TL;DR
This paper introduces a novel approach combining model updates and falsification to provide formal safety guarantees for reinforcement learning in complex, heterogeneous environments, addressing limitations of existing methods.
Contribution
It presents verification-preserving model updates that enable formal safety guarantees across multiple environmental models in reinforcement learning.
Findings
First approach to formal safety guarantees in heterogeneous environments
Combines design-time model updates with runtime falsification
Ensures safety in complex, real-world settings
Abstract
The desire to use reinforcement learning in safety-critical settings has inspired a recent interest in formal methods for learning algorithms. Existing formal methods for learning and optimization primarily consider the problem of constrained learning or constrained optimization. Given a single correct model and associated safety constraint, these approaches guarantee efficient learning while provably avoiding behaviors outside the safety constraint. Acting well given an accurate environmental model is an important pre-requisite for safe learning, but is ultimately insufficient for systems that operate in complex heterogeneous environments. This paper introduces verification-preserving model updates, the first approach toward obtaining formal safety guarantees for reinforcement learning in settings where multiple environmental models must be taken into account. Through a combination of…
Click any figure to enlarge with its caption.
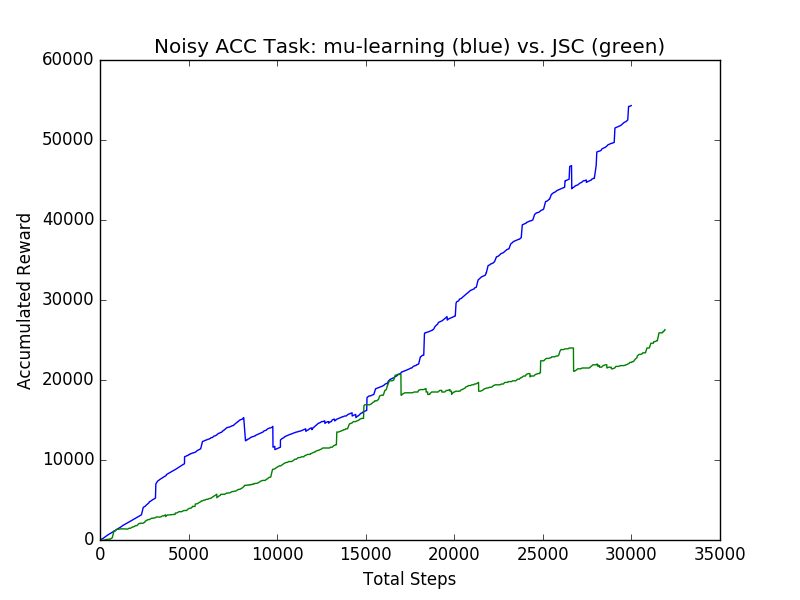 Figure 1
Figure 1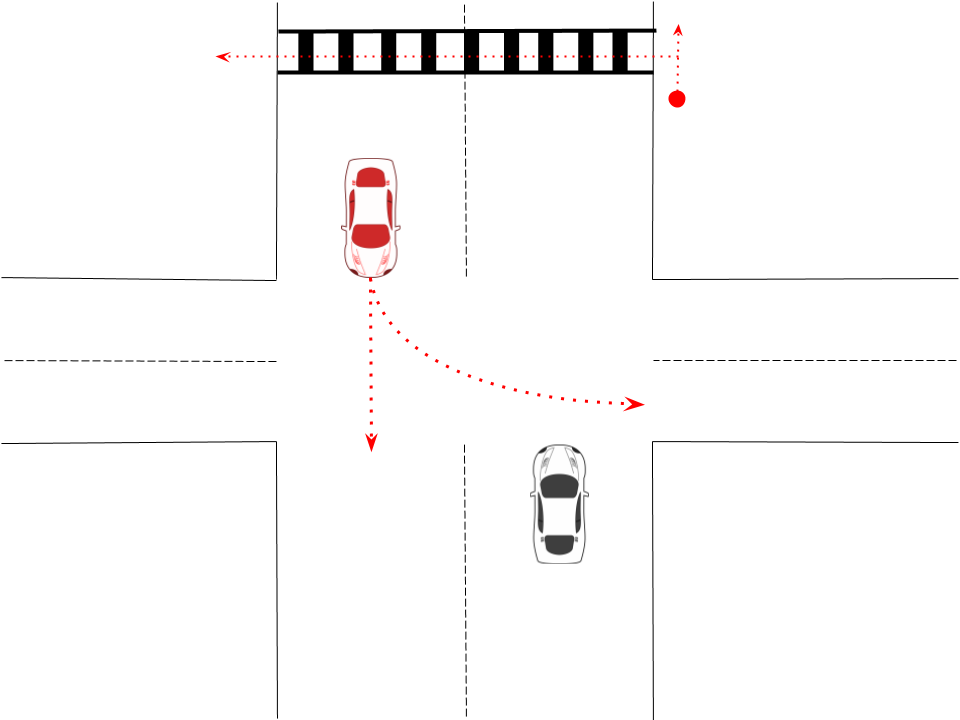 Figure 3
Figure 3| Program Statement | Meaning |
|---|---|
| Sequentially composes after . | |
| Executes either or nondeterministically. | |
| Repeats zero or more times nondeterministically. | |
| Evaluates term and assigns result to variable . | |
| Nondeterministically assign arbitrary real value to . | |
| Continuous evolution for any duration within domain . | |
| Aborts if formula is not true. |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\SetWatermarkText
\SetWatermarkAngle0 \NewEnvironkillcontents
11institutetext: Computer Science Department, Carnegie Mellon University
Pittsburgh, USA
11email: {nathanfu, aplatzer}@cs.cmu.edu
Verifiably Safe Off-Model
Reinforcement Learning††thanks: This research was sponsored by the Defense Advanced Research Projects Agency (DARPA) under grant number FA8750-18-C-0092.
Nathan Fulton
André Platzer
Abstract
The desire to use reinforcement learning in safety-critical settings has inspired a recent interest in formal methods for learning algorithms. Existing formal methods for learning and optimization primarily consider the problem of constrained learning or constrained optimization. Given a single correct model and associated safety constraint, these approaches guarantee efficient learning while provably avoiding behaviors outside the safety constraint. Acting well given an accurate environmental model is an important pre-requisite for safe learning, but is ultimately insufficient for systems that operate in complex heterogeneous environments. This paper introduces verification-preserving model updates, the first approach toward obtaining formal safety guarantees for reinforcement learning in settings where multiple environmental models must be taken into account. Through a combination of design-time model updates and runtime model falsification, we provide a first approach toward obtaining formal safety proofs for autonomous systems acting in heterogeneous environments.
1 Introduction
The desire to use reinforcement learning in safety-critical settings has inspired several recent approaches toward obtaining formal safety guarantees for learning algorithms. Formal methods are particularly desirable in settings such as self-driving cars, where testing alone cannot guarantee safety [22]. Recent examples of work on formal methods for reinforcement learning algorithms include justified speculative control [14], shielding [3], logically constrained learning [17], and constrained Bayesian optimization [16]. Each of these approaches provide formal safety guarantees for reinforcement learning and/or optimization algorithms by stating assumptions and specifications in a formal logic, generating monitoring conditions based upon specifications and environmental assumptions, and then leveraging these monitoring conditions to constrain the learning/optimization process to a known-safe subset of the state space.
Existing formal methods for learning and optimization consider the problem of constrained learning or constrained optimization [3, 14, 16, 17]. They address the question: assuming we have a single accurate environmental model with a given specification, how can we learn an efficient control policy respecting this specification?
Correctness proofs for control software in a single well-modeled environment are necessary but not sufficient for ensuring that reinforcement learning algorithms behave safely. Modern cyber-physical systems must perform a large number of subtasks in many different environments and must safely cope with situations that are not anticipated by system designers. These design goals motivate the use of reinforcement learning in safety-critical systems. Although some formal methods suggest ways in which formal constraints might be used to inform control even when modeling assumptions are violated [14], none of these approaches provide formal safety guarantees when environmental modeling assumptions are violated.
Holistic approaches toward safe reinforcement learning should provide formal guarantees even when a single, a priori model is not known at design time. We call this problem verifiably safe off-model learning. In this paper we introduce a first approach toward obtaining formal safety proofs for off-model learning. Our approach consists of two components: (1) a model synthesis phase that constructs a set of candidate models together with provably correct control software, and (2) a runtime model identification process that selects between available models at runtime in a way that preserves the safety guarantees of all candidate models.
Model update learning is initialized with a set of models. These models consist of a set of differential equations that model the environment, a control program for selecting actuator inputs, a safety property, and a formal proof that the control program constrains the overall system dynamics in a way that correctly ensures the safety property is never violated.
Instead of requiring the existence of a single accurate initial model, we introduce model updates as syntactic modifications of the differential equations and control logic of the model. We call a model update verification-preserving if there is a corresponding modification to the formal proof establishing that the modified control program continues to constrain the system of differential equations in a way that preserves the original model’s safety properties.
Verification-preserving model updates are inspired by the fact that different parts of a model serve different roles. The continuous portion of a model is often an assumption about how the world behaves, and the discrete portion of a model is derived from these equations and the safety property. For this reason, many of our updates inductively synthesize ODEs (i.e., in response to data from previous executions of the system) and then deductively synthesize control logic from the resulting ODEs and the safety objective.
Our contributions enabling verifiably safe off-model learning include:
-
A set of verification preserving model updates (VPMUs) that systematically update differential equations, control software, and safety proofs in a way that preserves verification guarantees while taking into account possible deviations between an initial model and future system behavior.
-
A reinforcement learning algorithm, called model update learning (learning), that explains how to transfer safety proofs for a set of feasible models to a learned policy. The learned policy will actively attempt to falsify models at runtime in order to reduce the safety constraints on actions.
These contributions are evaluated on a set of hybrid systems control tasks. Our approach uses a combination of program repair, system identification, offline theorem proving, and model monitors to obtain formal safety guarantees for systems in which a single accurate model is not known at design time. This paper fully develops an approach based on a general idea that was first presented in an invited vision paper on Safe AI for CPS by the authors [13].
The approach described in this paper is model-based but does not assume that a single correct model is known at design time. Model update learning allows for the possibility that all we can know at design time is that there are many feasible models, one of which might be accurate. Verification-preserving model updates then explain how a combination of data and theorem proving can be used at design time to enrich the set of feasible models.
We believe there is a rich space of approaches toward safe learning in-between model-free reinforcement learning (where formal safety guarantees are unavailable) and traditional model-based learning that assumes the existence of a single ideal model. This paper provides a first example of such an approach by leveraging inductive data and deductive proving at both design time and runtime.
The remainder of this paper is organized as follows. We first review the logical foundations underpinning our approach. We then introduce verification-preserving model updates and discuss how experimental data may be used to construct a set of explanatory models for the data. After discussing several model updates, we introduce the learning algorithm that selects between models at runtime. Finally, we discuss case studies that validate both aspects of our approach. We close with a discussion of related work.
2 Background
This section reviews existing approaches toward safe on-model learning and discusses the fitness of each approach for obtaining guarantees about off-model learning and then introduces the specification language and logic used throughout the rest of this paper.
Alshiekh et al. and Hasanbeig et al. propose approaches based on Linear Temporal Logic [3, 17]. Alshiekh et al. synthesize monitoring conditions based upon a safety specification and an environmental abstraction. In terms of this formalism, the goal of off-model learning is to systematically expand the environmental abstraction based upon both design-time insights about how the system’s behavior might change over time and also based upon observed data at runtime. Jansen et al. extend the approach of Alshiekh et al. by observing that constraints should adapt whenever runtime data suggests that a safety constraint is too restrictive to allow progress toward an over-arching objective [20]. Herbert et al. address the related problem of safe motion planning by using offline reachability analysis of pursuit-evasion games to pre-compute an overapproximate monitoring condition that is used to constrain an online planner [9, 19].
The above-mentioned approaches have an implicit or explicit environmental model. Even when these environmental models are accurate, reinforcement learning is still necessary because these models focus exclusively on safety and are often nondeterministic. Resolving this nondeterminism in a way that is not only safe but is also effective at achieving other high-level objectives is a task that is well-suited to reinforcement learning.
We are interested in how to provide formal safety guarantees even when there is not a single accurate model available at design time. Achieving this goal requires two novel contributions. We must first find a way to generate a robust set of feasible models given some combination of an initial model and data on previous runs of the system (because formal safety guarantees are stated with respect to a model). Given such a set of feasible models, we must then learn how to safely identify which model is most accurate so that the system is not over-constrained at runtime.
To achieve these goals, we build on the safe learning work for a single model by Fulton et al. [14]. We choose this approach as a basis for verifiably safe learning because we are interested in safety-critical systems that combine discrete and continuous dynamics, because we would like to produce explainable models of system dynamics (e.g., systems of differential equations as opposed to large state machines), and, most importantly, because our approach requires the ability to systematically modify a model together with that model’s safety proof.
Following [14], we recall Differential Dynamic Logic [26, 27], a logic for verifying properties about safety-critical hybrid systems control software, the ModelPlex synthesis algorithm in this logic [25], and the KeYmaera X theorem prover [12] that will allow us to systematically modify models and proofs together.
Hybrid (dynamical) systems [4, 27] are mathematical models that incorporate both discrete and continuous dynamics. Hybrid systems are excellent models for safety-critical control tasks that combine the discrete dynamics of control software with the continuous motion of a physical system such as an aircraft, train, or automobile. Hybrid programs [26, 27, 28] are a programming language for hybrid systems. The syntax and informal semantics of hybrid programs is summarized in Table 1. The continuous evolution program is a continuous evolution along the differential equation system for an arbitrary duration within the region described by formula .
Hybrid Program Semantics
The semantics of the hybrid programs described by Table 1 are given in terms of transitions between states [27, 28], where a state assigns a real number to each variable . We use to refer to the value of a term in a state . The semantics of a program , written , is the set of pairs for which state is reachable by running from state . For example, is:
[TABLE]
for a hybrid program and state where is set of all states such that .
Differential Dynamic Logic
Differential dynamic logic (d) [26, 27, 28] is the dynamic logic of hybrid programs. The logic associates with each hybrid program modal operators and , which express state reachability properties of . The formula states that the formula is true in all states reachable by the hybrid program , and the formula expresses that the formula is true after some execution of . The d formulas are generated by the grammar
[TABLE]
where are arithmetic expressions over the reals, and are formulas, ranges over hybrid programs, and is a comparison operator . The quantifiers quantify over the reals. We denote by the fact that formula is true in state ; e.g., we denote by the fact that implies for all states . Similarly, denotes the fact that has a proof in d. When is true in every state (i.e., valid) we simply write .
Example 1 (Safety specification for straight-line car model)
[TABLE]
This formula states that if a car begins with a non-negative velocity, then it will also always have a non-negative velocity after repeatedly choosing new acceleration ( or [math]), or coasting and moving for a nondeterministic period of time.
Throughout this paper, we will refer to sets of actions. An action is simply the effect of a loop-free deterministic discrete program without tests. For example, the programs and are the actions available in the above program. Notice that actions can be equivalently thought of as mappings from variables to terms. We use the term action to refer to both the mappings themselves and the hybrid programs whose semantics correspond to these mappings. For an action , we write to mean the effect of taking action in state ; i.e., the state such that .
ModelPlex
Safe off-model learning requires noticing, at runtime, when a system deviates from model assumptions. Therefore, our approach depends upon the ability to check, at runtime, whether the current state of the system can be explained by a hybrid program.
The KeYmaera X theorem prover implements the ModelPlex algorithm [25]. ModelPlex constructs an implication or equivalence proof between a d formula of the form and a monitoring condition expressed as a formula of quantifier-free real arithmetic. The monitoring condition is then used to extract provably correct monitors that check whether observed transitions comport with modeling assumptions. ModelPlex can produce monitors that enforce models of control programs as well as monitors that check whether the model’s ODEs comport with observed state transitions.
ModelPlex controller monitors are boolean functions that return false if the controller portion of a hybrid systems model has been violated. A controller monitor for a model is a function from states and actions to booleans such that if then . We sometimes also abuse notation by using controller monitors as an implicit filter on ; i.e., such that iff is true.
ModelPlex also produces model monitors, which check whether the model is accurate. A model monitor for a safety specification is a function such that if . For the sake of brevity, we also define as the model monitor applied after taking an action () in a state and then following the plant in a model of form . Notice that if the model has this canonical form and if if for an action , then .
The KeYmaera X system is a theorem prover [12] that provides a language called Bellerophon for scripting proofs of d formulas [11]. Bellerophon programs, called tactics, construct proofs of d formulas. This paper proposes an approach toward updating models in a way that preserves safety proofs. Our proposed approach simultaneously changes a system of differential equations, control software expressed as a discrete loop-free program, and the formal proof that the controller properly selects actuator values such that desired safety constraints are preserved throughout the flow of a system of differential equations.
3 Verification-Preserving Model Updates
A verification-preserving model update (VPMU) is a transformation of a hybrid program accompanied by a proof that the transformation preserves key safety properties [13]. VPMUs capture situations in which a model and/or a set of data can be updated in a way that captures possible runtime behaviors which are not captured by an existing model.
Definition 1 (VPMU)
A verification-preserving model update is a mapping which takes as input an initial d formula with an associated Bellerophon tactic e of , and produces as output a new d formula and a new Bellerophon tactic f such that f is a proof of .
Before discussing our VPMU library, we consider how a set of feasible models computed using VPMUs can be used to provide verified safety guarantees for a family of reinforcement learning algorithms. The primary challenge is to maintain safety with respect to all feasible models while also avoiding overly conservative monitoring constraints by falsifying some of these models at runtime.
4 Verifiably Safe RL with Multiple Models
VPMUs may be applied any time at which system designers can characterize likely ways in which an existing model will deviate from reality. Model updates are easiest to apply at design time because of the computational overhead of computing both model updates and corresponding proof updates. This section introduces model update learning, which explains how to take a set of models generated using VPMUs at design time to provide safety guarantees at runtime.
Model update learning is based on a simple idea: begin with a set of feasible models and act safely with respect to all feasible models. Whenever a model does not comport with observed dynamics, the model becomes infeasible and is therefore removed from the set of feasible models. We introduce two variations of learning: a basic algorithm that chooses actions without considering the underlying action space, and an algorithm that prioritizes actions that rule out feasible models (adding an eliminate choice to the classical explore/exploit tradeoff [32]).
All learning algorithms use monitored models; i.e., models equipped with ModelPlex controller monitors and model monitors.
Definition 2 (Monitored Model)
A monitored model is a tuple where is a d formula of the form , and ctrl is a loop-free program, and the entire formula contains exactly one modality, and the formulas and are the control monitor and model monitor corresponding to , as defined in Section 2.
Monitored models may have a continuous action space because of both tests and the nondeterministic assignment operator. We sometimes introduce additional assumptions on the structure of the monitored models. A monitored model over a finite action space is a monitored model where is finite for all . A time-aware monitored model is a monitored model such that the differential equations contain a local clock which is reset at each control step.
Model update learning, or learning, leverages verification-preserving model updates to maintain safety while selecting an appropriate environmental model. We now state and prove key safety properties about the learning algorithm.
Definition 3 (learning Process)
A learning process for a finite set of monitored models is defined as a tuple of countable sequences where U are actions in a finite set of actions (i.e., mappings from variables to values), elements of the sequence S are states, and Mon are monitored models with . Let where cm and mm are the monitors corresponding to the model . Let always return true for .
A learning process is a learning process satisfying the following additional conditions:
-
action availability: in each state there is at least one action such that for all , ,
-
actions are safe for all feasible models: ,
-
feasible models remain in the feasible set: if and then .
Note that learning processes are defined over an environment that determines the sequences U and S111Throughout the paper, we denote by S a specific sequence of states and by the set of all states., so that . In our algorithms, the set never retains elements that are inconsistent with the observed dynamics at the previous state. We refer to the set of models in as the set of feasible models for .
Notice that the safe actions constraint is not effectively checkable without extra assumptions on the range of parameters. Two canonical choices are discretizing options for parameters or including an effective identification process for parameterized models.
Our safety theorem focuses on time-aware learning processes, i.e., those whose models are all time-aware; similarly, a finite action space learning process is a learning process in which all models have a finite action space. The basic correctness property for a learning process is the safe reinforcement learning condition: the system never takes unsafe actions.
Definition 4 (learning process with an accurate model)
Let be a learning process. Assume there is some element with the following properties. First, . Second, . Third, implies for a mapping from states and actions to new states. When only one element of satisfies these properties we call that element the distinguished and/or accurate model and say that the process is accurately modeled with respect to a mapping .
The mapping is often called an environment, and we will often elide the environment for which the process is accurate when it is obvious from context.
Theorem 4.1 (Safety)
If is a learning process with an accurate model, then for all .
Proof
Let be the distinguished model for . Proceed by induction on the length of S with the hypothesis that and . Let be the environment with respect to which is defined.
By the definition of a learning process with an accurate model, and .
Now, assume and . By the definition of a learning process, we therefore know that either
[TABLE]
or else
[TABLE]
However, the second cannot be the case due to the hypothesis that is the accurate model (Definition 4). Therefore, it must be that . From this fact, Definition 4, and the fact that is distinguished, it follows that . This, together with the fact that \vdash_{\text{{d{\kern-0.70004pt}\mathcal{L}}}}\varphi^{*}, the shape assumption on , and the soundness of d, implies that .
What remains to be shown is that . Notice that
[TABLE]
must be true because is the accurate model. By the inductive hypothesis know also that . By definition, feasible models remain in the feasible set (Definition 3); i.e., the above two facts establish that .
Listing 1 defines a learning algorithm that produces a learning process. The inputs are:
(a) A set of M models each with a method which implements the evaluation of its model monitor in the given previous and next state and actions and a method which implements evaluation of its controller monitor,
(b) an action space A and an initial state ,
(c) an environment function that computes state updates and rewards in response to actions, and
(d) a function that selects an action from a set of available actions and update updates a table or approximation. Our approach is generic and works for any reinforcement learning algorithm; therefore, we leave these functions abstract.
It augments an existing reinforcement learning algorithm, defined by update and choose, by restricting the action space at each step so that actions are only taken if they are safe with respect to all feasible models. The feasible model set is updated at each control set by removing models that are in conflict with observed data.
The learning algorithm rules out incorrect models from the set of possible models by taking actions and observing the results of those actions. Through these experiments, the set of relevant models is winnowed down to either the distinguished correct model , or a set of models containing and other models that cannot be distinguished from .
4.1 Active Verified Model Update Learning
Removing models from the set of possible models relaxes the monitoring condition, allowing less conservative and more accurate control decisions. Therefore, this section introduces an active learning refinement of the learning algorithm that prioritizes taking actions that help rule out models that are not . Instead of choosing a random safe action, learning prioritizes actions that differentiate between available models. We begin by explaining what it means for an algorithm to perform good experiments.
Definition 5 (Active Experimentation)
A learning process with an accurate model has locally active experimentation provided that: if and there exists an action that is safe for all feasible models (see Definition 3) in state such that taking action results in the removal of from the model set, then . Experimentation is er-active if the following conditions hold: there exists an action that is safe for all feasible models (see Definition 3) in state , and taking action results in the removal of from the model set, then with probability .
Definition 6 (Distinguishing Actions)
Consider a learning process with an accurate model (see Definition 4). An action distinguishes from if , and for some .
The active learning algorithm uses model monitors to select distinguishing actions, thereby performing active experiments which winnow down the set of feasible models. The inputs to active-learn are the same as those to Listing 1 with two additions:
-
models are augmented with an additional prediction method p that returns the model’s prediction of the next state given the current state, a candidate action, and a time duration.
-
An elimination rate er is introduced, which plays a similar role as the classical explore-exploit rate except that we are now choosing whether to insist on choosing a good experiment.
The active-learn algorithm is guaranteed to make some progress toward winnowing down the feasible model set whenever .
Theorem 4.2
Let be a finite action space learning process with an accurate model . Then for all .
Proof
Let and let be the environment over which is defined. By Definition 4,
[TABLE]
Suppose now that for some . The crucial observation is that , which will directly imply that due to the fact that feasible models remain in the feasible set (Definition 3).
So, it suffices to show that . However, notice that this follows directly from the definition of an accurate model (Definition 4).
Theorem 4.3
*Let be a finite action space er-active learning process under environment and with an accurate model . Assume has an accurate model and that every other model has in each state an action that is safe for all models and distinguishes from .
Then .*
Proof
Consider . Note that for all is directly implied by Theorem 4.2. Let be the number of non- elements in . It suffices to show that . Notice that because each is falsifiable at step , the probability that non- elements remain in after steps is which tends to [math] as .
Corollary 1
Let be a finite action space er-active learning process under environment and with an accurate model . If each model has in each state an action that is safe for all models and distinguishes from , then Mon converges to a.s.
Proof
The conclusion follows from Theorem 4.3 as long as is never removed. Proceed by induction on the length of Mon. In the base case, recall that . Suppose, then, that . We assume is accurately modeled with respect to , which by Definition 4 implies for all elements in the sequences U and S. Therefore, must contain by the inductive hypothesis applied to the third condition (“feasible models remain in the feasible set”) of Definition 3.
Although locally active experimentation is not strong enough to ensure that eventually converges to a minimal set of models222 with the parameters are a counter example [10, Section 8.4.4]., our experimental validation demonstrates that this heuristic is none-the-less effective on some representative examples of model update learning problems.
5 A Model Update Library
So far, we have established how to obtain safety guarantees for reinforcement learning algorithms given a set of formally verified d models. We now turn our attention to the problem of generating such a set of models by systematically modifying d formulas and their corresponding Bellerophon tactical proof scripts. This section introduces five generic model updates that provide a representative sample of the kinds of computations that can be performed on models and proofs to predict and account for runtime model deviations333Extended discussion of these model updates is available in [10, Chapters 8 and 9]. Implementations are available at https://nfulton.org/vpmu..
The simplest example of a VPMU instantiates a parameter whose value is not known at design time but can be determined at runtime via system identification. Consider a program modeling a car whose acceleration depends upon both a known control input and parametric values for maximum braking force and maximum acceleration . Its proof is
[TABLE]
This model and proof can be updated with concrete experimentally determined values for each parameter by uniformly substituting the variables and with concrete values in both the model and the tactic.
The Automatic Parameter Instantiation update improves the basic parameter instantiation update by automatically detecting which variables are parameters and then constraining instantiation of parameters by identifying relevant initial conditions.
The Replace Worst-Case Bounds with Approximations update improves models designed for the purpose of safety verification. Often a variable occurring in the system is bounded above (or below) by its worst-case value. Worst-case analyses are sufficient for establishing safety but are often overly conservative. The approximation model update replaces worst-case bounds with approximate bounds obtained via series expansions. The proof update then introduces a tactic on each branch of the proof that establishes our approximations are upper/lower bounds by performing.
Models often assume perfect sensing and actuation. A common way of robustifying a model is to add a piecewise constant noise term to the system’s dynamics. Doing so while maintaining safety invaraints requires also updating the controller so that safety envelope computations incorporate this noise term. The Add Disturbance Term update introduces noise terms to differential equations, systematically updates controller guards, and modifies the proof accordingly.
Uncertainty in object classification is easy to model in terms of sets of feasible models. In the simplest case, a robot might need to avoid an obstacle that is either static, moves in a straight line, or moves sinusoidally. Our generic model update library contains an update that changes the model by making a static point dynamic. For example, one such update introduces the equations to a system of differential equations in which the variables do not have differential equations. The controller is updated so that any statements about separation between and require global separation of from the circle on which moves. The proof is also updated by prepending to the first occurrence of a differential tactic on each branch with a sequence of differential cuts that characterize circular motion.
Model updates also provide a framework for characterizing algorithms that combine model identification and controller synthesis. One example is our synthesis algorithm for systems whose ODEs have solutions in a decidable fragment of real arithmetic (a subset of linear ODEs). Unlike other model updates, we do not assume that any initial model is provided; instead, we learn a model (and associated control policy) entirely from data. The Learn Linear Dynamics update takes as input: (1) data from previous executions of the system, and (2) a desired safety constraint. From these two inputs, the update computes a set of differential equations odes that comport with prior observations, a corresponding controller ctrl that enforces the desired safety constraint with corresponding initial conditions init, and a Bellerophon tactic prf which proves . The full mechanism is beyond the scope of this paper and is explained in greater detail by Chapter 9 of [10].
Significance of Selected Updates
The updates described in this section demonstrate several possible modes of use for VPMUs and learning. VPMUS can update existing models to account for systematic modeling errors (e.g., missing actuator noise or changes in the dynamical behavior of obstacles). VPMUs can automatically optimize control logic in a proof-preserving fashion. VPMUS can also be used to generate accurate models and corresponding controllers from experimental data made available at design time, without access to any prior model of the environment.
6 Experimental Validation
The learning algorithms introduced in this paper are designed to answer the following question: given a set of possible models that contains the one true model, how can we safely perform a set of experiments that allow us to efficiently discover a minimal safety constraint? In this section we present several experiments which demonstrate the use of learning in safety-critical settings.
Overall, these experiments empirically validate our theorems by demonstrating that learning processes with accurate models do not violate safety constraints.
Our simulations use a conservative discretization of the hybrid systems models, and we translated monitoring conditions by hand into Python from ModelPlex’s C output. Although we evaluate our approach in a research prototype implemented in Python for the sake of convenience, there is a verified compilation pipeline for models implemented in d that eliminates uncertainty introduced by discretization and hand-translations [7].
Adaptive Cruise Control Adaptive Cruise Control (ACC) is a common feature in new cars. ACC systems change the speed of the car in response to the changes in the speed of traffic in front of the car; e.g., if the car in front of an ACC-enabled car begins slowing down, then the ACC system will decelerate to match the velocity of the leading car. Our first set of experiments consider a simple linear model of ACC in which the acceleration set-point is perturbed by an unknown parameter ; i.e., the relative position of the two vehicles is determined by the equations .
In [14], the authors consider the collision avoidance problem when a noise term is added so that . We are able to outperform the approach in [14] by combining the Add Noise Term and Parameter Instantiation updates; we outperform in terms of both avoiding unsafe states and in terms of cumulative reward. These two updates allow us to insert a multiplicative noise term into these equations, synthesize a provably correct controller, and then choose the correct value for this noise term at runtime. Unlike [14], learning avoids all safety violations. The graph in Figure 1 compares the Justified Speculative Control approach of [14] to our approach in terms of cumulative reward; in addition to substantially outperforming the JSC algorithm of [14], learning also avoids 204 more crashes throughout a 1,000 episode training process.
A Hierarchical Problem Model update learning can be extended to provide formal guarantees for hierarchical reinforcement learning algorithms [6]. If each feasible model corresponds to a subtask, and if all states satisfying termination conditions for subtask are also safe initial states for any subtask reachable from , then learning directly supports safe hierarchical reinforcement learning by re-initializing to the initial (maximal) model set whenever reaching a termination condition for the current subtask.
We implemented a variant of learning that performs this re-initialization and validated this algorithm in an environment where a car must first navigate an intersection containing another car and then must avoid a pedestrian in a crosswalk (as illustrated in Figure 1). In the crosswalk case, the pedestrian at may either continue to walk along a sidewalk indefinitely or may enters the crosswalk at some point between (the boundaries of the crosswalk). This case study demonstrates that safe hierarchical reinforcement learning is simply safe learning with safe model re-initialization.
7 Related Work
Related work falls into three broad categories: safe reinforcement learning, runtime falsification, and program synthesis.
Our approach toward safe reinforcement learning differs from existing approaches that do not include a formal verification component (e.g., as surveyed by García and Fernández [15] and the SMT-based constrained learning approach of Junges et al. [21]) because we focused on verifiably safe learning; i.e., instead of relying on oracles or conjectures, constraints are derived in a provably correct way from formally verified safety proofs. The difference between verifiably safe learning and safe learning is significant, and is equivalent to the difference between verified and unverified software. Unlike most existing approaches our safety guarantees apply to both the learning process and the final learned policy.
Section 2 discusses how our work relates to the few existing approaches toward verifiably safe reinforcement learning. Unlike those [3, 17, 20, 14], as well as work on model checking and verification for MDPs [18], we introduce an approach toward verifiably safe off-model learning. Our approach is the first to combine model synthesis at design time with model falsification at runtime so that safety guarantees capture a wide range of possible futures instead of relying on a single accurate environmental model. Safe off-model learning is an important problem because autonomous systems must be able to cope with unanticipated scenarios. Ours is the first approach toward verifiably safe off-model learning.
Several recent papers focus on providing safety guarantees for model-free reinforcement learning. Trust Region Policy Optimization [31] defines safety as monotonic policy improvement, a much weaker notion of safety than the constraints guaranteed by our approach. Constrained Policy Optimization [1] extends TRPO with guarantees that an agent nearly satisfies safety constraints during learning. Brázdil et al. [8] give probabilistic guarantees by performing a heuristic-driven exploration of the model. Our approach is model-based instead of model-free, and instead of focusing on learning safely without a model we focus on identifying accurate models from data obtained both at design time and at runtime. Learning concise dynamical systems representations has one substantial advantage over model-free methods: safety guarantees are stated with respect to an explainable model that captures the safety-critical assumptions about the system’s dynamics. Synthesizing explainable models is important because safety guarantees are always stated with respect to a model; therefore, engineers must be able to understand inductively synthesized models in order to understand what safety properties their systems do (and do not) ensure.
Akazaki et al. propose an approach, based on deep reinforcement learning, for efficiently discovering defects in models of cyber-physical systems with specifications stated in signal temporal logic [2]. Model falsification is an important component of our approach; however, unlike Akazaki et al., we also propose an approach toward obtaining more robust models and explain how runtime falsification can be used to obtain safety guarantees for off-model learning.
Our approach includes a model synthesis phase that is closely related to program synthesis and program repair algorithms [23, 24, 29]. Relative to work on program synthesis and repair, VPMUs are unique in several ways. We are the first to explore hybrid program repair. Our approach combines program verification with mutation. We treat programs as models in which one part of the model is varied according to interactions with the environment and another part of the model is systematically derived (together with a correctness proof) from these changes. This separation of the dynamics into inductively synthesized models and deductively synthesized controllers enables our approach toward using programs as representations of dynamic safety constraints during reinforcement learning.
Although we are the first to explore hybrid program repair, several researchers have explored the problem of synthesizing hybrid systems from data [5, 30]. This work is closely related to our Learn Linear Dynamics update. Sadraddini and Belta provide formal guarantees for data-driven model identification and controller synthesis [30]. Relative to this work, our Learn Linear Dynamics update is continuous-time, synthesizes a computer-checked correctness proof (as opposed to a least violation criterion implied by the synthesis algorithm, both not independently checked by a theorem prover), and does not require dynamics to be compact, bounded, and locally connected. Unlike Asarin et al. [5], our full set of model updates is sometimes capable of synthesizing nonlinear dynamical systems from data (e.g., the static circular update) and produces computer-checked correctness proofs for permissive controllers.
8 Conclusions
This paper introduces an approach toward verifiably safe off-model learning that uses a combination of design-time verification-preserving model updates and runtime model update learning to provide safety guarantees even when there is no single accurate model available at design time. We introduced a set of model updates that capture common ways in which models can deviate from reality, and introduced an update that is capable of synthesizing ODEs and provably correct controllers without access to an initial model. Finally, we proved safety and efficiency theorems for active learning and evaluated our approach on some representative examples of hybrid systems control tasks. Together, these contributions constitute a first approach toward verifiably safe off-model learning.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Achiam, J., Held, D., Tamar, A., Abbeel, P.: Constrained policy optimization. In: Precup, D., Teh, Y.W. (eds.) Proceedings of the 34th International Conference on Machine Learning (ICML 2017). Proceedings of Machine Learning Research, vol. 70, pp. 22–31. PMLR (2017)
- 2[2] Akazaki, T., Liu, S., Yamagata, Y., Duan, Y., Hao, J.: Falsification of cyber-physical systems using deep reinforcement learning. In: Havelund, K., Peleska, J., Roscoe, B., de Vink, E. (eds.) Formal Methods. pp. 456–465. Springer International Publishing, Cham (2018)
- 3[3] Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., Topcu, U.: Safe reinforcement learning via shielding. In: Mc Ilraith, S.A., Weinberger, K.Q. (eds.) Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI 2018). AAAI Press (2018)
- 4[4] Alur, R., Courcoubetis, C., Henzinger, T.A., Ho, P.: Hybrid automata: An algorithmic approach to the specification and verification of hybrid systems. In: Grossman, R.L., Nerode, A., Ravn, A.P., Rischel, H. (eds.) Hybrid Systems. LNCS, vol. 736, pp. 209–229. Springer (1992)
- 5[5] Asarin, E., Bournez, O., Dang, T., Maler, O., Pnueli, A.: Effective synthesis of switching controllers for linear systems. Proceedings of the IEEE 88 (7), 1011–1025 (July 2000)
- 6[6] Barto, A.G., Mahadevan, S.: Recent advances in hierarchical reinforcement learning. Discrete Event Dynamic Systems 13 (1-2), 41–77 (2003)
- 7[7] Bohrer, B., Tan, Y.K., Mitsch, S., Myreen, M.O., Platzer, A.: Veri Phy: Verified controller executables from verified cyber-physical system models. In: Grossman, D. (ed.) Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2018). pp. 617–630. ACM (2018)
- 8[8] Brázdil, T., Chatterjee, K., Chmelik, M., Forejt, V., Kretínský, J., Kwiatkowska, M.Z., Parker, D., Ujma, M.: Verification of markov decision processes using learning algorithms. In: Automated Technology for Verification and Analysis - 12th International Symposium (ATVA 2014). pp. 98–114 (2014)
