Periocular Recognition in the Wild with Orthogonal Combination of Local Binary Coded Pattern in Dual-stream Convolutional Neural Network
Leslie Ching Ow Tiong, Andrew Beng Jin Teoh, Yunli Lee

TL;DR
This paper introduces a dual-stream CNN with a novel color-based texture descriptor, OC-LBCP, for improved periocular recognition in unconstrained environments, and provides a new dataset for benchmarking.
Contribution
It proposes a multilayer fusion dual-stream CNN incorporating OC-LBCP and introduces a new dataset for periocular recognition in the wild.
Findings
The proposed method outperforms existing approaches on benchmark datasets.
Late-fusion layers improve recognition accuracy.
The new Ethnic-ocular dataset provides a valuable resource for future research.
Abstract
In spite of the advancements made in the periocular recognition, the dataset and periocular recognition in the wild remains a challenge. In this paper, we propose a multilayer fusion approach by means of a pair of shared parameters (dual-stream) convolutional neural network where each network accepts RGB data and a novel colour-based texture descriptor, namely Orthogonal Combination-Local Binary Coded Pattern (OC-LBCP) for periocular recognition in the wild. Specifically, two distinct late-fusion layers are introduced in the dual-stream network to aggregate the RGB data and OC-LBCP. Thus, the network beneficial from this new feature of the late-fusion layers for accuracy performance gain. We also introduce and share a new dataset for periocular in the wild, namely Ethnic-ocular dataset for benchmarking. The proposed network has also been assessed on one publicly available dataset,…
Click any figure to enlarge with its caption.
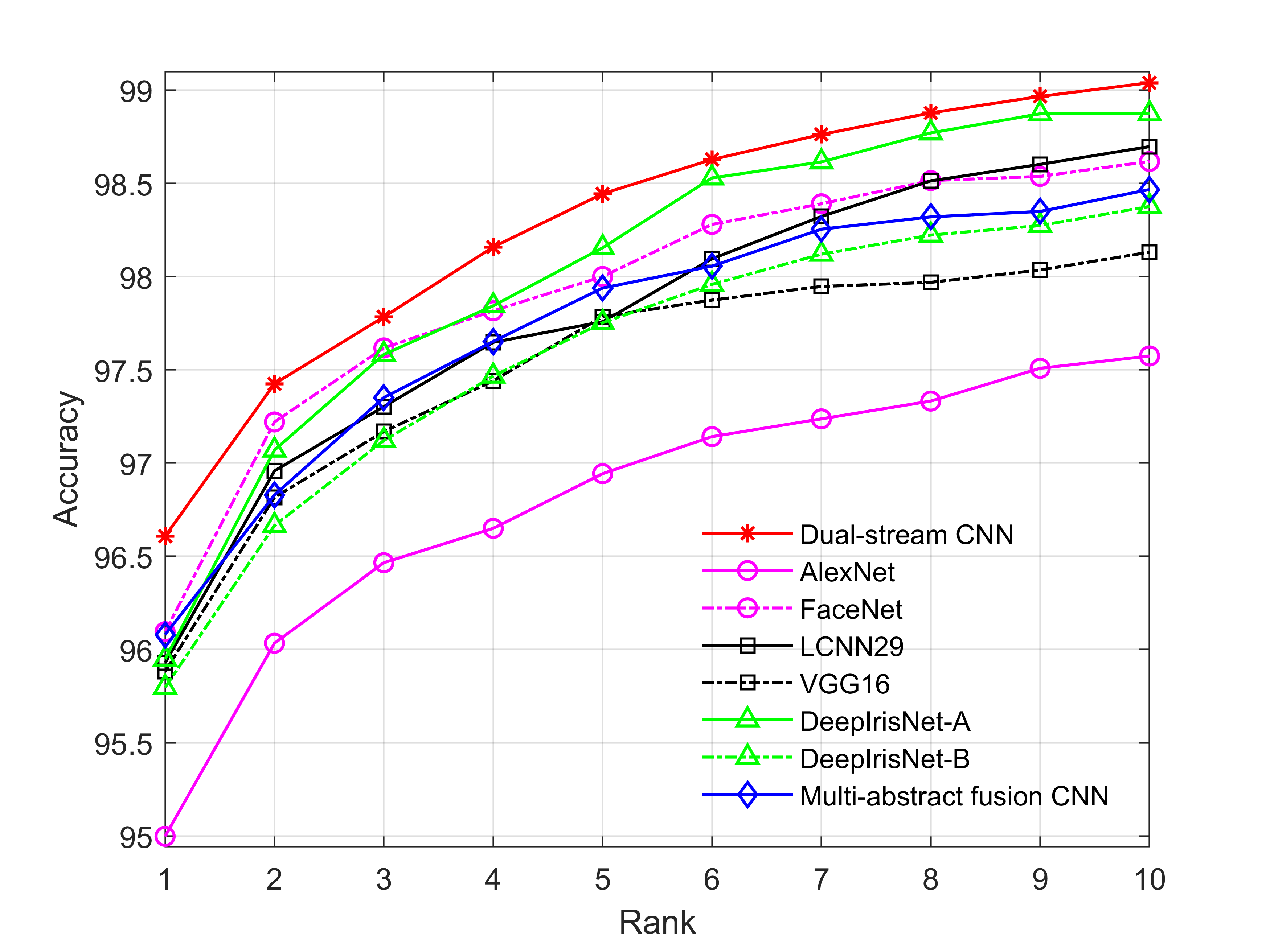 Figure 1
Figure 1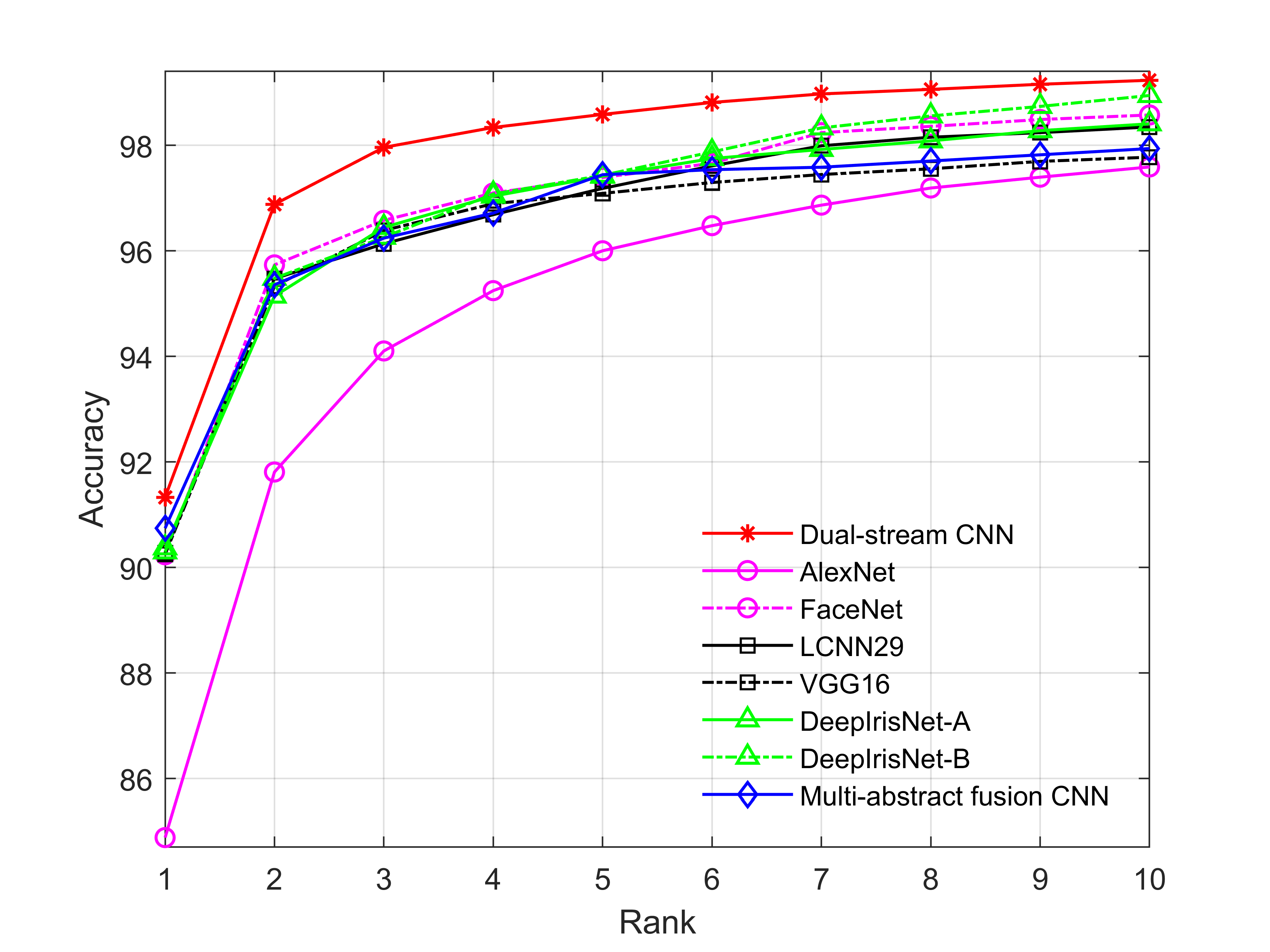 Figure 2
Figure 2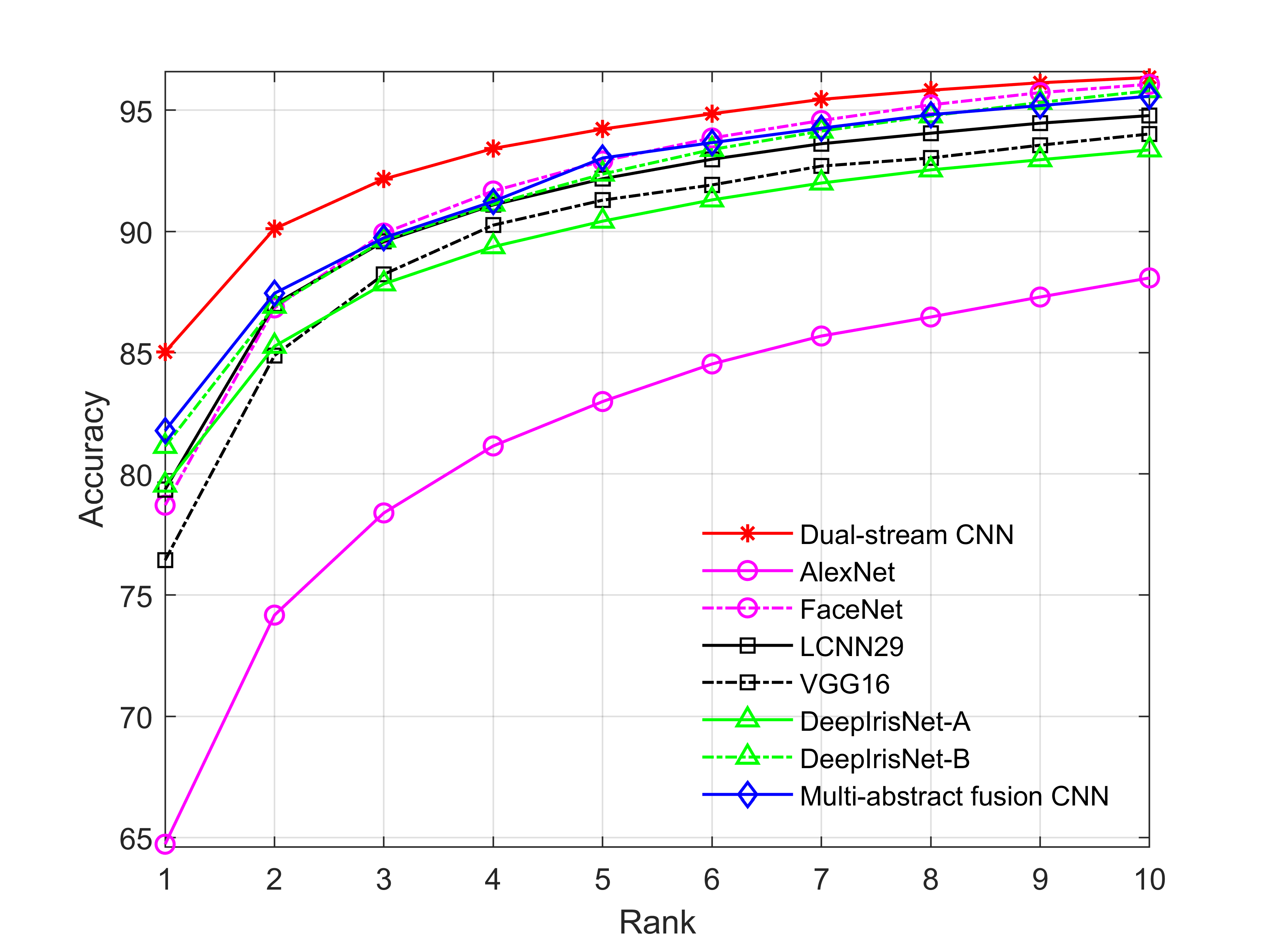 Figure 3
Figure 3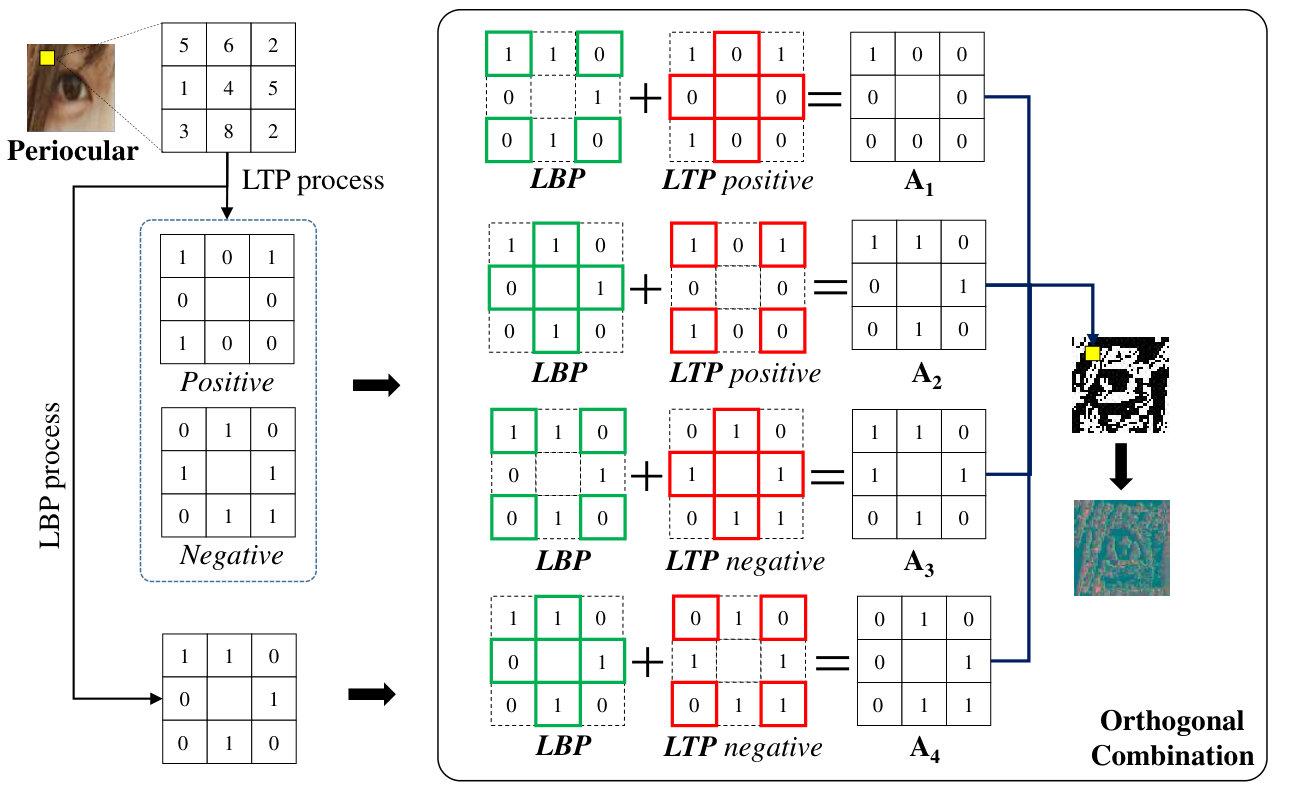 Figure 1
Figure 1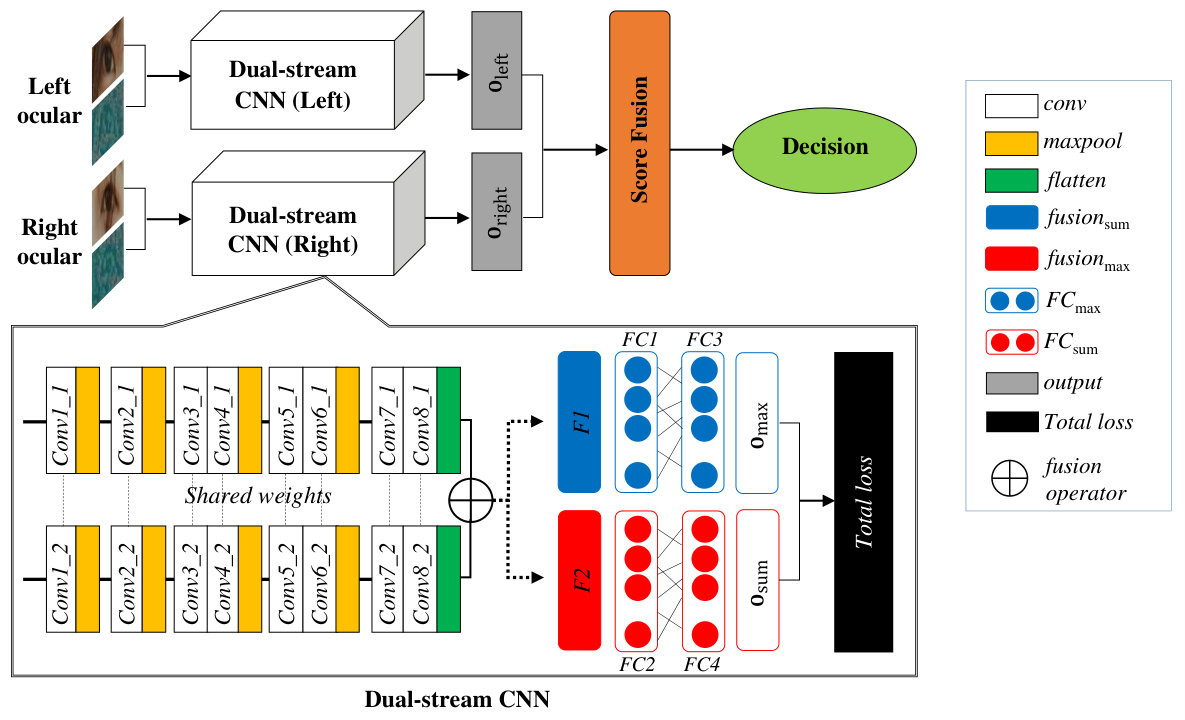 Figure 2
Figure 2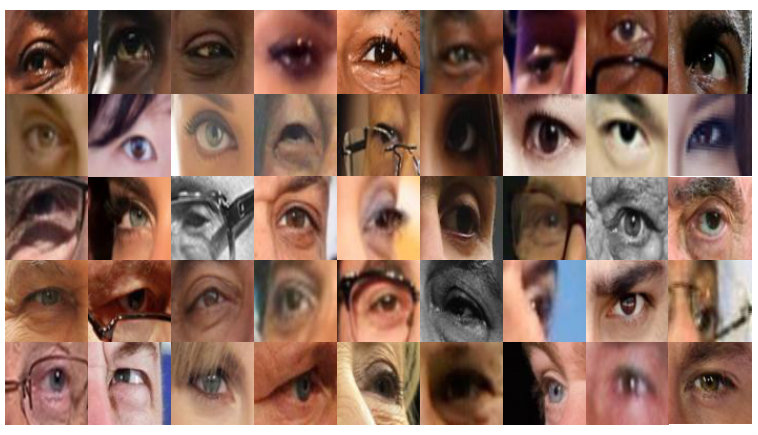 Figure 3
Figure 3 Figure 3
Figure 3| Layer | Configuration |
|---|---|
| , | f.m.: 648080; f.: 22; maxpool: 22 |
| , | f.m.: 1284040; f.: 22; maxpool: 22 |
| , | f.m.: 2562020; f.: 22 |
| , | f.m.: 2562020; f.: 22; maxpool: 22 |
| , | f.m.: 5121010; f.: 22 |
| , | f.m.: 5121010; f.: 22; maxpool: 22 |
| , | f.m.: 51255; f.: 22 |
| , | f.m.: 51255; f.: 22 |
| , | 114,096 |
| , | 114,096 |
| , | 114,096 |
| , | 114,096 |
| , | 11 |
| Approaches | Accuracy (%) |
|---|---|
| CNN using RGB data | 80.81.4 |
| CNN using OC-LBCP | 66.62.2 |
| Dual-stream CNN (without shared weights) | 82.11.6 |
| Proposed network | 85.01.9 |
| Approach | Ethnic-ocular (%) | UBIPr (%) | ||
|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-1 | Rank-5 | |
| AlexNet | 64.723.28 | 82.982.52 | 84.882.50 | 96.011.77 |
| FaceNet | 78.713.66 | 92.191.59 | 90.241.43 | 97.360.44 |
| LCNN-29 | 79.352.64 | 92.171.80 | 90.281.71 | 97.180.67 |
| VGG-16 | 76.432.16 | 91.291.54 | 90.241.38 | 97.091.14 |
| DeepIrisNet-A | 79.543.12 | 90.432.44 | 90.301.16 | 97.411.07 |
| DeepIrisNet-B | 81.133.08 | 92.371.20 | 90.201.66 | 97.430.54 |
| Multi-abstract fusion CNN | 81.793.54 | 93.031.33 | 90.751.01 | 97.440.34 |
| Proposed network | 85.031.88 | 94.231.26 | 91.281.18 | 98.590.44 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Periocular Recognition in the Wild with Orthogonal Combination of Local Binary Coded Pattern in Dual-stream Convolutional Neural Network
Leslie Ching Ow Tiong
KAIST
291 Daehak-ro, Yuseong-gu,
Daejeon 34141,
Republic of Korea
Andrew Beng Jin Teoh
Yonsei University
50 Yonsei-ro, Sinchon-dong,
Seodaemun-gu, Seoul,
Republic of Korea
Yunli Lee
Sunway University
5 Jln. Universiti, Bdr. Sunway,
47500 Petaling Jaya, Selangor,
Malaysia
Abstract
In spite of the advancements made in the periocular recognition, the dataset and periocular recognition in the wild remains a challenge. In this paper, we propose a multilayer fusion approach by means of a pair of shared parameters (dual-stream) convolutional neural network where each network accepts RGB data and a novel colour-based texture descriptor, namely Orthogonal Combination-Local Binary Coded Pattern (OC-LBCP) for periocular recognition in the wild. Specifically, two distinct late-fusion layers are introduced in the dual-stream network to aggregate the RGB data and OC-LBCP. Thus, the network beneficial from this new feature of the late-fusion layers for accuracy performance gain. We also introduce and share a new dataset for periocular in the wild, namely Ethnic-ocular dataset for benchmarking. The proposed network has also been assessed on one publicly available dataset, namely UBIPr. The proposed network outperforms several competing approaches on these dataset.
1 Introduction
In recent years, periocular recognition is gaining attention from the biometrics community due to its promising recognition performance [8]. Periocular usually refers to the region around the eyes, preferably including the eyebrow. An early study of the periocular recognition was done by Park et al. [19], which demonstrated promising results in controlled environments. The authors utilised several texture descriptors such as Histogram of Orientation and Gradient (HOG), Local Binary Pattern (LBP), and Scale Invariant Feature Transform (SIFT), followed by score fusion for decision. Several studies such as [15] also focus on using texture descriptors and learning models for periocular recognition. They combined several texture descriptors for a better feature representation. Another work reported in [9], convolved the HOG and LBP that generated from periocular images with Gabor filters and followed by concatenation. Although all the existing approaches achieved decent recognition performances, these approaches were less robust to the “in the wild” variations such as pose alignments, illuminations, glasses, and occlusions.
Since 2012, Convolutional Neural Network (CNN) has gained an exponential attention to learn high-dimensional data in the computer vision domain [13]. CNN with colour-based texture descriptors have successfully been employed in numerous vision applications, such as emotional recognition [14] and texture classification [7]. Both [14] and [7] demonstrated that using the colour texture do provide complementary information to improve CNN in extracting feature representations. In their analysis, they showed that texture descriptors are ubiquitous enough to represent an object, especially when the shape cannot be visualised clearly.
For periocular recognition in controlled environments, [12] exploited two CNNs, which extract comprehensive periocular information from left and right oculars. [21] and [29] focused on the feature extraction based on regions-of-interest of periocular with CNNs. Both networks exploit prior knowledge by discarding unnecessary information to enhance CNN in periocular recognition. However, these networks are not well-performed in the wild environment, such as when the periocular images are misaligned or the periocular images does not include the eyebrows or ocular perfectly. A very recent work [25] proposed a multimodal CNN, namely multi-abstract fusion CNN where the features fusion for iris, face and fingerprint takes place at fully-connected (fc) layer. A fusion layer is designed to fuse the different levels of fc layers as multi-feature representations with sole RGB data. However, this work only limited to RGB data, which could be of limited in information.
In this paper, we investigate a fusion approach with a dual-stream CNN where each network accepts RGB data and a novel colour-based texture descriptor, namely Orthogonal Combination-Local Binary Coded Pattern (OC-LBCP) for periocular recognition in the wild. Both networks are shared in parameters and a late fusion takes place at the last convolutional (conv) layer before fc layer. OC-LBCP exploits the colour information in texture representation and can extract features with higher discriminative capability.
This paper also attempts to address periocular recognition in the wild challenge, which remains not well-covered by the existing datasets [2, 18, 22] and research community [12, 25]. The periocular recognition in the wild challenges are associated to the huge differences of the periocular images due to sensors location, pose alignments, level of illuminations, occlusions, and others. Specifically, the appearances of periocular region images with cosmetic products and plastic surgery may jeopardise the accuracy performance severely. Most of the existing periocular datasets such as CASIA-iris distance [2] dataset and UBIPr dataset [18] were collected randomly under controlled environments and contained limitation for ethnicity. [23] also revealed that each ethnic group has a unique shape of periocular and skin texture of periocular regions.
We therefore create a new dataset, namely Ethnic-ocular111Ethnic-ocular dataset is available at: https://www.dropbox.com/sh/vgg709to25o01or/AAB4-20q0nXYmgDPTYdBejg0a?dl=0 by collecting the periocular region images in the wild to validate the proposed method. The dataset is created based on five ethnic groups namely African, Asian, Latin American, Middle Eastern, and White. As a result, our dataset is designed in such way to avoid unbalanced selection as there are differences in the configuration of oculars among different ethnicities.
Thus, the contributions of this paper are as follows:
- •
Investigate periocular recognition in the wild with the combination of RGB data and the proposed colour-based texture descriptor OC-LBCP for dual-stream CNN.
- •
To offer a better feature representation for periocular recognition in the wild, two distinct late-fusion layers are introduced in the dual-stream CNN. The role of the late-fusion layers is to aggregate the RGB data and OC-LBCP. Thus, the dual-stream CNN beneficial from this new features of the late-fusion layers to deliver better accuracy performance.
- •
A new periocular dataset, namely Ethnic-ocular dataset is created, containing periocular images in the wild. The images are collected across highly uncontrolled subject-camera distances, low-resolution images, different appearances, occlusions, glasses, poses, time, locations, and illuminations. The dataset also provides training and testing schemes for performance analysis and evaluation.
This paper is organised as follows; Section 2 presents the structure of OC-LBCP. Section 3 explains the presentation of our proposed network, dual-stream CNN with late-fusion layers. Section 4 presents the detailed information of proposed dataset. Section 5 describes the presentation of experimental analysis and results. A conclusion is summarised in Section 6.
2 Colour-based texture descriptor
We devise a colour-based texture descriptor known as OC-LBCP by means of orthogonal combination of Local Binaray Pattern (LBP) [17] and Local Ternary Pattern (LTP) [26]. LBP is to summarise the local structure in an image by comparing each pixel with its neighbourhood. This descriptor works by thresholding a 33 neighbourhood using the grey level of the central pixel in the binary code. LTP is an extension of the primary LBP with three-valued codes by neighbouring pixels with thresholding to form a ternary pattern. The ternary pattern results in a large range, so the ternary pattern is split into two positive and negative binary patterns as depicted in Figure 1.
The OC-LBCP is designed to reduce the sensitivity of image noise and levels of illumination by creating better texture information of an object. Suppose be an image, where and are the height and width, respectively. Butterworth filter is applied to I to separate the illumination component from I and enhance the reflectance [10].
Next, orthogonal combination of binary codes from LBP and LTP operators is carried out. Figure 1 illustrates the orthogonal combination by concatenating the LBP and LTP binary codes into four orthogonal groups, namely , , , and . The orthogonal combinations are beneficial to achieve illumination invariance by removing outlying disturbances. To generate , we select the bits from red line boxes in LTP positive and the values from green line boxes in LBP (see Figure 1); then, concatenated all of them. The same process is repeated for , , and . The OC-LBCP is formed by choosing the largest binary codes from the orthogonal groups. The OC-LBCP is formed by combining the features as follows:
[TABLE]
where represents the four orthogonal groups with binary codes.
To map into a colour space, we define a colour pattern matrix to represent the similarity of the image intensity patterns across all possible code values based on [14]. The colour mapping transforms OC-LBCP into a colour-based texture representation, which reflects the differences in the intensity patterns.
The colour pattern matrix is computed based on the Earth Movers Distance by following [14]. Then, apply Multi-Dimensional Scaling (MDS) to seek a mapping of the codes into a low dimensional metric space:
[TABLE]
where and are the coordinates in colour pattern matrix and is the floor function.
3 Dual-stream convolutional neural network
Dual-stream CNN was originally designed to extract features from temporal and structural streams for action detection and recognition [11]. Our work is motivated by the dual-stream CNN where RGB data and texture descriptor are conceived as the first and second stream. As shown in Figure 2, the network consists of eight pairs of shared conv layers and eight max-pooling (maxpool) layers, where it is designed to learn the correspondence between the RGB data and OC-LBCP and to discriminate between themselves with the shared weights. Table 1 tabulates the proposed network architecture. The shared conv layer is given as a pair conv layer, with their parameters shared.
3.1 Late-fusion layers
To integrate the information from the dual inputs, we merge the flatten layers ( and in Table 1) by creating late-fusion layers to strengthen the feature activations of the network. Therefore, two fusion layers, namely max and sum layers are introduced, to fuse the features at flatten layers. To be specific, max layer takes a larger activation from or with nodes (). On the other hand, sum fusion layer takes a sum of activations of and .
3.2 Training with total loss
For training, a total loss function that composed of summation of cross entropy of logit vector of max fusion and sum fusion and their respective one-hot encoded labels as follows is utilised:
[TABLE]
where . , and denote class label, the numbers of training sample, and the number of class, respectively. Since a periocular region can be either left or right oculars; we therefore train each side with separate dual-stream CNN (see Figure 2).
3.3 Testing with score fusion layer
Let and be the softmax vectors of respective max (after ) and sum () output layer and is the number of classes. The two softmax vectors are aggregated yield . Since there are two dual-stream CNN, each for left and right ocular, thus we differentiate the softmax vector o to and , respectively.
To determine the identity of an unknown input based on the trained network, we follow the identification protocol where the testing set, which is not overlapping with training set is divided according to gallery and probe sets. Each subject in the gallery set is composed of his/her left and right softmax vectors where .
For a given probe with its left and right ocular softmax vectors , we compute the fused score with sum rule as:
[TABLE]
where and is the cosine similarity distance. Finally, the identity of , can be decided based on
[TABLE]
4 Ethnic-ocular dataset
To design our dataset, we follow the example of FaceScrub [16] dataset collection. Our goal is to produce a large collection of periocular images based on different ethnic groups for recognising individuals. Thus, all the periocular images are collected in the wild, such as uncontrolled subject-camera distances, locations, poses, appearances with and without make-up, and level of illuminations.
4.1 Collection setup and information
We began with 250 subject names from FaceScrub dataset and the 784 subject names from BBC News [1], CNN News [3], and Naver News [5], in order to search for the images of these subjects across Google image search engine. In the search, the top 300 images for each subject were downloaded. We first extracted facial regions in these images by using the Viola-Jones face detector from Matlab [4]. The views of facial region in these images are between -45*∘* and 45*∘*. The images were manually verified to ensure that the images are correctly labelled by the subjects.
The dataset contains 85,394 images (includes left and right oculars) of 1,034 subjects. To extract the periocular region from each image, we first aligned all the images by fixing the coordinates of facial feature points based on the Viola-Jones face detector bounding box. Then, the images were cropped into left and right oculars by using the technique from [27], and the results were resized to 8080 pixels individually as shown in Figure 3.
4.2 Benchmark protocols
The dataset provides training and testing protocols; 623 subjects were randomly selected as training and the rest of the subjects were used as testing. In the testing, we have divided the images such that the ratio between the gallery sets and probe sets is 50:50. This division process was repeated three times.
5 Experiments
We used the proposed dataset namely Ethnic-ocular dataset and one public dataset - UBIPr [18] as the target datasets to evaluate the performances of the dual-stream CNN and other benchmark approaches. All the configurations of approaches are described next.
5.1 Experimental setup
5.1.1 Proposed network
Dual-stream CNN is implemented by using the TensorFlow [6] toolkit. We applied an annealed learning rate, which started from and it is subsequently reduced by for every 10 epochs. The minimum learning rate was defined as . An Adam optimizer was applied, where the weight decay and momentum were set to and 0.9, respectively. The batch size was set to 64 and the training was carried out across 200 epochs. The training was done by using our dataset and it was performed by an NVidia Titan Xp GPU.
5.1.2 Benchmark approaches
Seven deep networks were selected to evaluate the performance of periocular recognition, namely AlexNet [13], FaceNet [24], LCNN-29 [28], VGG-16 [20], DeepIrisNet-A [12], DeepIrisNet-B [12], and Multi-abstract fusion CNN [25]. Here we use the pre-trained models that were provided by the authors. All the networks are trained with left and right oculars, respectively. In the cases of DeepIrisNet-A, DeepIrisNet-B, and Multi-abstract fusion CNN, we tried our best effort to implement these networks from scratch by following [12] and [25], respectively, as the networks are not publicly available.
5.2 Experimental results
This section presents the experimental results on the tasks of periocular recognition. We conducted the experiments on periocular recognition in the wild and controlled environments. We evaluated the performance using Cumulative Matching Characteristic (CMC) curve with 95% confidence interval (CI).
5.2.1 Performance evaluation on proposed network vs single-stream CNN
This section analyses the robustness and performance of our proposed network. Table 2 presents the performance analysis on the capability of a single-stream CNN with respective features, followed by dual-stream CNN without sharing the weights in conv and fc layers, and our proposed network. Note that, the dual-stream CNN without sharing the weights also implemented the late-fusion and score fusion. This experiment was conducted using Ethnic-ocular dataset.
Table 2 shows that our proposed network achieved the highest rank-1 recognition accuracy with 85.01.9%. However, single-stream CNN only achieved 80.81.4% and 66.62.2% with RGB data and OC-LBCP, respectively. As compared to single-stream CNN, the results indicate that the late-fusion layers are significant to correlate the RGB data and OC-LBCP in order to achieve better recognition performance. The analysis demonstrated that our proposed network provides more complementary information than single-stream CNN.
Compared with dual-stream CNN without shared weights, the experimental results in Table 2 show that our proposed network is well-performed than dual-stream CNN without shared weights at least 2.9% improvement. This is because our proposed network utilised the shared conv and the fusion fc layers to aggregate the RGB data and OC-LBCP. As a result, the proposed have successfully transformed the new knowledge representations in the network to perform better recognition.
5.2.2 Performance evaluation on proposed network vs benchmark approaches
UBIPr dataset:
To verify the robustness of our proposed network, we also conducted the performance on more subjective experiment with UBIPr dataset. This dataset consists of 342 subjects with varying different subject-camera distances, poses, illumination, and occlusion. This experiment evaluated the performance of all the approaches with varying pose and subject-camera distances. Six images from each subject were randomly selected as a gallery set; the remaining images were used as a probe set. The selection process was repeated three times.
Table 3 presents that dual-stream CNN achieves the highest average rank-1 and rank-5 recognition accuracies with 91.281.18% and 98.590.44%, respectively. The second best is achieved by multi-abstract fusion CNN with 90.751.01% and 97.440.34% as rank-1 and rank-5 accuracies. Figure 4a shows that our network outperforms most of the benchmark approaches and achieves the highest recall rate against all other approaches for all ranks recognition.
Ethnic-ocular dataset:
We presented the experimental results in Table 3 by following the recognition protocol as mentioned in Section 4.2. To evaluate the performance of the proposed network, we compared our results with seven benchmark approaches (see Table 3). For the results of recognition, our proposed network achieved 85.031.88% and 94.231.26% as rank-1 and rank-5 accuracies, respectively. Figure 4b illustrates the CMC curve of our proposed network, which outperformed other benchmark approaches from rank-1 to rank-10 recognition accuracies.
Besides, the results proved that our network can learn new features from the late-fusion layers for better recognition. The effectiveness of these fusion layers provides strong support to our assumption that multi-feature learning achieves significantly better results than using raw data.
6 Conclusion
This paper outlined a plausible perspective into how machine interpretation of periocular images in the wild could benefit from the RGB data and colour-texture descriptors, known as OC-LBCP. In addition, a dual-stream CNN utilized the late-fusion feature learning, which shown contribute to a more robust feature representation in recognition. We observed that accessing to dual inputs (RGB data and OC-LBCP) significantly outperformed the existing descriptors. We also introduced a new Ethnic-ocular dataset, which consists of a large collection of periocular images based on different ethnic groups for recognising individuals. Good performances were obtained for both controlled and in the wild environments of periocular recognition with the proposed network. However, this work is limited to case of individual who is wearing sunglass. In future, we aim to explore generative adversarial network to reconstruct new periocular images without sunglasses.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] BBC News. [Online]. Available: http://www.bbc.com/news.
- 2[2] CASIA iris database. [Online]. Available: http://biometrics.idealtest.org.
- 3[3] CNN News. [Online]. Available: https://edition.cnn.com/.
- 4[4] Matlab object detector. [Online]. Available: https://uk.mathworks.com/help/vision/ref/vision.cascadeobj ectdetector-system-object.html.
- 5[5] Naver News. [Online]. Available: http://news.naver.com/.
- 6[6] Tensor Flow. [Online]. Available: https://tensorflow.org.
- 7[7] R. M. Anwer, F. S. Khan, J. van de Weijer, M. Molinier, and J. Laaksonen. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J. Photogramm. Remote Sens. , 138:74–85, 2018.
- 8[8] E. Barroso, G. Santos, L. Cardoso, C. Padole, and H. Proença. Periocular recognition: How much facial expressions affect performance? Pattern Anal. Appl. , 19(2):517–530, 2016.