TL;DR
Drynx is a decentralized system that allows privacy-preserving statistical analysis and machine learning on sensitive distributed datasets, ensuring data confidentiality, correctness, and auditability without requiring trust in any single entity.
Contribution
It introduces a modular, efficient framework combining cryptographic techniques for secure, verifiable, and privacy-preserving data analysis on distributed datasets.
Findings
Training logistic regression on large distributed data in under 2 seconds
Verification of query correctness completed in less than 22 seconds
Supports secure computation of various statistical measures and machine learning models
Abstract
Data sharing has become of primary importance in many domains such as big-data analytics, economics and medical research, but remains difficult to achieve when the data are sensitive. In fact, sharing personal information requires individuals' unconditional consent or is often simply forbidden for privacy and security reasons. In this paper, we propose Drynx, a decentralized system for privacy-conscious statistical analysis on distributed datasets. Drynx relies on a set of computing nodes to enable the computation of statistics such as standard deviation or extrema, and the training and evaluation of machine-learning models on sensitive and distributed data. To ensure data confidentiality and the privacy of the data providers, Drynx combines interactive protocols, homomorphic encryption, zero-knowledge proofs of correctness, and differential privacy. It enables an efficient and…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3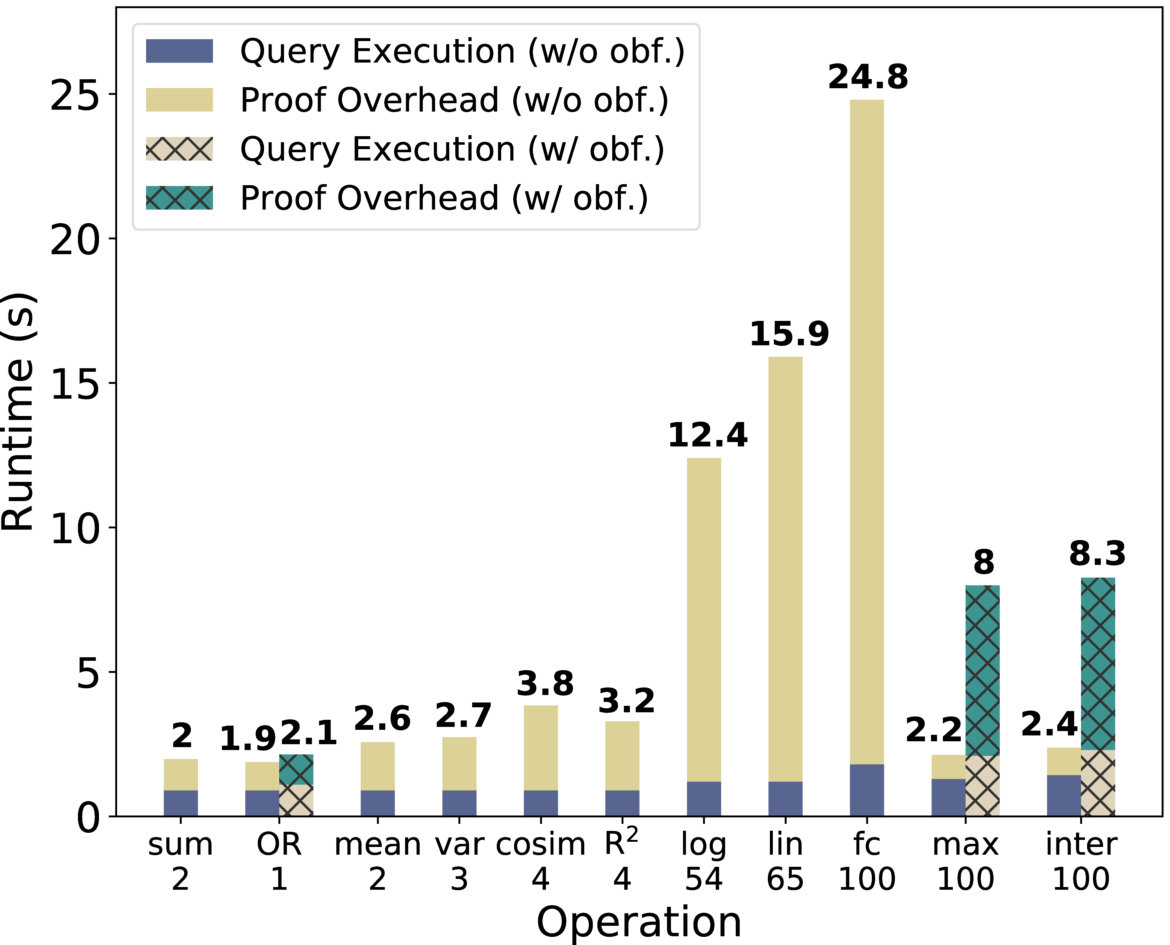 Figure 4
Figure 4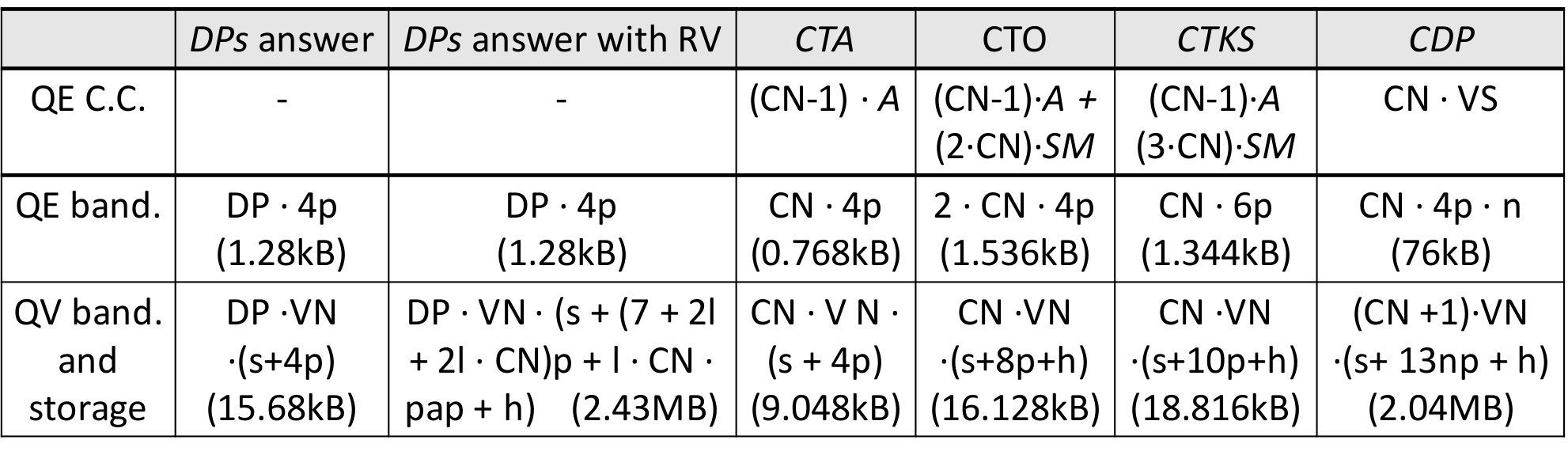 Figure 5
Figure 5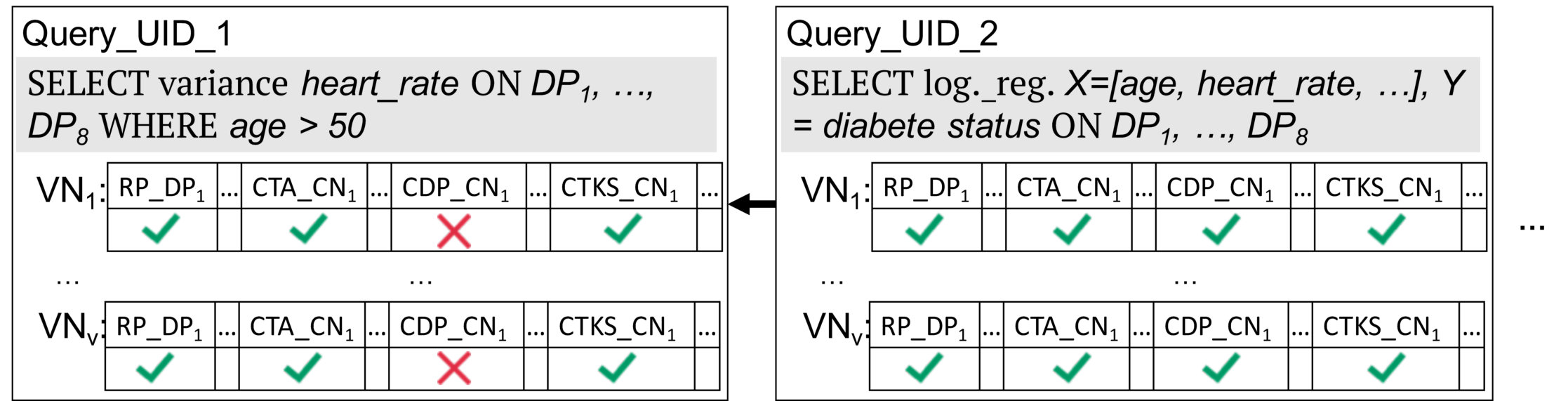 Figure 6
Figure 6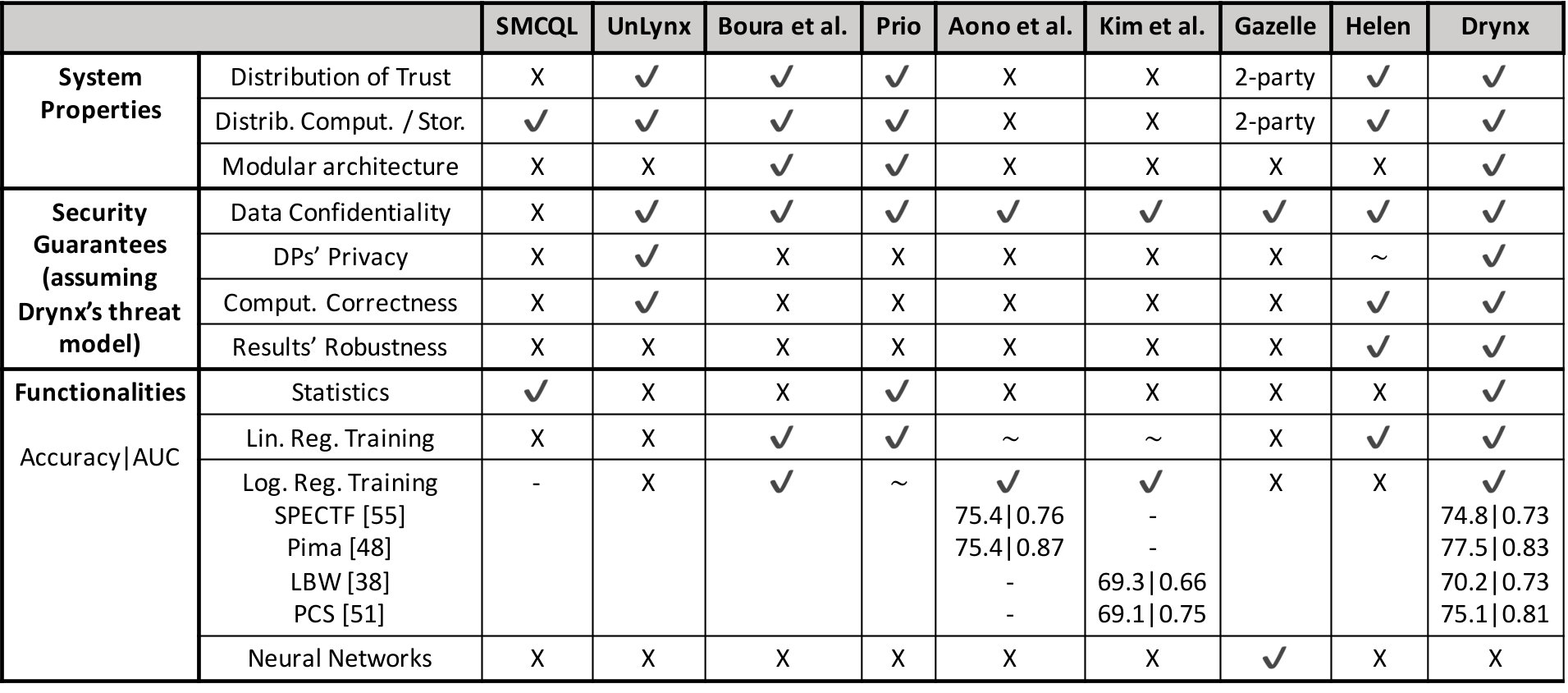 Figure 7
Figure 7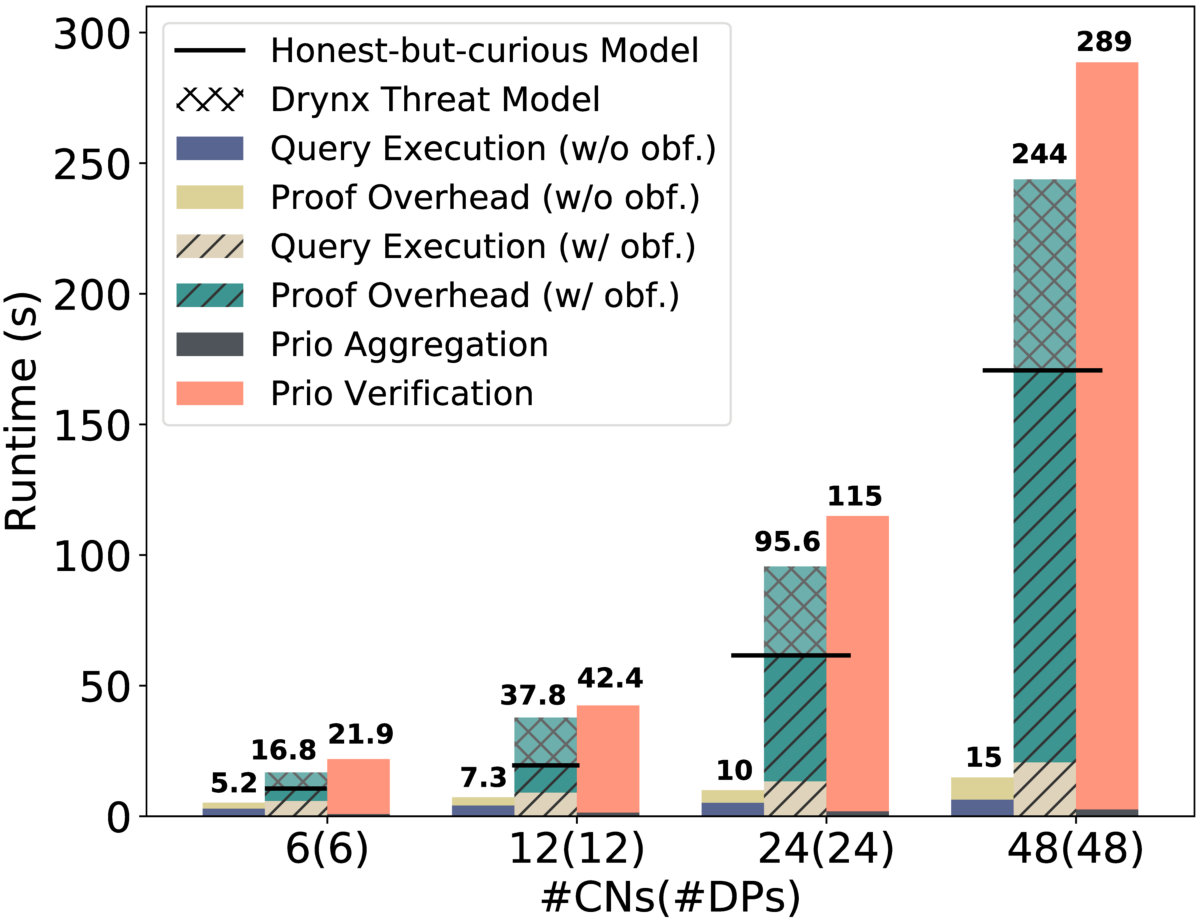 Figure 8
Figure 8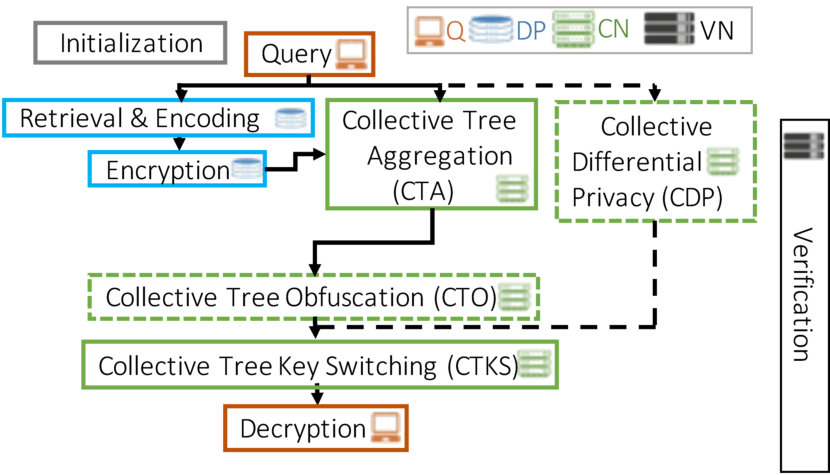 Figure 9
Figure 9 Figure 10
Figure 10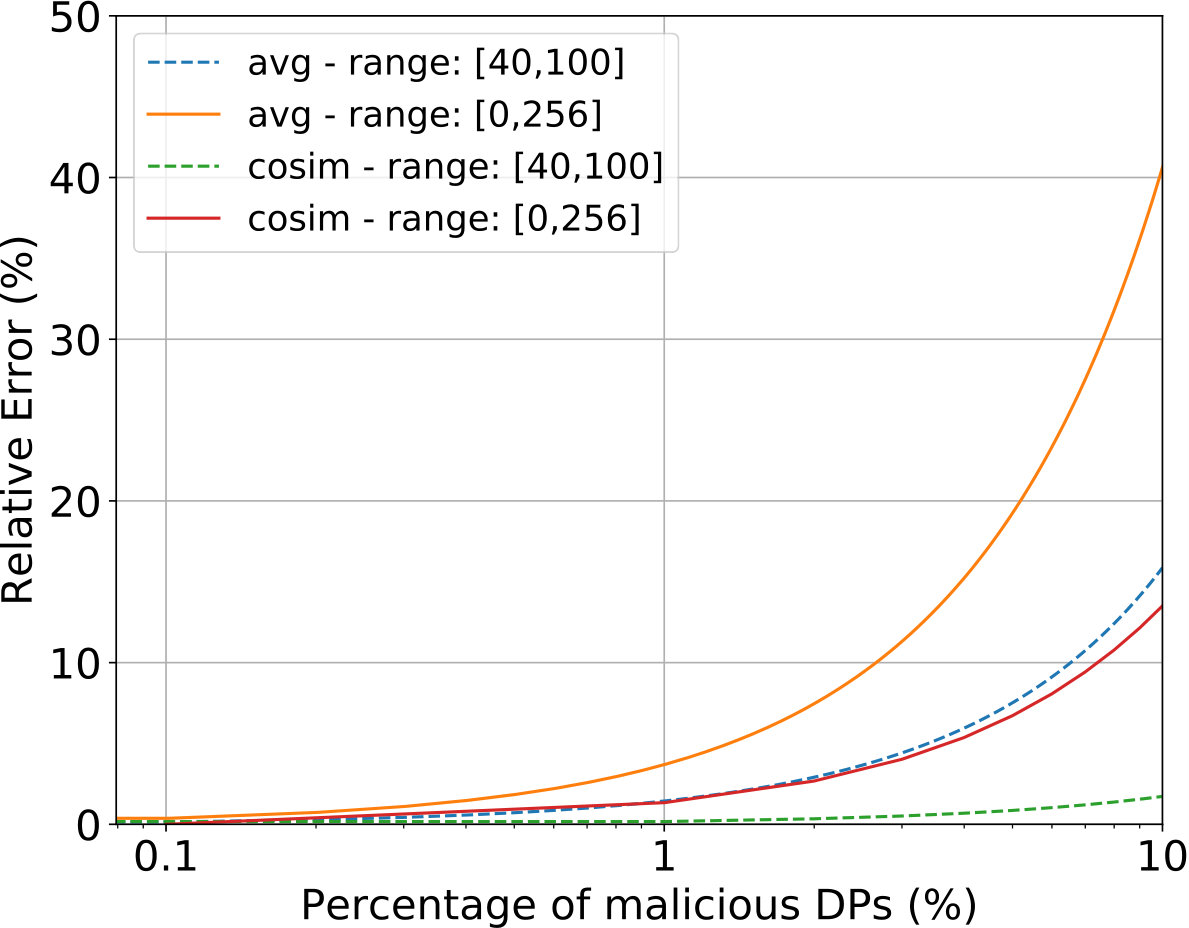 Figure 11
Figure 11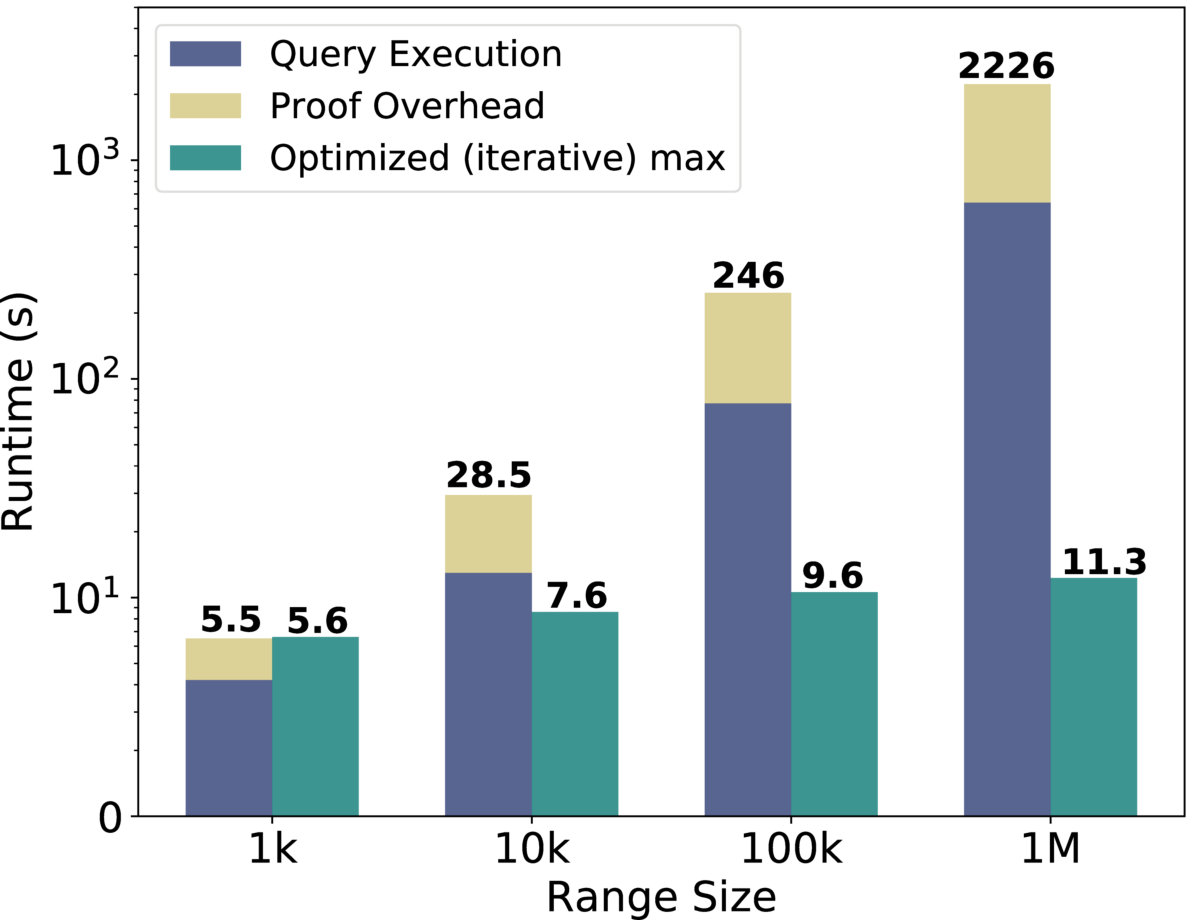 Figure 12
Figure 12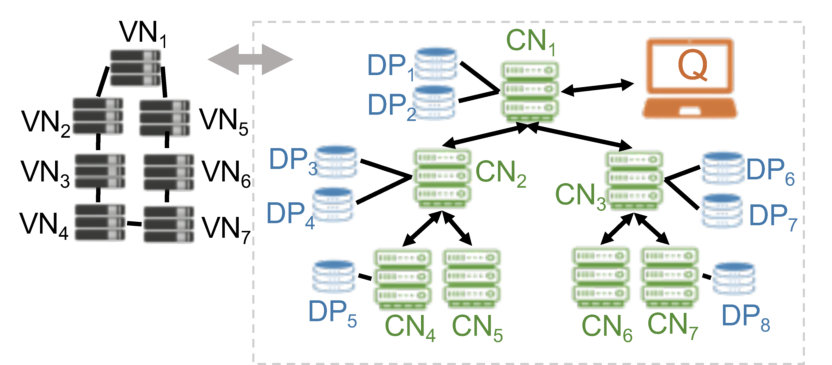 Figure 13
Figure 13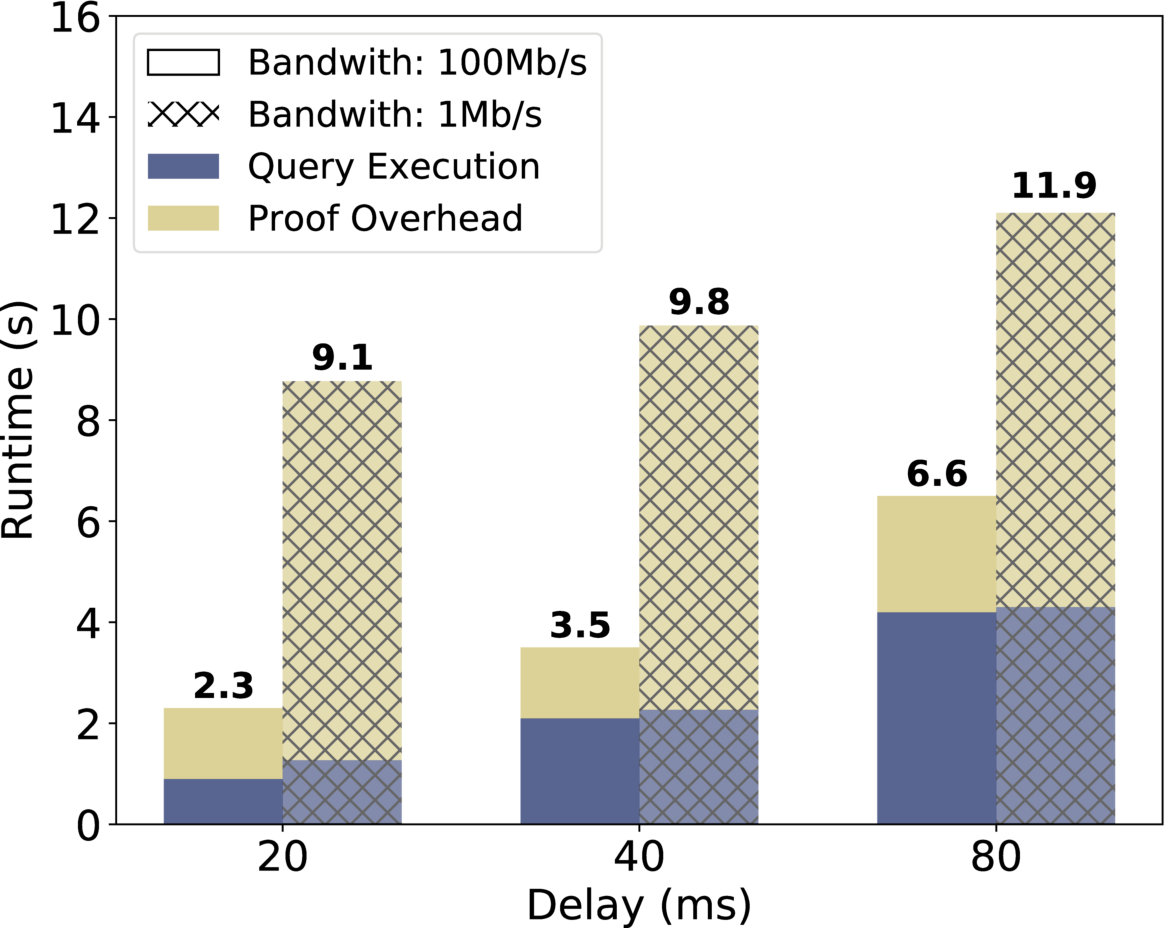 Figure 14
Figure 14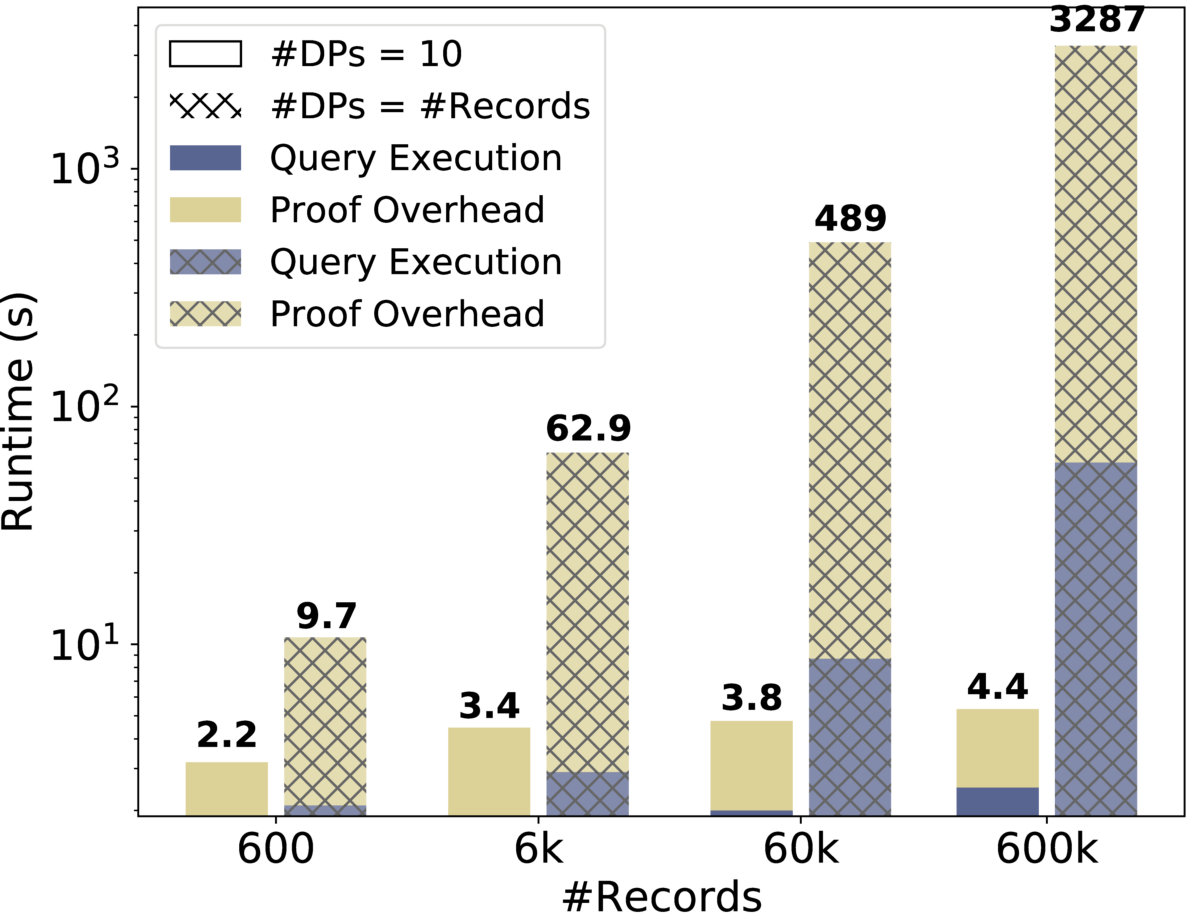 Figure 15
Figure 15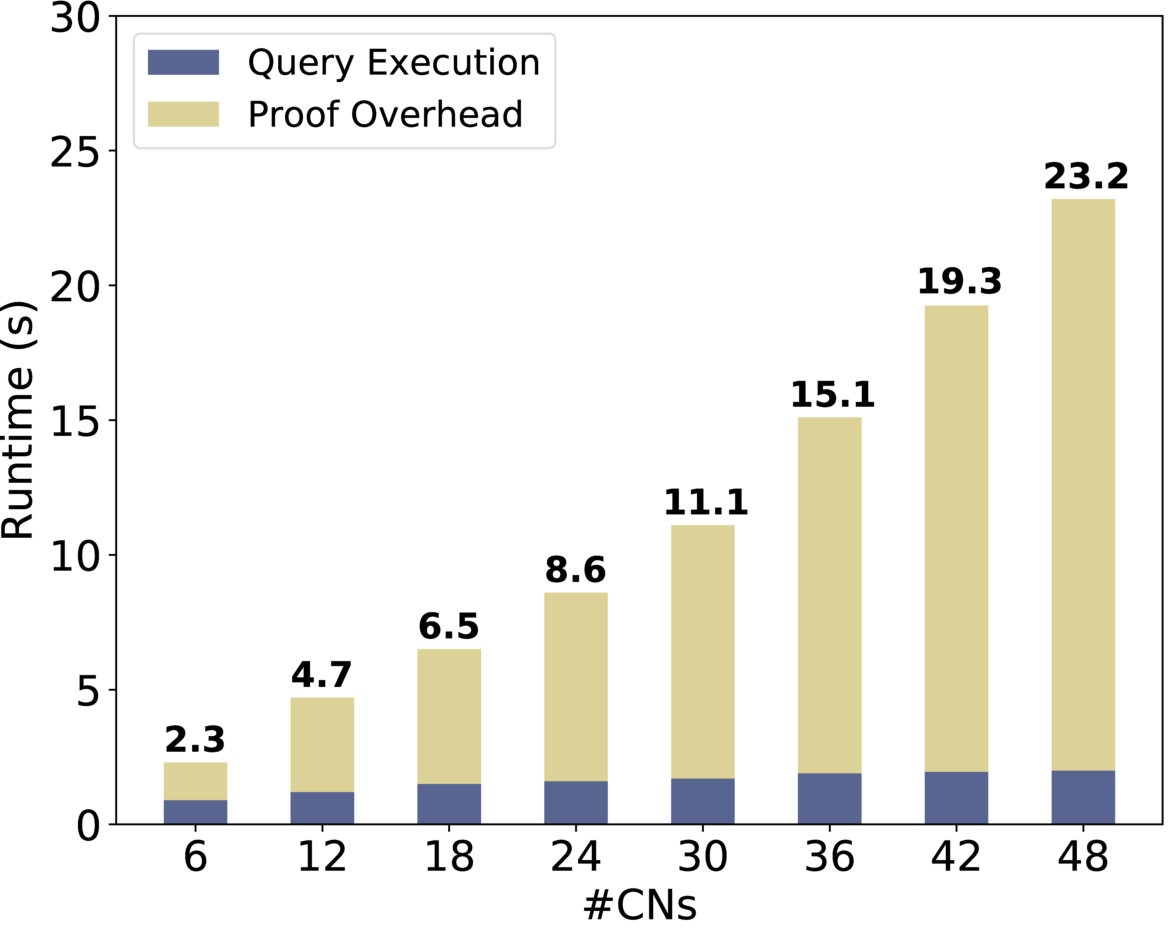 Figure 16
Figure 16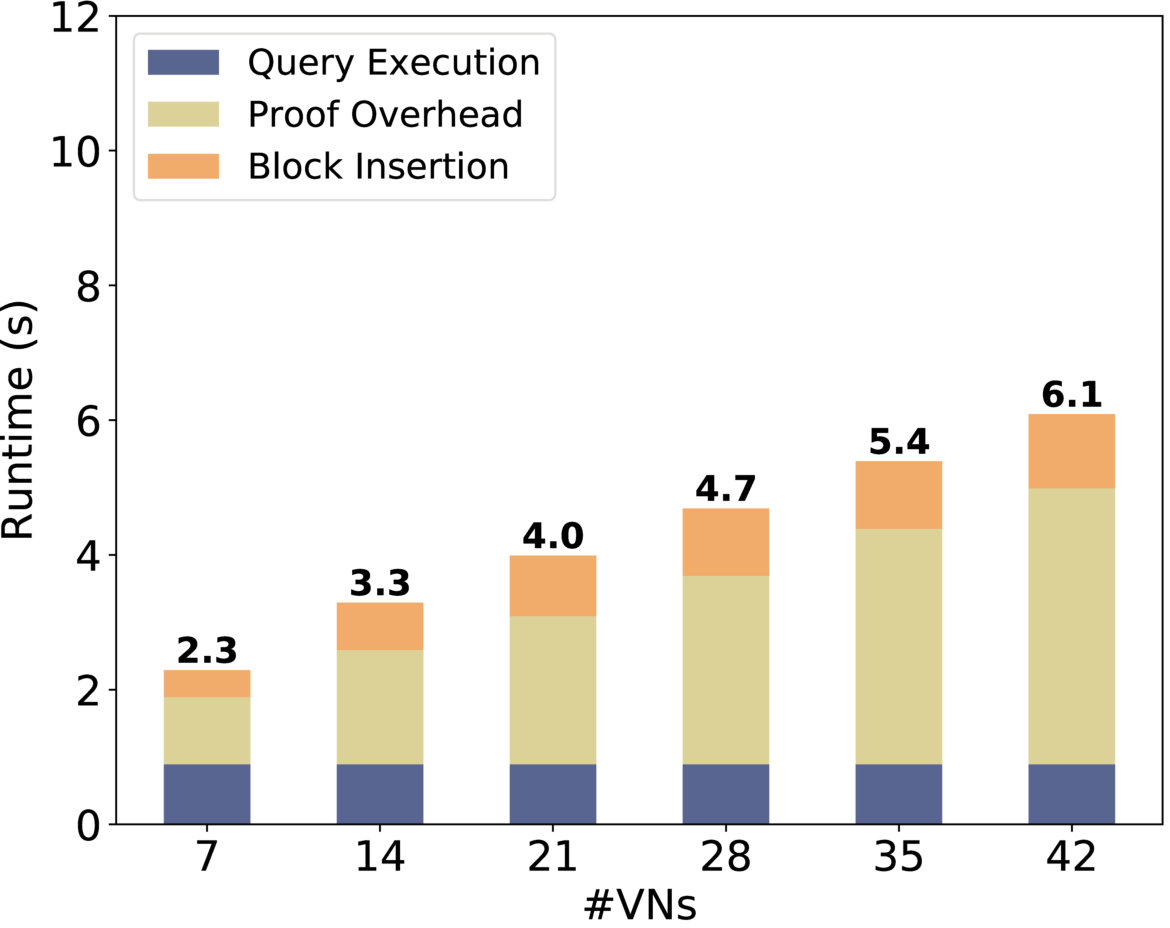 Figure 17
Figure 17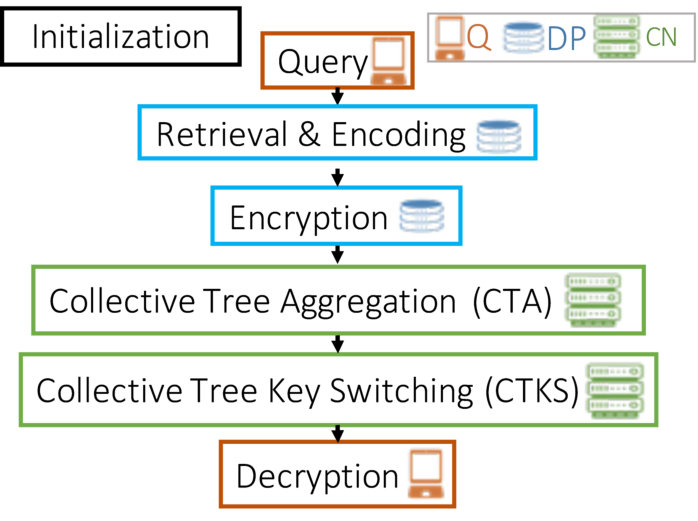 Figure 18
Figure 18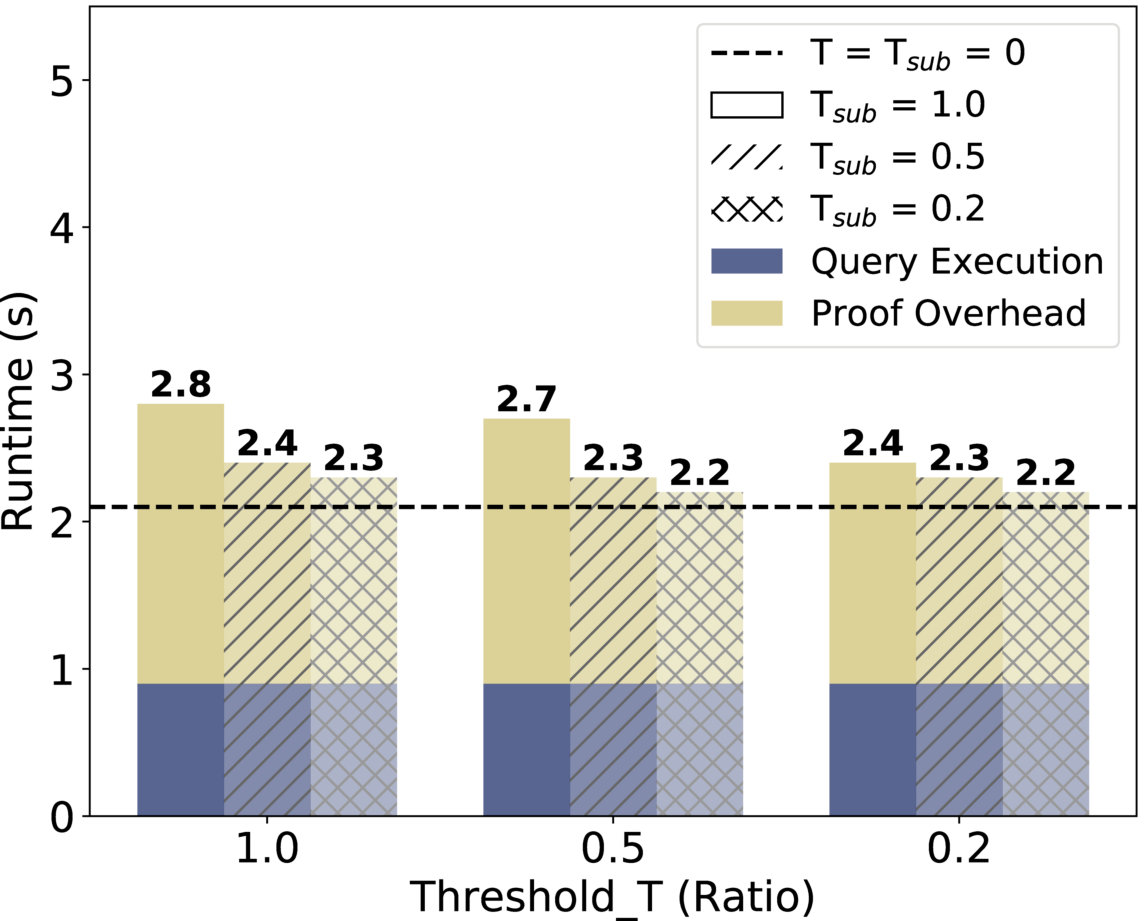 Figure 19
Figure 19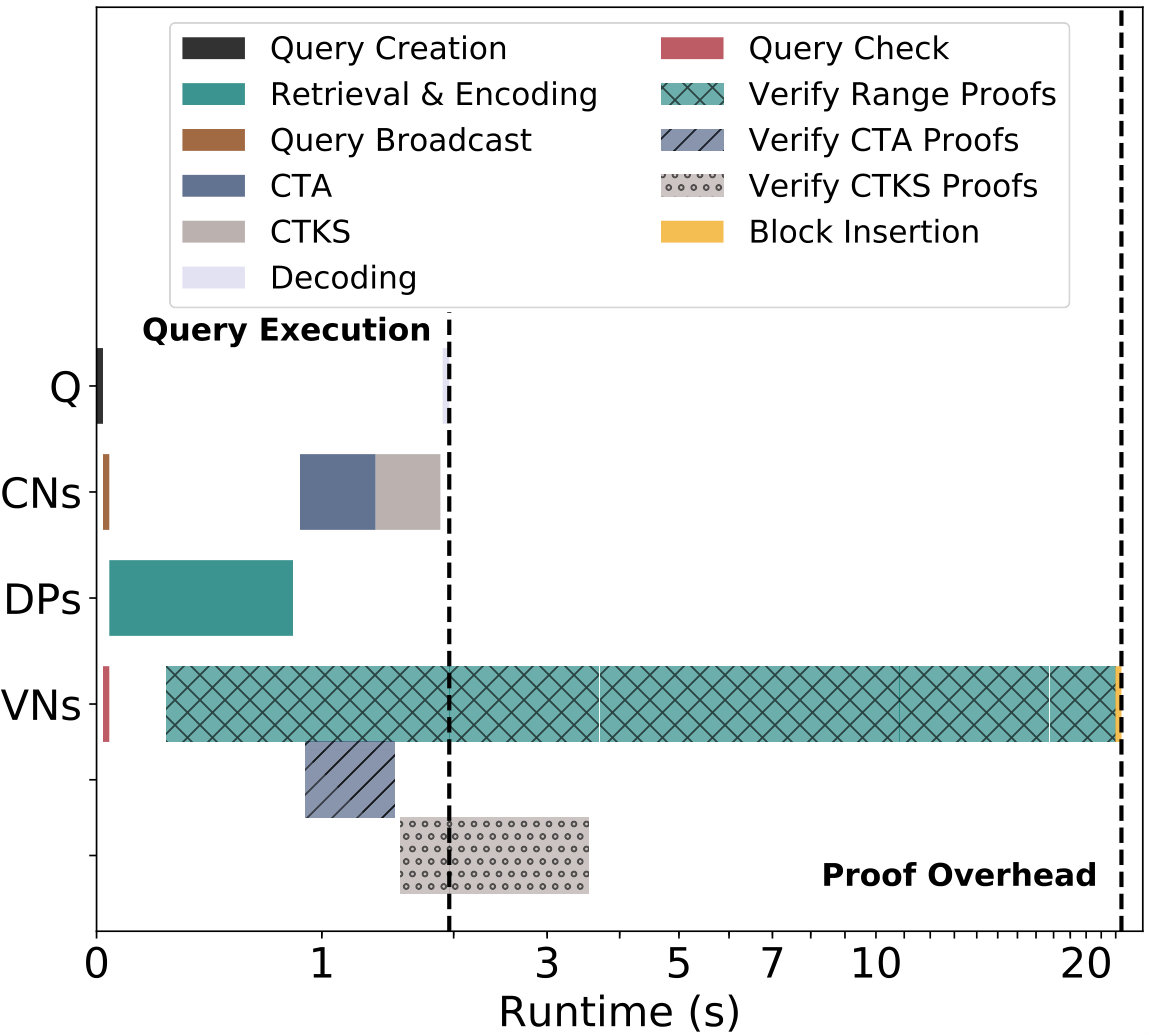 Figure 20
Figure 20| Operat. () | (on ) | |
| () | ||
| sum | ([], ) | |
| mean | ([], ) | |
| variance | ([, ], | |
| std. dev. | ) | |
| ([],) or ([], ) | ||
| min/max | ([, …, ], ) | |
| or ([, …, ], ) | ||
| frequ. count | ([, …, ], ) | |
| set int/un | ([, …, ], ) | |
| or ([, …, ], ) | ||
| cosim | ([ | |
| ], ) | ||
| ([, | ||
| ], ) |
| Symbol | Description |
|---|---|
| , | Hospitals & Patients Data Sharing |
| , , | Elliptic curve; base point on , prime |
| EΩ() = | ElG encrypt. of under key , |
| nonce | |
| pub. coll. key | |
| (, ) | priv., pub. key |
| , , , , | ZKPs pub. (uppercase), discrete log. |
| , , | Querier, Data Provider, |
| , | Computing & Verifying Node |
| Threshold of honest | |
| , , | linear combi., encoding, records |
| , | vector, count |
| , , | Coll. Tree Aggr., Obfusc., Key Switch. |
| ’s contribution in | |
| , | secret random nonce |
| , (, , ) | Coll. Diff. Privacy & params. |
| , | Range, default range |
| , (, , , , ) | Range proof priv., pub. values |
| , | Proofs and sub-proofs verif. thresh. |
| Tot. & records, dataset dim. | |
| , | proof, sub-proof |
| prob. of verif. |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\DeclareCaptionType
copyrightbox
Drynx: Decentralized, Secure, Verifiable System for Statistical Queries and Machine Learning on Distributed Datasets
David Froelicher, Juan R. Troncoso-Pastoriza, Joao Sa Sousa, and Jean-Pierre Hubaux This work was partially supported by the grant #2017-201 of the Strategic Focal Area “Personalized Health and Related Technologies (PHRT)” of the ETH Domain.D. Froelicher is with the Laboratory for Data Security and DeDiS Laboratory, Ecole Polytechnique Federale de Lausanne, 1015 Lausanne, Switzerland, e-mail: [email protected]. Joao Sa Sousa, Juan R. Troncoso-Pastoriza and Jean-Pierre Hubaux are with the Laboratory for Data Security, Ecole Polytechnique Federale de Lausanne, 1015 Lausanne, Switzerland, e-mail: [email protected].
Abstract
Data sharing has become of primary importance in many domains such as big-data analytics, economics and medical research, but remains difficult to achieve when the data are sensitive. In fact, sharing personal information requires individuals’ unconditional consent or is often simply forbidden for privacy and security reasons. In this paper, we propose Drynx, a decentralized system for privacy-conscious statistical analysis on distributed datasets. Drynx relies on a set of computing nodes to enable the computation of statistics such as standard deviation or extrema, and the training and evaluation of machine-learning models on sensitive and distributed data. To ensure data confidentiality and the privacy of the data providers, Drynx combines interactive protocols, homomorphic encryption, zero-knowledge proofs of correctness, and differential privacy. It enables an efficient and decentralized verification of the input data and of all the system’s computations thus provides auditability in a strong adversarial model in which no entity has to be individually trusted. Drynx is highly modular, dynamic and parallelizable. Our evaluation shows that it enables the training of a logistic regression model on a dataset (12 features and 600,000 records) distributed among 12 data providers in less than 2 seconds. The computations are distributed among 6 computing nodes, and Drynx enables the verification of the query execution’s correctness in less than 22 seconds.
Index Terms:
decentralized system, distributed datasets, privacy, statistics, machine learning, homomorphic encryption, zero-knowledge proofs, differential privacy.
I Introduction
To produce meaningful results, statistical and machine-learning analyses often demand large amounts of data. Although data storage and computation costs have dropped over the years, notably due to low-cost and powerful cloud-computing solutions, the sharing of these data is still cumbersome. Massive amounts of data are generated daily to track individuals’ actions, health, shopping habits, interests, political and religious views [1], but privacy concerns and ethical/legal constraints often prohibit or discourage the sharing of personal and sensitive data. In Europe, the new data-protection regulation, General Data Protection Regulation (GDPR) [2], effective since May 2018, requires that (a) the collection and use of personal data can only be done with the consent of the subject and (b) that the data have to be anonymized or encrypted before being shared. This leads to a conundrum, especially in domains such as demography, finance and health, where data have to be shared, e.g., for enabling research, but they also need to be protected to ensure individuals’ fundamental right to privacy. Cross-border data sharing is even more challenging, as the legislations among countries can be heterogeneous, forcing companies to geographically adapt their own privacy measures.
Multiple examples show that even when data can be shared, a centralization of the data can have serious consequences, affecting hundreds of millions of individuals [3, 4]; this was the case with the Equifax breach [4], in which personal information (including social-security numbers and credit-card information) of more than 143 million consumers (about 40% of the US population) was compromised. Centralized solutions are subject to multiple threats as the central database, which stores data from multiple mutually-untrusted sources, constitutes a high-value target for possible attackers and a single point of failure.
Existing solutions for secure databases [5, 6, 7, 8, 9] usually add a cryptographic layer on top of the query engine or focus exclusively on the data-release privacy, e.g., by using differential privacy. However, most of these solutions have a significant performance overhead or are still fully centralized hence either have a single point of failure, or do not protect the data during the query execution.
In this context, decentralized data-sharing systems [10, 11, 12, 13, 14, 15] have raised considerable interest and are key enablers for privacy-conscious big-data analysis. By distributing the storage and the computation, thus avoiding single points of failure, these systems enable data sharing and minimize the risks incurred by centralized solutions. Nevertheless, many of these systems rely on honest-but-curious or trusted third-party assumptions that might not provide sufficient guarantees when the data to be shared are highly sensitive, valuable, influential or private. Other solutions with stronger threat models, e.g., UnLynx [16], are limited in the computations they support, e.g., sum only. Moreover, none of these solutions considers the possibility that both computing entities and data providers can be malicious.
Improving upon and using some techniques introduced in UnLynx, we propose Drynx, an operational, decentralized and secure system that enables queriers to compute statistical functions and to train and evaluate machine-learning models on data hosted at different sources, i.e., on distributed datasets. Drynx ensures data confidentiality, data providers’ () privacy and protects individuals’ data from potential inferences stemming from the release of end results, i.e., it ensures differential privacy. It also provides computation correctness. Finally, it ensures that strong outliers, either maliciously or erroneously input by , cannot influence the results beyond a certain limit, and we denote this by results robustness. These guarantees are ensured in a strong adversarial model where no entity has to be individually trusted and a fraction of the system’s entities can be malicious. Drynx relies on interactive protocols, homomorphic encryption, zero-knowledge proofs of correctness and distributed differential privacy. It is scalable, dynamic and modular: Any entity can leave or join the system at any time and Drynx offers security features or properties that can be enforced depending on the application, e.g., differential privacy.
In this paper, we make the following contributions:
- •
We propose Drynx, an efficient, modular and parallel system that enables privacy-preserving statistical queries and the training and evaluation of machine-learning regression models on distributed datasets.
- •
We present a system that provides data confidentiality and individuals’ privacy, even in the presence of a strong adversary. It ensures the correctness of the computations, protects data providers’ privacy and guarantees robustness of query results.
- •
We propose techniques that enable full and lightweight auditability of query execution. Drynx relies on a new efficient distributed solution for storing and verifying proofs of query validity, computation correctness, and input data ranges. We exemplify and evalutate the implementation of this solution by using a blockchain.
- •
We propose and implement an efficient, modular and multi-functionality query-execution pipeline by
- –
introducing Collective Tree Obfuscation, a new distributed protocol that enables a collective and verifiable obfuscation of encrypted data;
- –
presenting multiple data-encoding techniques that enable distributed computations of advanced statistics on homomorphically encrypted data. We propose new encodings, and improvements and adaptations of previously introduced private-aggregation encodings to our framework and security model;
- –
adapting an existing zero-knowledge scheme for input-range validation to our security model;
- –
proposing a new construction of the Key Switching protocol introduced in UnLynx [16], improving both its performance and capabilities.
To the best of our knowledge, Drynx is the only operational system that provides the aforementioned security and privacy guarantees. Drynx implementation is fully available at www.github.com/ldsec/drynx.
II Related Work
Centralized systems for privacy-preserving data sharing [8, 17, 18, 19] and trusted-hardware based solutions [20] usually require one entity, i.e., a central entity or a hardware provider, to be trusted, which constitutes a single point of failure. Even though these systems can be more efficient than their decentralized counterparts, they often require a centralization or outsourcing of the data storage, which goes against regulations or is cumbersome to achieve [21] and can be inappropriate for sensitive data. In Drynx, we avoid these issues by decentralizing data-storage, computation and correctness verification, thus efficiently distributing trust.
In order to execute queries and compute statistics on distributed datasets, multiple decentralized solutions [10, 12, 14, 22, 23, 24, 25] rely on techniques that have a high expressive power, such as secret sharing and garbled circuits. These solutions are often flexible in the computations they offer but usually assume (a) honest-but-curious computing parties and (b) no collusion or a 2-party model. Furthermore, they do not provide a way to check the computations undertaken in the system. Although they might efficiently distribute trust, their strong honesty assumptions are risky when the data or the computed statistics are highly sensitive. Bater et al. [10] enable the evaluation of various SQL queries on datasets hosted by a set of distrustful data providers, but both the data providers and the computing entity are trusted to follow the protocol. Corrigan-Gibbs and Boneh [26] propose Prio, a system that ensures privacy as long as one computing entity out of is honest, but it only guarantees end results robustness in the case where the involved parties are all honest-but-curious. Moreover, Prio does not protect against DPs colluding among themselves or with the computing nodes. In Drynx, no entity has to be individually trusted in order to provide both privacy and robustness.
Systems relying on homomorphic encryption [11, 13, 16, 27, 28, 29] are often limited in the functionalities they offer (e.g., sum only). They present high-performance overhead in comparison with their less secure counterparts or still rely on honest-but-curious parties. In our previous work, we presented UnLynx [16], a decentralized system that enables the computation of (only) sums on distributed datasets and ensures ’ privacy and data confidentiality. UnLynx assumes to be honest-but-curious and, unlike Drynx, it does not ensure end results robustness. Moreover, UnLynx does not provide a practical solution for auditability. In this work, we show how to overcome these limitations and provide a system that enables secure computations of multiple operations in a stronger threat model.
There are multiple solutions proposed for the problem of training machine-learning models on distributed data in a privacy-preserving way [13, 27, 30, 31, 32, 33, 34, 35, 36]. Mohassel and Zhang [30] propose a two-party solution, SecureML; it enables the training of specific models, e.g., linear regression. Boura et al. [31] present a solution that relies on a novel and more flexible approximation of the logistic regression function but assumes honest-but-curious parties. Nikolaenko et al. [27] and Juvekar et al. [32] combine homomorphic encryption and garbled circuits to perform private ridge-regression and neural-network inference, respectively. Aono et al. [33] and Kim et al. [13] rely on homomorphic encryption to train an approximated logistic regression function. Zheng et al. [36] combine homomorphic encryption and distributed convex optimization, in their system called Helen, in order to collaboratively train linear models. Recently, multiple solutions based on federated learning (relying on differential privacy and edge computing) have been proposed [24, 37, 38, 39, 40, 41, 42]. These solutions aim at protecting the resulting model from inference attacks [43, 44]. Some of these works [37, 39] assume a trusted party that holds the data, trains the machine-learning model, and performs the noise addition to achieve differential privacy guarantees. Other works [24, 29, 38, 45, 46] propose solutions for distributed settings in which the parties exchange differentially private model parameters with the help of an untrusted server that trains a collective global model. These approaches are computationally efficient but usually require very high privacy budgets to obtain a useful collective model (due to the noise addition); hence it is unclear what privacy protection they achieve in practice [47]. To this end, some works attempt to obtain more useful models in the distributed setting by combining differential privacy with homomorphic encryption [40, 41] or multi-party computation techniques [42]. However, most of these solutions are specifically tailored, parameterized and optimized for a given operation, e.g. gradient descent, and would require a redesign if used for different operations. Finally, they assume a weaker threat model with honest-but-curious computing parties and, unlike Drynx, they do not enable verification of computation correctness and results robustness.
III Background
We introduce Drynx’s main components and two exemplifying use cases. We describe the cryptographic tools that we use to distribute trust and workload. We present the blockchains that we use to implement our solution to ensure Drynx’s correctness and auditability. Finally, we introduce the notion of differential privacy and verifiable shuffle, which are at the core of our solution to ensure individuals’ privacy.
III-A Use Cases
We illustrate Drynx’s utility in the medical sector, as it is a paradigmatic example where privacy is paramount and data sharing is needed. Recently, multiple initiatives have emerged to realize the promise of personalized medicine and to address the challenges posed by the increasing digitalization of medical data [48, 49, 50]. In this context, the ability to share highly sensitive medical data while protecting patients’ privacy is becoming of primary importance. We illustrate the possible use of Drynx in two specific settings that cover most medical data sharing scenarios: (1) Hospital Data Sharing (), where multiple hospitals enable statistical computations and the training of machine-learning models across their datasets of patients (e.g., [50, 51]), and (2) Personal Data Sharing (), where a medical institute runs studies, e.g., on heart issues, by directly computing on data collected from people’s wearables (e.g., [52, 53]).
III-B ElGamal Homomorphic Encryption
Drynx requires an additively homomorphic cryptosystem; we choose to rely on the Elliptic Curve ElGamal (ECEG) [54], which enables an efficient use of zero-knowledge proofs for correctness [55]. However, Drynx’s functionality is not bound to this choice and can be achieved with other cryptosystems. ECEG relies on the difficulty of computing a discrete logarithm in a finite field; in this case, an Elliptic Curve subgroup of , with a big prime. The encryption of a message is EΩ() = , where is a uniformly-random nonce in , is a base point on an elliptic curve and a public key. The table of symbols is presented in Appendix A. The additive homomorphic property states that EΩ() = EΩ() + EΩ() for any messages and and for any scalars and . In order to decrypt a ciphertext , the holder of the corresponding private key () multiplies and yielding and subtracts this point from . The result is then mapped back to , e.g., by using a hashtable. Drynx relies on fixed-point representation to encrypt floating values.
III-C Zero-Knowledge Proofs
Universally-verifiable zero-knowledge proofs (ZKPs) can be used to ensure computation integrity and to prove that encrypted data are within given ranges. In Drynx, we choose to verify computation integrity by using the proofs for general statements about discrete logarithms, introduced by Camenisch and Stadler [55]. These proofs enable a verifier to check that the prover knows the discrete logarithms and of the public values and and that they satisfy a linear equation
[TABLE]
where , , are public points on . This is done without revealing any information about or .
The input-range validation is done by relying on the proofs proposed by Camenisch and Chaabouni [56], with which we can prove that a secret message lies in a given range with and integers, without disclosing . The prover writes the base-u decomposition of its secret value and commits to the u-ary digits by using the verifier signatures on these digits. The created commitments prove to the verifier that . We present this proof, adapted to our framework, in Algorithm 1. Finally, both proofs can be made non-interactive through the Fiat-Shamir heuristic [57].
III-D Interactive Protocols
Interactive protocols can be used to distribute the computations and the trust among multiple computing nodes . In Drynx, each possesses a private-public key pair (, ) where is a uniformly-random scalar in and is a point on . The ’ collective public key is . The corresponding secret key is never reconstructed such that a message encrypted by using can be decrypted only with the participation of all . An attacker would have to compromise all in order to decrypt a message. As shown in Section V, to produce the intended results, Drynx protocols require the participation of all the .
III-E Blockchains
A blockchain is usually a public, append-only ledger that is distributively maintained by a set of nodes and serves as an immutable ledger [58, 59]. Its main applications are in cryptocurrencies [59, 60] but is also used in other domains, e.g., health care [61]. Data are bundled into blocks that are validated through the consensus [62, 63] of the maintaining nodes. Each block contains a pointer (i.e., a cryptographic hash) to the previous valid block, a timestamp, a nonce, and application-specific data. The chain of these blocks forms the blockchain.
III-F Differential Privacy
Differential privacy is an approach for privacy-preserving reporting results on statistical datasets, introduced by Dwork [64]. This approach guarantees that a given randomized statistic, , computed on a dataset , behaves similarly when computed on a neighbor dataset that differs from in exactly one element. More formally, (, )-differential privacy [65] is defined by , where and are privacy parameters: the closer to 0 they are, the higher the privacy level is. (, )-differential privacy is often achieved by adding noise to the output of a function . This noise can be drawn from the Laplace distribution with mean 0 and scale , where , the sensitivity of the original real valued function , is defined by . Other mechanisms, e.g., relying on a Gaussian distribution, have also been proposed [66, 67].
III-G Verifiable Shuffles
To randomly select a value from a public list of noise values and to ensure differential privacy, we rely on a verifiable shuffle [68, 69, 70, 71]. We implemented and use the verifiable shuffle of ElGamal pairs, described by Neff [69]. This protocol takes as input a list of ElGamal pairs and outputs pairs such that for all , , where is a re-randomization factor, is a permutation and is a public key. The permutation is used to change the order of the ElGamal pairs and is used to modify the value of the ciphertext encrypting a message such that its decryption still outputs . As a result, an adversary not knowing the decryption key and the is unable to link back any ciphertext with a ciphertext . Neff provides a method for proving that such a shuffle is done correctly, i.e., that there exists a permutation and re-randomization factors such that = SHUFFLE{}_{\upsilon,r^{\prime\prime}_{i,j}}$$(input), without revealing anything about or . This is achieved by using honest-verifier zero-knowledge proofs, introduced by Neff [68, 69].
IV System Overview
In this section, we describe the system and threat models, before presenting Drynx’s functionality and security requirements.
IV-A System Model
The system model is represented in Figure 1. For simplicity, we describe here the logical roles in Drynx, and in Section VIII we discuss the fact that a physical node can simultaneously play multiple roles.
A querier can execute a statistical query and the training and evaluation of a machine-learning model on distributed datasets held by . The collectively handle the computations in the system; i.e., from ’s perspective, they emulate a central server and provide answers to her queries. The verifying nodes’ () role is to provide auditability; they collectively verify the query execution and immutably store the corresponding proofs. They enable an auditor, e.g., or an external entity, to easily verify (audit) the correctness of the query execution.
In Drynx’s typical workflow, the query is defined by the querier and is then broadcast to the and . The answer with their encrypted responses that are then collectively aggregated and processed by the , before the result is sent to . We assume that the used data formats are sufficiently homogeneous among different and that the are able to interpret the queries, e.g., there is a common ontology of attributes and the query-language is agreed-on during system setup.
An exemplifying instantiation of this system model in the scenario (Section III-A) would feature the as universities that want to enable researchers () to compute on data held by multiple hospitals (). can be independent or governmental institutions ensuring that data protection regulations are respected.
We assume that the system’s topology and public information, e.g., public keys, are known by all entities. Authentication and authorization are out of scope of this paper and we briefly discuss them in Section VIII.
IV-B Threat Model
We assume a strong threat model:
- •
Queriers. They are considered malicious as they can try to infer information about the from the queries end results or by colluding with other entities in the system.
- •
Computing Nodes. We consider an Anytrust model [72], which means that all Drynx’s security and privacy guarantees (Section IV-D) are ensured, as long as at least one of the is honest-but-curious (or plain honest).
- •
Data Providers. The are considered malicious as they can try to produce an incorrect answer to a query in order to bias the final results. They can also collude with other nodes to infer information about other or about a query end-results.
- •
Verifying Nodes. We assume that a threshold number of the is honest. This threshold, e.g., out of , where is the number of , is defined depending on the consensus algorithm [62, 63] that is used to ensure a correct and immutable storage of the proofs’ verification results.
IV-C Functional Requirements
Drynx enables the computation on distributed datasets of any operation in the family of encodable operations. An encodable operation can be separated in two parts: the ’ local computations and the collective aggregation. In the collective part, the computations are executed on encrypted data and are thus limited by the homomorphism in the used cryptographic scheme, e.g., additions and/or multiplications. ’ computations are executed locally and are therefore not limited.
Definition 1**.**
An encodable operation computed among is defined by:
[TABLE]
in which the encoding is defined by
[TABLE]
where is a vector of values computed on a set of records, where stands for cardinality. is the set of all distributed datasets’ records, is the set of records that belong to , and is a polynomial combination of the outputs of the encodings . The encodings are defined as locally computed functions on the subsets () of each . It is also possible to express an encodable operation as a recursive function:
[TABLE]
In Drynx, for any specific operation , each creates an encoding computed on its set of records . Then, is executed in two parts: the first aggregate all ’ encodings outputs () and, if needed, the querier post-processes on the aggregated result (e.g, if involves information-preserving operations not executable by the CNs under homomorphic encryption).
We give here an instantiation of Definition 1 that enables the computation of the average, and in Section VII we show how an encoding can be instantiated to enable the computation of: sum, count, frequency count, average, variance, standard deviation, cosine similarity, min/max, AND/OR and set intersection/union, and the training and evaluation of linear and logistic regression models.
For example, if wants to compute the average () heart rate over multiple patients across hospitals ( (Section III-A)), each hospital () answers with the encoding of its (encrypted) local sum of each patient’s heart rate (): . These encodings are then (homomorphically) added across all hospitals, and can (decrypt and) compute the global average by using . We remark here that whereas and are application dependent, the workflow is common to all the possible operations.
Finally, in Drynx, an auditor can efficiently audit a query execution. Moreover, the proofs required for auditability are produced such that their creation does not affect the query runtime.
IV-D Security Requirements
Drynx must ensure:
- •
Data confidentiality. The data input by the have to remain confidential at any time. Only is able to see the query answer.
- •
’ privacy. No entity is able to infer information about one single or about any individual storing his data in a ’s database.
- •
Query Execution Correctness. We consider the query execution to be correct when both results robustness and computation correctness requirements are met:
- –
Results robustness. The query results are protected against strong outliers, either maliciously or erroneously input by the .
- –
Computation correctness. Any computation undertaken by the is correctly executed.
V Drynx Design
To overcome the limitations in existing works and meet the requirements presented in the previous section, we propose a novel system model in which we enable query auditability by introducing . Additionally, Drynx provides multiple functionalities in a stronger threat model by relying on that encode locally computed results proven to be within a certain range. It limits the trust in by controlling that their results are in these pre-defined ranges. We propose a system that remains generic and practical while operating in a threat model stronger than existing works. We discuss now the design of this system.
In Drynx’s Security Design (Section V-A), we show how we build Drynx to meet all its security requirements:
- •
In Section V-A1, we introduce a simple query-execution pipeline enabling Drynx’s functionalities and protecting data confidentiality.
- •
In Section V-A2, we build upon the previously introduced query-execution pipeline and explain how to ensure s’ privacy by introducing the new concept of a neutral encoding. This enables a to privately choose whether to answer a query. We also explain how Drynx handles bit-wise operations and maintains ’ privacy. Finally, we introduce distributed differential privacy that is used to ensure that no entity infers information about a single or individual from the query end results.
- •
In Section V-A3, we show how we provide auditability in an efficient way by relying on a set of . We describe how Drynx ensures results robustness by leveraging on range proofs and how all Drynx’s computations can be verified by relying on proofs of correctness.
In Drynx’s Optimized Design (Section V-B), we discuss how to optimize Drynx’s performance:
- •
In Section V-B1, we present Drynx’s full query-execution pipeline. We show how multiple parts of the query execution and verification can be run concurrently thus optimize Drynx’s runtime.
- •
In Section V-B2, we introduce a tradeoff between security and performance by enabling a probabilistic verification of the query execution.
V-A Drynx Security Design
We present Drynx core security architecture.
V-A1 Data Confidentiality
First, we introduce a confidential distributed data-sharing system (Figure 2) that can run the same operations as Drynx, but only meets one of the security requirements: data confidentiality.
We describe the query execution protocol, and sketch the proof of confidentiality for this system. Afterwards, we describe how to enhance this construction to meet Drynx’s other security requirements without breaking data confidentiality.
Initialization. Each and generates its own private-public key-pair . The ’ public keys are then summed up in order to create , the ’ public collective key that is used to encrypt all the processed data. 2. 2.
Query. formulates the query that is broadcast in clear through the to the . Although the querier could directly communicate with the , our choice simplifies the communication scheme and the synchronisation inside the system, as the have to know the query and receive the inputs to perform the computations in the remaining steps. The query defines the operation, the attributes on which the operation is computed, the participating and (optionally) the filtering conditions. Drynx works independently of the query language. We illustrate its use with a SQL-like query to compute the average heart rate among patients for which data are held by :
SELECT average ON WHERE 3. 3.
Retrieval & Encoding. The compute their local answer by following which is defined in the operation encoding (Definition 1). For this purpose, they first locally retrieve the corresponding data. 4. 4.
Encryption. The encrypt their encoded answer under and send the corresponding ciphertexts back to the . 5. 5.
Collective Tree Aggregation (). The collectively aggregate all ’ responses by executing a protocol relying on the Collective Aggregation protocol defined in UnLynx [16]. The are organized into a tree structure such that each waits to receive the aggregation results from its children and sums them up before passing the result on to its own parent. 6. 6.
Collective Tree Key Switching (). The collectively convert the aggregated result, encrypted under , to the same result encrypted under ’s public key , without ever decrypting. This protocol (Protocol 6) is a new construction of the Key Switching proposed in UnLynx [16]. Conceptually, each partially decrypts (i.e., the term in the computation in step 2) and re-encrypts it with ’s public key (i.e., the term in step 2).
[TABLE]
We improve the efficiency of by changing the way the ciphertexts are transformed and by organizing the in a tree structure, thus reducing its execution time. In this structure, multiple can perform their local operations (3 scalar multiplications and 1 addition) in parallel, and the requires aggregations and communications between the nodes. We show the computational complexity of all Drynx protocols in Table II. 7. 7.
Decryption. decrypts and decodes the query results.
Security Arguments. We show that, as long as one is honest, an adversary who controls the remaining , and cannot break data confidentiality. Without loss of generality, we assume that at least one is honest, as only in this case there is data to protect from the adversary. We sketch the proof by relying on the real/ideal simulation paradigm [73] and show that an adversary cannot distinguish a “real” world experiment, in which the adversary is given “real” data (sent by honest ), and an “ideal” world experiment, in which the adversary is given data (e.g., random) generated by a simulator. It can be shown that the send encrypted data that are never decrypted before being aggregated and re-encrypted () under ’s public key. Therefore, due to the cryptosystem’s semantic security, the adversary cannot distinguish between a simulation and a real experiment. It can be seen that data confidentiality is thus ensured during end-to-end query execution:
In Retrieval & Encoding, the operate only on their local data and no external data is seen by any malicious party. In Encryption, the encrypt their responses with and these responses are aggregated, still under encryption, in . The (summed) ciphertexts cannot be decrypted unless all collude, which is not possible as they follow an Anytrust model. Finally, in (Protocol 6), a ciphertext is switched from to ’s public key such that can decrypt:
- •
in * Steps: 1-3. * The ciphertext is encrypted under and thus cannot be decrypted without the collusion of all .
- •
in * Step: 4. * The ciphertext is always where and and can only be decrypted if the collude with , who is the intended recipient of the message.
V-A2 DPs’ Privacy
Drynx protects s’ and individuals’ privacy by ensuring that (a) each can privately decide whether to answer a query, (b) only the result of the operation, as defined by the operation encoding, is disclosed to , and (c) no entity can infer information about a single or individual.
Neutral Response
If a determines that a query can jeopardize its privacy, it can choose to not respond, or answer with a neutral response, thus hiding its refusal to participate in the query without distorting the query results. For this purpose we define neutral response:
Definition 2**.**
A sends a neutral response by defining its response encoding (Definition 1) by , where is the neutral vector such that with being any encoding vector; as computes on 0 records.
In Section VII, we describe how a neutral response can be generated for each listed encoding.
Security Arguments. A not answering a query would suggest (leak) to other entities that this query is too sensitive for it. ’ responses are always encrypted and, due to the indistinguishability property of the underlying cryptosystem, a neutral response is indistinguishable from a non-neutral one, thus effectively hiding the ’s refusal.
Privacy-Preserving Bit-wise Operations
In Drynx, ’ responses are summed through the available additive homomorphism; if these responses are binary, the result of the sum can leak to more than the operation result. For example, when an OR operation is executed over a set of , should only know if the answer is (1) or (0). Nevertheless, if the ’ responses are naively summed, gets the number of that answered ‘1’ and ‘0’. To overcome this issue, we propose the Collective Tree Obfuscation () protocol, detailed in Protocol V-A2. For bit-wise operations, is run between steps and of the query execution. In , the collectively obfuscate a ciphertext by multiplying it with a random secret.
enables privacy-preserving bit-wise operations in Drynx as a ‘1’ is obfuscated to a random value whereas ‘0’ is preserved. To know the result of the operation, only checks if the final value is ‘0’ or not.
[TABLE]
Security Arguments. Protocol V-A2 does not hinder the confidentiality of and indeed obliviously and statistically obfuscates . The confidentiality relies on the cryptosystem’s semantic security, as remains encrypted during the whole protocol execution. A multiplicative blinding of in is defined by , where is a secret scalar value in . The output of the protocol is the encryption of . We can rewrite by separating the contributions of the honest (at least one due to our Anytrust model assumption) and malicious : . Even if an adversary knows , the other term ensures a multiplicative blinding of in .
Distributed Differential Privacy
Drynx relies on the Collective Differential Privacy () protocol, introduced in Unlynx [16], to ensure differential privacy, and prevent information inference about some and/or individuals from the query results. For completeness, we briefly present the (Protocol V-A2) and refer to [16] for more details. The choice of parameters depends on the application’s privacy policy and is out of the scope of this paper.
[TABLE]
Security Arguments. We observe that the list of noise values is verifiably generated from the differential privacy parameters and that all the privately shuffle the values. This protocol’s security is analyzed in details in UnLynx [16].
V-A3 Query Execution Correctness
We first describe how Drynx provides auditability by enabling an efficient verification of the query execution correctness. The latter is achieved by guaranteeing results robustness and computation correctness. The first is ensured by limiting the ’ values to be in a specific range (by means of range proofs) and the second by using ZKPs for all the computations.
Auditability
To provide an efficient solution for the query verification, Drynx relies on a set of that verify the query correctness in parallel to its execution and without affecting its runtime. After each operation, , the and create proofs of correct computations or value range that they sign with their private key (to provide authentication). Their signed proofs are sent to all the . This enables an efficient query execution as the proof creation and verification are executed independently from it.
In order to implement this solution, we can rely on the distributed architecture of the and can provide integrity and immutability by using a blockchain, i.e., the proof blockchain. This enables the public and immutable storage of both the query and its verification results. Moreover, it enables an efficient and lightweight verification of the query correctness. An auditor, e.g., , has only to request the block corresponding to the query, to verify the signatures and to check the query verification results. We detail this in Protocol V-A3 and show an example of the proof blockchain in Figure 3.
[TABLE]
Security Arguments. If an entity trusts a threshold of the , it can verify the query correct execution by checking the corresponding block in the proof blockchain. The verifier can check that nodes agree on the correctness of the proofs. A block is created for every query, even if the proofs are wrong, thus enabling any entity to determine which parties were involved in incorrectly computed queries. Otherwise, as all the proofs are universally verifiable and stored by all , an auditor, not trusting of the , can request the proofs from a subset of them and check the proofs by itself.
Results Robustness
If the querier defines a query with range boundaries on the ’ values, the are requested to create proofs of range by following the algorithm detailed in Algorithm 1. This algorithm is built by adapting the -range proof scheme proposed by Camenisch et al. [56] to the Anytrust model. In this algorithm, the prover, i.e., , writes its secret value in base- and commits to the -ary digits by using the s’ signatures on these digits ( in Algorithm 1). The created commitments complete the proof. To adapt this algorithm to the Anytrust model, the must compute multiple proof elements, i.e., , , , by combining all ’ signatures, i.e., , . This ensures that the uses at least one ’s signature for which it does not know the underlying secret. The same transformation in [56] can be applied to generalize the proof to any range .
Security Arguments. Both the correctness and the zero-knowledge property of the range proof are proven by Camenisch et al. [56].
These proofs are universally verifiable and sound in the Anytrust model. The latter comes from the fact that the elements depending on the ’ secrets are computed as a combination of all their public signatures. As at least one is honest-but-curious, one of the is unknown (not revealed) to the (prover).
Computation Correctness
In order to ensure the correctness of the query execution, each computation executed by a has to be proven correct.
- •
Collective Tree Aggregation. The provide to-be-aggregated input ciphertexts and the resulting ciphertexts that constitute the ZKP.
- •
Collective Tree Obfuscation. The produce an obfuscation proof by relying on Expression (1) in Section III-C. Each multiplies by to obtain the obfuscated ciphertext with (a) and (b) . For both equations, is the discrete logarithm; we have the public values , for (a) and , for (b), which constitute the proof.
- •
Collective Differential Privacy. In this protocol, each sequentially executes a Neff shuffle and produces the corresponding ZKP of correctness described in Section III-G. This proof basically contains the input and output lists, the public key encrypting the ciphertexts, and commitment values.
- •
Collective Tree Key Switching. The create the ZKP by applying Equation (1) in Section III-C, in which we have , , the discrete logarithms of and , respectively. All points , , , and are made public and do not leak any information about the underlying secrets.
Security Arguments. We rely on proofs that are universally verifiable and zero-knowledge. They do not affect data confidentiality beyond what can be inferred from the proven facts themselves.
V-B Drynx Optimized Design
We present Drynx’s final query execution pipeline, before describing how the query verification’s performance can be optimized.
V-B1 Full Query Execution Pipeline
We show Drynx’s full pipeline in Figure 4. Query execution and verification are executed concurrently and multiple steps of the query execution can be executed in parallel. The aggregate each ’s response in , as soon as they receive it. The noise generated from the has to be added after all the results have been aggregated. However, if the differential privacy parameters are predefined, this protocol can be executed independently from the other steps or even pre-computed.
V-B2 Probabilistic Query Verification
To improve the performance of the query verification, we enable a probabilistic verification of the proofs by the . We show that this strategy still enables a verifier to detect a misbehaving entity with a high probability, yet considerably improves performance (see Section IX). A proof for a specific operation (e.g., for a set of ciphertexts ) can have multiple sub-proofs (e.g., for one ciphertext ). One proof is considered incorrect if one or more of the sub-proofs is incorrect. We introduce the two thresholds and that define the probability of verifying a single proof and a sub-proof, respectively. We modify the ’ operations in step 2 of the Query Execution described in Protocol V-A3, by adding this probabilistic verification based on and . Each stores all the proof it receives. It then generates a random value ; if , it starts the probabilistic verification of the sub-proofs. For each sub-proof, the same method is applied, using .
Security Arguments. The probabilistic verification does not necessarily compromise the security level of the system, given that the verification of each proof is redundantly done by each . A proof is verified with a probability , where is the number of , and a sub-proof with a probability . The probability that a proof or a sub-proof is verified by at least nodes is
[TABLE]
where is either (for a proof) or (for a sub-proof). For example, if , and , all the proofs are at least partially verified and each sub-proof is verified by with . Each sub-proof is thus verified by at least of the with a high probability. Due to the honesty assumption, a sub-proof is at least verified by one honest with a high probability. Moreover, the thresholds and can be set to arbitrarily reduce the probability that one sub-proof is not verified by at least one honest node. Therefore, if all the that participated in the verification agree on the result, the auditor knows the proof is correct, otherwise it can either choose to only trust some of the or fetch all proofs and verify them itself, as all the proofs are universally verifiable. For example, an auditor can choose to verify only the proofs that were not checked by any of the she trusts.
VI Security Analysis
We employed only existing, peer-reviewed cryptographic schemes and discussed the composability of the security of the different blocks in previous sections. We corroborate these arguments with a brief summary of the security analysis.
- •
Data confidentiality. In Section V-A1, we sketched the proof for confidentiality in our simplified system and discussed in Section V-A how further design choices do not hinder confidentiality. In summary, data confidentiality is ensured as the data are always encrypted and no operation, e.g., creation, affects it.
- •
’ privacy. can privately decide whether to answer a query, and differential privacy is ensured for the and individuals, which protects them from potential inferences stemming from the release of end results. The latter is ensured in Drynx by blindly adding noise, sampled from a specific distribution, to the query end results. As described in Section V-A2, this noise can be verified to be from a specific distribution (e.g., Laplacian) and no entity knows which noise value is added.
- •
Results robustness. This is ensured as all ’ values can be verified to be within a certain range and all ’ computations must be proven correct, as depicted in Section V-A3. By enforcing the generation of range proofs by , we protect against strong outliers, maliciously or erroneously input, which can significantly distort the query results. can still input incorrect values, but their influence on the final result is limited. We give an intuition on how robust a computation is against such behavior in Section IX-B.
- •
Computation correctness. The proofs of correct computations (Section V-A3) ensure that the ’ answers are correctly aggregated () and that the remaining steps (, , ) are correctly executed.
VII Encodings
We present a set of statistical computations that can be executed in Drynx. We then explain how to instantiate encodings (Definition 1) for the training of both linear and logistic regression machine-learning models. We adapt the logistic regression solution, proposed by Aono et al. [33], to our framework, thus enabling to train this model in a verifiable and privacy-preserving way, even in the presence of a strong adversary. Some of the encodings are adapted from the Corrigan-Gibbs and Boneh [26] system and improved upon.
Numerical Statistics. Table I lists a set of simple statistics that can be performed with Drynx. The sum, mean, variance, std. deviation, cosine similarity (cosim) and R2 operations are executed by requiring the to send the result of their local and partial statistic computation. As an example, for variance, each locally computes the sum of the values (records) that match the query, () where is ’s dataset cardinality, the square of those same values () and generates . These values are independently aggregated among all and the overall variance is computed by , after decryption, using the corresponding (defined in Table I). For the frequency count, are expected to send the vector filled with the number of occurrences () for specific values. The cosine similarity is computed between two vectors and , where each holds a subset of the coefficients of each vector.
Bit-Wise Statistics. As depicted in Table I, bit-wise operations can be executed in two ways: Each either (1) sends a random encrypted integer or (2) sends an encrypted bit . For (1), in the OR (resp. AND) case, each is requested to send an encrypted integer , where if the input is [math] (resp. ), and a random positive integer otherwise. The OR (resp. AND) expression is (resp. ) if the sum . obtains the final result by testing if the output is 0 or not. The result of this operation can be erroneous if , or in other words, if the order of the Elliptic Curve subgroup divides the sum of all ’ random values. This happens only with a probability smaller than (proof in Appendix B). This probability is close to 0 as is much bigger than the decryptable plaintext values, and can be further reduced by repeating the query. Alternatively, in (2) each has to send or encrypted value. This eliminates the error probability but requires more computations and proofs of correctness, as the have to prove that their values are in , and a protocol (Section V-A2) has to be executed to preserve privacy. The min (resp. max) is computed by applying the or operation element-wise among vectors . Each computes its local min (resp. max) in a specified range, e.g., [0:100], which is represented by . Each (resp. ) is encoded with a ‘1’ (or random) and a ‘0’ otherwise. The min (resp. max) across all corresponds to the leftmost (resp. rightmost) position with a ‘1’ in the vector resulting from the OR operation. Similarly, the set intersection (resp. union) is computed by using the AND (resp. OR) operation element-wise on the vectors .
Regression Models.
Linear Regressions. We assume a dataset distributed over the with features and a label value such that . Drynx computes the least-squares linear fit over all the by building a system of equations that can use in order to compute the linear regression coefficients :
[TABLE]
where all the sums are between and . Each sends , , , , , .
Logistic Regressions. We consider again a dataset of records (distributed among the ) with a dimension where each record consists of features and an offset term of 1, and is associated with a label . The original logistic regression cost function is
[TABLE]
where and , is the L2-regularization parameter. can be approximated by a linear function
[TABLE]
by using the fact that , where can be chosen as the first coefficients of the Taylor expansion of , or as the coefficients of the quadratic approximation that minimizes the area between the original function and its approximation. The coefficients are defined by
[TABLE]
where the are computed and encrypted by the before being collectively aggregated by the .
Neutral Response. A neutral response for and and set intersection is , and for other operations.
Optimized and Iterative Encoding Drynx can also be used in order to execute iterative processes, e.g., a k-means algorithm. In this case, each iteration can simply be mapped to a query sent to the system. An iterative process can also be used in order to optimize existing encodings, such as the min and max. In their basic versions, these encodings rely on a -bit vector in which each bit represents a value in a predefined range of size . This means that each sends ciphertexts. This process can be optimized by using a binary-search iterative process as depicted in Protocol VII. In the Range Reduction step, each query only requires one ciphertext per and reduces by half the range of possible answers. This step is repeated until this range is reduced to a predefined size . It must be noted that the execution of other iterative processes would work in a similar way: For example, for a k-means algorithm [74], performs one iteration by executing one query that includes the centroids in clear; the then assign their points to the closest centroid before aggregating their points by cluster; then, the same operation is repeated among all by using Drynx typical query workflow and computes the new centroids. As in Protocol VII and as described below, this algorithm leaks the intermediate results. We do not address the problem of hiding the intermediate results, e.g, by using differential privacy, in this work.
[TABLE]
Security Arguments. For all encoding and in each query, learns the elements of (aggregated over all ) and the (approximate) number of samples considered , as defined by encoding.
For the iterative process, in the Range Reduction, the ’ answers remain confidential, but the range is sent in clear in each query thus revealed to other entities. controls the size of the range of possible values that is leaked by defining an entropy limit . In the final step, the max query is privately executed on the remaining range. This provides a tradeoff between performance and privacy (that we analyze in Section IX). The number of ciphertexts is lowered to , which reduces the amount of computations and proofs by a factor . For example, if wants to know the ’ minimum value in with , the workload is reduced by a factor of and the query leaks a range of 100 possible minimum values.
VIII Discussion and Extensions
We illustrate multiple extensions for Drynx by relying on our use cases, and (Section III-A).
Modularity. Drynx is highly modular and some of its security features can be enabled or disabled, depending on the application. For example, if results robustness is not required, input-range validation can be omitted without hindering Drynx’s execution and the remaining security guarantees are preserved. The same applies for ’ privacy features, e.g., differential privacy.
For example, in , each hospital (or ) locally executes the query on multiple patient records and the range proofs can be omitted if the range of possible values is too broad or if the hospital is trusted to input correct values. Otherwise, the range boundaries have to be set accordingly. In this case, the querier has to use her knowledge on the attributes involved (e.g., age is between 0 and 150) and the information she has on the ’ data (e.g., have a maximum of data samples) to define the ranges. In , the ranges for the input values can be used to enforce tighter bounds (e.g., heart rate can only take values in [40,100] beats-per-minute) as each has one data record.
Drynx also enables the collective protection of data at rest by having locally encrypt their data with the ’ collective key . This limits the flexibility of the system as are then required to pre-compute all necessary inputs (e.g., the square root of the values to enable the computation of the variance) and the range proofs before entering the encrypted data in their databases. It also requires a fixed set of , as only they can operate with that pre-encrypted data.
As mentioned before, Drynx’s primary goal is to guarantee ’ privacy and still enable the queriers to obtain the results of computations performed over multiple databases. For this, Drynx enables optional security and privacy features, such as differential privacy. These features can be enabled or disabled depending on the application requirements, hence enabling multiple trade-offs between security and privacy, performance and accuracy (see below).
Collusion Resistance. Each participant can play multiple roles without hindering Drynx’s security. For example, in , a hospital can be a and also play the role of a , to ensure its data confidentiality without having to trust any other hospital. It can also be a thus take part in the verification process.
Availability. Drynx’s privacy and security guarantees hold even in the case where multiple or become unavailable. Any entity can leave or join the system without hindering Drynx’s operation, as long as they are not involved in a query under execution. In the event of a becoming unresponsive during the query execution, the and steps cannot be finalized, as they both require the participation of all . Therefore, in this case, the process is stopped and can request the same query by choosing another set of , e.g., by excluding the faulty (s). An unresponsive only reduces the number of responses included in the statistic being computed and does not disrupt Drynx’s process. Standard mechanisms, e.g., limiting the rate at which queries are accepted, can be implemented in Drynx to avoid DDoS attacks.
**Accuracy. There are several aspects that can influence output precision in Drynx. (a) We first remark that the ’ inputs to the system have to be approximated by fixed-point representation if they are floating values, as explained in Section III-B.
(b) Drynx’s encodings and query executions do not intrinsically hinder the accuracy of the computed results, as all operations are exact, as long as the target function is exactly encodable. In fact, it is worth noting that the encoding for the logistic regression training is built from an approximation of the original cost function.
Additionally, (c) the can privately decide whether to answer a query; this choice can influence the final result. However, the number of samples considered in the computation, i.e., in Definition 1, is always sent to , who can then observe if this number changed since her last query. It also enables her to take an informed decision on the statistical significance of the results, to accept them or not.
(d) Drynx can guarantee differential privacy by adding noise to the final result. In this case, Drynx returns approximate results, and the accuracy loss depends on the chosen privacy parameters and the executed operation. The choice of these parameters and the perturbation introduced in the results is thus orthogonal to this work.
Finally, (e) malicious can try to distort the query result by inputting erroneous values. Drynx limits malicious ’ influence on the final result by enabling the querier to restrict the range of possible inputs. This bounds the perturbation that some can generate on the results. If the inputs were not bounded, one malicious could completely distort the final result by inputting extreme values. It is difficult to provide hard numbers for the accuracy of Drynx in the presence of malicious , as it depends on many parameters such as the executed operation, the chosen input ranges, the number of and data records. Nonetheless, in Section IX we show how the use of ranges limits the influence of malicious in two examples.**
Authentication/Authorization. Authentication and authorization fall out of the scope of this paper, but for the sake of completeness we briefly mention here that Drynx can integrate off-the-shelf solutions based on federated or distributed architectures [75, 76, 77].
IX Performance Evaluation
We discuss our experimental setup and evaluate Drynx’s performance. We show that it scales almost (in some cases better than) linearly with the number of , and , and we compare Drynx against existing solutions. We also discuss multiple security, privacy and performance tradeoffs.
IX-A System Implementation
We implemented Drynx in Go [78], and our full code is publicly available [79]. We relied on Go’s native crypto-library and on public advanced crypto-libraries [80]. For the implementation of the proofs’ storage and verification, we use a skipchain [81], which is made of blockchain-like blocks that, to enable clients to efficiently navigate arbitrarily on the chain, also contain back-and-forward pointers to older and future blocks. We rely on a (private) permissioned blockchain [82], as in our examples and (Section III-A), the participants, i.e., researchers, patients or hospitals, have to be known and authorized. However, Drynx works independently of the blockchain type, and a permission-less blockchain can also be used in a less restrictive scenario. Drynx works independently of the used Elliptic Curve; we tested it on the Ed25519 [83] and bn256 Elliptic Curves [84]. Both curves provide 128-bit security, and we used bn256 by default as it enables pairing operations (required for range proofs). Our prototype is built as a modular library of protocols that can be combined in multiple ways. The communication between different participants relies on TCP with authenticated channels (through TLS).
IX-B System Evaluation
We used Mininet [85] to simulate a realistic virtual network between the nodes; we restricted the bandwidth of all connections between nodes to 100Mbps and imposed a latency of 20ms on all communication links. We evenly distributed the , , and on a set of 13 machines that have two Intel Xeon E5-2680 v3 CPUs with a 2.5GHz frequency that supports 24 threads on 12 cores and 256GB RAM.
We begin our evaluation by studying how the different steps in Drynx’s pipeline can be executed in parallel. We then show that Drynx’s runtime only slightly increases when the number of records per grows (and the number of remains constant).
In our default setup, we consider 6 CNs and 7 VNs. We set the proof verification thresholds and and show, in Section IX-B1, the effect of these thresholds on Drynx’s execution time. The joint use of these thresholds ensures that all the proofs are at least partially verified and that each sub-proof is verified by with a probability of . We show Drynx’runtime without the protocol as can be pre-computed or run in parallel with other steps. We notice that the ’s runtime depends on the number of and on the size of the list of noise values. This creates a tradeoff between privacy and performance as a greater provides a higher privacy level, as it reduces but also increases the time to generate and shuffle the list of noise values. With a Laplacian distribution and , ’s runtime is 2.9 seconds with an overhead of 8.1 seconds for the proof verification.
IX-B1 Drynx Evaluation
Parallel Execution. Figure 5(a) shows the runtime for training a logistic regression model. We use a randomly-generated dataset of 12 floating-point features and 600,000 records split among 12 . We remark that the operations are verified in parallel to the query execution; this parallelization enables to obtain the query results as soon as it is computed (denoted by query execution dashed line). At the end of the verification process, an auditor can check the query by verifying the signature and the query-proofs map of the corresponding block in the proofs blockchain, which in this case takes 0.4 seconds. The blocks’ sizes are small as they only contain the query and the corresponding query-proofs map; in this example one block is 56kB.
Scaling. We show how Drynx’s execution time evolves with an increasing number of data records (Figure 5(b)), and (Figure 5(c)) and (Figure 5(d)). Inspired by and , we simulate the computation of the heart-rate variance (values between ) over a set of distributed patients. In Figure 5(b), we observe that Drynx scales better with (a) the number of records per (and fixed number of ) than (b) with the number of ; case (a) represents , where a is an hospital with a database of multiple patients, whereas case (b) represents , where each patient is a ( ). This is because (a) enables the to locally pre-aggregate their data, thus reducing the amount of proofs and computations. For Figures 5(c) and 5(d) and for the remaining part of the evaluation, we set the number of to 10 per . In , this could correspond to a use case in which some are hospitals and the others are independent doctors sharing their data. We observe that Drynx’s runtime increases with the number of , , and . However, an increasing number of and also means a higher security level, as the trust is distributed among more entities.
Operations. Figure 5(e) shows Drynx’s runtime for all the operations with a large integer range of for each of the ’ inputs (the size of the ’ inputs is shown below each operation). We observe that for all operations, the query execution time is always below 1.5 seconds; and the overhead incurred by the proofs verification increases with the size of the ’ inputs. This is expected, as the larger the DPs’ inputs become, the more ciphertexts there are for the system to process, and more proofs there are to verify. We also observe that bit-wise operations take more time when the opt to send a bit value that is then obfuscated (using the protocol).
Verification Thresholds. In Figure 5(f), we show how the different thresholds on the proofs verification affect Drynx’s performance with a variance query. It can be seen that sending the proofs (communication time is denoted by a dashed line) is the most time consuming part, and that reducing the thresholds reduces the verification time. For example, by having and , we effectively reduce the verification workload by a factor close to 0.8, and a sub-proof is still verified by of the with a high probability ().
Malicious DPs. By enforcing ’ values to be within a specific range, Drynx limits the influence of malicious on the computed statistic. We illustrate this in a simple and realistic example (using from Section III-A) by computing the average heart rate over a dataset of 8922 hypertensive patients [86]. The real heart-rate values are limited to be between 40 bpm (beats per minute) and 100 bpm and, as presented by Lorgis et al. [86], the average value obtained among honest is 70 bpm with a 95% confidence interval of bpm. Each patient () must send (Definition 1), in which has to be in and in . In order to maximize the result’s distortion, a malicious can send an extreme value, which is within the range bounds. We assume that all malicious collude and send the same value , and that the computed average is given by , where and are the numbers of honest and dishonest , and is the sum of sent by malicious . The relative error is . We remark that a malicious can maximize this error with a valid input by sending . In Figure 5(g), we observe that with 1% of malicious for the range [40,100], the highest relative error is . This error corresponds to 1 bpm, still in the 95% confidence interval. We observe similar results when the cosine similarity is computed in the same settings. For this example, we also present the worst-case scenario in which the cosine similarity computed on the honest is 1 and the malicious input extreme values from the range of accepted values to reduce the similarity. As shown in Figure 5(g), these numbers highly depend on the chosen bounds. Even if many other factors influence this error (e.g., the computed operation and the distribution of the values), it shows that Drynx can limit the power of malicious .
Iterative Queries. Figure 5(h) depicts how Drynx’s runtime can be reduced by using multiple queries to execute a min/max operation in a binary-search style. This represents a tradeoff between privacy and performance, as each iterative query is sent in clear, leaking the interval where the min/max value is. We assume that sets the entropy limit , in other words, another entity in the system can learn that the min/max is in an interval of at least 100 values. The precise value is kept private. We observe that the execution time is not improved when the range is small, but is greatly reduced when the range grows, reaching an execution time reduction of almost at a range size of 100,000.
Communication. Figure 5(i) depicts Drynx’s runtime evolution with respect to both the communication delay and bandwidth capacity with a heart rate variance query. We remark that when the latter is reduced by a factor 100, the runtime increases by a factor 2 or 3. This shows that our system is more sensitive to communication delay than bandwidth capacity.
Bandwidth. In Table II, we present the computation and bandwidth complexities for 1 ciphertext (i.e., 2 points (2p) on the Elliptic Curve, 2p = 64 bytes) per . We use , , and as the numbers of corresponding entities in the system. is the size of the Schnorr signature [57] ( bytes), is the hash size ( bytes), comes from the range for the range proofs (), is a pairing point’s size ( bytes) and is the number of values that are used in the (). We do not include the computational complexity for the local computations executed by the and . We refer to Neff’s work [69] for the complexity of the verifiable shuffle (). We observe that when the number of and increases, the computational, bandwidth and storage costs increase for all the steps. As having more or improves the security and the distribution of the workload in the system, it creates a tradeoff between security, efficiency, and scalability.
IX-B2 Comparison with Existing Works
We supplement the related work’s overview, described in Section II, by presenting here a qualitative and quantitative comparison with multiple systems that are Drynx’s closest related works. We compare Drynx against SMCQL [10], UnLynx [16], Prio [26], Boura et al. [31], Aono et al. [33], Kim et al. [13] and Gazelle [32]. In Table 6(a), we show that Drynx provides several functionalities in a strong threat model and achieves results that can rival with other secure and dedicated approaches, notably in the training of logistic regression models as depicted in Figure 6(a). Drynx performs as well or better than its two closest related works, UnLynx and Prio, and provides better security guarantees.
We observe that solutions based exclusively on secret sharing and garbled circuits, namely SMCQL [10], Prio [26] and Boura et al. [31], offer multiple or advanced functionalities but fail to provide proofs of correct executions. Systems solely based on homomorphic encryption (HE), namely UnLynx [16], Aono et al. [33], Helen [36] and Kim et al. [13], are limited in the functionalities they offer. Furthermore, Aono et al. [33] and Kim et al. [13] rely on data centralization. Gazelle [32] combines HE and garbled circuits and enables complex evaluations of neural networks, but does not protect ’ privacy or provide computation correctness. Contrarily, Drynx enables multiple operations while distributing trust, computations, and data storage, and it provides strict security guarantees in a stronger adversarial model.
We quantitatively compare Drynx to Unlynx [16] and Prio [26], which are, to the best of our knowledge, the closest prior works. Drynx’s query execution time for the sum is faster than UnLynx, as we improved the protocol by enabling its execution in a tree fashion, thus reducing its execution complexity from to . Unlike UnLynx, Drynx enables the verification of ’ value ranges, which, for the computation of a sum, adds an overhead of only 0.6 seconds (out of a total time of 2 seconds, as depicted in Figure 5(e)). However, Drynx enables a faster scalable verification of proofs by an auditor. After the proofs are verified and the results stored in the proof blockchain, an auditor can simply request and verify the corresponding block, which in this case takes approximately 0.4s. In Unlynx, an auditor has to request the proofs from each entity and verify them by itself, which takes 1.4s.
Prio [26] relies on secret-shared non-interactive proofs that are created by the to prove the correctness of their inputs to the system and that are collectively verified by the . Even though both systems have similar functionalities, Prio provides input-range verification and computation correctness only when all the are honest-but-curious. We adapted the Gorrigan-Gibbs prototype implementation [91] of Prio to a similar deployment environment as Drynx so that both use the same communication settings, thus enabling a fair comparison. In Figure 6(b), we compare Prio’s runtime in an illustrative example by using the min operation on the range with increasing number of and , against multiple settings of Drynx. This figure shows that Drynx significantly outperforms Prio when computing min without using obfuscation () hence accepts a small probability of error () and avoids the need for range proofs. If we use obfuscation, Drynx scales similarly as Prio, but it must be noted that Drynx performs its operations in a stronger threat model. When used in Prio’s threat model (delimited by a black line), Drynx is about two times faster. This is because each range proof can be sent and verified by a single as all are considered honest-but-curious under Prio’s threat model.
X Conclusion
We have proposed Drynx, a novel system that enables a querier to compute statistics and train machine-learning models on distributed datasets in a strong adversarial model where no entity is individually trusted. Drynx provides query-execution auditability and ensures the end-to-end confidentiality of the data. It protects the privacy of the data providers and relies on an immutable and distributed ledger to provide efficient correctness verification and proofs storage. Drynx is highly modular, offering configurable tradeoffs between security, privacy, and efficiency. Finally, Drynx enables privacy-preserving computations of widely-used statistics on sensitive and distributed data, thus offering features that are absolutely needed in crucial areas such as user-behavior analysis or research for personalized medicine.
Acknowledgment
The authors would like to thank Henry Corrigan-Gibbs and all members of the Laboratory for Data Security at EPFL for their helpful feedback and their support.
Appendix A Table of Symbols
Appendix B Error Probability
In Section VII, we notice that the result of bit-wise operations, when are requested to answer with random values , can be erroneous with a probability smaller than . We demonstrate here this result and provide an expression for the probability of error where is the number of .
[TABLE]
We have and .
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] “Big Data Privacy is a Bigger Issue Than You Think.” https://www.techrepublic.com/article/big-data-privacy-is-a-bigger-issue-than-you-think (25.06.2018).
- 2[2] “GDPR,” https://www.eugdpr.org (25.07.2018).
- 3[3] “A new data breach may have exposed … every American adult,” https://tinyurl.com/ydz 7jpdk (4.02.2019).
- 4[4] “Equifax Breach,” https://tinyurl.com/y 9h 4pgsk (4.02.2019).
- 5[5] V. Bindschaedler, R. Shokri, and C. A. Gunter, “Plausible deniability for privacy-preserving data synthesis,” VLDB , vol. 10, no. 5, 2017.
- 6[6] X. Hu, M. Yuan, J. Yao, Y. Deng, L. Chen, Q. Yang, H. Guan, and J. Zeng, “Differential Privacy in Telco Big Data Platform,” VLDB , vol. 8, no. 12, 2015.
- 7[7] N. Johnson, J. P. Near, and D. Song, “Towards Practical Differential Privacy for SQL Queries,” VLDB , vol. 11, no. 5, 2018.
- 8[8] R. A. Popa, C. Redfield, N. Zeldovich, and H. Balakrishnan, “Crypt DB: protecting confidentiality with encrypted query processing,” in SOSP . ACM, 2011.
