SECTOR: A Neural Model for Coherent Topic Segmentation and Classification
Sebastian Arnold, Rudolf Schneider, Philippe Cudr\'e-Mauroux, Felix A., Gers, Alexander L\"oser

TL;DR
SECTOR is a neural model that segments documents into coherent sections and classifies their topics, supported by a new large dataset, achieving significant improvements over previous methods.
Contribution
We introduce SECTOR, a neural architecture for joint topic segmentation and classification, along with WikiSection, a large dataset for training and evaluation.
Findings
Achieved 71.6% F1 in segmenting and classifying topics in English city documents.
SECTOR outperforms previous CNN-based classifiers by 29.5 F1 points.
Demonstrated effectiveness across multiple architectures and languages.
Abstract
When searching for information, a human reader first glances over a document, spots relevant sections and then focuses on a few sentences for resolving her intention. However, the high variance of document structure complicates to identify the salient topic of a given section at a glance. To tackle this challenge, we present SECTOR, a model to support machine reading systems by segmenting documents into coherent sections and assigning topic labels to each section. Our deep neural network architecture learns a latent topic embedding over the course of a document. This can be leveraged to classify local topics from plain text and segment a document at topic shifts. In addition, we contribute WikiSection, a publicly available dataset with 242k labeled sections in English and German from two distinct domains: diseases and cities. From our extensive evaluation of 20 architectures, we report…
Click any figure to enlarge with its caption.
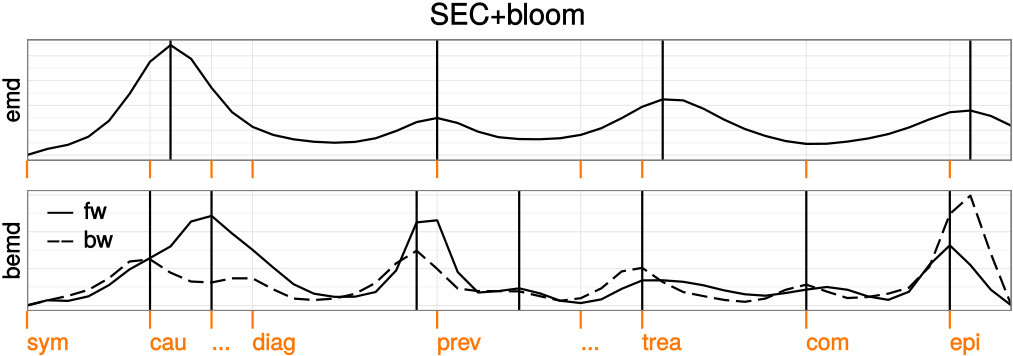 Figure 1
Figure 1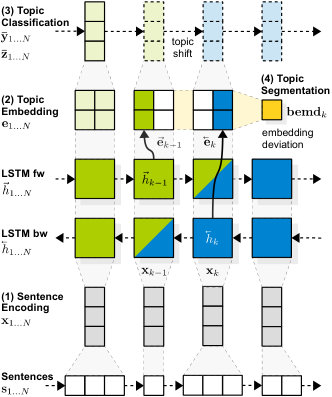 Figure 2
Figure 2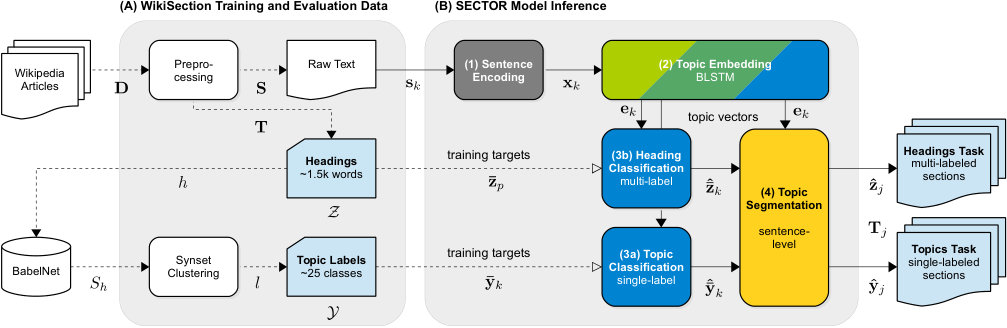 Figure 3
Figure 3 Figure 4
Figure 4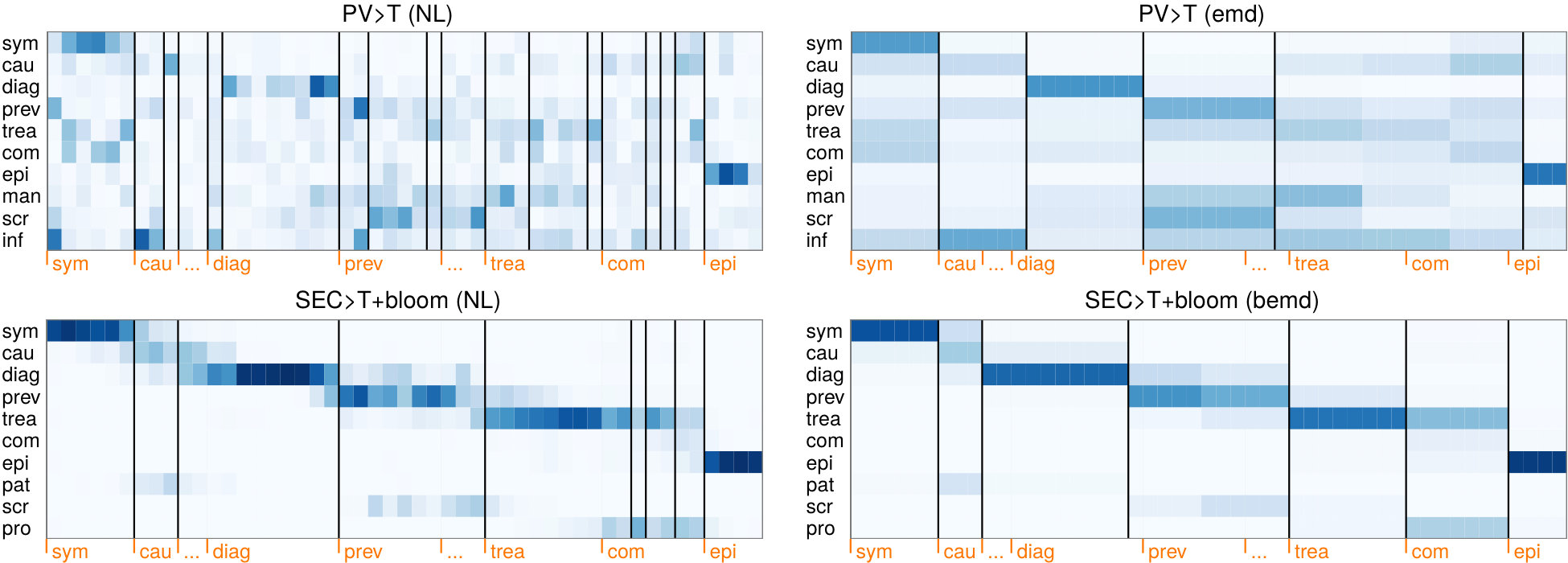 Figure 5
Figure 5| Dataset | disease | city | ||
|---|---|---|---|---|
| language | en | de | en | de |
| total docs | 3.6k | 2.3k | 19.5k | 12.5k |
| avg sents per doc | 58.5 | 45.7 | 56.5 | 39.9 |
| avg sects per doc | 7.5 | 7.2 | 8.3 | 7.6 |
| headings | 8.5k | 6.1k | 23.0k | 12.2k |
| topics | 27 | 25 | 30 | 27 |
| coverage | 94.6% | 89.5% | 96.6% | 96.1% |
| rank | heading | label | freq | |||||||
| 0 | Diagnosis | diagnosis | 0.68 | 3,854 | ||||||
| \hdashline1 | Treatment | treatment | 0.69 | 3,501 | ||||||
\hdashline
|
|
|
|
|
||||||
| \hdashline … | ||||||||||
\hdashline
|
|
|
|
|
||||||
| \hdashline22 | Pathogenesis | mechanism | 0.16 | 205 | ||||||
| \hdashline23 | Medications | medication | 0.14 | 186 | ||||||
| \hdashline … | ||||||||||
\hdashline
|
|
|
|
|
||||||
\hdashline
|
|
|
|
|
||||||
\hdashline
|
|
|
|
|
||||||
|
|
|
|
|
|||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| model configuration | segm. | ||||||||||||||||||||||
| Classification with newline prior segmentation | |||||||||||||||||||||||
| PV>T* | NL | 35.6 | 31.7 | 47.2 | 36.0 | 29.6 | 44.5 | 22.5 | 52.9 | 63.9 | 27.2 | 42.9 | 55.5 | ||||||||||
| CNN>T* | NL | 31.5 | 40.4 | 55.6 | 31.6 | 38.1 | 53.7 | 13.2 | 66.3 | 76.1 | 13.7 | 63.4 | 75.0 | ||||||||||
| SEC>T+bow | NL | 25.8 | 54.7 | 68.4 | 25.0 | 52.7 | 66.9 | 21.0 | 43.7 | 55.3 | 20.2 | 40.5 | 52.2 | ||||||||||
| SEC>T+bloom | NL | 22.7 | 59.3 | 71.9 | 27.9 | 50.2 | 65.5 | 9.8 | 74.9 | 82.6 | 11.7 | 73.1 | 81.5 | ||||||||||
| SEC>T+emb* | NL | 22.5 | 58.7 | 71.4 | 23.6 | 50.9 | 66.8 | 10.7 | 74.1 | 82.2 | 10.7 | 74.0 | 83.0 | ||||||||||
| Classification and segmentation on plain text | |||||||||||||||||||||||
| C99 | 37.4 | n/a | n/a | 42.7 | n/a | n/a | 36.8 | n/a | n/a | 38.3 | n/a | n/a | |||||||||||
| TopicTiling | 43.4 | n/a | n/a | 45.4 | n/a | n/a | 30.5 | n/a | n/a | 41.3 | n/a | n/a | |||||||||||
| TextSeg | 24.3 | n/a | n/a | 35.7 | n/a | n/a | 19.3 | n/a | n/a | 27.5 | n/a | n/a | |||||||||||
| PV>T* | max | 43.6 | 20.4 | 36.5 | 44.3 | 19.3 | 34.6 | 31.1 | 28.1 | 43.1 | 36.4 | 20.2 | 35.5 | ||||||||||
| PV>T* | emd | 39.2 | 32.9 | 49.3 | 37.4 | 32.9 | 48.7 | 24.9 | 53.1 | 65.1 | 32.9 | 40.6 | 55.0 | ||||||||||
| CNN>T* | max | 40.1 | 26.9 | 45.0 | 40.7 | 25.2 | 43.8 | 21.9 | 42.1 | 58.7 | 21.4 | 42.1 | 59.5 | ||||||||||
| SEC>T+bow | max | 30.1 | 40.9 | 58.5 | 32.1 | 38.9 | 56.8 | 24.5 | 28.4 | 43.5 | 28.0 | 26.8 | 42.6 | ||||||||||
| SEC>T+bloom | max | 27.9 | 49.6 | 64.7 | 35.3 | 39.5 | 57.3 | 12.7 | 63.3 | 74.3 | 26.2 | 58.9 | 71.6 | ||||||||||
| SEC>T+bloom | emd | 29.7 | 52.8 | 67.5 | 35.3 | 44.8 | 61.6 | 16.4 | 65.8 | 77.3 | 26.0 | 65.5 | 76.7 | ||||||||||
| SEC>T+bloom | bemd | 26.8 | 56.6 | 70.1 | 31.7 | 47.8 | 63.7 | 14.4 | 71.6 | 80.9 | 16.8 | 70.8 | 80.1 | ||||||||||
| SEC>T+bloom+rank* | bemd | 26.8 | 56.7 | 68.8 | 33.1 | 44.0 | 58.5 | 15.7 | 71.1 | 79.1 | 18.0 | 66.8 | 76.1 | ||||||||||
| SEC>T+emb* | bemd | 26.3 | 55.8 | 69.4 | 27.5 | 48.9 | 65.1 | 15.5 | 71.6 | 81.0 | 16.2 | 71.0 | 81.1 | ||||||||||
|
|
|
|
|
|||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| model configuration | segm. | ||||||||||||||||||||||
| CNN>H* | max | 40.9 | 36.7 | 31.5 | 41.3 | 14.1 | 21.1 | 36.9 | 43.3 | 46.7 | 42.2 | 40.9 | 46.5 | ||||||||||
| SEC>H+bloom | bemd | 35.4 | 35.8 | 38.2 | 36.9 | 31.7 | 37.8 | 20.0 | 65.2 | 62.0 | 23.4 | 49.8 | 53.4 | ||||||||||
| SEC>H+bloom+rank | bemd | 40.2 | 47.8 | 49.0 | 42.8 | 28.4 | 33.2 | 41.9 | 66.8 | 59.0 | 34.9 | 59.6 | 54.6 | ||||||||||
| SEC>H+emb* | bemd | 30.7 | 50.5 | 57.3 | 32.9 | 26.6 | 36.7 | 17.9 | 72.3 | 71.1 | 19.3 | 68.4 | 70.2 | ||||||||||
| SEC>H+emb+rank* | bemd | 30.5 | 47.6 | 48.9 | 42.9 | 32.0 | 36.4 | 16.1 | 65.8 | 59.0 | 18.3 | 69.2 | 58.9 | ||||||||||
| SEC>H+emb@fullwiki* | bemd | 42.4 | 9.7 | 17.9 | 42.7 | (0.0) | (0.0) | 20.3 | 59.4 | 50.4 | 38.5 | (0.0) | (0.1) | ||||||||||
| Segmentation | Wiki-50 | Cities | Elements | Clinical | |||
|---|---|---|---|---|---|---|---|
| and multi-label classification | |||||||
| GraphSeg | 63.6 | n/a | 40.0 | n/a | 49.1 | n/a | – |
| BayesSeg | 49.2 | n/a | 36.2 | n/a | 35.6 | n/a | 57.8 |
| TextSeg | 18.2* | n/a | 19.7* | n/a | 41.6 | n/a | 30.8 |
| SEC>H+emb@en_disease | – | – | – | – | 43.3 | 9.5 | 36.5 |
| SEC>C+emb@en_disease | – | – | – | – | 45.1 | n/a | 35.6 |
| SEC>H+emb@en_city | 30.0 | 31.4 | 28.2 | 56.5 | 41.0 | 7.9 | – |
| SEC>C+emb@en_city | 31.3 | n/a | 22.9 | n/a | 48.8 | n/a | – |
| SEC>H+emb@cities | 33.3 | 15.3 | 21.4* | 52.3* | 39.2 | 12.1 | 37.7 |
| SEC>H+emb@fullwiki | 28.6* | 32.6* | 33.4 | 40.5 | 42.8 | 14.4 | 36.9 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Natural Language Processing Techniques · Text and Document Classification Technologies
MethodsSigmoid Activation · Tanh Activation · Long Short-Term Memory
SECTOR: A Neural Model for Coherent Topic Segmentation
and Classification
Sebastian Arnold
Rudolf Schneider
Beuth University of Applied
Sciences Berlin, Germany
{sarnold, ruschneider}@
beuth-hochschule.de &Philippe Cudré-Mauroux
University of Fribourg
Fribourg, Switzerland
[email protected] &Felix A. Gers
Alexander Löser
Beuth University of Applied
Sciences Berlin, Germany
{gers, aloeser}@
beuth-hochschule.de
Abstract
When searching for information, a human reader first glances over a document, spots relevant sections and then focuses on a few sentences for resolving her intention. However, the high variance of document structure complicates to identify the salient topic of a given section at a glance. To tackle this challenge, we present SECTOR, a model to support machine reading systems by segmenting documents into coherent sections and assigning topic labels to each section. Our deep neural network architecture learns a latent topic embedding over the course of a document. This can be leveraged to classify local topics from plain text and segment a document at topic shifts. In addition, we contribute WikiSection, a publicly available dataset with 242k labeled sections in English and German from two distinct domains: diseases and cities. From our extensive evaluation of 20 architectures, we report a highest score of 71.6% F1 for the segmentation and classification of 30 topics from the English city domain, scored by our SECTOR LSTM model with bloom filter embeddings and bidirectional segmentation. This is a significant improvement of 29.5 points F1 compared to state-of-the-art CNN classifiers with baseline segmentation.
1 Introduction
Today’s systems for natural language understanding are comprised of building blocks that extract semantic information from the text, such as named entities, relations, topics or discourse structure. In traditional natural language processing (NLP), these extractors are typically applied to bags of words or full sentences Hirschberg and Manning (2015). Recent neural architectures build upon pre-trained word or sentence embeddings Mikolov et al. (2013); Le and Mikolov (2014), which focus on semantic relations that can be learned from large sets of paradigmatic examples, even from long ranges Dieng et al. (2017).
From a human perspective, however, it is mostly the authors themselves who help best to understand a text. Especially in long documents, an author thoughtfully designs a readable structure and guides the reader through the text by arranging topics into coherent passages Glavaš et al. (2016). In many cases, this structure is not formally expressed as section headings (e.g. in news articles, reviews, discussion forums) or it is structured according to domain-specific aspects (e.g. health reports, research papers, insurance documents).
Ideally, systems for text analytics, such as topic detection and tracking (TDT) Allan (2002), text summarization Huang et al. (2003), information retrieval (IR) Dias et al. (2007) or question answering (QA) Cohen et al. (2018) could access a document representation that is aware of both topical (i.e. latent semantic content) and structural information (i.e. segmentation) in the text MacAvaney et al. (2018). The challenge in building such a representation is to combine these two dimensions which are strongly interwoven in the author’s mind. It is therefore important to understand topic segmentation and classification as a mutual task that requires to encode both topic information and document structure coherently.
In this article, we present Sector111 Our source code is available under the Apache License 2.0 at https://github.com/sebastianarnold/SECTOR, an end-to-end model which learns an embedding of latent topics from potentially ambiguous headings and can be applied to entire documents to predict local topics on sentence level. Our model encodes topical information on a vertical dimension and structural information on a horizontal dimension. We show that the resulting embedding can be leveraged in a downstream pipeline to segment a document into coherent sections and classify the sections into one of up to 30 topic categories reaching 71.6% – or alternatively attach up to 2.8k topic labels with 71.1% MAP. We further show that segmentation performance of our bidirectional LSTM architecture is comparable to specialized state-of-the-art segmentation methods on various real-world datasets.
To the best of our knowledge, the combined task of segmentation and classification has not been approached on full document level before. There exist a large number of datasets for text segmentation, but most of them do not reflect real-world topic drifts Choi (2000); Sehikh et al. (2017), do not include topic labels Eisenstein and Barzilay (2008); Jeong and Titov (2010); Glavaš et al. (2016) or are heavily normalized and too small to be used for training neural networks Chen et al. (2009). We can utilize a generic segmentation dataset derived from Wikipedia that includes headings Koshorek et al. (2018), but there is also a need in IR and QA for supervised structural topic labels Agarwal and Yu (2009); MacAvaney et al. (2018), different languages and more specific domains, such as clinical or biomedical research Tepper et al. (2012); Tsatsaronis et al. (2012) and news-based TDT Kumaran and Allan (2004); Leetaru and Schrodt (2013).
Therefore we introduce WikiSection222The dataset is available under the CC BY-SA 3.0 license at https://github.com/sebastianarnold/WikiSection, a large novel dataset of 38k articles from the English and German Wikipedia labeled with 242k sections, original headings and normalized topic labels for up to 30 topics from two domains: diseases and cities. We chose these subsets to cover both clinical/biomedical aspects (e.g. symptoms, treatments, complications) and news-based topics (e.g. history, politics, economy, climate). Both article types are reasonably well-structured according to Wikipedia guidelines Piccardi et al. (2018), but we show that they are also complementary: diseases is a typical scientific domain with low entropy, i.e. very narrow topics, precise language and low word ambiguity. In contrast, cities resembles a diversified domain, with high entropy, i.e. broader topics, common language and higher word ambiguity, and will be more applicable to e.g. news, risk reports or travel reviews.
We compare Sector to existing segmentation and classification methods based on latent dirichlet allocation (LDA), paragraph embeddings, convolutional neural networks (CNNs) and recurrent neural networks (RNNs). We show that Sector significantly improves these methods in a combined task by up to 29.5 points when applied to plain text with no given segmentation.
The rest of this article is structured as follows: We introduce related work in Section 2. Next, we describe the task and dataset creation process in Section 3. We formalize our model in Section 4. We report results and insights from the evaluation in Section 5. Finally, we conclude in Section 6.
2 Related Work
The analysis of emerging topics over the course of a document is related to a large number of research areas. In particular, topic modeling Blei et al. (2003) and topic detection and tracking (TDT) Jin et al. (1999) focus on representing and extracting the semantic topical content of text. Text segmentation Beeferman et al. (1999) is used to split documents into smaller coherent chunks. Finally, text classification Joachims (1998) is often applied to detect topics on text chunks. Our method unifies those strongly interwoven tasks and is the first to evaluate the combined topic segmentation and classification task using a corresponding dataset with long structured documents.
Topic modeling
is commonly applied to entire documents using probabilistic models, such as latent Dirichlet allocation (LDA) Blei et al. (2003). AlSumait et al. (2008) introduced an online topic model that captures emerging topics when new documents appear. Gabrilovich and Markovitch (2007) proposed the Explicit Semantic Analysis method in which concepts from Wikipedia articles are indexed and assigned to documents. Later, and to overcome the vocabulary mismatch problem, Cimiano et al. (2009) introduced a method for assigning latent concepts to documents. More recently, Liu et al. (2016) represented documents with vectors of closely related domain keyphrases. Yeh et al. (2016) proposed a conceptual dynamic LDA model for tracking topics in conversations. Bhatia et al. (2016) utilized Wikipedia document titles to learn neural topic embeddings and assign document labels. Dieng et al. (2017) focused on the issue of long-range dependencies and proposed a latent topic model based on recurrent neural networks (RNNs). However, the authors did not apply the RNN to predict local topics.
Text segmentation
has been approached with a wide variety of methods. Early unsupervised methods utilized lexical overlap statistics Hearst (1997); Choi (2000), dynamic programming Utiyama and Isahara (2001), Bayesian models Eisenstein and Barzilay (2008) or point-wise boundary sampling Du et al. (2013) on raw terms.
Later, supervised methods included topic models Riedl and Biemann (2012) by calculating a coherence score using dense topic vectors obtained by LDA. Bayomi et al. (2015) exploited ontologies to measure semantic similarity between text blocks. Alemi and Ginsparg (2015) and Naili et al. (2017) studied how word embeddings can improve classical segmentation approaches. Glavaš et al. (2016) utilized semantic relatedness of word embeddings by identifying cliques in a graph.
More recently, Sehikh et al. (2017) utilized long short-term memory (LSTM) networks and showed that cohesion between bidirectional layers can be leveraged to predict topic changes. In contrast to our method, the authors focused on segmenting speech recognition transcripts on word level without explicit topic labels. The network was trained with supervised pairs of contrary examples and was mainly evaluated on artificially-segmented documents. Our approach extends this idea so it can be applied to dense topic embeddings which are learned from raw section headings.
Wang et al. (2017) tackled segmentation by training a CNN to learn coherence scores for text pairs. Similar to Sehikh et al. (2017), the network was trained with short contrary examples and no topic objective. The authors showed that their point-wise ranking model performs well on datasets by Jeong and Titov (2010). In contrast to our method, the ranking algorithm strictly requires a given ground truth number of segments for each document and no topic labels are predicted.
Koshorek et al. (2018) presented a large new dataset for text segmentation based on Wikipedia that includes section headings. The authors introduced a neural architecture for segmentation which is based on sentence embeddings and four layers of bidirectional LSTM. Similar to Sehikh et al. (2017), the authors used a binary segmentation objective on sentence level, but trained on entire documents. Our work takes up this idea of end-to-end training and enriches the neural model with a layer of latent topic embeddings that can be utilized for topic classification.
Text classification
is mostly applied at paragraph or sentence level using machine learning methods such as Support Vector Machines Joachims (1998) or, more recently, shallow and deep neural networks Hoa T. Le et al. (2018); Conneau et al. (2017). Notably, Paragraph Vectors Le and Mikolov (2014) is an extension of word2vec for learning fixed-length distributed representations from texts of arbitrary length. The resulting model can be utilized for classification by providing paragraph labels during training. Furthermore, Kim (2014) has shown that convolutional neural networks (CNNs) combined with pre-trained task-specific word embeddings achieve highest scores for various text classification tasks.
Combined approaches
of topic segmentation and classification are rare to find. Agarwal and Yu (2009) approached to classify sections of BioMed Central articles into four structural classes (introduction, methods, results and discussion). However, their manually-labeled dataset only contains a sample of sentences from the documents, so they evaluated sentence classification as an isolated task. Chen et al. (2009) introduced two Wikipedia-based datasets for segmentation, one about large cities, the second about chemical elements. While these datasets have been used to evaluate word-level and sentence-level segmentation Koshorek et al. (2018), we are not aware of any topic classification approach on this dataset.
Tepper et al. (2012) approached segmentation and classification in a clinical domain as supervised sequence labeling problem. The documents were segmented using a Maximum Entropy model and then classified into 11 or 33 categories. A similar approach by Ajjour et al. (2017) used sequence labeling with a small number of 3–6 classes. Their model is extractive, so it does not produce a continuous segmentation over the entire document. Finally, Piccardi et al. (2018) did not approach segmentation, but recommended an ordered set of section labels based on Wikipedia articles.
Eventually, we are inspired by passage retrieval Liu and Croft (2002) as an important downstream task for topic segmentation and classification. For example, Hewlett et al. (2016) proposed WikiReading, a QA task to retrieve values from sections of long documents. The objective of TREC Complex Answer Retrieval is to retrieve a ranking of relevant passages for a given outline of hierarchical sections Nanni et al. (2017). Both tasks highly depend on a building block for local topic embeddings such as our proposed model.
3 Task Overview and Dataset
We start with a definition of the WikiSection machine reading task shown in Figure 1. We take a document consisting of consecutive sentences and empty segmentation as input. In our example, this is the plain text of a Wikipedia article (e.g. about Trichomoniasis333https://en.wikipedia.org/w/index.php?title=Trichomoniasis&oldid=814235024) without any section information. For each sentence , we assume a distribution of local topics that gradually changes over the course of the document.
The task is to split into a sequence of distinct topic sections , so that each predicted section contains a sequence of coherent sentences and a topic label that describes the common topic in these sentences. For the document Trichomoniasis, the sequence of topic labels is symptom, cause, diagnosis, prevention, treatment, complication, epidemiology .
3.1 WikiSection Dataset
For the evaluation of this task, we created WikiSection, a novel dataset containing a gold standard of 38k full-text documents from English and German Wikipedia comprehensively annotated with sections and topic labels (see Table 1).
The documents originate from recent dumps in English444https://dumps.wikimedia.org/enwiki/20180101 and German555https://dumps.wikimedia.org/dewiki/20180101. We filtered the collection using SPARQL queries against Wikidata Tanon et al. (2016). We retrieved instances of Wikidata categories disease (Q12136) and their subcategories, e.g. Trichomoniasis or Pertussis, or city (Q515), e.g. London or Madrid.
Our dataset contains the article abstracts, plain text of the body, positions of all sections given by the Wikipedia editors with their original headings (e.g. "Causes | Genetic sequence") and a normalized topic label (e.g. disease.cause). We randomized the order of documents and split them into 70% training, 10% validation, 20% test sets.
3.2 Preprocessing
To obtain plain document text, we used Wikiextractor666http://attardi.github.io/wikiextractor/, split the abstract sections and stripped all section headings and other structure tags except newline characters and lists.
Vocabulary mismatch in section headings.
Table 3.2 shows examples of section headings from disease articles separated into head (most common), torso (frequently used) and tail (rare). Initially, we expected articles to share congruent structure in naming and order. Instead, we observe a high variance with 8.5k distinct headings in the diseases domain and over 23k for English cities. A closer inspection reveals that Wikipedia authors utilize headings at different granularity levels, frequently copy and paste from other articles, but also introduce synonyms or hyponyms, which leads to a vocabulary mismatch problem Furnas et al. (1987). As a result, the distribution of headings is heavy-tailed across all articles. Roughly 1% of headings appear more than 25 times while the vast majority (88%) appear 1 or 2 times only.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Agarwal and Yu (2009) Shashank Agarwal and Hong Yu. 2009. Automatically classifying sentences in full-text biomedical articles into introduction, methods, results and discussion. Bioinformatics , 25(23):3174–3180.
- 2Ajjour et al. (2017) Yamen Ajjour, Wei-Fan Chen, Johannes Kiesel, Henning Wachsmuth, and Benno Stein. 2017. Unit segmentation of argumentative texts. In Proceedings of the 4th Workshop on Argument Mining , pages 118–128.
- 3Alemi and Ginsparg (2015) Alexander A. Alemi and Paul Ginsparg. 2015. Text segmentation based on semantic word embeddings. Co RR , cs.CL/1503.05543 v 1.
- 4Allan (2002) James Allan. 2002. Introduction to topic detection and tracking. In Topic Detection and Tracking , pages 1–16. Springer.
- 5Al Sumait et al. (2008) Loulwah Al Sumait, Daniel Barbará, and Carlotta Domeniconi. 2008. On-line LDA: Adaptive topic models for mining text streams with applications to topic detection and tracking. In Eighth IEEE International Conference on Data Mining , pages 3–12. IEEE.
- 6Arora et al. (2017) Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2017. A simple but tough-to-beat baseline for sentence embeddings. In ICLR 2017: 5th International Conference on Learning Representations .
- 7Bayomi et al. (2015) M. Bayomi, K. Levacher, M. R. Ghorab, and S. Lawless. 2015. Onto Seg: A novel approach to text segmentation using ontological similarity. In 2015 International Conference on Data Mining Workshop , pages 1274–1283. IEEE.
- 8Beeferman et al. (1999) Doug Beeferman, Adam Berger, and John Lafferty. 1999. Statistical models for text segmentation. Machine Learning , 34(1):177–210.