenging to achieve an appropriate ranking even with the precise ranking [9].
3.5 Supplementary Verification with Mean Activation
To verify the generality of our proposed methodology, we evaluate the proposed approach with another widely-used channel pruning approach, i.e., the mean activation approach. Experimental results on classification accuracy are shown in Fig. 4. Once again, it is observed that our approach achieves almost identical performance with the baseline while our computation time for ranking is negligibly shot since we do not need to redo feed-forward process in a separate phrase.
4 Conclusion
In this paper, we proposed a novel channel pruning framework that integrates the ranking phase and the fine-tuning phase by sharing intermediate computation results. Extensive experiments showed that our approach can significantly reduce the ranking time while achieving almost identical classification accuracy with the state-of-the-art channel pruning methods with data-driven filter ranking criteria. The proposed approach would significantly facilitate the pruning practice, especially on resource-constrained platforms.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Forrest Iandola, Matt Moskewicz, Sergey Karayev, Ross Girshick, Trevor Darrell, and Kurt Keutzer, “Densenet: Implementing efficient convnet descriptor pyramids,” ar Xiv preprint ar Xiv:1404.1869 , 2014.
- 2[2] Chengcheng Li, Zi Wang, and Hairong Qi, “Fast-converging conditional generative adversarial networks for image synthesis,” ar Xiv preprint ar Xiv:1805.01972 , 2018.
- 3[3] Eric M Christiansen, Samuel J Yang, D Michael Ando, Ashkan Javaherian, Gaia Skibinski, Scott Lipnick, Elliot Mount, Alison O’Neil, Kevan Shah, Alicia K Lee, et al., “In silico labeling: Predicting fluorescent labels in unlabeled images,” Cell , vol. 173, no. 3, pp. 792–803, 2018.
- 4[4] Yuanchao Su, Jun Li, Antonio Plaza, Andrea Marinoni, Paolo Gamba, and Somdatta Chakravortty, “Daen: Deep autoencoder networks for hyperspectral unmixing,” IEEE Transactions on Geoscience and Remote Sensing , 2019.
- 5[5] Zi Wang, Dali Wang, Chengcheng Li, Yichi Xu, Husheng Li, and Zhirong Bao, “Deep reinforcement learning of cell movement in the early stage of c. elegans embryogenesis,” ar Xiv preprint ar Xiv:1801.04600 , 2018.
- 6[6] Dali Wang, Zheng Lu, Yichi Xu, Zi Wang, Chengcheng Li, Anthony Santella, and Zhirong Bao, “Cellular structure image classification with small targeted training samples,” bio Rxiv , p. 544130, 2019.
- 7[7] Song Han, Jeff Pool, John Tran, and William Dally, “Learning both weights and connections for efficient neural network,” in Advances in neural information processing systems , 2015, pp. 1135–1143.
- 8[8] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf, “Pruning filters for efficient convnets,” ar Xiv preprint ar Xiv:1608.08710 , 2016.