TL;DR
This paper introduces an exponential family simultaneous component analysis (ESCA) model that effectively separates common and distinct information in multiple mixed-type data sets, enhancing integrative data analysis.
Contribution
The paper proposes a novel ESCA model with a structured sparse pattern to disentangle global, local, and unique data variations, accommodating mixed data types.
Findings
The ESCA model accurately separates common and specific data variations.
The method outperforms existing approaches in simulations and real CLL data analysis.
The algorithm guarantees monotonic decrease of the objective function.
Abstract
Multiple sets of measurements on the same objects obtained from different platforms may reflect partially complementary information of the studied system. The integrative analysis of such data sets not only provides us with the opportunity of a deeper understanding of the studied system, but also introduces some new statistical challenges. First, the separation of information that is common across all or some of the data sets, and the information that is specific to each data set is problematic. Furthermore, these data sets are often a mix of quantitative and discrete (binary or categorical) data types, while commonly used data fusion methods require all data sets to be quantitative. In this paper, we propose an exponential family simultaneous component analysis (ESCA) model to tackle the potential mixed data types problem of multiple data sets. In addition, a structured sparse pattern…
Click any figure to enlarge with its caption.
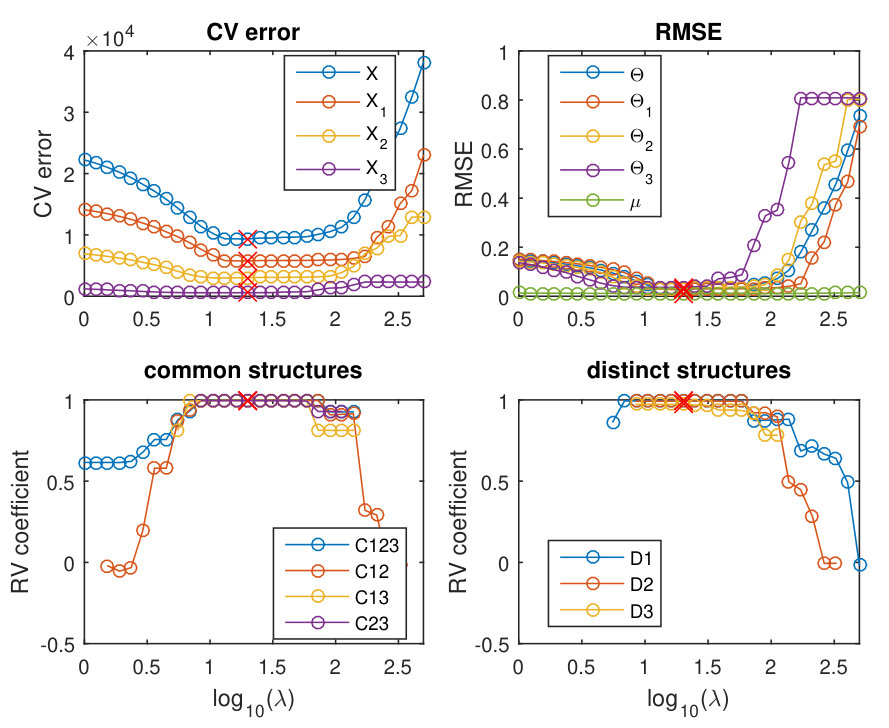 Figure 1
Figure 1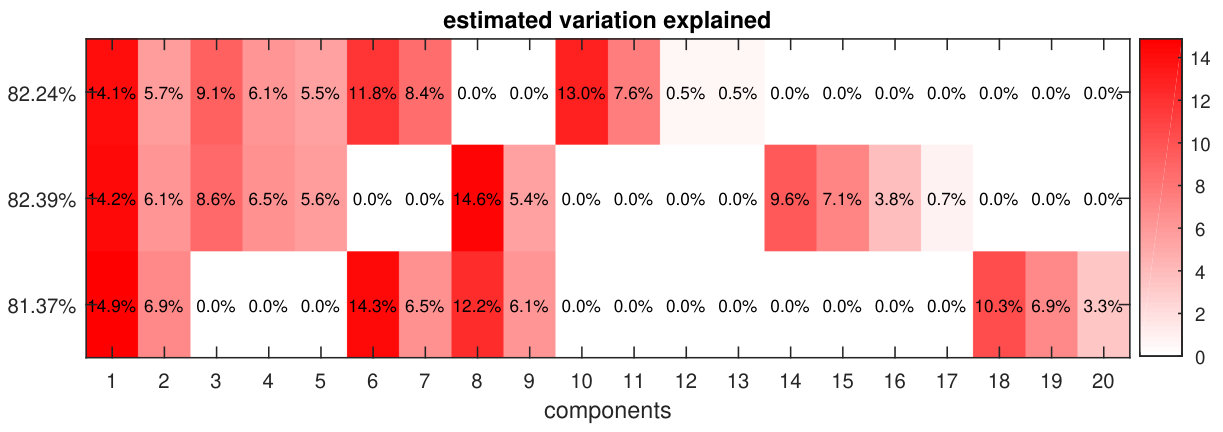 Figure 2
Figure 2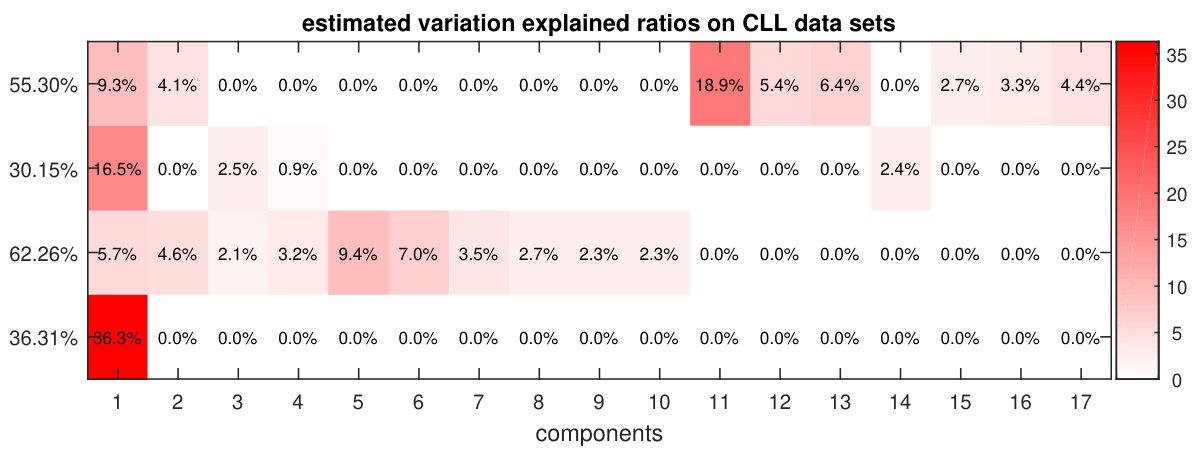 Figure 3
Figure 3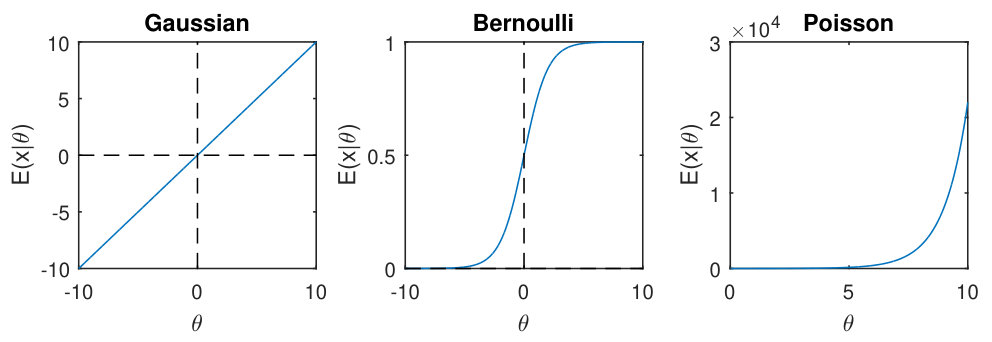 Figure 4
Figure 4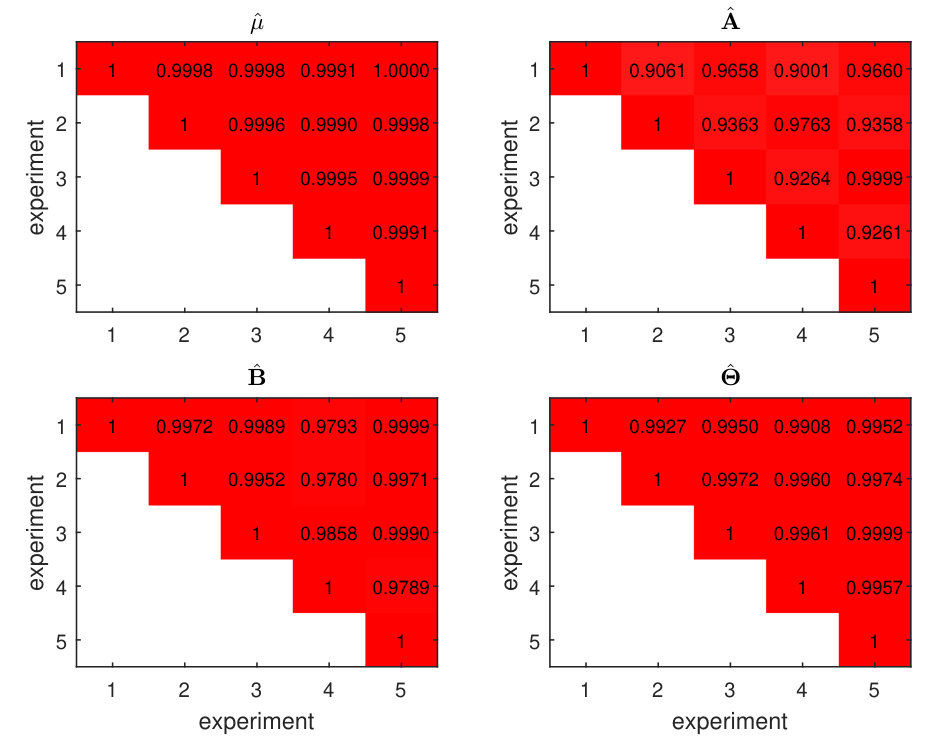 Figure 5
Figure 5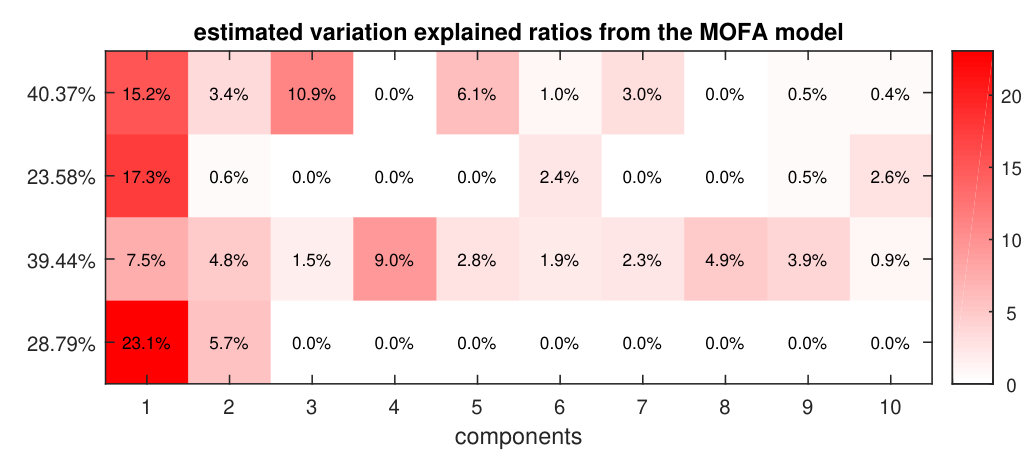 Figure 6
Figure 6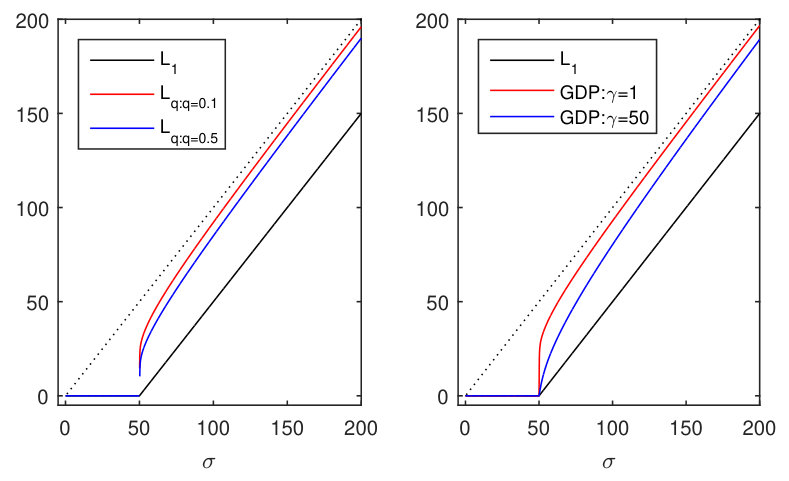 Figure 7
Figure 7 Figure 8
Figure 8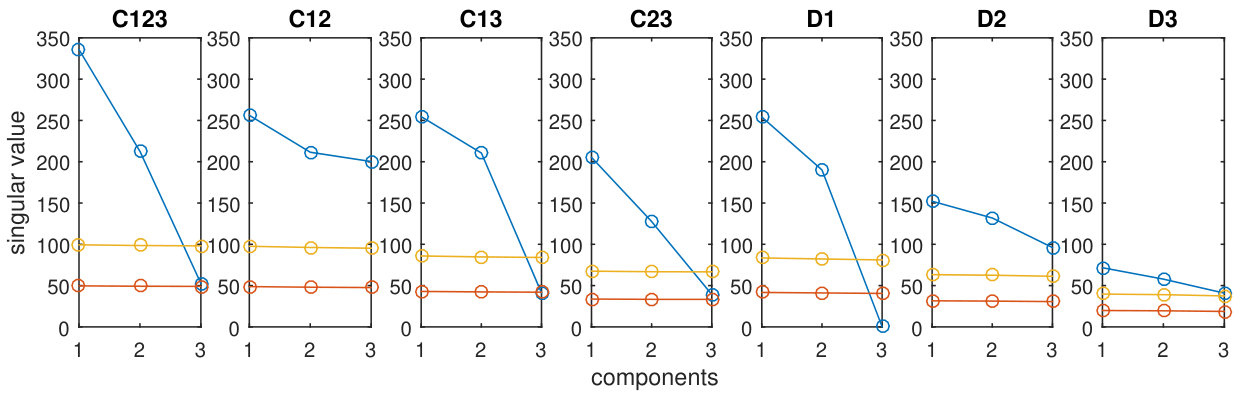 Figure 9
Figure 9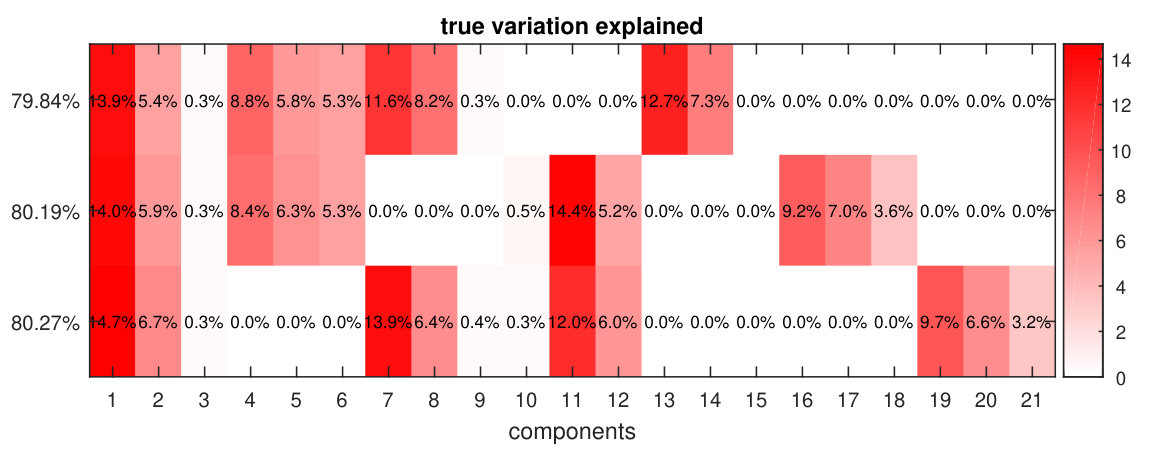 Figure 10
Figure 10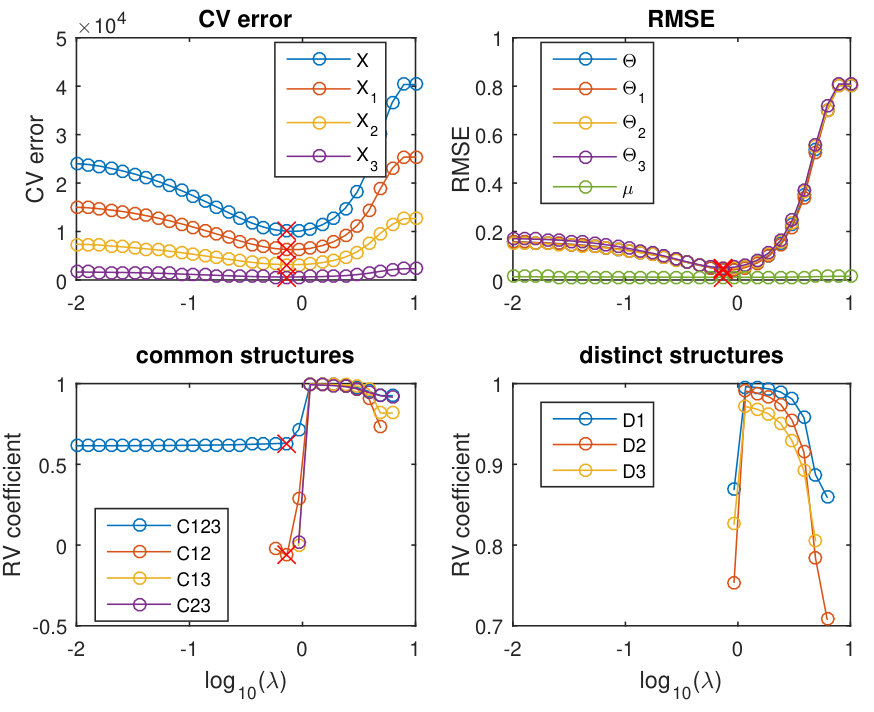 Figure 11
Figure 11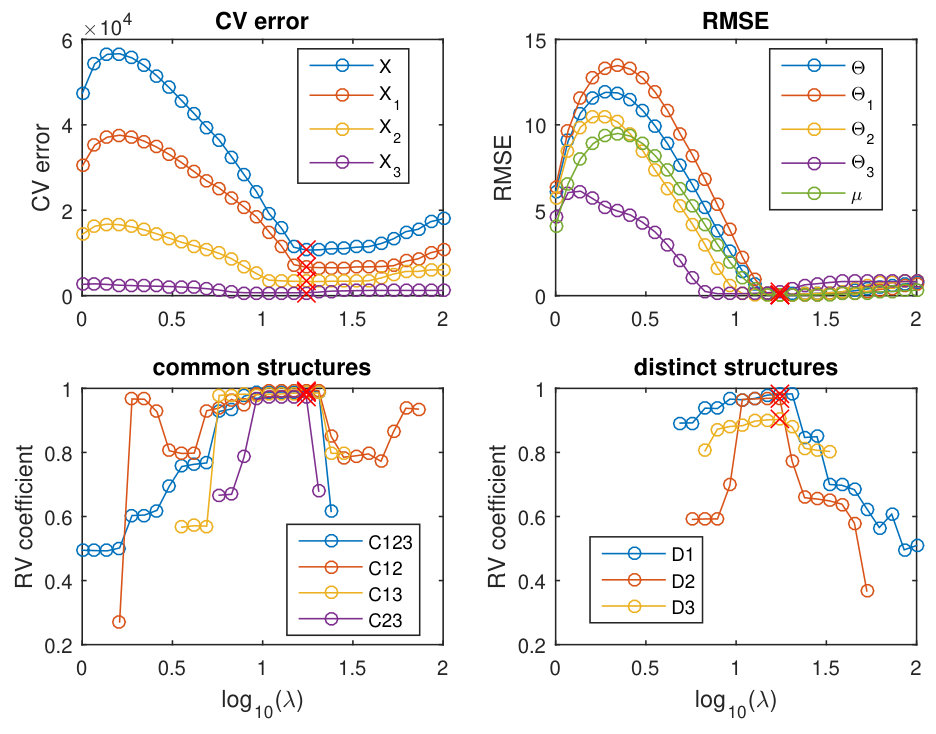 Figure 12
Figure 12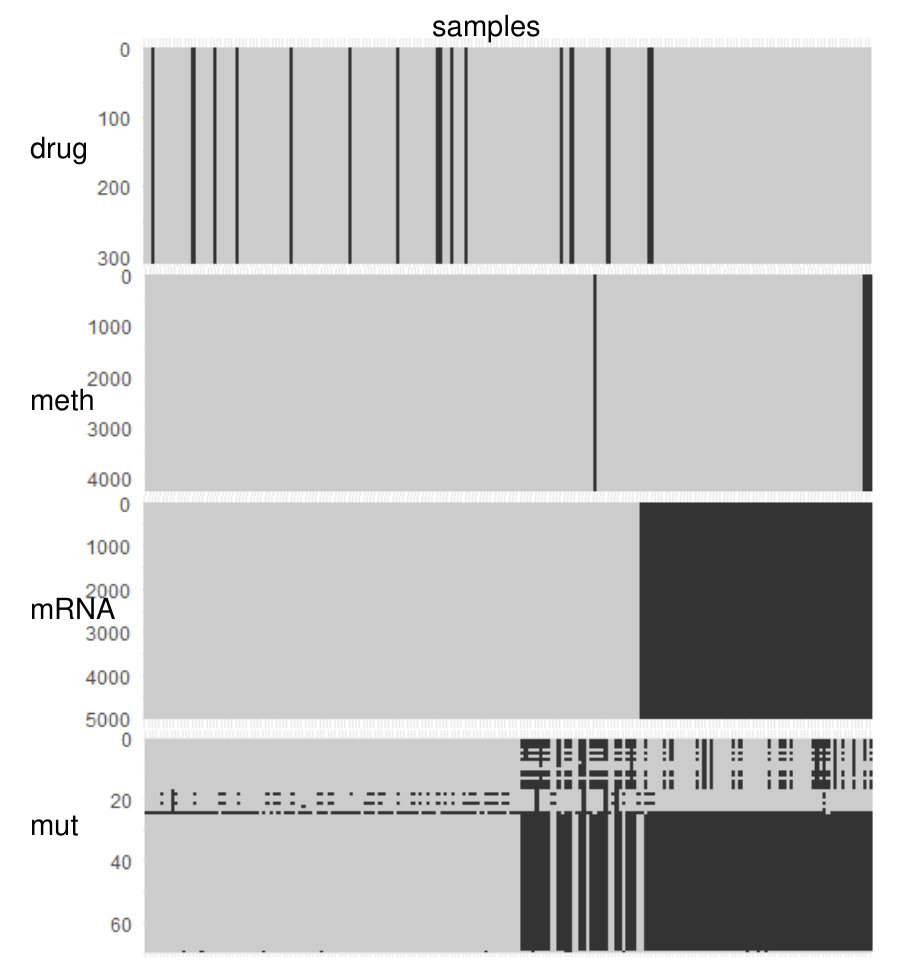 Figure 13
Figure 13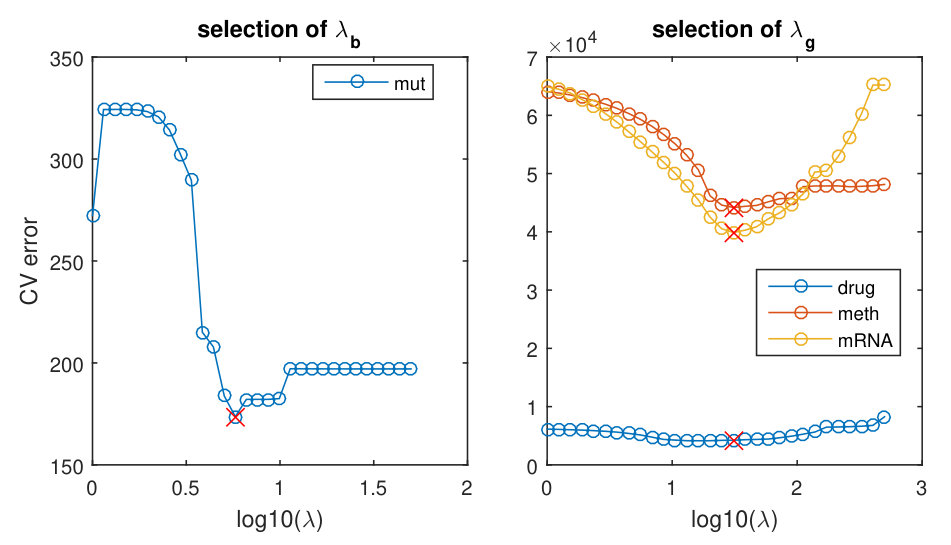 Figure 14
Figure 14| penalty | formula | supergradient |
|---|---|---|
| group lasso | ||
| group | ||
| group GDP |
| case | method | C123 | C12 | C13 | C23 | D1 | D2 | D3 |
|---|---|---|---|---|---|---|---|---|
| 1 | P-ESCA | 0(0) | 0.998(3) | 0.999(3) | 0.999(3) | 0(0) | 0(0) | 0(0) |
| SLIDE | 0(0) | 0.998(3) | 0.998(3) | 0.998(3) | 0(0) | 0(0) | 0(0) | |
| 2 | P-ESCA | 0.996(3) | 0(0) | 0(0) | 0(0) | 0.997(3) | 0.985(3) | 0.973(3) |
| SLIDE | 0.996(3) | 0(0) | 0(0) | 0(0) | 0.997(3) | 0.985(3) | 0.973(3) | |
| 3 | P-ESCA | 0.998(3) | 0.997(3) | 0.997(3) | 0.995(3) | 0.996(3) | 0.994(3) | 0.976(3) |
| SLIDE | 0.995(3) | 0.996(3) | 0.993(3) | 0.991(3) | 0.995(3) | 0.994(3) | 0.976(3) | |
| 4 | P-ESCA | 1(3) | 1(3) | 1(3) | 0.999(3) | 0.997(3) | 0.995(3) | 0.977(3) |
| SLIDE | 1(3) | 1(3) | 0.999(3) | 0.999(3) | 0.997(3) | 0.994(3) | 0.977(3) | |
| 5 | P-ESCA | 1(3) | 1(3) | 1(3) | 1(3) | 0.998(3) | 0.995(3) | 0.977(3) |
| SLIDE | 0.999(3) | 1(3) | 0.999(3) | 0.999(3) | 0.997(3) | 0.995(3) | 0.977(3) | |
| 6 | P-ESCA | 0.998(3) | 1(3) | 0.994(3.1) | 0.999(3) | 0.998(2.9) | 0.999(3) | 0.998(3) |
| SLIDE | 0.996(3) | 0.999(3) | 0.998(3) | 0.998(3) | 0.999(3) | 0.999(3) | 0.997(3) | |
| 7 | P-ESCA | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) |
| SLIDE | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(1.4) |
| case | method | C123 | C12 | C13 | C23 | D1 | D2 | D3 |
|---|---|---|---|---|---|---|---|---|
| 1 | P-ESCA | 0(0) | 0.993(2.9) | 0.994(2.9) | 0.991(2.5) | 0(0.2) | 0(0.5) | 0(0) |
| MOFA | 0(0) | 0.834(2.1) | 0.984(3.2) | 0.989(3.2) | 0(1.4) | 0(1 ) | 0(0) | |
| 2 | P-ESCA | 0.993(2.6) | 0(0.4) | 0(0) | 0(0 ) | 0.990(3 ) | 0.982(3) | 0.914(3) |
| MOFA | 0.959(2.7) | 0(0 ) | 0(0.1) | 0(0.2) | 0.964(3.2) | 0.975(3.1) | 0.885(2.6) | |
| 3 | P-ESCA | 0.956(1.9) | 0.959(4) | 0.972(1.8) | 0.939(1.9) | 0.967(4.3) | 0.945(4.1) | 0.878(2.6) |
| MOFA | 0.940(2.6) | 0.925(2.3) | 0.977(3.2) | 0.956(3.1) | 0.936(3.6) | 0.934(3.7) | 0.848(2.3) | |
| 4 | P-ESCA | 0.992(2.3) | 0.988(3.3) | 0.981(2.4) | 0.980(2.2) | 0.831(3.6) | 0.838(3.2 ) | 0.151(0.2) |
| MOFA | 0.986(2.9) | 0.955(2.9) | 0.990(3 ) | 0.985(2.9) | 0.960(2.6) | 0.929(2.3) | 0.220(0.3) | |
| 5 | P-ESCA | 0.980(2.1) | 0.990(3.8) | 0.991(2.5) | 0.986(2.6) | 0.916(3.4) | 0.808(2.3) | 0.074(0.1) |
| MOFA | 0.915(3.1) | 0.956(2.8) | 0.991(2.9) | 0.984(3 ) | 0.878(2.6) | 0.917(2 ) | 0.193(0.3) | |
| 6 | P-ESCA | 0.192(0.2) | 0.981(4.7) | 0.984(2.3) | 0.979(2.6) | 0.991(4.6) | 0.988(3 ) | 0.963(2.8) |
| MOFA | 0.525(1.1) | 0.949(2.1) | 0.980(3.7) | 0.979(3.4) | 0.978(4.3) | 0.977(4.2) | 0.953(3.1) | |
| 7 | P-ESCA | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) |
| MOFA | NA | NA | NA | NA | NA | NA | NA |
| case | method | C123 | C12 | C13 | C23 | D1 | D2 | D3 |
|---|---|---|---|---|---|---|---|---|
| 1 | ESCA | 0(0) | 0.997(2.8) | 0.987(2.3) | 0.993(3) | 0(0.9) | 0(0) | 0(0) |
| MOFA | 0(0) | 0.826(2.5) | 0.978(3) | 0.973(3.7) | 0(1.6) | 0(0.5) | 0(0) | |
| 2 | ESCA | 0.978(2.3) | 0(0.5) | 0(0) | 0(0) | 0.993(3.2) | 0.981(3) | 0.918(2.9) |
| MOFA | 0.984(2.7) | 0(0.1) | 0(0) | 0(0.2) | 0.533(4.2) | 0.975(3) | 0.895(2.7) | |
| 3 | ESCA | 0.975(2) | 0.972(3.9) | 0.945(1.5) | 0.974(2.2) | 0.932(4.6) | 0.968(3.8) | 0.892(2.6) |
| MOFA | 0.914(3) | 0.879(2.7) | 0.962(2.7) | 0.971(3.1) | 0.475(4.6) | 0.970(2.9) | 0.860(2.5) | |
| 4 | ESCA | 0.998(2.7) | 0.995(2.9) | 0.917(1.6) | 0.991(2.4) | 0.547(4.8) | 0.909(3.3) | 0(0) |
| MOFA | 0.856(3.7) | 0.547(2) | 0.788(3.7) | 0.990(3) | 0.378(4.9) | 0.935(2.8) | 0.398(0.6) | |
| 5 | ESCA | 0.982(2.1) | 0.995(3.4) | 0.994(2.2) | 0.994(2.8) | 0.698(4.3) | 0.929(3.1) | 0.164(0.2) |
| MOFA | 0.677(3.3) | 0.691(2) | 0.916(3.3) | 0.991(3.1) | 0.316(5.2) | 0.835(2.8) | 0.475(0.8) | |
| 6 | ESCA | 0(0) | 0.980(5.1) | 0.971(1.8) | 0.989(2.5) | 0.989(5.1) | 0.992(3.5) | 0.966(2.9) |
| MOFA | 0.624(1.4) | 0.750(1.9) | 0.899(3.9) | 0.985(3.4) | 0.837(6.2) | 0.978(4.3) | 0.954(2.9) | |
| 7 | ESCA | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) |
| MOFA | NA | NA | NA | NA | NA | NA | NA |
| case | method | C123 | C12 | C13 | C23 | D1 | D2 | D3 |
|---|---|---|---|---|---|---|---|---|
| 1 | P-ESCA | 0(0) | 0.998(3) | 0.997(2.4) | 0.999(2.9) | 0(0.6) | 0(0.1) | 0(0) |
| MOFA | 0(0) | 0.528(3.8) | 0.998(2.8) | 0.998(2.9) | 0(0.4) | 0(0.3) | 0(0) | |
| 2 | P-ESCA | 0.971(2.4) | 0(0.6) | 0(0) | 0(0) | 0.998(3) | 0.995(3) | 0.920(2.9) |
| MOFA | 0.987(2.8) | 0(1.2) | 0(0) | 0(0) | 0.997(3) | 0.994(3) | 0.899(2.8) | |
| 3 | P-ESCA | 0.984(2.2) | 0.977(3.8) | 0.979(2.2) | 0.981(2.2) | 0.970(3.8) | 0.968(3.8) | 0.922(3) |
| MOFA | 0.977(2.7) | 0.524(4.3) | 0.993(2.8) | 0.989(2.9) | 0.989(3.2) | 0.980(3.1) | 0.888(2.3) | |
| 4 | P-ESCA | 0.996(3) | 0.965(3 ) | 0.997(2.6) | 0.996(2.4) | 0.941(3.4) | 0.899(3.6) | 0.844(2.4) |
| MOFA | 0.955(4) | 0.673(3.1) | 0.903(2.9) | 0.997(2.9) | 0.920(3) | 0.983(3.1) | 0.703(1.2) | |
| 5 | P-ESCA | 0.996(2.4) | 0.998(3.6) | 1(2.6) | 0.999(2.6) | 0.978(3.4) | 0.952(3.4) | 0.808(1.8) |
| MOFA | 0.761(3.9) | 0.715(3.2) | 0.999(3) | 0.998(2.9) | 0.995(3.1) | 0.982(3.2) | 0.494(0.7) | |
| 6 | P-ESCA | 0.348(0.5) | 0.984(5.5) | 0.992(2.4) | 0.996(2.5) | 0.997(3.6) | 0.997(3.5) | 0.970(3) |
| MOFA | 0.894(2) | 0.949(5) | 0.925(3.2) | 0.972(3) | 0.933(3) | 0.973(3.1) | 0.960(2.9) | |
| 7 | P-ESCA | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) | 0(0) |
| MOFA | NA | NA | NA | NA | NA | NA | NA |
| Distribution | |||
|---|---|---|---|
| Gaussian | 1 | ||
| Bernoulli | |||
| Poisson |
| (time) | (time) | (time)) | |||
|---|---|---|---|---|---|
| 0.9920 0 (9.01) | 1.0029 0 (2.46) | 1.0183 0 (17.06) | |||
| 99.7148 0.7469 (10.66) | 24.9525 0 (2.96) | 1.1609 0.2437 (76.33) | |||
| 0.9892 0 (10.92) | 0.9793 0 (2.80) | ||||
| 99.8457 0 (10.79) | 24.7688 0 (3.43) | ||||
| 0.9896 0 (10.90) | |||||
| 100.1774 0 (10.75) |
| case | C123 | C12 | C13 | C23 | D1 | D2 | D3 |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 2 | 3 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 10 | 5 | 5 | 5 | 1 | 1 | 1 |
| 5 | 5 | 10 | 10 | 10 | 1 | 1 | 1 |
| 6 | 1 | 5 | 5 | 5 | 10 | 10 | 10 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| case | method | |||||
|---|---|---|---|---|---|---|
| 1 | P-ESCA | 0.0167 | 0.0181 | 0.0152 | 0.0135 | 0.0102 |
| SLIDE | 0.0178 | 0.0194 | 0.0161 | 0.0145 | 0.0102 | |
| 2 | P-ESCA | 0.0251 | 0.0241 | 0.0255 | 0.0334 | 0.0100 |
| SLIDE | 0.0269 | 0.0259 | 0.0273 | 0.0349 | 0.0100 | |
| 3 | P-ESCA | 0.0274 | 0.0266 | 0.0278 | 0.0333 | 0.0097 |
| SLIDE | 0.0298 | 0.0290 | 0.0301 | 0.0366 | 0.0097 | |
| 4 | P-ESCA | 0.0064 | 0.0062 | 0.0065 | 0.0076 | 0.0099 |
| SLIDE | 0.0068 | 0.0066 | 0.0069 | 0.0081 | 0.0099 | |
| 5 | P-ESCA | 0.0052 | 0.0051 | 0.0052 | 0.0063 | 0.0099 |
| SLIDE | 0.0055 | 0.0054 | 0.0056 | 0.0067 | 0.0099 | |
| 6 | P-ESCA | 0.0064 | 0.0062 | 0.0065 | 0.0078 | 0.0100 |
| SLIDE | 0.0068 | 0.0066 | 0.0068 | 0.0082 | 0.0100 | |
| 7 | P-ESCA | 0.0099 | 0.0097 | 0.0104 | 0.0098 | 0.0099 |
| SLIDE | 0.0132 | 0.0097 | 0.0104 | 0.0658 | 0.0099 |
| case | method | |||||
|---|---|---|---|---|---|---|
| 1 | P-ESCA | 0.0530 | 0.0450 | 0.0498 | 0.1218 | 0.0265 |
| MOFA | 0.4762 | 0.5004 | 0.4518 | 0.4130 | 0.9999 | |
| 2 | P-ESCA | 0.0528 | 0.0488 | 0.0511 | 0.1009 | 0.0223 |
| MOFA | 0.5951 | 0.5911 | 0.5936 | 0.6432 | 1.0000 | |
| 3 | P-ESCA | 0.0830 | 0.0651 | 0.0775 | 0.2922 | 0.0331 |
| MOFA | 0.5037 | 0.4965 | 0.5077 | 0.5558 | 0.9999 | |
| 4 | P-ESCA | 0.1080 | 0.0673 | 0.1240 | 0.4298 | 0.0731 |
| MOFA | 0.3297 | 0.3233 | 0.3322 | 0.3805 | 0.9999 | |
| 5 | P-ESCA | 0.1225 | 0.0750 | 0.1506 | 0.4546 | 0.0860 |
| MOFA | 0.3267 | 0.3196 | 0.3302 | 0.3802 | 0.9998 | |
| 6 | P-ESCA | 0.1066 | 0.0662 | 0.1275 | 0.4123 | 0.0752 |
| MOFA | 0.3324 | 0.3259 | 0.3364 | 0.3788 | 0.9999 | |
| 7 | P-ESCA | 0.0130 | 0.0129 | 0.0129 | 0.0133 | 0.0130 |
| MOFA | NA | NA | NA | NA | NA |
| case | method | |||||
|---|---|---|---|---|---|---|
| 1 | P-ESCA | 0.0376 | 0.0078 | 0.0463 | 0.0855 | 0.0210 |
| MOFA | 0.1674 | 0.0023 | 0.3422 | 0.4241 | 1.0000 | |
| 2 | P-ESCA | 0.0415 | 0.0105 | 0.0544 | 0.0985 | 0.0167 |
| MOFA | 0.1663 | 0.0020 | 0.3259 | 0.3894 | 1.0000 | |
| 3 | P-ESCA | 0.0552 | 0.0110 | 0.0708 | 0.1874 | 0.0231 |
| MOFA | 0.2008 | 0.0029 | 0.3346 | 0.3847 | 1.0000 | |
| 4 | P-ESCA | 0.0712 | 0.0021 | 0.0986 | 0.4200 | 0.0750 |
| MOFA | 0.1674 | 0.0023 | 0.3422 | 0.4241 | 1.0000 | |
| 5 | P-ESCA | 0.0775 | 0.0018 | 0.1107 | 0.4023 | 0.0806 |
| MOFA | 0.1663 | 0.0020 | 0.3259 | 0.3894 | 1.0000 | |
| 6 | P-ESCA | 0.0731 | 0.0027 | 0.0878 | 0.3086 | 0.0626 |
| MOFA | 0.2008 | 0.0029 | 0.3346 | 0.3847 | 1.0000 | |
| 7 | P-ESCA | 0.0107 | 0.0050 | 0.0129 | 0.0116 | 0.0107 |
| MOFA | NA | NA | NA | NA | NA |
| case | method | |||||
|---|---|---|---|---|---|---|
| 1 | P-ESCA | 0.0143 | 0.0089 | 0.0069 | 0.0555 | 0.0092 |
| MOFA | 0.0831 | 0.0091 | 0.0071 | 0.5825 | 1.0000 | |
| 2 | P-ESCA | 0.0266 | 0.0126 | 0.0136 | 0.0955 | 0.0091 |
| MOFA | 0.1314 | 0.0129 | 0.0139 | 0.7284 | 1.0000 | |
| 3 | P-ESCA | 0.0268 | 0.0137 | 0.0143 | 0.1158 | 0.0095 |
| MOFA | 0.0973 | 0.0139 | 0.0145 | 0.6701 | 1.0000 | |
| 4 | P-ESCA | 0.0149 | 0.0030 | 0.0032 | 0.1505 | 0.0233 |
| MOFA | 0.0381 | 0.0031 | 0.0032 | 0.4400 | 1.0000 | |
| 5 | P-ESCA | 0.0174 | 0.0025 | 0.0025 | 0.1897 | 0.0314 |
| MOFA | 0.0359 | 0.0025 | 0.0026 | 0.4197 | 1.0000 | |
| 6 | P-ESCA | 0.0249 | 0.0032 | 0.0033 | 0.1719 | 0.0281 |
| MOFA | 0.0527 | 0.0033 | 0.0034 | 0.3869 | 1.0000 | |
| 7 | P-ESCA | 0.0068 | 0.0050 | 0.0048 | 0.0123 | 0.0068 |
| MOFA | NA | NA | NA | NA | NA |
| data set | data type | size | |||
|---|---|---|---|---|---|
| drug | quantitative | 17 | 17 | 18 | |
| meth | quantitative | 8 | 9 | 9 | |
| mRNA | quantitative | 16 | 18 | 17 | |
| mut | binary | 1 | 1 | 0 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Separating common (global and local) and distinct variation in multiple mixed types data sets
Yipeng Song
Swammerdam Institute for Life Sciences, University of Amsterdam
Johan A. Westerhuis
Swammerdam Institute for Life Sciences, University of Amsterdam
Age K. Smilde
Swammerdam Institute for Life Sciences, University of Amsterdam
Abstract
Multiple sets of measurements on the same objects obtained from different platforms may reflect partially complementary information of the studied system. The integrative analysis of such data sets not only provides us with the opportunity of a deeper understanding of the studied system, but also introduces some new statistical challenges. First, the separation of information that is common across all or some of the data sets, and the information that is specific to each data set is problematic. Furthermore, these data sets are often a mix of quantitative and discrete (binary or categorical) data types, while commonly used data fusion methods require all data sets to be quantitative. In this paper, we propose an exponential family simultaneous component analysis (ESCA) model to tackle the potential mixed data types problem of multiple data sets. In addition, a structured sparse pattern of the loading matrix is induced through a nearly unbiased group concave penalty to disentangle the global, local common and distinct information of the multiple data sets. A Majorization-Minimization based algorithm is derived to fit the proposed model. Analytic solutions are derived for updating all the parameters of the model in each iteration, and the algorithm will decrease the objective function in each iteration monotonically. For model selection, a missing value based cross validation procedure is implemented. The advantages of the proposed method in comparison with other approaches are assessed using comprehensive simulations as well as the analysis of real data from a chronic lymphocytic leukaemia (CLL) study.
Availability: the codes to reproduce the results in this article are available at https://gitlab.com/uvabda.
Keywords: Data fusion, mixed data types, common and distinct variation, concave penalty.
1 Introduction
Multiple data sets measured on the same samples are becoming increasingly common in different research areas, from biology, food science to psychology. One typical example from biological research is the GDSC1000 study, in which 926 cell lines are fully characterized with respect to point mutation, copy number alternation (CNA), methylation, gene expression and drug responses [1]. However, these comprehensive measurements from the same cell lines not only provide the opportunity for a deeper understanding of the studied biological system, but also introduce statistical challenges.
The first challenge is how to separate the information that is common across all or some of the data sets, and the information which is specific to each data set (often called distinct). These different sources of information have to be disentangled from every data set to have a holistic understanding of the studied system. The second challenge is that measurements from different platforms can be of different data type, such as binary, quantitative or counts. These different data types have different mathematical properties, which should be taken into account in the data analysis. For example, the measurement of a binary variable only has two possible exclusive outcomes, often classified as “1” and “0”. Examples of binary data in biology include point mutation, and the binarized CNA and methylation data sets [1]. Taking binary measurements “1”, “0” as the quantitative values 1, 0, and casting them into the classical data fusion methods that assume data sets to be quantitative, clearly neglects their binary nature.
In this paper, we focus on the component or latent variable based data fusion approaches, although other approaches exist such as undirected graphical model based methods which are able to explore the association between data sets of different data types [2], or between variables of different data types [3, 4]. Two commonly used latent variable based data fusion methods are simultaneous component analysis (SCA) [5] and iCluster [6], which both focus on using low dimensional structures to approximate the common variation across all the data sets. Both of these approaches have already been generalized to discrete data sets [7, 8]. In addition, the concept of common and distinct variation in data fusion has been framed in [9, 10], and several methods [11, 12, 13, 14, 10] have been proposed. One typical example is JIVE [11]. The JIVE model directly specifies the components for the global common variation (variation across all the data sets) and the distinct variation (variation specific to each data set) in the model, and estimates them simultaneously. However, in the JIVE model the local common variation (variation across some of the data sets) is ignored. Direct generalization of JIVE to account for the local common variation is infeasible as with the increase of the number of data sets, the possible combinations of local common variation blows up exponentially. Other methods [13, 12] encounter similar problems with respect to the estimation of local common variation. In addition, the model selection procedure in these methods is still an unsolved issue [15]. A promising solution was provided in [16, 17], in which a group regularization procedure was applied to provide structured sparsity on the loading matrix where the loadings of all variables of a given data set are forced to 0 to disentangle the common (global and local) and distinct variation indirectly. Details will be shown in the following model section. In the SLIDE model [17], first a series of structured sparsity patterns on the loading matrix of a SCA model are learned using a group lasso penalty. Then, these learned structured sparsity patterns are imposed as hard constraints on the loading matrix of a SCA model, and the appropriate model is selected by Bi-cross-validation [18]. The Bayesian counterpart of the SLIDE model is the group factor analysis model [16], and the generalization of the group factor analysis to mixed data types is the MOFA model [19]. These two Bayesian models use automatic relevance determination procedure to induce the structured sparsity.
The first contribution in this paper is the generalization of the SCA model to the exponential family SCA (ESCA) model by exploiting the exponential family distribution to account for potentially different data types, such as binary, quantitative or count data. The generalization is done in a similar way as the extension of principal component analysis (PCA) to exponential family PCA [20]. The second contribution is the use of a nearly unbiased group concave penalty to induce a structured sparse pattern on the loading matrix of the ESCA model to disentangle the common (global and local) and distinct variation of multiple data sets of mixed data types. In the SLIDE model [17], the structured sparse pattern is induced by the group lasso penalty, which shrinks in the group level (the groups) as a lasso penalty, and in the individual level (the individual elements inside a group) as a ridge regression penalty. However, a lasso type penalty leads to biased parameter estimation, as the same degree of shrinkage is applied to all the parameters. This will shrink the nonzero parameters too much and as a result makes the prediction or cross validation error based model selection procedures inconsistent [21, 22]. On the other hand, concave penalties, such as generalized double Pareto (GDP) shrinkage [23] or bridge () penalty [24], are capable to achieve nearly unbiased estimation of the parameters while producing sparse solutions. Therefore, we replaced the group lasso penalty by a group concave penalty on the loadings. The group concave penalty shrinks the group level as a concave penalty, and it shrinks on the individual level as ridge regression penalty. The third contribution lies in the derived model fitting algorithm and the model selection procedure. A Majorization-Minimization based algorithm is derived to fit the proposed penalized ESCA (P-ESCA) model. Analytical form solutions for updating all the parameters of the model in each iteration are derived, and the algorithm will decrease the objective function in each iteration monotonically. Furthermore, the missing value problem is tackled in the developed algorithm, and this option is used in the cross validation procedure for the model selection. The proposed model is similar to the MOFA model, but differences exist in the way how the model is derived, how the structured sparsity is achieved, and how the model is selected.
Both the performance of the proposed P-ESCA model, and the effectiveness of the model selection procedure are validated by extensive simulations under different situations. The performance of the P-ESCA method is compared with SLIDE and MOFAs. Finally, P-ESCA is exemplified by the explorative analysis of the chronic lymphocytic leukaemia (CLL) data sets [25, 19].
2 P-ESCA model
In this section, we will introduce the generalization of the ESCA model. And, we will show how to use the group concave penalty to induce the structured sparse pattern on the loading matrix of an ESCA model to disentangle the common (global and local) variation and distinct variation of multiple data sets.
2.1 Exponential family SCA
The quantitative measurements from different platforms on the same objects result into quantitative data sets, , and the data set () has variables. In the classical SCA model, we decompose the data sets as , in which () is a column vector with ones; () is the column offset term; () is the common score matrix; () and () are the loading matrix and residual term respectively for and is the number of components. In addition, constraints and , in which is the identity matrix, are imposed to make the model identifiable. The SCA model tries to discover the common column subspace, which is spanned by the columns of the score matrix , in data sets to represent their common information. The column offset terms can be removed by column centering of the corresponding data sets . The parameters in the SCA model can be estimated by minimizing the sum of squares , in which is the relative weight of the data set .
The least squares loss criterion in the classical SCA model is only appropriate for quantitative data sets. When some or all data sets are of another data type, such as binary data, classical SCA model is not appropriate anymore. Motivated by the previous research on exponential family PCA model [26], we use the exponential family distribution to account for the different data types of multiple data sets, such as Bernoulli distribution for binary data, Poisson distribution for count data and Gaussian distribution for quantitative data.
Assume follows the exponential dispersion family distribution [27], and and are the natural parameter and the dispersion parameter respectively. The probability density or mass function can be specified as , in which is the log-partition function, and is a function which does not depend on the natural parameter . Tab. S1 lists the log-partition function and its first and second order derivatives , for Gaussian, Bernoulli and Poisson distributions. The relationship always hold in the exponential family distribution. Fig. S1 visualizes this relationship for the Gaussian, Bernoulli and Poisson distributions. If the data set is quantitative, according to the probabilistic interpretation of the PCA model [28], we assume there is a natural parameter matrix () underlying , and the low dimensional structure exists in , and , and elements in the error term follows a normal distribution . The conditional mean of the observed given the low dimensional structure assumption is , in which is the first order derivative of the log-partition function for the Gaussian distribution (Tab. S1). In exponential family PCA, the same idea has been generalized to other members of exponential family distributions by assuming and , in which the function form of depends on the used probability distribution (Tab. S1).
In the exponential family PCA model, the elements in are conditionally independent, given the low dimensional structure assumption as . Take and as the element of and respectively. The conditional log-likelihood of observing can be expressed as , in which indicates the inner product, for matrices, ; , a constant does not depend on the unknown parameter ; and are the element-wise log-partition function and the known dispersion parameter respectively for the data set . In the ESCA model, we assume that the natural parameter matrices lie in the same column subspace, which is spanned by the common score matrix . To make the model identifiable, constraints and are imposed. The optimization problem associated with this ESCA model can be expressed as follows,
[TABLE]
2.2 Separating common (global and local) and distinct variation in multiple data sets via structured sparsity
The drawback of the SCA or ESCA models is that only the global common components, which account for the common variation across all the data sets, is allowed. However, the real situation in multiple data sets integration can be far more complex as local common variation across some of the data sets and distinct variation in each data set are expected as well. Directly specifying the components in the ESCA model for common (global and local) and distinct variation in the same way as JIVE model [11] is infeasible, as the number of possible combinations of local common variation will blow up exponentially with an increasing number of data sets. A promising solution is using structured sparsity on the loading matrix to disentangle the common (global and local) and distinct variation indirectly [16, 17]. Structured sparsity of the data set specific loading matrices in component based data fusion methods has been explored by [29, 30]. The idea of using structured sparsity to disentangle the common (global and local) and distinct variation in multiple quantitative data sets is made explicit in [16, 17]. To illustrate the idea, we use an example with three quantitative data sets. Suppose we construct a SCA model on three column centered quantitative data sets , the common score matrix is , the corresponding loading matrices are , and , in which is the residual term for data set. If the structured sparsity pattern in is expressed as follows,
[TABLE]
in which indicates the column of the loading matrix , then we have the following relationships,
[TABLE]
Here indicates the column of the common score matrix . The first component represents the global common variation across three data sets; the , and components represent the local common variation across two data sets and the , and components represent the distinct variation specific to each single data set. In this way, the structured sparsity pattern in the loading matrices can be used to separate the common (global and local) and distinct variation of multiple quantitative data sets.
2.3 Group concave penalty
In [29, 30, 17], the structured sparsity is induced by a group lasso penalty on the columns of . The used group lasso penalty is , in which is the tuning parameter, indicates the column of the loading matrix , and indicates the norm of a vector. This group lasso penalty shrinks as a lasso penalty and the elements inside as a ridge penalty. However, lasso type penalty leads to biased parameter estimation as the same degree of shrinkage is applied to all the parameters, which will shrink the nonzero parameters too much and makes the prediction or cross validation error based model selection procedures inconsistent [21, 22]. This leads in general to the selection of too complex models. The SLIDE model [17] solves the model selection problem in a two stages manner. First, varying degrees of regularization are imposed to induce a series of structured sparse loading patterns. Then these structured sparse patterns are taken as hard constraints on a new SCA model, in which a Bi-cross validation procedure [18] is used for the final selection. This two stages approach is similar to the often used re-estimation trick in lasso regression. However, such a two-step strategy cannot easily be generalized to the ESCA model. For example, if a binary data set is used and the structured sparse pattern is imposed as a hard constraint on the loading matrices in a ESCA model, the estimated loadings of the binary data set can easily go to infinity [31, 8].
The above issue introduced by the biased estimation of lasso type penalties can be alleviated by using concave penalties [24, 23], which can achieve sparse solutions and nearly unbiased parameter estimation simultaneously. Therefore, in this paper, we applied group concave penalties, generalized double Pareto (GDP) shrinkage [23] and bridge () penalty [24] are included as special cases, on the loading matrices of the ESCA model to induce structured sparse pattern. Take , in which is the column of , and is a general concave penalty function in Tab. 1. The penalty on can be expressed as , in which is the tuning parameter. The group lasso penalty is a special case of the group (bridge) penalty by setting . The thresholding properties of the group penalty, group GDP penalty and group lasso can be found in Fig. S2. In order to account for the situation that the data sets have an unequal number of variables, we add the weights in the same way as in the standard group lasso regression problem, i.e. . The group concave penalty on can be expressed as \sum_{l}\Big{[}\lambda_{l}\sqrt{J_{l}}\sum_{r}g(\sigma_{lr})\Big{]}. Based on successful results in previous work [8] we will focus on the GDP penalty, which is differentiable everywhere in its domain and its performance is insensitive to the selection of the hyper-parameter . We given an example in Fig. S3 to show how the group GDP () penalty induces structured sparsity pattern on the loading matrices .
2.4 Identifiability
The constraint makes the column offset terms identifiable. The columns of the score matrix span the joint subspace , in which indicates the column subspace. The structured sparse pattern on the loading matrices and the multiplication of the score and loading matrices provide a way to separate the joint subspace into subspaces col(GC), col(LC), col(D) corresponding to the global common, local common and distinct variation, . If the orthogonality constraint is imposed, the separated subspaces col(GC), col(LC), col(D), corresponding to the global common, local common and distinct variation, are orthogonal to each other, and unique as . Furthermore, there is no rotational freedom for the components within the subspace corresponding to the global common or local common or distinct variation. This is because an orthogonal rotation operation will alter the value of the penalty function on the loading matrix even though the structured sparse pattern is unchanged. Since the separated subspaces are unique and there is no rotational freedom for the subspaces, the score matrix and loading matrix are unique. Therefore, the model is identifiable with respect to the parameters , and .
2.5 Regularized likelihood criterion
The regularized likelihood criterion of fitting the proposed P-ESCA model can be derived as follows. To tackle the missing value problem, weighting matrices are introduced. For the data set , we introduce a same size weighting matrix , in which if the corresponding element in is missing, while vise versa. This option is the basis for different missing value based cross validation approaches. The corresponding optimization problem can be expressed as follows,
[TABLE]
in which indicates the element-wise matrix multiplication.
3 Algorithm
The original problem in equation 2 is difficult to optimize directly because of the non-convex orthogonality constraint and the group concave penalty . However, by using the Majorization-Minimization (MM) principle, the original difficult problem can be majorized to a simpler problem, for which analytical form solutions can be derived for all the parameters. According to the MM principal, the derived algorithm will monotonously decrease the loss function in each iteration. Further details of the MM principle can be found in [32, 33].
3.1 The majorization of the regularized likelihood criterion
Take as the loss function for fitting the data set , and as the group concave penalty for the loading matrix . We can majorize and respectively as follows.
The majorization of
Given , we have . The first and second gradients of with respect to are and . Assume that is upper bounded by a constant , which will be detailed below. If represents the general representation of , then according to the Taylor’s theorem and the assumption that for all , we have the following inequality,
[TABLE]
Here is an approximation of at the iteration and is an unknown constant. Combining the above inequality and the majorization step [34] of transforming a weighted least square problem to a least squares problem, we have the following inequality,
[TABLE]
in which is the approximation of during the iteration. For the Bernoulli distribution, an elegant bound can be used [35]; for the Gaussian likelihood, ; for the Poisson distribution, is unbounded, however, we can always set .
The majorization of
Assume is the approximation of , and . According to the definition of a concave function [36], we always have the inequality , in which and is the set of supergradients (the counterpart concept of the subgradient for a concave function) of the function at . When the supergradient is unique, then . Therefore, can be majorized as follows,
[TABLE]
The majorization of the regularized likelihood criterion
Combining the above two majorization steps, we have majorized the original complex problem in the equation 2 to a simper problem in each iteration as follows,
[TABLE]
3.2 Block coordinate descent
The majorized optimization problem in equation 6 can be solved by the block coordinate descent approach, and the analytic solution can be derived for all the parameters.
Updating
When fixing all other parameters except , the analytic solution of in equation (6) is simply the column mean of , .
Updating
When fixing all other parameters except , and deflating the offset term , the loss function in equation (6) becomes , in which is the column centering matrix. If we take , the above equation can also be written in this way . To simplify the equations, we set and . Then, we take as the row concatenation of , , and take as the column concatenation of , . After that, we have . Updating equivalents to minimizing . Assume the SVD decomposition of is , the analytic solution for is . The derivation of the above solution is shown in the following paragraph.
To simplify the derivation, we take and . So the optimization problem is . This equation can be expanded as . Since , the above optimization problem equivalents to maximizing a trace function problem, . Assume the SVD decomposition of is , we have . According to the Kristof theorem [37], we have , in which is the diagonal element of , and this upper-bound can be achieved by setting .
Updating
Because , it is easy to prove that . Also, because of that the least squares problems are decomposable, we have , in which is the column of . In this way, we have the following optimization problem,
[TABLE]
The above optimization problem is equivalent to finding the proximal operator of a (or Euclidean) norm, and the analytic solution exists [38]. Take , the analytical solution of is . To update the parameter , we can simply apply this proximal operator to all the columns of .
Initialization and stopping criteria
The initialization of the parameters , , can be set to the results of a classical SCA model on or to accept user imputed initializations. The relative change of the objective function is used as the stopping criteria. Pseudocode of the algorithm described above is shown in Algorithm 1, in which is the value of the objective function in iteration, is the tolerance of relative change of the objective function.
3.3 Variation explained ratio of the P-ESCA model
For the quantitative data set , the parameters are , and . The total variation explained ratio of the model for is defined as . And the variation explained ratio for the component on is defined as . For the binary data set, we use a similar strategy as the MOFA model [19], where the is taken as the pseudo during the iteration, and rather than is used to compute the variation explained ratios. The multiple data sets can also be taken as a single full data set. In that case the values are taken as the weights for them, and then we can compute the variation explained ratios of each component for this full data set. The full single data set and the weighting matrix are the column concatenation of and , in which is replaced by if the data set is not quantitative. The offset term and the loading matrix are the row concatenation of and and the score matrix .
4 Simulation process
To evaluate the proposed model and the model selection procedure, three data sets of different data types with underlying global, local common and distinct structures are simulated. The following simulations and experiments focus on the quantitative and binary data types. We will first show the simulation of the structure , in which is the row concatenation of , . The structure can be expressed in the SVD type as (, ), in which , is a diagonal matrix, and the structured sparse pattern exists in the matrix . First, all the elements in and are simulated from the standard normal distribution. To make sure that , simulated is first column centered, and then it is orthogonalized by the SVD algorithm to have . Also, is orthogonalized by the QR algorithm to obtain . In this example 21 components are predefined, 7 groups of global, local common and distinctive nature, 3 components each. The structure of these components are set in as indicated below,
[TABLE]
in which indicates the loadings for the first three components for data set 1, etc. After that, 21 values are sampled from , and their absolute values are taken as the diagonal elements of . Furthermore, an extra diagonal matrix , which has the same size as matrix , is used to adjust the signal to noise ratios (SNRs) in simulating different global, local common and distinct structures. Then we have . In order to define the SNR, we have to specify the noise term for the data set . If is quantitative, all the elements in can be sampled from . If is binary, according to the latent variable interpretation of logistic PCA [39], we assume there is a continuous latent matrix underlying the binary observation , and the elements of the noise term follow the standard logistic distribution. After the specification of the noise terms, we can adjust the diagonal elements in to satisfy the predefined SNRs in simulating the global, local common and distinct structures. We restrict the diagonal elements of for the same structure to share a single value to have a unique solution. For example, for the global structure , the corresponding noise term is , and the SNR of the global structure as defined as . The SNRs for the simulation of the local common (C12, C13, C23) and distinct (D1, D2, D3) structures are defined in the same way.
If is quantitative, we simply sample all the elements in from the standard normal distribution. If is binary, the column offset represents the logit transformation of the marginal probabilities of binary variables. In our simulation, we will first sample marginal probabilities from a Beta distribution. The Beta distribution can be specified in the following way. For example, if we have 100 samples of a binary variable and we assume the marginal probability to be 0.1, this means we only observe “1”s. If we model them as Binomial observations with parameter , and use a uniform prior distribution for , then the posterior distribution of is [40]. After generating marginal probabilities from this Beta distribution, the logit transformation of this vector of probabilities are set as . If is quantitative, is simulated as , and all the elements of are sampled from . If is binary, we have , and all the elements of are sampled from the Bernoulli distributions, whose probabilities are the corresponding elements in the inverse logit transformation of . An equivalent way to simulate the binary is to first generate , in which all the elements in are sampled from the standard logistic distribution. Then, all the elements in are the binary observations of the corresponding elements of , if , and vise versa. In the following sections, we will use Gaussian-Gaussian-Gaussian (G-G-G) to represent the simulation of three quantitative data sets; Bernoulli-Bernoulli-Bernoulli (B-B-B) for the simulation of three binary data sets; G-B-B for a quantitative data set and two binary data sets and G-G-B for two quantitative data sets and a binary data set.
5 Evaluation matrices and model selection
To evaluate the accuracy of the model in estimating the simulated parameters, such as and , the relative mean squared error (RMSE) is used. If, for example, the simulated parameter is , , and its estimation is , the RMSE is defined as . All of the following evaluation matrices , and will be used in the experimental section. To evaluate the recovered subspaces with respect to the simulated global common, local common and distinct structures, the modified RV coefficient [41] is used. If the simulated global structure is , and its estimation is , the similarity between the subspaces of and is calculated by the modified RV coefficient.
For the real data sets, we can use the cross validation (CV) error as the proxy of the prediction error to estimate the performance of the model. From each data set , we will randomly select 10% non-missing elements as , and these selected elements in are set to missing values. The remaining elements form the training set . For binary data, the selection of the test set samples is performed in a stratified manner to tackle the situation of unbalanced binary data. Here the test set consist of 10% “1”s and “0”s which are randomly selected from as . A P-ESCA model is constructed on the training sets , to obtain an estimation of , in which . Then the parameters corresponding to are indexed out. The CV error for is obtained as the negative log likelihood of using to predict .
If the data sets are of the same data type, a single tuning parameter is used to replace the during the model selection. First, are split into and in the same way as described above. Then values are selected (with equal distance in log-space) and for each value a P-ESCA model is constructed on the training sets . A warm start strategy is used, in which the outputs of a previous model are used to initialize the next model with a slightly higher regularization strength. The warm start strategy has a special meaning in the current context. If some component loadings are shrunk to 0 in the previous model, they will also be 0 in the next models with higher values. Thus, the search space of the next model will be constrained based on the learned structured sparse pattern in the previous model. In this way, with increasing , components are removed adaptively. We prefer to select the model with the minimum CV error on and the corresponding value of is . After that we re-fit a P-ESCA model with on the full data sets and the outputs derived from the selected model with minimum CV error are used for initialization in order to preserve the learned structured sparse pattern.
If the data sets are of mixed data types, we prefer to use distinct tuning parameters for each data type. Suppose we have three data sets , of which is quantitative and are binary. We specify two tuning parameters and for the loading matrices corresponding to the quantitative and binary data sets. A heuristic model selection approach, which has the same computational complexity as tuning a single parameter, can be used for the model selection. The splitting of into the training and test sets is the same as discussed above. Then again, values of and are selected with equal distance in log-space. For the first model, we fix to be 0 or a very small value, and tune in the same way as above. The model with the minimum CV error on the binary test sets is selected, and the corresponding value of is . After that, is fixed to , and the outputs of the above selected model are set as the initialization for the models in the model selection of , which is done in the same way as described above. The model with the minimum CV error on the quantitative test set is selected, and the corresponding value of is . After the model selection, we re-fit the P-ESCA model on the full data sets with the and and again the outputs of the selected model in the model selection process are used for initialization.
6 Experiments
6.1 Evaluating the estimation procedure
The dispersion parameters of the Bernoulli and Poisson distributions can always set to , while for the Binomial distribution with experiments, it can always be set to . However, for a Gaussian distribution, the dispersion parameter represents the variance of the noise term, and is assumed to be known. Suppose we have a data set , we prefer to use a PCA model to estimate the before constructing a P-ESCA model. The rank of the PCA model is selected by a missing value based cross validation procedure similar as described above. Details of the estimation procedure are shown in the supplementary. After obtaining an estimation of , it can be casted into the model or the data set can be scaled by , which is the estimated standard deviation. We simulated G-G-G, G-G-B and G-B-B data sets to test the estimation procedure. The parameters in the simulation are set as , , , ; the SNRs of the global, local common and distinct structures are all set to 1; the marginal probability is set to to simulate unbalanced binary data sets. The estimation procedure was repeated 3 times and the average is taken as the estimation. As shown in Tab. S2, the mean estimated dispersion parameters in different situations are quite accurate, and the estimations derived from the 3 times repetitions are very stable.
6.2 An example of CV error based model selection
We use the simulated G-G-G data sets as an example to show how the model selection is performed when multiple data sets are of the same data type. The following parameters are used in the simulation, , , , ; the SNRs of global, local common and distinct structures are all set to 1; all the dispersion parameters are set to be 1. The signals, which are taken as the singular values of the simulated structures, and the noises, which are taken as the singular values of the corresponding residual terms, are characterized in Fig. S4. The true variation explained ratios of each component in every data set is computed using the simulated parameters, and is visualized in Fig. S5. For the model selection procedure, the maximum number of iterations is set to 500; the stopping criteria is set to ; 30 values are selected from the interval equidistant in log-space; 50 components are used in the initialization. The values of in the P-ESCA model are set to the estimated values from the above estimation procedure.
Fig. 1 shows how the CV errors, RMSEs and the RV coefficients change with respect to when a P-ESCA model with a group GDP () penalty is used. The top figures in Fig. 1 show that the CV errors change in a similar way as the RMSEs. The model with minimum CV error has low RMSEs in estimating the simulated parameters (Fig. 1 top right) and correctly identifies the dimensions of the subspaces for the global, local common and distinct structures (Fig. 1 bottom). However, when the group lasso penalty is used this was not the case. Fig. S6 shows that when a group lasso penalty is used, the models with minimal CV error do not coincide with the correct dimensions of the subspaces. In the model with minimum CV error, almost all the components are assigned to the global structure. This result relates to the fact that the lasso type penalty over-shrinks the non-zero parameters, and then CV error based model selection procedure tends to select a too complex model to compensate the biased parameter estimation. On the other hand, as the GDP penalty achieves nearly unbiased parameter estimation, the CV error based model selection procedure correctly identifies the correct model.
After the model selection, a high precision P-ESCA model () with a group GDP penalty is re-fitted on the full data sets with the value of corresponding to the minimum CV error and the selected structured sparse pattern. For this selected model, the RMSEs in estimating , , , and are 0.0259, 0.0239, 0.0285, 0.0335 and 0.0096 respectively. The RV coefficients in estimating the global common structure C123 is 0.9985; local common structures C12, C13 and C23, 0.9977, 0.9969, 0.9953; the distinct structures D1, D2 and D3, 0.9961, 0.9937, 0.9779. The variation explained ratios of each component on the three data sets computed using the estimated parameters, visualized in Fig. 2, are very similar to the true ones in Fig. S5. These values are very useful in exploring the constructed model.
6.3 Full characterization of the P-ESCA model when applied to multiple quantitative data sets
When applied to multiple quantitative data sets, our model is similar as the SLIDE model, except that we use different penalties and a different model selection procedure. The details of the differences between the two approaches are summarized in the supplementary. Since the concave GDP penalty is capable to achieve a nearly unbiased estimation of the parameters, the P-ESCA model with a group GDP penalty is expected to achieve similar performance to the two stages procedure used in the SLIDE model. Therefore, we simulated seven realistic cases by adjusting the SNRs of the simulated structures to compare the performance of these two models and their model selection procedures. The SNRs of the simulated structures corresponding to these seven cases are listed in Tab. S3. Case 1: only the local common structures exist and they have unequal SNRs; case 2: the JIVE case, only the global common and distinct structures exist, and they are all of low SNRs; case3: all the simulated structures are of low SNRs; case 4: global common structure dominate the simulation; case 5: local common structures dominate the simulation; case 6: distinct structures dominate the simulation; case 7: none of the global, local common and distinct structures exist.
The following parameters are used in the G-G-G data simulations, , , , , all of the are set to 1. In order to have exactly 3 components for all the simulated structures, we reject the simulations of which the singular values of the three components of any specific structure are not 2 times larger than the singular value of the corresponding residual term. The P-ESCA model with a group GDP () penalty is selected and re-fitted on the full data sets in the same way as above. For the SLIDE model, the simulated data sets are column centered and block-scaled by the Frobenius norm of each data set. Then the SLIDE model is selected and fitted using the default parameters. The deflated column offset term is taken as the estimated . The derived loading matrices are re-scaled by the corresponding Frobenius norm of each data set. G-G-G data sets are simulated for all the 7 cases, and for each case, the simulation experiment (data simulation, model selection, fitting the final model) is repeated 10 times for both the P-ESCA model and the SLIDE model. The mean RV coefficients in evaluating the estimated global, local common and distinct structures and the corresponding mean estimated ranks are shown in Tab. 2, and the mean RMSEs in estimating the simulated parameters are shown in Tab. S4. In all 7 cases, these two methods have very accurate estimation of the subspaces corresponding to the global, local common and distinct structures, and of the simulated parameters , which is the column concatenation of , , and , which is row concatenation of . For some of the cases there is a slight advantage for the P-ESCA model.
6.4 Full characterization of the P-ESCA model when applied to multiple binary data sets
The performance of the proposed P-ESCA model are fully characterized with respect to multiple binary data sets. Here we make a comparison to the MOFA model, which is the Bayesian counterpart of P-ESCA. In the P-ESCA model, the structured sparse pattern is induced through a group concave penalty, and the model selection is done through missing value based cross validation, while in the MOFA model, the structured sparse pattern is induced through the automatic relevance determination approach and the model is selected through maximizing the marginal likelihood. In addition, MOFA model also shrinks a component to be 0 when its variation explained ratios for all the data sets are less than a threshold, whose default value is 0. The details of the differences are summarized in the supplementary. For the model selection of the P-ESCA model, the range of values is , and the other parameters are the same as before. To give an impression of the model selection process, we also characterized how the CV errors, RMSEs and the RV coefficients change with respect to in the P-ESCA model with a group GDP penalty on the simulated B-B-B data sets in Fig. S7. For the MOFA model, the default parameters are used, but as exact sparsity cannot be achieved by the automatic relevance determination procedure used in the MOFA model, we take a component for a single data set to be 0 when the variation explained ratio of this component on this data set is less than .
In the seven B-B-B simulations cases, we set , and the marginal probability to be to simulate very unbalanced binary data sets. Other parameters are the same as in the G-G-G simulation cases. The mean RV coefficients in evaluating the estimated global, local common and distinct structures and the corresponding mean estimated ranks are shown in Tab. 3, and the mean RMSEs in estimating the simulated parameters are shown in Tab. S5. Compared to the results derived from the P-ESCA model on the G-G-G data sets (Tab. 2), the recovered subspaces related to the global, local common and distinct structures from P-ESCA model on B-B-B data sets are less accurate with respect to RV coefficient and rank estimation, especially when the SNR of a specific structure is much lower than others (in case 4, 5, 6). However, given the fact that all the three data sets only have binary observations, the recovered subspaces are accurate enough. Furthermore, it is interesting to find that such low RMSEs in estimating , (Tab. S5) can be achieved solely from a model on multiple binary data sets. Although these results are a little bit counter intuitive, it is coordinate with the previous research [39, 8]. According to our previous research [8], this result mainly relates to the fact that the GDP penalty can achieve nearly unbiased parameter estimation. On the other hand, the RMSEs in estimating the simulated parameters from the MOFA model (Tab. S5) are much larger. Especially for the estimation of the simulated column offset term, all the elements in the estimated from the MOFA model are very close to 0, and are far away from the simulated . However, the recovered subspaces from the MOFA model are comparable to the results derived from the P-ESCA model (Tab. 3).
6.5 Full characterization of the P-ESCA model when applied to multiple data sets of mixed data types
The proposed P-ESCA model is also fully characterized on the simulated multiple data sets of mixed quantitative and binary data types. Both G-B-B and G-G-B data sets are simulated for all the seven simulation cases. We set , all of to be 1, the marginal probability in simulating unbalanced data sets to be . Other parameters are the same as above. The range of values for loadings related to the quantitative data sets is , and for loadings related to binary data sets is . The mean RV coefficients of the estimated global, local common and distinct structures and the corresponding mean ranks estimation from the P-ESCA and the MOFA model in the seven G-B-B simulation cases are shown in Tab. 4, for the G-G-B simulation the results are shown in Tab. 5. The mean RMSEs in estimating the simulated parameters are shown in Tab. S6, for the G-B-B simulations are in Tab. S7. Similar to the previous results of B-B-B simulations, the P-ESCA model can achieve quite accurate estimates of the subspaces related to the global, local common and distinct structures (Tab. 4, Tab. 5) when the SNRs of different structures are relative equal. However, when the SNR of a specific structure is very low compared to others (in case 4, 5, 6), the P-ESCA model has difficulty for its recovery. However, compared to the MOFA model, P-ESCA can achieve better results with respect to the recovered subspaces (Tab. 4, Tab. 5) and estimation of the simulated parameters (Tab. S6, Tab. S7) in G-B-B and G-G-B simulations.
7 Real data analysis
We applied the P-ESCA model on the chronic lymphocytic leukaemia (CLL) data set [25, 19], which was used in the paper of the MOFA model, to give an example of the real data analysis. For the 200 samples in the CLL data set, not all of them are fully characterized for all the measurements. Drug response data has 184 samples and 310 variables; DNA methylation data, 196 samples and 4248 variables; transcriptome data, 136 samples and 5000 variables; mutation data, 200 samples and 69 binary variables. The missing pattern of the CLL data sets is visualized in Fig. S8. Except for the missing values related to the samples that were not measured by a specific platform, there are also some selected variables missing in the mutation data (Fig. S8). All the quantitative data sets are first column centered and scaled by the sample standard deviation of each variable. After that, the dispersion parameters of the quantitative data sets are estimated by the estimation procedure. Rank estimation of each single data set was performed three times and results are shown in Tab. S8. The P-ESCA model with a GDP () is selected and re-fitted on the CLL data sets in the same way as described above. The initial number of components is set to 50. The selected model has 41 components, and if we take each loading vector related to a single data set in a component as a group, there are 51 non-zero loading groups. The model selection results are shown in Fig. S9. Since the variation explained ratios of 41 components are difficult to visualize, we only show the components (Fig. 3), whose variation explained ratio are larger than 2% for at least one data set. The above procedure (processing, model selection, fitting the final model) is repeated 5 times to test its stability. The Pearson coefficient matrix for the 5 estimations of the and the RV coefficient matrices for the 5 estimations of the , and are shown in Fig. S10.
In [19], a 10 components MOFA model is selected on the CLL data sets. The variation explained plots of the 10 components MOFA model, reproduced from [19], is shown in Fig. S11. There is some overlap between the two models (Fig. 3, Fig. S11). Both models have one strong common component in which all data sets participate, and a common component in which two (P-ESCA) or three (MOFA) data sets participate. Furthermore the drug response and the transcriptomic (mRNA) data have extra distinct components. The variation explained is somewhat higher for the P-ESCA model which also uses extra components. The amount of variation explained is the highest for the drug response and mRNA data sets. The main difference between the models is the fact that P-ESCA only finds a single component relevant for the binary mutation data while MOFA finds two. The comparison of the two models with respect to the estimated is infeasible because the column offset term is not included in this 10 components MOFA model. In general the P-ESCA result is more complex than the results in [19] in terms of number of selected components and variation explained. However, this is mainly because, during the model selection of [19], the minimum variation explained threshold is set to 2%. If we set the threshold to the default value 0%, and set the initial number of components to be 50, and other parameters are kept the same, a 50 components MOFA model is selected.
8 Discussion
In this paper, we generalized an exponential family SCA (ESCA) model for the data integration of multiple data sets of mixed data types. Then, we introduced the nearly unbiased group concave penalty to induce structured sparsity pattern on the loading matrices of the ESCA model to separate the global, local common and distinct variation. An efficient MM algorithm with analytical form updates for all the parameters was derived to fit the proposed group concave penalty penalized ESCA (P-ESCA) model. In addition, a missing value based cross validation procedure is developed for the model selection. In many different realistic simulations (different SNR levels, and combinations of quantitative and or binary data sets of different), the P-ESCA model and the model selection procedure work well with respect to recovering the subspaces related to the global, local common and distinct structures, and the estimation of the simulated parameters.
The performance of the P-ESCA model and the cross validation based model selection procedure relate to the fact that the used group concave penalty can achieve nearly unbiased estimation of the parameters while generating sparse solutions. The nearly unbiased parameter estimation makes the P-ESCA model have high accuracy in the estimation of the simulated parameters, and the cross validation error based model selection procedure is consistent. Another key point of the model selection procedure is that the randomly sampled non-missing elements are usually a typical set of elements from the population. This makes the CV error a good proxy of the prediction error of the model. The rank estimation in different repetitions of the model selection procedure is robust and only differ slightly with respect to the very weak components.
When applied to multiple quantitative data sets, the proposed P-ESCA model can achieve slightly better performance than the SLIDE model in recovering the subspaces of the simulated structures and in estimating the simulated parameters. Also, since missing value problems (missing values in a single data set, or missing complete samples in one or some of the data sets) are very common in practice, the option of tackling missing values is a big advantage. In the P-ESCA model and its model selection procedure, the effect of missing values is masked in a very natural way, making full use of the available data sets. When applied to the multiple binary data sets or the mixed quantitative and binary data sets, the proposed P-ESCA model has better performance than the MOFA model in recovering the subspaces of the simulated structures and in estimating the simulated parameters. Furthermore, the exact orthogonality constraint can be achieved in the P-ESCA model, which is crucial for the uniqueness of the recovered subspaces related to the global, local common and distinct variation.
Supplementary files
estimation using PCA
Before constructing an ESCA or P-ESCA model, the dispersion parameter of a quantitative data set , which is the variance of the residual term, is assumed to be known. Assume the column centered quantitative data set is (), and the PCA model of can be expressed as . () and () are the score and loading matrix respectively; () is the residual term and elements in , ; is the true low rank of . In order to tackle the potential missing value problem, we also introduce the weighting matrix in the same way as above. The maximum likelihood estimation of can be expressed as , in which is the number of non-missing elements in . Since this is a biased estimation of , we can adjust the estimation according to the degree of freedom as . The parameters , and are estimated as follows.
We select the rank using a similar model selection strategy as in the main text. We first split into and in the same way as in the main text. Then, a series of PCA models with different number of components are constructed on , and the CV error is defined as the least square error in fitting . After that is set to the number of components of the model with the minimum CV error. Then a rank PCA model is constructed on the full data , and we get an estimate of and . Then is set to . The EM type algorithm used to fit the PCA model with the option of missing values is implemented in Matlab in the same way as in [34].
The difference between the SLIDE model and the P-ESCA model when applied to multiple quantitative data sets
- •
Different processing steps. The SLIDE model does column centering and block scaling using the Frobenius norm of the corresponding data set to preprocess the data. Then the relative weights of the data sets in the SCA model are set to 1. On the other hand, we estimate the dispersion parameter (variation of the noise term) of each data set and the inverse of the estimated dispersion parameter is equivalent to the relative weight of the data sets in the SCA model.
- •
Different penalty terms. The SLIDE model uses the group lasso penalty to induce the structured sparsity. Because of the block scaling processing step, there is no weight on the group lasso penalty to accommodate for the potential unequal number of variables in different data sets. On the other hand, the weighted group concave penalty is used in the P-ESCA model.
- •
Option for missing values. The option of tackling the missing value problem is not included in the SLIDE model.
- •
Different model selection procedures. The SLIDE model uses a two stages approach to do model selection, while our model selection approach is as described as in the main text.
The difference between the MOFA model and the P-ESCA model
- •
Different origins. Although these two methods are similar with respect to what they can do, they have different origins. The MOFA model is developed in the Bayesian probabilistic matrix factorization framework in the same line as the group factor analysis model and the factor analysis model, while the P-ESCA model is derived in the deterministic matrix factorization framework in the same line as the SLIDE model, the SCA model and the PCA model.
- •
Different ways in inducing structured sparsity. In the P-ESCA model, the structured sparse pattern is induced through a group concave penalty, while in the MOFA model, it is induced through the automatic relevance determination approach. The group concave penalty can shrink a group of elements to be exactly 0, while the automatic relevance determination cannot achieve exact sparsity. In addition, MOFA model also shrinks a component to be 0 when its variation explained ratios for all the data sets are less than a threshold, whose default value is 0.
- •
Different model selection procedures. The P-ESCA model is selected by a missing value based CV approach; while the selection of a MOFA model relies on maximizing the marginal likelihood. In theory, maximizing the marginal likelihood has no difficulty in tuning multiple parameters, while the CV based model selection procedure is infeasible for such task.
- •
Orthogonality constraint. The orthogonality constraint can only be achieved in the P-ESCA model. Whether this property is meaningful or not depends on the specific research question. However, the constraint is crucial for the proof of the uniqueness of the recovered subspaces corresponding to the global, local common and distinct variation.
Supplementary tables and figures
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] F. Iorio, T. A. Knijnenburg, D. J. Vis, G. R. Bignell, M. P. Menden, M. Schubert, N. Aben, E. Gonçalves, S. Barthorpe, H. Lightfoot, et al. , “A landscape of pharmacogenomic interactions in cancer,” Cell , vol. 166, no. 3, pp. 740–754, 2016.
- 2[2] M. Michaut, N. Aben, L. F. A. Wessels, J. A. Westerhuis, Y. Song, A. K. Smilde, and H. A. L. Kiers, “i TOP: inferring the topology of omics data,” Bioinformatics , vol. 34, pp. i 988–i 996, 09 2018.
- 3[3] J. D. Lee and T. J. Hastie, “Learning the structure of mixed graphical models,” Journal of Computational and Graphical Statistics , vol. 24, no. 1, pp. 230–253, 2015.
- 4[4] J. Cheng, T. Li, E. Levina, and J. Zhu, “High-dimensional mixed graphical models,” Journal of Computational and Graphical Statistics , vol. 26, no. 2, pp. 367–378, 2017.
- 5[5] K. Van Deun, A. K. Smilde, M. J. van der Werf, H. A. L. Kiers, and I. Van Mechelen, “A structured overview of simultaneous component based data integration,” BMC Bioinformatics , vol. 10, no. 1, p. 246, 2009.
- 6[6] R. Shen, A. B. Olshen, and M. Ladanyi, “Integrative clustering of multiple genomic data types using a joint latent variable model with application to breast and lung cancer subtype analysis,” Bioinformatics , vol. 25, no. 22, pp. 2906–2912, 2009.
- 7[7] Q. Mo, S. Wang, V. E. Seshan, A. B. Olshen, N. Schultz, C. Sander, R. S. Powers, M. Ladanyi, and R. Shen, “Pattern discovery and cancer gene identification in integrated cancer genomic data,” Proceedings of the National Academy of Sciences , vol. 110, no. 11, pp. 4245–4250, 2013.
- 8[8] Y. Song, J. A. Westerhuis, N. Aben, L. F. Wessels, P. J. Groenen, and A. K. Smilde, “Generalized simultaneous component analysis of binary and quantitative data,” ar Xiv preprint ar Xiv:1807.04982 , 2018.
