Color Image and Multispectral Image Denoising Using Block Diagonal Representation
Zhaoming Kong, Xiaowei Yang

TL;DR
This paper introduces a novel patch-level block diagonal representation for color and multispectral image denoising, demonstrating that a trained global basis combined with local PCA transforms yields competitive results efficiently.
Contribution
It emphasizes the importance of patch-level representation using block diagonal matrices and proposes a simple, effective transform-threshold-inverse method with fast implementation.
Findings
Competitive denoising results on simulated and real datasets
Robustness and efficiency demonstrated through extensive experiments
Effective use of global patch basis and local PCA transforms
Abstract
Filtering images of more than one channel is challenging in terms of both efficiency and effectiveness. By grouping similar patches to utilize the self-similarity and sparse linear approximation of natural images, recent nonlocal and transform-domain methods have been widely used in color and multispectral image (MSI) denoising. Many related methods focus on the modeling of group level correlation to enhance sparsity, which often resorts to a recursive strategy with a large number of similar patches. The importance of the patch level representation is understated. In this paper, we mainly investigate the influence and potential of representation at patch level by considering a general formulation with block diagonal matrix. We further show that by training a proper global patch basis, along with a local principal component analysis transform in the grouping dimension, a simple…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4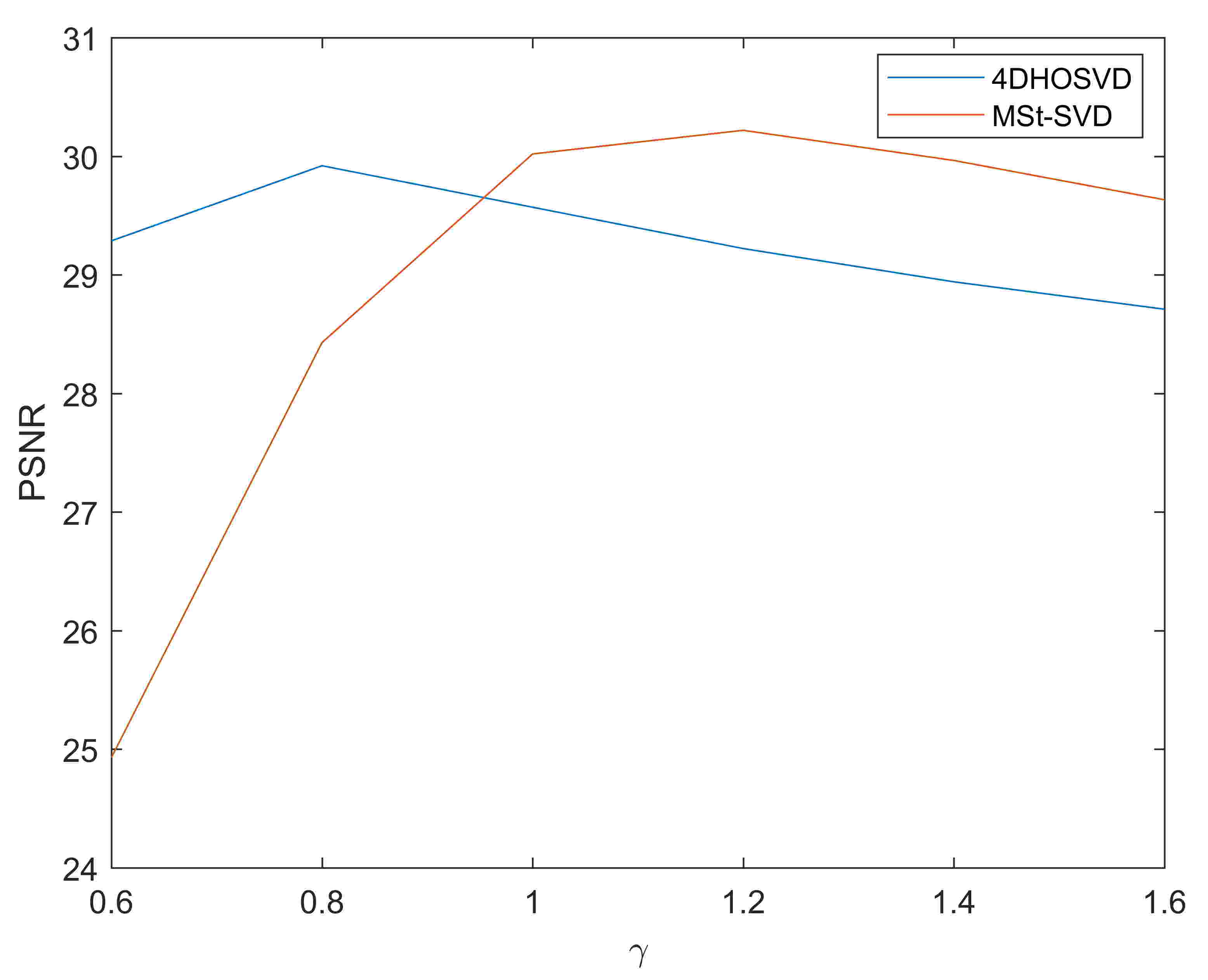 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Method | LSCD | WTR1 | FFD-Net | LLRT |
| 10 | 15 | 15 | 20 | |
| Method | 4DHOSVD1 | CBM3D | MSt-SVD | CMSt-SVD |
| 30 | 20 | 30 | 25 |
| Methods | Canon 5D ISO = 3200 | Canon D600 ISO = 3200 | Nikon D800 ISO = 1600 | Nikon D800 ISO = 3200 | Nikon D800 ISO = 6400 | Average | Time (s) | ||||||||||
| LSCD | 37.86 | 36.21 | 35.52 | 34.65 | 36.26 | 38.24 | 37.90 | 38.88 | 38.32 | 37.45 | 36.49 | 37.73 | 32.33 | 32.55 | 32.62 | 36.20 | 9.68 |
| LLRT | 39.23 | 36.31 | 35.93 | 34.74 | 36.83 | 40.58 | 37.39 | 40.27 | 37.78 | 39.79 | 37.34 | 41.03 | 35.09 | 34.05 | 34.11 | 37.36 | |
| WTR1 | 41.09 | 36.92 | 36.25 | 34.68 | 36.48 | 40.52 | 38.26 | 41.40 | 38.61 | 39.98 | 37.70 | 41.36 | 35.16 | 34.22 | 34.43 | 37.81 | |
| TNRD | 39.51 | 36.47 | 36.45 | 34.79 | 36.37 | 39.49 | 38.11 | 40.52 | 38.17 | 37.69 | 35.90 | 38.21 | 32.81 | 32.33 | 32.29 | 36.61 | N/A |
| MLP | 39.00 | 36.34 | 36.33 | 34.70 | 36.20 | 39.33 | 37.95 | 40.23 | 37.94 | 37.55 | 35.91 | 38.15 | 32.69 | 32.33 | 32.29 | 36.46 | N/A |
| DnCNN | 37.26 | 34.13 | 34.09 | 33.62 | 34.48 | 35.41 | 35.79 | 36.08 | 35.48 | 34.08 | 33.70 | 33.31 | 29.83 | 30.55 | 30.09 | 33.86 | N/A |
| GID | 40.82 | 37.19 | 36.92 | 35.32 | 36.62 | 38.68 | 38.88 | 40.66 | 39.20 | 37.92 | 36.62 | 37.64 | 33.01 | 32.93 | 32.96 | 37.02 | 55.60 |
| WCMNNM | 41.20 | 37.25 | 36.48 | 35.54 | 37.03 | 39.56 | 39.26 | 41.45 | 39.54 | 38.94 | 37.40 | 39.42 | 34.85 | 33.97 | 33.97 | 37.72 | 318.29 |
| FFD-Net | 39.40 | 37.02 | 36.53 | 34.97 | 36.73 | 41.02 | 38.66 | 41.53 | 38.80 | 40.15 | 37.61 | 41.18 | 34.13 | 33.66 | 33.69 | 37.68 | 28.98 |
| TWSC | 40.55 | 35.92 | 35.15 | 35.36 | 37.09 | 41.13 | 39.36 | 41.91 | 38.81 | 40.27 | 37.22 | 42.09 | 35.53 | 34.15 | 33.93 | 37.90 | 480.80 |
| CBM3D | 40.77 | 37.31 | 36.98 | 35.21 | 36.76 | 40.13 | 39.02 | 41.65 | 39.40 | 39.59 | 37.49 | 39.47 | 34.13 | 33.73 | 33.85 | 37.69 | 6.98 |
| CBM3D_best | 40.96 | 37.31 | 37.15 | 35.38 | 36.81 | 40.45 | 39.25 | 41.65 | 39.59 | 39.86 | 37.54 | 40.38 | 34.85 | 33.92 | 34.16 | 37.95 | 6.98 |
| 4DHOSVD1 | 40.22 | 36.97 | 36.55 | 35.02 | 36.60 | 39.78 | 38.85 | 41.35 | 39.11 | 39.24 | 37.28 | 39.47 | 34.40 | 33.81 | 34.01 | 37.51 | 120.18 |
| MSt-SVD | 40.33 | 37.25 | 36.83 | 35.16 | 36.71 | 40.29 | 38.97 | 41.49 | 39.24 | 39.61 | 37.43 | 39.93 | 34.34 | 33.82 | 33.96 | 37.69 | 110.06 |
| CMSt-SVD | 40.79 | 37.37 | 37.01 | 35.29 | 36.95 | 40.93 | 39.21 | 41.98 | 39.54 | 39.98 | 37.65 | 40.05 | 34.50 | 33.93 | 34.01 | 37.95 | 98.88 |
| Dataset | Index | LLRT | WTR1 | FFD-Net | GID | TWSC | MCWNNM | 4DHOSVD1 | CBM3D | CBM3D_best | CMSt-SVD |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CC60 | PSNR | 38.51 | 39.69 | 39.73 | 38.41 | 39.66 | 39.03 | 39.15 | 39.40 | 39.68 | 39.75 |
| SSIM | 0.9636 | 0.9764 | 0.9770 | 0.9633 | 0.9759 | 0.9698 | 0.9729 | 0.9740 | 0.9775 | 0.9756 | |
| Xu | PSNR | 38.51 | 38.56 | 38.56 | 38.37 | 38.62 | 38.51 | 38.51 | 38.69 | 38.81 | 38.82 |
| SSIM | 0.9707 | 0.9669 | 0.9658 | 0.9675 | 0.9674 | 0.9671 | 0.9673 | 0.9694 | 0.9712 | 0.9694 |
| Camera | # of Images | Index | LLRT | FFD-Net | GID | TWSC | MCWNNM | 4DHOSVD1 | CBM3D | CBM3D_best | CMSt-SVD |
|---|---|---|---|---|---|---|---|---|---|---|---|
| HUAWEI HONOR 6X | 30 | PSNR | 39.54 | 40.05 | 39.52 | 39.71 | 39.46 | 39.82 | 39.97 | 40.48 | 40.08 |
| SSIM | 0.9669 | 0.9669 | 0.9653 | 0.9651 | 0.9610 | 0.9658 | 0.9669 | 0.9740 | 0.9674 | ||
| IPHONE 5S | 36 | PSNR | 40.02 | 40.60 | 40.12 | 40.27 | 39.87 | 40.68 | 40.77 | 41.25 | 40.84 |
| SSIM | 0.9676 | 0.9645 | 0.9642 | 0.9617 | 0.9567 | 0.9664 | 0.9668 | 0.9758 | 0.9668 | ||
| IPHONE 6S | 67 | PSNR | 39.72 | 40.49 | 40.16 | 40.12 | 40.18 | 40.36 | 40.55 | 41.16 | 40.53 |
| SSIM | 0.9663 | 0.9707 | 0.9670 | 0.9619 | 0.9628 | 0.9671 | 0.9693 | 0.9783 | 0.9674 | ||
| CANON 100D | 55 | PSNR | 41.84 | 41.67 | 40.86 | 41.65 | 41.47 | 41.41 | 41.69 | 42.08 | 41.99 |
| SSIM | 0.9784 | 0.9768 | 0.9743 | 0.9767 | 0.9774 | 0.9771 | 0.9780 | 0.9808 | 0.9794 | ||
| CANON 600D | 25 | PSNR | 42.53 | 42.55 | 41.60 | 42.52 | 42.07 | 42.14 | 42.54 | 42.89 | 42.75 |
| SSIM | 0.9816 | 0.9824 | 0.9790 | 0.9824 | 0.9795 | 0.9810 | 0.9836 | 0.9851 | 0.9840 | ||
| SONY A6500 | 36 | PSNR | 45.71 | 45.71 | 44.94 | 45.48 | 45.37 | 45.56 | 45.70 | 45.81 | 45.89 |
| SSIM | 0.9899 | 0.9901 | 0.9887 | 0.9896 | 0.9894 | 0.9901 | 0.9902 | 0.9904 | 0.9903 |
| Methods | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | ERGAS | SAM | PSNR | SSIM | ERGAS | SAM | PSNR | SSIM | ERGAS | SAM | PSNR | SSIM | ERGAS | SAM | |
| Noisy | 28.13 | 0.4371 | 236.40 | 0.7199 | 18.59 | 0.1069 | 676.01 | 1.0085 | 14.15 | 0.0475 | 1126.7 | 1.1461 | 8.13 | 0.0136 | 2253.4 | 1.3074 |
| PARAFAC | 35.39 | 0.8759 | 108.78 | 0.2363 | 33.65 | 0.8294 | 125.13 | 0.3291 | 31.52 | 0.7393 | 154.19 | 0.4351 | 27.13 | 0.4637 | 250.68 | 0.6681 |
| LRTA | 41.36 | 0.9499 | 49.53 | 0.1718 | 36.06 | 0.8775 | 90.50 | 0.2446 | 33.52 | 0.8201 | 121.15 | 0.2897 | 30.06 | 0.7138 | 180.03 | 0.3649 |
| LRMR | 39.27 | 0.9094 | 64.81 | 0.3343 | 31.36 | 0.6451 | 157.65 | 0.6021 | 26.67 | 0.4000 | 264.28 | 0.7534 | 26.67 | 0.1850 | 469.26 | 0.9306 |
| 4DHOSVD1 | 45.43 | 0.9811 | 30.83 | 0.1084 | 39.78 | 0.9336 | 59.12 | 0.2272 | 36.82 | 0.8722 | 83.36 | 0.3385 | 32.66 | 0.7307 | 134.34 | 0.5599 |
| BM4D | 44.61 | 0.9784 | 33.32 | 0.1289 | 38.80 | 0.9283 | 65.23 | 0.2579 | 35.98 | 0.8685 | 91.19 | 0.3557 | 31.84 | 0.7197 | 144.91 | 0.5160 |
| TDL | 44.41 | 0.9797 | 34.32 | 0.1048 | 39.07 | 0.9493 | 63.18 | 0.1493 | 36.46 | 0.9171 | 85.24 | 0.2008 | 32.92 | 0.8284 | 128.15 | 0.3132 |
| ISTReg | 45.77 | 0.9802 | 30.53 | 0.1086 | 40.51 | 0.9488 | 53.05 | 0.1374 | 37.75 | 0.9271 | 70.16 | 0.1619 | 33.01 | 0.8648 | 120.77 | 0.2376 |
| LLRT | 46.60 | 0.9868 | 26.75 | 0.0842 | 41.49 | 0.9681 | 48.50 | 0.1221 | 38.65 | 0.9482 | 67.56 | 0.1551 | 35.39 | 0.9154 | 99.37 | 0.1962 |
| MSt-SVD | 45.20 | 0.9814 | 32.05 | 0.1064 | 40.23 | 0.9530 | 56.26 | 0.1737 | 37.73 | 0.9285 | 75.03 | 0.2231 | 34.20 | 0.8800 | 115.24 | 0.3142 |
| Index | PARAFAC | LRTA | 4DHOSVD1 | BM4D | TDL | LLRT | MSt-SVD |
|---|---|---|---|---|---|---|---|
| PSNR | 32.7 | 33.0 | 38.1 | 36.6 | 32.3 | 38.3 | 39.3 |
| SSIM | 0.79 | 0.74 | 0.91 | 0.86 | 0.74 | 0.92 | 0.94 |
| ERGAS | 137.9 | 132.6 | 71.9 | 89.7 | 140.9 | 70.8 | 62.4 |
| SAM | 0.40 | 0.45 | 0.33 | 0.40 | 0.48 | 0.21 | 0.19 |
| Time (m) | 4.8 | 0.6 | 5.5 | 10.1 | 1.2 | 48.8 | 6.2 |
| Parameter | 4DHOSVD | MSt-SVD | ||
|---|---|---|---|---|
| Color Image | MSI | Color Image | MSI | |
| 8 | 8 | 8 | 8 | |
| 30 | 30 | 30 | 30 | |
| 20 | 16 | 20 | 16 | |
| 4 | 4 | 4 | 4 | |
| 0.8 | 1 | 1.1 (), 1.2 () | 4 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Color Image and Multispectral Image Denoising Using Block Diagonal Representation
Zhaoming Kong and Xiaowei Yang Zhaoming Kong (E-mail: [email protected]) and Xiaowei Yang ([email protected]) are with the school of Software Engineering, South China University of Technology, Guangdong Province, China.
Abstract
Filtering images of more than one channel is challenging in terms of both efficiency and effectiveness. By grouping similar patches to utilize the self-similarity and sparse linear approximation of natural images, recent nonlocal and transform-domain methods have been widely used in color and multispectral image (MSI) denoising. Many related methods focus on the modeling of group level correlation to enhance sparsity, which often resorts to a recursive strategy with a large number of similar patches. The importance of the patch level representation is understated. In this paper, we mainly investigate the influence and potential of representation at patch level by considering a general formulation with block diagonal matrix. We further show that by training a proper global patch basis, along with a local principal component analysis transform in the grouping dimension, a simple transform-threshold-inverse method could produce very competitive results. Fast implementation is also developed to reduce computational complexity. Extensive experiments on both simulated and real datasets demonstrate its robustness, effectiveness and efficiency.
Index Terms:
Color image denoising, multispectral image denoising, non-local filters, transform domain techniques, block diagonal representation
I Introduction
IMAGE denoising plays an important role in modern image processing systems. The past few decades witness great achievements in this field [1], and methods that utilize self-similarity and non-local characteristics of natural images have drawn much attention due to their simplicity and effectiveness. Recently, great achievement is made by the well-known BM3D algorithm [2] which combines the nonlocal filters [3] and transform domain techniques [4]. Methods that share similar idea and procedure of BM3D are widely adopted to handle grayscale image [5, 6, 7]. When the input is color image (sRGB) or multispectral image that contains rich information and delivers more faithful representation for real scenes, directly applying the grayscale denoising algorithm to each channel [3] or spectral band [8] often fails to produce satisfactory results, and therefore efforts to understand and address noise reduction issue have been made from several different perspectives.
First, two main solutions are proposed to improve the channel-by-channel or band-by-band approach. The first strategy proposes to transform the original image into a less correlated color or band space, such that denoising in each transformed channel or band could be performed independently. the representative work is the color BM3D (CBM3D) which applies BM3D to the luminance-chrominance space [9]. The second strategy jointly characterizes the RGB channels or bands for better use of spectral correlation. Methods that fall into such category are widely considered with different priors and regularization. Briefly, [10] proposes a multichannel nonlocal fusion (MNLF) approach, [11] introduces color line to model the correlation among neighbouring pixels and channels, and [12] considers the spatial and spectral dependencies. Sparse and low rank priors are also adopted in several competitive methods [13, 14, 15]. Besides, to avoid vectorization of image patch, some recent works incorporate tensor representation [16] with higher order singular value decomposition (HOSVD) [17, 18, 7], low rank tensor approximation (LRTA) framework [19], Laplacian Scale Mixture modeling [20] and Hyper-Laplacian regularization [21].
In addition to the design of denoising strategy, noise modeling is also important. Most of existing methods consider additive white Gaussian noise (AWGN) and some efficient noise estimation methods [22, 23] can be employed. Besides, some non i.i.d. Gaussian denoisers are proposed for filtering Poission noise [24], mixed Gaussian and impulsive noise [25] and stripe noise [26]. In fact, noise in real-world images may be multiplicative and signal dependent [27], making noise modeling and estimation much more complex and challenging. [28] and [29] consider the non-linear processing steps in the camera pipeline in the noise model, and [30, 31, 32] combine external and internal priors. Some methods [33, 34, 35, 36], including the well-known software toolbox Neat Image (NI)111Neatlab ABSoft. https://ni.neatvideo.com/home are developed for noise reduction of real-world images. Apart from the conventional transform-domain approaches, many recent competitive methods [37, 38, 39, 40] are based on the advent of deep learning technique as a powerful feature extraction tool.
In order to compare different denoising methods, several real-world color image and multispectral image datasets [41, 28, 42, 43, 44, 45, 46] of various scenes are constructed, and each scene of a color image includes noisy and ”ground-truth” image pairs. A simple and reasonable approach adopted by [41, 28, 43, 46] to obtain ”ground-truth” image is to capture the same and unchanged scene for many times and compute their mean image. Different from the image averaging approach, [42] utilizes the Tobit regression to estimate the parameters of the noise process by accessing only two images, and [44] generates a high quality smartphone image denoising dataset with careful post-processing. Interestingly, recent experiments on real-world datasets show that BM3D based methods [9, 47] still demonstrate the most competitive performance in terms of both effectiveness and efficiency. The implementation details are unknown and there is debate [48, 49] that they may have touched the ceiling of image denoising.
Many competitive methods [13, 21, 15] attempt to approach the optimal performance by modeling the redundancy and correlation at group level with some iterative strategies [50] and a large number of similar patches. However, influence of the patch level representation is less carefully studied. Although the use of tensor representation may help preserve some structure information, the straightforward folding and unfolding operation may not fully exploit the relationship among all channels or spectral bands. In this paper, we investigate the potential and influence of patch level representation, and establish a general formulation with block diagonal matrix. We demonstrate that the combination of a proper global patch basis and local PCA can produce very competitive performance in terms of both efficiency and effectiveness. Extension to non-Gaussian noise in hyperspectral image is also discussed. Efforts have been made to reduce computational complexity, and all results reported in our paper could be reproduced very efficiently.
The rest of this paper is organized as follows: In Section II, related work is studied. In Section III, general formulation and the proposed denoising method are introduced. Section IV presents experiments on both simulated and real-world datasets. Conclusions are drawn in Section V.
II Related Works and Formulation
II-A Notations
Tensor is a multidimensional array, also known as a multi-way array, and its order is defined as the number of its dimension. In this paper, we mainly adopt the mathematical notations and preliminaries of tensors from [16]. Vectors and matrices are first- and second- order tensors which are denoted by boldface lowercase letters and capital letters , respectively. A higher order tensor (the tensor of order three or above) is denoted by calligraphic letters, e.g., . An th-order tensor is denoted as . The -mode product of a tensor by a matrix , denoted by is also a tensor. The mode- matricization or unfolding of , denoted by , maps tensor elements to matrix element where , with . The Frobenius norm of a tensor is defined as .
II-B Framework and Problem Formulation
The most popular and successful framework credited to [2] follows three consecutive steps: grouping, collaborative filtering and averaging. The flowchart of this paradigm is illustrated as Fig. 1. Specifically, given a reference patch , the grouping step stacks some similar overlapping patches located in a local window into a group represented by matrix or higher order tensor with certain matching criteria [53, 54, 55]. One simple and commonly adopted metric is Euclidean distance measured by , . Collaborative filtering is then performed on group to utilize the nonlocal similarity feature and estimate clean underlying patches from noisy observation, and it can be generally formulated as
[TABLE]
where and are noisy and underlying clean group of patches, respectively, measures the conformity between and , and represents certain priors [56]. Low rank approximation is adopted in [57, 13, 21, 51] based on nuclear norm minimization [58] with , or tensor trace norm [59] with . Authors in [60, 15, 52, 61] utilize sparse coding scheme that represents with a dictionary and sparse coding atoms by minimizing
[TABLE]
The state-of-the-art BM3D and HOSVD algorithms attempt to model sparsity in the transform domain by shrinking coefficients under a pre-defined threshold via
[TABLE]
Some representative techniques and priors are listed in Table I. After collaborative filtering, the estimated clean patches are averagely written back to their original location to further smooth out noise. More specifically, every pixel of the denoised image is the (weighted) average of all pixels at the same position of filtered group , which can be formulated as
[TABLE]
where and denote weight and pixel, respectively.
II-C Multiway filtering technique
In this paper, we focus on the collaborative filtering step with transform domain technique, and regardless of different categorization criteria, it can be roughly modeled as an inverse problem with multiway filtering technique [62], which applies a specific transform and constraint to each dimension of a group of similar image patches. The organization of image patches and choice of transform and constraint often determine the denoising strategy, and the variations are quite extensive [9, 7, 20, 51]. In this subsection we introduce the representative 4DHOSVD and CBM3D for color image denoising, and our analysis can be extended to multispectral image with slight modification. For simplicity, a group of similar patches is denoted by .
Both CBM3D and 4DHOSVD can be represented with the fourth-order tensor decomposition framework in [16] via
[TABLE]
where is core tensor (coefficient), , , , and are corresponding mode transforms. The major difference between CBM3D and 4DHOSVD is that CBM3D uses pre-defined discrete cosine transform (DCT) and opponent color space represented as a matrix
[TABLE]
specifically, the first slice of each patch in the new color space can be regarded as luminance channel, and the other two slices as chrominance channel. CBM3D is very efficient because it does not have to train local transforms, and its grouping step is performed only on the luminance channel. For 4DHOSVD, all mode transform matrices including are learned by solving
[TABLE]
Compared with CBM3D, 4DHOSVD imposes a stronger constraint and requires the orthogonality of color space transform.
III Image Denoising Using Block Diagonal Representation
Using a 4D transform in equation (5) for CBM3D may be a little confusing, because after a certain color space transform, the original R, G, B channels are computed separatedly in the new color space, which also holds for 4DHOSVD if all mode transforms are obtained. Therefore, it may be expected to re-formulate (5) as independent channel-wise (third-order tensor) transform. In this section, we first generalize patch-level representation via block diagonal matrix, then discuss the proper choice for patch-level basis, and explain how it could be properly incorporated into the block diagonal representation and efficiently applied to image denoising.
III-A Block Diagonal Representation and Formulation of f-diagonal Tensor Decomposition
We notice that (5) can be rewritten as
[TABLE]
where is equivalent to applying to each patch of via
[TABLE]
where and represent the number of similar patches and the -th patch of , respectively. For simplicity, we use to denote . Then we could define the block diagonal operator via
[TABLE]
where each matrix on the diagonal position is a linear combination of all frontal slices of via
[TABLE]
according to (9) and (10), can be denoted as an f-diagonal tensor
[TABLE]
where . Based on (8) and (12), the 4D transform (5) is equivalent to
[TABLE]
where we make an abuse use of (10) to denote and as
[TABLE]
The same group representation is applied for all frontal slices in (12) mainly because of two reasons. First, the patch-wise similarity often used in the grouping process does not guarantee slice-wise simialrity. Furthermore, according to equation (11), the new color space are a linear combination of R, G, B channels, thus are not totally de-correlated. Therefore, there exists a trade-off between the slice-wise and patch-wise relationship. Interestingly, CBM3D subtly takes care of this issue by considering only the luminance channel similarity. To narrow such gap, a suitable alternative to utilizing more group-level information (grouping more patches), is the recursive use of patch-level correlation via block circulant representation (BCR) [63].
Specifically, for each patch of color image, its BCR is a block circulant matrix [63] of size defined by
[TABLE]
thus, similar to (12), a block circulant tensor of size can be denoted as
[TABLE]
Fig. 2 gives a straightforward illustration of (15) and (16), and some interesting feature is given in Appendix A.
Following the idea of multiway transform technique in (5) and based on (27), the third-order tensor decomposition of (16) is
[TABLE]
Obtaining two factor matrices and requires the eigenvalue decomposition of two large block circulant matrices. Using fast Fourier transform (FFT) [64], the block circulant tensor decomposition problem in (17) can be re-formulated as following f-diagonal tensor decomposition in the Fourier domain222More details are given in Appendix B.
[TABLE]
Where , and is the FFT matrix defined as
[TABLE]
The conjugate feature of indicates that whichever the threshold technique (low-rank or hard-threshold) is adopted, only the first and second slices in the Fourier domain need to be computed. This strategy can be extended to handle multispectral images by considering only the first slices in the Fourier domain, where is the number of spectral bands.
III-B Equivalence of f-diagonal Tensor Decomposition in the Fourier Domain
In fact, the computation of (18) does not require explicit formulation of f-diagonal tensor in the Fourier domain. We introduce t-SVD or tensor-SVD [65, 66], a new third-order tensor decomposition framework that demonstrates competitive performance in many applications [67, 68, 69]. t-SVD mainly relies on the definition of t-product between two third-order tensors using (10) in the Fourier domain.
Definition 1** (t-product).**
The t-product between two third-order tensor and is an tensor given by
[TABLE]
where and .
The t-SVD of a third-order tensor can be defined as the t-product of three third-order tensor via
[TABLE]
which can be computed as
[TABLE]
with an abuse use of t-product, the core tensor can be obtained by
[TABLE]
where can be computed as the -th mode tensor-matrix product in the Fourier domain. is a third-order tensor with its first frontal slice equal to and other frontal slices equal to . Furthermore, and can be obtained by minimizing a non-local t-SVD (NL-tSVD) problem
[TABLE]
After some threshold technique, the filtered group can be obtained by the inverse transform of (23) via
[TABLE]
III-C Threshold technique
For multiway filtering approaches described in (5), there are roughly two strategies to encourage the sparsity of linear approximation in the transform domain: threshold core tensor (via L0-norm [70], Wiener filter [71, 7], soft- or hard-thresholding [7]), and threshold factor matrices via low rank prior [72]. Directly modeling each mode of 4D data with low rank prior raises two major concerns. First, the possible combination of rank estimation along each mode is extensive, and it risks falling into the unbalance trap introduced in [73]. Briefly, given a 4D group of patches , its first mode unfolding is a skinny matrix , since , then the rank of along the first mode is assumed very low, which risks the loss of more information [73]. To solve these issues, although not explicitly stated, some methods [20, 21] reshape into a third-order tensor by vectorizing its frontal slices, and impose the low rank constraint only to its grouping dimension. We notice that the block matrix representation in (15) may alleviate the unbalance issue, which may further account for the superiority of low rank t-SVD based methods [69, 74]. However, choosing the multi-rank of f-diagonal tensor (12) in the Fourier domain is not easy. In this paper, we adopt the simple hard-thresholding technique to achieve tensor sparsity.
III-D Global basis and local group representation
The presence of noise in the training process could distort the local representation and introduce some unwanted artifacts. Some recent denoising strategies [75, 76] consider information of the whole image and learn a global representation to render more robustness. CBM3D shares the same idea by applying a pre-defined transform for all patches. t-SVD is also a suitable alternative as a global basis because it preserves the spatial information, and the pre-defined FFT transform along the third mode could make it less sensitive to the variation of noise. The global patch representation can be trained with randomly sampled patches, but for simplicity, all the reference patches are used.
If the patch representation is acquired, then grouping and collaborative filtering could be viewed as a feature extraction and patch classification process that takes care of nonlocal similarity. Therefore, some simple and effective classification method such as PCA can be utilized. We term the combination of global t-SVD basis and local PCA transform as ’multispectral t-SVD (MSt-SVD)’, and detailed implementation is given in Algorithm 1 and Fig. 3. Comparing the FFT matrix in (19) and the opponent color mode transform matrix of CBM3D in (6), it can be seen that the first slice in the Fourier domain corresponding to the first row of can be regarded as luminance channel, thus similar to CBM3D, the grouping process and the training of local PCA can be performed by considering only the first slices of all patches in the Fourier domain. Obviously, this implementation can save computational time on grouping and training. This efficient modification of MSt-SVD for color image is termed ’color MSt-SVD’ (CMSt-SVD), and its implementation is briefed in Algorithm 2.
Interestingly, the relationship among nonlocal t-SVD, CBM3D and 4DHOSVD is therefore established using block diagonal representation in the Fourier domain.
III-E Computational complexity
In this subsection, we compare the computational complexity of CBM3D, 4DHOSVD and the proposed MSt-SVD. For simplicity, we assume that the number of image pixels is , that the average time to compute similar patches per reference patch is , that the average number of patches similar to the reference patch is , and that the size of the patch is (). According to [7], the time complexity of 4DHOSVD and CBM3D are and , respectively. The computational burden of MSt-SVD mainly lies in the PCA transform and patch level t-SVD transform , leading to a total complexity of . Considering that MSt-SVD is a one step algorithm and does not require the training of patch level transform for each group, it is competitive in terms of efficiency.
IV Experiments
In this section, we evaluate the performance of MSt-SVD and CMSt-SVD for color image and multispectral image denoising. All the results of compared methods are obtained by fine-tuned parameters or from the authors’ papers. All the experiments are performed on a moderate laptop equipped with Core(TM) i5-8250U @ 1.8 GHz and 8GB RAM. Our software package is publicly available333https://github.com/ZhaomingKong, which includes a fast C++ mex-function that could help reproduce all our results of color image and multispectral image denoising within 10 and 100 seconds, respectively.
IV-A Experimental setting for color image
A brief description of four publicly available real-world datasets is listed in Table II, and more detailed information is in [43] and [46].
The representative compared methods for color image denoising include: CBM3D [9], 4DHOSVD1 (hard-thresholding) [7], WTR1 [51], Neat Image (NI), TNRD [77], GID [32], MCWNNM [13], TWSC [15], LSCD [78], and LLRT [21]. Three representative neural network based methods MLP [37], DnCNN [38] and FFD-Net [40] are also included in our comparison. Considering the computational complexity of some compared methods and for fair comparison, all methods are tuned to produce their best average results, and the input noise level of some Gaussian denoisers is listed in Table III. In practical implementation, however, should be tuned for every image, so to better understand the effectiveness of state-of-the-art CBM3D, the best result of CBM3D on every image is reported, and this implementation is termed ’CBM3D_best’. PSNR and SSIM indices are employed for objective evaluation.
IV-B Experimental results for color image
IV-B1 Experiments on CC15
The fine-tuned results of TNRD, MLP and DnCNN in [13] are used. PSNR result of every image and average computational time are listed in Table IV444CBM3D and LSCD use a C++ mex function, while other methods are implemented purely with Matlab., and visual evaluations are given in Fig. 4 and Fig. 5. Table IV shows that the simple CMSt-SVD consistently outperforms MSt-SVD and 4DHOSVD1, and both MSt-SVD and CMSt-SVD are able to produce very competitive performance in terms of both effectiveness and efficiency. Fig. 4 shows that the representative low-rank based method LLRT and the sparse coding scheme TWSC produce satisfactory results in homogenous regions, because the underlying clean patches share much similar feature, and thus can be modeled as a low-rank or sparse coding problem. But as illustrated in Fig. 5, when the ground truth image contains more details or local variations, clear over-smooth effects can be observed. Interestingly, the state-of-the-art neural network FFD-Net shows similar effects. Besides, compared with CBM3D and CMSt-SVD, the local 4DHOSVD transform is more easily affected by the presence of noise, which is incorporated in the training process of color mode transform.
IV-B2 Experiments on CC60, Xu-100 and our datasets
Table V and VI list the average PSNR and SSIM values of several competitive methods. It is obvious that CMSt-SVD still demonstrates one of the best performance. Our visual evaluations in Fig. 6 and Fig. 8 further illustrate the over-smooth effects of the sparse coding scheme and state-of-the-art neural network, while Fig. 7 shows that many competitive methods including NI, 4DHOSVD, MCWNNM and GID produce color artifacts to some degree, which is similar to our observation in Fig. 4.
IV-B3 Visual evaluation on dnd dataset [42]
The ground truth images of this dataset is not available, so we choose one severely corrupted image that contains lines, smooth regions, color texture and details. The input noise level of MSt-SVD555An efficient tool is available at github.com/ZhaomingKong/Pure_Image and CBM3D is tuned to achieve the best possible visual effects, and about is used for both MSt-SVD and CBM3D. Also, the parameters of commercial software Neat Image are carefully chosen to compare their difference. Fig. 9 shows the visual comparison. Unfortunately, all compared methods introduce unwanted artifacts. Neat Image presents the best results at line areas, while MSt-SVD produces sharper details with the green color uniformly distributed. The benchmark CBM3D with predefined transforms seeks a balance between details and smoothness.
IV-C Experimental setting for multispectral image
The representative compared methods for multispectral image denoising include: LRTA [19], PARAFAC [79], 4DHOSVD1, LLRT, BM4D [47], TDL [80], ISTReg [81], LRMR [82] and Nmog [35].
Four quality indices are employed for multispectral image: PSNR, SSIM, ERGAS [83] and SAM [84]. EGRAS and SAM are spectral-based evaluation indices, and the smaller EGRAS and SAM values are, the better the restored images are.
Three publicly available datasets are used: Columbia Multispectral Dataset (CAVE)666www1.cs.columbia.edu/CAVE/databases/multispectral for simulated experiments, Harvard Hyperspectral Dataset (HHD)777vision.seas.harvard.edu/hyperspec/index.html [45] and Urban888www.tec.army.mil/hypercube dataset for the real cases.
IV-D Experimental results for Multispectral image
IV-D1 i.i.d. Gaussian Noise
The whole CAVE database consisting of 32 hyperspectral images is used in our synthetic tests. The images of size are captured with the wavelengths in the range of 400-700 nm at an interval of 10 nm. In this experiment, entries in all slices were corrupted by zero-mean i.i.d Gaussian noise with . Since LRMR and ISTReg require much more memory space, their results are copied from [13]. Detailed results are listed in Table VII, visual effect comparison is given in Fig. 10. It can be seen that the recursive use of patch level information by MSt-SVD may better preserve details.
IV-D2 non i.i.d. Gaussian Noise
Entries in all slices were corrupted by zero-mean Gaussian noise with increasing intensity from 21 to 51, and for fair comparison, the input noise level for all compared methods is taken as the average number 36. The detailed results and visual evaluations are given in Table VIII999BM4D uses a C++ mex-function with parallel implementation and TDL uses some mature toolboxes. and Fig. 11, respectively. Comparing Table IV and Table VIII, it is interesting to see that compared with 4DHOSVD, MSt-SVD is faster in dealing with color images but slower in multispectral images, this is because the for-loop of Matlab slice-by-slice computation in the Fourier domain is slow, and our C++ mex-function can reduce the total time to 1.5 minutes.
IV-D3 Experiments on HHD data
There are 50 images of size , and some of them are clearly contaminated by noise. Considering the large size of noisy images, we mainly examine the effectiveness of MSt-SVD on handling real multispectral image, and compare it with the efficient benchmark TDL. The input noise level is manually tuned for both TDL and MSt-SVD to balance smooth effects and details, and is used for MSt-SVD to save some time. Visual evaluation is given in Fig. 12, and the artifacts produced by TDL can be seen in Fig. 12(e) and Fig. 12(k).
IV-D4 Experiments on Urban HSI data
The full Urban dataset of size is used, and some of the bands are contaminated by stripe noise in Fig. 13(a) and Fig. 14(a). As illustrated in 13(b), naively applying MSt-SVD fails to remove stripe noise. In fact, the influence of the sparse stripe noise may be amplified by recursively computing the row- and column-wise relationship. According to (27), the use of block representation (15) does not change the group level representation, thus the influence of stripe noise could be attenuated by adopting sparsity in the grouping dimension. Specifically, we first reshape the original data as a new image of size , such that stripe noise sparsely spread along the grouping dimension, and then apply MSt-SVD to the new data, the final filtered image is obtained by reshaping it back to the original size. We term this simple operation ’twist MSt-SVD’ and notice that it does not increase computational burden. Since many compared methods can not handle the stripe noise [35], we use the benchmark Nmog for visual effects comparison. Fig. 13(d) and Fig. 14(c) demonstrate the effectiveness of the twist implementation. Considering its efficiency, its performance may be improved by further modeling of tensor sparsity [70].
IV-E Choice of parameters
Among all free parameters, the hard-threshold parameter directly controls the core tensor sparsity in the transform domain, so we mainly investigate how could influence the proposed MSt-SVD and choose , and = 30 according to the settings of 4DHOSVD in [7]. For 4DHOSVD in [7], the authors set based on [85] for their simulated experiments on Kodak gallery101010http://r0k.us/graphics/kodak/, where is the number of elements of a patch group. But we observe that it is chosen too large to provide over-smooth effects, so we multiply with a scale factor , and tune the averagely best PSNR value using the first 8 images of Kodak gallery. Fig. 15 shows the influence of on both 4DHOSVD and MSt-SVD, and the choice of parameters is detailed in Table IX. Fig. 16 gives an illustration of the influence of with Brodatz color texture111111http://multibandtexture.recherche.usherbrooke.ca/colored_brodatz_more.html. In real cases, the tuning of for MSt-SVD is efficient because some intermediate results can be preserved to avoid the recursive computation of grouping and local PCA transform.
V Conclusion
In this paper, we build the relationship among state-of-the-art transforms with block diagonal representation, and investigate the proper choice of patch level transform. According to our discussion and analysis, two simple and effective methods that combine a global t-SVD basis and local PCA transform are proposed. The proposed MSt-SVD and CMSt-SVD utilize more spatial information, and produce competitive performance with state-of-the-art filters in terms of both efficiency and effectiveness. Recently, some statistical properties of tensor decomposition [86] are studied, it is interesting to investigate a further understanding of both color image and multispectral image denoising with block diagonal representation. Besides, our future research also includes classification [87] and related image restoration problems [88].
Appendix A Some Features Related To Block Circulant Representation (15)
Theorem 1**.**
* is also a block circulant matrix.*
Theorem 2**.**
Two patches and are similar if and only if and are similar. More specifically,
[TABLE]
Theorem 3**.**
Given a group of similar patches , and its block circulant tensor representation in (16). If and are the last mode factor matrix of and , respectively, then
[TABLE]
The proof of above Theorem is not hard by checking corresponding definition. Theorem 1 offers an efficient implementation to compute product between a block circulant matrix and its transpose. Theorem 26 and Theorem 27 indicate that nonlocal similarity and linear representation do not change after block circulant operation.
Appendix B Re-formulation of Block Circulant Tensor Decomposition In The Fourier Domain
Theorem 4**.**
[64]** Given a patch and its block circulant representation in (15), there exists an orthogonal matrix that could transform into a block diagonal matrix via
[TABLE]
where represents the kronecker product, and , . Furthermore, according to the orthogonality, we have
[TABLE]
Acknowledgment
The authors would like to thank all the reviewers for their valuable comments, and appreciate all the authors for sharing their code and software package.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] P. Milanfar, “A tour of modern image filtering,” IEEE Signal Process. Mag. , vol. 30, no. 1, pp. 106–128, 2011.
- 2[2] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-d transform-domain collaborative filtering.” IEEE Trans. Image Process. , vol. 16, no. 8, pp. 2080–2095, 2007.
- 3[3] A. Buades, B. Coll, and J. M. Morel, “A review of image denoising algorithms, with a new one,” Multisc. Model. Simulat. , vol. 4, no. 2, pp. 490–530, 2005.
- 4[4] L. P. Yaroslavsky, K. O. Egiazarian, and J. T. Astola, “Transform domain image restoration methods: review, comparison, and interpretation,” Proceedings of SPIE - The International Society for Optical Engineering , pp. 155–169, 2001.
- 5[5] K. Dabov, A. Foi, and K. Egiazarian, “Video denoising by sparse 3d transform-domain collaborative filtering,” in Proc. Eur. Conf. Signal Process. , Sep. 2007, pp. 145–149.
- 6[6] S. Gu, L. Zhang, W. Zuo, and X. Feng, “Weighted nuclear norm minimization with application to image denoising,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR) , 2014, pp. 2862–2869.
- 7[7] A. Rajwade, A. Rangarajan, and A. Banerjee, “Image denoising using the higher order singular value decomposition,” IEEE Trans. Pattern Anal. Mach. Intell. , vol. 35, no. 4, pp. 849–862, 2013.
- 8[8] R. Yan, L. Shao, and Y. Liu, “Nonlocal hierarchical dictionary learning using wavelets for image denoising,” IEEE Trans. Image Process. , vol. 22, no. 12, pp. 4689–4698, 2013.