An In-Vehicle KWS System with Multi-Source Fusion for Vehicle Applications
Yue Tan, Kan Zheng, Lei Lei

TL;DR
This paper introduces a multi-source fusion approach for in-vehicle keyword spotting that combines vehicle data and acoustic analysis to improve detection accuracy during driving.
Contribution
It presents a novel fusion scheme integrating vehicle information with DNN-based speech recognition to enhance KWS performance in vehicle environments.
Findings
Improved precision and recall rates in KWS detection.
Enhanced system robustness with multi-source data fusion.
Reduced mean square error compared to baseline systems.
Abstract
In order to maximize detection precision rate as well as the recall rate, this paper proposes an in-vehicle multi-source fusion scheme in Keyword Spotting (KWS) System for vehicle applications. Vehicle information, as a new source for the original system, is collected by an in-vehicle data acquisition platform while the user is driving. A Deep Neural Network (DNN) is trained to extract acoustic features and make a speech classification. Based on the posterior probabilities obtained from DNN, the vehicle information including the speed and direction of vehicle is applied to choose the suitable parameter from a pair of sensitivity values for the KWS system. The experimental results show that the KWS system with the proposed multi-source fusion scheme can achieve better performances in term of precision rate, recall rate, and mean square error compared to the system without it.
Click any figure to enlarge with its caption.
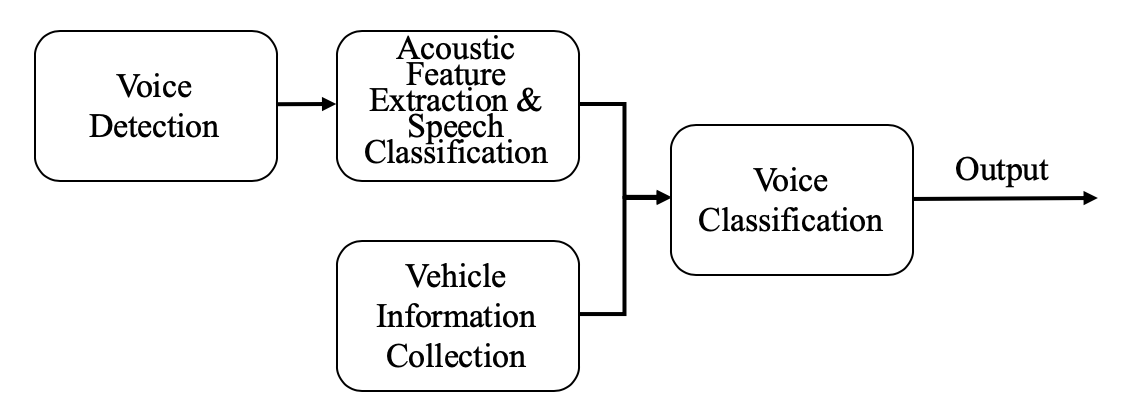 Figure 1
Figure 1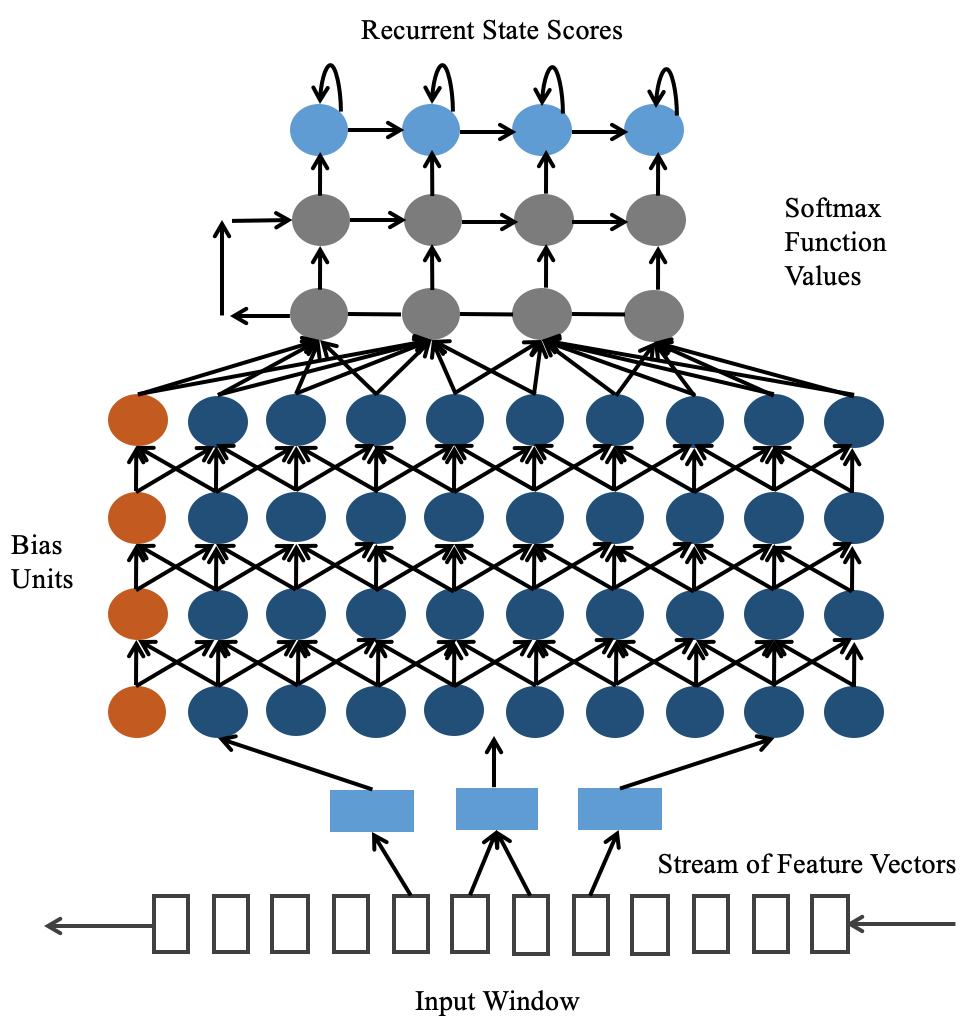 Figure 2
Figure 2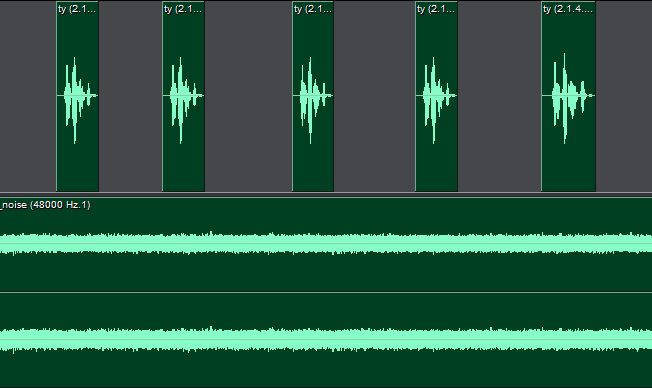 Figure 3
Figure 3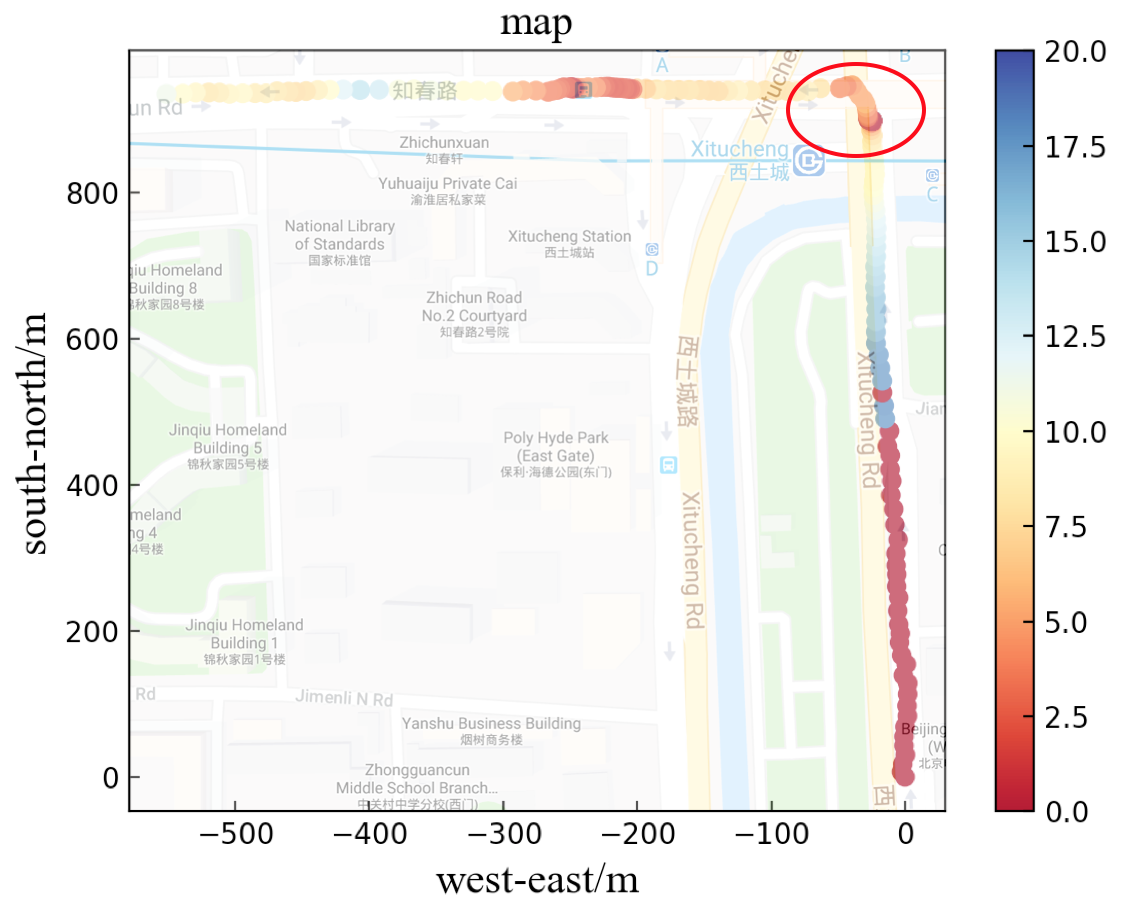 Figure 4
Figure 4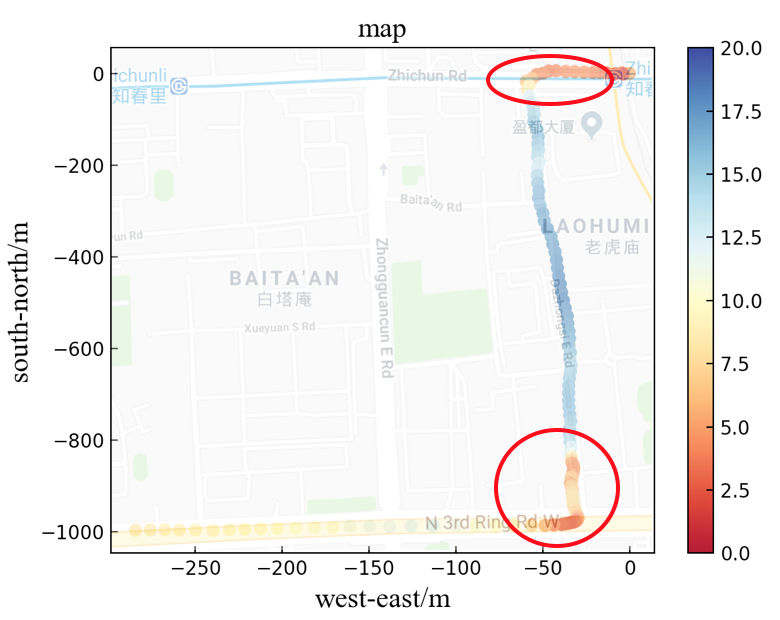 Figure 4
Figure 4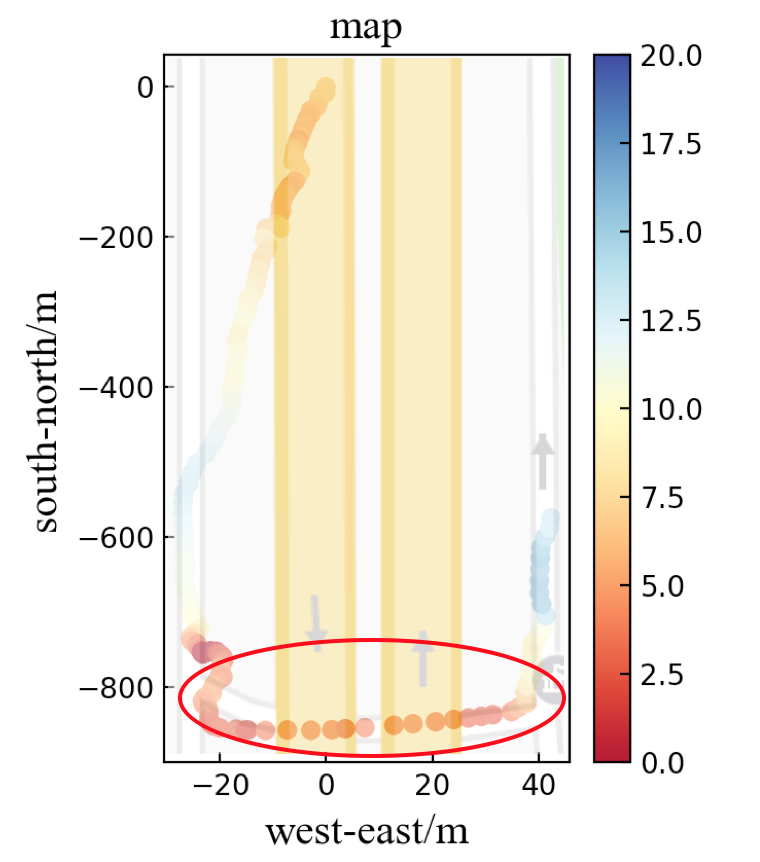 Figure 5
Figure 5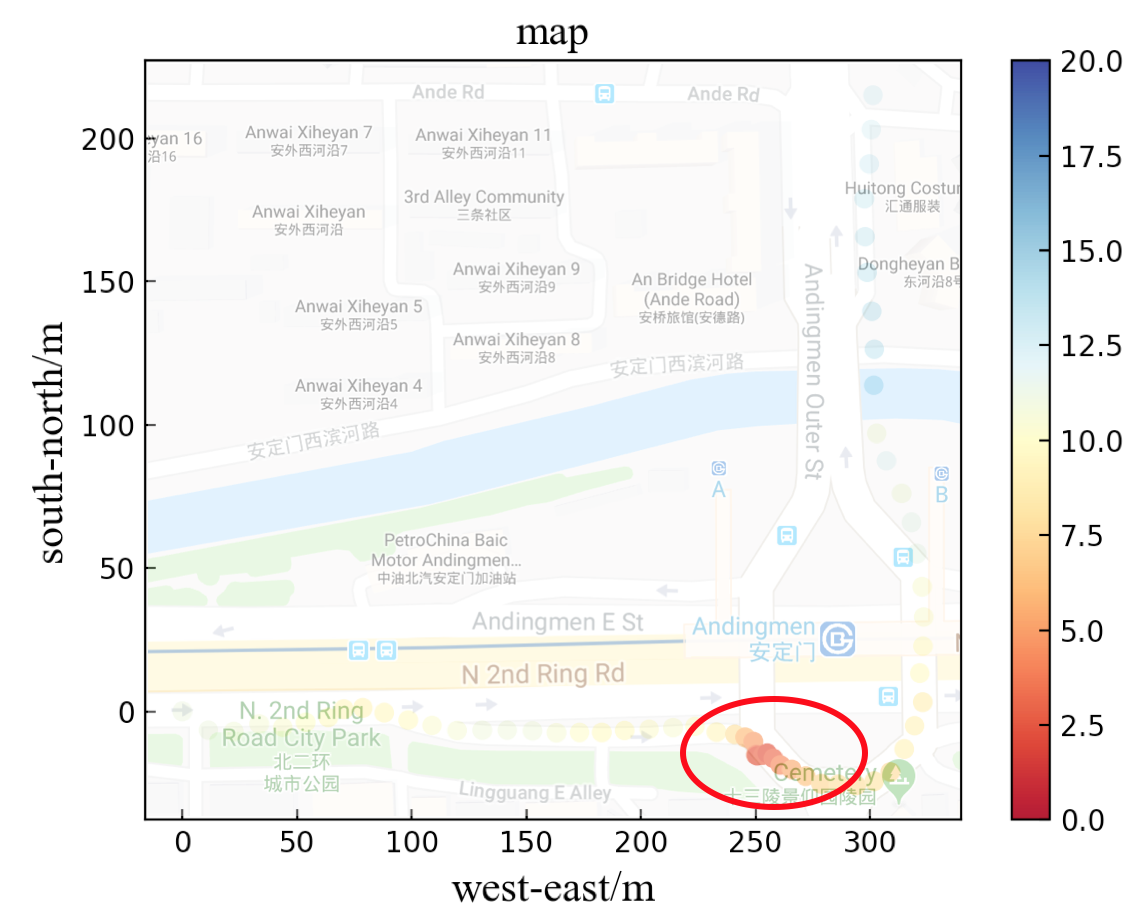 Figure 5
Figure 5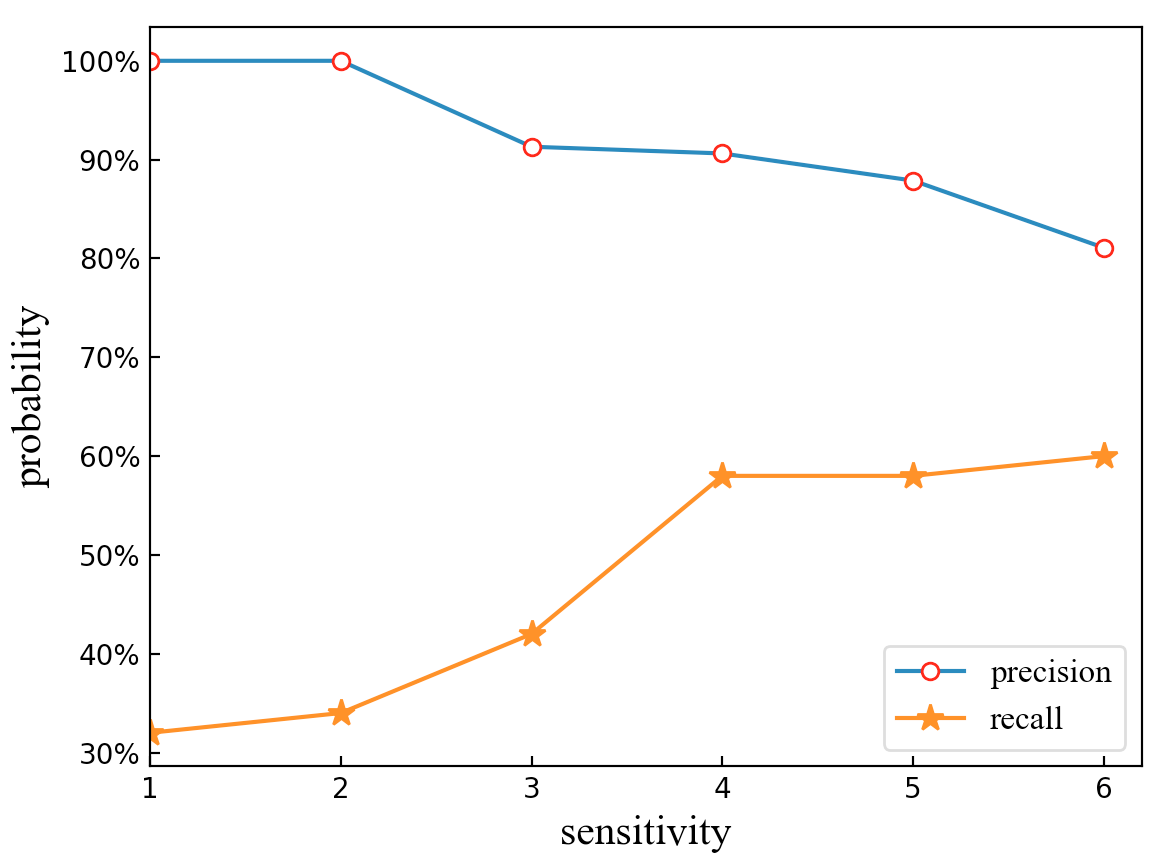 Figure 6
Figure 6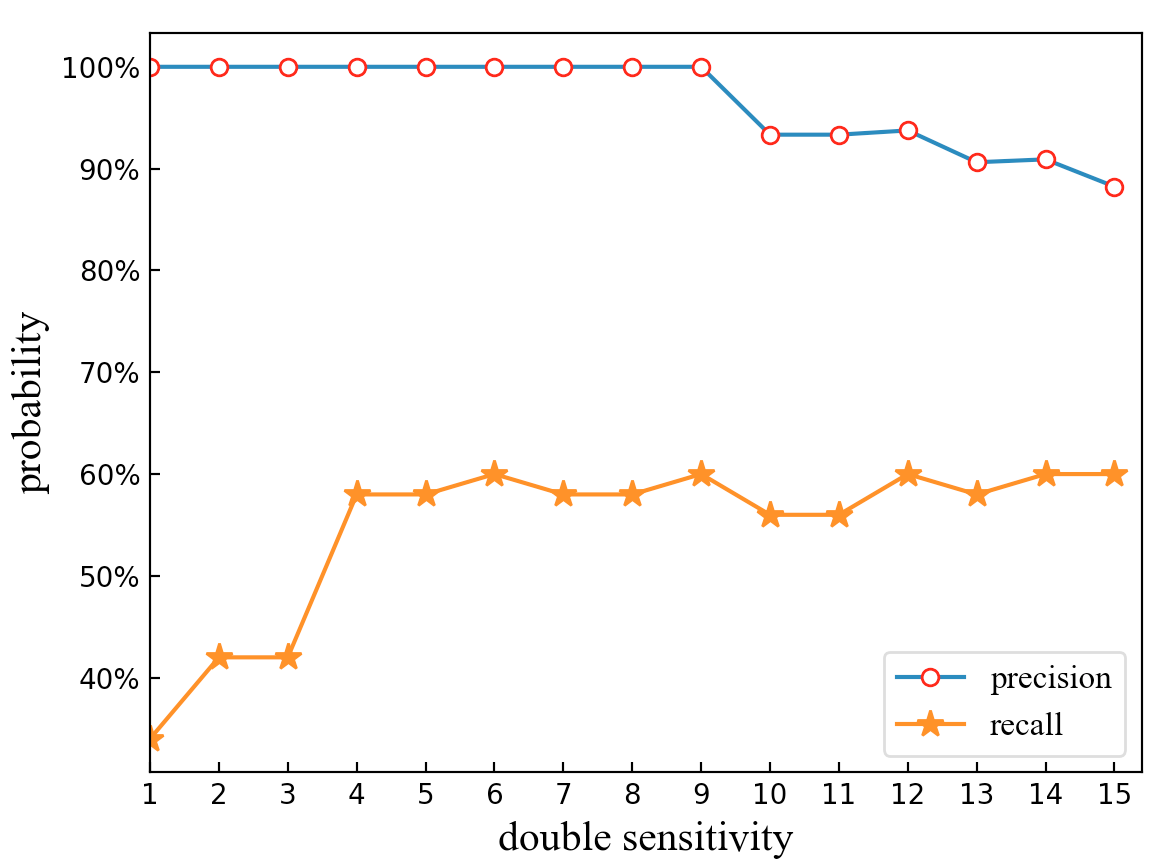 Figure 7
Figure 7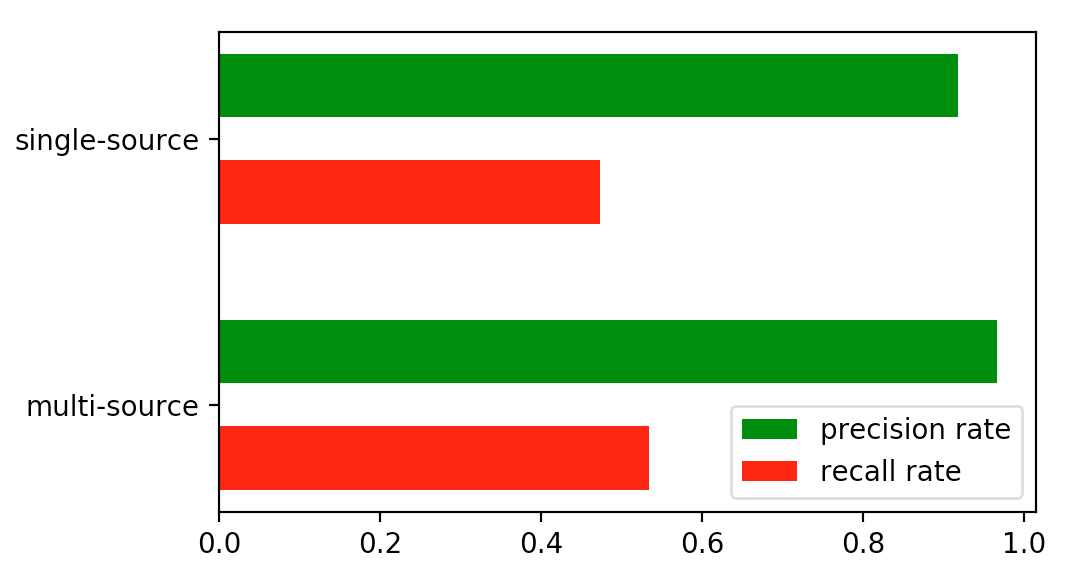 Figure 8
Figure 8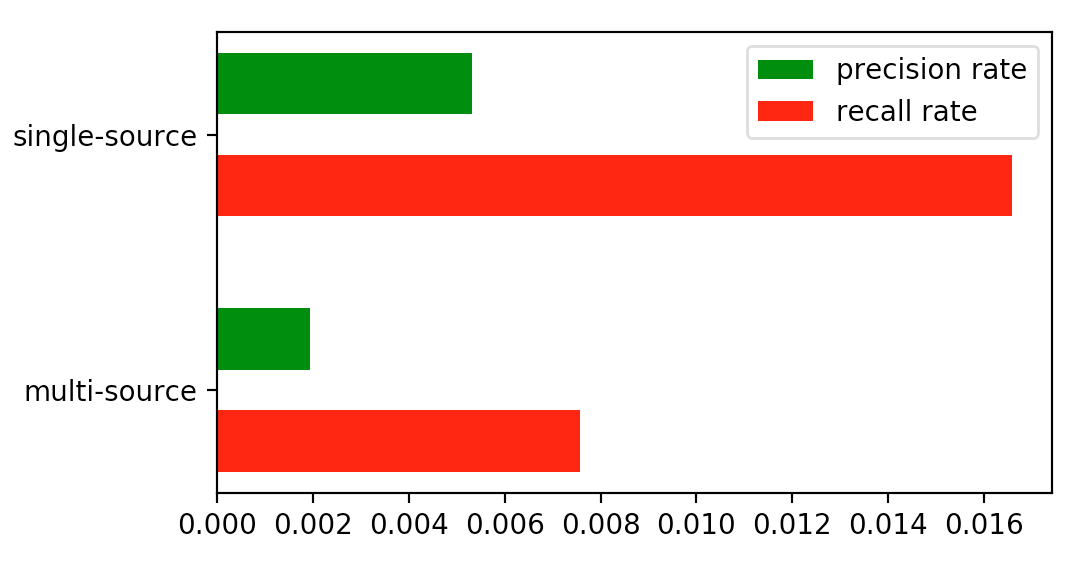 Figure 9
Figure 9| No. | |
|---|---|
| 1 | 0.495 |
| 2 | 0.50 |
| 3 | 0.52 |
| 4 | 0.55 |
| 5 | 0.57 |
| 6 | 0.58 |
| No. | ||
|---|---|---|
| 1 | 0.495 | 0.50 |
| 2 | 0.495 | 0.52 |
| 3 | 0.495 | 0.55 |
| 4 | 0.495 | 0.57 |
| 5 | 0.495 | 0.58 |
| 6 | 0.50 | 0.52 |
| 7 | 0.50 | 0.55 |
| 8 | 0.50 | 0.57 |
| 9 | 0.50 | 0.58 |
| 10 | 0.52 | 0.55 |
| 11 | 0.52 | 0.57 |
| 12 | 0.52 | 0.58 |
| 13 | 0.55 | 0.57 |
| 14 | 0.55 | 0.58 |
| 15 | 0.57 | 0.58 |
| Mean Value | Mean Square Error | |||
| precision rate | recall rate | precision rate | recall rate | |
| sigle-source | 91.81% | 47.33% | 0.00533 | 0.01659 |
| multi-source | 96.68% | 53.47% | 0.00194 | 0.00757 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVehicular Ad Hoc Networks (VANETs) · Real-Time Systems Scheduling · Real-time simulation and control systems
MethodsSPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
An In-Vehicle Keyword Spotting System with Multi-Source Fusion for Vehicle Applications
Yue Tan1, Kan Zheng1, Lei Lei2
1Intelligent Computing and Communication (IC2) Lab,
Key Laboratory of Universal Wireless Communications, Ministry of Education,
Beijing University of Posts and Telecommunications, Beijing, China,
2James Cook University, Australia
Abstract
In order to maximize detection precision rate as well as the recall rate, this paper proposes an in-vehicle multi-source fusion scheme in Keyword Spotting (KWS) System for vehicle applications. Vehicle information, as a new source for the original system, is collected by an in-vehicle data acquisition platform while the user is driving. A Deep Neural Network (DNN) is trained to extract acoustic features and make a speech classification. Based on the posterior probabilities obtained from DNN, the vehicle information including the speed and direction of vehicle is applied to choose the suitable parameter from a pair of sensitivity values for the KWS system. The experimental results show that the KWS system with the proposed multi-source fusion scheme can achieve better performances in term of precision rate, recall rate, and mean square error compared to the system without it.
Index Terms:
multi-source fusion, sensitivity value, vehicle information, keyword spotting
I Introduction
Keyword Spotting (KWS) System, also known as wake-word detection, refers to the task of detecting specified keyword from a continuous stream of audio provided by the users [1]. Keyword Spotting has been an active research area in speech recognition for decades, and widely used in numerous applications. Typical applications exist in environments with interference from background audio, reverberation distortion, and the sounds generated by the device in which the KWS is embedded. Nowadays, conversational human-technology interfaces become increasingly popular in a large number of applications. There are already millions of devices with embedded KWS systems. With the advances in deep learning and increase in the amount of available data, traditional approaches for KWS has been replaced by deep-learning-based approaches due to their superior performance.
As KWS is the most common way for human to interact with machine in vehicle and determines different states of the device or software system, the performance of KWS system is very crucial for vehicle applications [2]. Although there are different kinds of interferences, it is expected that the output of the KWS system has a high detection precision rate and recall rate to meet the users requirements.
The Hidden Markov Model (HMM) have been widely used in traditional KWS systems [3]. When the likelihood ratio of keyword model to background model exceeds the threshold, the system is triggered [4]. Also, Gaussian Mixture Models (GMM) are used to establish acoustic models. In recent years, deep neural network (DNN) is widely used in acoustic modeling and better performs than GMM [5]. Later, the systems based on a Convolutional Neural Network (CNN) or Deep Neural Network (DNN) instead of HMM, become popular since the amount of available data has been rapidly increased [6]. Although the above methods based on neural network have achieved good performance, there are still a few defects, e.g., the audio input has a strong dependency in time or frequency domains, the system needs broadband filters to model the context over the entire frame in terms of CNN [7]. Other related works explore discriminative models for keyword spotting based on large-margin formulation or recurrent neural networks [8][9]. However, the large-margin formulation based methods require processing of the entire utterance to find the optimal keyword region. This increases detection latency. Although some complicated structure of neural network are proposed to deal with them, the huge computation complexity becomes a huge challenge for real-time applications [3][10].
Most KWS systems use a single source of information as their input, e.g., the audio. However, in many applications, e.g., vehicle applications, the environmental information and sensor data are always available and easy to obtain, which may provide additional clues for KWS [11]. In order to improve the performance of KWS system for a keywords detecting task, these data can be used as a complement to the audio information. This multi-source fusion is accomplished by adjusting the parameters of DNN-based KWS system using the additional information.
In vehicles, the KWS system is used for a wide range of vehicle applications, which are crucial to the intelligent vehicular safety systems. Therefore, in this paper, we propose an in-vehicle KWS system with the multi-source fusion for vehicle applications. In this system, raw vehicle information is collected by an in-vehicle data acquisition platform [12][13]. The single-source system uses DNN to detect keywords and outputs the confidence score. The processed vehicle information is used as an additional source of the system and fused with DNN-based single-source KWS system. Thus, it provides the possibility for KWS system to make use of the dynamic vehicle information such as speed and direction when detecting the keywords spoken by driver. During this process, a better sensitivity value for the system is chosen by multi-source fusion algorithm. An appropriate sensitivity value can help KWS system achieve a higher accuracy when detecting keywords.
The rest of this paper is organized as follows: Section II describes the overall architecture of our system. Section III presents the implementation of the system in detail. In Section IV, we give the experimental results and analysis. Finally, conclusions are provided in Section V.
II System Overview
To improve the performance of in-vehicle KWS system, the real-time vehicle information is obtained and fed back to the KWS system [2]. Then, the system chooses suitable parameters, e.g., sensitivity value, and outputs the classification result. Fig.1 depicts the structure of an in-vehicle KWS system with multi-source fusion for vehicle applications. Five components are included as follows:
II-A Voice Detection
The initial step of the whole system is voice detection and pretreatment. The voice input is a continuous stream of audio from people. First, microphone converts the voice input into an instantaneous waveform sampling flow which is then converted to a sequence of frames by spectrum analyzer. After that, a certain number of frames are sent to the next step for feature extraction as a unit [14].
During voice detection and preprocessing, the frame length , and the number of frames are two variables involved. For example, when the vehicle is in complex traffic situations, should be shorter and should be larger.
The source of sound comes from microphone of mobile terminal in real-time working state. When the microphone is opening, it continuously extracts information from voice streams.
II-B Acoustic Feature Extraction & Speech Classification
The frames obtained in Step A are fed into the acoustic model, and acoustic features are extracted over the frames [15]. Then, the acoustic features are stacked as a larger vector, which is fed as input to the DNN. The structure of DNN is shown in Fig.2. DNN is trained to predict posterior probabilities for each output label from the stacked features. Output labels correspond to the keywords or some similar words. Finally, a simple posterior handling module combines the posteriors into a confidence score used for detection [1].
II-C Vehicle Information Collection
In vehicles, raw vehicle information is collected by an in-vehicle data acquisition platform. Vehicle information, as a new source for the single-source system, is collected while the user is driving. Raw vehicle information includes the longitude and latitude of the vehicle and is used to compute the speed and direction of vehicle. In order to improve the predictive precision rate and recall rate, the processed vehicle information is applied to choose suitable parameter, e.g., sensitivity value, for the original KWS system.
II-D Voice Classification
After combining with vehicle information, the system can choose the better one from a pair of sensitivity values. According to the speech classification result of DNN, voice classification result can be obtained. If the voice classification result suggests that the voice input is more likely to be the keywords being detected, related operating hardware and software can be activated. On the contrary, if the result indicates the voice input is related to other voice classification, nothing responses to the input.
III Implementation of KWS System with Multi-Source Fusion
In this section, the implementation of KWS system with multi-source fusion is presented in detail. The DNN-based single-source algorithm is conducted on a single-source voice detection system which uses 13-dimensional features and the features’ deltas as input to a trained model. The model is a 30-component diagonal covariance GMM, which generates posteriors to determine whether it is speech or not at every frame. After that, a number of frame posteriors are sent to a state machine. If most of them exceed a threshold, those frames are identified as speech regions. For speech regions, acoustic features are generated based on 40-dimensional log filterbank energies. Features are extracted every 10 over a window of 30 . Since each frame adds 10 of latency to KWS system, the input window is not symmetric. For the single-source DNN-based KWS system, we use 10 future frames and 30 frames in the past.
The DNN model used for KWS is a feed-forward fully connected neural network which includes hidden layers and hidden nodes every layer. Each node computes a non-linear function of the weighted sum of the previous layer’s output. For the hidden layers, Rectified Linear Unit (ReLU) function is used because it performs better than logistic function. The last layer has a softmax which outputs an estimate of the posterior of each output label. The size of the network is also decided by the number of output labels.
Suppose is the posterior for the label and the frame , and is the number of frames. In , takes values between , where [math] refers to the label which cannot be related to any part of the keywords. is used to represent the weights and biases of the deep neural network and are computed by minimizing the cost function over training data . For the DNN-based KWS, the labels represent the entire keywords or part of them.
DNN has produced label posteriors which are based on the frames. Those posteriors are related to confidence scores. If the confidence score exceeds the threshold, the system can be activated.
First, we need to smooth the posteriors over a time window of size . The posterior is denoted as , and smoothed posterior is denoted as . The smoothing result is given by (1),
[TABLE]
where , which means that is the index of the first frame within the smoothing window [16].
Then, the confidence score of frame is computed over the sliding window of size .
[TABLE]
where is the smoothed posterior in (1) and is the index of the first frame within the sliding window. Generally, the value of and are set according to the set. However, the performance is not very sensitive to and . Therefore, the multi-source fusion algorithm is proposed to help the system choose better sensitivity value [17]. How the vehicle information is processed to execute the algorithm is explained as follow.
When the vehicle is moving, a set of real-time information is collected for analysis. The data includes latitude, longitude and altitude of the vehicle and the timestamp of the record time. Vehicle information can be calculated on the basis of this raw data.
The workflow of multi-source fusion is depicted in Algorithm 1. The input consists of vehicle information set , a continuous stream of audio , double sensitivity values , and the thresholds of the variation of speed and direction , . As mentioned in Section II, firstly, the stream of audio is converted to a sequence of frames . Then, a certain number of frames are fed as input to DNN. DNN extracts features over these frames, which are denoted as . Meanwhile, vehicle information set is preprocessed to provide additional source for the system, which is denoted as AS: . For each , we calculate \Delta$$s and \Delta$$d and compare to and , respectively. Finally, the sensitivity value of KWS system is determined by \Delta$$s and \Delta$$d. The result of KWS is generated with one of the sensitivity value.
In complex traffic situations, drivers are more frequently involved in traffic accidents, especially for inexperienced drivers. As for this situation, drivers are more likely to ask for help from the navigation system by using KWS system. As an additional source, the vehicle information is used for the selection of better sensitivity. Since the KWS with multi-source fusion dynamically tunes the sensitivity value, the system in vehicle improves the predictive recall rate and real-time rate.
It is assumed that the system has two kinds of states, normal state and sensitive state. When the system is in normal state, the recall rate is , and while in sensitive state, the recall rate is . It is obvious that p_{2}$$>$$p_{1}. The average time proportion of sensitive state is supposed to be . It is presumed that the probability that the in-vehicle data acquisition platform outputs the correct information is .
Based on this assumption, the recall rate of single-source KWS system is
[TABLE]
The recall rate of multi-source KWS system is
[TABLE]
[TABLE]
It can be seen from (5) that the recall rate of KWS system is improved after multi-source fusion scheme is used.
When the KWS system is in sensitive state, the length of each frame gets shorter, which contributes to the enhancement of real time rate. The state change of vehicle is precisely captured by the system. It is hard for a single-source system to do that because we cannot find an appropriate sensitivity value for all the states. Although DNN applied here has already reached a high accuracy, it is difficult for a single sensitivity value to satisfy all potential state.
IV Experimental Results and Analysis
IV-A Experimental Environment
The in-vehicle data acquisition platform runs on any iOS-based smart portable devices and collects sensor information. A few roads near Beijing University of Posts and Telecommunications are chosen as test roads to simulate the trajectories of a normal driver. These trajectories include making a turn, turning around, entering a roundabout, etc. The experiments are conducted in the mobile terminal. To avoid noise distractions, the test is carried out in a quiet environment.
IV-B Test Set
Experiments are performed on a test set which combines real voice including the keywords as positive examples and phrase including parts of the keywords or some similar words as negative examples [1]. The test set is generated by: (1) generating noise by simulating the vehicle environment; (2) recording the keywords; (3) adjusting the characteristic of recording to expand the test set.
First, white Gaussian noise with different power is generated to simulate the vehicle environment. Then, the experimental content is recorded, which consists of the keywords, words pronounced similar to keywords, everyday words and common phrase for driving. There are in total four possible speakers with different pronunciation characteristics. The gender ratio of the speakers is .
On the basis of raw audio files, a professional audio processing softwarecool edit pro is employed to adjust the tone and speed of each fragment. In this way, multiple samples are obtained. In this way, the test set of both positive and negative examples is expanded. Finally, the audio test set consists of 50 positive examples and 50 negative examples. The keywords is HEY, ATOM , and related negative examples include HEY, ATO , HEY, TOM , HELLO, ATOM , etc.
The voice segments of positive and negative cases are mixed with Gaussian white noise. The range of signal-to-noise (SNR) ratio is 5-10 . A fragment of test set which combines human voice and white Gaussian noise is shown in Fig.3.
IV-C Experimental Results
The vehicle information are visualized in Fig.4, in which the horizontal axis presents the displacement from west to east and the vertical axis presents the displacement from north to south. Speed is presented by the scatters in different colors, and the unit of speed is . When the vehicle is approaching the intersection, it always decreases the speed at first and then increases it.
Similarly, in Fig.5, when the vehicle is turning around, it slows down to nearly zero speed and passes the U-turn at a low velocity. When it finishes turning around, it speeds up to a normal level. As for entering a roundabout, the vehicle always reduces the speed to adapt to different angles of the roads.
A KWS system is built to get the results. The system uses DNN model which is trained to recognize keywords like HEY, ATOM . The baseline result is obtained by testing the single-source system. After that, multi-source fusion scheme is adopted to get the result for comparison.
The sensitivity value of the system can be adjusted from [math] to . The larger the value is, the more sensitive the KWS system is and the system is more likely to detect keywords and be activated. The acceptable range of sensitivity is . When the sensitivity value is too large, the response rate to negative cases increases sharply. When the sensitivity value is too small, the response rate to positive cases decreases sharply.
6 sensitivity values are chosen for test, which are listed in Table I. For each value, experiments on KWS system are conducted and results are shown in Fig.6. It shows a relation between sensitivity value and precision, recall rate. With the increase of sensitivity, the precision rate shows a downward trend, and the recall rate shows an upward trend. The precision rate changes from to while the recall rate changes from to .
Relatively speaking, most KWS systems have a high precision rate, which means that they are not easy to be activated by words other than keywords. However, recall rate is not always acceptable. When people utter the keyword, system cannot always succeed in activating the system. Therefore, improving the recall rate is usually the main goal of improving the KWS system.
For multi-source fusion scheme, the system can automatically adjust the sensitivity value according to the vehicle information. When the vehicle is moving in a straight line or there is no significant fluctuation in speed, the sensitivity of system is set to be a lower value which is denoted as . When the direction of the vehicle changes and the speed changes significantly, the sensitivity of system is set to be a higher value which is denoted as . 15 sets of double sensitivity values are listed and they are numbered from to as is shown in Table II.
Each group in Table II is tested and its precision and recall rate are recorded and presented in Fig.7, where the horizontal axis is the sequence number of double sensitivity combination and the vertical axis is the precision and recall rate. After using multi-source fusion scheme, the precision rate changes from to while the recall rate still changes from to . However, it is clear to see that from the 4th group, the recall rate stabilizes at a relatively high level and the precision rate keeps above . As a result of the improvement of recall rate, the probability that people utter the correct keyword but fail to activate the system is significantly reduced.
Table III indicates the different mean value and mean square error of precision rate (PR) and recall rate (RR) between single-source and multi-source fusion system. The KWS system with multi-source fusion achieves a improvement in mean PR and a improvement in mean RR. As is shown in Table III, there is a large gap in mean square error of PR and RR between two systems. A reduction in mean square error of PR and reduction in mean square error of RR are achieved compared to the single-source system, which increases the availability and reliability of KWS system.
The precision and recall rate of the KWS system can be significantly improved by setting the appropriate double sensitivity value. KWS system with multi-source fusion can choose appropriate parameters according to current state, which enhances the performance of the system.
V Conclusions
In this paper, DNN has been used to detect keyword from a continuous stream of audio and get the precision and recall rate. Based on this, an in-vehicle KWS system with multi-source fusion is proposed for vehicle applications. Vehicle information is used as a complement to the audio information for KWS system. KWS system with multi-source fusion can adjust the sensitivity value for DNN-based single-source KWS system and the experimental results show that automatically adjusting sensitivity value is feasible and optimize the system effectively to achieve better performance in both precision rate and recall rate.
Acknowledgement
This work was supported by the National Natural Science Foundation of China (NSFC) under Grant Number 61671089.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] G. Chen, C. Parada, G. Heigold Chen, “Small-footprint keyword spotting using deep neural networks,” IEEE International Conference on Acoustics, Speech and Signal Processing , pp.4087-4091, 2014.
- 2[2] Y. Zheng, X. Shi, A. Sathyanarayana, N. Shokouhi, “In-vehicle speech recognition and tutorial keywords spotting for novice drivers’ performance evaluation,” IEEE Intelligent Vehicles Symposium , pp.168-173, 2015.
- 3[3] I. Szoke, P. Schwarz, P. Matejka, L. Burget, M. Karafi t, “Comparison of keyword spotting approaches for informal continuous speech,” INTERSPEECH , pp.633-636, 2005.
- 4[4] M. Weintraub, “LVCSR log-likelihood ratio scoring for keyword spotting,” IEEE International Conference on Acoustics, Speech, and Signal Processing , vol.1, pp.297-300, 1995.
- 5[5] M. Sun, D. Snyder, Y. Gao, V. Nagaraja, M. Rodehorst, et al, “Compressed Time Delay Neural Network for Small-Footprint Keyword Spotting,” INTERSPEECH , pp.3607-3611, 2017.
- 6[6] SO. Arik, M. Kliegl, R. Child, J. Hestness, A. Gibiansky, et al, “Convolutional Recurrent Neural Networks for Small-Footprint Keyword Spotting,” INTERSPEECH , pp.1606-1610, 2017.
- 7[7] G. Tucker, M. Wu, M. Sun, S. Panchapagesan, et al, “Model Compression Applied to Small-Footprint Keyword Spotting,” INTERSPEECH , pp.1878-1882, 2016.
- 8[8] S. Tabibian, A. Akbari, B. Nasersharif, “An evolutionary based discriminative system for keyword spotting,” IEEE, International Symposium on Artificial Intelligence and Signal Processing , pp.83-88, 2011.