Visual SLAM: Why Bundle Adjust?
\'Alvaro Parra, Tat-Jun Chin, Anders Eriksson, Ian Reid

TL;DR
This paper proposes replacing bundle adjustment in visual SLAM with rotation averaging and a quasi-convex formulation, simplifying the process and improving robustness during slow or rotational movements.
Contribution
It introduces a novel SLAM optimization approach that avoids the complexities of bundle adjustment by focusing on rotation averaging and efficient position estimation.
Findings
Simplifies SLAM by removing the need for full bundle adjustment.
Improves robustness during slow or rotational motions.
Achieves globally optimal camera position estimation.
Abstract
Bundle adjustment plays a vital role in feature-based monocular SLAM. In many modern SLAM pipelines, bundle adjustment is performed to estimate the 6DOF camera trajectory and 3D map (3D point cloud) from the input feature tracks. However, two fundamental weaknesses plague SLAM systems based on bundle adjustment. First, the need to carefully initialise bundle adjustment means that all variables, in particular the map, must be estimated as accurately as possible and maintained over time, which makes the overall algorithm cumbersome. Second, since estimating the 3D structure (which requires sufficient baseline) is inherent in bundle adjustment, the SLAM algorithm will encounter difficulties during periods of slow motion or pure rotational motion. We propose a different SLAM optimisation core: instead of bundle adjustment, we conduct rotation averaging to incrementally optimise only…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1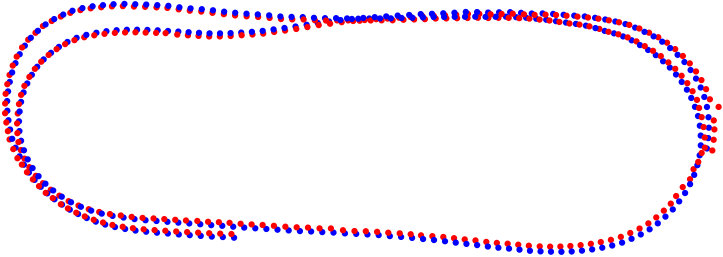 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4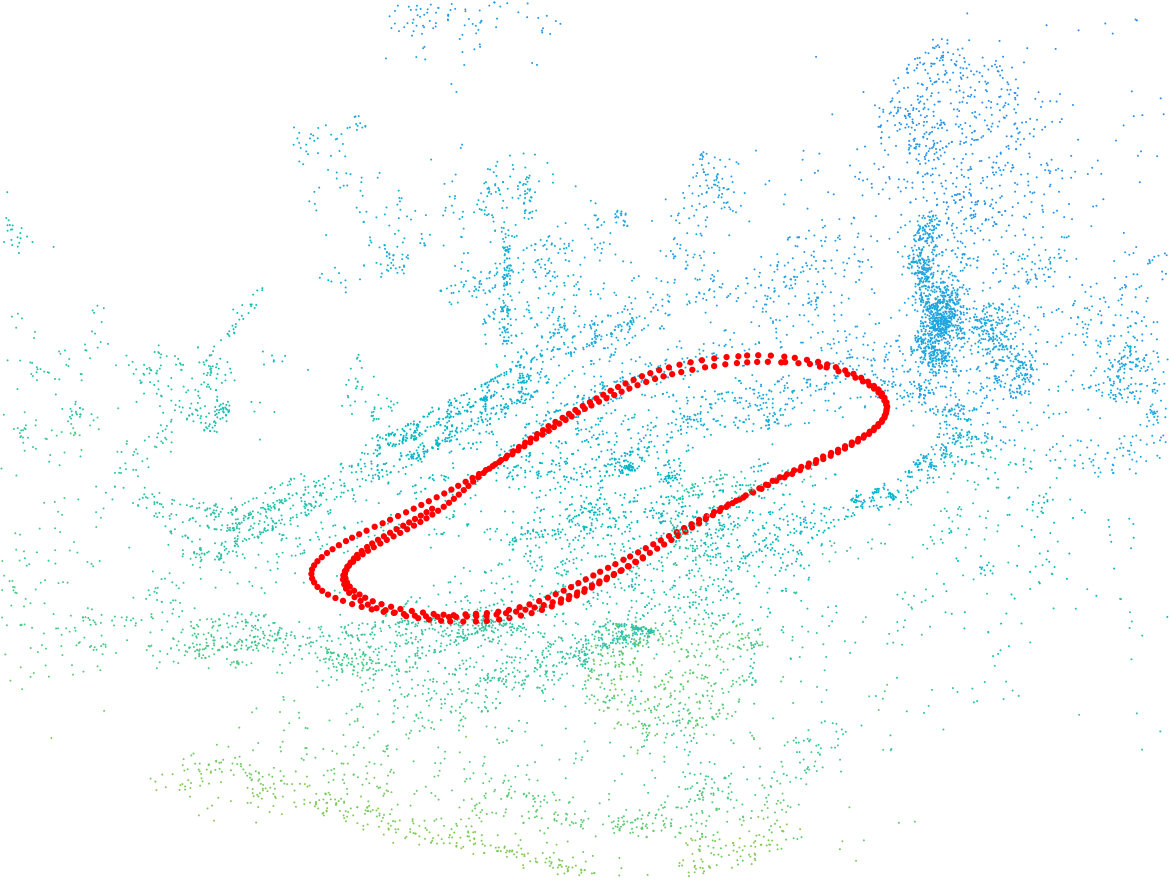 Figure 5
Figure 5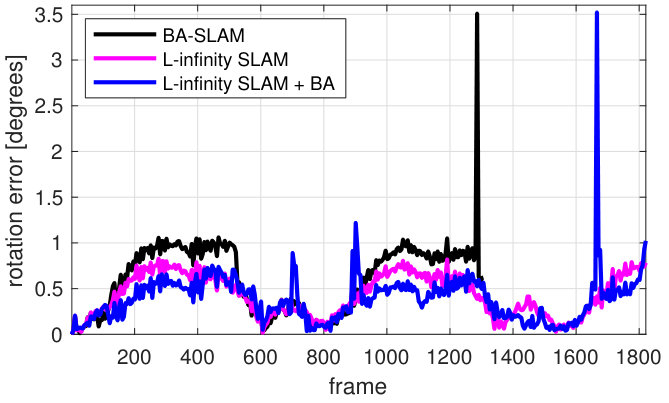 Figure 6
Figure 6 Figure 7
Figure 7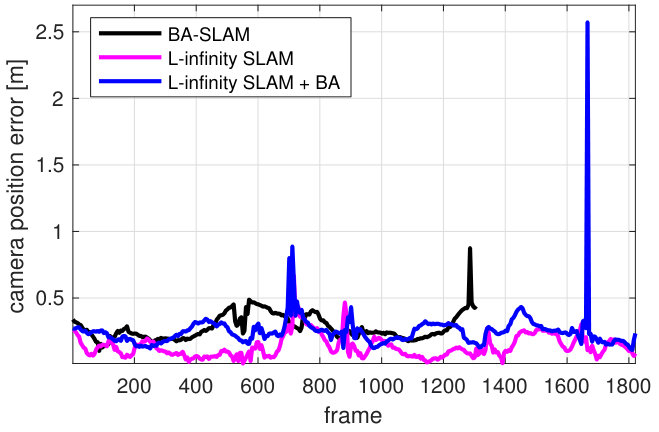 Figure 8
Figure 8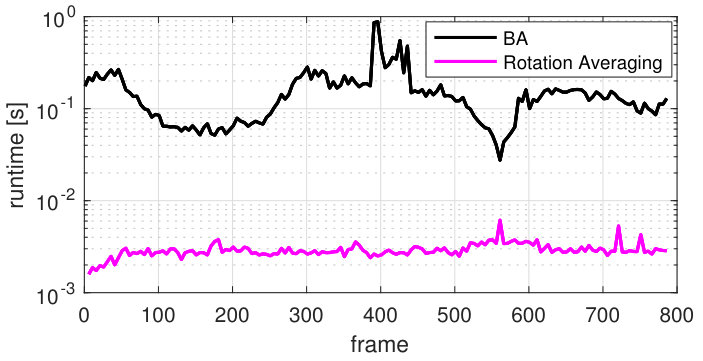 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12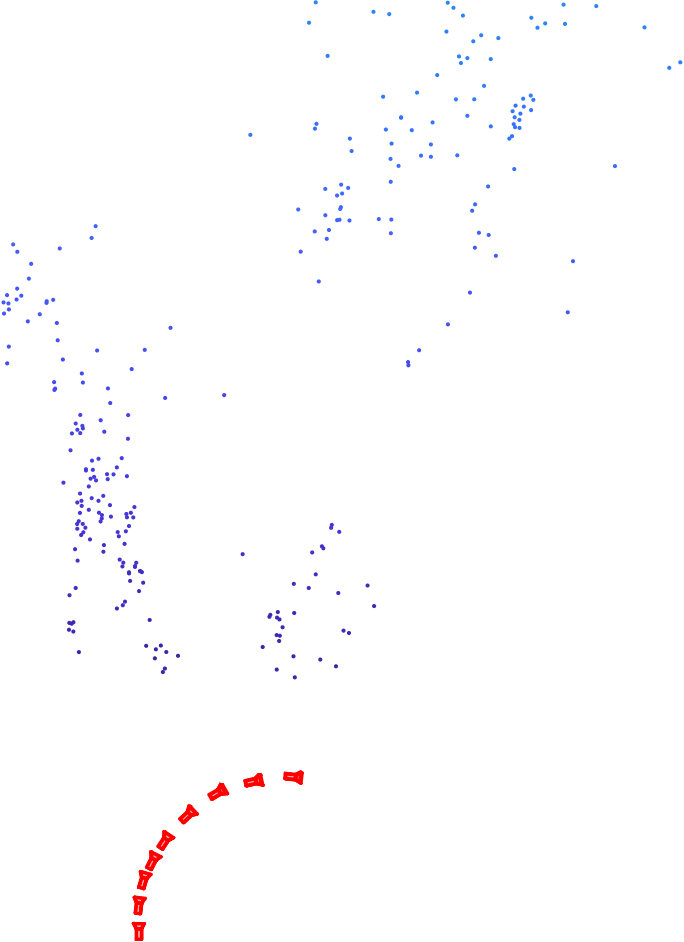 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Visual SLAM: Why Bundle Adjust?
Álvaro Parra Bustos1, Tat-Jun Chin1, Anders Eriksson2 and Ian Reid1 1School of Computer Science, The University of Adelaide.2School of Electrical Engineering and Computer Science, Queensland University of Technology
Abstract
Bundle adjustment plays a vital role in feature-based monocular SLAM. In many modern SLAM pipelines, bundle adjustment is performed to estimate the 6DOF camera trajectory and 3D map (3D point cloud) from the input feature tracks. However, two fundamental weaknesses plague SLAM systems based on bundle adjustment. First, the need to carefully initialise bundle adjustment means that all variables, in particular the map, must be estimated as accurately as possible and maintained over time, which makes the overall algorithm cumbersome. Second, since estimating the 3D structure (which requires sufficient baseline) is inherent in bundle adjustment, the SLAM algorithm will encounter difficulties during periods of slow motion or pure rotational motion.
We propose a different SLAM optimisation core: instead of bundle adjustment, we conduct rotation averaging to incrementally optimise only camera orientations. Given the orientations, we estimate the camera positions and 3D points via a quasi-convex formulation that can be solved efficiently and globally optimally. Our approach not only obviates the need to estimate and maintain the positions and 3D map at keyframe rate (which enables simpler SLAM systems), it is also more capable of handling slow motions or pure rotational motions.
I INTRODUCTION
Let be the 2D coordinates of the -th scene point as seen in the -th image . Given a set of observations, structure-from-motion (SfM) aims to estimate the 3D coordinates of the scene points and 6DOF poses of the images that agree with the observations. The bundle adjustment (BA) formulation is
[TABLE]
where is the projection of onto (assuming calibrated cameras). In practice, not all are visible in every , thus some of the terms are dropped. For ease of exposition, we follow [1] and regard the image set as inputs to BA, bearing in mind that the effective inputs are the observations and the visibility matrix.
As a non-linear least squares problem, (1) is usually solved by gradient descent methods, e.g., Levenberg-Marquardt, which require initialisation for all unknowns. Thus, apart from the images , the total inputs to a BA instance typically include the initial values for and .
BA is justifiable in the maximum likelihood sense if the errors due to the uncertainty in localising the feature points are Normally distributed. However, it is not obvious that available feature detectors satisfy this property [2, 3, 4]. While this does not reduce the usefulness of BA, its statistical validity should not be taken for granted.
I-A BA-SLAM
Roughly speaking, monocular feature-based SLAM [5] (henceforth, “SLAM”) is the execution of SfM incrementally to process streaming input images , where
[TABLE]
Several influential works [6, 7, 1, 8] have cemented the importance of BA in SLAM. Algorithm 1, which is adapted from [1, Table 1], describes a SLAM optimisation core based on BA over keyframes. Specifically:
- •
In Step 5, new scene points are “spawned” if the current frame does not adequately observe the map .
- •
In Step 7 (a.k.a. local mappping), BA is used to estimate the camera trajectory and 3D map in the current time window. Often, local mapping is preceded by camera tracking to accurately initialise the current pose . See [1, Sec. 5.3] or [8, Sec. V] for examples.
- •
In Step 9 (a.k.a. loop closure), a system-wide BA is executed to reoptimise all the variables and redistribute accumulated drift errors. Implicit in Algorithm 1 is the introduction of covisibility information between and older keyframes, prior to BA. Often, Step 9 is preceded by pose graph optimisation [9, 10, 11, 12] to give a more accurate initialisation of the poses.
Note that Algorithm 1 is merely a “basic recipe” for SLAM. In practice, “what will make or break a real-time SLAM system are all the (often heuristic) nitty-gritty details” [13], e.g., how to select features/keyframes, how to update the covisibility graph, how to select/merge/prune 3D points, etc. However, since our focus is on optimisation, Algorithm 1 is sufficient to capture the core algorithmic elements of SLAM systems based on BA, such as ORB-SLAM [8].
I-B Why do we want an alternative to BA-SLAM?
I-B1 High system complexity
Besides computing the trajectory and map in the current vicinity, Step 7 in BA-SLAM plays a more basic role: incrementally estimating the variables in small BA “chunks” to serve as initialisation for the system-wide BA in Step 9. Note that since (1) is amenable to only locally optimal solutions, without good initial values for the large number of variables (poses and 3D points), Step 9 will converge to poor solutions.
Therefore, unavoidably all variables must be estimated as accurately as possible and updated at keyframe rate throughout the lifetime of the algorithm—we argue that this increases the complexity of SLAM systems. For example, while Algorithm 1 shows only the creation of new 3D points (Step 5), in a practical system (e.g., [8]) a host of other heuristics are required for map maintenance, e.g., map point selection, point culling, map updating and aggregation. Many of these heuristics contain a number of thresholds, which, if not tuned carefully, will lead to system failure.
I-B2 Difficulties due to pure rotational motion
More fundamentally, since the estimation of 3D points (which require sufficient baseline) are essential, it is unavoidable that a system based on BA-SLAM will encounter numerical issues during periods of pure rotational motion or slow motion [14, Sec. 7.1], and will require special treatment to deal with this problem [15, 16, 17, 18]. This issue is particularly acute at the start of the sequence where the camera is usually slow moving111Pioneers of monocular SLAM [5] call the deliberate motion to initialise a SLAM algorithm the “SLAM wiggle”.. For example, in ORB-SLAM, elaborate map initialisation heuristics [8, Sec. IV] (cf. Step 1 in Algorithm 1) are used to combat inaccuracies due to insufficient translations. However, experienced users of ORB-SLAM cite its difficulty to initialise on challenging image sequences.
II L-infinity SLAM
Towards simpler visual SLAM systems, we propose a novel optimisation core called L-infinity SLAM; see Algorithm 2. A main distinguishing factor is that the online effort (Steps 4 and 8) are devoted to estimating only the camera orientations via rotation averaging [19, 20]. Given the orientations, a separate optimisation via the known rotation problem [21, 22] (Steps 5 and 9) is conducted to obtain the camera positions and 3D map—since rotation averaging can be done independently from position and map estimation, Steps 5 and 9 can be performed in a lower priority thread.
II-A Rotation averaging and known rotation problem
Given a set of relative rotations between pairs of overlapping images , the goal of rotation averaging is to estimate the absolute rotations that are consistent with the relative rotations (Sec. III-A will provide details on estimating relative rotations in our work). Following [20], we chose the chordal metric for rotations, which yields the rotation averaging formulation
[TABLE]
where is the covisibility graph. In Step 3 of L-infinity SLAM, the covisibility graph in the window is used, while in Step 8, the system-wide covisibility graph (updated to account for loop closure) is used. Sec. III will describe the specific algorithm for (3).
Given a set of absolute camera orientations , the known rotation problem (KRot) [21] optimises the camera positions and 3D points as
[TABLE]
subject to cheirality constraints (details in Sec. III). Observe that unlike (1) which minimises the sum of squared reprojection errors, (4) minimises the maximum reprojection error, which can be viewed as the -norm of the vector of reprojection errors (leading to the name “L-infinity SLAM”).
At this juncture, it is vital to note that (4) is quasi-convex, which is amenable to efficient global solution [21, 22]. In our work, a novel variant of KRot is proposed specifically for the loop closure optimisation in Step 9; details in Sec. III.
II-B Benefits of L-infinity SLAM
II-B1 Simplicity
As alluded to above, tracking and loop-closing in L-infinity SLAM estimate only orientations. Since positions and 3D map are obtained via an independent optimisation problem that can be solved globally optimally, the results of Steps 5 and 9 do not affect the results of subsequent instances222Their results can be used to warm start the subsequent instances, but this is an optional computational consideration.. Therefore, there is no need to accurately calculate positions and 3D map on-the-fly and maintain/propagate them. Note that in Algorithm 2, Steps 5 and 9 are shown mainly to make the overall functionality of L-infinity SLAM equivalent to BA-SLAM. Contrast this to the equivalent steps in BA-SLAM (Steps 7 and 9 in Algorithm 1), whose resulting quality are vital at all times to ensure correct operation.
A signficant advantage of the processing flow of L-infinity SLAM is that many tasks related to map maintenance (e.g., feature/map point selection, point culling, map updating and aggregation) can be done in a low priority thread, or even offline if there is no need for on-the-fly position and map estimation (e.g., the application in [23]). This has the potential to significantly simplify visual SLAM systems.
II-B2 Handling pure rotation motion
It is well-known that under epipolar geometry, camera orientation can be estimated independently from the translation [24]. Hence, since the online routines in L-infinity SLAM estimate orientations only, a real-time system based on L-infinity SLAM is less likely to encounter difficulties due to pure or close-to-pure rotational motions. Potential numerical issues due to insufficient baselines between camera views can be handled in the low-priority thread that estimates position and 3D map. Sec. IV-B will provide results that illustrate this advantage of L-infinity SLAM over BA-SLAM.
II-C Concerns on global optimality and outliers
Some readers may find it disconcerting that in L-infinity SLAM the estimation of the variables are detached. First, note that we have not claimed that L-infinity SLAM is globally optimal in all variables. Second, there is ample evidence [25, 20] that rotation averaging algorithms are capable of producing highly-accurate orientation estimates, independently from positions and 3D points. Since the quasiconvex estimation for positions and 3D points is globally optimal, the overall quality of L-infinity SLAM will be high, as we will demonstrate in Sec. IV.
Also, a common impression of estimation is its sensitivity to outliers. Note, however, that both the and norms have a breakdown point of 0 [26], hence both norms are equally susceptible to outliers. In practical BA-SLAM systems, a typical remedy is to pass the residual through an isotropic robust norm (e.g., Cauchy norm). Likewise, there are efficient and theoretically justified techniques to identify and remove outliers in estimation [27, 28]. Hence, outliers do not present a problem for L-infinity SLAM.
III Algorithmic details
In this section, we describe the details of the core optimisation routines in L-infinity SLAM. Consider a calibrated camera with the camera intrinsic matrix. Let
[TABLE]
be the projection matrix of the j-th image with assumed known rotation matrix in and unknown translation vector in . For simplicity, we assume . For an arbitrary , derivations are still valid if camera extrinsics are recovered by applying to and , which now form the three first columns and the last column of .
III-A Estimating relative motions
L-infinity SLAM estimates camera rotations from relative camera rotations in the covisibility graph . We simply estimate from the essential matrix which can be decomposed into and a relative translation direction (). A weakness of this decomposition is the need of images with sufficient displacement; however, other methods can be used to estimate relative motions [24, 29, 30]. In the case of low displacement, we estimated by rotationally aligning backprojected feature rays by using a rotation only variant of Trimmed ICP [31].
III-B Rotation averaging
Several methods exist to solve (3) [32, 19, 33, 20]. Here we adopt the robust method of [33] which uses an iteratively reweighted least-squares approach in . The method in [33] is simpler than BA as, for example, no linearisation and no estimation of a damping factor is required.
III-C Known rotation problem
By referring to as the first two rows of , and to as the third row of (similarly for and ), the projection of onto the -th image is given by
[TABLE]
and the known rotation problem (4) can be rewritten by adding an extra variable as
[TABLE]
where
[TABLE]
Cheirality constraints (7c) impose to to lie in front of the cameras in which is visible.
Intuitively, defines the sublevel sets of the objective in (4), i.e., the maximum over the LHS of (7b). For a fixed ,
[TABLE]
defines a convex set hence the objective is quasi-convex and is a quasi-convex problem. For a detailed proof of being a quasi-convex problem the reader can refer to [34].
III-C1 Solving the known rotation problem
can be rewritten as
[TABLE]
in which the Cheirality constraints (7c) are implicit in (11b) as both the LHS of (11b) and are non-negative. If is fixed, constraints (11b) became second-order cones which allows to solve () by using bisection trough SOCP feasibility tests [21]. Several other methods solve through SOCP sub-problems. [35] shown that Gugat’s algorithm [36] outperforms among this type of methods (bisection, Brent’s algorithm[37], and Dinkelbach’s algorithm [38, 22]). Recently, Zhang et al. [39] presented a method, named Res-Int, which outperformed existent methods by alternating between pose estimation and triangulation to efficiently partition the problem into small sub-problems without compromising global optimality. As a result, Res-Int solves in about 3 seconds for moderate size input (around 15 images and 3000 3D points).
We use Res-Int as the known_rotation_prob routine in Line 5 in Algorithm 2 since its superior performance. Although Res-Int converges in a few seconds for moderate problems (as those optimised for a moving window in Algorithm 2), its performance is still inadequate for medium to large size problems ( 3D points, images) that Algorithm 2 optimises when detecting a loop. For such problems, Res-Int could take from a few minutes to hours to converge (see [39, Table 2]). To efficiently address loop closure, we propose a new formulation that incorporates relative camera translation directions (obtained from the essential matrix) to alleviate the size of the problem but still produce an accurate result.
III-D Known rotation problem with translation direction constraints
Solving KRot in Step 9 in Algorithm 2 can be excessively time-consuming as a loop can be detected at an advanced stage generating a large input size. Instead, we propose to address loop closure over a sample of the input with a formulation that incorporates camera translation directions.
Inspired by the quasi-convex approach of Sim and Hartley [40] to estimate the camera translations from and known camera rotations, we constrained camera positions
[TABLE]
in the known rotation problem to agree up to an angular threshold
[TABLE]
to
[TABLE]
which is the relative translation direction in world coordinates (we explicitly apply to in (14) in case and therefore is not a rotation matrix).
We observed that the method of [40] was unable to produce satisfactory results (see results in Sec. IV) for loop closure, arguably since no structural information is optimised thus camera positions were not sufficiently constrained. On the other hand, adding angle constraints (13) to it allows to efficiently solve loop closure ( s) with a sparse set of 3D points (300 points for result in Fig. 2b). Our proposition yields the following problem.
[TABLE]
where
[TABLE]
and is a rotation matrix such that
[TABLE]
Similarly to the method in [40], is valid for $\alpha<$$$. For derivation details of the camera translation direction constraints (15c) please refer to [40].
IV Results
Here we compare L-infinity SLAM (Algorithm 2) against BA-SLAM (Algorithm 1) on real data with precise ground truth. The used dataset, provided by Maptek333https://www.maptek.com/, was captured with a system equipped with a high precision INS (refer to [23] for system’s details). Mounted on a truck, a forward looking camera captured a video together with inertial measurements providing the ground truth for the camera poses.
Experiments were run on a PC with a quad-core 2.5GHz Intel core i7 CPU and 16GB of RAM. We implemented L-infinity SLAM and BA-SLAM in MATLAB with the following optimisation routines:
- •
BA: implemented in C++ using the Ceres solver [41].
- •
rotation_averaging: code provided in [33].
- •
known_rotation_prob: code provided in [39].
- •
krot_tdc: implemented in MATLAB using SeDuMi [42].
IV-A Results for the Maptek dataset
We sampled the full sequence (1833 frames) into 358 keyframes. We detected the occurrence of a loop by using provided ground truth in both BA-SLAM and L-infinity SLAM. Since the moving camera describes a two-loop sequence (see the ground truth in Fig. 2), after completing the first loop (at frame 790), a loop is detected for each consecutive keyframe. To solve loop closure in L-infinity SLAM, we fed krot_tdc with 300 uniformly sampled feature tracks (we used the same sample size for loop closure in BA-SLAM). krot_tdc accurately solved loop closure (see Fig 1) in 90.54 s in a MATLAB single-thread implementation. Since its quasi-convex nature, krot_tdc does not have to be invoked at each loop detection; here we invoked krot_tdc at the last keyframe only. On the contrary, BA-SLAM could be incapable of fixing the drift produced if invocations of BA are skipped (e.g., failing in detecting a loop on a real-world system). We set a window size equal to 10.
To compare BA-SLAM and L-infinity SLAM, Fig. 1 plots the camera position error and camera rotation error for both methods. BA-SLAM was unable to complete the sequence –the camera got disconnected at frame 1356, i.e., no feature track existed for the visited keyframe. This disconnection was a consequence of the outlier removal heuristic used for BA-SLAM (removing a feature track if the distance of the camera position to any visible 3D point is above a threshold; 150 m for this experiment) which failed by eliminating inliers when BA was unable to produce an accurate result. We observed that BA is prone to fail on reduced data input, hence BA-SLAM needs to keep a large number of feature tracks. The optimisation approach of L-infinity SLAM admits less risky outlier removal strategies (e.g. eliminating the support set) without the need of keeping a large number of tracks. As result, BA-SLAM achieved lower camera position () and camera rotation ($<$$$) errors than BA-SLAM.
We also ran BA after krot_tdc on same feature tracks. The camera position and rotation error tend to be lowered; however, BA produced significant error in several camera poses as depicted in Fig. 1.
IV-A1 krot_tdc vs the camera recovering method in [40]
We ran the method in [40] with the same relative translation directions and camera rotations used to solve loop closure. As depicted in Fig. 3, recovering camera positions is unachievable from measurements only. In addition, Fig. 4 shows known_rotation_prob failed on producing an accurate result when solving loop closure on the same tracks we used with krot_tdc.
IV-A2 Map reconstruction
Since we reconstructed 300 scene points only when solving loop closure, we used the quasi-convex method in [39] to triangulate all scene points. Fig. 6 shows the scene reconstruction and the camera positions.
IV-B Low speed and high rotational motion
We tested L-Infinity SLAM against ORB-SLAM with a video recorded with a smart-phone by a pedestrian while turning right; Fig. 5a displays two frames of the video. ORB-SLAM failed to build an initial map (see Fig. 5c), arguably, since the low baseline of frames from the walking speed sequence with rotational motion (see camera poses in Fig. 5b). Unlike ORB-SLAM, the quasi-convex formulation of L-Infinity SLAM does not required any initial map to track camera motions. As result, only L-infinity SLAM produced a reconstruction (see Fig. 5b).
IV-C Runtime of online routines
To compare the efficiency L-infinity SLAM against BA-SLAM for rotation only camera motions, we measured the runtime of incremental rotation averaging and incremental BA, which are the fundamental optimisation routines for this problem. We used a window size equal to 10 and plotted the runtimes for the first loop of the Maptek dataset in Fig. 7 (in log scale). Rotation averaging is an order of magnitude faster than BA which indicates the superior efficiency of L-infinity SLAM over BA-SLAM for rotation only problems.
V CONCLUSIONS
We presented L-infinity SLAM to be a simpler alternative to SLAM systems based on bundle adjustment. Driven by globally optimal quasi-convex optimisation, there is no need to maintain an accurate map and camera motions at key-frame rate as demanded by systems based on bundle adjustment. Instead, the online effort is devoted to efficiently estimating camera orientations through rotation averaging. To efficiently solve loop closure, we proposed a variant of the known rotation problem which incorporates relative translation directions to accurately solve camera drifts when optimising over a sample of feature tracks. Also, L-infinity SLAM is a simple and efficient alternative for applications requiring estimating slow motions or only rotational motions. We hope L-infinity SLAM can motivate future research on quasi-convex optimisation in the SLAM community.
ACKNOWLEDGEMENT
This work was supported by ARC Grants LP140100946 and CE140100016.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] H. Strasdat, J. M. M. Montiel, and A. J. Davison, “Visual SLAM: why filter?” Image and Vision Computing , vol. 30, no. 2, pp. 65–77, 2012.
- 2[2] Y. Kanazawa and K. Kanatani, “Do we really have to consider covariance matrices for image features?” in ICCV , 2001.
- 3[3] K. Kanatani, “Uncertainty modeling and model selection for geometric inference,” IEEE TPAMI , vol. 26, no. 10, pp. 1307–1319, 2004.
- 4[4] ——, “Statistical optimization for geometric fitting: theoretical accuracy bound and high order error analysis,” IJCV , vol. 80, pp. 167–188, 2008.
- 5[5] A. J. Davison, I. D. Reid, N. M. Molton, and O. Stasse, “Mono SLAM: real-time single camera SLAM,” IEEE TPAMI , vol. 29, no. 6, pp. 1–16, 2007.
- 6[6] C. Engels, H. Stewénius, and D. Nistér, “Bundle adjustment rules,” Photogrammetric Computer Vision , vol. 2, 2006.
- 7[7] G. Klein and D. W. Murray, “Parallel tracking and mapping for small AR workspaces,” in ISMAR , 2007.
- 8[8] R. Mur-Artal, J. Montiel, and J. Tardos, “ORB-SLAM: a versatile and accurate monocular SLAM system,” IEEE TRO , vol. 31, no. 5, pp. 1147–1163, 2015.