A Theory of Selective Prediction
Mingda Qiao, Gregory Valiant

TL;DR
This paper develops a theory for selective prediction in online data streams, showing that many statistics can be estimated accurately without distributional assumptions, and resolves an open problem regarding the error bounds for density prediction.
Contribution
It introduces a model of selective prediction, proves bounds on prediction error for arbitrary sequences, and resolves an open question on the accuracy of density prediction in online settings.
Findings
Expected squared error bounded by O(1/log n)
Matching lower bound established for density prediction
Applicable to general statistics of sequences
Abstract
We consider a model of selective prediction, where the prediction algorithm is given a data sequence in an online fashion and asked to predict a pre-specified statistic of the upcoming data points. The algorithm is allowed to choose when to make the prediction as well as the length of the prediction window, possibly depending on the observations so far. We prove that, even without any distributional assumption on the input data stream, a large family of statistics can be estimated to non-trivial accuracy. To give one concrete example, suppose that we are given access to an arbitrary binary sequence of length . Our goal is to accurately predict the average observation, and we are allowed to choose the window over which the prediction is made: for some and , after seeing observations we predict the average of . This…
Click any figure to enlarge with its caption.
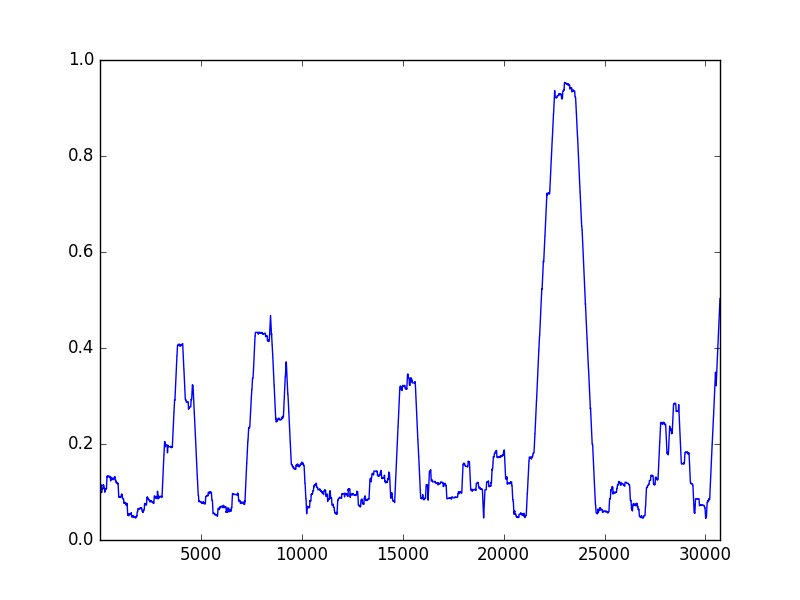 Figure 1
Figure 1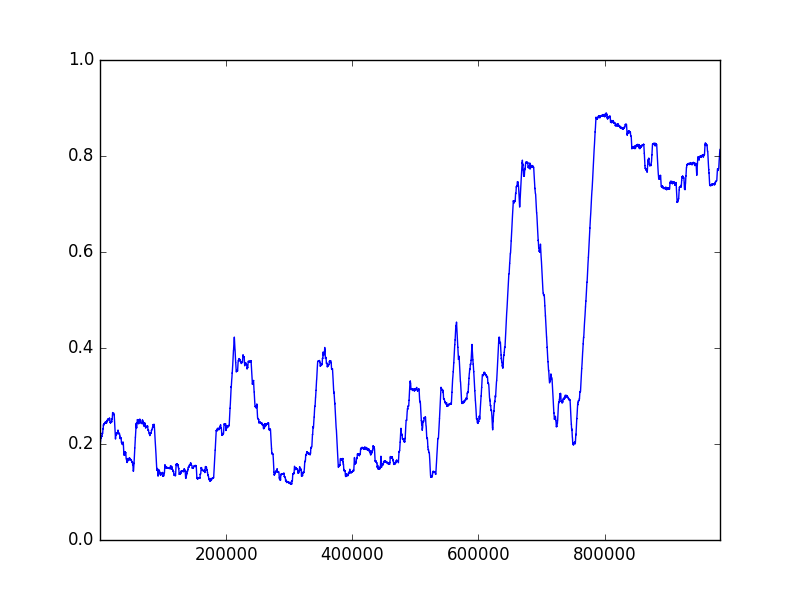 Figure 2
Figure 2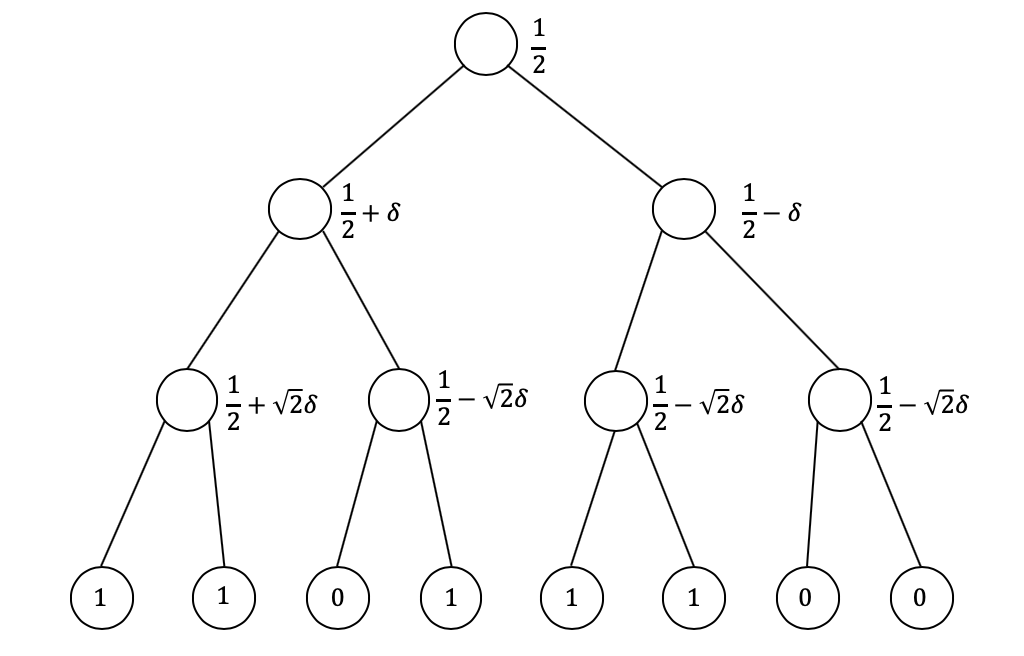 Figure 1
Figure 1| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 1 | 1 | 1 | 1 | |||||
| 1 | 1 | 1 | 1 | |||||
| 1 | 1 | 1 | 1 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Bandit Algorithms Research · Machine Learning and Algorithms · Optimization and Search Problems
A Theory of Selective Prediction
Mingda Qiao
Gregory Valiant
[email protected] This work is supported by NSF awards CCF-1704417 and AF:1813049 and by ONR award N00014-18-1-2295.
Abstract
We consider a model of selective prediction, where the prediction algorithm is given a data sequence in an online fashion and asked to predict a pre-specified statistic of the upcoming data points. The algorithm is allowed to choose when to make the prediction as well as the length of the prediction window, possibly depending on the observations so far. We prove that, even without any distributional assumption on the input data stream, a large family of statistics can be estimated to non-trivial accuracy. To give one concrete example, suppose that we are given access to an arbitrary binary sequence of length . Our goal is to accurately predict the average observation, and we are allowed to choose the window over which the prediction is made: for some and , after seeing observations we predict the average of . This particular problem was first studied in [Dru13] and referred to as the “density prediction game”. We show that the expected squared error of our prediction can be bounded by and prove a matching lower bound, which resolves an open question raised in [Dru13]. This result holds for any sequence (that is not adaptive to when the prediction is made, or the predicted value), and the expectation of the error is with respect to the randomness of the prediction algorithm. Our results apply to more general statistics of a sequence of observations, and we highlight several open directions for future work.
1 Introduction
Consider the following prediction problem: each day you observe the stock market, and at some point within the next days, you must make a prediction about the average return, or average volatility, of the stock market over some (future) period of time. Crucially, you get to choose both the timepoint within the days when you make the prediction, as well as the interval over which your prediction spans. Without any distributional assumptions on the daily movements in the stock market, is it possible to accurately make such a prediction about the future? As we show, the answer is “yes”, and the expected error of the prediction tends to zero as —the length of the window in which the prediction must occur—tends to infinity, assuming an absolute bound on the magnitude of daily fluctuations.
We consider several new angles to this age-old problem of making an accurate prediction about the future, given access to a sequence of observations. The setting we consider abstracts three crucial properties of the above prediction problem: 1) We make no distributional assumptions about the sequence of observations. 2) The sequence, while possibly adversarial, is not adaptive, and is chosen independently of our prediction and when we make it. 3) We decide both when to make our prediction, as well as the duration over which our prediction spans (provided that both occur within some pre-specified horizon, denoted by in the example above).
In some sense, this model can be viewed as an exploration of the power that comes with being able to decide when to make a prediction about the future, in a world which, while possibly adversarial and changeable, is indifferent to your predictions (i.e. adversarial but non-adaptive). As such, it captures a number of important and natural online prediction tasks, beyond the toy example of stock-market predictions.
A general formalization of this selective prediction problem can be framed as follows. We are given a family of functions where each . The prediction procedure proceeds as the following game. A sequence of length is chosen adversarially at the beginning of the game. The prediction game proceeds in rounds. At each time step , the player can make a claim in the following form: the function value of the next entries of the sequence () is . In this case, the game terminates immediately and the player incurs a loss of , where is the actual function value on . Two natural loss functions that we focus on are the squared loss and the absolute loss . If the player does not make a prediction at time , the next data point is revealed to the player and the game continues. The player must predict exactly once before the data sequence is entirely observed.
Facing an arbitrary and possibly adversarial data sequence, the predictor is only entitled the power of choosing the window over which the prediction is made. This power is indeed minimal in the sense that if the adversary knows in advance either the time step at which a prediction is made or the window length , the predictor cannot achieve a non-trivial loss even for the task of predicting the arithmetic mean; see Section 2.2 for more details.
This setting, and a related setting where one is must make a prediction about a single timestep, were first considered in [Dru13]. These models deviate significantly from many other prediction settings, which typically either make strong distributional assumptions on the sequence of observations (e.g., that they are drawn independently, or generated from a Markov model, Hidden Markov Model, or exchangeable sequence, etc.), or make no assumptions but quantify the accuracy in terms of some notion of “regret” with respect to a limited set of benchmarks. Additionally, most previously studied prediction settings assume that the predictor must make a prediction at a specified time, or must make predictions at every time step. We discuss these differences, and connections to other settings more in Section 1.2.
1.1 Overview of Results
Estimating the arithmetic mean.
We first state our main results on the concrete task of predicting the average of a bounded real-valued sequence.
Theorem 1.1**.**
Suppose that and the function family is the arithmetic mean, i.e.,
[TABLE]
There exists a prediction algorithm that achieves an expected squared loss of on any sequence of length . Moreover, this bound is tight: there is a distribution over sequences of length for which no algorithm can achieve an expected loss better than .
The upper bound of was first given in [Dru13], and the matching lower bound resolves one of the main open questions posed in that work. At an intuitive level, the mean estimation algorithm follows from the observation that a sequence cannot have a high variance on both small and large scales: if an adversary generates a uniformly random sequence in in the hope that each single data point is hard to predict, the average of the whole sequence would concentrate around and thus be predictable.
The lower bound proof amounts to constructing a sequence with moderate variance at all different scales, simultaneously. Hence, no matter when the prediction algorithm chooses to make a prediction, and no matter the chosen time window, there will be a significant amount of variance in the values, conditioned on the sequence up to the time of prediction. Consequently, the prediction algorithm has no hope in achieving too small a loss.
Estimating smooth functions.
The positive result extends to other function families beyond the arithmetic mean. One such function family is the collection of all Lipschitz functions with respect to the earth mover’s distance defined as follows. For a real sequence of length , let denote the uniform distribution on the multiset , i.e., assigns probability mass to each .
Definition 1.2**.**
The earth mover’s distance between two real sequences and is defined as the Wasserstein distance between and with respect to the metric .
Definition 1.3**.**
A function is -smooth if and only if it is -Lipschitz in earth mover’s distance, i.e., for any .
We show that on bounded sequences, smooth functions can be estimated up to an absolute loss of , where is the smoothness parameter and is the length of the input sequence.
Theorem 1.4**.**
Suppose and every function in is -smooth. There exists a prediction algorithm that achieves an expected absolute loss of on any sequence of length .
Estimating concatenation-concave functions.
In addition to the positive result on smooth functions, which only applies to functions on , we consider the following class of concatenation-concave functions that admit a more general domain.
Definition 1.5**.**
A function family is concatenation-concave if and only if for any and with , it holds that
[TABLE]
where is a shorthand for .
Note that the arithmetic mean is concatenation-concave, with all inequalities in the above definition being equalities. Another family of concatenation-concave functions of practical importance is the following “learnability” function. Suppose that is a given model class, which can be equivalently viewed as a family of bounded loss functions mapping to . The learnability of a data sequence is defined as , the minimum average loss when we fit the sequence using a model in class .
The learnability function is not captured by the family of smooth functions in the previous paragraph—in fact, may not even be associated with a non-trivial metric. On the other hand, it can be easily verified that the learnability function is concatenation-concave.
Our positive result for concatenation-concave functions states that any bounded concatenation-concave function can be estimated with an expected squared loss of . This result is especially striking when considered in the context of estimating learnability, as the prediction accuracy is independent of the complexity of model class .
Theorem 1.6**.**
Assuming that the function family is concatenation-concave and bounded in , there exists a prediction algorithm that achieves an expected squared loss of on any sequence of length .
Fitting unseen data.
Given that we can accurately estimate the learnability of future data with respect to any model class, it is natural to ask whether we can identify a model that actually fits the unseen data well. To this end, we consider the following generalization of our prediction model: instead of predicting , the predictor is required to output a model in that fits well. The setting remains selective in the sense that and are still chosen by the prediction algorithm. The loss of the prediction is defined as the excess risk
[TABLE]
By our results on mean estimation and a standard uniform convergence argument over , we can easily obtain an upper bound on the optimal excess risk. Note that in this prediction task, the loss bound indeed depends on the cardinality of . In classic learning theory, however, the dependence of the excess risk on is typically logarithmic. It remains a compelling open question whether the excess risk can be further improved to as classical learning theory suggests, or whether a polynomial dependence on is inevitable in the worst case.
1.2 Related Work
Most closely related to this paper is the work of [Dru13], which studies several prediction problems in the setting where we are given access to an arbitrary (adversarial) infinite binary sequence, and attempt to predict the value of a single index, or predict the fraction of 1’s in a future interval. Crucially, the predictor is also allowed to choose the prediction window selectively. [Dru13] shows that given a horizon of length , one can achieve a squared error of at most in expectation, which translates into an expected squared loss of in our setting. Our work recovers this result as a special case, and proves a matching lower bound which implies that this exponential dependence on is necessary.
The recent work [FKT17] proves a local repetition lemma, which states that a sufficiently long sequence must exhibit a certain level of pattern at some time scale. The difference from our work is the interpretation of this observation: while [FKT17] addresses the online learning setting where the regret is defined with respect to a set of “stateful” policies that can be represented by state machines, we consider the problem of directly predicting an arbitrary sequence and aim to generalize this observation to a broader class of prediction and learning tasks.
More broadly, sequential prediction and decision making is a major subject of research in many different fields. Early study on this problem dates back to the pioneering work of [Han57] in the 1950s. This problem, along with many of its extensions, is addressed under various terminologies in different communities, including “universal prediction” in information theory [FMG92], “universal portfolios” in mathematical finance [Cov91, CO96, BK99] and “online learning” in machine learning theory [LW94, CBFH*+*97, CBL06]. In particular, our approach is closely related to yet different from the online learning formulation. In online learning, the predictor has access to a class of strategies (also known as “experts”). The prediction algorithm leverages the expert advice and makes sequential prediction on every time step. The performance of the predictor is measured in terms of the regret, defined as the difference between the incurred loss and the loss of the best expert in hindsight.
There is also a large body of work on “conformal prediction” in the online setting where datapoints are revealed one at a time (see e.g. the book [VGS05]). This body of work is largely concerned with understanding how confidently one can make a prediction about the label, , given and a sequence of labeled data . In general, strong positive results exist in the independent setting where data is drawn independently from a fixed distribution, and also in the more general setting where the sequence of data is assumed to be exchangeable.
The selective prediction model we consider is significantly different from the above two settings. In contrast to the regret minimization framework, we do not restrict ourselves to a specified family of experts; instead, we evaluate the predictor solely based on the expected loss rather than the loss relative to the best expert. In contrast to work on conformal prediction, our results hold without any distributional assumptions on the sequence of data. Crucially, to enable these strong results, in our model the prediction algorithm is allowed to be selective in the sense that its prediction may not necessarily cover the entire time horizon, and the prediction can be made over an interval of arbitrary length instead of a single observation.
We note that the recent work of [SKLV18] addresses the problem of predicting the distribution of the next observation in the data sequence from a different perspective. The focus of their work is whether accurate prediction can be made using a small memory, and their results apply to the scenario where the data stream is drawn from a distribution with bounded mutual information between the past and the future (for example, a sequence generated by a hidden Markov model). In contrast, our model captures the prediction of a more general family of statistics of the upcoming observations, and we make no distributional assumptions on the sequence.
Another related line of research concerns the estimation of learnability given limited data. In more detail, given labeled data drawn i.i.d. from an underlying distribution, we are asked to estimate how well a given model class can fit the distribution. It is shown that for linear models, a sample of size is sufficient for accurate estimation [Dic14, KV18], and this is much less than the amount of data needed to learn a linear model. Our work is incomparable to this line of research, since our results apply to the more general setting where the data are not assumed to be i.i.d. and the model class can be arbitrary.
2 Tight Loss Bounds for Mean Estimation
We start by studying a special case of the general prediction problem: estimating the mean of a bounded sequence. Without loss of generality, we assume that the instance space is . The function value on a subsequence of numbers is simply the arithmetic mean, i.e., .
2.1 Selective Predictor with Vanishing Loss
We begin by presenting the simple prediction scheme from [Dru13] that achieves an error which goes to zero as tends to infinity, and include a slightly simpler proof of the loss. In the following, we assume that the sequence length is a power of two. Let denote the uniform distribution over the finite set .
Algorithm 1 chooses the prediction window by drawing and randomly at the beginning. Then, at time , the algorithm predicts that the average of the next numbers is close to that of the most recent numbers. We prove in the following that Algorithm 1 achieves a squared loss of .
Lemma 2.1**.**
Suppose that the instance space is and the function family is the arithmetic mean. For any integer , Algorithm 1 achieves an expected squared loss of at most on any sequence of length .
Remark 2.2**.**
Lemma 2.1 directly implies that squared loss can be achieved in the general case that is not a power of two, thus proving the upper bound part of Theorem 1.1. Indeed, choosing and running Algorithm 1 as if the sequence is of length gives an expected squared loss of at most .
Proof.
For integer and , let denote the maximum expected squared loss that Algorithm 1 incurs on a sequence of numbers between [math] and with average . We prove by induction on that , which directly implies the proposition.
When , Algorithm 1 reduces to predicting that , and the squared loss can be bounded as follows:
[TABLE]
For , we note that with probability , Algorithm 1 chooses and predicts that the last numbers have the same average as the first numbers. Let and denote the averages of the first and last numbers, respectively. Then, the squared loss in in this case is given by . With probability , the algorithm chooses some and the algorithm is equivalent to running the same algorithm either on either the first numbers or the last numbers. By the induction hypothesis, the conditional expected squared loss is upper bounded by
[TABLE]
Based on the above analysis, we have
[TABLE]
which completes the proof. ∎
2.2 Selectivity is Necessary
Algorithm 1 is selective in the sense that it randomly chooses the time step as well as the window length for its prediction. Such selectivity is crucial to achieving a sub-constant loss. Intuitively, if is known to the adversary, the data stream can be chosen such that the first elements are independent of the rest, rendering any meaningful prediction unfeasible. Likewise, if the prediction window is of fixed length , the data sequence can be constructed as blocks of size , which also leads to a constant lower bound on the prediction loss. Finally, if the time, , of the prediction can be chosen, but the window must contain the remaining observations, a constant lower bound also exists. The formal proof of the following proposition is deferred to Appendix A.
Proposition 2.3**.**
Suppose that prediction algorithm , when running on a sequence of length , either: (1) always predicts at the same time , (2) always chooses the same window length , or (3) chooses , but must make a prediction over the entire window of remaining timesteps. Then, there exists a binary sequence of length on which incurs an expected squared loss of at least .
2.3 Matching Lower Bound
The prediction scheme in Algorithm 1 may appear not to leverage all the power of the predictor; indeed, the algorithm chooses the prediction window at the beginning of the algorithm, while the model in general allows the algorithm to make the decision adaptively. Nevertheless, we show in the following that such adaptivity brings little marginal gain—the upper bound in Lemma 2.1 is optimal up to a constant factor.
The key in our lower bound proof is to construct a sequence that simultaneously satisfies an anti-concentration property on both small and large timescales. Such a sequence guarantees that even after the predictor observes a prefix of the sequence, the average of the future data sequence still has a large conditional variance given the prefix. This implies a lower bound on the expected squared error achievable by any prediction algorithm.
Again, we focus on the case that is a power of two, as the proof can be extended to the general case (losing at most a constant factor) by the same argument as in Remark 2.2. Consider a perfect binary tree with leaves. In the following, we assign a real value between [math] and to each node in the tree recursively, and the sequence is chosen as the values on the leaves. Let . The value of the root is defined as . Then, for each node at the -th level of the tree (the root being at level [math] and leaves at level ), we choose its value randomly and independently from such that the expectation of the value equals the value of its parent. In particular, if the parent has value , the node takes value
[TABLE]
the probabilities are switched in the other case. Note that by our choice of , all leaves will be assigned values in and thus the resulting sequence is bounded. See Figure 1 for a realization of the construction when . Also see Figure 2 for plots of a sample sequence for . Note that after taking the moving average at different scales, the sequence still exhibits strong anti-concentration. (In contrast, the moving average of a uniformly random bit string would concentrate around at larger scales.)
Let denote the distribution of the sequence that we defined as above. We show that any algorithm will incur an squared loss in expectation given a random sequence drawn from . By an averaging argument, there exists a sequence on which the algorithm incurs an squared loss. This proves the lower bound part of Theorem 1.1.
Lemma 2.4**.**
For any integer and , any prediction algorithm for the arithmetic mean incurs an expected squared loss of at least on a random sequence drawn from .
Remark 2.5**.**
Since the arithmetic mean is both -smooth (Definition 1.3) and concatenation-concave (Definition 1.5), Lemma 2.4 implies that an squared loss is inevitable for these two function families.
Proof.
We show that for any and , conditioned on any prefix of the sequence, the variance in is at least . The theorem follows from the observation that this is the smallest expected squared loss that can be achieved when the player decides to predict the average of .
Fix and . By our construction of , there exists integer such that and contains a contiguous subsequence of length that exactly corresponds to the leaves in a subtree of height . Let denote the root of the subtree. We can actually prove a stronger claim: the variance in is lower bounded by , even when conditioned on the values of all nodes in the binary tree except the subtree rooted at .
Let be the parent of . Let and denote the values of and respectively. It can be verified from the construction that . Since the subtree rooted at has leaves, the value of node contributes at least a fraction to the average . It follows that the conditional variance in is lower bounded by . ∎
3 Estimating General Functions
We extend the positive results for mean estimation to more general function families. It turns out that Algorithm 1 has a stronger guarantee beyond mean estimation: we will show that exactly the same algorithm also achieves a vanishing loss on smooth functions and concatenation-concave functions.
3.1 Smooth Functions
Recall that Algorithm 1 chooses and randomly, and then uses as an estimate for . We show in the following that the sequences and are close in earth mover’s distance defined as in Definition 1.2. The prediction loss can then be bounded using the smoothness of .
Lemma 3.1**.**
Suppose that and every function in is -smooth. For any integer , Algorithm 1 achieves an expected absolute loss of at most on any sequence of length .
Lemma 3.1 implies Theorem 1.4 by the argument in Remark 2.2.
Proof.
Let and denote subsequences and . In the following, we prove the an upper bound on the expected earth mover’s distance between and :
[TABLE]
where the expectation is taken over the randomness in and .
It is well-known that the earth mover’s distance between two distributions on can be rewritten as
[TABLE]
Recall that (resp. ) denotes the uniform distributions naturally defined by (resp. ), i.e., .
Fix and consider an auxiliary sequence defined as follows:
[TABLE]
Then, and are exactly the means of subsequences and , respectively. Since is bounded in , by Lemma 2.1,
[TABLE]
Taking an integral over proves that
[TABLE]
which completes the proof, since the expected absolute loss is upper bounded by
[TABLE]
due to the -smoothness of . ∎
3.2 Concatenation-Concave Functions
Algorithm 1 also applies to the case where the function family to be predicted is concatenation-concave. The proof resembles that of Lemma 2.1, yet a slightly different induction hypothesis is used. Again, Lemma 3.2 readily extends to the general case where the sequence length is not a power of two and thus proves Theorem 1.6.
Lemma 3.2**.**
Suppose that the function family is concatenation-concave and bounded in . For any integer , Algorithm 1 achieves an expected squared loss of at most on any sequence of length .
Proof.
For integer and , let denote the maximum expected squared loss that Algorithm 1 incurs on a sequence of length with function value . Let and . By the concatenation-concavity of , we have . In the following, we prove by induction that , which further implies that for any .
When , the squared loss is upper bounded by
[TABLE]
Suppose that . With probability , Algorithm 1 chooses and the loss is given by . With probability , the algorithm chooses , and the algorithm is equivalent to running the same algorithm on either the first or last entries of the sequence. The conditional expected loss in this case is upper bounded, thanks to the induction hypothesis, by
[TABLE]
To sum up, we have
[TABLE]
as desired, where the last step follows from and the monotonicity of on . ∎
4 Fitting Unseen Data
In this section, we study the problem of finding a model that fits the upcoming data points with a small excess risk. We consider a finite model class , each element of which can be viewed as a loss function . The goal of the player is to choose some time step and window length and output a model that minimizes the excess risk defined as follows:
[TABLE]
A natural approach to this problem is to follow the strategy in Algorithm 1 and output the “empirical risk minimizer” (ERM) of observed data. We formally state the algorithm as follows. The excess risk of Algorithm 2 can be bounded by a uniform convergence argument over all models in .
Proposition 4.1**.**
For any integer and finite model class , Algorithm 2 achieves an expected excess risk of at most on any sequence of length .
Proof.
Let and denote sequences and . For , let denote the average loss of on sequence . By a standard uniform convergence argument, the expected excess risk of Algorithm 2 is upper bounded by
[TABLE]
∎
Falling short of proving a lower bound that matches Proposition 4.1, we show that further improving the excess risk would require a more sophisticated prediction scheme than Algorithm 2. In particular, Proposition 4.2 states that when , Algorithm 2 incurs a constant excess risk in expectation and thus the upper bound in Proposition 4.1 is almost tight for Algorithm 2.
Proposition 4.2**.**
For any integer , there exists a model class of size and a sequence of length such that Algorithm 2 incurs an expected excess risk of at least on .
Proof.
Let and . Each is defined as:
[TABLE]
where . The input sequence is defined as . An example of the construction with is shown in Table 1.
Let and denote subsequences and . For , let denote the average loss of on sequence . It can be verified that
[TABLE]
By our choice of , is always the unique minimizer of . Thus, Algorithm 2 always outputs . Moreover, when (which happens with probability ), the resulting excess risk is at least . This proves the lower bound of on the expected excess risk incurred by Algorithm 2. ∎
Appendix A Proof of Proposition 2.3
Proof of Proposition 2.3.
In the first case that is known to the adversary, we simply construct a binary sequence such that , and is randomly drawn from with equal probability. When makes a prediction at time , the actual average of the sequence is either [math] or with equal probability. It can be verified that any algorithm must achieve an expected squared loss of at least .
Now we consider the second case, where the window length is fixed. We choose and construct a sequence consisting of blocks of length . Each block consists of the same value, which is chosen from uniformly and independently at random. Whenever Algorithm makes a prediction, by our choice of , the prediction window of size must contain an entire block. Since the variance in the average of the block is and the block contributes an fraction to the average that aims to predict, the variance in the arithmetic mean is then lower bounded by . This implies a lower bound of on the squared loss.
In the third case, the prediction algorithm chooses , but is forced to make a prediction over the entire remaining timesteps. In this case, consider constructing an adversarial distribution over sequences of length such that the first block of values are all identical and are chosen to either all be 0 or all be 1 with probability 1/2 of each choice, then next block of are identical and randomly selected to be either 0 or 1, and similarly for the next block of , , , etc. Let denote the time at which the prediction algorithm makes its prediction. There will always some for which the block of size is contained within the final timesteps, and for which is at least a fraction of . Hence the variance in the average value due to that block alone implies a lower bound of at least on the expected squared loss of any prediction. ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[BK 99] Avrim Blum and Adam Kalai. Universal portfolios with and without transaction costs. Machine Learning , 35(3):193–205, 1999.
- 2[CBFH + 97] Nicolo Cesa-Bianchi, Yoav Freund, David Haussler, David P Helmbold, Robert E Schapire, and Manfred K Warmuth. How to use expert advice. Journal of the ACM (JACM) , 44(3):427–485, 1997.
- 3[CBL 06] Nicolo Cesa-Bianchi and Gábor Lugosi. Prediction, learning, and games . Cambridge university press, 2006.
- 4[CO 96] Thomas M Cover and Erik Ordentlich. Universal portfolios with side information. Transactions on Information Theory (TIT) , 42(2):348–363, 1996.
- 5[Cov 91] Thomas M Cover. Universal portfolios. Mathematical Finance , 1(1):1–29, 1991.
- 6[Dic 14] Lee H Dicker. Variance estimation in high-dimensional linear models. Biometrika , 101(2):269–284, 2014.
- 7[Dru 13] Andrew Drucker. High-confidence predictions under adversarial uncertainty. Transactions on Computation Theory (TOCT) , 5(3):12, 2013.
- 8[FKT 17] Uriel Feige, Tomer Koren, and Moshe Tennenholtz. Chasing ghosts: competing with stateful policies. SIAM Journal on Computing , 46(1):190–223, 2017.