Delog: A Privacy Preserving Log Filtering Framework for Online Compute Platforms
Amey Agrawal, Abhishek Dixit, Namrata Shettar, Darshil Kapadia, Rohit, Karlupia, Vikram Agrawal, Rajat Gupta

TL;DR
Delog is a privacy-preserving log filtering framework for online platforms that uses distributed parsing with Locality Sensitive Hashing to improve error detection and log relevance, demonstrating scalability and superior performance.
Contribution
The paper introduces Delog, a novel privacy-preserving log filtering framework with a scalable distributed parsing algorithm leveraging LSH, outperforming existing methods.
Findings
Outperforms state-of-the-art log parsing methods.
Scales effectively to large datasets with millions of log lines.
Maintains privacy of user logs while enabling useful log analysis.
Abstract
In many software applications, logs serve as the only interface between the application and the developer. However, navigating through the logs of long-running applications is often challenging. Logs from previously successful application runs can be leveraged to automatically identify errors and provide users with only the logs that are relevant to the debugging process. We describe a privacy preserving framework which can be employed by Platform as a Service (PaaS) providers to utilize the user logs generated on the platform while protecting the potentially sensitive logged data. Further, in order to accurately and scalably parse log lines, we present a distributed log parsing algorithm which leverages Locality Sensitive Hashing (LSH). We outperform the state-of-the-art on multiple datasets. We further demonstrate the scalability of Delog on publicly available Thunderbird log dataset…
Click any figure to enlarge with its caption.
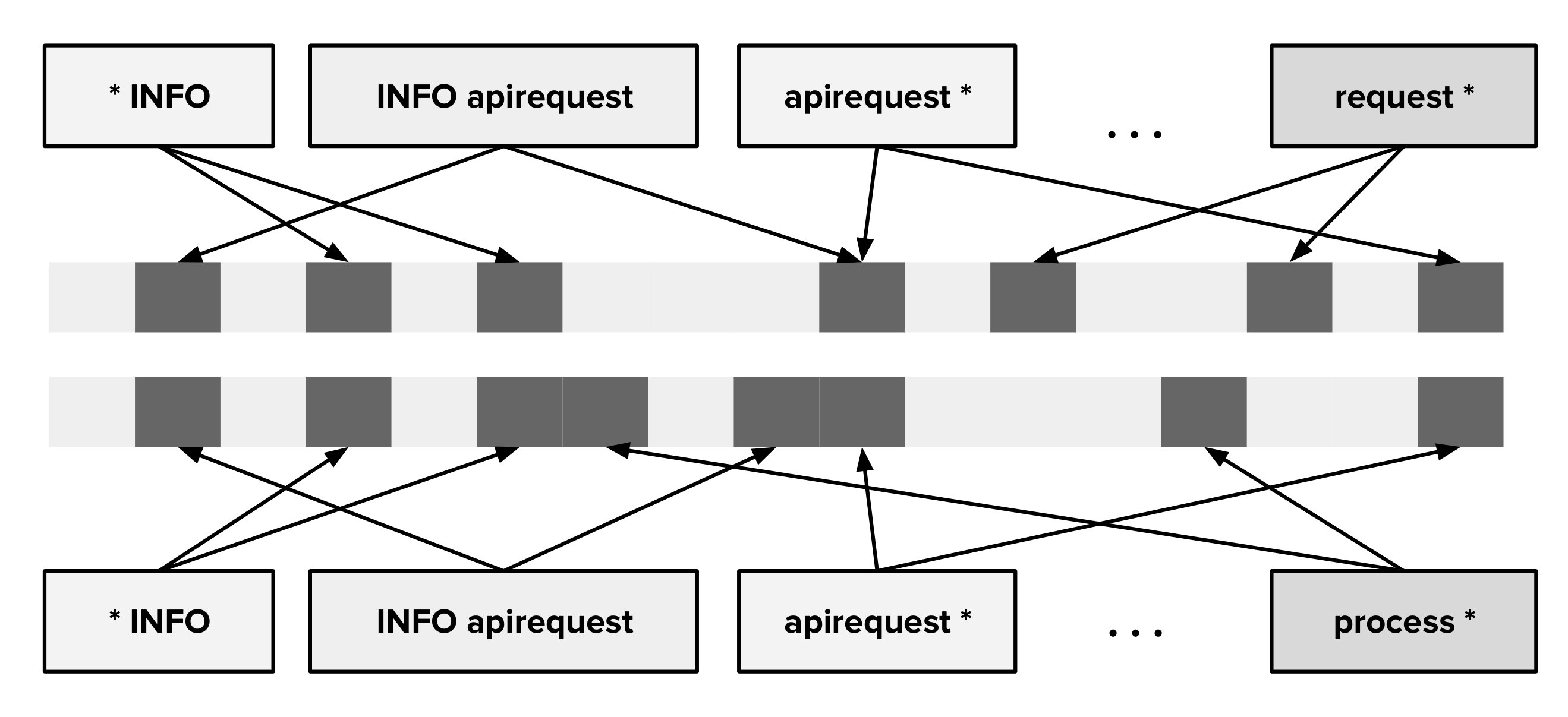 Figure 1
Figure 1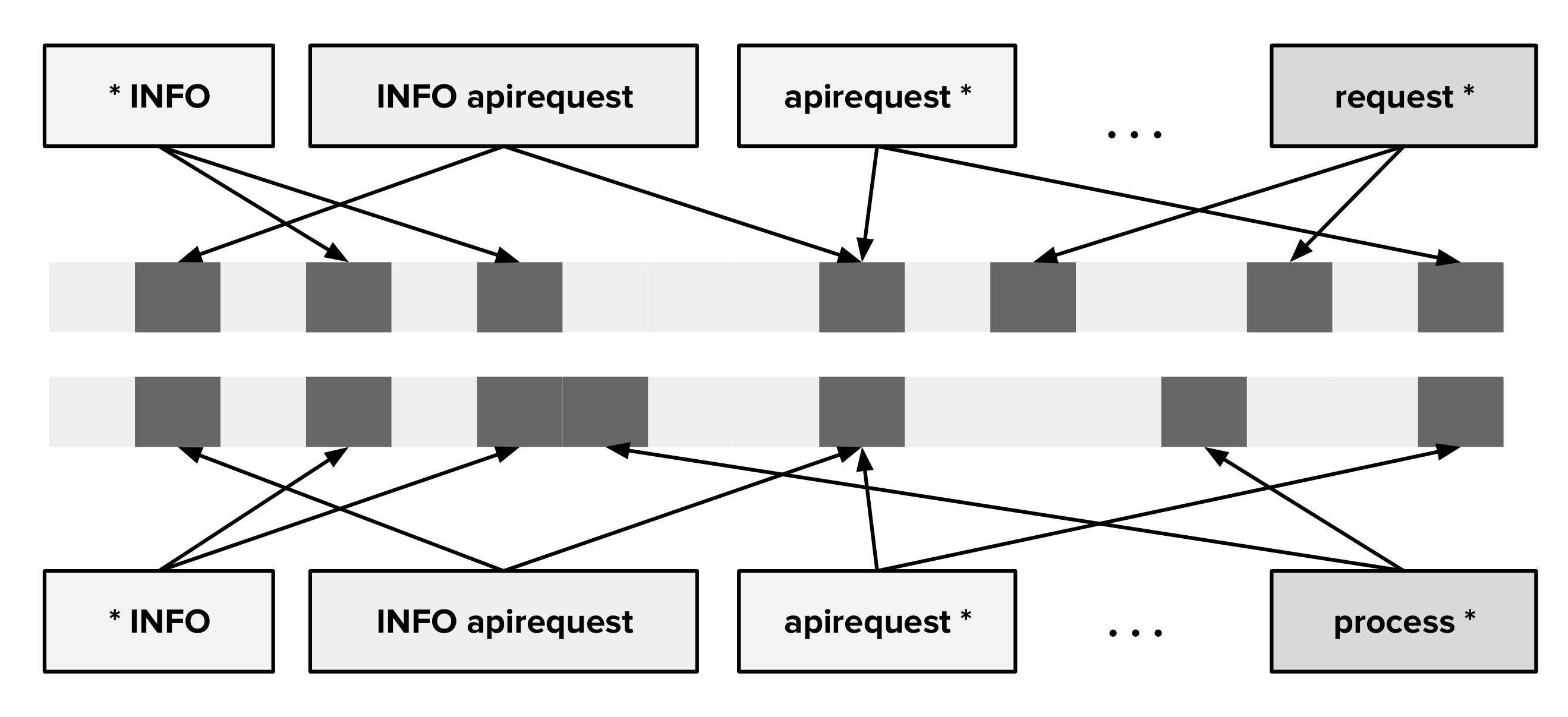 Figure 2
Figure 2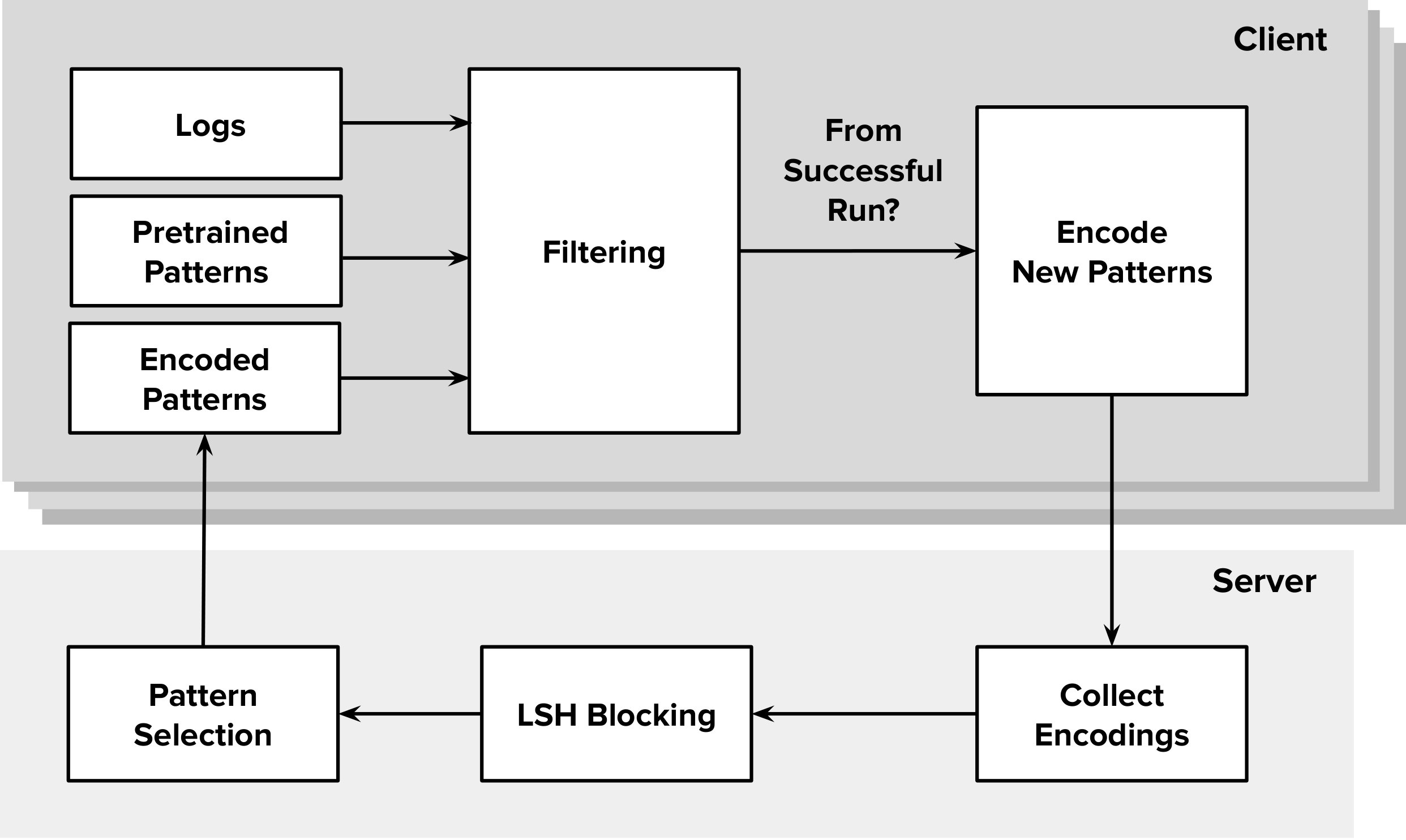 Figure 3
Figure 3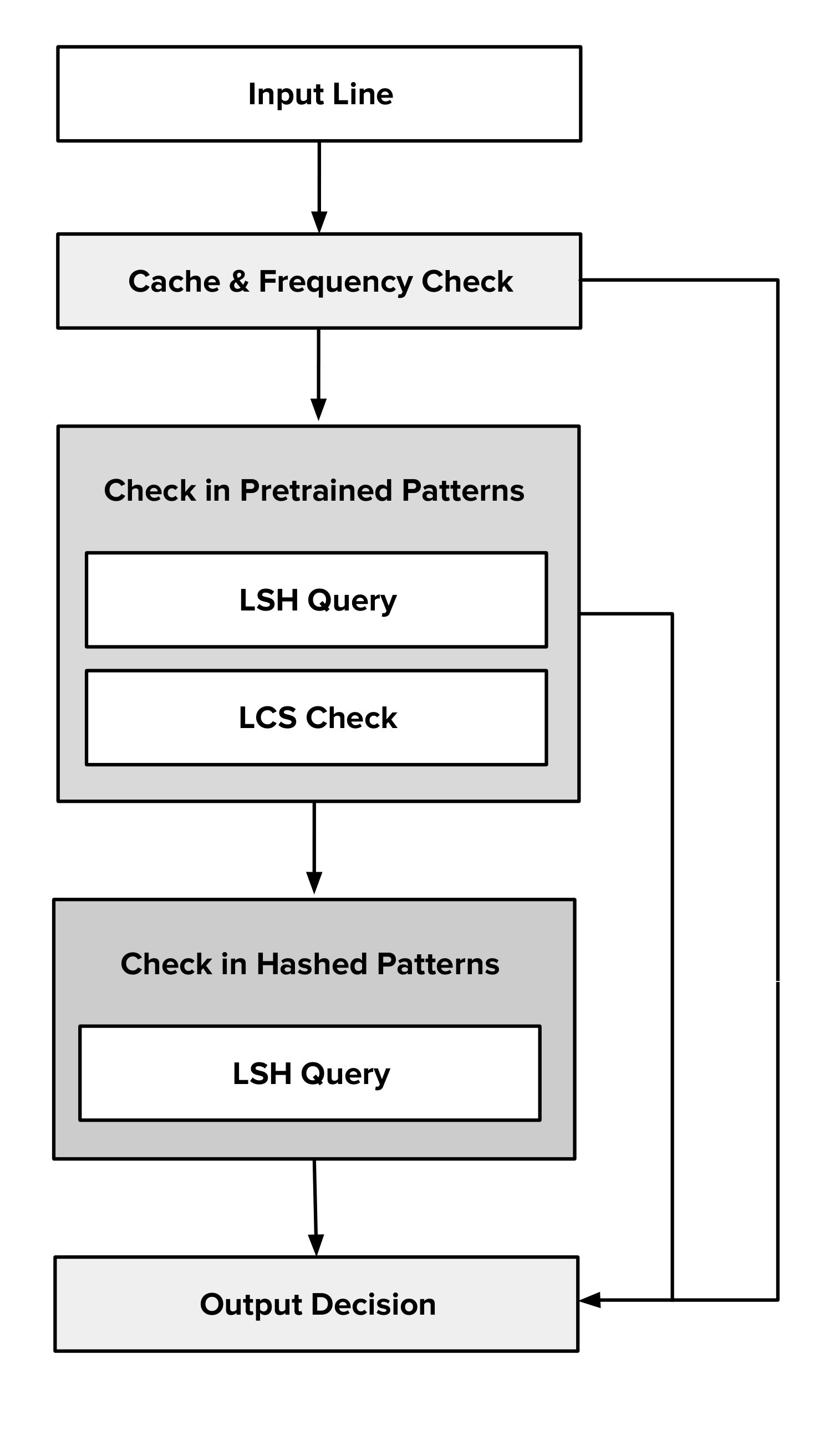 Figure 4
Figure 4 Figure 5
Figure 5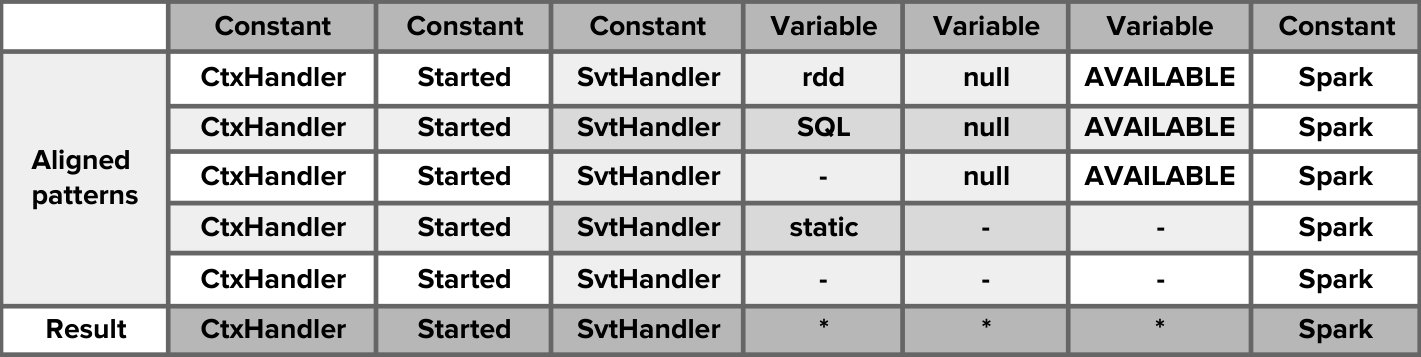 Figure 6
Figure 6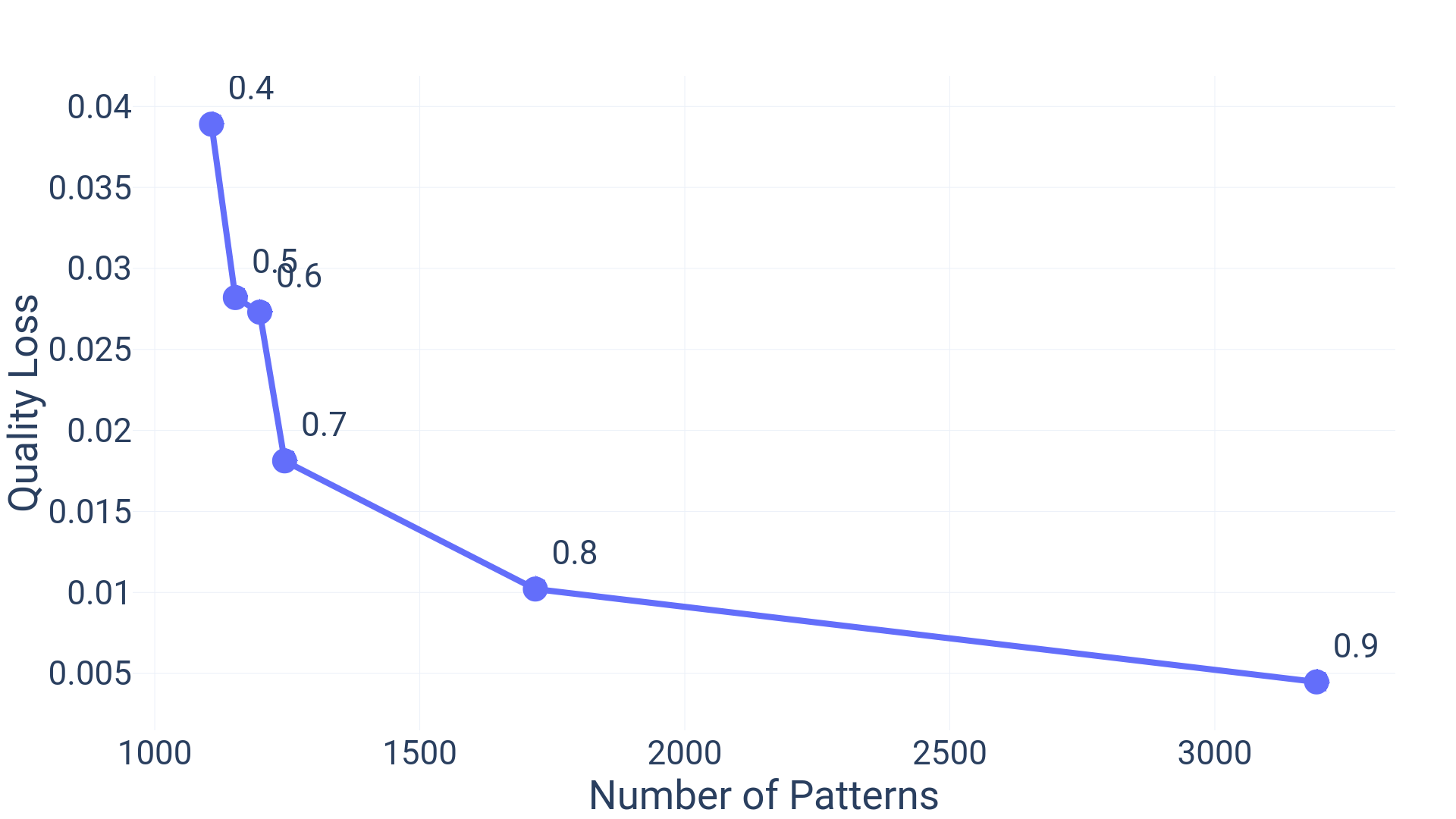 Figure 7
Figure 7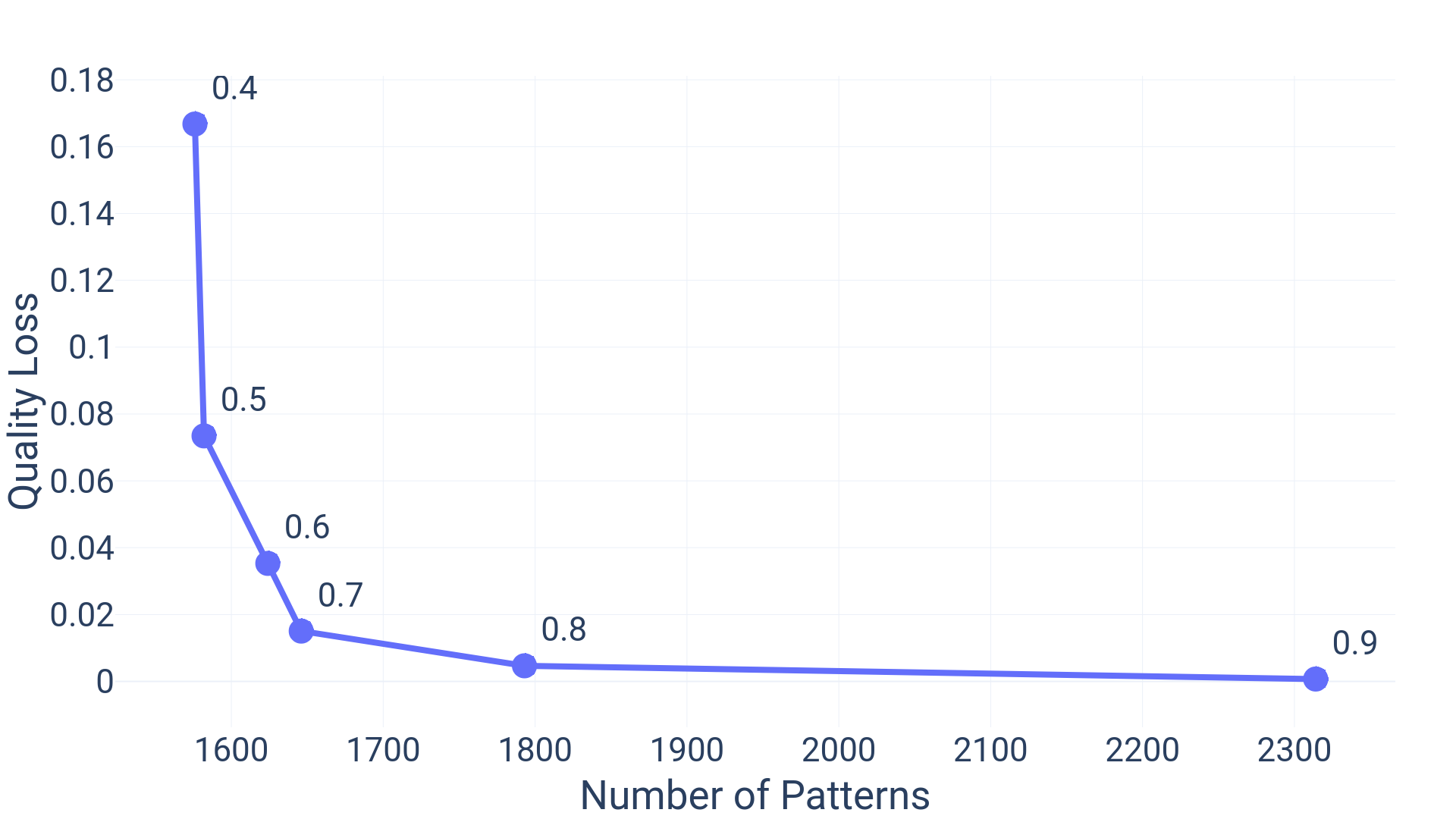 Figure 8
Figure 8| Dataset | Number of Lines | Total Size |
|---|---|---|
| Zookeeper | 74,380 | 10 MB |
| HPC | 433,490 | 32 MB |
| BGL | 4,747,963 | 109 MB |
| Presto-5.2M | 5,200,000 | 1.48 GB |
| HDFS | 11,175,629 | 1.57 GB |
| Spark-13M | 13,000,000 | 2.10 GB |
| Presto | 16,222,793 | 4.73 GB |
| Hive | 39,010,740 | 7.9 GB |
| HDFS2 | 71,118,073 | 16.06GB |
| Spark | 96,503,051 | 14.75 GB |
| Windows | 114,608,388 | 26.09GB |
| Thunderbird | 211,212,192 | 29.60 GB |
| Zook-eeper | HPC | BGL | Presto-5.2M | HDFS | Spark-13M | Presto | Spark | Hive | Thund-erbird | Wind-ows | HDFS2 | |
| SHISO | 2.7385 | 4.6333 | - | - | - | - | - | - | - | - | - | - |
| Spell | 0.0002 | 0.0091 | - | - | - | - | - | - | - | - | - | - |
| Drain | 0.0042 | 0.1 | 0.0849 | 120.9164 | 0.0013 | 0.6445 | - | - | - | - | - | - |
| IPLoM | 0.0053 | 1.8697 | 0.0091 | 7.3184 | 0.0004 | 7.13 | - | - | - | - | - | - |
| Logan | 0.0377 | 0.0598 | 0.0211 | 0.0123 | 0.0107 | 0.0056 | 0.0069 | 0.0048 | 0.0135 | - | 0.0437 | 0.0057 |
| Delog | 0.0002 | 0.0005 | 0.0019 | 0.0144 | 0.0009 | 0.0025 | 0.0104 | 0.0038 | 0.0159 | 0.0012 | 0.0397 | 0.0013 |
| Zook-eeper | HPC | BGL | Presto-5.2M | HDFS | Spark-13M | Presto | Spark | Hive | Thund-erbird | Wind-ows | HDFS2 | |
| SHISO | 42 | 90 | - | - | - | - | - | - | - | - | - | - |
| Spell | 168 | 230 | - | - | - | - | - | - | - | - | - | - |
| Drain | 89 | 147 | 1202 | 1466 | 48 | 1001 | - | - | - | - | - | - |
| IPLoM | 91 | 119 | 2765 | 3748 | 41 | 738 | - | - | - | - | - | - |
| Logan | 100 | 138 | 261 | 2391 | 48 | 895 | 5514 | 2979 | 6432 | - | 2595 | 180 |
| Delog | 117 | 306 | 1896 | 2829 | 45 | 808 | 461 | 852 | 7887 | 27784 | 3415 | 163 |
| Dataset | Original lines | After Preprocessing | Output Patterns |
|---|---|---|---|
| BGL | 4747963 | 3748 (0.07%) | 1896 (50.58%) |
| HPC | 433490 | 947 (0.21%) | 306 (32.31%) |
| Zookeeper | 74380 | 122 (0.16%) | 117 (95.90%) |
| HDFS | 11175629 | 47 | 45 (95.74%) |
| Spark-13m | 13000000 | 1187 | 808 (68.07%) |
| Presto-5.2m | 5200000 | 6566 (0.12%) | 2829 (43.08%) |
| Zook-eeper | HPC | BGL | Presto-5.2M | HDFS | Spark-13M | Presto | Spark | Hive | Thund-erbird | Wind-ows | HDFS2 | |
| SHISO | 129.69 | 656.90 | - | - | - | - | - | - | - | - | - | - |
| Spell | 13.60 | 76.69 | - | - | - | - | - | - | - | - | - | - |
| Drain | 3.48 | 16.26 | 156.17 | 436.07 | 559.67 | 7044.18 | - | - | - | - | - | - |
| IPLoM | 2.18 | 11.25 | 93.23 | 583.55 | 379.03 | 896.22 | - | - | - | - | - | - |
| Logan | 1.13 | 3.78 | 24.16 | 68.34 | 53.39 | 119.03 | 21.38 | 42.76 | 1660.54 | - | 179.87 | 29.03 |
| Delog | 2.03 | 4.23 | 16.08 | 27.27 | 27.42 | 48.59 | 21.13 | 84.16 | 313.96 | 225.71 | 109.54 | 41.27 |
| Parameter | Value |
|---|---|
| 0.65 | |
| LSH Shingles | 2-gram |
| LSH Number of Permutations | 100 |
| LSH Jaccard Threshold | 0.75 |
| 0.7 | |
| 0.7 |
| Parameter | Minimum Value | Maximum Value | Step |
| 0.3 | 0.9 | 0.1 | |
| LSH Shingles | 1-ngram | 5-gram | 1 |
| LSH Number of Permutations | 16 () | 512 () | |
| LSH Jaccard Threshold | 0.3 | 0.9 | 0.1 |
| 0.3 | 0.9 | 0.1 |
| Dataset | LSH Shingles | LSH Jaccard Threshold | LSH Number of Permutations | Number of Patterns | Loss | ||
|---|---|---|---|---|---|---|---|
| Zookeeper | 0.6 | 4 | 0.7 | 16 | 0.4 | 107 | 0.0050 |
| HPC | 0.7 | 4 | 0.7 | 32 | 0.4 | 309 | 0.0063 |
| BGL | 0.7 | 4 | 0.7 | 64 | 0.5 | 1470 | 0.0026 |
| HDFS | 0.6 | 4 | 0.7 | 16 | 0.4 | 42 | 0.0 |
| Evaluation Metric | M1 | M2 | M3 |
|---|---|---|---|
| Output Patterns | 1588 | 774 | 563 |
| False Negatives | 0 | 12 | - |
| False Negative Rate | 0% | 2.13% | - |
| False Positives | 1023 | 222 | - |
| False Discovery Rate | 64.42% | 28.68% | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSoftware System Performance and Reliability · Network Security and Intrusion Detection · Internet Traffic Analysis and Secure E-voting
Delog: A Privacy Preserving Log Filtering Framework for Online Compute Platforms
Amey Agrawal1, Abhishek Dixit1, Namrata A Shettar1, Darshil Kapadia2 ,
Vikaram Agrawal1, Rajat Gupta1, and Rohit Karlupia1 2Work done during an internship at Qubole
1 Qubole India
Bengaluru, India
Email: [email protected]
2 BITS Pilani
Vidyavihar, India
Email: [email protected]
Abstract
In many software applications, logs serve as the only interface between the application and the developer. However, navigating through the logs of long-running applications is often challenging. Logs from previously successful application runs can be leveraged to automatically identify errors and provide users with only the logs that are relevant to the debugging process. We describe a privacy preserving framework which can be employed by Platform as a Service (PaaS) providers to utilize the user logs generated on the platform while protecting the potentially sensitive logged data. Further, in order to accurately and scalably parse log lines, we present a distributed log parsing algorithm which leverages Locality Sensitive Hashing (LSH). We outperform the state-of-the-art on multiple datasets. We further demonstrate the scalability of Delog on publicly available Thunderbird log dataset with close to 27,000 unique patterns and 211 million lines.
Index Terms:
Log parsing, Locality Sensitive Hashing, Multiple Sequence Alignment, Bloom Filter, Privacy Preserving
I Introduction
Online cloud computing platforms have made large scale distributed computing accessible at affordable prices, leading to a surge in usage of distributed computing frameworks like Apache Spark [1], Hive [2] and Presto [3]. However, in case of application failures, the user has to navigate through massive amounts of recorded logs to diagnose issues, causing a dip in productivity and unsatisfactory user experience.
In this paper, we describe a log filtering framework, Delog, which identifies anomalous logs at run time in order to minimize the manual effort required by the user in case of failures. We use a simple assumption that any log pattern that frequently occurs in successful application runs is irrelevant to identification of errors. Further, every log line is considered to be a string generated from a template where some tokens are constants while others represent values of certain variables. The process of identifying patterns in log lines is formally known as log parsing. Log parsing techniques try to extract unique patterns which correspond to specific system events by recognizing variables.
Some of the existing works in log parsing [4], [5] use distributed computing to solve the problems posed by large volumes of logs generated in production use cases. However, their performance deteriorates with increasing number of unique log patterns. To address this problem, we propose a novel algorithm based on Locality Sensitive Hashing (LSH) which can efficiently handle datasets with large number of patterns. We demonstrate the efficacy of Delog on Hive and Thunderbird [6] datasets where existing techniques perform poorly. We further perform a grid search over the model hyperparameters to exhibit their robustness across datasets.
Most previous studies [7], [5], [8] on log parsing make an assumption that the token count for instances of a given log pattern remains constant. However, we find this assumption to be limiting. Consider the following token sequences, “ContextHandler Started ServeletContextHandler rdd null AVAILABLE Spark” and “ContextHandler Started ServeletContextHandler static Spark”. Here a single variable (corresponding to ‘%s’ in the code) is printing multiple tokens and hence, the token count of the two sequences is different though both are instances of a single log pattern, “ContextHandler Started ServeletContextHandler * Spark”. We attend to such cases using sequence alignment, which allows us to obtain optimal reduced form of a log pattern and leads to better generalization ability.
Modern applications use multiple third party libraries and frameworks for different problem domains. Therefore, it is impossible to train an algorithm for all possible kinds of log patterns beforehand. A Platform as a Service provider can mitigate this problem by learning patterns from user generated application logs. However, application logs can contain sensitive data including secret keys, usernames and business data. To address this, we propose a privacy preserving framework which uses novel Bloom filter based data encoding technique [9] to utilize user logs without compromising user privacy.
To summarize, our key contributions in this work are:
- •
We propose a novel log parsing algorithm that can process datasets with large number of patterns while keeping the pattern quality high.
- •
We describe a log filtering method which can save time for a user trying to diagnose application issues by navigating through logs.
- •
We propose a privacy preserving framework that securely utilizes user generated log data to improve filtering performance.
- •
We release 111https://github.com/qubole/qubole-log-datasets a synthetic dataset which can be used to evaluate the performance of privacy preserving log filtering frameworks in future.
The rest of this paper is organized as follows: In Section II, we introduce the log parsing algorithm. Section III presents the log filtering methodology in detail. The privacy preserving framework to learn from user logs is described in section IV. Evaluation and experimental results of our approach is present in Sections V and VI. The related works and conclusion are presented in Section VII and Section VIII, respectively.
II Log Parsing
Log parsing is typically the first step of any log processing system. In order to obtain high quality log patterns, we develop a novel log parsing algorithm which can scale to handle datasets with large number of patterns. Our log parsing technique consists of three stages. The first stage involves preprocessing input log lines to identify trivial variables. These preprocessed lines are then divided into blocks containing similar lines. Finally, each block is reduced to a single log pattern by identifying constant tokens. In the rest of this section, we discuss each step of the parsing algorithm in detail.
II-A Preprocessing of Log Lines
In the preprocessing stage, we split each input line at the spaces to create a sequence of tokens. First, we filter out easy to identify variables like URLs and file paths from the list of tokens. Then we split the remaining tokens on every non-alphanumeric character and identify numbers, hexadecimal numbers and encoded strings. This helps us to handle tokens like IP Addresses (“127.0.0.1”), dates (“10/01/2018”), and other similar tokens without having to match manually defined regular expressions. All the remaining unidentified tokens are marked as strings. In the next step, consecutive non-string tokens occurring in the pattern are replaced by a wild card. Finally, we remove the duplicate patterns to return a set of unique lines in the processed file. We speed up the preprocessing stage by introducing Least Recently Used (LRU) caches on costly tokenization operations.
II-B Blocking Preprocessed Lines
We typically observe that the number of unique lines obtained after preprocessing is less than 0.1% of the original number of lines in the file. However, this number can still be large and finding similar lines by naive comparisons can be costly. To reduce the costly matching operations, we block the preprocessed lines using minhash-based Locality Sensitive Hashing (LSH) [10]. Considering the nature of log datasets, we use token-level shingles as opposed to the more traditional character-level shingles. This further helps in reducing the hash compute and comparison time. We create candidate log pattern blocks using the LSH with an empirically chosen Jaccard similarity threshold.
II-C Block Verification
Since both minhash and LSH are probabilistic data structures, there could be errors in the blocks formed by the method described in II-B. We use Longest Common Subsequence (LCS) algorithm to identify any outliers within a block. For a LSH block comprising of n patterns , …, , we regroup them into k blocks , , … …. such that any two patterns in a block will satisfy the similarity constraint given by equation 1. To reduce the number of LCS computations while clustering, we assume a transitive relationship between the patterns within the same LSH block. This implies that if a pattern P satisfies the similarity constraint with any one pattern in the block , it will satisfy the constraint for all the patterns in the block . Using this transitive property, we iteratively assign each pattern in the original LSH block to a regrouped block which satisfies the constraint. We introduce a new block if we find no suitable block for assignment.
[TABLE]
where , are two patterns and is an empirically determined constant.
II-D Sequence Alignment
By observing the log patterns generated by existing parsing algorithm, we notice that some string variables can consist of more than one token. Methods like LKE [7] and POP [5], check the distribution of tokens at a given position in a block of similar log patterns for reduction. However, such approaches produce sub-optimal results when the sequences do not align. To overcome this limitation, we create a variation of iterative Multiple Sequence Alignment (MSA) algorithm to progressively align sequences. We exploit the shorter lengths and higher similarity between log pattern sequences to simplify and speed up the alignment process. We use Needleman-Wunsch algorithm [11] for pairwise alignment of sequences. We sort the patterns in a block by sequence length and then progressively align sequences longest to shortest. At each step, subsets of previously aligned sequences are updated such that the length of all aligned sequences is equal. Details of this step are shown in the Algorithm 1.
II-E Alignment Matrix for Pattern Reduction
Consider a block of aligned pattern sequences denoted as , , … . Each pattern contains tokens , , …, . We visualize these sequences of patterns as an alignment matrix, where each row represents a pattern in the block as depicted in Figure 2. Intuitively, for any given column, if the frequency of a certain token is high, the token position should belong to a constant. On the other hand if a column corresponds to a variable, there should be a lot more variation in the column values. For each column where frequency of mode is denoted as , we label it as a constant if it satisfies the heuristic constraint defined in equation 2.
[TABLE]
where n is the number of patterns in the matrix and is an empirically determined constant. The remaining columns which do not satisfy equation 2 are labeled as variable columns.
A row is considered a misfit in the matrix if for any column labeled as a constant, the value of token is not same as the mode of . After eliminating misfit rows we simply return the reduced pattern by picking modal value tokens for constant columns and wildcards for variable columns.
II-F Iterative reduction
During the blocking stage, some similar patterns might end up in different blocks due to the approximate nature of LSH. To obtain the optimal set of patterns we iteratively repeat the steps described between subsections II-B and II-E until the number of patterns becomes constant.
III Filtering Error Logs
One of the key applications of log parsing techniques has been to filter out the anomalies from the logs of failed application runs. This helps in easier and swift error detection and in turn can save a lot of time for developers. This is especially true for applications like Apache Spark and Apache Hive where the size of logs can be as large as tens of gigabytes, making it nearly impossible to manually identify the errors from these logs. We identify the commonly occurring patterns by training Delog on logs of successful application runs. Then, we can filter the lines matching these patterns from the log files and in turn we will be left with anomalies, error messages and stack traces. The subsequent subsections describe the anomaly detection algorithm in further detail.
III-A Learning Patterns
To initialize the filtering model for a given application, we parse logs of previously successful runs of the application. However many a time, logs of successful job runs also contain some intermittent failures which succeed on retries. Hence, to avoid missing some key anomalies and errors in the the log file, not all of the patterns learned are used for filtering. We use a greedy approach where we first sort the patterns in our training data set on the basis of frequency and then we iteratively pick the patterns till we achieve a ninety eight percent coverage of the training dataset. The number of patterns selected through this approach will vary for each application type. For example, we observe that for the Spark dataset, we can achieve ninety eight percent coverage through only top five percent patterns. Moreover, we also observe that certain log lines like application start and application termination appear only once in each file but are present in all the files. Therefore, we make sure to include those patterns as well which are present in seventy percent log files or more.
III-B Preprocessing of Input Lines
The first step of the filtering algorithm is same as the first step of the training algorithm where we identify meaningful tokens from the log lines and convert the log lines into patterns. We cache these preprocessed patterns in order to avoid reprocessing the identical log lines in the subsequent stages.
III-C Candidate Pair Identification
In this step, we use minhash LSH [10] to match the lines obtained from the preprocessing stage with the set of patterns obtained from the training stage of the algorithm. For each preprocessed line, we identify candidate pairs by querying LSH for an empirically chosen Jaccard similarity threshold.
III-D LCS Matching
To concretely identify a valid match, we scan the candidate pairs to find the first pattern which satisfies the constraint given by equation 1. If the constraint is satisfied by at least one candidate pattern, we conclude that the corresponding log line is not of much relevance for error detection. Otherwise, we infer that the log line is an anomaly and should be included in the filtered logs.
III-E Frequency Based Filtering
The list of patterns generated from the training stage of the algorithm may not include all the possible log patterns which can be generated from a given application type. This is because the generated logs can depend on a variety of factors like application configurations, environment variables, user behavior etc. Therefore, it is possible to encounter log lines which do not match our trained data set but are of little value for anomaly and error detection. In order to avoid this, we keep a frequency filter for every unmatched log line such that,
[TABLE]
Where is the frequency of the log line and is a constant. We filter out the log lines that do not satisfy the constraint defined in equation 3 from our output and treat them similar to a pattern from the training set. The value of the constant needs to be determined empirically and depends on the application type. For example, we observe that two hundred and fifty is a suitable value for Spark applications.
IV Privacy Preserving Framework
In subsection III-E we present a way to improve performance on user logs in wild by tracking the frequency of preprocessed patterns. However, such an approach cannot re-utilize knowledge from previous application runs to improve the results in future. In this section, we propose a framework which can learn from user generated logs while preserving user privacy at the same time.
IV-A Client-Server Setup
On an online cloud computing platform, hundreds of users run their applications at any given point of time. The platform provider can run a service on the user systems which would aggregate and encode patterns from logs of successful application runs in a homomorphic fashion. These encoded patterns are then sent to a central repository. During the future runs of the application, the encoded log patterns can be fetched from the repository and utilized for matching.
IV-B Encoding of Log Patterns
Schnell et al. [12] in their work on record linking, show a novel use of bloom filters for homomorphic encoding of strings. For each pattern we create a bitmap by inserting hashes of token level shingles (n-grams) into a bloom filter as shown in Figure 4. It is extremely difficult to reconstruct input pattern from such an encoding. To compare any two patterns we can directly compute the Jaccard similarity of their corresponding bitmaps.
IV-C Processing at Server
After collecting the pattern encodings from all clients, the server creates blocks of similar patterns using LSH. Total frequency of each block is computed and the patterns are selected using a method similar to the one described in subsection III-A. These selected patterns are then communicated back to the clients. The LSH is configured with a high Jaccard similarity threshold, so as to minimize false positives.
IV-D Inference Procedure
In addition to the method described in section III, the clients use encoded log patterns received from the server. A log line which does not match to any of the pretrained patterns is then encoded and looked for in the set of encoded patterns. A LSH is used to speed up the search for candidate pairs and we validate the candidate patterns by computing Jaccard similarity between the bitmaps. Any pattern with a valid match is then excluded from the output.
V Evaluating Log Parser
V-A Experimental Setup
In this section, we compare Delog with some notable log parsing algorithms like SHISO [13], Spell [14], Drain [15], IPLoM [8] and Logan [4]. We run our experiments on Amazon EC2 r3.8xlarge instances with 32 virtual cores. We run Delog as a Spark application deployed in Yarn client mode on a five node cluster with 128 cores to take advantage of the distributed processing.
We omit results for some algorithms on specific datasets if they fail to finish processing in a reasonable time.
V-B Datasets
We evaluate Delog on 10 real-world datasets including seven publicly available datasets and three proprietary datasets. Six of these datasets comprise of distributed system logs, namely: Zookeeper [15], HDFS [16], HDFS2 [6], Spark, Presto and Hive. BGL [17], Thunderbird and HPC [18] datasets comprise of system logs from super-computers. Finally, Windows [6] dataset is made of operating system logs generated from computers running Windows 7. Each of Spark, Presto and Hive datasets are generated by thousands of unique queries run on Amazon Elastic Compute Cloud clusters used for analytics inside our organization. Since the Spark, Hive and Presto datasets are business sensitive and closed, our experiments on publicly available datasets of Thunderbird, Windows and HDFS made available by [6] provide scope for easier comparison with other distributed techniques in future.
The Thunderbird logs are largest by volume with a total of two hundred and eleven millions lines. Further more, it contains close to twenty seven thousand patterns due of which the existing distributed log parsing algorithms fail to parse in reasonable time. Our experiments with the Thunderbird dataset are the first reported results of log parsing on a dataset of such scale. Table I contains the details of size and number of log lines in these datasets.
V-C Evaluation Metric
Earlier works quantify the accuracy of log parser using metrics like F-measure. However, this involves manually obtaining patterns for the dataset. Since this is not feasible for large datasets like Hive [2] and Spark [1], we decide to use the quality loss metric used in Logan [4]. Quality loss is computed using equation 5 and it penalizes those patterns in which meaningful tokens are lost and converted into wildcards. Logan [4] uses another function called length factor which penalizes the algorithms for generating too many patterns. A naive parser which returns every single line in the dataset without any processing would have a zero quality loss, but would receive high penalty through length factor. On the other hand, an ideal log parser would minimize the number of log patterns while keeping the quality loss low. Although Logan combines quality loss and length factor to come up with a new loss function, we observe that it becomes difficult to capture the impact of quality factor this way. Therefore, we separately compare algorithms for their quality scores and the number of patterns they generate.
[TABLE]
[TABLE]
Where, where is the set of all identified patterns and is the average length of all sequences matched to pattern during training.
V-D Observations
V-D1 Parse Quality
Looking at the tables II and III, we observe that Delog consistently produces high quality patterns across datasets with a reasonable number of output patterns. High loss value along with fewer patterns in SHISO [13] suggests that many meaningful tokens are lost. IPLoM [8] performs well for HDFS [19] dataset but it fails in terms of quality of patterns when it comes to other datasets. Drain’s algorithm over simplifies log patterns leading to steep decline in the parse quality as we can see in the Presto dataset.
V-D2 Run Time
Table V shows that for most of the datasets, Delog outperforms other algorithms in run time efficiency. Since Delog uses minhash LSH to identify pattern blocks, we see that it performs better than the previous state-of-the-art, Logan222We obtain additional performance improvements over results reported by authors [4] by optimizing the number of shards such that parallelism is improved. [4] especially for large datasets. For the Hive dataset which has high number of patterns, Delog is 5x than Logan. Further, we find that Delog is the only log algorithm which can process the Thunderbird dataset in respectable amount of time because of its sub-linear complexity in number of patterns.
V-D3 Impact of Preprocessing
Table IV shows number of initial patterns obtained after the preprocessing stage. In most datasets, we see that the number of patterns after preprocessing is less than 0.5% of the original lines in the dataset. This can be attributed to the large number of numerical and URL variables in the log patterns. The rest of our training pipeline is dedicated to identifying string variables. Depending on the nature of the dataset, we notice a two to three fold reduction in the number of patterns after the iterative reduction step.
V-D4 Tuning MinHash LSH
We use Presto-5.2m dataset to demonstrate parameter tuning for pattern selection using quality loss and number of patterns. Figure 6 shows the impact of changing Jaccard Similarity threshold on the number of output patterns and the quality loss. We see that using a Jaccard similarity threshold of 0.7 for LSH blocking gives an optimal number of patterns along with a desirable quality loss value. Further increasing the Jaccard similarity threshold value leads to a steep increase in number of patterns for a marginal improvement in the quality loss. Similarly, if we decrease the Jaccard similarity threshold in order to reduce the number of patterns, we see that the quality of our patterns significantly goes down.
V-D5 Tuning LCS Matching Fraction
The LCS based regrouping of patterns described in subsection II-C helps in identification of incorrectly blocked patterns. We observe from figure 7 that changing LCS matching threshold () from 0.4 to 0.7 leads to a significant reduction in quality loss. However, further increase in LCS matching fraction from 0.8 to 0.9 leads to an enormous increase in number of patterns without any substantial dip in the quality loss. Though the optimal value of LCS matching fraction will vary from one dataset to another and needs to be determined empirically.
V-E Robustness of Hyperparameters
Our model requires tuning a number of hyperparameters such as LSH Jaccard Similarity threshold, LCS matching fraction and LSH Number of permutations. While working with massive log datasets, tuning hyperparameters could be costly and time consuming. Hence, we use a fixed set of hyperparameters as described in Table VI for all the reported results. We also perform an exhaustive grid search over Zookeeper, HPC, BGL and HDFS datasets to identify optimal hyperparameters by finding the elbow point. Table VIII shows that the optimal hyperparameters across the evaluated datasets have similar values, thus demonstrating the robustness of these hyperparameters.
VI Evaluating Privacy Preserving Filtering Framework
VI-A Experimental Setup
In order to evaluate our privacy preserving framework, we generate a synthetic data set. The set of patterns used to generate the synthetic dataset are divided into two groups, one representing patterns from ‘success’ and other representing patterns from ‘error’. The training set is generated using success patterns only, whereas the test set consists of both success and error patterns. We initialize our model with a fraction of success patterns and then learn rest of the success patterns in a privacy preserving manner. We calculate the false discovery rates and false negative rates for our model and compare them with those of a model trained on the complete training data to evaluate the correctness of our privacy preserving algorithm.
VI-B Dataset Generation
First, we extract all the patterns from a set of log files obtained from different applications and designate 75% of them as success patterns and remaining as error patterns. While generating the training set, we subdivide the success patterns into two sets. Patterns from the first set appear in every file of the training data, while the patterns from the other set are scattered among different files so as to ensure that no single file contains all the success patterns. Test set has similar distribution of success patterns along with randomly chosen mix of error patterns. Each of the training and test set contains eight files with fifteen-thousand lines each. The test and training data combined contain a total of 12968 patterns.
VI-C Observations
VI-C1 Training with Privacy Preserving Model
We initialized our clients by training them with one third of the training data. We sequentially process the remaining files in the training set to learn new patterns and update the set of pattern encodings. For the sake of this experiment, we skip the pattern selection part described in IV-C. We observe that once the model learns encodings for a given file, it can identify the learned patterns with zero false positives and an average false negative rate of 0.14%.
VI-C2 Evaluation on Test Data
Once trained with pattern encodings, we then run our model on the test set. Table IX shows a comparison of the performance of our privacy preserving model (M2) against a model (M3) trained on entirety of the training set and a model (M1) trained only with one third train data set without our privacy preserving updates. We consider model (M3) as the source of truth to calculate false negative and false discovery rate. As Table IX shows, privacy preserving learning helps in reducing the number of output patterns to half. We gain a twofold reduction in false discovery rate while the false negative rate stays at about two percent. Since, while debugging an application we do not want to miss any important line which may contain information relevant to problem identification, we tune the LSH parameters to minimize the false negative rate.
VII Related Works
VII-A Log Parsing
Log parsing is a widely studied subject and various groups have attempted to devise several log parsing techniques in the past. Fu et al. [20] cluster log lines on the basis of weighted edit distance. On the other hand, LKE [7], POP [5] and IPLoM [8] attempt to segregate the log lines in various clusters such that all the lines in a cluster correspond to the same template. However, each of the above groups have used different techniques to cluster the log lines. LKE [7] use the edit distance between between each pair of log lines whereas POP [5] and IPLoM [8] use number of tokens in a line to create initial clusters. POP [5] and IPLoM [8] further split these initial clusters by identifying the tokens which occur most frequently at a given position and then splitting the clusters at these positions. IPLoM [8] then find bijective relations between unique tokens, while POP [5] use relative frequency analysis for further subdivision of these clusters.
Vaarandi et al. [21] use a different technique where they identify most commonly occurring tokens in the logs and use them to represent each template. Makanju et al. [22] use a simple technique of iteratively partitioning logs into sub-partitions to extract log events.
Logan [4], Drain [15] and Spell [14] update log lines in order to reduce compute and memory overheads. Logan uses distributed compute with Apache Spark to reduce the training time. However, Zhu et al. [6] show that these existing techniques deteriorate in both accuracy and performance when datasets contain large number of unique patterns. As we show in section V, Delog scales notably well on datasets with large number of patterns.
VII-B Log Processing for Problem Identification
Use of machine learning and data mining techniques for anomaly detection in application logs is becoming increasingly common. Liang et al. [23] use a SVM classifier whereas Lou et al. [24] propose mining the invariants among log events to detect errors and anomalies.
Log3C [25] uses a cascading clustering algorithm for clustering log sequences. These clustered sequences are then correlated with system Key Performance Indicators (KPI) using regression analysis. The clusters having high correlation with actual problems are identified. Similarly, Yuan et al. Beschastnikh et al.[26], Shang et al. [27] and Ding et al. [28, 29] have proposed some other problem identification techniques but most relevant to our work is the log classification method proposed by Lin et al. [30]. They generate vector encoding of log sequences using Inverse Document Frequency (IDF) scores to calculate the similarity between client logs and stack traces of already known errors. However, this method requires log sequence level indicators of the application state and cannot be used in a privacy sensitive environment.
VIII Conclusion
For most of the datasets, Delog fares almost two times better in training time performance as compared to the previous state of the art, Logan [4]. Moreover, the quality of patterns generated by Delog is also consistently better than the existing parsing algorithms. We use a minhash based LSH algorithm to obtain sub-linear complexity in number of patterns. The Thunderbird, Windows and Spark datasets used by us are the largest datasets to be used for log parsing so far. Delog is the only log parsing algorithm which is able to successfully parse the Thunderbird dataset in a respectable amount of time. We also perform exhaustive hyperparameter search across four datasets to demonstate the robustness of hyperparameter across datasets.
Delog also uses a privacy preserving technique to constantly learn new patterns from client logs. User logs are homomorphically encrypted using a novel bloom filter based approach. We perform experiments on a synthetic dataset to demonstrate the efficacy of this approach in log filtering.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica, “Spark: Cluster computing with working sets.” Hot Cloud , vol. 10, no. 10-10, p. 95, 2010.
- 2[2] A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka, N. Zhang, S. Antony, H. Liu, and R. Murthy, “Hive-a petabyte scale data warehouse using hadoop,” in Data Engineering (ICDE), 2010 IEEE 26th International Conference on . IEEE, 2010, pp. 996–1005.
- 3[3] “Presto: Distributed sql query engine for big data.” [Online]. Available: https://prestodb.io/
- 4[4] A. Agrawal, R. Karlupia, and R. Gupta, “Logan: A distributed online log parser,” in 35th IEEE International Conference on Data Engineering . IEEE, 2019.
- 5[5] P. He, J. Zhu, S. He, J. Li, and M. R. Lyu, “Towards automated log parsing for large-scale log data analysis,” IEEE Transactions on Dependable and Secure Computing , 2017.
- 6[6] J. Zhu, S. He, J. Liu, P. He, Q. Xie, Z. Zheng, and M. R. Lyu, “Tools and benchmarks for automated log parsing,” ar Xiv preprint ar Xiv:1811.03509 , 2018.
- 7[7] Q. Fu, J.-G. Lou, Y. Wang, and J. Li, “Execution anomaly detection in distributed systems through unstructured log analysis,” in Data Mining, 2009. ICDM’09. Ninth IEEE International Conference on . IEEE, 2009, pp. 149–158.
- 8[8] A. Makanju, A. N. Zincir-Heywood, and E. E. Milios, “A lightweight algorithm for message type extraction in system application logs,” IEEE Transactions on Knowledge and Data Engineering , vol. 24, no. 11, pp. 1921–1936, 2012.