Two-Stage Transfer Learning for Heterogeneous Robot Detection and 3D Joint Position Estimation in a 2D Camera Image using CNN
Justinas Miseikis, Inka Brijacak, Saeed Yahyanejad, Kyrre Glette, Ole, Jakob Elle, Jim Torresen

TL;DR
This paper introduces a two-stage transfer learning method for real-time detection and 3D joint position estimation of heterogeneous robots using only 2D images, eliminating the need for Eye-to-Hand calibration.
Contribution
It presents a novel two-stage transfer learning approach to adapt a multi-objective CNN for different robot types with minimal training data, enabling flexible and calibration-free collision detection.
Findings
Real-time robot detection with CNN in 2D images.
Effective adaptation to multiple robot types with small datasets.
Potential applications in flexible robot safety systems.
Abstract
Collaborative robots are becoming more common on factory floors as well as regular environments, however, their safety still is not a fully solved issue. Collision detection does not always perform as expected and collision avoidance is still an active research area. Collision avoidance works well for fixed robot-camera setups, however, if they are shifted around, Eye-to-Hand calibration becomes invalid making it difficult to accurately run many of the existing collision avoidance algorithms. We approach the problem by presenting a stand-alone system capable of detecting the robot and estimating its position, including individual joints, by using a simple 2D colour image as an input, where no Eye-to-Hand calibration is needed. As an extension of previous work, a two-stage transfer learning approach is used to re-train a multi-objective convolutional neural network (CNN) to allow it to…
Click any figure to enlarge with its caption.
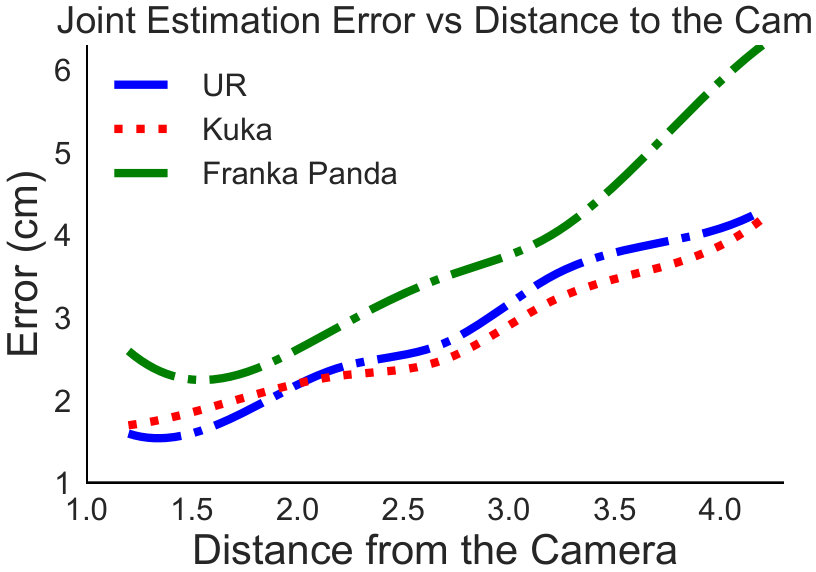 Figure 1
Figure 1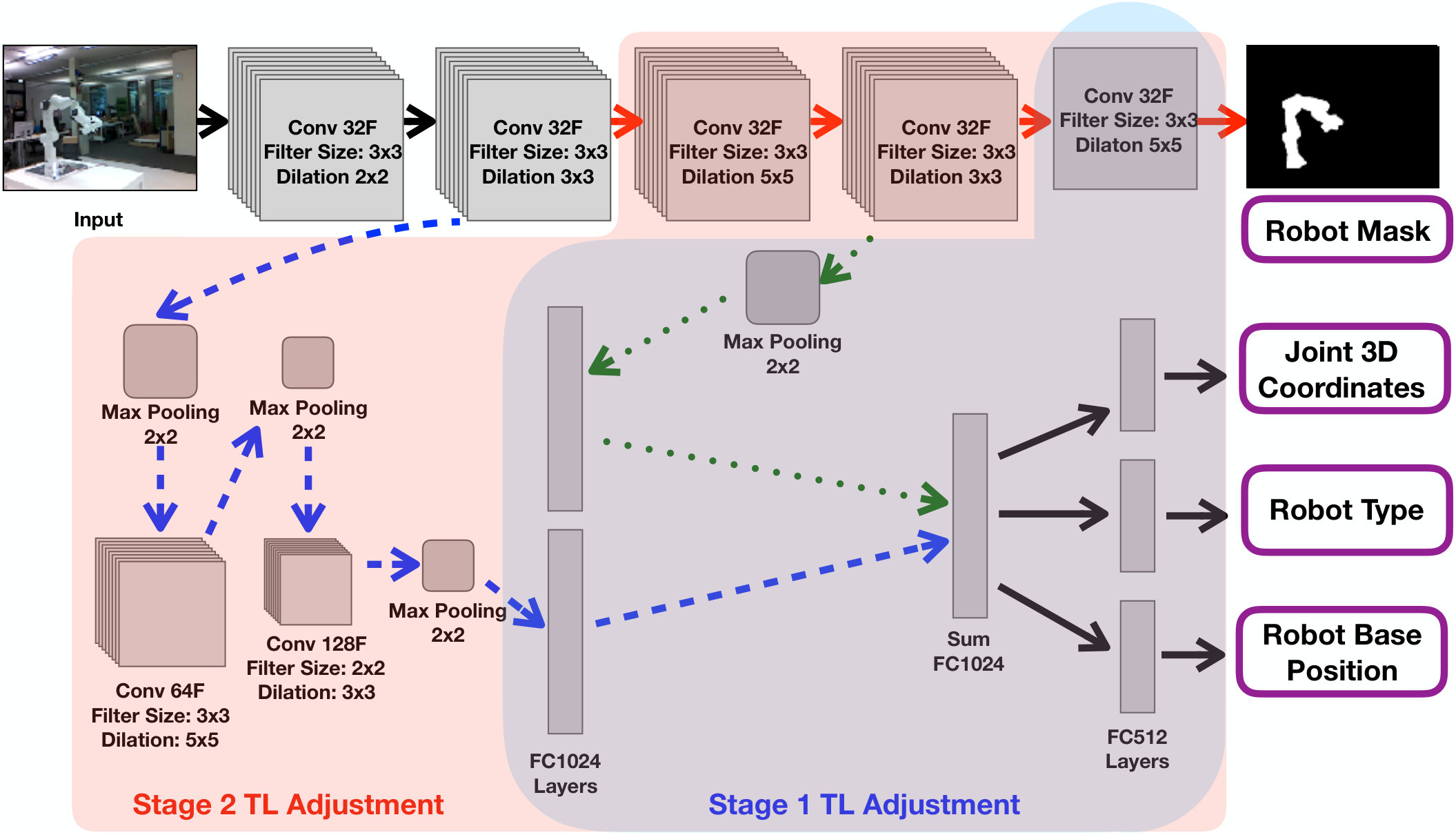 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4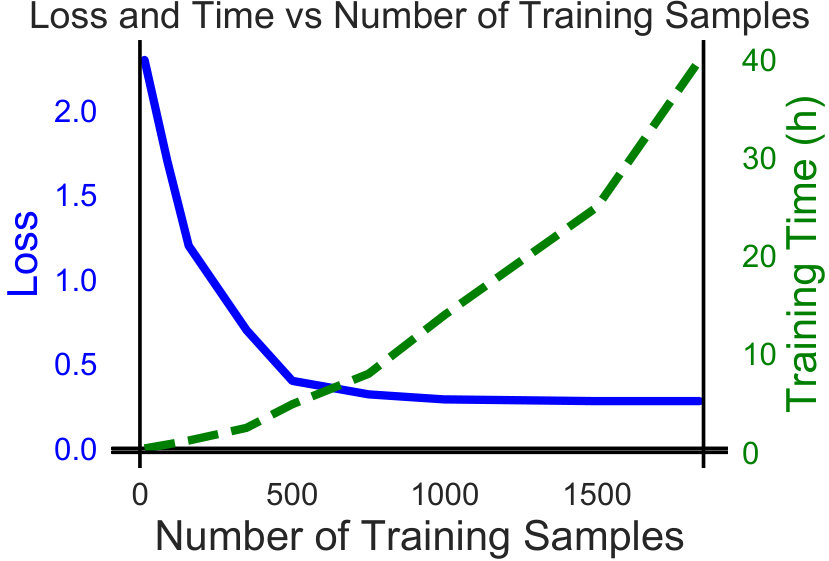 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10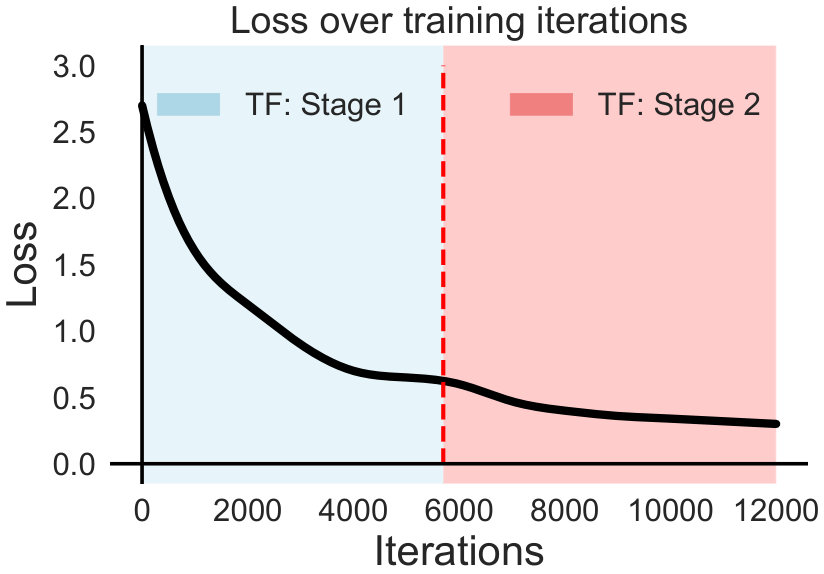 Figure 11
Figure 11 Figure 12
Figure 12| Robot Type | Number of Datasets | Total Number of Samples |
|---|---|---|
| Universal Robots | ||
| Kuka LBR iiwa | ||
| Franka Panda | 5 |
| Measure | UR | Kuka | Franka Panda |
|---|---|---|---|
| Mask Accuracy, % | |||
| Robot Type Accuracy, % | |||
| Joint Pos Error (Median) | |||
| Base Pos Error (Median) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Two-Stage Transfer Learning for Heterogeneous Robot Detection and 3D Joint Position Estimation in a 2D Camera Image Using CNN
Justinas Mišeikis1, Inka Brijačak2, Saeed Yahyanejad3, Kyrre Glette4, Ole Jakob Elle5, Jim Torresen6 145**6Justinas Mišeikis, Kyrre Glette, Ole Jakob Elle and Jim Torresen are with the Department of Informatics, University of Oslo, Oslo, Norway2**3 Inka Brijačak and Saeed Yahyanejad are with the Joanneum Research - Robotics, Klagenfurt am Wörthersee, Austria4**6Kyrre Glette and Jim Torresen also have affiliation with RITMO, University of Oslo5Ole Jakob Elle has his main affiliation with The Intervention Centre, Oslo University Hospital, Oslo, Norway [email protected]146{justinm,kyrrehg,jimtoer}@ifi.uio.no2[email protected]3[email protected]
Abstract
Collaborative robots are becoming more common on factory floors as well as regular environments, however, their safety still is not a fully solved issue. Collision detection does not always perform as expected and collision avoidance is still an active research area. Collision avoidance works well for fixed robot-camera setups, however, if they are shifted around, Eye-to-Hand calibration becomes invalid making it difficult to accurately run many of the existing collision avoidance algorithms. We approach the problem by presenting a stand-alone system capable of detecting the robot and estimating its position, including individual joints, by using a simple 2D colour image as an input, where no Eye-to-Hand calibration is needed. As an extension of previous work, a two-stage transfer learning approach is used to re-train a multi-objective convolutional neural network (CNN) to allow it to be used with heterogeneous robot arms. Our method is capable of detecting the robot in real-time and new robot types can be added by having significantly smaller training datasets compared to the requirements of a fully trained network. We present data collection approach, the structure of the multi-objective CNN, the two-stage transfer learning training and test results by using real robots from Universal Robots, Kuka, and Franka Emika. Eventually, we analyse possible application areas of our method together with the possible improvements.
I INTRODUCTION
Collaborative robots are gaining popularity as an advanced version of traditional industrial robots. Not only they are capable of reliably performing high-precision complex movements repetitively without any fatigue or rest, but they are also claimed to be safe to operate around humans. Instead of fully separating them from people (e.g., using fences or light curtains), they are capable of sharing the same workspace with humans given the sophisticated collision detection systems. However, these systems do not always work as expected and might exert excess forces before stopping [1]. Furthermore, in some situations, like a robot located in a surgery theatre, collisions are not acceptable, and full collision avoidance should be implemented. This coincides with the goals of the Industry 4.0 concept [2].
A crucial part for the obstacle avoidance is getting real-time measurements of the workspace and environment around the robot. Such sensing can be done using a variety of sensors: laser scanners, mono and stereo vision, RGB-D cameras, ultrasound sensors and motion capture systems.
Even with advanced sensing systems, the problem still stands in the requirement of having a reliable calibration between the sensors and the robot - so-called Eye-to-Hand calibration [3]. Such a calibration maps the coordinate frames of the robot and vision sensors into a common coordinate frame. As a result, the position of an obstacle detected by one of the sensors can be easily calculated in point of view of the robot, and the necessary action is taken to avoid it. There are reliable and even automatic ways of performing Eye-to-Hand calibration, however, if any of the sensors is unexpectedly moved in relation to the robot, and unaccounted for, the calibration becomes invalid and the system might malfunction [4]. This can be an issue in dynamic environments like a surgery theatre, where there is a lot of human movement, as well as the equipment is constantly shifted around. Similar works and research on dynamic obstacle avoidance for robot arms normally require a fully-calibrated robot-camera system, which can be a challenge in non-static configuration setups [5] [6].
We have shown that the transfer learning approach can be used to adapt the system trained to recognise and estimate the position of the robot base and joints from one robot model to a new unseen one by having a limited amount of data [7] [8]. We base our work on a previously trained multi-objective CNN on Universal Robots (UR) and extend our work in the following manner. Instead of adapting the network to the new robot type, we adjust the CNN to incorporate new robot types, while still being able to recognise previously trained robots. Eventually, the proposed system is capable of identifying 5 different robots. Furthermore, with the help of motion capture system tracking the camera, we collected a complex training datasets with the camera being moved around in an unconstrained manner, obtaining a variety of viewing angles of the robots in front of complex backgrounds. A more thorough analysis also shows the impact of the accuracy depending on the distance between the camera and the robot.
This paper is organized as follows. First, we provide an overview of related work in Section II. We present the system setup and dataset collection in Section III. Then, we explain the proposed method and CNN structure and configuration in Section IV and the transfer learning procedure in Section V. We provide experiments and results in Section VI, followed by relevant conclusions and future work in Section VII.
II RELATED WORK
With the recent deep learning revolution in computer vision, especially for classification tasks, like ImageNet, it has been proven that it is possible to learn to identify objects in difficult environments and conditions [9].
In order to train a deep learning network, large amounts of training data are needed with precisely marked ground truth data. Collecting such training datasets can be a time-consuming task. However, transfer learning approach is useful when a fully trained system exists for one type of the problem and can be adapted for different datasets by adjusting some of the parameters of the network while keeping other parameters fixed [9]. This has been proven to work for mid-level image representations in object classification, using the pre-trained network on natural images to adapt for medical image recognition and even emotion recognition [10] [11] [12]. Another interesting application of transfer learning is to use a fully trained network on night-time satellite imagery of poverty areas and adapt it to recognise poverty areas from daytime satellite imagery [13]. Furthermore, detailed analyses of the transfer learning approaches were made with surveys of the techniques used and various CNN structures [14] [15].
Moreover, CNN based work in the field of human pose estimation in 2D [16], known as OpenPose, allowed further improvements on 3D human pose estimation with the help of a depth sensor [17]. The accuracy for a human keypoint in 3D is around , mainly due to the inaccuracy of the depth sensor which grows with distance from the sensor.
On the other hand, many purely geometrical techniques have been employed to determine the position and orientation of an object from a single image by using some prior knowledge about the target object [18] [19]. In general, with these methods, they try to find patterns and features such as edges and corners which match the expected model and accordingly estimate the position and orientation. Some other researchers exploited the existence of a 3D model such as a CAD model [20] [21] to increase the accuracy of the estimation. Although the precision of their method is higher compared to our CNN-based method, they mainly suffer from a major drawback: they can only perform with solid and rigid objects which clearly does not apply to robot manipulators. Another problem is the necessity of having a 3D model available beforehand, which in our method is substituted with the training procedure. However, our method performs more robustly in case of deviation from the model in case of physical damages or attached end-effectors, and it can also use the image colour information which is normally missing in a 3D model.
III SYSTEM SETUP AND DATASET COLLECTION
Deep learning networks are capable of robustly recognising objects in complex backgrounds, but in order to achieve good performance, a large amount of precisely marked and diverse training data is needed. Considering the setup of three heterogeneous robotic manipulators, a system had to be set up to generate training data with accurate ground truth data marked automatically, given that manual ground truth generation for such datasets would take up a significant amount of time and effort.
Our setup consists of the following three robot types:
- •
Universal Robots: UR3, UR5, UR10, 6 DoF, Figure 1(a)
- •
KUKA LBR iiwa - 7 R800, 7 DoF, Figure 1(b)
- •
Franka Emika - Panda, 7 DoF, Figure 1(c)
This two-stage transfer learning work, as the basis, uses already trained multi-objective CNN [7], which was trained on datasets containing all three robot models from UR. Datasets containing KUKA LBR iiwa were previously collected for our one-stage transfer learning project [8]. All these datasets were collected using Kinect V2 sensor with necessary Eye-to-Hand calibration [22] every time position of the camera changed relative to the robot-base in order to achieve a high variety of backgrounds.
Table I summarizes all datasets collected for each robot with their number of recordings where they differ by camera placement relative to the robot, illumination, background.
New datasets containing Franka Emika Panda robot were recorded with free-moving Intel RealSense R200 RGB-D camera instead of Kinect V2. Since Eye-to-Hand calibration is only valid for the fixed camera setups, we could not use this method for the camera to robot coordinates-transformation measurements. Instead of performing Eye-to-Hand calibration, we have placed Optitrack (Motion Capture System) [23] markers over the moving camera and around the base of the robot in order to bring both systems into one coordinate frame of Optitrack (Figure 2). Since Optitrack’s marker (Rigid-Body or Rig) origin is not exactly aligned with the camera’s optical frame origin, extrinsic calibration was performed as described in [24] by observing and detecting one additional rig, that was fixed in the Optitrack frame, with our RGB camera from multiple positions. Example frames taken from the whole dataset can be seen in Figure 3.
Once all the transformations are connected in one coordinate system, a precise robot mask that is separating a robot body from the background when overlaying a colour image, used as a ground truth for teaching the CNN, can be calculated. It is done automatically by using ROS with MoveIt package [25]. The robot model, taken from the Robot Description Format (URDF) files and mesh files provided by the robot manufacturers, is updated with the live information from robot’s joints encoder readings to create robot shape in real-time [26]. This shape is transformed to depth camera’s coordinate frame and mask image is constructed.
In order to ensure the robustness of the system, robot movements were programmed so that each robot joint is moved through the full range of motion in combination with other joints taking into account self-collision and table collision avoidance. Also, a trigger signal is used to save the data after each robot movement. With each trigger, we save camera colour images, robot joints and Cartesian coordinates, as well as ground-truth robot mask images. Moreover, to ensure a perfect overlap between colour and depth images, internal extrinsic camera calibration was used. All the input images are also rectified and have the resolution of pixels. Testing and validation sets were divided by the ratios of and respectively based on random sampling.
IV CNN STRUCTURE AND CONFIGURATION
The structure of a multi-objective CNN is identical to previous work, where it was trained on UR robots [7]. The network trains for multiple outputs simultaneously by taking a single 2D colour image as an input. The network in this paper is trained on four objectives: Robot mask, Robot type, 3D Robot base position and 3D Position of the robot joints.
The network has multiple branches, with some of the convolutional layers shared and then branched off to optimise specifically for each of the objectives. The structure of the multi-objective CNN can be seen in Figure 4.
IV-A Loss Functions
The loss function is needed to define the quality of training and drive the CNN towards achieving better results. Given four different outputs of the network, four loss functions need to be defined and eventually combined in a single one for the training process. Firstly, we describe each one of them and then explain how they are connected together.
Normally, the robot body takes up a rather small area in the whole image. For UR datasets, the area of the robot body is between , for Kuka datasets, it is between and for Franka Panda, it is between . Given a standard approach for the pixel classification loss function, an accuracy of over could be reached by classifying the whole image as background. This is conceptually wrong, so the loss function is adapted by calculating the foreground weight as defined in Equation 1. It is based on the inverse probability of the foreground and background classes, where .
[TABLE]
The background weight is calculated in Equation 2.
[TABLE]
Definition of the loss function for the robot mask is done in two steps. First, a per-pixel loss is calculated in Equation 3, where is , is and is the ground truth value from the mask image.
[TABLE]
Then, a normalised loss calculation is done for the whole image in Equation 4. In order to keep the same learning parameters independent of the input image size, a normalisation factor is used, which is a number of pixels in the image.
[TABLE]
Estimation of the 3D coordinates of the robot base and robot joints are defined as a regression problem instead of classification. Loss function uses the Euclidean distance between the ground truth and estimated values by the CNN. For the robot joints estimation, the loss function is described in Equation 5, where is the number of joints, is the ground truth position of each joint and is the estimated values by the neural network.
[TABLE]
The loss function for the coordinates of the robot base is calculated in Equation 6. is the ground truth position of the robot base in 3D, and is the estimated 3D position of the robot base. These positions are relative to the coordinate frame of the camera.
[TABLE]
A multi-class categorical cross-entropy approach is used to identify the robot type . is calculated in Equation 7, where is the ground truth labels, are the predicted labels and , where contains all the available types of robots in the dataset.
[TABLE]
Eventually, all four previously defined loss functions are combined into a single loss function to be used in the training of the multi-objective CNN. The final loss function is calculated as a weighted sum of all the loss functions, as shown in Equation 8. The larger the weight , the higher the impact on the corresponding value.
[TABLE]
V TRAINING USING TRANSFER LEARNING
A common approach to training such a system would be to train the whole system using full datasets of all the robots. However, this would take a significant amount of computation and time. Overall, the goal of this work is to analyse the possibility of having a pre-trained system and expand it to include more robot types while having a limited amount of training data and time.
Transfer learning allows us to use a fully trained system for one robot type and then adjust it to include the newly provided training data. This is done by freezing the parameters in some of the layers while adjusting the remaining ones. Given this partial adjustment, the training time and amount of training data required can be significantly reduced.
The system was fully trained using UR robots with Kuka and Franka Panda robots added using the transfer learning approach. One crucial difference is that UR robots have 6 joints, while Kuka and Franka Panda are 7 joint robots. In general, it has been found that first convolutional layers tend to learn general visual features, while further layers figure out specific visual cues of the objects. Both, UR and Kuka robots have bright coloured joint covers, while the rest of the robot is silver, however, Franka Panda is mainly black and white, as seen in Figure 1.
Due to these differences, a two-stage transfer learning approach was taken up, as shown in Figure 4. In the first step, just the final layers of the multi-objective CNN are trained. This allows the network to adjust the dense layers to select the best-learned features for the robot recognition using currently learned visual cues. Only a small part of the CNN is adjusted, so the learning process is fast, and it re-learns robot classification and position estimation using current convolutional layer parameters.
However, after some point the learning process saturates and no more improvements are observed, defined by the reduction of loss. At this stage, the second part of the CNN is unlocked, allowing to modify parameters for the additional convolutional layers. This results in modifications of the visual cues that are learned as well as adjusting the final dense layers. The training speed is slower compared to the first stage of learning, but the loss is reduced even further.
In order to add the new robot types using the transfer learning approach, the new training dataset has to include both, the robot that the network was originally trained on, as well as the new robot(s) that should be recognised.
Weights for the loss function are adjusted to give more impact to identifying mask and robot type compared to our previous work. Selected weight values, based on trial and error from a number of experiments, were as follows: : , : , : and : .
The number of training samples varied by the experiment and the input size of the images was scaled down and cropped to pixels for all the datasets. The pixel intensity values of the input images were normalised to the range between 0 and 1. The learning rate was set to at the start of the training and then gradually decreased towards as the training progressed.
VI EXPERIMENTS AND RESULTS
The main goal of the experiments was to evaluate the capability of including new robot types by using the two-stage transfer learning method while using a multi-objective CNN fully trained on UR robots as a starting point.
Each of the experiments was conducted by taking a different size transfer learning dataset using a randomised sample selection to maximise the diversity of the data. The maximum amount of data was limited by the Kuka robot dataset to ensure the same amount of samples in each test for each of the robot types.
The system was evaluated using a testing set by comparing the output against the ground truth data. The robot mask accuracy is defined by counting the number of pixels in the CNN output image that match the ground truth mask. For the robot joint and base coordinates, the Euclidean distance between the CNN estimated results and ground truth results was calculated. We compare the results between each of the robot type in a number of categories. Results are summarised in Table II and visualisation of estimations plotted on top of the testing set samples can be seen in Figure 6.
All of the robots had joint 3D position estimation error under , with the base position estimation error under . The mask accuracy estimation exceeded for UR and Kuka robots, while for Franka Panda it was a bit lower at . Robot type was recognised correctly in all of the cases for Kuka robot, while UR and Franka Panda recognition were and respectively. Overall, it was noticed that given the distinct features, the CNN performed the best on Kuka robot, while low contrast Franka Panda robot had the worst results, but not far behind.
Considering overall performance of the two-stage transfer learning, as shown in Figure 5(a), for the multi-objective CNN, it can be seen that the loss function stops improving when having datasets of size between and training samples for each of the robot type, which corresponds to to hours of training time. Increasing the number of training samples beyond does not improve the learning process, but significantly increases the training time.
Compared to the previously presented work in [7], the detection accuracy of the current two-stage transfer learning approach achieved similar accuracy in a joint position error of vs and slightly worse accuracy for the robot mask estimation: vs in the previous work. The full training time of the multi-objective CNN for UR robots took hours vs hours in the current work.
The performance of each training stage of transfer learning is shown in Figure 5(b). Stage 1, with parameters in final CNN layers being adjusted, saturates after iterations. Afterwards, further layers are unlocked switching to Stage 2 and the loss function reduces even further settling down between iterations.
Furthermore, we analyse the impact of the joint and base position estimation depending on the distance between the camera and the robot, visualised in Figure 5(c). There is close to a linear relationship between the distance between the robot and the accuracy of the 3D position estimation of the robot joints. Interestingly, at a very close distance of 1.2 meters, Franka Panda robot shows worse performance compared to 1.5 meter distance.
The detection time or forward-propagation of the multi-objective CNN was measured to be per frame on a nVidia GTX 1080 Ti graphics card.
VII CONCLUSIONS AND FUTURE WORK
In this paper, we have presented a two-stage transfer learning approach, which allows to re-train a previously trained multi-objective CNN to include numerous new robot types using a limited amount of training data. This approach reduces the time spent on collecting datasets with ground truth data, as well as the training time of the network itself. Furthermore, a concept of a multi-objective CNN capable of identifying heterogeneous robots, classifying their types and estimating 3D positions of their joints and base was proven. A simple 2D colour image was used as an input and Kuka and Franka Panda robots were mounted with two-finger grippers on the end-effector, which were not taken into account by the CNN. The network successfully estimated the position of the robot as the was no end-effector present. If the TCP of the end-effector would be required, it could be calculated by adding the necessary CAD model or offset information to the estimated position of the end-effector.
With the detection time of under , the system has proven to be capable of working in real-time. At the current stage, a powerful GPU is needed to run it, however, a goal of optimising it for smaller mobile systems could be pursued. In this case, it could be implemented in small wearable cameras to be used both, for mobile robots or for human operators working in a robotised environments and used as a safety system, which can detect possible collisions without having any direct communication between the devices. The outcome could be a valuable measure for various safety applications in Human-Robot Interaction scenarios, where we need to know the position of the human and robot and their individual joints respective to each other.
The achieved robot joint position estimation is not accurate enough for visual servoing operations, but future work can focus on accuracy improvements. We believe that by using higher resolution images, multi-sensor detection and tracking in time series, the accuracy of our system could be improved. Furthermore, an analysis of the impact on the detection accuracy depending on the weight selection of loss functions and layer selection for the transfer learning will be done. With the current results, a high-level control is still possible for human-robot and robot-robot interaction.
Additionally, with the given robot mask detection in a 2D image, some robot self-inspection could be done to detect any damage, especially for autonomous robots operating in remote or disaster areas, where people do not have access to, for example for planetary exploration rovers.
ACKNOWLEDGMENT
This work is partially supported by The Research Council of Norway as a part of the Engineering Predictability with Embodied Cognition (EPEC) project, under grant agreement 240862, and Research Council of Norway through its Centres of Excellence scheme, project number 262762, and by the Austrian Ministry for Transport, Innovation and Technology (BMVIT) within the project framework CollRob (Collaborative Robotics).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] I. Bonev, “Should We Fence the Arms of Universal Robots?” http://coro.etsmtl.ca/blog/?p=299 , ETS, 2014, accessed September 5, 2018.
- 2[2] J. Lee, B. Bagheri, and H.-A. Kao, “A cyber-physical systems architecture for industry 4.0-based manufacturing systems,” Manufacturing Letters , vol. 3, pp. 18–23, 2015.
- 3[3] R. K. Lenz and R. Y. Tsai, “Calibrating a cartesian robot with eye-on-hand configuration independent of eye-to-hand relationship,” IEEE Transactions on Pattern Analysis & Machine Intelligence , no. 9, pp. 916–928, 1989.
- 4[4] J. Miseikis, K. Glette, O. J. Elle, and J. Torresen, “Automatic calibration of a robot manipulator and multi 3d camera system,” in System Integration (SII), 2016 IEEE/SICE International Symposium on . IEEE, 2016, pp. 735–741.
- 5[5] J. Mainprice and D. Berenson, “Human-robot collaborative manipulation planning using early prediction of human motion,” in Intelligent Robots and Systems (IROS), 2013 IEEE/RSJ International Conference on . IEEE, 2013, pp. 299–306.
- 6[6] J. Mišeikis, K. Glette, O. J. Elle, and J. Torresen, “Multi 3D camera mapping for predictive and reflexive robot manipulator trajectory estimation,” in Computational Intelligence (SSCI), 2016 IEEE Symposium Series on . IEEE, 2016, pp. 1–8.
- 7[7] J. Miseikis, I. Brijacak, S. Yahyanejad, K. Glette, O. J. Elle, and J. Torresen, “Multi-Objective Convolutional Neural Networks for Robot Localisation and 3D Position Estimation in 2D Camera Images,” in 2018 15th International Conference on Ubiquitous Robots (UR) , June 2018, pp. 597–603.
- 8[8] J. Mišeikis, I. Brijacak, S. Yahyanejad, K. Glette, O. J. Elle, and J. Torresen, “Transfer learning for unseen robot detection and joint estimation on a multi-objective convolutional neural network,” in 2018 IEEE International Conference on Intelligence and Safety for Robotics (ISR) , Aug 2018, pp. 337–342.