Low-rank tensor approximation for Chebyshev interpolation in parametric option pricing
Kathrin Glau, Daniel Kressner, Francesco Statti

TL;DR
This paper introduces a low-rank tensor approximation method using tensor train format to efficiently perform high-dimensional Chebyshev interpolation in parametric option pricing, overcoming the curse of dimensionality.
Contribution
It extends Chebyshev interpolation for high-dimensional problems by exploiting low-rank tensor structures, enabling efficient computation in up to 25-dimensional parameter spaces.
Findings
The method effectively handles high-dimensional parameter spaces in option pricing.
Numerical results show the low-rank structure and efficiency of the approach.
Compared to existing techniques, the proposed method demonstrates superior performance.
Abstract
Treating high dimensionality is one of the main challenges in the development of computational methods for solving problems arising in finance, where tasks such as pricing, calibration, and risk assessment need to be performed accurately and in real-time. Among the growing literature addressing this problem, Gass et al. [14] propose a complexity reduction technique for parametric option pricing based on Chebyshev interpolation. As the number of parameters increases, however, this method is affected by the curse of dimensionality. In this article, we extend this approach to treat high-dimensional problems: Additionally exploiting low-rank structures allows us to consider parameter spaces of high dimensions. The core of our method is to express the tensorized interpolation in tensor train (TT) format and to develop an efficient way, based on tensor completion, to approximate the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2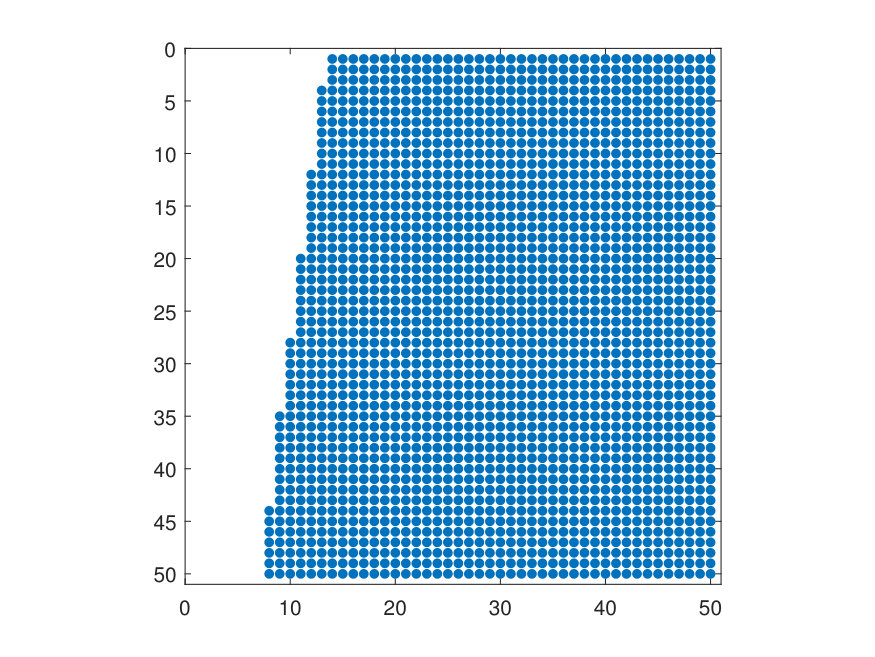 Figure 3
Figure 3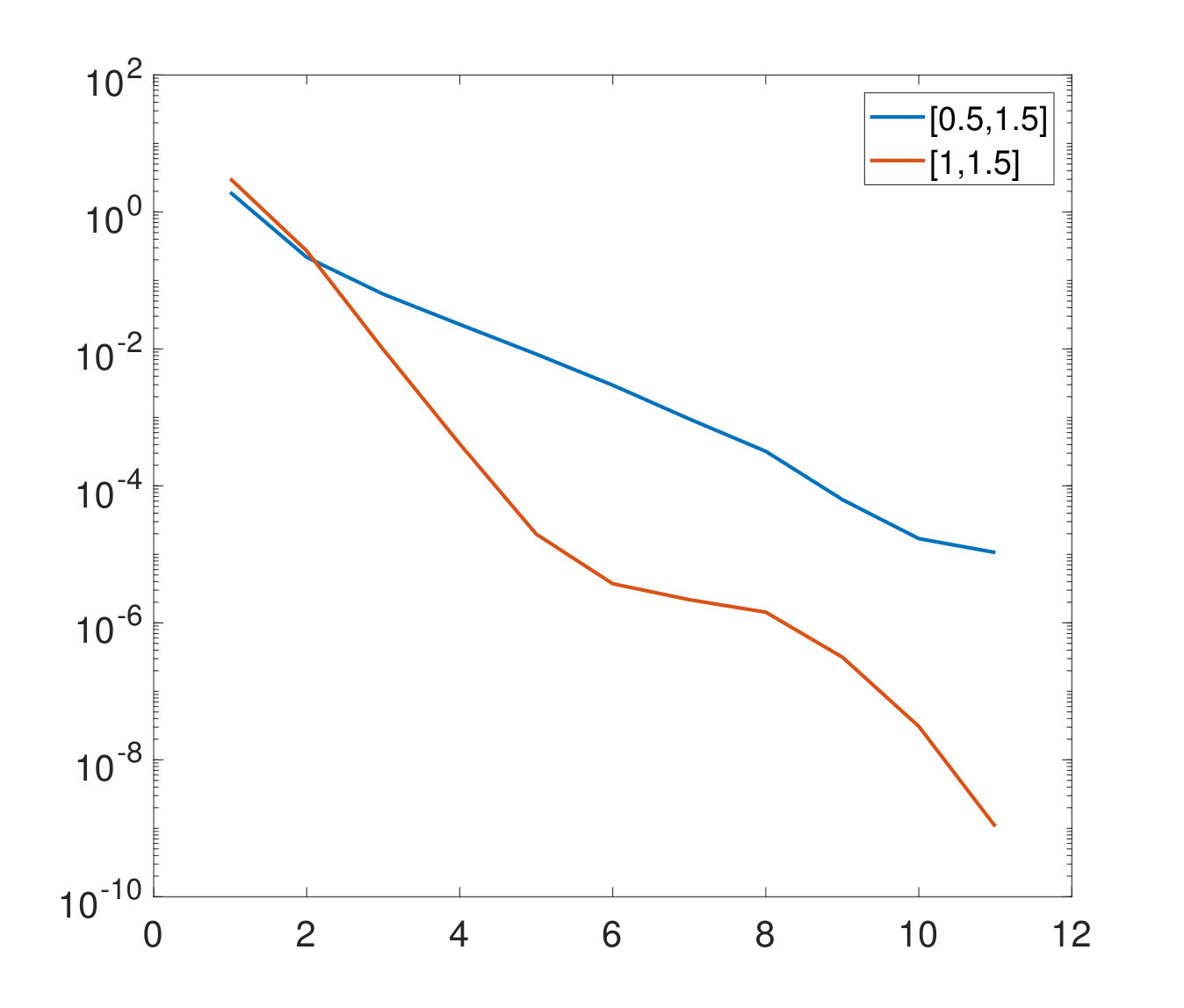 Figure 4
Figure 4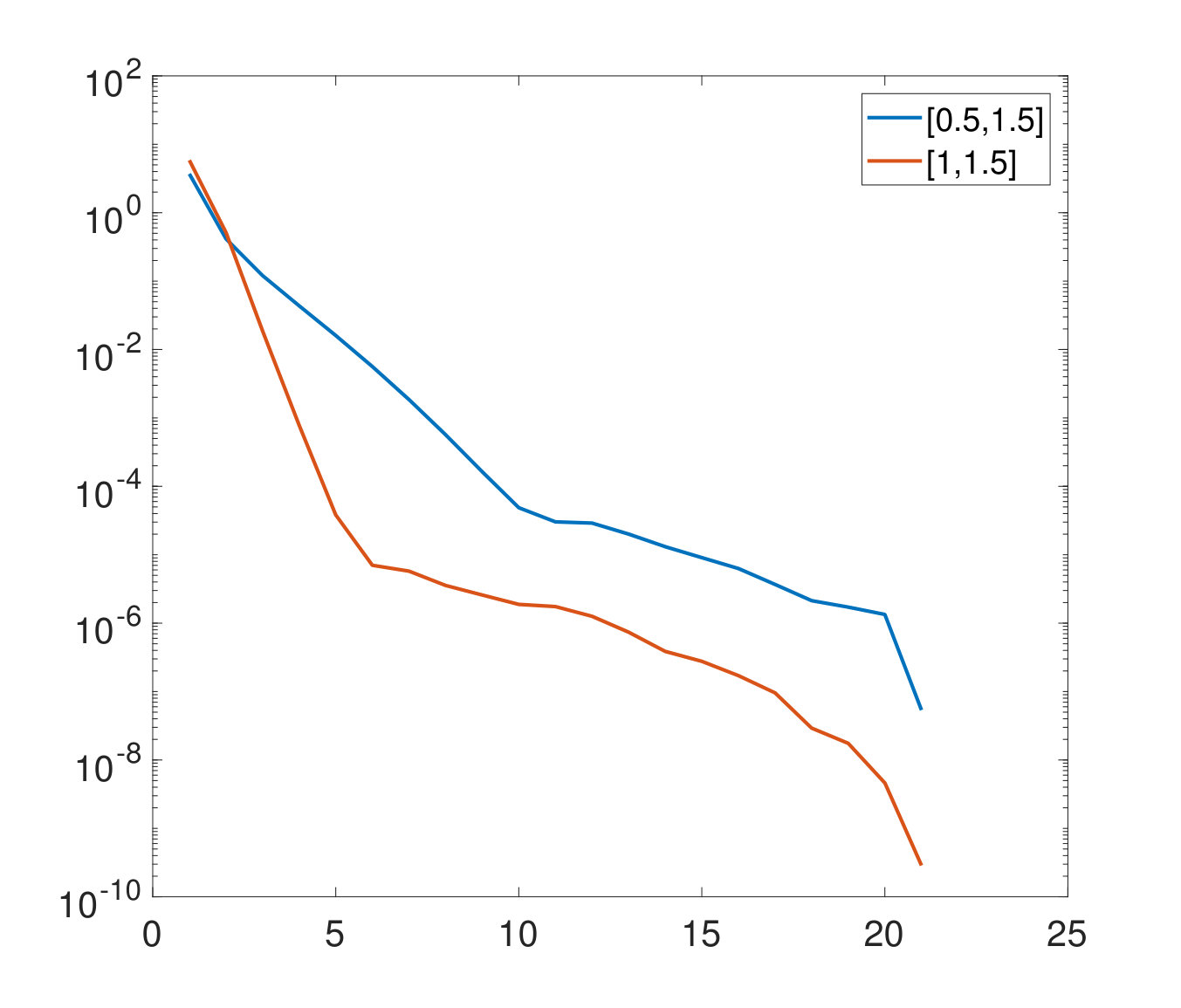 Figure 5
Figure 5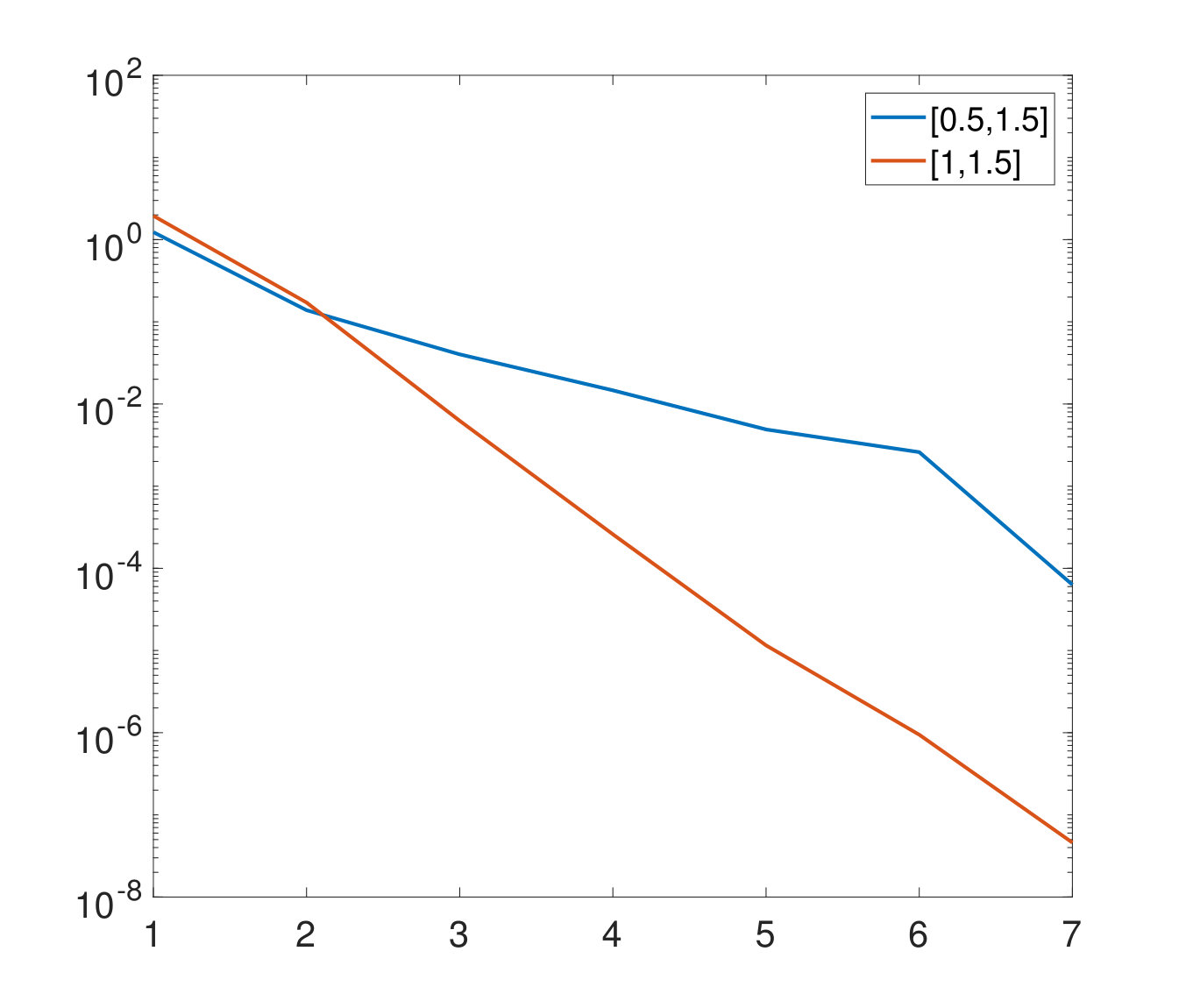 Figure 6
Figure 6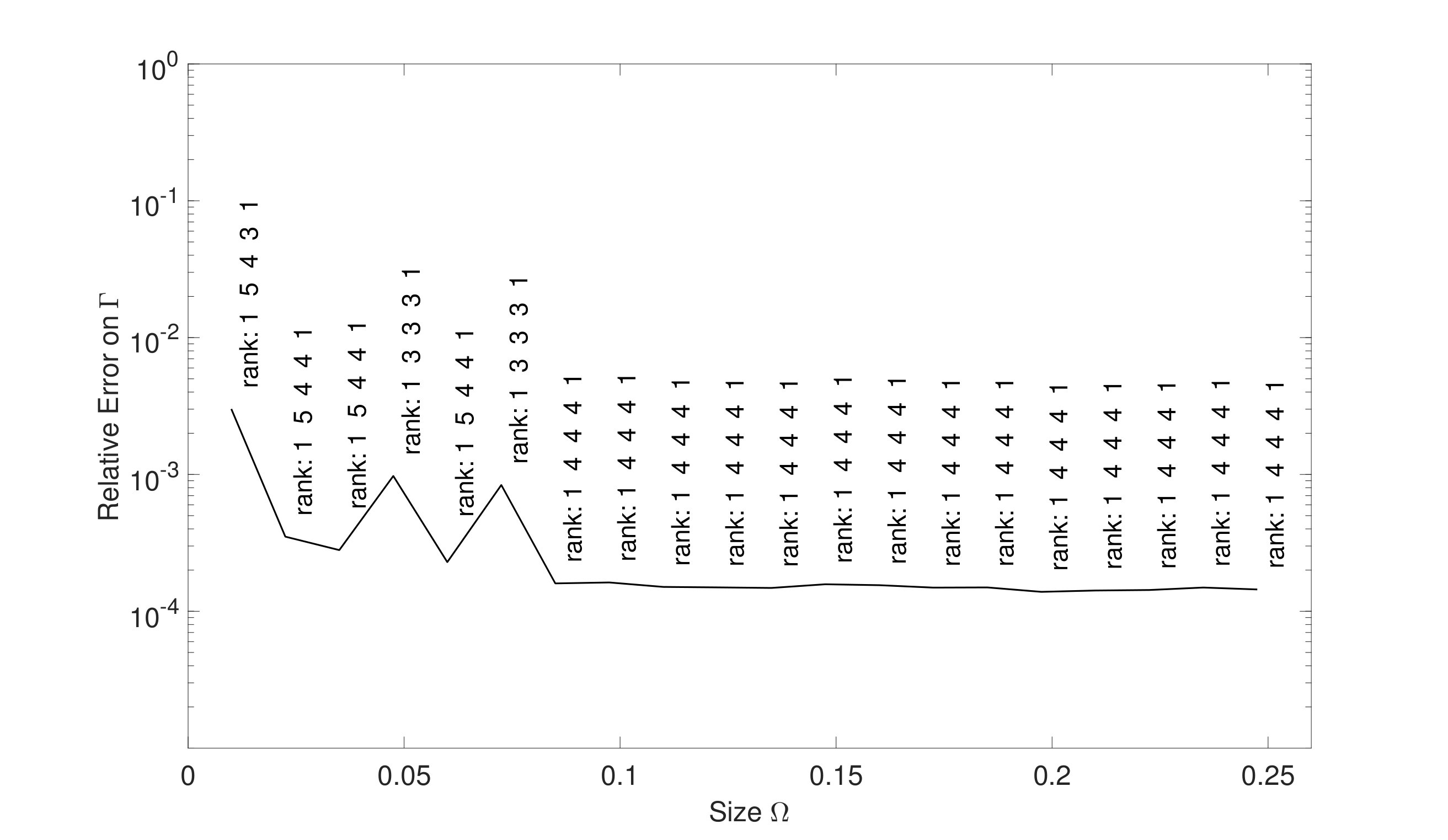 Figure 7
Figure 7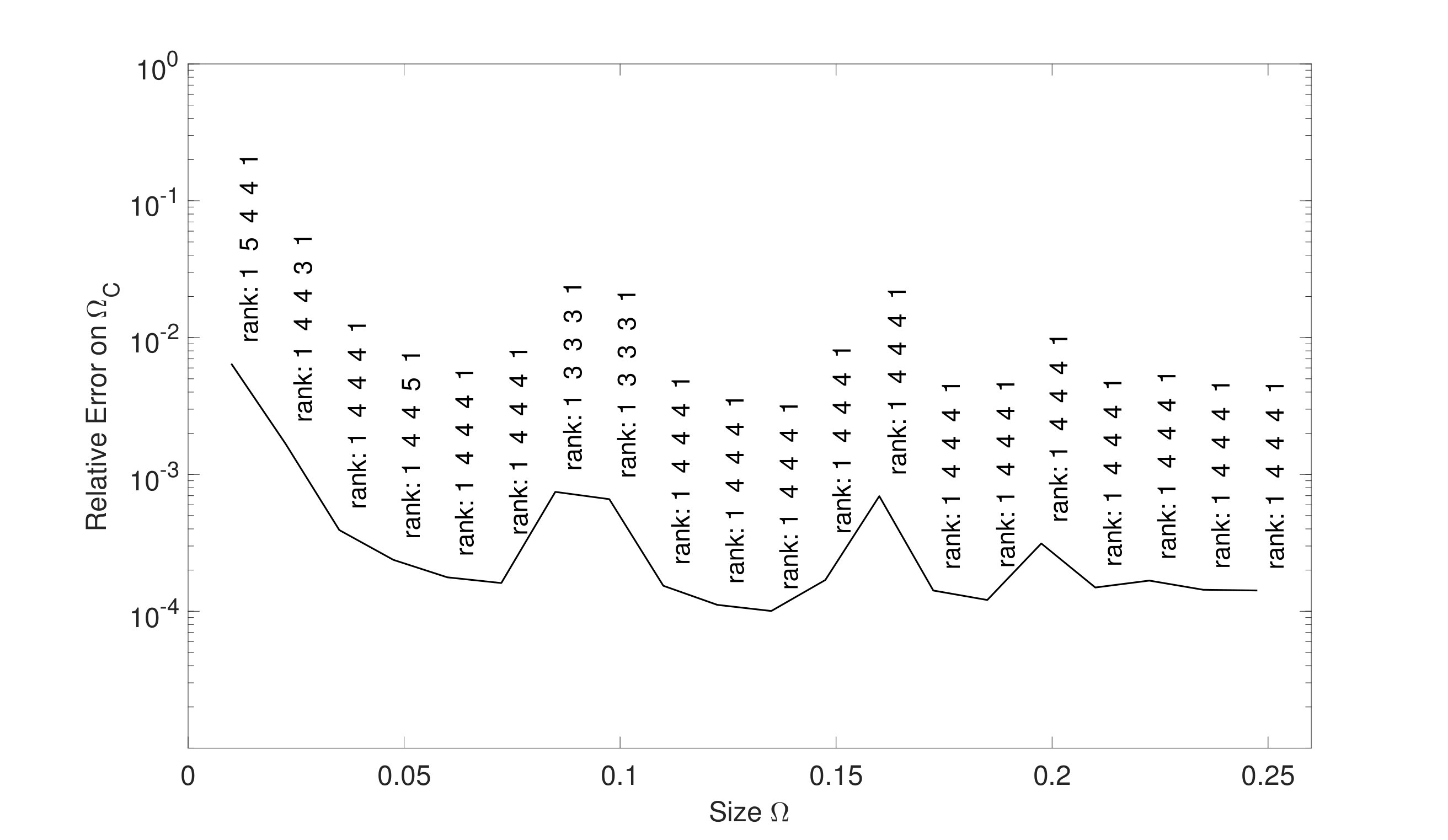 Figure 8
Figure 8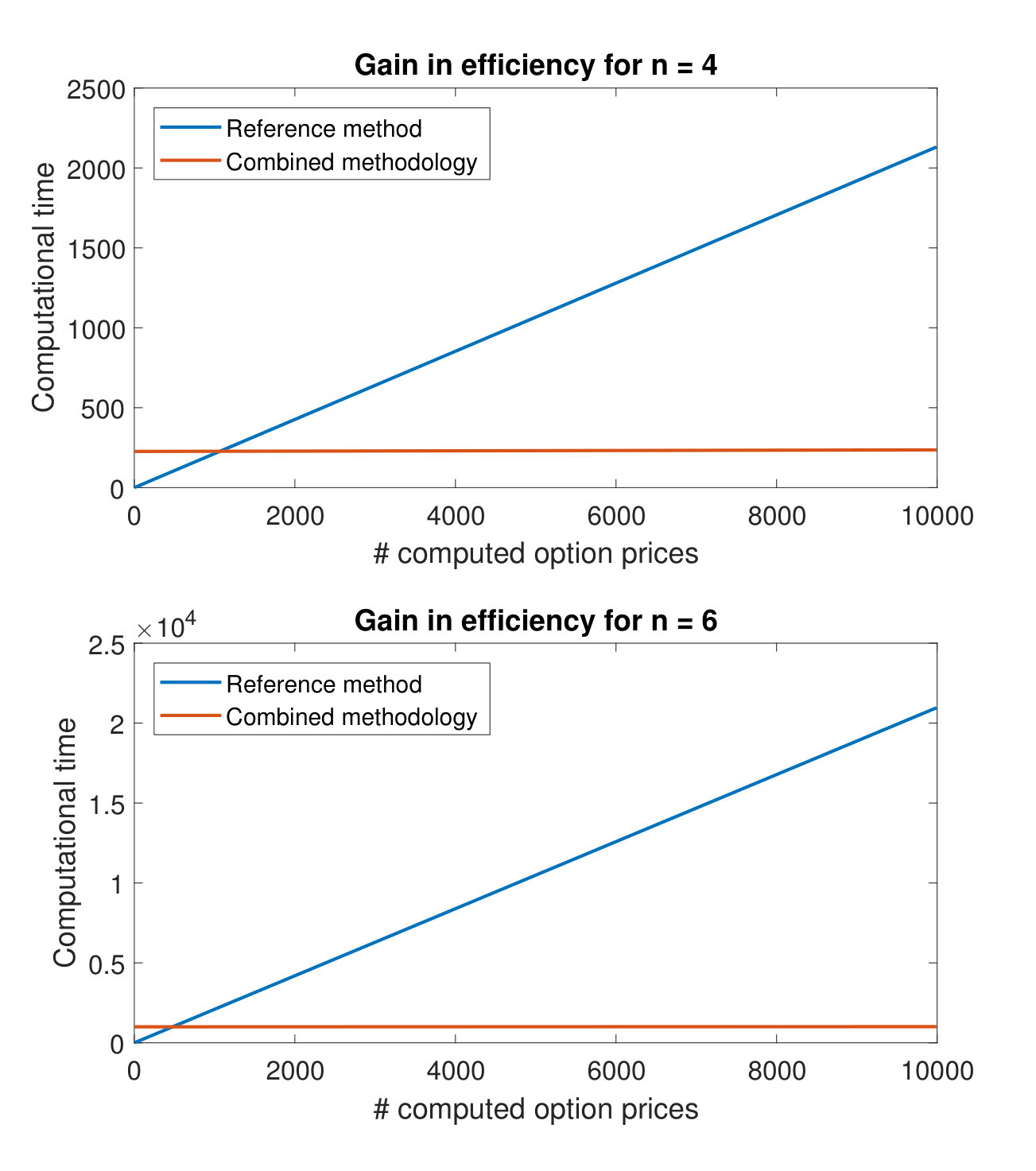 Figure 9
Figure 9 Figure 10
Figure 10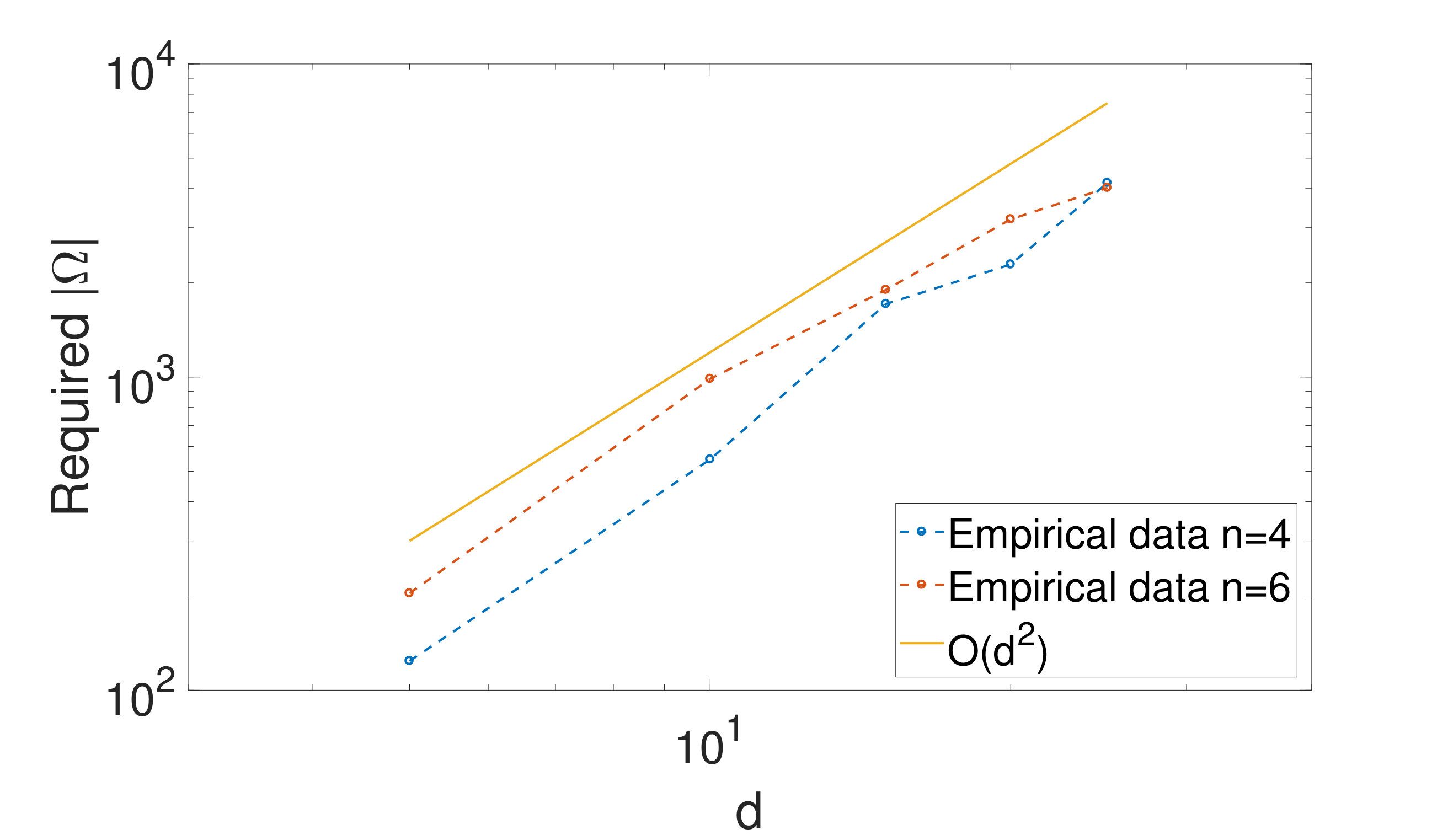 Figure 11
Figure 11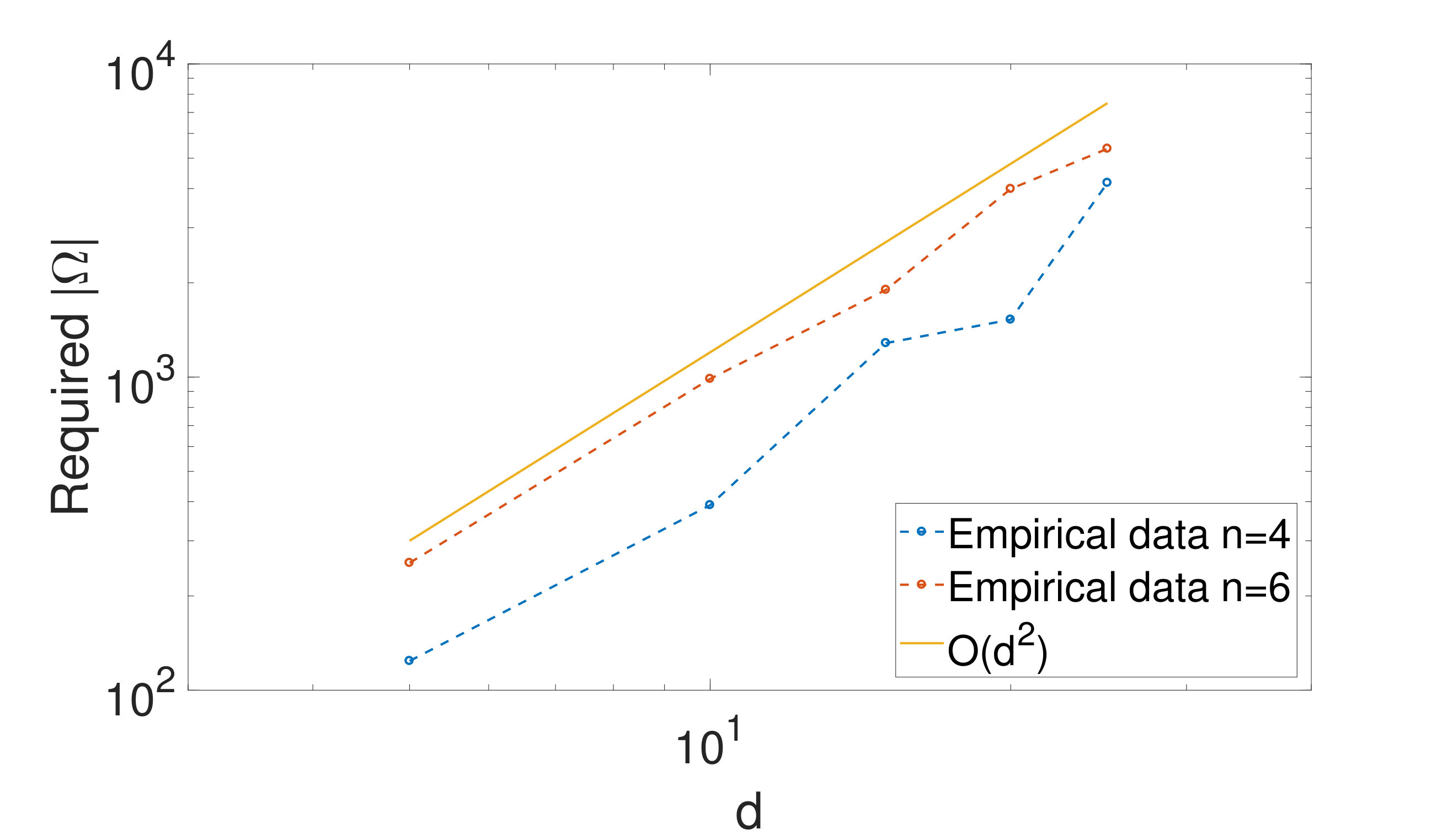 Figure 12
Figure 12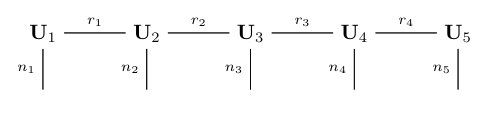 Figure 2
Figure 2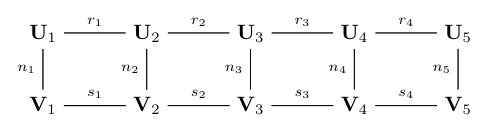 Figure 14
Figure 14| final | rel err on last | rel err on full | completion time (s) |
|---|---|---|---|
| 8050 (5 %) | 366.12 |
| time reference method (s) | time interpolation (s) | max abs error |
|---|---|---|
| initial | ||||||||
|---|---|---|---|---|---|---|---|---|
| 5 | 0 | 31 | 31 | |||||
| 10 | 0 | 78 | 78 | |||||
| 15 | 0 | 214 | 214 | |||||
| 20 | 0 | 763 | 763 | |||||
| 25 | 0 | 2086 | 2086 | |||||
| 5 | 0 | 17 | 17 | |||||
| 10 | 0 | 282 | 141 | |||||
| 15 | 0 | 475 | 475 | |||||
| 20 | 0 | 798 | 798 | |||||
| 25 | 0 | 1341 | 1341 |
| final | rel err on last | completion time (s) | ||
|---|---|---|---|---|
| 5 | 124 | 9.90 | ||
| 10 | 546 | 67.44 | ||
| 15 | 1712 | 171.14 | ||
| 20 | 2289 | 193.90 | ||
| 25 | 4172 | 226.38 | ||
| 5 | 204 | 52.55 | ||
| 10 | 987 | 198.27 | ||
| 15 | 1900 | 429.39 | ||
| 20 | 3192 | 732.49 | ||
| 25 | 4023 | 999.25 |
| time reference method (s) | time interpolation (s) | max abs error | ||
|---|---|---|---|---|
| 5 | ||||
| 10 | ||||
| 15 | ||||
| 20 | ||||
| 25 | ||||
| 5 | 1.84 | |||
| 10 | 1.91 | |||
| 15 | 1.99 | |||
| 20 | 2.04 | |||
| 25 | 2.10 |
| final | rel err on last | completion time (s) | ||
|---|---|---|---|---|
| 5 | 124 | 8.95 | ||
| 10 | 390 | 65.73 | ||
| 15 | 1284 | 118.73 | ||
| 20 | 1526 | 168.20 | ||
| 25 | 4172 | 215.44 | ||
| 5 | 255 | 66.54 | ||
| 10 | 987 | 200.15 | ||
| 15 | 1900 | 432.58 | ||
| 20 | 3990 | 852.13 | ||
| 25 | 5364 | 1335.76 |
| time reference method (s) | time interpolation (s) | max abs error | ||
|---|---|---|---|---|
| 5 | 0.18 | |||
| 10 | 0.20 | |||
| 15 | 0.20 | |||
| 20 | 0.23 | |||
| 25 | 0.23 | |||
| 5 | 1.85 | |||
| 10 | 1.90 | |||
| 15 | 1.99 | |||
| 20 | 2.06 | |||
| 25 | 2.15 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Low-rank tensor approximation for Chebyshev interpolation in parametric option pricing111The authors would like to thank Jonas Ballani for helpful discussions on this work.
Kathrin Glau222Queen Mary University of London, Mile End Road, E1 4NS London, United Kingdom, [email protected]
Daniel Kressner333École Polytechnique Fédérale de Lausanne, Station 8, 1015 Lausanne, Switzerland ([email protected], http://anchp.epfl.ch)
Francesco Statti444École Polytechnique Fédérale de Lausanne, Station 8, 1015 Lausanne, Switzerland ([email protected], http://people.epfl.ch/francesco.statti). Research supported through the European Research Council under the European Unionfls Seventh Framework Programme (FP/2007-2013) / ERC Grant Agreement n. 307465-POLYTE.
(February 11, 2019)
Abstract
Treating high dimensionality is one of the main challenges in the development of computational methods for solving problems arising in finance, where tasks such as pricing, calibration, and risk assessment need to be performed accurately and in real-time. Among the growing literature addressing this problem, Gass et al. [14] propose a complexity reduction technique for parametric option pricing based on Chebyshev interpolation. As the number of parameters increases, however, this method is affected by the curse of dimensionality. In this article, we extend this approach to treat high-dimensional problems: Additionally exploiting low-rank structures allows us to consider parameter spaces of high dimensions. The core of our method is to express the tensorized interpolation in tensor train (TT) format and to develop an efficient way, based on tensor completion, to approximate the interpolation coefficients. We apply the new method to two model problems: American option pricing in the Heston model and European basket option pricing in the multi-dimensional Black-Scholes model. In these examples we treat parameter spaces of dimensions up to 25. The numerical results confirm the low-rank structure of these problems and the effectiveness of our method compared to advanced techniques.
Key words
Chebyshev interpolation, parametric option pricing, high-dimensional problem, tensor train format, low-rank tensor approximation, tensor completion
1 Introduction
Financial problems are, by their nature, multi- and high-dimensional, because a large number of risk factors contribute to the prices of each financial asset. Moreover, the banking, insurance and hedge fund industry draws on investments in large portfolios. The interdependencies of both the risk factors and the assets make basic computational tasks such as model calibration, pricing, and hedging as well as more global tasks such as uncertainty quantification, risk assessment and capital reserve calculation computationally extremely challenging, see for instance [5].
Automatic and high-speed trading challenge the computational methods in that the results need to be available fast and with minimal storage requirement. Moreover, we observe rising regulatory requirements. On the one hand, more realistic modeling demands more prudent considerations, which leads to rising computational complexity. On the other hand, the availability of requested performance characteristics is expected to be delivered within shorter periods of time. This poses a high challenge for traditional approaches, which typically suffer from low convergence rates in higher dimensions, see for instance [9, 12].
For the reasons explained above, the development of efficient computational methods for high-dimensional problems in finance is an utmost active field of research in both academia and industry. For example, further developments of the Monte Carlo method have been very successfully applied to financial problems; we refer to [35, 16] for the quasi Monte Carlo method and to [15] for the multilevel Monte Carlo method. Besides stochastic integration, deterministic numerical integration has been exploited using sparse grid techniques, see [19, 27, 6]. Also PDE methods have been extended to multivariate problems in finance. For instance using operator splitting methods as in [28], principal component analysis and expansions as in [42], and wavelet compression techniques proposed in [36, 25, 26].
Exploiting the particular structure of a problem, complexity reduction techniques exhibit great potential to save run-time and storage capacity while maintaining the required accuracy. In numerical analysis and a large variety of applications, for example in engineering and medicine, complexity reduction techniques have been developed and implemented with great success. For instance the field of reduced basis methods to efficiently solve parametric partial differential equations (PDEs) has experienced a tremendous development over the last decade, see, e.g., [23, 40, 41] and the references therein. Pioneered by [43, 10] the potential of reduced basis methods is also increasingly exploited for problems in finance; see [8, 37, 7] for examples. These methods can be viewed as high-dimensional interpolation methods that are trained in an offline step to solve a specific class of parametric PDEs. In this article we explore direct interpolation of multivariate functions as a unified approach to complexity reduction for finance.
Our starting point is the tensorized Chebyshev interpolation of conditional expectations in the parameter and state space, as introduced in [14]. Having observed for a large set of applications that these functions are highly regular, admitting sensitivities of high order or even being analytic, and that the domain of interest can be restricted to a hyperrectangular, Chebyshev interpolation is a promising choice: Its convergence is subexponential for multivariate analytic functions, its implementation is numerically stable, and the coefficients are simply given by a linear transformation of the function values at the nodal points. In this article we exploit this favorable structure further for high dimensionality. In passing, we point out that, while we choose Chebyshev interpolation for the reasons listed in this paragraph, the technique presented in this paper extends to other tensorized interpolation techniques. Also, our approach is applicable beyond option pricing and finance.
The basis of our approach is the following. In an offline phase, the price as function of parameters , is evaluated at selected parameter samples to prepare an approximation by tensorized Chebyshev polynomials with pre-computed Fourier coefficients , as follows,
[TABLE]
To evaluate the function in the online phase, only the multivariate polynomials on the right-hand side need to be evaluated. However, implementing (1) in a straightforward manner exposes the method to the curse of dimensionality in both the offline and the online phase: In the offline phase, the prices need to be evaluated on a tensorized grid of Chebyshev nodes, amounting to parameter samples when nodes are required for each parameter. This is computationally costly, especially if the underlying pricing method is already computationally demanding. In the online phase alike, operations are needed for evaluating the approximating multivariate polynomial. Even for a number as low as , corresponding to quadratic polynomials, a problem with parameters becomes infeasible.
One approach to breaking the curse of dimensionality that has already proven effective in a number of areas is to exploit low-rank structures of high-dimensional tensors; see [18, 20, 29] and the references therein. These techniques reduce, sometimes dramatically, memory requirements and the cost of operating with tensors. In the context of parametric PDEs, low-rank tensor structures have been successfully exploited in, e.g., [1, 4, 30, 34, 45]. As option prices are characterized as solutions of parabolic PDEs, this gives hope that low-rank structures can be exploited in finance as well. The following questions arise:
Can we detect low-rank structures for the problem of form (1)? Existing theoretical studies only provide partial answers to this question, either not reflecting the observed effectiveness of low-rank techniques or being limited to rather specific function classes; see [11, 20, 44] for examples. We therefore approach the question from an experimental perspective and analyze examples of different nature and different dimensionality in Section 3. The results clearly indicate an approximate low-rank structure of the tensor containing the prices evaluated at the nodes of the tensorized Chebyshev grid. In the specific case of the interpolation of American option prices in the Heston model in five parameters we can explicitly compare the full tensor with the one resulting from low-rank approximation. We perform this comparison in Section 3.1, which confirms the low-rank structure of . In Section 3.2 we consider prices of basket options in the Black-Scholes model with up to underlyings and interpolate in the initial values of the underlyings. Although the resulting full tensor is too large to be explicitly computed and compared with, we provide a structural analysis in Section 3.2.3 that explains why is expected to exhibit low-rank structure.
How can we exploit low-rank structures for the problem of form (1)? Expressing the problem in a tensor format reveals that exploiting the tensor structure itself (even without low-rank structure) leads to a considerable efficiency gain in both the offline and the online phase. Next, we explore existing low-rank tensor techniques. In order to efficiently exploit these techniques for problem (1), we need to introduce several new components resulting in the new method. We detail these steps below.
In order to construct the interpolation coefficients in the offline phase, it is first required to compute or approximate all values of the tensor , containing the prices in the tensorized Chebyshev grid. Evaluating explicitly is too costly for larger , especially when the underlying pricing procedure is computationally expensive. Instead we only compute part of the entries of and then need to deal with an incomplete tensor. This leads us to the following first step:
We start by computing the prices for a small portion of the Chebyshev grid points only. Then, we adapt a completion algorithm (in Section 2.3) which allows us to approximate the tensor of prices for the complete Chebyshev grid by fitting tensors of pre-specified low rank to the provided data points. As it is not reasonable to assume a priori knowledge of low-rank structure, the completion procedure needs to be combined with an adaptive rank and sampling strategy. Specifically, we repeat the process of adding new samples and increasing the pre-specified rank until an adequate stopping criterion is fulfilled. This completion algorithm is designed to work with tensors built and stored in tensor train (TT) format.
With the low-rank approximation of the tensor in TT format at hand, we can then approximate efficiently the Fourier coefficients . This is the last step of the offline phase:
The computation of the tensor , containing the Fourier coefficients , is computed by a sequence of tensor-matrix multiplications. The particular structure of the involved matrices facilitates the use of the fast Fourier transform, leading to a complexity of , where is determined by the ranks of . This step is explained in Section 2.4.2.
Suppose now that, in the online phase, we want to compute the interpolated price (1) for a new set of parameter samples. Given the tensor in TT format, the evaluation of (1) for a price is performed efficiently as follows:
First, each of the Chebyshev polynomials involved in the tensorized Chebyshev basis is evaluated in . It turns out that (1) can be viewed as inner product between and a rank-one tensor. Thanks to the TT format, the complexity of computing this inner product is ; see Section 2.2. As long as is reasonably small, this compares favorably with the operations needed by the standard approach.
In Section 3, we test the performance of the new method for two different option pricing problems, the interpolation of
- –
American option prices in the Heston model in parameters, and of
- –
prices of basket options in the Black-Scholes model in up to underlyings.
At comparable accuracy, the interpolation in American option prices reveals a promising gain in efficiency when compared to an ADI-based PDE solver. The efficiency gain for the basket option prices is shown in comparison to a Monte Carlo simulation with variance reduction.
2 TT format and tensor completion for Chebyshev interpolation
This section describes the methodology proposed in this work. We start with recalling the tensorized Chebyshev interpolation method from [14]. After introducing the TT format [39], we present and extend the tensor completion approach from [45]. Finally, we explain how to combine these algorithms in order to efficiently price parametric options for a large number of parameters.
2.1 Chebyshev interpolation for parametric option pricing
We consider an option price that depends on a vector of parameters contained in ; general hyperrectangular parameter domains can be addressed by a suitable affine transformation. The basic idea developed in [14] consists of using tensorized Chebyshev interpolation in the parameters (model and payoff parameters) to increase the efficiency of computing option prices, while maintaining satisfactory accuracy. Writing for the price evaluated in , the Chebyshev interpolation of order with is given by
[TABLE]
The basis functions are constructed from Chebyshev polynomials by
[TABLE]
and the coefficients are defined as
[TABLE]
where indicates that the first and the last summand are halved. The tensor contains the prices on the tensorized Chebyshev grid:
[TABLE]
where is defined via Chebyshev nodes for and . A convergence analysis of the tensorized Chebyshev interpolation in the setting of option pricing is given in [14].
The tensor in equation (4) is of order and size . The interpolation procedure first requires to compute each entry of this tensor with the reference method. This becomes expensive when the interpolation order and the dimension increase. We will use tensor completion to lower this cost.
Remark 2.1** (Choice of interpolation order).**
In our numerical experiments, the interpolation order is chosen a priori for simplicity. However, this choice can be made adaptively as explained in [22] for the case (the extension to general is straightforward).
2.2 TT format
For recalling the TT format introduced in [39], we consider a general tensor of order . For each , the entries of can be rearranged into a matrix
[TABLE]
which is called the th unfolding of . For this purpose, the first indices of are merged into the row index and the last indices into a column index; see [39] for a formal definition. The TT ranks of form an integer tuple
[TABLE]
Every entry can be expressed as a product of matrices
[TABLE]
with a matrix of size . For each , one can then collect the matrices , into a third order tensor of size . These tensors are called TT cores and, by construction, we have
[TABLE]
Figure 1 illustrates this so-called TT decomposition by a tensor network diagram [38].
Provided that the TT ranks remain moderate, a significant memory reduction is obtained by storing instead of the TT cores: from to , where and .
Some operations can be effected quite cheaply in the TT format for tensors of low TT ranks. Let us first consider the inner product of two tensors defined as
[TABLE]
where stacks the entries of a tensor into a long vector. The corresponding tensor network diagram when and are both in TT decomposition is shown in Figure 2. It can be seen that the summations in (7) become contractions between the TT cores of and . By carrying out these contractions of cores from the left to right, the cost of evaluating the inner product reduces from to , where denotes the maximum of all involved TT ranks.
The mode- matrix multiplication between a tensor and a matrix results in a tensor defined by
[TABLE]
We will denote this operation by . If is in TT decomposition (6) then it is straightforward to obtain a TT decomposition for , by performing a mode- matrix multiplication of with . Letting denote the cost of multiplying with a vector, this requires operations instead of the operations needed when is a general tensor.
2.3 Completion algorithm
The goal of completion algorithms is to reconstruct a given data set from a small fraction of its entries. As this is clearly an ill-posed task, one needs to additionally impose some regularization, such as smoothness conditions. In this work, we impose low TT ranks on the tensor containing the prices and reconstruct using the completion algorithm proposed in [45].
In the following, we briefly summarize the approach from [45]. Let denote the original data tensor for which only the entries in a (small) training set are known. When aiming at fitting a tensor of fixed (low) TT ranks to this data, completion takes the form of the constrained optimization problem
[TABLE]
where denotes the orthogonal projection onto and is the norm induced by the inner product (7). It is known that is a smooth embedded submanifold, which enables one to apply Riemannian optimization techniques to (8). Specifically, in [45] it is proposed to employ a Riemannian conjugate gradient (CG) method (see Algorithm 1 in [45]). This method produces iterates that stay on the manifold and, in turn, can be stored and manipulated efficiently in the TT format. One iteration requires operations, where denotes the cardinality of .
Our stopping criterion of Riemannian CG is designed to attain a level of accuracy warranted by the data and the chosen TT ranks. Following [45], we choose a test set of, say, additional parameter samples not in the training set . Letting denote the th iterate of Riemannian CG algorithm, we measure the errors on the training and the test set:
[TABLE]
The algorithm is stopped once these errors stagnate, that is,
[TABLE]
holds for some small .
2.3.1 Adaptive rank and adaptive sampling strategy
To set up the optimization problem (8), two issues remain to be discussed: The choice of the TT ranks and a suitable training set . For our application, these are not known a priori and thus need to be chosen adaptively.
Concerning the choice of TT ranks, we follow the adaptive strategy proposed in [45]. We start by solving (8) for the smallest sensible choice of TT ranks, . Most likely, this choice will not suffice to obtain satisfactory accuracy and the error on the test set will be relatively large. To decrease it, the obtained solution is used as starting value for Riemannian CG applied again to (8), but this time with the increased TT ranks as discussed in [45]. See also [47] for a greedy rank update procedure in the context of matrix completion. The described procedure is repeated by increasing cyclically every TT rank . The overall algorithm stops as soon as increasing any of the TT ranks does not improve the test set error anymore or the maximal possible rank is reached; see Algorithm 1.
For the adaptive choice of the sampling set , which has not been addressed in [45], we present two different strategies. The core idea is to gradually increase the size of in order to improve the approximation of the tensor. Both strategies are also combined with Algorithm 1 and they differ only in the measurement of the error.
The steps of the first adaptive sampling strategy are as follows.
Start with a sample set of small size and a test set of a certain prescribed size . Run Algorithm 1. 2. 2.
Measure the relative error on the test set and stop if the stopping criterion is satisfied. If not satisfied, add the test set to the sample set and create a new test set of size . In our applications, this corresponds to computing new option prices on the Chebyshev grid using the reference method. 3. 3.
Run again Algorithm 1 from line 2 to the end, by using a rank approximation of the result from the previous step as initial guess for the CG algorithm. 4. 4.
Repeat 1-3 until a maximal sampling percentage is reached or an a priori chosen stopping criterion is satisfied.
The pseudo-code in Algorithm 2 summarizes this first strategy.
The second adaptive sampling strategy that we propose is designed in a similar way. The only difference is that the error is measured on an a priori defined fixed set and not on , which changes at each step. Therefore, this strategy follows the same steps as the first one, with the only difference that in Step 2 we measure the error on the set , which has been previously defined. The algorithm summarizing this second strategy can be obtained by replacing line 3 and line 12 in Algorithm 2 with
[TABLE]
The stopping criterion of line 13 can be also defined in different ways. We choose to stop the algorithm if one of the following criteria is satisfied:
if , where is a prescribed tolerance; 2. 2.
if where is a prescribed tolerance; 3. 3.
if such that .
The first criterion allows us to stop as soon as the error goes below a certain level, the second stops the algorithm whenever the error stagnates and the last one when the TT rank has reached the maximal allowed rank at least in one mode .
We test the new adaptive sampling strategies on a problem with known solution in the next section.
2.3.2 Numerical test for adaptive sampling strategies
We consider the problem of Chapter 5.4.2 in [45] and we apply our adaptive sampling strategies to it in order to compare them and to investigate their advantages and disadvantages. We expect a similar performance of both strategies in terms of accuracy and compression. In this numerical example, as well as in the rest of the paper, we choose to be the 2-norm and in (9). The problem consists of discretizing the function
[TABLE]
using equally spaced discretization points on in each mode. We aim at reconstructing the tensor containing the function values in the grid. In Algorithm 2 we set the maximum rank to and we start with an initial sampling set satisfying . Moreover, we set the acceptance parameter of Algorithm 1 to . In order to analyze the behavior of the error, we do not impose any stopping criterion, but we let our adaptive sampling strategies run until . The size of each is set to and for the second strategy. Figures 4 and 4 show the results for the two different strategies.
First, we observe that both strategies eventually reach the same accuracy and the same final TT ranks, which makes both of them valid. We observe an oscillatory behavior in Figure 4. This non-smooth decay can be expected since in each step the error is measured on a different test set . We observe that the amplitude of the oscillations becomes smaller as increases. This indicates an error stagnation over the whole tensor which cannot be improved by enlarging further. On the other hand, the error in the second strategy behaves almost monotonically and stagnates much earlier than in the previous case. This is due to the fact that we measure it on the fixed set . In practice, the earlier error stagnation of the second strategy is preferable as it triggers the stopping criterion 2. However, the second strategy has the disadvantage of the initial additional cost of evaluating the tensor in the set . In our numerical experiments in Section 3 we choose the first strategy, which turned out to be more favorable since the stopping criterion 1 was triggered.
2.4 Combined methodology
We are now in the position to combine the concepts and the algorithms in order to develop an efficient procedure for high-dimensional tensorized Chebyshev interpolation.
We would like to price options that depend on a vector of varying parameters. It is reasonable to assume that every combination of parameters belongs to a compact hyper-rectangular . For example, if time-to-maturity belongs to the set of varying parameters, we can assume that ; similarly for the other payoff or model parameters. The combined methodology consists of two phases: offline phase and online phase, as already introduced in [14].
2.4.1 Offline phase - Computation of
The offline phase starts by performing following operations:
Fix an interpolation order and compute the entries of the tensor (as defined in (4)) from an a priori chosen subset of Chebyshev nodes, using the reference pricing technique. 2. 2.
Apply tensor completion with adaptive sampling strategy (Algorithm 2) in order to get a low-rank approximation of the tensor in TT format.
For simplicity, we denote the obtained low-rank approximation of again by . In the last step of the offline phase we construct the interpolation coefficients, defined in (4). We denote the tensor of coefficients by . Its entries are therefore given by (adjusting the ordering according the Sections 2.1 and 2.2)
[TABLE]
for and . The tensor can be efficiently computed in TT format, as explained in the following subsection.
2.4.2 Offline phase - Efficient computation of
In order to explain the algorithm we first consider the simple case . In this case and are in , where is the chosen interpolation order. The entries of are given by
[TABLE]
so that the whole vector can be computed via the matrix-vector multiplication
[TABLE]
and we denote by the matrix multiplying in (11).
For a general dimension , the same reasoning can be applied and the tensor of interpolation coefficients can be computed by sub-sequentially multiplying with () via the mode- multiplication, defined in Section 2.2. The final procedure for an efficient computation of is given in Algorithm 3.
Note that if (as for example in our numerical experiments in Section 3), Algorithm 3 can be further simplified by computing the matrix only once. The particular structure of the matrices allows us to apply a Fast-Fourier-Transform based algorithm which computes each mode multiplication in (instead of ) as mentioned in Section 3). Therefore, the total complexity for computing is .
The offline phase can be finally completed by performing the step
Construct the tensor as explained in Algorithm 3.
2.4.3 Online phase
Once we have stored in TT format, we can use it to compute every option price via interpolation during the online phase. For any particular choice of parameters , we first perform the step
Evaluate the Chebyshev tensor basis (3) in .
This step returns a tensor of TT rank , that we store in TT format. The interpolated price, defined in (2), can now be rewritten as the inner product
[TABLE]
The final step of our combined methodology is then defined as
Compute the interpolated price (12) in TT format as in (7).
If we consider a fixed interpolation order in each dimension and if the TT ranks of and are approximately , then the total cost for performing both Step 3 and Step 5 is given by . These two steps are represented via a tensor network diagram in Figure 5 (for ), where we denoted by the core tensors of and by the ones of .
Finally, we summarize our complete methodology in Algorithm 4.
In the next section we see how this combined methodology performs on concrete examples.
3 Financial applications and numerical experiments
Putting the new approach to test, we implement the method described in Section 2 for two different types of applications. In the first one, we tackle computational intense option pricing methods in a parametric model. We treat option prices as functions in the parameter space which consists of model and option parameters. We then approximate the price function by Chebyshev interpolation in the parameter space. This approach has been successfully tested in cases where the parameter space is low-dimensional. In various applications, several varying parameters are of interest. If the interpolation is even efficient in the full parameter space, it is indeed a new pricing methodology. Here, we combine Chebyshev interpolation and low-rank approximation to cope with higher dimensionality in the parameter space. Already for pricing single asset options, it is promising to tackle medium and high-dimensional parameters spaces in this approach. As a generic example, we choose to approximate American put option prices in the Heston model with the varying parameters and . It turns out that the computational complexity reduces significantly in this case.
As second type of application we examine the interpolation of basket option prices in the -variate Black-Scholes model as function of the initial stock prices. This is a prototypical example for the computation of generalized conditional moments of high-dimensional Markov processes.
All algorithms have been implemented in Matlab and run on a standard laptop (Intel Core i7, 2 cores, 256kB/4MB L2/L3 cache). In order to deal with tensors, we used the toolboxes [39] by Oseledets and [2, 3], while for the completion algorithm we used the TT completion toolbox described in [32, 33, 45, 46]. Note that in this toolbox the most expensive steps have been implemented in C using the Mex-function capabilities of Matlab.
3.1 Pricing American options in Heston’s model
We consider pricing single asset American put options in the Heston model. As introduced by Heston in [24], the price dynamics of the financial asset under the risk neutral measure are given by
[TABLE]
where the square of the volatility is modeled by the square root process
[TABLE]
Here, the two Brownian motions and are correlated with correlation parameter , mean-reversion rate , long-term mean , volatility of the variance and, finally, fixed and deterministic continuously compounding interest rate .
The price of an American option at time , maturing at , with initial underlying price and initial volatility is given by
[TABLE]
where the is taken over all stopping times in . Here, denotes the payoff function of the European put option, i.e.
[TABLE]
where denotes the strike price.
It is well-known (see e.g. [13]) that the price (13) of the American option satisfies the following partial differential complementarity problem (PDCP):
[TABLE]
where is the infinitesimal generator of in the Heston model, defined as
[TABLE]
The problem (14) has been well studied in the literature and different pricing algorithms have been developed so far. In our example we consider, as reference method for our combined methodology, the pricing algorithm explained in [21]. More precisely, the authors propose different schemes for the time discretization and we consider the Hundsdorfer Verwer - Ikonen Toivanen (HV-IT) scheme, explained at page 219 of [21].
Solving the discretized PDCP yields an approximate price for all values of and in each grid point of the pre-specified domain. For many applications we would like to have the solution at hand for other parameters (as well). In calibration, for instance, we observe and , and one could estimate from historical stock price data. Then the calibration problem reduces to fitting the parameters to the observed option price data. To do so one needs to solve an optimization problem where prices need to be computed for large sets of parameters . Since the price for different maturities can be obtained by rescaling and , effectively we need the prices for combinations of the parameters and . This motivates the following set up, where we fix the model and payoff parameters
[TABLE]
and we let vary the five parameters
[TABLE]
in their corresponding domain.
In order to compute the reference prices we consider equidistant spatial grid points in both directions and with , time steps and the Crank-Nicholson time stepping scheme.
We start by performing the offline phase of Algorithm 4. We consider an interpolation order in each direction and we construct the tensor by tensor completion as explained in Section 2.3. We apply the first adaptive sampling strategy as in Algorithm 2. We choose the completion parameters as
[TABLE]
For this particular example, we were also able to explicitly construct the full tensor (in more than 1 hour and 40 minutes!). In Table 1 we show the size of the final set (first column), the relative error of the completed tensor on the last (second column), the relative error between the obtained completed tensor and the full one (third column), the runtime of the completion, Algorithm 2, in seconds (fourth column), the TT-rank of (fifth column), the storage needed to save in TT format, denoted by store(TT) and measured in bytes (sixth column) and finally, the storage needed to save the full tensor, denoted by store(full) and again measured in bytes. Matlab requires bytes to store a floating-point number of type double, which gives us the formula store(full) for the storage of the full tensor and store(TT) for the storage of the tensor in TT format, see [39].
Table 1 shows that a sample set of is sufficient for the algorithm to reach the prescribed accuracy. Furthermore, the relative error of the completed tensor in the 2-norm over the last test sample parameter space and the relative error over the full tensor, i.e. over all Chebyshev nodes, is only in the th digit. This is one order of magnitude smaller than the relative error on the full . This is a good indication that the approach can be extended to more complex cases, where the computation of the full tensor is not feasible any more (see Section 3.2). The completion time was about minutes. Finally, the rank properties together with its storage reduction of a factor of confirm the low-rank structure of the problem.
For constructing the tensor (last step of the offline phase) we applied Algorithm 3 and the computation time was seconds, which is negligible compared to the completion time. Hence, almost all the computation time in the offline phase is spent in the construction of the tensor .
Next, we compute American put option prices for the online phase in both ways using our methodology and the reference algorithm. We compute prices with random model parameters uniformly drawn from the reference set . We measure the maximal absolute error over the computed options prices, i.e. we report the quantity
[TABLE]
where is a vector containing all interpolated prices for the different choices of model parameters; analogously is for the reference method. In Table 2 we also report the computation time for computing one single option price for both methods. One can notice that the online phase of the interpolation compared to the reference method accelerates the procedure by a factor of . The accuracy of the reference method is reported in part C of Figure 1 in [21] for one specific parameter set to be of the order in the maximum norm. The interpolation error is one order smaller, making the new procedure at least as accurate as the reference method. Therefore, we can conclude that the methodology strongly outperforms the reference method in the online phase while keeping the same accuracy.
We would like to emphasize that this approach can be further extended to an interpolation in the full set of parameters . Since then the offline phase needs to be performed only once, this would result in a new pricing method. Here, in the offline phase one could explore the fact that the PDCP solver returns the price for all in the grid to make the sampling steps more efficient. This opens up an interesting topic for future research.
3.2 Basket options in multivariate Black-Scholes model
In the -variate Black-Scholes model with assets , the risk neutral dynamics are given by
[TABLE]
where is a fixed deterministic interest rate, is the vector of volatilities and is a vector of correlated Brownian motions with correlation matrix . The solution to (15) is given by
[TABLE]
In this section we apply the new methodology in order to price basket options with payoff function defined as
[TABLE]
where is the strike and is a vector of weights satisfying . The risk neutral price at time of the basket option with maturity is, as usual, given by
[TABLE]
From now on, we consider the parameters and the correlation matrix to be fixed, and we let the vector of initial asset prices be the varying parameter. The reference pricing algorithm will be of Monte Carlo (MC) type combined with a variance reduction technique. In particular, we use the control variates method presented in [17], where the control variate is given by
[TABLE]
Since the only varying parameter is the vector of initial asset prices, it is very convenient to split the Monte Carlo simulation in two parts in order to make the completion more efficient. More precisely, in a pre-computation phase (Algorithm 5) we simulate a certain number of realizations (e.g. ) of
[TABLE]
and in a second moment we multiply the vector (for all required parameter combinations) with all the realizations and we compute the Monte Carlo price by applying the chosen variance reduction technique (Algorithm 6). In order to generate the correlated random variables , we use the Cholesky factorization of the correlation matrix, which is then multiplied by a vector of independently generated standard normal distributed random variates. Note that in Algorithm 6 represents the Hadamard (component-wise) product between vectors.
Algorithm 5 is executed at the beginning of the whole procedure and Algorithm 6 whenever needed in later stages. The advantage of splitting the MC algorithm is twofold. Firstly, it supports a considerable gain in efficiency in the performance of the completion algorithm: When we adaptively increment the sampling set (which consists of sampling Chebyshev nodes in ) in Algorithm 2, we need to compute new prices in the Chebyshev grid, which can be done by using Algorithm 6 only. The second advantage regards the analysis of the methodology and the completion accuracy: Since we use the same set of simulations for every Chebyshev price, the MC simulation does not introduce any further error to the completion. Moreover, we will see in Section 3.2.3 that this splitting procedure allows for a qualitative analysis of the rank structure of .
Next, we perform numerical experiments for different settings of model parameters, first for uncorrelated then for correlated assets.
3.2.1 Basket options of uncorrelated assets
In this example we consider the special case of uncorrelated assets. We investigate the performance of the proposed method for two different interpolation orders and . We apply the combined methodology (Algorithm 4) to portfolios consisting of assets. The set of fixed parameters is given by
[TABLE]
where denotes the identity matrix. We let vary in the hyper-rectangular
[TABLE]
so that we consider ITM options and ATM options as well.
For each value of , we start by performing Algorithm 5 with for and with for . In a second moment we construct the tensor by applying the tensor completion with the adaptive sampling strategy of Algorithm 2 (first strategy). Table 3 shows the completion parameters for each value of and each interpolation order. The results of the tensor completions are displayed in Table 4. As in the previous subsection, we report the final size of the set , the relative error measured on the last set , the completion time and the memory needed to store both the obtained tensor in TT format and the full tensor. For the TT ranks of the completed tensor, we do not report the full tuple (see Definition (5)) but only the quantity .
It is interesting to analyze the size of the finally obtained set in Algorithm 2 for different values of and (different sizes of ). Figure 6 shows a plot of (final) against for the two chosen interpolation orders. The graphical representation clearly suggests that the number of sampled entries, i.e. , required for the chosen tolerance for a fixed interpolation order and for a fixed is roughly of , whereas the size of the full tensor is . On the practical side, this means that by the completion algorithm we can reduce the complexity of the first step of the offline phase from an exponential growth down to a quadratic growth in the dimensionality. The exponential growth typically is referred to as curse of dimensionality. The reduction in absolute numbers is already tremendous for and , where we observe and the full tensor size equals . The compression is dramatic for and , namely the numbers of required entries shrinks by a factor of more than .
As in the previous numerical example, the computation time to build the tensor of interpolation coefficients is negligible in the offline phase. Indeed, for all choices of and it is less than seconds, for instance seconds for and , and seconds for and .
We now perform the online phase of Algorithm 4 in order to see how efficient becomes pricing basket options in the new setting. We start by computing 100 basket option prices via Chebyshev interpolation (combined methodology), choosing random initial asset prices in the reference hypercube . We then compare the obtained prices with reference prices computed by applying the reference method (Monte Carlo with control variates) with new simulations for and new simulations for . In particular, we measure again the maximal absolute error over all computed prices
[TABLE]
where is a vector containing all 100 interpolated prices for the different choices of ; analogously is for the reference method. The errors together with the computational times are shown in Table 5. Note that we report again the computational time to compute one single option price.
One can see that the online phase of the new procedure compared to the MC reference method accelerates the computation of a factor between 200 and 400 for and of a factor between 2000 and 4000 for . Note that the difference in the acceleration between the two chosen interpolation orders is given by the different numbers of simulations chosen in the MC reference method ( for and for ). Therefore, for both interpolation orders and for all choices of , the acceleration is dramatic. In order to judge the accuracy of our method we have computed the confidence interval of the reference method, which results to be of a size between and for all choices of and or . This, together with the last column of Table 5, leads us to the conclusion that the new method is as accurate as the reference MC algorithm.
Finally, in Figure 7 we show the gain in efficiency of the new method when computing basket option prices for and both choices of interpolation orders. In particular, on the x-axis we consider a possible number of computed prices and on the y-axis we present
the computational time of the reference MC method, 2. 2.
the computational time of the new combined methodology (offline phase + online phase ),
required to compute the corresponding amount of prices.
The plots in Figure 7 show that after an initial investment the computational time grows very slowly in the number of computed prices for the new method. This is due to the fact that the online phase in Algorithm 4 is very cheap, as shown in the numerical experiments. This proves that the method is useful whenever one can split the task in a pre-computational phase during idle times and a run-time phase where execution is required to be fast. Moreover, it will outperform the reference methods if a large number of prices needs to be computed. The first plot in Figure 7 indicates that for the case it is convenient to use the reference MC method if we want to compute up to option prices. For the case the break-even point is already reached with prices.
3.2.2 Basket options of correlated assets
In this second numerical experiment we repeat the test of the previous subsection but, this time, we consider correlated assets. In particular, we choose again the interpolation orders , and the other parameters are given by
[TABLE]
where denotes a random correlation matrix. The free parameters , are again contained in [1;1.5]. We perform the offline phase by considering again the set of completion parameters listed in Table 3. The obtained results of the completion are now in Table 6 and Figure 8 shows the required size of to go below the tolerance for and for . We notice that the completion results are similar to the case of uncorrelated assets and that scales again like . The computational time to construct was again measured to be less than seconds for all choices of and .
The online phase is performed similarly to the previous chapter, in particular we compute again 100 prices using the new method and the reference one. The MC parameters are set as before and the results are shown in Table 7.
The performance of the new method in terms of accuracy and computational efficiency is similar to the one observed in the case of uncorrelated assets. To summarize, the new methodology achieves a very good performance for uncorrelated as well as for correlated assets.
3.2.3 Rank structure of
In this section we qualitatively analyze the rank structure of the tensor . For simplicity, we perform this analysis for the standard Monte Carlo approach (without any variance reduction technique). Assume that we have already simulated the realizations of the correlated geometric Brownian motions stored in the matrix (Algorithm 5). Then, the price in the point is given by the function
[TABLE]
where is the hyper-rectangular domain for the interpolation, is the -th row of and is the number of Monte Carlo simulations. This expression can be rewritten in the form
[TABLE]
where the ’s are coefficients multiplying depending on the -th simulation and on the -th weight . The function is piecewise affine in the variables .
To explore the rank structure of let us consider the case of a single Monte Carlo simulation . Then is of the form
[TABLE]
Now we analyze three different cases. First, consider the case where the price is positive for any in the hyper-rectangular . Here, is affine. This implies that the TT ranks are bounded by . This follows from the fact that the CP rank (rank of the Canonical Polyadic Decomposition, see [31]) of , which is an upper bound for each in the TT ranks (see [20]), is equal to . Second, if we observe a vanishing price for all in the hyper-rectangular, then is the zero-tensor, which has rank [math]. These two cases obviously yield a low-rank structure of , a favorable case for the new combined methodology.
In the third case where is only piecewise affine the situation is more complex and to gain an intuition we consider the case , where is of the form
[TABLE]
on a squared domain . Now, define the set
[TABLE]
When intersects the domain it cuts it in two regions. Only if and are of a specific form that leads L to be the diagonal of , the rank of is almost full. In the Monte Carlo simulation context, this special case is very unlikely. In all other cases, exhibits a lower rank structure. In particular, we expect the rank to be the lower the more the sizes of the two regions differ.
In order to visualize these findings we consider three different pairs together with , and evaluate the corresponding on the discretized using 50 equidistant points in each direction. Figure 9 shows the sparsity pattern and the rank of the obtained matrices .
This qualitative explanation indicates that the rank structure of depends on . We expect the rank to be lower for domains with an asymmetry with respect to the strike . Next we construct as in the experiments of Section 3.2 for , and different interpolation orders for both and . In particular, we first construct the matrix via Algorithm 5 with simulations and subsequently compute using Algorithm 6. In Figure 10 we display the decay of the singular values for all treated cases. As expected, the decay is faster for . However, also for the decay of the singular values is reasonably fast. This implies that the new methodology would be still beneficial in this case.
4 Summary and future work
We have presented a unified approach to efficiently compute parametric option prices. The starting point of our methodology was the Chebyshev interpolation technique developed in [14], which we briefly summarized in Section 2.1. We refined both the offline and the online phase to treat high-dimensional problems with parameter spaces up to dimension . We have exploited the low-rank structure of the tensors involved in the interpolation procedure, which have been stored in TT format (summarized in Section 2.2). In particular, we have developed a completion technique (explained in Section 2.3) which allows us the construct the tensor , containing the option prices in the Chebshev tensor grid. All ingredients have been efficiently assembled to finally build a combined methodology, explained in Section 2.4.
In the second part of the paper, Section 3, we have tested our approach in two different concrete option pricing settings: We have treated the American option pricing problem in the Heston model (Section 3.1) and the European basket option pricing problem in the -dimensional Black and Scholes model (Section 3.2). Both examples show that our approach allows for a substantial gain in efficiency, while maintaining very accurate results, whose precision is comparable to the one of the considered reference methods. For instance, the interpolation of American option prices in parameters accelerates the procedure by a factor of , when compared to the FD reference method [21]. For basket option pricing with underlyings the efficiency gain reaches factors up to . See Tables 2, 5, 7 and Figure 7 for further results. Finally, for both examples we qualitatively investigated the rank structure of , which confirmed that our initial low-rank assumption was indeed reasonable. For instance, for the American put, we obtain a compression factor of of the completed tensor with respect to the full one, with a relative error in the th digit only, see Table 1. For the basket option the full tensor containing prices in the Chebyshev grid is too large to be computed, however in Section 3.2.3 it is qualitatively explained why is expected to have a low-rank structure. This is also confirmed by the compression rates observed in Tables 4 and 6 that go up to .
Seen the promising performance of this new approach and considering the fact that this methodology can be easily tailored to different problem settings, we expect it to be applicable in several domains in finance. For instance, pricing, calibration and sensitivity analysis in equity markets, fixed income and credit, and parameter uncertainty quantification are some of the possible domains of application.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Bachmayr and A. Cohen , Kolmogorov widths and low-rank approximations of parametric elliptic PD Es , Math. Comp., 86 (2017), pp. 701–724, http://dx.doi.org/10.1090/mcom/3132 .
- 2[2] B. W. Bader and T. G. Kolda , Algorithm 862: MATLAB tensor classes for fast algorithm prototyping , ACM Transactions on Mathematical Software, 32 (2006), pp. 635–653, http://dx.doi.org/10.1145/1186785.1186794 .
- 3[3] B. W. Bader, T. G. Kolda, et al. , Matlab tensor toolbox version 2.6 . Available online, February 2015, http://www.sandia.gov/~tgkolda/Tensor Toolbox/ .
- 4[4] J. Ballani and L. Grasedyck , Hierarchical tensor approximation of output quantities of parameter-dependent PD Es , SIAM/ASA J. Uncertain. Quantif., 3 (2015), pp. 852–872, http://dx.doi.org/10.1137/140960980 .
- 5[5] D. Barrera, S. Crépey, B. Diallo, G. Fort, E. Gobet, and U. Stazhynski , Stochastic approximation schemes for economic capital and risk margin computations . Forthcoming in ESAIM: Proceedings and Surveys, https://math.maths.univ-evry.fr/crepey/papers/SA-EC-RM.pdf, 2019.
- 6[6] C. Bayer, M. Siebenmorgen, and R. Tempone , Smoothing the payoff for efficient computation of basket option prices , Quant. Finance, 18 (2018), pp. 491–505, http://dx.doi.org/10.1080/14697688.2017.1308003 .
- 7[7] O. Burkovska, K. Glau, M. Mahlstedt, and B. Wohlmuth , Complexity reduction for calibration of American options . Forthcoming in J. Comput. Finance, https://arxiv.org/abs/1611.06452, 2017.
- 8[8] O. Burkovska, B. Haasdonk, J. Salomon, and B. Wohlmuth , Reduced basis methods for pricing options with the Black-Scholes and Heston models , SIAM J. Financial Math., 6 (2015), pp. 685–712, http://dx.doi.org/10.1137/140981216 .