Learning Deep Stochastic Optimal Control Policies using Forward-Backward SDEs
Marcus Pereira, Ziyi Wang, Ioannis Exarchos, and Evangelos A., Theodorou

TL;DR
This paper introduces a scalable deep learning framework for stochastic optimal control based on forward-backward SDEs, applicable to complex robotics systems under uncertainty.
Contribution
It presents a novel neural network architecture leveraging forward-backward SDEs for decision-making in stochastic control, extending applicability to general robotics problems.
Findings
Effective in three non-linear simulated systems
Handles control constraints successfully
Scalable to complex stochastic systems
Abstract
In this paper we propose a new methodology for decision-making under uncertainty using recent advancements in the areas of nonlinear stochastic optimal control theory, applied mathematics, and machine learning. Grounded on the fundamental relation between certain nonlinear partial differential equations and forward-backward stochastic differential equations, we develop a control framework that is scalable and applicable to general classes of stochastic systems and decision-making problem formulations in robotics and autonomy. The proposed deep neural network architectures for stochastic control consist of recurrent and fully connected layers. The performance and scalability of the aforementioned algorithm are investigated in three non-linear systems in simulation with and without control constraints. We conclude with a discussion on future directions and their implications to robotics.
Click any figure to enlarge with its caption.
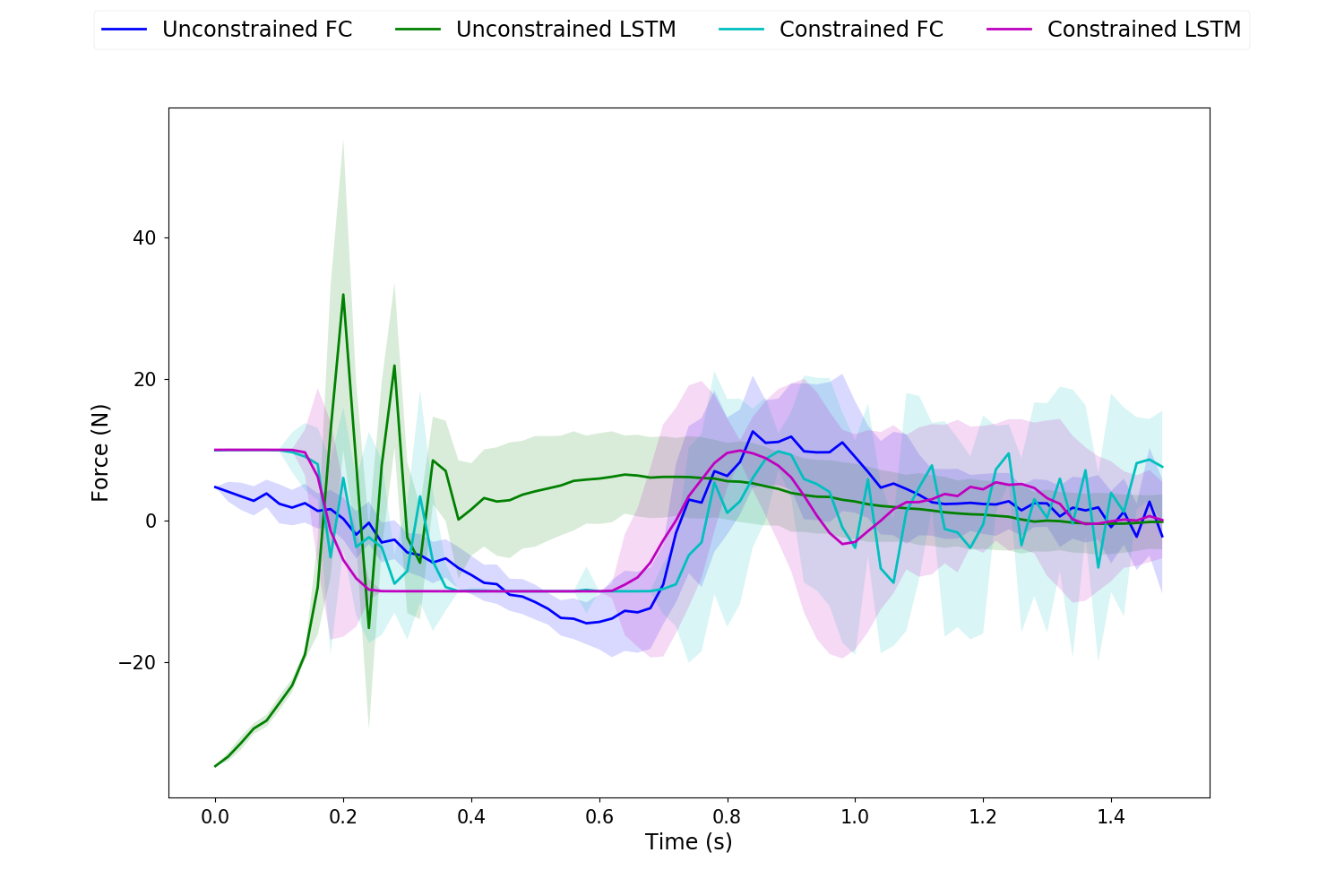 Figure 1
Figure 1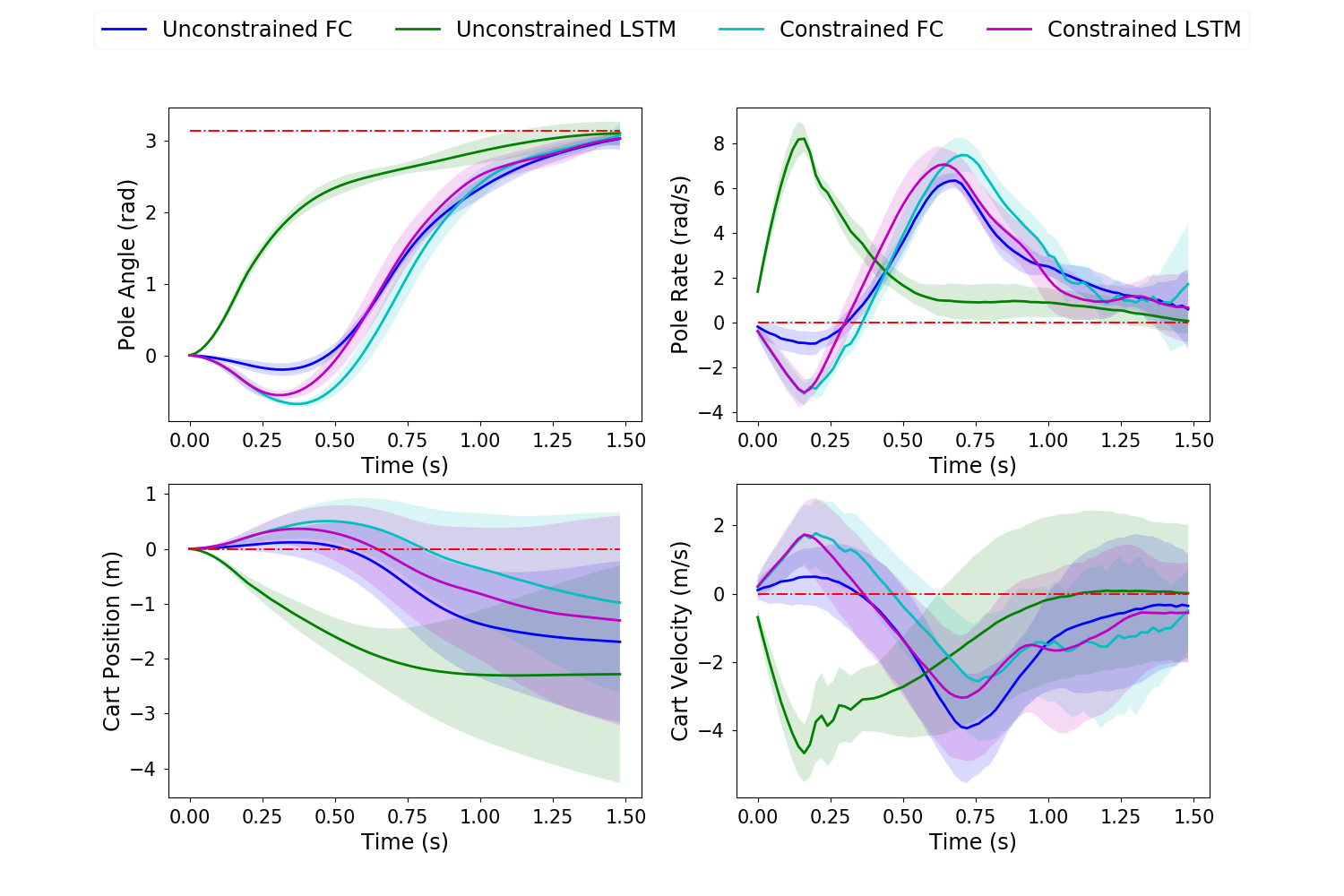 Figure 2
Figure 2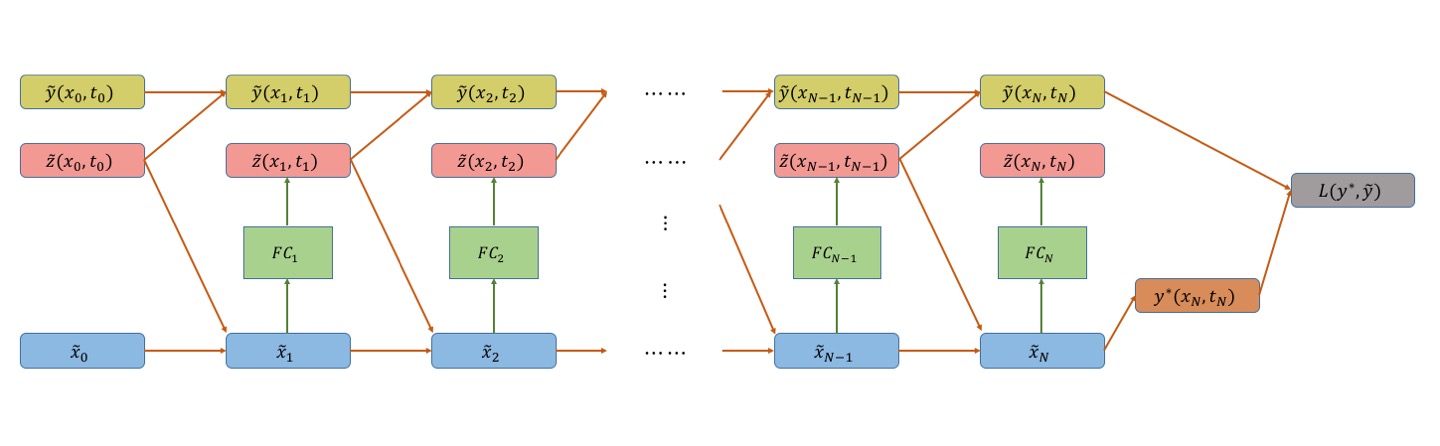 Figure 3
Figure 3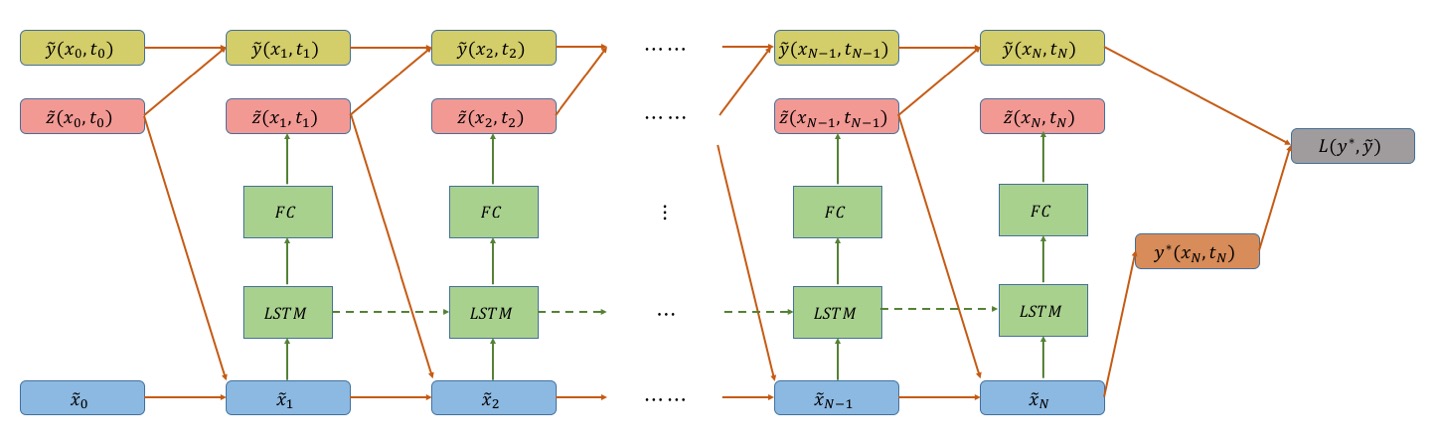 Figure 4
Figure 4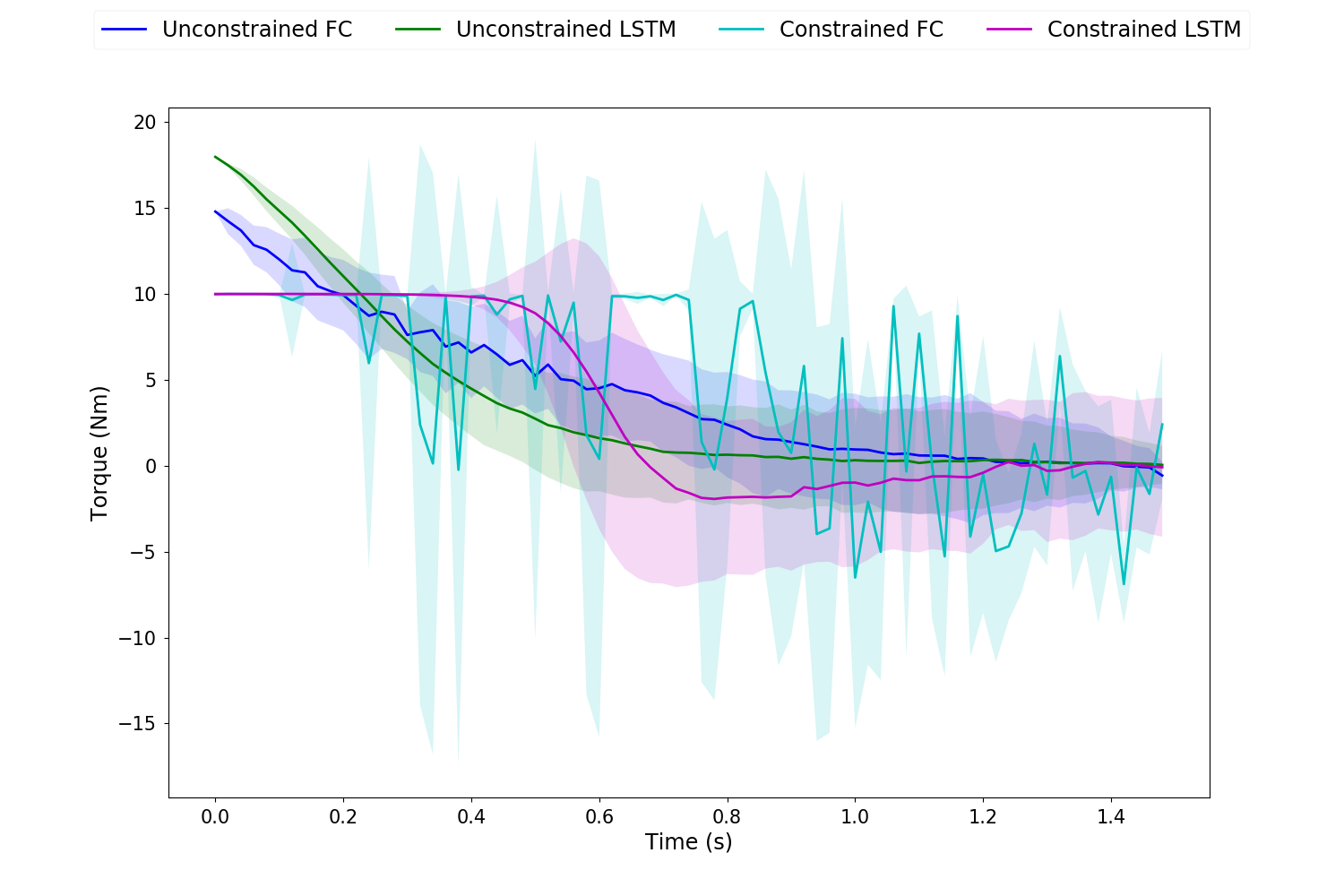 Figure 5
Figure 5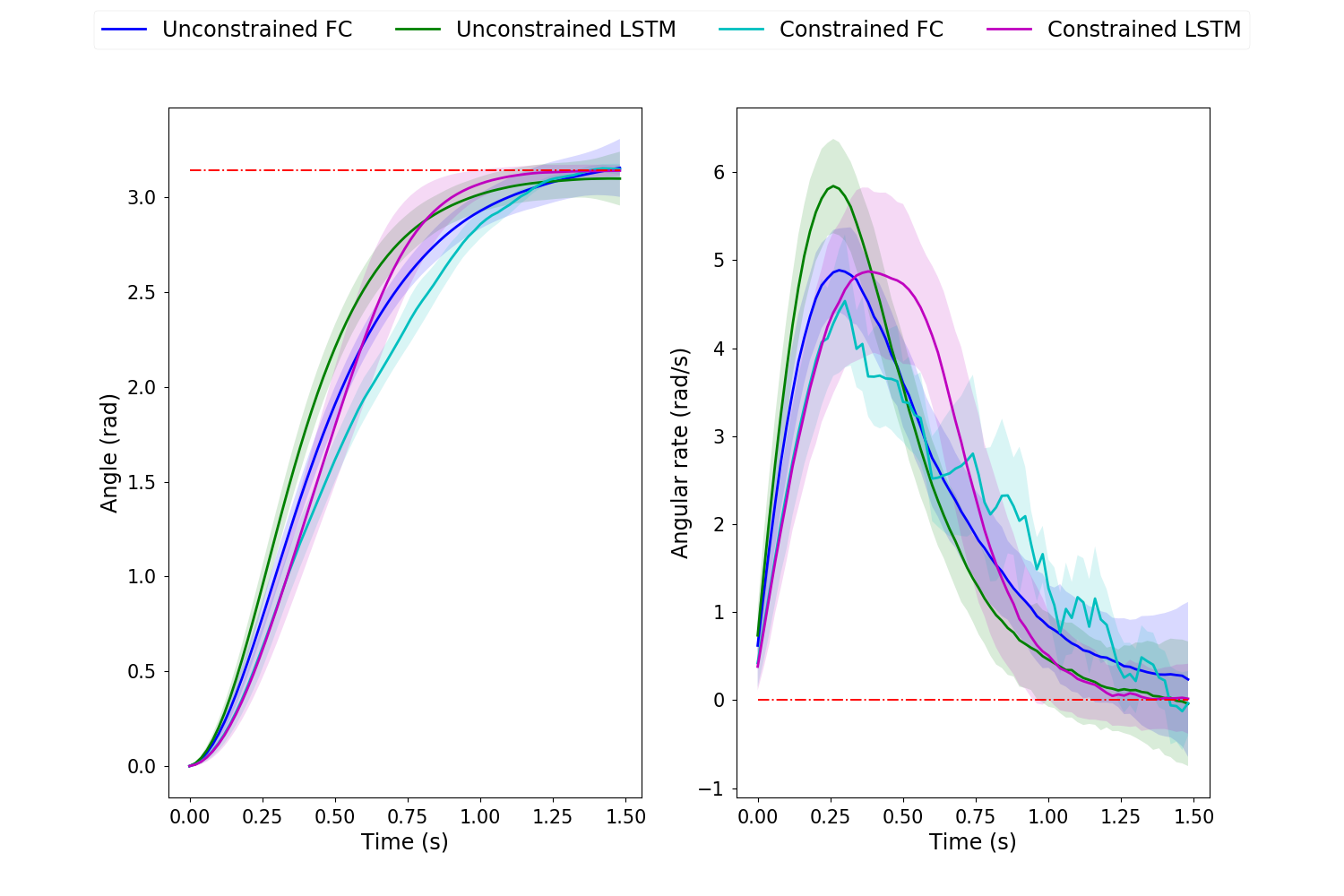 Figure 6
Figure 6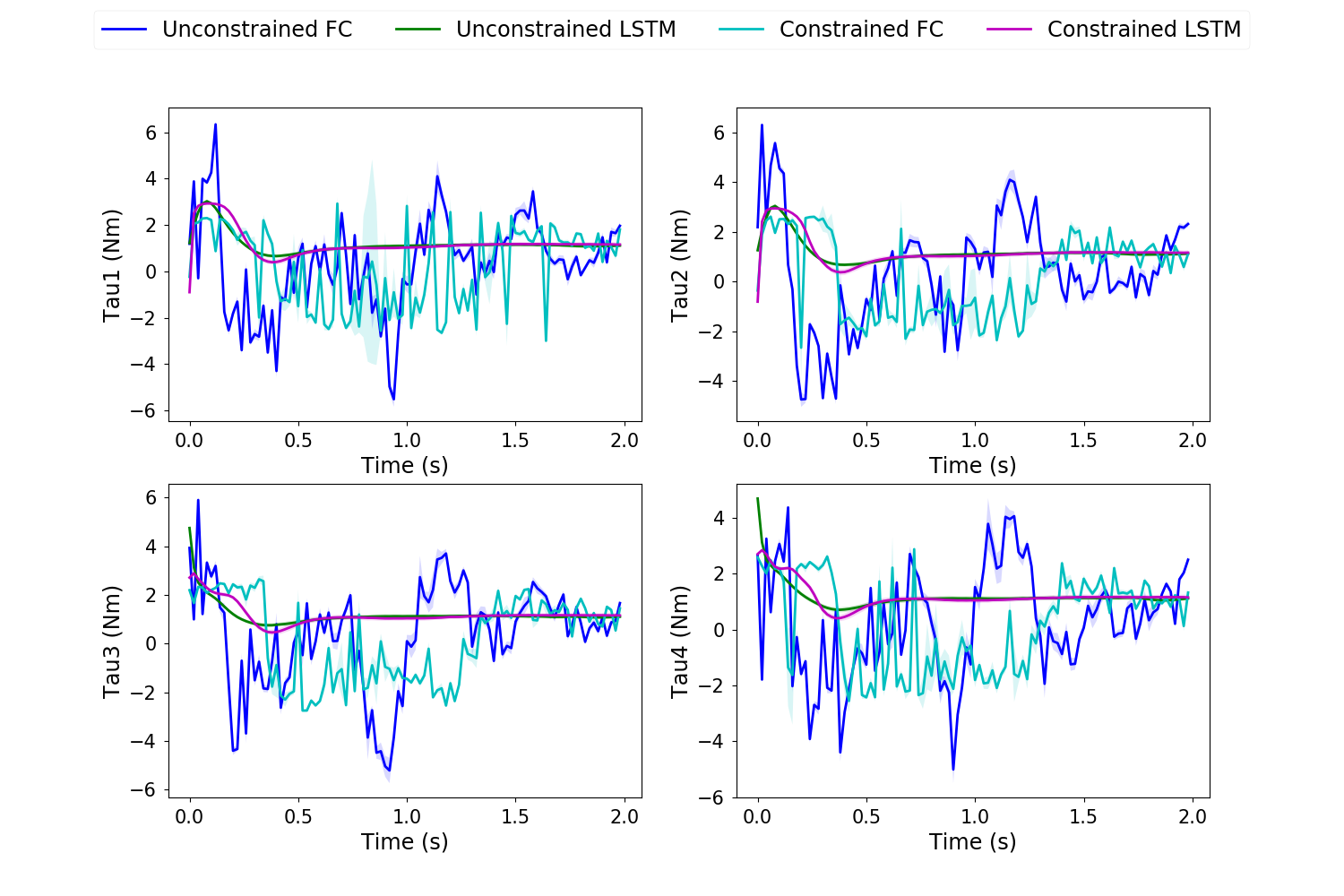 Figure 7
Figure 7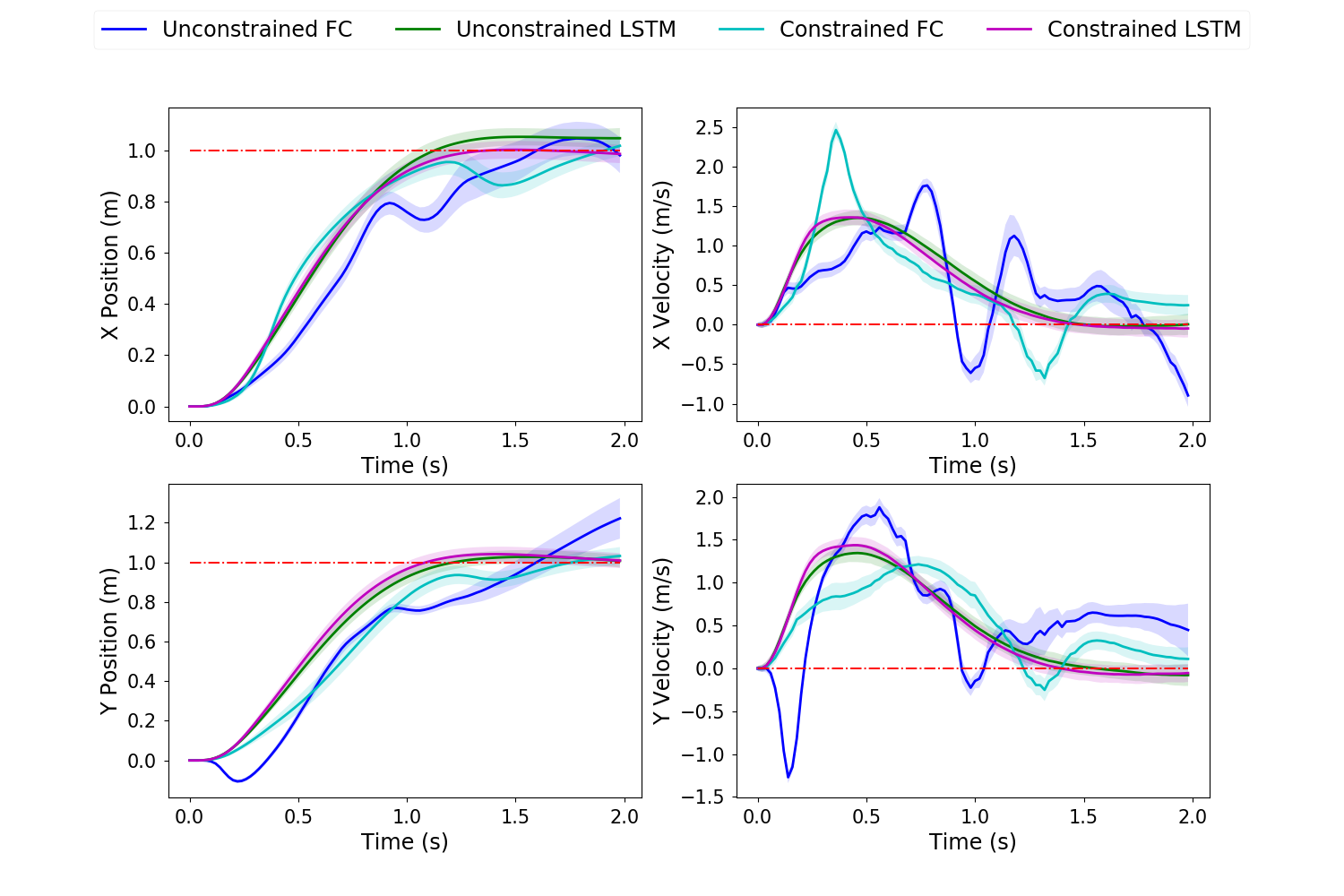 Figure 8
Figure 8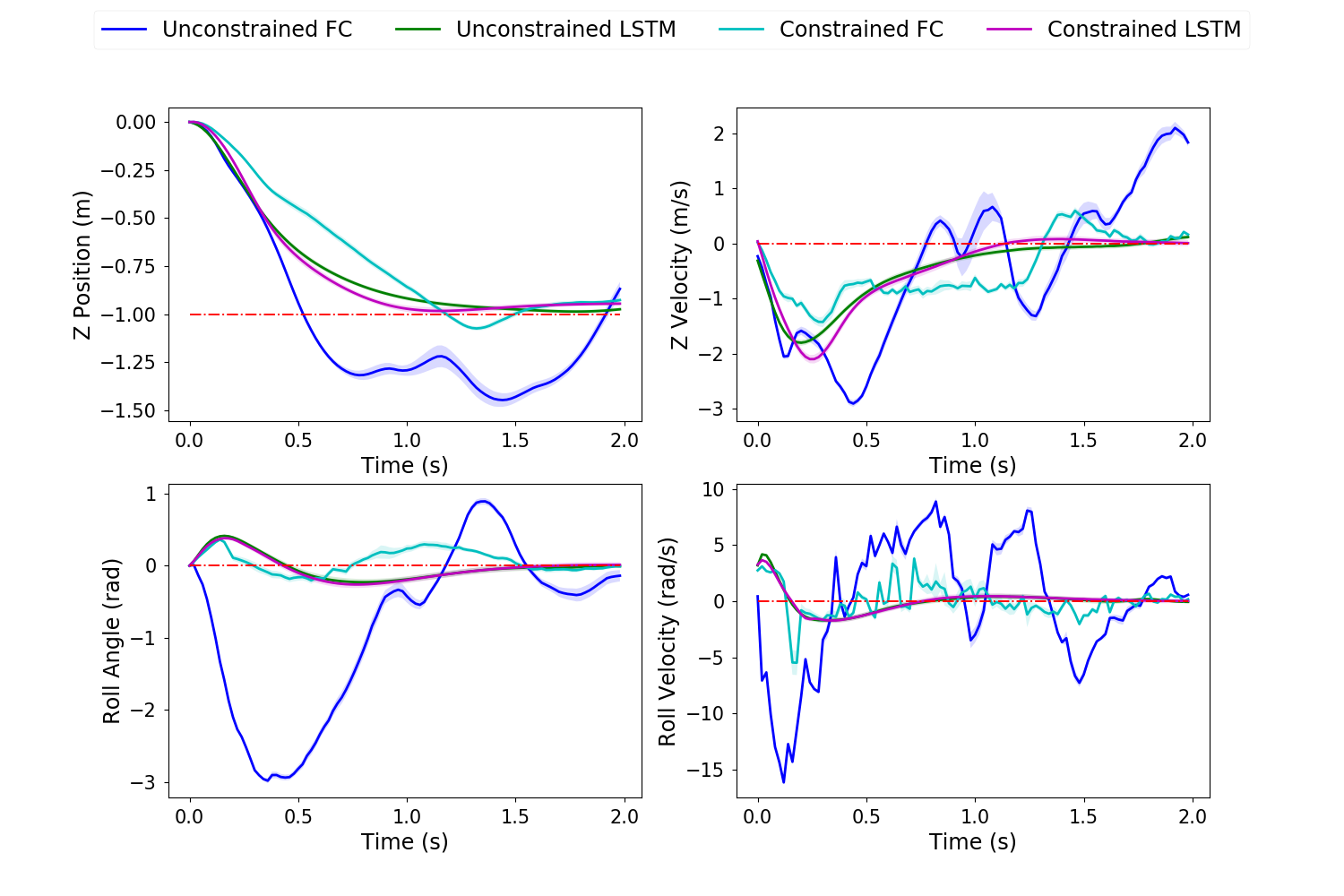 Figure 9
Figure 9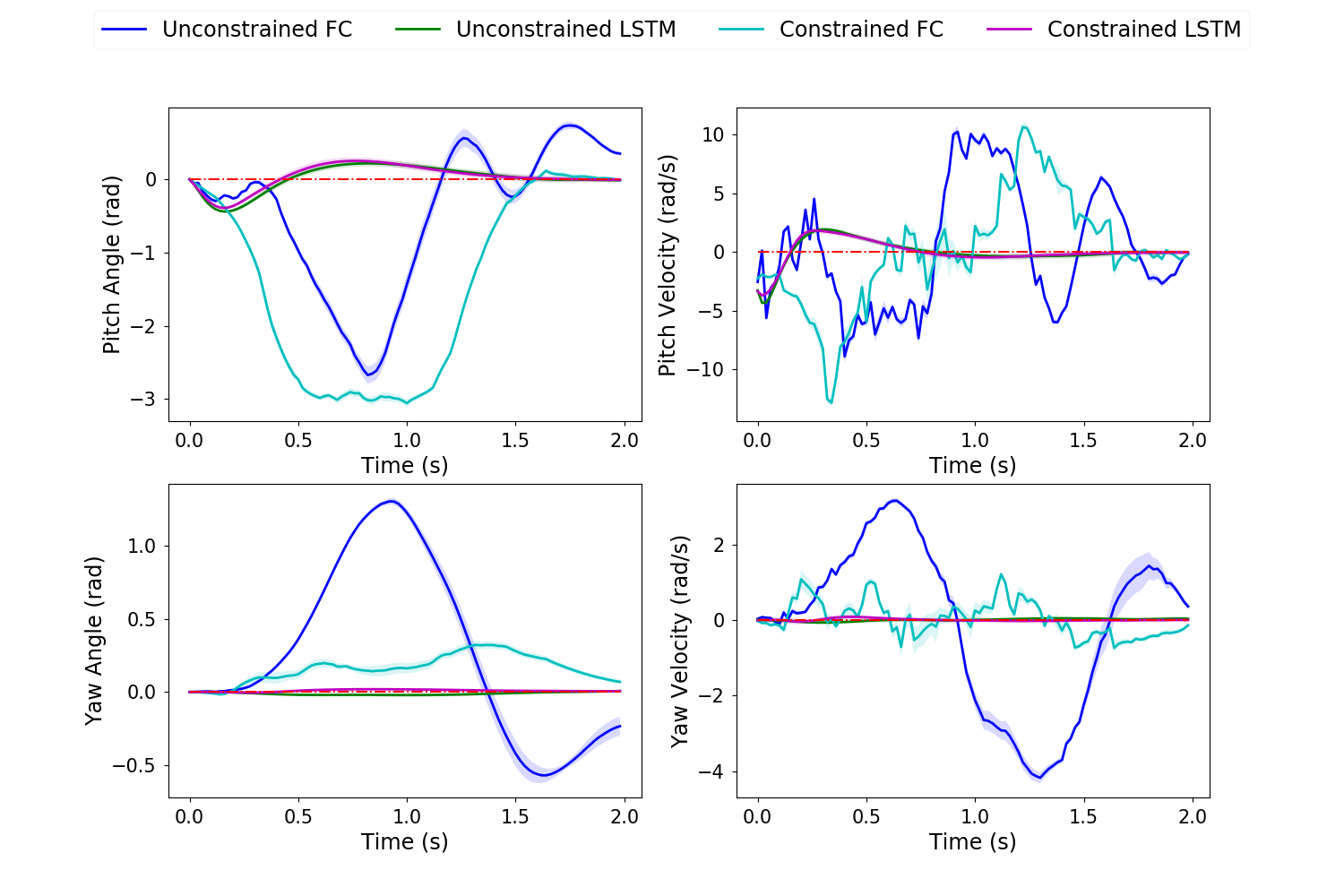 Figure 10
Figure 10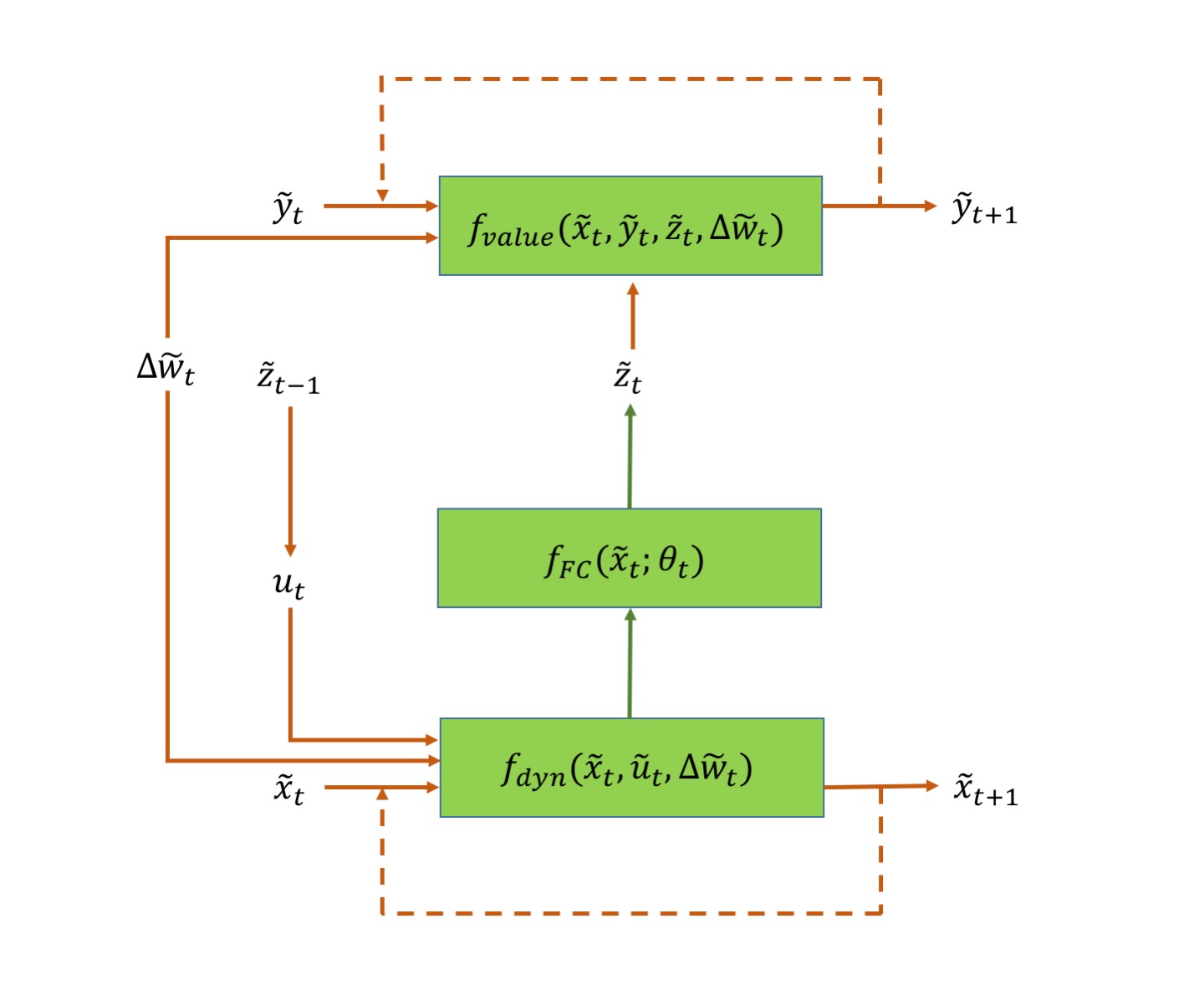 Figure 11
Figure 11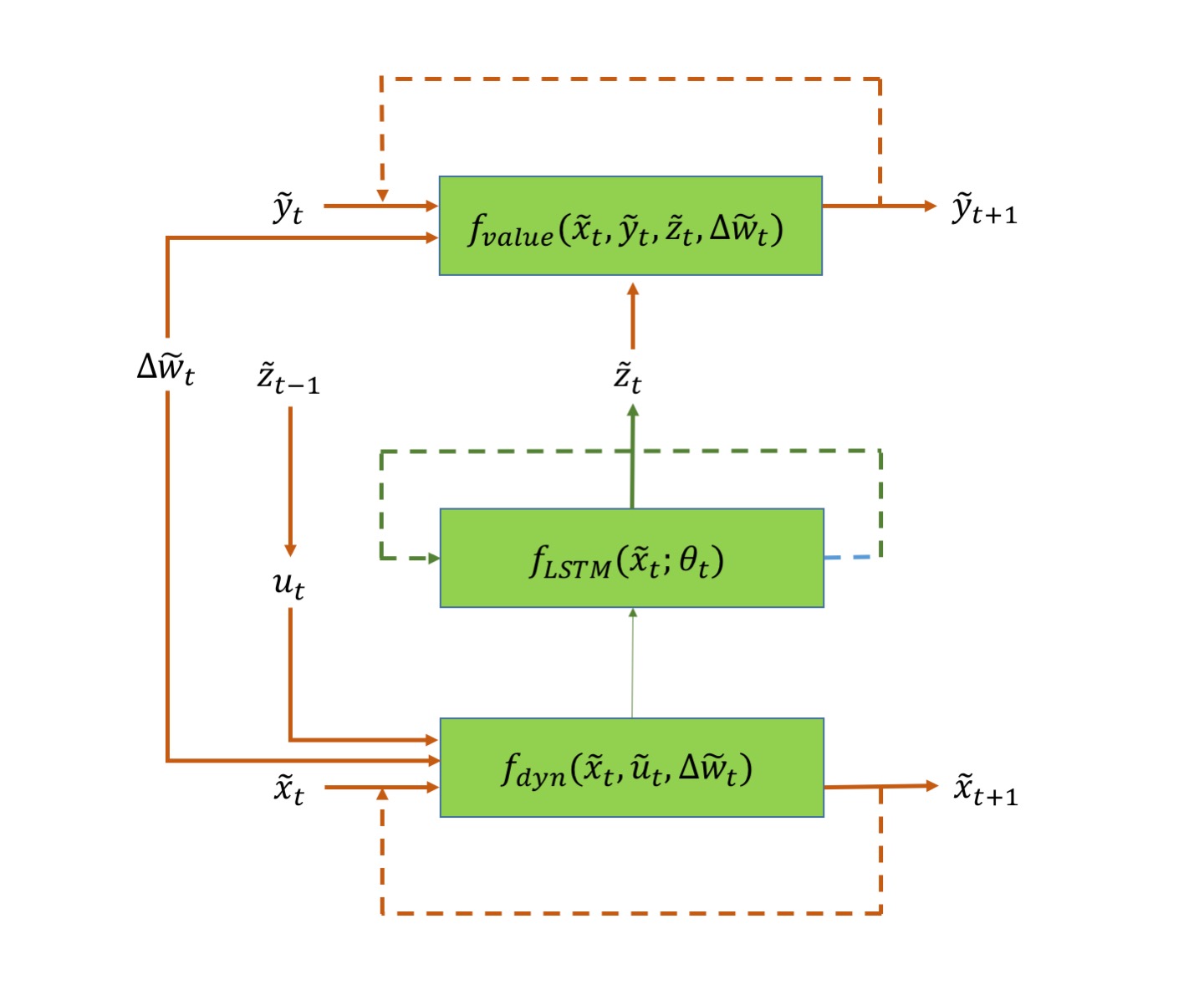 Figure 12
Figure 12Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
DNN Deep Neural Network DP Dynamic Programming FBSDE Forward-Backward Stochastic Differential Equation LSTM Long-Short Term Memory FC Fully Connected DDP Differential Dynamic Programming HJB Hamilton-Jacobi-Bellman PDE Partial Differential Equation PI Path Integral NN Neural Network GPs Gaussian Processes SOC Stochastic Optimal Control RL Reinforcement Learning MPOC Model Predictive Optimal Control IL Imitation Learning RNN Recurrent Neural Network DL Deep Learning SGD Stochastic Gradient Descent
Learning Deep Stochastic Optimal Control Policies using Forward-Backward SDEs
Marcus A. Pereira1†∗, Ziyi Wang2∗, Ioannis Exarchos3 and Evangelos A. Theodorou1,2 1Institute for Robotics and Intelligent Machines, Georgia Institute of Technology2The Center for Machine Learning, Georgia Institute of Technology3School of Medicine, Emory University*∗*Equal contribution†Correspondence to Marcus A. Pereira: [email protected]
Abstract
In this paper we propose a new methodology for decision-making under uncertainty using recent advancements in the areas of nonlinear stochastic optimal control theory, applied mathematics, and machine learning. Grounded on the fundamental relation between certain nonlinear partial differential equations and forward-backward stochastic differential equations, we develop a control framework that is scalable and applicable to general classes of stochastic systems and decision-making problem formulations in robotics and autonomy. The proposed deep neural network architectures for stochastic control consist of recurrent and fully connected layers. The performance and scalability of the aforementioned algorithm are investigated in three non-linear systems in simulation with and without control constraints. We conclude with a discussion on future directions and their implications to robotics.
I Introduction
Over the past 15 years there has been significant interest from the robotics community in developing algorithms for stochastic control of systems operating in dynamic and uncertain environments. This interest was initiated by two main developments related to theory and hardware. From a theoretical standpoint, there has been a better – and in some sense deeper – understanding of connections between different disciplines. As an example, the connections between optimality principles in control theory and information theoretic concepts in statistical physics are well understood so far [1, 2, 3, 4]. These connections have resulted in novel algorithms that are scalable, real-time, and can handle complex nonlinear dynamics [5]. On the hardware side, there have been significant technological developments that made possible the use of high performance computing for real-time Stochastic Optimal Control (SOC) in robotics [6].
Traditionally, SOC problems are solved using Dynamic Programming (DP). Dynamic Programming requires solving a nonlinear second order Partial Differential Equation (PDE) known as the Hamilton-Jacobi-Bellman (HJB) equation [7]. It is well-known that the HJB equation suffers from the curse of dimensionality. One way to tackle this problem is through an exponential transformation to linearize the HJB equation, which can then be solved with forward sampling using the linear Feynman-Kac lemma [8] [9]. While the linear Feynman-Kac lemma provides a probabilistic representation of the solution to the HJB that is exact, its application relies on certain assumptions between control authority and noise. In addition, the exponential transformation of the value function reduces the discriminability between good and bad states, which makes the computation of the optimal control policy difficult.
An alternative approach to solve SOC problems is to transform the HJB into a system of Forward-Backward Stochastic Differential Equations using a nonlinear version of the Feynman-Kac lemma [10, 11]. This is a more general approach compared to the standard Path Integral control framework, in that it does not rely on any assumptions between control authority and noise. In addition, it is valid for general classes of stochastic processes including jump-diffusions and infinite dimensional stochastic processes [12, 13]. However, the main challenge in using the nonlinear Feynman-Kac lemma lies in the solution of the backward SDE. This process requires the back-propagation of a conditional expectation, and thus cannot be solved by simple trajectory integration, as it is done with forward SDEs. Therefore, numerical approximation techniques are needed for utilization in an actual algorithm. Exarchos and Theodorou [14] developed an importance sampling based iterative scheme by approximating the conditional expectation at every time step using linear regression (see also [15] and [16]). However, this method suffers from compounding errors from Least Squares approximation at every time step.
Recently, the idea of using Deep Neural Networks and other data-driven techniques for approximating the solutions of non-linear PDEs has been garnering significant attention. In Raissi et al. [17], DNNs were used for both solving and data-driven discovery of the coefficients of non-linear PDEs popular in physics literature such as the Schrödinger, the Allen-Cahn, the Navier-Stokes, and the Burgers equations. They have demonstrated that their DNN-based approach can surpass the performance of other data-driven methods such as sparse linear regression proposed by Rudy et al. [18]. On the other hand, using DNNs for end-to-end Model Predictive Optimal Control (MPOC) has also become a popular research area. Pereira et al. [19] introduced a DNN architecture for Imitation Learning (IL), inspired by MPOC, based on the Path Integral (PI) Control approach alongside Amos et al. [20] who introduced an end-to-end MPOC architecture that uses the KKT conditions of the convex approximation. Pan et al. [21] demonstrated the MPOC capabilities of a DNN control policy using only camera and wheel speed sensors, through IL. Morton et al. [22] used a Koopman operator based DNN model for learning the dynamics of fluids and performing MPOC for suppressing vortex shedding in the wake of a cylinder.
This tremendous success of DNNs as universal function approximators [23] inspires an alternative scheme to solve systems of FBSDEs. Recently, Han et al. [24] introduced a Deep Learning based algorithm to solve FBSDEs associated with nonlinear parabolic PDEs. Their framework was applied to solve the HJB equation for a white-noise driven linear system to obtain the value function at the initial time step. This framework, although effective for solving parabolic PDEs, can not be applied directly to solve the HJB for optimal control of unstable nonlinear systems since it lacks sufficient exploration and is limited to only states that can be reached by purely noise driven dynamics. This problem was addressed in [14] through application of Girsanov’s theorem, which allows for the modification of the drift terms in the FBSDE system thereby facilitating efficient exploration through controlled forward dynamics.
In this paper, we propose a novel framework for solving SOC problems of nonlinear systems in robotics. The resulting algorithms overcome limitations of previous work in [24] by exploiting Girsanov’s theorem as in [14] to enable efficient exploration and by utilizing the benefits of recurrent neural networks in learning temporal dependencies. We begin by proposing essential modifications to the existing framework of FBSDEs to utilize the solutions of the HJB equation at every timestep to compute an optimal feedback control which thereby drives the exploration to optimal areas of the state space. Additionally, we propose a novel architecture that utilizes Long-Short Term Memory (LSTM) networks to capture the underlying temporal dependency of the problem. In contrast to the individual Fully Connected (FC) networks in [24], our proposed architecture uses fewer parameters, is faster to train, scales to longer time horizons and produces smoother control trajectories. We also extend our framework to problems with control-constraints which are very relevant to most applications in Robotics wherein actuation torques must not violate specified box constraints. Finally, we compare the performance of both network architectures on systems with nonlinear dynamics such as pendulum, cartpole and quadcopter in simulation.
The rest of this paper is organized as follows: in Section II we reformulate the stochastic optimal control problem in the context of FBSDE. In Section III we use the same FBSDE framework to the control constrained case. Then we provide the Deep FBSDE Control algorithm in Section IV. The simulation results are included in Section V. Finally we conclude the paper and discuss future research directions.
II Stochastic Optimal Control through FBSDE
II-A Problem Formulation
Let () be a complete, filtered probability space on which a -dimensional standard Brownian motion is defined, such that is the normal filtration of . Consider a general stochastic nonlinear system with control affine dynamics,
[TABLE]
where, , is the time horizon, is the state vector, is the control vector, represents the drift, represents the actuator dynamics, represents the diffusion. The Stochastic Optimal Control problem can be formulated as minimization of an expected cost functional given by
[TABLE]
where is the terminal state cost, is the running state cost and is a positive definite matrix. The expectation is taken with respect to the probability measure over the space of trajectories induced by controlled stochastic dynamics. With the set of all admissible controls , we can define the value function as,
[TABLE]
Using stochastic Bellman’s principle, as shown in [10], if the value function is in , then its solution can be found with Ito’s differentiation rule to satisfy the Hamilton-Jacobi-Bellman equation,
[TABLE]
where denote the gradient and Hessian of respectively. The explicit dependence on independent variables in the PDE above and all PDEs henceforth is omitted for the sake of conciseness, but will be maintained for their corresponding SDEs for clarity. For the chosen form of the cost functional integrand, the infimum operation can be carried out by taking the gradient of the terms inside, known as the Hamiltonian, with respect to and setting it to zero,
[TABLE]
Therefore, the optimal control is obtained as
[TABLE]
Plugging the optimal control back into the original HJB equation, the following form of the equation is obtained,
[TABLE]
II-B Non-linear Feynman-Kac lemma
Here we restate the non-linear Feynman-Kac lemma from [14]. Consider the Cauchy problem,
[TABLE]
wherein the functions , , and satisfy mild regularity conditions [14]. Then, (8) admits a unique (viscosity) solution , which has the following probabilistic representation,
[TABLE]
wherein \big{(}x(\cdot),y(\cdot),z(\cdot)\big{)} is the unique solution of an FBSDE system. The forward component of that system is given by
[TABLE]
where, without loss of generality, is chosen as a n-dimensional Brownian motion. The process , satisfying the above forward SDE, is also called the state process. The associated backward SDE is
[TABLE]
The function is called the generator or driver.
We assume that there exists a matrix-valued function such that the controls matrix in (1) can be decomposed as for all , satisfying the same mild regularity conditions. This decomposition can be justified as the case of stochastic actuators, where noise enters the system through the control channels. Under this assumption, we can apply the nonlinear Feynman-Kac lemma to the HJB PDE (7) and establish equivalence to (8) with coefficients of (8) given by
[TABLE]
II-C Importance Sampling for Efficient Exploration
There are several cases of systems in which the goal state practically cannot be reached by the uncontrolled stochastic system dynamics. This issue can be eliminated if one is given the ability to modify the drift term of the forward SDE. Specifically, by changing the drift, we can direct the exploration of the state space towards the given goal state, or any other state of interest, reachable by control. Through Girsanov’s theorem [25] on change of measure, the drift term in the forward SDE (11) can be changed if the backward SDE (12) is compensated accordingly. This is known as the importance sampling for FBSDEs. This results in a new system of FBSDEs in certain sense equivalent to the original ones,
[TABLE]
along with the compensated BSDE,
[TABLE]
for any measurable, bounded and adapted process . We refer the readers to proof of Theorem 1 in [14] for the full derivation of change of measure for FBSDEs. The PDE associated with this new system is given by
[TABLE]
which is identical to the original problem (8) as we have merely added and subtracted the term . Recalling the decomposition of control matrix in the case of stochastic actuators, the modified drift term can be applied with any nominal control to achieve the controlled dynamics,
[TABLE]
with . The nominal control can be any open or closed-loop control, a random control, or a control calculated from a previous run of the algorithm.
II-D FBSDE Reformulation
Solutions to BSDEs need to satisfy a terminal condition, and thus, integration needs to be performed backwards in time, yet the filtration still evolves forward in time. It turns out that a terminal value problem involving BSDEs admits an adapted solution if one back-propagates the conditional expectation of the process. This was the basis of the approximation scheme and corresponding algorithm introduced in [14]. However, this scheme is prone to approximation errors introduced by least squares estimates which compound over time steps. On the other hand, the Deep Learning (DL)-based approach in [24] uses the terminal condition of the BSDE as a prediction target for a self-supervised learning problem with the goal of using back-propagation to estimate the value function at the initial timestep. This was achieved by treating the value at the initial timestep, , as one of the trainable parameters of a DL model. There is a two-fold advantage of this approach: (i) starting with a random guess of , the backward SDE can be forward propagated instead. This eliminates the need to back-propagate a least-squares estimate of the conditional expectation to solve the BSDE and instead treat the BSDE similar to the FSDE, and (ii) the approximation errors at every time step are compensated by the backpropagation training process of DL. This is because the individual networks, at every timestep, contribute to a common goal of predicting the target terminal condition and are jointly trained.
In this work, we combine the importance sampling concepts for FBSDEs with the Deep Learning techniques that allows for the forward sampling of the BSDE and propose a new algorithm for Stochastic Optimal Control problems. The novelty of our approach is to incorporate importance sampling for efficient exploration in the DL model. Instead of the original HJB equation (7), we focus on obtaining solutions for the modified HJB PDE in (16) by using the modified FBSDE system (14), (15). Additionally, we explicitly compute the control at every time step using the analytical expression for optimal control (6) in the computational graph. Similar to [24], the FBSDE system is solved by integration of both the SDEs forward in time as follows,
[TABLE]
and
[TABLE]
III Stochastic Control Problems with Control Constraints
The framework we have considered so far can be suitably modified to accommodate a certain type of control constraints, namely upper and lower bounds . Specifically, each control dimension component satisfies for all . Such control constraints are common in mechanical systems, where control forces and/or torques are bounded, and may be readily introduced in our framework via the addition of a “soft” constraint, integrated within the cost functional. In recent work, Exarchos et al. [26] showed how box-type control constraints for -optimal control problems (also called minimum fuel problems), can be incorporated into an FBSDE scheme. These are in contrast to the more frequently used quadratic control cost ( or minimum energy) SOC problems. Indeed, one can replace the cost functional given by (2) with .
[TABLE]
where
[TABLE]
are constant weights, denotes the sigmoid (tanh-like) function that saturates at infinity, i.e., , while is a dummy variable of integration. A suitable example along with its inverse is
[TABLE]
Following the same procedure as in Section II, we set the derivative of the Hamiltonian equal to zero and obtain
[TABLE]
By introducing the notation
[TABLE]
where (not to be confused with the terminal cost ) denotes the i-th column of , we may write the optimal control in component-wise notation as
[TABLE]
The optimal control can be written equivalently in vector form. Indeed, if is the vector of bounds, is a diagonal matrix of the reciprocals of the weights and is a diagonal matrix of the bounds, one readily obtains
[TABLE]
Substituting the equation of the constrained controls into eqn. 16 results in
[TABLE]
where is specified by the expression that follows:
[TABLE]
IV Deep FBSDE Controller
In this section we present the algorithm for the Deep FBSDE stochastic controller and discuss the underlying network architectures.
Algorithm: The task horizon in continuous-time can be discretized as , where . Here we abuse the notation as both the continuous time variable and discrete time index. With this we can also discretize all the variables as step functions such that if the discrete time index is between the time interval \big{[}t\Delta t,(t+1)\Delta t\big{)}.
The Deep FBSDE algorithm, as shown in Alg. 1, solves the finite time horizon control problem by approximating the gradient of the value function at every time step with a DNN parameterized by . Note that the superscript is the batch index, and the batch-wise calculation can be implemented in parallel. The initial value and its gradient are parameterized by trainable variables and are randomly initialized. The optimal control action is calculated using the discretized version of (6) (or (26) for the control constrained case). The dynamics and value function are propagated using the Euler integration scheme, as shown in the algorithm. The function is calculated using (13) (or (28) for the control constrained case). The predicted final value is compared against the true final value to calculate the loss. The networks can be trained with any one of the variants of Stochastic Gradient Descent (SGD) such as the Adam optimizer [27] until convergence with custom learning rate scheduling. The trained networks can then be used to predict the optimal control at every time step starting from the given initial condition .
Network Architectures: The network architectures illustrated in figures 1 and 2, are extensions of the network introduced in [24] (refer to fig. 4 in the paper). The neural network architectures in figures 1 and 2 have additional connections (highlighted by boldfaced arrows) that use the predicted gradient of the value function at every time step to compute and apply an optimal feedback control. An architecture similar to fig. 1 was introduced in [28] to solve model-based Reinforcement Learning (RL) problems posed as finite time horizon SOC problems. This consisted of a FC network at every timestep to predict an action as a function of the current state. The networks were stacked together to form one large deep network which was trained in an end-to-end fashion with the goal of minimizing the accumulated cost (or maximizing accumulated reward). In contrast, the network architecture in fig. 1 uses the explicit form of the optimal feedback control (eq. (6) or eq. (26)) at every timestep calculated using the value function gradient predicted by the network. In addition, we use the prediction to propagate the value function according to the BSDE (19) and minimize the difference between the propagated value function and the true value function at the final state. This, however, creates a new path for gradient backpropagation through time [29] which introduces both advantages and challenges for training the networks. The advantage being a direct influence of the weights on the state cost leading to accelerated convergence. Nonetheless, this passage also leads to the vanishing gradient problem, which has been known to plague training of Recurrent Neural Networks for long sequences (or time horizons).
To tackle this problem, we propose a new LSTM-based network architecture, as shown in fig. 2, which can effectively deal with the vanishing gradient problem [30] as it allows for the gradient to flow unchanged. Additionally, since the weights are shared across all time steps, the total number of parameters to train is far less than the FC structure. These features allows the algorithm to scale to optimal problems of long time horizons. Intuitively, one can also think of the use of LSTM as modeling the time evolution of , in contrast to the FC structure, which acts independently at every time step.
V Simulation Results
We applied the Deep FBSDE controller to systems of pendulum, cartpole and quadcopter for the task of reaching a target final state. The trained networks are evaluated over 128 trials and the results are compared between the different network architectures for both the unconstrained and control constrained case. We use FC and LSTM to denote experiments with the network architectures in fig. 1 and 2 respectively. We use 2 layer FC and LSTM networks and tanh activation for all experiments, with . All experiments were conducted in TensorFlow [31] on an Intel i7-4820k CPU Processor. A comparison of training time and trainable parameter number is shown in fig. 3, where it is clear that the LSTM network saves at least 20% of training time and has much fewer parameters than the FC network.
In all trajectory plots, the solid line represents the mean trajectory, and shaded region shows the 95% confidence region. To differentiate between the 4 cases, we use blue for unconstrained FC, green for unconstrained LSTM, cyan for constrained FC and magenta for constrained LSTM.
V-A Pendulum
The algorithm was applied to the pendulum system for the swing-up task with a time horizon of 1.5 seconds. The equation of motion for the pendulum is given by
[TABLE]
The initial pendulum angle is 0 , and the target pendulum angle and rate are and 0 respectively. A maximum torque constraint of is used for the control constrained cases.
Fig. 4 shows the state trajectories across the 4 case. It can be observed that the swing-up task is completed in all casess with low variance. However, the pole rate does not return to 0 for unconstrained FC, as compared to unconstrained LSTM. When the control is constrained, the pendulum angular rate becomes serrated for FC while remaining smooth for LSTM. This also more noticeable in the control torques (fig. 5). The control torques becomes very spiky for FC due to the independent networks at each time step. On the other hand, the hidden temporal connection within LSTM allows for smooth and optimally behaved control policy.
V-B Cart Pole
The algorithm was applied to the cart-pole system for the swing-up task with a time horizon of 1.5 seconds. The equations of motion for the cart-pole are given by
[TABLE]
The initial pole angle is 0 , and the target pole angle is with target pole and cart velocities of 0 and 0 respectively. Note that despite the target of 0 for cart position, we do not penalize non-zero cart position in training. A maximum force constraint of 10 is used for the control constrained case.
The cart-pole states are shown in fig. 6. Similar to the pendulum experiment, the swing-up task is completed with low variance acrossed all cases. Interestingly, when control is constrained, both FC and LSTM swing the pole in the direction opposite to target at first and utilize momentum to complete the task. Another interesting observation is that in the unconstrained case, the LSTM-policy is able to exploit long-term temporal connections to initially apply large controls to swing-up the pole and then focus on decelerating the pole for the rest of the time horizon, whereas the FC-policy appears to be more myopic resulting in a delayed swing-up action. Similar to the pendulum experiment, under control constraint the FC-policy results in sawtooth-like controls while the LSTM-policy outputs smooth control trajectories.
V-C Quadcopter
The algorithm was applied to the quadcopter system for the task of flying from its initial position to a target final position with a time horizon of 2 seconds. The quadcopter dynamics used is described in detail by Habib et al. [32]. The initial condition is 0 across all states, and the target is 1 upward, forward and to the right from the initial location with zero velocities and attitude. The controls are motor torques. A maximum torque constraint of 3 is imposed for the control constrained case.
This task required individual FC networks. After extensive experimentation, we conclude that tuning the FC-based policy becomes significantly difficult and cumbersome as the time horizon of the task increases. On the other hand, tuning our proposed LSTM-based policy was equivalent to that for the cart-pole and pendulum experiments. Moreover, the shared weights across all time steps results in faster build-times and run-times of the TensorFlow computational graph. As seen in the figures (8-10) from our experiments, the performance of the LSTM-based policies surpassed that of the FC-based policies (especially for the attitude states) due to exploiting long term temporal dependence and ease of tuning.
VI Conclusions
In this paper, we proposed the Deep FBSDE Control algorithm that utilizes fully connected and recurrent layers based on the LSTM network architecture. The proposed algorithm solves finite time horizon Stochastic Optimal Control problems for nonlinear systems with control-affine dynamics and constraints in the controls.
The architectures presented in this paper can be extended in many different ways, some of which include:
- •
Risk-Sensitive and Min-Max Stochastic Optimal Control: This type of Stochastic Optimal Control problems result in the so-called Hamilton-Jacobi-Bellman-Isaacs PDE. The min-max formulations are typically used to model stochastic disturbances with unknown mean. Solving these SOC problems will result in robust policies in robotics.
- •
Stochastic Optimal Control** of systems with generalized stochasticities:** For systems with Lévy and jump-diffusion noise, the resulting HJB equation is a partial-integro-differential equation. Stochastic models that include jump-diffusions could be used to model wind-gust or ground forces in terrestrial vehicles.
- •
Non-affine control dynamics: Very often in robotics dynamics are represented by function approximators such as DNNs or Gaussian Processes (GPs). This choice results in dynamics that are non-affine in controls. A potential new direction is to generalize the Deep FBSDE Control algorithm for such representations.
Acknowledgments
This research was supported by the Amazon Web Services Machine Learning Research Awards and the NSF CMMI award #1662523.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dai Pra et al. [1996-12-08] P. Dai Pra, L. Meneghini, and W. Runggaldier. Connections between stochastic control and dynamic games. Mathematics of Control, Signals, and Systems (MCSS) , 9(4):303–326, 1996-12-08. URL http://dx.doi.org/10.1007/BF 01211853 . · doi ↗
- 2Fleming [1971] W.H. Fleming. Exit probabilities and optimal stochastic control. Applied Math. Optim , 9:329–346, 1971.
- 3Theodorou and Todorov [2012] E.A Theodorou and E. Todorov. Relative entropy and free energy dualities: Connections to path integral and kl control. In the Proceedings of IEEE Conference on Decision and Control , pages 1466–1473, Dec 2012. doi: 10.1109/CDC.2012.6426381 .
- 4Theodorou [2015] E. A. Theodorou. Nonlinear stochastic control and information theoretic dualities: Connections, interdependencies and thermodynamic interpretations. Entropy , 17(5):3352, 2015.
- 5Williams et al. [2018] G. Williams, P. Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou. Information-theoretic model predictive control: Theory and applications to autonomous driving. IEEE Transactions on Robotics , 34(6):1603–1622, Dec 2018. ISSN 1552-3098. doi: 10.1109/TRO.2018.2865891 .
- 6NVIDIA [Aug 31, 1999] NVIDIA. Nvidia launches the world’s first graphics processing unit: Geforce 256. Aug 31, 1999. URL https://www.nvidia.com/object/IO_20020111_5424.html .
- 7Bellman [2013] Richard Bellman. Dynamic programming . Courier Corporation, 2013.
- 8Theodorou et al. [2010] E. A. Theodorou, J. Buchli, and S. Schaal. A Generalized Path Integral Control Approach to Reinforcement Learning . J. Mach. Learn. Res. , 11:3137–3181, December 2010. ISSN 1532-4435.