Guessing random additive noise decoding with symbol reliability information (SRGRAND)
Ken R. Duffy, Muriel M\'edard, Wei An

TL;DR
This paper introduces SRGRAND, a universal decoding scheme that uses symbol reliability information to improve decoding performance for various codes, especially in low-latency applications.
Contribution
It develops a novel universal decoding algorithm incorporating soft symbol reliability, with two decoding methods and analysis of error exponents and complexity.
Findings
SRGRAND outperforms hard detection methods in simulations.
The algorithms achieve near-ML performance for random codes.
Error exponents and complexity bounds are established for the proposed methods.
Abstract
The design and implementation of error correcting codes has long been informed by two fundamental results: Shannon's 1948 capacity theorem, which established that long codes use noisy channels most efficiently; and Berlekamp, McEliece, and Van Tilborg's 1978 theorem on the NP-hardness of decoding linear codes. These results shifted focus away from creating code-independent decoders, but recent low-latency communication applications necessitate relatively short codes, providing motivation to reconsider the development of universal decoders. We introduce a scheme for employing binarized symbol soft information within Guessing Random Additive Noise Decoding, a universal hard detection decoder. We incorporate codebook-independent quantization of soft information to indicate demodulated symbols to be reliable or unreliable. We introduce two decoding algorithms: one identifies a conditional…
Click any figure to enlarge with its caption.
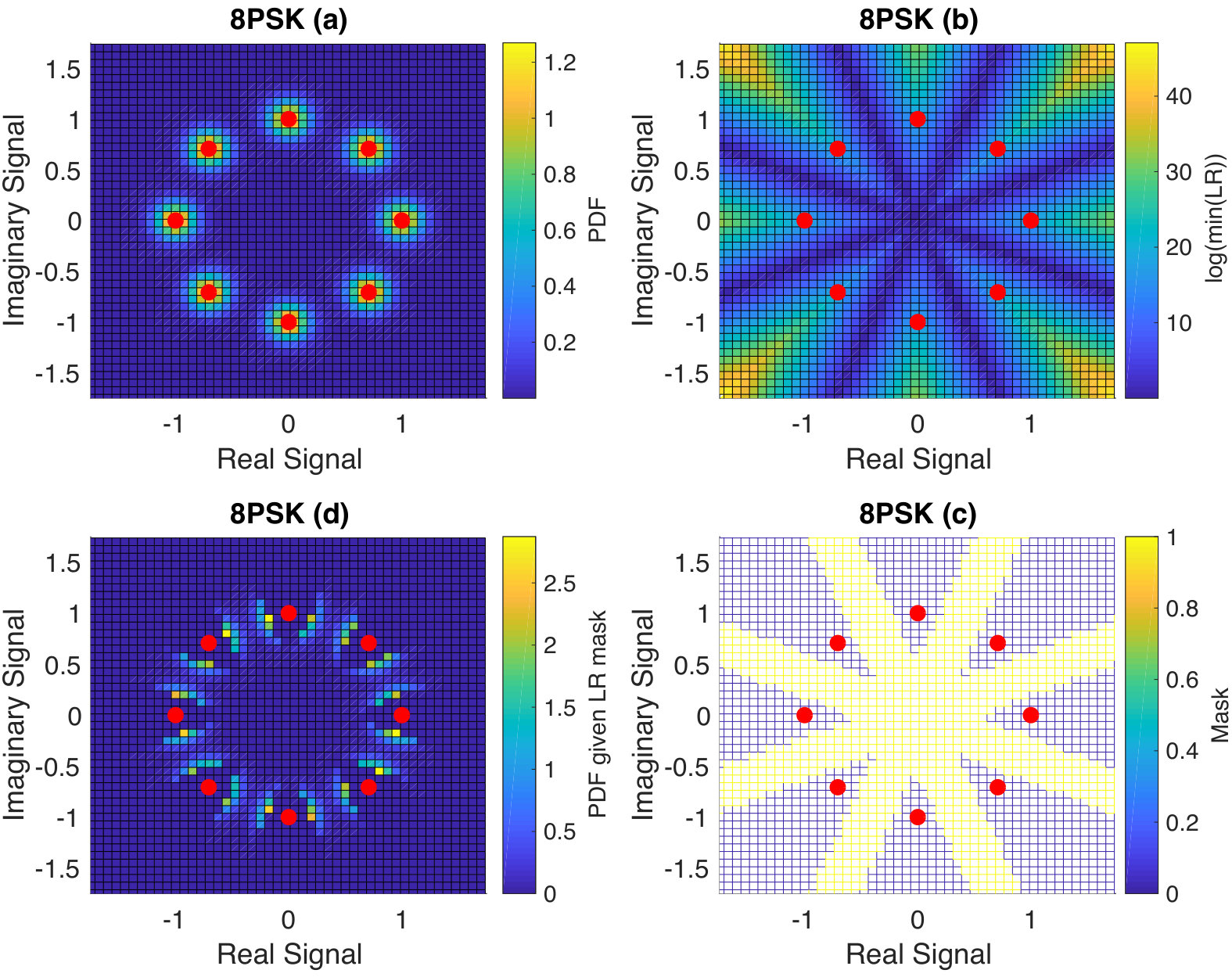 Figure 0
Figure 0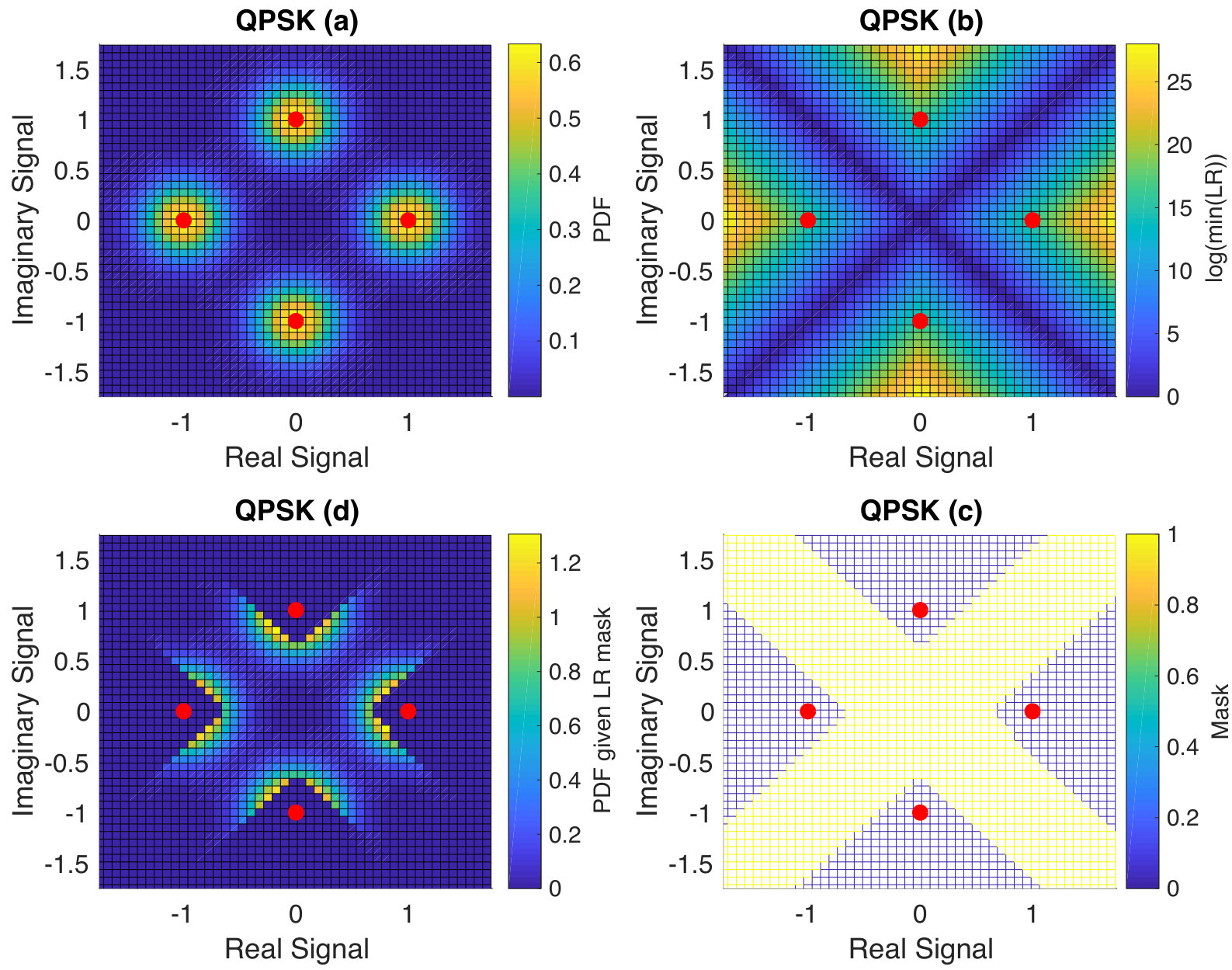 Figure 0
Figure 0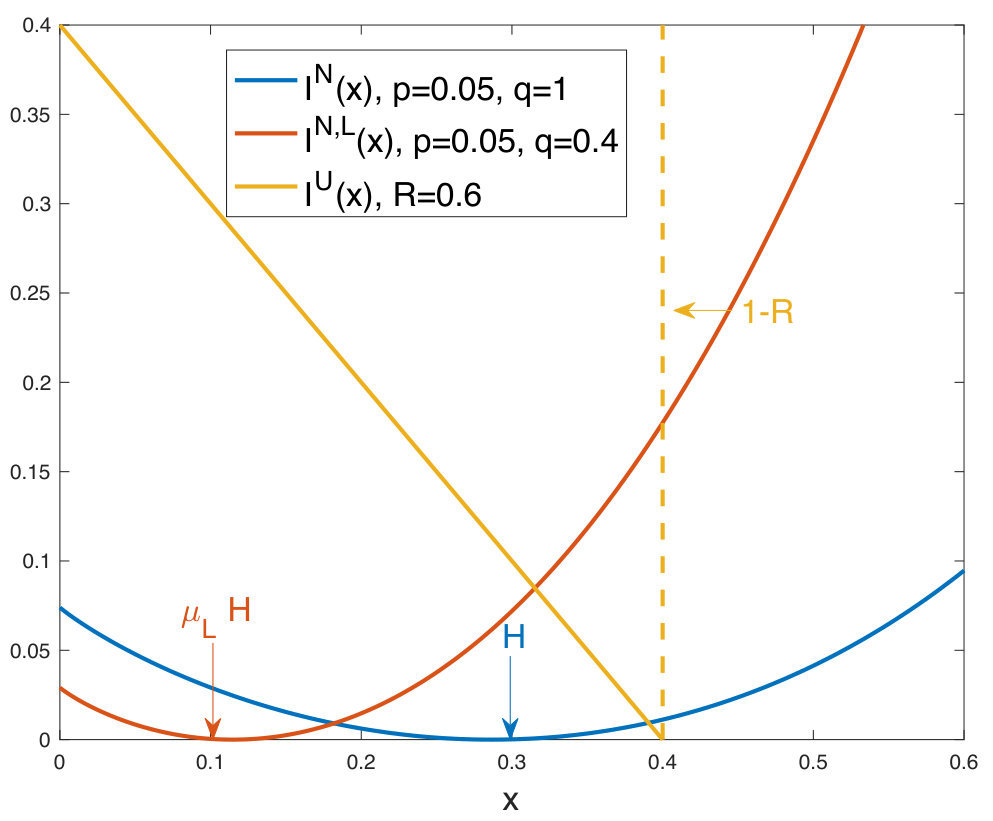 Figure 1
Figure 1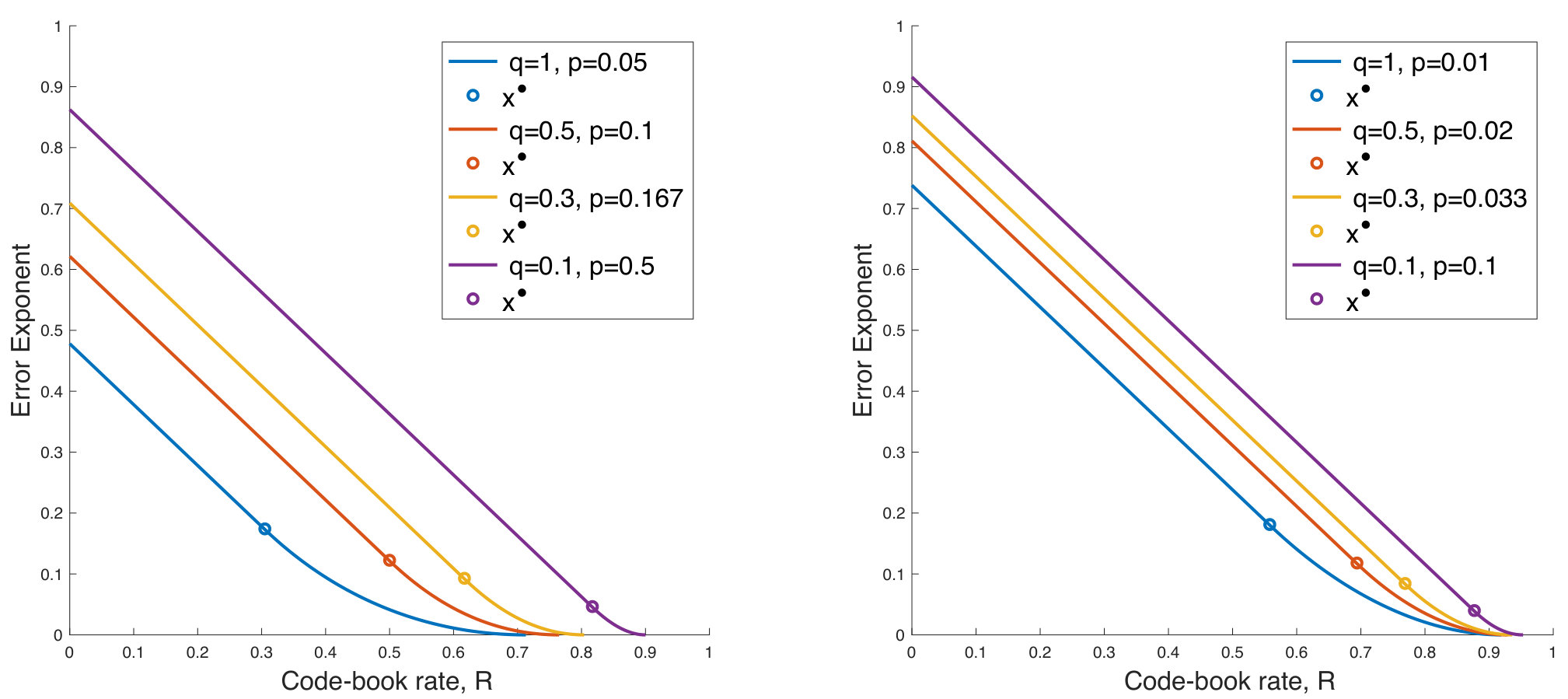 Figure 4
Figure 4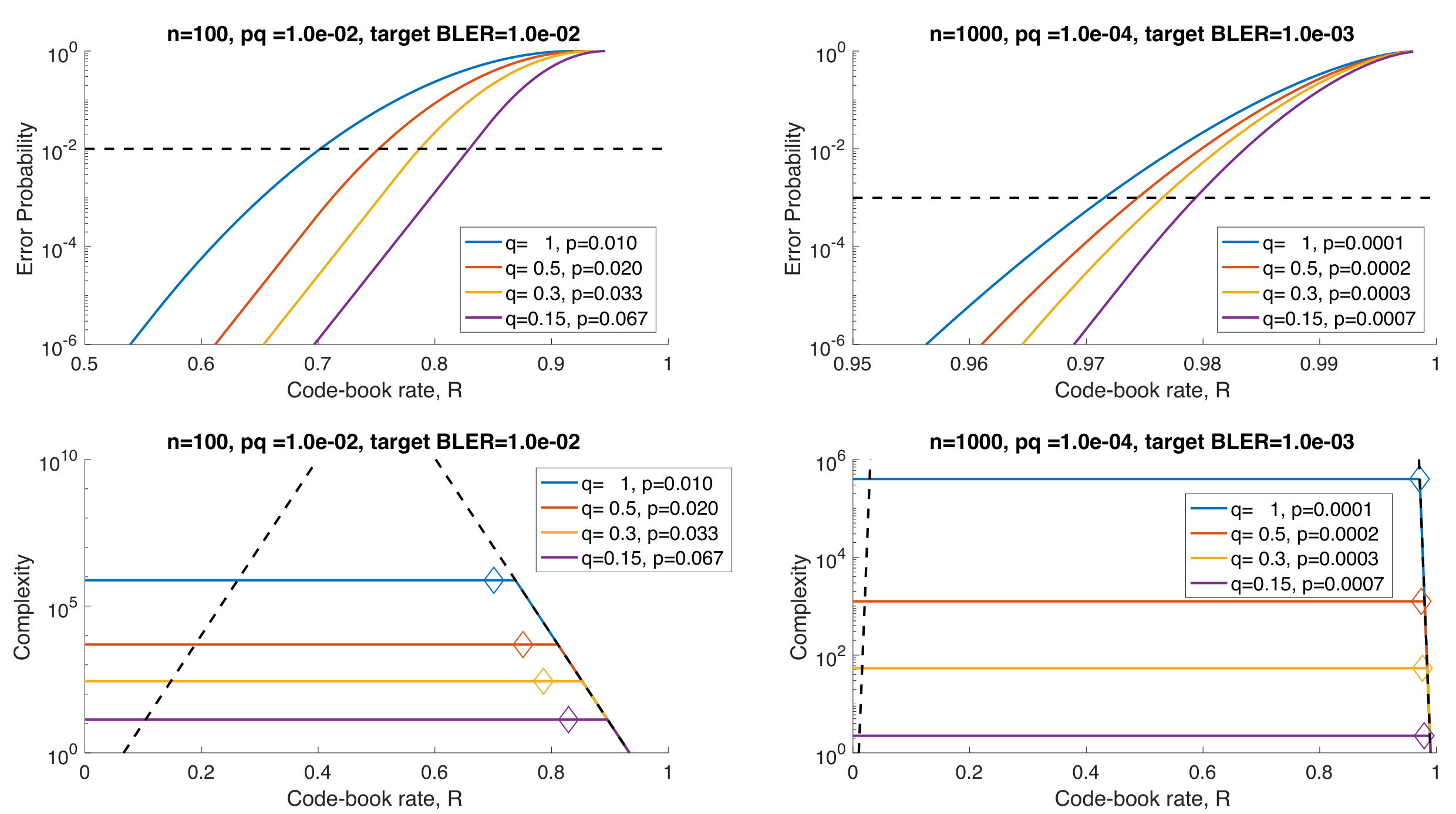 Figure 5
Figure 5 Figure 6
Figure 6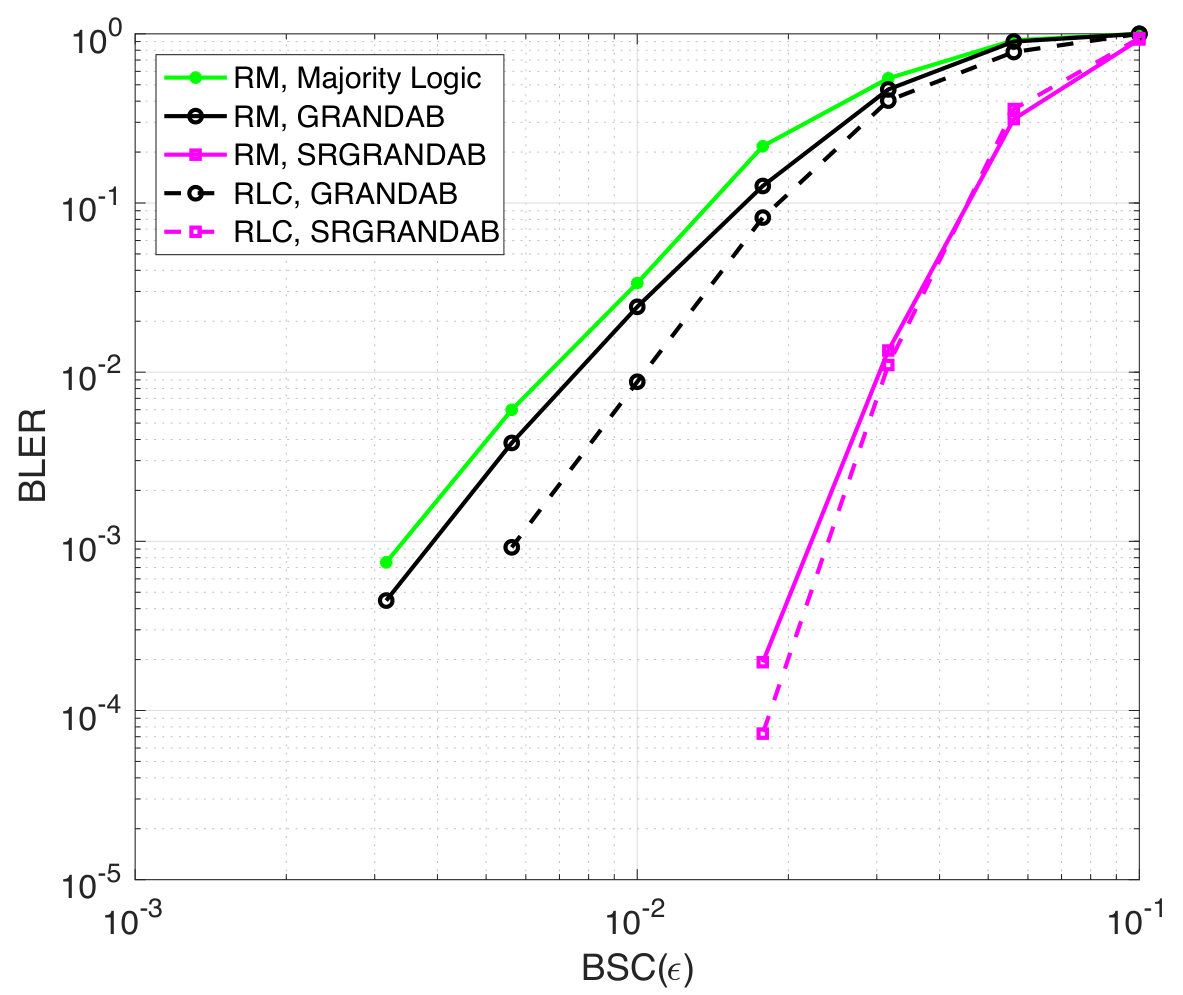 Figure 6
Figure 6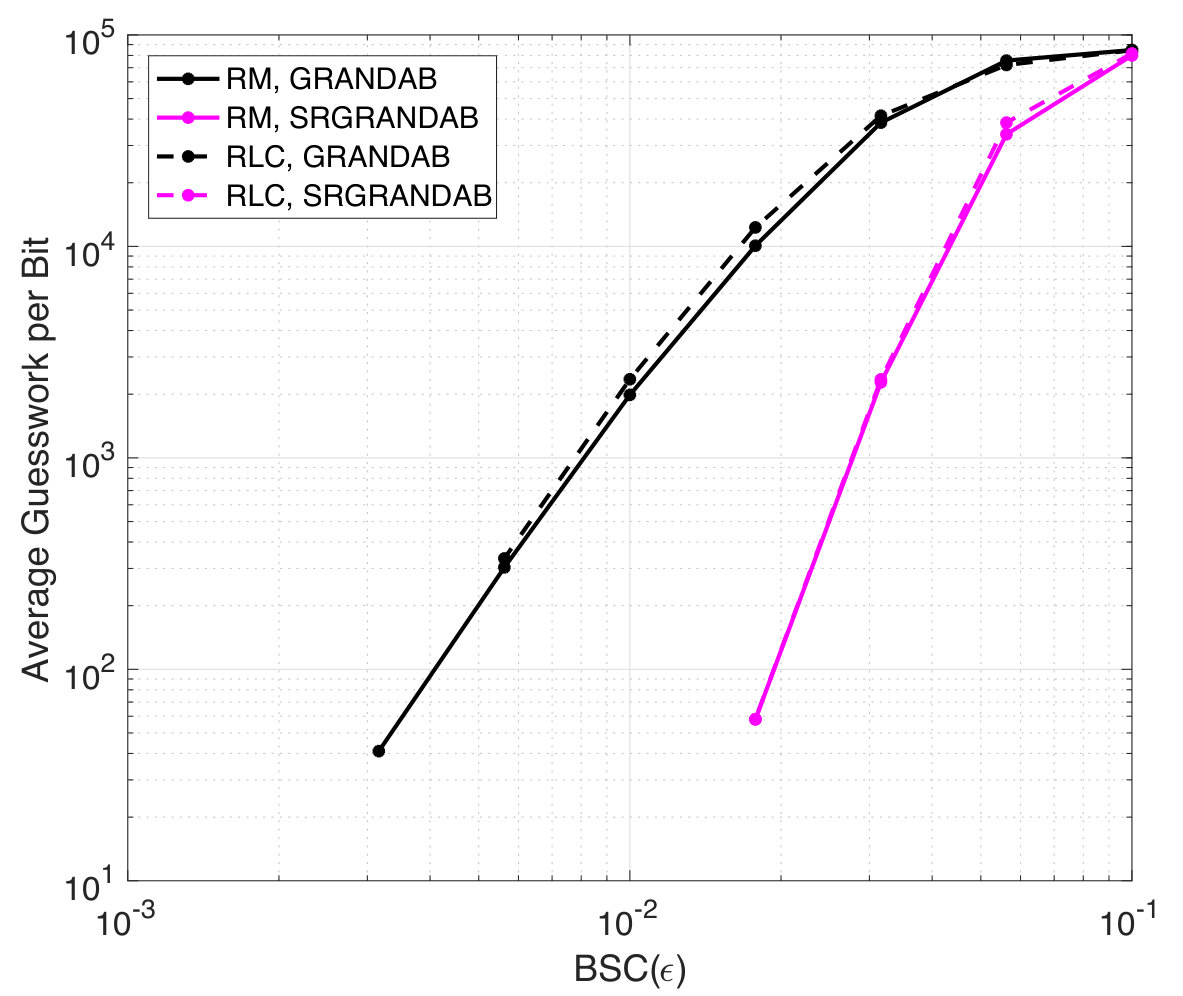 Figure 6
Figure 6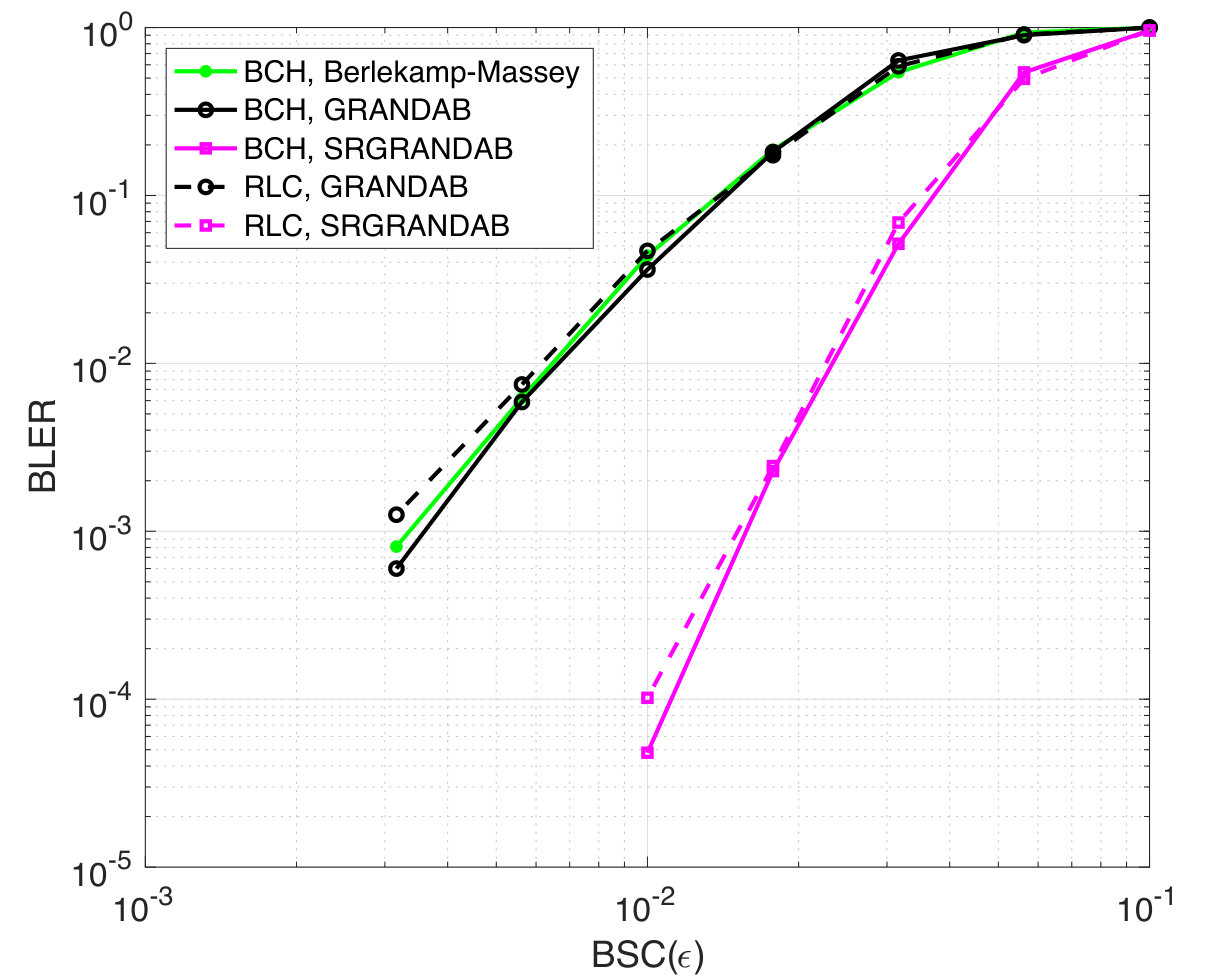 Figure 7
Figure 7 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Guessing random additive noise decoding with symbol reliability information (SRGRAND)
Ken R. Duffy1, Muriel Médard2 and Wei An2
1Hamilton Institute, Maynooth University, Ireland. E-mail: [email protected].
2Research Laboratory of Electronics, Massachusetts Institute of Technology, U.S.A. E-mail: [email protected], [email protected].
Abstract
The design and implementation of error correcting codes has long been informed by two fundamental results: Shannon’s 1948 capacity theorem, which established that long codes use noisy channels most efficiently; and Berlekamp, McEliece, and Van Tilborg’s 1978 theorem on the NP-hardness of decoding linear codes. These results shifted focus away from creating code-independent decoders, but recent low-latency communication applications necessitate relatively short codes, providing motivation to reconsider the development of universal decoders.
We introduce a scheme for employing binarized symbol soft information within Guessing Random Additive Noise Decoding, a universal hard detection decoder. We incorporate codebook-independent quantization of soft information to indicate demodulated symbols to be reliable or unreliable. We introduce two decoding algorithms: one identifies a conditional Maximum Likelihood (ML) decoding; the other either reports a conditional ML decoding or an error. For random codebooks, we present error exponents and asymptotic complexity, and show benefits over hard detection.
As empirical illustrations, we compare performance with majority logic decoding of Reed-Muller codes, with Berlekamp-Massey decoding of Bose-Chaudhuri-Hocquenghem codes, with CA-SCL decoding of CA-Polar codes, and establish the performance of Random Linear Codes, which require a universal decoder and offer a broader palette of code sizes and rates than traditional codes.
Keywords: Universal decoding, symbol reliability information, random codes.
I Introduction
††footnotetext: A subset of these results was presented at the 2019 IEEE International Symposium on Information Theory, Paris, France, [1] and at the 2020 Annual Conference on Information Sciences and Systems, Princeton, USA [2]. In this article lower case letters correspond to realizations of upper-case random variables or their normalized limits, apart from for noise where is used as denotes the code block-length. Logs are taken base throughout, and we assume that corresponds to no noise.
Since Shannon’s 1948 opus [3] it has been known that channel capacity, the highest rate that an error correcting code can operate at while guaranteeing error-free communication over a noisy channel, is governed by the Shannon entropy of the channel’s noise. By considering structureless random codes, his mathematical results proved that channel capacity is only achievable in the limit as the length of the error correcting code becomes large. By 1968, it was confirmed that his core theorems hold if structureless random codes are replaced with Random Linear Codes (RLCs) [4], which offer a more efficiently stored codebook description. In 1978, however, Berlekamp, McEliece, and Van Tilborg reported that maximum likelihood (ML) decoding of linear codes is an NP-complete problem [5], establishing that there exists a sequence of linear codes for which the decoding complexity is exponential as a function of block length. This feature, which underpins the McEliece cryptosystem [6], effectively halted practical consideration of universal decoding algorithms, with a couple of notable exceptions recounted in the Related Work.
The focus on long codes led to a working paradigm of pairing structured codes and code-specific decoders. Examples of such pairings are Reed-Muller (RM) codes [7, 8] with Majority Logic decoding, Reed-Solomon codes [9] with Berlekamp-Massey (BM) decoding [10, 11, 12], Low Density Parity Check Codes (LDPCs) [13] with belief propagation decoding [14], and, most recently, CRC-Assisted Polar (CA-Polar) codes, used in control channel communications in 5G New Radio (NR), with CRC-Assisted Successive Cancellation List (CA-SCL) decoding [15, 16, 17]. The structured nature of these codes leads to restrictions on lengths and rates. They are usually constructed based on the assumption of independent and identically distributed noise, which is then approximated through significant interleaving, with attendant delays. From an implementation point of view, distinct hardware is required for each code-decoder pair, and sometimes for different rates of the same code-decoder pair.
Many current communication systems require low-latency operation, where small bursts of data need efficient transmission [18, 19, 20]. Indeed, ultra-reliable low-latency communication (URLLC) is an important use-case in the 5G NR standard [21, 22]. Delivering URLLC necessitates efficient decoding of short, high-rate codes, motivating revisiting the possibility of high-accuracy universal decoders. Guessing Random Additive Noise Decoding (GRAND) [23, 24, 25], first proposed in 2018 for hard detection channels, is a class of decoding algorithms that can decode any code. GRAND’s practical promise as a single efficient mechanism for any moderate redundancy code is such that circuit-based implementations have already been investigated [26, 27, 28] that avail of the inherent high level of parallelizability of the algorithm. That work demonstrates GRAND’s performance credentials in hard detection channels, such as data storage system applications or communication systems with only hard detection demodulation.
GRAND’s universal premise is that for a communication to be decodable the received signal must faithfully contain information regarding the transmitted code-word and the error effect of the noise experienced on the channel. While most decoding algorithms utilize the codebook’s structure to identify the transmitted code-word, GRAND endeavors to find the effect of the noise and so recover the transmitted code-word. To do this, it requires two devices: a method by which to query if a string is an element of the codebook; and a mechanism to sequentially create putative noise-effect sequences in decreasing order of their likelihood of occurrence on the channel. Armed with these, GRAND aims to produce an error corrected decoding for any block code, without restriction to binary or, indeed, linear codes.
Pseudo-code for GRAND can be found in Algorithm 1, where the key step is “ next most likely noise effect sequence”. In the work that introduced GRAND the decoder only had access to a statistical description of the channel and hard-detection information. In that setting, GRAND provides ML decoding so long as the ordering of the putative noise effects matches the statistical description of the channel, even for channels with temporal noise correlations [24]. For standard models of hard detection noise effects from a highly interleaved channel or one subject to Markovian burst errors without an interleaver, dynamically creating putative noise effects is possible with simple logic [25]. That putative noise effects can be readily generated in parallel has been exploited in published hardware implementations of GRAND that perform multiple codebook membership queries per clock-cycle [26, 27, 28].
Incorporating soft information from per-realization measurements of received signals is known to be able to improve decoding significantly [29], but it is unclear how to do so with GRAND. It seems fraught at first blush as soft information seeks to represent continuous observations at the receiver, while GRAND searches over a collection of discrete noise effects on demodulated signals. A naïve approach, in which fine quantization of noise leads to guessing over a larger space of possible noise realizations, is inherently undesirable from a complexity perspective.
Here we consider the problem of incorporating binary symbol reliability information to GRAND where soft information per received symbol is limited to a single bit to indicate whether a demodulated symbol has been demodulated with confidence or not. Analysis of the resulting schema, Symbol Reliability GRAND (SRGAND), results in: a universal ML decoder conditioned on one bit of symbol reliability information per received symbol; simulated performance for established linear codes and for RLCs, which exist at all lengths and rates and have theoretically desirable properties [30], but require a universal decoder; the mathematical evaluation of SRGRAND’s complexity, showing an improvement vis-à-vis GRAND; error exponents for conditional ML decoding in the presence of a single bit of symbol reliability, and success exponents for the likelihood of correct decoding when the code-rate exceeds capacity.
II Symbol reliability.
Essentially all digital communications involve taking discrete data, channel coding them to add robustness to noise, and then modulating those digital data into signals suitable for transmission and reception. For example, Phase Shift Keying (PSK), widely used in wireless communications systems, encodes groups of binary data into one of a finite set of phases of a carrier signal. To avail of better channel conditions in practice, not only is the codebook rate increased, but a modulation with a larger number of bits per modulated symbol is also employed. An illustration of Quadrature PSK (QPSK) is provided in Fig. 1. With transmitted symbols indicated by the red dots, assuming all symbol transmissions are equally likely and they are disturbed by independent additive Gaussian channel noise (AWGN), the probability density of a received signal being observed is indicated by the heat maps in Fig. 1 (a). Hard detection demodulation maps each received signal to the nearest potentially-transmitted symbol. One metric of confidence that a hard demodulated symbol corresponds to the transmitted one is the minimum across all possible alternate symbols of the Likelihood Ratio (LR) that a received signal was observed given the hard detection symbol was transmitted as compared with the alternate. The resulting LR surface is depicted in Fig. 1 (b). Instead of solely reporting the hard detection output, we envisage a further codebook independent quantization of the received signal into a symbol reliability indicator that separates reliably received symbols from unreliable ones. The principle behind the approach is illustrated in Fig. 1 (c) where a thresholding of the LR results in a masked region such that if a signal is received within that region, the hard detection demodulated symbol is flagged as being unreliable. The probability density of receiving a signal conditional on being in the masked region of potentially noise-impacted symbols is shown in Fig. 1 (d). Thus, the uncertainty region corresponding to the potentially noise-impacted symbols serves as a mask that labels received symbols whose values are questionable, enabling the decoder to focus on them. As the GRAND approach is codebook independent and noise-centric, we establish that we can incorporate symbol reliability information in a way that results in reduced complexity.
Our mathematical abstraction of this reliability information assumes that symbols received from the channel have been accurately indicated to be error free or to have possibly been subjected to independent additive random noise. SRGRAND then provides an ML decoding conditioned on the mask that was provided. In practice, creation of this symbol reliability information corresponds to a situation where soft information, such as instantaneous Signal to Interference plus Noise Ratios (SINR), has been thresholded so as to provide false negatives with a sufficient small likelihood that poor masking, i.e. incorrect identification of potentially noise-impacted symbols, does not dominate the block error probability. In effect, this symbol reliability information is a codebook-independent quantization of soft information [31]. In Section VII, using a simple threshold rule, for an additive white Gaussian noise channel we empirically find that the provision of symbol reliability information results in a 0.75 to 1 dB gain over optimal ML hard detection decoding, even when the symbol reliability information is potentially erroneous.
III Guessing Random Additive Noise Decoding
The contribution of the current article is to identify how to incorporate symbol reliability information into the GRAND approach, and the ensuant increased capacity, reduced block error probability, and decreased complexity. We assume that, as well as being in receipt of a channel output, , the receiver is provided with a vector of symbol reliability information, taking values in where a [math] truthfully indicates a symbol has not been subject to noise while a indicates it may have been. This model is similar in spirit to the well-known Gilbert-Elliott model [32, 33], although our results will hold for channel state process that have more involved correlation structures than Markovian. The core idea is that the vector be used as a mask that separates symbols that require guessing, since they are potentially noise-impacted, from those that do not.
III-A GRAND
Consider a hard-detection channel with inputs, , and outputs, , consisting of blocks of symbols from a finite alphabet . Assume that channel input is altered by random noise effects, , that are independent of the channel input and also take values in . Assume the function, , describing the channel’s action, is invertible so that knowing the output and input the noise can be recovered:
[TABLE]
In the hard detection setting, the receiver is solely provided with the discrete channel output .
Assuming code-words are selected uniformly at random, to implement ML decoding, the sender and receiver first share a codebook consisting of elements of . For a given channel output , denote the conditional probability of the received sequence given the transmitted code-word was by for . The ML decoding is then
[TABLE]
For hard detection, the principle underlying the algorithms in [23, 24] is to focus on identifying the noise that was experienced in the channel rather than directly trying to identify the transmitted code-word. Based on a statistical model of the symbol-level channel, the receiver achieves this by first rank-ordering noise sequences from most likely to least likely, breaking ties arbitrarily. In that order, the decoder sequentially queries whether the sequence that remains when the effect of the putative noise is removed from the received signal is an element of the codebook. The first instance where the answer is in the affirmative is the decoded element. To see that GRAND corresponds to ML decoding for channels described in Eq. (1), note that, owing to the definition of in Eq. (2),
[TABLE]
Irrespective of how the codebook is constructed, by sequentially subtracting noise sequence effects from the received sequence in order from the most likely to least likely and querying if it is in the codebook, the first identified element is a ML decoding. GRAND can be thought of as a guessing race where the querying process is halted either with success on identifying the true noise, and hence the transmitted code-word, or with an error on identifying a non-transmitted element of the codebook [24]. The second algorithm considered in [24], GRANDAB (GRAND with ABandonment), follows the same procedure as GRAND, but abandons noise guessing and declares an error if more than queries have been made, where is the Shannon entropy rate of the noise and is arbitrary. If more than queries are needed to identify a ML decoding, then the noise has been sufficiently unusual that, in query number terms, it is beyond the Shannon typical set. As a result, the block-error rate cost of abandoning is asymptotically negligible. Note the conditional likelihood that a ML decoding is in error increases as the number of queries made before identification of a codebook element increases, so one is abandoning a less certain decoding.
III-B SRGRAND
The adaptation of this noise guessing principle to the symbol reliability setting results in a ML decoder conditioned on the veracity of that symbol reliability information. SRGRAND that proceeds as follows:
- •
Given channel output and symbol reliability information , initialize , set the non-noise-impacted symbol locations of guessed noise sequence to [math], and set the masked (i.e. potentially noise-impacted) entries of to be the most likely noise effect sequence of length .
- •
While , increase by and change the masked potentially noise-impacted symbols to be the next most likely noise effect sequence of length .
- •
The that results from this while loop is the decoded element.
Note that SRGRAND can directly co-opt sequential noise pattern generators that were developed for GRAND by restricting their application to masked symbols alone.
Based on the same logic as for GRAND, which has only hard detection information, this procedure identifies a conditional ML decoding in this setting, but, depending on , it will have performed fewer queries than GRAND and the output element is more likely to be the transmitted one, owing to the targeted nature of the querying. While SRGRAND always returns an element of the codebook that is a ML decoding conditioned on the symbol reliability information, the version with abandonment, SRGRANDAB, either provides a conditional ML decoding or returns an erasure. Without impacting the capacity-achieving nature of the decoder, several distinct abandonment thresholds, which can be used in combination, are possible and result in reduced decoding complexity. We comment on two other possibilities in Section VIII, and prove results for one representative rule:
- •
With being the random number of potentially noise-impacted symbols, assuming it exists, let be the long run average proportion of potentially noise-impacted symbols. SRGRANDAB proceeds as SRGRAND, but abandons and declares an error without providing an element of the codebook if more than queries are made, where is the Shannon entropy of the noise for a potentially noise-impacted symbol, and is arbitrary.
This is similar to the GRANDAB abandonment rule, but where enough queries are made to cover the typical set of the average number of potentially noise-impacted symbols.
In Section V we mathematically determine the gain in capacity, reduction in block error rate, and decrease in complexity that can be obtained by leveraging this symbol reliability information within the GRAND approach. The desirable features of GRAND stem from its focus on the noise rather than on the codebook as transmissions that are subject to light noise are quickly decoded, irrespective of the codebook construction or its rate, and these properties are preserved as we incorporate the symbol reliability information. We illustrate the gains to be obtained by considering a worked mathematical example in Section VI and, in Section VII, simulated performance evaluation with Reed-Muller (RM), Bose-Chaudhuri-Hocquenghem (BCH), CA-Polar, and RLC that also treats the possibility of decoding errors due to erroneous masks.
IV Related Work
While the vast majority of codes and decoding systems, including all those currently used in practice, are co-designed, a few universal decoders have been developed. The original ML decoder works by computing the conditional probability of the received signal for every element of the not-necessarily-linear codebook and selecting the most likely. This approach means it can be used with structureless codes stored in a dictionary, and for channels with memory so long as the decoder has an accurate statistical description of it. This brute force evaluation requires an enormous number of real-valued computations for every received code-word, rendering the approach infeasible for all but the shortest of codes [34]. It is, however, amenable to mathematical analysis and remains of theoretical importance in the provision of performance bounds for an optimal decoder.
Restricting to binary linear codes, universal decoders have been studied for both cryptographical and communications purposes. Finding its roots in Prange’s seminal research [35], Information Set Decoding (ISD) and its variants [36, 37, 38, 39, 40, 41] are randomized algorithms used to assess mathematically the security provided by code-based cryptosystems as the code becomes long. The core cryptographic scenario essentially maps to memoryless hard detection channels. Given a binary linear code-word and a received hard detection communication that has been subject to a known number of flipped bits, for each demodulated binary output the basic version of ISD works in two iterated steps until a decoding is found. The first is a transformation where the columns of the binary parity check matrix are randomly permuted and Gaussian elimination is performed to rewrite the code in systematic format. In the second step, for a number of columns that is less than the code’s correction capability, the difference between the syndrome and all linear combinations of that number of columns is evaluated. Once this difference is found to be the zero vector, the Gaussian elimination transformation is inverted to identify the decoded code-word. Probabilistic analysis of the algorithm provides worse case bounds for decoding any code, and later tweaks to the algorithm serve to reduce the exponent in the complexity as a function of code-length. To use ISD for communications requires some adaptation owing to the assumption of an a priori known number of flipped bits.
In communications, soft information has been exploited to produce approximate ML decoders for binary linear codes. In 1974 [42] Dorsch introduced the idea of the Most Reliable Basis (MRB), and developments on that theme have led to Ordered Statistics Decoding (OSD) [43] and its variants [44, 45, 46, 47, 48, 49, 50]. The principle underlying OSD is to approximate ML decoding by computing conditional probabilities of the received signal for a substantially smaller list than the whole codebook, which one hopes contains the ML decoding. The number of real-valued conditional probabilities that must then be computed per received signal is determined by the size of the list. As with ISD, in OSD the linear code’s column order is re-arranged and Gaussian elimination used to systematize it, but rather than using repeated random permutations the columns are ordered once in terms of decreasing bit reliability of the received transmission as determined from the soft information. The most reliable bits are hard demodulated and a list of all binary sequences within a fixed Hamming distance, , of that sequence is created. Each of those sequences are multiplied by the revised code generator to create putative code-words in the MRB. The conditional probabilities of the received sequences for these code-words, rather than all code-words, is then computed. The most likely one is identified and converted back to the original basis as the decoding. OSD’s approximation relies on the principle that if one takes a hard decision on the most reliable channel observations, depending on channel conditions, only few errors are expected within them, with the majority of the errors introduced by the channel instead being contained within the least reliable channel outputs, which are essentially ignored for decoding purposes. The larger the list, the better the approximation to ML decoding.
The original hard detection GRAND algorithm [23, 24, 25] is a true ML block-code decoder for hard detection channels subject to noise with or without memory. GRAND’s operation requires a method to query a string’s membership of a codebook. If the code is unstructured and stored in a dictionary, each query corresponds to a tree-search with a complexity that is logarithmic in the code-length. If the code was a Cyclic Redundancy Check (CRC) code, which is traditionally only used for error detection, checking for codebook membership requires only a simple polynomial calculation. If the code is linear in any field, codebook membership can be determined by a single matrix multiplication and comparison. The matrix multiplication results in the evaluation of a syndrome, but GRAND is not a syndrome decoder. No syndrome table is kept and, if channel conditions change, GRAND naturally adapts its decoding without recomputing an entire syndrome table. This latter point is particularly significant in the presence of soft information, which effectively serves to provide a distinct channel for each communication.
V Mathematical Analysis
As in [24], for the analysis of SRGRAND and SRGRANDAB we exploit the fact that the algorithm is a race between sequential queries either identifying the noise in the channel, which results in a correct decoding, or encountering a non-transmitted element of the codebook, which results in an error. The difference with SRGRAND is that the decoder is faster and more precise than GRAND because it only asks questions of the sub-string that has been potentially impacted by noise. While the analysis is more involved, the results obtained are, possibly surprisingly, as clean as in the hard detection setting. Our mathematical treatment relies on techniques from Large Deviation Theory. While we endeavour to provide guiding heuristics, to follow the arguments in detail requires familiarity with that theory [51, 52, 53].
To analyze the algorithm, we recall notions of guesswork [54, 55]. Given the receiver is told that symbols have been potentially impacted by noise, it creates a list of noise sequences, , ordered from most likely to least likely, with ties broken arbitrarily: . For a sequence, , its guesswork is the integer . For example, if the channel were binary, , and noise was Bernoulli for some , then the guesswork order follows Hamming weight. For independent and identically distributed noise on more general alphabets, the family of measures that share the same guesswork order are described by an exponential family [56].
Assumption 1** (Noise distribution).**
When noise occurs, it is independent and identically distributed as where for .
Under Assumption 1, if one must guess the entire noise string of length , Arikan [55] first established how the non-negative moments of guesswork, for , scale in in terms of Rényi entropies of order . Building on those and subsequent results that treated negative moments, [57] for and for , and more general noise sources, it was established [58] that the logarithm of guesswork satisfies a Large Deviation Principle (LDP) [51]. The LDP provides estimates on the distribution of the number of queries required to correctly identify a noise-string and was used as the basis to analyze one side of the decoding race in the hard detection setting [23, 24]. Recall that all logarithms are base .
Proposition 1** (Guesswork Moments and Large Deviation Principle [55, 57, 58]).**
Under assumption 1, if so that all received symbols are potentially impacted by noise, and are distributed as , the scaled Cumulant Generating Function (sCGF) of exists:
[TABLE]
where is the Rényi entropy of a single noise element, , with parameter
[TABLE]
Moreover, given , the process satisfies a LDP (e.g. [51]) with convex rate-function
[TABLE]
Heuristically, Eq. (4) implies that for large . As , with high probability the number of queries until is identified concentrates at . The probability that is identified in either fewer or more queries decays exponentially in with a rate governed by the convex function defined in Eq. (4). Setting in Eq. (3), as Arikan originally did in his investigation of sequential decoding, establishes that the expected guesswork grows exponentially in with rate . which is greater than the Shannon entropy, . That the zero of the rate-function in Eq. (4) occurs at ensures, however, that the majority of the probability is accumulated by making queries up to and including the Shannon typical set. The apparent discrepancy in these two facts occurs because the guesswork distribution has a long tail that dominates its average but has little probability.
In the symbol reliability setting, it is not necessary to guess a noise-string of length . Instead, one must guess a random number of symbols corresponding to those inside the mask that are potentially noise-impacted. To that end, we have the following assumption on the size of the mask, which is the number of potentially noise-impacted symbols per transmission.
Assumption 2** (Number of potentially noise-impacted symbols - size of mask).**
With being the mask size, i.e. the number of potentially noise-impacted symbols in a block of length , the proportion of them, , satisfies a LDP with a strictly convex rate-function such that if and , where . Define the sCGF for to be , which exists in the extended reals owing to Varadhan’s Lemma (e.g. [51][Theorem 4.3.1]).
Roughly, Assumption 2, which is true for a broad class of processes including i.i.d., Markov and general mixing, e.g. [51], says the probability of having potentially noise impacted symbols decays exponentially in with a rate, , that is positive unless is the mean , i.e. .
With some abuse of notation for Shannon entropy, under Assumptions 1 and 2, recalling that we define all logarithms as base , the symbol reliability decoding channel’s capacity, is upper bounded by
[TABLE]
where is the Shannon entropy of , we have upper-bounded the entropy of the input by , and used the fact that the channel is invertible (i.e. Eq. (1)). Through constructing SRGRAND and SRGRANDAB, we will show is attainable.
Under Assumptions 1 and 2, in a distinct context and for a distinct purpose, it was established in [59] that with a random number of characters to be guessed one has the following LDP.
Proposition 2** (LDP for guessing subordinated noise [59]).**
Under assumptions 1 and 2, the joint subordinated guesswork and length process satisfies a LDP with the jointly convex rate-function
[TABLE]
where is the guesswork rate-function defined in Eq. (4) and is the length rate-function defined in Assumption 2. Note that , where is Shannon entropy of a noise-impacted symbol and is the average number of potentially noise-impacted symbols.
The subordinated guesswork process satisfies a LDP with the convex rate function
[TABLE]
The sCGF for , the Legendre-Fenchel transform of , is given by the composition of the sCGF for the length with the sCGF for the guesswork of non-subordinated noise
[TABLE]
In particular, the average number of queries required to identify subordinated noise is given by
[TABLE]
Roughly speaking, the joint LDP indicates that, for large , and in Eq. (6) can be interpreted as follows: if the number of potentially noise-impacted symbols is , which is exponentially unlikely with rate , then having the logarithm of the subordinated guesswork be has essentially the same likelihood as , which has rate as a total deviation of must be accrued over a smaller proportion of potentially noise-impacted symbols. The unconditioned LDP follows from the large deviations mantra that rare events occur in the most likely way, so that the rate-function is determined from the proportion of potentially noise-impacted symbols that gives the smallest decay rate for the probability.
Results on the subordinated guesswork process governed by the rate-function in Eq. (7) are sufficient to enable us to prove a Channel Coding Theorem for the symbol reliability channel. Finer-grained results on error exponents that depend on the proportion of symbols that were noise-impacted, however, follow from the LDP for the joint subordinated guesswork and length process governed by the rate-function given in Eq. (6).
We note that is a convex function whose derivative at the origin is , the mean number of potentially noise-impacted symbols, so that . Hence, from Eq. (9), the average number of queries until the true channel-noise is identified grows exponentially in at a potentially larger rate than the guesswork required for the average proportion of potentially noise-impacted symbols. Despite that, the zero of the rate-function in Eq. (7) occurs at , so that the majority of the likelihood of identifying the true subordinated noise occurs by the Shannon entropy of the typical set of average number of potentially noise-impacted symbols. Thus, while stochastic fluctuations in the number of potentially noise-impacted symbols has relevance to complexity and error exponents, that variability has no impact on capacity. In a manner akin to GRANDAB, without loss of capacity, complexity can be ameliorated by abandoning guessing after a suitable number of queries.
To mathematically characterize the number of queries made until a non-transmitted code-word is identified, which is the second part of the guesswork decoding race, we assume that the codebook is created uniformly at random. For uniformly distributed codebooks, the location of each element in the guessing order of a received transmission is itself uniform in . The distribution of the number of guesses until any non-transmitted element of the codebook is hit upon is thus distributed as the minimum of uniform random variables. We can, therefore, use the following result from [23, 24], again recalling that our logarithm is base .
Proposition 3** (LDP for Guessing a Non-transmitted Code-word [23, 24]).**
Assume that for some , and that are independent random variables, each uniformly distributed in . Defining , then and satisfies a LDP with the lower semi-continuous rate-function
[TABLE]
A graphical representation of the rate-functions that determine the asymptotic likelihoods of outcomes of this guessing race can be found in Fig. 2. When all symbols are subject to noise, as in [23, 24], the channel is within capacity so long as the zero of the rate-function for guessing noise, which occurs at the Shannon entropy rate of the noise , is smaller than the zero of the rate-function for identifying a non-transmitted code-word, which occurs at , where is the normalized codebook rate. As in all likelihood the correct decoding is identified after fewer queries than an incorrect element of the codebook would be identified, the algorithm experiences concentration onto a correct decoding, which leads to the proof of the classical hard detection Channel Coding Theorem, , in [23, 24]. In the present paper, the zero of the rate function for the subordinated noise-guessing occurs at , the average number of potentially noise-impacted symbols times the Shannon entropy of the noise. So long as is smaller than , noise-guessing concentrates on identifying correct decodings before erroneous ones, leading to the Symbol Reliability Channel Coding Theorem, proved below, where any is achievable.
The proportion of potentially noise-impacted symbols is available to the receiver and so it is reasonable to consider error exponents subject to its knowledge. We characterize these error exponents in terms of and the rate-function given in Eq. (6).In particular, define
[TABLE]
to be the probability exponent that the proportion of potentially noise-impacted symbols, representing the size of the mask, is , and that there is an error, as the number of queries required to identify a non-transmitted code-word is smaller than the number of queries required to identify the true noise.
Theorem 1** (Symbol Reliability Channel Coding Theorem).**
Assuming , under Assumptions 1 and 2, and those of Proposition 3, we have that the probability that the conditional ML decoding of SRGRAND is incorrect decays exponentially in ,
[TABLE]
If exists such that
[TABLE]
which is analogous to one minus Gallager’s critical rate, then the joint error exponent of (11), subject to a given proportion of potentially noise-impacted symbols satisfies
[TABLE]
*The unconditioned SRGRAND error rate is *
[TABLE]
With , abandoning guessing if queries have been made without identifying an element of the codebook, the SRGRANDAB error rate is also negative,
[TABLE]
If, in addition, defined in Eq. (13) exists then the expression simplifies to where is the conditional ML decoding error rate in Eq. (15).
Proof.
As is independent of , we have that satisfies a LDP with rate-function . Noting the equivalence of the following two events,
[TABLE]
By the contraction principle (e.g. [51][Theorem 4.2.1]) with the continuous function , the process satisfies a LDP with rate-function .
Consider defined in Eq. (14), where the limits exist as the rate-functions are convex and so continuous on the interior of where they are finite,
[TABLE]
This final expression essentially encapsulates that the error exponent is the exponent for the likelihood that the proportion of potentially noise-impacted symbols, or size of the mask, is , plus the smallest exponent (corresponding to the most likely event) for the minimum of the scaled uniforms being at , while the scaled sub-ordinated guesswork occurs at any value at least as large as .
For , is linearly decreasing, while is convex in with minimum, zero, at . Thus if , setting and , . If, alternatively, , then as both and , as a function of , are strictly decreasing on ,
[TABLE]
which is strictly positive as is strictly decreasing to [math] on while is strictly increasing in on the same range. Assuming defined in Eq. (13), exists, as is decreasing at rate and then if , i.e. if ,
[TABLE]
as . If, instead, , then the infimum occurs at and
[TABLE]
and the expression in (14) follows. The unconditional error exponent, in Eq. (15), is obtained from that in (14) by the contraction principle, projecting out , giving . If , then . If , then Finally, if , then inverting the Legendre-Fenchel transform in the last step.
To determine the error exponent of SRGRANDAB, by the Principle of the Largest Term [51, Lemma 1.2.15] it suffices to consider only the smallest of the two exponential rates in Eq. (16). The first term is the error rate for GRAND. The second term is the exponent of the probability of error due to abandonment of guessing. Note that and the result follows from the LDP as is convex and increasing for . ∎
Consider the error exponent for the conditional ML decoding via SRGRAND, in (14). The exponent for the likelihood that the proportion of potentially noise-impacted symbols, , which is approximately , is . The error-exponent is then as in a channel where only a proportion of transmitted symbols are in the mask of symbols subject to noise [24]. The unconditional equivalent, in Eq. (15) identifies the most likely proportion of noise-impacted symbols that may give rise to an error for a given codebook rate. For SRGRANDAB, an error occurs either if the identified conditional ML decoding is in error or if abandonment occurs. The more likely of these two events dominates in the limit.
Combining Propositions 2 and 3 in a distinct way enables us to determine the asymptotic complexity of the SRGRAND and SRGRANDAB in terms of the number of queries until a decoding, correct or incorrect, is identified: That is, the algorithm terminates when the channel noise or a non-transmitted element of the codebook are identified, whichever occurs first. On the scale of large deviations, if the codebook is within capacity, , then it becomes apparent that the sole impact of the codebook is to curtail excessive guessing when unusual noise occurs. The number of guesses SRGRANDAB makes until terminating is The final term corresponds to the abandonment threshold, curtailing guessing shortly after the Shannon typical set for an average number of potentially noise impacted symbols.
Theorem 2** (Complexity of SRGRAND and SRGRANDAB).**
If , under Assumptions 1 and 2, and those of Proposition 3, the scaled complexity of SRGRAND, , satisfies the LDP with a convex rate-function
[TABLE]
and the expected number of guesses for SRGRAND to find a conditional ML decoding satisfies With , the complexity of SRGRANDAB, , satisfies a LDP with a convex rate function
[TABLE]
*and the expected number of guesses until SRGRANDAB terminates, , satisfies *
Proof.
Consider the process , following [24][Proposition 2], as is a continuous function, by the contraction principle it satisfies a LDP with rate-function . If , as for . Alternatively, if ,
[TABLE]
as is decreasing for . If , then note the geometric consideration
[TABLE]
where in the last inequality we have set . As min-entropy is less than Shannon entropy and as is convex, for all while is increasing on and so for .
To obtain the scaling result for we invert the transformation from the rate function to its Legendre-Fenchel transform, the sCGF of the process via Varadhan’s Theorem [51][Theorem 4.3.1]. In particular, note that, regardless of whether is convex or not,
[TABLE]
The final component of the minimum satisfies an LDP with a rate function and . and, again, as minimum is continuous by the contraction principle the LDP with a rate-function given in Eq. (18) and the scaling of follows from similar considerations. ∎
Theorem 2 effectively says that in SRGRAND the algorithm terminates with a correct decoding so long as the number of queries made before identifying an element of the codebook is less than for some . If more queries than that are made, the conditional ML decoding will be erroneous. SRGRAND queries until it identifies the true noise or until an erroneous identification, whichever comes first. In this realization of SRGRANDAB, querying is abandoned for noise sequences beyond the typical set of the average number of potentially noise impacted symbols, curtailing complexity.
VI Mathematical Example: Symbol Reliability Binary Symmetric Channel (SR-BSC)
We consider a setting where it is possible to mathematically compare channels with and without knowledge of the symbol reliability information vector , the Symbol Reliability Binary Symmetric Channel (SR-BSC). For the SR-BSC, we assume that each transmitted symbol is potentially impacted independently by noise with probability . Code-book and noise symbols take values in a binary alphabet , is addition in , and thus [math] represents the no-noise character. Given a symbol has been potentially noise-impacted, the conditional probability that the corresponding bit has been flipped is , and . The overall bit-flip probability of the SR-BSC is thus . We consider capacity and error exponents, which are properties of ML decoding no matter whether it is identified by the noise-guessing methodology or by brute force, as well as complexity, which is a feature of the noise-guessing approach. From Eq. (5), the capacity of the symbol reliability channel is where is the binary Shannon entropy. The corresponding hard detection channel is a BSC with probability and so the hard detection channel capacity is As is concave, for all and , and so the capacity of the channel with symbol reliability information is necessarily higher. Depending on the parametrization, the symbol reliability channel’s capacity can be several orders of magnitude larger than the hard detection capacity.
As the symbol reliability information is constructed of i.i.d. elements, the rate function governing the LDP for the proportion of noise impacted symbols, in Assumption 2, is the Kullback-Leibler divergence, , which has the corresponding sCGF
[TABLE]
The rate function for LDP of the rescaled guesswork in Eq. (4) is the Legendre-Fenchel transform, , of
[TABLE]
From Eq. (8), the sCGF for the subordinated guesswork of true noise is , where and are given by Eq. (19) and Eq. (20), respectively. The exponent of the average complexity required to identify the true noise in the symbol reliability channel is given by , while for the hard detection channel it is
Armed with the sCGFs for the proportion of potentially noise impacted bits and for the rescaled logarithm of the guesswork of potentially noise impacted bits, the asymptotic error exponent given in (15) is readily computable numerically. Recall that, as a function of the codebook rate , this is the exponent in the decay rate in the likelihood than a conditional ML decoding is in error as the block length increases.
While prefactors are not captured in the asymptotic analysis of Theorems 1 and 2, they allow the following approximations. The conditional ML probability of error is approximately , which holds true regardless of whether it is identified by SRGRAND or brute force, where the expression for can be found in Eq. (15). For SRGRAND decoding, our measure of complexity is the average number of guesses per bit per decoding, approximately For comparison, we define the complexity of the computation of the ML decoding in Eq. (2) by the method described in [60] to be the number of conditional probabilities that must be computed per bit before rank ordering and determining the most likely codebook element, equal to , where we are equating the work performed in one noise guess, which amounts to checking if a string is an element of the codebook, with the computation of one conditional probability.
For two values of block size, and , and pairs such that is constant and so comparable with the hard detection channel, Fig. 4 plots the approximate error probabilities and complexity as a function of codebook rate. The upper panels show the error probabilities with a target block error rate indicated by the dashed horizontal line. The provision of symbol reliability information greatly improves the block error probability, even though in this comparison the conditional probability of a bit flip given symbol reliability information increases as the symbol reliability probability decreases.
The lower two panels show the approximate complexity. The dashed line gives the approximate complexity for the approach in [60], which grows exponentially in , when computing a conditional probability for every codeword. In contrast, the complexity of the SRGRAND approach is initially flat. As the rate, , increases, eventually the SRGRAND complexity drops, as encountering an erroneous element of the codebook clips the long guessing tail of true noise. The diamonds indicate the rate above which the target block error rate would be violated.
VII Empirical Performance Evaluation
A distinctive aspect of the GRAND approach is that it is readily implemented and can be used with any block code construction. While the theoretical results in Section VI are for uniform-at-random codebooks, in practice nearly all error correction codebooks are linear in a finite field with input bits and coded bits. Associated with each code is a check matrix and to test if a string, , is in the codebook a single matrix multiplication and comparison, , suffice, in the appropriate field. Here we compare the decoding performance of GRANDAB, SRGRANDAB for four types of binary linear codes.
VII-A The Symbol Reliability Binary Symmetric Channel
In the context of the SR-BSC introduced in Section VI, when the unconditional bit flip probability is , we set the probability that a bit is marked as unreliable to be and the bit flip probability conditioned on unreliability to be . For hard detection GRANDAB, putative noise strings are queried in order of Hamming weight. Within each set of strings with the same Hamming weight, the ordering is arbitrary and we do so in the order illustrated in Fig. 5, first panel. For SRGRANDAB, we assume that the channel state is known and use the same search pattern, but confined to querying only bits for which the channel state was marked as unreliable for any given communication. For GRANDAB, we set the abandonment threshold to check for up to four bit-flips. For SRGRANDAB, we allow the same number of codebook queries as GRANDAB before abandoning and reporting a decoding error.
RM codes, which only exist for some pairs, are broadly used in wireless communications and have a well-established hard detection decoder, majority logic decoding [12]. Fig. 5 reports Block Error Rates (BLER) as a function of the bit flip probability for a rate , , RM code. As majority logic decoding is tailored to a BSC and is known to be accurate in that setting, its performance is only slightly degraded from the ML BLER that GRANDAB provides. The provision of reliability information to SRGRANDAB gives it a distinct advantage, resulting in significantly enhanced BLER. The right panel reports the average number of codebook queries per received bit that GRANDAB and SRGRANDAB make. As each query solely requires a matrix multiplication by a sparse vector, for typical target BLER of or lower, the complexity requirements of GRANDAB and SRGRANDAB are modest.
Since the 1960s, RLCs have been known to be capacity-achieving if twined with ML decoding [4] with the same error exponents as those for uniform-at-random codebooks [61]. Those results hinge on a proof that at high rates the average RLC is a good one. The lack of an efficient decoder that can accurately decode any linear, high-rate codebook has meant, however, that this avenue is little explored. Here we consider the application of GRANDAB and SRGRANDAB for decoding RLCs. For any pair we can construct systematic binary RLCs by making a random generator matrix , where is the identity matrix and the entries of the random check matrix are independent Bernoulli 1/2 random variables. To check if is a member of the codebook, one can test if , obviating the need for the receiver to determine the associated check matrix. Consistently with theoretical results, in an empirical evaluation codes are re-randomized after each use. In practice, the sender and receiver could share a seed for the random number generator from which the check matrix is produced.
Fig. 5 also reports the BLER and complexity performance of GRANDAB and SRGRANDAB for [128,99] RLCs, so that the results are directly comparable to those for RM codes. With hard detection ML decoding by GRANDAB, it can be seen that RLCs slightly outperform RM codes, leading to better BLER and comparable decoding complexity. This result is potentially surprising as the re-randomization in the RLC would lead one to suspect that some codes are poor performers, but is consistent with theory that says that RLCs are typically good. The provision of symbol reliability information changes matters and SRGRANDAB gets equally good performance from both RM and RLCs. The use of RLCs, which necessitates a universal decoder, holds appeal as changing codebooks may provide enhanced security, and our results suggest there is no loss in terms of error performance in using them.
For a rate , BCH Fig. 6 reports BLER as a function of , as well as RLCs of the same rate. The results mirror those found for RM codes, where the dedicated hard detection decoder provides similar performance to the universal GRANDAB and the provision of symbol reliability information leads SRGRANDAB to significantly outperform both. As with RM codes, RLCs, which can only be efficiently decoded with the GRAND approach, lead to similar BLERs as the BCH code with essentially identical complexity for both. The latter is not surprising as the complexity of GRANDAB and SRGRANDAB is largely dominated by properties of the noise rather than those of the codebook. These results suggest that for BLER performance of moderate-redundancy codes, the accuracy of the decoding mechanism is more important than the codebook structure, opening up a rich palette of code sizes and rates for URLLC in a single algorithmic instantiation.
VII-B Quantizing Soft Information to Create Symbol Reliability Information
The mathematical analysis assumes that the mask provided to the decoder, , is correct, with symbols accurately tagged as reliable or unreliable. In practice, that requires binary quantization of soft information. Should quantization result in a symbol being reliable when it is not, that would necessarily result in an erroneous decoding or abandonment. Here we illustrate simple means by which mask creation can be achieved such that the frequency of provision of erroneous masks, the Mask Error Rate (MER), does not dominate the BLER. The masking rule is a function of the SNR, the length and redundancy of the code.
Consider an AWGN with noise variance is and a transmitter-receiver pair employing BPSK with transmitted the binary symbols corresponding to . We wish to identify a threshold, , such that if the absolute value of a received signal is beyond it is likely to be reliable. Given , the probability an individual bit is erroneously labeled as reliable when it is incorrect is , where is a Gaussian with mean zero and variance one. Thus, for a code of length we have that the likelihood one or more bits are erroneously marked as reliable, resulting in a mask error, is . Hence, by setting a target MER as a function of the code length and SNR such that the MER will not dominate the BLER, the receiver determines the static signal threshold by , where is the inverse of a Normal distribution. In addition, we set the mask so it always includes the least reliable bits, which allows SRGRAND to do a small amount of corrective work if necessary. In particular, that avoids circumstances where the reception is indicated to be error free, but the received demodulated signal is not in the codebook.
Figure 7 shows results of this system for two CA-Polar codes, [128,116] and [512,500], and a BCH [1023,1013] code. Green lines correspond to full soft decoding with CA-SCL of CA-Polar codes [62] using a list-size of [63, 64, 65], and BM decoding of the BCH code. Black lines indicate optimal ML decoding with hard detection GRAND. The blue lines indicate the contribution to BLER that comes from the masks being in error, MER, where static target mask error rates are determined in advance and used to identify the marking threshold . The magenta lines report the overall SRGRAND BLER, inclusive of the MER. At a BLER of , these results demonstrate a BLER gain of 0.75 to 1dB can be obtained with SRGRAND over ML hard detection decoding, irrespective of code-length.
VIII Discussion
We have introduced SRGRAND and SRGRANDAB, two noise-centric decoding algorithms using symbol reliability information. By using the symbol reliability information to mask symbols that are reliable and guessing noise only on unreliable symbols, these algorithms can realize higher rates, with lower error probabilities, and less complexity, than without symbol reliability information.
All of the GRAND algorithms are suitable for use with any codebook so long as testing membership of the codebook for a string of symbols is efficient. For linear codes, such testing requires only a matrix multiplication over a finite field. CRC codes, CA-Polar Codes and RLCs are all linear. Moreover, guesswork orders are known to be robust to mismatch [66], and so decoding precision should not be sensitive to minor imprecision in the channel noise model.
We empirically compared SRGRAND and SRGRANDAB with the well established majority logic decoding of RM codes and BM decoding of a BCH code. The provision of symbol reliability information to SRGRANDAB results in substantially better performance. As the algorithms are universal, they enable us to empirically consider decoding RLCs, which is little explored outside of theory. The BLER performance is comparable with the highly structured RM and BCH codes of the same rate. This opens the possibility of using SRGRANDAB for security, based on a principle of having the sender and receiver use a distinct linear code drawn using a cryptographically secure random number generator for each transmission.
While we presented results for one SRGRANDAB abandonment rule that reduces average algorithmic complexity without sacrificing channel capacity, others are possible and, indeed, can be used in combination. Here we mention two more. The first is a natural extension to the rule of abandoning guessing when coverage of the typical set for the average number of potentially noise impacted symbols. In the symbol reliability model, the specific number of potentially noise-impacted symbols, , for each received transmission, , is known to the algorithm and querying is abandoned after guesses. Analysis of the impact of this rule on error exponents and complexity follows the same line of argument as presented in the paper, though the resulting expressions are less elegant. A distinct alternative is not to guess at all if too many symbols are reported to be potentially noise impacted; i.e. if . It is straight forward to show this rule does not impact capacity, but an analysis of complexity, which would now be conditional on , would not follow immediately from the large deviation arguments presented here. The analysis in this paper for codes of fixed length could, however, be readily extended to decoding with symbol reliability information for variable length codes [67, 68] and rateless codes.
SRGRAND avails of symbol reliability information, which is the most succinct form of soft information, and lends itself to both mathematical analysis and implementation in hardware, seeing a to dB gain over hard detection GRAND. A natural question is how to use more fine-grained soft information in a GRAND algorithm, what the additional algorithmic complexity would be, and what performance gains would be available. By creating a bespoke noise effect query order for each reception, it is possible to use one real-valued piece of soft information per bit to identify soft-detection ML decodings [69]. Although the resulting algorithm does not lend itself to theoretical determination of error exponents or to efficient implementation in hardware due to the need for dynamic memory, a software implementation enables the empirical evaluation of a bound on the achievable performance for a given code. A heuristic algorithm that uses bits of soft information per received bit has been reported that appears to empirically approximate the performance available from full soft information with a simpler algorithm [70, 71]. Again, its construction does not lend itself to mathematical identification of error exponents, but it is more suitable for implementation in hardware and an architecture for it has been proposed [72], albeit one that is significantly more complex in terms of energy and area than is the case for GRAND [26, 27] or would be for SRGRAND. The question of whether SRGRAND could be augmented to avail of more finely quantized soft information while retaining the simplicity of its operation remains outstanding.
The GRAND algorithms can themselves provide, in addition to a decoding, soft information through the number of noise queries. A lower number of guesses corresponds to a higher likelihood of correct decoding. Such soft information can be of use, for example, for component codes in a concatenated code or Turbo code [73, 74, 75, 76]. Thus one may envisage using the information on decoding reliability of SRGRAND and SRGRANDAB in a manner akin to the reliability information provided by the Soft-Output Viterbi Algorithm [73, 74, 77, 75, 78], by the operation of Turbo decoding [76, 79, 80, 81, 82, 83, 84], by the syndrome information used in Ordered Statistics Decoding (OSD) [43, 85, 86], or other soft-input, soft-output schemes [87, 88, 68, 89]. In general, we can envisage in future work systems that meld equalization and decoding as in [90] or soft information originating from other decoding processes, [91, 92, 93, 94, 95].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. R. Duffy and M. Médard, “Guessing random additive noise decoding with soft detection symbol reliability information,” in IEEE Int. Symp. on Inf. Theory , 2019.
- 2[2] K. R. Duffy, A. Solomon, K. M. Konwar, and M. Médard, “5G NR CA-Polar maximum likelihood decoding by GRAND,” in Annual Conference on Information Sciences and Systems , 2020.
- 3[3] C. E. Shannon, “A Mathematical Theory of Communication,” Bell Syst. Tech. J. , vol. 27, pp. 379–423, 623–656, 1948.
- 4[4] R. G. Gallager, Information Theory and Reliable Communication . New York, NY, USA: John Wiley & Sons, Inc., 1968.
- 5[5] E. Berlekamp, R. Mc Eliece, and H. Van Tilborg, “On the inherent intractability of certain coding problems (corresp.),” IEEE Trans. Inf. Theory , vol. 24, no. 3, pp. 384–386, 1978.
- 6[6] R. J. Mc Eliece, “A public-key cryptosystem based on algebraic,” Deep Space Network Progress Report , vol. 42-44, pp. 114–116, 1978.
- 7[7] I. Reed, “A class of multiple-error-correcting codes and the decoding scheme,” Transactions of the IRE Professional Group on Information Theory , vol. 4, no. 4, pp. 38–49, 1954.
- 8[8] D. E. Muller, “Application of boolean algebra to switching circuit design and to error detection,” Transactions of the IRE professional group on electronic computers , no. 3, pp. 6–12, 1954.