De-identification without losing faces
Yuezun Li, Siwei Lyu

TL;DR
This paper introduces a face de-identification method that preserves facial attributes like expressions while concealing identities, using attribute transfer models and a small set of donor faces to ensure natural appearance and privacy protection.
Contribution
The proposed method uniquely combines facial attribute transfer with limited donor faces to achieve high-quality de-identification without losing essential facial features.
Findings
Effective privacy protection in images and videos.
High visual quality of de-identified faces.
Preservation of facial attributes like expressions.
Abstract
Training of deep learning models for computer vision requires large image or video datasets from real world. Often, in collecting such datasets, we need to protect the privacy of the people captured in the images or videos, while still preserve the useful attributes such as facial expressions. In this work, we describe a new face de-identification method that can preserve essential facial attributes in the faces while concealing the identities. Our method takes advantage of the recent advances in face attribute transfer models, while maintaining a high visual quality. Instead of changing factors of the original faces or synthesizing faces completely, our method use a trained facial attribute transfer model to map non-identity related facial attributes to the face of donors, who are a small number (usually 2 to 3) of consented subjects. Using the donors' faces ensures that the natural…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6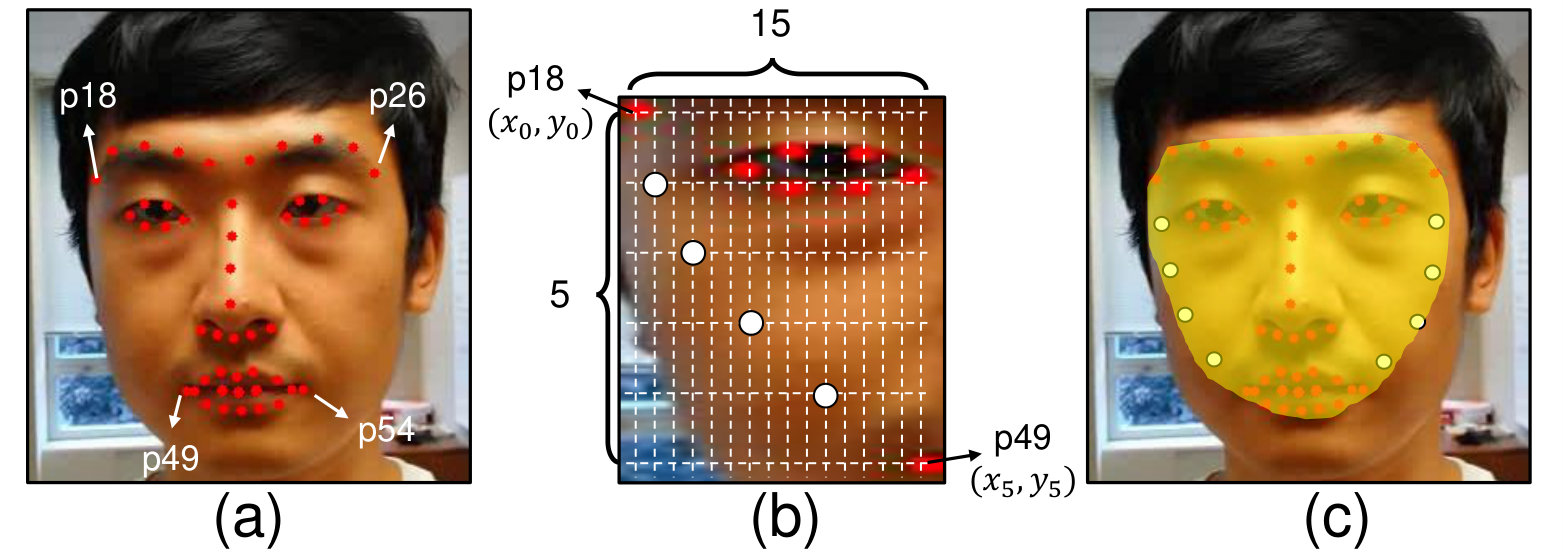 Figure 7
Figure 7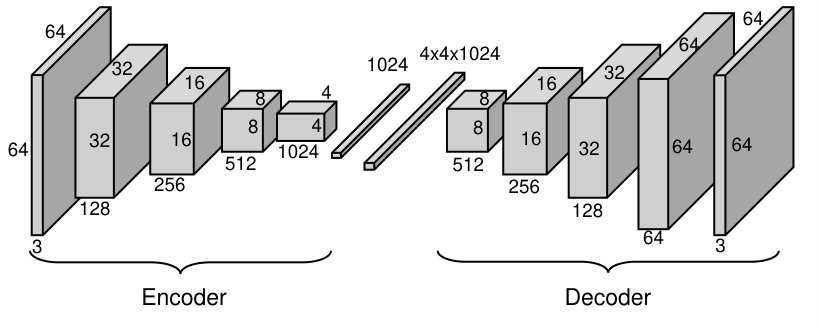 Figure 8
Figure 8 Figure 9
Figure 9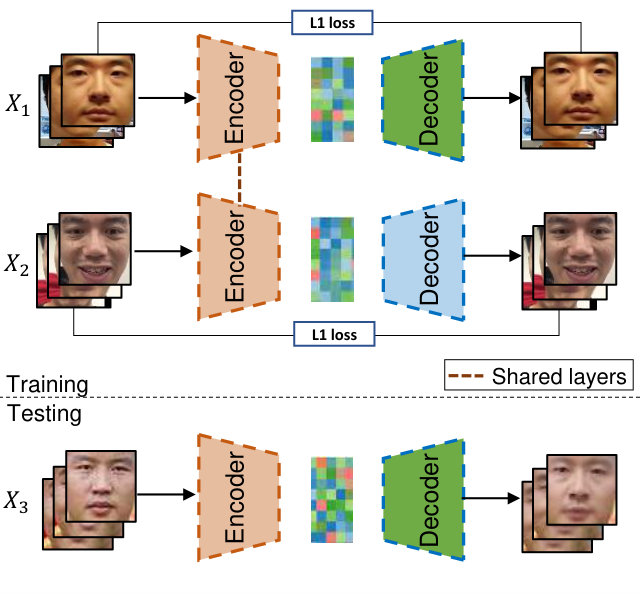 Figure 10
Figure 10 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace recognition and analysis · Generative Adversarial Networks and Image Synthesis · Biometric Identification and Security
De-identification without losing faces
Abstract
Training of deep learning models for computer vision requires large image or video datasets from real world. Often, in collecting such datasets, we need to protect the privacy of the people captured in the images or videos, while still preserve the useful attributes such as facial expressions. In this work, we describe a new face de-identification method that can preserve essential facial attributes in the faces while concealing the identities. Our method takes advantage of the recent advances in face attribute transfer models, while maintaining a high visual quality. Instead of changing factors of the original faces or synthesizing faces completely, our method use a trained facial attribute transfer model to map non-identity related facial attributes to the face of donors, who are a small number (usually 2 to 3) of consented subjects. Using the donors’ faces ensures that the natural appearance of the synthesized faces, while ensuring the identity of the synthesized faces are changed. On the other hand, the FATM blends the donors’ facial attributes to those of the original faces to diversify the appearance of the synthesized faces. Experimental results on several sets of images and videos demonstrate the effectiveness of our face de-ID algorithm.
1 Introduction
Recent years have seen great successes of deep neural networks in solving various computer vision problems including face detection, face recognition and emotion classification. The training of deep neural networks predicate on large-scale and carefully annotated image/video datasets. However, unlike images and videos enacted by consented subjects, for those collected from real world, the law requires that the privacy of the people inadvertently captured by camera need to be protected before such data can be used. As face is the most identifiable part of a human, visual anonymity can be achieved by changing the faces, a problem commonly known as face de-identification (face de-ID).
The simplest face de-ID method is to obfuscate faces in images by blurring or pixelation (e.g., in Google Map Street View). However, it is not as effective as one may think, because it is possible to identify a particular subject by comparing faces after the obfuscation operations, known as a parrot attack [1]. Moreover, the complete removal of faces from images and videos makes them useless for training deep neural networks that analyze facial expressions or other non-identity related attributes. Moreover, images and videos with faces obfuscated do not look “natural”.
More sophisticated face de-ID methods focus on changing faces rather than removing them. Early works (e.g., [1, 2, 3, 4]) generate de-IDed faces by removing high frequency details, but they usually lead to faces with blurred appearances. The developments of image synthesis methods based on deep neural networks, in particular, generative adversary networks (GANs) [5], inspire a new vein of face de-ID methods [6, 7], which uses synthesized faces to replace the originals. However, these methods typically requires a large number of face images in training. Furthermore, they cannot be extended to face de-ID tasks for videos, as they can only generate individual images and cannot maintain temporal consistency between video frames.
In this work, we describe a new face de-ID method based on a deep neural network based image style transfer model [8]. Our method treats the non-identity related facial attributes as the style of the original face, and use a trained facial attribute transfer model (FATM) to map them to the face of donors, who are a small number (usually 2 to 3) of consented subjects. The FATM is composed of an encoder and a decoder. The encoder maps the input original face to an identity-neural representation (the code), and the decoder combines the code with the donors’ identity to create new faces. Using the donors’ faces ensures the natural appearance of the synthesized faces. On the other hand, FATM blends the donors’ facial attributes to those of the targets’ to generate synthesized faces of different identities. The training of FATM can be achieved with much smaller set of images – typically images is enough in comparison to tens of thousands required to train a full blown GAN model. This means efficient training and run-time efficiency. Experimental results on several sets of images and videos demonstrate the effectiveness of our method.
2 Related works
Early methods,e.g., [1, 2, 3, 4], substitute original faces with the average of face images of the -closest identities to the subject from a closed set of facial images. Subsequently, variations in face poses are considered to improve the robustness of face de-ID methods in [9]. The work [10] de-identified the face images by adding designed noise patterns. In [11], a new objective function combining face de-ID and face verification is introduced to ensure the original and de-IDed face to have common facial attributes but different identities. The work of [12] proposed an adaptive filtering method for face de-identification with expressions preserved in images. The diversity of the de-IDed faces is considered in [13] to avoid generating faces that all look alike.
More recently, deep neural networks have been used for face de-ID. The work of [14] uses GANs to generate de-ID faces, which is extended by Karla *et al. *in [6] for full body synthesis. However, the GAN synthesized de-IDed faces suffer from artifacts such as the skin color disparity between the de-IDed face and the surrounding area. Original faces are partially replaced in [7] using GAN based in-painting method, which uses facial landmarks as an input to the GAN model for consistent head poses with the original faces. However, temporal consistencies of faces across different video frames and subtle face attributes are not well preserved in this method.
3 Methods
In this work, we describe a different approach to face de-ID based on the neural network based image style transfer model of [8]. We use synthesized faces created by transferring facial expressions of the original subject (the ’target’) to the faces of another subject (the ’donor’), a consented subject who grants rights to use his/her face images. The replacement of the target’s facial attributes with the donor’s conceal the target’s identity, while the preserved facial expressions keep the utility of the resulting image as training data.
The overall pipeline of our face de-ID method is shown in Figure 1. The input is a RGB image or video frame containing the face of the target. We first run a face detector and crop each detected face using the bounding boxes. Then, a facial landmark extraction algorithm is applied to the extracted face to locate landmark points corresponding to distinct facial structures such as the tips of eyes, eyebrows, nose, mouth and contour. These landmark points are then matched to the landmark points of a “standard” face, which has a fixed size with a frontal orientation, with an affine transform. The affine transform is obtained by minimizing the distortion between the two sets of landmark points. Using this affine transform, we then warp every pixel of the extracted face to the pose of the standard face, and resize it to have dimension of pixels. The rectified face is fed to the facial attributes transfer model (FATM), which will be described in detail subsequently. FATM synthesizes a face based on the donor’s identity and the facial expression, head orientation, lighting condition, skin color and other facial characteristics of the target’s face. The synthesized face image is resized to the original face, and warped back to the original configuration using the inverse of the same affine transform previously estimated. After that, the synthesized face is trimmed with a face mask obtained from the landmark points to blend into the surrounding context. The face mask is created from the convex hull of landmarks of the eye browns and the bottom outline of mouth, and interpolated points on both side of the faces to maximally cover the facial area. For instance, from the left side of the face, we choose two extreme landmark points corresponding to the leftmost tip of the eyebrow and leftmost tip of the mouth, the coordinates of which are denoted as and , respectively. Then we use an interpolation scheme to generate four more points in between these two landmark points for , Figure 2. A similar procedure is repeated for the right side of the face. As the last step, we apply adaptive Gaussian smoothing of the boundary before finally splicing it into the original image to conceal the boundary of splicing. The whole process is automated and runs with minimum manual intervention.
3.1 Facial Attribute Transfer Model (FATM)
The facial attribute transfer model (FATM) is the core component of our face de-ID method. Inspired by the deep image style transfer framework [8], FATM is composed by a pair of deep neural networks: the encoder and the decoder. The encoder converts the input face to a representative feature (the ’code’), and the decoder reverses the process to synthesize a face from the code. Specifically, we refer to face images of the same subject as a face set. Different face sets share the same encoder , but each have a dedicated decoder. This specific structure is to ensure the encoder to capture the identity-independent attributes common to all face sets, while the individual decoders can preserve identity-dependent attributes of each subject and map such attributes onto the synthesized faces.
The specific neural network architecture of the encoder and the decoder is shown in Figure 3. The encoder has four convolution (Conv) layers and two fully connected (FC) layers. The four convolution layer has , and convolution kernels, respectively. The convolution kernels all have size pixels with stride of pixels. The leaky RELU function, defined as , where is the input, is adopted as the nonlinear activation function of each convolution layer. The two fully connected layers have dimensions and , respectively. The code is the output of the last fully connected layer in the encoder, which is a -dimensional vector. Similarly, the decoder has four de-convolution (Upscale) layers, with , and convolution kernels of size and strides pixels, respectively. The nonlinear activation function for these convolution layers is the same leaky RELU function as in the encoder. The final output from the decoder is reshuffled to 2D images of pixels, and the final synthesized face of RGB color is produced using convolution kernels of size with stride on last layer.
3.2 Training FATM
The encoder and decoder networks are trained in tandem in an unsupervised manner, using face sets from multiple subjects but do not need to have any correspondence in facial attributes such as expressions, head orientations, lighting, etc, so relatively little labeling effort is required. The face sets are first processed with face detection, landmark extraction and rectification to be the training data for the two networks.
Learning FATM is equivalent to find optimal parameters for the common encoder , and individual decoder . Figure 4 illustrate the training of the FATM with two face sets and . Specifically, we first use and to form an encoder-decoder pair, and optimize their parameters to minimize the reconstruction errors for faces in . The reconstruction error for one face is given by . The parameter update is performed with the back-propagation algorithm implemented with stochastic gradient update with an ADAM optimizer. We set the batch size to , and the initial learning rate to be . Then, a similar procedure is performed for , this time with the encoder-decoder pair . When updating on is complete, we go back updating the parameters of encoder-decoder pair and the iteration goes on for times.
To improve the visual quality of the synthesized faces, we also take several measures to increase the diversity of the training data. In each training round, we use input face regions that are slightly larger than , and then select randomly cropped face regions iteration to simulate the variations of locations of faces; we also apply random rotation, horizontal mirroring, and scaling to the faces to simulate different viewing angle and distance of the faces. Variations in skin color affect the visual quality of generated faces and the major cause of conspicuous artifact in the synthesized faces. Hence, we further randomize the color of the training faces in the brightness, contrast, distortion and sharpness in each iteration to simulate the variations in skin color.
4 Evaluations
We perform several sets of experiments to evaluate the performance of our face de-ID algorithm and compare with state-of-the-art methods.
Datasets: We use donor faces from six individuals who have signed consensus forms for the use of their face images. The donor face set is obtained from 60 video clips (10 from each of the six subjects) of approximate 30 seconds in length (30 frame-per-second) and or pixels in resolution. As a result, we have in total high resolution face images to train the FATM model.
We evaluate our method using two popular face image datasets, namely the LFW dataset [15] and the PIPA dataset [16]. The LFW dataset is designed for testing face verification performance. As such it contains around images of faces collected from the Internet. The size of image in LFW is fixed to pixels. PIPA dataset [16] is a more challenging dataset, which contains images collected from public Flickr photo albums in an unconstrained setting. This dataset has about individuals with diverse poses, clothing, camera viewpoints, lighting conditions and image resolutions.
Runtime details. We use the face detection and landmark location functionalities from package DLib [17]. The training and evaluation of our algorithm is performed on a computer with Intel Xeon(R) CPU X5570 2.93GHz and NVIDIA GTX GPU. The code implementing the training and evaluation uses Google Tensorflow 1.3.0 with CUDA 8.0 on Ubuntu 16.04. The training time for FATM is around 72 hours on our current training dataset. Generating a synthetic de-IDed face including post-processing takes about seconds on average.
Evaluating face de-identification. To provide a quantitative performance evaluation of the face de-identification, we follow the work of [12] that uses face verification evaluation on the LFW dataset for this purpose. Specifically, we randomly select image pairs from the LFW dataset, each corresponding to two images of the same subject differing in background, head pose, apparels and/or facial expressions. We apply our face de-ID method on one image in each pair and then feed both images to a state-of-the-art face verification algorithm provided by Dlib111The Dlib face verification algorithm is based on the ResNet-34 network [19] and can achieve accuracy on LFW dataset. to determine if they are from the same subject. If the de-identification is effective, the two images should be classified as from different identities. On the pairs, the face verification accuracy is and before and after de-identification respectively, i.e., are determined to be from different subjects. In comparison, the method of [12] is only effective in de-identifying the subjects.
We also conduct a self de-identification experiment [10], where we compare the de-IDed image with its corresponding original image. In this case, all other factors stay the same and the only change to each image occur at the face region. However, in this case, the effective rate of de-identification drops to . In particular, as shown in Figure 7, even though many de-IDed images visually appear to be from different subject, the face verification algorithm determines they are from the same subject nevertheless. This is a puzzling result, but we speculate that it is due to the specific design of face verification algorithm. Specifically, our method only replaces the center area of the face, and leaves the target’s hair and face shape unchanged. However, hair and face shape are two cues for the Dlib face verification algorithm, so some of such faces are still being classified as from the same subject, even though the locations of facial parts are different.
Comparing visual qualities. We show several examples of the de-IDed images in Figure 6 using images from the LFW dataset and the PIPA dataset, respectively. One potential limitation of our method is that we only use limited number of donors, which may reduce the diversity of the synthesized de-IDed faces. However, visual examples of de-IDed faces as shown in Figure 6 suggest that this is not the case. We think the reason is that the learned decoder in the FATM model is capable of mixing facial attributes of the target with those of the donor, and in doing so creates new face images with variations in skin color, facial characteristics and expressions that are different from the original donors. This further improves the naturalness of the de-IDed faces. Figure 9 shows an example of our method on a surveillance video from the ChokePoint dataset [20]. Note that the replacement of central face area in our method results in better temporal consistencies.
Figure 5 shows a comparison of the visual quality of our method with that of several previous face de-ID methods including the -Same method [1], MF() [18], and adaptive filtering [12]. As we see from the results, other face de-ID methods introduce various artifacts, such as blurring and change of facial expressions. In comparison, our method exhibits better visual quality and the original facial expression.
To quantitatively analyze the visual quality, we randomly select images from LFW and PIPA dataset respectively and run our algorithm over them. We evaluate the visual quality of de-IDed images using SSIM [21]. The higher SSIM score denotes the better visual quality. The average SSIM scores for our method are on LFW and on PIPA. In comparison, the most recent work [7] has an average SSIM score on PIPA.
Failure Cases: However, there are also cases when the neural network based FATM fails to generate a good face image, as shown in a few examples in Figure 8. The failures can be attributed to occlusions of the target face by other objects (e.g., eye glasses), unusual facial expressions, and strongly non-frontal head orientations.
5 Conclusion
In this work, we describe a new face de-identification method that can preserve essential facial attributes in the faces while concealing the identities. Our method takes advantage of the recent advances in face attribute transfer models, while maintaining a high visual quality. Instead of changing factors of the original faces or synthesizing faces completely, our method use a trained facial attribute transfer model to map non-identity related facial attributes to the face of donors, who are a small number (usually 2 to 3) of consented subjects. Using the donors’ faces ensures that the natural appearance of the synthesized faces, while ensuring the identity of the synthesized faces are changed. On the other hand, the FATM blends the donors’ facial attributes to those of the original faces to diversify the appearance of the synthesized faces. Experimental results on several sets of images and videos demonstrate the effectiveness of our face de-ID algorithm.
For future works, we would like to improve the neural network based FATM to handle more variations in head poses, lighting and facial occlusions. Furthermore, randomness can be introduced to the synthesize process to improve the diversity of the faces and remove the original target’s identity more effectively.
Acknowledgement. This material is based upon work supported by the United States Air Force Research Laboratory (AFRL) and the Defense Advanced Research Projects Agency (DARPA) under Contract No. FA8750-16-C-0166. The views, opinions and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Elaine M Newton, Latanya Sweeney, and Bradley Malin, “Preserving privacy by de-identifying face images,” TKDE , 2005.
- 2[2] Ralph Gross, Edoardo Airoldi, Bradley Malin, and Latanya Sweeney, “Integrating utility into face de-identification,” in International Workshop on Privacy Enhancing Technologies , 2005.
- 3[3] Ralph Gross, Latanya Sweeney, Fernando De la Torre, and Simon Baker, “Model-based face de-identification,” in IEEE Workshop on Privacy Research in Vision (PRV) , 2006.
- 4[4] Ralph Gross, Latanya Sweeney, Fernando De La Torre, and Simon Baker, “Semi-supervised learning of multi-factor models for face de-identification,” in CVPR , 2008.
- 5[5] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative adversarial nets,” in NIPS , 2014.
- 6[6] Karla Brkic, Ivan Sikiric, Tomislav Hrkac, and Zoran Kalafatic, “I know that person: Generative full body and face de-identification of people in images,” in CVPR Workshops , 2017.
- 7[7] Qianru Sun, Liqian Ma, Seong Joon Oh, Luc Van Gool, Bernt Schiele, and Mario Fritz, “Natural and effective obfuscation by head inpainting,” in CVPR , 2018.
- 8[8] Ming-Yu Liu, Thomas Breuel, and Jan Kautz, “Unsupervised image-to-image translation networks,” in NIPS . 2017.