Asymptotic resolution bounds of generalized modularity and multi-scale community detection
Xiaoyan Lu, Brendan Cross, Boleslaw K. Szymanski

TL;DR
This paper establishes asymptotic bounds for the resolution parameter in generalized modularity to improve community detection in heterogeneous networks, and proposes a heuristic for multi-scale community detection.
Contribution
It provides the first theoretical bounds on the resolution parameter for generalized modularity in realistic networks and introduces a multi-scale detection heuristic.
Findings
Resolution limit explained via random graph properties
Communities with lower intra- than inter-community density are merged
Proposed heuristic detects communities at multiple scales
Abstract
The maximization of generalized modularity performs well on networks in which the members of all communities are statistically indistinguishable from each other. However, there is no theory bounding the maximization performance in more realistic networks where edges are heterogeneously distributed within and between communities. Using the random graph properties, we establish asymptotic theoretical bounds on the resolution parameter for which the generalized modularity maximization performs well. From this new perspective on random graph model, we find the resolution limit of modularity maximization can be explained in a surprisingly simple and straightforward way. Given a network produced by the stochastic block models, the communities for which the resolution parameter is larger than their densities are likely to be spread among multiple clusters, while communities for which the…
Click any figure to enlarge with its caption.
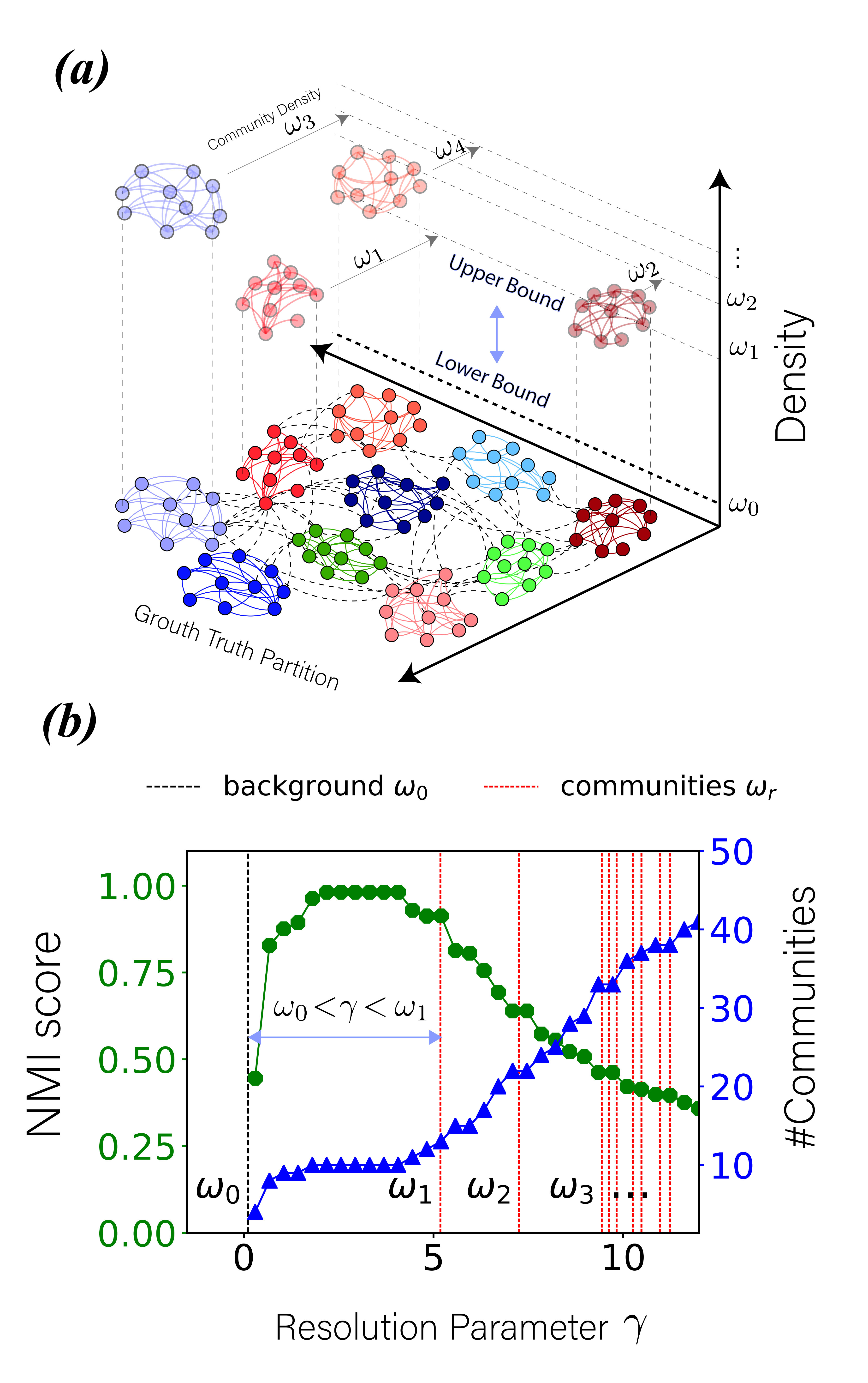 Figure 2
Figure 2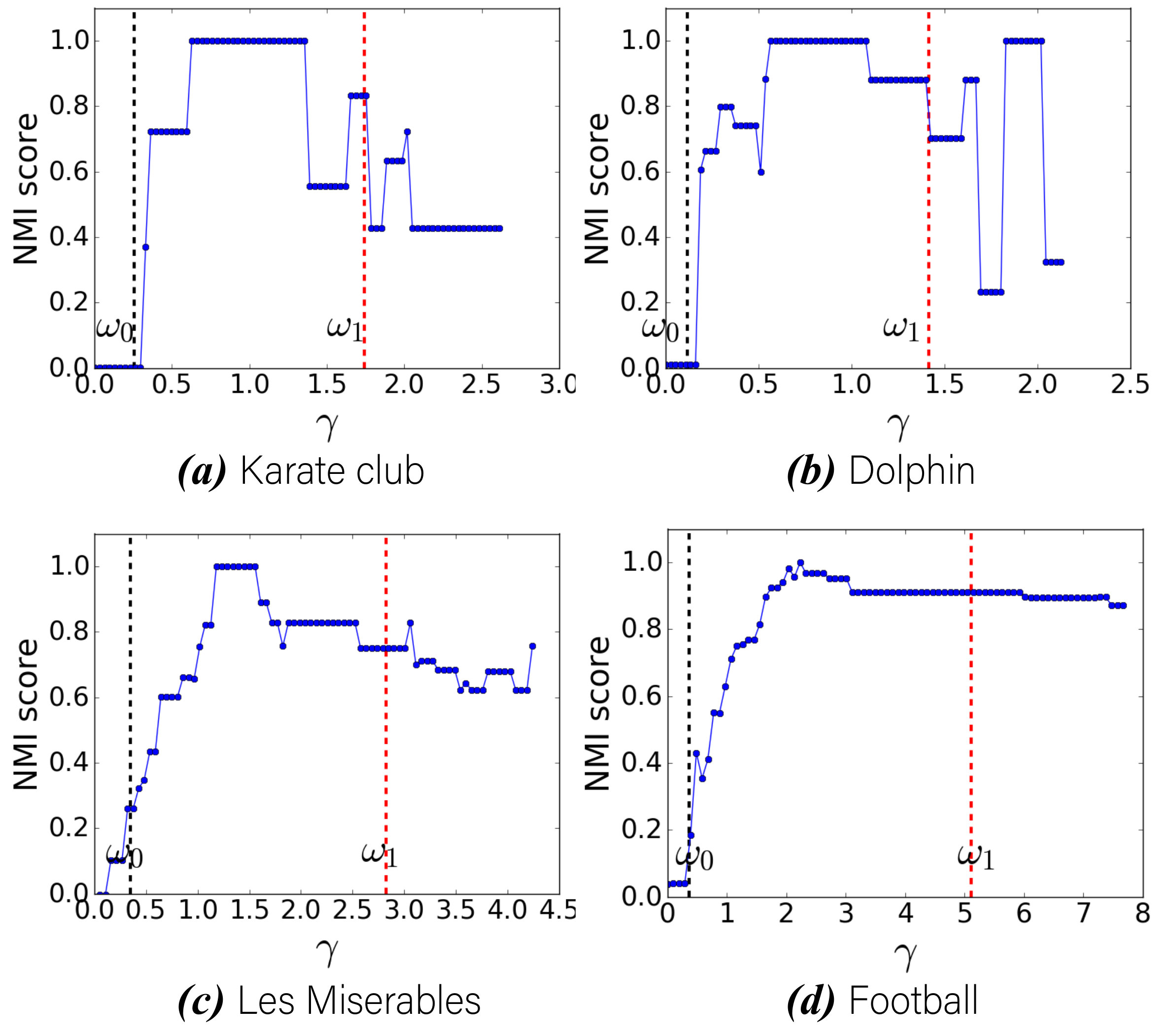 Figure 6
Figure 6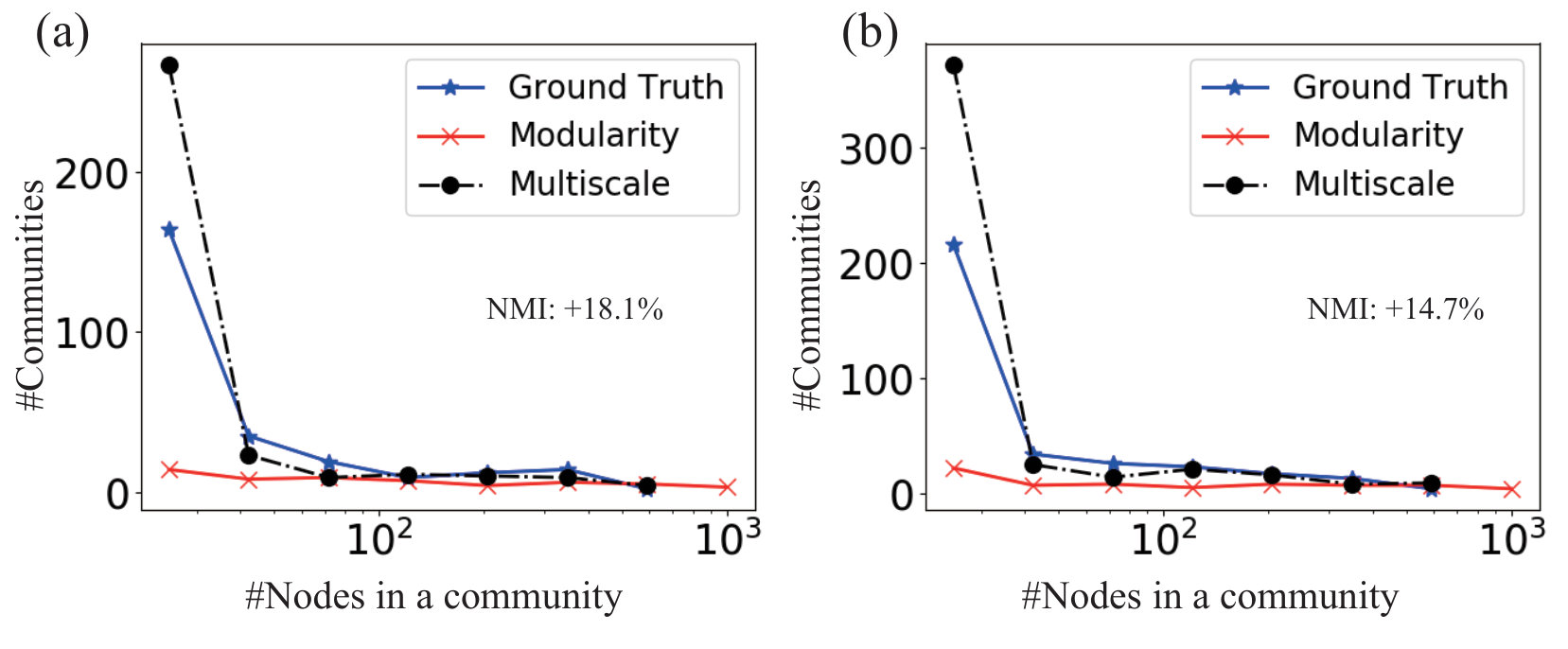 Figure 3
Figure 3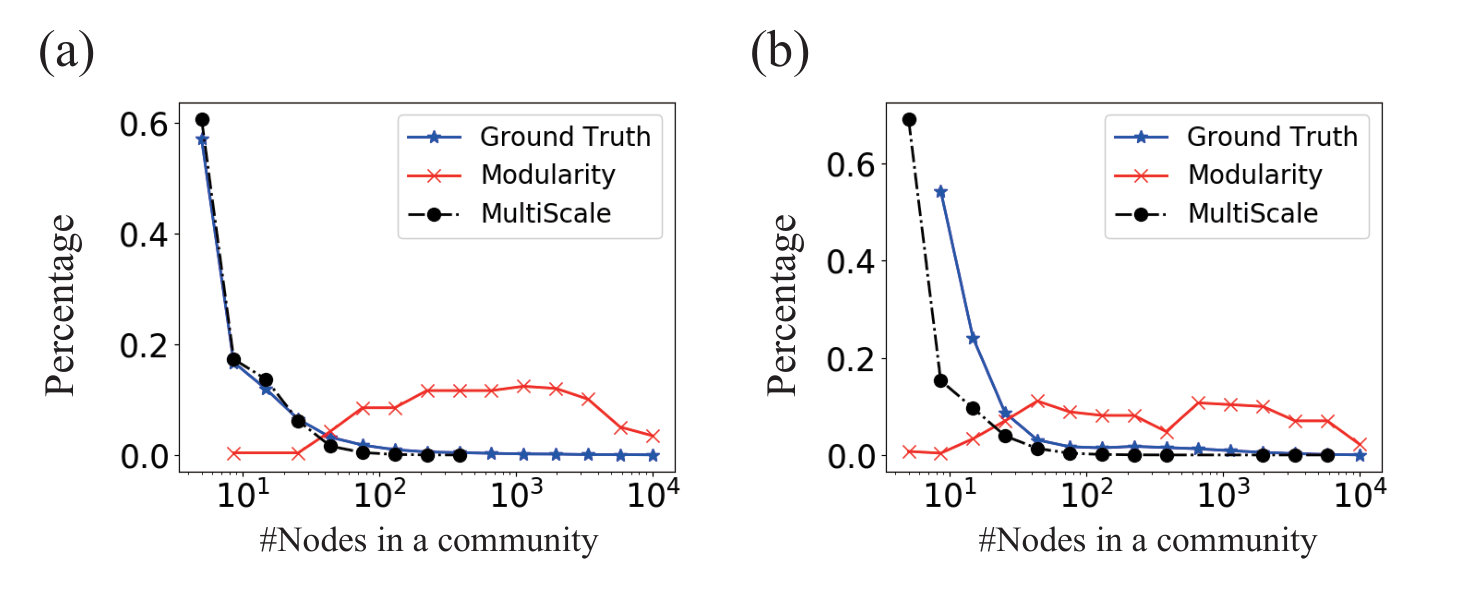 Figure 4
Figure 4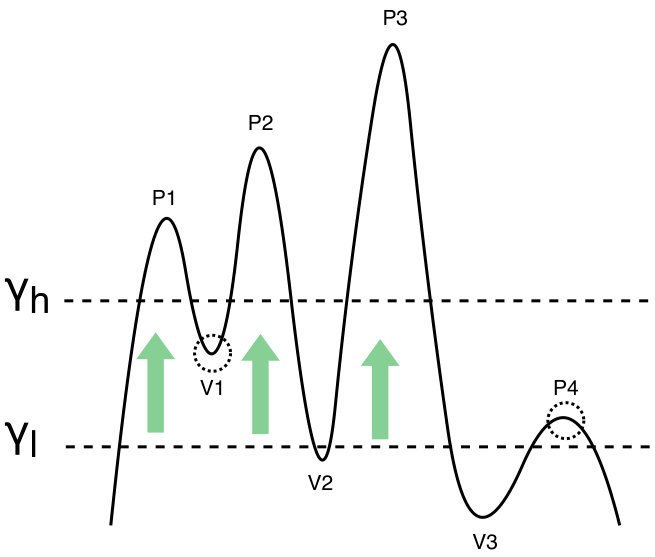 Figure 5
Figure 5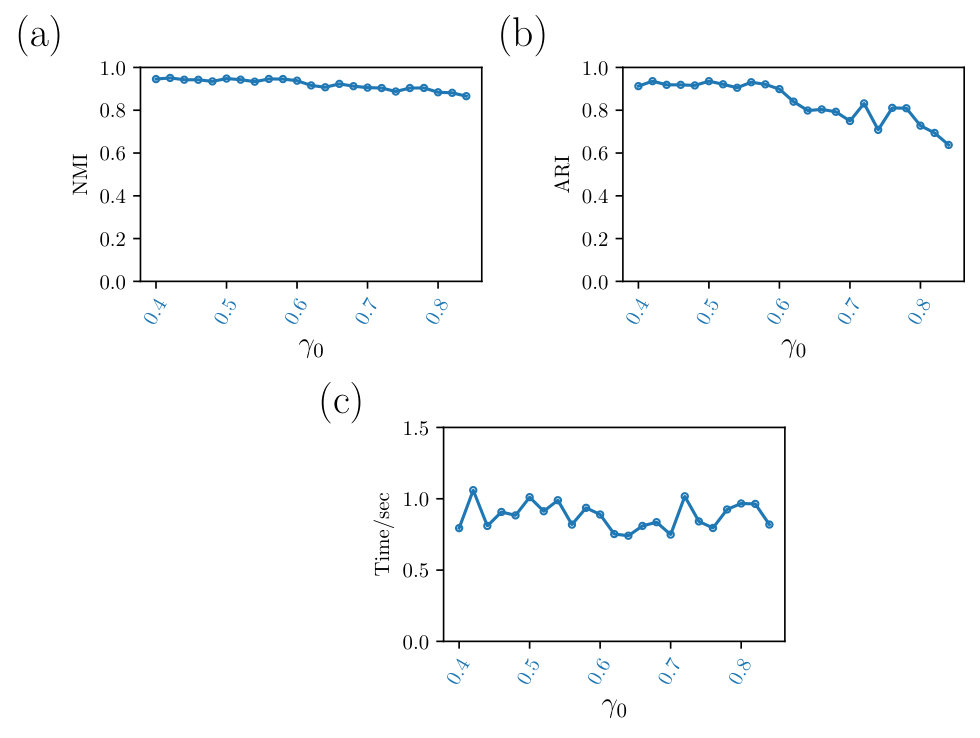 Figure 7
Figure 7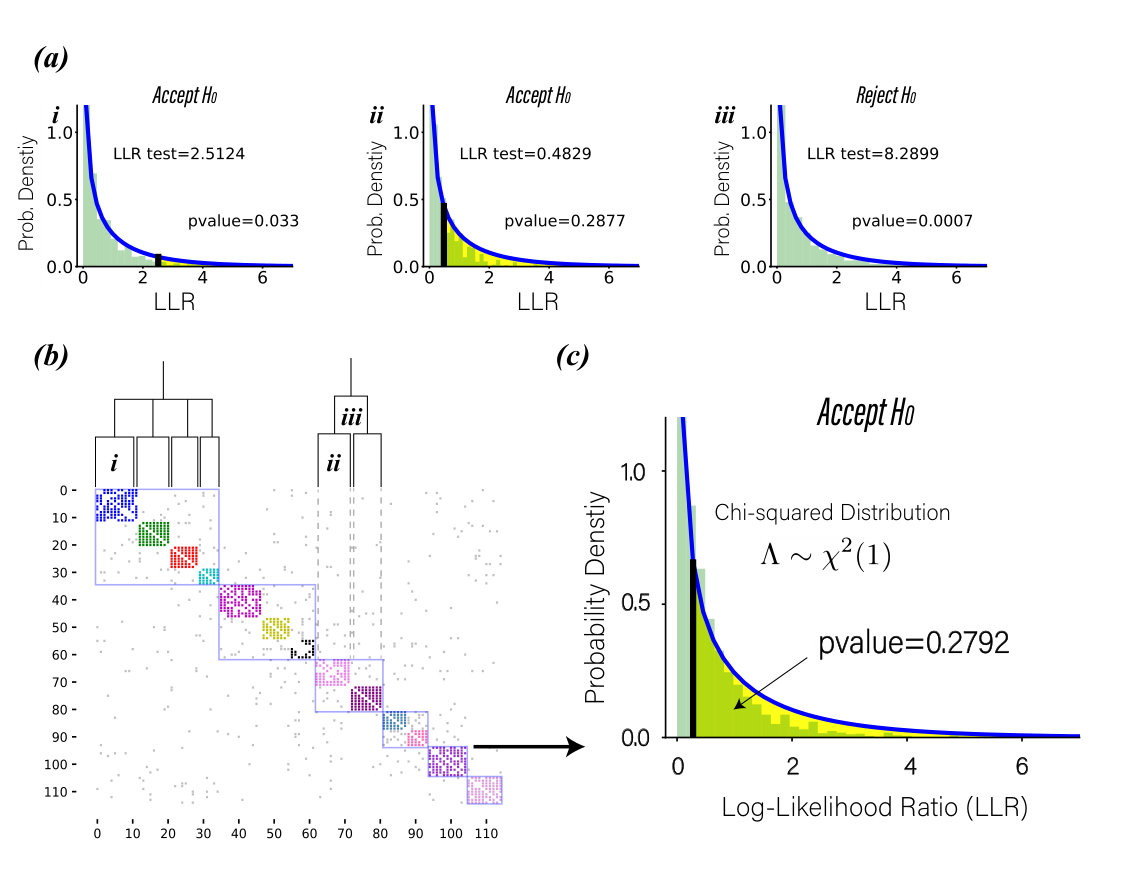 Figure 7
Figure 7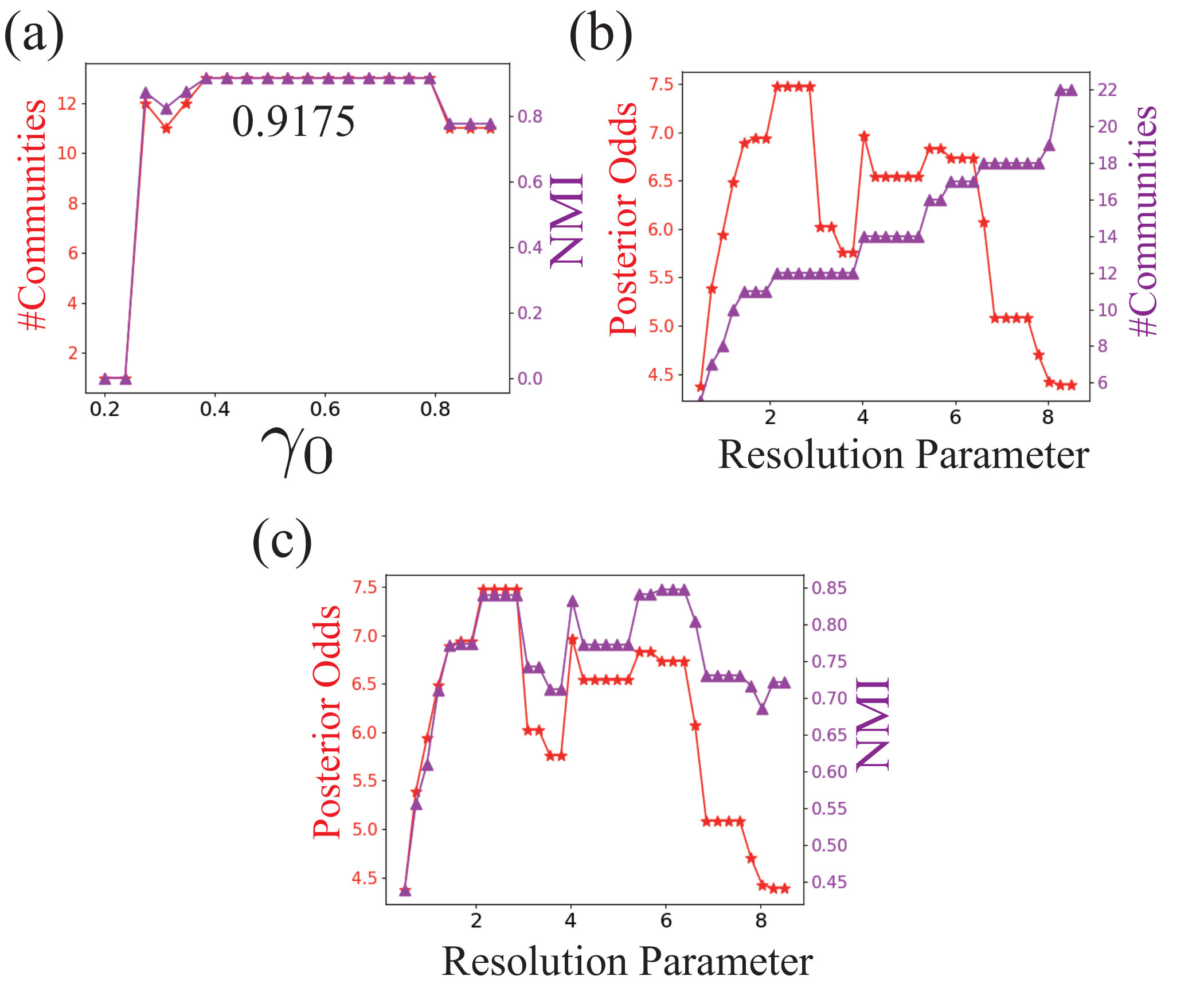 Figure 8
Figure 8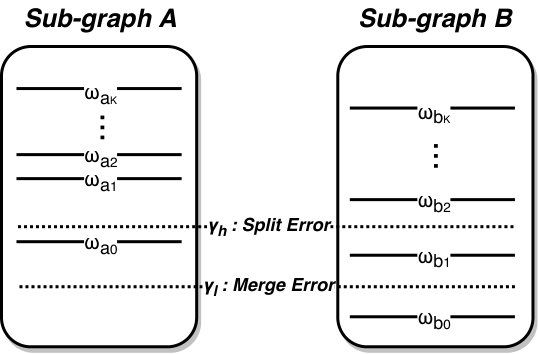 Figure 9
Figure 9 Figure 10
Figure 10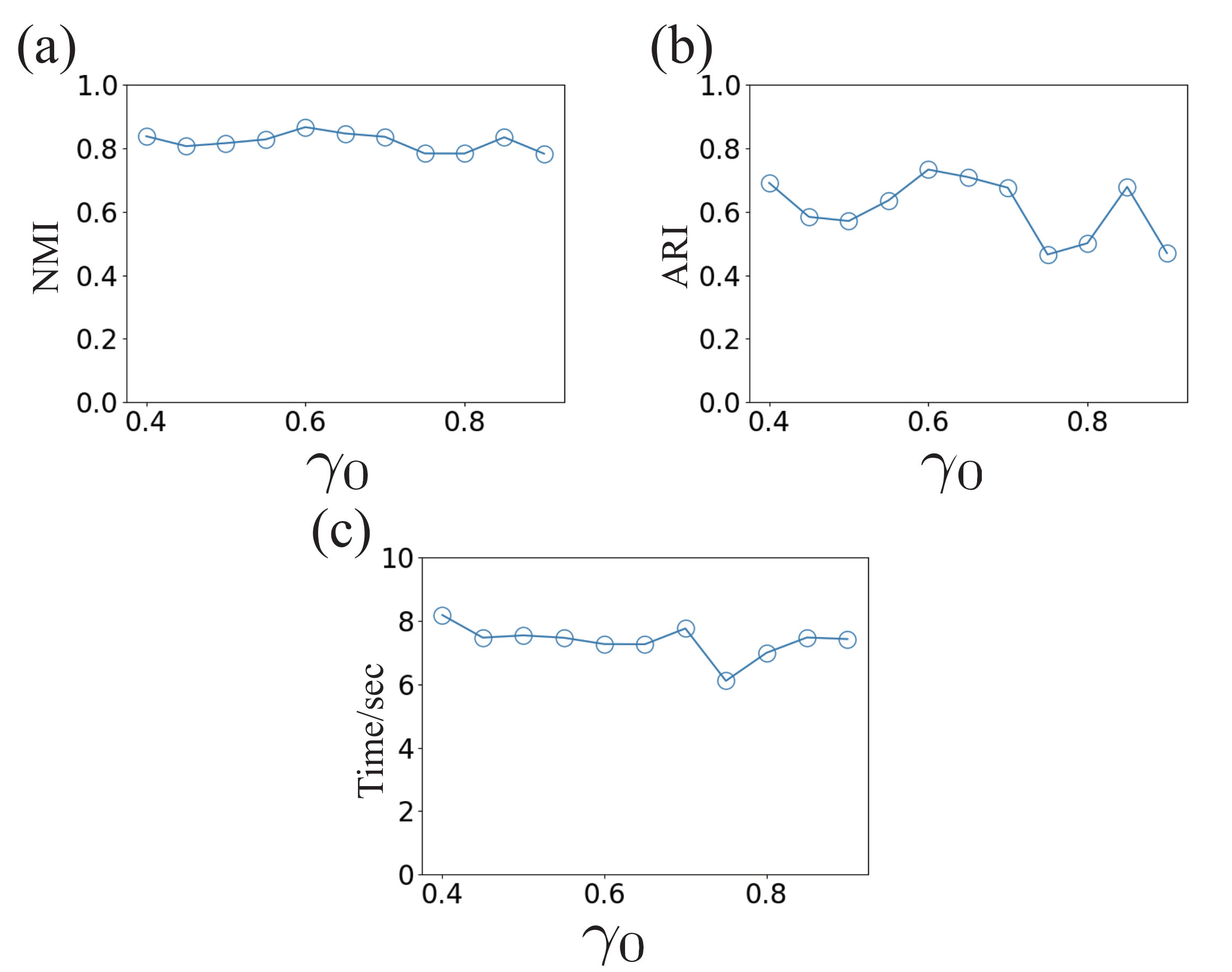 Figure 11
Figure 11| Network | interval | |||||
|---|---|---|---|---|---|---|
| Karate club | 34 | 78 | 2 | 0.78 | (0.26, 1.74) | (0.63, 1.37) |
| Dolphin social | 62 | 159 | 2 | 0.59 | (0.12, 1.42) | (0.58, 2.0) |
| Les Miserables | 77 | 254 | 6 | 1.36 | (0.35, 2.83) | (1.15, 1.54) |
| #Nodes | #Edges | Metrics | Louvain | CPM | Multi-scale |
|---|---|---|---|---|---|
| 30,000 | 139685 | ARI | 0.45 | 0.90 | 0.93 |
| NMI | 0.88 | 0.94 | 0.96 | ||
| 40,000 | 186471 | ARI | 0.69 | 0.93 | 0.95 |
| NMI | 0.89 | 0.96 | 0.97 | ||
| 50,000 | 233100 | ARI | 0.68 | 0.93 | 0.93 |
| NMI | 0.89 | 0.96 | 0.96 | ||
| 60,000 | 277207 | ARI | 0.70 | 0.89 | 0.93 |
| NMI | 0.87 | 0.94 | 0.95 |
| Metrics | Louvain | Multi-scale | ||||
|---|---|---|---|---|---|---|
| ARI | 0.55 | 0.76 | 0.91 | 0.93 | 0.72 | 0.94 |
| NMI | 0.77 | 0.86 | 0.92 | 0.93 | 0.88 | 0.95 |
| Time (sec) | 0.57 | 0.47 | 0.35 | 0.38 | 0.53 | 1.05 |
| Amazon | DBLP | |||
|---|---|---|---|---|
| NMI | F-measure | NMI | F-measure | |
| Louvain | 0.56 | 0.47 | 0.36 | 0.14 |
| CPM | 0.68 | 0.46 | 0.60 | 0.24 |
| Multi-scale | 0.69 | 0.49 | 0.64 | 0.26 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Asymptotic resolution bounds of generalized modularity and multi-scale community detection
Xiaoyan Lu
Brendan Cross
Boleslaw K. Szymanski
Department of Computer Science, Rensselaer Polytechnic Institute, Troy, NY, USA
Network Science and Technology Center, Rensselaer Polytechnic Institute, Troy, NY, USA
Społeczna Akademia Nauk, Łódź, Poland
Abstract
The maximization of generalized modularity performs well on networks in which the members of all communities are statistically indistinguishable from each other. However, there is no theory bounding the maximization performance in more realistic networks where edges are heterogeneously distributed within and between communities. Using the random graph properties, we establish asymptotic theoretical bounds on the resolution parameter for which the generalized modularity maximization performs well. From this new perspective on random graph model, we find the resolution limit of modularity maximization can be explained in a surprisingly simple and straightforward way. Given a network produced by the stochastic block models, the communities for which the resolution parameter is larger than their densities are likely to be spread among multiple clusters, while communities for which the resolution parameter is smaller than their background inter-community edge density will be merged into one large component. Therefore, no suitable resolution parameter exits when the intra-community edge density in a subgraph is lower than the inter-community edge density in some other subgraph. For such networks, we propose a progressive agglomerative heuristic algorithm to detect practically significant communities at multiple scales.
keywords:
community detection, modularity maximization, resolution limit, stochastic block model, Bayes model selection
††journal: Journal of Information Sciences
1 Introduction
In complex networks, community structures are widely observed. Detecting such community structures can be viewed as partitioning of the network into clusters in which the nodes are more densely connected to each other than to the nodes in the rest of the network. Modularity maximization [19] is one of the state-of-the-art methods for community detection. It aims at discovering the partition of the network that maximizes modularity, a well-known quality measure of network community structure.
Modularity maximization, however, suffers from the so-called resolution limit problem [9, 12] that is this method’s tendency to detect communities of similar properties. In such cases, standard modularity reaches maximum by combining some small well-formed communities into inappropriate large clusters or by spreading some large well-formed communities among smaller ones. Some variants of the modularity function have been proposed either to resolve this problem [2, 15, 29] or to enable detection of communities at different scales [14, 27, 25, 28]. A popular choice for the latter is the generalized modularity of Reichardt and Bornholdt [26], which scales the discovered community sizes according to a simple resolution parameter.
Besides the maximization of modularity and its generalized version, an alternative approach to detect communities is the statistical inference to fit the generative model to the observed network data. The inference assumes that the random graph model produced the observed network provided as input. The statistical inference aims at recovering a partition that maximizes the likelihood of the random graph model generating the observed network data.
One widely used generative model for community structure is the degree-corrected stochastic block model [11] where nodes are organized into blocks while edges are placed between the nodes independently at random111In the Supplementary Material, we discuss in detail various stochastic block model variants and the related work on modularity maximization in the literature.. The maximization of the generalized modularity [20] is shown to be equivalent to the maximum-likelihood estimation (MLE) of the degree-corrected planted partition model, a special case of the degree-corrected stochastic block model, on the same graph. Yet, there is no asymptotic bounds defining generalized modularity maximization’s performance in more realistic networks generated by the degree-corrected stochastic block model. As illustrated by Fig. 1, our work aims at answering the important question about the performance of the generalized modularity on such networks.
Specifically, we establish here an asymptotic theoretical upper and lower bounds on the resolution parameter of generalized modularity. This result bridges the gap between the literature on the resolutions limits of modularity-based community detection [8, 9] and the random graph models [11, 20]. Given a resolution parameter within the established range, we show that maximizing the generalized modularity is still likely to detect the correct communities, regardless whether the equivalence between generalized modularity maximization and the MLE of stochastic block model holds or not. When the resolution parameter of the generalized modularity is larger than the upper bound we developed, some well-formed communities are likely to be spread among multiple clusters to increase the generalized modularity. However, when the resolution parameter of generalized modularity is smaller than the lower bound we developed, some communities may be inappropriately merged into one large component.
The experimental results of modularity maximization on synthetic network agree with our findings that the generalized modularity performs best when resolution parameter lies well within the interval defined by our derived analytical bounds. Experimentally, and without any explanation why, the authors of [7, 18, 28] established that the suitable values of the resolution parameter occur in the widest interval in which the generalized modularity maximization produces the consistent partitions. The authors of [29] introduce the class of quality measures that are "resolution-limit-free". The generalized modularity does not fall into this category because the resolution parameter performs best within an interval conditioned on the number of clusters on the ring network of cliques [9]. Our work derives such interval of the resolution parameter in the boarder degree-corrected stochastic block graphs, thus connecting the literature on resolutions bounds for community detection [9, 8] with the multi-scale community discovery [7, 18, 33].
Furthermore, our findings shed light on the adaptation of the generalized modularity to networks in which there is no universal resolution parameter to detect all communities. That happens only when the lower bound of the resolution parameter may be higher than its upper bound. Therefore, some well-formed communities either are split into multiple clusters or merged into one large component. The problem is analogous to identifying mountains with varied heights of their peaks and valleys by scanning mountainsides at a single altitude. Such scan either would miss the low peaks seeing just background behind them, or would treat the higher peaks as one mountain as their mountainsides would form single base unbroken by valleys.
To address the above-mentioned problem, we propose a progressive agglomerative heuristic algorithm that systematically adjusts the resolution parameter. The algorithm recursively splits the resulting clusters of the previous level to detect smaller communities. As the recursion proceeds, the algorithm gradually increases the resolution parameter for high-resolution community detection in local clusters of the network. The algorithm proceeds until none of the currently found clusters contains communities that are practically significant as measured by Bayes model selection [3]. Compared to the algorithms using a uniform resolution parameter, our approach does not require multiple re-estimation of the resolution parameter for the entire network [20] that can be computationally prohibitively costly for large networks.
To summarize, this paper makes the following contributions to our understanding of multi-scale community detection, resolution limit and generalized modularity:
Asymptotic upper and lower bounds on the resolution parameter of generalized modularity linking the resolutions limits of modularity-based community detection [8, 9] to the random graph models [11, 20].
- 2.
A simple theoretical explanation of the resolution limit, confirming the previous experimental and theoretical findings [7, 18, 28, 28] that the suitable resolution parameters occur in the widest interval in which the generalized modularity maximization produces the consistent partitions.
- 3.
A highly efficient multi-scale modularity-based heuristic community detection algorithm that does not require multiple re-estimation of the resolution parameter.
2 Approach
2.1 Asymptotic bounds on resolution parameter
The generalized modularity of Reichardt and Bornholdt [26] can be defined as
[TABLE]
where is the number of edges with both endpoints inside the community , is the sum of the degrees of nodes in community , and is the total number of edges in the network.
Merging two different communities, and , results in the following equations: the total number of edges inside the merged community becomes where is the number of edges between communities and . The sum of degrees of the nodes inside the merged community is . Hence, given the formalization of the generalized modularity in Eq. (1), the optimization algorithm is able to detect two well-formed communities and if the change of generalized modularity from merging and is non-positive, leading to the inequality
[TABLE]
which can be rewritten in the alternative way as
[TABLE]
Otherwise, when the , communities and are merged to increase . Clearly, one can always increase so that Eq. (3) holds for any small and . Howether, a large may result in inappropriate split of some communities. To see this point, consider a community comprised of two sets of nodes and with sums of degrees and respectively, and edges between nodes in and . To avoid splitting community into and , the inequality
[TABLE]
must hold. Given Eq. (3) and Eq. (4), we have
[TABLE]
A simple and straightforward explanation of the resolution limit found by Fortunato et al. [9] is that in realistic networks the above inequality may not hold. Indeed, it is likely that in a large network there exist communities and with small and and community with large sum of node degrees , such that the inequality above does not hold because , giving rise to resolution limit anomaly.
The degree-corrected stochastic block model222See the Supplementary Material for the formal definition of the model. is a generative model of the graph in which nodes are organized as blocks and edges are placed between nodes independently at random. Following the notations in [20], the degree-corrected stochastic block model assumes the number of edges between nodes and follows the Poisson distribution with the mean defined as
[TABLE]
where for node , is the block assignment of this node and is its degree. Note that the model defines , i.e., a half the number for the self-edge. Given the nodes’ degrees and , is the expected number of edges between different nodes and , or a half that number for self-edges, in the graph ensembles generated by the configuration model [17]. Thus, represents the ratios of the expected numbers of edges in the stochastic block model and the configuration model. In the rest of the paper, we refer to the parameter as the edge density between blocks and and to the matrix as the density matrix of the model.
The expected number of edges between two communities and in the degree-corrected stochastic block model is
[TABLE]
The expected number of edges between two subsets of nodes and inside the same community is
[TABLE]
where is the diagonal element in the density matrix.
Using the resolution inequality from Eq. (5), these approximations lead to the range
[TABLE]
within which a uniform value avoids the resolution limit trap. This result connects the resolution limit of generalized modularity with the random graph models.
Eq. (9) indicates that the suitable value should be as small as possible to avoid splitting of any well-defined communities, i.e. for any . Otherwise, when is larger than the density parameter of some loose community , this community is likely to be split. However, should not be larger than any background inter-community density, i.e. for every pair of . Otherwise, the communities and are likely to be merged inappropriately into one cluster to maximize the generalized modularity.
The degree-corrected planted partition model is a special case of the degree-corrected stochastic block model where for every pair of different communities and for every community . Therefore, Eq. (9) also applies to the graphs generated by the degree-corrected planted partition model. In such a case, Eq. (9) becomes . As shown in [20], when , the generalized modularity maximization is equivalent to the maximum likelihood estimation of the degree-corrected planted partition model. Using this equivalence condition in the inequality, we obtain
[TABLE]
which can be proven333Dividing Eq. (10) by on both sides and denoting leads to inequality which can be formally proved using the well-known upper and lower bounds of the natural logarithm for any . given any positive values. Hence, the maximum likelihood estimation of the degree-corrected planted partition model always resides within the bounds we derive here.
2.2 Plateaus problem
In a network generated by the degree-corrected stochastic block model with for some and , Eq. (9) indicates that a uniform resolution parameter is not sufficient for the recovery of communities , and . Given the ground truth communities, the posterior estimates of the density matrix is for each pair of communities or for each community . To ensure the correct recovery of the ground truth, the resolution parameter should satisfy
[TABLE]
for any communities and .
The classical example of resolution limit trap is presented in [12] where an undirected unweighted network contains three communities: two cliques and one random graph, and every two communities are connected by one single edge. Suppose each clique includes 6 nodes and the random graph contains 100 nodes and 956 edges. Given the three communities, the posterior estimation of the density matrix of the degree-corrected stochastic block model is
[TABLE]
where the first row and column correspond to the random graph while the remaining rows and columns correspond to the two cliques respectively. There is no suitable resolution parameter to detect three communities in this case because the density parameter for the edges between two cliques is larger than the density parameter for the edges inside random graph . When applying generalized modularity maximization, adopting a resolution parameter larger than , makes it likely that two cliques will be detected, but the random graph will get split into smaller communities. On the other hand, a resolution parameter within preserves the random graph as one complete community, but the two cliques will be merged into one community.
Intuitively, the issue is analogous to searching for mountains that are located at different plateaus while using a single altitude, see Fig. 2. Such search either would miss the lower mountains, or would treat the higher peaks as one mountain. Specifically, when using resolution parameter , the left two high peaks in Fig. 2 are considered one “mountain" - two well-formed dense communities are merged. If we adopt a resolution parameter , the low peak on the right is ignored - a loose community is split into multiple smaller clusters. Notably, this issue cannot be avoided as long as the valley of the left two peaks is higher than the height of the right-most peak.
More formally, given the density matrix of a degree-corrected stochastic block model and a set of communities , the sub-matrix formed by the rows and columns in corresponds to a subgraph in the network. Let and denote the inter-communities density parameter for subgraphs A and B, respectively. In Fig. 3, using causes Split Error which splits some community with in B while using causes Merge Error which merges all communities in subgraph A.
This problem is more common in large networks than in small ones, as large networks are more likely to have inhomogeneous subgraphs. For this reason, a uniform resolution limit parameter is not sufficient to resolve communities located at different “plateaus”. Motivated by this “plateaus” phenomenon, we propose a multi-scale community detection algorithm which gradually increases the resolution parameter to detect community in local subgraphs.
2.3 Multi-scale community detection
So far, we presented the bounds on the resolution parameter for community detection in graphs generated by the degree-corrected stochastic block model. The bounds defined in Eq. (9) give rise to the “plateaus" problem when no single resolution parameter exists. When the resolution parameter takes an inappropriate value, maximizing the generalized modularity cannot discover all communities.
For this reason, we propose a heuristic algorithm that iteratively applies growing resolution parameters to detect recursively communities at different scales. This process is illustrated in Fig. 2. In the first step, the generalized modularity maximization algorithm uses a small resolution parameter , which is likely to merge adjacent dense communities into clusters. Then, it applies a higher to detect communities in each of the resulting clusters.
Specifically, at each level of recursion, the algorithm applies a small resolution parameter in attempt to avoid inappropriately splitting of loose communities. However, it is likely to merge inappropriately small well-formed dense communities into a large cluster. Therefore, the currently found subgraphs are passed to the next level of recursion to detect communities in them. This idea is illustrated in Fig. 2 where the peaks located at higher plateaus need scans at high altitude (large ’s) for each to have its own community.
It is worth noting that the interval [11] scales with the number of edges in the graph. As the recursion proceeds to obtain smaller subgraphs, applying a resolution parameter in a subgraph with edges is equivalent to applying in the original graph with edges. For the simplicity, we always use the same small resolution parameter in all subgraphs at each level of recursion. This approach is approximately equivalent to increasing the resolution parameter at each level recursion.
The remaining challenge is to determine when to terminate the recursion. As the network breaks into smaller subgraphs recursively, the algorithm should stop when there is actually only one community in each subgraph. Indeed, one can always increase the resolution parameter to detect higher resolution communities in this subgraph. However,it does not mean the current subgraph always contains community structures. For instance, an Erdos-Renyi random graph [6] can be partitioned into communities as long as the resolution parameter is high enough. However, we cannot claim that such Erdos-Renyi random graph contains a community structure.
To ensure the detected communities are meaningful, we use the Bayes model selection [3] to evaluate the practical significance of the partitions at each level of recursion. Specifically, given a subgraph obtained at a certain recursion level, we are interested in whether or not this subgraph is more likely to be generated by the configuration model than by a degree-corrected planted partition model with the multiple blocks. If true, the agglomerative heuristic algorithm terminates at this recursion level and accepts the current subgraph as a single community in the result. Otherwise, the algorithm continues by applying this model selection process for each of the detected blocks.
For a particular subgraph with adjacent matrix , the null hypotheses here is that the subgraph is generated by the random graph model , which is a special case of the degree-corrected planted partition model, in which single community exists. The alternative, nested hypothesis is the degree-corrected planted partition model along with the block assignment found by maximization of generalized modularity. We choose the planted partition model rather than the stochastic degree model as the alternative hypothesis because this model is generally simpler, thus leading to a Bayes posterior odds which can be efficiently computed. The Bayes posterior odds [3] can be represented as
[TABLE]
where is the marginal likelihood of generating the subgraph by , given the degree sequence , and block assignment . Likewise, is the marginal likelihood for the random graph model . We formulate the priors and in the Supplementary Material. Function does not need to be fully defined because its two appearances cancel themselves out. The logarithm of the Bayes posterior odds has a simple form of
[TABLE]
where is the number communities, is the number of nodes in community, the entropy functions are and , and the coefficients and are defined as
[TABLE]
The Supplementary Material details the mathematical derivation of .
Another widely used approach for model selection is the likelihood ratio test. Although the likelihood ratio test statistic is easy to obtain for and , the null distribution of the test statistic in case of generative models used here does not follow the chi-squared distribution [31]. Thus, it requires enumerating a series of the null networks generated by to calculate the p-value for this test, which is computationally inefficient for large networks. Therefore, we adopt the Bayes model selection to determine the termination condition at each level of the recursion.
The pseudo code of the proposed multi-scale community detection algorithm is illustrated in Alg. 1. Given a graph , the algorithm maximizes the generalized modularity with a small resolution parameter , which results in a partition of the network (Line 2). For each detected community, the algorithm tests its significance using Eq. (14). If such community is significant, i.e. , then it is added to the result . Otherwise, the multi-scale algorithm repeats the above procedure on the subgraph with nodes in this detected community.
3 Experimental Results
To evaluate the performance of the proposed multi-scale community detection algorithm, we compare it with the state-of-art Louvain algorithm [1] and CPM algorithm [29], on several real and synthetic networks summarized in Table 1.
We adopted the Louvain and CPM algorithm implementations by Vincent Traag built on top of the igraph library444https://github.com/vtraag/louvain-igraph/. For the networks with pre-defined ground truth communities, the quality of the detected communities is evaluated using the Normalized Mutual Information (NMI) and Adjusted Rand Index (ARI) metrics that are defined in the Supplementary Material.
3.1 Validation of resolution bounds
We validate the asymptotic bounds on the resolution parameters on a simplified version of the degree-corrected stochastic block model assuming the off-diagonal elements of the density matrix all have the same value , while the diagonal elements have different values for each . The formal definition of this so-called extended degree-corrected planted partition model can be found in the Supplementary Material.
Suppose there are communities with the density parameters monotonically ordered by their indices, according to the bounds in Eq. (9), the value of the resolution parameter should satisfy
[TABLE]
so that all communities can be detected.
In our experiments, the extended degree-corrected planted partition model generates a network comprised of ten communities, each has ten nodes and a density illustrated by the red vertical lines in Fig. 4. The background inter-community density is chosen as , a value much smaller than any intra-community densities. The performance of community detection is measured by the normalized mutual information (NMI) metric [30] that compares the detected partition with the ground truth partition used for generation.
As Fig. 4(b) shows, the generalized modularity performs well with resolution parameter in the interval , generally matching the derived theoretical bound . As approaches either side of the bound, the resolution parameter is either higher or lower than desired. The asymptotic bounds defined here are derived by approximating the number of edges with the corresponding expectation in the random graph model (Eq. (7), (8)). Hence, as is getting closer and closer to either or , the asymptotic results are getting further and further away from the true values, causing the NMI score to drop. This scenario is illustrated in Fig. 4(a) where every community is placed at the height corresponding to its density . When the resolution parameter is between the asymptotic bounds, the modularity maximization can successfully detect communities. However, when the resolution parameter is larger than the density of any of the communities, those communities are at risk of being split into smaller parts.
We test the performance of our algorithm on a range of empirical networks with nodes and edges, including the Karate club network [34], the dolphin social network [16] and the network of interactions between fictional characters in the novel Les Miserables [21]. For each network, we compute the maximum-likelihood estimates of the background edge density and the lowest intra-community edge density 555See the Supplementary Material for the formal derivations of the maximum-likelihood estimates for and in the extended degree-corrected planted partition model., fitting an extended degree-corrected planted partition model given the number of communities and the optimal value of obtained by the statistical inference [20]. Then, we compute the modularity maximization results with a total of different resolution parameters in the range and compare these results with the communities produced with from this range. The subrange that produces an NMI score higher than is shown in Table 2. As shown in Fig. 5, although these empirical networks are not generated by the extended degree-corrected planted partition model, the stable intervals of resolution parameter lie inside the asymptotic lower and upper bounds established here.
3.2 Synthetic Networks
One of the standard sources of community structures for the evaluation of community detection algorithms is the LFR benchmark [13] which generates networks based on a set of pre-defined ground truth communities. In so generated networks, both the degree and community size distributions follow the power law. The main benefit of using LFR benchmark is that the ground truth communities are known. The generated networks vary with the following three parameters: which is an exponent of the node degree in the power law distribution, which is an exponent of the community size in the power law distribution, and which is the density parameter that defines the fraction of all edges that have both endpoints inside the same community. The LFR benchmark is closely related to the microcanonical degree-corrected stochastic block model [23] that imposes the degree sequence as the hard constraint for all sample networks of the ensemble. Since the generated networks have the known ground truth communities, we consider the alignment of the detected communities with such ground truth a reliable quality measurement for these communities.
In our experiments, the networks generated by the LFR benchmarks have the average node degree of 9.3 and the numbers of nodes ranging from 6,000 to 15,000. The exponents and are set to 3.0 and 1.5 respectively and the density parameter is equal to 0.25. We compare the multi-scale algorithm with two state-of-the-art algorithms the Louvain algorithm [1] and CPM algorithm [29]. Since these algorithms require a single resolution parameter, we test their performance using their own resolution parameters over a wide range of commonly used values, respectively, and record the best values of NMI and ARI metrics in Table 3 The results show that the proposed multi-scale community detection algorithm performs modestly better than the two state-of-the-art modularity maximization algorithms. It should be noted that the strongest advantage of the multi-scale algorithm over other modularity maximization algorithms is its ability to avoid resolution limit anomaly. The results indicate that it is unlikely that the resolution limit anomaly was present in the used LFR benchmark networks.
We compare the performance of Louvain algorithm maximizing the generalized modularity and the proposed multi-scale community detection algorithm with different values of resolution parameters on the LFR generated network with 5,000 node and 23,234 edges. As Table 4 illustrates, the proposed multi-scale community detection approach outperforms the Louvain algorithm. When the resolution parameter takes different values, the community structures found by maximizing the generalized modularity are worse than the results produced by the multi-scale community detection algorithm. A plausible reason could be that, due to the “plateaus” problem mentioned above, there may not be any appropriate resolution parameter capable of avoiding all the unnecessary splits and merges at the same time. Hence, no matter what value the resolution parameter takes, maximizing the generalized modularity suffers from the resolution limit. In contrast, the proposed multi-scale community detection algorithm attempts to adapt resolution parameter to actual density in different regions of a graph. Therefore, it achieves better performance in terms of the ARI and NMI scores.
Fig. 6 shows the multi-scale community detection algorithm’s sensitivity to the choice of the initial resolution parameter . When takes different values in the range , the quality of the communities detected on a LFR network of 5,000 nodes remains relatively consistent. Using the different values for the multi-scale algorithm, the NMI scores of the detected communities are above . The ARI scores are also relatively stable when is smaller than 0.7. The variation of the execution time is small as illustrated by Fig. 6.
3.3 Real Networks
We test the performance of the proposed multi-scale community detection algorithm on two large real networks. The first is the DBLP co-authorship network where edges connect every pair of authors who published at least one paper together. The second network is the Amazon product co-purchasing network, in which edges connect the frequently co-purchased products. According to [32], the publication venue, e.g., journal or conference, defines an individual ground-truth community in the DBLP network. In the Amazon network, each product category provided by Amazon defines each ground-truth community. Although these meta-data may not correlate well with the topological community structure [22], comparing the detected communities with the pre-defined meta-data of network provide a good hint for community detection performance in general. In addition, we only compare the detected communities with the top-5,000 communities defined in [32] to reduce the bias introduced by the meta-data.
In Table 5, we show the NMI and F-measure for the multi-scale algorithm with and CPM algorithm with resolution parameter on Amazon and DBLP networks. We also run Louvain algorithm with a range of resolution parameter values and show the results with the parameter value that yielded the best NMI and F-measure scores. The defintion of F-measure [30] is as follows.
[TABLE]
where is the set of nodes in the detected community while is the set of nodes in the ground truth community . The total number of nodes in a network is denoted as and denotes the indices of the top-5,000 high-quality ground truth communities. The results show that on DBLP data, the performance of the multi-scale algorithm exceeds Louvain performance by 86% and CPA performance by 8%, indicating that Louvain suffers from the effects of resolution limit anomaly much stronger than CPM algorithm does.
Fig. 7 shows the distribution of the size of the detected communities in two real networks whose ground truth communities are defined in [32]. The distribution of the communities detected by the proposed multi-scale algorithm matches the distribution for the so-defined ground truth communities. The modularity maximization algorithm, however, produces relatively fewer small communities due to the resolution limit. The multi-scale detection algorithm does not suffer from this issue, hence, in both the Amazon network and the DBLP network, there are many more small communities than the large ones.
4 Conclusions
The real networks are not necessarily generated by any random graph model - all the assumptions about network generation here are only approximations of the real community structures. But we show that if the densities of edges in communities are much larger than the background density of edges across communities, the degree-corrected planted partition model is still a good approximation that avoids the resolution limit problem, when a resolution parameter is chosen from the theoretical range given in Eq. (16). We also show that, there is more complicated problem described as “plateaus” problem where no single resolution parameter exist satisfying all bounds. We propose a multi-scale community detection algorithm that requires minimal modification to the original modularity maximization method, thus preserving the high speed and robustness of modularity maximization.
Since the degree-corrected planted partition model equivalent to the generalized modularity is much simpler than the degree-corrected stochastic block model, its performance on realistic large networks is inevitably limited. Although one can infer the block assignments of stochastic block model to obtain communities, this inference is actually much more complicated than maximizing generalized modularity. In practice, modularity maximization via the agglomerative heuristics iteratively merges neighboring blocks [4]. In contrast, the merging operation in the inference of stochastic block model involves many more (not necessarily adjacent) blocks as candidates [24]. One advantage of the inference approach is that it uses the model selection to prevent overfitting the community models [10]. Therefore, we believe that finding a well-defined simple quality measure that takes into account the model complexity would be of great value.
In addition, edge weighting schemes [5, 15] are effective approaches to tolerate the modularity resolution limit. The “plateaus” problem indicates the resolution limit arises during the heterogeneous community formation. Edge weighting may be able to fix such heterogeneity. Other future works include applying more capable models as nested hypothesis in the hypothesis testing framework and extending the multi-scale community detection algorithm to weighted and directed networks.
Acknowledgments
This work was supported in part by the Army Research Laboratory (ARL) through the Cooperative Agreement (NS CTA) Number W911NF-09-2-0053, and by the Office of Naval Research (ONR) under Grant N00014-15-1-2640. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies either expressed or implied of the Army Research Laboratory or the U.S. Government.
References
- Blondel et al. [2008]
Blondel, V. D., Guillaume, J.-L., Lambiotte, R., and Lefebvre, E. (2008).
Fast unfolding of communities in large networks.
J. Statist. Mech.: Theory and Exp., 2008(10):P10008.
- Chen et al. [2014]
Chen, M., Kuzmin, K., and Szymanski, B. K. (2014).
Community detection via maximization of modularity and its variants.
IEEE Trans. Comput. Social Sys., 1(1):46–65.
- Chipman et al. [2001]
Chipman, H., George, E. I., McCulloch, R. E., Clyde, M., Foster, D. P., and Stine, R. A. (2001).
The practical implementation of bayesian model selection.
Lecture Notes-Monograph Series, pages 65–134.
- Clauset et al. [2004]
Clauset, A., Newman, M. E., and Moore, C. (2004).
Finding community structure in very large networks.
Phys. Rev. E, 70(6):066111.
- De Meo et al. [2013]
De Meo, P., Ferrara, E., Fiumara, G., and Provetti, A. (2013).
Enhancing community detection using a network weighting strategy.
Inf. Sci., 222:648–668.
- Erds and Rényi [1960]
Erds, P. and Rényi, A. (1960).
On the evolution of random graphs.
Publ. Math. Inst. Hungar. Acad. Sci, 5:17–61.
- Fenn et al. [2009]
Fenn, D. J., Porter, M. A., McDonald, M., Williams, S., Johnson, N. F., and Jones, N. S. (2009).
Dynamic communities in multichannel data: An application to the foreign exchange market during the 2007–2008 credit crisis.
Chaos: Interdisciplinary J. Nonlinear Sci., 19(3):033119.
- Fortunato [2010]
Fortunato, S. (2010).
Community detection in graphs.
Phys. Rep., 486(3):75–174.
- Fortunato and Barthelemy [2007]
Fortunato, S. and Barthelemy, M. (2007).
Resolution limit in community detection.
Proc. Nat. Acad. Sci., 104(1):36–41.
- Ghasemian et al. [2019]
Ghasemian, A., Hosseinmardi, H., and Clauset, A. (2019).
Evaluating overfit and underfit in models of network community structure.
IEEE Transactions on Knowledge and Data Engineering.
- Karrer and Newman [2011]
Karrer, B. and Newman, M. E. (2011).
Stochastic blockmodels and community structure in networks.
Phys. Rev. E, 83(1):016107.
- Lancichinetti and Fortunato [2011]
Lancichinetti, A. and Fortunato, S. (2011).
Limits of modularity maximization in community detection.
Phys. Rev. E, 84(6):066122.
- Lancichinetti et al. [2008]
Lancichinetti, A., Fortunato, S., and Radicchi, F. (2008).
Benchmark graphs for testing community detection algorithms.
Phys. Rev. E, 78(4):046110.
- Lewis et al. [2010]
Lewis, A. C., Jones, N. S., Porter, M. A., and Deane, C. M. (2010).
The function of communities in protein interaction networks at multiple scales.
BMC Sys. Biol., 4(1):100.
- Lu et al. [2018]
Lu, X., Kuzmin, K., Chen, M., and Szymanski, B. K. (2018).
Adaptive modularity maximization via edge weighting scheme.
Inf. Sci., 424:55–68.
- Lusseau et al. [2003]
Lusseau, D., Schneider, K., Boisseau, O. J., Haase, P., Slooten, E., and Dawson, S. M. (2003).
The bottlenose dolphin community of doubtful sound features a large proportion of long-lasting associations.
Behav. Ecol. and Sociobiol., 54(4):396–405.
- Molloy and Reed [1995]
Molloy, M. and Reed, B. (1995).
A critical point for random graphs with a given degree sequence.
Random Structures & Algorithms, 6(2-3):161–180.
- Mucha et al. [2010]
Mucha, P. J., Richardson, T., Macon, K., Porter, M. A., and Onnela, J.-P. (2010).
Community structure in time-dependent, multiscale, and multiplex networks.
Sci., 328(5980):876–878.
- Newman [2006]
Newman, M. E. (2006).
Modularity and community structure in networks.
Proc. Nat. Acad. Sci., 103(23):8577–8582.
- Newman [2016]
Newman, M. E. (2016).
Equivalence between modularity optimization and maximum likelihood methods for community detection.
Phys. Rev. E, 94(5):052315.
- Newman and Girvan [2004]
Newman, M. E. and Girvan, M. (2004).
Finding and evaluating community structure in networks.
Phys. Rev. E, 69(2):026113.
- Peel et al. [5878]
Peel, L., Larremore, D. B., and Clauset, A. (2016, arXiv:1608.05878).
The ground truth about metadata and community detection in networks.
- Peixoto [2012]
Peixoto, T. P. (2012).
Entropy of stochastic blockmodel ensembles.
Physical Review E, 85(5):056122.
- Peixoto [2014]
Peixoto, T. P. (2014).
Hierarchical block structures and high-resolution model selection in large networks.
Phys. Rev. X, 4(1):011047.
- Porter et al. [2009]
Porter, M. A., Onnela, J.-P., and Mucha, P. J. (2009).
Communities in networks.
Notices AMS, 56(9):1082–1097.
- Reichardt and Bornholdt [2006]
Reichardt, J. and Bornholdt, S. (2006).
Statistical mechanics of community detection.
Phys. Rev. E, 74(1):016110.
- Simon [1991]
Simon, H. A. (1991).
The architecture of complexity.
In Facets Sys. Sci., pages 457–476. New York City, NY, USA: Springer.
- Traag et al. [2013]
Traag, V. A., Krings, G., and Van Dooren, P. (2013).
Significant scales in community structure.
Sci. Rep., 3:2930.
- Traag et al. [2011]
Traag, V. A., Van Dooren, P., and Nesterov, Y. (2011).
Narrow scope for resolution-limit-free community detection.
Physical Review E, 84(1):016114.
- Wagner and Wagner [2007]
Wagner, S. and Wagner, D. (2007).
Comparing clusterings: an overview.
Universität Karlsruhe, Fakultät für Informatik.
- Yan et al. [2014]
Yan, X., Shalizi, C., Jensen, J. E., Krzakala, F., Moore, C., Zdeborová, L., Zhang, P., and Zhu, Y. (2014).
Model selection for degree-corrected block models.
Journal of Statistical Mechanics: Theory and Experiment, 2014(5):P05007.
- Yang and Leskovec [2015]
Yang, J. and Leskovec, J. (2015).
Defining and evaluating network communities based on ground-truth.
Knowl. and Inf. Sys., 42(1):181–213.
- Young et al. [2015]
Young, J.-G., Allard, A., Hebert-Dufresne, L., and Dube, L. J. (2015).
A shadowing problem in the detection of overlapping communities: Lifting the resolution limit through a cascading procedure.
PloS ONE, 10(10):e0140133.
- Zachary [1977]
Zachary, W. W. (1977).
An information flow model for conflict and fission in small groups.
J. Anthropological Res., 33(4):452–473.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Blondel et al. [2008] Blondel, V. D., Guillaume, J.-L., Lambiotte, R., and Lefebvre, E. (2008). Fast unfolding of communities in large networks. J. Statist. Mech.: Theory and Exp. , 2008(10):P 10008.
- 2Chen et al. [2014] Chen, M., Kuzmin, K., and Szymanski, B. K. (2014). Community detection via maximization of modularity and its variants. IEEE Trans. Comput. Social Sys. , 1(1):46–65.
- 3Chipman et al. [2001] Chipman, H., George, E. I., Mc Culloch, R. E., Clyde, M., Foster, D. P., and Stine, R. A. (2001). The practical implementation of bayesian model selection. Lecture Notes-Monograph Series , pages 65–134.
- 4Clauset et al. [2004] Clauset, A., Newman, M. E., and Moore, C. (2004). Finding community structure in very large networks. Phys. Rev. E , 70(6):066111.
- 5De Meo et al. [2013] De Meo, P., Ferrara, E., Fiumara, G., and Provetti, A. (2013). Enhancing community detection using a network weighting strategy. Inf. Sci. , 222:648–668.
- 6Erds and Rényi [1960] Erds, P. and Rényi, A. (1960). On the evolution of random graphs. Publ. Math. Inst. Hungar. Acad. Sci , 5:17–61.
- 7Fenn et al. [2009] Fenn, D. J., Porter, M. A., Mc Donald, M., Williams, S., Johnson, N. F., and Jones, N. S. (2009). Dynamic communities in multichannel data: An application to the foreign exchange market during the 2007–2008 credit crisis. Chaos: Interdisciplinary J. Nonlinear Sci. , 19(3):033119.
- 8Fortunato [2010] Fortunato, S. (2010). Community detection in graphs. Phys. Rep. , 486(3):75–174.