Effective Network Compression Using Simulation-Guided Iterative Pruning
Dae-Woong Jeong, Jaehun Kim, Youngseok Kim, Tae-Ho Kim, Myungsu, Chae

TL;DR
This paper introduces a simulation-guided iterative pruning method for neural network compression, significantly improving performance at the same pruning levels and enabling deployment in resource-limited systems.
Contribution
It presents a novel simulation-based iterative pruning approach that enhances network compression effectiveness compared to existing methods.
Findings
Achieved higher performance than existing pruning methods.
Effective in reducing network size while maintaining accuracy.
Demonstrated improved compression results through experiments.
Abstract
Existing high-performance deep learning models require very intensive computing. For this reason, it is difficult to embed a deep learning model into a system with limited resources. In this paper, we propose the novel idea of the network compression as a method to solve this limitation. The principle of this idea is to make iterative pruning more effective and sophisticated by simulating the reduced network. A simple experiment was conducted to evaluate the method; the results showed that the proposed method achieved higher performance than existing methods at the same pruning level.
Click any figure to enlarge with its caption.
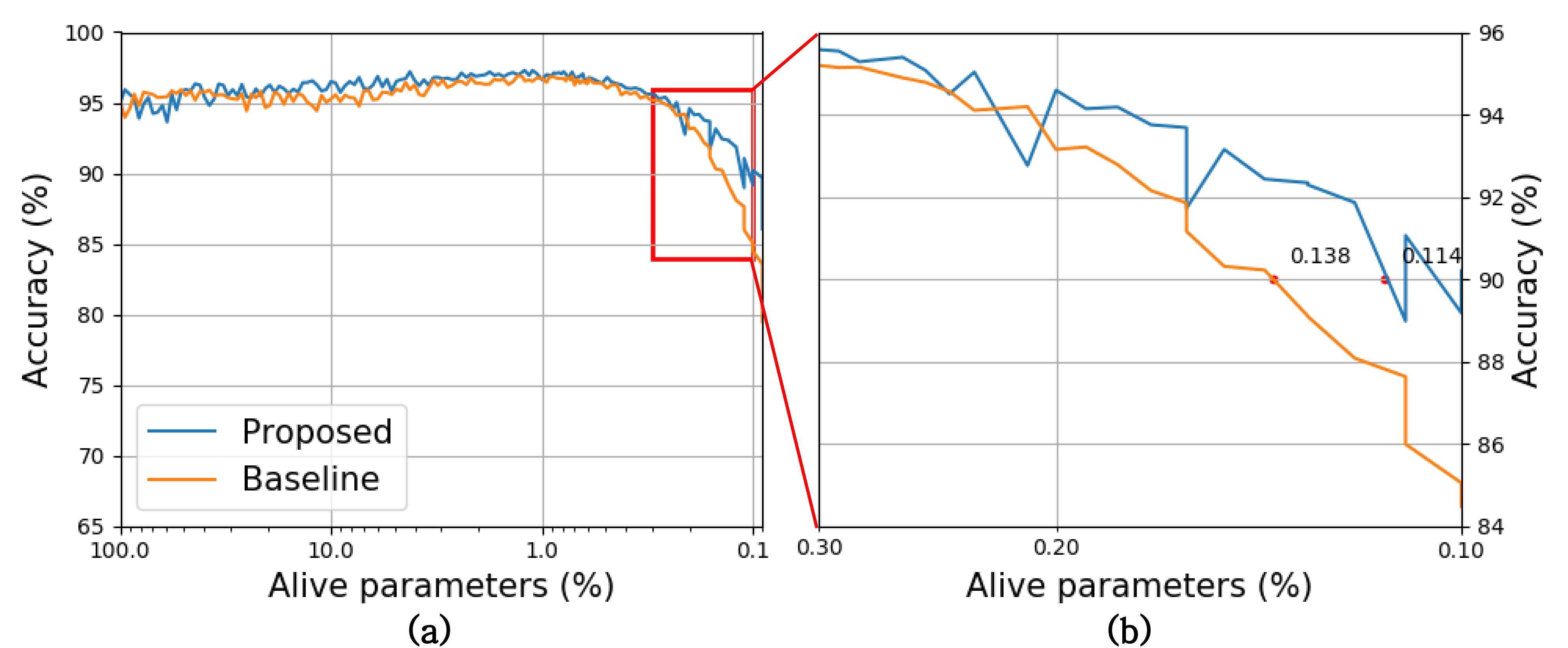 Figure 1
Figure 1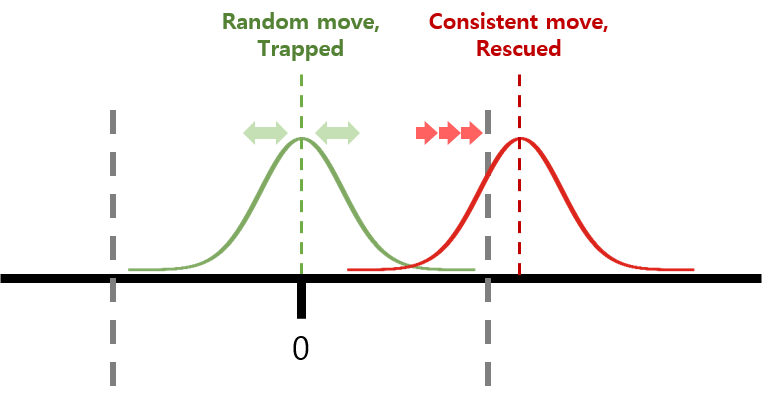 Figure 2
Figure 2Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEmbedded Systems Design Techniques · Software Testing and Debugging Techniques · Algorithms and Data Compression
MethodsPruning
Effective Network Compression Using Simulation-Guided Iterative Pruning
Dae-Woong Jeong
Information and Electronics Research Institute, KAIST
[email protected] &Jaehun Kim
School of Computing, KAIST
[email protected] &Youngseok Kim††footnotemark:
NOTA Incorporated
[email protected] &Tae-Ho Kim
KAIST Institute for AI, KAIST
[email protected] &Myungsu Chae
NOTA Incorporated
[email protected] The authors contributed equally to this work.Corresponding author.
Abstract
Existing high-performance deep learning models require very intensive computing. For this reason, it is difficult to embed a deep learning model into a system with limited resources. In this paper, we propose the novel idea of the network compression as a method to solve this limitation. The principle of this idea is to make iterative pruning more effective and sophisticated by simulating the reduced network. A simple experiment was conducted to evaluate the method; the results showed that the proposed method achieved higher performance than existing methods at the same pruning level.
1 Introduction
Advances in deep neural networks have heavily contributed to the recent popularity of AI. Most algorithms that exhibit state-of-the-art performance in various fields [1, 2] are based on deep neural networks. However, it is difficult to implement deep neural networks without utilizing high-end computing because of their complex and massive network structure. To supply the computing power, most of the existing products based on deep neural networks are processed by high-end servers, which brings about three critical limitations on latency, network cost, and privacy. Therefore, it is necessary to implement deep neural networks on independent clients rather than on servers. Network compression technology is becoming very important as a tool to achieve this.
Various studies on network compression have been extensively performed [3, 4, 5, 6, 7, 8, 9, 10, 11]. Additionally, among existing network compression methods, iterative pruning is one of the most renowned methods, as it has been proven to be effective in several previous studies [12, 13, 14], and is considered to be a state-of-the-art technique [12]. In the iterative pruning process, the importance of weights in the original network are first evaluated; then, the weights with low importance are removed prior to retraining of the remaining weights for fine-tuning. This pruning process is iteratively performed until the stopping condition is satisfied. However, in this process, the importance of weights is solely determined as based on the original network; thus, it is possible that the pruned weight may be appropriate for implementation in the retrained network. Therefore, we propose a more effective and sophisticated weight pruning method that is based on simulation of a reduced network.
2 Simulation-Guided Iterative Pruning
In this section, the proposed method of simulation-guided iterative pruning for effective network compression is introduced. Algorithm 1 shows the detailed algorithm of the proposed method. The main distinction from the baseline model [12] is that the proposed method utilizes the temporarily reduced network in the simulation.
In the first step of the simulation, the importance of each weight in the original network is calculated, and the original network itself is separately stored in the memory. Then, the weights in the original network with importance below a certain threshold are temporarily set to zero to create a temporarily reduced network. Here, a predetermined percentile threshold, rather than the threshold in the baseline method, is used to ensure consistency throughout the iterative simulation process. The gradients for each weight of the temporarily reduced network, including zero weights, are then calculated by using a batch of training data. These gradients are applied to the stored original network rather than the reduced network. Then, this simulation process begins again from the first step, incorporating the changes made to the original network, and repeats until the network is sufficiently simulated.
After this simulation process, the importance of the weights are computed, and weights below the threshold are removed as described above for the iterative pruning method. Then, the pruned weights are permanently fixed, and the entire process is repeated with a higher threshold and no retraining process.
The proposed approach can supplement the limitations of the baseline model. Figure 1 conceptualizes the iterative simulation process; the horizontal axis corresponds to weight values, and the grey dashed lines indicate the pruning threshold. The green dashed line indicates the ideal value of a truly insignificant weight that is positioned near zero; the red dashed line indicates the ideal value of a weight that is considered to be significant. Since the learning process of the network implements a stochastically chosen batch of data, the ideal value of a significant weight is also stochastically distributed near the absolute ideal value, as is shown in the figure. In this case, even if the absolute ideal value of the significant weight is larger than the threshold, the value of the weight could be undesirably categorized as within the cut-off range. Pruning of this particular type of weight results in unnecessary loss of information. Therefore, it is important to distinguish between the truly insignificant weights and significant but miscategorized weights. Here, when the weight value is set to zero during the simulation, the gradient of the insignificant weight has a randomized direction because the absolute ideal value is sufficiently close to zero. On the other hand, the direction of the gradient of the significant weight is unchanged until the weight is rescued through the iterative simulation. Moreover, unlike the baseline method, this screening process relies on simulation of a pruned network, and thus enables more sophisticated pruning.
3 Experiment
3.1 Experimental Setup
For the experiment, we respectively applied the proposed and baseline algorithms to MNIST data [15]. The network architecture used for each algorithm was a fully-connected LeNet [15]. The architecture comprises three hidden layers, with each layer respectively consisting of 784, 300, and 100 nodes in sequence. The final output layer consists of 10 nodes.
In the experiment, the batch size was set as 50, and the optimizer was the Adam optimizer. The loss term of L2 regularization was 0.0001, and the learning rate was 0.005. Pruning began with a model that was first trained on 10 epochs and a batch size of 50. For each iteration, the percentile threshold for pruning was set as 5%, and the pruned weight was set to zero.
3.2 Experimental Result
Figure 2 shows the performances of the proposed and baseline algorithms implemented in this experiment. The experimental results are presented as classification accuracy as a function of the ratio of alive parameters in the pruning process. Figure 2 (a) shows that there is no significant difference in performance, even when the number of parameters is reduced by 1%. In addition, the performance of the baseline algorithm is drastically degraded as the number of the surviving parameters drops below 1%, whereas that of the proposed algorithm remains relatively high at the same level.
Figure 2 (b) is an enlargement of the results in the red box of figure 2 (a); the difference between the performances of the two algorithms dramatically increases. The results show that the proposed algorithm performs network compression more effectively than the baseline algorithm at the same performance level. Specifically, the proposed algorithm compressed the network into 0.114% of its original size while maintaining a classification accuracy of 90%, whereas the baseline algorithm can only compress the same network into 0.138% of its original size.
4 Conclusion
In this paper, we proposed a novel method to compress deep neural networks. We focused on making the iterative pruning process more effective by simulating a temporarily reduced network. With this method, the reduced network enables collaborative learning of a more suitable structure and optimal weights. The experiment to evaluate the method showed that the proposed algorithm outperforms the baseline algorithm. The proposed method can be used to mount a high-performance deep learning model onto an embedded system with limited resources.
Acknowledgment
This work (Grants No. S2520005) was supported by Business for Startup growth and technological development(TIPS Program) funded Korea Ministry of SMEs and Startups in 2018.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. ar Xiv preprint ar Xiv:1409.1556 , 2014.
- 2[2] Myungsu Chae, Tae-Ho Kim, Young Hoon Shin, Jun-Woo Kim, and Soo-Young Lee. End-to-end multimodal emotion and gender recognition with dynamic joint loss weights. ar Xiv preprint ar Xiv:1809.00758 , 2018.
- 3[3] Yihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural networks. In International Conference on Computer Vision (ICCV) , volume 2, 2017.
- 4[4] Namhoon Lee, Thalaiyasingam Ajanthan, and Philip HS Torr. Snip: Single-shot network pruning based on connection sensitivity. ar Xiv preprint ar Xiv:1810.02340 , 2018.
- 5[5] Hengyuan Hu, Rui Peng, Yu-Wing Tai, and Chi-Keung Tang. Network trimming: A data-driven neuron pruning approach towards efficient deep architectures. ar Xiv preprint ar Xiv:1607.03250 , 2016.
- 6[6] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. ar Xiv preprint ar Xiv:1608.08710 , 2016.
- 7[7] Yiwen Guo, Anbang Yao, and Yurong Chen. Dynamic network surgery for efficient dnns. In Advances In Neural Information Processing Systems , pages 1379–1387, 2016.
- 8[8] Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Quantized neural networks: Training neural networks with low precision weights and activations. The Journal of Machine Learning Research , 18(1):6869–6898, 2017.